Post Syndicated from Navnit Shukla original https://aws.amazon.com/blogs/big-data/reference-guide-for-building-a-self-service-analytics-solution-with-amazon-sagemaker/
Organizations today face a critical challenge with fragmented data scattered across multiple silos, including data lakes, warehouses, SaaS applications, and legacy systems. This disconnect prevents businesses from gaining a holistic view of their customers, optimizing operations, and making real-time data-driven decisions. To stay competitive, companies are turning to self-service analytics, enabling both business and technical users to quickly access, explore, and analyze data without dependency on IT teams.
However, implementing self-service analytics comes with significant challenges. Organizations must address integrating data from diverse sources for seamless access, creating business and technical catalogs to improve data discoverability, enabling data lineage and quality to build trust and reliability, implementing fine-grained access controls to ensure security and compliance, providing role-specific tools for data engineers, analysts, and artificial intelligence (AI)/machine learning (ML) teams, and establishing governance frameworks to enforce policies and regulatory requirements.
In this post, we show how to use Amazon SageMaker Catalog to publish data from multiple sources, including Amazon S3, Amazon Redshift, and Snowflake. This approach enables self-service access while ensuring robust data governance and metadata management. By centralizing metadata, users can improve data discoverability, lineage tracking, and compliance while empowering analysts, data engineers, and data scientists to derive AI-driven insights efficiently and securely. We use a sample retail use case to demonstrate the solution, making it easier to understand how these capabilities can be applied to real-world scenarios.
Amazon SageMaker: Enabling self-service analytics
Amazon SageMaker brings together AWS AI/ML and analytics capabilities, delivering an integrated experience for analytics and AI with unified data access, enabling teams to:
- Discover and access data stored across Amazon S3, Amazon Redshift, and other third-party sources through the Lakehouse architecture.
- Perform complete AI and analytics workflows using familiar AWS services for data analysis, processing, model training, and generative AI app development.
- Use Amazon Q Developer, an advanced generative AI assistant to accelerate software development.
- Ensure enterprise-grade security with built-in governance, fine-grained access controls, and secure artifact sharing with Amazon SageMaker Catalog.
- Collaborate in shared projects, allowing teams to work together efficiently while maintaining compliance and governance.
Retail use case overview
In our example, a retail organization operates across multiple business units, each storing data in different platforms, creating challenges in data access, consistency, and governance.

Figure 1: High-level architecture of our retail use case showing data flow across multiple systems
Our retail organization faces data fragmentation across its business units:
- The Wholesale Sales business unit stores its data in Amazon S3.
- The Store Sales business unit maintains its transactional data in Amazon Redshift.
- Online Sales Data is stored in Snowflake.
These disparate data sources result in data silos, inconsistent schemas, duplication, and missing values, making it difficult for analysts and AI-driven solutions to derive meaningful insights.
Data model
The following Entity-Relationship (ER) Diagram represents the dataset structure and relationships between different entities in Wholesale, Retail, and Online Sales Data:

Figure 2: Entity-Relationship Diagram showing the relationships between different data entities
Key entities in our data model
Our sample dataset models a multi-channel retail business with interconnected entities representing products, sales channels, customers, and locations.
- PRODUCTS is a central entity that links to WHOLESALE_SALES, RETAIL_SALES, and ONLINE_SALES, representing product transactions across different sales channels.
- WHOLESALE_SALES records bulk transactions where WAREHOUSES distribute products to retailers. Each sale is associated with a PRODUCT and a WAREHOUSE.
- RETAIL_SALES captures individual purchases made in physical STORES. Each transaction involves a PRODUCT and a STORE, along with details like quantity sold, discount applied, and revenue.
- ONLINE_SALES tracks e-commerce transactions where customers buy products online. Each record links to a CUSTOMER and a PRODUCT, along with details like quantity, price, and shipping information.
- CUSTOMERS represent buyers in the system and are linked to ONLINE_SALES (for purchasing) and CUSTOMER_REVIEWS (for leaving product reviews).
- CUSTOMER_REVIEWS stores feedback provided by customers for products they purchased online. Each review is linked to an ONLINE_SALES order, a CUSTOMER, and a PRODUCT.
- STORES represent physical retail locations where products are sold. They are associated with RETAIL_SALES, indicating that products are purchased in-store.
- WAREHOUSES are responsible for stocking and distributing products through WHOLESALE_SALES transactions. They manage stock levels and facilitate bulk sales to retailers.
Data distribution across systems
To simulate a real-world enterprise scenario, our data is distributed across multiple systems and AWS accounts as follows:
| Accounts | Location | Tables |
| Wholesale | Amazon S3 | WHOLESALE_SALES, PRODUCT, WAREHOUSE |
| Store | Amazon Redshift | RETAIL_SALES, STORE, PRODUCT |
| Online Sales | Snowflake | ONLINE_SALES, CUSTOMER, CUSTOMER_REVIEWS, PRODUCT |
Assumptions
We are making the following assumptions for this implementation.
- Three AWS accounts: Wholesale account, Store account, and Centralized Processing account.
- A Snowflake account for online sales.
- Create the distributed data across the accounts as specified in the data model section using this sample scripts.
- Create an AWS Identity and Access Management (IAM) role with permissions needed to setup cross account resources.
Building the SageMaker Catalog
In this section, we walk through the process of creating the SageMaker Catalog from multiple sources using Amazon SageMaker Unified Studio.
Step 1: Setting up your SageMaker Unified Studio environment
Before we begin building our data catalog, we cover some terminology for SageMaker Unified Studio.
Domain: A domain in Amazon SageMaker Unified Studio is a logical boundary that serves as the primary container for all your data assets, users, and resources, allowing efficient data organization and management.
Domain Units: Domain units are subcomponents within a domain that help organize related projects and resources together, enabling hierarchical structuring of your data management activities.
Blueprint: A blueprint in Amazon SageMaker Unified Studio is a template that defines standardized configurations for projects, including what resources are provisioned, and what tools, and parameters are applied.
Project Profile: A project profile is a collection of blueprints which are configurations used to create projects. A project profile can define if a particular blueprint is enabled during the creation of the project, or available later for the project users to enable on-demand.
Project: A project in Amazon SageMaker Unified Studio is a boundary within a domain where users can collaborate with others to work on a business use case. In projects, users can create and share data and resources.
Now, we can set up our Amazon SageMaker Unified Studio environment.
Create a SageMaker domain
- Open the Amazon SageMaker management console in the Centralized Processing account and use the region selector in the top navigation bar to choose the appropriate AWS Region.
- Choose Create a Unified Studio domain.
- Choose Quick setup as explained in Create an Amazon SageMaker Unified Studio domain – quick setup.

- For Create IAM Identity Center User, search for SSO users through email addresses.
If there is no Amazon Identity Access Manager (IAM) Identity Center instance, a prompt appears to enter your name after your email address. This creates a new local IAM Identity Center instance. - Choose Create domain.

Log in to SageMaker Unified Studio
Now that we have created a new SageMaker Unified Studio domain, complete the following steps to visit the Amazon SageMaker Unified Studio.
- On the SageMaker platform console, open the details page of your domain.

- Choose the link for Amazon SageMaker Unified Studio URL.
- Log in with your SSO credentials.

Now you signed in to the SageMaker Unified Studio.
Create a project
The next step is to create a project. Complete the following steps:
- On the SageMaker Unified Studio, choose Select a project on the top menu, and choose Create project.
- For Project name, enter a name (such as AnyCompanyDataPlatform).
- For Project profile, choose All capabilities.
- Choose Continue.

- Review the input and choose Create project. This project serves as a collaborative workspace for our data integration efforts.

Wait for the project to be created. Project creation can take about five minutes. Then The SageMaker Unified Studio console goes to the project’s home page.
Step 2: Connecting to data sources
Now, we connect to our various data sources to bring them into our data catalog.
Importing existing AWS Glue Data Catalog (Wholesale Sales Data)
We first import the wholesale sales data from Amazon S3 in the Wholesale account into Amazon SageMaker Unified Studio.
Set up cross-account access
- Log in to Centralized Processing account and create a Glue Crawler role named glue-cross-s3-access with the AWSGlueServiceRole and cross account S3 access policy for Wholesale account.
Sample cross account S3 access policy: - Log in to the Wholesale account and create an S3 bucket policy that grants access to S3 data files for the previously created glue-cross-s3-access role of the Centralized Processing account.
- Log in to the Centralized Processing account and create a database named anycompanydatacatlog from the AWS Glue.
- Grant permissions to the glue-cross-s3-access role for the anycompanydatacatalog database in AWS Lake Formation.
- Run the Glue Crawler using the glue-cross-s3-access role to scan the S3 bucket in the Wholesale account. For more information, refer to the tutorial explaining how to catalog S3 data using the Glue crawler.
- Verify the
anycompanydatacatlogdatabase and its corresponding tables.


Configure the Glue data catalog assets
- Download the provided scripts from the Bring Your Own Glue Data Catalog Assets repository.
- Copy the Amazon SageMaker Unified Studio project role ARN from project overview section.

- Add the same Amazon SageMaker Unified Studio project role as LakeFormation Data Lake Administrator.

Import the assets into Amazon SageMaker Unified Studio
- Open AWS CloudShell in the Centralized Processing account console.
- Upload the previously downloaded bring_your_own_gdc_assets.py file to AWS CloudShell.

- Run the import script in AWS CloudShell with following parameters.
- project-role-arn: Enter the project role ARN of SageMaker Unified Studio.
- database-name: Enter the database name of Glue Catalog (such as
anycompanydatacatalog). - region: Enter the region of SageMaker Unified Studio (such as
us-east-1).

Verify the imported wholesale sales data
- In the Centralized Processing account, go to the SageMaker Unified Studio console, choose your project.
- Choose Data in the navigation pane.

- Confirm that the wholesale_db database and its tables (WHOLESALE_SALES, PRODUCT, WAREHOUSE) are now available under
anycompanydatacatalog.



Connecting to Amazon Redshift (Stores sales data)
In this step, we bring stores sales data from Amazon Redshift in the Store account into Amazon SageMaker Unified Studio.
Set up cross-account access
- Login to the Store account, create a virtual private cloud (VPC) peering connection between the Store account and the Centralized Processing account, which hosts the Amazon SageMaker Unified Studio, and configure route tables following the documentation.
- Update your Redshift VPC security group’s rule to include the Centralized Processing account’s IPv4 CIDR range, enabling network connectivity and allowing incoming requests from the Centralized Processing account to access the Store account resources.
Create a federated connection for Amazon Redshift
- In the Centralized Processing account, go to the SageMaker Unified Studio console, choose your project.
- Choose Data in the navigation pane.
- In the data explorer, choose the plus sign to add a data source.

- Under add a data source, choose Add connection, then choose Amazon Redshift.
- Enter the following parameters in the connection details, and choose Add data.
- Name: Enter the connection name (such as
anycompanyredshift). - Host: Enter the Amazon Redshift cluster endpoint.
- Port: Enter the port number (Amazon Redshift uses 5439 as the default port).
- Database: Enter the database name
- Authentication: Choose either the database username and password credentials or AWS Secrets Manager. We recommend using AWS Secrets Manager.

- Name: Enter the connection name (such as


After the connection is established, the federated catalog is created, as shown in the following screenshot. This catalog uses the AWS Glue connection to Amazon Redshift. The databases, tables, and views are automatically cataloged in the catalog section and registered with Lake Formation.

Verify the stores sales data
- Visit the Catalog section in SageMaker Unified Studio.
- Confirm that the retails sales public database and its tables (RETAIL_SALES, STORE, PRODUCT) are now available.


Connecting to Snowflake (online sales data)
In this step, we bring online sales data from Snowflake into Amazon SageMaker Unified Studio.
Create a federated connection for Snowflake
- In the Centralized Processing account, go to the SageMaker Unified Studio console, choose your project.
- Choose Data in the Navigation Pane.
- In the data explorer, choose the plus sign (+) to add a data source.
- Under Add a data source, choose Add connection, then choose Snowflake.

- Enter the following parameters in the connection details, and choose Add data.
- Name: Enter the connection name (such as
anycompanysnowflake). - Host: Enter the Snowflake cluster endpoint.
- Port: Enter the port number (Snowflake uses 443 as the default port).
- Database: Enter the database name (such as
anycompanyonlinesales). - Warehouse: Enter the warehouse name (such as COMPUTE_WH).
- Authentication: Choose either the database username and password credentials or Secrets Manager.

- Name: Enter the connection name (such as


After the connection is established, the federated catalog is created for Snowflake. This catalog uses the AWS Glue connection to Snowflake. The databases, tables, and views are automatically cataloged in the Data Catalog and registered with Lake Formation.
Verify the online sales data
- Go to the Catalog section in SageMaker Unified Studio.
- Confirm that the Online sales public database and its tables (CUSTOMER_REVIEWS, CUSTOMER, ONLINE_SALES, PRODUCT) are now available.


Step 3: Analyze the data together
Once all the data from different data sources has been cataloged, we can analyze it using Amazon Athena query engine from Amazon SageMaker Unified Studio.
- In the Centralized Processing account, go to the SageMaker Unified Studio console, choose your project.
- Choose Query Editor from the Build section.

- Select Athena (Lakehouse) as a connection.
- Run queries joining multiple data source catalogs to analyze the data.

Example: What is the total revenue generated from wholesale, retail, and online sales for each product?

Similarly, users can derive valuable business insights by querying across catalogs for different analytical questions.
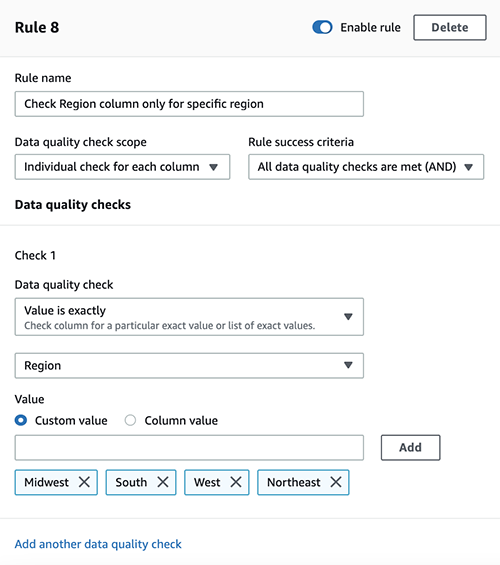
Step 4: Creating a Business Glossary
A business glossary helps standardize terminology across the organization and makes data more discoverable. Now we create a business glossary for Wholesale data PRODUCT.
- In the Navigation Pane, choose Data and select Publish to Catalog for the Wholesale data PRODUCT table.

- Choose Assets and choose the products table.

- Create a Glossary named ‘Product‘ and a Term named ‘Sales‘ from Metadata entities.

- Choose Generate Descriptions to automatically generate summary of your data using AI. Choose Add Terms.

- Choose ACCEPT ALL for Automated Metadata Generation.

- Choose sales term and choose Add Terms.

- Choose Publish Asset.

- Choose Assets and then Published. We can now see a published asset that is searchable and available to request for subscription.









Similarly, you can create business glossaries for other data products by following the above steps.
Step 5: Setting up access controls
To ensure proper governance, set up fine-grained access controls.
- For each user create a new single sign-on (SSO) user
- Create the following roles and permissions to attach to the SSO user:
| Role | Description | Access Level |
|---|---|---|
| Data Steward | Manages the data catalog and glossary | Full access to catalog and glossary |
| ETL Developer | Develops data integration pipelines | Read/write access to data sources and AWS Glue |
| Data Analyst | Analyzes sales data | Read-only access to all sales data |
| AI Engineer | Builds forecasting models | Read access to sales data, full access to SageMaker features |
Benefits of SageMaker Catalog
By implementing a self-service business data catalog using Amazon SageMaker Unified Studio, our retail organization achieves several key benefits:
- Unified data access: Users can discover and access data from Amazon S3, Redshift, and Snowflake through a single interface.
- Standardized metadata: The business glossary ensures consistent terminology across the organization.
- Governance and compliance: Fine-grained access controls ensure that users only access data they’re authorized to see.
- Collaboration: Different teams (ETL developers, data analysts, AI engineers) can collaborate within a shared environment.
Cleanup
To avoid incurring additional charges associated with the resources created in this post, make sure to delete the following items from your AWS account:
- The Amazon SageMaker domain.
- The Amazon S3 bucket associated with the Amazon SageMaker domain.
- Cross-account resources such as VPC peering connections, security groups, route tables, AWS Glue Data Catalog entries, and associated IAM roles4. The tables and databases created in this post.
Conclusion
In this post, we demonstrated how Amazon SageMaker Catalog provides a unified approach to data publishing, discovery, and analysis across multiple data sources. Using a retail scenario, we showed how to import data from Amazon S3, Amazon Redshift, and Snowflake into Amazon SageMaker Unified Studio, and how to join and analyze data from these multiple sources to derive meaningful business insights.
By centralizing metadata and enabling cross-source data integration, data is easily discovered across an organization, multiple data sources can be joined and comprehensive analysis performed without moving or duplicating data. This unified approach maintains strong governance with consistent policies, security, and compliance across all data sources while enabling self-service analytics that reduce time-to-insight for your teams.
To learn more about Amazon SageMaker and how to get started, refer to the Amazon SageMaker User Guide.



 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through  Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI. Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions.
Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.

 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.” He can be reached via
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.” He can be reached via  Mike Mosher is s Senior Principal Cloud Platform Network Architect at a multi-national financial credit reporting company. He has more than 16 years of experience in on-premises and cloud networking and is passionate about building new architectures on the cloud that serve customers and solve problems. Outside of work, he enjoys time with his family and traveling back home to the mountains of Colorado.
Mike Mosher is s Senior Principal Cloud Platform Network Architect at a multi-national financial credit reporting company. He has more than 16 years of experience in on-premises and cloud networking and is passionate about building new architectures on the cloud that serve customers and solve problems. Outside of work, he enjoys time with his family and traveling back home to the mountains of Colorado.






















 Navnit Shuklaserves as an AWS Specialist Solution Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.
Navnit Shuklaserves as an AWS Specialist Solution Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS. Patrick Muller works as a Senior Data Lab Architect at AWS. His main responsibility is to assist customers in turning their ideas into a production-ready data product. In his free time, Patrick enjoys playing soccer, watching movies, and traveling.
Patrick Muller works as a Senior Data Lab Architect at AWS. His main responsibility is to assist customers in turning their ideas into a production-ready data product. In his free time, Patrick enjoys playing soccer, watching movies, and traveling. Amogh Gaikwad is a Senior Solutions Developer at Amazon Web Services. He helps global customers build and deploy AI/ML solutions on AWS. His work is mainly focused on computer vision, and natural language processing and helping customers optimize their AI/ML workloads for sustainability. Amogh has received his master’s in Computer Science specializing in Machine Learning.
Amogh Gaikwad is a Senior Solutions Developer at Amazon Web Services. He helps global customers build and deploy AI/ML solutions on AWS. His work is mainly focused on computer vision, and natural language processing and helping customers optimize their AI/ML workloads for sustainability. Amogh has received his master’s in Computer Science specializing in Machine Learning. Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and tradeoffs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family – usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and tradeoffs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family – usually on tennis courts.
























 Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud.
Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud. Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ.
Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ. Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.