Post Syndicated from Piyali Kamra original https://aws.amazon.com/blogs/architecture/a-multi-dimensional-approach-helps-you-proactively-prepare-for-failures-part-3-operations-and-process-resiliency/
In Part 1 and Part 2 of this series, we discussed how to build application layer and infrastructure layer resiliency.
In Part 3, we explore how to develop resilient applications, and the need to test and break our operational processes and run books. Processes are needed to capture baseline metrics and boundary conditions. Detecting deviations from accepted baselines requires logging, distributed tracing, monitoring, and alerting. Testing automation and rollback are part of continuous integration/continuous deployment (CI/CD) pipelines. Keeping track of network, application, and system health requires automation.
In order to meet recovery time and point objective (RTO and RPO, respectively) requirements of distributed applications, we need automation to implement failover operations across multiple layers. Let’s explore how a distributed system’s operational resiliency needs to be addressed before it goes into production, after it’s live in production, and when a failure happens.
Pattern 1: Standardize and automate AWS account setup
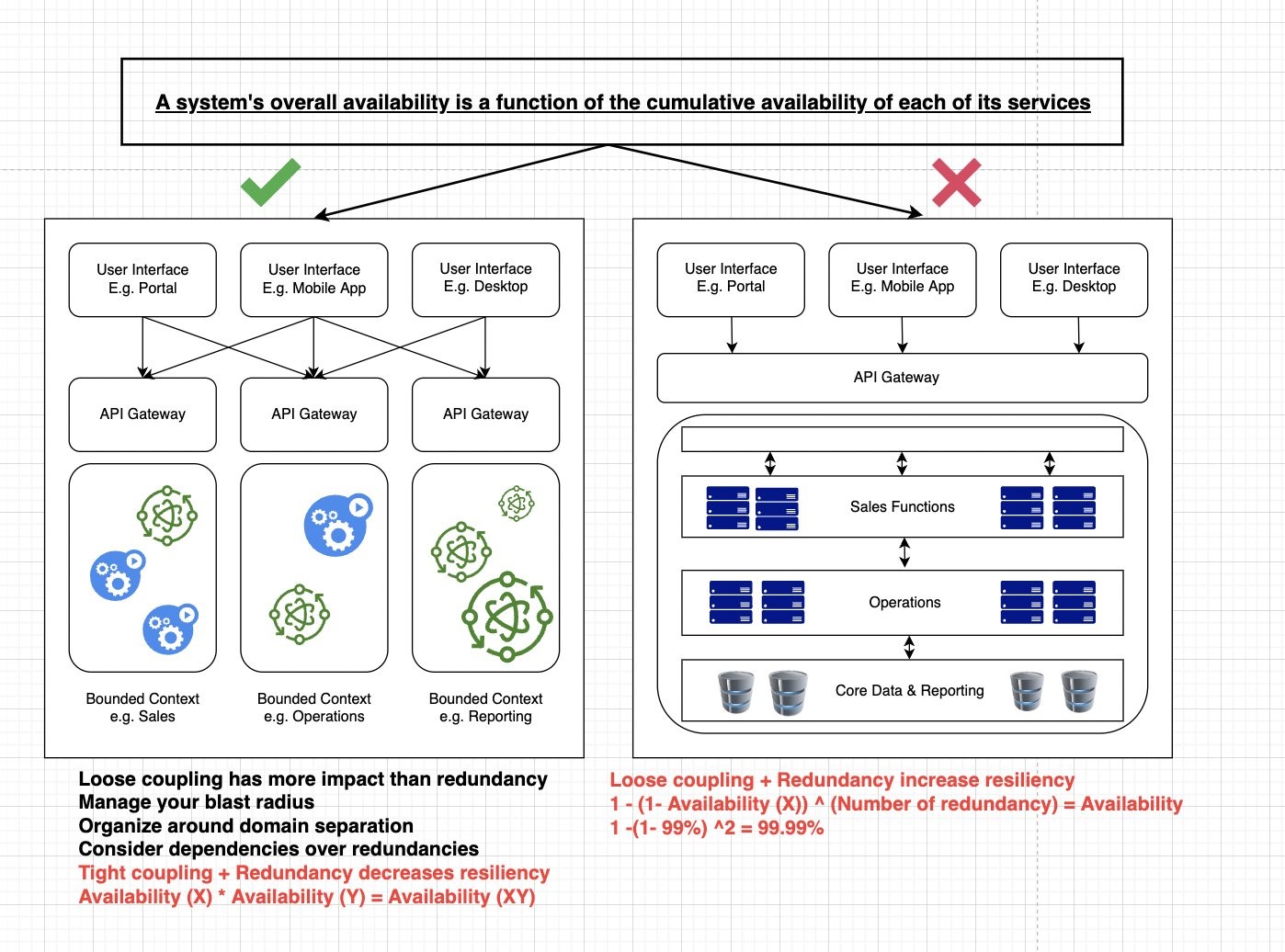
Create processes and automation for onboarding users and providing access to AWS accounts according to their role and business unit, as defined by the organization. Federated access to AWS accounts and organizations simplifies cost management, security implementation, and visibility. Having a strategy for a suitable AWS account structure can reduce the blast radius in case of a compromise.
- Have auditing mechanisms in place. AWS CloudTrail monitors compliance, improving security posture, and auditing all the activity records across AWS accounts.
- Practice the least privilege security model when setting up access to the CloudTrail audit logs plus network and applications logs. Follow best practices on service control policies and IAM boundaries to help ensure your AWS accounts stay within your organization’s access control policies.
- Explore AWS Budgets, AWS Cost Anomaly Detection, and AWS Cost Explorer for cost-optimizing techniques. The AWS Compute Optimizer and Instance Scheduler on AWS resource resizing and auto-shutdown for non-working hours. A Beginner’s Guide to AWS Cost Management explores multiple cost-optimization techniques.
- Use AWS CloudFormation and AWS Config to detect infrastructure drift and take corrective actions to make resources compliant, as demonstrated in Figure 1.

Figure 1. Compliance control and drift detection
Pattern 2: Documenting knowledge about the distributed system
Document high-level infrastructure and dependency maps.
Define availability characteristics of distributed system. Systems have components with varying RTO and RPO needs. Document application component boundaries and capture dependencies with other infrastructure components, including Domain Name System (DNS), IAM permissions; and access patterns, secrets, and certificates. Discover dependencies through solutions, such as Workload Discovery on AWS, to plan resiliency methods and ensure the order of execution of various steps during failover are correct.
Capture non-functional requirements (NFRs), such as business key performance indicators (KPIs), RTO, and RPO, for your composing services. NFRs are quantifiable and define system availability, reliability, and recoverability requirements. They should include throughput, page-load, and response time requirements. Quantify the RTO and RPO of different components of the distributed system by defining them. The KPIs measure if you are meeting the business objectives. As mentioned in Part 2: Infrastructure layer, RTO and RPO help define the failover and data recovery procedures.
Pattern 3: Define CI/CD pipelines for application code and infrastructure components
Establish a branching strategy. Implement automated checks for version and tagging compliance in feature/sprint/bug fix/hot fix/release candidate branches, according to your organization’s policies. Define appropriate release management processes and responsibility matrices, as demonstrated in Figures 2 and 3.
Test at all levels as part of an automated pipeline. This includes security, unit, and system testing. Create a feedback loop that provides the ability to detect issues and automate rollback in case of production failures, which are indicated by business KPI negative impact and other technical metrics.

Figure 2. Define the release management process

Figure 3. Sample roles and responsibility matrix
Pattern 4: Keep code in a source control repository, regardless of GitOps
Merge requests and configuration changes follow the same process as application software. Just like application code, manage infrastructure as code (IaC) by checking the code into a source control repository, submitting pull requests, scanning code for vulnerabilities, alerting and sending notifications, running validation tests on deployments, and having an approval process.
You can audit your infrastructure drift, design reusable and repeatable patterns, and adhere to your distributed application’s RTO objectives by building your IaC (Figure 4). IaC is crucial for operational resilience.

Figure 4. CI/CD pipeline for deploying IaC
Pattern 5: Immutable infrastructure
An immutable deployment pipeline launches a set of new instances running the new application version. You can customize immutability at different levels of granularity depending on which infrastructure part is being rebuilt for new application versions, as in Figure 5.
The more immutable infrastructure components being rebuilt, the more expensive deployments are in both deployment time and actual operational costs. Immutable infrastructure also is easier to rollback.

Figure 5. Different granularity levels of immutable infrastructure
Pattern 6: Test early, test often
In a shift-left testing approach, begin testing in the early stages, as demonstrated in Figure 6. This can surface defects that can be resolved in a more time- and cost-effective manner compared with after code is released to production.

Figure 6. Shift-left test strategy
Continuous testing is an essential part of CI/CD. CI/CD pipelines can implement various levels of testing to reduce the likelihood of defects entering production. Testing can include: unit, functional, regression, load, and chaos.
Continuous testing requires testing and breaking existing boundary conditions, and updating test cases if the boundaries have changed. Test cases should test distributed systems’ idempotency. Chaos testing benefits our incidence response mechanisms for distributed systems that have multiple integration points. By testing our auto scaling and failover mechanisms, chaos testing improves application performance and resiliency.
AWS Fault Injection Simulator (AWS FIS) is a service for chaos testing. An experiment template contains actions, such as StopInstance and StartInstance, along with targets on which the test will be performed. In addition, you can mention stop conditions and check if they triggered the required Amazon CloudWatch alarms, as demonstrated in Figure 7.

Figure 7. AWS Fault Injection Simulator architecture for chaos testing
Pattern 7: Providing operational visibility
In production, operational visibility across multiple dimensions is necessary for distributed systems (Figure 8). To identify performance bottlenecks and failures, use AWS X-Ray and other open-source libraries for distributed tracing.
Write application, infrastructure, and security logs to CloudWatch. When metrics breach alarm thresholds, integrate the corresponding alarms with Amazon Simple Notification Service or a third-party incident management system for notification.
Monitoring services, such as Amazon GuardDuty, are used to analyze CloudTrail, virtual private cloud flow logs, DNS logs, and Amazon Elastic Kubernetes Service audit logs to detect security issues. Monitor AWS Health Dashboard for maintenance, end-of-life, and service-level events that could affect your workloads. Follow the AWS Trusted Advisor recommendations to ensure your accounts follow best practices.

Figure 8. Dimensions for operational visibility (click the image to enlarge)
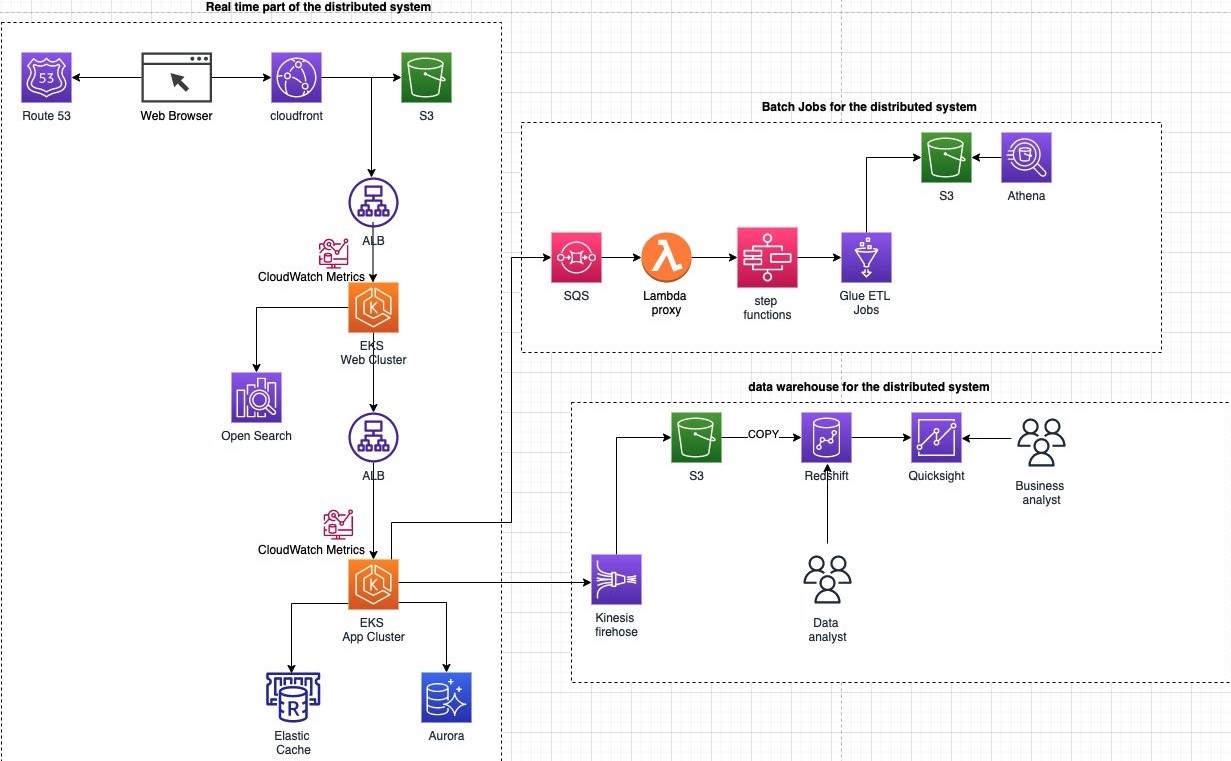
Figure 9 explores various application and infrastructure components integrating with AWS logging and monitoring components for increased problem detection and resolution, which can provide operational visibility.

Figure 9. Tooling architecture to provide operational visibility
Having an incident response management plan is an important mechanism for providing operational visibility. Successful execution of this requires educating the stakeholders on the AWS shared responsibility model, simulation of anticipated and unanticipated failures, documentation of the distributed system’s KPIs, and continuous iteration. Figure 10 demonstrates the features of a successful incidence response management plan.

Figure 10. An incidence response management plan (click the image to enlarge)
Conclusion
In Part 3, we discussed continuous improvement of our processes by testing and breaking them. In order to understand the baseline level metrics, service-level agreements, and boundary conditions of our system, we need to capture NFRs. Operational capabilities are required to capture deviations from baseline, which is where alerting, logging, and distributed tracing come in. Processes should be defined for automating frequent testing in CI/CD pipelines, detecting network issues, and deploying alternate infrastructure stacks in failover regions based on RTOs and RPOs. Automating failover steps depends on metrics and alarms, and by using chaos testing, we can simulate failover scenarios.
Prepare for failure, and learn from it. Working to maintain resilience is an ongoing task.