Post Syndicated from Luis Pastor original https://aws.amazon.com/blogs/security/minimize-risk-through-defense-in-depth-building-a-comprehensive-aws-control-framework/
Security and governance teams across all environments face a common challenge: translating abstract security and governance requirements into a concrete, integrated control framework. AWS services provide capabilities that organizations can use to implement controls across multiple layers of their architecture—from infrastructure provisioning to runtime monitoring. Many organizations deploy multi-account environments with AWS Control Tower, or Landing Zone Accelerator to implement a foundational baseline of controls and security architecture. Once their environment is provisioned, organizations typically look to add additional detective controls from services such as AWS Security Hub and AWS Config based on security, compliance, and operational requirements. While this sequence is a great start, there are more opportunities during this time to implement layered defense-in-depth coverage to enhance your security posture.
Highly regulated industries such as fintech and financial services are often viewed as the gold standard for governance and security controls. While these sectors have established robust frameworks, there’s consistently room for improvement and valuable lessons for other industries looking to enhance their control environments. However, many organizations struggle to move beyond a basic compliance-focused approach. In our experience working with customers across various sectors, this limited perspective often stems from multiple factors, including:
- Immediate compliance pressures
- Resource constraints
- Limited understanding of control maturity pathways
- Focus on detection rather than prevention
- A tendency to prioritize technology-agnostic controls over bult-in AWS capabilities, leading to unnecessarily complex implementations
The good news? A more comprehensive approach that uses AWS preventative, proactive, detective, and responsive controls can significantly reduce risk while decreasing operational overhead through automation.
In this post, we outline a practical framework that you can adopt to evolve your security and governance controls strategy. We explore how your organization can mature from a detection-focused security posture to a multi-layered control framework, using real-world examples across the resource lifecycle, including infrastructure-as-code testing and preventative controls such as service control policies (SCPs), resource control policies (RCPs), and declarative policies (DPs).
Drawing from best practices in highly regulated industries while incorporating modern cloud capabilities through services such as AWS Organizations and AWS Control Tower, we provide a structured framework that you can use to elevate your organization’s control environment beyond basic compliance requirements.
Customer challenges in implementing controls
Organizations face several significant challenges when attempting to implement a comprehensive control framework in AWS. Let’s explore the main obstacles:
Resource constraints and expertise gaps
Security teams often find themselves caught between limited resources and expanding responsibilities in the cloud. With constrained budgets and personnel, teams typically gravitate toward quick wins through detective controls, which appear straightforward to implement initially. While this provides immediate visibility, it can leave critical gaps in security posture. Many teams lack comprehensive expertise across all control types, particularly in implementing preventative, proactive, and responsive controls effectively. The pressure to demonstrate immediate security improvements, combined with day-to-day operational demands, frequently results in tactical solutions rather than strategic, layered security approaches.
Analysis paralysis
Deciding which tools to prioritize can be a challenge; the breadth of options and extensive capabilities available across AWS security services and third-party tools can feel overwhelming at times. Security teams struggle to determine the optimal mix of controls for their environment and where to begin implementation. This challenge is compounded by the complexity of mapping technical compliance requirements to cloud-focused capabilities and maintaining visibility into emerging threats as the security landscape evolves. The layers of abstraction created by proliferating security controls can further obscure clear decision-making, leading teams to delay critical security improvements while seeking perfect solutions.
Misunderstanding of defense in depth
Defense in depth as a concept is good, but it can be misunderstood and difficult to achieve, leading to vulnerabilities in the security architecture. A common misconception is that a single strong control, separation of duties in AWS Identity and Access Management (IAM) roles, least permission in IAM policies, and so on, provide sufficient protection. This overlooks the crucial value of implementing controls at multiple points and how different control types can be combined to create a robust security posture. Teams often miss how organizational controls like SCPs can work in harmony with workload-specific controls to achieve greater protection. The role of preventative controls in guiding technical implementations is frequently under appreciated.
Maturity journey challenges
The path to security maturity presents numerous obstacles. Many organizations remain stuck in the early stages, implementing detective controls but never progressing to preventative measures. Security controls are often implemented in isolation, without consideration for the broader security landscape. Organizations struggle to create and follow a clear roadmap for evolving their security posture, and measuring improvement over time proves challenging.
Scale and consistency issues
As AWS environments grow, maintaining consistent governance and security becomes increasingly complex. Organizations face mounting challenges in managing exceptions and special cases across their expanding infrastructure. These interrelated challenges often result in controls implementations that fail to achieve their intended risk reduction goals. You need a structured approach to overcome these obstacles and implement comprehensive security controls, which we explore in the following sections.
Strategic investment in security
While implementing comprehensive controls requires an initial investment in time and resources, the long-term benefits fundamentally transform how organizations operate.
The foundation for this transformation begins with establishing baseline controls through proven starting points such as AWS Control Tower and its customization options. AWS Control Tower provides building blocks for secure multi-account architectures with hundreds of security capabilities and proactive controls already built in. Rather than trying to create baselines from scratch by wrangling vast amounts of account-level or resource-specific controls, you can use these accelerators to rapidly establish a strong security foundation. With these baseline controls in place, this transformation extends beyond security teams to enable the entire organization to operate more efficiently. Development and operations teams can deploy faster with confidence when security guardrails are in place. Security becomes an enabler rather than a bottleneck, so that teams across the organization can innovate while maintaining a strong security posture.
As you mature your organization’s control framework through automation and layered defenses, a security transformation occurs. Security teams shift from constant firefighting to proactive risk management. Automated policy enforcement replaces manual reviews, and the time previously spent on routine tasks can be redirected to strategic initiatives.
Understanding control types and their interplay
AWS defines distinct types of controls to build a comprehensive security framework. Let’s examine each type and how they work together, using a common scenario: preventing public Amazon Simple Storage Service (Amazon S3) bucket exposure.
Preventative controls
Preventative controls establish the foundation of a secure environment by defining the policies, standards, and requirements that guide security implementations. At their core, these controls encompass corporate security policies that outline acceptable resource configurations across the organization. They work in conjunction with compliance requirements and frameworks to help maintain regulatory alignment, while architectural standards and guidelines provide technical direction for implementations. Data classification policies play a crucial role by determining specific security requirements based on data sensitivity.
To illustrate how preventative controls work in practice, consider a common S3 bucket security requirement. A typical preventative control might establish a corporate policy stating All S3 buckets must be private by default, with public access granted only through an approved exception process. This simple but effective policy sets clear expectations and requirements before a technical implementation begins.
- Organization level: SCPs blocking public S3 bucket creation.
- Resource level:
- RCPs enforcing network access controls, such as requiring authenticated access or limiting requests to your organization’s network range.
- SCPs to stop malicious overwrites of S3 objects using SSE-C encryption by blocking
s3:PutObject requests with customer-provided keys unless explicitly allowed, paired with AWS IAM Roles Anywhere for short-term credential enforcement.
```json
// SCP to block SSE-C unless explicitly allowed
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenySSECEncryption",
"Effect": "Deny",
"Action": "s3:PutObject",
"Resource": "*",
"Condition": {
"Null": {
"s3:x-amz-server-side-encryption-customer-algorithm": "false"}
} }
]}
Proactive controls
Proactive controls act as an early warning system, identifying and addressing potential security issues before they manifest in your environment. These controls work by validating configurations and changes against established security requirements during the development and deployment phases. Through automated validation and policy enforcement at build and deploy time, proactive controls help prevent misconfigurations from reaching production environments, reducing the operational overhead of fixing security issues after the fact. Think of proactive controls as your first line of defense in maintaining a secure cloud environment. In AWS, these can be implemented at multiple levels:
- Amazon S3 Block Public Access settings at the account level.
- Policy-as-code checks in continuous integration and delivery (CI/CD) pipelines (such as CFN-Nag, or AWS Config proactive rules).
- AWS CloudFormation hooks for pre-deployment validation and policy enforcement.
- AWS Config rules in proactive mode to evaluate resources before creation.
- At the resource level, you can use:
- IAM policies restricting bucket policy modifications
- CloudFormation Guard rules
#####################################
## Gherkin ##
#####################################
# Rule Identifier:
# S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
# Description:
# Checks if your Amazon S3 bucket either has the Amazon S3 default encryption enabled or that the Amazon S3 bucket policy
# explicitly denies put-object requests without server side encryption that uses AES-256 or AWS Key Management Service.
# Reports on:
# AWS::S3::Bucket
# Evaluates:
# AWS CloudFormation
# Rule Parameters:
# NA
# Scenarios:
# a) SKIP: when there are no S3 resource present
# b) PASS: when all S3 resources Bucket Encryption ServerSideEncryptionByDefault is set to either "aws:kms" or "AES256"
# c) FAIL: when all S3 resources have Bucket Encryption ServerSideEncryptionByDefault is not set or does not have "aws:kms" or "AES256" configurations
# d) SKIP: when metadata includes the suppression for rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED
#
# Select all S3 resources from incoming template (payload)
#
let s3_buckets_server_side_encryption = Resources.*[ Type == 'AWS::S3::Bucket'
Metadata.cfn_nag.rules_to_suppress not exists or
Metadata.cfn_nag.rules_to_suppress.*.id != "W41"
Metadata.guard.SuppressedRules not exists or
Metadata.guard.SuppressedRules.* != "S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED"
]
rule S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED when %s3_buckets_server_side_encryption !empty {
%s3_buckets_server_side_encryption.Properties.BucketEncryption exists
%s3_buckets_server_side_encryption.Properties.BucketEncryption.ServerSideEncryptionConfiguration[*].ServerSideEncryptionByDefault.SSEAlgorithm in ["aws:kms","AES256"]
<<
Violation: S3 Bucket must enable server-side encryption.
Fix: Set the S3 Bucket property BucketEncryption.ServerSideEncryptionConfiguration.ServerSideEncryptionByDefault.SSEAlgorithm to either "aws:kms" or "AES256"
>>
}
Source: aws-guard-rules-registry
Detective controls
Detective controls provide continuous visibility into your security posture by monitoring for and identifying potential security violations or unauthorized changes within your environment. While preventative controls aim to stop issues before they occur, detective controls help you maintain awareness of your security state and can identify when preventative controls have been bypassed or failed. These controls form a critical layer of defense by enabling rapid identification of security issues and providing the visibility needed for effective incident response and compliance reporting. While many organizations start and stop here, detective controls are only part of the solution:
- AWS Config rules monitoring for public buckets
- Security Hub findings to flag non-compliant resources
- AWS IAM Access Analyzer evaluations
Responsive controls
Responsive controls complete the security lifecycle by providing automated and manual mechanisms to address security issues after they’re detected. These controls define and implement the actions taken when security violations are identified, ranging from automated remediation of common misconfigurations to coordinated incident response procedures for complex security events. By establishing clear response patterns and using automation where appropriate, responsive controls help facilitate consistent and timely handling of security issues while reducing the mean time to remediation. Responsive controls address violations when they occur:
The power comes not from implementing these controls in isolation, but from using them together in a coordinated way. This layered approach begins with preventative controls to establish the requirements, followed by proactive controls to block most potential violations at the source. Issues that manage to slip through are caught by detective controls, while responsive controls automatically remediate identified problems. Throughout this process, comprehensive documentation tracks issues, remediation plans, and progress, such as through a plan of action and milestones (POAM), helping to make sure that compliance requirements are met and improvements can be measured over time.
Implementation lifecycles: Ideal compared to reality
You can follow one of two paths when implementing security controls: starting fresh with a comprehensive approach or evolving from an existing detective-focused implementation. Let’s examine both scenarios.
Starting fresh: The ideal approach
When starting from scratch, you have a unique opportunity to build your security and governance following an ideal approach. Your team can take advantage of this clean slate to architect controls and processes methodically, free from legacy constraints. The following steps offer guidance though establishing a strong foundation while maintaining the flexibility you need as your business grows.
- Rationalize controls against requirements and risk profile:
- Choose appropriate security frameworks (for example, CIS and NIST).
- Map compliance, regulatory, legal, and contractual requirements to your base framework.
- Define clear security objectives and success criteria for your security and compliance program.
- Design a comprehensive control strategy:
- Document control requirements across all four types (preventive, proactive, detective, and responsive controls). You can use the framework to decide which controls are best for each type of requirement.
- Plan implementation phases and priorities.
- Define metrics for measuring effectiveness.
- Implement controls in layers:
- Start with AWS Control Tower, which gives you foundational controls to mature from. You can add customizations if required.
- Think about additional preventative controls that can help establish a stronger security and compliance posture.
- Deploy proactive controls to stop violations.
- Add detective controls as safeguards.
- Implement responsive controls for automated or manual remediation.
- Monitor and assess effectiveness
- Evaluate control performance against defined metrics.
- Identify gaps and areas for improvement.
- Adjust controls based on emerging threats and changing requirements.
- Implement continuous improvement feedback loop.
Evolution from detective controls: The common path
Most organizations find themselves starting with detective controls and face challenges in maturing from there:
- Initial state:
- Baseline detective controls through Security Hub and AWS Config
- Manual remediation processes
- Limited visibility into security posture
- Maturation steps:
- Analyze findings to identify patterns
- Implement automated remediation for common issues
- Add preventative and proactive controls based on recurring events
- Periodically refine and update policies
- Optimization:
- Review control effectiveness
- Identify gaps in coverage
- Implement additional preventative, proactive, detective, and responsive measures
- Automate processes where possible
The goal: Comprehensive and layered security controls
The goal of implementing security controls across multiple layers isn’t just about compliance or following best practices—it’s about creating a robust, resilient security posture that can effectively help prevent, detect, and respond to security issues. Let’s explore why this approach is crucial:
Why multiple control layers matter
Security controls shouldn’t exist in isolation. When implementing a security requirement, you should consider:
- How can we prevent this issue from occurring?
- How will we detect if our preventative controls fail?
- What should happen when we detect a violation?
- What policies and standards guide these decisions?
Moving beyond detection
While detective controls are important, they signal that a security violation has already occurred. A mature security posture requires:
- Strong preventative controls to stop violations before they happen
- Detective controls as a safety net if there is drift or a violation
- Automated remediation where possible, to reduce exposure time
- Clear policies to guide implementation and decisions
- Measuring success
You should measure the effectiveness of your control framework through several key performance indicators. Success can be seen in the steady reduction of security findings over time, coupled with decreasing time-to-remediation metrics. The maturity of the framework becomes evident through an increasing percentage of automated remediation activities and a declining number of recurring issues. These improvements manifest in better audit outcomes, providing tangible evidence that the control framework is delivering its intended results.
Practical implementation: From theory to practice
Let’s examine how to implement a comprehensive control framework using a common security requirement: preventing exposure of sensitive data through public S3 buckets. This example demonstrates how different control types work together to create defense in depth. While not every control might be necessary for every situation, each should be carefully considered and evaluated based on various factors including system criticality, data sensitivity, operational overhead, and organizational risk tolerance. The decision to implement or omit specific controls should be deliberate and documented, rather than occurring by default.
The architecture will have layers and components like the following.
- Preventative layer:
- Service control policies (SCPs) or resource control policies (RCPs)
- S3 Block Public Access
- IAM policies
- Detective layer:
- Responsive layer:
- AWS Config auto-remediation
- Lambda functions
- Systems Manager automation
Building controls at each layer
An effective security and compliance strategy includes all four types of security controls. While preventative controls are a first line of defense to help prevent unauthorized access or unwanted changes to your network, it’s important to make sure that you establish detective and responsive controls so that you know when an event occurs and can take immediate and appropriate action to remediate it. Using proactive controls adds another layer of security because it complements preventative controls, which are generally stricter in nature.
Begin by defining your security objectives, then establish clear policies to meet those objectives:
- Define organizational and business objectives:
- Identify data protection goals
- Determine acceptable risk levels
- Align with compliance requirements
- Establish clear policies:
- For example, document business requirements for external data sharing and access controls in security policies. These requirements will drive technical decisions around AWS storage configurations such as S3 bucket policies and public access settings.
- Define permitted use cases for public access.
- Establish exception processes.
- Set clear ownership and responsibilities.
Deploy preventative guardrails:
- Organization level:
- SCPs to block public bucket creation at the organization level
- Account-level S3 Block Public Access settings to enforce account-level restrictions
- Resource level:
- IAM policies restricting bucket policy modifications
- S3 bucket policy templates with controlled deployment
- RCPs to enforce rules on specific resource types across your organization
Deploy proactive guardrails:
- Infrastructure as code:
- Implement policy-as-code checks in CI/CD pipelines using:
- CloudFormation Guard
- cfn-nag
- AWS Config proactive rules
- Integrate with pull request workflows
- AWS Control Tower proactive controls:
- Enable relevant optional AWS Control Tower guardrails
Add detective controls by creating a monitoring framework:
- AWS CloudTrail for comprehensive API activity logging and auditing to enable investigation of unauthorized access attempts and configuration changes.
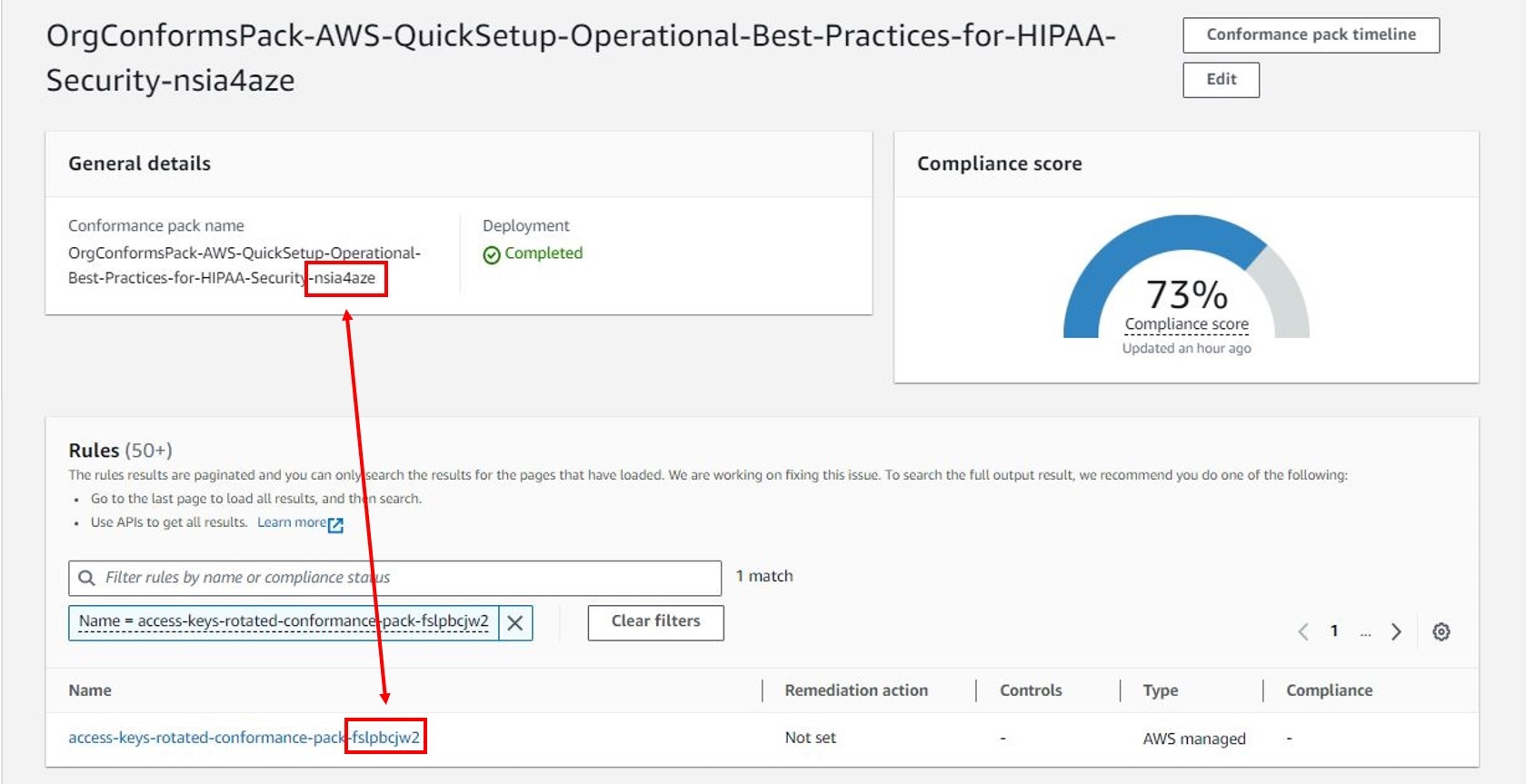
- AWS Config rules for bucket configuration. AWS Config rules or AWS Config conformance packs deployed for the entire organization can monitor S3 bucket configurations for compliance.
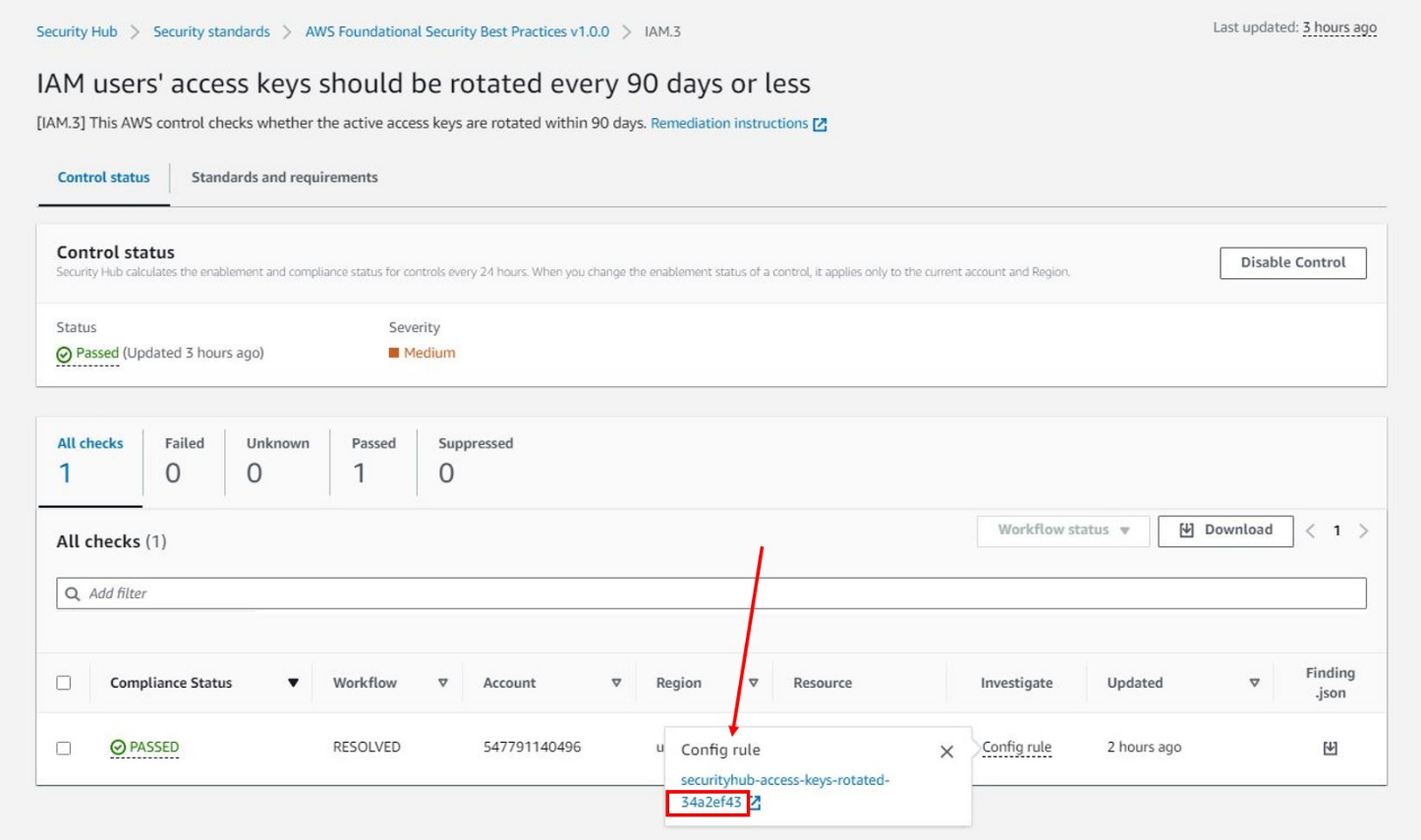
- Security Hub findings for continuous assessment by aggregating findings and flagging non-compliant resources.
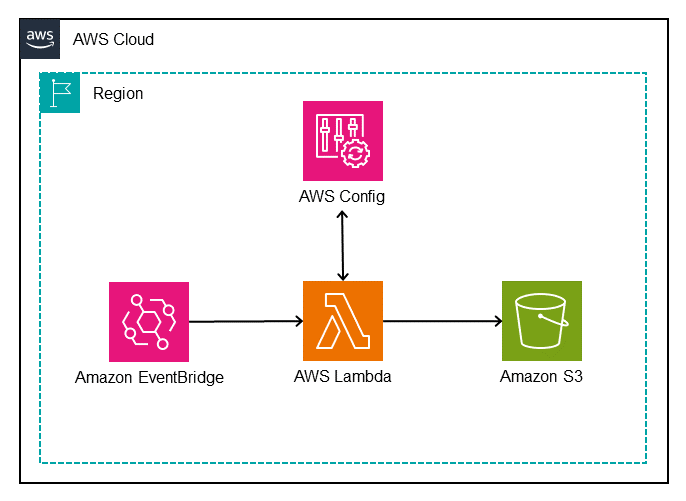
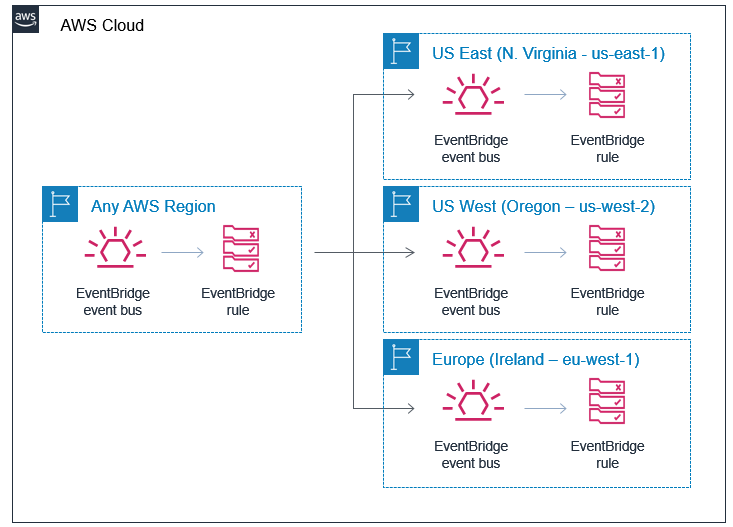
- Amazon EventBridge rules for policy changes to detect and route S3 bucket policy modifications.
- IAM Access Analyzer for external access review.
- Regular compliance reporting, which can be automated through AWS Audit Manager.
Implement responsive controls by automating remediation where possible:
- Security Hub and Systems Manager integration to automate incident response workflows.
- Custom Lambda functions for specific use cases.
- Integration with ITSM for human review when needed.
- AWS Config remediation rules For example, the AWSConfigRemediation-ConfigureS3PublicAccessBlock runbook configures an AWS account’s S3 Block Public Access settings based on the values you specify in the runbook parameters.
The following table describes control types, what a basic implementation includes, and the services and methods used for advanced implementation.
| Control type |
Basic implementation |
Advanced implementation |
| Preventative |
Documentation, peer reviews |
SCPs, RCPs, DPs, IAM policies, and S3 Block Public Access |
| Detective |
Security Hub, AWS Config rules |
Security Hub, AWS Config, and CloudWatch alerts |
| Responsive |
Manual remediation |
Auto-remediation through AWS Config, Systems Manager, EventBridge, and Lambda |
| Compliance |
One-time checks |
CIS/NIST mapping with Security Hub and automation of evidence collection and reporting using AWS Audit Manager |
| Automation |
Limited |
Full CI/CD Integration (for example, using CloudFormation or Terraform) |
| Cost optimization effort |
High (manual effort) |
Low (automation reduces overhead) |
Scaling and management considerations
As your security and governance program matures, scaling these controls across a growing organization requires thoughtful management and automation. This section explores key considerations for effectively managing your security posture at scale, optimizing costs, and maintaining consistency across your AWS environment. Whether you’re expanding across multiple accounts, business units, or AWS Regions, these practices help you balance security requirements with operational efficiency and cost management.
Use AWS services effectively:
- Consider deploying AWS Control Tower for consistent account setup and centrally deploying and managing controls at scale across multiple use cases and organizational units.
- AWS Organizations can aid hierarchical policy management and the implementation of:
- IAM policies for identity-based guardrails and permissions
- SCPs for access guardrails
- RCPs define permissions based on resource attributes
- DPs to help facilitate consistent resource configurations across your organization
- Tag policies for consistent resource categorization
- Backup policies for data protection standards
- AI service opt-out policies for data privacy requirements
- Cost allocation tag policies to standardize cost attribution
- Data residency policies to enforce regional restrictions
- Implement resource governance through policy integration
- For example, use Organizations tag policies to enforce a
Confidential tag on S3 buckets storing personally identifiable information (PII). Combine this with SCPs that mandate AES-256 encryption for tagged buckets, overriding developer attempts to disable it.
- Using backup policies to enforce retention rules (for example,
Retention=7 years).
- Use DPs to help maintain consistent security configurations across resources, such as enforcing encryption settings on Amazon Elastic Block Store (Amazon EBS) volumes or requiring specific security group rules.
- Centralize logging and monitoring
Manage compliance exceptions:
- Implement clear exception processes
- Document and track approved exceptions
- Establish regular periodic reviews of exceptions
- Use time-bound approvals with automated expiration
Optimize costs:
- Use periodic instead of continuous checking where appropriate
- Implement targeted monitoring based on resource criticality
- Use AWS Config recordings effectively
- Balance automation costs against manual effort
Conclusion: Moving forward with control maturity
Implementing a comprehensive control framework is a journey, not a destination. Start from your organization’s current position, whether that’s with basic detective controls or a fresh implementation, and focus on progressive improvement rather than attempting to implement everything at once. Success comes from carefully documenting decisions about control implementation, regularly reviewing them, and using automation to reduce operational overhead while improving consistency. Progress can be measured through concrete metrics: reduced findings, faster remediation times, and increased automation.
Remember that the goal extends beyond better security—it’s about transforming security and governance from a reactive operation to a strategic enabler that provides real business value. This transformation manifests through reduced risk from systematic controls, improved operational efficiency through automation, and enhanced visibility and governance. Perhaps most importantly, it frees security teams to focus on strategic initiatives rather than routine operational tasks.
By following this approach, you can build a robust security and governance posture that not only protects your organization’s AWS environment but also supports business innovation and growth. The result is a security program that evolves alongside the business, enabling rather than hindering progress, while maintaining a strong approach that can scale with your organization’s needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.

 A photo taken by Thembile Martis in AWS Summit Amsterdam 2025
A photo taken by Thembile Martis in AWS Summit Amsterdam 2025