Post Syndicated from Venkata Sistla original https://aws.amazon.com/blogs/big-data/patterns-for-enterprise-data-sharing-at-scale/
Data sharing is becoming an important element of an enterprise data strategy. AWS services like AWS Data Exchange provide an avenue for companies to share or monetize their value-added data with other companies. Some organizations would like to have a data sharing platform where they can establish a collaborative and strategic approach to exchange data with a restricted group of companies in a closed, secure, and exclusive environment. For example, financial services companies and their auditors, or manufacturing companies and their supply chain partners. This fosters development of new products and services and helps improve their operational efficiency.
Data sharing is a team effort, it’s important to note that in addition to establishing the right infrastructure, successful data sharing also requires organizations to ensure that business owners sponsor data sharing initiatives. They also need to ensure that data is of high quality. Data platform owners and security teams should encourage proper data use and fix any privacy and confidentiality issues.
This blog discusses various data sharing options and common architecture patterns that organizations can adopt to set up their data sharing infrastructure based on AWS service availability and data compliance.
Data sharing options and data classification types
Organizations operate across a spectrum of security compliance constraints. For some organizations, it’s possible to use AWS services like AWS Data Exchange. However, organizations working in heavily regulated industries like federal agencies or financial services might be limited by the allow listed AWS service options. For example, if an organization is required to operate in a Fedramp Medium or Fedramp High environment, their options to share data may be limited by the AWS services that are available and have been allow listed. Service availability is based on platform certification by AWS, and allow listing is based on the organizations defining their security compliance architecture and guidelines.
The kind of data that the organization wants to share with its partners may also have an impact on the method used for data sharing. Complying with data classification rules may further limit their choice of data sharing options they may choose.
The following are some general data classification types:
- Public data – Important information, though often freely available for people to read, research, review and store. It typically has the lowest level of data classification and security.
- Private data – Information you might want to keep private like email inboxes, cell phone content, employee identification numbers, or employee addresses. If private data were shared, destroyed, or altered, it might pose a slight risk to an individual or the organization.
- Confidential or restricted data – A limited group of individuals or parties can access sensitive information often requiring special clearance or special authorization. Confidential or restricted data access might involve aspects of identity and authorization management. Examples of confidential data include Social Security numbers and vehicle identification numbers.
The following is a sample decision tree that you can refer to when choosing your data sharing option based on service availability, classification type, and data format (structured or unstructured). Other factors like usability, multi-partner accessibility, data size, consumption patterns like bulk load/API access, and more may also affect the choice of data sharing pattern.

In the following sections, we discuss each pattern in more detail.
Pattern 1: Using AWS Data Exchange
AWS Data Exchange makes exchanging data easier, helping organizations lower costs, become more agile, and innovate faster. Organizations can choose to share data privately using AWS Data Exchange with their external partners. AWS Data Exchange offers perimeter controls that are applied at identity and resource levels. These controls decide which external identities have access to specific data resources. AWS Data Exchange provides multiple different patterns for external parties to access data, such as the following:
- AWS Data Exchange for Amazon Redshift
- AWS Data Exchange for AWS Lake Formation (currently in preview)
- AWS Data Exchange for Data APIs
- AWS Data Exchange for data files
- AWS Data Exchange for Amazon S3 (currently in preview)
The following diagram illustrates an example architecture.
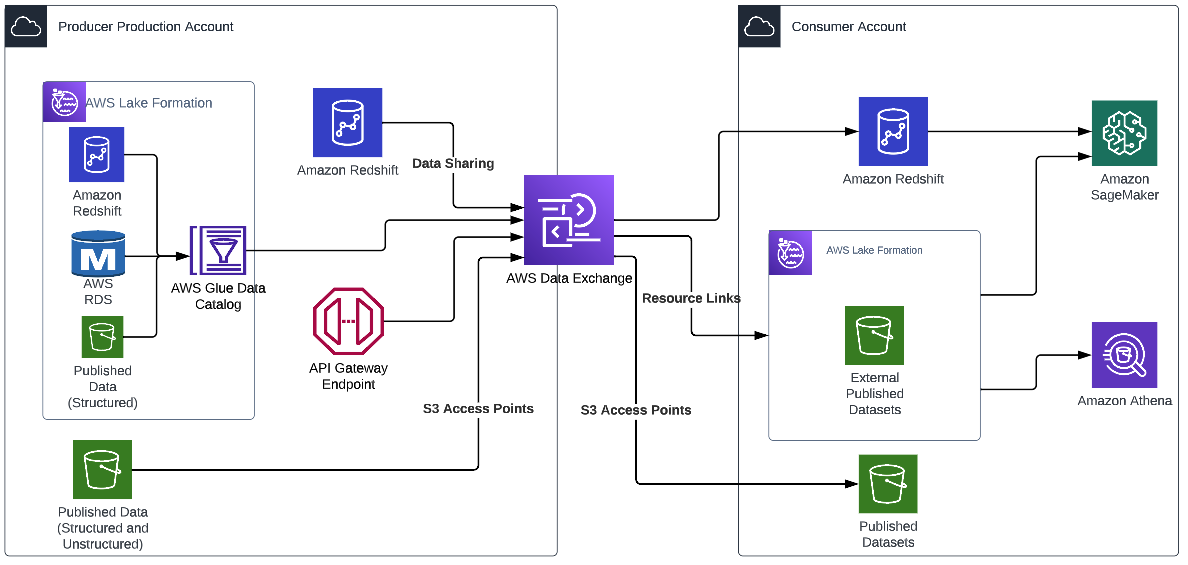
With AWS Data Exchange, once the dataset to share (or sell) is configured, AWS Data Exchange automatically manages entitlements (and billing) between the producer and the consumer. The producer doesn’t have to manage policies, set up new access points, or create new Amazon Redshift data shares for each consumer, and access is automatically revoked if the subscription ends. This can significantly reduce the operational overhead in sharing data.
Pattern 2: Using AWS Lake Formation for centralized access management
You can use this pattern in cases where both the producer and consumer are on the AWS platform with an AWS account that is enabled to use AWS Lake Formation. This pattern provides a no-code approach to data sharing. The following diagram illustrates an example architecture.
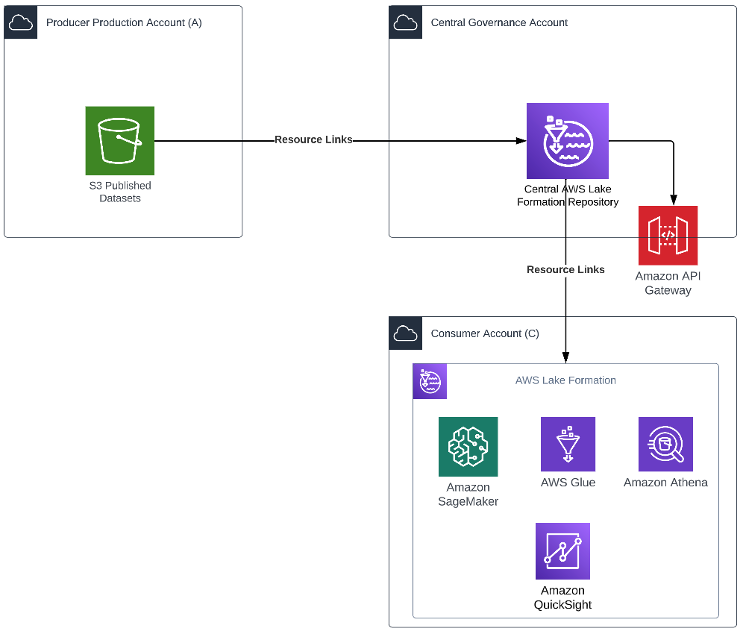
In this pattern, the central governance account has Lake Formation configured for managing access across the producer’s org accounts. Resource links from the production account Amazon Simple Storage Service (Amazon S3) bucket are created in Lake Formation. The producer grants Lake Formation permissions on an AWS Glue Data Catalog resource to an external account, or directly to an AWS Identity and Access Management (IAM) principal in another account. Lake Formation uses AWS Resource Access Manager (AWS RAM) to share the resource. If the grantee account is in the same organization as the grantor account, the shared resource is available immediately to the grantee. If the grantee account is not in the same organization, AWS RAM sends an invitation to the grantee account to accept or reject the resource grant. To make the shared resource available, the consumer administrator in the grantee account must use the AWS RAM console or AWS Command Line Interface (AWS CLI) to accept the invitation.
Authorized principals can share resources explicitly with an IAM principal in an external account. This feature is useful when the producer wants to have control over who in the external account can access the resources. The permissions the IAM principal receives are a union of direct grants and the account-level grants that are cascaded down to the principals. The data lake administrator of the recipient account can view the direct cross-account grants, but can’t revoke permissions.
Pattern 3: Using AWS Lake Formation from the producer external sharing account
The producer may have stringent security requirements where no external consumer should access their production account or their centralized governance account. They may also not have Lake Formation enabled on their production platform. In such cases, as shown in the following diagram, the producer production account (Account A) is dedicated to its internal organization users. The producer creates another account, the producer external sharing account (Account B), which is dedicated for external sharing. This gives the producer more latitude to create specific policies for specific organizations.
The following architecture diagram shows an overview of the pattern.
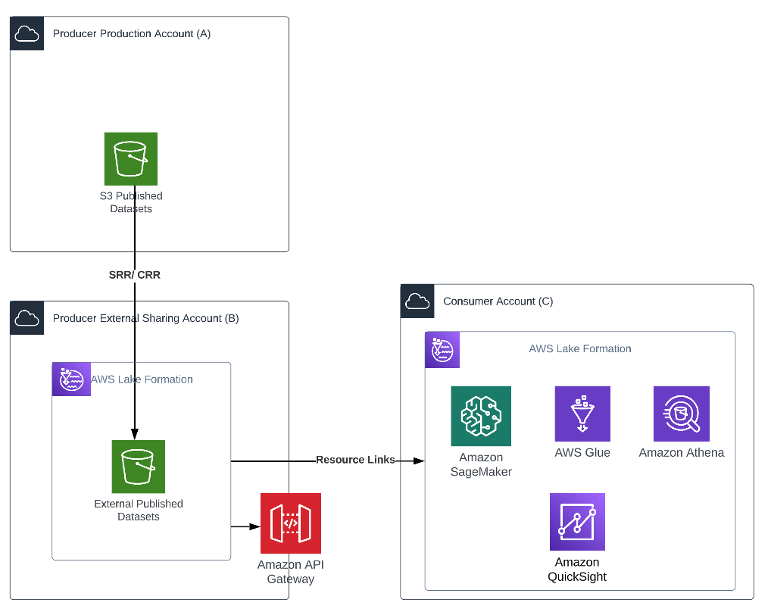
The producer implements a process to create an asynchronous copy of data in Account B. The bucket can be configured for Same Region Replication (SRR) or Cross Region Replication (CRR) for objects that need to be shared. This facilitates automated refresh of data to the external account to the “External Published Datasets” S3 bucket without having to write any code.
Creating a copy of the data allows the producer to add another degree of separation between the external consumer and its production data. It also helps meet any compliance or data sovereignty requirements.
Lake Formation is set up on Account B, and the administrator creates resources links for the “External Published Datasets” S3 bucket in its account to grant access. The administrator follows the same process to grant access as described earlier.
Pattern 4: Using Amazon Redshift data sharing
This pattern is ideally suited for a producer who has most of their published data products on Amazon Redshift. This pattern also requires the producer’s external sharing account (Account B) and the consumer account (Account C) to have an encrypted Amazon Redshift cluster or Amazon Redshift Serverless endpoint that meets the prerequisites for Amazon Redshift data sharing.
The following architecture diagram shows an overview of the pattern.
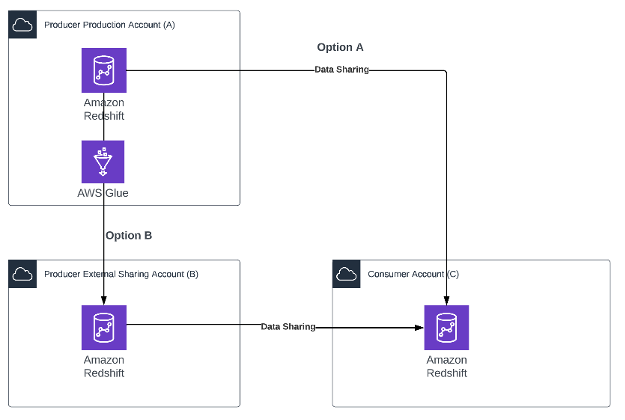
Two options are possible depending on the producer’s compliance constraints:
- Option A – The producer enables data sharing directly on the production Amazon Redshift cluster.
- Option B – The producer may have constraints with respect to sharing the production cluster. The producer creates a simple AWS Glue job that copies data from the Amazon Redshift cluster in the production Account A to the Amazon Redshift cluster in the external Account B. This AWS Glue job can be scheduled to refresh data as needed by the consumer. When the data is available in Account B, the producer can create multiple views and multiple data shares as needed.
In both options, the producer maintains complete control over what data is being shared, and the consumer admin maintains full control over who can access the data within their organization.
After both the producer and consumer admins approve the data sharing request, the consumer user can access this data as if it were part of their own account without have to write any additional code.
Pattern 5: Sharing data securely and privately using APIs
You can adopt this pattern when the external partner doesn’t have a presence on AWS. You can also use this pattern when published data products are spread across various services like Amazon S3, Amazon Redshift, Amazon DynamoDB, and Amazon OpenSearch Service but the producer would like to maintain a single data sharing interface.
Here’s an example use case: Company A would like to share some of its log data in near-real time with its partner Company B, who uses this data to generate predictive insights for Company A. Company A stores this data in Amazon Redshift. The company wants to share this transactional information with its partner after masking the personally identifiable information (PII) in a cost-effective and secure way to generate insights. Company B doesn’t use the AWS platform.
Company A establishes a microbatch process using an AWS Lambda function or AWS Glue that queries Amazon Redshift to get incremental log data, applies the rules to redact the PII, and loads this data to the “Published Datasets” S3 bucket. This instantiates an SRR/CRR process that refreshes this data in the “External Sharing” S3 bucket.
The following diagram shows how the consumer can then use an API-based approach to access this data.
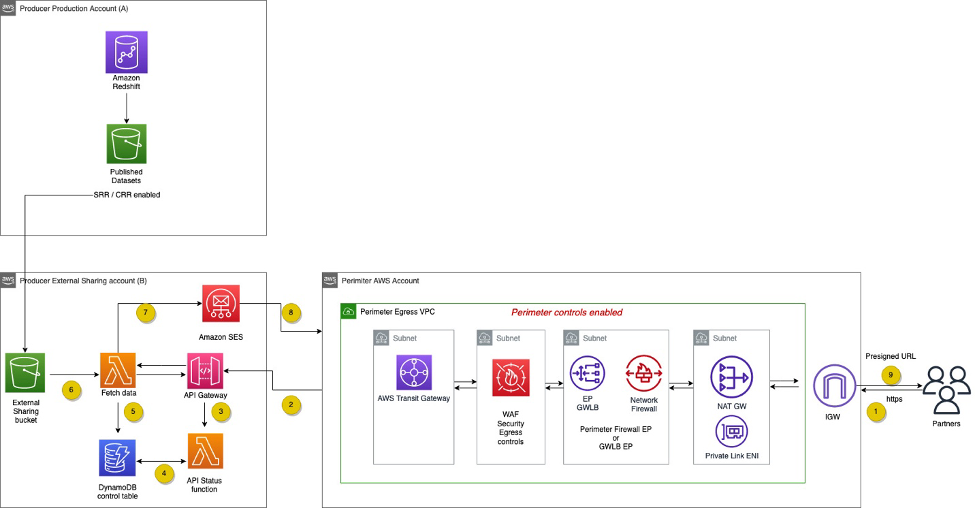
The workflow contains the following steps:
- An HTTPS API request is sent from the API consumer to the API proxy layer.
- The HTTPS API request is forwarded from the API proxy to Amazon API Gateway in the external sharing AWS account.
- Amazon API Gateway calls the request receiver Lambda function.
- The request receiver function writes the status to a DynamoDB control table.
- A second Lambda function, the poller, checks the status of the results in the DynamoDB table.
- The poller function fetches results from Amazon S3.
- The poller function sends a presigned URL to download the file from the S3 bucket to the requestor via Amazon Simple Email Service (Amazon SES).
- The requestor downloads the file using the URL.
- The network perimeter AWS account only allows egress internet connection.
- The API proxy layer enforces both the egress security controls and perimeter firewall before the traffic leaves the producer’s network perimeter.
- The AWS Transit Gateway security egress VPC routing table only allows connectivity from the required producer’s subnet, while preventing internet access.
Pattern 6: Using Amazon S3 access points
Data scientists may need to work collaboratively on image, videos, and text documents. Legal and audit groups may want to share reports and statements with the auditing agencies. This pattern discusses an approach to sharing such documents. The pattern assumes that the external partners are also on AWS. Amazon S3 access points allow the producer to share access with their consumer by setting up cross-account access without having to edit bucket policies.
Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations, such as GetObject and PutObject. Each access point has distinct permissions and network controls that Amazon S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy attached to the underlying bucket.
The following architecture diagram shows an overview of the pattern.
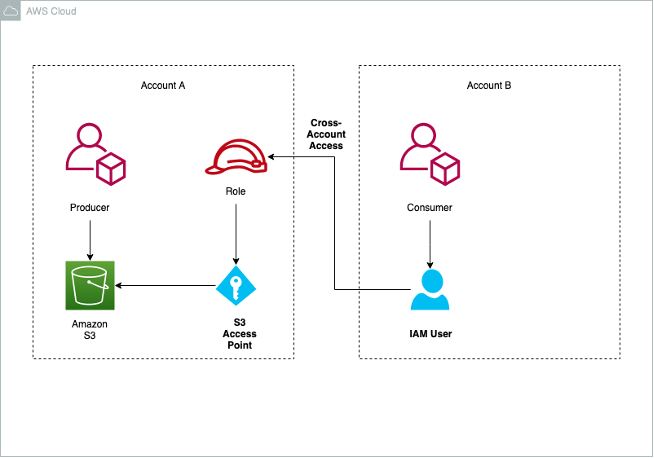
The producer creates an S3 bucket and enables the use of access points. As part of the configuration, the producer specifies the consumer account, IAM role, and privileges for the consumer IAM role.
The consumer users with the IAM role in the consumer account can access the S3 bucket via the internet or restricted to an Amazon VPC via VPC endpoints and AWS PrivateLink.
Conclusion
Each organization has its unique set of constraints and requirements that it needs to fulfill to set up an efficient data sharing solution. In this post, we demonstrated various options and best practices available to organizations. The data platform owner and security team should work together to assess what works best for your specific situation. Your AWS account team is also available to help.
Related resources
For more information on related topics, refer to the following:
- Data perimeters on AWS
- AWS Data Exchange
- Securely share your data across AWS accounts using AWS Lake Formation
- Sharing data across clusters in Amazon Redshift
- Setting up cross-account Amazon S3 access with S3 Access Points
About the Authors
 Venkata Sistla is a Cloud Architect – Data & Analytics at AWS. He specializes in building data processing capabilities and helping customers remove constraints that prevent them from leveraging their data to develop business insights.
Venkata Sistla is a Cloud Architect – Data & Analytics at AWS. He specializes in building data processing capabilities and helping customers remove constraints that prevent them from leveraging their data to develop business insights.
 Santosh Chiplunkar is a Principal Resident Architect at AWS. He has over 20 years of experience helping customers solve their data challenges. He helps customers develop their data and analytics strategy and provides them with guidance on how to make it a reality.
Santosh Chiplunkar is a Principal Resident Architect at AWS. He has over 20 years of experience helping customers solve their data challenges. He helps customers develop their data and analytics strategy and provides them with guidance on how to make it a reality.