Post Syndicated from Aurelien Plancque original https://aws.amazon.com/blogs/devops/mastering-amazon-q-developer-with-rules/
When I first started working with Amazon Q Developer, I was impressed by its capabilities, but I quickly found myself in a familiar pattern. Development teams using AI assistants face a common challenge: repeatedly explaining coding standards, workflow preferences, and established patterns in every conversation. This repetitive setup reduces productivity and creates inconsistent AI guidance across team members. Sound familiar?
That’s when I discovered the power of custom rules – and it completely transformed how I work with AI assistance.
What Are Amazon Q Developer Rules?
Rules in Amazon Q Developer are a way to build a library of coding standards and best practices that are automatically used as context when interacting with the assistant.
These rules are defined in Markdown files stored in your project’s .amazonq/rules folder. Once created, they automatically become part of the context for developers interacting with Amazon Q Developer within your project, maintaining consistency across team members regardless of their experience level. Currently, rules are supported in the Amazon Q Developer IDE extensions and in the Amazon Q Developer CLI.
The Power of Rules-Based AI Assistance
What I find most compelling about rules-based AI assistance is how it minimizes the repetitive setup that usually comes with AI interactions. Instead of repeatedly instructing your AI assistant on your preferences and standards for each request, you can define these once as rules. This creates a consistent, predictable AI experience that automatically respects your team’s conventions and best practices.
The real game-changer for me has been the consistency. Whether I’m working on a new feature, debugging an issue, or reviewing code, Amazon Q Developer now understands my context from the start. This means I can focus on the actual problem-solving instead of repeatedly explaining how I like things done.
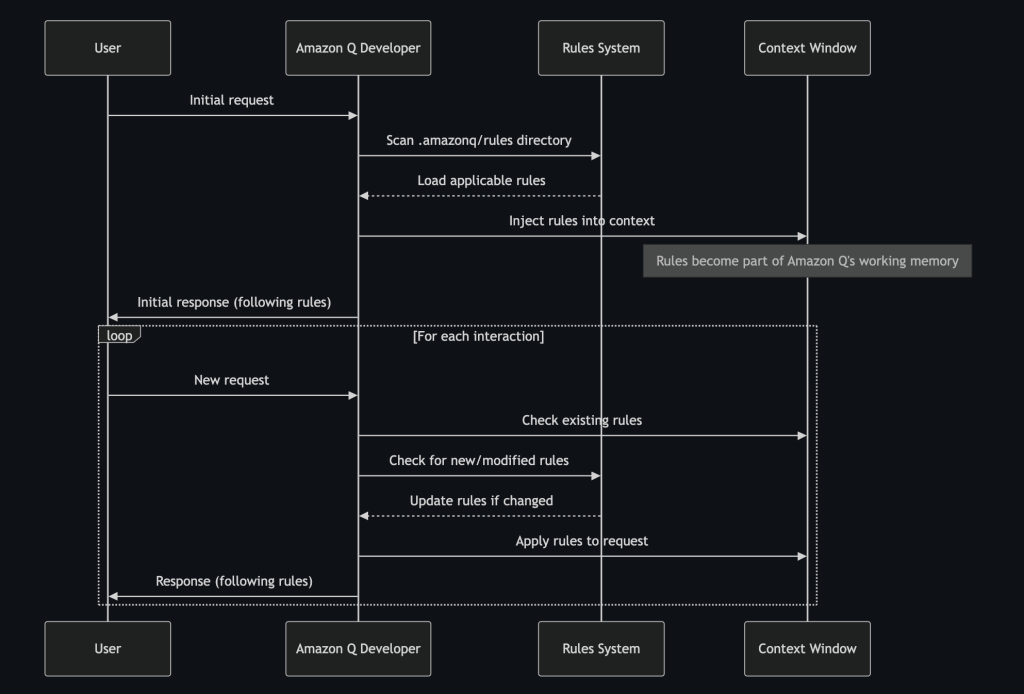
Understanding the Rule Lifecycle
One thing that consistently surprises developers is how seamlessly rules integrate into Amazon Q Developer workflow. Understanding when and how rules are injected into the context helps you make the most of this capability. Here’s how the process works:

The rule lifecycle in Amazon Q Developer
Rules are injected at several key moments:
1. Initial Context Loading: When you first interact with Amazon Q Developer in a project, it scans the `.amazonq/rules` directory and loads the applicable rules into its context.
2. Request Processing: Before generating a response, Amazon Q Developer evaluates your request against the loaded rules to determine which ones apply.
3. Response Generation: While crafting its response, Amazon Q Developer follows the instructions from applicable rules, prioritizing them based on their specified priority levels.
4. Dynamic Updates: If you modify existing rules or add new ones during a session, Amazon Q Developer detects these changes and updates its behavior accordingly.
This continuous integration makes sure that Amazon Q Developer’s responses consistently align with your standards without requiring you to repeat instructions in every conversation.
Why Rules-Based AI Makes a Difference ?
What I’ve found most valuable about this approach is how it transforms the AI from a generic assistant into something that feels like it truly understands your team’s way of working. Here are the key benefits I’ve experienced:
Consistency: Every team member gets the same AI-guided experience, making sure code and documentation remain consistent regardless of who wrote them.
Knowledge Preservation: Rules capture your team’s accumulated wisdom and best practices, making them accessible to everyone.
Reduced Cognitive Load: You can focus on solving problems rather than remembering and enforcing standards.
Faster Onboarding: New team members automatically receive guidance aligned with your team’s practices.
Adaptability: Rules can evolve alongside your project, making sure AI assistance remains relevant as your needs change.
The difference between generic AI assistance and rules-guided assistance becomes clear quickly. Generic AI might suggest any valid solution, while rules-guided AI suggests solutions that fit your specific context and standards.
Building Effective Rules: A Practical Approach
Now that you’ve seen the power of rules, let me walk you through how to create them. While there’s no “official” format for Amazon Q Developer rules (the beauty is in the flexibility!), the approach I’m about to share has consistently delivered excellent results for me and my team.
Rule File Format and Location
Here’s what I’ve learned about organizing rules for Amazon Q Developer:
- Rules must be written in Markdown format (.md files)
- They should be placed in the
.amazonq/rules directory of your project
- You can use a filename of your choice, though descriptive names help with organization (examples:
monitoring-rule.md, frontend-react.rule.md)
- Rules can be organized in sub-directories for better structure (for example,
.amazonq/rules/frontend/react.rule.md)
- The filename itself is arbitrary – Amazon Q Developer will read the .md files in the directory. However, using meaningful names makes your rule system easier to maintain as it grows.
Essential Rule Structure
What I find works best is a well-crafted rule file that contains these key sections:
# Rule Name
## Purpose
A clear, concise statement explaining why this rule exists.
## Instructions
- Specific directives for Amazon Q Developer to follow
- Additional instructions with their own identifiers
- Conditions under which instructions apply
## Priority
[Critical/High/Medium/Low]
## Error Handling
- How Amazon Q Developer should behave when exceptions occur
- Fallback strategies when primary instructions can't be followed
Let me show you this structure in action with a complete example of a monitoring rule that has been particularly effective for my team:
# Monitoring
## Purpose
This rule ensures that monitoring coverage is maintained when major features are added to the project.
## Instructions
- When implementing a major feature (new service, API endpoint, or core functionality), ALWAYS check if MONITORING_PLAN.md needs updates.
- Major features include: new microservices, AI integrations, WebSocket endpoints, database operations, external API integrations, or user-facing functionality.
- ALWAYS update MONITORING_PLAN.md to include relevant metrics, dashboards, and alerts for the new feature.
- When updating monitoring plan, include: custom metrics, CloudWatch dashboards, alarms, and logging requirements specific to the new feature.
- After updating MONITORING_PLAN.md, ALWAYS output "📊 Updated monitoring plan for: [feature description]".
## Priority
High
## Error Handling
- If MONITORING_PLAN.md doesn't exist, create it with basic monitoring structure and note the creation
- If monitoring plan is unreadable, create a backup and start fresh with current feature requirements
- If unsure whether a feature qualifies as "major", err on the side of caution and update monitoring plan
I saved this as monitoring.rule.md in my project’s .amazonq/rules directory.
Rule Components That Work
Now let me break down each component and show you why this structure works so well.
Rule Name
Think of this as the “class name” for your rule. It should be descriptive and domain-specific, like “Frontend – React” or “Monitoring.” This helps organize your rules into logical categories and makes them easier to maintain as your ruleset grows.
Purpose
This section is crucial, it’s where you explain the “why” behind your rule. What I’ve learned is that a clear purpose helps Amazon Q Developer understand the intent behind your instructions, allowing it to make better decisions when faced with edge cases. For example:
## Purpose
Ensures consistent monitoring coverage is maintained when adding new features to the project.
This simple statement guides Amazon Q Developer to prioritize monitoring considerations, even when they’re not explicitly mentioned in your request.
Instructions
This is where the magic happens. Instructions are specific directives that shape Amazon Q Developer’s behavior. What I’ve found works best is when each instruction:
- Is clear and actionable
- Focuses on a single aspect of behavior
- Uses consistent formatting for easy scanning
For example:
## Instructions
- When implementing a major feature, ALWAYS check if MONITORING_PLAN.md needs updates.
- Major features include: new microservices, AI integrations, WebSocket endpoints.
- After updating MONITORING_PLAN.md, output "📊 Updated monitoring plan for: [feature]".
These clear, focused instructions give Amazon Q Developer specific guidance on how to behave in different situations, maintaining consistent responses across your team.
Priority
Not all rules are created equal. What I’ve discovered is that the priority level helps Amazon Q Developer resolve conflicts when multiple rules could apply to a situation. I typically use four levels:
- Critical: Must be followed without exception
- High: Should be followed unless conflicting with a critical rule
- Medium: Important guidelines that shape behavior
- Low: Preferences that can be overridden when necessary
Error Handling
This often-overlooked section is what makes rules robust in real-world scenarios. Good error handling instructions tell Amazon Q Developer what to do when things don’t go as planned:
## Error Handling
- If MONITORING_PLAN.md doesn't exist, create it with basic monitoring structure
- If unsure whether a feature qualifies as "major," err on the side of caution
These fallback strategies make sure Amazon Q Developer remains helpful even when facing unexpected situations.
Seeing Rules in Action
To show you how effective this structure can be, let me give you a simple example. Without rules, asking Amazon Q Developer to “add a new React component for user profiles” might result in a component that doesn’t match your project’s patterns.
But with a well-crafted frontend rule, Amazon Q Developer would automatically:
- Check existing component structures
- Follow your naming conventions
- Create appropriate prop interfaces
- Add the right level of documentation
- Place the file in your preferred directory structure
All without you having to specify these details every time!
Making Rules Transparent: A Game-Changing Technique
One particularly powerful technique I’ve discovered is teaching Amazon Q Developer to explicitly acknowledge which rules it’s following. This isn’t a default behavior of Amazon Q Developer, but rather a custom enhancement you can implement through a specific conversation rule.
Adding Unique Identifiers for Traceability
The key to this system is adding unique identifiers (IDs) to each instruction in your rules. For example:
## Instructions
- When implementing a major feature, ALWAYS check if MONITORING_PLAN.md needs updates. (ID: CHECK_MONITORING_PLAN)
- Major features include: new microservices, AI integrations, WebSocket endpoints. (ID: MAJOR_FEATURE_CRITERIA)
- After updating MONITORING_PLAN.md, output "📊 Updated monitoring plan for: [feature]". (ID: ANNOUNCE_MONITORING_UPDATE)
These IDs serve as “traceable markers” that Amazon Q Developer can reference when following a rule.
Creating the Acknowledgment Behavior
Next, you can create a conversation rule that instructs Amazon Q Developer to acknowledge which rules it’s following. Here’s a complete example of such a rule:
# Conversation
## Purpose
This rule defines how Amazon Q Developer should behave in conversations, including how it should acknowledge other rules it's following.
## Instructions
- ALWAYS consider your rules before using a tool or responding. (ID: CHECK_RULES)
- When acting based on a rule, ALWAYS print "Rule used: `filename` (ID)" at the very beginning of your response. (ID: PRINT_RULES)
- If multiple rules are matched, list all: "Rule used: `file1.rule.md` (ID1), `file2.rule.md` (ID2)". (ID: PRINT_MULTIPLE)
- DO NOT start responses with general mentions about using rules or context, but DO print specific rule usage as specified above. (ID: NO_GENERIC_MENTIONS)
## Priority
Critical
## Error Handling
- If rule files are unreadable, continue but note the issue
- If multiple conflicting rules apply, follow the highest priority rule and note the conflict
Save this as conversation.rule.md in your .amazonq/rules directory.
When Amazon Q Developer follows a rule, it will now explicitly state which rule and identifier guided its actions:

You can get Amazon Q Developer to state which instruction it is following.
What I find most valuable about this simple addition is the remarkable benefits it creates:
- Transparency: Team members can immediately see which guidelines influenced Amazon Q Developer’s response
- Debugging: When Amazon Q Developer behaves unexpectedly, you can identify which rule caused the behavior
- Learning: New team members discover relevant rules by seeing which ones are being applied
- Validation: You can confirm that your rules are working as intended
- Continuous Improvement: Identify which rules are most frequently used and which might need refinement
By making rules visible, you turn Amazon Q Developer into a collaborative partner that not only follows your guidelines and helps team members discover and engage with your established practices. The IDs aren’t just organizational tools—they’re the foundation of a self-documenting AI assistance workflow that grows more valuable as your rule system expands.
Getting Started with Your Own Rules
What I love about this approach is that you can start small. Begin with one or two rules addressing your most common pain points, then expand as you see the benefits. Some good starting points include:
- Code style and organization rules
- Documentation standards
- Testing requirements
- Git commit message formats
Remember, the goal isn’t to create an exhaustive rulebook—it’s to capture the aspects of your development process that matter most to your team’s productivity and code quality.
Practical Examples: Rules in Action
To show you the real-world impact of rules, let me walk you through some concrete scenarios that demonstrate how rules transform the AI assistance experience. These examples show the difference between generic AI help and rules-guided assistance.
Scenario 1: Time-Based Data Analysis
This scenario demonstrates how rules help Amazon Q Developer understand your environment’s context for time-related operations and analysis. Here are examples of this rule in action in VS Code.
Here is a rule I use to inform Amazon Q Developer how to behave when it needs to understand the current time:
# Time
## Purpose
This rule defines how Amazon Q Developer (the agent) handles time-related operations and queries
## Instructions
- When determining the current time, ALWAYS use bash commands with AEST timezone: `date` (ID: GET_AEST_TIME)
- When timestamps are needed for logging or documentation, use ISO format with AEST timezone (ID: ISO_TIMESTAMP)
- When comparing times or calculating durations, ensure all times are in AEST for consistency (ID: CONSISTENT_TIMEZONE)
- For time-sensitive operations, always verify the current AEST time before proceeding (ID: VERIFY_TIME)
## Priority
Medium
## Error Handling
- If date command fails, note the system time issue and continue with available information
- If timezone conversion is needed, use appropriate date formatting commands
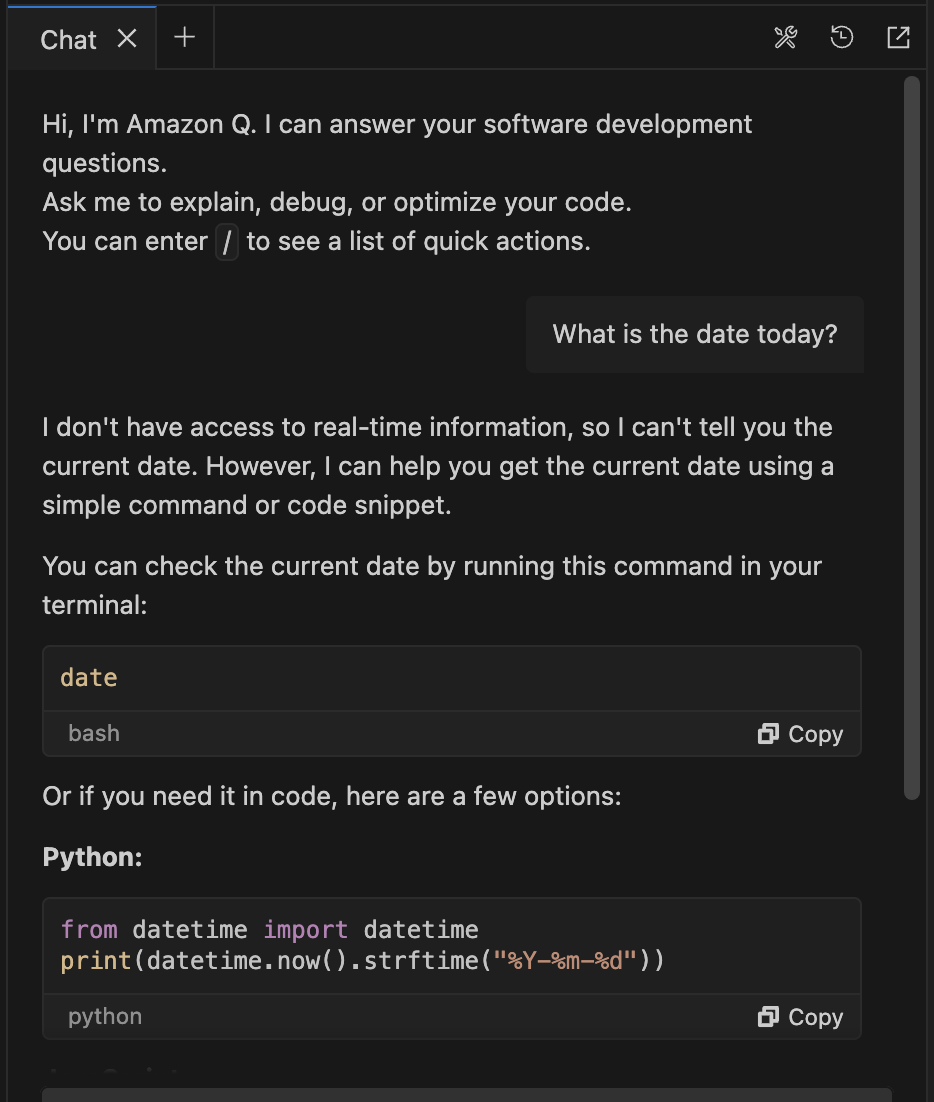
Without Rules:
When Amazon Q Developer doesn’t have the time rule, it lacks the context needed for time-based queries:

An Amazon Q Developer interaction without a time rule
As you can see, without the rule, Amazon Q Developer needs clarification about timezone context and doesn’t know how to determine the current time in your environment.
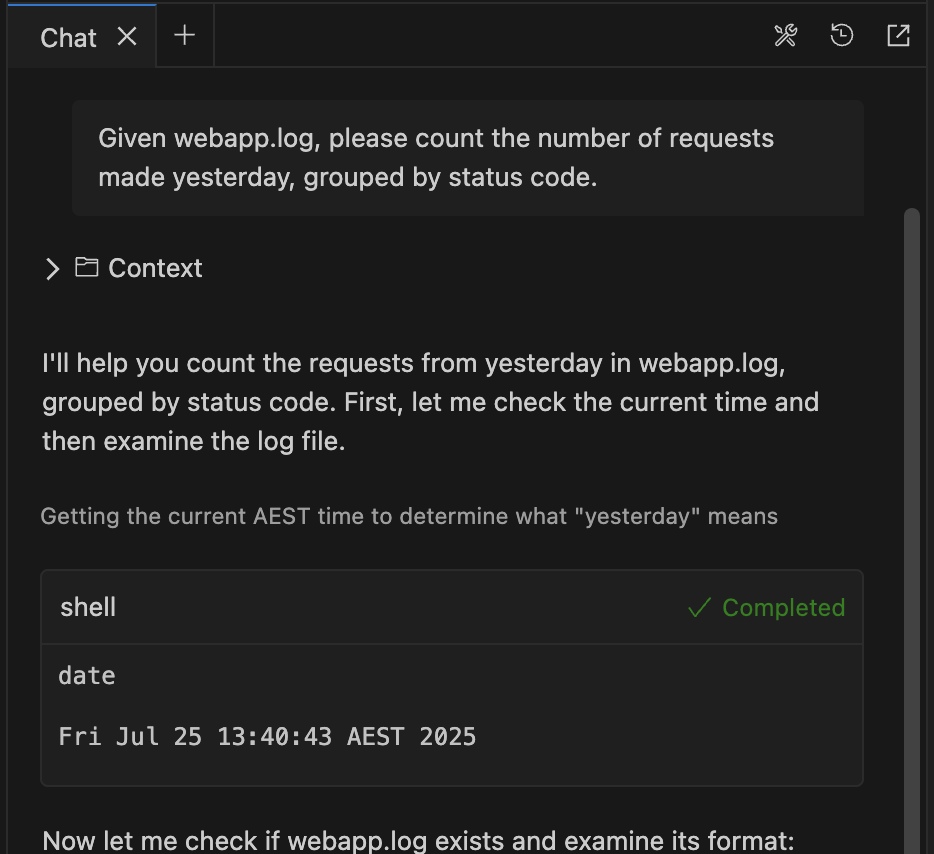
With the Time Rule:
Here’s a similar query with the time rule in place:

Amazon Q Developer follows the instructions of the rule
Notice how Amazon Q Developer immediately uses the `date` command to get the current AEST time, exactly as specified in the rule, without needing clarification.
The Impact:
- Automatic Context: Amazon Q Developer immediately knows to use the
date command to get AEST time
- No Clarification Needed: It understands “yesterday” relative to the current AEST time without asking
- Consistent Behavior: The same approach works for other time-based queries across team members
- Environmental Awareness: It knows exactly how to determine time in your specific system environment
- Transparent Process: You can see it’s following the rule by using the bash
date command as specified
This example shows how the time rule transforms a potentially confusing interaction into a smooth, context-aware analysis that works consistently every time.
Scenario 2: Frontend Component Development
This scenario demonstrates how rules can help prevent technical debt accumulation and maintain consistent component architecture across your team.
Without Rules:
When Amazon Q Developer doesn’t have frontend-specific guidance, different developers can get inconsistent suggestions for component creation. Some might create reusable components immediately, others get copy-paste solutions, and component organization varies based on individual preferences.
With Frontend Rules:
Here’s a real React rule from my development workflow that addresses these consistency issues:
# Frontend - React
## Purpose
Defines how to act when writing React
## Instructions
- ALWAYS evaluate reusability potential for new visual elements using these criteria: used in 2+ places, has configurable props, or represents a common UI pattern. (ID: EVALUATE_REUSABILITY)
- If reusability potential is high (meets 2+ criteria above), create a dedicated component in appropriate folder (components/, shared/, or ui/) with clear prop interfaces and JSDoc comments. (ID: CREATE_REUSABLE_COMPONENT)
- When creating reusable components, include explicit comments explaining: purpose, key props, usage examples, and any important behavior. (ID: DOCUMENT_COMPONENTS)
- Follow existing component structure and naming conventions found in the project's components folder. (ID: FOLLOW_CONVENTIONS)
- Prefer composition over inheritance - create small, focused components that can be combined. (ID: PREFER_COMPOSITION)
## Priority
Medium
## Error Handling
- If component folder structure is unclear, place new components in src/components/ and ask user for preferred organization
- If existing conventions are inconsistent, follow the most recent or most common pattern and note the inconsistency
The Impact:
- Consistent Architecture: Team members get the same component creation guidance regardless of experience level
- Reduced Technical Debt: Automatic evaluation of reusability helps prevent duplicated UI elements
- Better Documentation: Components automatically include proper JSDoc comments and usage examples
- Maintainable Structure: Consistent naming conventions and folder organization across the project
- Scalable Patterns: Composition-focused approach creates more flexible, reusable components
This make sure that whether a junior developer or senior architect is working with Amazon Q Developer, the resulting components follow the same quality standards and architectural patterns.
Scenario 3: Version Control Workflow
This scenario demonstrates how rules can act as safety mechanisms and workflow controllers, facilitating consistent practices around version control operations.
Without Rules:
Amazon Q Developer might suggest git operations without considering your team’s workflow preferences or safety requirements. It could recommend immediate pushes, generic commit messages, or skip confirmation steps that help prevent mistakes.
With Git Rules:
Here’s a real git rule that transforms how Amazon Q Developer handles version control operations:
# Git
## Purpose
This rule dictates Amazon Q Developer (the agent) behavior related to git.
## Instructions
- ALWAYS ask confirmation from the user before pushing to git (ID: GIT_PUSH)
- ALWAYS ensure commit messages are meaningful and detailed, including what was changed and why (ID: GIT_COMMIT)
- Commit message should be accurate but playful and not too formal, with comprehensive details about the changes (ID: GIT_COMMIT_STYLE)
- Include specific files/components modified and the impact of changes in commit messages (ID: GIT_COMMIT_DETAILS)
## Priority
Medium
## Error Handling
N/A
Here’s this rule in action when I asked Amazon Q Developer to commit our changes:
> Let's commit our latest changes to git.
> Rule used: git.rule.md (GIT_COMMIT), git.rule.md (GIT_COMMIT_STYLE),
git.rule.md (GIT_COMMIT_DETAILS)
I'll commit all the changes we've made to remove messaging functionality and
focus the platform on location-based discovery. Let me create a comprehensive
commit with all the modifications.
🛠 Using tool: execute_bash (trusted)
● I will run the following shell command:
cd /path/to/your/project/rules-blog && git status
↳ Purpose: Check git status to see all changed files
On branch main
Changes not staged for commit:
[... output truncated for brevity ...]
Untracked files:
[... output truncated for brevity ...]
● Completed in 0.54s
🛠 Using tool: execute_bash (trusted)
● I will run the following shell command:
cd /path/to/your/project/rules-blog && git add.
↳ Purpose: Add all changes to git staging
● Completed in 0.101s
🛠 Using tool: execute_bash (trusted)
● I will run the following shell command:
cd /path/to/your/project/rules-blog && git commit -m "🎯 Refocus platform on location-based discovery: Remove messaging, complete React app
Major platform refocus to pure location-based discovery:
MESSAGING FUNCTIONALITY REMOVED:
[... output truncated for brevity ...]
DOCUMENTATION UPDATES:
[... output truncated for brevity ...]
INFRASTRUCTURE IMPROVEMENTS:
[... output truncated for brevity ...]
PLATFORM FOCUS NOW:
✅ Location-based discovery
✅ Browsing and following
✅ Information and contact details
✅ Notifications by location
❌ No messaging/booking - pure discovery platform
Files modified: 13 core files, 1 new frontend package
Infrastructure: 7 Lambda functions, tagged resources, clean API
Tests: 12/12 passing, production build successful"
[... output truncated for brevity ...]
Note: Notice how Amazon Q Developer automatically shows Rule used: git.rule.md (GIT_COMMIT), git.rule.md (GIT_COMMIT_STYLE), git.rule.md (GIT_COMMIT_DETAILS) at the beginning of its response – this is the rule transparency system we discussed earlier in action, showing exactly which rule instructions guided the commit message creation.
The Impact:
- Helps Prevent Accidents: The confirmation requirement stops accidental pushes that could disrupt team workflows
- Consistent Commit Quality: Commit messages follow the same detailed, informative style regardless of who’s working
- Team Personality: The “playful but not too formal” style maintains team culture while preserving professionalism
- Better Git History: Detailed commit messages make code archaeology much more straightforward for future debugging
- Workflow Safety: Acts as a guardrail that respects human oversight in critical operations
This rule shows how Amazon Q Developer can be more than just a code assistant – it becomes a workflow partner that understands and enforces your team’s operational preferences and safety requirements.
What’s Next for Rules-Based Development
Through this exploration of Amazon Q Developer rules, we’ve discovered how a simple concept – defining your preferences once instead of repeating them constantly – can transform your development workflow. The key learnings are clear: rules help you avoid repetitive setup, help with team consistency, preserve institutional knowledge, and create transparent AI interactions that grow more valuable over time.
Reduced cognitive load, faster onboarding, consistent code quality, and AI assistance that truly understands your team’s context – what started as a solution to repetitive explanations has evolved into a comprehensive system for scaling development practices across my team.
My Amazon Q Developer rules system continues to evolve, and I’m excited about the possibilities ahead. As more teams adopt this approach, I expect we’ll see community-shared rule libraries and even more sophisticated customization options.
What I find most promising is how rules create a foundation for more advanced AI assistance. When your AI assistant understands your context deeply, it can provide more sophisticated suggestions and catch potential issues before they become problems.
I encourage you to start experimenting with rules – pick one area where you find yourself repeating instructions to AI assistants and create your first rule. You’ll be surprised how quickly this approach transforms your development workflow.
The key is to remember that rules aren’t about constraining creativity – they’re about freeing you to focus on the interesting problems by automating the routine decisions. When Amazon Q Developer knows how you like things done, you can spend more time on what you’re building and less time on how to build it.
Ready to get started with Amazon Q Developer rules? Check out the Amazon Q Developer documentation for setup instructions and more examples.