Post Syndicated from Explosm.net original https://explosm.net/comics/a-few-words
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/a-few-words
New Cyanide and Happiness Comic
Post Syndicated from Ziad Wali original https://aws.amazon.com/blogs/big-data/modernize-amazon-redshift-authentication-by-migrating-user-management-to-aws-iam-identity-center/
Amazon Redshift is a powerful cloud-based data warehouse that organizations can use to analyze both structured and semi-structured data through advanced SQL queries. As a fully managed service, it provides high performance and scalability while allowing secure access to the data stored in the data warehouse. Organizations worldwide rely on Amazon Redshift to handle massive datasets, upgrade their analytics capabilities, and deliver valuable business intelligence to their stakeholders.
AWS IAM Identity Center serves as the preferred platform for controlling workforce access to AWS tools, including Amazon Q Developer. It allows for a single connection to your existing identity provider (IdP), creating a unified view of users across AWS applications and applying trusted identity propagation for a smooth and consistent experience.
You can access data in Amazon Redshift using local users or external users. A local user in Amazon Redshift is a database user account that is created and managed directly within the Redshift cluster itself. Amazon Redshift also integrates with IAM Identity Center, and supports trusted identity propagation, so you can use third-party IdPs such as Microsoft Entra ID (Azure AD), Okta, Ping, OneLogin, or use IAM Identity Center as an identity source. The IAM Identity Center integration with Amazon Redshift supports centralized authentication and SSO capabilities, simplifying access management across multi-account environments. As organizations grow in scale, it is recommended to use external users for cross-service integration and centralized access management.
In this post, we walk you through the process of smoothly migrating your local Redshift user management to IAM Identity Center users and groups using the RedshiftIDCMigration utility.
The following diagram illustrates the solution architecture.
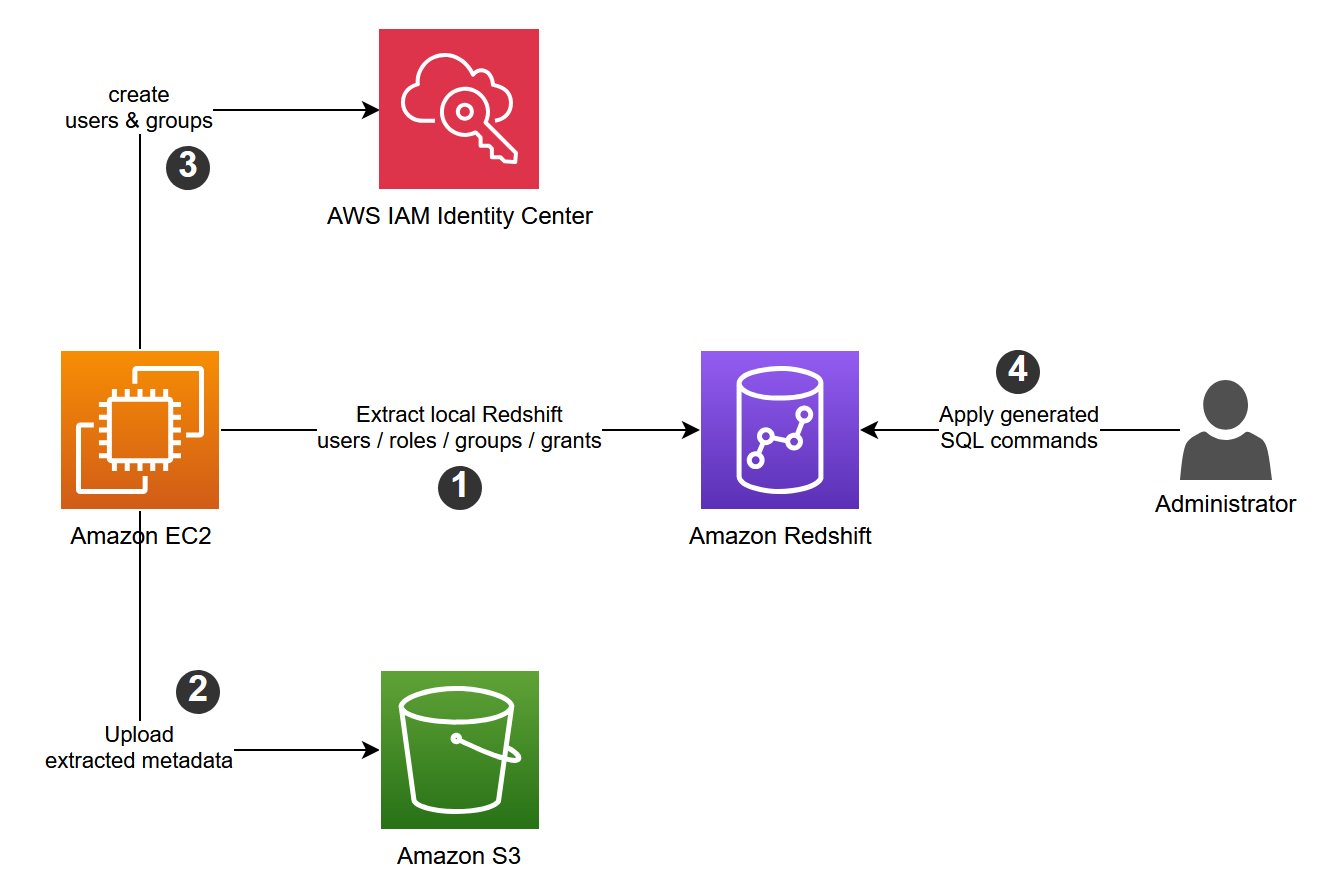
The RedshiftIDCMigration utility accelerates the migration of your local Redshift users, groups, and roles to your IAM Identity Center instance by performing the following activities:
Before running the utility, complete the following prerequisites:
The utility will be run from either an EC2 instance or CloudShell. If you’re using an EC2 instance, an IAM role is attached to the instance. Make sure that the IAM role used during the execution has the following permissions (if not, create a new policy with those permissions and attach it to the IAM role):
Download the following utility artifacts from the GitHub repo:
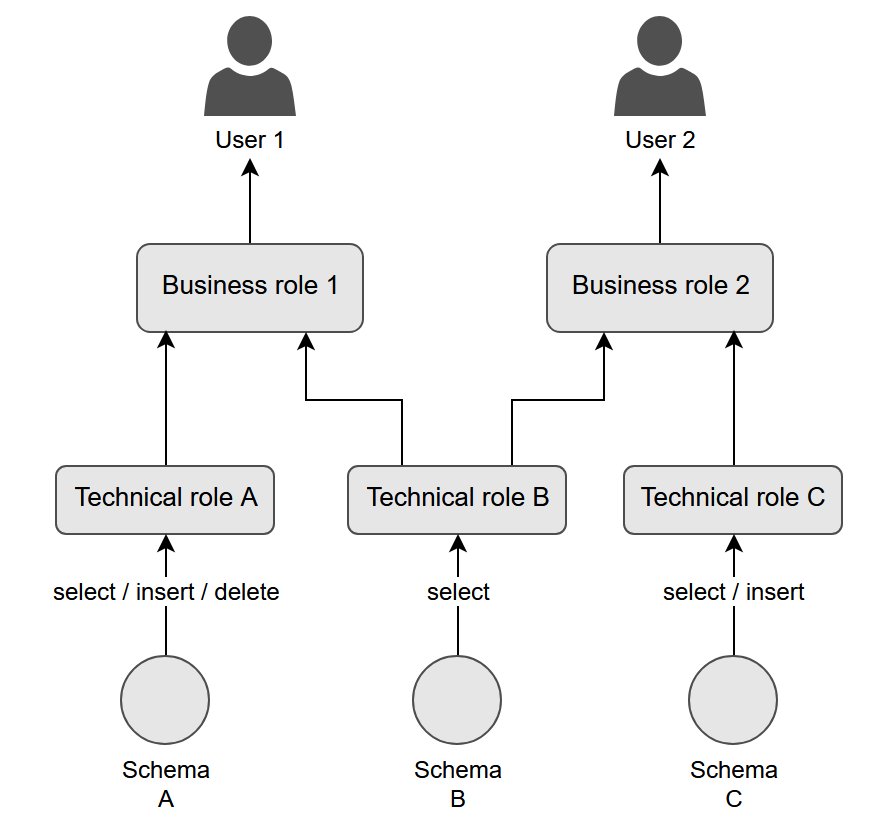
This test case is designed to offer practical experience and familiarize you with the utility’s functionality. The scenario is structured around a hierarchical nested roles system, starting with object-level permissions assigned to technical roles. These technical roles are then allocated to business roles. Finally, business roles are granted to individual users. To enhance the testing environment, the scenario also incorporates a user group.The following diagram illustrates this hierarchy.
Set up two separate schemas (tickit and tpcds) in a Redshift database using the create schema command. Then, create and populate a few tables in each schema using the tickit and tpcds sample datasets.
Specify the appropriate IAM role Amazon Resource Name (ARN) in the copy commands if necessary.
Create users with the following code:
Create business users with the following code:
Create technical roles with the following code:
Create groups with the following code:
To grant rights to the technical roles, use the following code:
To grant the technical roles to the business roles, use the following code:
To grant the business roles to users, use the following code:
To grant rights to the groups, use the following code:
To add users to the groups, use the following code:
Complete the following steps to deploy the solution:
redshift_unload.ini:
provisioned or serverless${cluster_identifier} (required if cluster_type is provisioned)${database_user}${database_name}${host_url} (required if cluster_type is provisioned)${port_number}${workgroup_name} (required if cluster_type is serverless)${region}${S3_bucket_name}roles.csvusers.csvrole_memberships.csvidc_config.ini:
${region}${account_id}${identity_store_id} (available on the IAM Identity Center console Settings page)${iam_identity_center_instance_arn} (available on the IAM Identity Center console Settings page)${permission_set_arn}True or False (True if permission_set_arn is defined)${S3_bucket_name}users.csvroles.csvrole_memberships.csvidc_redshift_unload_indatabase_groups_roles_users.py either from CloudShell or your EC2 instance:python idc_redshift_unload_indatabase_groups_roles_users.pyidc_add_users_groups_roles_psets.py either from CloudShell or your EC2 instance:python idc_add_users_groups_roles_psets.pyvw_local_ugr_to_idc_urgr_priv.sql file and run it in the query editor to create the vw_local_ugr_to_idc_urgr_priv view.For example, consider the following existing grants:
These grants are converted to the following code:
idc_based_grants column.When you have completed the process, you should have the following configuration:
If you encounter an issue while connecting to Amazon Redshift with the query editor using IAM Identity Center, refer to Troubleshooting connections from Amazon Redshift query editor v2.
Consider the following when using this solution:
vw_local_ugr_to_idc_urgr_priv.sqlto create roles and grant permissions to the IdP users and groups passed through IAM Identity Center.If you have completed the testing scenario, clean up your environment:
tickit and tpcds schemas.You can use the FORCE parameter when dropping the roles to remove associated assignments.
In this post, we showed how to migrate your Redshift local user management to IAM Identity Center. This transition offers several key advantages for your organization, such as simplified access management through centralized user and group administration, a streamlined user experience across AWS services, and reduced administrative overhead. You can implement this migration process step by step, so you can test and validate each step before fully transitioning your production environment.
As organizations continue to scale their AWS infrastructure, using IAM Identity Center becomes increasingly valuable for maintaining secure and efficient access management, including Amazon SageMaker Unified Studio for an integrated experience for all your data and AI.
Post Syndicated from Ramya Bhat original https://aws.amazon.com/blogs/big-data/implement-fine-grained-access-control-using-amazon-opensearch-service-and-json-web-tokens/
This post demonstrates how to build a secure search application using Amazon OpenSearch Service and JSON Web Tokens (JWTs). We discuss the basics of OpenSearch Service and JWTs and how to implement user authentication and authorization through an existing identity provider (IdP). The focus is on enforcing fine-grained access control based on user roles and permissions.
JWT authentication and authorization for your OpenSearch Service domain provides a robust mechanism that addresses requirements for fine-grained access control. An IdP is a service that stores and manages user identities and their access rights, enabling centralized user authentication across multiple applications. The IdP issues JWTs, which are secure tokens containing claims about the authenticated user. By using JWTs from the IdP, you can:
The JWT integration helps organizations:
Key benefits of the solution include:
The ability to dynamically filter sensitive information based on token claims enhances data security while reducing the complexity of managing multiple authentication systems. This capability is made possible through the fine-grained access control (FGAC) feature in OpenSearch Service, which enforces document- and field-level access based on user roles.
In this post, we explore a user workflow with multiple roles and access level requirements. A research institution wants to build a secure search application with controlled access to biomedical databases specifically PubMed (a comprehensive database of biomedical literature) and Clinical Trials (a registry of medical research studies). Different research teams require varying levels of access to these datasets based on their roles and clearance levels. The following hierarchical access structure defines the user roles and their corresponding permission levels for accessing PubMed and Clinical Trials databases:
To implement this use case, we use JWTs generated by the supported IdP, which encode role-specific information. This setup makes sure OpenSearch Service can validate tokens before returning search results, dynamically filtering sensitive data based on the user’s JWT claims and fine-grained access control settings.
The technical workflow for using JWT authorization with OpenSearch Service involves several key stages:
This workflow provides a standardized approach to authentication and authorization while streamlining user interactions with the search application. The solution makes sure each user sees only the information appropriate to their role, maintaining data privacy and organizational security standards.
You must enable JWT authentication and authorization, and fine-grained access control during the OpenSearch Service domain creation process. For more information, refer to Configuring JWT authentication and authorization and Fine-grained access control in Amazon OpenSearch Service.
The following diagram illustrates the solution architecture.
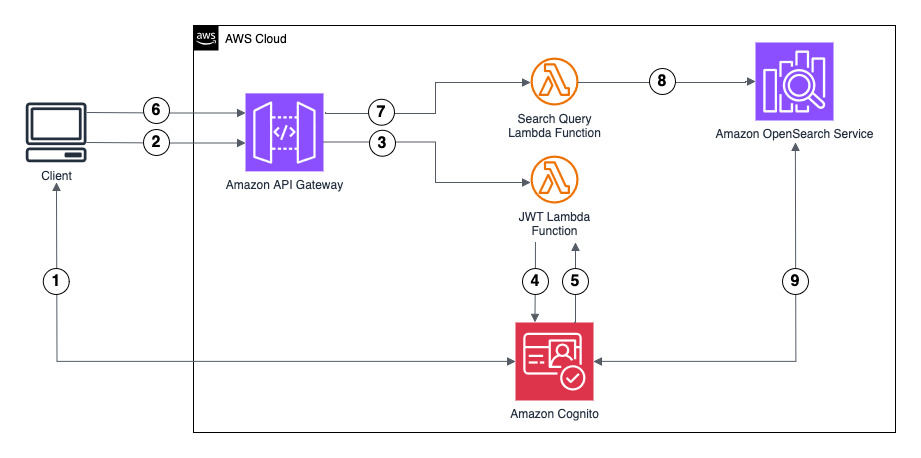
This solution demonstrates authentication using Amazon Cognito as the IdP to generate the JWT. However, you can use another supported IdP. The ID token includes group membership information that OpenSearch Service maps to roles configured using fine-grained access control.
The user flow consists of the following steps:
The following diagram illustrates the request flow.
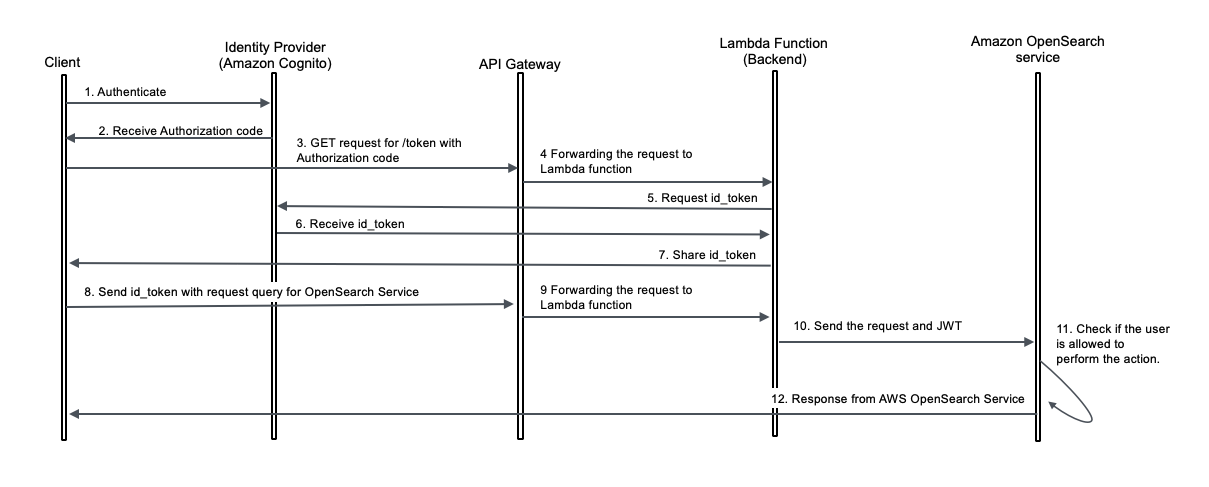
Before you deploy the solution, make sure you have the following prerequisites:
To deploy the solution resources, we use an AWS CloudFormation template. Launch the AWS CloudFormation template with the following Launch Stack button.
![]()
Enter an appropriate stack name. This name is used as a prefix for resources like OpenSearch Service domains and Lambda functions. Keep the default settings, and choose Create.
The stack deployment takes approximately 15–20 minutes. When deployment is complete, the stack status shows as CREATE_COMPLETE.
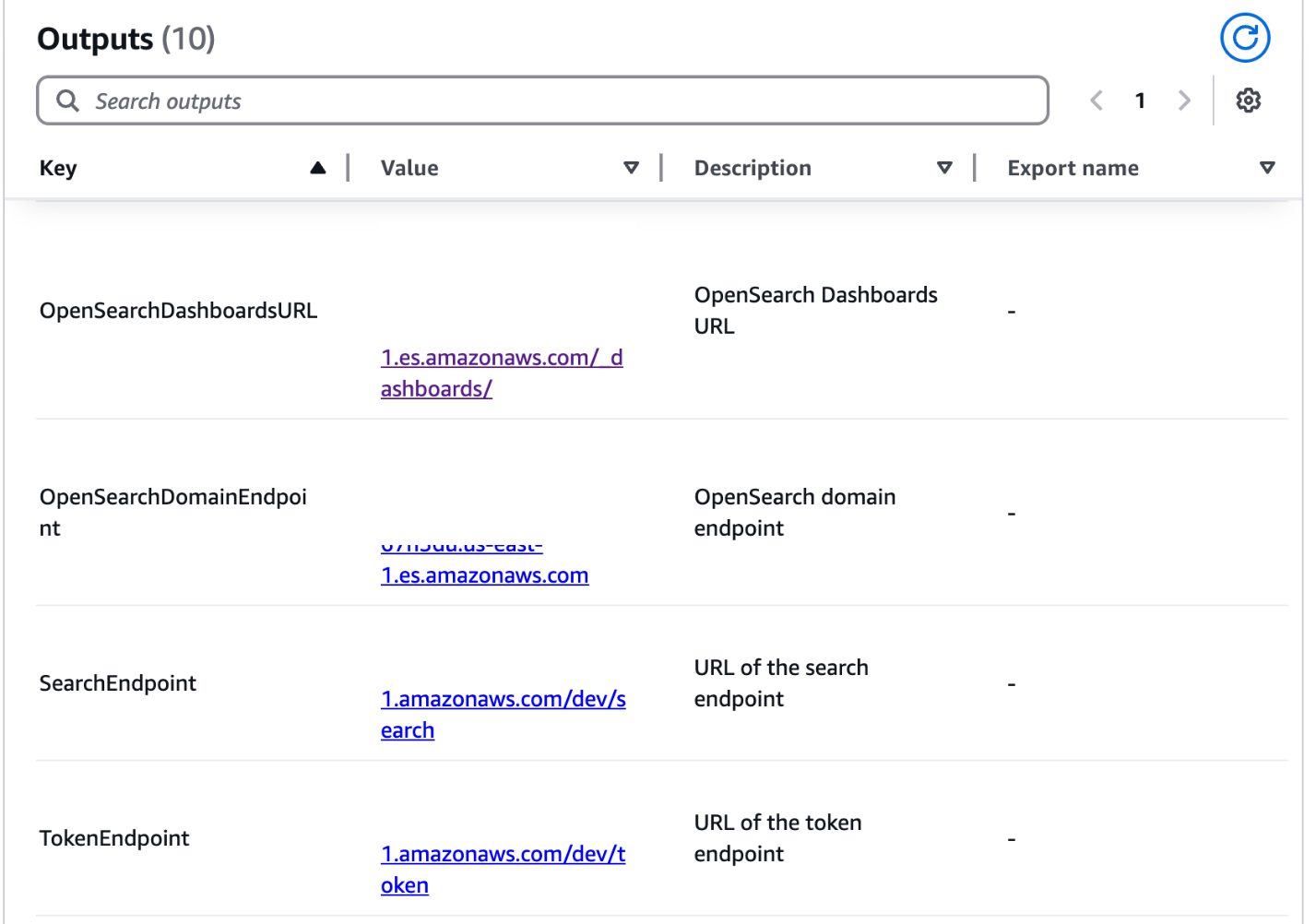
The outputs for this CloudFormation stack show important information regarding the deployed resources. This information will be referenced throughout different sections of this post.
On the Outputs tab, note the following values:
On the Resources tab, locate the following information:
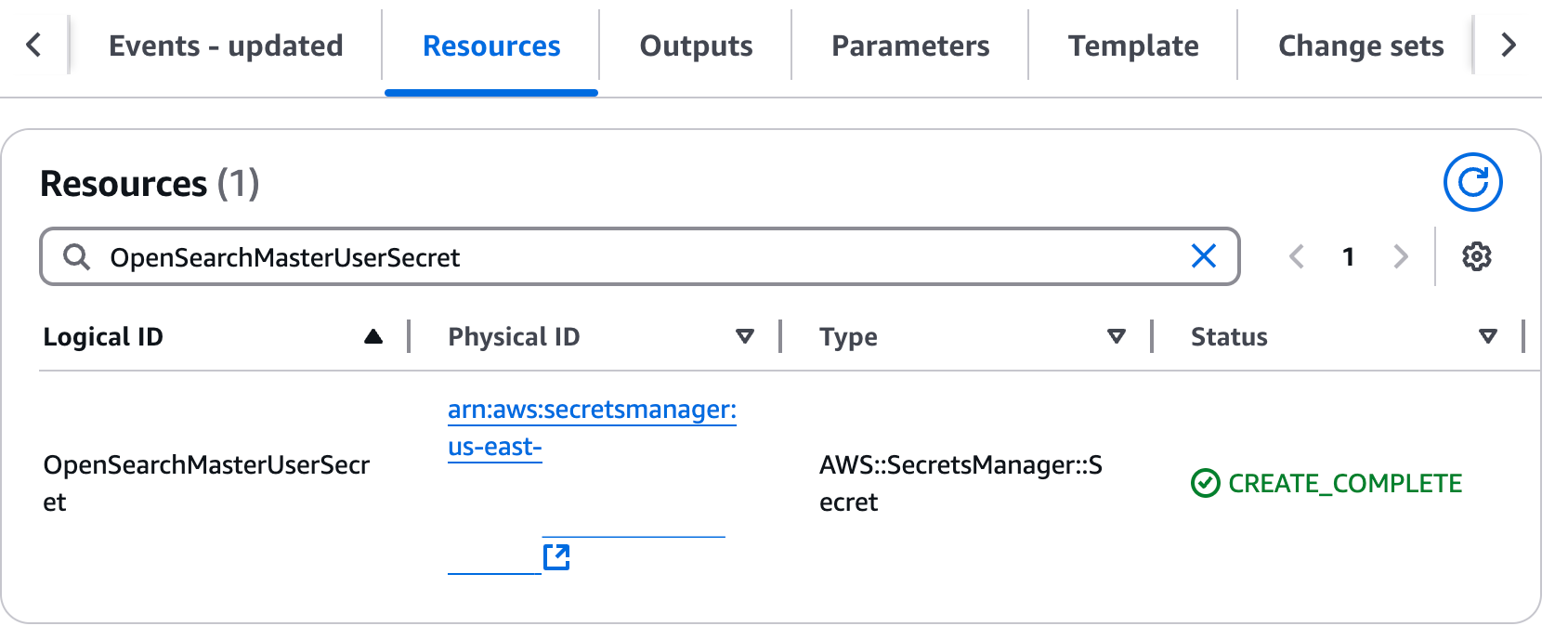
In a separate browser tab, log in to the OpenSearch dashboard using OpenSearchDashboardsURL and user credentials noted previously.
Complete the following steps to map your IAM role to both the all_access and security_manager roles in OpenSearch Service:
SharedLambdaRoleArn.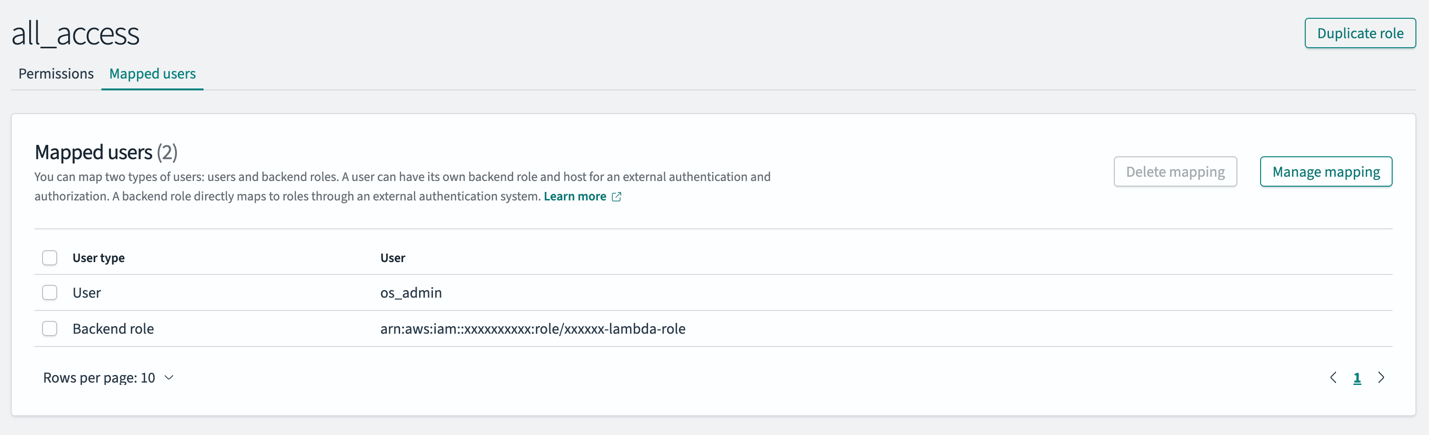
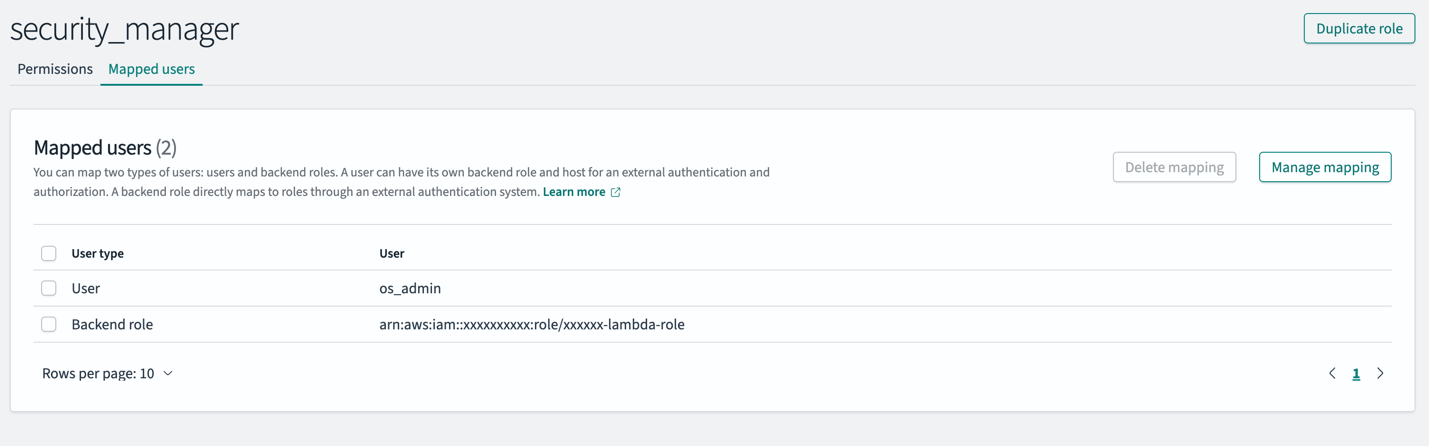
These steps ensure the IAM role attached to the Lambda function has the necessary permissions to ingest data (all_access) and create roles (security_manager) within the OpenSearch Service domain.
In this sample setup, the Lambda function handles bulk ingestion and role creation without granting any direct access to users, and all_access is provided to the Lambda role solely to enable ingestion. FGAC in OpenSearch provides in-depth access control, allowing you to further tighten the Lambda role permissions by granting only the necessary CRUD operations, rather than full access for ingestion. For more details, refer to Defining users and roles and Fine-grained access control in OpenSearch.
On the CloudFormation stack’s Resources tab, locate the IngestDataAndCreateBackendRoles Lambda function. Open the Lambda function, choose Test, and execute it. You can confirm the function’s successful execution by checking Amazon CloudWatch Logs.
This Lambda function is designed to perform bulk ingestion and role creation in the OpenSearch Service domain. It ingests sample clinical research data into OpenSearch Service, creating two indexes (pubmed and clinical_trials), and sets up required OpenSearch Service roles. We explore these roles in detail in the next section.
In this step, we define two key OpenSearch Service roles:
We have already created these roles by running the Lambda function in the previous section. The following code is the pubmed-admin OpenSearch Service role description:
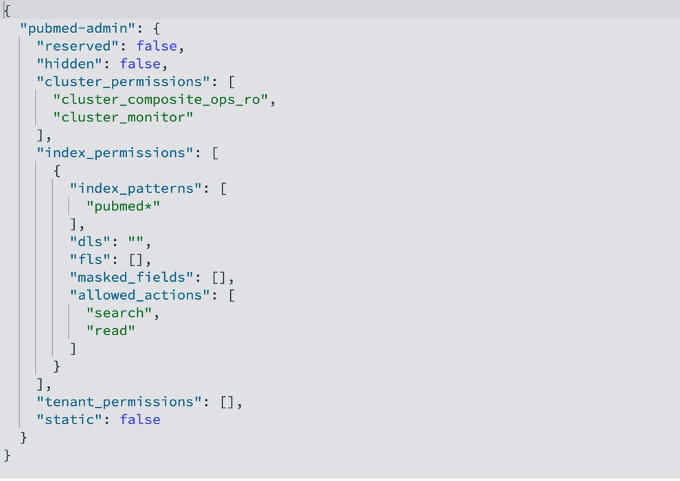
The following code is the pubmed-limited OpenSearch Service role description:

The pubmed-admin and pubmed-limited roles serve different purposes, and their main distinction lies in how they control data visibility. Document-level security (DLS) lets you restrict a role to a subset of documents in an index, while field-level security (FLS) lets you control which document fields a user can see. The limited role is configured with FLS to expose only the journal, title, and abstract fields, while masked fields anonymize sensitive data such as journal. On top of these, you can apply DLS to hide specific records, for example, to prevent users from viewing documents from certain journals or publication years. In your use cases, use DLS and FLS to control document and field visibility for different users. These roles are fully configurable; you can add, remove, or update document and field access at any time to match evolving security or business requirements.
To enforce access control, users need to be mapped to appropriate OpenSearch Service roles on OpenSearch Dashboards. Complete the following steps to map users to the OpenSearch Service roles:
pubmed-admin role.pubmed_admin_group.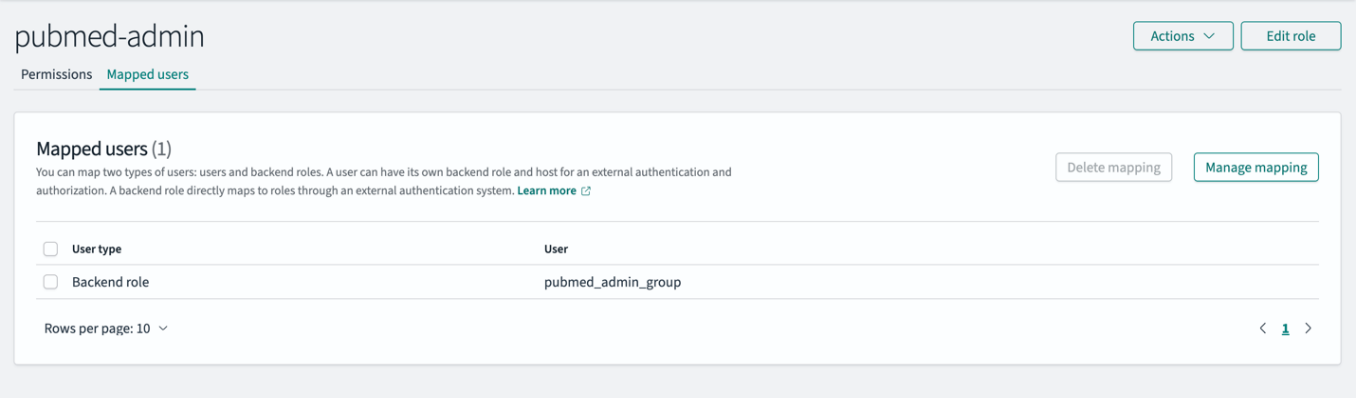
Backend roles simplify access management in OpenSearch Service. Instead of mapping individual users to OpenSearch service roles, you can map roles to backend roles that users share. This approach lets you map IdP groups directly to the OpenSearch service roles. OpenSearch Service provides options when configuring your OpenSearch Service domain to map JWT claims to OpenSearch Service roles using the roles key.
In this solution, the JWT contains a field called cognito:groups that will be mapped as the roles key. In every JWT, this field has a value for the appropriate group the user belongs to. Based on the field value in the JWT and the mapping defined in the previous step for different research groups, OpenSearch Service domain dynamically assigns permissions:
Take a look at the examples below to understand what a JWT header and payload look like.
Sample JWT header:
Sample JWT payload:
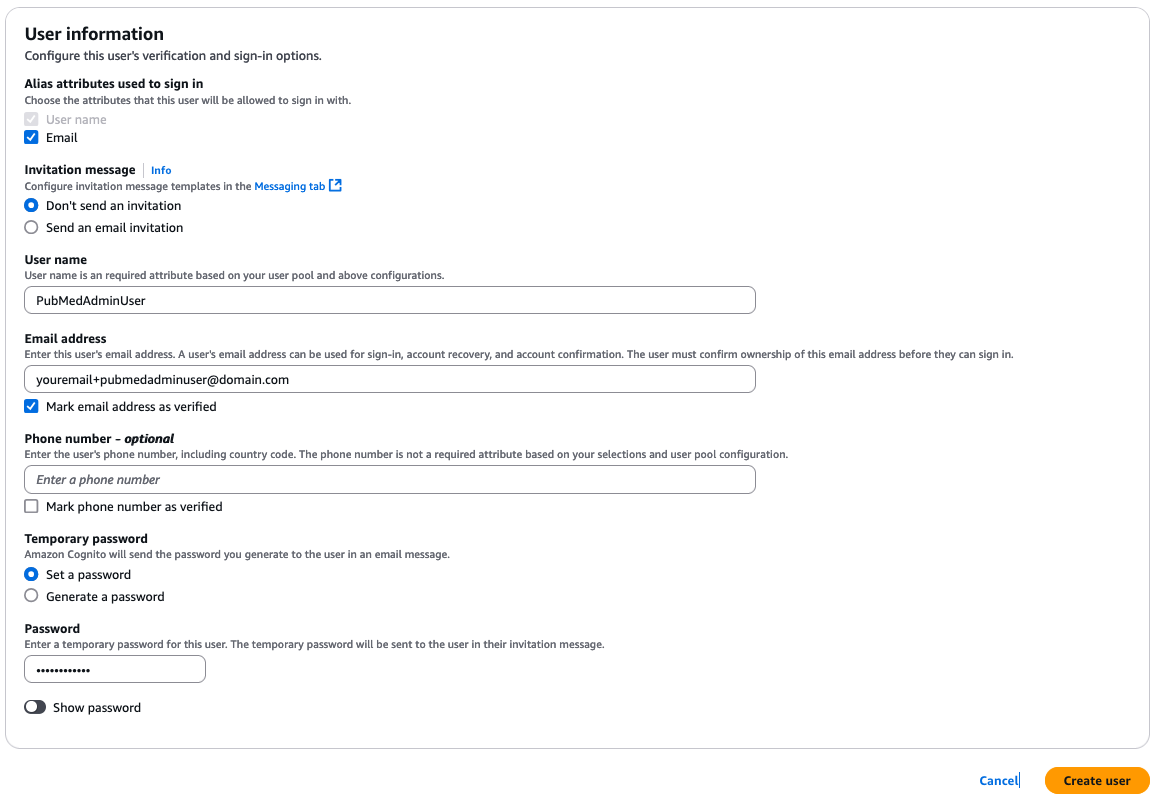
In this section, we create the following Amazon Cognito users:
The email address required for each user should be unique. If your email domain supports email alias, you can add a suffix to your own email address by using [email protected]. The following screenshot shows our users.
On the CloudFormation stack’s Resources tab, locate the UserPool Amazon Cognito user pool that you noted earlier. Open the user pool in a new browser tab.
To create the Amazon Cognito users, complete the following steps for each user:
We create the following groups in Amazon Cognito:
The following screenshot shows created groups.
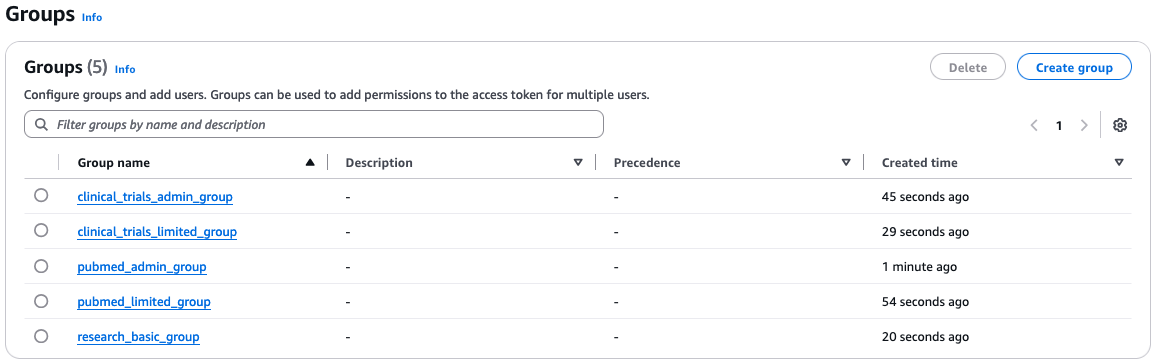
To create the Amazon Cognito groups, complete the following steps for each group:
The users should be added to the groups as follows:
PubMedAdminUser to the pubmed_admin_group groupPubMedLimitedUser to the pubmed_limited_group groupClinicalTrialsAdminUser to the clinical_trials_admin_group groupClinicalTrialsLimitedUser to the clinical_trials_limited_group groupResearchBasicUser to the research_basic_group groupTo add users to their respective group, complete the following steps for each group:
Before running the test queries in the next section, you must obtain the id_token (JWT) for the specified users. The tokens will expire in 60 minutes. If the token is expired for a user, you must log in again to get a fresh token. To log in with your user to get the id_token, complete the following steps:
This example demonstrates how OpenSearch Service filters search results based on user permissions. We test searches using JWTs for two different users to verify access controls. Each user’s search results are limited to the indexes and documents allowed by their assigned roles.
On the CloudFormation stack’s Resources tab, locate the RestAPI value that you noted earlier. Open the API gateway in a new browser tab.
Complete the following steps to test the search API for each of the scenarios mentioned in this section:
When submitting queries to OpenSearch Service, make sure all double quotation marks are escaped to prevent syntax errors. Additionally, make sure you complete your query before your JWT expires, or you will need to generate a new token. If you attempt to use an expired token, it will result in an error.
For Scenarios 1 and 2, log in with your PubMedAdmin user, and for Scenarios 3 and 4, log in with your PubMedLimitedUser to obtain the required id_token.
In this first query, we query the pubmed index with the credentials of user PubMedAdminUser, which is part of pubmed_admin_group:
Add the following values to the respective input fields:
"{\"query\":{\"match_all\":{}}}"&index=pubmed
The following screenshot shows our query results.
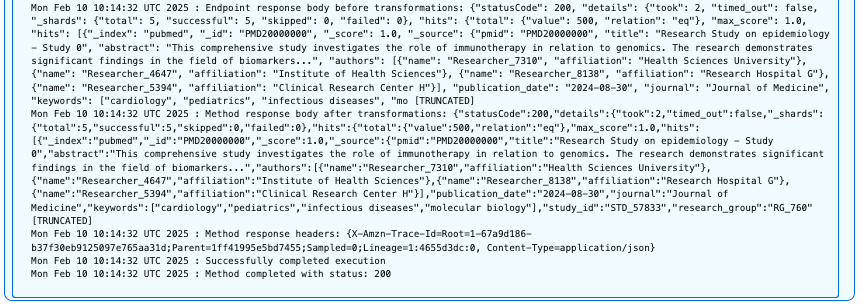
Users with the pubmed_admin role have full access to the PubMed index and can perform unrestricted searches across all fields and document types. This query successfully returns documents with the HTTP 200 status code because the user has complete read permissions on this index.
Next, we query the clinical-trials index with the credentials of user PubMedAdminUser, who is part of pubmed_admin_group:
Add the following values to the respective input fields:
"{\"query\":{\"match_all\":{}}}"&index=clinical-trialsid_token:<id-token-for-PubMedAdminUser>
The following screenshot shows our query results.
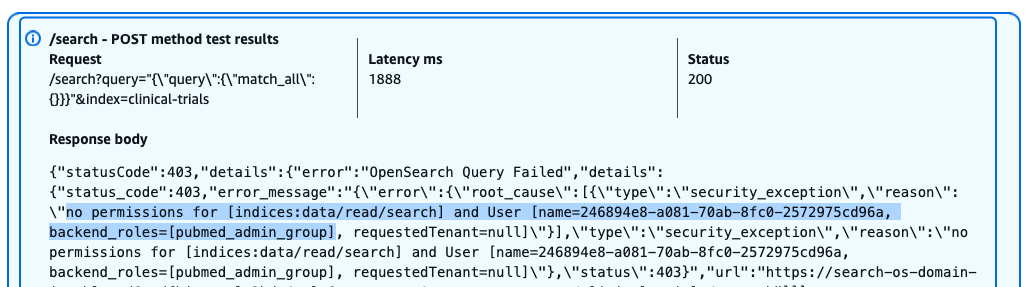
Despite having admin privileges for PubMed data, this user receives a 403 Forbidden response when attempting to access the clinical-trials index. The error message indicates the lack of necessary permissions for performing search operations on this index.
Now we query allowed fields in the pubmed index with the credentials of user PubMedLimitedUser, which is part of pubmed_limited_group:
Add the following values to the respective input fields:
"{\"query\":{\"match\":{\"title\": \"molecular biology\"}}}"&index=pubmedid_token:<id-token-for-PubMedLimitedUser>
The following screenshot shows our query results.
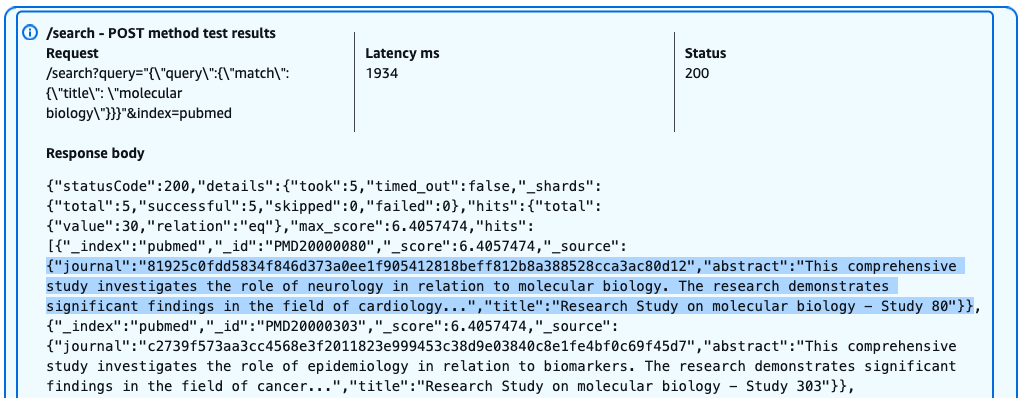
Users with the pubmed_limited role can successfully query specific fields like title, but with restricted access to sensitive information. The query returns results with the HTTP 200 status code, but the journal field is anonymized due to field-level security policies. Users can search and view certain fields while having sensitive data automatically masked or excluded from their results.
Lastly, we query unauthorized fields in the pubmed index with the credentials of user PubMedLimitedUser, which is part of pubmed_limited_group:
Add the following values to the respective input fields:
"{\"query\":{\"match\":{\"research_group\":\"RG_345\"}}}"&index=pubmedid_token:<id-token-for-PubMedLimitedUser>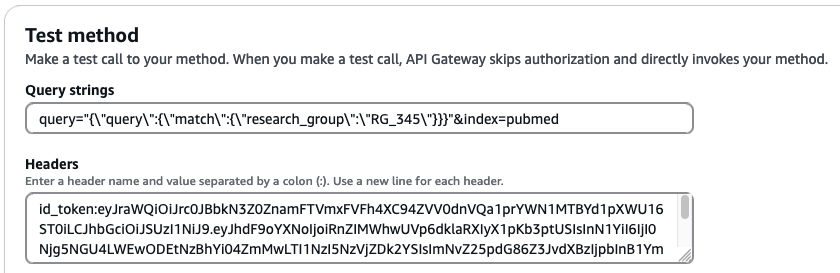
The following screenshot shows our query results.
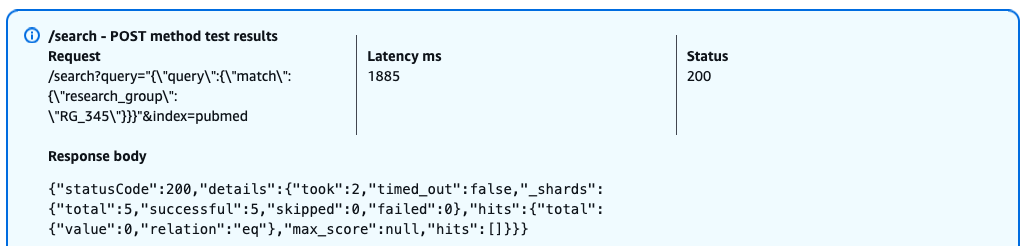
When a user with the pubmed_limited role attempts to query the restricted research_group field, OpenSearch returns a successful response (HTTP 200) but with empty results. This behavior occurs because field-level security is enforcing access controls instead of returning a HTTP 403 error, it silently filters out the restricted field from both the query and results. This security-by-obscurity approach means that users can’t determine whether their query failed due to lack of permissions or genuine absence of matching documents.
To avoid incurring further AWS usage charges, delete the resources created in this post by deleting the CloudFormation stack. This step will remove all resources except Lambda layers. To delete the Lambda layers, navigate to the Layers page on the Lambda console, and delete the layers named <CloudFormation-Stack-Name>-requests and <CloudFormation-Stack-Name>-crypt.
In this post, we discussed how JWTs provide a robust and scalable authentication mechanism that can be integrated with existing IdPs. We also demonstrated how to seamlessly integrate fine-grained access control across search applications. Organizations can define granular permissions within their IdP, making sure sensitive information remains protected. The JWT integration with OpenSearch Service enables secure, efficient access control, so users can only access role-appropriate information while simplifying compliance and access management.
If you have feedback about this post, leave them in the comments section. If you have questions about this post, start a new thread on AWS Security, Identity, and Compliance re:Post or contact AWS Support.
 Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors.
Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors.
 Shubhansu Sawaria is a Sr. Delivery Consultant – SRC at AWS, based in Bangalore, India. He specializes in designing and implementing comprehensive AWS Cloud security solutions. He has developed security solutions for startups, banks, and healthcare organizations. His expertise helps organizations elevate their cloud security infrastructures, achieve compliance objectives, and provide robust data protection.
Shubhansu Sawaria is a Sr. Delivery Consultant – SRC at AWS, based in Bangalore, India. He specializes in designing and implementing comprehensive AWS Cloud security solutions. He has developed security solutions for startups, banks, and healthcare organizations. His expertise helps organizations elevate their cloud security infrastructures, achieve compliance objectives, and provide robust data protection.
 Soujanya Konka is a Sr. Solutions Architect and Analytics Specialist at AWS, focused on helping customers build their ideas in the cloud. She has expertise in designing and implementing enterprise search solutions and advanced data analytics at scale.
Soujanya Konka is a Sr. Solutions Architect and Analytics Specialist at AWS, focused on helping customers build their ideas in the cloud. She has expertise in designing and implementing enterprise search solutions and advanced data analytics at scale.
Post Syndicated from Thomas Cardenas original https://aws.amazon.com/blogs/big-data/how-ancestry-optimizes-a-100-billion-row-iceberg-table/
This is a guest post by Thomas Cardenas, Staff Software Engineer at Ancestry, in partnership with AWS.
Ancestry, the global leader in family history and consumer genomics, uses family trees, historical records, and DNA to help people on their journeys of personal discovery. Ancestry has the largest collection of family history records, consisting of 40 billion records. They serve more than 3 million subscribers and have over 23 million people in their growing DNA network. Their customers can use this data to discover their family story.
Ancestry is proud to connect users with their families past and present. They help people learn more about their own identity by learning about their ancestors. Users build a family tree through which we surface relevant records, historical documents, photos, and stories that might contain details about their ancestors. These artifacts are surfaced through Hints. The Hints dataset is one of the most interesting datasets at Ancestry. It’s used to alert users that potential new information is available. The dataset has multiple shards, and there are currently 100 billion rows being used by machine learning models and analysts. Not only is the dataset large, it also changes rapidly.
In this post, we share the best practices that Ancestry used to implement an Apache Iceberg-based hints table capable of handling 100 billion rows with 7 million hourly changes. The optimizations covered here resulted in cost reductions of 75%.
Ancestry’s Enterprise Data Management (EDM) team faced a critical challenge—how to provide a unified, performant data ecosystem that could serve diverse analytical workloads across financial, marketing, and product analytics teams. The ecosystem needed to support everything from data scientists training recommendation models to geneticists developing population studies—all requiring access to the same Hints data.
The ecosystem around Hints data had been developed organically, without a well-defined architecture. Teams independently accessed Hints data through direct service calls, Kafka topic subscriptions, or warehouse queries, creating significant data duplication and unnecessary system load. To reduce cost and improve performance, EDM implemented a centralized Apache Iceberg data lake on Amazon Simple Storage Service (Amazon S3), with Amazon EMR providing the processing power. This architecture, shown in the following image, creates a single source of truth for the Hints dataset while using Iceberg’s ACID transactions, schema evolution, and partition evolution capabilities to handle scale and update frequency.
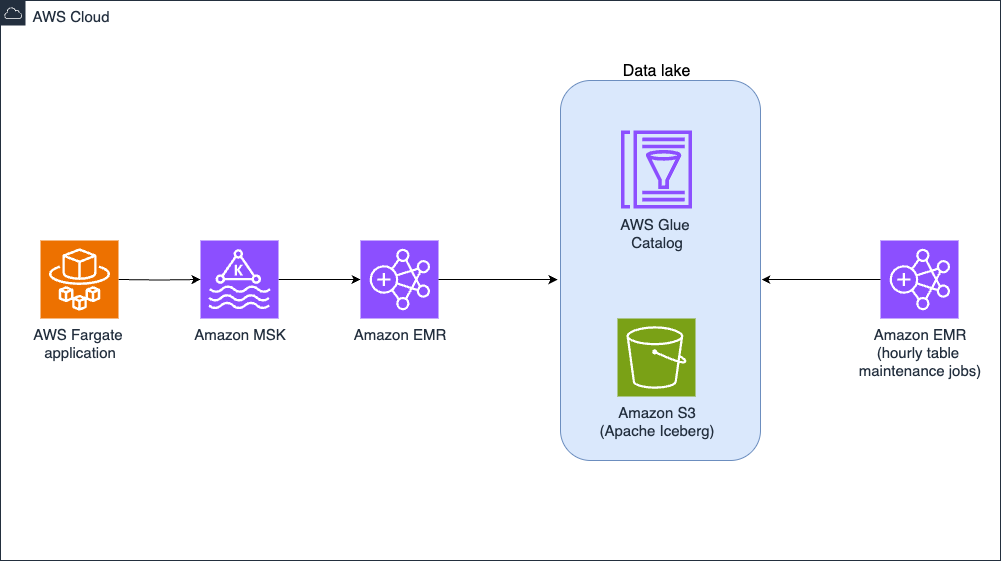
Hints table management architecture
Managing datasets exceeding one billion rows presents unique challenges, and Ancestry faced this challenge with the trees collection of 20–100 billion rows across multiple tables. At this scale, dataset updates require careful execution to control costs and prevent memory issues. To solve these challenges, EDM chose Amazon EMR on Amazon EC2 running Spark to write Iceberg tables on Amazon S3 for storage. With large and steady Amazon EMR workloads, running the clusters on Amazon EC2, as opposed to Serverless, proved cost effective. EDM has scheduled an Apache Spark job to run every hour on their Amazon EMR on EC2. This job uses the merge operation to update the Iceberg table with recently changed rows. Performing updates like this on such a large dataset can easily lead to runaway costs and out-of-memory errors.
The engineers needed to enable fast, row-level updates without impacting query performance or incurring substantial cost. To achieve this, Ancestry used a combination of partitioning strategies, table configurations, Iceberg procedures, and incremental updates. The following is covered in detail:
Developing an effective partitioning strategy was crucial for the 100-billion-row Hints table. Iceberg supports various partition transforms including column value, temporal functions (year, month, day, hour), and numerical transforms (bucket, truncate). Following AWS best practices, Ancestry carefully analyzed query patterns to identify a partitioning approach that would support these queries while balancing these two competing considerations:
Through query pattern analysis, Ancestry discovered that most analytical queries filtered on hint status (particularly pending status) and hint type. This insight led us to implement a two-level partitioning strategy-first on status and then on type, which dramatically reduced the amount of data scanned during typical queries.
To further optimize query performance, Ancestry implemented strategic data organization within partitions using Iceberg’s sort orders. While Iceberg doesn’t maintain perfect ordering, even approximate sorting significantly improves data locality and compression ratios.
For the Hints table with 100 billion rows, Ancestry faced a unique challenge: the primary identifiers (PersonId and HintId) are high-cardinality numeric columns that would be prohibitively expensive to sort completely. The solution uses Iceberg’s truncate transform function to support sorting on just a portion of the number, effectively creating another partition by grouping a collection of IDs together. For example, we can specify truncate(100_000_000, hintId) to create groups of 100 million hint IDs, greatly improving the performance of queries that specify that column.
With 7 million changes to the Hints table occurring hourly, optimizing write performance became critical to the architecture. In addition to making sure queries performed well, Ancestry also needed to make sure our frequent updates would perform well in both time and cost. It was quickly discovered that the default copy-on-write (CoW) strategy, which copies an entire file when any part of it changes, was too slow and expensive for their use case. Ancestry was able to get the performance we needed by instead specifying the merge-on-read (MoR) update strategy, which maintains new information in diff files that are reconciled on read. The large updates that happen every hour led us to choose faster updates at the cost of slower reads.
The frequent updates mean files are constantly needing to be re-written to maintain performance. Iceberg provides the rewrite_data_files procedure for compaction, but default configurations proved insufficient for our scale. Leaving the default configuration in place, the rewrite operation wrote to five partitions at a time and didn’t meet our performance objective. We found that increasing the concurrent writes improved performance. We used the following set of parameters, setting a relatively high max-concurrent-file-group-rewrites value of 100 to more efficiently deal with our thousands of partitions. The default of rewriting only one file at a time couldn’t keep up with the frequency of our updates.
Key optimizations in Ancestry’s approach include:
max-concurrent-file-group-rewrites from the default 5 to 100, enabling parallel processing of our thousands of partitions. This increased compute costs but was necessary to help ensure that the jobs finished.partial-progress to create compaction checkpoints, essential when operating at our scale where failures are particularly costly.rewrite-all to true helps ensure that both data files and delete files are compacted, preventing the accumulation of delete files. By default, the delete files created as part of this strategy aren’t re-written and would continue to accumulate, slowing queries.We arrived at these optimizations through successive trials and evaluations. For example, with our very large dataset, we discovered that we could use a WHERE clause to limit re-writes to a single partition. Based on the partitions, we see varied execution times and resource utilization. For some partitions, we needed to reduce concurrency to avoid running into out of memory errors.
Iceberg tables maintain snapshots to preserve the history of the table, allowing you to time travel through the changes. As these snapshots accrue, they add to storage costs and degrade performance. This is why maintaining an Iceberg table requires you to periodically call the expire_snapshots procedure. We found we needed to enable concurrency for snapshot management so that it would complete in a timely manner:
Consider how to balance performance, cost, and the need to keep historical records depending on your use case. When you do so, note that there is a table-level setting for maximum snapshot age which can override the retain_last parameter and retain only the active snapshot.
We use Storage-Partitioned Joins (SPJ) in Iceberg tables to minimize expensive shuffles during data processing. SPJ is an advanced Iceberg feature (available in Spark 3.3 or later with Iceberg 1.2 or later) that uses the physical storage layout of tables to eliminate shuffle operations entirely. For our Hints update pipeline, this optimization was transformational.
SPJ is especially useful during MERGE INTO operations, where datasets have identical partitioning. Proper configuration helps ensure effective use of SPJ to optimize joins.
SPJ has a few requirements such as both tables must be Iceberg partitioned the same way and joined on the partition key. Then Iceberg will know that it doesn’t have to shuffle the data when the tables are loaded. This even works when there are a different number of partitions on either side.
Updates to the Hints database are first staged in the Hint Changes database where data is transformed from the original Kafka data format into how it will look in the target (Hints) table. This is a temporary Iceberg table where we are able to perform audits using Write-Audit-Publish (WAP) pattern. In addition to using the WAP pattern we are able to use the SPJ functionality.
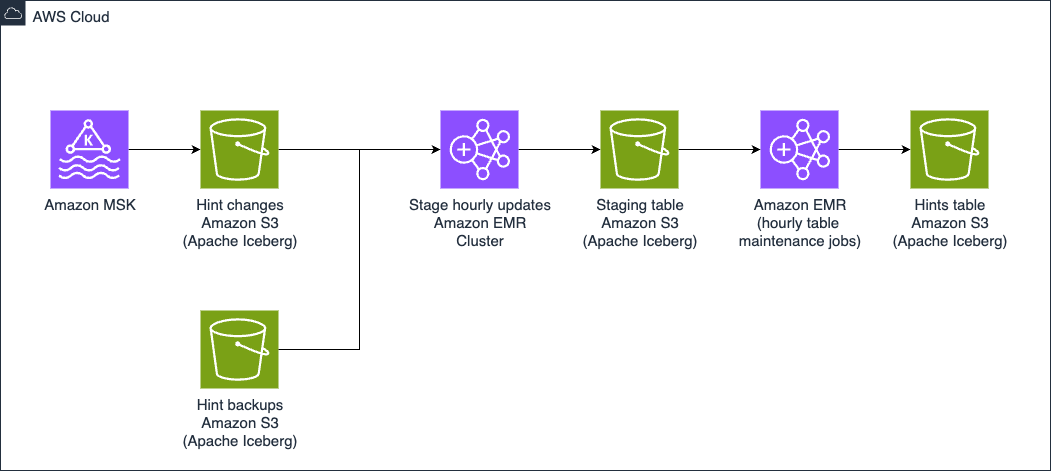
The Hints data pipeline
Another strategy to reduce shuffle is minimizing the data involved in joins by dynamically pushing down filters. In production, these filters vary between batches, so a multi-step operation is often necessary for setting up merges. The following example code first limits its scope by setting minimum and maximum values for the ID, then performs an update or delete to the target table depending on whether a target value exists.
This technique reduces cost in several ways: the bounded merge reduces the number of affected rows, it allows for predicate pushdown optimization, which filters at the storage layer, and it reduces shuffle operations when compared with a join.
Apart from the Hints table, we have implemented over 1,000 Iceberg tables in our data ecosystem. The following are some key insights that we observed:
MERGE is typically the most expensive action, so this is where we spent the most time optimizing. It was still our best option.Organizations can use Apache Iceberg tables on Amazon S3 with Amazon EMR to manage massive datasets with frequent updates. Many customers will be able to achieve excellent performance with a low maintenance burden by using the AWS Glue table optimizer for automatic, asynchronous compaction. Some customers, like Ancestry, will require custom optimizations of their maintenance procedures to meet their cost and performance goals. These customers should start with a careful assessment of query patterns to develop a partitioning strategy to minimize the amount of data that needs to be read and processed. Update frequency and latency requirements will dictate other choices, like whether merge-on-read or copy-on-write is the better strategy.
If your organization faces similar challenges with high volumes of data requiring frequent updates, you can use a combination of Apache Iceberg’s advanced features with AWS services like Amazon EMR Serverless, Amazon S3, and AWS Glue to build a truly modern data lake that delivers the scale, performance, and cost-efficiency you need.
Post Syndicated from Home Assistant original https://www.youtube.com/shorts/kzRIK3L7vOs
Post Syndicated from jzb original https://lwn.net/Articles/1035332/
Alyssa Rosenzweig has written a blog post
about her work to help ship a “great driver
” for the Apple M1
GPU that supports OpenGL, Vulkan, and enables gaming with Proton.
We’ve succeeded beyond my dreams. The challenges I chased, I have
tackled. The drivers are fully upstream in Mesa. Performance isn’t too
bad. With the Vulkan on Apple myth busted, conformant Vulkan is now
coming to macOS via LunarG’s
KosmicKrisp project building on my work.Satisfied, I am now stepping away from the Apple ecosystem. My
friends in the Asahi Linux orbit will carry the torch from here.
Rosenzweig indicates her next project will be working on Intel’s
Xe-HPG graphics architecture. LWN covered her talk on Apple
M1/M2 GPU drivers in October 2024.
Post Syndicated from Explosm.net original https://explosm.net/comics/refill
New Cyanide and Happiness Comic
Post Syndicated from jzb original https://lwn.net/Articles/1034560/
The Extensible
Stylesheet Language Transformations (XSLT) language is used by web
browsers to style XML content to make it easily readable; XSLT is part of the
HTML living
standard that is maintained by the Web Hypertext Application Technology
Working Group (WHATWG). Only a small fraction of web sites serve
content that requires web browsers to support XSLT, in part because
major browser implementations have neglected the technology over the past 25
years. Now, it seems, they would like to rid themselves of it
entirely. A plan
to disable XSLT in Blink (Chrome’s rendering engine) and a pull request by
a Google Chrome developer to remove mentions of the specification from
the HTML standard have been met with opposition, but arguments in
favor of XSLT have proven ineffective.
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=GWVSeLEcBm4
Post Syndicated from Will Taillac original https://www.servethehome.com/sandisk-wd-blue-sn5100-2tb-pcie-gen4-nvme-ssd-review/
In our SanDisk WD Blue SN5100 review, we see how this drive performs compared to the SN5000 and other PCIe Gen4 NVMe SSDs
The post Sandisk WD Blue SN5100 2TB PCIe Gen4 NVMe SSD Review appeared first on ServeTheHome.
Post Syndicated from jzb original https://lwn.net/Articles/1035321/
The GhostBSD project has released version 25.02 of the
FreeBSD-based desktop operating system. This release brings GhostBSD
up to date with FreeBSD 14.3,
includes enhancements for the Software Station package management
application, and introduces an “OS X-like
” desktop environment
based on GNUstep called Gershwin:
This early preview includes:
- GNUstep-based desktop environment with familiar OS X-style
interface- Seamless integration with GhostBSD tools through wrappers for
installer, Software Station, Backup Station, and Update Station- Support for running non-GNUstep applications alongside GNUstep
apps- Several included GNUstep applications to get you started
LWN covered GhostBSD
in June 2024.
Post Syndicated from Kari Rivas original https://www.backblaze.com/blog/the-gold-standard-of-cloud-security-why-our-soc2-type-2-compliance-sets-backblaze-apart/

As more organizations rely on the cloud to store critical data, the stakes around compliance and security keep rising. Regulations like GDPR and HIPAA are putting pressure on businesses to demonstrate that their data handling practices are sound, and customers increasingly want evidence—not just assurances—that their data is protected.
Every cloud provider claims to be “secure.” But as a risk owner and decision-maker, you need more than a marketing tagline. You need proof. That’s where SOC 2 Type 2 compliance comes in. At Backblaze, we don’t just meet this benchmark—we go beyond it. Unlike many cloud storage providers (CSPs) that may have only SOC 2 compliant data centers, Backblaze has also undergone the rigorous SOC 2 assessment at the company level.
SOC 2 (aka System and Organization Controls) is an assessment created by the American Institute of Certified Public Accountants (AICPA). It evaluates how service providers operate based on Trust Services Criteria:
Every SOC 2 assessment includes Security as the foundation, and organizations may also be evaluated against additional criteria that align with their services. Our assessment covers both Security and Availability, demonstrating that our systems are protected against unauthorized access and are resilient, reliable, and consistently accessible when you need them.
At Backblaze, we’ve put the right controls in place to meet these standards, such as:
The business impact? You can rely on us to keep your data safe and accessible—without adding unnecessary risk to your operations.
There are two types of SOC 2 examinations:
Backblaze has achieved and consistently maintained SOC 2 Type 2 compliance. That distinction matters—it means you’re not just trusting that we say the right things, but that we do the right things, day in and day out.
SOC 2 compliance isn’t just a checkbox exercise. It provides meaningful assurances that directly affect your business:
In short, SOC 2 compliance reduces uncertainty—making it easier for you to move forward with cloud adoption and scale with confidence.
It’s important to distinguish between compliance at the data center level and compliance at the company level.
Backblaze offers both. Our data centers are SOC 2 compliant, and our company is also SOC 2 Type 2 compliant.
Think of it like a bank: Secure vaults are critical (data centers), but so are strong internal policies and trained staff (company compliance). And, of course, you want both. That’s what we call defense in depth—end-to-end assurance that reduces risk and builds trust.
Surprisingly, you’ll find that many CSPs have SOC 2 data centers, but do not hold SOC 2 compliance at the company level.
SOC 2 evaluations are performed by independent third-party CPA firms, which ensures the results are objective and credible. The process includes:
At Backblaze, this isn’t a one-and-done exercise. We undergo annual audits, maintain robust monitoring, and test our systems regularly. For example:
Each step reinforces our commitment to security and transparency—so you don’t have to take our word for it.
Policies and processes are the backbone of an effective SOC 2 program. At Backblaze, these policies aren’t just written down; they’re embedded in how we operate every day.
Changes that impact our systems, infrastructure, or software are controlled, tested, and approved before release. This prevents unauthorized or accidental changes that could disrupt operations or compromise security. For customers, this means you can rely on a stable, reliable storage platform that won’t jeopardize your workflows.
We log system activities, monitor access attempts, and alert on high priority security events around the clock. We have implemented features such as Anomaly Alerts to support notifying customers about unusual file upload and download patterns. Bucket Access Logs give you visibility into who accessed your data and when—adding both accountability and an audit trail for incident response.
Physical media like drives are tightly controlled throughout their lifecycle. When a drive reaches end-of-life, it undergoes a secure erasure process. If it is not able to be securely erased, the device is destroyed, ensuring data is completely unrecoverable.
Protecting data also means protecting the environment where it lives. Our data centers are equipped with redundant power and cooling systems, fire suppression, and environmental monitoring. Facilities are staffed 24/7/365 to respond to incidents in real time. These measures ensure uptime and business continuity—even in the face of physical disruptions like outages or natural disasters.
Each of these policies maps directly back to Trust Services Criteria, but more importantly, they translate into reduced risk, stronger reliability, and greater peace of mind for your business.
If you’re evaluating cloud storage providers, you can request a copy of our SOC 2 Type 2 report through Whistic. Backblaze currently offers 3 profiles on Whistic: Education Industry profile link, EU Customers profile link, or All Other Customers profile link. Once you have signed up, or signed in, you will be able to view or download the applicable documents and questionnaires.
Backblaze’s combination of SOC 2 compliant data centers and company-wide SOC 2 Type 2 compliance provides a higher level of assurance than many providers offer. That additional assurance is a powerful differentiator, especially for businesses in regulated industries.
And we’re not stopping here. Security isn’t static. We commit to annual assessments, continuous monitoring, and adapting to new threats as they emerge—so you can trust that your data is in good hands today, tomorrow, and beyond.
The post The Gold Standard of Cloud Security: Why Our SOC2 Type 2 Compliance Sets Backblaze Apart appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=EpFFyQ7rv8Q
Post Syndicated from Michelle Chen original https://blog.cloudflare.com/ai-gateway-aug-2025-refresh/
Getting the observability you need is challenging enough when the code is deterministic, but AI presents a new challenge — a core part of your user’s experience now relies on a non-deterministic engine that provides unpredictable outputs. On top of that, there are many factors that can influence the results: the model, the system prompt. And on top of that, you still have to worry about performance, reliability, and costs.
Solving performance, reliability and observability challenges is exactly what Cloudflare was built for, and two years ago, with the introduction of AI Gateway, we wanted to extend to our users the same levels of control in the age of AI.
Today, we’re excited to announce several features to make building AI applications easier and more manageable: unified billing, secure key storage, dynamic routing, security controls with Data Loss Prevention (DLP). This means that AI Gateway becomes your go-to place to control costs and API keys, route between different models and providers, and manage your AI traffic. Check out our new AI Gateway landing page for more information at a glance.
When using an AI provider, you typically have to sign up for an account, get an API key, manage rate limits, top up credits — all within an individual provider’s dashboard. Multiply that for each of the different providers you might use, and you’ll soon be left with an administrative headache of bills and keys to manage.
With AI Gateway, you can now connect to major AI providers directly through Cloudflare and manage everything through one single plane. We’re excited to partner with Anthropic, Google, Groq, OpenAI, and xAI to provide Cloudflare users with access to their models directly through Cloudflare. With this, you’ll have access to over 350+ models across 6 different providers.
You can now get billed for usage across different providers directly through your Cloudflare account. This feature is available for Workers Paid users, where you’ll be able to add credits to your Cloudflare account and use them for AI inference to all the supported providers. You’ll be able to see real-time usage statistics and manage your credits through the AI Gateway dashboard. Your AI Gateway inference usage will also be documented in your monthly Cloudflare invoice. No more signing up and paying for each individual model provider account.

Usage rates are based on then-current list prices from model providers — all you will need to cover is the transaction fee as you load credits into your account. Since this is one of the first times we’re launching a credits based billing system at Cloudflare, we’re releasing this feature in Closed Beta — sign up for access here.
Although we’ve introduced unified billing, some users might still want to manage their own accounts and keys with providers. We’re happy to say that AI Gateway will continue supporting our BYO Key feature, improving the experience of BYO Provider Keys by integrating with Cloudflare’s secrets management product Secrets Store. Now, you can seamlessly and securely store your keys in one centralized location and distribute them without relying on plain text. Secrets Store uses a two level key hierarchy with AES encryption to ensure that your secret stays safe, while maintaining low latency through our global configuration system, Quicksilver.
You can now save and manage keys directly through your AI Gateway dashboard or through the Secrets Store dashboard, API, or Wrangler by using the new AI Gateway scope. Scoping your secrets to AI Gateway ensures that only this specific service will be able to access your keys, meaning that secret could not be used in a Workers binding or anywhere else on Cloudflare’s platform.

You can pass your AI provider keys without including them directly in the request header. Instead of including the actual value, you can deploy the secret only using the Secrets Store reference:
curl -X POST https://gateway.ai.cloudflare.com/v1/<ACCOUNT_ID>/my-gateway/anthropic/v1/messages \
--header 'cf-aig-authorization: CLOUDFLARE_AI_GATEWAY_TOKEN \
--header 'anthropic-version: 2023-06-01' \
--header 'Content-Type: application/json' \
--data '{"model": "claude-3-opus-20240229", "messages": [{"role": "user", "content": "What is Cloudflare?"}]}'Or, using Javascript:
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic({
apiKey: "CLOUDFLARE_AI_GATEWAY_TOKEN",
baseURL: "https://gateway.ai.cloudflare.com/v1/<ACCOUNT_ID>/my-gateway/anthropic",
});
const message = await anthropic.messages.create({
model: 'claude-3-opus-20240229',
messages: [{role: "user", content: "What is Cloudflare?"}],
max_tokens: 1024
});By using Secrets Store to deploy your secrets, you no longer need to give every developer access to every key — instead, you can rely on Secrets Store’s role-based access control to further lock down these sensitive values. For example, you might want your security administrators to have Secrets Store admin permissions so that they can create, update, and delete the keys when necessary. With Cloudflare audit logging, all such actions will be logged so you know exactly who did what and when. Your developers, on the other hand, might only need Deploy permissions, so they can reference the values in code, whether that is a Worker or AI Gateway or both. This way, you reduce the risk of the secret getting leaked accidentally or intentionally by a malicious actor. This also allows you to update your provider keys in one place and automatically propagate that value to any AI Gateway using those values, simplifying the management.
We made it super easy for people to try out different AI models – but the developer experience should match that as well. We found that each provider can have slight differences in how they expect people to send their requests, so we’re excited to launch an automatic translation layer between providers. When you send a request through AI Gateway, it just works – no matter what provider or model you use.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_PROVIDER_API_KEY", // Provider API key
// NOTE: the OpenAI client automatically adds /chat/completions to the end of the URL, you should not add it yourself.
baseURL:
"https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_id}/compat",
});
const response = await client.chat.completions.create({
model: "google-ai-studio/gemini-2.0-flash",
messages: [{ role: "user", content: "What is Cloudflare?" }],
});
console.log(response.choices[0].message.content);When we first launched Cloudflare Workers, it was an easy way for people to intercept HTTP requests and customize actions based on different attributes. We think the same customization is necessary for AI traffic, so we’re launching Dynamic Routes in AI Gateway.
Dynamic Routes allows you to define certain actions based on different request attributes. If you have free users, maybe you want to ratelimit them to a certain request per second (RPS) or a certain dollar spend. Or maybe you want to conduct an A/B test and split 50% of traffic to Model A and 50% of traffic to Model B. You could also want to chain several models in a row, like adding custom guardrails or enhancing a prompt before it goes to another model. All of this is possible with Dynamic Routes!
We’ve built a slick UI in the AI Gateway dashboard where you can define simple if/else interactions based on request attributes or a percentage split. Once you define a route, you’ll use the route as the “model” name in your input JSON and we will manage the traffic as you defined.

import OpenAI from "openai";
const cloudflareToken = "CF_AIG_TOKEN";
const accountId = "{account_id}";
const gatewayId = "{gateway_id}";
const baseURL = `https://gateway.ai.cloudflare.com/v1/${accountId}/${gatewayId}`;
const openai = new OpenAI({
apiKey: cloudflareToken,
baseURL,
});
try {
const model = "dynamic/<your-dynamic-route-name>";
const messages = [{ role: "user", content: "What is a neuron?" }];
const chatCompletion = await openai.chat.completions.create({
model,
messages,
});
const response = chatCompletion.choices[0].message;
console.log(response);
} catch (e) {
console.error(e);
}Earlier this year we announced Guardrails in AI Gateway and now we’re expanding our security capabilities and include Data Loss Prevention (DLP) scanning in AI Gateway’s Firewall. With this, you can select the DLP profiles you are interested in blocking or flagging, and we will scan requests for the matching content. DLP profiles include general categories like “Financial Information”, “Social Security, Insurance, Tax and Identifier Numbers” that everyone has access to with a free Zero Trust account. If you would like to create a custom DLP profile to safeguard specific text, the upgraded Zero Trust plan allows you to create custom DLP profiles to catch sensitive data that is unique to your business.

False positives and grey area situations happen, we give admins controls on whether to fully block or just alert on DLP matches. This allows administrators to monitor for potential issues without creating roadblocks for their users.. Each log on AI gateway now includes details about the DLP profiles matched on your request, and the action that was taken:

If you think about the history of Cloudflare, you’ll notice similar patterns that we’re following for the new vision for AI Gateway. We want developers of AI applications to be able to have simple interconnectivity, observability, security, customizable actions, and more — something that Cloudflare has a proven track record of accomplishing for global Internet traffic. We see AI Gateway as a natural extension of Cloudflare’s mission, and we’re excited to make it come to life.
We’ve got more launches up our sleeves, but we couldn’t wait to get these first handful of features into your hands. Read up about it in our developer docs, give it a try, and let us know what you think. If you want to explore larger deployments, reach out for a consultation with Cloudflare experts.

Post Syndicated from Michelle Chen original https://blog.cloudflare.com/workers-ai-partner-models/
When we first launched Workers AI, we made a bet that AI models would get faster and smaller. We built our infrastructure around this hypothesis, adding specialized GPUs to our datacenters around the world that can serve inference to users as fast as possible. We created our platform to be as general as possible, but we also identified niche use cases that fit our infrastructure well, such as low-latency image generation or real-time audio voice agents. To lean in on those use cases, we’re bringing on some new models that will help make it easier to develop for these applications.
Today, we’re excited to announce that we are expanding our model catalog to include closed-source partner models that fit this use case. We’ve partnered with Leonardo.Ai and Deepgram to bring their latest and greatest models to Workers AI, hosted on Cloudflare’s infrastructure. Leonardo and Deepgram both have models with a great speed-to-performance ratio that suit the infrastructure of Workers AI. We’re starting off with these great partners — but expect to expand our catalog to other partner models as well.
The benefits of using these models on Workers AI is that we don’t only have a standalone inference service, we also have an entire suite of Developer products that allow you to build whole applications around AI. If you’re building an image generation platform, you could use Workers to host the application logic, Workers AI to generate the images, R2 for storage, and Images for serving and transforming media. If you’re building Realtime voice agents, we offer WebRTC and WebSocket support via Workers, speech-to-text, text-to-speech, and turn detection models via Workers AI, and an orchestration layer via Cloudflare Realtime. All in all, we want to lean into use cases that we think Cloudflare has a unique advantage in, with developer tools to back it up, and make it all available so that you can build the best AI applications on top of our holistic Developer Platform.
Leonardo.Ai is a generative AI media lab that trains their own models and hosts a platform for customers to create generative media. The Workers AI team has been working with Leonardo for a while now and have experienced the magic of their image generation models firsthand. We’re excited to bring on two image generation models from Leonardo: @cf/leonardo/phoenix-1.0 and @cf/leonardo/lucid-origin.
“We’re excited to enable Cloudflare customers a new avenue to extend and use our image generation technology in creative ways such as creating character images for gaming, generating personalized images for websites, and a host of other uses… all through the Workers AI and the Cloudflare Developer Platform.” – Peter Runham, CTO, Leonardo.Ai
The Phoenix model is trained from the ground up by Leonardo, excelling at things like text rendering and prompt coherence. The full image generation request took 4.89s end-to-end for a 25 step, 1024×1024 image.
curl --request POST \
--url https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/leonardo/draco-1.0 \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: application/json' \
--data '{
"prompt": "A 1950s-style neon diner sign glowing at night that reads '\''OPEN 24 HOURS'\'' with chrome details and vintage typography.",
"width":1024,
"height":1024,
"steps": 25,
"seed":1,
"guidance": 4,
"negative_prompt": "bad image, low quality, signature, overexposed, jpeg artifacts, undefined, unclear, Noisy, grainy, oversaturated, overcontrasted"
}'

The Lucid Origin model is a recent addition to Leonardo’s family of models and is great at generating photorealistic images. The image took 4.38s to generate end-to-end at 25 steps and a 1024×1024 image size.
curl --request POST \
--url https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/leonardo/lucid-origin \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: application/json' \
--data '{
"prompt": "A 1950s-style neon diner sign glowing at night that reads '\''OPEN 24 HOURS'\'' with chrome details and vintage typography.",
"width":1024,
"height":1024,
"steps": 25,
"seed":1,
"guidance": 4,
"negative_prompt": "bad image, low quality, signature, overexposed, jpeg artifacts, undefined, unclear, Noisy, grainy, oversaturated, overcontrasted"
}'

Deepgram is a voice AI company that develops their own audio models, allowing users to interact with AI through a natural interface for humans: voice. Voice is an exciting interface because it carries higher bandwidth than text, because it has other speech signals like pacing, intonation, and more. The Deepgram models that we’re bringing on our platform are audio models which perform extremely fast speech-to-text and text-to-speech inference. Combined with the Workers AI infrastructure, the models showcase our unique infrastructure so customers can build low-latency voice agents and more.
“By hosting our voice models on Cloudflare’s Workers AI, we’re enabling developers to create real-time, expressive voice agents with ultra-low latency. Cloudflare’s global network brings AI compute closer to users everywhere, so customers can now deliver lightning-fast conversational AI experiences without worrying about complex infrastructure.” – Adam Sypniewski, CTO, Deepgram
@cf/deepgram/nova-3 is a speech-to-text model that can quickly transcribe audio with high accuracy. @cf/deepgram/aura-1 is a text-to-speech model that is context aware and can apply natural pacing and expressiveness based on the input text. The newer Aura 2 model will be available on Workers AI soon. We’ve also improved the experience of sending binary mp3 files to Workers AI, so you don’t have to convert it into an Uint8 array like you had to previously. Along with our Realtime announcements (coming soon!), these audio models are the key to enabling customers to build voice agents directly on Cloudflare.
With the AI binding, a call to the Nova 3 speech-to-text model would look like this:
const URL = "https://www.some-website.com/audio.mp3";
const mp3 = await fetch(URL);
const res = await env.AI.run("@cf/deepgram/nova-3", {
"audio": {
body: mp3.body,
contentType: "audio/mpeg"
},
"detect_language": true
});
With the REST API, it would look like this:
curl --request POST \
--url 'https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/deepgram/nova-3?detect_language=true' \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: audio/mpeg' \
--data-binary @/path/to/audio.mp3
As well, we’ve added WebSocket support to the Deepgram models, which you can use to keep a connection to the inference server live and use it for bi-directional input and output. To use the Nova model with WebSocket support, it would look like this:
curl --request POST \
--url 'https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/deepgram/nova-3?detect_language=true' \
--header 'Authorization: Bearer {TOKEN}' \
--header 'Content-Type: audio/mpeg' \
--data-binary @/path/to/audio.mp3As well, we’ve added WebSocket support to the Deepgram models, which you can use to keep a connection to the inference server live and use it for bi-directional input and output. To use the Nova model with WebSocket support, check out our Developer Docs.
All the pieces work together so that you can:
Capture audio with Cloudflare Realtime from any WebRTC source
Pipe it via WebSocket to your processing pipeline
Transcribe with audio ML models Deepgram running on Workers AI
Process with your LLM of choice through a model hosted on Workers AI or proxied via AI Gateway
Orchestrate everything with Realtime Agents
Check out our developer docs for more details, pricing and how to get started with the newest partner models available on Workers AI.
Post Syndicated from Sven Sauleau original https://blog.cloudflare.com/how-cloudflare-runs-more-ai-models-on-fewer-gpus/
As the demand for AI products grows, developers are creating and tuning a wider variety of models. While adding new models to our growing catalog on Workers AI, we noticed that not all of them are used equally – leaving infrequently used models occupying valuable GPU space. Efficiency is a core value at Cloudflare, and with GPUs being the scarce commodity they are, we realized that we needed to build something to fully maximize our GPU usage.
Omni is an internal platform we’ve built for running and managing AI models on Cloudflare’s edge nodes. It does so by spawning and managing multiple models on a single machine and GPU using lightweight isolation. Omni makes it easy and efficient to run many small and/or low-volume models, combining multiple capabilities by:
Spawning multiple models from a single control plane,
Implementing lightweight process isolation, allowing models to spin up and down quickly,
Isolating the file system between models to easily manage per-model dependencies, and
Over-committing GPU memory to run more models on a single GPU.
Cloudflare aims to place GPUs as close as we possibly can to people and applications that are using them. With Omni in place, we’re now able to run more models on every node in our network, improving model availability, minimizing latency, and reducing power consumed by idle GPUs.
Here’s how.
At a high level, Omni is a platform to run AI models. When an inference request is made on Workers AI, we load the model’s configuration from Workers KV and our routing layer forwards it to the closest Omni instance that has available capacity. For inferences using the Asynchronous Batch API, we route to an Omni instance that is idle, which is typically in a location where it’s night.
Omni runs a few checks on the inference request, runs model specific pre and post processing, then hands the request over to the model.

If you’re developing an AI application, a typical setup is having a container or a VM dedicated to running a single model with a GPU attached to it. This is simple. But it’s also heavy-handed — because it requires managing the entire stack from provisioning the VM, installing GPU drivers, downloading model weights, and managing the Python environment. At scale, managing infrastructure this way is incredibly time consuming and often requires an entire team.
If you’re using Workers AI, we handle all of this for you. Omni uses a single control plane for running multiple models, called the scheduler, which automatically provisions models and spawns new instances as your traffic scales. When starting a new model instance, it downloads model weights, Python code, and any other dependencies. Omni’s scheduler provides fine-grained control and visibility over the model’s lifecycle: it receives incoming inference requests and routes them to the corresponding model processes, being sure to distribute the load between multiple GPUs. It then makes sure the model processes are running, rolls out new versions as they are released, and restarts itself when detecting errors or failure states. It also collects metrics for billing and emits logs.
The inference itself is done by a per-model process, supervised by the scheduler. It receives the inference request and some metadata, then sends back a response. Depending on the model, the response can be various types; for instance, a JSON object or a SSE stream for text generation, or binary for image generation.
The scheduler and the child processes communicate by passing messages over Inter-Process Communication (IPC). Usually the inference request is buffered in the scheduler for applying features, like prompt templating or tool calling, before the request is passed to the child process. For potentially large binary requests, the scheduler hands over the underlying TCP connection to the child process for consuming the request body directly.
Typically, deploying a model requires its own dedicated container, but we want to colocate more models on a single container to conserve memory and GPU capacity. In order to do so, we needed finer-grained controls over CPU memory and the ability to isolate a model from its dependencies and environment. We deploy Omni in two configurations; a container running multiple models or bare metal running a single model. In both cases, process isolation and Python virtual environments allow us to isolate models with different dependencies by creating namespaces and are limited by cgroups.
Python doesn’t take into account cgroups memory limits for memory allocations, which can lead to OOM errors. Many AI Python libraries rely on psutil for pre-allocating CPU memory. psutil reads /proc/meminfo to determine how much memory is available. Since in Omni each model has its own configurable memory limits, we need psutil to reflect the current usage and limits for a given model, not for the entire system.
The solution for us was to create a virtual file system, using fuse, to mount our own version of /proc/meminfo which reflects the model’s current usage and limits.
To illustrate this, here’s an Omni instance running a model (running as pid 8). If we enter the mount namespace and look at /proc/meminfo it will reflect the model’s configuration:
# Enter the mount (file system) namespace of a child process
$ nsenter -t 8 -m
$ mount
...
none /proc/meminfo fuse ...
$ cat /proc/meminfo
MemTotal: 7340032 kB
MemFree: 7316388 kB
MemAvailable: 7316388 kBIn this case the model has 7Gib of memory available and the entire container 15Gib. If the model tries to allocate more than 7Gib of memory, it will be OOM killed and restarted by the scheduler’s process manager, without causing any problems to the other models.
For isolating Python and some system dependencies, each model runs in a Python virtual environment, managed by uv. Dependencies are cached on the machine and, if possible, shared between models (uv uses symbolic links between its cache and virtual environments).
Also separated processes for models allows to have different CUDA contexts and isolation for error recovery.
Some models don’t receive enough traffic to fully utilize a GPU, and with Omni we can pack more models on a single GPU, freeing up capacity for other workloads. When it comes to GPU memory management, Omni has two main jobs: safely over-commit GPU memory, so that more models than normal can share a single GPU, and enforce memory limits, to prevent any single model from running out of memory while running.
Over-committing memory means allocating more memory than is physically available to the device.
For example, if a GPU has 10 Gib of memory, Omni would allow 2 models of 10Gib each on that GPU.
Right now, Omni is configured to run 13 models and is allocating about 400% GPU memory on a single GPU, saving up 4 GPUs. Omni does this by injecting a CUDA stub library that intercepts CUDA memory allocations (cuMalloc* or cudaMalloc*) calls and forces memory allocations to be performed in unified memory mode.
In Unified memory mode CUDA shares the same memory address space for both the GPU and the CPU:

CUDA’s unified memory mode
In practice this is what memory over-commitment looks like: imagine 3 models (A, B and C). Models A+B fit in the GPU’s memory but C takes up the entire memory.
Models A+B are loaded first and are in GPU memory, while model C is in CPU memory

Omni receives a request for model C so models A+B are swapped out and C is swapped in.

Omni receives a request for model B, so model C is partly swapped out and model B is swapped back in.

Omni receives a request for model A, so model A is swapped back in and model C is completely swapped out.

The trade-off is added latency: if performing an inference requires memory that is currently on the host system, it must be transferred to the GPU. For smaller models, this latency is minimal, because with PCIe 4.0, the physical bus between your GPU and system, provides 32 GB/sec of bandwidth. On the other hand, if a model need to be “cold started” i.e. it’s been swapped out because it hasn’t been used in a while, the system may need to swap back the entire model – a larger sized model, for example, might use 5Gib of GPU memory for weights and caches, and would take ~156ms to be swapped back into the GPU. Naturally, over time, inactive models are put into CPU memory, while active models stay hot in the GPU.
Rather than allowing the model to choose how much GPU memory it uses, AI frameworks tend to pre-allocate as much GPU memory as possible for performance reasons, making co-locating models more complicated. Omni allows us to control how much memory is actually exposed to any given model to prevent a greedy model from over-using the GPU allocated to it. We do this by overriding the CUDA runtime and driver APIs (cudaMemGetInfo and cuMemGetInfo). Instead of exposing the entire GPU memory, we only expose a subset of memory to each model.
AI models can run in a variety of inference engines or backends: vLLM, Python, and now our very own inference engine, Infire. While models have different capabilities, each model needs to support Workers AI features, like batching and function calling. Omni acts as a unified layer for integrating these systems. It integrates into our internal routing and scheduling systems, and provides a Python API for our engineering team to add new models more easily. Let’s take a closer look at how Omni does this in practice:
from omni import Response
import cowsay
def handle_request(request, context):
try:
json = request.body.json
text = json["text"]
except Exception as err:
return Response.error(...)
return cowsay.get_output_string('cow', text)Similar to how a JavaScript Worker works, Omni calls a request handler, running the model’s logic and returning a response.
Omni installs Python dependencies at model startup. We run an internal Python registry and mirror the public registry. In either case we declare dependencies in requirements.txt:
cowsay==6.1The handle_request function can be async and return different Python types, including pydantic objects. Omni will convert the return value into a Workers AI response for the eyeball.
A Python package is injected, named omni, containing all the Python APIs to interact with the request, the Workers AI systems, building Responses, error handling, etc. Internally we publish it as regular Python package to be used in standalone, for unit testing for instance:
from omni import Context, Request
from model import handle_request
def test_basic():
ctx = Context.inactive()
req = Request(json={"text": "my dog is cooler than you!"})
out = handle_request(req, ctx)
assert out == """ __________________________
| my dog is cooler than you! |
==========================
\\
\\
^__^
(oo)\\_______
(__)\\ )\\/\\
||----w |
|| ||"""Omni allows us to run models more efficiently by spawning them from a single control plane and implementing lightweight process isolation. This enables quick starting and stopping of models, isolated file systems for managing Python and system dependencies, and over-committing GPU memory to run more models on a single GPU. This improves the performance for our entire Workers AI stack, reduces the cost of running GPUs, and allows us to ship new models and features quickly and safely.
Right now, Omni is running in production on a handful of models in the Workers AI catalog, and we’re adding more every week. Check out Workers AI today to experience Omni’s performance benefits on your AI application.
Post Syndicated from Vlad Krasnov original https://blog.cloudflare.com/cloudflares-most-efficient-ai-inference-engine/
Inference powers some of today’s most powerful AI products: chat bot replies, AI agents, autonomous vehicle decisions, and fraud detection. The problem is, if you’re building one of these products on top of a hyperscaler, you’ll likely need to rent expensive GPUs from large centralized data centers to run your inference tasks. That model doesn’t work for Cloudflare — there’s a mismatch between Cloudflare’s globally-distributed network and a typical centralized AI deployment using large multi-GPU nodes. As a company that operates our own compute on a lean, fast, and widely distributed network within 50ms of 95% of the world’s Internet-connected population, we need to be running inference tasks more efficiently than anywhere else.
This is further compounded by the fact that AI models are getting larger and more complex. As we started to support these models, like the Llama 4 herd and gpt-oss, we realized that we couldn’t just throw money at the scaling problems by buying more GPUs. We needed to utilize every bit of idle capacity and be agile with where each model is deployed.
After running most of our models on the widely used open source inference and serving engine vLLM, we figured out it didn’t allow us to fully utilize the GPUs at the edge. Although it can run on a very wide range of hardware, from personal devices to data centers, it is best optimized for large data centers. When run as a dedicated inference server on powerful hardware serving a specific model, vLLM truly shines. However, it is much less optimized for dynamic workloads, distributed networks, and for the unique security constraints of running inference at the edge alongside other services.
That’s why we decided to build something that will be able to meet the needs of Cloudflare inference workloads for years to come. Infire is an LLM inference engine, written in Rust, that employs a range of techniques to maximize memory, network I/O, and GPU utilization. It can serve more requests with fewer GPUs and significantly lower CPU overhead, saving time, resources, and energy across our network.
Our initial benchmarking has shown that Infire completes inference tasks up to 7% faster than vLLM 0.10.0 on unloaded machines equipped with an H100 NVL GPU. On infrastructure under real load, it performs significantly better.
Currently, Infire is powering the Llama 3.1 8B model for Workers AI, and you can test it out today at @cf/meta/llama-3.1-8b-instruct!
Thanks to industry efforts, inference has improved a lot over the past few years. vLLM has led the way here with the recent release of the vLLM V1 engine with features like an optimized KV cache, improved batching, and the implementation of Flash Attention 3. vLLM is great for most inference workloads — we’re currently using it for several of the models in our Workers AI catalog — but as our AI workloads and catalog has grown, so has our need to optimize inference for the exact hardware and performance requirements we have.
Cloudflare is writing much of our new infrastructure in Rust, and vLLM is written in Python. Although Python has proven to be a great language for prototyping ML workloads, to maximize efficiency we need to control the low-level implementation details. Implementing low-level optimizations through multiple abstraction layers and Python libraries adds unnecessary complexity and leaves a lot of CPU performance on the table, simply due to the inefficiencies of Python as an interpreted language.
We love to contribute to open-source projects that we use, but in this case our priorities may not fit the goals of the vLLM project, so we chose to write a server for our needs. For example, vLLM does not support co-hosting multiple models on the same GPU without using Multi-Instance GPU (MIG), and we need to be able to dynamically schedule multiple models on the same GPU to minimize downtime. We also have an in-house AI Research team exploring unique features that are difficult, if not impossible, to upstream to vLLM.
Finally, running code securely is our top priority across our platform and Workers AI is no exception. We simply can’t trust a 3rd party Python process to run on our edge nodes alongside the rest of our services without strong sandboxing. We are therefore forced to run vLLM via gvisor. Having an extra virtualization layer adds an additional performance overhead to vLLM. More importantly, it also increases the startup and tear down time for vLLM instances — which are already pretty long. Under full load on our edge nodes, vLLM running via gvisor consumes as much as 2.5 CPU cores, and is forced to compete for CPU time with other crucial services, that in turn slows vLLM down and lowers GPU utilization as a result.
While developing Infire, we’ve been incorporating the latest research in inference efficiency — let’s take a deeper look at what we actually built.
Infire is composed of three major components: an OpenAI compatible HTTP server, a batcher, and the Infire engine itself.

An overview of Infire’s architecture
When a model is first scheduled to run on a specific node in one of our data centers by our auto-scaling service, the first thing that has to happen is for the model weights to be fetched from our R2 object storage. Once the weights are downloaded, they are cached on the edge node for future reuse.
As the weights become available either from cache or from R2, Infire can begin loading the model onto the GPU.
Model sizes vary greatly, but most of them are large, so transferring them into GPU memory can be a time-consuming part of Infire’s startup process. For example, most non-quantized models store their weights in the BF16 floating point format. This format has the same dynamic range as the 32-bit floating format, but with reduced accuracy. It is perfectly suited for inference providing the sweet spot of size, performance and accuracy. As the name suggests, the BF16 format requires 16 bits, or 2 bytes per weight. The approximate in-memory size of a given model is therefore double the size of its parameters. For example, LLama3.1 8B has approximately 8B parameters, and its memory footprint is about 16GB. A larger model, like LLama4 Scout, has 109B parameters, and requires around 218GB of memory. Infire utilizes a combination of Page Locked memory with CUDA asynchronous copy mechanism over multiple streams to speed up model transfer into GPU memory.
While loading the model weights, Infire begins just-in-time compiling the required kernels based on the model’s parameters, and loads them onto the device. Parallelizing the compilation with model loading amortizes the latency of both processes. The startup time of Infire when loading the Llama-3-8B-Instruct model from disk is just under 4 seconds.
The Infire server is built on top of hyper, a high performance HTTP crate, which makes it possible to handle hundreds of connections in parallel – while consuming a modest amount of CPU time. Because of ChatGPT’s ubiquity, vLLM and many other services offer OpenAI compatible endpoints out of the box. Infire is no different in that regard. The server is responsible for handling communication with the client: accepting connections, handling prompts and returning responses. A prompt will usually consist of some text, or a “transcript” of a chat session along with extra parameters that affect how the response is generated. Some parameters that come with a prompt include the temperature, which affects the randomness of the response, as well as other parameters that affect the randomness and length of a possible response.
After a request is deemed valid, Infire will pass it to the tokenizer, which transforms the raw text into a series of tokens, or numbers that the model can consume. Different models use different kinds of tokenizers, but the most popular ones use byte-pair encoding. For tokenization, we use HuggingFace’s tokenizers crate. The tokenized prompts and params are then sent to the batcher, and scheduled for processing on the GPU, where they will be processed as vectors of numbers, called embeddings.
The most important part of Infire is in how it does batching: by executing multiple requests in parallel. This makes it possible to better utilize memory bandwidth and caches.
In order to understand why batching is so important, we need to understand how the inference algorithm works. The weights of a model are essentially a bunch of two-dimensional matrices (also called tensors). The prompt represented as vectors is passed through a series of transformations that are largely dominated by one operation: vector-by-matrix multiplication. The model weights are so large, that the cost of the multiplication is dominated by the time it takes to fetch it from memory. In addition, modern GPUs have hardware units dedicated to matrix-by-matrix multiplications (called Tensor Cores on Nvidia GPUs). In order to amortize the cost of memory access and take advantage of the Tensor Cores, it is necessary to aggregate multiple operations into a larger matrix multiplication.
Infire utilizes two techniques to increase the size of those matrix operations. The first one is called prefill: this technique is applied to the prompt tokens. Because all of the prompt tokens are available in advance and do not require decoding, they can all be processed in parallel. This is one reason why input tokens are often cheaper (and faster) than output tokens.

How Infire enables larger matrix multiplications via batching
The other technique is called batching: this technique aggregates multiple prompts into a single decode operation.
Infire mixes both techniques. It attempts to process as many prompts as possible in parallel, and fills the remaining slots in a batch with prefill tokens from incoming prompts. This is also known as continuous batching with chunked prefill.
As tokens get decoded by the Infire engine, the batcher is also responsible for retiring prompts that reach an End of Stream token, and sending tokens back to the decoder to be converted into text.
Another job the batcher has is handling the KV cache. One demanding operation in the inference process is called attention. Attention requires going over the KV values computed for all of the tokens up to the current one. If we had to recompute those previously encountered KV values for every new token we decode, the runtime of the process would explode for longer context sizes. However, using a cache, we can store all of the previous values and re-read them for each consecutive token. Potentially the KV cache for a prompt can store KV values for as many tokens as the context window allows. In LLama 3, the maximal context window is 128K tokens. If we pre-allocated the KV cache for each prompt in advance, we would only have enough memory available to execute 4 prompts in parallel on H100 GPUs! The solution for this is paged KV cache. With paged KV caching, the cache is split into smaller chunks called pages. When the batcher detects that a prompt would exceed its KV cache, it simply assigns another page to that prompt. Since most prompts rarely hit the maximum context window, this technique allows for essentially unlimited parallelism under typical load.
Finally, the batcher drives the Infire forward pass by scheduling the needed kernels to run on the GPU.
Developing Infire gives us the luxury of focusing on the exact hardware we use, which is currently Nvidia Hopper GPUs. This allowed us to improve performance of specific compute kernels using low-level PTX instructions for this specific architecture.
Infire just-in-time compiles its kernel for the specific model it is running, optimizing for the model’s parameters, such as the hidden state size, dictionary size and the GPU it is running on. For some operations, such as large matrix multiplications, Infire will utilize the high performance cuBLASlt library, if it would deem it faster.
Infire also makes use of very fine-grained CUDA graphs, essentially creating a dedicated CUDA graph for every possible batch size on demand. It then stores it for future launch. Conceptually, a CUDA graph is another form of just-in-time compilation: the CUDA driver replaces a series of kernel launches with a single construct (the graph) that has a significantly lower amortized kernel launch cost, thus kernels executed back to back will execute faster when launched as a single graph as opposed to individual launches.
We ran synthetic benchmarks on one of our edge nodes with an H100 NVL GPU.
The benchmark we ran was on the widely used ShareGPT v3 dataset. We ran the benchmark on a set of 4,000 prompts with a concurrency of 200. We then compared Infire and vLLM running on bare metal as well as vLLM running under gvisor, which is the way we currently run in production. In a production traffic scenario, an edge node would be competing for resources with other traffic. To simulate this, we benchmarked vLLM running in gvisor with only one CPU available.
|
requests/s |
tokens/s |
CPU load |
|
|
Infire |
40.91 |
17224.21 |
25% |
|
vLLM 0.10.0 |
38.38 |
16164.41 |
140% |
|
vLLM under gvisor |
37.13 |
15637.32 |
250% |
|
vLLM under gvisor with CPU constraints |
22.04 |
9279.25 |
100% |
As evident from the benchmarks we achieved our initial goal of matching and even slightly surpassing vLLM performance, but more importantly, we’ve done so at a significantly lower CPU usage, in large part because we can run Infire as a trusted bare-metal process. Inference no longer takes away precious resources from our other services and we see GPU utilization upward of 80%, reducing our operational costs.
This is just the beginning. There are still multiple proven performance optimizations yet to be implemented in Infire – for example, we’re integrating Flash Attention 3, and most of our kernels don’t utilize kernel fusion. Those and other optimizations will allow us to unlock even faster inference in the near future.
Running AI inference presents novel challenges and demands to our infrastructure. Infire is how we’re running AI efficiently — close to users around the world. By building upon techniques like continuous batching, a paged KV-cache, and low-level optimizations tailored to our hardware, Infire maximizes GPU utilization while minimizing overhead. Infire completes inference tasks faster and with a fraction of the CPU load of our previous vLLM-based setup, especially under the strict security constraints we require. This allows us to serve more requests with fewer resources, making requests served via Workers AI faster and more efficient.
However, this is just our first iteration — we’re excited to build in multi-GPU support for larger models, quantization, and true multi-tenancy into the next version of Infire. This is part of our goal to make Cloudflare the best possible platform for developers to build AI applications.
Want to see if your AI workloads are faster on Cloudflare? Get started with Workers AI today.
Post Syndicated from corbet original https://lwn.net/Articles/1034849/
The Internet is a wonderful thing; it allows anybody to look up
information of interest. Included in all of that is the history of the
free-software development community; how we got to where we are says a lot
about why things are the way they are and what might come next. So the
takeover of Groklaw rings a loud alarm; we have been reminded that history
stored on the Internet is an ephemeral thing and cannot be expected to
remain available forever.
Post Syndicated from jzb original https://lwn.net/Articles/1035307/
Security updates have been issued by Debian (node-cipher-base), Fedora (keylime-agent-rust and libtiff), Oracle (aide, kernel, mod_http2, pam, pki-deps:10.6, python-cryptography, python3, python3.12, and thunderbird), SUSE (cheat, ffmpeg, firebird, govulncheck-vulndb, postgresql17, tomcat, tomcat10, tomcat11, ucode-intel-20250812, and v2ray-core), and Ubuntu (binutils, gst-plugins-base1.0, gst-plugins-good1.0, and linux-raspi-realtime).
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=oFwphCFrJCk