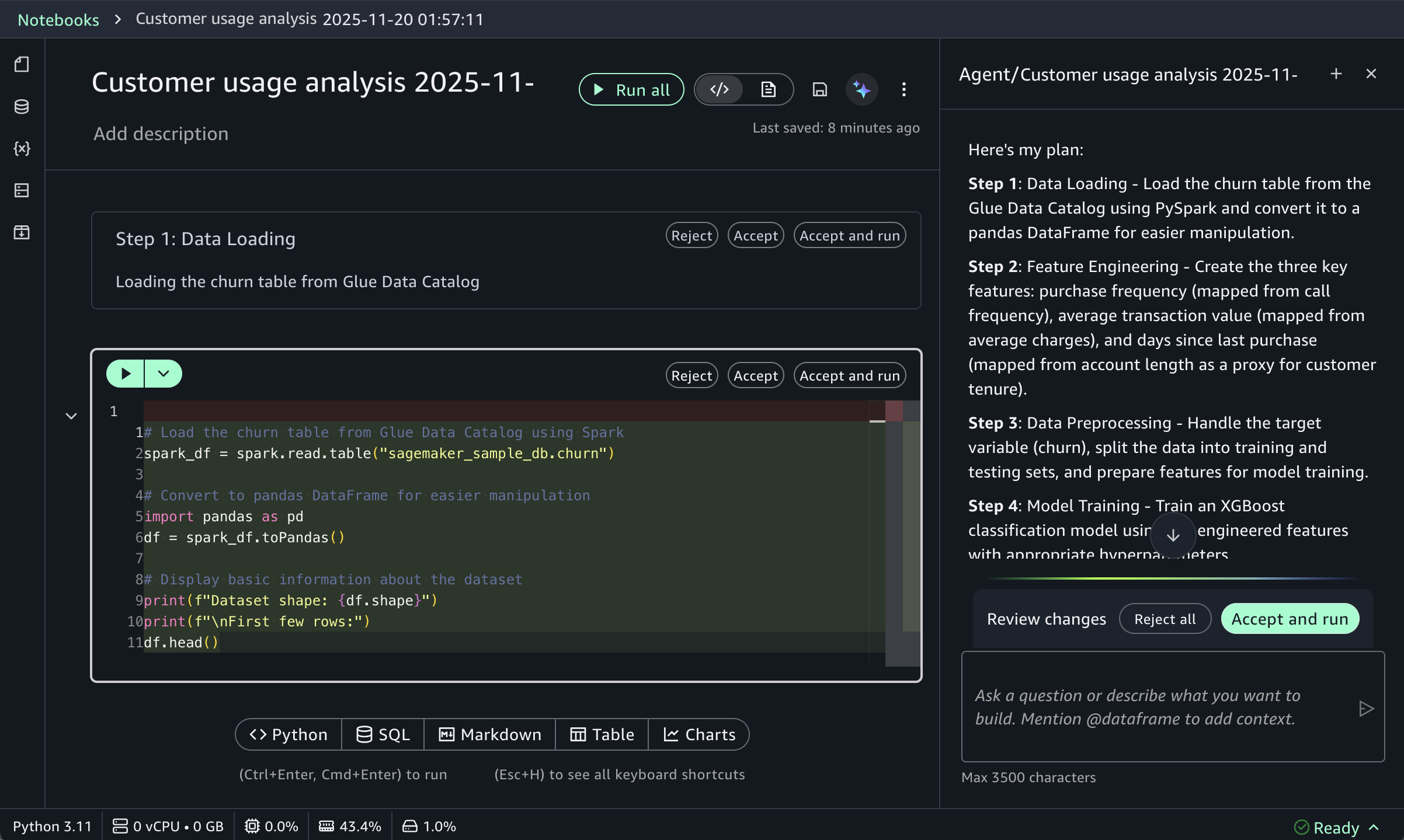
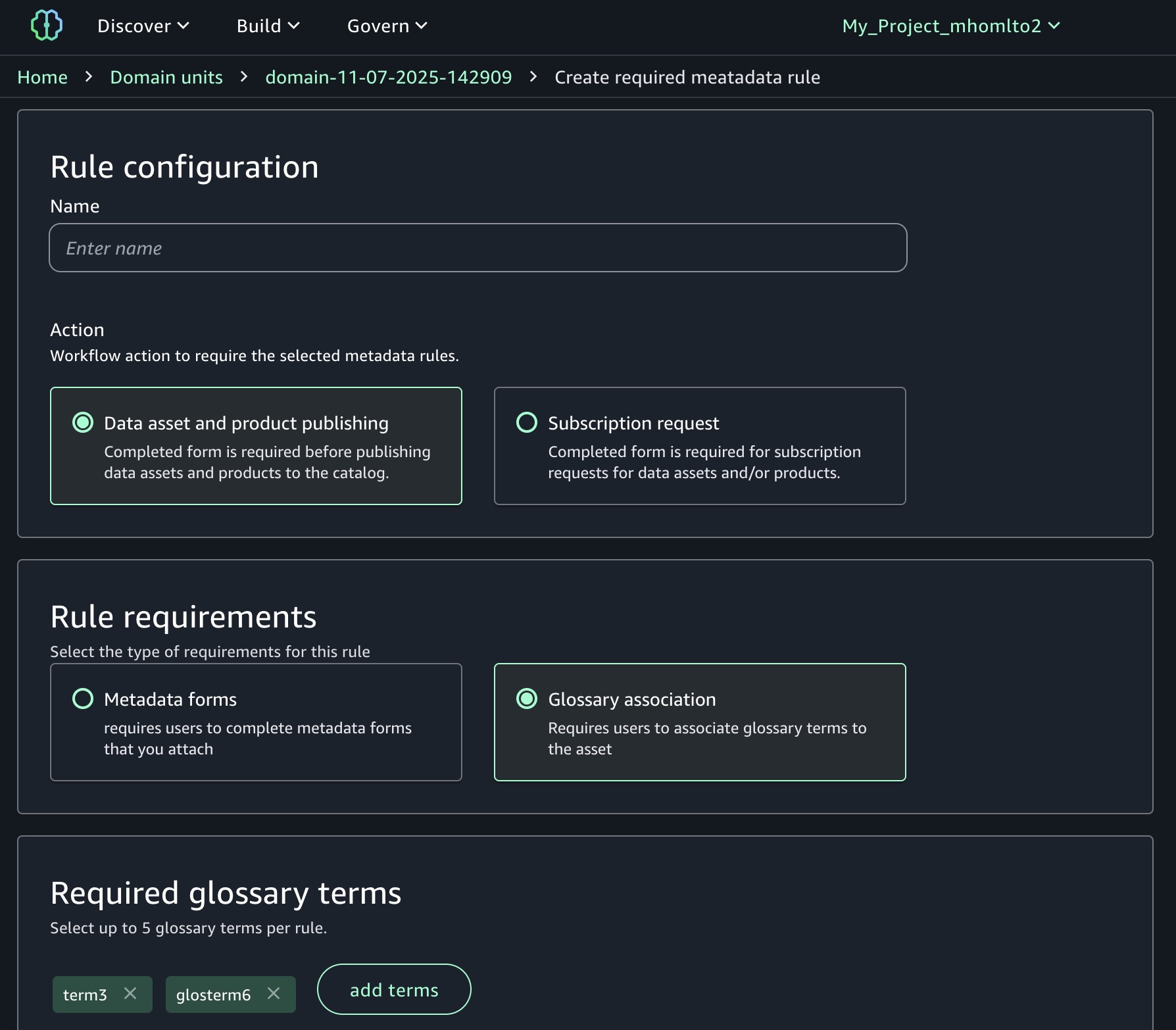
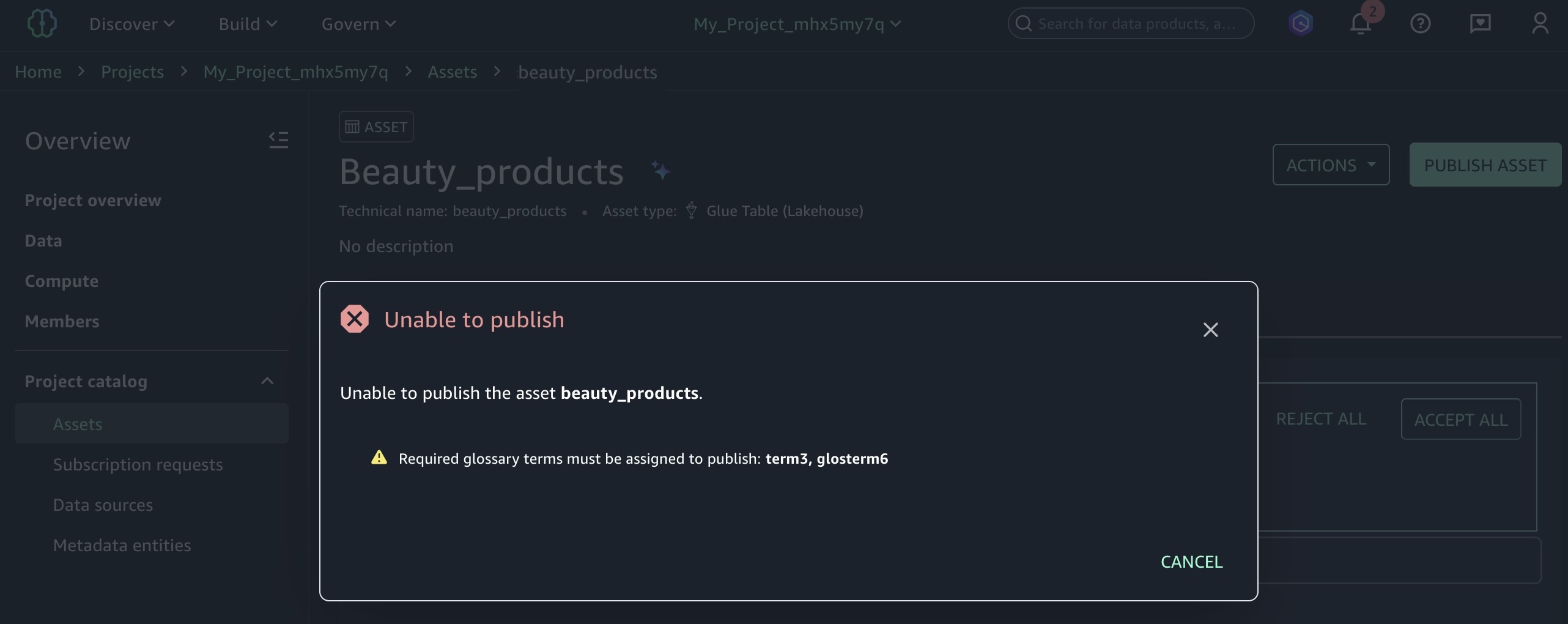
Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/amazon-ec2-c8id-m8id-and-r8id-instances-with-up-to-22-8-tb-local-nvme-storage-are-generally-available/
Last year, we launched the Amazon Elastic Compute Cloud (Amazon EC2) C8i instances, M8i instances, and R8i instances powered by custom Intel Xeon 6 processors available only on AWS with sustained all-core 3.9 GHz turbo frequency. They deliver the highest performance and fastest memory bandwidth among comparable Intel processors in the cloud.
Today we’re announcing new Amazon EC2 C8id, M8id, and R8id instances backed by up to 22.8TB of NVMe-based SSD block-level instance storage physically connected to the host server. These instances offer 3 times more vCPUs, memory and local storage compared to previous sixth-generation instances.
These instances deliver up to 43% higher compute performance and 3.3 times more memory bandwidth compared to previous sixth-generation instances. They also deliver up to 46% higher performance for I/O intensive database workloads, and up to 30% faster query results for I/O intensive real-time data analytics compared to previous sixth generation instances.
- C8id instances are ideal for compute-intensive workloads, including those that need access to high-speed, low-latency local storage like video encoding, image manipulation, and other forms of media processing.
- M8id instances are best for workloads that require a balance of compute and memory resources along with high-speed, low-latency local block storage, including data logging, media processing, and medium-sized data stores.
- R8id instances are designed for memory-intensive workloads such as large-scale SQL and NoSQL databases, in-memory databases, large-scale data analytics, and AI inference.
C8id, M8id, and R8id instances now scale up to 96xlarge (versus 32xlarge sizes in the sixth generation) with up to 384 vCPUs, 3TiB of memory, and 22.8TB of local storage that make it easier to scale up applications and drive greater efficiencies. These instances also offer two bare metal sizes (metal-48xl and metal-96xl), allowing you to right size your instances and deploy your most performance sensitive workloads that benefit from direct access to physical resources.
The instances are available in 11 sizes per family, as well as two bare metal configurations each:
| Instance Name | vCPUs | Memory (GiB) (C/M/R) | Local NVMe storage (GB) | Network bandwidth (Gbps) | EBS bandwidth (Gbps) |
|---|---|---|---|---|---|
| large | 2 | 4/8/16* | 1 x 118 | Up to 12.5 | Up to 10 |
| xlarge | 4 | 8/16/32* | 1 x 237 | Up to 12.5 | Up to 10 |
| 2xlarge | 8 | 16/32/64* | 1 x 474 | Up to 15 | Up to 10 |
| 4xlarge | 16 | 32/64/128* | 1 x 950 | Up to 15 | Up to 10 |
| 8xlarge | 32 | 64/128/256* | 1 x 1,900 | 15 | 10 |
| 12xlarge | 48 | 96/192/384* | 1 x 2,850 | 22.5 | 15 |
| 16xlarge | 64 | 128/256/512* | 1 x 3,800 | 30 | 20 |
| 24xlarge | 96 | 192/384/768* | 2 x 2,850 | 40 | 30 |
| 32xlarge | 128 | 256/512/1024* | 2 x 3,800 | 50 | 40 |
| 48xlarge | 192 | 384/768/1536* | 3 x 3,800 | 75 | 60 |
| 96xlarge | 384 | 768/1536/3072* | 6 x 3,800 | 100 | 80 |
| metal-48xl | 192 | 384/768/1536* | 3 x 3,800 | 75 | 60 |
| metal-96xl | 384 | 768/1536/3072* | 6 x 3,800 | 100 | 80 |
*Memory values are for C8id/M8id/R8id respectively.
These instances support the Instance Bandwidth Configuration (IBC) feature like other eighth-generation instance types, offering flexibility to allocate resources between network and Amazon Elastic Block Store (Amazon EBS) bandwidth. You can scale network or EBS bandwidth by 25%, allocating resources optimally for each workload. These instances also use sixth-generation AWS Nitro cards offloading CPU virtualization, storage, and networking functions to dedicated hardware and software, enhancing performance and security for your workloads.
You can use any Amazon Machine Images (AMIs) that include drivers for the Elastic Network Adapter (ENA) and NVMe to fully utilize the performance and capabilities. All current generation AWS Windows and Linux AMIs come with the AWS NVMe driver installed by default. If you use an AMI that does not have the AWS NVMe driver, you can manually install AWS NVMe drivers.
As I noted in my previous blog post, here are a couple of things to remind you about the local NVMe storage on these instances:
- You don’t have to specify a block device mapping in your AMI or during the instance launch; the local storage will show up as one or more devices (
/dev/nvme[0-26]n1on Linux) after the guest operating system has booted. - Each local NVMe device is hardware encrypted using the
XTS-AES-256block cipher and a unique key. Each key is destroyed when the instance is stopped or terminated. - Local NVMe devices have the same lifetime as the instance they are attached to and do not persist after the instance has been stopped or terminated.
To learn more, visit Amazon EBS volumes and NVMe in the Amazon EBS User Guide.
Now available
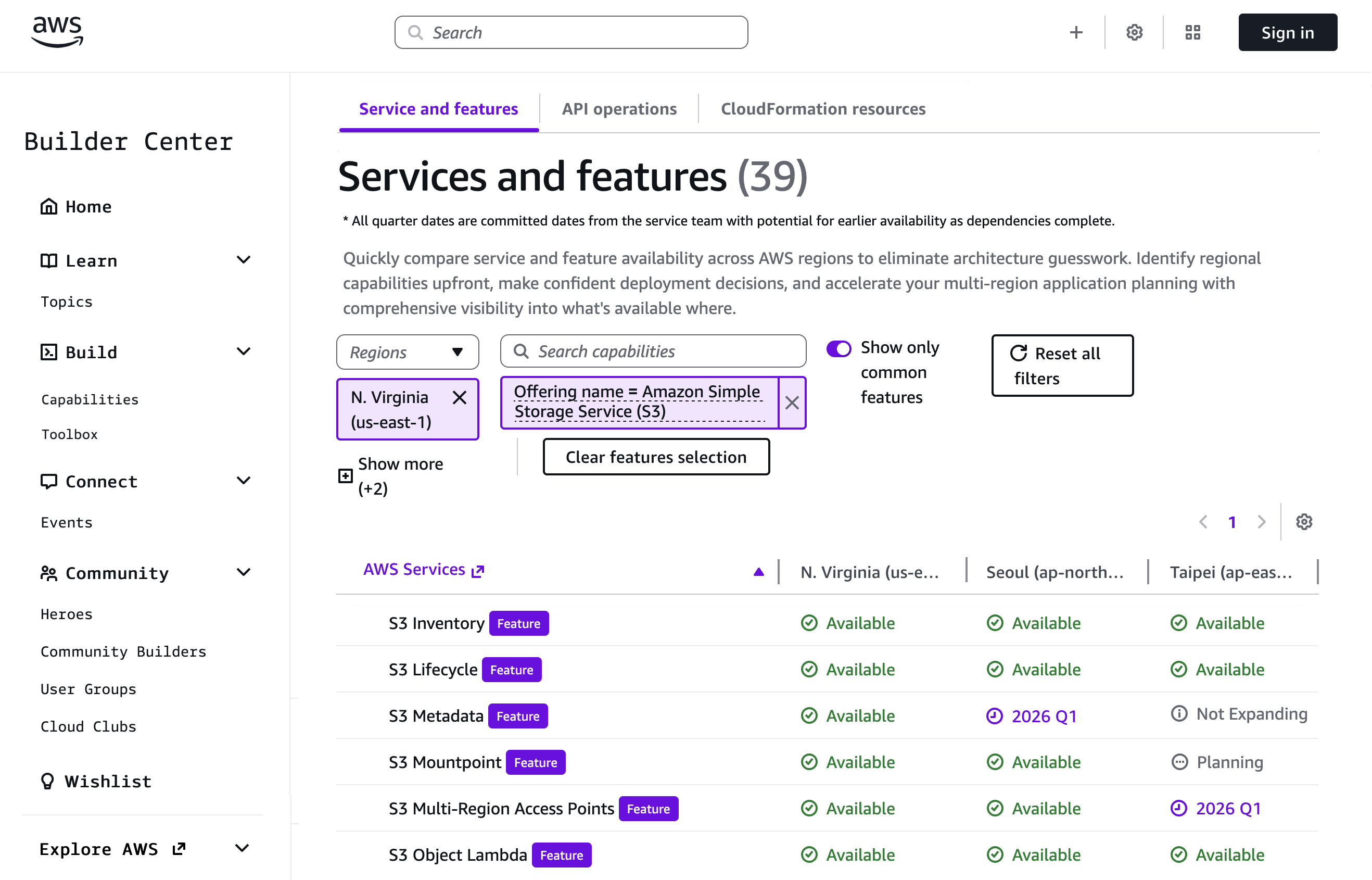
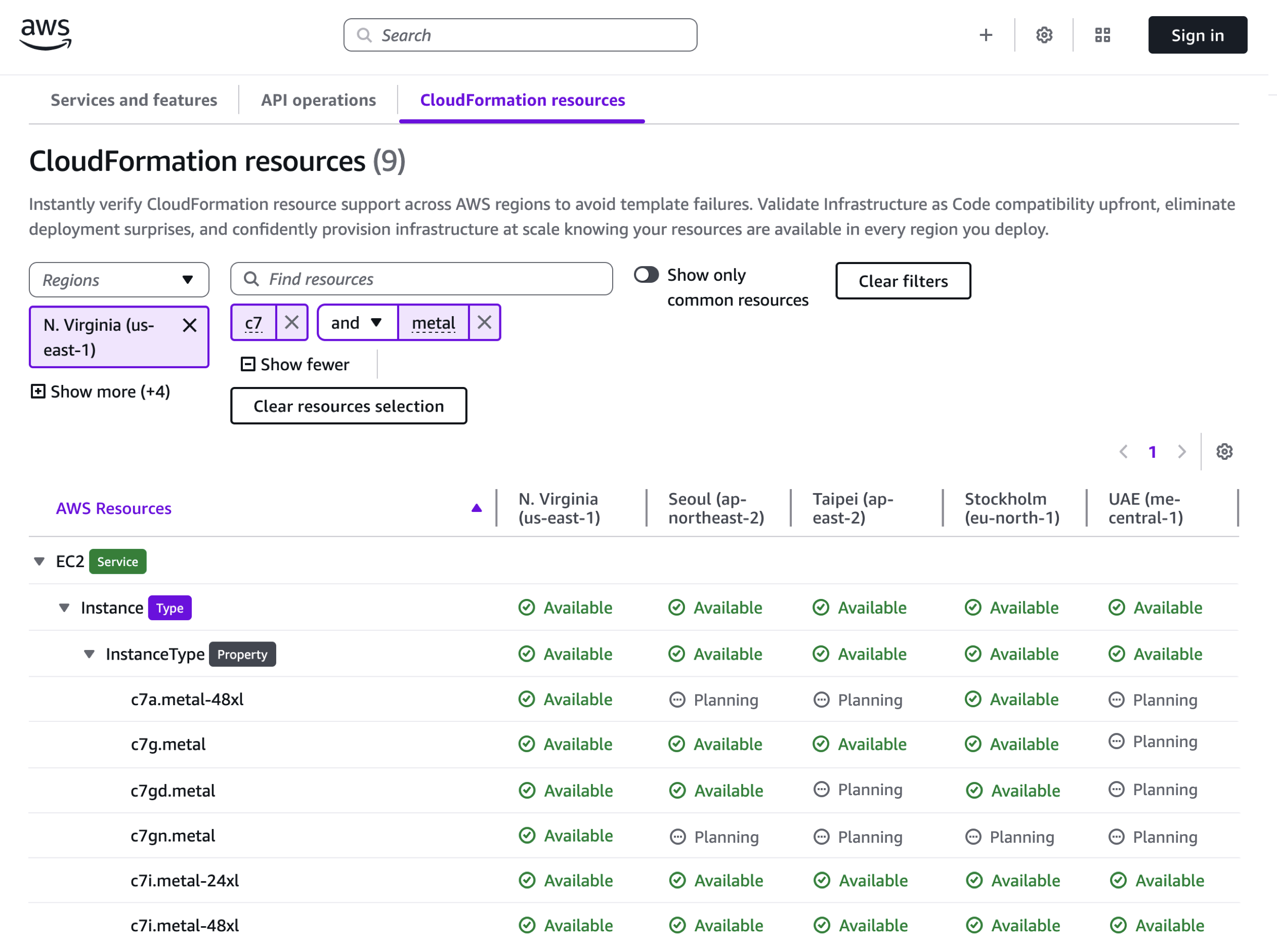
Amazon EC2 C8id, M8id and R8id instances are available in US East (N. Virginia), US East (Ohio), and US West (Oregon) AWS Regions. R8id instances are additionally available in Europe (Frankfurt) Region. For Regional availability and a future roadmap, search the instance type in the CloudFormation resources tab of AWS Capabilities by Region.
You can purchase these instances as On-Demand Instances, Savings Plans, and Spot Instances. These instances are also available as Dedicated Instances and Dedicated Hosts. To learn more, visit the Amazon EC2 Pricing page.
Give C8id, M8id, and R8id instances a try in the Amazon EC2 console. To learn more, visit the EC2 C8i instances, M8i instances, and R8i instances page and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Channy
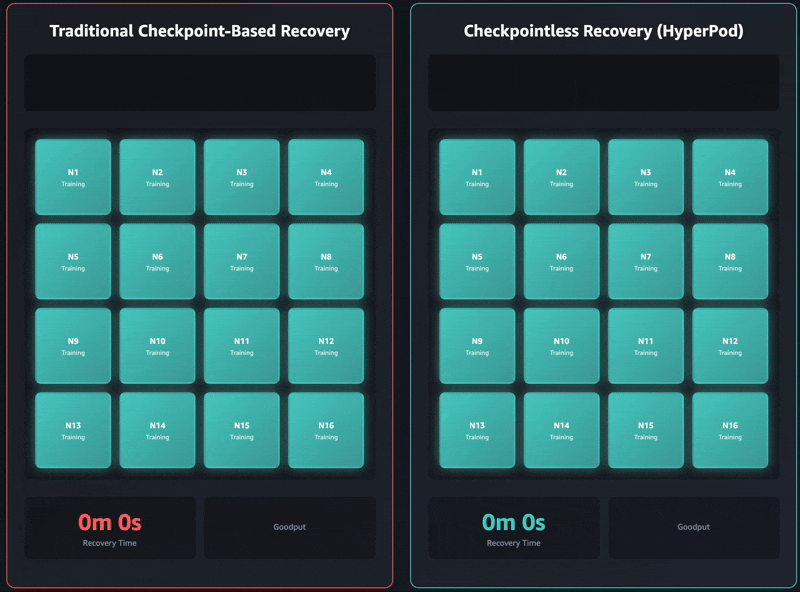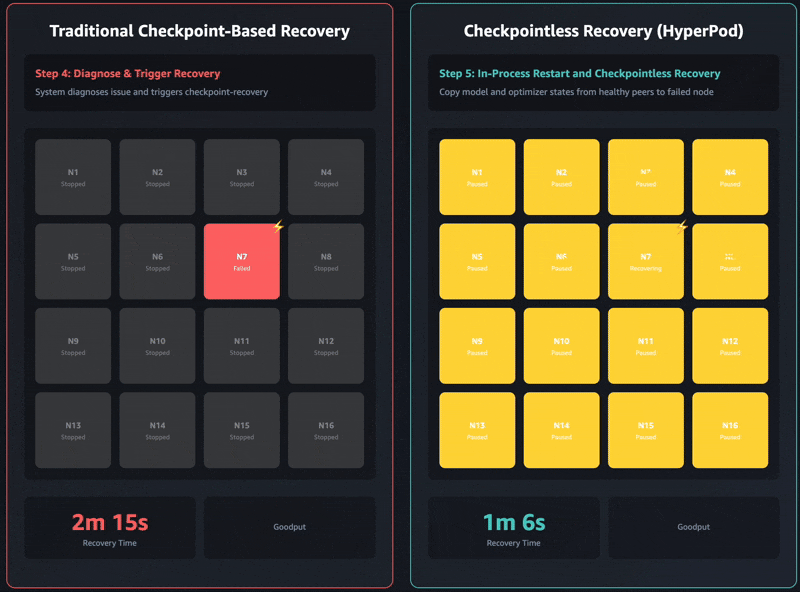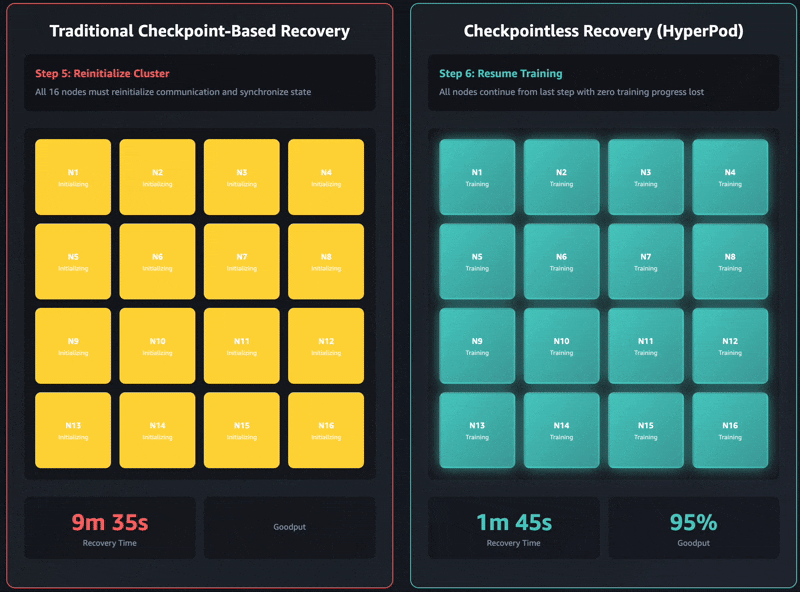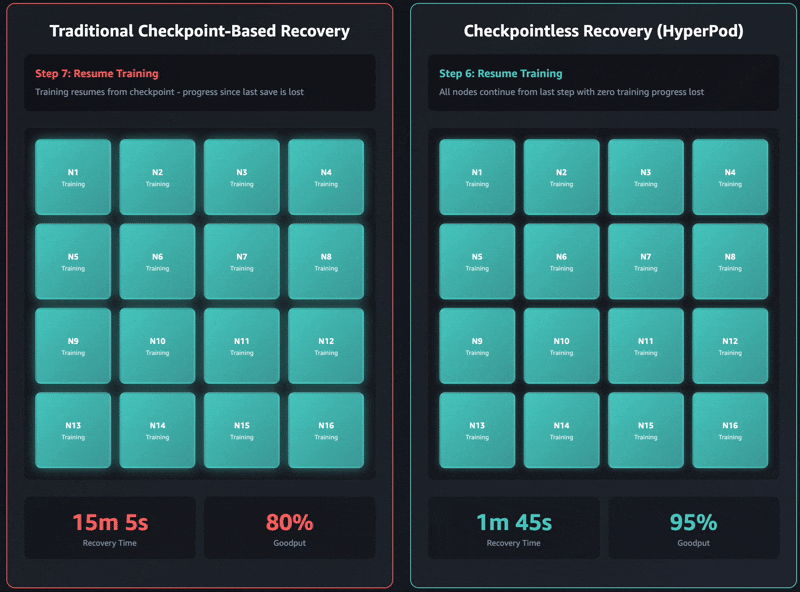
 Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.