The xsnow
application, which generates an animated snowfall effect (and other
pleasant diversions) for X11 desktops, does not seem like an obvious
channel for political statements. Nevertheless, xsnow’s maintainer
seems to have included a political protest in the program: an
Easter egg that is triggered when the program’s language is set to Russia
(“ru”). One user has complained that this functionality should be
removed from the Debian xsnow
package, but Debian does not seem to have any rules that forbid
such a feature outright.
The Kubernetes project has published a blog
post explaining its AI
policy:
The main problem is that AI has made generating code fast but there
has been very little improvement in maintaining code bases. In this
post, we will highlight the ways the Kubernetes community is adapting
to the world of AI assisted coding.
The first step of this journey was to develop an AI policy. This
seems mundane and bureaucratic but there were many PRs that derailed
into discussions around AI usage. The AI policy helps steer the
conversation around the project’s stance on AI and provides a clear
signal to contributors on how to use these tools responsibly.
Of note, the project requires disclosure when AI tools have been
used to assist in the creation of a contribution but forbids the use
of listing AI as a co-author or including “assisted-by” or
“co-developed” trailers to attribute work to an LLM tool.
Mageia 10 has been
released with the 6.18 Linux kernel, DNF 5.4.0, RPM 4.20.1,
and an increase in hardware requirements for x86 32-bit systems; users now
need a CPU with SSE2 features. See the release
notes for a full list of updates, and the errata page
for known problems.
Agentic AI workflows coordinate multiple agents that reason, plan, and act across multi-step processes. Each step is expensive, non-deterministic, and unpredictable in latency. Human review gates can pause execution for days. Transient failures are expected, and restarting a half-finished workflow wastes time and money. Duplicate actions, like charging a payment twice or sending the same request again, create financial and compliance risk. Until now, solving these problems meant building custom infrastructure such as state machines, queues, checkpoint stores before writing a single line of business logic.
Prior authorization is one of the most time-consuming steps in healthcare delivery. A provider must get approval from an insurer before certain treatments or medications are covered. The insurer evaluates whether the care is medically necessary, safe, and cost-effective.
Agentic AI is transforming this process. What previously took days — extracting clinical data, evaluating medical necessity, checking payer-specific criteria, and getting physician sign-off — can now be handled by AI agents that pull records, apply guidelines, and draft justification letters automatically.
This post shows how AWS Lambda durable functions can orchestrate an agentic healthcare prior authorization workflow. The pipeline coordinates multiple AI agents, a human review gate, and an external payer submission into a single fault-tolerant function. Using two key patterns — callbacks for human-in-the-loop approvals and asynchronous agent invocations, and polling for long-running external tasks — Lambda durable functions let you focus on the clinical workflow rather than building custom state machines, retry logic, and checkpoint infrastructure.
Overview of AWS Lambda durable functions
Lambda durable functions extend the standard Lambda programming model with a checkpoint and replay mechanism. You wrap your handler with the durable execution SDK, which enhances the Lambda context with durable operations such as context.step(), context.waitForCallback(), and context.waitForCondition(). These operations checkpoint progress, handle failures, and suspend execution during wait periods. If a failure occurs or the function resumes after being suspended, Lambda invokes your function again. It restores the previous state by replaying the event handler from the start and skipping over previously completed durable operations. Lambda durable functions offer additional patterns such as parallel execution, durable invocations, and saga-style compensations. Refer to the AWS Durable Execution SDK Developer Guide for the full set of capabilities.
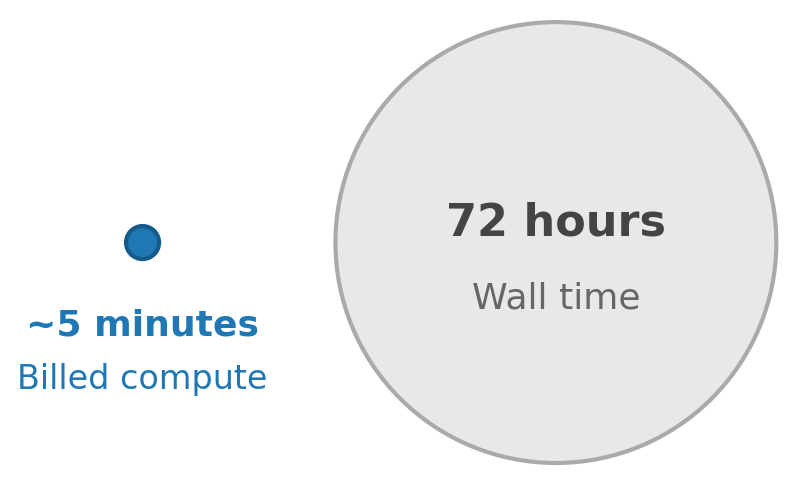
Agentic AI workflows are a natural fit for durable functions because each agent invocation is typically expensive, slow, and prone to transient failures, which are exactly the properties that benefit from automatic checkpointing and replay. Beyond orchestrating agent steps, durable functions can pause the workflow execution for external input. You can suspend the execution until a human approval arrives, or poll an external system for completion with configurable backoff. For on-demand functions, you don’t incur compute charges while execution is suspended (see Lambda pricing for details).
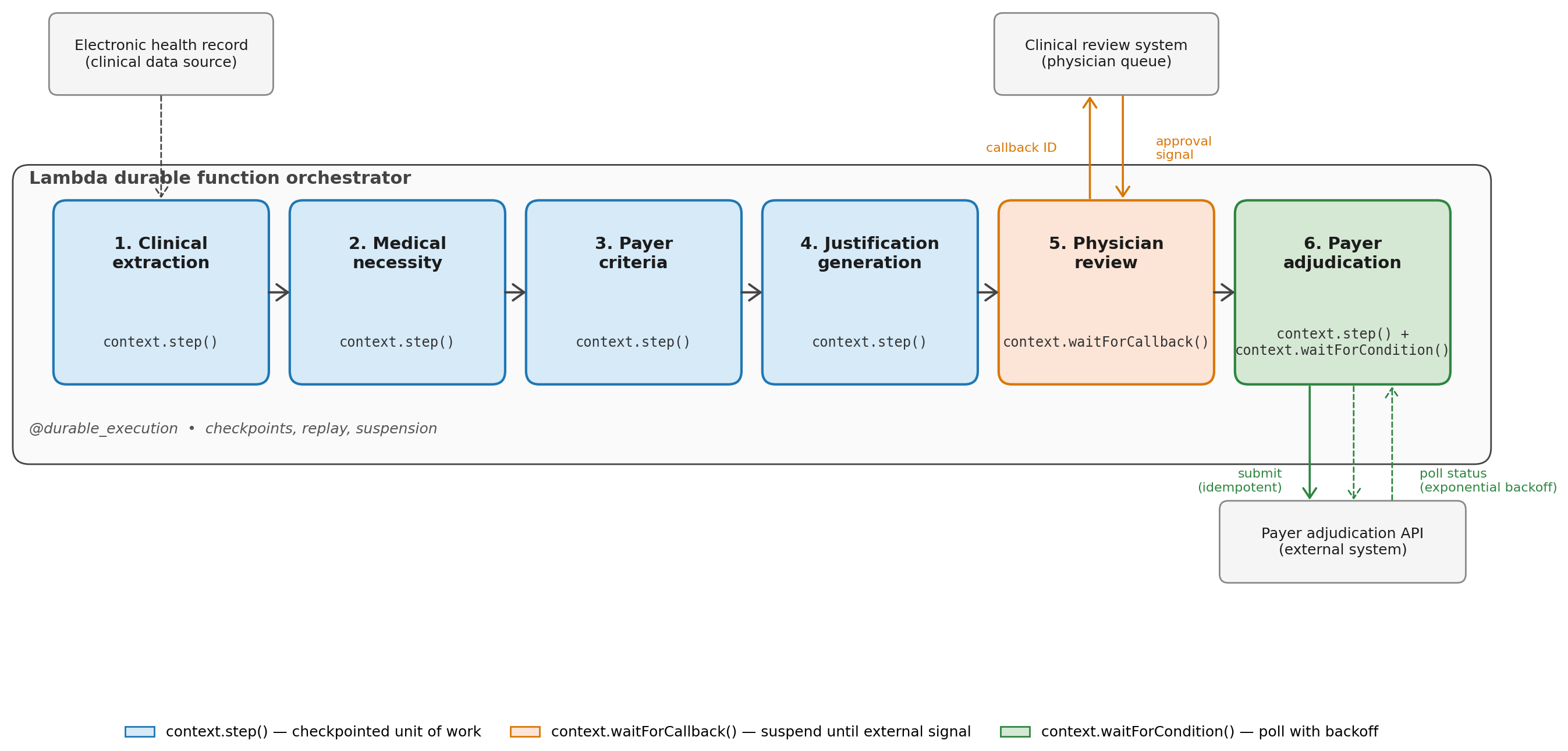
The healthcare prior authorization pipeline
The prior authorization workflow orchestrator coordinates four AI agents, a human review gate, and a payer submission.
Clinical extraction agent (step). Extracts relevant clinical data (diagnosis codes, procedure history, lab results) from the patient’s medical records.
Medical necessity agent (step). Evaluates whether the procedure meets clinical guidelines based on the extracted data.
Payer criteria agent (step). Checks the specific payer’s authorization requirements and identifies any missing documentation.
Justification generation agent (step). Produces the prior authorization justification letter using the outputs of the previous three agents.
Physician review (callback). The orchestrator suspends and waits for a physician to review and approve the generated justification. Because this uses waitForCallback(), the function incurs no compute charges while the physician takes minutes, hours, or days to respond.
Payer submission and adjudication (polling). Once approved, the orchestrator submits the authorization request to the payer system using an idempotent step with a clientRequestToken (shown in the code below) to help prevent duplicate submissions. It then polls the payer’s adjudication status using waitForCondition() with exponential backoff, suspending between each check.
Figure 2. The six-stage prior authorization pipeline, orchestrated by a single Lambda durable function.
Putting it together in code
The entire pipeline, from agent steps to human review to payer submission and polling, lives in a single function that reads top to bottom:
The orchestrator is designed to handle the failure modes that come up in real workflows:
An agent step fails. If the medical necessity agent fails after the clinical extraction agent has completed, Lambda durable function replays the handler, skips the extraction step which was already checkpointed, and retries only the failed step. This helps avoid re-incurring the time, cost, and token spend of completed steps.
The physician rejects the justification. The callback returns approved: false, the orchestrator returns a REJECTED status, and no payer submission occurs.
Payer adjudication exceeds the max attempts.waitForCondition() raises a timeout error after the configured attempt limit, which you can catch and route to a manual review queue or compensating action.
The submit step retries after a transient failure. Because the submission carries a clientRequestToken derived from the execution ID, retries against the payer are idempotent at the payer API level, which helps prevent duplicate authorization requests.
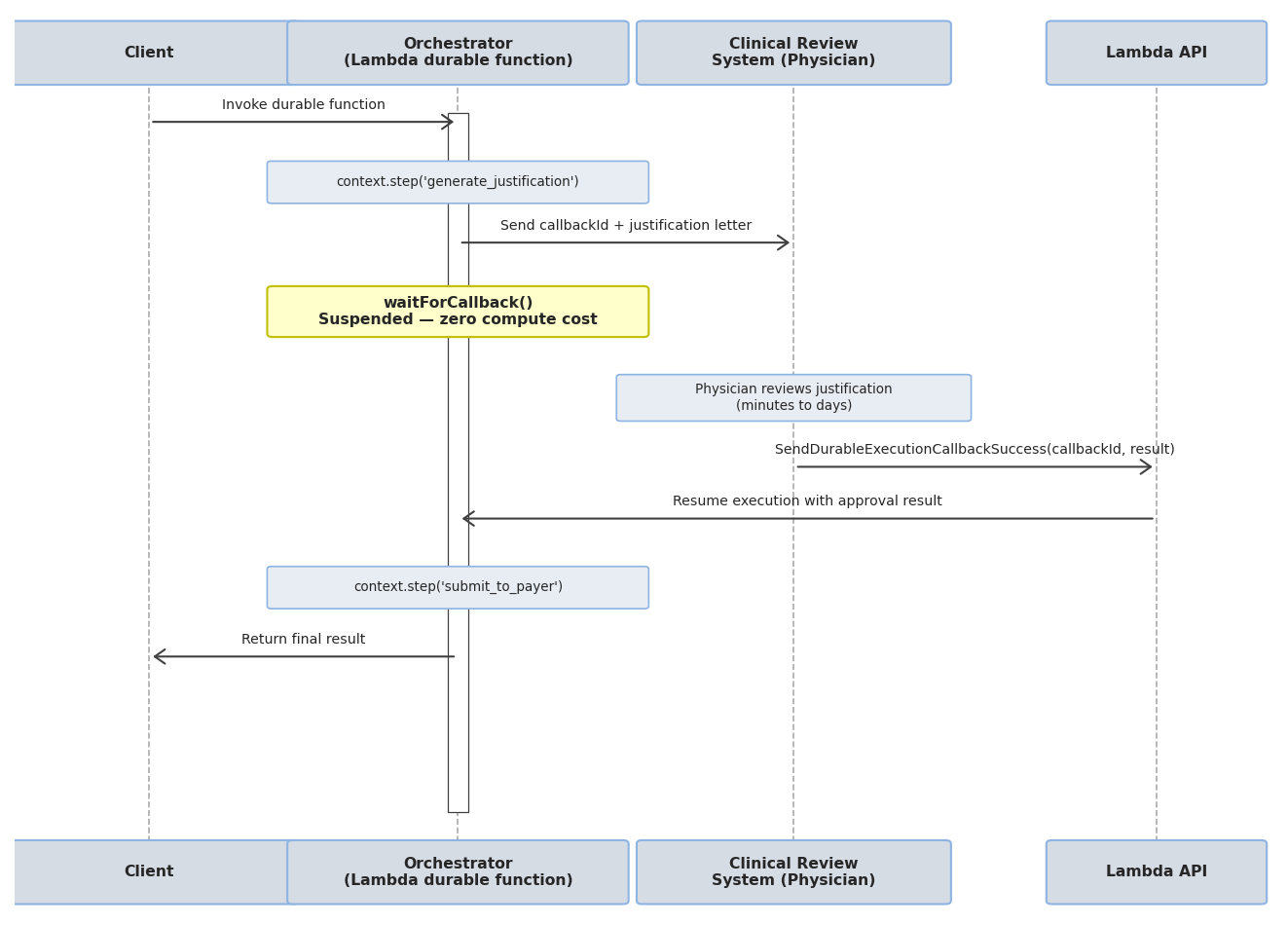
The callback pattern
The callback pattern allows the orchestrator to suspend execution and wait for an external signal before resuming. When the durable function reaches a context.waitForCallback(), it sends a unique callbackId to an external system and then suspends. When the external system completes its work, it calls the Lambda API with SendDurableExecutionCallbackSuccess (or SendDurableExecutionCallbackFailure) to resume the orchestrator from where it left off.
In the prior authorization pipeline, this is how the physician review step works. After the justification generation agent produces a letter, the orchestrator emits a callback ID to the clinical review system and suspends. The physician receives the draft in their review queue, reads it, and either approves or rejects it through the review UI. The UI calls the Lambda callback API with the result, and the orchestrator resumes with the approval decision.
Because the function is fully suspended, it incurs no compute charges during the review window, whether that’s 10 minutes or 3 days.
Figure 3. The callback flow for the physician review step. The orchestrator emits a callback ID to the clinical review system and suspends. When the physician approves or rejects, the review system calls SendDurableExecutionCallbackSuccess to resume the orchestrator with the decision.
The callback pattern is appropriate when:
A human needs to review and approve a result (hours to days).
An external agent is invoked asynchronously and the orchestrator should resume when it finishes.
A webhook or third-party system signals completion.
The polling pattern
When an external system cannot send a callback, for example a payer API that offers no webhook support, the polling pattern provides an alternative. The orchestrator monitors the long-running task by periodically checking its status using context.waitForCondition().
It runs a check function periodically as configured by a wait strategy and evaluates the result. If the task isn’t complete, suspends for a configurable delay before checking again. The function incurs no compute charges during each wait interval. Each poll result is automatically checkpointed, so on replay the orchestrator skips previously completed checks.
In the prior authorization pipeline, this is how the payer adjudication step works. Most payer APIs accept a submission and return a tracking ID, but don’t push a completion signal back. The orchestrator calls waitForCondition() with the payer’s status API, an exponential backoff strategy (30 seconds to 5 minutes), and a maximum attempt count that covers the payer’s typical adjudication window.
Lambda durable functions provide waitForCondition() with built-in support for configurable backoff strategies, maximum attempt limits, and timeouts, which can help reduce the need for separate polling infrastructure such as scheduled rules, state machines, or custom retry logic.
Figure 4. The polling flow for the payer adjudication step
Polling is appropriate when:
An async job does not support callbacks.
An external API or system exposes only a status or Describe endpoint.
The orchestrator waits for a resource to become available.
Cost and operational concerns
Here are a few implications when using orchestration of agentic workflows with Lambda durable functions:
Retries don’t re-run completed agents. If the fourth agent fails, the first three are not re-invoked, so the organization does not pay token costs twice for the same work.
Idempotency tokens help prevent duplicate payer submissions. A retry that crosses the submission step reuses the clientRequestToken, which helps the payer deduplicate on their side. This is an important property when duplicate authorization requests can trigger compliance issues.
Replay-aware logger streamlines logging. The SDK’s logger (context.logger) is replay-aware, meaning that it automatically suppresses duplicate log lines during replay.
Operational visibility is consolidated. Instead of stitching together logs from a state machine, a queue, a checkpoint table, and a poller, the entire workflow is one function with one execution history. Lambda publishes durable-execution-specific Amazon CloudWatch metrics, including ApproximateRunningDurableExecutions, DurableExecutionDuration, and DurableExecutionFailed, so you can track running workflows, detect failures, and set alarms at the execution level. Lambda also publishes durable execution status change events to Amazon EventBridge (RUNNING, SUCCEEDED, FAILED, TIMED_OUT) for triggering notifications or downstream workflows, and you can enable AWS X-Ray for distributed tracing across the entire execution. For more details, see Monitoring durable functions in the Lambda developer guide.
Using coding agents to build and test durable functions
To accelerate building agentic workflow orchestration with Lambda durable functions, you can use the Kiro power for Lambda durable functions or the Agent Plugin for AWS Serverless, which is available in any AI coding assistant tool that supports agent plugins such as Claude Code and Cursor. You can also install agent skills from the plugin individually in any AI coding assistant tool that supports agent skills. This helps your coding agents such as Kiro to:
Scaffold an orchestrator function from a prose description of the workflow, wiring up context.step(), wait_for_callback(), and wait_for_condition() calls based on the described stages.
Generate unit tests that exercise the replay behavior, including tests that inject failures at specific steps to confirm that completed checkpoints are skipped on retry.
Generate integration tests that simulate callback delivery and polling responses so you can validate end-to-end behavior without a full external system.
Conclusion
Agentic AI workflows can be non-deterministic, long-running, and failure-prone. Lambda durable functions can help address these challenges by adding checkpointing, replay, and suspension to the Lambda programming model, so completed work is skipped on retry and failures resume exactly where they occurred.
In this post, we walked through a healthcare prior authorization pipeline to illustrate two patterns: Callbacks for human-in-the-loop approvals and asynchronous agent invocations, and polling for monitoring long-running external tasks.
Beyond these two patterns, Lambda durable functions offer additional capabilities for building resilient workflows such as parallel execution, child contexts for isolated execution context for grouping operations, and saga-style compensations. Refer to the Lambda durable functions Developer Guide for the full set of capabilities. For pricing of on-demand and provisioned-concurrency functions, see the Lambda pricing page.
Figure 1. Autoregressive homepage generation. GenPage builds a Netflix homepage one row or entity at a time, each one conditioned on what’s already on the page and the user’s context.
Introduction
The Netflix homepage is the first thing users see when they open the app and the primary way they discover content to enjoy. Almost every part of it is personalized, including which rows appear, which entities show up within those rows, and how everything is arranged on the page.
Constructing that homepage is a genuinely hard problem. It is not simply producing one ranked list. The homepage is a structured, two-dimensional layout, made up of recommendation rows and the entities within them. Here, an entity can be a movie, show, game, live event, or other recommendable item. Each choice can affect the value of the others. Traditionally, it is built through a complex, multi-stage pipeline, with separate components for candidate generation and ranking at both the row and entity levels.
We saw an opportunity to rethink this design. Large language models have shown that a single generative model can perform diverse tasks just by generating a response to a prompt. Inspired by this prompt-response paradigm, we trained a single generative model to build the homepage by directly answering one question:
Given everything we know about this user and this request, what homepage should we generate to maximize user satisfaction?
We call this approach GenPage. It treats the user history and request context as the prompt, and autoregressively generates the entire homepage as the response (Figure 1). Unlike most generative recommenders, such as TIGER, HSTU, and OneRec, which generate flat ranked lists, GenPage generates the rows, entities, and layout together.
This shift is motivated by several goals:
End-to-end modeling. A single transformer model that constructs the page from raw input signals can replace a complex multi-stage recommender stack. This reduces the number of ML models to maintain, avoids misaligned objectives across stages, and eliminates much of the traditional feature engineering.
Whole-page optimization via reinforcement learning (RL). Autoregressive page generation makes it possible to optimize for page-level rewards with RL. This can capture interactions across rows and entities, such as diversity or the balance between rows with different stopping power. For example, a Continue Watching row near the top of the page may strongly satisfy a user’s immediate intent, but also reduce how much of the page they browse. Modeling these interactions at the page level lets us align the system more directly with user satisfaction than entity-level objectives alone.
Better scaling behavior. A generative transformer model gives us a clearer path to improving quality through more data, compute, and model capacity, without repeatedly redesigning the system.
Flexibility and extensibility. The prompt-response paradigm is flexible by design. By simplifying feature engineering and enabling whole-page optimization, GenPage makes it easier to support new product experiences, such as additional content types like live events, games, and podcasts; layouts beyond the current two-dimensional structure; personalized UI components; and per-entity artwork personalization, all with fewer architectural changes.
Bringing GenPage into production at Netflix also required solving challenges specific to industry-scale recommender systems. Because the homepage is generated in real time, serving latency is a primary engineering constraint. We also need to handle entity cold start in a constantly evolving catalog, keep the model fresh as user interests and cultural trends shift, and enforce complex product and business rules on the generated output.
Despite these challenges, GenPage has already had substantial production impact. In an online A/B test against a mature, highly optimized multi-stage production recommender, GenPage delivered statistically significant gains on the core user engagement metric we use for launch decisions, while reducing end-to-end serving latency by 20%.
Offline, two findings stood out. First, enriching the prompt helped more than scaling model capacity in our current regime. Second, RL post-training increased homepage diversity even though diversity was not part of the objective.
We expect this approach to generalize to many personalization settings. In this post, we focus on Netflix homepage construction as a concrete case study, sharing our design, trade-offs, and lessons learned.
Data
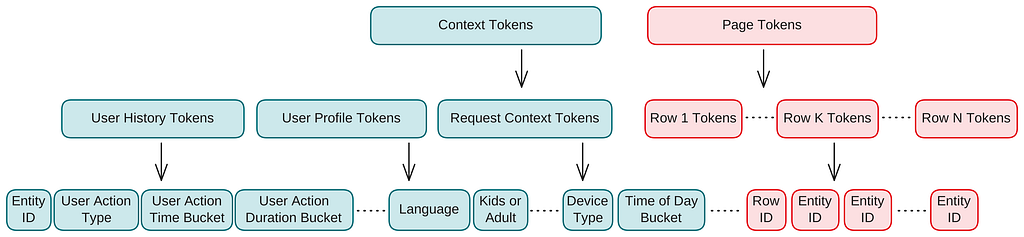
Moving from a traditional recommender to a generative transformer requires us to rethink how the data is represented. Similar to how an LLM turns text into tokens, GenPage represents both the user context and the generated homepage as one sequence of discrete tokens (Figure 2). This sequence includes the full structured homepage layout, with multiple rows and the entities inside them, so the model can generate the page holistically rather than scoring each row or entity in isolation.
Figure 2. Tokenization of Netflix homepage construction data. The context tokens function as the prompt, drawing from diverse data sources including user history, profile attributes, and request context, with example tokens shown for each source. The page tokens represent the generated response, encoding the structured layout of rows and entities.
Each training example represents a homepage impression and consists of three components:
Context: user engagement history, profile attributes, and request context.
Page: the recommended rows and entities shown on the homepage, in layout order.
Feedback: user interactions with that page, such as play, thumbs-up, or abandonment for entities on the page.
Only the context and page are tokenized as model inputs and outputs. Feedback is used to derive supervision signals via our internal reward system (see the Reward system section).
Instead of using an off-the-shelf text tokenizer, we build a domain-specific tokenizer for the homepage construction data. This is a proven approach in recommender systems and other specialized domains including computer vision, biology, and chemistry, where the raw data is not naturally represented as text. Compared with generic text tokenization, this gives us two key advantages:
Computational efficiency. Custom tokenization significantly reduces sequence length, lowering inference cost and latency. For example, representing the event “User watched Orange Is the New Black for 50 minutes 30 days ago.” would require 16 tokens with the GPT-5 tokenizer, whereas our scheme compresses it to 4 tokens: [Entity_ID], [Action_Type], [Action_Time_Bucket], and [Action_Duration_Bucket].
Product control. A direct mapping between tokens and product concepts, such as rows and entities, makes it easier to control what the model can generate. This is crucial for enforcing business rules on the final homepage.
Context tokens
Context tokens encode user engagement history, user profile, and request context.
We represent user history as a sequence of user actions. For each action, we extract key metadata, including the action type, entity ID, timestamp, and duration. These actions include both explicit signals, such as play, add to My List, and thumbs-up, and implicit signals, such as trailer views or visits to a details page.
User profile tokens capture attributes such as language and profile type. Request context tokens encode signals like time of day, day of week, and device.
Some data sources are too long to include directly as raw token sequences. A user’s full impression history, for example, would be prohibitively expensive to represent in full. In these cases, we use a summarized version. This is a pragmatic trade-off: while GenPage aims to operate on raw inputs as much as possible, handcrafted summaries still introduce a form of prompt engineering into the pipeline. Learning to compress these long data sources end to end is an important direction for future work.
To help the model distinguish between data sources, we insert special tokens that mark the start of each segment. Continuous signals, such as timestamps and durations, are bucketized into discrete ranges to keep the vocabulary finite.
Page tokens
Each entity, such as a show, movie, or game, and each row, such as Korean TV Shows, is represented as a single token. The homepage is serialized in layout order: left to right, then top to bottom. We update the entity and row vocabulary daily to incorporate newly added entities and rows. Entities that are still out of vocabulary at serving time are handled through semantic embedding fusion and fallback tokens, both described later.
In principle, the same paradigm can extend to any output that can be expressed as a linear token sequence. This includes layouts beyond the current two-dimensional structure, such as one-dimensional feeds or mixed layouts, as well as personalized UI components and per-entity outputs such as personalized artwork. We leave these extensions to future work.
Paginated recommendation
To make recommendations responsive to in-session user preferences, the homepage is often generated incrementally, a few rows at a time. Before each pagination request, we append the page tokens from previously generated rows to the prompt, along with the user’s latest engagements on those rows from Netflix’s real-time event-logging infrastructure. This allows the model to generate the next set of recommendations using both the user’s long-term preferences and their most recent in-session behavior.
Reward system
To quantify the long-term value of a recommendation, we rely on an internal reward system described in prior work. The reward system is tuned through online A/B testing to align with long-term user satisfaction and serves as the primary supervision signal for both supervised and reinforcement learning.
The reward system processes user feedback and assigns a scalar reward for every impressed entity on the homepage. For instance, a TV show binge-watched in one night reflects stronger user satisfaction and receives a higher reward than a movie watched for only 10 minutes. An impressed entity that the user abandons receives a negative reward.
We define the page-level reward as the sum of rewards across all impressed entities on the homepage.
Model architecture
GenPage uses a standard decoder-only transformer architecture, the same general architecture behind many modern LLMs. This choice keeps the model simple and flexible, while also letting us benefit from the broad ecosystem of tooling around transformer training and serving.
One architectural detail is that we untie the input embedding and output projection weights. This is useful because pretraining and post-training place different demands on the logits. Next-token prediction pretraining optimizes a softmax over the vocabulary, while weighted binary classification (WBC) post-training optimizes per-token sigmoid scores, as described below. Untying the weights gives the model more flexibility to adapt to both objectives.
Training recipe
Our training pipeline mirrors the LLM recipe: we first teach the model the “language” of the Netflix homepage through pretraining, then align its outputs with user satisfaction through post-training. For post-training, we explore two alternative approaches: weighted binary classification (WBC) and reinforcement learning (RL).
WBC is simpler to optimize and aligns directly with the entity-level objectives of our production ranking models. RL is harder to evaluate and optimize, but it is the key path to GenPage’s full vision of page-level optimization, with the flexibility to incorporate test-time reasoning and multi-token entity representations.
Pretraining via next-token prediction
We pretrain the model with a standard next-token prediction objective: given the context tokens and a prefix of page tokens, the model learns to predict the next page token. This stage focuses on representation learning, teaching the model the relationship between user contexts and successful homepages. Note that our context-page training examples resemble the prompt-response pairs used in LLM supervised fine-tuning (SFT) more than the raw text used in LLM pretraining. We nonetheless call this stage pretraining because we train the model from scratch rather than fine-tuning from an existing checkpoint.
Unlike LLMs, which often face a scarcity of high-quality labeled data, recommender systems have an abundance of user feedback. For pretraining, we use homepage impressions that received positive feedback when served in production, bootstrapping the model to generate pages similar to those produced by the existing production system.
However, pretraining mainly teaches GenPage to imitate the production system. It does not directly optimize the magnitude of the reward, and as GenPage becomes part of production, repeatedly training on pages generated by earlier versions of the model can risk model degeneration. To address these limitations, we explore two post-training approaches.
Post-training via weighted binary classification
One effective way to align the generative model with user satisfaction is weighted binary classification (WBC). At a high level, WBC turns generation into token-level value prediction: given the user context and the tokens generated so far, the model learns to estimate the value of generating each possible next row or entity token.
This objective is easier to optimize than page-level RL. By decomposing the homepage into per-token targets, WBC provides token-level credit assignment by construction, rather than requiring RL to infer how each generated decision contributed to the final page-level reward.
This training setup is enabled by our custom tokenization. Each page token corresponds directly to a specific entity or row, making it straightforward to assign a reward. For every impressed entity on the page, our reward system provides a scalar reward based on user feedback. For each impressed row, we derive a row-level reward by aggregating the rewards of the entities in that row.
From each reward, we derive a binary label from its sign, such as positive engagement versus abandonment, and a weight from its magnitude, such as binge-watching receiving a higher weight than a short play. We then optimize a weighted binary cross-entropy loss on the logit for the corresponding token. Under this setup, the logit for a token can be interpreted as the model’s value estimate for generating that token at that position.
Although the model is trained as a value predictor, it can still generate pages autoregressively. At each step, the model scores the candidate next tokens, greedily selects the token with the highest value, and appends it to the prefix. This process repeats token by token until the full homepage is generated.
Post-training via reinforcement learning
Our second post-training approach is reinforcement learning (RL). WBC is effective for optimizing entity-level metrics, but it does not directly optimize the homepage as a whole. RL treats page generation as a sequential decision-making problem, allowing the model to optimize a page-level reward while preserving the flexibility of autoregressive generation.
This opens the door to several important capabilities:
Whole-page optimization. RL directly optimizes an aggregate page-level reward, allowing the model to account for interactions across rows and entities, such as diversity, stopping power, and page-level business constraints.
Test-time reasoning. Analogous to its application in LLMs, RL can optimize reasoning capabilities for generative recommendation. Reasoning outputs can also be viewed as a form of automated feature engineering.
Multi-token entity support. In our current tokenization, each entity and row is represented as a single token, so rewards map cleanly to individual tokens. In more complex settings, however, an entity may require multiple tokens, such as [Show_ID] plus [Episode_#] for an episode, or a sequence of semantic ID tokens. In that case, WBC’s per-token labeling becomes ambiguous because a single entity-level reward must be distributed across multiple tokens. RL avoids this issue by optimizing the sequence-level return, making it a more natural fit for variable-length, multi-token entities.
Inspired by the RLHF recipe used to align large language models, we adopt a two-step approach. First, we train a reward model that predicts the page-level reward for a generated page. This reward model is distinct from the reward system described earlier. The reward system converts observed user feedback into a scalar reward for a page that was actually shown, whereas the reward model predicts the page-level reward for a generated page without showing it to the user. This prediction is what lets RL optimize against arbitrary candidate pages during training.
Training against a reward model avoids the high variance of off-policy correction on logged or predicted propensities, but introduces the risk of reward hacking. Since the reward model is trained on data generated from the production policy, it is most reliable on pages similar to those the production policy generates. We therefore use a KL penalty to keep the policy close to the pretrained checkpoint, which itself was trained to mimic the production policy. This keeps the pages within the reward model’s region of coverage and limits opportunities for reward hacking.
For the RL algorithm, we adopt Dr. GRPO, a variant of GRPO that mitigates biases in the training objective. To train the model within this framework, we need the following components:
Prompts: production user requests, represented by context tokens.
Policy and reference models: both are initialized from the pretrained checkpoint; the reference model anchors the KL penalty discussed above.
Reward model: a dedicated transformer-based reward model, also initialized from the pretrained checkpoint, predicts the page-level outcome reward, using the sum of entity-level rewards from our internal reward system as the supervision target. We also incorporate rule-based format rewards to guide the RL policy. For example, the page should resemble a list of rows, and business-critical rows or entities should not appear too low on the page.
Addressing production challenges
Cold start
New entities lack the rich interaction data needed to learn robust token embeddings. We address this through two complementary strategies:
Context injection. We inject metadata about new or time-sensitive entities (e.g., Live Now events) directly into the context tokens, providing the model with semantic and time-sensitive information.
Semantic embedding fusion. Rather than relying solely on entity ID embeddings learned from user interaction data, we represent each entity as a fusion of its ID embedding and a content-based embedding derived from semantic information such as synopses, cast, transcripts, genres, and video content. This fused embedding serves as the input embedding for the entity’s token in the transformer. During training, with small probability, we randomly replace an entity ID token with the generic fallback token (described below), so the model learns to make recommendations from the content-based embedding alone. This ensures that a new entity has a meaningful representation in the same latent space as established entities as soon as its content metadata is available — even before it has any interaction data.
Multi-cadence incremental training
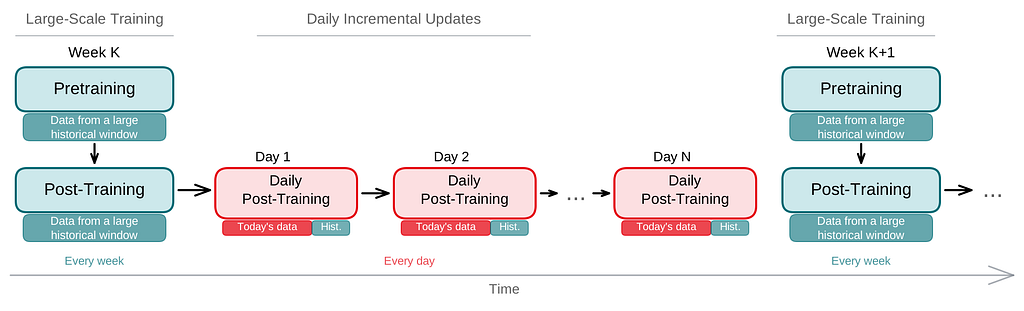
At Netflix scale, daily retraining of a large transformer from scratch is prohibitively expensive, but recommendation models must remain fresh to capture shifting trends and new catalog additions. We address this with a multi-cadence incremental training strategy (Figure 3).
Figure 3. Multi-cadence incremental training. Periodic large-scale pretraining and post-training passes run on a broad historical window. Between them, daily incremental updates combine the latest day’s data with a sampled subset of past data to keep the model fresh while avoiding catastrophic forgetting.
Our training pipeline operates on a cyclic schedule with two distinct rhythms. At a tunable cadence, we conduct a large-scale pretraining and post-training pass on data from a broad historical window. Between these passes, each day we perform an incremental update by continuing post-training from the previous day’s checkpoint, using a mix of the latest day’s data and a sampled subset of past data. This helps the model stay current with new trends and catalog changes while preventing overfitting and catastrophic forgetting.
To manage the daily influx of new tokens (e.g., new entities, rows), we employ fallback tokens. New tokens are initialized using fallback tokens of their type (e.g., [Row_Fallback_Token] for new rows, [Entity_Fallback_Token] for new entities). During training, we randomly replace a small percentage of known tokens with fallback tokens, teaching the model to handle unknown tokens gracefully.
Enforcing business rules
A Netflix homepage must satisfy structural constraints (e.g., organized as a list of rows) as well as product logic such as deduplication, row pinning, and category consistency (e.g., entities in a Comedy row must be comedies). While training signals can encourage rule adherence, they cannot guarantee strict compliance.
We enforce these rules at inference time through constrained decoding. At each autoregressive generation step, we compute a mask of eligible tokens based on the applicable business rules and apply it to the output logits, allowing only rule-compliant tokens to be generated. This is greatly simplified by our custom tokenization: because each entity and row is a single token, business rules map directly to token-level masks, avoiding the multi-token bookkeeping that constrained decoding requires over a text vocabulary. For example, to pin a specific row (e.g., popular games) at a fixed position (e.g., row position 2), we simply mask out all other tokens at that position.
Hybrid row decoding
Autoregressive generation ensures that each newly generated token is conditioned on the full preceding context, but generating every entity token one at a time can be expensive. We leverage the structure of the homepage to balance inference efficiency with the amount of contextual information available to each generated token.
Within each row, the first few entities are especially important: they receive the most user attention and strongly shape the row’s perceived quality and theme. To reduce inference latency, we use a hybrid row decoding strategy. The model autoregressively generates only the first few entities in each row. Conditioned on this generated prefix, we obtain logits for all eligible entities in a single forward pass and select the top-scoring remaining entities, subject to the same inference-time business-rule constraints described above.
This approach preserves autoregressive conditioning where it matters most while avoiding the latency and cost of decoding long rows token by token.
Offline experiments
We ran a series of ablations on Netflix internal data to understand how different components of GenPage affect model quality. Because the system was developed iteratively, individual ablations span different training configurations and data snapshots, so we report only relative comparisons within each study. Unless otherwise noted, experiments use ~200M-parameter models and report results on a held-out evaluation set.
Does pretraining help?
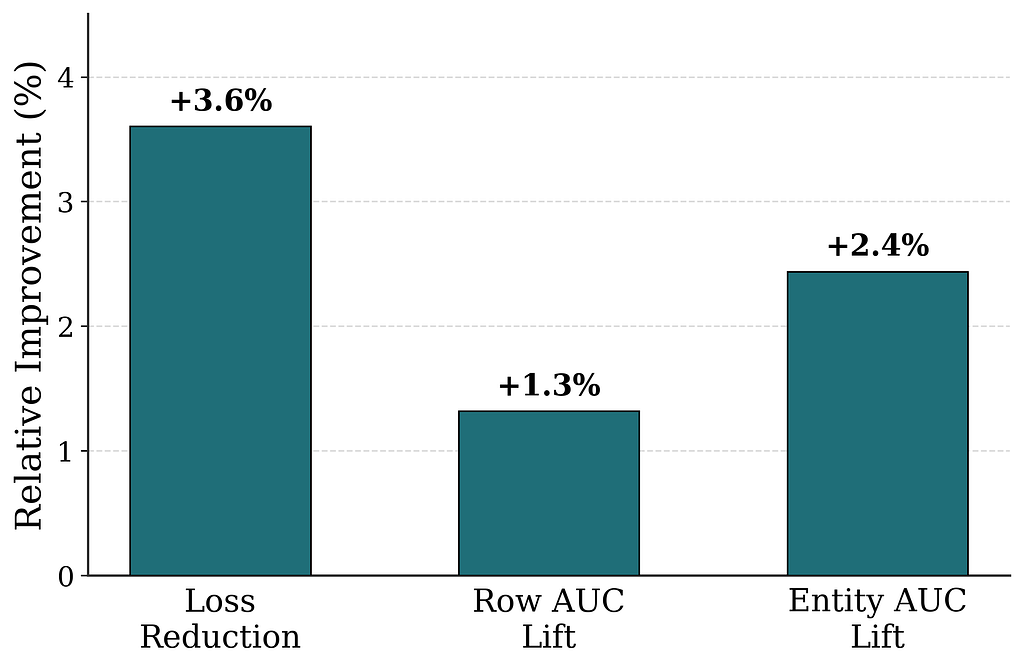
We compare WBC post-training with and without a preceding next-token-prediction pretraining stage. Figure 4 shows that pretraining yields substantial improvements across all metrics.
Figure 4. Relative improvement from pretraining (versus WBC post-training without a pretraining stage), across loss reduction, row AUC lift, and entity AUC lift. Loss is the weighted binary cross-entropy; Row and Entity AUC are sample-weighted ROC-AUC over row and entity targets.
The gains may look small in absolute terms, but they are large in our production regime: setting aside the sample weighting, an Entity AUC lift from 0.91 to 0.92 means that for a randomly drawn pair of impressed entities, the model’s misranking rate drops from 9% to 8% — a magnitude of improvement we rarely observe from a single change on a mature production system. Pretraining the model on the “language” of the Netflix homepage provides a strong initialization for post-training, mirroring the pretrain-then-post-train recipe behind modern LLMs.
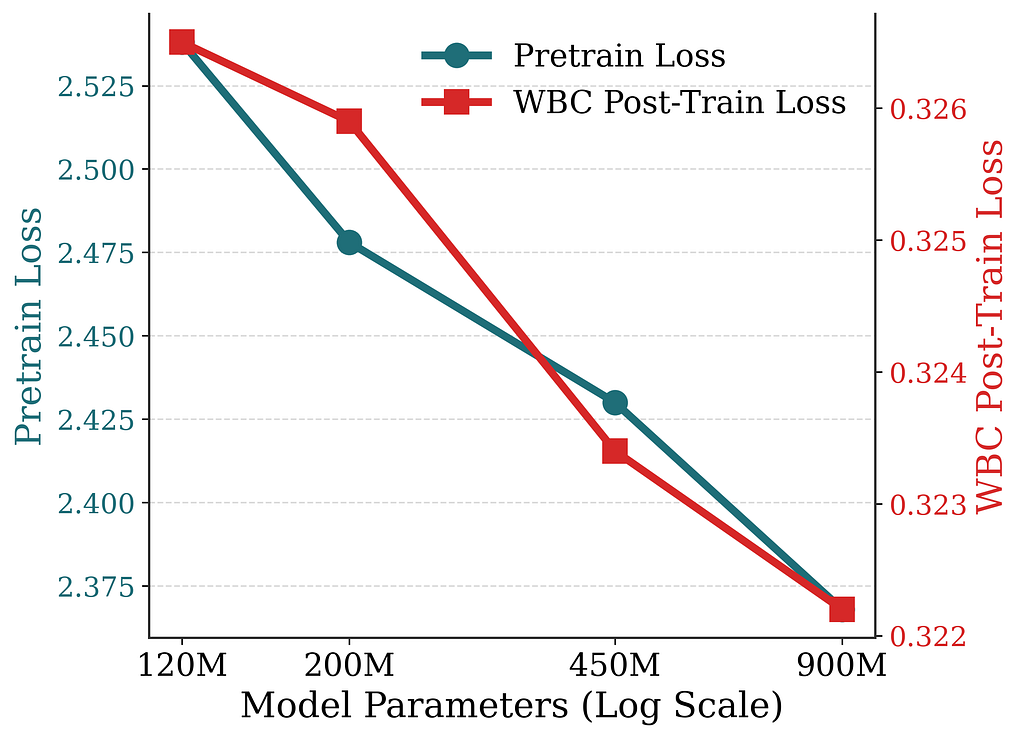
How does performance scale with model size?
We sweep model size from ~120M to ~900M parameters (Figure 5) and report the next-token-prediction loss from pretraining and the WBC loss from post-training. Both losses decrease in a power-law-like fashion, mirroring the scaling trends seen in LLMs. This confirms that the generative approach scales favorably with model size, suggesting that recommendation quality can be further improved by scaling capacity.
Figure 5. Pretraining and WBC post-training losses as model size scales from 120M to 900M parameters. Both decrease in a power-law-like fashion, mirroring LLM scaling trends.
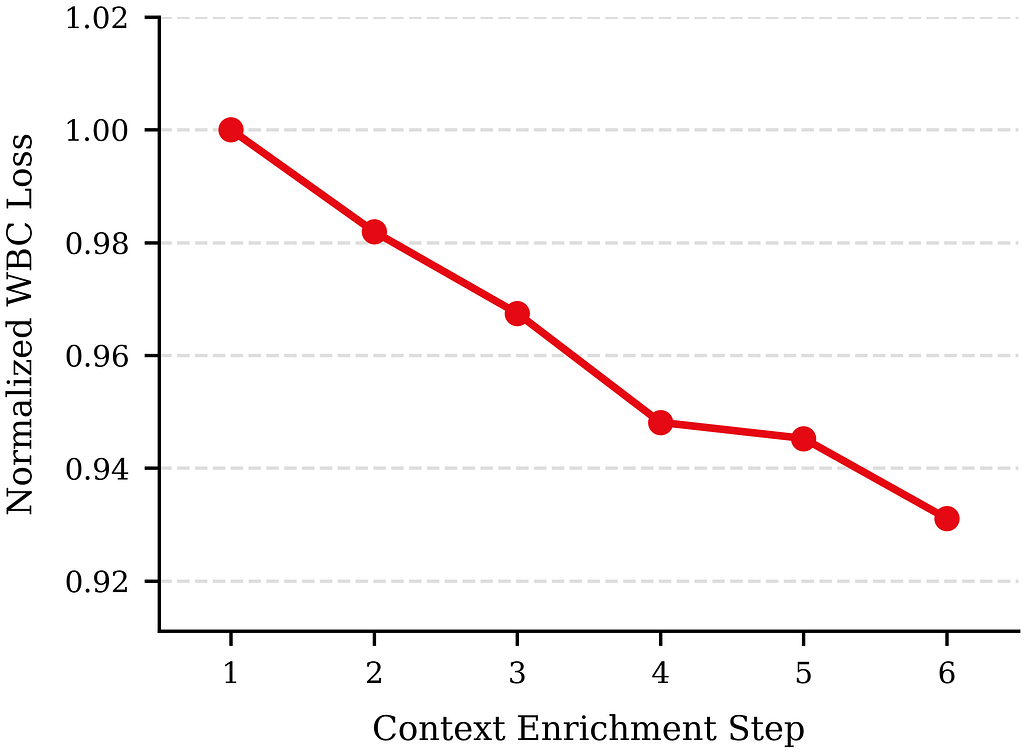
How does performance scale with information in the user context?
Over the course of development, we progressively enriched the prompt, both by adding new data sources to the context and by refining how each source is tokenized. With model size held fixed, the WBC post-training loss decreases substantially as the context is enriched (Figure 6).
Figure 6. WBC post-training loss as we progressively enrich the user context tokens. Loss is normalized to the first step (= 1.0).
The model-size sweep and the context-enrichment sweep span different axes and are not strictly comparable: the model-size study covers roughly an order of magnitude in parameters, while the context study spans the full trajectory of our prompt design. Even so, the gap between the two is striking. Scaling the model from 120M to 900M parameters reduces WBC loss by roughly 1.3%, whereas the cumulative effect of enriching the context is around 6.9%. In several cases, a single well-designed context addition delivers a larger improvement than the entire ~7.5× model-capacity scaling.
This suggests that, in our regime, enriching the prompt — both what we put in the context and how we tokenize it — yields a substantially larger improvement than scaling model capacity. Personalization quality appears to be bottlenecked first by the information and representation available to the model, and only then by capacity. We expect context enrichment to dominate until the context is saturated, at which point model capacity becomes the primary driver.
Does RL post-training optimize at the page level?
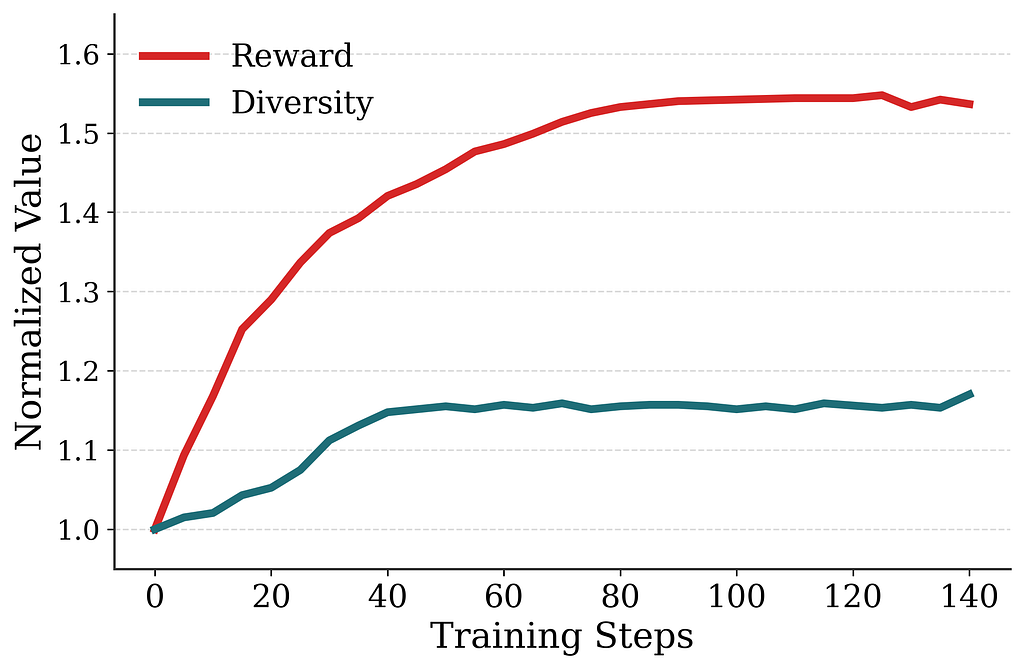
In offline evaluations (Figure 7), RL post-training consistently improves the page-level reward over the pretrained checkpoint, but this is largely confirmatory: the reward is computed using the same model the policy is optimizing against. More interestingly, although diversity is not part of the RL objective, homepage diversity — measured via pairwise embedding distance among entities on the page — also increases over the course of training. This suggests that the RL-trained policy is optimizing the page as a whole rather than myopically optimizing each token in isolation.
Figure 7. RL post-training dynamics. Reward and diversity are shown relative to the initial checkpoint (1.0). Reward rises as expected; diversity also rises, despite not being part of the RL objective.
Online evaluation
We conducted an online A/B test against the current production homepage recommender using GenPage. In this test, GenPage decoded over the existing production row and entity candidate sets, which help handle many business rules (such as eligibility).
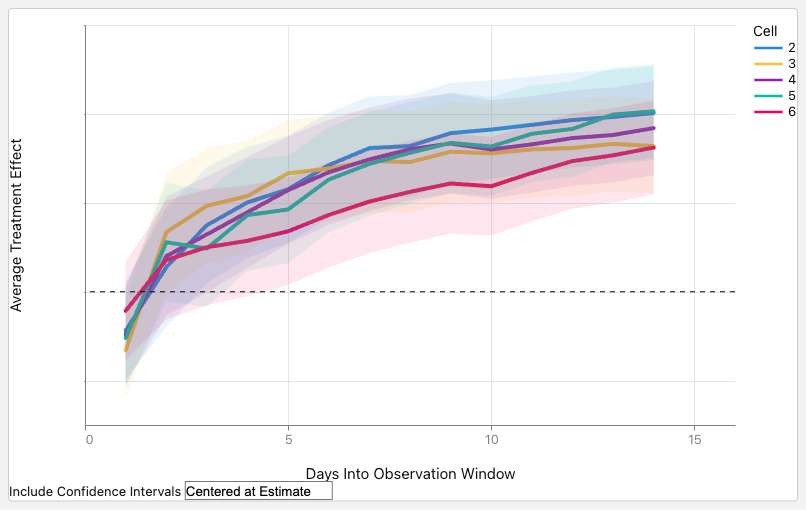
Figure 8 shows the result: all variants delivered statistically significant improvements on the core user engagement metric we use for launch decisions (p < 0.001) against a mature, highly optimized multi-stage production baseline. The variants differed in their training-data configurations; that they all delivered comparable lifts suggests the gain is robust to these design choices rather than dependent on a particular configuration.
Figure 8. Daily core user engagement metric over a 14-day online A/B test. The figure shows the average treatment effect of several GenPage variants (differing in training-data configurations) against the production baseline. Shaded regions are 95% confidence intervals. All variants delivered statistically significant improvements over production.
Alongside the engagement wins, we observed unintended shifts in the distribution of impressed entity categories (e.g., new vs. established titles, TV shows vs. movies). These shifts are not necessarily negative, but they are not something we explicitly optimized for, and they warrant deeper investigation. We suspect these shifts reflect GenPage personalizing more precisely than the production stack — consistent with an increase in homepage impression efficiency, i.e., users engaging with what they saw using fewer impressions. This sharper personalization appears to surface production-inherited components (such as the reward system) that aren’t yet aligned with the new generative paradigm. We plan to characterize the drivers of these shifts and, where appropriate, tune these components so the resulting distributions better align with desired product behavior.
We also observed strong responsiveness to in-session signals: the latest in-session actions quickly influenced subsequent recommendations and faded back to long-term preferences after a day or two, confirming that the model effectively attends to action timestamps. This responsiveness emerges naturally from the generative formulation, without the extensive manual feature engineering used in our production stack.
Contrary to the common assumption that generative models are slower, GenPage reduced end-to-end serving latency by 20% relative to the baseline. By replacing multiple ranking stages and heavy feature computation with a single transformer operating on raw tokenized inputs, we eliminated substantial serving complexity and computational overhead. Custom tokenization and hybrid row decoding further reduced the number of decoding steps, and thus latency. The 20% reduction was achieved without exhausting the available optimizations; further reductions are possible, and this headroom can be reinvested in capacity or richer prompts.
Conclusion
We presented GenPage, an early step toward end-to-end generative Netflix homepage construction: representing user context as a tokenized prompt and generating the entire homepage autoregressively in real time. This collapses the traditional multi-stage recommender stack into a single transformer that can be optimized end-to-end.
In online A/B tests against a mature, highly optimized multi-stage production system, GenPage delivered statistically significant gains on the core user engagement metric we use for launch decisions, while reducing end-to-end serving latency by 20%. Achieving this required adapting the LLM training recipe — pretraining followed by WBC or RL post-training — together with a set of domain-specific techniques: custom tokenization for serving efficiency and product control, context injection and semantic embedding fusion for entity cold start, multi-cadence incremental training for model freshness, constrained decoding for business-rule enforcement, and hybrid row decoding for inference efficiency.
Two offline findings stand out. First, in our current regime, enriching the prompt yields a substantially larger improvement than scaling model capacity — a takeaway we expect to generalize to other industry-scale personalization settings, at least until the available context is fully exploited. Second, RL post-training increases homepage diversity even though diversity is not part of the objective — an indication that page-level optimization captures interactions across rows and entities.
Several pieces of the full vision are still in progress: long context still relies on handcrafted summarization, and broader LLM-style capabilities — language, multimodality, and reasoning — have not yet been incorporated. One promising direction here is a hybrid tokenization combining our domain-specific tokens with generic text tokens, retaining structured control while inheriting the strengths of general-purpose LLMs; conceptually, this introduces an additional recommendation modality into an LLM.
More broadly, we expect many advances from the LLM ecosystem to transfer naturally to this setting, and the boundary between an LLM and a recommender system may increasingly blur. Our results suggest this is a viable path toward simpler recommender systems that align more directly with user satisfaction.
Acknowledgments
Contributors to this work (in alphabetical order): Abhishek Agrawal, Baolin Li, Casey Stella, Daneo Zhang, Dan Zheng, Donnie DeBoer, Fengdi Che, Fernando Amat Gil, Grace Huang, Inbar Naor, Ishita Verma, Jason Uh, Jimmy Patel, Justin Basilico, Lanxi Huang, Lingyi Liu, Liping Peng, Louis Wang, Michelle Kislak, Nathan Kallus, Nicolas Hortiguera, Paran Jain, Qusai Al-Rabadi, Rein Houthooft, Ryan Lee, Santino Ramos, Scarlet Chen, Shaojing Li, Sheallika Singh, Si Cheng, Wei Wang, and ZQ Zhang.
As AI-driven vulnerability discovery accelerates, the cybersecurity ecosystem is being forced to examine whether the standards, disclosure processes, and prioritization frameworks defenders rely on can still keep pace. Many of those systems were built around human-speed discovery, manageable vulnerability volumes, and exploitability confirmed after the fact, which leaves them under increasing strain as frontier AI capabilities mature.
During a private sector consultation with the White House in June, Corey Thomas and I presented Rapid7’s new policy paper, Modernizing Global Vulnerability Standards, which lays out where today’s vulnerability management infrastructure is breaking under AI-era conditions and what governments, security companies, and frontier AI providers need to do next.
In recent guidance, the Five Eyes cyber security agencies warned that AI is rapidly transforming cyber risk by increasing the speed, scale, and sophistication of threats, lowering barriers for malicious actors, and requiring leaders to reassess long-standing assumptions about resilience and accountability.
AI vulnerability discovery is changing the rules
In April 2026, Anthropic, OpenAI, and Google DeepMind each announced production-grade AI systems capable of discovering, chaining, and, in some cases, remediating software vulnerabilities at machine speed. In the same period, the Stanford HAI AI Index 2026 Cybench benchmark showed unguided AI agent solve rates on cybersecurity tasks rising from 15% to 93% in a single year.
These are deployed capabilities on a steep improvement curve. Faster discovery can help security teams identify weaknesses earlier, validate risk more effectively, and improve remediation workflows. It also increases the pressure on every system that decides how vulnerabilities are verified, scored, disclosed, prioritized, and fixed.
Vulnerability management standards were built for human speed
For decades, the security community has depended on shared infrastructure to make vulnerability management work. CVE identifiers, CVSS scoring, the National Vulnerability Database, the CISA Known Exploited Vulnerabilities catalog, and the Exploit Prediction Scoring System all help organizations understand what a vulnerability is, how severe it may be, whether it is being exploited, and how urgently it should be addressed.
Those systems were built around several assumptions: vulnerability discovery would be human-led, volume would remain manageable, exploitability would usually be confirmed after the fact, and organizations would have time to assess and respond. As AI-driven discovery challenges each of those assumptions, existing strain across the vulnerability ecosystem becomes much harder to absorb.
CVE submissions already grew 263% between 2020 and 2025 from human-speed growth alone. NIST acknowledged in April 2026 that the National Vulnerability Database can no longer keep pace and is shifting to risk-based triage. If AI-driven discovery dramatically increases volume, the prioritization problem becomes even more acute.
The issue for defenders is whether organizations can understand which vulnerabilities are actually exploitable, which are reachable in their environments, which can be chained together, and which require immediate action.
AI-era vulnerability prioritization needs reform
The paper argues that the prioritization gap is the most urgent and least addressed part of the problem. Traditional severity scores can miss the way attackers chain multiple lower-severity issues into a serious compromise. KEV remains one of the strongest signals available to defenders, but it is retrospective by design because it depends on confirmed exploitation in the wild. EPSS is trained on historical attacker behavior, which may not reflect what AI-assisted attackers can now do.
To close that gap, we propose reforms that would help move vulnerability prioritization closer to real-world risk. These include recognizing verified AI-demonstrated exploitability, adding chaining-risk metadata to vulnerability records, and requiring reachability guidance alongside AI-discovered findings.
The goal is to help organizations understand how dangerous a vulnerability is in practice, in their environment, rather than relying only on abstract severity.
AI vulnerability policy needs verification, access, and accountability
The paper also outlines a broader policy agenda – we call for updates to the Vulnerabilities Equities Process, investment in CVE and NVD infrastructure, standardized capability disclosure from AI labs, stronger international coordination, and clear CISA leadership.
We also propose three access and verification standards for the security community:
Independent verification before access expansion
Broad but curated access through transparent processes
Rigorous data standards for published capability claims
The frontier model providers building these capabilities deserve credit for acting responsibly as they develop programs in real time. But individual access programs cannot carry the weight of ecosystem governance on their own. The security community needs shared standards backed by independent verification and institutional accountability.
The next phase of cybersecurity resilience
This paper is part of a wider conversation we recently explored on Rapid7’s Experts on Experts: Commanding Perspectives, where Corey and I discussed AI, compliance, industry accountability, and the shift toward more resilient security operations.
AI-driven vulnerability discovery has crossed a threshold. The question now is whether the policy, standards, and operational systems around it can adapt quickly enough to help defenders use these capabilities safely and effectively.
Read the full paper, Modernizing Global Vulnerability Standards, to explore Rapid7’s recommendations for verification, access, disclosure, prioritization, and institutional accountability in the age of AI-driven vulnerability discovery.
We’ve taken one small step towards robot police officers: a drone capable of disarming a suspect:
In a June 22 video posted on the Sacramento County Sheriff’s Office’s Instagram page, an officer wearing goggles can be seen operating a drone to retrieve a knife from an armed suspect hiding inside a cluttered house. “After not responding to negotiators, a drone was deployed inside the residence,” the post says. “Drone pilots located the suspect hiding in a corner of a garage” and then used a high-powered magnet attached to the drone to grab the knife out of the suspect’s hand. In the video which is soundtracked by the “Mission: Impossible” theme song—the intercepted knife can be seen spinning around in the air as the drone carries it back to the deputies.
The 7.2-rc1 kernel prepatch is out for
testing. Linus said: “So two weeks have passed, and the merge window is
closed. Things look reasonably normal for this release (knock wood).“
For Computex 2026, Asustor had their upcoming third-generation Flashstor NASes on display. With support for either 6 or 12 M.2 SSDs, these all-flash NASes continue to be an interesting offering
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.