Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/cloud-101-data-egress-fees-explained/

You can imagine data egress fees like tolls on a highway—your data is cruising along trying to get to its destination, but it has to pay a fee for the privilege of continuing its journey. If you have a lot of data moving across a cloud environment, or a lot of toll booths (multiple services) to pass through, those egress fees can add up quickly.
Data egress fees are charges you incur for moving data out of a cloud service provider’s network. These data transfer fees can be a big part of your cloud bill depending on how you use the cloud.
For example, sending data between availability zones or to an external location like a local server can significantly increase costs. And, they’re frequently a reason behind surprise AWS bills.
So, let’s take a closer look at egress, egress fees, Backblaze’s smarter cloud storage pricing, and ways you can reduce or eliminate these fees.
What is data egress?
In computing generally, data egress refers to the transfer or movement of data from a specific location, such as a data center, private network, or virtual network, to an external location. In a cloud environment, egress typically happens whenever data flows out of the same data center, moves between availability zones, or transfers to another cloud region.
For example, data moving from one cloud provider to other cloud providers, or even across services within the same cloud, can incur data egress costs. These egress charges are determined by factors such as the egress pricing model of the provider and whether the transfer happens within the same region or across regions.
In the simplest terms, data egress is the outbound flow of data.

While data ingress—the inbound flow of data—often incurs no cost, data transfer fees associated with egress can lead to significant network costs, especially in cases involving large-scale data traffic or vendor lock-in.
Egress vs. ingress: What’s the difference?
While egress pertains to data exiting a system, ingress refers to data entering a system. When you download something, you’re egressing data from a cloud service or data center. When you upload something, you’re ingressing data to that environment.
Unsurprisingly, most cloud storage providers do not charge you fees to ingress data—they want you to store your data on their platform, so why would they? However, you may see API transaction fees when you’re ingressing data, depending on the provider or the pricing tier.
Data egress costs can be significant, especially for data flowing between multiple services, moving out of the same data center, or crossing availability zones or cloud regions. These costs are often part of egress pricing strategies that, while designed to cover network costs, can discourage customers from extracting data or transferring it to other cloud providers.
So, it’s worth spending some time to understand those nuances when you’re optimizing costs for complex workloads. And yes, we know that’s easier said than done.
Egress vs. download
You might hear egress referred to as download, and that’s not wrong, but there are some nuances. Egress applies not only to downloads, but also when you migrate data between cloud services, for example. (So, egress includes downloads, but it’s not limited to them.)
In the context of cloud service providers, the distinction between egress and download may not always be explicitly stated. Some providers classify data egress charges differently, depending on whether the data is leaving their cloud environment, moving to another cloud region, or crossing between availability zones.
The terminology and pricing structures vary, so review the specific service terms and egress pricing details provided by your platform. This is important when managing data transfer fees or mitigating associated costs.
How do egress fees work?
Data egress fees are charges incurred when data is transferred out of a cloud provider’s environment. These fees are often associated with cloud computing services, where users pay not only for the resources they consume within the cloud (such as storage and compute) but also for the data that is transferred from the cloud to external destinations.
There are a number of scenarios where a cloud provider typically charges for egress:
- When you’re migrating data from one cloud to another.
- When you’re downloading data from a cloud to a local repository.
- When you move data between regions or zones with certain cloud providers.
- When an application, end user, or content delivery network (CDN) requests data from your cloud storage bucket.
The fees can vary depending on the amount of data transferred, the destination of the data, and the cloud networking setup. For example, transferring data between regions within the same cloud provider’s network might incur lower fees than transferring data to the internet or a different cloud provider.
Data egress fees are an important consideration for organizations using cloud services, and they can impact the overall cost of hosting and managing data in the cloud. It’s important to know the pricing details related to data egress in the cloud provider’s pricing documentation, as these fees can contribute significantly to the total cost of using cloud services.d. It’s important to be aware of the pricing details related to data egress in the cloud provider’s pricing documentation, as these fees can contribute significantly to the total cost of using cloud services.
Why do cloud providers charge egress fees?
Both ingressing and egressing data incur costs for cloud providers. They have to build and maintain a robust cloud networking infrastructure to allow users to do that, including switches, routers, fiber cables, etc. They also have to have enough of that infrastructure on hand to meet customer demand, not to mention staff to deploy and maintain it.
However, most cloud providers don’t charge ingress fees, only egress fees. It would be hard to entice people to use your service if you charged them extra for uploading their data. But, once cloud providers have your data, they want you to keep it there. This pricing model creates an incentive for users to keep their cloud data within the provider’s environment, contributing to vendor lock-in.
Charging you to remove it is one way cloud providers like AWS, Google Cloud, and Microsoft Azure do that. These data egress costs can represent a significant portion of the total bill for organizations that rely heavily on data transfers across multiple services or cloud regions.
What are AWS’s egress fees?
AWS S3 gives customers 100GB of data transfer out to the internet free each month, with some caveats—that 100GB excludes data sAWS S3 gives customers 100GB of data transfer out to the internet free each month, with some caveats—that 100GB excludes data stored in China and GovCloud. After that, the published rates for U.S. regions for data transferred over the public internet are as follows as of the date of publication:
- The first 10TB per month is $0.09 per GB.
- The next 40TB per month is $0.085 per GB.
- The next 100TB per month is $0.07 per GB.
- Anything greater than 150TB per month is $0.05 per GB.
Additionally, AWS charges for data transfers between certain services and regions, which can complicate cost structures. For instance, data transfer between Availability Zones within the same AWS Region is charged at $0.01 per GB. Look at AWS’s detailed pricing documentation to understand these charges fully.
The following diagram illustrates the complexity of AWS’s data transfer pricing:
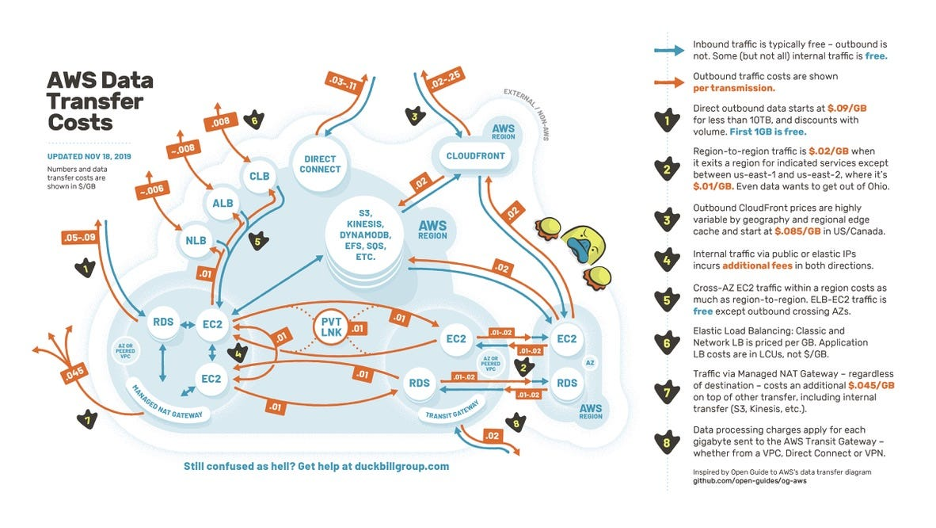
How can I reduce egress fees?
If you’re using cloud services, minimizing your egress fees is probably a high priority. Companies like the Duckbill Group (the creators of the diagram above) exist to help businesses manage their AWS bills. In fact, there’s a whole industry of consultants that focuses solely on reducing your AWS bills.
Aside from hiring a consultant to help you spend less, there are a few simple ways to lower your egress fees:
- Use a content delivery network (CDN): If you’re hosting an application, using a CDN can lower your egress fees since a CDN will cache data on edge servers. That way, when a user sends a request for your data, it can pull it from the CDN server rather than your cloud storage provider where you would be charged egress.
- Optimize data transfer protocols: Choose efficient data transfer protocols that minimize the amount of data transmitted. For example, consider using compression or delta encoding techniques to reduce the size of transferred files. Compressing data before transfer can reduce the volume of data sent over the network, leading to lower egress costs. However, the effectiveness of compression depends on the nature of the data.
- Utilize cloud providers that focus on interoperability: Some cloud providers offer free data transfer with a range of other cloud partners.
- Be aware of tiering: It may sound enticing to opt for a cold(er) storage tier to save on storage, but some of those tiers come with much higher egress fees.
- Consolidate workloads in the same region: Minimize inter-region data transfers by keeping applications, services, and data storage within the same cloud region whenever possible. Transferring data between regions often incurs additional charges that can quickly add up.
- Use point-to-point networking or directprivate connect: If your business frequently transfers large volumes of data, consider setting up a private network connection, like Megaport, PacketFabric, or Console Connect. These services provide dedicated bandwidth at a predictable cost, potentially lowering overall egress fees.
- Plan data extractions strategically: Instead of frequent, small data extractions, batch your transfers into fewer, larger downloads. This can help you better manage costs by avoiding repeated charges for smaller-scale egress operations.
- Monitor and analyze data flows: Use tools or dashboards to monitor data traffic within your cloud environment. Identifying patterns in data usage can help pinpoint unnecessary transfers or optimize workflows to limit costly egress activities.
How does Backblaze reduce egress fees?
There’s one more way you can drastically reduce egress, and we’ll just come right out and say it: Backblaze gives you free egress up to 3x the average monthly storage and unlimited free egress through a number of CDN and compute partners, including Fastly, Cloudflare, Bunny.net, and Vultr.
Why do we offer free egress? Supporting an open cloud environment is central to our mission, so we expanded free egress to all customers so they can move data when and where they prefer.
Cloud providers like AWS and others charge high egress fees that make it expensive for customers to use multi-cloud infrastructures and therefore lock in customers to their services. These walled gardens hamper innovation and long-term growth. By eliminating restrictive egress fees, we enable businesses to adopt multi-cloud strategies without the financial penalty of moving their data.
By partnering with leading CDN providers and compute platforms, we’ve built a system where you can move data seamlessly while enjoying cost savings that other providers don’t offer.
Free egress = A better, multi-cloud world
The bottom line: the high egress fees charged by hyperscalers like AWS, Google, and Microsoft are a direct impediment to a multi-cloud future driven by customer choice and industry need. And, a multi-cloud future is something we believe in. So go forth and build the multi-cloud future of your dreams, and leave worries about high egress fees in the past.
The post Cloud Egress Fees: What They Are And How To Reduce Them appeared first on Backblaze Blog | Cloud Storage & Cloud Backup




























 ︎
︎



























 )
) 



{kind=link}