Post Syndicated from Joe Chapman original https://aws.amazon.com/blogs/architecture/creating-a-multi-region-application-with-aws-services-part-3-application-management-and-monitoring/
In Part 1 of this series, we built a foundation for your multi-Region application using AWS compute, networking, and security services. In Part 2, we integrated AWS data and replication services to move and sync data between AWS Regions.
In Part 3, we cover AWS services and features used for messaging, deployment, monitoring, and management.
Developer tools
Automation that uses infrastructure as code (IaC) removes manual steps to create and configure infrastructure. It offers a repeatable template that can deploy consistent environments in different Regions.
IaC with AWS CloudFormation StackSets uses a single template to create, update, and delete stacks across multiple accounts and Regions in a single operation. When writing an AWS CloudFormation template, you can change the deployment behavior by pairing parameters with conditional logic. For example, you can set a “standby” parameter that, when “true,” limits the number of Amazon Elastic Compute Cloud (Amazon EC2) instances in an Amazon EC2 Auto Scaling group deployed to a standby Region.
Applications with deployments that span multiple Regions can use cross-Region actions in AWS CodePipeline for a consistent release pipeline. This way you won’t need to set up different actions in each Region. EC2 Image Builder and Amazon Elastic Container Registry (Amazon ECR) have cross-Region copy features to help with consistent AMI and image deployments, as covered in Part 1.
Event-driven architecture
Decoupled, event-driven applications produce a more extensible and maintainable architecture by having each component perform its specific task independently.
Amazon EventBridge, a serverless event bus, can send events between AWS resources. By utilizing cross-Region event routing, you can share events between workloads in different Regions (Figure 1) and accounts. For example, you can share health and utilization events across Regions to determine which Regional workload deployment is best suited for requests.
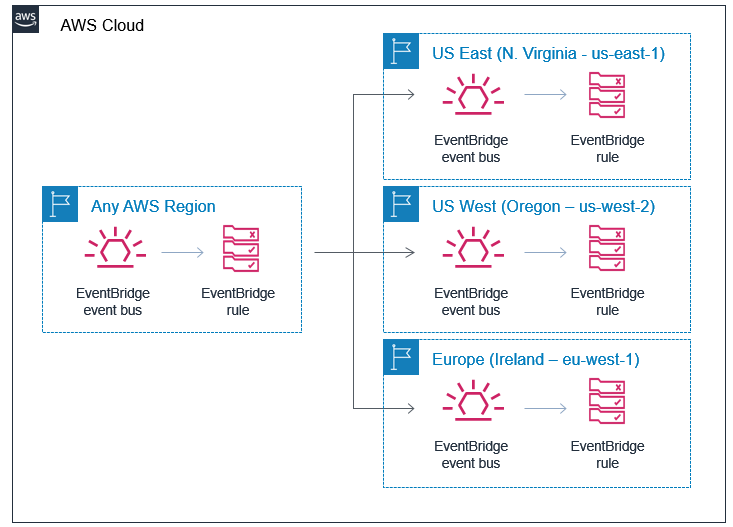
Figure 1. EventBridge routing events from one Region to event buses in other Regions
If your event-driven application relies on pub/sub messaging, Amazon Simple Notification Service (Amazon SNS) can fan out to multiple destinations. When the destination targets are Amazon Simple Queue Service (Amazon SQS) queues or AWS Lambda functions, Amazon SNS can notify recipients in different Regions. For example, you can send messages to a central SQS queue that processes orders for a multi-Region application.
Monitoring and observability
Observability becomes even more important as the number of resources and deployment locations increases. Being able to quickly identify the impact and root cause of an issue will influence recovery activities, and ensuring your observability stack is resilient to failures will help you make these decisions. When building on AWS, you can pair the health of AWS services with your application metrics to obtain a more complete view of the health of your infrastructure.
AWS Health dashboards and APIs show account-specific events and scheduled activities that may affect your resources. These events cover all Regions, and can expand to include all accounts in your AWS Organization. EventBridge can monitor events from AWS Health to take immediate actions based on an event. For example, if multiple services are reporting as degraded, you could set the EventBridge event target to an AWS Systems Manager automated runbook that prepares your disaster recovery (DR) application for failover.
AWS Trusted Advisor offers actionable alerts to optimize cost, increase performance, and improve security and fault tolerance. Trusted Advisor shows results across all Regions and can generate a report that shows an aggregated view of all check results across all accounts within an organization.
To maintain visibility over an application deployed across multiple Regions and accounts, you can create a Trusted Advisor dashboard and an operations dashboard with AWS Systems Manager Explorer. The operations dashboard offers a unified view of resources, such as Amazon EC2, Amazon CloudWatch, and AWS Config data. You can combine the metadata with Amazon Athena to create a multi-Region and multi-account inventory view of resources.
You can view metrics from applications and resources deployed across multiple Regions in the CloudWatch console. This makes it easy to create graphs and dashboards for multi-Region applications. Cross-account functionality is also available in CloudWatch, so you can create a centralized view of dashboards, alarms, and metrics across your organization.
Amazon OpenSearch Service aggregates unstructured and semi-structured log files, messages, metrics, documents, configuration data, and more. Cross-cluster replication replicates indices, mappings, and metadata in an active-passive setup from one OpenSearch Service domain to another. This reduces latency across Regions and ensures high availability of your data.
AWS Resilience Hub assesses and tracks the resiliency of your application. It checks how well an application will maintain availability when performing a Regional failover. For example, it can check if an application has cross-Region replication configured on Amazon Simple Storage Service (Amazon S3) buckets or that Amazon Relational Database Service (Amazon RDS) instances have a cross-Region read-replica. Figure 2 shows an output of a Resilience Hub assessment. It recommends use of Route 53 Application Recovery Controller (covered in Part 1) to ensure the Amazon EC2 Auto Scaling group in a Region is scaled and ready to accept traffic before we fail over to it.

Figure 2. Resilience Hub recommendations
Management: Governance
Growing an application into a new country means there may be additional data privacy laws and regulations to follow. These will vary depending on the country, and we encourage you to investigate with your legal team to fully understand how this affects your application.
AWS Control Tower supports data compliance by providing guardrails to control and meet data residency requirements. These guardrails are a collection of Service Control Policies (SCPs) and AWS Config rules. You can implement them independently of AWS Control Tower if needed. Additional security-centric multi-Region services are covered in part 1.
AWS Config provides a detailed view of the configuration and history of AWS resources. An AWS Config aggregator collects configuration and compliance data from multiple accounts and Regions into a central account. This centralized view offers a comprehensive view of the compliance and actions on resources, regardless of which account or Region they reside in.
Management: Operations
Several AWS Systems Manager capabilities allow for easier administration of AWS resources, especially as applications grow. Systems Manager Automation simplifies common maintenance and deployment tasks for AWS resources with automated runbooks. These runbooks automate actions on resources across Regions and accounts. You can pair Systems Manager Automation with Systems Manager Patch Manager to ensure instances maintain the latest patches across accounts and Regions. Figure 3 shows Systems Manager running several automation documents on a multi-Region architecture.
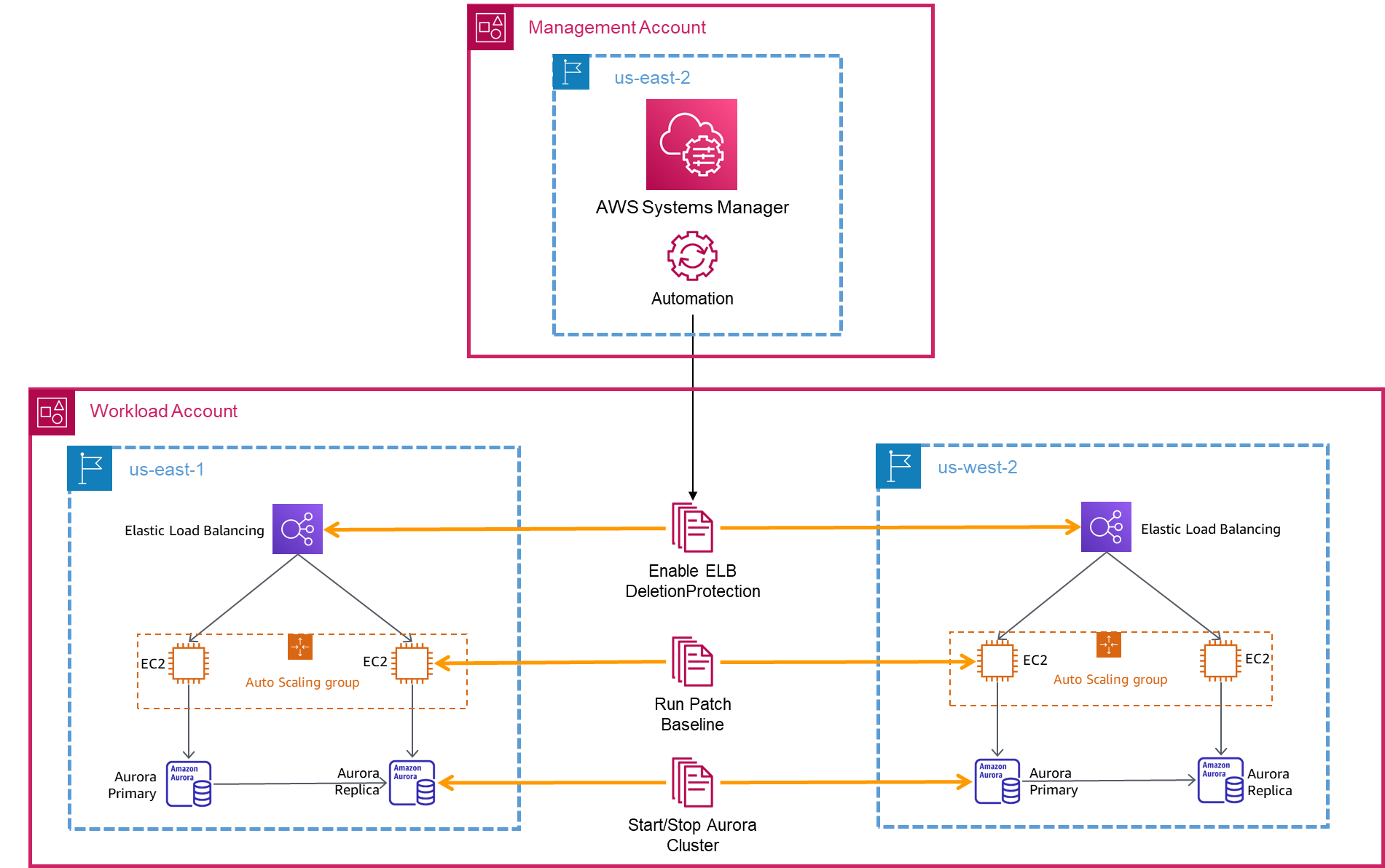
Figure 3. Using Systems Manager automation from a central operations AWS account to automate actions across multiple Regions
Bringing it together
At the end of each part of this blog series, we build on a sample application based on the services covered. This shows you how to bring these services together to build a multi-Region application with AWS services. We don’t use every service mentioned, just those that fit the use case.
We built this example to expand to a global audience. It requires high availability across Regions, and favors performance over strict consistency. We have chosen the following services covered in this post to accomplish our goals, building on our foundation from part 1 and part 2:
- CloudFormation StackSets to deploy everything with IaC. This ensures the infrastructure is deployed consistently across Regions.
- AWS Config rules provide a centralized place to monitor, record, and evaluate the configuration of our resources.
- For added observability, we created dashboards with CloudWatch dashboard, Personal Health dashboard, and Trusted Advisor dashboard.

Figure 4. Building an application with multi-Region services
While our primary objective is expanding to a global audience, we note that some of the services such as CloudFormation StackSets rely on Region 1. Each Regional deployment is set up for static stability, but if there were an outage in Region 1 for an extended period of time, our DR playbook would outline how to make CloudFormation changes in Region 2.
Summary
Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming.
In this 3-part blog series, we’ve explored AWS services with features to assist you in building multi-Region applications. In Part 1, we built a foundation with AWS security, networking, and compute services. In Part 2, we added in data and replication strategies. Finally, in Part 3, we examined application and management layers.
Ready to get started? We’ve chosen some AWS Solutions, AWS Blogs, and Well-Architected labs to help you!
Other posts in this series
- Creating a Multi-Region Application with AWS Services – Part 1, Compute, Networking, and Security
- Creating a Multi-Region Application with AWS Services – Part 2, Data and Replication