Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/new-for-aws-global-accelerator-internet-protocol-version-6-ipv6-support/
IPv6 adoption has consistently increased over the last few years, especially among mobile networks. The main reasons to move to IPv6 are:
- The limited availability of IPv4 addresses can limit the ability to scale up public-facing web and applications servers.
- IPv6 users from mobile networks experience better performance when their network traffic doesn’t need to manage IPv6 to IPv4 translation.
- You might need to comply with regulatory rules (such as the Federal Acquisition Regulation in US) to run specific internet traffic over IPv6.
Based on this, we found that we could help improve the network path that your customers use to reach your applications by adding IPv6 support to AWS Global Accelerator. Global Accelerator uses the AWS global network to route network traffic and keep packet loss, jitter, and latency consistently low. Customers like Atlassian, New Relic, and SkyScanner already use Global Accelerator to improve the global availability and performance of their applications.
Global Accelerator provides two global static public IPs that act as a fixed entry point to your application. You can update your application endpoints without making user-facing changes to the IP address. If you configure more than one application endpoint, Global Accelerator automatically reroutes your traffic to your nearest healthy available endpoint to mitigate endpoint failure.
Starting today, you can provide better network performance by routing IPv6 traffic through Global Accelerator to your application endpoints running in AWS Regions. Global Accelerator now supports two types of accelerators: dual-stack and IPv4-only. With a dual-stack accelerator, you are provided with a pair of IPv4 and IPv6 global static IP addresses that can serve both IPv4 and IPv6 traffic.
For existing IPv4-only accelerators, you can update your accelerators to dual-stack to serve both IPv4 and IPv6 traffic. This update enables your accelerator to serve IPv6 traffic and doesn’t impact existing IPv4 traffic served by the accelerator.
Dual-stack accelerators supporting both IPv6 and IPv4 traffic require dual-stack endpoints in the back end. For example, Application Load Balancers (ALBs) can have their IP address type configured as either IPv4-only or dual stack, allowing them to accept both IPv4 or IPv6 client connections. Today, dual-stack ALBs are supported as endpoints for dual-stack accelerators.
Deploying a Dual-Stack Application
To test this new feature, I need a dual-stack application with an ALB entry point. The application must be deployed in Amazon Virtual Private Cloud (Amazon VPC) and support IPv6 traffic. I don’t happen to have IPv6-ready VPCs in my account. I can follow these instructions to migrate an existing VPC that supports IPv4 only to IPv6, or I can create a VPC that supports IPv6 addressing. For this post, I choose to create a VPC.
In the AWS Management Console, I navigate to the Amazon VPC Dashboard. I choose Launch VPC Wizard. In the wizard, I enter a value for the Name tag. This value will be used to auto-generate Name tags for all resources in the VPC. Then, I select the option to associate an Amazon-provided IPv6 CIDR block. I leave all other options to their default values and choose Create VPC.

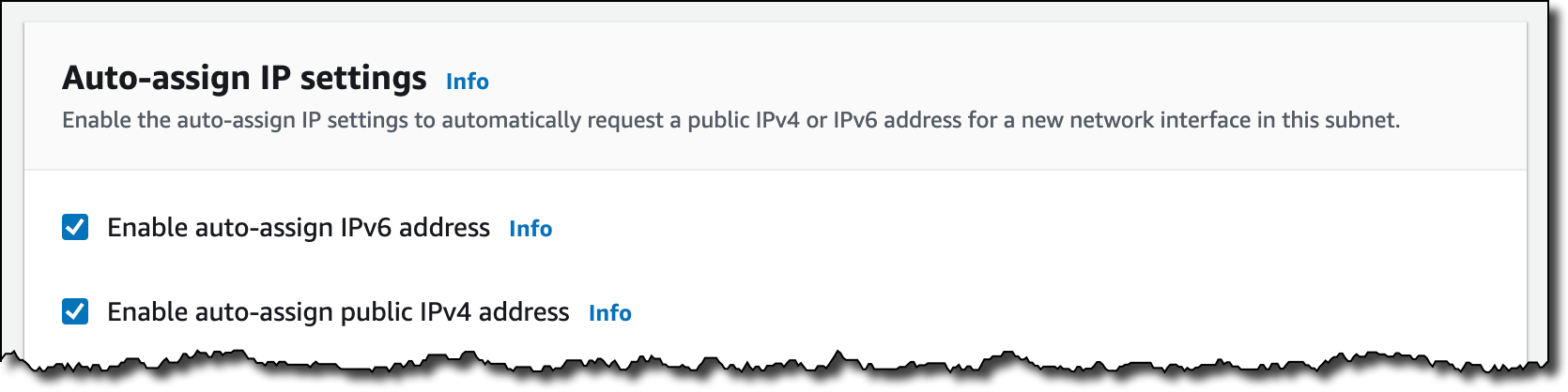
After less than a minute, the VPC is ready. I edit the settings of both public subnets to enable the Auto-assign IP settings to automatically request both a public IPv4 address and an IPv6 address for new network interfaces in this subnet.
Now, I want to deploy an application in this VPC. The application will be the endpoint for my accelerator. I view and download the WordPress scalable and durable AWS CloudFormation template from the Sample solutions section of the CloudFormation documentation. This template deploys a full WordPress website behind an ALB. The web tier is scalable and implemented as an EC2 Auto Scaling group. The MySQL database is managed by Amazon Relational Database Service (RDS).
Before deploying the stack, I edit the template to make a few changes. First, I add a DBSubnetGroup resource:
"DBSubnetGroup" : {
"Type": "AWS::RDS::DBSubnetGroup",
"Properties": {
"DBSubnetGroupDescription" : "DB subnet group",
"SubnetIds" : { "Ref" : "Subnets"}
}
},Then, I add the DBSubnetGroupName property to the DBInstance resource. In this way, the database created by the template will be deployed in the same subnets (and VPC) as the web servers.
"DBSubnetGroupName" : { "Ref" : "DBSubnetGroup" },The last change adds the IpAddressType property to the ApplicationLoadBalancer resource to create a dual-stack load balancer that has IPv6 addresses and will be ready to be used with the new dual-stack option of Global Accelerator.
"IpAddressType": "dualstack",Because IpAddressType is set to dualstack, the ALB created by the stack will also have IPv6 addresses and will be ready to be used with the new dual-stack option of Global Accelerator.
In the CloudFormation console, I create a stack and upload the template I just edited. In the template parameters, I enter a database user and password to use. For the VpcId parameter, I select the IPv6-ready VPC I just created. For the Subnets parameter, I select the two public subnets of the same VPC. After that, I go to the next steps and create the stack.
After a few minutes, the stack creation is complete. To access the website, I need to open network access to the load balancer. In the EC2 console, I create a security group that allows public access using the HTTP and HTTPS protocols (ports 80 and 443).

I choose Load balancers from the navigation pane and select the ALB used by my application. In the Security section, I choose Edit security groups and add the security group I just created to allow web access.

Now, I look for the dual-stack (A or AAAA Record) DNS name of the load balancer. I open a browser and connect using the DNS name to complete the configuration of WordPress.

When connecting again to the endpoint, I see my new (and empty) WordPress website.

Using Dual-Stack Accelerators with Support for Both IPv6 and IPv4 traffic
Now that my application is ready, I add a dual-stack accelerator in front of the dual-stack ALB. In the Global Accelerator console, I choose Create accelerator. I enter a name for the accelerator and choose the Standard accelerator type.

To route both IPv4 and IPv6 through this accelerator, I select the Dual-stack option for the IP address type.

Then I add a listener for port 80 using the TCP protocol.

For that listener, I configure an endpoint group in the AWS Region where I have my application deployed.

I choose Application Load Balancer for the Endpoint type and select the ALB in the CloudFormation stack.
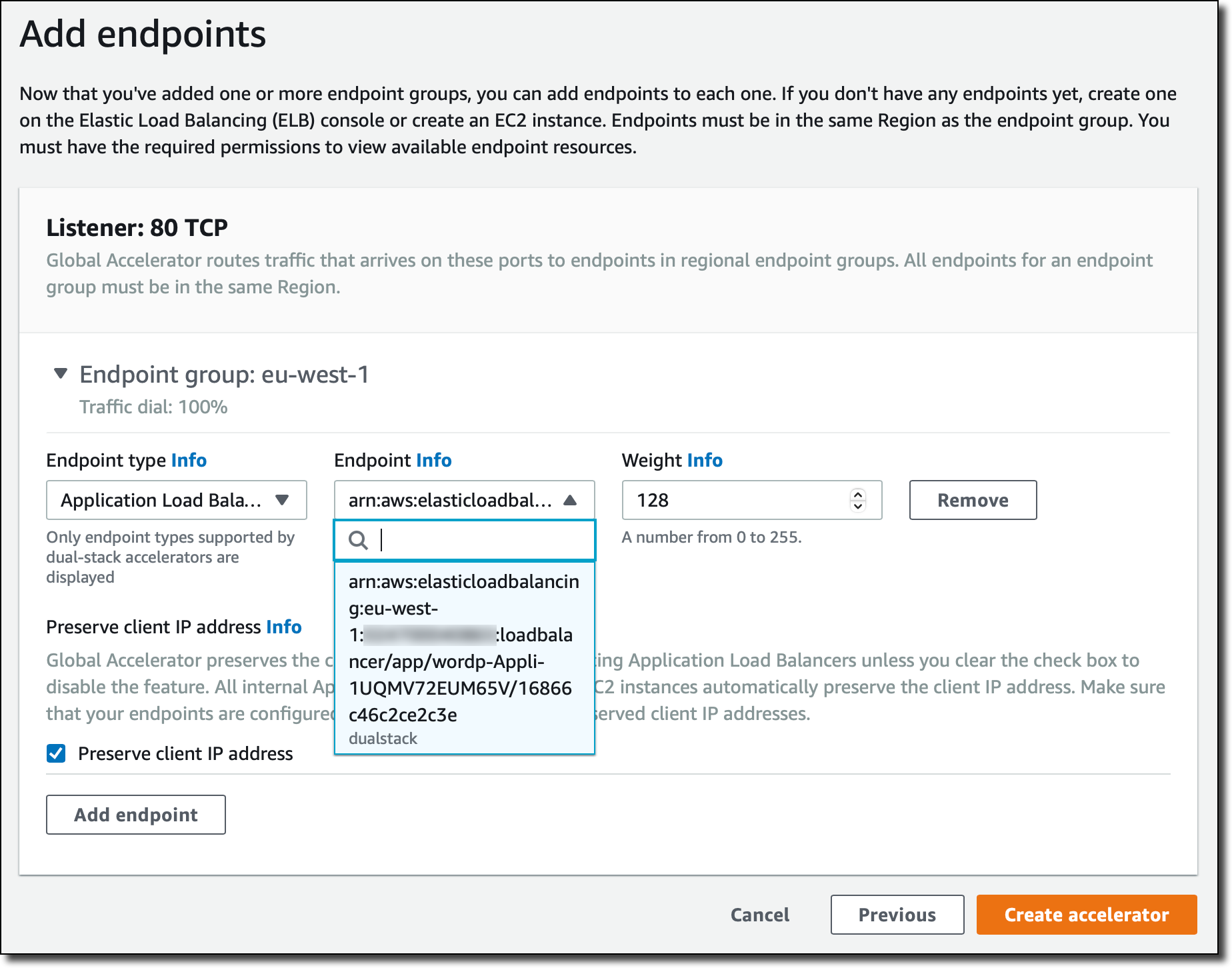
Then, I choose Create accelerator. After a few minutes, the accelerator is deployed, and I have a dual-stack DNS name to reach the ALB using IPv4 or IPv6 depending on the network used by the client.
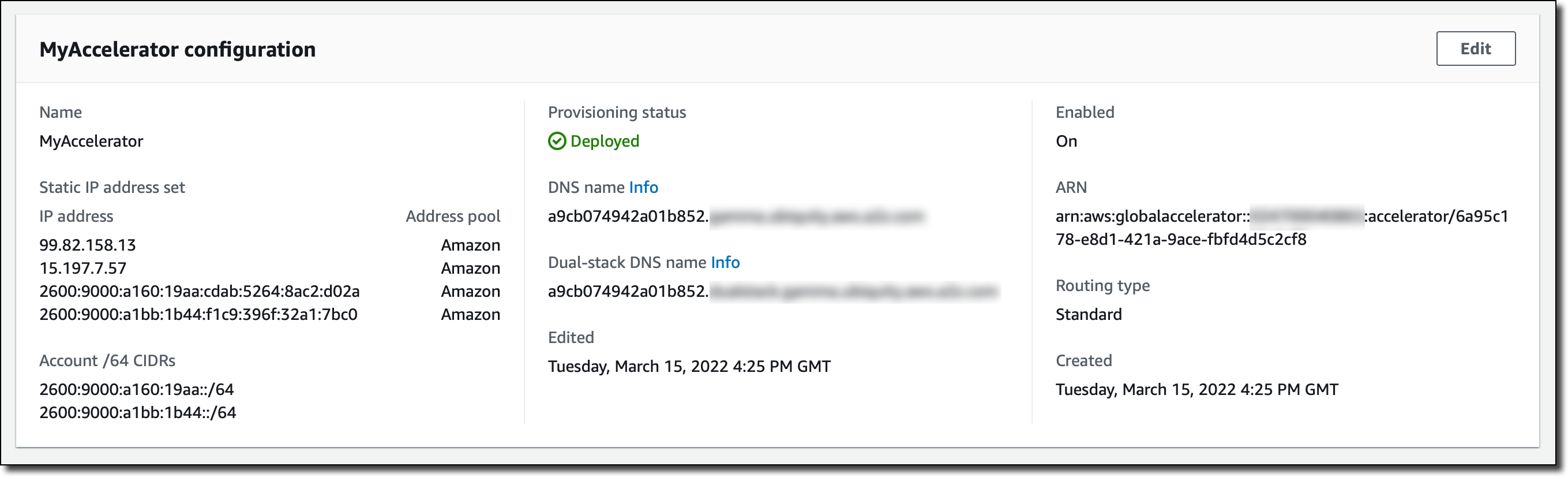
Now, my customers can use the IPv4 and IPv6 addresses or, even better, the dual-stack DNS name of the accelerator to connect to the WordPress website. If there is a front-end or mobile application my customers use to connect to the WordPress REST APIs, I can use the dual-stack DNS name so that clients will connect using their preferred IPv4 or IPv6 route.
To understand if the communication between Global Accelerator and the ALB is working, I can monitor the new FlowsDrop Amazon CloudWatch metric. This metric tells me if Global Accelerator is unable to route IPv6 traffic through the endpoint. For example, that can happen if, after the creation of the accelerator, the configuration of the ALB is updated to use IPv4 only.
Availability and Pricing
You can configure dual-stack accelerators using the AWS Management Console, the AWS Command Line Interface (CLI), and AWS SDKs. You can use dual-stack accelerators to optimize access to your applications deployed in any commercial AWS Region.
Protocol translation is not supported, neither IPv4 to IPv6 nor IPv6 to IPv4. For example, Global Accelerator will not allow me to configure a dual-stack accelerator with an IPv4-only ALB endpoint. Also, for IPv6 ALB endpoints, client IP preservation must be enabled.
There are no additional costs for using dual-stack accelerators. You pay for the hours and the amount of data transfer in the dominant direction used by traffic to or from the accelerator. Data transfer costs depend on the location of your clients and the AWS Regions where you are running your applications. For more information, see the Global Accelerator pricing page.
— Danilo