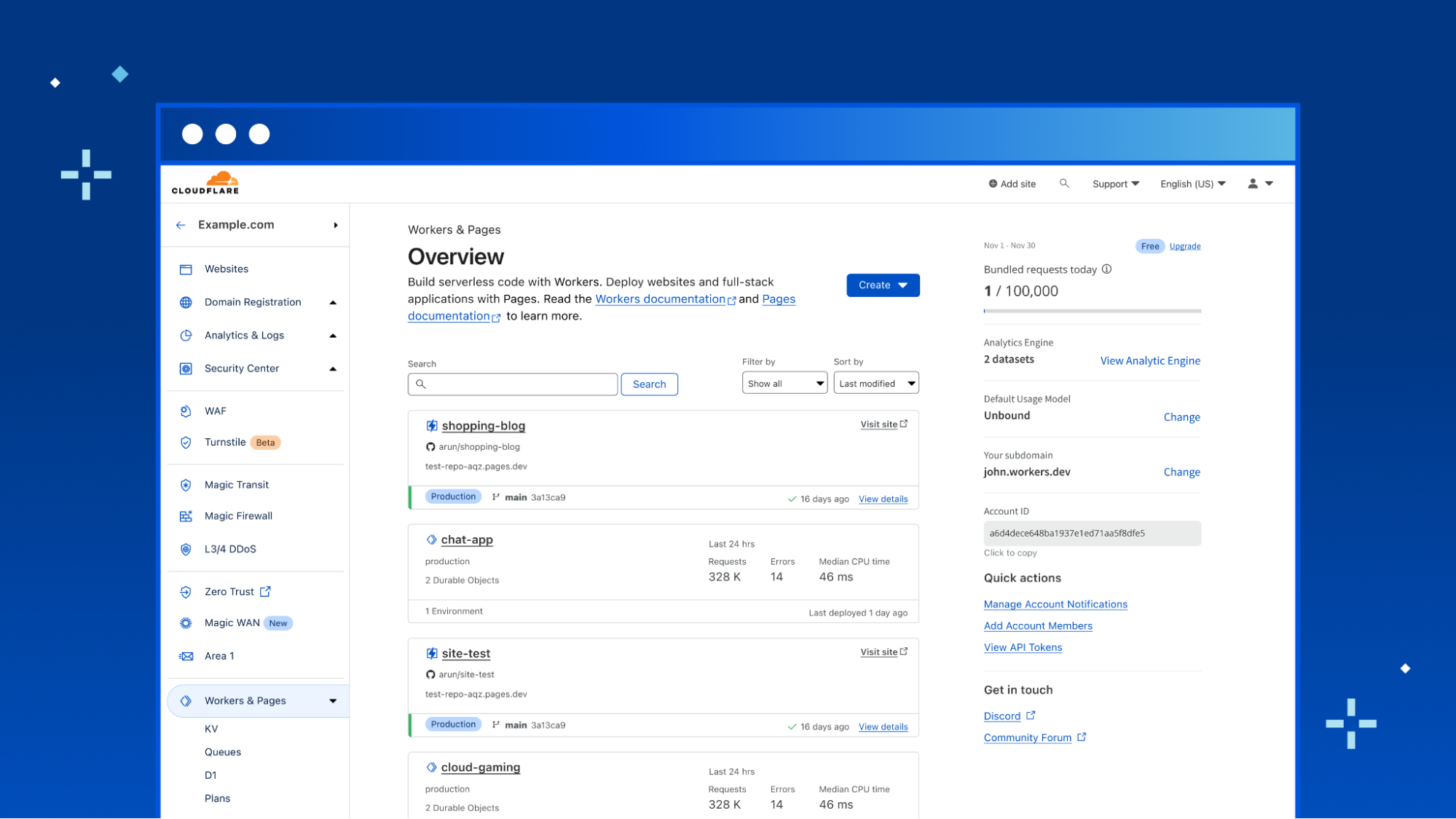
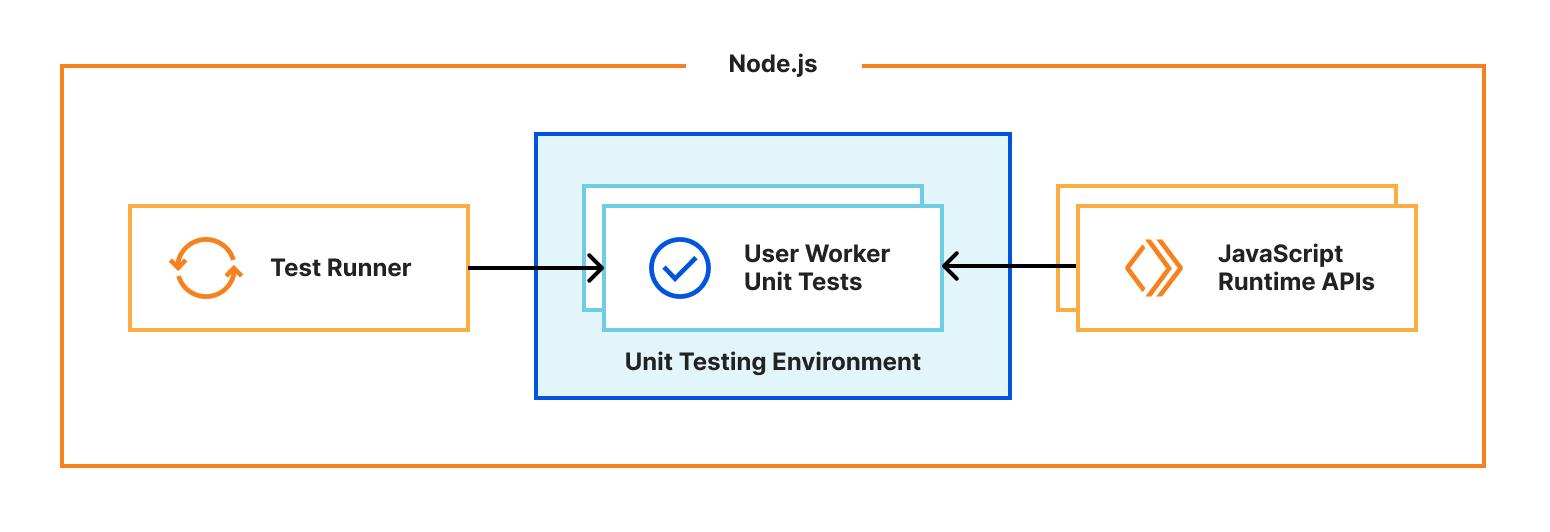
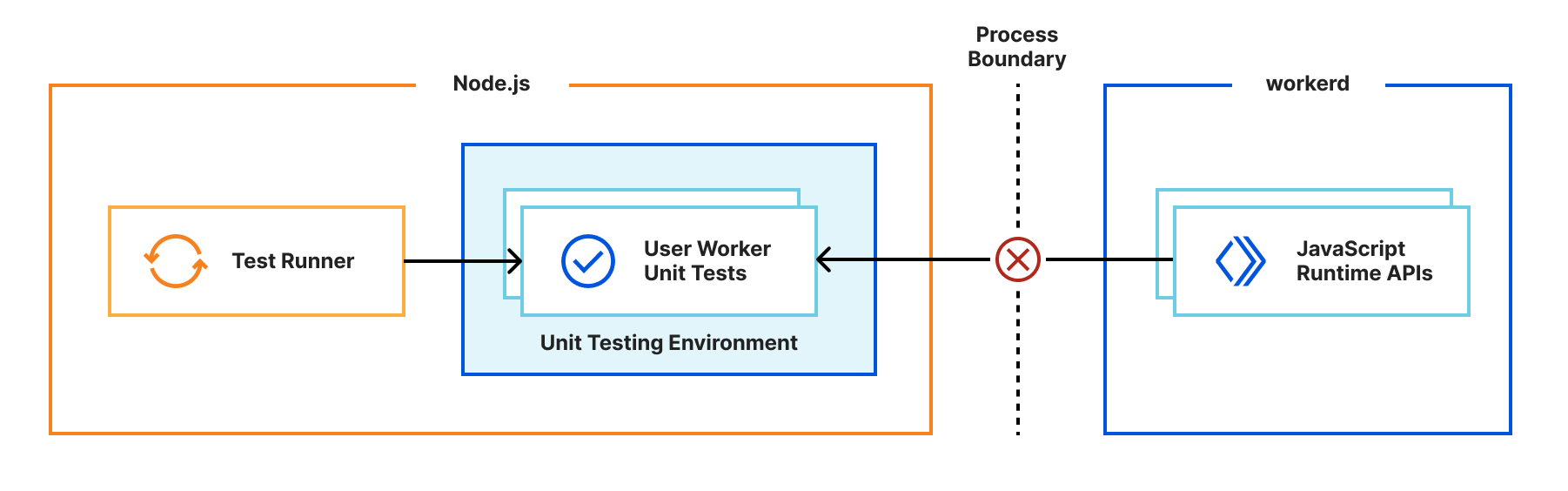
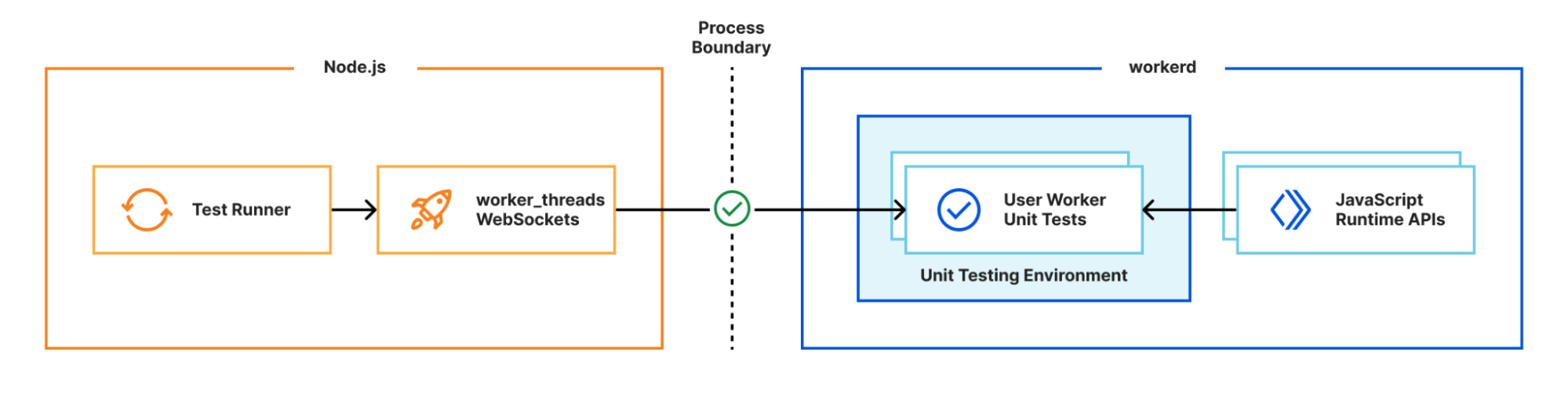
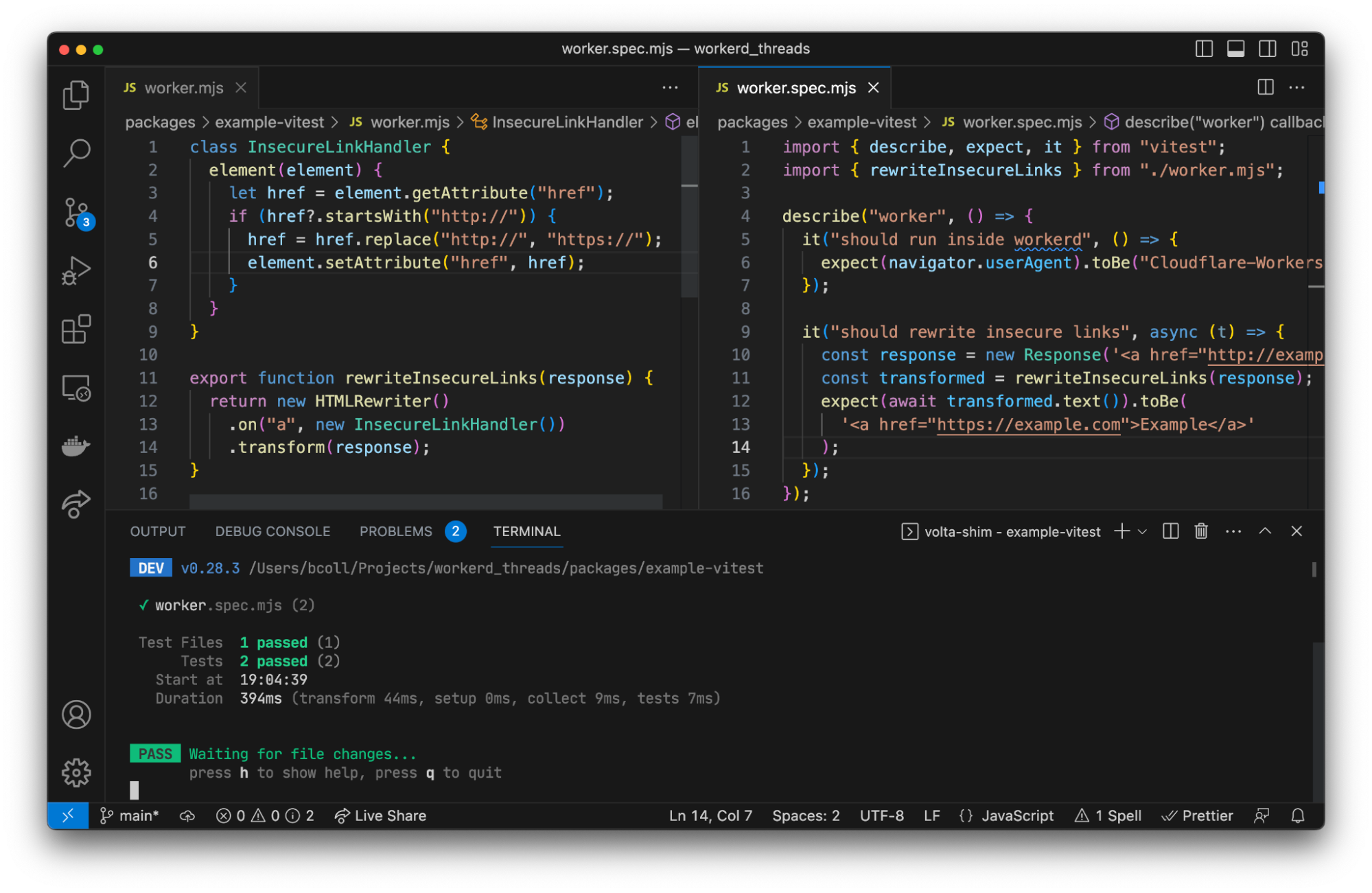
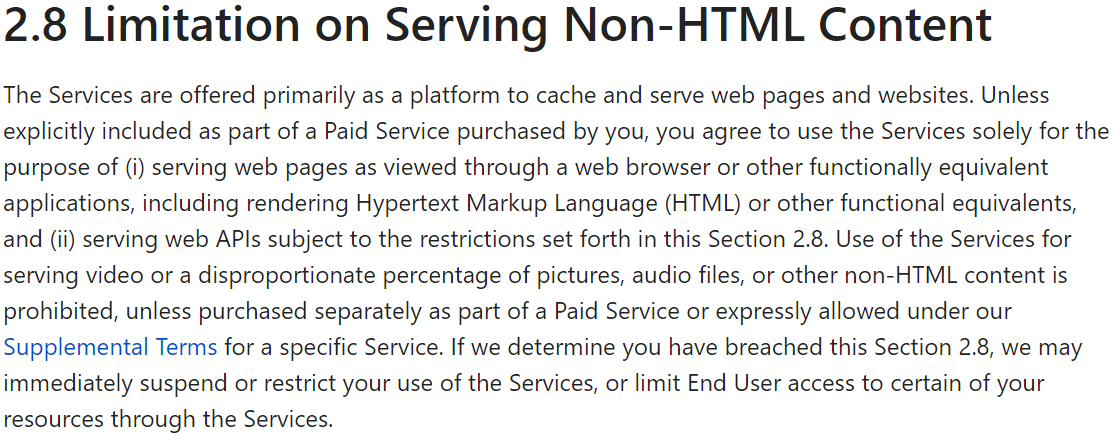
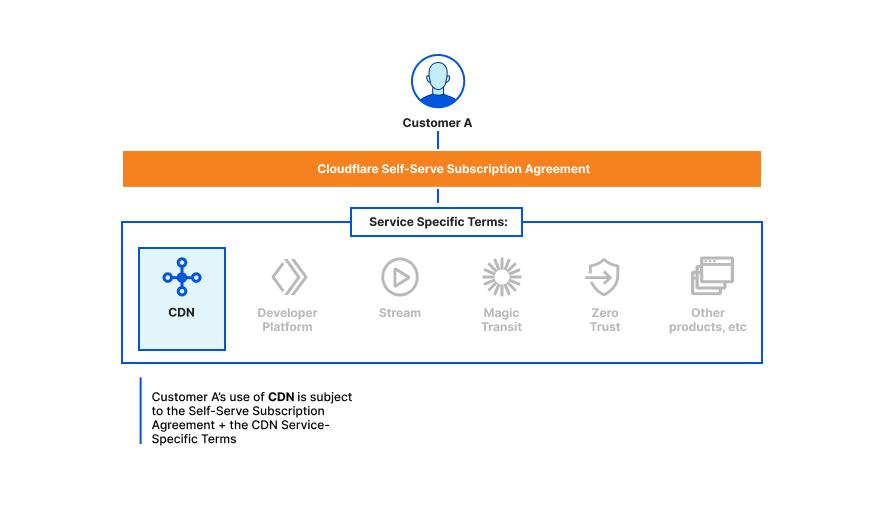
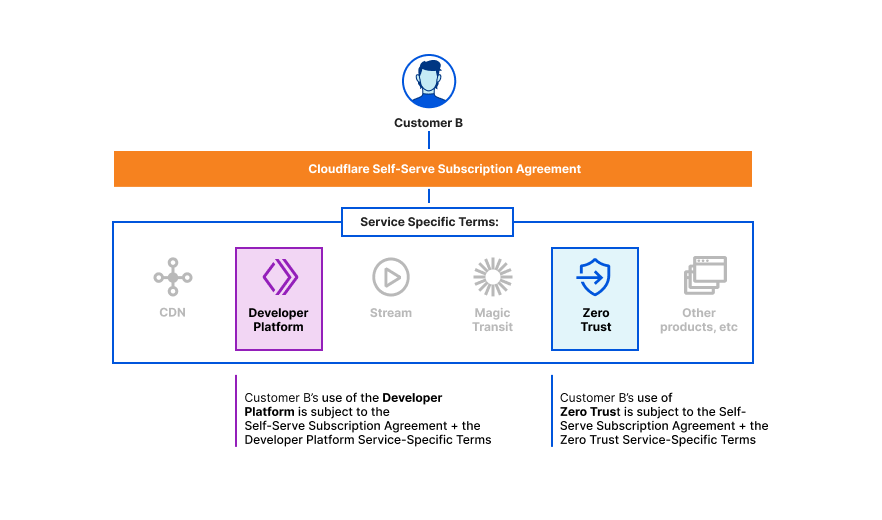
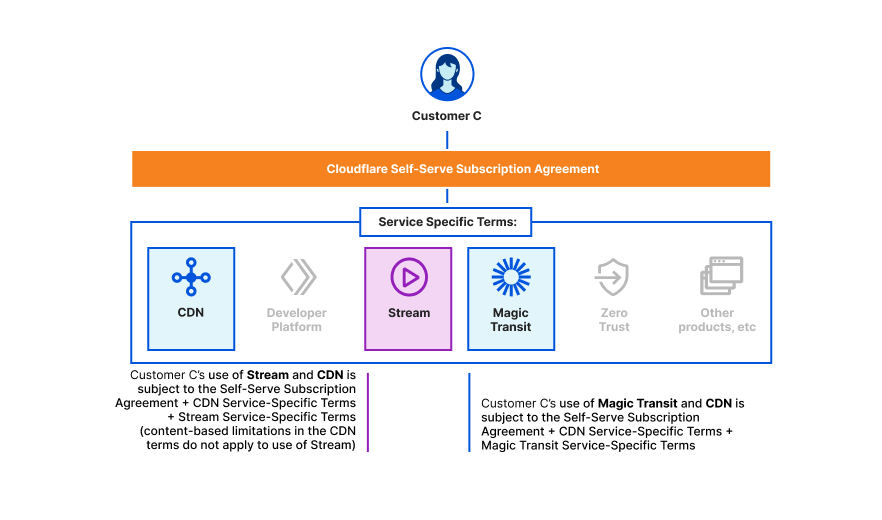
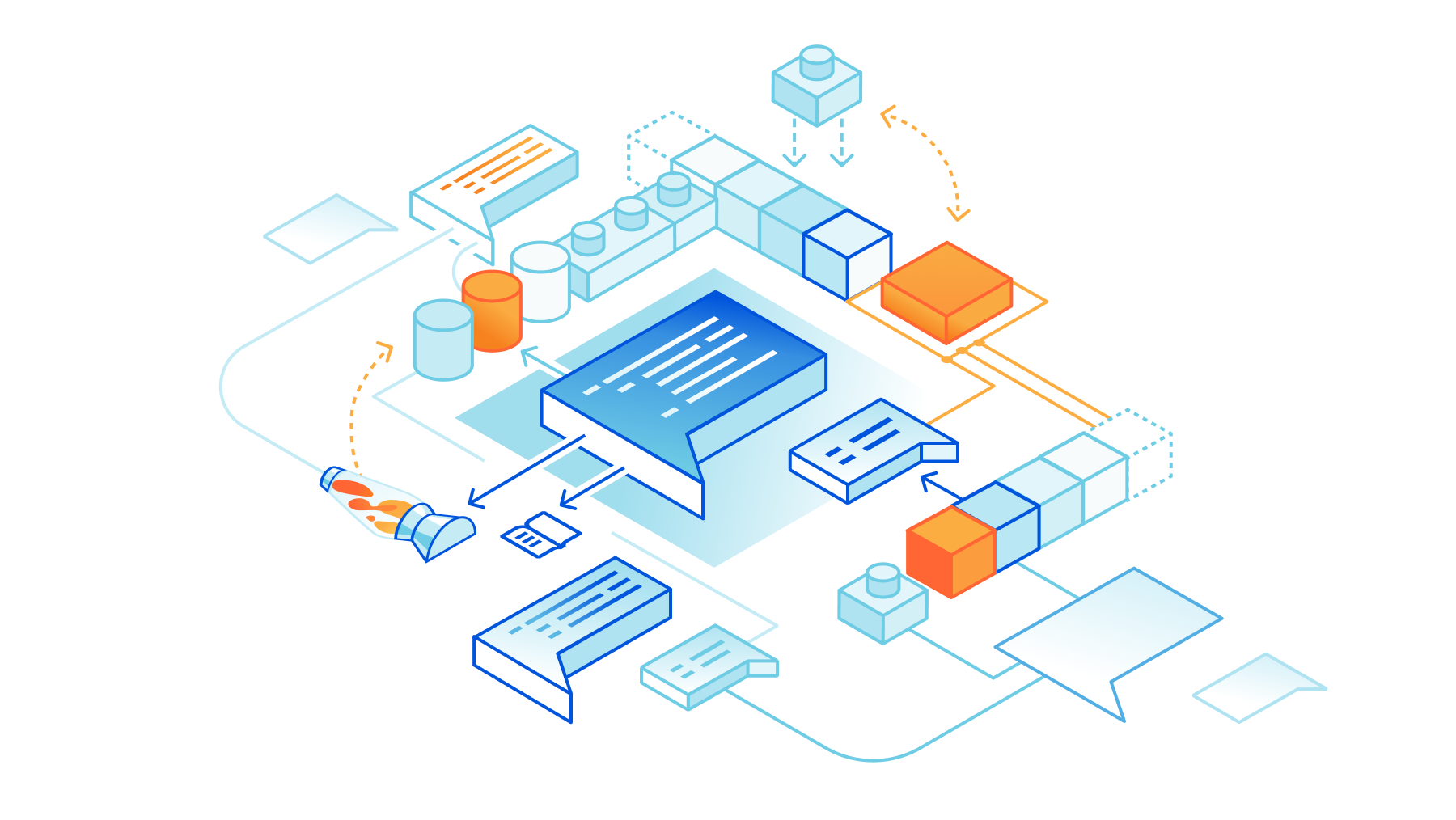
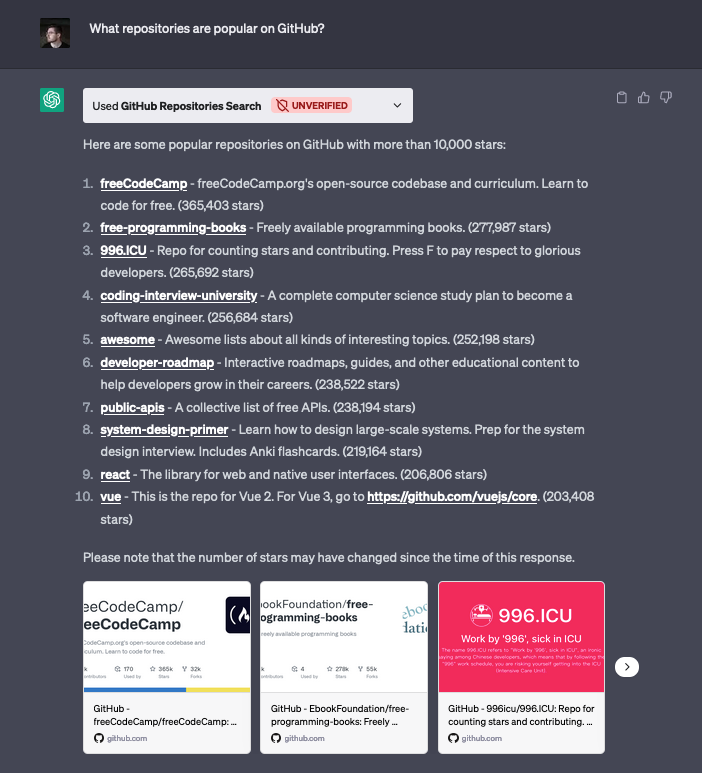
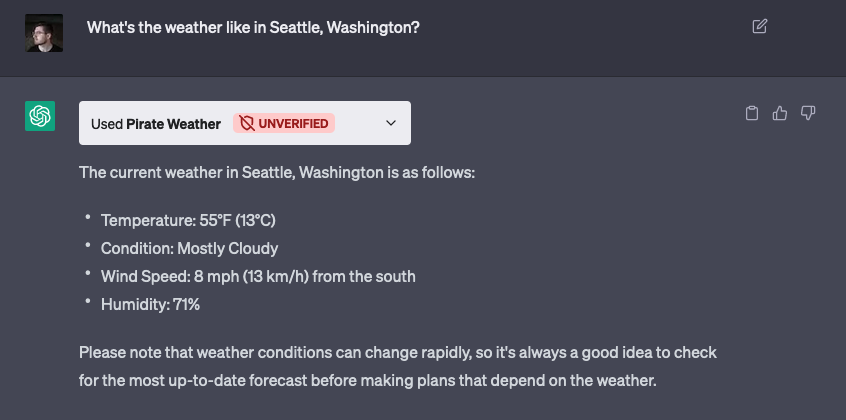
We’re excited to announce Secrets Store – Cloudflare’s new secrets management offering!
A secrets store does exactly what the name implies – it stores secrets. Secrets are variables that are used by developers that contain sensitive information – information that only authorized users and systems should have access to.
If you’re building an application, there are various types of secrets that you need to manage. Every system should be designed to have identity & authentication data that verifies some form of identity in order to grant access to a system or application. One example of this is API tokens for making read and write requests to a database. Failure to store these tokens securely could lead to unauthorized access of information – intentional or accidental.
The stakes with secret’s management are high. Every gap in the storage of these values has potential to lead to a data leak or compromise. A security administrator’s worst nightmare.
Developers are primarily focused on creating applications, they want to build quickly, they want their system to be performant, and they want it to scale. For them, secrets management is about ease of use, performance, and reliability. On the other hand, security administrators are tasked with ensuring that these secrets remain secure. It’s their responsibility to safeguard sensitive information, ensure that security best practices are met, and to manage any fallout of an incident such as a data leak or breach. It’s their job to verify that developers at their company are building in a secure and foolproof manner.
In order for developers to build at high velocity and for security administrators to feel at ease, companies need to adopt a highly reliable and secure secrets manager. This should be a system that ensures that sensitive information is stored with the highest security measures, while maintaining ease of use that will allow engineering teams to efficiently build.
Why Cloudflare is building a secrets store
Cloudflare’s mission is to help build a better Internet – that means a more secure Internet. We recognize our customers’ need for a secure, centralized repository for storing sensitive data. Within the Cloudflare ecosystem, are various places where customers need to store and access API and authorization tokens, shared secrets, and sensitive information. It’s our job to make it easy for customers to manage these values securely.
The need for secrets management goes beyond Cloudflare. Customers have sensitive data that they manage everywhere – at their cloud provider, on their own infrastructure, across machines. Our plan is to make our Secrets Store a one-stop shop for all of our customer’s secrets.
The evolution of secrets at Cloudflare
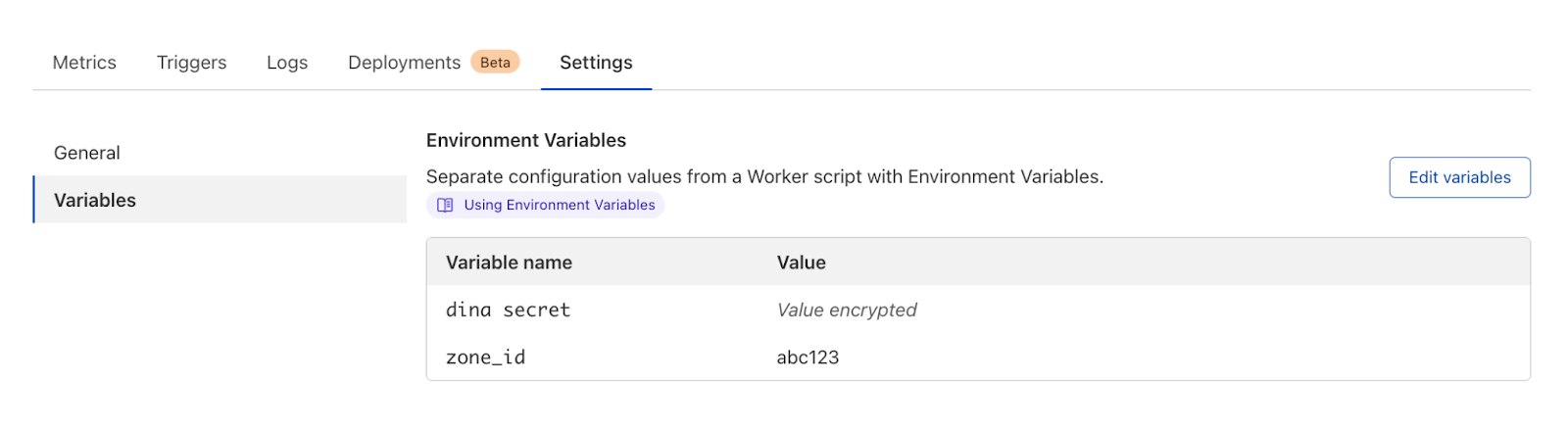
In 2020, we launched environment variables and secrets for Cloudflare Workers, allowing customers to create and encrypt variables across their Worker scripts. By doing this, developers can obfuscate the value of a variable so that it’s no longer available in plaintext and can only be accessed by the Worker.
Adoption and use of these secrets is quickly growing. We now have more than three million Workers scripts that reference variables and secrets managed through Cloudflare. One piece of feedback that we continue to hear from customers is that these secrets are scoped too narrowly.
Today, customers can only use a variable or secret within the Worker that it’s associated with. Instead, customers have secrets that they share across Workers. They don’t want to re-create those secrets and focus their time on keeping them in sync. They want account level secrets that are managed in one place but are referenced across multiple Workers scripts and functions.
Outside of Workers, there are many use cases for secrets across Cloudflare services.
Inside our Web Application Firewall (WAF), customers can make rules that look for authorization headers in order to grant or deny access to requests. Today, when customers create these rules, they put the authorization header value in plaintext, so that anyone with WAF access in the Cloudflare account can see its value. What we’ve heard from our customers is that even internally, engineers should not have access to this type of information. Instead, what our customers want is one place to manage the value of this header or token, so that only authorized users can see, create, and rotate this value. Then when creating a WAF rule, engineers can just reference the associated secret e.g.“account.mysecretauth”. By doing this, we help our customers secure their system by reducing the access scope and enhance management of this value by keeping it updated in one place.
With new Cloudflare products and features quickly developing, we’re hearing more and more use cases for a centralized secrets manager. One that can be used to store Access Service tokens or shared secrets for Webhooks.
With the new account level Secrets Store, we’re excited to give customers the tools they need to manage secrets across Cloudflare services.
Securing the Secret Store
To have a secrets store, there are a number of measures that need to be in place, and we’re committing to providing these for our customers.
First, we’re going to give the tools that our customers need to restrict access to secrets. We will have scope permissions that will allow admins to choose which users can view, create, edit, or remove secrets. We also plan to add the same level of granularity to our services – giving customers the ability to say “only allow this Worker to access this secret and only allow this set of Firewall rules to access that secret”.
Next, we’re going to give our customers extensive audits that will allow them to track the access and use of their secrets. Audit logs are crucial for security administrators. They can be used to alert team members that a secret was used by an unauthorized service or that a compromised secret is being accessed when it shouldn’t be. We will give customers audit logs for every secret-related event, so that customers can see exactly who is making changes to secrets and which services are accessing and when.
In addition to the built-in security of the Secrets Store, we’re going to give customers the tools to rotate their encryption keys on-demand or at a cadence that fits the right security posture for them.
Sign up for the beta
We’re excited to get the Secrets Store in our customer’s hands. If you’re interested in using this, please fill out this form, and we’ll reach out to you when it’s ready to use.
“Our goal for LangChain is to empower developers around the world to build with AI. We want LangChain to work wherever developers are building, and to spark their creativity to build new and innovative applications. With this new launch, we can't wait to see what developers build with LangChainJS and Cloudflare Workers. And we're excited to put more of Cloudflare's developer tools in the hands of our community in the coming months.” – Harrison Chase, Co-Founder and CEO, LangChain
In this post, we’ll share why we’re so excited about LangChain and walk you through how to build your first LangChainJS + Cloudflare Workers application.
For the uninitiated, LangChain is a framework for building applications powered by large language models (LLMs). It not only lets you fairly seamlessly switch between different LLMs, but also gives you the ability to chain prompts together. This allows you to build more sophisticated applications across multiple LLMs, something that would be way more complicated without the help of LangChain.
Building your first LangChainJS + Cloudflare Workers application
There are a few prerequisites you have to set up in order to build this application:
An OpenAI account: If you don’t already have one, you can sign up for free.
A paid Cloudflare Workers account: If you don’t already have an account, you can sign up here and upgrade your Workers for $5 per month.
Node & npm: If this is your first time working with node, you can get it here.
Next create a new folder called langchain-workers, navigate into that folder and then within that folder run wrangler init.
When you run wrangler init you’ll select the following options:
✔Would you like to use git to manage this Worker? … yes
✔ No package.json found. Would you like to create one? … yes
✔ Would you like to use TypeScript? … no
✔ Would you like to create a Worker at src/index.js? › Fetch handler
✔ Would you like us to write your first test? … no
With our Worker created, we’ll need to set up the environment variable for our OpenAI API Key. You can create an API key in your OpenAI dashboard. Save your new API key someplace safe, then open your wrangler.toml file and add the following lines at the bottom (making sure to insert you actual API key):
[vars]
OPENAI_API_KEY = "sk…"
Then we’ll install LangChainjs using npm:
npm install langchain
Before we start writing code we can make sure everything is working properly by running wrangler dev. With wrangler dev running you can press b to open a browser. When you do, you'll see “Hello World!” in your browser.
A sample application
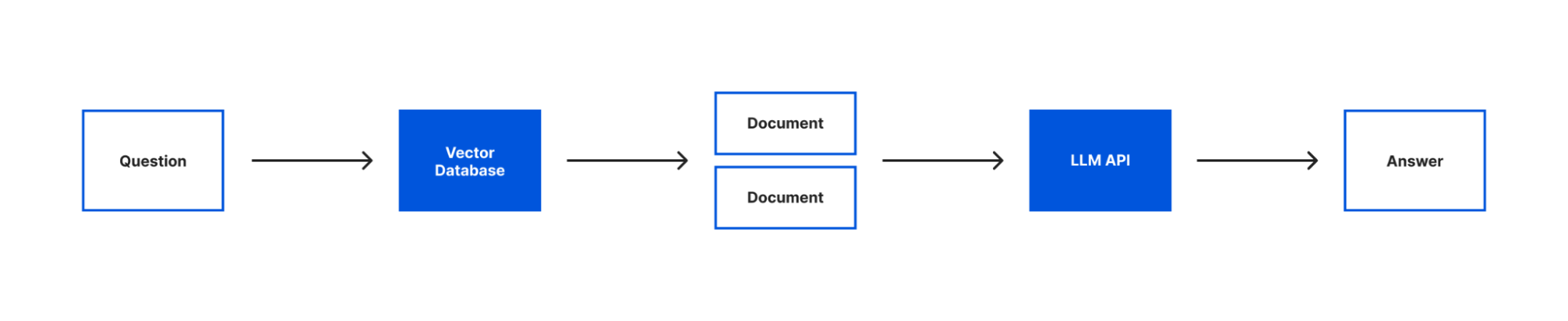
One common way you may want to use a language model is to combine it with your own text. LangChain is a great tool to accomplish this goal and that’s what we’ll be doing today in our sample application. We’re going to build an application that lets us use the OpenAI language model to ask a question about an article on Wikipedia. Because I live in (and love) Brooklyn, we’ll be using the Wikipedia article about Brooklyn. But you can use this code for any Wikipedia article, or website, you’d like.
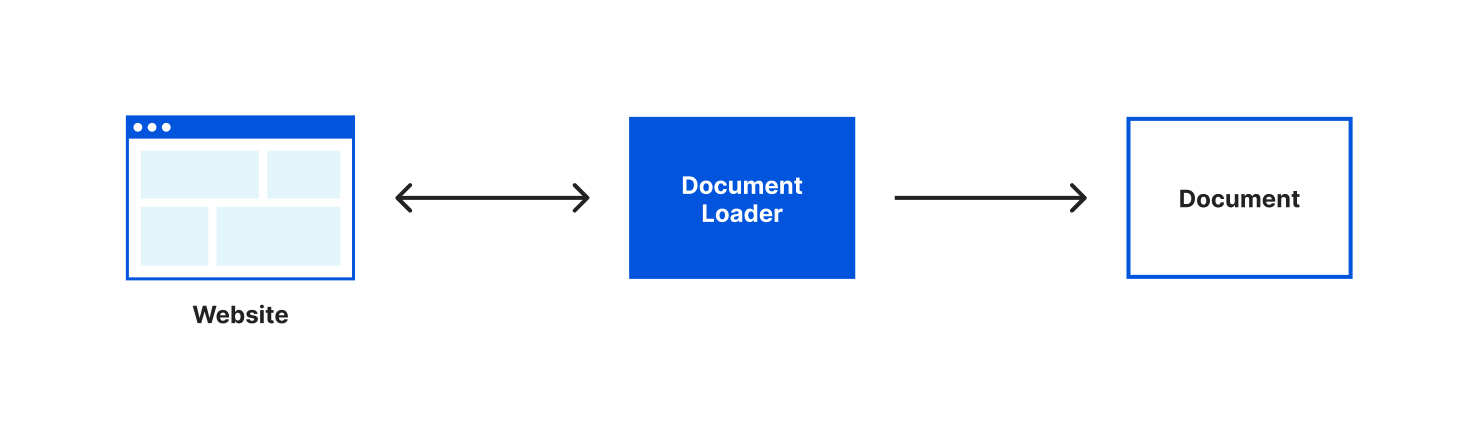
Because language models only know about the data that they were trained on, if we want to use a language model with new or specific information we need a way to pass a model that information. In LangChain we can accomplish this using a ”document”. If you’re like me, when you hear “document” you often think of a specific file format but in LangChain a document is an object that consists of some text and optionally some metadata. The text in a document object is what will be used when interacting with a language model and the metadata is a way that you can track information about your document.
Most often you’ll want to create documents from a source of pre-existing text. LangChain helpfully provides us with different document loaders to make loading text from many different sources easy. There are document loaders for different types of text formats (for example: CSV, PDFs, HTML, unstructured text) and that content can be loaded locally or from the web. A document loader will both retrieve the text for you and load that text into a document object. For our application, we’ll be using the webpages with Cheerio document loader. Cheerio is a lightweight library that will let us read the content of a webpage. We can install it using npm install cheerio.
After we’ve installed cheerio we’ll import the CheerioWebBaseLoader at the top of our src/index.js file:
import { CheerioWebBaseLoader } from "langchain/document_loaders/web/cheerio";
With CheerioWebBaseLoader imported, we can start using it within our fetch function:.
In this code, we’re configuring our loader with the Wikipedia URL for the article about Brooklyn, run the load() function and log the result to the console. Like I mentioned earlier, if you want to try this with a different Wikipedia article or website, LangChain makes it very easy. All we have to do is change the URL we’re passing to our CheerioWebBaseLoader.
Let’s run wrangler dev, load up our page locally and watch the output in our console. You should see:
Loaded page
Array(1) [ Document ]
Our document loader retrieved the content of the webpage, put that content in a document object and loaded it into an array.
This is great, but there’s one more improvement we can make to this code before we move on – splitting our text into multiple documents.
Many language models have limits on the amount of text you can pass to them. As well, some LLM APIs charge based on the amount of text you send in your request. For both of these reasons, it’s helpful to only pass the text you need in a request to a language model.
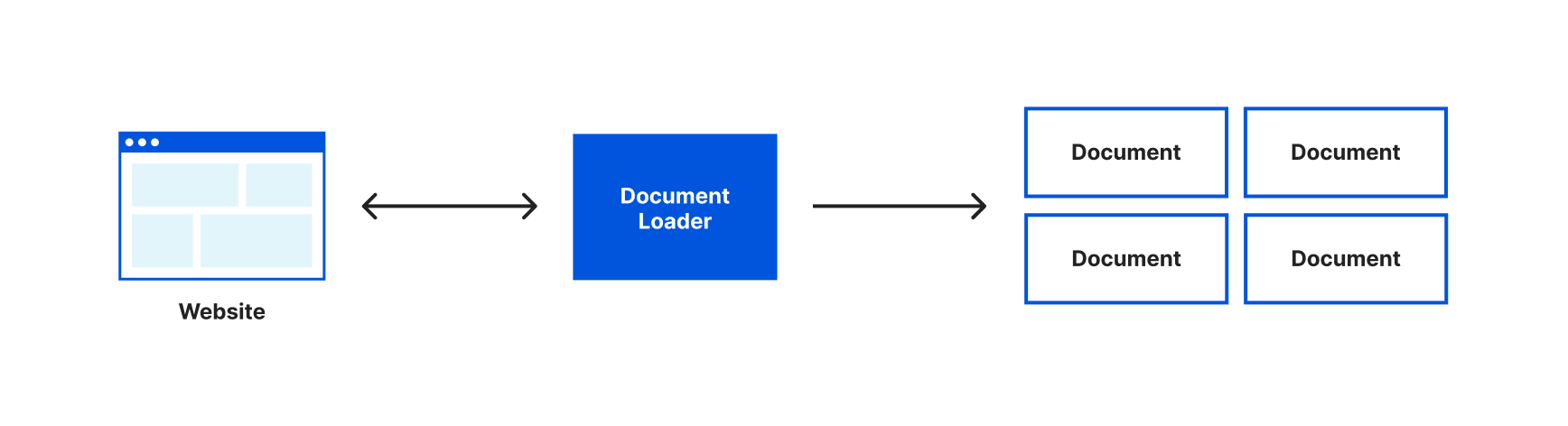
Currently, we’ve loaded the entire content of the Wikipedia page about Brooklyn into one document object and would send the entirety of that text with every request to our language model. It would be more efficient if we could only send the relevant text to our language model when we have a question. The first step in doing this is to split our text into smaller chunks that are stored in multiple document objects. To assist with this LangChain gives us the very aptly named Text Splitters.
We can use a text splitter by updating our loader to use the loadAndSplit() function instead of load(). Update the line where we assign docs to this:
const docs = await loader.loadAndSplit();
Now start the application again with wrangler dev and load our page. This time in our console you’ll see something like this:
Instead of an array with one document object, our document loader has now split the text it retrieved into multiple document objects. It’s still a single Wikipedia article, LangChain just split that text into chunks that would be more appropriately sized for working with a language model.
Even though our text is split into multiple documents, we still need to be able to understand what text is relevant to our question and should be sent to our language model. To do this, we’re going to introduce two new concepts – embeddings and vector stores.
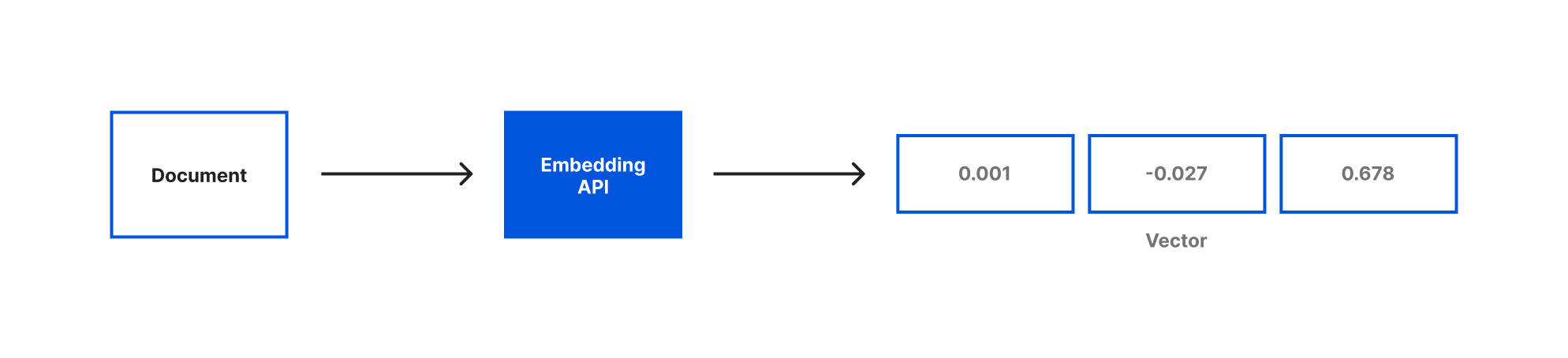
Embeddings are a way of representing text with numerical data. For our application we’ll be using OpenAI Embeddings to generate our embeddings based on the document objects we just created. When you generate embeddings the result is a vector of floating point numbers. This makes it easier for computers to understand the relatedness of the strings of text to each other. For each document object we pass the embedding API, a vector will be created.
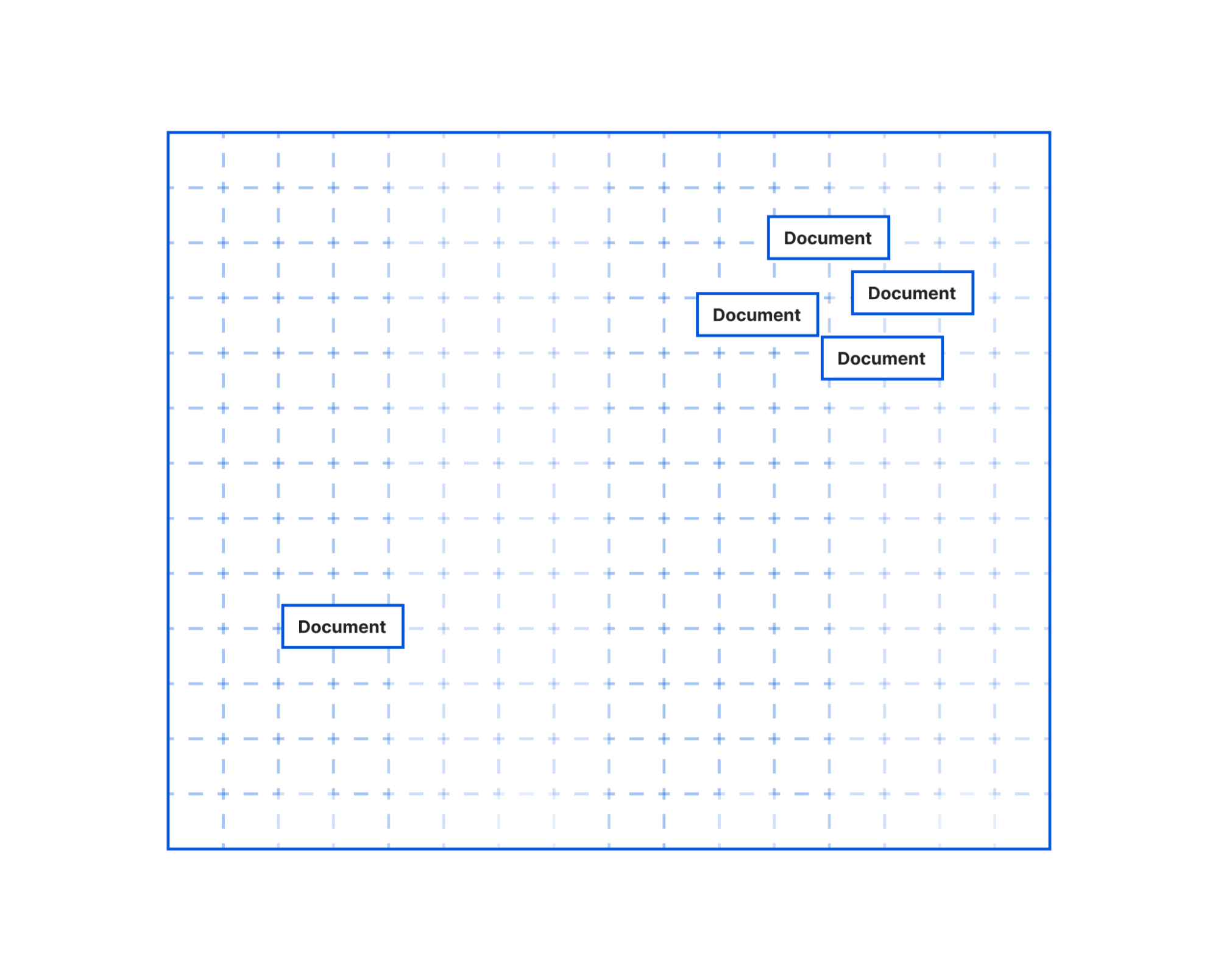
When we compare vectors, the closer numbers are to each other the more related the strings are. Inversely, the further apart the numbers are then the less related the strings are. It can be helpful to visualize how these numbers would allow us to place each document in a virtual space:
In this illustration, you could imagine how the text in the document objects that are bunched together would be more similar than the document object further off. The grouped documents could be text pulled from the article’s section on the history of Brooklyn. It’s a longer section that would have been split into multiple documents by our text splitter. But even though the text was split the embeddings would allow us to know this content is closely related to each other. Meanwhile, the document further away could be the text on the climate of Brooklyn. This section was smaller, not split into multiple documents, and the current climate is not as related to the history of Brooklyn, so it’s placed further away.
Embeddings are a pretty fascinating and complicated topic. If you’re interested in understanding more, here's a great explainer video that takes an in-depth look at the embeddings.
Once you’ve generated your documents and embeddings, you need to store them someplace for future querying. Vector stores are a kind of database optimized for storing & querying documents and their embeddings. For our vector store, we’ll be using MemoryVectorStore which is an ephemeral in-memory vector store. LangChain also has support for many of your favorite vector databases like Chroma and Pinecone.
We’ll start by adding imports for OpenAIEmbeddings and MemoryVectorStore at the top of our file:
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
Then we can remove the console.log() function we had in place to show how our loader worked and replace them with the code to create our Embeddings and Vector store:
const store = await MemoryVectorStore.fromDocuments(docs, new OpenAIEmbeddings({ openAIApiKey: env.OPENAI_API_KEY}));
With our text loaded into documents, our embeddings created and both stored in a vector store we can now query our text with our language model. To do that we’re going to introduce the last two concepts that are core to building this application – models and chains.
When you see models in LangChain, it’s not about generating or creating models. Instead, LangChain provides a standard interface that lets you access many different language models. In this app, we’ll be using the OpenAI model.
Chains enable you to combine a language model with other sources of information, APIs, or even other language models. In our case, we’ll be using the RetreivalQAChain. This chain retrieves the documents from our vector store related to a question and then uses our model to answer the question using that information.
To start, we’ll add these two imports to the top of our file:
import { OpenAI } from "langchain/llms/openai";
import { RetrievalQAChain } from "langchain/chains";
Then we can put this all into action by adding the following code after we create our vector store:
const model = new OpenAI({ openAIApiKey: env.OPENAI_API_KEY});
const chain = RetrievalQAChain.fromLLM(model, store.asRetriever());
const question = "What is this article about? Can you give me 3 facts about it?";
const res = await chain.call({
query: question,
});
return new Response(res.text);
In this code the first line is where we instantiate our model interface and pass it our API key. Next we create a chain passing it our model and our vector store. As mentioned earlier, we’re using a RetrievalQAChain which will look in our vector store for documents related to our query and then use those documents to get an answer for our query from our model.
With our chain created, we can call the chain by passing in the query we want to ask. Finally, we send the response text we got from our chain as the response to the request our Worker received. This will allow us to see the response in our browser.
With all our code in place, let’s test it again by running wrangler dev. This time when you open your browser you will see a few facts about Brooklyn:
Right now, the question we’re asking is hard coded. Our goal was to be able to use LangChain to ask any question we want about this article. Let’s update our code to allow us to pass the question we want to ask in our request. In this case, we’ll pass a question as an argument in the query string (e.g. ?question=When was Brooklyn founded). To do this we’ll replace the line we’re currently assigning our question with the code needed to pull a question from our query string:
const { searchParams } = new URL(request.url);
const question = searchParams.get('question') ?? "What is this article about? Can you give me 3 facts about it?";
This code pulls all the query parameters from our URL using a JavaScript URL’s native searchParams property, and gets the value passed in for the “question” parameter. If a value isn’t present for the “question” parameter, we’ll use the default question text we were using previously thanks to JavaScripts’s nullish coalescing operator.
With this update, run wrangler dev and this time visit your local url with a question query string added. Now instead of giving us a few fun facts about Brooklyn, we get the answer of when Brooklyn was founded. You can try this with any question you may have about Brooklyn. Or you can switch out the URL in our document loader and try asking similar questions about different Wikipedia articles.
With our code working locally, we can deploy it with wrangler publish. After this command completes you’ll receive a Workers URL that runs your code.
You + LangChain + Cloudflare Workers
You can find our full LangChain example application on GitHub. We can’t wait to see what you all build with LangChain and Cloudflare Workers. Join us on Discord or tag us on Twitter as you’re building. And if you’re ever having any trouble or questions, you can ask on community.cloudflare.com.
I remember when the first iPhone was announced in 2007. This was NOT an iPhone as we think of one today. It had warts. A lot of warts. It couldn’t do MMS for example. But I remember the possibility it brought to mind. No product before had seemed like anything more than a product. The iPhone, or more the potential that the iPhone hinted at, had an actual impact on me. It changed my thinking about what could be.
In the years since no other product came close to matching that level of awe and wonder. That changed in March of this year. The release of GPT-4 had the same impact I remember from the iPhone launch. It’s still early, but it's opened the imagination, and fears, of millions of developers in a way I haven’t seen since that iPhone announcement.
That excitement has led to an explosion of development and hundreds of new tools broadly grouped into a category we call generative AI. Generative AI systems create content mimicking a particular style. New images that look like Banksy or lyrics that sound like Taylor Swift. All of these Generative AI tools, whether built on top of GPT-4 or something else, use the same basic model technique: a transformer.
Attention is all you need
GPT-4 (Generative Pretrained Transformer) is the most advanced version of a transformer model. Transformer models all emerged from a seminal paper written in 2017 by researchers at the University of Toronto and the team at Google Brain, titled Attention is all you need. The key insight from the paper is the self-attention mechanism. This mechanism replaced recurrent and convolutional layers, allowing for faster training and better performance.
The secret power of transformer models is their ability to efficiently process large amounts of data in parallel. It's the transformers' gargantuan scale and extensive training that makes them so appealing and versatile, turning them into the Swiss Army knife of natural language processing. At a high level, Large Language Models (LLMs) are just transformer models that use an incredibly large number of parameters (billions), and are trained on incredibly large amounts of unsupervised text (the Internet). Hence large, and language.
Unleashing the potential of LLMs in consumer-facing AI tools has opened a world of possibilities. But possibility also means new risk: developers must now navigate the unique security challenges that arise from making powerful new tools widely available to the masses.
First and foremost, consumer-facing applications inherently expose the underlying AI systems to millions of users, vastly increasing the potential attack surface. Since developers are targeting a consumer audience, they can't rely on trusted customers or limit access based on geographic location. Any security measure that makes it too difficult for consumers to use defeats the purpose of the application. Consequently, developers must strike a delicate balance between security and usability, which can be challenging.
The current popularity of AI tools makes explosive takeoff more likely than in the past. This is great! Explosive takeoff is what you want! But, that explosion can also lead to exponential growth in costs, as the computational requirements for serving a rapidly growing user base can become overwhelming.
In addition to being popular, Generative AI apps are unique in that calls to them are incredibly resource intensive, and therefore expensive for the owner. In comparison, think about a more traditional API that Cloudflare has protected for years. A product API. Sites don’t want competitors calling their product API and scraping data. This has an obvious negative business impact. However, it doesn’t have a direct infrastructure cost. A product list API returns a small amount of text. An attacker calling it 4 million times will have a negligible cost to an infrastructure bill. But generative models can cost cents, or in the case of image generation even tens of cents per call. An attacker gaining access and generating millions of calls has a real cost impact to the developers providing those APIs.
Not only are the costs for generating content high, but the value that end users are willing to pay is high as well. Customers tell us that they have seen multiple instances of bad actors accessing an API without paying, then reselling the content they generate for 50 cents or more per call. The huge monetary opportunity of exploitation means attackers are highly motivated to come back again and again, refactoring their approach each time.
Last, consumer-facing LLM applications are generally designed as a single entry point for customers, almost always accepting query text as input. The open-text nature of these calls makes it difficult to predict the potential impact of a single request. For example, a complex query might consume significant resources or trigger unexpected behavior. While these APIs are not GraphQL based, the challenges are similar. When you accept unstructured submissions, it's harder to create any type of rule to prevent abuse.
Tips for protecting your Generative AI application
So you've built the latest generative AI sensation, and the world is about to be taken by storm. But that success is also about to make you a target. What's the trick to stopping all those attacks you’re about to see? Well, unfortunately there isn’t one. For all the reasons above, this is a hard, persistent problem with no simple solution. But, we’ve been fortunate to work with many customers who have had that target on their back for months, and we’ve learned a lot from that experience. Here are some recommendations that will give you a good foundation for making sure that you, and only you, reap the rewards of your hard work.
1. Enforce tokens for each user. Enforcing usage based on a specific user or user session is straightforward. But sometimes you want to allow anonymous usage. While anonymous usage is great for demos and testing, it can lead to abuse. If you must allow anonymous usage, create a “stickier” identification scheme that persists browser restarts and incognito mode. Your goal isn’t to track specific users, but instead to understand how much an anonymous user has already used your service so far in demo / free mode.
2. Manage quotas carefully. Your service likely incurs costs and charges users per API call, so it likely makes sense to set a limit on the number of times any user can call your API. You may not ever intend for the average user to hit this limit, but having limits in place will protect against that user’s API key becoming compromised and shared amongst many users. It also protects against programming errors that could result in 100x or 1000x expected usage, and a large unexpected bill to the end user.
3. Block certain ASNs (autonomous system numbers) wholesale. Blocking ASNs, or even IPs wholesale is an incredibly blunt tool. In general Cloudflare rarely recommends this approach to customers. However, when tools are as popular as some generative AI applications, attackers are highly motivated to send as much traffic as possible to those applications. The fastest and cheapest way to accomplish this is through data centers that usually share a common ASN. Some ASNs belong to ISPs, and source traffic from people browsing the Internet. But other ASNs belong to cloud compute providers, and mainly source outbound traffic from virtual servers. Traffic from these servers can be overwhelmingly malicious. For example, several of our customers have found ASNs where 88-90% of the traffic turns out to be automated, while this number is usually only 30% for average traffic. In cases this extreme, blocking entire ASNs can make sense.
4. Implement smart rate limits. Counting not only requests per minute and requests per session, but also IPs per token and tokens per IP can guard against abuse. Tracking how many different IPs are using a particular token at any one time can alert you to a user's token being leaked. Similarly, if one IP is rotating through tokens, looking at each token’s session traffic would not alert you to the abuse. You’d need to look at how many tokens that single IP is generating in order to pinpoint that specific abusive behavior.
5. Rate limit on something other than the user. Similar to enforcing tokens on each user, your real time rate limits should also be set on your sticky identifier.
6. Have an option to slow down attackers. Customers often think about stopping abuse in terms of blocking traffic from abusers. But blocking isn’t the only option. Attacks not only need to be successful, they also need to be economically feasible. If you can make requests more difficult or time-consuming for abusers, you can ruin their economics. You can do this by implementing a waiting room, or by challenging users. We recommend a challenge option that doesn’t give real users an awful experience. Challenging users can also be quickly enabled or disabled as you see abuse spike or recede.
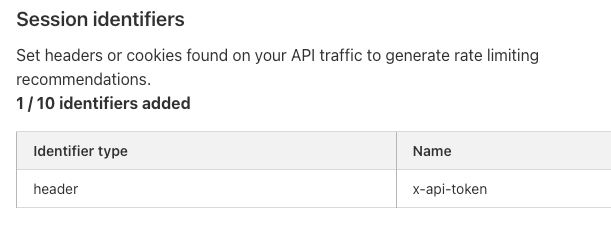
7. Map and analyze sequences. By sampling user sessions that you suspect of abuse, you can inspect their requests path-by-path in your SIEM. Are they using your app as expected? Or are they circumventing intended usage? You might benefit from enforcing a user flow between endpoints.
8. Build and validate an API schema. Many API breaches happen due to permissive schemas. Users are allowed to send in extra fields in requests that grant them too many privileges or allow access to other users’ data. Make sure you build a verbose schema that outlines what intended usage is by identifying and cataloging all API endpoints, then making sure all specific parameters are listed as required and have type limits to them.
We recently went through the transition to an OpenAPI schema ourselves for api.cloudflare.com. You can read more about how we did it here. Our schema looks like this:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
9. Analyze the depth and complexity of queries. Are your APIs driven by GraphQL? GraphQL queries can be a source of abuse since they allow such free-form requests. Large, complex queries can grow to overwhelm origins if limits aren’t in place. Limits help guard against outright DoS attacks as well as developer error, keeping your origin healthy and serving requests to your users as expected.
For example, if you have statistics about your GraphQL queries by depth and query size, you could execute this TypeScript function to analyze them by quantile:
import * as ss from 'simple-statistics';
function calculateQuantiles(data: number[], quantiles: number[]): {[key: number]: string} {
let result: {[key: number]: string} = {};
for (let q of quantiles) {
// Calculate quantile, convert to fixed-point notation with 2 decimal places
result[q] = ss.quantile(data, q).toFixed(2);
}
return result;
}
// Example usage:
let queryDepths = [2, 2, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 1, 1, 1, 1, 1, 1, 1, 1];
let querySizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2];
console.log(calculateQuantiles(queryDepths, [0.5, 0.75, 0.95, 0.99]));
console.log(calculateQuantiles(querySizes, [0.5, 0.75, 0.95, 0.99]));
The results give you a sense for the depth of the average query hitting your endpoint, grouped by quantile:
Actual data from your production environment would provide a threshold to start an investigation into which queries to further log or limit. A simpler option is to use a query analysis tool, like Cloudflare’s, to make the process automatic.
10. Use short-lived access tokens and long-lived refresh tokens upon successful authentication of your users. Implement token validation in a middleware layer or API Gateway, and be sure to have a dedicated token renewal endpoint in your API. JSON Web Tokens (JWTs) are popular choices for these short-lived tokens. When access tokens expire, allow users to obtain new ones using their refresh tokens. Revoke refresh tokens when necessary to maintain system security. Adopting this approach enhances your API's security and user experience by effectively managing access and mitigating the risks associated with compromised tokens.
11. Communicate directly with your users. All of the above recommendations are going to make it a bit more cumbersome for some of your customers to use your product. You are going to get complaints. You can reduce these by first, giving clear communication to your users explaining why you put these measures in place. Write a blog about what security measures you did and did not decide to implement and have dev docs explaining troubleshooting steps to resolve. Second, give your users concrete steps they can take if they are having trouble, and a clear way to contact you directly. Feeling inconvenienced can be frustrating, but feeling stuck can lose you a customer.
Conclusion: this is the beginning
Generative AI, like the first iPhone, has sparked a surge of excitement and innovation. But that excitement also brings risk, and innovation brings new security holes and attack vectors. The broadness and uniqueness of generative AI applications in particular make securing them particularly challenging. But as every scout knows, being prepared ahead of time means less stress and worry during the journey. Implementing the tips we've shared can establish a solid foundation that will let you sit back and enjoy the thrill of building something special, rather than worrying what might be lurking around the corner.
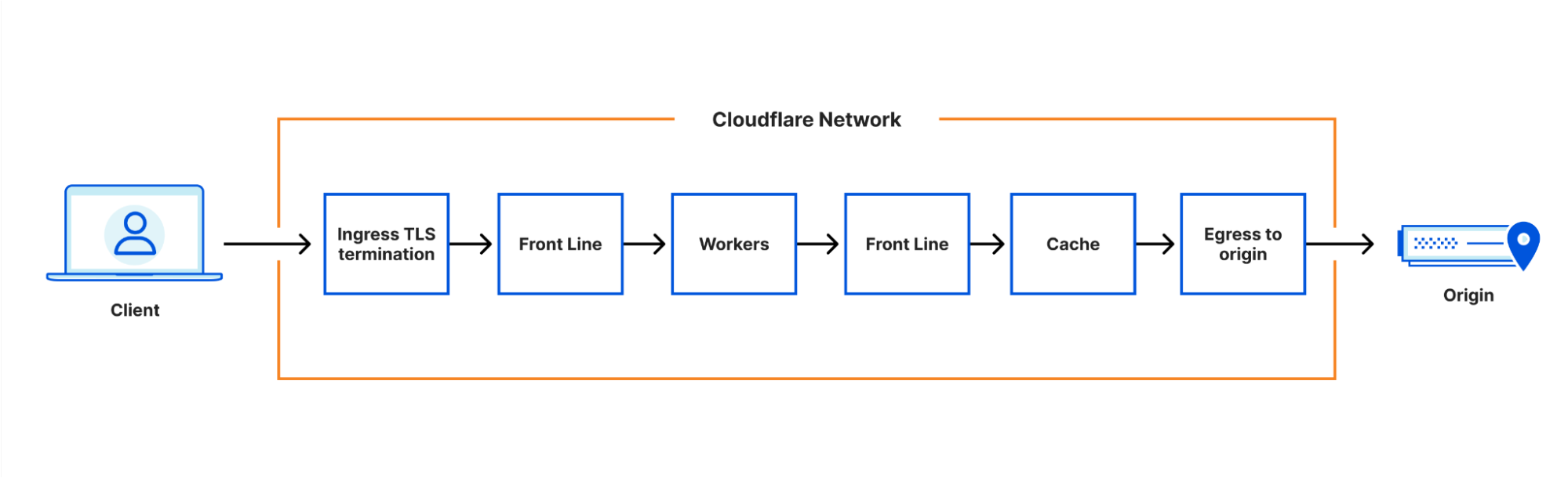
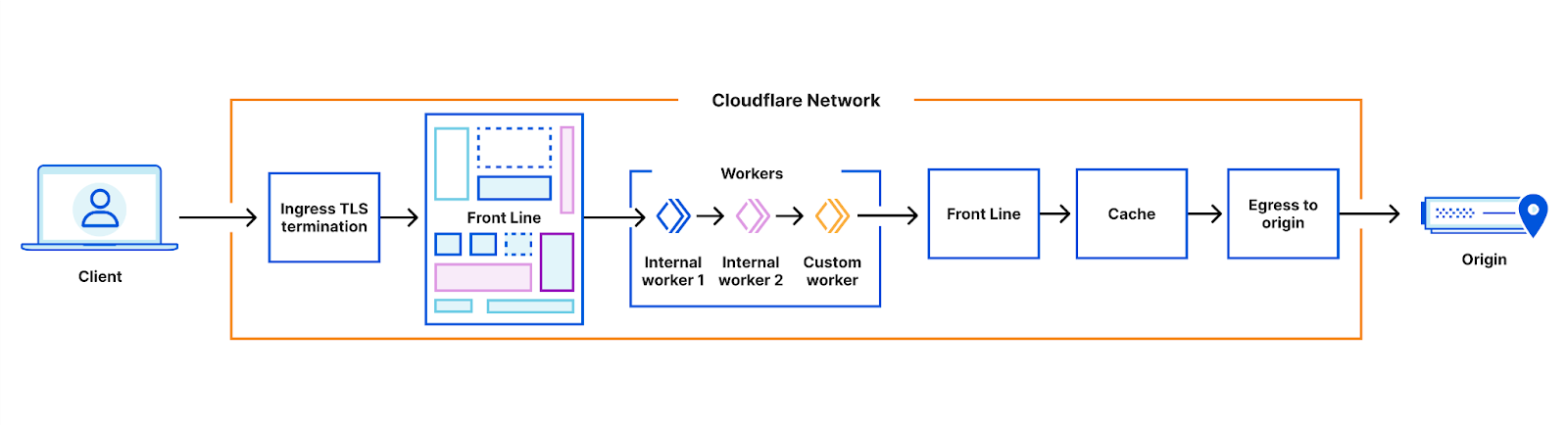
Cloudflare’s website, application security and performance products handle upwards of 46 million HTTP requests per second, every second. These products were originally built as a set of native Linux services, but we’re increasingly building parts of the system using our Cloudflare Workers developer platform to make these products faster, more robust, and easier to develop. This blog post digs into how and why we’re doing this.
System architecture
Our architecture can best be thought of as a chain of proxies, each communicating over HTTP. At first, these proxies were all implemented based on NGINX and Lua, but in recent years many of them have been replaced – often by new services built in Rust, such as Pingora.
The proxies each have distinct purposes – some obvious, some less so. One which we’ll be discussing in more detail is the FL service, which performs “Front Line” processing of requests, applying customer configuration to decide how to handle and route the request.
This architecture has worked well for more than a decade. It allows parts of the system to be developed and deployed independently, parts of the system to be scaled independently, and traffic to be routed to different nodes in our systems according to load, or to ensure efficient cache utilization.
So, why change it?
At the level of latency we care about, service boundaries aren’t cheap, particularly when communicating over HTTP. Each step in the chain adds latency due to communication overheads, so we can’t add more services as we develop new products. And we have a lot of products, with many more on the way.
To avoid this overhead, we put most of the logic for many different products into FL. We’ve developed a simple modular architecture in this service, allowing teams to make and deploy changes with some level of isolation. This has become a very complex service which takes a constant effort by a team of skilled engineers to maintain and operate.
Even with this effort, the developer experience for Cloudflare engineers has often been much harder than we would like. We need to be able to start working on implementing any change quickly, but even getting a version of the system running in a local development environment is hard, requiring installation of custom tooling and Linux kernels.
The structure of the code limits the ease of making changes. While some changes are easy to make, other things run into surprising limits due to the underlying platform. For example, it is not possible to perform I/O in many parts of the code which handle HTTP response processing, leading to complex workarounds to preload resources in case they are needed.
Deploying updates to the software is high risk, so is done slowly and with care. Massive improvements have been made in the past years to our processes here, but it’s not uncommon to have to wait a week to see changes reach production, and changes tend to be deployed in large batches, making it hard to isolate the effect of each change in a release.
Finally, the code has a modular structure, but once in production there is limited isolation and sandboxing, so tracing potential side effects is hard, and debugging often requires knowledge of the whole system, which takes years of experience to obtain.
Developer platform to the rescue
As soon as Cloudflare workers became part of our stack in 2017, we started looking at ways to use them to improve our ability to build new products. Now, in 2023, many of our products are built in part using workers and the wider developer platform; for example, read this post from the Waiting Room team about how they use Workers and Durable Objects, or this post about our cache purge system doing the same. Products like Cloudflare Zero Trust, R2, KV, Turnstile, Queues, and Exposed credentials check are built using Workers at large scale, handling every request processed by the products. We also use Workers for many of our pieces of internal tooling, from dashboards to building chatbots.
While we can and do spend time improving the tooling and architecture of all our systems, the developer platform is focussed all the time on making developers productive, and being as easy to use as possible. Many of the other posts this week on this blog talk about our work here. On the developer platform, any customer can get something running in minutes, and build and deploy full complex systems within days.
We have been working to give developers working on internal Cloudflare products the same benefits.
Customer workers vs internal workers
At this point, we need to talk about two different types of worker.
The first type is created when a customer writes a Cloudflare Worker. The code is deployed to our network, and will run whenever a request to the customer’s site matches the worker’s route. Many Cloudflare engineering teams use workers just like this to build parts of our product – for example, we wrote about our Coreless Purge system for Cache recently. In these cases, our engineering teams are using exactly the same process and tooling as any Cloudflare customer would use.
However, we also have another type of worker, which can only be deployed by Cloudflare. These are not associated with a single customer. Instead, they are run for all customers for which a particular product or other piece of logic needs to be performed.
For the rest of this post, we’re only going to be talking about these internal workers. The underlying tech is the same – the difference to remember is that these workers run in response to requests from many Cloudflare customers rather than one.
Initial integration of internal workers
We first integrated internal workers into our architecture in 2019, in a very simple way. An ordered chain of internal workers was created, which run before any customer scripts.
I previously said that adding more steps in our chain would cause excessive latency. So why isn’t this a problem for internal workers?
The answer is that these internal workers run within the same service as each other, and as customer workers which are operating on the request. So, there’s no need to marshal the request into HTTP to pass it on to the next step in the chain; the runtime just needs to pass a memory reference around, and perform a lightweight shift of control. There is still a cost of adding more steps – but the cost per step is much lower.
The integration gave us several benefits immediately. We were able to take advantage of the strong sandbox model for workers, removing any risk of unexpected side effects between customers or requests. It also allowed isolated deployments – teams could deploy their updates on their own schedule, without waiting for or disrupting other teams.
However, it also had a number of limitations. Internal workers could only run in one place in the lifetime of a request. This meant they couldn’t affect services running before them, such as the Cloudflare WAF.
Also, for security reasons, internal workers were published with an internal API using special credentials, rather than the public workers API. In 2019, this was no big deal, but since then there has been a ton of work to improve tooling such as wrangler, and build the developer platform. All of this tooling was unavailable for internal workers.
We had very limited observability of internal workers, lacking metrics and detailed logs, making them hard to debug.
We realized that we could do a lot more with the platform to improve our development processes. We also wondered how far it would be possible to go with the platform. Would it be possible to migrate all the logic implemented in the NGINX-based FL service to the developer platform? And if not, why not?
So we started, in late 2021, with a prototype. This routed traffic directly from our TLS ingress service to our workers runtime, skipping the FL service. We named this prototype Flame.
It worked. Just about. Most importantly for a prototype, we could see that we were missing some fundamental capabilities. We couldn’t access other Cloudflare internal services, such as our DNS infrastructure or our customer configuration database, and we couldn’t emit request logs to our data pipeline, for analytics and billing purposes.
We rely heavily on caching for performance, and there was no way to cache state between requests. We also couldn’t emit HTTP requests directly to customer origins, or to our cache, without using our full existing chain-of-proxies pipeline.
Also, the developer experience for this prototype was very poor. We couldn’t take advantage of all the developer experience work being put into wrangler, due to the need to use special APIs to deploy internal workers. We couldn’t record metrics and traces to our standard observability tooling systems, so we were blind to the behavior of the system in production. And we had no way to perform a controlled and gradual deployment of updated code.
Improving the developer platform for internal services
We set out to address these problems one by one. Wherever possible, we wanted to use the same tooling for internal purposes as we provide to customers. This not only reduces the amount of tooling we need to support, but also means that we understand the problems our customers face better, and can improve their experience as well as ours.
Tooling and routing
We started with the basics – how can we deploy code for internal services to the developer platform.
I mentioned earlier that we used special internal APIs for deploying our internal workers, for “security reasons”. We reviewed this with our security team, and found that we had good protections on our API to identify who was publishing a worker. The main thing we needed to add was a secure registry of accounts which were allowed to use privileged resources. Initially we did this by hard-coding a set of permissions into our API service – later this was replaced by a more flexible permissions control plane.
Even more importantly, there is a strong distinction between publishing a worker and deploying a worker.
Publishing is the process of pushing the worker to our configuration store, so that the code to be run can be loaded when it is needed. Internally, each worker version which is published creates a new artifact in our store.
The Workers runtime uses a capability-based security model. When it is published, each script is bundled together with a list of bindings, representing the capabilities that the script has to access other resources. This mechanism is a key part of providing safety – in order to be able to access resources, the script must have been published by an account with the permissions to provide the capabilities. The secure management of bindings to internal resources is a key part of our ability to use the developer platform for internal systems.
Deploying is the process of hooking up the worker to be triggered when a request comes in. For a customer worker, deployment means attaching the worker to a route. For our internal workers, deployment means updating a global configuration store with the details of the specific artifact to run.
After some work, we were finally able to use wrangler to build and publish internal services. But there was a problem! In order to deploy an internal worker, we needed to know the identifier for the artifact which was published. Fortunately, this was a simple change: we updated wrangler to output debug information which contained this information.
A big benefit of using wrangler is that we could make tools like “wrangler test” and “wrangler dev” work. An engineer can check out the code, and get going developing their feature with well-supported tooling, and within a realistic environment.
Event logging
We run a comprehensive data pipeline, providing streams of data for our customers to allow them to see what is happening on their sites, for our operations teams to understand how our system is behaving in production, and for us to provide services like DoS protection and accurate billing.
This pipeline starts from our network as messages in Cap’n Proto format. So we needed to build a new way to push pieces of log data to our internal pipeline, from inside a worker. The pipeline starts with a service called “logfwdr”, so we added a new binding which allowed us to push an arbitrary log message to the logfwdr service. This work was later a foundation of the Workers Analytics Engine bindings, which allow customers to use the same structured logging capabilities.
Observability
Observability is the ability to see how code is behaving. If you don’t have good observability tooling, you spend most of your time guessing. It’s inefficient and frankly unsafe to operate such a system.
At Cloudflare, we have very many systems for observability, but three of the most important are:
Unstructured logs (“syslogs”). These are ingested to systems such as Kibana, which allow searching and visualizing the logs.
Metrics. Also emitted from all our systems, these are a set of numbers representing things like “CPU usage” or “requests handled”, and are ingested to a massive Prometheus system. These are used for understanding the overall behavior of our systems, and for alerting us when unexpected or undesirable changes happen.
Traces. We use systems based around Open Telemetry to record detailed traces of the interactions of the components of our system. This lets us understand which information is being passed between each service, and the time being spent in each service.
Initial support for syslogs, metrics and traces for internal workers was built by our observability team, who provided a set of endpoints to which workers could push information. We wrapped this in a simple library, called “flame-common”, so that emitting observability events could be done without needing to think about the mechanics behind it.
Our initial wrapper looked something like this:
import { ObservabilityContext } from "flame-common";
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext
): Promise<Response> {
const obs = new ObservabilityContext(request, env, ctx);
// Logging to syslog and kibana
obs.logInfo("some information")
obs.logError("an error occurred")
// Metrics to Prometheus
obs.counter("rps", "how many requests per second my service is doing")?.inc();
// Tracing
obs.startSpan("my code");
obs.addAttribute("key", 42);
},
};
An awkward part of this API was the need to pass the “ObservabilityContext” around to be able to emit events. Resolving this was one of the reasons that we recently added support for AsyncLocalStorage to the Workers runtime.
While our current observability system works, the internal implementation isn’t as efficient as we would like. So, we’re also working on adding native support for emitting events, metrics and traces from the Workers runtime. As we did with the Workers Analytics Engine, we want to find a way to do this which can be hooked up to our internal systems, but which can also be used by customers to add better observability to their workers.
Accessing internal resources
One of our most important internal services is our configuration store, Quicksilver. To be able to move more logic into the developer platform, we need to be able to access this configuration store from inside internal workers. We also need to be able to access a number of other internal services – such as our DNS system, and our DoS protection systems.
Our systems use Cap’n Proto in many places as a serialization and communication mechanism, so it was natural to add support for Cap’n Proto RPC to our Workers runtime. The systems which we need to talk to are mostly implemented in Go or Rust, which have good client support for this protocol.
We therefore added support for making connections to internal services over Cap’n Proto RPC to our Workers runtime. Each service will listen for connections from the runtime, and publish a schema to be used to communicate with it. The Workers runtime manages the conversion of data from JavaScript to Cap’n Proto, according to a schema which is bundled together with the worker at publication time. This makes the code for talking to an internal service, in this case our DNS service being used to identify the account owning a particular hostname, as simple as:
let ownershipInterface = env.RRDNS.getCapability();
let query = {
request: {
queryName: url.hostname,
connectViaAddr: control_header.connect_via_addr,
},
};
let response = await ownershipInterface.lookupOwnership(query);
Caching
Computers run on cache, and our services are no exception. Looking at the previous example, if we have 10,000 requests coming in quick succession for the same hostname, we don’t want to look up the hostname in our DNS system for each one. We want to cache the lookups.
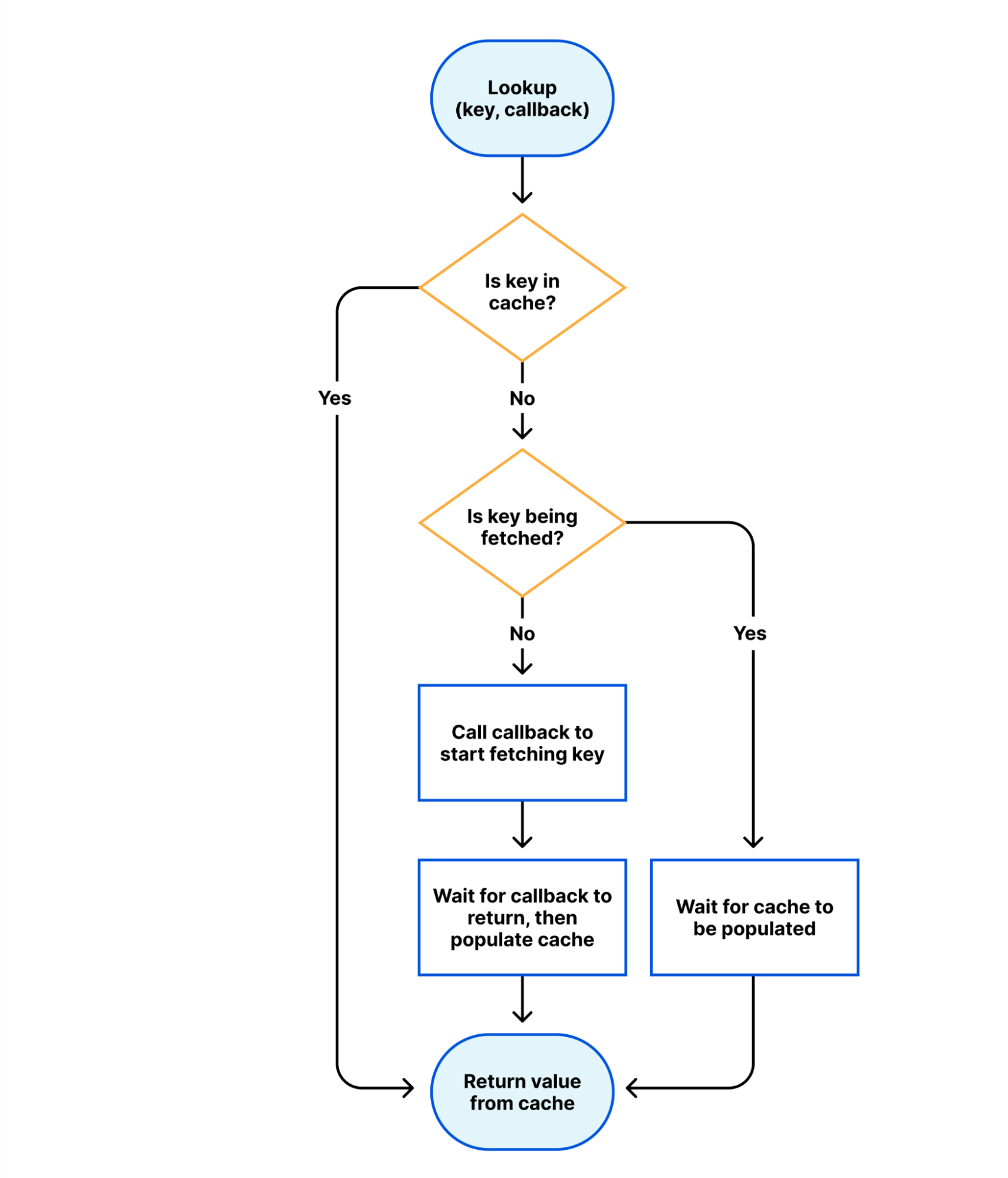
At first sight, this is incompatible with the design of workers, where we give no guarantees of state being preserved between requests. However, we have added a new internal binding to provide a “volatile in-memory cache”. Wherever it is possible to efficiently share this cache between workers, we will do so.
The following flowchart describes the semantics of this cache.
To use the cache, we simply need to wrap a block of code in a call to the cache:
const owner = await env.OWNERSHIPCACHE.read<OwnershipData>(
key,
async (key) => {
let ownershipInterface = env.RRDNS.getCapability();
let query = {
request: {
queryName: url.hostname,
connectViaAddr: control_header.connect_via_addr,
},
};
let response = await ownershipInterface.lookupOwnership(query);
const value = response.response;
const expiration = new Date(Date.now() + 30_000);
return { value, expiration };
}
);
This cache drastically reduces the number of calls needed to fetch external resources. We are likely to improve it further, by adding support for refreshing in the background to reduce P99 latency, and improving observability of its usage and hit rates.
Direct egress from workers
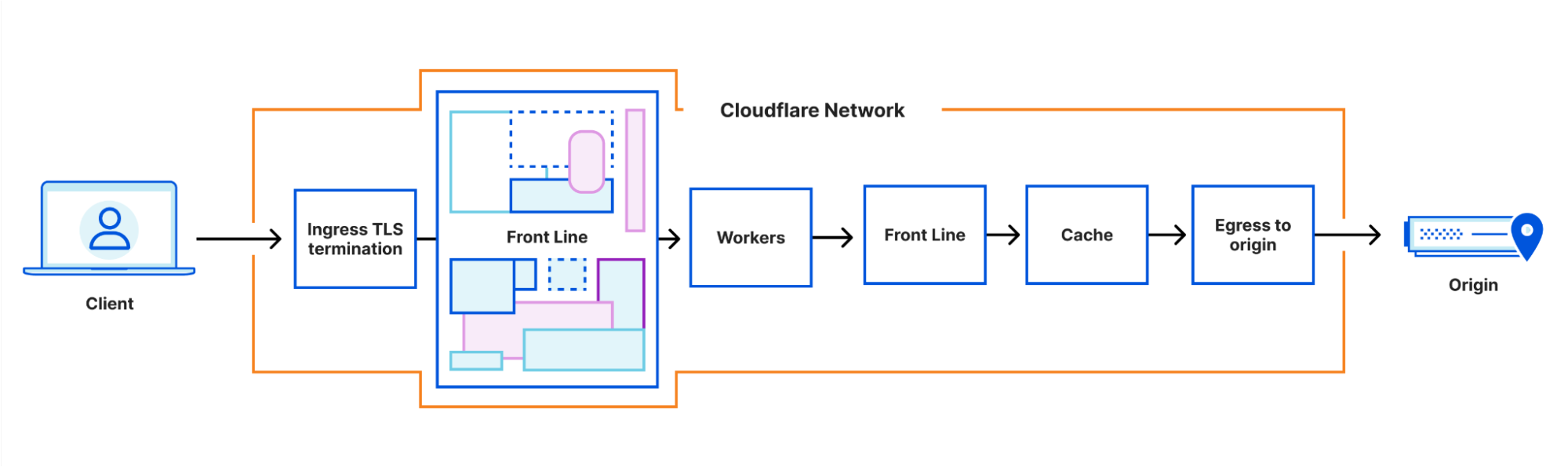
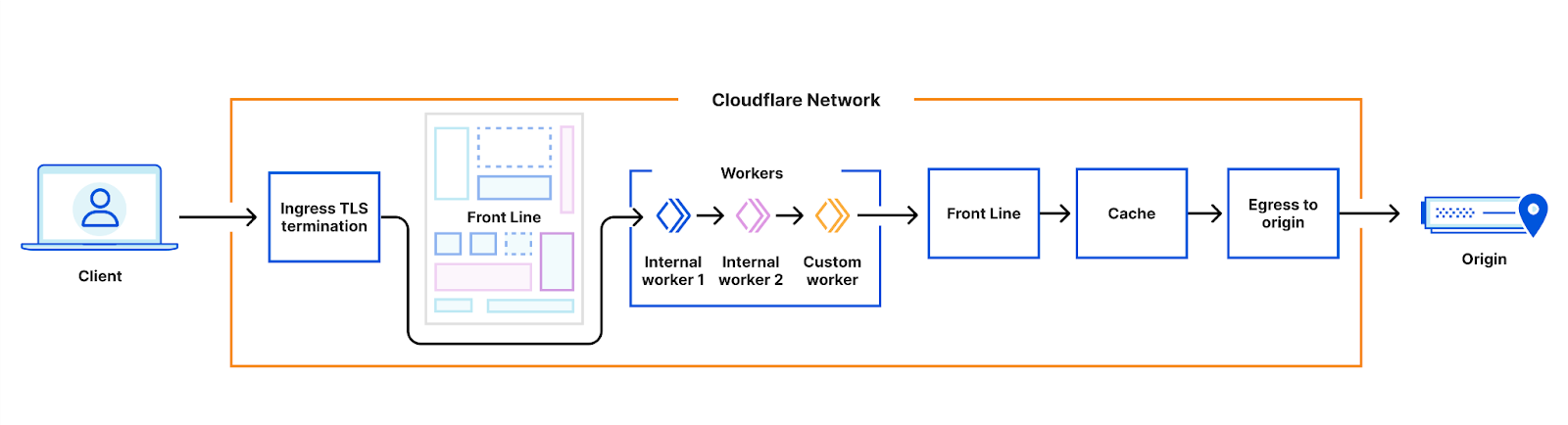
If you looked at the architecture diagrams above closely, you might have noticed that the next step after the Workers runtime is always FL. Historically, the runtime only communicated with the FL service – allowing some product logic which was implemented in FL to be performed after workers had processed the requests.
However, in many cases this added unnecessary overhead; no logic actually needs to be performed in this step. So, we’ve added the ability for our internal workers to control how egress of requests works. In some cases, egress will go directly to our cache systems. In others, it will go directly to the Internet.
Gradual deployment
As mentioned before, one of the critical requirements is that we can deploy changes to our code in a gradual and controlled manner. In the rare event that something goes wrong, we need to make sure that it is detected as soon as possible, rather than triggering an issue across our entire network.
Teams using internal workers have built a number of different systems to address this issue, but they are all somewhat hard to use, with manual steps involving copying identifiers around, and triggering advancement at the right times. Manual effort like this is inefficient – we want developers to be thinking at a higher level of abstraction, not worrying about copying and pasting version numbers between systems.
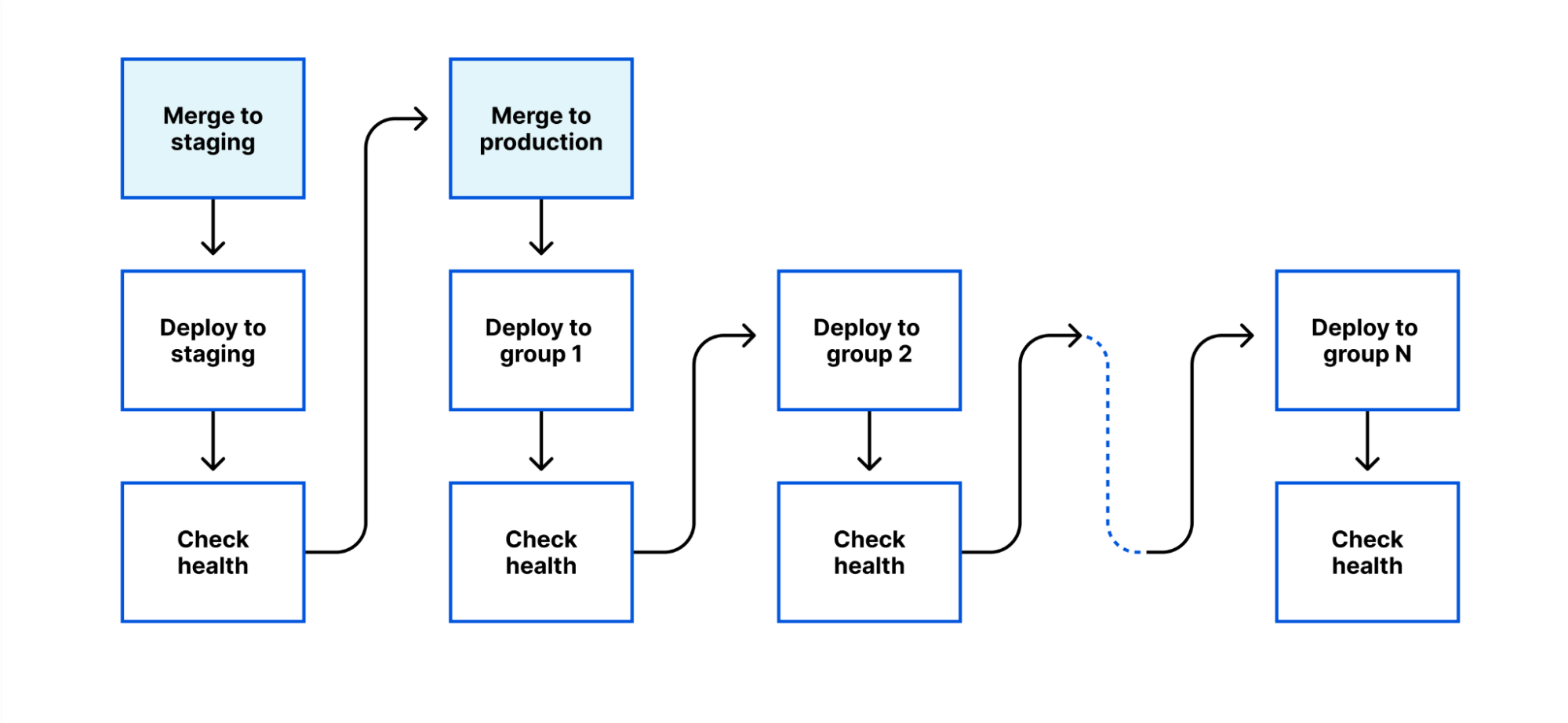
We’ve therefore built a new deployment system for internal workers, based around a few principles:
Control deployments through git. A deployment to an internal-only environment would be triggered by a merge to a staging branch (with appropriate reviews). A deployment to production would be triggered by a merge to a production branch.
Progressive deployment. A deployment starts with the lowest impact system (ideally, a pre-production system which mirrors production, but has no customer impact if it breaks). It then progresses through multiple stages, each one with a greater level of impact, until the release is completed.
Health-mediated advancement. Between each stage, a set of end-to-end tests is performed, metrics are reviewed, and a minimum time must elapse. If any of these fail, the deployment is paused, or reverted; and this happens automatically, without waiting for a human to respond.
This system allows developers to focus on the behavior of their system, rather than the mechanics of a deployment.
There are still plenty of plans for further improvement to many of these systems – but they’re running now in production for many of our internal workers.
Moving from prototype to production
Our initial prototype has done its job: it’s shown us what capabilities we needed to add to our developer platform to be able to build more of our internal systems on it. We’ve added a large set of capabilities for internal service development to the developer platform, and are using them in production today for relatively small components of the system. We also know that if we were about to build our application security and performance products from scratch today, we could build them on the platform.
But there’s a world of difference between having a platform that is capable of running our internal systems, and migrating existing systems over to it. We’re at a very early stage of migration; we have real traffic running on the new platform, and expect to migrate more pieces of logic, and some full production sites, to run without depending on the FL service within the next few months.
We’re also still working out what the right module structure for our system is. As discussed, the platform allows us to split our logic into many separate workers, which communicate efficiently, internally. We need to work out what the right level of subdivision is to match our development processes, to keep our code understandable and maintainable, while maintaining efficiency and throughput.
What’s next?
We have a lot more exploration and work to do. Anyone who has worked on a large legacy system knows that it is easy to believe that rewriting the system from scratch would allow you to fix all its problems. And anyone who has actually done this knows that such a project is doomed to be many times harder than you expect – and risks recreating all the problems that the old architecture fixed long ago.
Any rewrite or migration we perform will need to give us a strong benefit, in terms of improved developer experience, reliability and performance.
And it has to be possible to migrate without slowing down the pace at which we develop new products, even for a moment.
In fact, this isn’t even the first time we’ve rewritten our entire technical architecture for this very system. The first version of our performance and security proxy was implemented in PHP. This was retired in 2013 after an effort to rebuild the system from scratch. One interesting aspect of that rewrite is that it was done without stopping. The new system was so much easier to build that the developers working on it were able to catch up with the changes being made in the old system. Once the new system was mostly ready, it started handling requests; and if it found it wasn’t able to handle a request, it fell back to the old system. Eventually, enough logic was implemented that the old system could be turned off, leading to:
Our systems are a lot more complicated than they were in 2013. The approach we’re taking is one of gradual change. We will not rebuild our systems as a new, standalone reimplementation. Instead, we will identify separable parts of our systems, where we can have a concrete benefit in the immediate future, and migrate these to new architectures. We’ll then learn from these experiences, feed them back into improving our platform and tooling, and identify further areas to work on.
Modularity of our code is of key importance; we are designing a system that we expect to be modified by many teams. To control this complexity, we need to introduce strong boundaries between code modules, allowing reasoning about the system to be done at a local level, rather than needing global knowledge.
Part of the answer may lie in producing multiple different systems for different use cases. Part of the strength of the developer platform is that we don’t have to publish a single version of our software – we can have as many as we need, running concurrently on the platform.
The Internet is a wild place, and we see every odd technical behavior you can imagine. There are standards and RFCs which we do our best to follow – but what happens in practice is often undocumented. Whenever we change any edge case behavior of our system, which is sometimes unavoidable with a migration to a new architecture, we risk breaking an assumption that someone has made. This doesn’t mean we can never make such changes – but we do need to be deliberate about it and understand the impact, so that we can minimize disruption.
To help with this, another essential piece of the puzzle is our testing infrastructure. We have many tests that run on our software and network, but we’re building new capabilities to test every edge-case behavior of our system, in production, before and after each change. This will let us experiment with a great deal more confidence, and decide when we migrate pieces of our system to new architectures whether to be “bug-for-bug” compatible, and if not, whether we need to warn anyone about the change. Again – this isn’t the first time we’ve done such a migration: for example, when we rebuilt our DNS pipeline to make it three times faster, we built similar tooling to allow us to see if the new system behaved in any way differently from the earlier system.
The one thing I’m sure of is that some of the things we learn will surprise us and make us change direction. We’ll use this to improve the capabilities and ease of use of the developer platform. In addition, the scale at which we’re running these systems will help to find any previously hidden bottlenecks and scaling issues in the platform. I look forward to talking about our progress, all the improvements we’ve made, and all the surprise lessons we’ve learnt, in future blog posts.
I want to know more
We’ve covered a lot here. But maybe you want to know more, or you want to know how to get access to some of the features we’ve talked about here for your own projects.
If you’re interested in hearing more about this project, or in letting us know about capabilities you want to add to the developer platform, get in touch on Discord.
We launched Workers for Platforms, our Workers offering for SaaS businesses, almost exactly one year ago to the date! We’ve seen a wide array of customers using Workers for Platforms – from e-commerce to CMS, low-code/no-code platforms and also a new wave of AI businesses running tailored inference models for their end customers!
Let’s take a look back and recap why we built Workers for Platforms, show you some of the most interesting problems our customers have been solving and share new features that are now available!
What is Workers for Platforms?
SaaS businesses are all too familiar with the never ending need to keep up with their users' feature requests. Thinking back, the introduction of Workers at Cloudflare was to solve this very pain point. Workers gave our customers the power to program our network to meet their specific requirements!
Need to implement complex load balancing across many origins? Write a Worker. Want a custom set of WAF rules for each region your business operates in? Go crazy, write a Worker.
We heard the same themes coming up with our customers – which is why we partnered with early customers to build Workers for Platforms. We worked with the Shopify Oxygen team early on in their journey to create a built-in hosting platform for Hydrogen, their Remix-based eCommerce framework. Shopify’s Hydrogen/Oxygen combination gives their merchants the flexibility to build out personalized shopping for buyers. It’s an experience that storefront developers can make their own, and it’s powered by Cloudflare Workers behind the scenes. For more details, check out Shopify’s “How we Built Oxygen” blog post.
Oxygen is Shopify's built-in hosting platform for Hydrogen storefronts, designed to provide users with a seamless experience in deploying and managing their ecommerce sites. Our integration with Workers for Platforms has been instrumental to our success in providing fast, globally-available, and secure storefronts for our merchants. The flexibility of Cloudflare's platform has allowed us to build delightful merchant experiences that integrate effortlessly with the best that the Shopify ecosystem has to offer. – Lance Lafontaine, Senior Developer Shopify Oxygen
Another customer that we’ve been working very closely with is Grafbase. Grafbase started out on the Cloudflare for Startups program, building their company from the ground up on Workers. Grafbase gives their customers the ability to deploy serverless GraphQL backends instantly. On top of that, their developers can build custom GraphQL resolvers to program their own business logic right at the edge. Using Workers and Workers for Platforms means that Grafbase can focus their team on building Grafbase, rather than having to focus on building and architecting at the infrastructure layer.
Our mission at Grafbase is to enable developers to deploy globally fast GraphQL APIs without worrying about complex infrastructure. We provide a unified data layer at the edge that accelerates development by providing a single endpoint for all your data sources. We needed a way to deploy serverless GraphQL gateways for our customers with fast performance globally without cold starts. We experimented with container-based workloads and FaaS solutions, but turned our attention to WebAssembly (Wasm) in order to achieve our performance targets. We chose Rust to build the Grafbase platform for its performance, type system, and its Wasm tooling. Cloudflare Workers was a natural fit for us given our decision to go with Wasm. On top of using Workers to build our platform, we also wanted to give customers the control and flexibility to deploy their own logic. Workers for Platforms gave us the ability to deploy customer code written in JavaScript/TypeScript or Wasm straight to the edge. – Fredrik Björk, Founder & CEO at Grafbase
Over the past year, it’s been incredible seeing the velocity that building on Workers allows companies both big and small to move at.
New building blocks
Workers for Platforms uses Dynamic Dispatch to give our customers, like Shopify and Grafbase, the ability to run their own Worker before user code that’s written by Shopify and Grafbase’s developers is executed. With Dynamic Dispatch, Workers for Platforms customers (referred to as platform customers) can authenticate requests, add context to a request or run any custom code before their developer’s Workers (referred to as user Workers) are called.
This is a key building block for Workers for Platforms, but we’ve also heard requests for even more levels of visibility and control from our platform customers. Delivering on this theme, we’re releasing three new highly requested features:
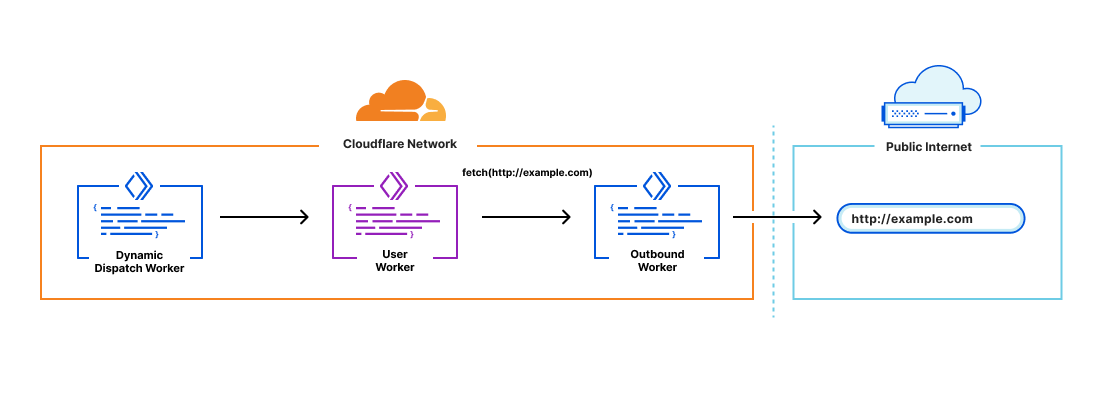
Outbound Workers
Dynamic Dispatch gives platforms visibility into all incoming requests to their user’s Workers, but customers have also asked for visibility into all outgoing requests from their user’s Workers in order to do things like:
Log all subrequests in order to identify malicious hosts or usage patterns
Create allow or block lists for hostnames requested by user Workers
Configure authentication to your APIs behind the scenes (without end developers needing to set credentials)
Outbound Workers sit between user Workers and fetch() requests out to the Internet. User Workers will trigger a FetchEvent on the Outbound Worker and from there platform customers have full visibility over the request before it’s sent out.
It’s also important to have context in the Outbound Worker to answer questions like “which user Worker is this request coming from?”. You can declare variables to pass through to the Outbound Worker in the dispatch namespaces binding:
From there, the variables declared in the binding can be accessed in the Outbound Worker through env. <VAR_NAME>.
Custom Limits
Workers are really powerful, but, as a platform, you may want guardrails around their capabilities to shape your pricing and packaging model. For example, if you run a freemium model on your platform, you may want to set a lower CPU time limit for customers on your free tier.
Custom Limits let you set usage caps for CPU time and number of subrequests on your customer’s Workers. Custom limits are set from within your dynamic dispatch Worker allowing them to be dynamically scripted. They can also be combined to set limits based on script tags.
Here’s an example of a Dynamic Dispatch Worker that puts both Outbound Workers and Custom Limits together:
export default {
async fetch(request, env) {
try {
let workerName = new URL(request.url).host.split('.')[0];
let userWorker = env.dispatcher.get(
workerName,
{},
{// outbound arguments
outbound: {
customer_name: workerName,
url: request.url},
// set limits
limits: {cpuMs: 10, subRequests: 5}
}
);
return await userWorker.fetch(request);
} catch (e) {
if (e.message.startsWith('Worker not found')) {
return new Response('', { status: 404 });
}
return new Response(e.message, { status: 500 });
}
}
};
They’re both incredibly simple to configure, and the best part – the configuration is completely programmatic. You have the flexibility to build on both of these features with your own custom logic!
Tail Workers
Live logging is an essential piece of the developer experience. It allows developers to monitor for errors and troubleshoot in real time. On Workers, giving users real time logs though wrangler tail is a feature that developers love! Now with Tail Workers, platform customers can give their users the same level of visibility to provide a faster debugging experience.
Tail Worker logs contain metadata about the original trigger event (like the incoming URL and status code for fetches), console.log() messages and capture any unhandled exceptions. Tail Workers can be added to the Dynamic Dispatch Worker in order to capture logs from both the Dynamic Dispatch Worker and any User Workers that are called.
A Tail Worker can be configured by adding the following to the wrangler.toml file of the producing script
Tail Workers are full-fledged Workers empowered by the usual Worker ecosystem. You can send events to any HTTP endpoint, like for example a logging service that parses the events and passes on real-time logs to customers.
Try it out!
All three of these features are now in open beta for users with access to Workers for Platforms. For more details and try them out for yourself, check out our developer documentation:
Workers for Platforms is an enterprise only product (for now) but we’ve heard a lot of interest from developers. In the later half of the year, we’ll be bringing Workers for Platforms down to our pay as you go plan! In the meantime, if you’re itching to get started, reach out to us through the Cloudflare Developer Discord (channel name: workers-for-platforms).
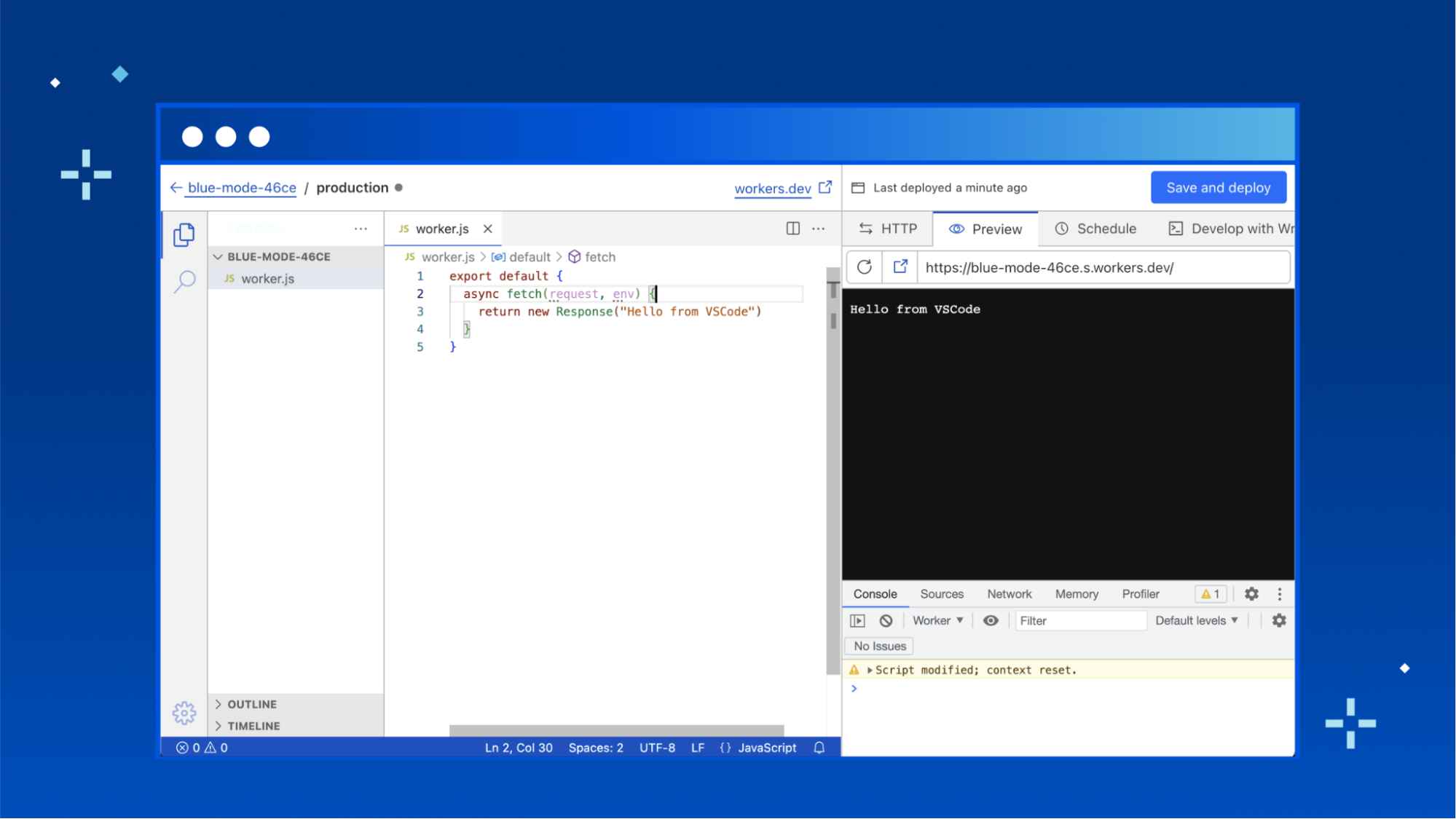
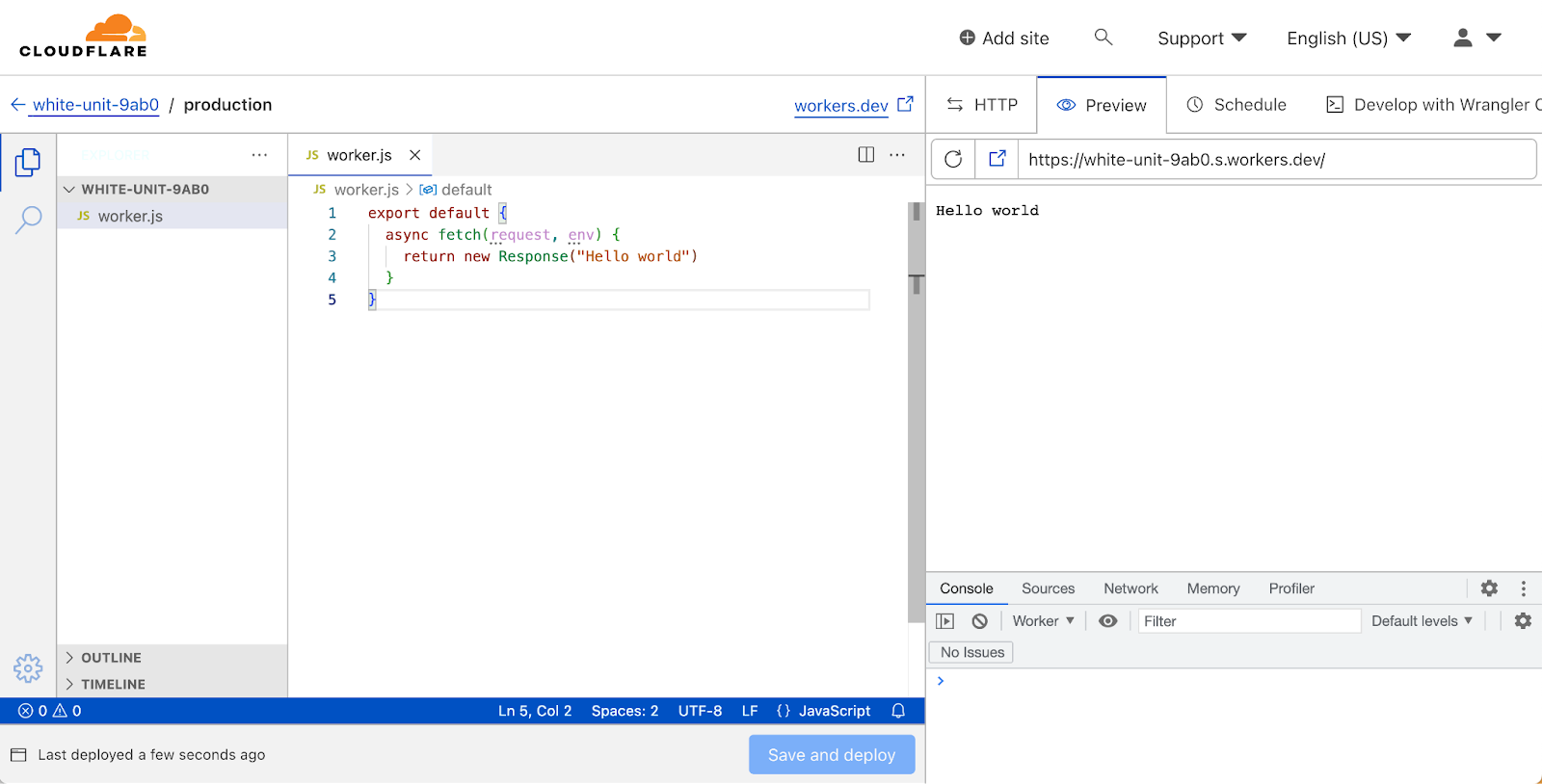
Quick Edit is a development experience for Cloudflare Workers, embedded right within the Cloudflare dashboard. It’s the fastest way to get up and running with a new worker, and lets you quickly preview and deploy changes to your code.
We’ve spent a lot of recent time working on upgrading the local development experience to be as useful as possible, but the Quick Edit experience for editing Workers has stagnated since the release of workers.dev. It’s time to give Quick Edit some love and bring it up to scratch with the expectations of today's developers.
Before diving into what’s changed—a quick overview of the current Quick Edit experience:
We used the robust Monaco editor, which took us pretty far—it’s even what VSCode uses under the hood! However, Monaco is fairly limited in what it can do. Developers are used to the full power of their local development environment, with advanced IntelliSense support and all the power of a full-fledged IDE. Compared to that, a single file text editor is a step-down in expressiveness and functionality.
VSCode for Web
Today, we’re rolling out a new Quick Edit experience for Workers, powered by VSCode for Web. This is a huge upgrade, allowing developers to work in a familiar environment. This isn’t just about familiarity though—using VSCode for Web to power Quick Edit unlocks significant new functionality that was previously only possible with a local development setup using Wrangler.
Support for multiple modules!
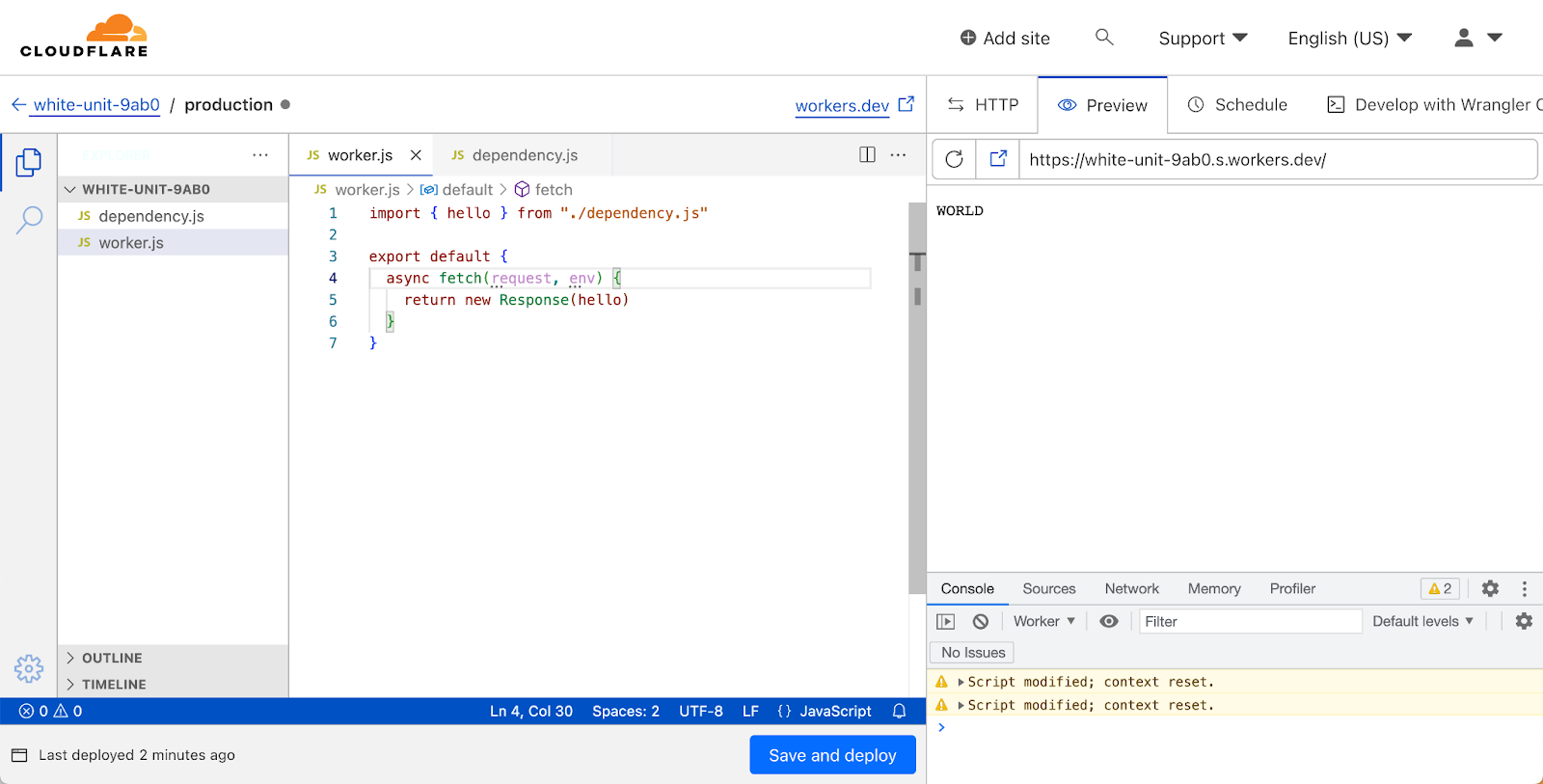
Cloudflare Workers released support for the Modules syntax in 2021, which is the recommended way to write Workers. It leans into modern JavaScript by leveraging the ES Module syntax, and lets you define Workers by exporting a default object containing event handlers.
There are two sides of the coin when it comes to ES Modules though: exports and imports. Until now, if you wanted to organise your worker in multiple modules you had to use Wrangler and a local development setup. Now, you’ll be able to write multiple modules in the dashboard editor, and import them, just as you can locally. We haven’t enabled support for importing modules from npm yet, but that’s something we’re actively exploring—stay tuned!
Edge Preview
When editing a worker in the dashboard, Cloudflare spins up a preview of your worker, deployed from the code you’re currently working on. This helps speed up the feedback loop when developing a worker, and makes it easy to test changes without impacting production traffic (see also, wrangler dev).
However, the in-dashboard preview hasn’t historically been a high-fidelity match for the deployed Workers runtime. There were various differences in behaviour between the dashboard preview environment and a deployed worker, and it was difficult to have full confidence that a worker that worked in the preview would work in the deployed environment.
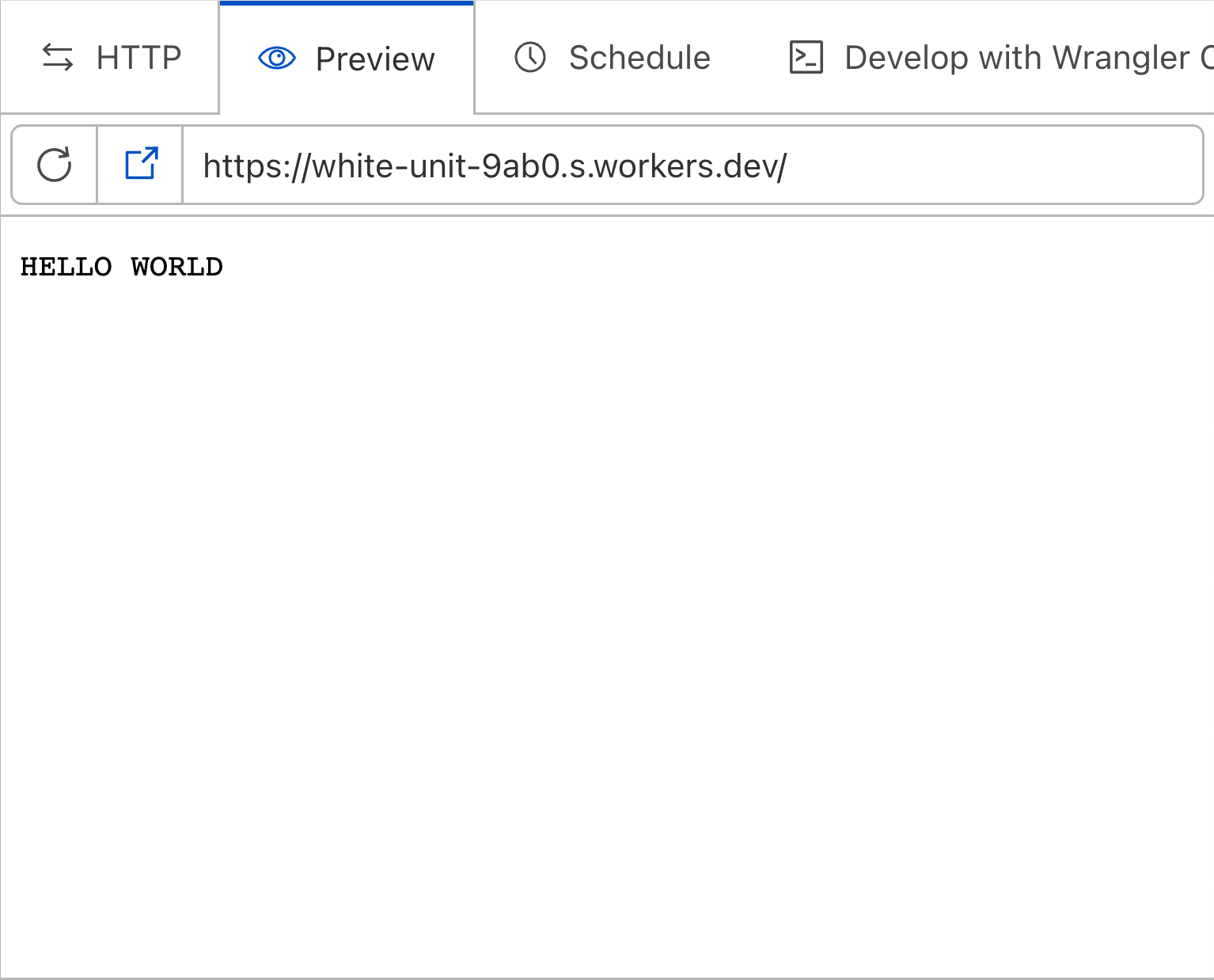
That changes today! We’ve changed the dashboard preview environment to use the same system that powers wrangler dev. This means that your preview worker will be run on Cloudflare's global network, the same environment as your deployed workers.
Helpful error messages
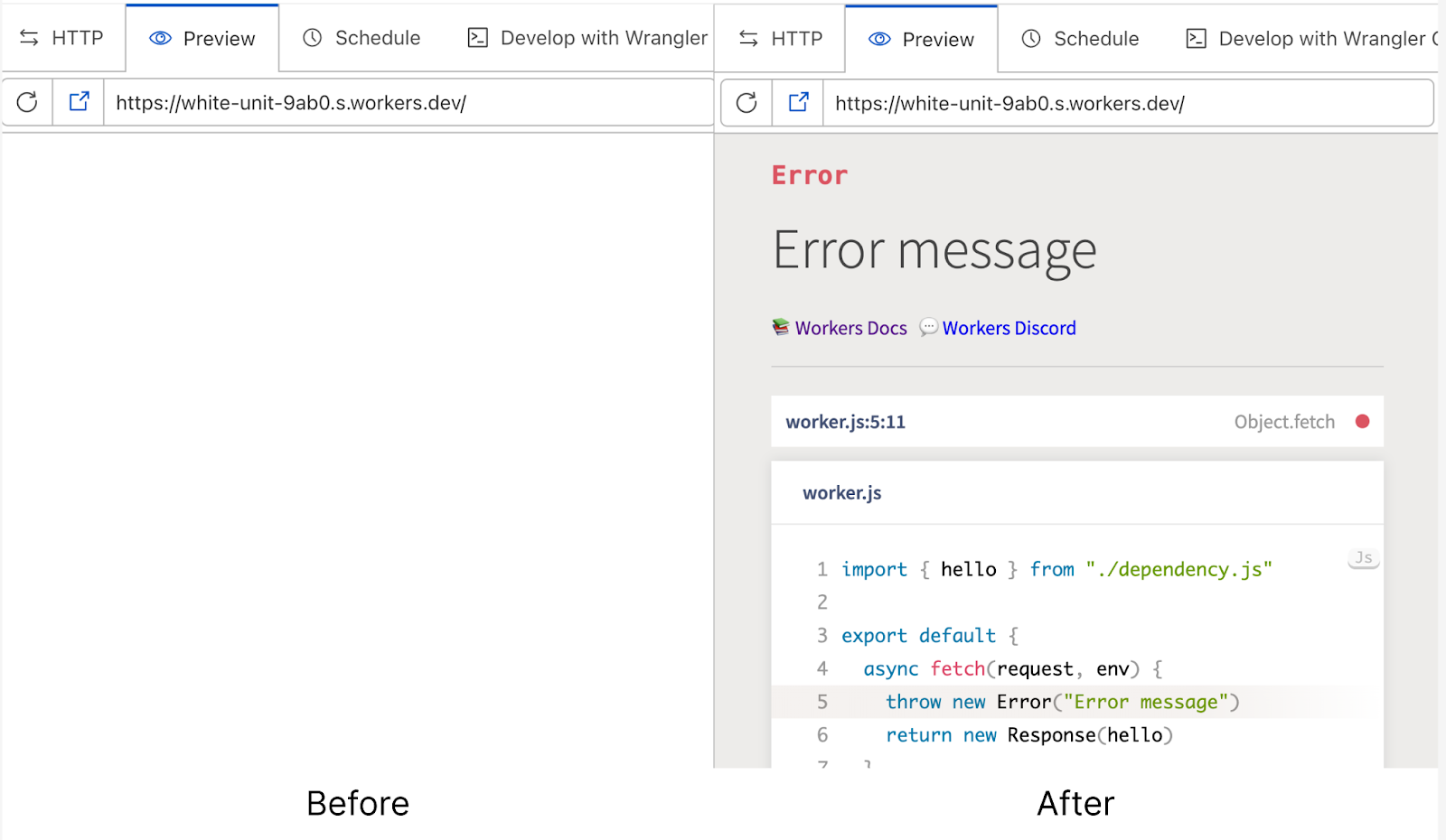
In the previous dashboard editor, the experience when your code throws an error wasn’t great. Unless you wrap your worker code in a try-catch handler, the preview will show a blank page when your worker throws an error. This can make it really tricky to debug your worker, and is pretty frustrating. With the release of the new Quick Editor, we now wrap your worker with error handling code that shows helpful error pages, complete with error stack traces and detailed descriptions.
Typechecking
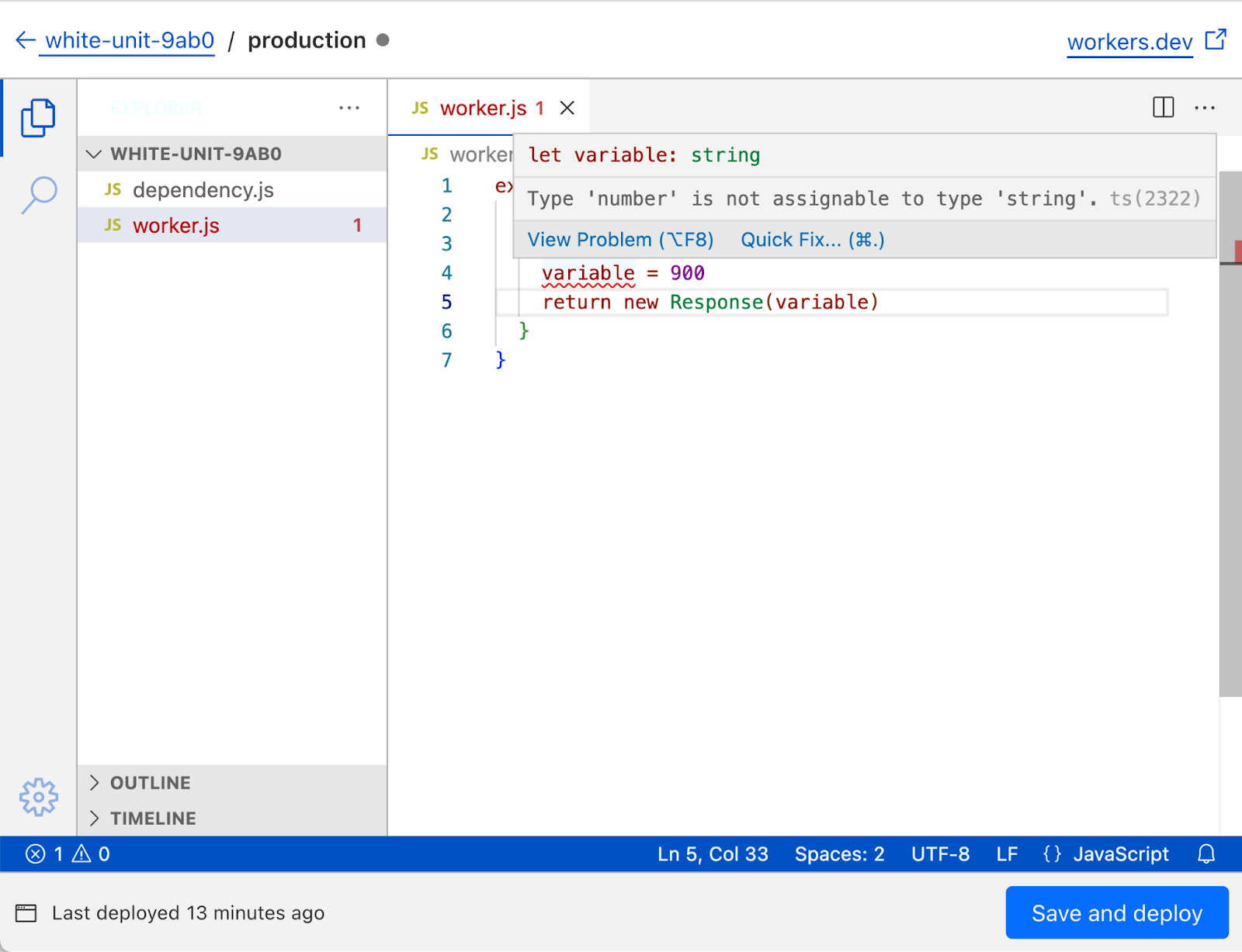
TypeScript is incredibly popular, and developers are more and more used to writing their workers in TypeScript. While the dashboard editor still only allows JavaScript files (and you’re unable to write TypeScript directly) we wanted to support modern typed JavaScript development as much as we could. To that end, the new dashboard editor has full support for JSDoc TypeScript syntax, with the TypeScript environment for workers (link) preloaded. This means that writing code with type errors will show a familiar squiggly red line, and Cloudflare APIs like HTMLRewriter will be autocompleted.
How we built it
It wouldn’t be a Cloudflare blog post without a deep dive into the nuts and bolts of what we’ve built!
First, an overview—how does this work at a high level? We embed VSCode for Web in the Cloudflare dashboard as an iframe, and communicate with it over a MessageChannel. When the iframe is loaded, the Cloudflare dashboard sends over the contents of your worker to a VSCode for Web extension. This extension seeds an in-memory filesystem from which VSCode for Web reads. When you edit files in VSCode for Web, the updated files are sent back over the same MessageChannel to the Cloudflare dashboard, where they’re uploaded as a previewed worker to Cloudflare's global network.
As with any project of this size, the devil is in the details. Let’s focus on a specific area —how we communicate with VSCode for Web’s iframe from the Cloudflare dashboard.
The MessageChannel browser API enables relatively easy cross-frame communication—in this case, from an iframe embedder to the iframe itself. To use it, you construct an instance and access the port1 and port2 properties:
const channel = new MessageChannel()
// The MessagePort you keep a hold of
channel.port1
// The MessagePort you send to the iframe
channel.port2
We store a reference to the MessageChannel to use across component renders with useRef(), since React would otherwise create a new MessageChannel instance with every render.
With that out of the way, all that remains is to send channel.port2 to VSCode for Web’s iframe, via a call to postMessage().
// A reference to the iframe embedding VSCode for Web
const editor = document.getElementById("vscode")
// Wait for the iframe to load
editor.addEventListener('load', () => {
// Send over the MessagePort
editor.contentWindow.postMessage('PORT', '*', [
channel.port2
]);
});
An interesting detail here is how the MessagePort is sent over to the iframe. The third argument to postMessage() indicates a sequence of Transferable objects. This transfers ownership of port2 to the iframe, which means that any attempts to access it in the original context will throw an exception.
At this stage the dashboard has loaded an iframe containing VSCode for Web, initialised a MessageChannel, and sent over a MessagePort to the iframe. Let’s switch context—the iframe now needs to catch the MessagePort and start using it to communicate with the embedder (Cloudflare’s dashboard).
window.onmessage = (e) => {
if (e.data === "PORT") {
// An instance of a MessagePort
const port = e.ports[0]
}
};
Relatively straightforward! With not that much code, we’ve set up communication and can start sending more complex messages across. Here’s an example of how we send over the initial worker content from the dashboard to the VSCode for Web iframe:
// In the Cloudflare dashboard
// The modules that make up your worker
const files = [
{
path: 'index.js',
contents: `
import { hello } from "./world.js"
export default {
fetch(request) {
return new Response(hello)
}
}`
},
{
path: 'world.js',
contents: `export const hello = "Hello World"`
}
];
channel.port1.postMessage({
type: 'WorkerLoaded',
// The worker name
name: 'your-worker-name',
// The worker's main module
entrypoint: 'index.js',
// The worker's modules
files: files
});
If you’d like to learn more about our approach, you can explore the code we’ve open sourced as part of this project, including the VSCode extension we’ve written to load data from the Cloudflare dashboard, our patches to VSCode, and our VSCode theme.
We’re not done!
This is a huge overhaul of the dashboard editing experience for Workers, but we’re not resting on our laurels! We know there’s a long way to go before developing a worker in the browser will offer the same experience as developing a worker locally with Wrangler, and we’re working on ways to close that gap. In particular, we’re working on adding Typescript support to the editor, and supporting syncing to external Git providers like GitHub and GitLab.
We’d love to hear any feedback from you on the new editing experience—come say hi and ask us any questions you have on the Cloudflare Discord!
Today, we’re thrilled to announce that Pages and Workers will be joining forces into one singular product experience!
We’ve all been there. In a surge of creativity, you visualize in your head the application you want to build so clearly with the pieces all fitting together – maybe a server side rendered frontend and an SQLite database for your backend. You head to your computer with the wheels spinning. You know you can build it, you just need the right tools. You log in to your Cloudflare dashboard, but then you’re faced with an incredibly difficult decision:
Cloudflare Workers or Pages?
Both seem so similar at a glance but also different in the details, so which one is going to make your idea become a reality? What if you choose the wrong one? What are the tradeoffs between the two? These are questions our users should never have to think about, but the reality is, they often do. Speaking with our wide community of users and customers, we hear it ourselves! Decision paralysis hits hard when choosing between Pages and Workers with both products made to build out serverless applications.
In short, we don’t want this for our users — especially when you’re on the verge of a great idea – no, a big idea. That’s why we’re excited to show off the first milestone towards bringing together the best of both beloved products — Workers and Pages into one powerful development platform! This is the beginning of the journey towards a shared fate between the two products, so we wanted to take the opportunity to tell you why we were doing this, what you can use today, and what’s next.
More on the “why”
The relationship between Pages and Workers has always been intertwined. Up until today, we always looked at the two as siblings — each having their own distinct characteristics but both allowing their respective users to build rich and powerful applications. Each product targeted its own set of use cases.
Workers first started as a way to extend our CDN and then expanded into a highly configurable general purpose compute platform. Pages first started as a static web hosting that expanded into Jamstack territory. Over time, Pages began acquiring more of Workers' powerful compute features, while Workers began adopting the rich developer features introduced by Pages. The lines between these two products blurred, making it difficult for our users to understand the differences and pick the right product for their application needs.
We know we can do better to help alleviate this decision paralysis and help you move fast throughout your development experience.
Cool, but what do you mean?
Instead of being forced to make tradeoffs between these two products, we want to bring you the best of the both worlds: a single development platform that has both powerful compute and superfast static asset hosting – that seamlessly integrates with our portfolio of storage products like R2, Queues, D1, and others, and provides you with rich tooling like CI/CD, git-ops workflows, live previews, and flexible environment configurations.
All the details in one place
Today, a lot of our developers use both Pages and Workers to build pieces of their applications. However, they still live in separate parts of the Cloudflare dashboard and don’t always translate from one to the other, making it difficult to combine and keep track of your app’s stack. While we’re still vision-boarding the look and feel, we’re planning a world where users have the ability to manage all of their applications in one central place.
No more scrambling all over the dashboard to find the pieces of your application – you’ll have all the information you need about a project right at your fingertips.
Primitives
With Pages and Workers converging, we’ll also be redefining the concept of a “project” , introducing a new blank canvas of possibilities to plug and play. Within a project, you will be able to add (1) static assets, (2) serverless functions (Workers), (3) resources or (4) any combination of each.
To unlock the full potential of your application, we’re exploring project capabilities that allow you to auto-provision and directly integrate with resources like KV, Durable Objects, R2 and D1. With the possibility of all of these primitives on a project, more importantly, you'll be able to safely perform rollbacks and previews, as we'll keep the versions of your assets, functions and resources in sync with every deployment. No need to worry about any of them becoming stale on your next deployment.
Deployments
One of Pages’ most notable qualities is its git-ops centered deployments. In our converged world, you’ll be able to optionally connect, build and deploy git repos that contain any combination of static assets, serverless functions and bindings to resources, as well as take advantage of the same high-performance CI system that exists in Pages today.
Like Pages, you will be able to preview deployments of your project with unique URLs protected by Cloudflare Access, available in your PRs or via Wrangler command. Because we know that great ideas take lots of vetting before the big release, we’ll also have a first-class concept of environments to enable testing in different setups.
Local development
Arguably one of the most important parts to consider is our local development story in a post-converged world. This developer experience should be no different from how we’re converging the products. In the future, as you work with our Wrangler CLI, you can expect a unified and predictable set of commands to use on your project – e.g. a simple wrangler dev and wrangler deploy. Using a configuration file that applies to your entire project along with all of its components, you can have the confidence that your command will act on the entire project – not just pieces of it!
What are the benefits?
With Workers and Pages converging, we’re not just unlocking all the golden developer features of each product into one development platform. We’re bringing all the performance, cost and load benefits too. This includes:
Super low latency with globally distributed static assets and compute on our network that is just 50ms away from 95% of Internet-connected world-wide population.
Free egress and also free static asset hosting.
Standards-based JavaScript runtime with seamless compatibility across the packages and libraries you're already familiar with.
Seamless migrations for all
If you’re already a Pages or Workers user and are starting to get nervous about what this means for your existing projects – never fear. As we build out this merged architecture, seamless migration is our top priority and the North Star for every step on the way to a unified development platform. Existing projects on both Pages and Workers will continue to work without users needing to lift a finger. Instead, you'll see more and more features become available to enrich your existing projects and workflows, regardless of the product you started with.
What’s new today?
We’ll be working over the next year to converge Pages and Workers into one singular experience, blending not only the products themselves but also our product, engineering and design teams behind the scenes.
While we can’t wait to welcome you to the new converged world, this change unfortunately won’t happen overnight. We’re planning to hit some big but incremental milestones over the next few quarters to ensure a smooth transition into convergence, and this Developer Week, we’re excited to take our first step toward convergence. In the dashboard, things might feel a bit different!
Get started together
Combining the onboarding experience for Pages and Workers into one flow, you’ll notice some changes on our dashboard when you’re creating a project. We’re slowly bringing the two products closer together by unifying the creation flow giving you access to create either a Pages project or Worker from one screen.
Go faster with templates
We understand the classic developer urge to immediately get hands dirty and hit the ground running on their big vision. We’re making it easier than ever to go from an idea to an application that’s live on the Cloudflare network. In a couple of clicks, you can deploy a starter template, ranging from a simple Hello World Worker to a ChatGPT plugin. In the future, we’re working on Pages templates in our dashboard, allowing you to automatically create a new repo and deploy starter full-stack apps with a couple of buttons.
Your favorite full stack frameworks at your fingertips
We're not stopping with static templates or our dashboard either. Bringing the framework of your choice doesn't mean you have to leave behind the tools you already know and love. If you’re itching to see just what we mean when we say “deploy with your favorite full-stack framework” or “check out the power of Workers”, simply execute:
npm create cloudflare@latest
from your terminal and enjoy the ride! This new CLI experience integrates with CLIs from some of our first class and solidly supported full-stack frameworks like Angular, Next, Qwik and Remix giving you full control of how you create new projects. From this tool you can also deploy a variety of Workers using our powerful starter templates, with a wizard-like experience.
One singular place to find all of your applications
We’re taking one step closer to a unified experience by merging the Pages and Workers project list dashboards together. Once you’ve deployed your application, you’ll notice all of your Pages and Workers on one page, so you don’t have to navigate to different parts of your dashboard. Track your usage analytics for Workers / Pages Functions in one spot. In the future, these cards won’t be identifiable as Pages and Workers – just “projects” with a combination of assets, functions and resources!
What’s next?
As we begin executing, you’ll notice that each product will slowly become more and more similar as we unlock features for each platform until they’re ready to be one such as git integration for your Workers and a config file for your Pages projects!
Keep an eye out on Twitter to hear about the newest capabilities and more on what’s to come in every milestone.
Have thoughts?
Of course, we wouldn’t be able to build an amazing platform without first listening to the voice of our community. In fact, we’ve put together a survey to collect more information about our users and receive input on what you’d like to see. If you have a few minutes, you can fill it out or reach out to us on the Cloudflare Developers Discord or Twitter @CloudflareDev.
Cloudflare Pages launched over two years ago in December 2020, and since then, we have grown Pages to build millions of deployments for developers. In May 2022, to support developers with more complex requirements, we opened up Pages to empower developers to create deployments using their own build environments — but that wasn't the end of our journey. Ultimately, we want to be able to allow anyone to use our build platform and take advantage of the git integration we offer. You should be able to connect your repository and have it just work on Cloudflare Pages.
Today, we're introducing a new beta version of our build system (a.k.a. "build image") which brings the default set of tools and languages up-to-date, and sets the stage for future improvements to builds on Cloudflare Pages. We now support the latest versions of Node.js, Python, Hugo and many more, putting you on the best path for any new projects that you undertake. Existing projects will continue to use the current build system, but this upgrade will be available to opt-in for everyone.
New defaults, new possibilities
The Cloudflare Pages build system has been updated to not only support new versions of your favorite languages and tools, but to also include new versions by default. The versions of 2020 are no longer relevant for the majority of today's projects, and as such, we're bumping these to their more modern equivalents:
Node.js' default is being increased from 12.18.0 to 18.16.0,
Python 2.7.18 and 3.10.5 are both now available by default,
Ruby's default is being increased from 2.7.1 to 3.2.2,
Yarn's default is being increased from 1.22.4 to 3.5.1,
And we're adding pnpm with a default version of 8.2.0.
These are just some of the headlines — check out our documentation for the full list of changes.
We're aware that these new defaults constitute a breaking change for anyone using a project without pinning their versions with an environment variable or version file. That's why we're making this new build system opt-in for existing projects. You'll be able to stay on the existing system without breaking your builds. If you do decide to adventure with us, we make it easy to test out the new system in your preview environments before rolling out to production.
Additionally, we're now making your builds more reproducible by taking advantage of lockfiles with many package managers. npm ci and yarn --pure-lockfile are now used ahead of your build command in this new version of the build system.
For new projects, these updated defaults and added support for pnpm and Yarn 3 mean that more projects will just work immediately without any undue setup, tweaking, or configuration. Today, we're launching this update as a beta, but we will be quickly promoting it to general availability once we're satisfied with its stability. Once it does graduate, new projects will use this updated build system by default.
We know that this update has been a long-standing request from our users (we thank you for your patience!) but part of this rollout is ensuring that we are now in a better position to make regular updates to Cloudflare Pages' build system. You can expect these default languages and tools to now keep pace with the rapid rate of change seen in the world of web development.
We very much welcome your continued feedback as we know that new tools can quickly appear on the scene, and old ones can just as quickly drop off. As ever, our Discord server is the best place to engage with the community and Pages team. We’re excited to hear your thoughts and suggestions.
Our modular and scalable architecture
Powering this updated build system is a new architecture that we've been working on behind-the-scenes. We're no strangers to sweeping changes of our build infrastructure: we've done a lot of work to grow and scale our infrastructure. Moving beyond purely static site hosting with Pages Functions brought a new wave of users, and as we explore convergence with Workers, we expect even more developers to rely on our git integrations and CI builds. Our new architecture is being rolled out without any changes affecting users, so unless you're interested in the technical nitty-gritty, feel free to stop reading!
The biggest change we're making with our architecture is its modularity. Previously, we were using Kubernetes to run a monolithic container which was responsible for everything for the build. Within the same image, we'd stream our build logs, clone the git repository, install any custom versions of languages and tools, install a project's dependencies, run the user's build command, and upload all the assets of the build. This was a lot of work for one container! It meant that our system tooling had to be compatible with versions in the user's space and therefore new default versions were a massive change to make. This is a big part of why it took us so long to be able to update the build system for our users.
In the new architecture, we've broken these steps down into multiple separate containers. We make use of Kubernetes' init containers feature and instead of one monolithic container, we have three that execute sequentially:
clone a user's git repository,
install any custom versions of languages and tools, install a project's dependencies, run the user's build command, and
upload all the assets of a build.
We use a shared volume to give the build a persistent workspace to use between containers, but now there is clear isolation between system stages (cloning a repository and uploading assets) and user stages (running code that the user is responsible for). We no longer need to worry about conflicting versions, and we've created an additional layer of security by isolating a user's control to a separate environment.
We're also aligning the final stage, the one responsible for uploading static assets, with the same APIs that Wrangler uses for Direct Upload projects. This reduces our maintenance burden going forward since we'll only need to consider one way of uploading assets and creating deployments. As we consolidate, we're exploring ways to make these APIs even faster and more reliable.
Logging out
You might have noticed that we haven't yet talked about how we're continuing to stream build logs. Arguably, this was one of the most challenging pieces to work out. When everything ran in a single container, we were able to simply latch directly into the stdout of our various stages and pipe them through to a Durable Object which could communicate with the Cloudflare dashboard.
By introducing this new isolation between containers, we had to get a bit more inventive. After prototyping a number of approaches, we've found one that we like. We run a separate, global log collector container inside Kubernetes which is responsible for collating logs from a build, and passing them through to that same Durable Object infrastructure. The one caveat is that the logs now need to be annotated with which build they are coming from, since one global log collector container accepts logs from multiple builds. A Worker in front of the Durable Object is responsible for reading the annotation and delegating to the relevant build's Durable Object instance.
Caching in
With this new modular architecture, we plan to integrate a feature we've been teasing for a while: build caching. Today, when you run a build in Cloudflare Pages, we start fresh every time. This works, but it's inefficient.
Very often, only small changes are actually made to your website between deployments: you might tweak some text on your homepage, or add a new blog post; but rarely does the core foundation of your site actually change between deployments. With build caching, we can reuse some of the work from earlier builds to speed up subsequent builds. We'll offer a best-effort storage mechanism that allows you to persist and restore files between builds. You'll soon be able to cache dependencies, as well as the build output itself if your framework supports it, resulting in considerably faster builds and a tighter feedback loop from push to deploy.
This is possible because our new modular design has clear divides between the stages where we'd want to restore and cache files.
Start building
We're excited about the improvements that this new modular architecture will afford the Pages team, but we're even more excited for how this will result in faster and more scalable builds for our users. This architecture transition is rolling out behind-the-scenes, but the updated beta build system with new languages and tools is available to try today. Navigate to your Pages project settings in the Cloudflare Dashboard to opt-in.
Let us know if you have any feedback on the Discord server, and stay tuned for more information about build caching in upcoming posts on this blog. Later today (Wednesday 17th, 2023), the Pages team will be hosting a Q&A session to talk about this announcement on Discord at 17:30 UTC.
Hey web developers! We are about to shake things up a bit here at Cloudflare and wanted to give you a heads-up, so that you know what we are doing and where we are going. You might know Cloudflare as one of the best places to come to when you need to protect, speed up, or scale your web application, but increasingly Cloudflare is also becoming the best place to deploy and run your application!
Why deploy your application to Cloudflare? Two simple reasons. First, it removes lots of hassle of managing many separate systems and allows you to develop, deploy, monitor, and tune your application all in one place. Second, by deploying to Cloudflare directly, there is so much more we can do to optimize your application and get it to the hands, ears, or eyes of your users more quickly and smoothly.
So what’s changing? Quite a bit, actually. I’m not going to bore you with rehashing all the details as my most-awesome colleagues have written separate blog posts with all the details, but here is a high level rundown.
Cloudflare Workers + Pages = awesome development platform
Cloudflare Pages and Workers are merging into a single unified development and application hosting platform that offers:
Standards-based JavaScript and WASM runtime that already serves over 10 million requests per second at peak globally.
Access to powerful features like R2 (object storage with an S3-compatible API), low-latency globally replicated KV storage, Queues, D1 database, and many more.
Support for GitOps and CI/CD workflows and preview environments to boost development velocity.
… and so much more.
While mathematically proven to be wrong, we stubbornly believe that 1+1=3, and in this case this translates to Cloudflare Pages + Workers = way more than the sum of the parts. In fact, it’s an awesome foundation for one of a kind development platform that we are thrilled to be building for you.
We started this product convergence journey a few quarters ago, and early on agreed upon not leaving any of the existing applications behind. Instead, we’ll be bringing them over to this new world. Today we are ready to start sharing the incremental results, with so much more to come over the upcoming quarters. Want to know more? My colleague Nevi posted lots of spicy details in her blog post.
Smart Placement for Workers takes us beyond the edge!
Smart placement is, to put it simply, revolutionary for Cloudflare. It enables a new compute paradigm on our platform, unmatched by any other application hosting providers today. Do you have a typical full-stack application built with one of the many popular web frameworks? This feature is for you! And it works with both Workers and Pages!
While previously we always executed all applications at the “edge” of our global network — meaning, as close to the user as possible. With smart placement, we intelligently determine the best location within our network where the compute (your application) should run. We do this by observing your application’s behavior and what other network resources or endpoints the application interacts with. We then transparently spawn your application at an optimal location, usually close to where your data is stored, and route the incoming requests via our network to this location.
Smart placement enables applications to run near to the data these applications need to get stuff done. This is especially powerful for applications that interact with databases, object stores, or other backend endpoints, especially if these are centralized and not globally distributed.
Your user or clients requests still enter our lightning fast network in one of our 285+ datacenters in the world, close to their current location, but instead of spawning the application right there, we route the request to the most optimal datacenter, the one that is near the data or backend system the application talks to.
This doesn’t mean that compute at the edge is not cool anymore! It is! There are still many use-cases where running your application at the edge makes sense, and smart placement will determine this scenario and keep the application at the edge if that’s the right place for it to be. A/B testing, localization, asset serving, and others are use-cases that should almost always happen at the edge.
We continue to deliver on our goal to build the best development environment integrated directly into our lightning fast and globally distributed application platform. We’re launching Wrangler v3, with complete support for local-by-default development workflow. Powered by the open-source Cloudflare Workers JavaScript runtime — workerd, this change reduces development server startup time by 10x and script reload times by 60x — boosting your productivity and keeping you in the flow longer.
In the dashboard, we're introducing an upgraded and far more powerful online editor powered by VSCode – you can now finally edit multiple JavaScript modules in your browser, get an accurate edge preview of your code, friendly error pages, and type checking!
Finally, in both our dashboard editor and Wrangler, we've updated our workerd-customized Chrome DevTools to the latest version, providing even greater debugging and profiling capabilities, wherever you choose to work.
This is just the first wave of improvements to our development tooling space, you’ll see us iterating in this space over the next few quarters, but in the meantime, check out in-depth posts from Adam, Brendan, and Samuel with all the Wrangler v3 details and VSCode and dash editor improvements.
Increased memory, CPU, and application size limits and simplified pricing!
In the age of AI, WASM, and powerful full-stack applications, we’ve noticed that developers are hitting our current resource limits with increased frequency. We want to be a place where these applications thrive and developers are empowered to build bigger and more sophisticated applications. Therefore, within the next week we’ll be increasing application size limits (JavaScript/WASM bundle size) to 10MB (after gzip) and startup latency limit (script compile time) is being increased from 200ms to 400ms.
To further empower developers, we’re thinking about how to unify and simplify our billing model to make our pricing more straightforward, and increase limits such as memory limits by introducing tiers. Stay tuned for more information on these!
With these changes developers can build cooler apps and operate them for less! Cool, right?!?
Pages CI now with a modern build image!
The wait is finally over! Pages now use a modern build image to power the CI and integrated build system. With this improvement you can finally use recent versions of Node.js, pnpm, and many other tools used by developers today.
While delivering this improvement, we made it much easier for us to keep things up to date in the future, but also unlocked new features like build caching!
The updates are available to all new projects by default, while existing projects can opt in to newer defaults. Sounds like your cup of coffee? Read on in this blog post by Greg.
Enough already, let’s get started! …with your framework of choice and C3!
In addition to being a CDN, and place to deploy your Worker applications, Cloudflare is now also becoming the best place to run your full-stack web applications. This includes all full-stack web frameworks like Angular, Astro, Next, Nuxt, Qwik, Remix, Solid, Svelte, Vue, and others.
Our overall mission is to help build a better Internet, and my team’s contribution to this mission is to enable developers, but really just about anyone, to go from an idea to a deployed application in no time.
To enable developers to turn their ideas into deployed applications quickly and without any hassle we’ve built two things.
First, we partnered with many web framework authors to build new or improve existing adapters for all the popular JavaScript web frameworks. These adapters ensure that your application runs on our platform in the most efficient way, while having access to all the capabilities and features of our platform.
These adapters include the highly requested Next.js adapter, that we’ve just overhauled to be production ready and are launching 1.0.0 today! In partnership with the respective teams, we’ve built brand-new adapters for Angular, and Qwik, while improving Astro, Nuxt, Solid, and a few others.
Second, we developed a brand new sassy CLI we call C3 — short for create-cloudflare CLI, a sibling to our existing Wrangler CLI. If you are a developer who lives your life in terminal or local editors like VSCode, then this CLI is your single entry-point to the Cloudflare universe.
Run the C3 command, and we’ll get you started. You pick your framework of choice, we hand the control over to the CLI of the chosen framework as we don’t want to stand in between you and the hard-working framework authors that craft the experience for their framework. A minute or so later once all npm dependencies are installed, you get a URL from us with your application deployed. That’s it. From an idea to a URL that you can share with friends almost instantly! Boom.
The best place for your web applications
So to recap, our first class support for full-stack web frameworks, combined with the low latency and cost-effectiveness of our platform, as well as smart placement that allows the backend of the full-stack web application to run in the optimal location automagically, and all the remaining significant improvements in our developer tooling, makes Cloudflare THE best place to build and host web applications. This is our contribution to our mission to build a better Internet and push the Web forward.
We aspire to be the place people turn to when they want to get business done, or when they just want to be creative, explore ideas and have fun. It’s a long journey, and we’ve got a lot of interesting challenges ahead of us. Your input will be critical in guiding us. We are all thrilled to have the opportunity to be part of it and give it our best shot. You can join this journey too, and get started today:
For over a year now, we’ve been working to improve the Workers local development experience. Our goal has been to improve parity between users' local and production environments. This is important because it provides developers with a fully-controllable and easy-to-debug local testing environment, which leads to increased developer efficiency and confidence.
To start, we integrated Miniflare, a fully-local simulator for Workers, directly into Wrangler, the Workers CLI. This allowed users to develop locally with Wrangler by running wrangler dev --local. Compared to the wrangler dev default, which relied on remote resources, this represented a significant step forward in local development. As good as it was, it couldn’t leverage the actual Workers runtime, which led to some inconsistencies and behavior mismatches.
Last November, we announced the experimental version of Miniflare v3, powered by the newly open-sourced workerd runtime, the same runtime used by Cloudflare Workers. Since then, we’ve continued to improve upon that experience both in terms of accuracy with the real runtime and in cross-platform compatibility.
As a result of all this work, we are proud to announce the release of Wrangler v3 – the first version of Wrangler with local-by-default development.
A new default for Wrangler
Starting with Wrangler v3, users running wrangler dev will be leveraging Miniflare v3 to run your Worker locally. This local development environment is effectively as accurate as a production Workers environment, providing an ability for you to test every aspect of your application before deploying. It provides the same runtime and bindings, but has its own simulators for KV, R2, D1, Cache and Queues. Because you’re running everything on your machine, you won’t be billed for operations on KV namespaces or R2 buckets during development, and you can try out paid-features like Durable Objects for free.
In addition to a more accurate developer experience, you should notice performance differences. Compared to remote mode, we’re seeing a 10x reduction to startup times and 60x reduction to script reload times with the new local-first implementation. This massive reduction in reload times drastically improves developer velocity!
Remote development isn’t going anywhere. We recognise many developers still prefer to test against real data, or want to test Cloudflare services like image resizing that aren’t implemented locally yet. To run wrangler dev on Cloudflare’s network, just like previous versions, use the new --remote flag.
Deprecating Miniflare v2
For users of Miniflare, there are two important pieces of information for those updating from v2 to v3. First, if you’ve been using Miniflare’s CLI directly, you’ll need to switch to wrangler dev. Miniflare v3 no longer includes a CLI. Secondly, if you’re using Miniflare’s API directly, upgrade to miniflare@3 and follow the migration guide.
How we built Miniflare v3
Miniflare v3 is now built using workerd, the open-source Cloudflare Workers runtime. As workerd is a server-first runtime, every configuration defines at least one socket to listen on. Each socket is configured with a service, which can be an external server, disk directory or most importantly for us, a Worker! To start a workerd server running a Worker, create a worker.capnp file as shown below, run npx workerd serve worker.capnp and visit http://localhost:8080 in your browser:
If you’re interested in what else workerd can do, check out the other samples. Whilst workerd provides the runtime and bindings, it doesn’t provide the underlying implementations for the other products in the Developer Platform. This is where Miniflare comes in! It provides simulators for KV, R2, D1, Queues and the Cache API.
Building a flexible storage system
As you can see from the diagram above, most of Miniflare’s job is now providing different interfaces for data storage. In Miniflare v2, we used a custom key-value store to back these, but this had afewlimitations. For Miniflare v3, we’re now using the industry-standard SQLite, with a separate blob store for KV values, R2 objects, and cached responses. Using SQLite gives us much more flexibility in the queries we can run, allowing us to support future unreleased storage solutions. 👀
A separate blob store allows us to provide efficient, ranged, streamed access to data. Blobs have unguessable identifiers, can be deleted, but are otherwise immutable. These properties make it possible to perform atomic updates with the SQLite database. No other operations can interact with the blob until it's committed to SQLite, because the ID is not guessable, and we don't allow listing blobs. For more details on the rationale behind this, check out the original GitHub discussion.
Running unit tests inside Workers
One of Miniflare’s primary goals is to provide a great local testing experience. Miniflare v2 provided custom environments for popular Node.js testing frameworks that allowed you to run your tests inside the Miniflare sandbox. This meant you could import and call any function using Workers runtime APIs in your tests. You weren’t restricted to integration tests that just send and receive HTTP requests. In addition, these environments provide per-test isolated storage, automatically undoing any changes made at the end of each test.
In Miniflare v2, these environments were relatively simple to implement. We’d already reimplemented Workers Runtime APIs in a Node.js environment, and could inject them using Jest and Vitest’s APIs into the global scope.
For Miniflare v3, this is much trickier. The runtime APIs are implemented in a separate workerd process, and you can’t reference JavaScript classes across a process boundary. So we needed a new approach…
Many test frameworks like Vitest use Node’s built-in worker_threads module for running tests in parallel. This module spawns new operating system threads running Node.js and provides a MessageChannel interface for communicating between them. What if instead of spawning a new OS thread, we spawned a new workerd process, and used WebSockets for communication between the Node.js host process and the workerd “thread”?
We have a proof of concept using Vitest showing this approach can work in practice. Existing Vitest IDE integrations and the Vitest UI continue to work without any additional work. We aren’t quite ready to release this yet, but will be working on improving it over the next few months. Importantly, the workerd “thread” needs access to Node.js built-in modules, which we recently started rolling out support for.
Running on every platform
We want developers to have this great local testing experience, regardless of which operating system they’re using. Before open-sourcing, the Cloudflare Workers runtime was originally only designed to run on Linux. For Miniflare v3, we needed to add support for macOS and Windows too. macOS and Linux are both Unix-based, making porting between them relatively straightforward. Windows on the other hand is an entirely different beast… 😬
The workerd runtime uses KJ, an alternative C++ base library, which is already cross-platform. We’d also migrated to the Bazel build system in preparation for open-sourcing the runtime, which has good Windows support. When compiling our C++ code for Windows, we use LLVM's MSVC-compatible compiler driver clang-cl, as opposed to using Microsoft’s Visual C++ compiler directly. This enables us to use the "same" compiler frontend on Linux, macOS, and Windows, massively reducing the effort required to compile workerd on Windows. Notably, this provides proper support for #pragma once when using symlinked virtual includes produced by Bazel, __atomic_* functions, a standards-compliant preprocessor, GNU statement expressions used by some KJ macros, and understanding of the .c++ extension by default. After switching out unix API calls for their Windows equivalents using #if _WIN32 preprocessor directives, and fixing a bunch of segmentation faults caused by execution order differences, we were finally able to get workerd running on Windows! No WSL or Docker required! 🎉
Let us know what you think!
Wrangler v3 is now generally available! Upgrade by running npm install --save-dev wrangler@3 in your project. Then run npx wrangler dev to try out the new local development experience powered by Miniflare v3 and the open-source Workers runtime. Let us know what you think in the #wrangler channel on the Cloudflare Developers Discord, and please open a GitHub issue if you hit any unexpected behavior.
Earlier this year, we blogged about an incident where we mistakenly throttled a customer due to internal confusion about a potential violation of our Terms of Service. That incident highlighted a growing point of confusion for many of our customers. Put simply, our terms had not kept pace with the rapid innovation here at Cloudflare, especially with respect to our Developer Platform. We’re excited to announce new updates that will modernize our terms and cut down on customer confusion and frustration.
A bit of background on our legal terms of service
We want our terms to set clear expectations about what we’ll deliver and what customers can do with our services. But drafting terms is often an iterative process, and iteration over a decade can lead to bloat, complexity, and vestigial branches in need of pruning. Now, time to break out the shears.
Snip, snip
To really nip this in the bud, we started at the source–the content-based restriction housed in Section 2.8 of our Self-Serve Subscription Agreement:
Cloudflare is much, much more than a CDN, but that wasn’t always the case. The CDN was one of our first services and originally designed to serve HTML content like webpages. User attempts to serve video and other large files hosted outside of Cloudflare were disruptive on many levels. So, years ago, we added Section 2.8 to give Cloudflare the means to preserve the original intent of the CDN: limiting use of the CDN to webpages.
Over time, Cloudflare’s network became larger and more robust and its portfolio broadened to include services like Stream, Images, and R2. These services are explicitly designed to allow customers to serve non-HTML content like video, images, and other large files hosted directly by Cloudflare. And yet, Section 2.8 persisted in our Self-Serve Subscription Agreement–the umbrella terms that apply to all services. We acknowledge that this didn’t make much sense.
To address the problem, we’ve done a few things. First, we moved the content-based restriction concept to a new CDN-specific section in our Service-Specific Terms. We want to be clear that this restriction only applies to use of our CDN. Next, we got rid of the antiquated HTML vs. non-HTML construct, which was far too broad. Finally, we made it clear that customers can serve video and other large files using the CDN so long as that content is hosted by a Cloudflare service like Stream, Images, or R2. This will allow customers to confidently innovate on our Developer Platform while leveraging the speed, security, and reliability of our CDN. Video and large files hosted outside of Cloudflare will still be restricted on our CDN, but we think that our service features, generous free tier, and competitive pricing (including zero egress fees on R2) make for a compelling package for developers that want to access the reach and performance of our network.
Here are a few diagrams to help understand how our terms of service fit together for various use cases.
Customer A is on a free, pro, or business plan and wants to use the CDN service:
Customer B is on a free, pro, or business plan and wants to use the Developer Platform and Zero Trust services:
Customer C is on a free, pro, or business plan and wants to use Stream with the CDN service and Magic Transit with the CDN service:
Quality of life upgrades
We also took this opportunity to tune up other aspects of our Terms of Service to make for a more user-first experience. For example, we streamlined our Self-Serve Subscription Agreement to make it clearer and easier to understand from the start.
We also heard previous complaints and removed an old restriction on benchmarking–we’re confident in the performance of our network and services, unlike some of our competitors. Last but not least, we renamed the Supplemental Terms to the Service-Specific Terms and gave them a major facelift to improve clarity and usability.
Users first
We’ve learned a lot from our users throughout this process, and we are always grateful for your feedback. Our terms were never meant to act as a gating mechanism that stifled innovation. With these updates, we hope that customers will feel confident in building the next generation of apps and services on Cloudflare. And we’ll keep the shears handy as we continue to work to help build a better Internet.
R2 is the ideal object storage platform to build data lakes. It’s infinitely scalable, highly durable (eleven 9's of annual durability), and has no egress fees. Zero egress fees mean zero vendor lock-in. You are free to use the tools you want to get the maximum value from your data.
Today we’re excited to announce our partnership with Snowflake so that you can use Snowflake to query data stored in your R2 data lake and load data from R2 into Snowflake. Organizations use Snowflake's Data Cloud to unite siloed data, discover, and securely share data, and execute diverse analytic workloads across multiple clouds.
One challenge of loading data into Snowflake database tables and querying external data lakes is the cost of data transfer. If your data is coming from a different cloud or even different region within the same cloud, this typically means you are paying an additional tax for each byte going into Snowflake. Pairing R2 and Snowflake lets you focus on getting valuable insights from your data, without having to worry about egress fees piling up.
Getting started
Sign up for R2 and create an API token
If you haven’t already, you’ll need to sign up for R2 and create a bucket. You’ll also need to create R2 security credentials for Snowflake following the steps below.
Generate an R2 token
1. In the Cloudflare dashboard, select R2.
2. Select Manage R2 API Tokens on the right side of the dashboard.
3. Select Create API token.
4. Optionally select the pencil icon or R2 Token text to edit your API token name.
5. Under Permissions, select Edit.
6. Select Create API Token.
You’ll need the Secret Access Key and Access Key ID to create an external stage in Snowflake.
Note: You may need to contact your Snowflake account team to enable S3-compatible endpoints in Snowflake. Get more information here.
Loading data into Snowflake
To load data from your R2 data lake into Snowflake, use the COPY INTO <table> command.
COPY INTO t1
FROM @my_r2_stage/load/;
You can flip the table and external stage parameters in the example above to unload data from Snowflake into R2.
Querying data in R2 with Snowflake
You’ll first need to create an external table in Snowflake. Once you’ve done that you’ll be able to query your data stored in R2.
SELECT * FROM external_table;
For more information on how to use R2 and Snowflake together, refer to documentation here.
“Data is becoming increasingly the center of every application, process, and business metrics, and is the cornerstone of digital transformation. Working with partners like Cloudflare, we are unlocking value for joint customers around the world by helping save costs and helping maximize customers data investments,” – James Malone, Director of Product Management at Snowflake
Have any feedback?
We want to hear from you! If you have any feedback on the integration between Cloudflare R2 and Snowflake, please let us know by filling this form.
Be sure to check our Discord server to discuss everything R2!
While upgrading startups to the startup plan, I often get inquiries from startups that are fully bootstrapped and not affiliated with any accelerator program. Many of them, especially AI startups, are very promising and would benefit highly from the startup plan.
Typically, they also apply for the Workers Launchpad program, for whom semi-finalists can get upgraded to the startup plan as a benefit. But many of those startups would benefit from getting upgraded right away rather than wait for the review process for each cohort.
Starting today, AI startups no longer need an accelerator affiliation or an employee referral in order to qualify for the Startup Program.
Fill out this form with the email address associated with your Cloudflare account: form here. For accelerator, select “AI” from the dropdown menu. In the Comments section, include the following information:
Indication that the startup has raised less than $3M USD (e.g., link to Crunchbase).
Link to a landing page, pitch deck, or article that describes what the startup does. It should be apparent from these materials that the startup is an AI startup (e.g. mention LLMs if that’s what you’re using).
Which Cloudflare developer products are you using.
Today we’re excited to be launching Cursor – our experimental AI assistant, trained to answer questions about Cloudflare’s Developer Platform. This is just the first step in our journey to help developers build in the fastest way possible using AI, so we wanted to take the opportunity to share our vision for a generative developer experience.
Whenever a new, disruptive technology comes along, it’s not instantly clear what the native way to interact with that technology will be.
However, if you’ve played around with Large Language Models (LLMs) such as ChatGPT, it’s easy to get the feeling that this is something that’s going to change the way we work. The question is: how? While this technology already feels super powerful, today, we’re still in the relatively early days of it.
While Developer Week is all about meeting developers where they are, this is one of the things that’s going to change just that — where developers are, and how they build code. We’re already seeing the beginnings of how the way developers write code is changing, and adapting to them. We wanted to share with you how we’re thinking about it, what’s on the horizon, and some of the large bets to come.
How is AI changing developer experience?
If there’s one big thing we can learn from the exploding success of ChatGPT, it’s the importance of pairing technology with the right interface. GPT-3 — the technology powering ChatGPT has been around for some years now, but the masses didn’t come until ChatGPT made it accessible to the masses.
Since the primary customers of our platform are developers, it’s on us to find the right interfaces to help developers move fast on our platform, and we believe AI can unlock unprecedented developer productivity. And we’re still in the beginning of that journey.
Wave 1: AI generated content
One of the things ChatGPT is exceptionally good at is generating new content and articles. If you’re a bootstrapped developer relations team, the first day playing around with ChatGPT may have felt like you struck the jackpot of productivity. With a simple inquiry, ChatGPT can generate in a few seconds a tutorial that would have otherwise taken hours if not days to write out.
This content still needs to be tested — do the code examples work? Does the order make sense? While it might not get everything right, it’s a massive productivity boost, allowing a small team to multiply their content output.
In terms of developer experience, examples and tutorials are crucial for developers, especially as they start out with a new technology, or seek validation on a path they’re exploring.
However, with AI generated content, it’s always going to be limited to well, how much of it you generated. To compare it to the newspaper, this content is still one size fits all. If as a developer you stray ever so slightly off the beaten path (choose a different framework than the one tutorial suggests, or a different database), you’re still left to put the pieces together, navigating tens of open tabs in order to stitch together your application.
If this content is already being generated by AI, however, why not just go straight to the source, and allow developers to generate their own, personal guides?
Wave 2: Q&A assistants
Since developers love to try out new technologies, it’s no surprise that developers are going to be some of the early adopters for technology such as ChatGPT. Many developers are already starting to build applications alongside their trusted bard, ChatGPT.
Rather than using generated content, why not just go straight to the source, and ask ChatGPT to generate something that’s tailored specifically for you?
There’s one tiny problem: the information is not always up to date. Which is why plugins are going to become a super important way to interact.
But what about someone who’s already on Cloudflare’s docs? Here, you want a native experience where someone can ask questions and receive answers. Similarly, if you have a question, why spend time searching the docs, if you can just ask and receive an answer?
Wave 3: generative experiences
In the examples above, you were still relying on switching back and forth between a dedicated AI interface and the problem at hand. In one tab you’re asking questions, while in another, you’re implementing the answers.
But taking things another step further, what if AI just met you where you were? In terms of developer experience, we’re already starting to see this in the authoring phase. Tools like GitHub Copilot help developers generate boilerplate code and tests, allowing developers to focus on more complex tasks like designing architecture and algorithms.
Sometimes, however, the first iteration AI comes up with might not match what you, the developer had in mind, which is why we’re starting to experiment with a flow-based generative approach, where you can ask AI to generate several versions, and build out your design with the one that matches your expectations the most.
The possibilities are endless, enabling developers to start applications from prompts rather than pre-generated templates.
We’re excited for all the possibilities AI will unlock to make developers more productive than ever, and we’d love to hear from you how AI is changing the way you change applications.
We’re also excited to share our first steps into the realm of AI driven developer experience with the release of our first two ChatGPT plugins, and by welcoming a new member of our team —Cursor, our docs AI assistant.
Our first milestone to AI driven UX: AI Assisted Docs
As the first step towards using AI to streamline our developer experience, we’re excited to introduce a new addition to our documentation to help you get answers as quickly as possible.
How to use Cursor
Here’s a sample exchange with Cursor:
You’ll notice that when you ask a question, it will respond with two pieces of information: a text based response answering your questions, and links to relevant pages in our documentation that can help you go further.
Here’s what happens when we ask “What video formats does Stream support?”.
If you were looking through our examples you may not immediately realize that this specific example uses both Workers and R2.
In its current state, you can think of it as your assistant to help you learn about our products and navigate our documentation in a conversational way. We’re labeling Cursor as experimental because this is the very beginning stages of what we feel like a Cloudflare AI assistant could do to help developers. It is helpful, but not perfect. To deal with its lack of perfection, we took an approach of having it do fewer things better. You’ll find there are many things it isn’t good at today.
How we built Cursor
Under the hood, Cursor is powered by Workers, Durable Objects, OpenAI, and the Cloudflare developer docs. It uses the same backend that we’re using to power our ChatGPT Docs plugin, and you can read about that here.
It uses the “Search-Ask” method, stay tuned for more details on how you can build your own.
A sneak peek into the future
We’re already thinking about the future, we wanted to give you a small preview of what we think this might look like here:
With this type of interface, developers could use a UI to have an AI generate code and developers then link that code together visually. Whether that’s with other code generated by the AI or code they’ve written themselves. We’ll be continuing to explore interfaces that we hope to help you all build more efficiently and can’t wait to get these new interfaces in your hands.
We need your help
Our hope is to quickly update and iterate on how Cursor works as developers around the world use it. As you’re using it to explore our documentation, join us on Discord to let us know your experience.
When OpenAI launched ChatGPT plugins in alpha we knew that it opened the door for new possibilities for both Cloudflare users and developers building on Cloudflare. After the launch, our team quickly went to work seeing what we could build, and today we’re very excited to share with you two new Cloudflare ChatGPT plugins – the Cloudflare Radar plugin and the Cloudflare Docs plugin.
The Cloudflare Radar plugin allows you to talk to ChatGPT about real-time Internet patterns powered by Cloudflare Radar.
The Cloudflare Docs plugin allows developers to use ChatGPT to help them write and build Cloudflare applications with the most up-to-date information from our documentation. It also serves as an open source example of how to build a ChatGPT plugin with Cloudflare Workers.
Let’s do a deeper dive into how each of these plugins work and how we built them.
Cloudflare Radar ChatGPT plugin
When ChatGPT introduced plugins, one of their use cases was retrieving real-time data from third-party applications and their APIs and letting users ask relevant questions using natural language.
Cloudflare Radar has lots of data about how people use the Internet, a well-documented public API, an OpenAPI specification, and it’s entirely built on top of Workers, which gives us lots of flexibility for improvements and extensibility. We had all the building blocks to create a ChatGPT plugin quickly. So, that's what we did.
We added an OpenAI manifest endpoint which describes what the plugin does, some branding assets, and an enriched OpenAPI schema to tell ChatGPT how to use our data APIs. The longest part of our work was fine-tuning the schema with good descriptions (written in natural language, obviously) and examples of how to query our endpoints.
Amusingly, the descriptions ended up much improved by the need to explain the API endpoints to ChatGPT. An interesting side effect is that this benefits us humans also.
{
"/api/v1/http/summary/ip_version": {
"get": {
"operationId": "get_SummaryIPVersion",
"parameters": [
{
"description": "Date range from today minus the number of days or weeks specified in this parameter, if not provided always send 14d in this parameter.",
"required": true,
"schema": {
"type": "string",
"example": "14d",
"enum": ["14d","1d","2d","7d","28d","12w","24w","52w"]
},
"name": "dateRange",
"in": "query"
}
]
}
}
Luckily, itty-router-openapi, an easy and compact OpenAPI 3 schema generator and validator for Cloudflare Workers that we built and open-sourced when we launched Radar 2.0, made it really easy for us to add the missing parts.
import { OpenAPIRouter } from '@cloudflare/itty-router-openapi'
const router = OpenAPIRouter({
aiPlugin: {
name_for_human: 'Cloudflare Radar API',
name_for_model: 'cloudflare_radar',
description_for_human: "Get data insights from Cloudflare's point of view.",
description_for_model:
"Plugin for retrieving the data based on Cloudflare Radar's data. Use it whenever a user asks something that might be related to Internet usage, eg. outages, Internet traffic, or Cloudflare Radar's data in particular.",
contact_email: '[email protected]',
legal_info_url: 'https://www.cloudflare.com/website-terms/',
logo_url: 'https://cdn-icons-png.flaticon.com/512/5969/5969044.png',
},
})
We incorporated our changes into itty-router-openapi, and now it supports the OpenAI manifest and route, and a few other options that make it possible for anyone to build their own ChatGPT plugin on top of Workers too.
The Cloudflare Radar ChatGPT is available to non-free ChatGPT users or anyone on OpenAI’s plugin's waitlist. To use it, simply open ChatGPT, go to the Plugin store and install Cloudflare Radar.
Once installed, you can talk to it and ask questions about our data using natural language.
When you add plugins to your account, ChatGPT will prioritize using their data based on what the language model understands from the human-readable descriptions found in the manifest and Open API schema. If ChatGPT doesn't think your prompt can benefit from what the plugin provides, then it falls back to its standard capabilities.
Another interesting thing about plugins is that they extend ChatGPT's limited knowledge of the world and events after 2021 and can provide fresh insights based on recent data.
Here are a few examples to get you started:
"What is the percentage distribution of traffic per TLS protocol version?"
"What's the HTTP protocol version distribution in Portugal?"
Now that ChatGPT has context, you can add some variants, like switching the country and the date range.
“How about the US in the last six months?”
You can also combine multiple topics (ChatGPT will make multiple API calls behind the scenes and combine the results in the best possible way).
“How do HTTP protocol versions compare with TLS protocol versions?”
Out of ideas? Ask it “What can I ask the Radar plugin?”, or “Give me a random insight”.
Be creative, too; it understands a lot about our data, and we keep improving it. You can also add date or country filters using natural language in your prompts.
Cloudflare Docs ChatGPT plugin
The Cloudflare Docs plugin is a ChatGPT Retrieval Plugin that lets you access the most up-to-date knowledge from our developer documentation using ChatGPT. This means if you’re using ChatGPT to assist you with building on Cloudflare that the answers you’re getting or code that’s being generated will be informed by current best practices and information located within our docs. You can set up and run the Cloudflare Docs ChatGPT Plugin by following the read me in the example repo.
The plugin was built entirely on Workers and uses KV as a vector store. It can also keep its index up-to-date using Cron Triggers, Queues and Durable Objects.
The plugin is a Worker that responds to POST requests from ChatGPT to a /query endpoint. When a query comes in, the Worker converts the query text into an embedding vector via the OpenAI embeddings API and uses this to find, and return, the most relevant document snippets from Cloudflare’s developer documentation.
The way this is achieved is by first converting every document in Cloudflare’s developer documentation on GitHub into embedding vectors (again using OpenAI’s API) and storing them in KV. This storage format allows you to find semantically similar content by doing a similarity search (we use cosine similarity), where two pieces of text that are similar in meaning will result in the two embedding vectors having a high similarity score. Cloudflare’s entire developer documentation compresses to under 5MB when converted to embedding vectors, so fetching these from KV is very quick. We’ve also explored building larger vector stores on Workers, as can be seen in this demo of 1 million vectors stored on Durable Object storage. We’ll be releasing more open source libraries to support these vector store use cases in the near future.
So ChatGPT will query the plugin when it believes the user’s question is related to Cloudflare’s developer tools, and the plugin will return a list of up-to-date information snippets directly from our documentation. ChatGPT can then decide how to use these snippets to best answer the user’s question.
The plugin also includes a “Scheduler” Worker that can periodically refresh the documentation embedding vectors, so that the information is always up-to-date. This is advantageous because ChatGPT’s own knowledge has a cutoff of September 2021 – so it’s not aware of changes in documentation, or new Cloudflare products.
The Scheduler Worker is triggered by a Cron Trigger, on a schedule you can set (eg, hourly), where it will check which content has changed since it last ran via GitHub’s API. It then sends these document paths in messages to a Queue to be processed. Workers will batch process these messages – for each message, the content is fetched from GitHub, and then turned into embedding vectors via OpenAI’s API. A Durable Object is used to coordinate all the Queue processing so that when all the batches have finished processing, the resulting embedding vectors can be combined and stored in KV, ready for querying by the plugin.
This is a great example of how Workers can be used not only for front-facing HTTP APIs, but also for scheduled batch-processing use cases.
Let us know what you think
We are in a time when technology is constantly changing and evolving, so as you experiment with these new plugins please let us know what you think. What do you like? What could be better? Since ChatGPT plugins are in alpha, changes to the plugins user interface or performance (i.e. latency) may occur. If you build your own plugin, we’d love to see it and if it’s open source you can submit a pull request on our example repo. You can always find us hanging out in our developer discord.
The 1947 paper titled “Preparation of Problems for EDVAC-Type Machines” talks about the idea and usefulness of a “subroutine”. At the time there were only a tiny number of computers worldwide and subroutines were a novel idea, and it was clear that these subroutines were going to make programmers more productive: “Many operations which are thus excluded from the built-in set are still of sufficiently frequent occurrence to make undesirable the repetition of their coding in detail.”
Looking back it seems amazing that subroutines had to be invented, but at the time programmers wrote literally everything they needed to complete a task. That made programming slow, error-prone and restricted who could be a programmer to a relatively small group of people.
Luckily, things changed.
You can look at the history of computer programming as improvements in programmer productivity and widening the scope of who is a programmer. Think of syntax highlighting, high-level languages, IDEs, libraries and frameworks, APIs, Visual Basic, code completion, refactoring tools, spreadsheets, and so on.
And here we are with things changing again.
The new programmers
The recent arrival of LLMs capable of assisting programmers in writing, debugging and modifying code is yet another step. It’s a step at both making programmers more productive and helping more people be programmers.
As programmers a lot of what we do is arcane.
Sure, we have helped create the modern world, but we spend a lot of time on things that actually exclude many from being programmers. Think of how many times you’ve messed up syntax, misinterpreted the result of calling a function, or made an off-by-one error in a loop.
And we’re expected to operate at a concrete and abstract level simultaneously. We hold the architecture and state of a system in our heads, imagining the program as data flows through it, and worry about a missing semicolon.
This is, frankly, weird.
That weirdness is partly why the children’s programming language Scratch eliminates much of the arcana. It’s designed to stop the user making small mistakes that add up to not making progress on a program. Its on-screen shapes are designed to show how a program flows and loops. What if AI eliminates much of our odd work and lets people concentrate on the thing they are creating?
I think that would be wonderful and would open the world of programming to many, many more people. But we’re not there yet. We’re at the point where AIs are hugely helpful assistants in the traditional art of programming. And this week Cloudflare will introduce its own AI assistants to make programmers using Cloudflare Workers much more productive. And these assistants are going to help more people use the Cloudflare Developer Platform.
The new platforms
A developer platform without AI isn’t going to be much use. It’ll be a bit like a developer platform that can’t do floating point arithmetic, or handle a list of data. We’re going to see every developer platform have AI capability built in because these capabilities will allow developers to make richer experiences for users.
If you’ve used a phone’s picture library recently you’ve probably discovered that you can search by what’s in an image. Type ‘cat’ and you can see all the cat pictures you’ve taken. Image classification like this is an example of the sort of functionality that a developer platform should provide so that a programmer can build a productive and exciting experience for their users.
That’s why this week we’ll be announcing AI features built directly into the Cloudflare Workers platform so that developers have a rich toolset at their disposal. And they’ll be able to train and upload their own models to run on our global network.
AI systems, by their nature, require a lot of data both for training and for executing models. Think giga- to petabytes. And a lot of that data needs to move around. Unlike a database where data might largely be stored and accessed infrequently, AI systems are alive with moving data.
To accommodate that, platforms need to stop treating data as something to lock in developers with. Data needs to be free to move from system to system, from platform to platform, without transfer fees, egress or other nonsense. If we want a world of AI, we need a world of data fluidity. We’ll look this week at how Cloudflare (including our R2) enables that.
I like to think (it has to be!)
As I look back at 40 years of my programming life, I haven’t been this excited about a new technology… ever. That’s because AI is going to be a pervasive change to how programs get written, who writes programs and how all of us interact with software.
In a talk, Andrew Ng called AI “The New Electricity”. Does that seem exaggerated? I don’t think so. Electricity utterly altered work and life for everyone and has become so much part of life that when electricity supplies fail it’s a shock.
AI is going to have a similarly profound effect on the way we live and work, and will be equally pervasive. And AI is already here, not just in the form of ChatGPT and Google Bard, but through machine translation, agents like Siri and Alexa, and a myriad of unseen systems that do something humans can’t do: keep up with the speed of the Internet helping to protect it and us.
And, I predict, AI is going to help people be smarter. That effect has already been seen with the ancient game Go. In 2016, one of the world’s strongest Go players, Lee Sedol, was beaten by AlphaGo and later retired. But something interesting has happened: Go players playing against AI are getting stronger. Humans are learning new strategies and improving.
I think AI has the potential to do that for all of us. And for programmers I think it’ll make us more productive and make more people programmers.
Which makes me wonder what a 2047 paper entitled “Preparation of Programs for NEURAL-Type Machines” will introduce. What new exciting way of programming is there for us to discover in the next few years? What cybernetic ecology will be created that makes the flow of ideas from the brain to silicon so much quicker?
It is an incredibly exciting time to be a developer.
The frameworks, libraries and developer tools we depend on keep leveling up in ways that allow us to build more efficiently. On top of that, we’re using AI-powered tools like ChatGPT and GitHub Copilot to ship code quicker than many of us ever could have imagined. This all means we’re spending less time on boilerplate code and setup, and more time writing the code that makes our applications unique.
It’s not only a time when we’re equipped with the tools to be successful in new ways, but we're also finding inspiration in what’s happening around us. It feels like every day there’s an advancement with AI that changes the boundaries of what we can build. Across meetups, conferences, chat rooms, and every other place we gather as developers, we’re pushing each other to expand our ideas of what is possible.
With so much excitement permeating through the global developer community, we couldn’t imagine a better time to be kicking off Developer Week here at Cloudflare.
A focus on developer experience
A big part of any Innovation Week at Cloudflare is bringing you all new products to play with. And this year will be no different, there will be plenty of new products coming your way over the next seven days, and we can’t wait for you to get your hands on them. But we know that for developers it can sometimes be more exciting to see a tool you already use upgrade its developer experience than to get something new. That’s why as we’ve planned for this Developer Week we have been particularly focused on how we can make our developer experience more seamless by addressing many of your most requested features & fixes.
Part of making our developer experience more seamless is ensuring you all can bring the technologies you already know and love to Cloudflare. We’ve especially heard this from you all when it comes to deploying JAMstack applications on Cloudflare. Without spoiling too much, if you’re using a frontend framework and building JAMstack applications we’re excited about what we’re shipping for you this week.
A platform born in the Age of AI
We want developers to be able to build anything they’re excited about on Cloudflare. And one thing a lot of us are excited about right now are AI applications. AI is something that’s been part of Cloudflare’s foundation since the beginning. We are a company that was born in the age of AI. A core part of how we work towards our mission to help build a better Internet is by using machine learning to help protect your applications.
Through this week, we want to empower you with the tools and wisdom we’ve gathered around AI and machine learning. As well as showing you how to use Cloudflare with some of your new favorite AI developer tools. We’ll be shipping sample code, tutorials, tips and best practices. And that wisdom won’t only be coming from us, we’ll be sharing the stories of customers who have built on us and give you all an opportunity to learn from the companies that inspire us.
Why I joined Cloudflare
This is special Developer Week for me because it’s my first Developer Week at Cloudflare. I joined a little over a month ago to lead our Developer Relations & Community team.
When I found out I was joining Cloudflare I called up one of my closest friends, and mentors, to share the news. He immediately said “What are you going to do? Developers are all already using Cloudflare. No matter how big or small of a project I build, I always use Cloudflare. It’s the last thing I set up before I deploy.” He couldn’t have set the stage better for me to share why I’m excited to join and a theme you’ll see throughout this week.
For many developers, you know us for our CDN, and we are one of the last pieces of infrastructure you set up for your project. Since we launched Cloudflare Workers in 2017, we’ve been shipping tools intended to help empower you not only at the end of your journey, but from the moment you start building a new project. Myself, and my team, are here to help you discover and be successful with all of our developers tools. We’ll be here from the moment you start building, when you go into production and all the way through when you’re scaling your application to millions of users around the world.
Whether you are one of the over one million developers already building on Cloudflare or you’re starting to use us for the first time during this Developer Week, I can’t wait to meet you.
Welcome to Developer Week 2023
We’re excited to kick off another Developer Week. Through this week we’ll tell you about the new tools we’re shipping and share how many of them were built. We’ll show you how you can use them, and share stories from customers who are using our developer platform today. We hope you’ll be part of the conversation, whether that’s on discord, Cloudflare TV, community.cloudflare.com, or social media.
Today, we're open-sourcing our ChatGPT Plugin Quickstart repository for Cloudflare Workers, designed to help you build awesome and versatile plugins for ChatGPT with ease. If you don’t already know, ChatGPT is a conversational AI model from OpenAI which has an uncanny ability to take chat input and generate human-like text responses.
With the recent addition of ChatGPT plugins, developers can create custom extensions and integrations to make ChatGPT even more powerful. Developers can now provide custom flows for ChatGPT to integrate into its conversational workflow – for instance, the ability to look up products when asking questions about shopping, or retrieving information from an API in order to have up-to-date data when working through a problem.
That's why we're super excited to contribute to the growth of ChatGPT plugins with our new Quickstart template. Our goal is to make it possible to build and deploy a new ChatGPT plugin to production in minutes, so developers can focus on creating incredible conversational experiences tailored to their specific needs.
How it works
Our Quickstart is designed to work seamlessly with Cloudflare Workers. Under the hood, it uses our command-line tool wrangler to create a new project and deploy it to Workers.
When building a ChatGPT plugin, there are three things you need to consider:
The plugin's metadata, which includes the plugin's name, description, and other info
The plugin's schema, which defines the plugin's input and output
The plugin's behavior, which defines how the plugin responds to user input
To handle all of these parts in a simple, easy-to-understand API, we've created the @cloudflare/itty-router-openapi package, which makes it easy to manage your plugin's metadata, schema, and behavior. This package is included in the ChatGPT Plugin Quickstart, so you can get started right away.
To show how the package works, we'll look at two key files in the ChatGPT Plugin Quickstart: index.js and search.js. The index.js file contains the plugin's metadata and schema, while the search.js file contains the plugin's behavior. Let's take a look at each of these files in more detail.
In index.js, we define the plugin's metadata and schema. The metadata includes the plugin's name, description, and version, while the schema defines the plugin's input and output.
The configuration matches the definition required by OpenAI's plugin manifest, and helps ChatGPT understand what your plugin is, and what purpose it serves.
Here's what the index.js file looks like:
import { OpenAPIRouter } from "@cloudflare/itty-router-openapi";
import { GetSearch } from "./search";
export const router = OpenAPIRouter({
schema: {
info: {
title: 'GitHub Repositories Search API',
description: 'A plugin that allows the user to search for GitHub repositories using ChatGPT',
version: 'v0.0.1',
},
},
docs_url: '/',
aiPlugin: {
name_for_human: 'GitHub Repositories Search',
name_for_model: 'github_repositories_search',
description_for_human: "GitHub Repositories Search plugin for ChatGPT.",
description_for_model: "GitHub Repositories Search plugin for ChatGPT. You can search for GitHub repositories using this plugin.",
contact_email: '[email protected]',
legal_info_url: 'http://www.example.com/legal',
logo_url: 'https://workers.cloudflare.com/resources/logo/logo.svg',
},
})
router.get('/search', GetSearch)
// 404 for everything else
router.all('*', () => new Response('Not Found.', { status: 404 }))
export default {
fetch: router.handle
}
In the search.js file, we define the plugin's behavior. This is where we define how the plugin responds to user input. It also defines the plugin's schema, which ChatGPT uses to validate the plugin's input and output.
Importantly, this doesn't just define the implementation of the code. It also automatically generates an OpenAPI schema that helps ChatGPT understand how your code works — for instance, that it takes a parameter "q", that it is of "String" type, and that it can be described as "The query to search for". With the schema defined, the handle function makes any relevant parameters available as function arguments, to implement the logic of the endpoint as you see fit.
The quickstart smooths out the entire development process, so you can focus on crafting custom behaviors, endpoints, and features for your ChatGPT plugins without getting caught up in the nitty-gritty. If you aren't familiar with API schemas, this also means that you can rely on our schema and manifest generation tools to handle the complicated bits, and focus on the implementation to build your plugin.
Besides making development a breeze, it's worth noting that you're also deploying to Workers, which takes advantage of Cloudflare's vast global network. This means your ChatGPT plugins enjoy low-latency access and top-notch performance, no matter where your users are located. By combining the strengths of Cloudflare Workers with the versatility of ChatGPT plugins, you can create conversational AI tools that are not only powerful and scalable but also cost-effective and globally accessible.
Example
To demonstrate the capabilities of our quickstarts, we've created two example ChatGPT plugins. The first, which we reviewed above, connects ChatGPT with the GitHub Repositories Search API. This plugin enables users to search for repositories by simply entering a search term, returning useful information such as the repository's name, description, star count, and URL.
One intriguing aspect of this example is the property where the plugin could go beyond basic querying. For instance, when asked "What are the most popular JavaScript projects?", ChatGPT was able to intuitively understand the user's intent and craft a new query parameter for querying both by the number of stars (measuring popularity), and the specific programming language (JavaScript) without requiring any explicit prompting. This showcases the power and adaptability of ChatGPT plugins when integrated with external APIs, providing more insightful and context-aware responses.
The second plugin uses the Pirate Weather API to retrieve up-to-date weather information. Remarkably, OpenAI is able to translate the request for a specific location (for instance, “Seattle, Washington”) into longitude and latitude values – which the Pirate Weather API uses for lookups – and make the correct API request, without the user needing to do any additional work.
With our ChatGPT Plugin Quickstarts, you can create custom plugins that connect to any API, database, or other data source, giving you the power to create ChatGPT plugins that are as unique and versatile as your imagination. The possibilities are endless, opening up a whole new world of conversational AI experiences tailored to specific domains and use cases.
Get started today
The ChatGPT Plugin Quickstarts don’t just make development a snap—it also offers seamless deployment and scaling thanks to Cloudflare Workers. With the generous free plan provided by Workers, you can deploy your plugin quickly and scale it infinitely as needed.
Our ChatGPT Plugin Quickstarts are all about sparking creativity, speeding up development, and empowering developers to create amazing conversational AI experiences. By leveraging Cloudflare Workers' robust infrastructure and our streamlined tooling, you can easily build, deploy, and scale custom ChatGPT plugins, unlocking a world of endless possibilities for conversational AI applications.
Whether you're crafting a virtual assistant, a customer support bot, a language translator, or any other conversational AI tool, our ChatGPT Plugin Quickstarts are a great place to start. We're excited to provide this Quickstart, and would love to see what you build with it. Join us in our Discord community to share what you're working on!
But for some applications, data stored in R2 doesn’t need to be retained forever. Over time, as this data grows, it can unnecessarily lead to higher storage costs. Today, we’re excited to announce that Object Lifecycle Management for R2 is generally available, allowing you to effectively manage object expiration, all from the R2 dashboard or via our API.
Object Lifecycle Management
Object lifecycles give you the ability to define rules (up to 1,000) that determine how long objects uploaded to your bucket are kept. For example, by implementing an object lifecycle rule that deletes objects after 30 days, you could automatically delete outdated logs or temporary files. You can also define rules to abort unfinished multipart uploads that are sitting around and contributing to storage costs.
Getting started with object lifecycles in R2
Cloudflare dashboard
From the Cloudflare dashboard, select R2.
Select your R2 bucket.
Navigate to the Settings tab and find the Object lifecycle rules section.
Select Add rule to define the name, relevant prefix, and lifecycle actions: delete uploaded objects or abort incomplete multipart uploads.
Select Add rule to complete the process.
S3 Compatible API
With R2’s S3-compatible API, it’s easy to apply any existing object lifecycle rules to your R2 buckets.
Here’s an example of how to configure your R2 bucket’s lifecycle policy using the AWS SDK for JavaScript. To try this out, you’ll need to generate an Access Key.
import S3 from "aws-sdk/clients/s3.js";
const client = new S3({
endpoint: `https://${ACCOUNT_ID}.r2.cloudflarestorage.com`,
credentials: {
accessKeyId: ACCESS_KEY_ID, // fill in your own
secretAccessKey: SECRET_ACCESS_KEY, // fill in your own
},
region: "auto",
});
await client
.putBucketLifecycleConfiguration({
LifecycleConfiguration: {
Bucket: "testBucket",
Rules: [
// Example: deleting objects by age
// Delete logs older than 90 days
{
ID: "Delete logs after 90 days",
Filter: {
Prefix: "logs/",
},
Expiration: {
Days: 90,
},
},
// Example: abort all incomplete multipart uploads after a week
{
ID: "Abort incomplete multipart uploads",
AbortIncompleteMultipartUpload: {
DaysAfterInitiation: 7,
},
},
],
},
})
.promise();
For more information on how object lifecycle policies work and how to configure them in the dashboard or API, see the documentation here.
Speaking of documentation, if you’d like to provide feedback for R2’s documentation, fill out our documentation survey!
What’s next?
Creating object lifecycle rules to delete ephemeral objects is a great way to reduce storage costs, but what if you need to keep objects around to access in the future? We’re working on new, lower cost ways to store objects in R2 that aren’t frequently accessed, like long tail user-generated content, archive data, and more. If you’re interested in providing feedback and gaining early access, let us know by joining the waitlist here.
Join the conversation: share your feedback and experiences
If you have any questions or feedback relating to R2, we encourage you to join our Discord community to share! Stay tuned for more exciting R2 updates in the future.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.