Since the very initial announcement of Cloudflare Workers, we’ve provided a playground. The motivation behind that being a belief that users should have a convenient, low-commitment way to play around with and learn more about Workers.
Over the last few years, while Cloudflare Workers and our Developer Platform have changed and grown, the original playground has not. Today, we’re proud to announce a revamp of the playground that demonstrates the power of Workers, along with new development tooling, and the ability to share your playground code and deploy instantly to Cloudflare’s global network.
A focus on origin Workers
When Workers was first introduced, many of the examples and use-cases centered around middleware, where a Worker intercepts a request to an origin and does something before returning a response. This includes things like: modifying headers, redirecting traffic, helping with A/B testing, or caching. Ultimately the Worker isn’t acting as an origin in these cases, it sits between the user and the destination.
While Workers are still great for these types of tasks, for the updated playground, we decided to focus on the Worker-as-origin use-case. This is where the Worker receives a request and is responsible for returning the full response. In this case, the Worker is the destination, not middle-ware. This is a great way for you to develop more complex use-cases like user interfaces or APIs.
A new editor experience
During Developer Week in May, we announced a new, authenticated dashboard editor experience powered by VSCode. Now, this same experience is available to users in the playground.
Users now have a more robust IDE experience that supports: multi-module Workers, type-checking via JSDoc comments and the `workers-types` package, pretty error pages, and real previews that update as you edit code. The new editor only supports Module syntax, which is the preferred way for users to develop new Workers.
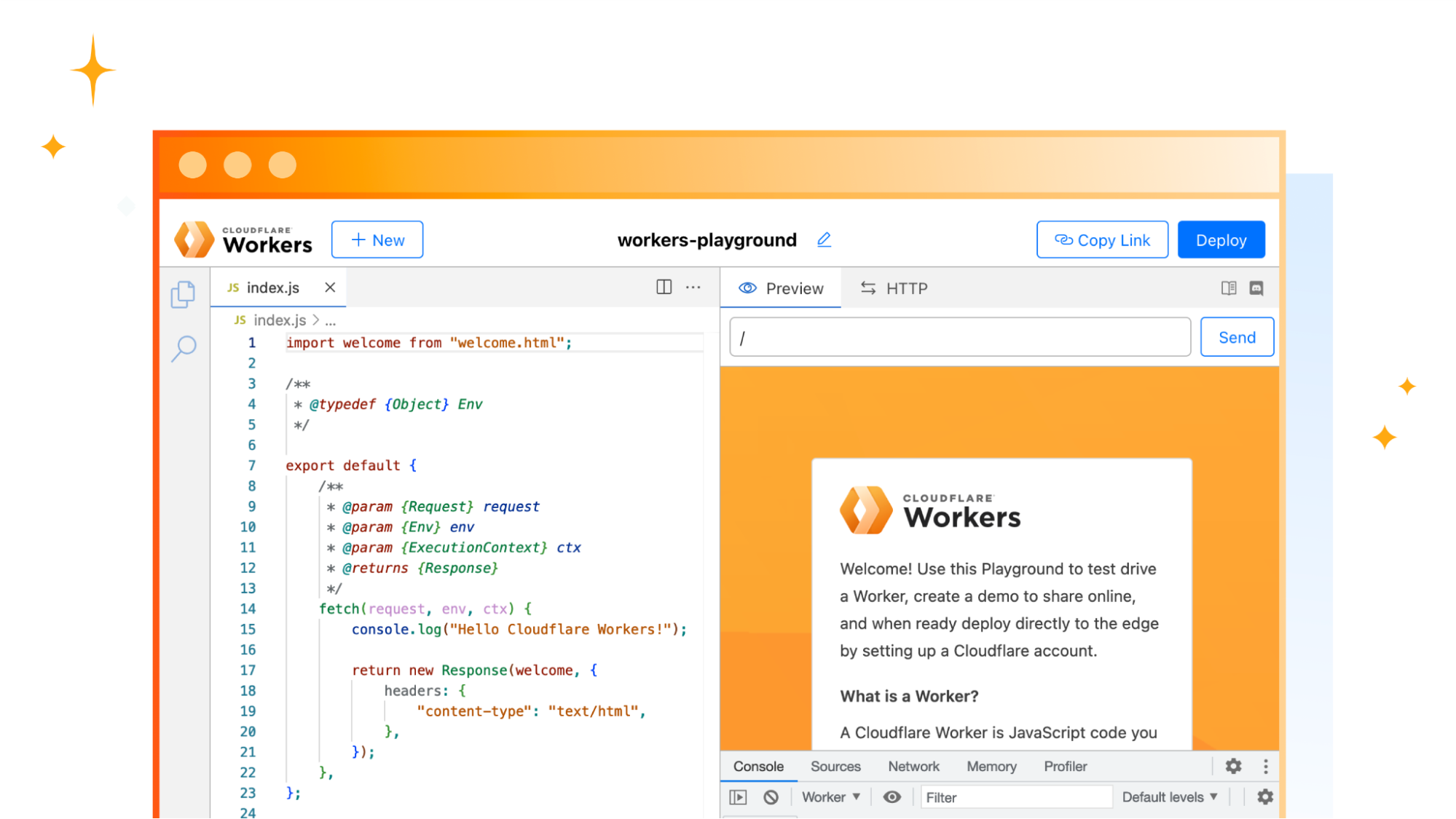
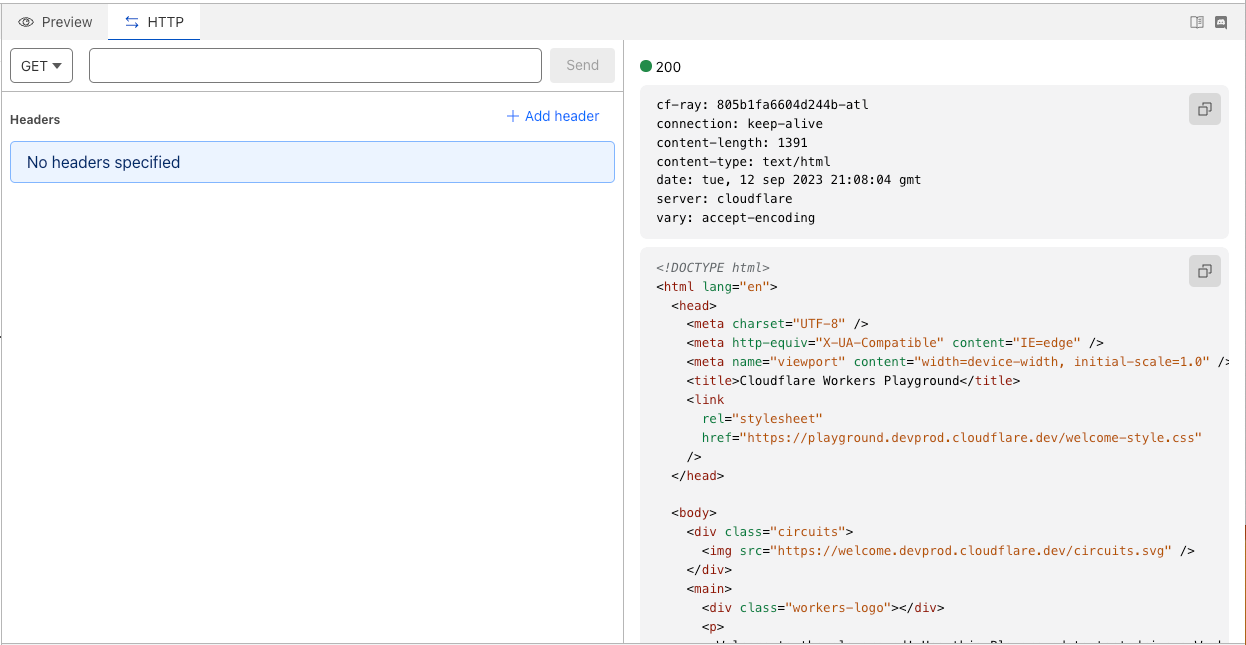
When the playground first loads, it looks like this:
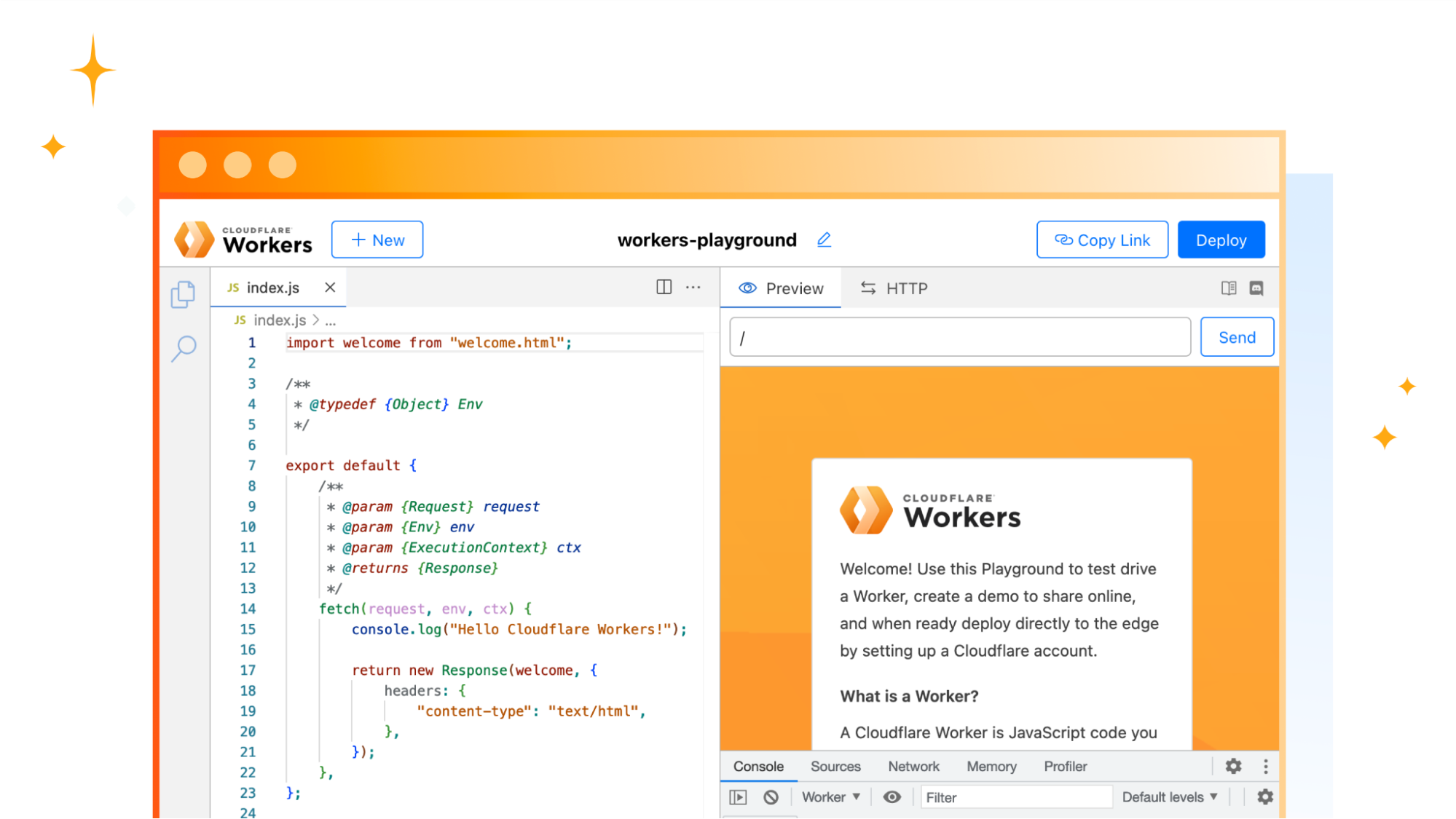
The content you see on the right is coming from the code on the left. You can modify this just as you would in a code editor. Once you make an edit, it will be updated shortly on the right as demonstrated below:
You’re not limited to the starter demo. Feel free to edit and remove those files to create APIs, user interfaces, or any other application that you come up with.
Updated developer tooling
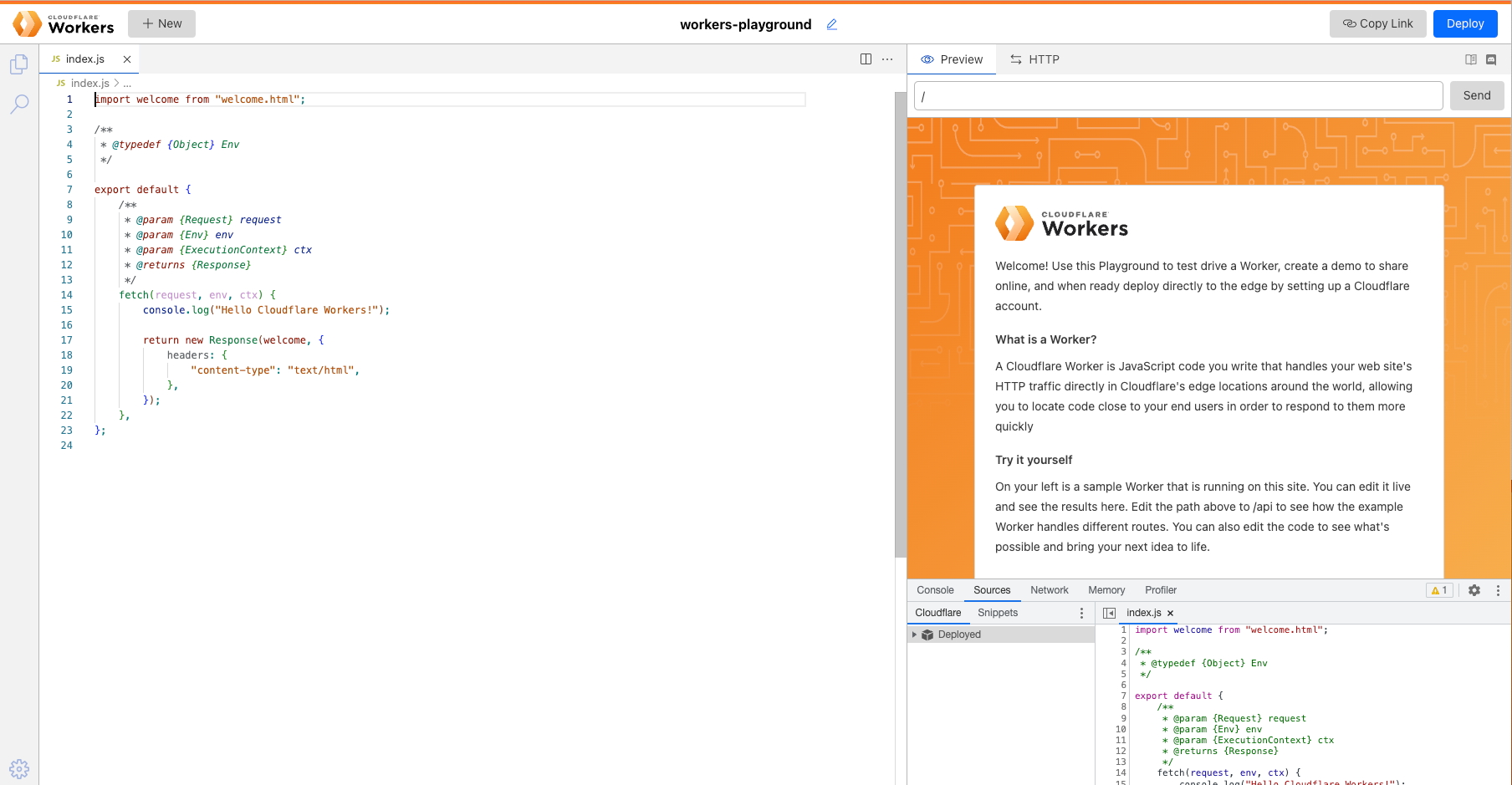
Along with the updated editor, the new playground also contains numerous developer tools to help give you visibility into the Worker.
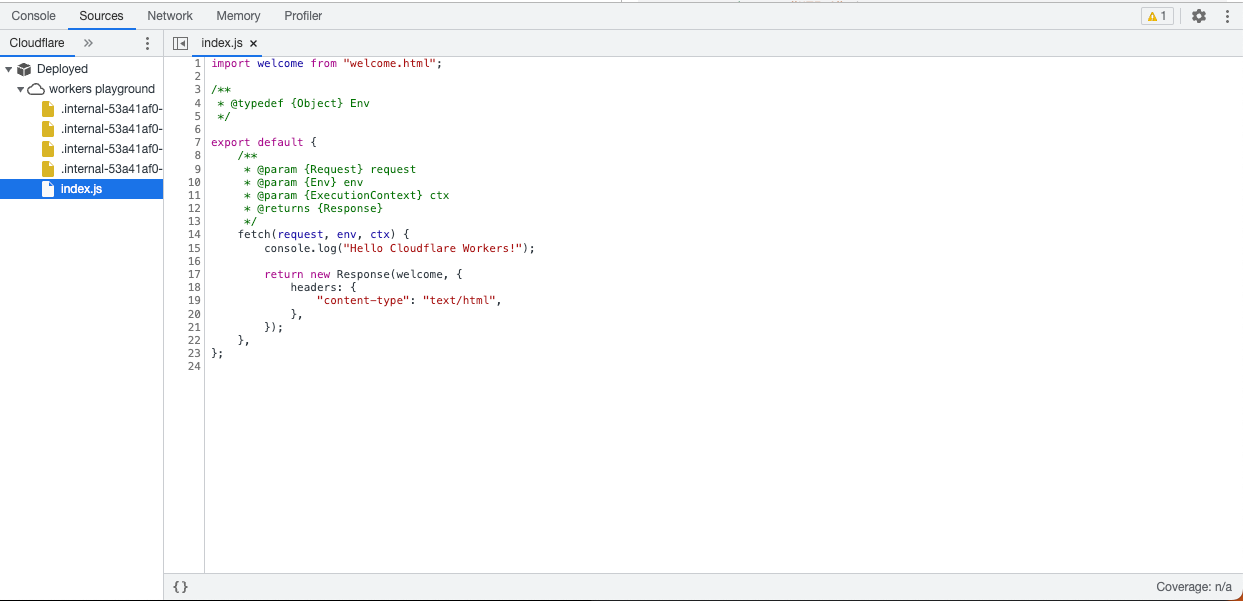
Playground users have access to the same Chrome DevTools technology that we use in the Wrangler CLI and the Dashboard. Within this view, you can: view logs, view network requests, and profile your Worker among other things.
At the top of the playground, you’ll also see an “HTTP” tab which you can use to test your Worker against various HTTP methods.
Share what you create
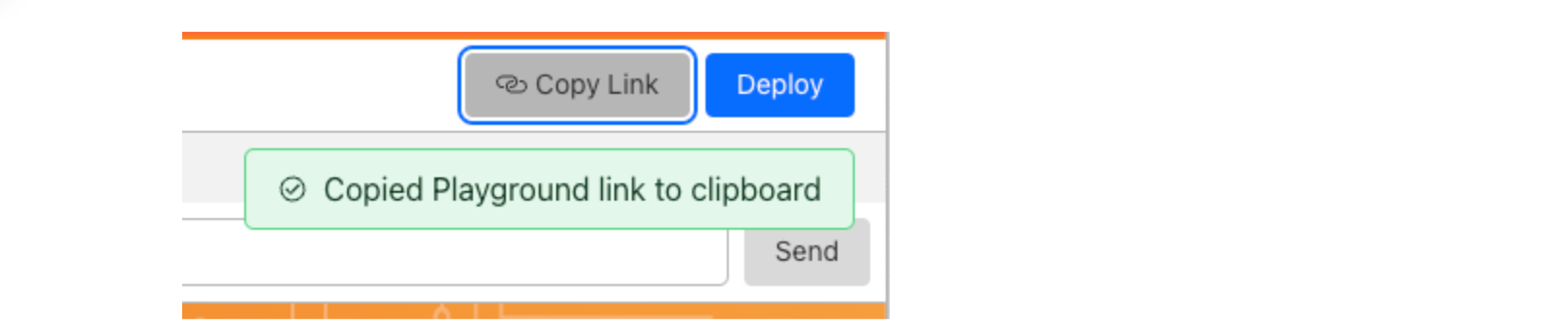
With all these improvements, we haven’t forgotten the core use of a playground—to share Workers with other people! Whatever your use-case; whether you’re building a demo to showcase the power of Workers or sending someone an example of how to fix a specific issue, all you need to do is click “Copy Link” in the top right of the Playground then paste the URL in any URL bar.
The unique URL will be shareable and deployable as long as you have it. This means that you could create quick demos by creating various Workers in the Playground, and bookmark them to share later. They won’t expire.
Deploying to the Supercloud
We also wanted to make it easier to go from writing a Worker in the Playground to deploying that Worker to Cloudflare’s global network. We’ve included a “Deploy” button that will help you quickly deploy the Worker you’ve just created.
If you don’t already have a Cloudflare account, you will also be guided through the onboarding process.
Last year, we announced the Browser Rendering API – letting users running Puppeteer, a browser automation library, directly in Workers. Puppeteer is one of the most popular libraries used to interact with a headless browser instance to accomplish tasks like taking screenshots, generating PDFs, crawling web pages, and testing web applications. We’ve heard from developers that configuring and maintaining their own serverless browser automation systems can be quite painful.
The Workers Browser Rendering API solves this. It makes the Puppeteer library available directly in your Worker, connected to a real web browser, without the need to configure and manage infrastructure or keep browser sessions warm yourself. You can use @cloudflare/puppeteer to run the full Puppeteer API directly on Workers!
We’ve seen so much interest from the developer community since launching last year. While the Browser Rendering API is still in beta (sign up to our waitlist to get access), we wanted to share a way to get more out of our current limits by using the Browser Rendering API with Durable Objects. We’ll also be sharing pricing for the Rendering API, so you can build knowing exactly what you’ll pay for.
Building a responsive web design testing tool with the Browser Rendering API
As a designer or frontend developer, you want to make sure that content is well-designed for visitors browsing on different screen sizes. With the number of possible devices that users are browsing on are growing, it becomes difficult to test all the possibilities manually. While there are many testing tools on the market, we want to show how easy it is to create your own Chromium based tool with the Workers Browser Rendering API and Durable Objects.
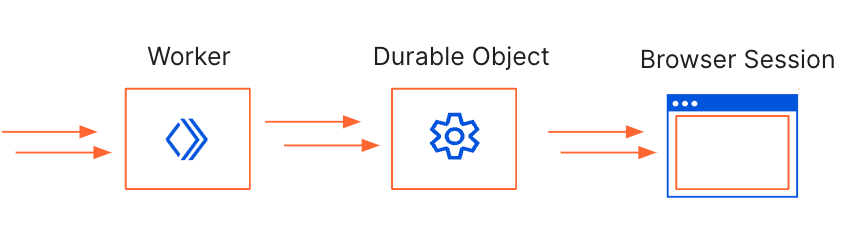
We’ll be using the Worker to handle any incoming requests, pass them to the Durable Object to take screenshots and store them in an R2 bucket. The Durable Object is used to create a browser session that’s persistent. By using Durable Object Alarms we can keep browsers open for longer and reuse browser sessions across requests.
Let’s dive into how we can build this application:
Create a Worker with a Durable Object, Browser Rendering API binding and R2 bucket. This is the resulting wrangler.toml:
name = "rendering-api-demo"
main = "src/index.js"
compatibility_date = "2023-09-04"
compatibility_flags = [ "nodejs_compat"]
account_id = "c05e6a39aa4ccdd53ad17032f8a4dc10"
# Browser Rendering API binding
browser = { binding = "MYBROWSER" }
# Bind an R2 Bucket
[[r2_buckets]]
binding = "BUCKET"
bucket_name = "screenshots"
# Binding to a Durable Object
[[durable_objects.bindings]]
name = "BROWSER"
class_name = "Browser"
[[migrations]]
tag = "v1" # Should be unique for each entry
new_classes = ["Browser"] # Array of new classes
2. Define the Worker
This Worker simply passes the request onto the Durable Object.
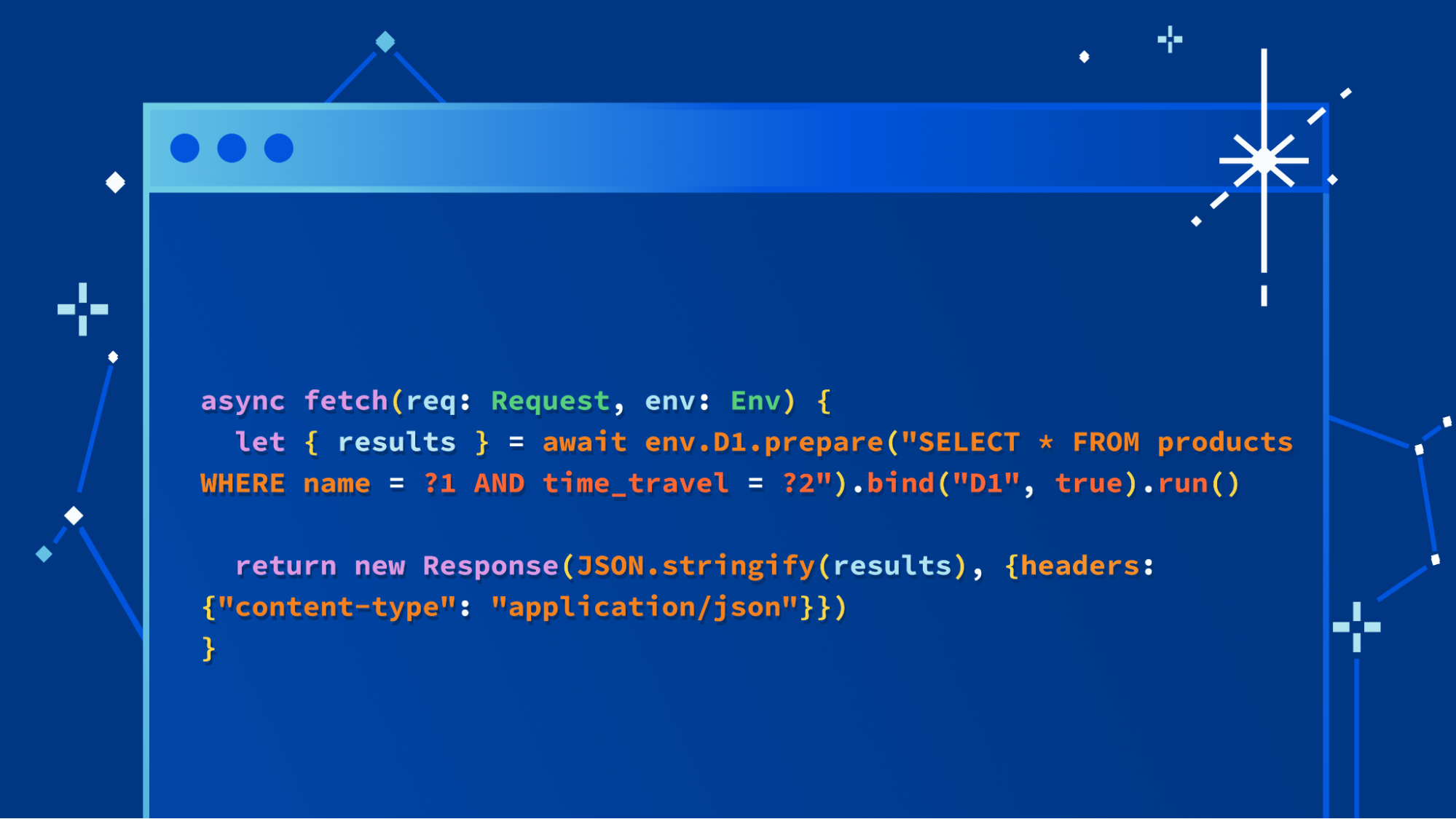
export default {
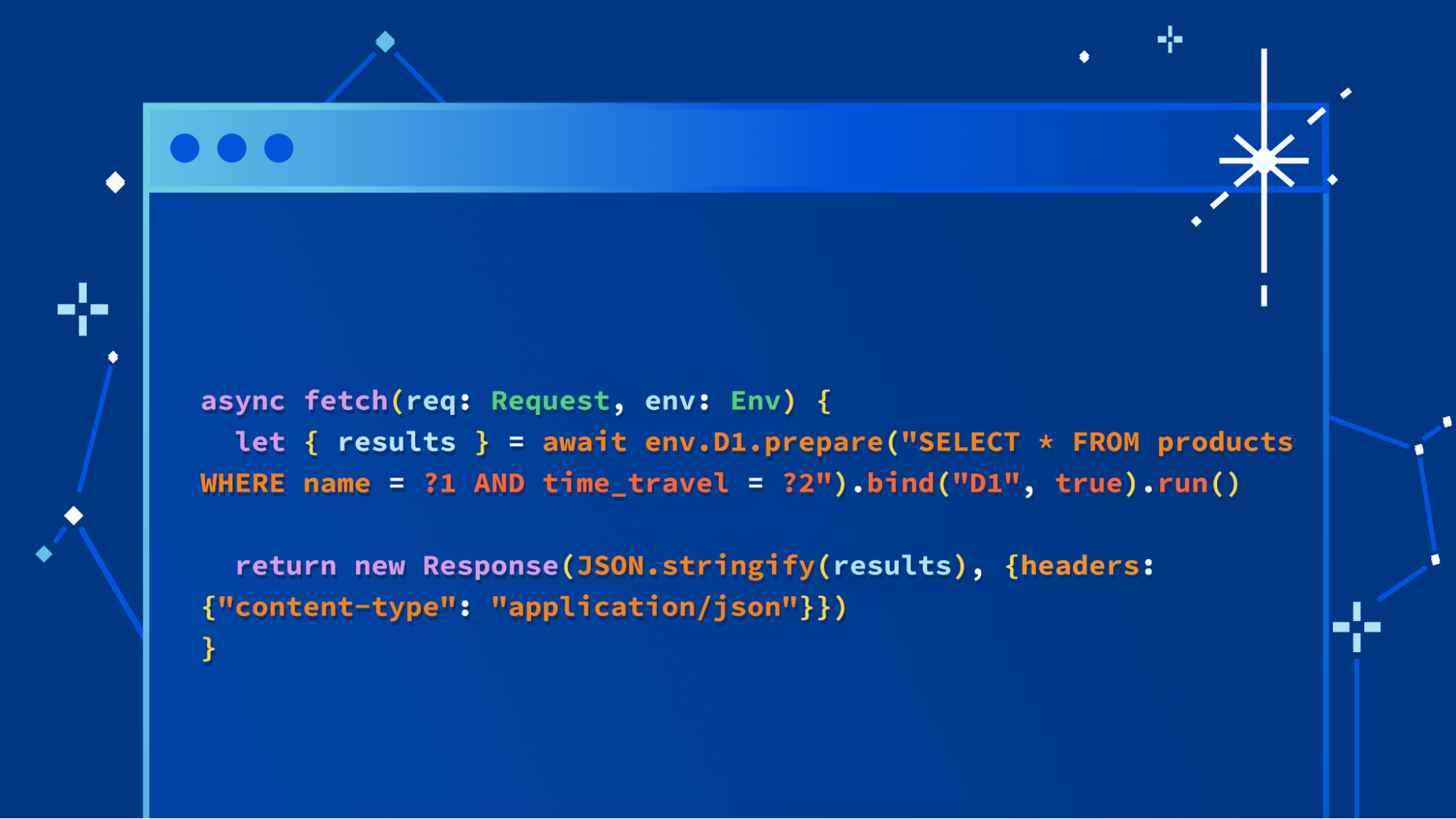
async fetch(request, env) {
let id = env.BROWSER.idFromName("browser");
let obj = env.BROWSER.get(id);
// Send a request to the Durable Object, then await its response.
let resp = await obj.fetch(request.url);
let count = await resp.text();
return new Response("success");
}
};
3. Define the Durable Object class
const KEEP_BROWSER_ALIVE_IN_SECONDS = 60;
export class Browser {
constructor(state, env) {
this.state = state;
this.env = env;
this.keptAliveInSeconds = 0;
this.storage = this.state.storage;
}
async fetch(request) {
// screen resolutions to test out
const width = [1920, 1366, 1536, 360, 414]
const height = [1080, 768, 864, 640, 896]
// use the current date and time to create a folder structure for R2
const nowDate = new Date()
var coeff = 1000 * 60 * 5
var roundedDate = (new Date(Math.round(nowDate.getTime() / coeff) * coeff)).toString();
var folder = roundedDate.split(" GMT")[0]
//if there's a browser session open, re-use it
if (!this.browser) {
console.log(`Browser DO: Starting new instance`);
try {
this.browser = await puppeteer.launch(this.env.MYBROWSER);
} catch (e) {
console.log(`Browser DO: Could not start browser instance. Error: ${e}`);
}
}
// Reset keptAlive after each call to the DO
this.keptAliveInSeconds = 0;
const page = await this.browser.newPage();
// take screenshots of each screen size
for (let i = 0; i < width.length; i++) {
await page.setViewport({ width: width[i], height: height[i] });
await page.goto("https://workers.cloudflare.com/");
const fileName = "screenshot_" + width[i] + "x" + height[i]
const sc = await page.screenshot({
path: fileName + ".jpg"
}
);
this.env.BUCKET.put(folder + "/"+ fileName + ".jpg", sc);
}
// Reset keptAlive after performing tasks to the DO.
this.keptAliveInSeconds = 0;
// set the first alarm to keep DO alive
let currentAlarm = await this.storage.getAlarm();
if (currentAlarm == null) {
console.log(`Browser DO: setting alarm`);
const TEN_SECONDS = 10 * 1000;
this.storage.setAlarm(Date.now() + TEN_SECONDS);
}
await this.browser.close();
return new Response("success");
}
async alarm() {
this.keptAliveInSeconds += 10;
// Extend browser DO life
if (this.keptAliveInSeconds < KEEP_BROWSER_ALIVE_IN_SECONDS) {
console.log(`Browser DO: has been kept alive for ${this.keptAliveInSeconds} seconds. Extending lifespan.`);
this.storage.setAlarm(Date.now() + 10 * 1000);
} else console.log(`Browser DO: cxceeded life of ${KEEP_BROWSER_ALIVE_IN_SECONDS}. Browser DO will be shut down in 10 seconds.`);
}
}
That’s it! With less than a hundred lines of code, you can fully customize a powerful tool to automate responsive web design testing. You can even incorporate it into your CI pipeline to automatically test different window sizes with each build and verify the result is as expected by using an automated library like pixelmatch.
How much will this cost?
We’ve spoken to many customers deploying a Puppeteer service on their own infrastructure, on public cloud containers or functions or using managed services. The common theme that we’ve heard is that these services are costly – costly to maintain and expensive to run.
While you won’t be billed for the Browser Rendering API yet, we want to be transparent with you about costs you start building. We know it’s important to understand the pricing structure so that you don’t get a surprise bill and so that you can design your application efficiently.
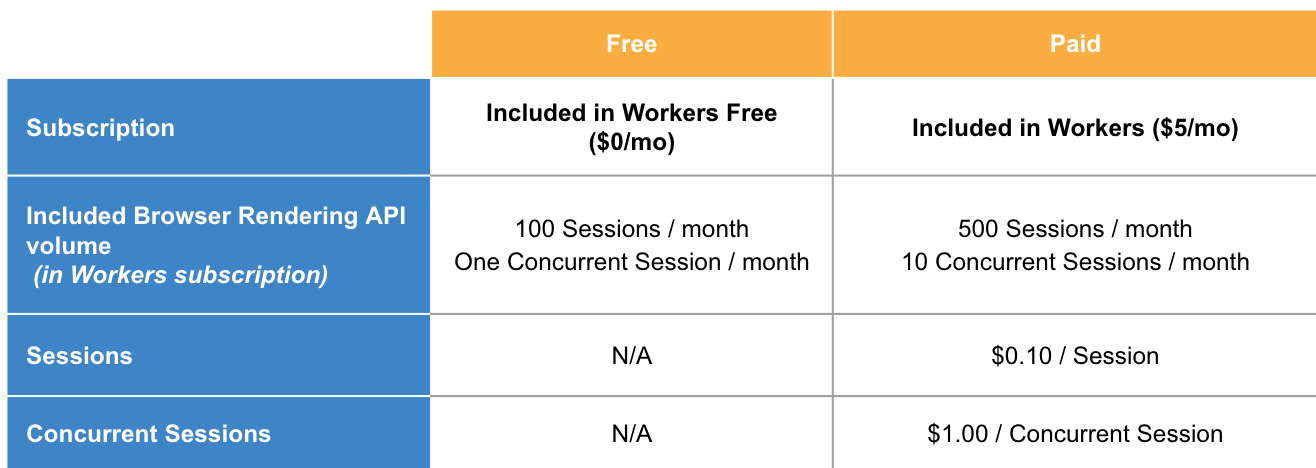
You pay based on two usage metrics:
Number of sessions: A Browser Session is a new instance of a browser being launched
Number of concurrent sessions: Concurrent Sessions is the number of browser instances open at once
Using Durable Objects to persist browser sessions improves performance by eliminating the time that it takes to spin up a new browser session. Since it re-uses sessions, it cuts down on the number of concurrent sessions needed. We highly encourage this model of session re-use if you expect to see consistent traffic for applications that you build on the Browser Rendering API.
If you have feedback about this pricing, we’re all ears. Feel free to reach out through Discord (channel name: browser-rendering-api-beta) and share your thoughts.
Get Started
Sign up to our waitlist to get access to the Workers Browser Rendering API. We’re so excited to see what you build! Share your creations with us on Twitter/X @CloudflareDev or on our Discord community.
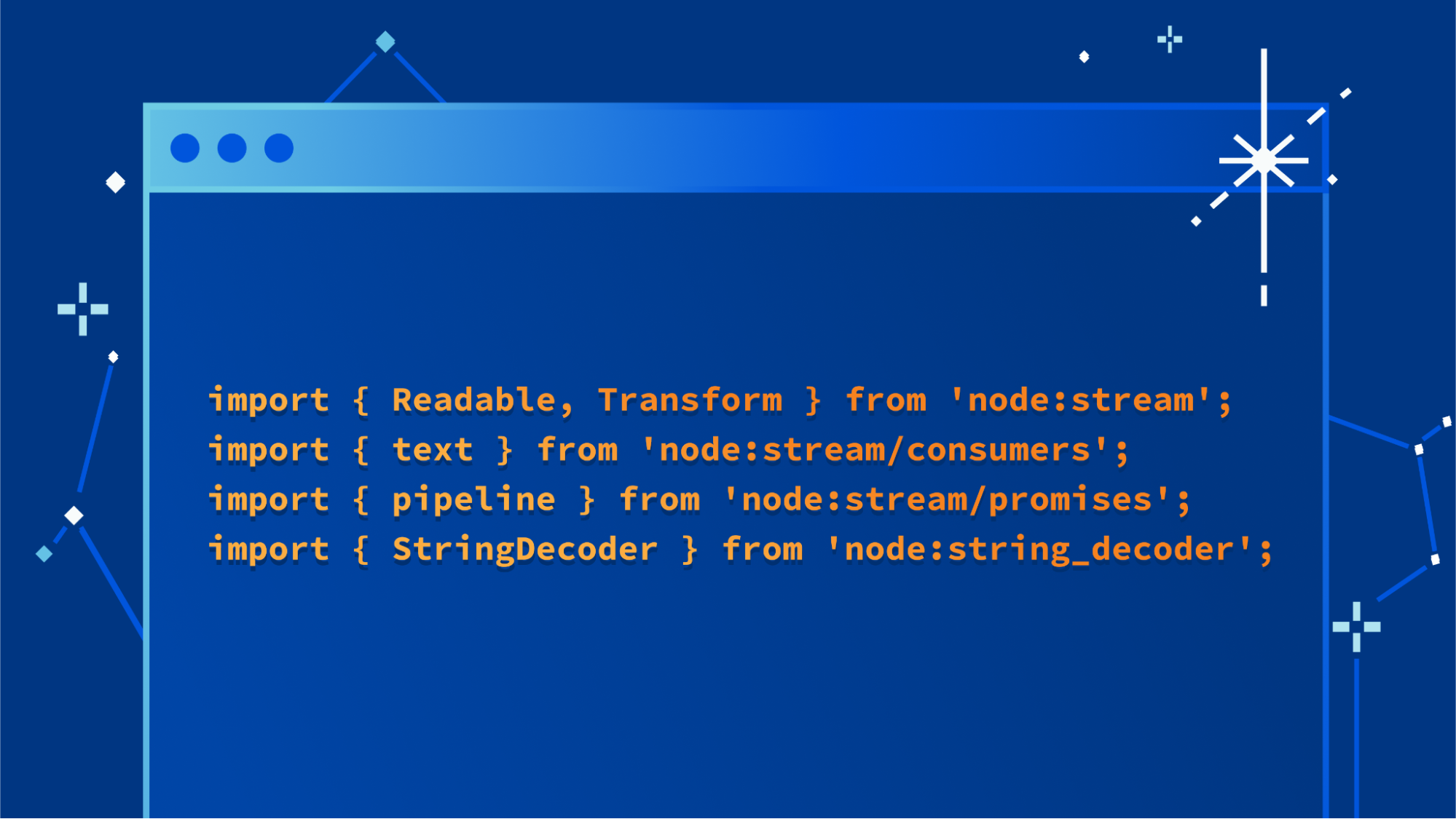
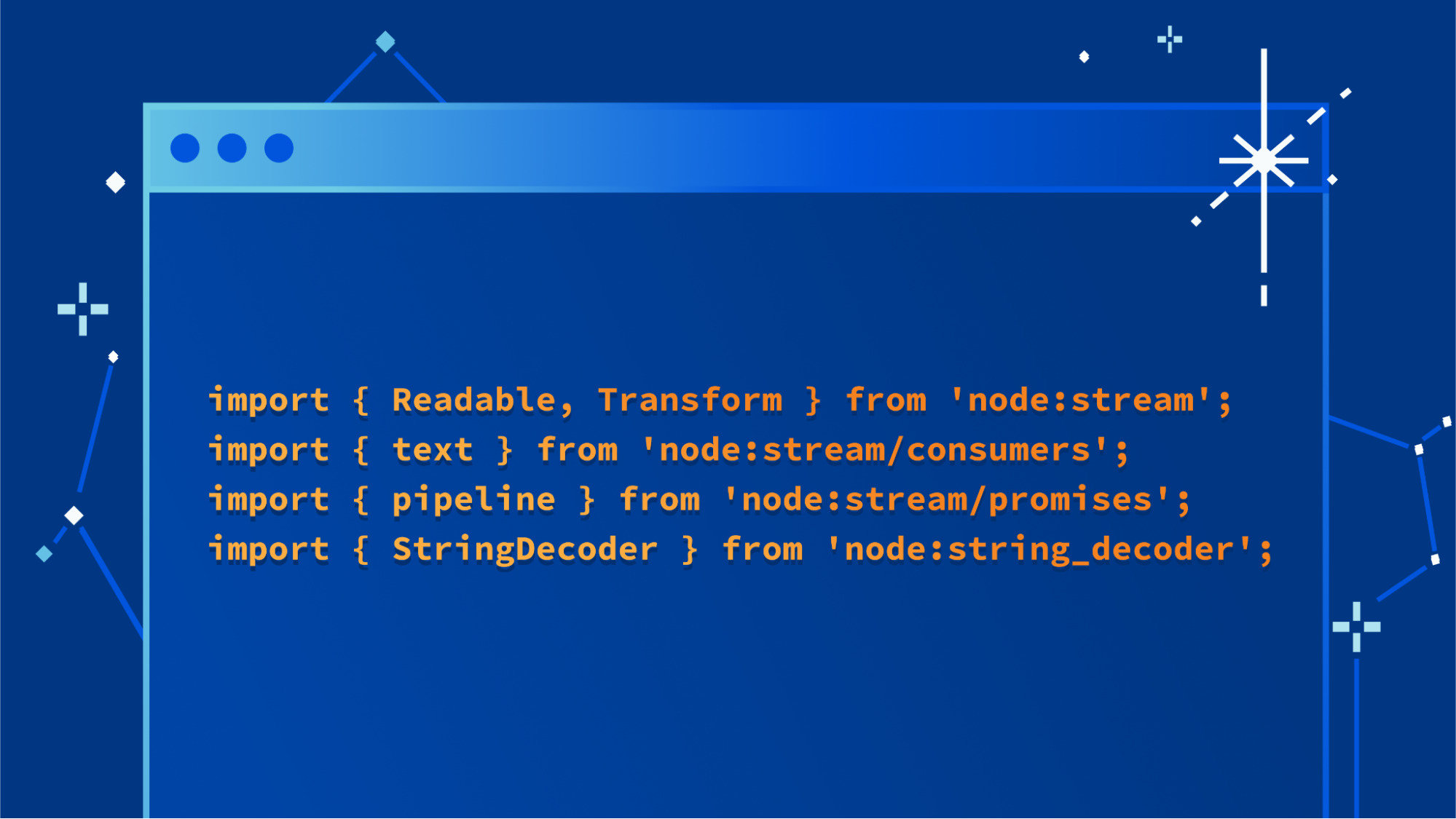
Today, we’re sharing that we’ve reached a new milestone in the path to making this API available across runtimes — engineers from Cloudflare and Vercel have published a draft specification of the connect() sockets API for review by the community, along with a Node.js compatible implementation of the connect() API that developers can start using today.
This implementation helps both application developers and maintainers of libraries and frameworks:
Maintainers of existing libraries that use the node:net and node:tls APIs can use it to more easily add support for runtimes where node:net and node:tls are not available.
JavaScript frameworks can use it to make connect() available in local development, making it easier for application developers to target runtimes that provide connect().
Why create a new standard? Why connect()?
As we described when we first announced connect(), to-date there has not been a standard API across JavaScript runtimes for creating and working with TCP or UDP sockets. This makes it harder for maintainers of open-source libraries to ensure compatibility across runtimes, and ultimately creates friction for application developers who have to navigate which libraries work on which platforms.
While Node.js provides the node:net and node:tls APIs, these APIs were designed over 10 years ago in the very early days of the Node.js project and remain callback-based. As a result, they can be hard to work with, and expose configuration in ways that don’t fit serverless platforms or web browsers.
The connect() API fills this gap by incorporating the best parts of existing socket APIs and prior proposed standards, based on feedback from the JavaScript community — including contributors to Node.js. Libraries like pg (node-postgres on Github) are already using the connect() API.
The proposed API is Promise-based and reuses existing standards whenever possible. For example, ReadableStream and WritableStream are used for the read and write ends of the socket. This makes it easy to pipe data from a TCP socket to any other library or existing code that accepts a ReadableStream as input, or to write to a TCP socket via a WritableStream.
The entrypoint of the API is the connect() function, which takes a string containing both the hostname and port separated by a colon, or an object with discrete hostname and port fields. It returns a Socket object which represents a socket connection. An instance of this object exposes attributes and methods for working with the connection.
A connection can be established in plain-text or TLS mode, as well as a special “starttls” mode which allows the socket to be easily upgraded to TLS after some period of plain-text data transfer, by calling the startTls() method on the Socket object. No need to create a new socket or switch to using a separate set of APIs once the socket is upgraded to use TLS.
For example, to upgrade a socket using the startTLS pattern, you might do something like this:
import { connect } from "@arrowood.dev/socket"
const options = { secureTransport: "starttls" };
const socket = connect("address:port", options);
const secureSocket = socket.startTls();
// The socket is immediately writable
// Relies on web standard WritableStream
const writer = secureSocket.writable.getWriter();
const encoder = new TextEncoder();
const encoded = encoder.encode("hello");
await writer.write(encoded);
Equivalent code using the node:net and node:tls APIs:
import net from 'node:net'
import tls from 'node:tls'
const socket = new net.Socket(HOST, PORT);
socket.once('connect', () => {
const options = { socket };
const secureSocket = tls.connect(options, () => {
// The socket can only be written to once the
// connection is established.
// Polymorphic API, uses Node.js streams
secureSocket.write('hello');
}
})
Use the Node.js implementation of connect() in your library
To make it easier for open-source library maintainers to adopt the connect() API, we’ve published an implementation of connect() in Node.js that allows you to publish your library such that it works across JavaScript runtimes, without having to maintain any runtime-specific code.
To get started, install it as a dependency:
npm install --save @arrowood.dev/socket
And import it in your library or application:
import { connect } from "@arrowood.dev/socket"
What’s next for connect()?
The wintercg/proposal-sockets-api is published as a draft, and the next step is to solicit and incorporate feedback. We’d love your feedback, particularly if you maintain an open-source library or make direct use of the node:net or node:tls APIs.
Once feedback has been incorporated, engineers from Cloudflare, Vercel and beyond will be continuing to work towards contributing an implementation of the API directly to Node.js as a built-in API.
Building modern full-stack applications requires connecting to many hosted third party services, from observability platforms to databases and more. All too often, this means spending time doing busywork, managing credentials and writing glue code just to get started. This is why we’re building out the Cloudflare Integrations Marketplace to allow developers to easily discover, configure and deploy products to use with Workers.
Earlier this year, we introduced integrations with Supabase, PlanetScale, Neon and Upstash. Today, we are thrilled to introduce our newest additions to Cloudflare’s Integrations Marketplace – Sentry, Turso and Momento.
Let's take a closer look at some of the exciting integration providers that are now part of the Workers Integration Marketplace.
Improve performance and reliability by connecting Workers to Sentry
When your Worker encounters an error you want to know what happened and exactly what line of code triggered it. Sentry is an application monitoring platform that helps developers identify and resolve issues in real-time.
The Workers and Sentry integration automatically sends errors, exceptions and console.log() messages from your Worker to Sentry with no code changes required. Here’s how it works:
You enable the integration from the Cloudflare Dashboard.
The credentials from the Sentry project of your choice are automatically added to your Worker.
You can configure sampling to control the volume of events you want sent to Sentry. This includes selecting the sample rate for different status codes and exceptions.
Cloudflare deploys a Tail Worker behind the scenes that contains all the logic needed to capture and send data to Sentry.
Like magic, errors, exceptions, and log messages are automatically sent to your Sentry project.
In the future, we’ll be improving this integration by adding support for uploading source maps and stack traces so that you can pinpoint exactly which line of your code caused the issue. We’ll also be tying in Workers deployments with Sentry releases to correlate new versions of your Worker with events in Sentry that help pinpoint problematic deployments. Check out our developer documentation for more information.
Develop at the Data Edge with Turso + Workers
Turso is an edge-hosted, distributed database based on libSQL, an open-source fork of SQLite. Turso focuses on providing a global service that minimizes query latency (and thus, application latency!). It’s perfect for use with Cloudflare Workers – both compute and data are served close to users.
Turso follows the model of having one primary database with replicas that are located globally, close to users. Turso automatically routes requests to a replica closest to where the Worker was invoked. This model works very efficiently for read heavy applications since read requests can be served globally. If you’re running an application that has heavy write workloads, or want to cut down on replication costs, you can run Turso with just the primary instance and use Smart Placement to speed up queries.
The Turso and Workers integration automatically pulls in Turso API credentials and adds them as secrets to your Worker, so that you can start using Turso by simply establishing a connection using the libsql SDK. Get started with the Turso and Workers Integration today by heading to our developer documentation.
Cache responses from data stores with Momento
Momento Cache is a low latency serverless caching solution that can be used on top of relational databases, key-value databases or object stores to get faster load times and better performance. Momento abstracts details like scaling, warming and replication so that users can deploy cache in a matter of minutes.
The Momento and Workers integration automatically pulls in your Momento API key using an OAuth2 flow. The Momento API key is added as a secret in Workers and, from there, you can start using the Momento SDK in Workers. Head to our developer documentation to learn more and use the Momento and Workers integration!
Try integrations out today
We want to give you back time, so that you can focus less on configuring and connecting third party tools to Workers and spend more time building. We’re excited to see what you build with integrations. Share your projects with us on Twitter (@CloudflareDev) and stay tuned for more exciting updates as we continue to grow our Integrations Marketplace!
If you would like to build an integration with Cloudflare Workers, fill out the integration request form and we’ll be in touch.
Today we are announcing new pricing for Cloudflare Workers and Pages Functions, where you are billed based on CPU time, and never for the idle time that your Worker spends waiting on network requests and other I/O. Unlike other platforms, when you build applications on Workers, you only pay for the compute resources you actually use.
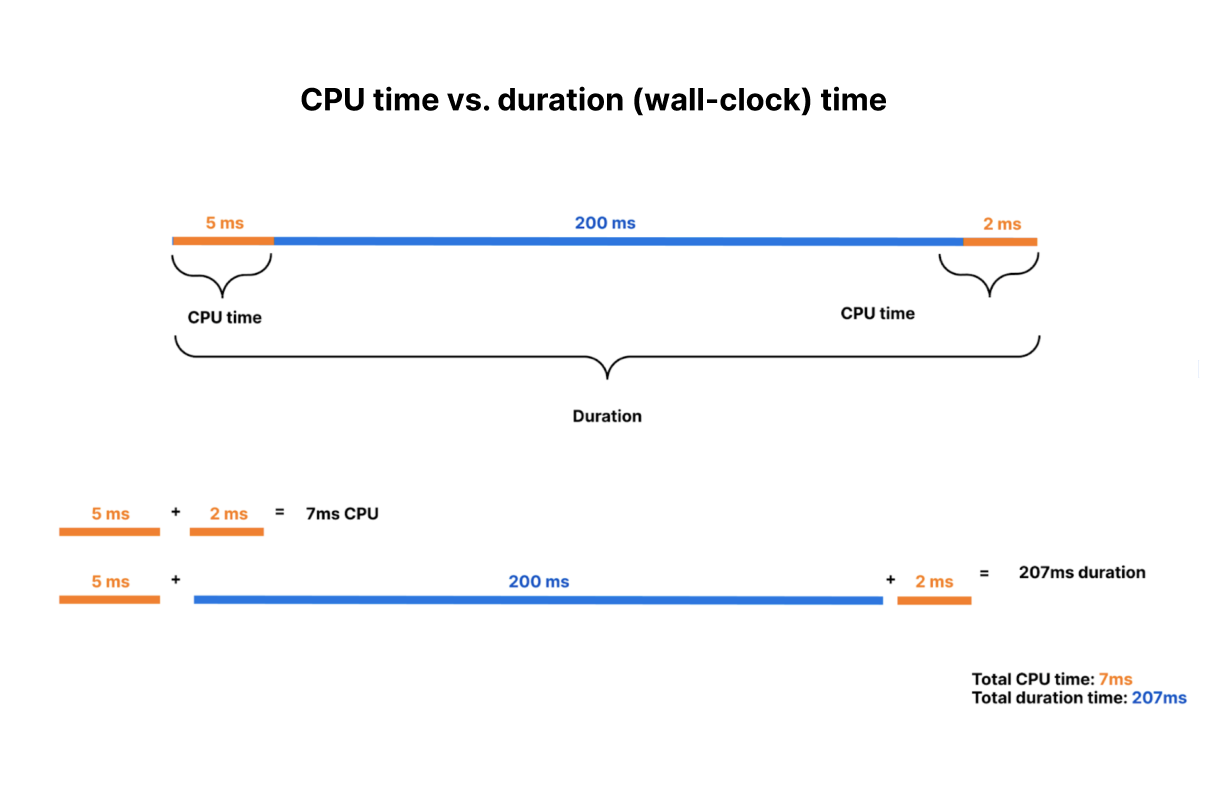
Why is this exciting? To date, all large serverless compute platforms have billed based on how long your function runs — its duration or “wall time”. This is a reflection of a new paradigm built on a leaky abstraction — your code may be neatly packaged up into a “function”, but under the hood there’s a virtual machine (VM). A VM can’t be paused and resumed quickly enough to execute another piece of code while it waits on I/O. So while a typical function might take 100ms to run, it might typically spend only 10ms doing CPU work, like crunching numbers or parsing JSON, with the rest of time spent waiting on I/O.
This status quo has meant that you are billed for this idle time, while nothing is happening.
With this announcement, Cloudflare is the first and only global serverless platform to offer standard pricing based on CPU time, rather than duration. We think you should only pay for the compute time you actually use, and that’s how we’re going to bill you going forward.
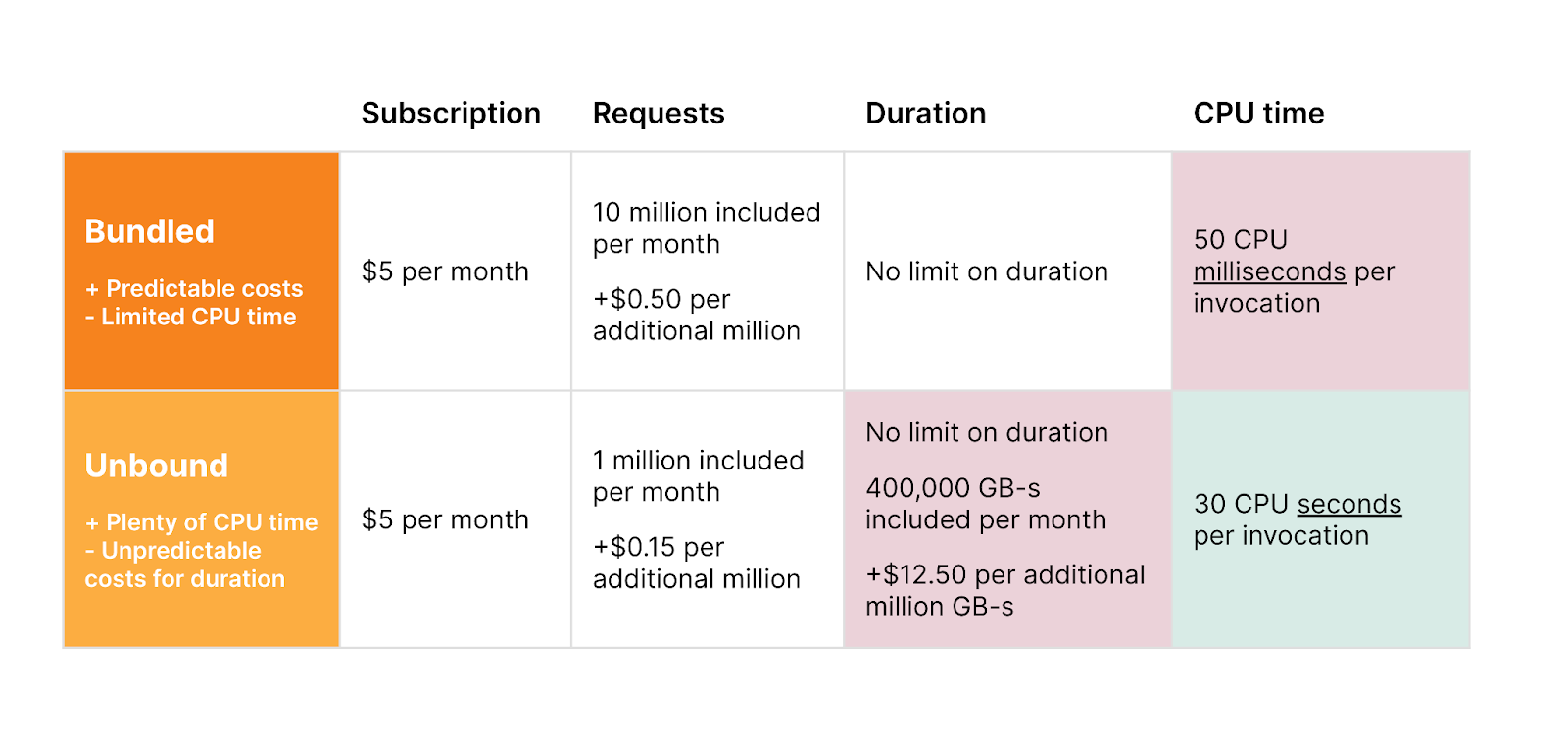
Old pricing — two pricing models, each with tradeoffs
New pricing — one simple and predictable pricing model
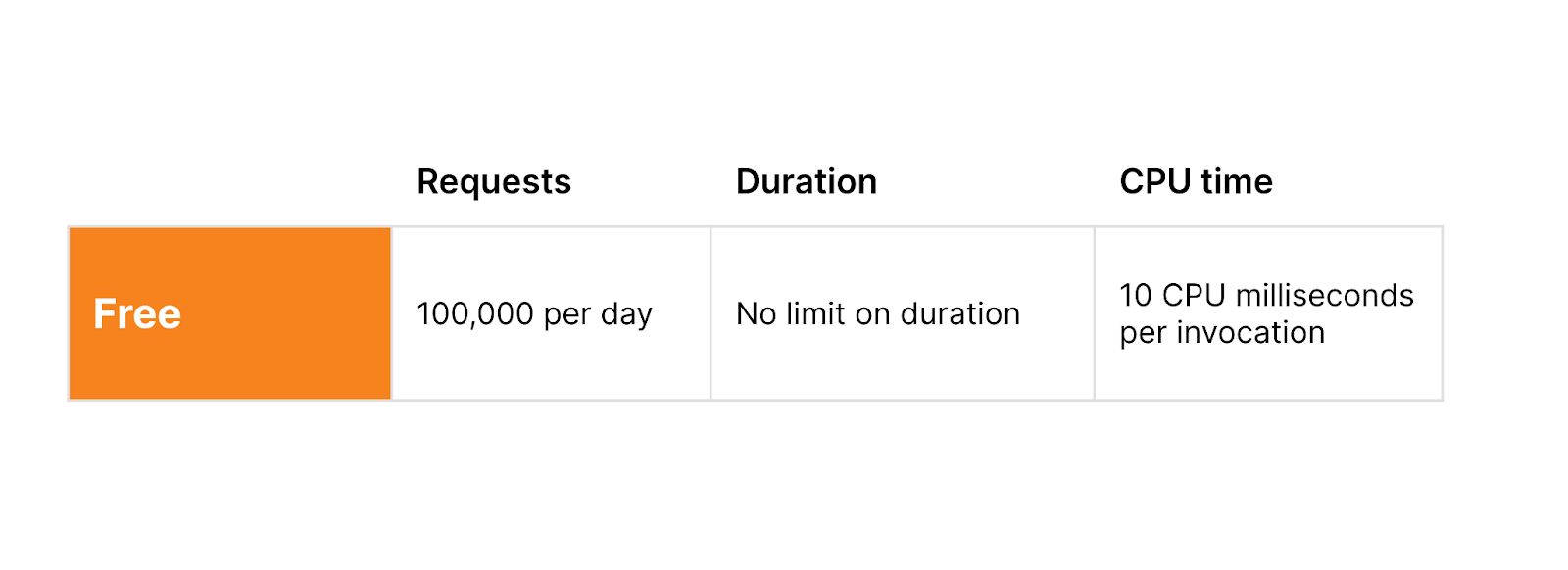
With the same generous Free plan
Unlike wall time (duration, or GB-s), CPU time is more predictable and under your control. When you make a request to a third party API, you can’t control how long that API takes to return a response. This time can be quite long, and vary dramatically — particularly when building AI applications that make inference requests to LLMs. If a request takes twice as long to complete, duration-based billing means you pay double. By contrast, CPU time is consistent and unaffected by time spent waiting on I/O — purely a function of the logic and processing of inputs on outputs to your Worker. It is entirely under your control.
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You’ll be able to estimate how much new pricing will cost in the Cloudflare dashboard. For the majority of current applications, new pricing is the same or less expensive than the previous Bundled and Unbound pricing plans.
If you’re on our Workers Paid plan, you will have until March 1, 2024 to switch to the new pricing on your own, after which all of your projects will be automatically migrated to new pricing. If you’re an Enterprise customer, any contract renewals after March 1, 2024, will use the new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect. And since CPU time is fully in your control, the more you optimize your Worker’s compute time, the less you’ll pay. Your incentives are aligned with ours, to make efficient use of compute resources on Region: Earth.
The challenge of truly scaling to zero
The beauty of serverless is that it allows teams to focus on what matters most — delivering value to their customers, rather than managing infrastructure. It saves you money by effortlessly scaling up and down all over the world based on your traffic, whether you’re an early stage startup or Shopify during Black Friday.
One of the promises of serverless is the idea of scaling to zero — once those big days subside, you no longer have to pay for virtual machines to sit idle before your autoscaling kicks in, or be charged by the hour for instances that you barely ended up using. No compute = no bills for usage. Or so, at least, is the promise of serverless.
Yet, there’s one hidden cost, where even in the serverless world you will find yourself paying for idle resources — what happens when your function is sitting around waiting on I/O? With pricing based on the duration that a function runs, you’re still billed for time that your service is doing zero work, and just waiting on network requests.
Most applications spend far more time waiting on this I/O than they do using the CPU, often ten times more.
Imagine a similar scenario in your own life — you grab a cab to go to the airport. On the way, the driver decides to stop to refuel and grab a snack, but leaves the meter running. This is not time spent bringing you closer to your destination, but it’s time that you’re paying for. Now imagine for the time the driver was refueling the car, the meter was paused. That’s the difference between CPU time and duration, or wall clock time.
But rather than waiting on the driver to refuel or grab a Snickers bar, what is it that you’re actually paying for when it comes to serverless compute?
Time spent waiting on services you don’t control
Most applications depend on one or many external service providers. Providers of hosted large language models (LLMs) like GPT-4 or Stable Diffusion. Databases as a service. Payment processors. Or simply an API request to a system outside your control. This is where software development is headed — rather than reinventing the wheel and slowly building everything themselves, both fast-moving startups and the Fortune 500 increasingly build using other services to avoid undifferentiated heavy lifting.
Every time an application interacts with one of these external services, it has to send data over the network and wait until it receives a response. And while some services are lightning fast, others can take considerable time, like waiting for a payment processor or for a large media file to be uploaded or converted. Your own application sits idle for most of the request, waiting on services outside your control.
Until today, you’ve had to pay while your application waits. You’ve had to pay more when a service you depend on has an operational issue and slows down, or times out in responding to your request. This has been a disincentive to incrementally move parts of your application to serverless.
Cloudflare’s new pricing: the first serverless platform to truly scale down to zero
The idea of “scale to zero” is that you never have to keep instances of your application sitting idle, waiting for something to happen. Serverless is more than just not having to manage servers or virtual machines — you shouldn’t have to provision and manage the number of compute resources that are available or warm.
Our new pricing takes the “scale to zero” concept even further, and extends it to whether your application is actually performing work. If you’re still paying while nothing is happening, we don’t think that’s truly scale to zero. Your application is idle. The CPU can be used for other tasks. Whether your application is “running” is an old concept lifted from an era before multi-tenant cloud platforms. What matters is if you are actually using compute resources.
Pay less, deploy everywhere, without hidden costs
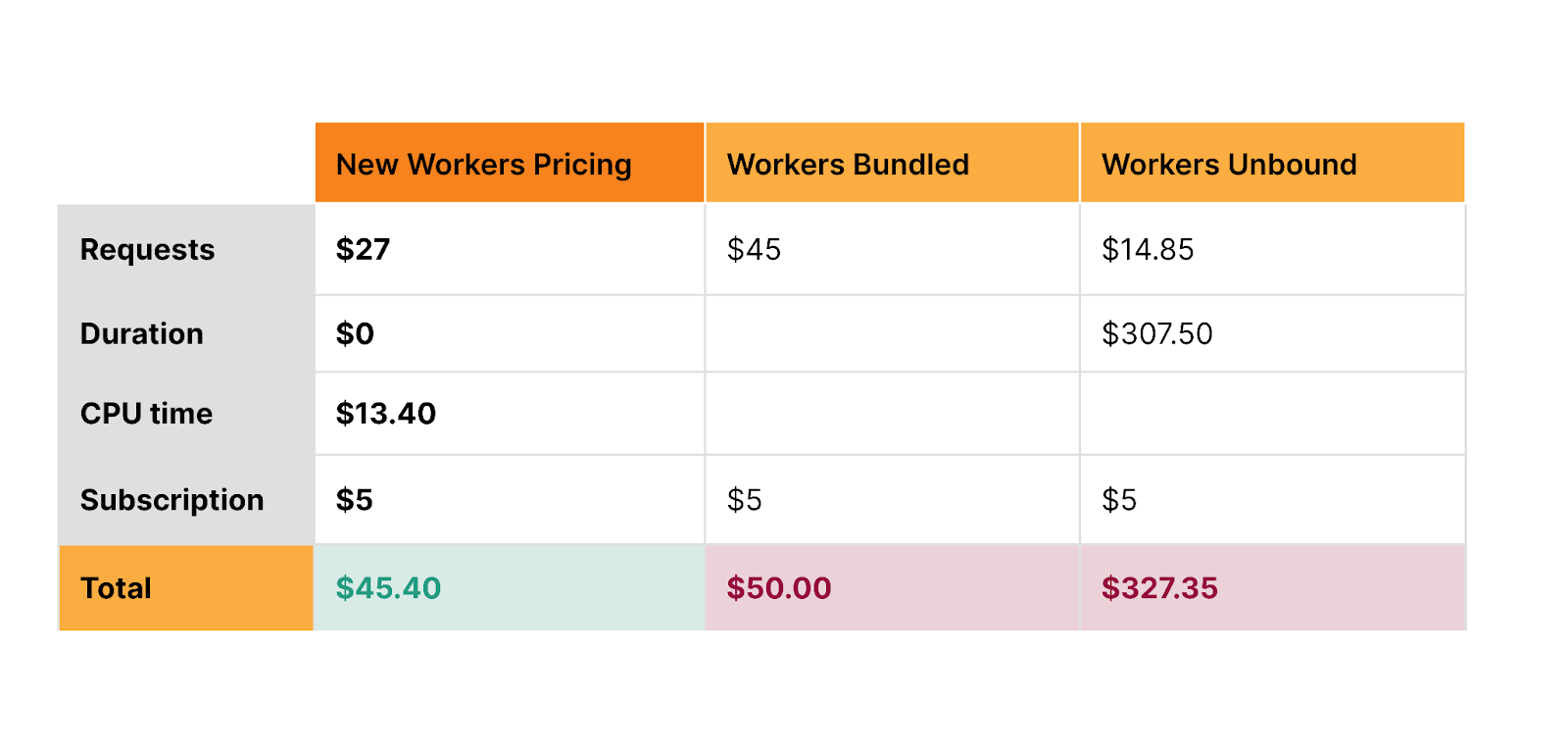
Let’s compare what you’d pay on new Workers pricing to AWS Lambda, for the following Worker:
One billion requests per month
Seven CPU milliseconds per request
200ms duration per request
The above table is for informational purposes only. Prices are limited to the public fees as of September 20, 2023, and do not include taxes and any other fees. AWS Lambda and Lambda @ Edge prices are based on publicly available pricing in US-East (Ohio) region as published on https://aws.amazon.com/lambda/pricing/
New Workers pricing makes building AI applications dramatically cheaper
Yesterday we announced a new suite of products to let you build AI applications on Cloudflare — Workers AI, AI Gateway, and our new vector database, Vectorize.
Nearly everyone is building new products and features using AI models right now. Large language models and generative AI models are incredibly powerful. But they aren’t always fast — asking a model to create an image, transcribe a segment of audio, or write a story often takes multiple seconds — far longer than a typical API response or database query that we expect to return in tens of milliseconds. There is significant compute work going on behind the scenes, and that means longer duration per request to a Worker.
New Workers pricing makes this much less expensive than it was previously on the Unbound usage model.
Let’s take the same example as above, but instead assume the duration of the request is two seconds (2000ms), because the Worker makes an inference request to a large AI model. With new Workers pricing, you pay the exact same amount, no matter how long this request takes.
No surprise bills — set a maximum limit on CPU time for each Worker
Surprise bills from cloud providers are an unfortunately common horror story. In the old way of provisioning compute resources, forgetting to shut down an instance of a database or virtual machine can cost hundreds of dollars. And accidentally autoscaling up too high can be even worse.
We’re building new safeguards to prevent these kinds of scenarios on Workers. As part of new pricing, you will be able to cap CPU usage on a per-Worker basis.
For example, if you have a Worker with a p99 CPU time of 15ms, you might use this to set a max CPU limit of 40ms — enough headroom to ensure that your worker will run successfully, while ensuring that even if you ship a bug that causes a CPU time to ratchet up dramatically, or have an edge case that causes infinite recursion, you can’t suddenly rack up a giant unexpected bill, or be vulnerable to a denial of wallet attack. This can be particularly helpful if your worker handles variable or user-generated input, to guard against edge cases that you haven’t accounted for.
Alternatively, if you’re running a production service, but want to make sure you stay on top of your costs, we will also be adding the option to configure notifications that can automatically email you, page you, or send a webhook if your worker exceeds a particular amount of CPU time per request. You will be able to choose at what threshold you want to be notified, and how.
New ways to “hibernate” Durable Objects while keeping connections alive
While Workers are stateless functions, Durable Objects are stateful and long-lived, commonly used to coordinate and persist real-time state in chat, multiplayer games, or collaborative apps. And unlike Workers, duration-based pricing fits Durable Objects well. As long as one or more clients are connected to a Durable Object, it keeps state available in memory. Durable Objects pricing will remain duration-based, and is not changing as part of this announcement.
What about when a client is connected to a Durable Object, but no work has happened for a long time? Consider a collaborative whiteboard app built using Durable Objects. A user of the app opens the app in a browser tab, but then forgets about it, and leaves it running for days, with an open WebSocket connection. Just like with Workers, we don’t think you should have to pay for this idle time. But until recently, there hasn’t been an API to signal to us that a Durable Object can be safely “hibernated”.
The recently introduced Hibernation API, currently in beta, allows you to set an automatic response to be used while hibernated and serialize state such that it survives hibernation. This gives Cloudflare the inputs we need in order to maintain open WebSocket connections from clients, while “hibernating” the Durable Object such that it is not actively running, and you are not billed for idle time. The result is that your state is always available in-memory when actually need it, but isn’t unnecessarily kept around when it’s not. As long as your Durable Object is hibernating, even if there are active clients still connected over a WebSocket, you won’t be billed for duration.
Snippets make Cloudflare’s CDN programmable — for free
What if you just want to modify a header, do a country code redirect, or cache a custom query? Developers have relied on Workers to program Cloudflare’s CDN like this for many years. With the announcement of Cloudflare Snippets last year, now in alpha, we’re making it free.
If you use Workers today for these smaller use cases, to customize any of Cloudflare’s application services, Snippets will be the optimal, zero cost option.
A serverless platform without limits
Developers are building ever larger and more complex full-stack applications on Workers each month. Our promise to you is to help you scale in any direction, without worrying about paying for idle time or having to manage and provision compute resources across regions.
This also means not having to worry about limits. Workers already serves many millions of requests per second, and scales and performs so well that we are rebuilding our own CDN on top of Workers. Individual Workers can now be up to 10MB, with a max startup time of 400ms, and can be easily composed together using Service Bindings. Entire platforms are built on top of Workers, with a growing number of companies allowing their own customers to write and deploy custom code and applications via Workers for Platforms. Some of the biggest platforms in the world rely on Cloudflare and the Workers platform during the most critical moments.
New pricing removes limits on the types of applications that could be built cost effectively with duration-based pricing. It removes the ceiling on CPU time from our original request-based pricing. We’re excited to see what you build, and are committed to being the development platform where you’re not constrained by limits on scale, regions, instances, concurrency or whatever else you need to handle to grow and operate globally.
When will new pricing be available?
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You will have until March 1, 2024, or the end of your Enterprise contract, whichever comes later, to switch to new pricing on your own, after which all of your projects will be automatically migrated to new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect.
Between now and then, we want to hear from you. We’ve based new pricing off feedback we’ve heard from developers building serverless applications, and companies estimating and projecting their costs. Tell us what you think of new pricing by sharing your feedback in this survey. We read every response.
Earlier in 2023, we announced Super Slurper, a data migration tool that makes it easy to copy large amounts of data to R2 from other cloud object storage providers. Since the announcement, developers have used Super Slurper to run thousands of successful migrations to R2!
While Super Slurper is perfect for cases where you want to move all of your data to R2 at once, there are scenarios where you may want to migrate your data incrementally over time. Maybe you want to avoid the one time upfront AWS data transfer bill? Or perhaps you have legacy data that may never be accessed, and you only want to migrate what’s required?
Today, we’re announcing the open beta of Sippy, an incremental migration service that copies data from S3 (other cloud providers coming soon!) to R2 as it’s requested, without paying unnecessary cloud egress fees typically associated with moving large amounts of data. On top of addressing vendor lock-in, Sippy makes stressful, time-consuming migrations a thing of the past. All you need to do is replace the S3 endpoint in your application or attach your domain to your new R2 bucket and data will start getting copied over.
How does it work?
Sippy is an incremental migration service built directly into your R2 bucket. Migration-specific egress fees are reduced by leveraging requests within the flow of your application where you’d already be paying egress fees to simultaneously copy objects to R2. Here is how it works:
When an object is requested from Workers, S3 API, or public bucket, it is served from your R2 bucket if it is found.
If the object is not found in R2, it will simultaneously be returned from your S3 bucket and copied to R2.
Note: Some large objects may take multiple requests to copy.
That means after objects are copied, subsequent requests will be served from R2, and you’ll begin saving on egress fees immediately.
Start incrementally migrating data from S3 to R2
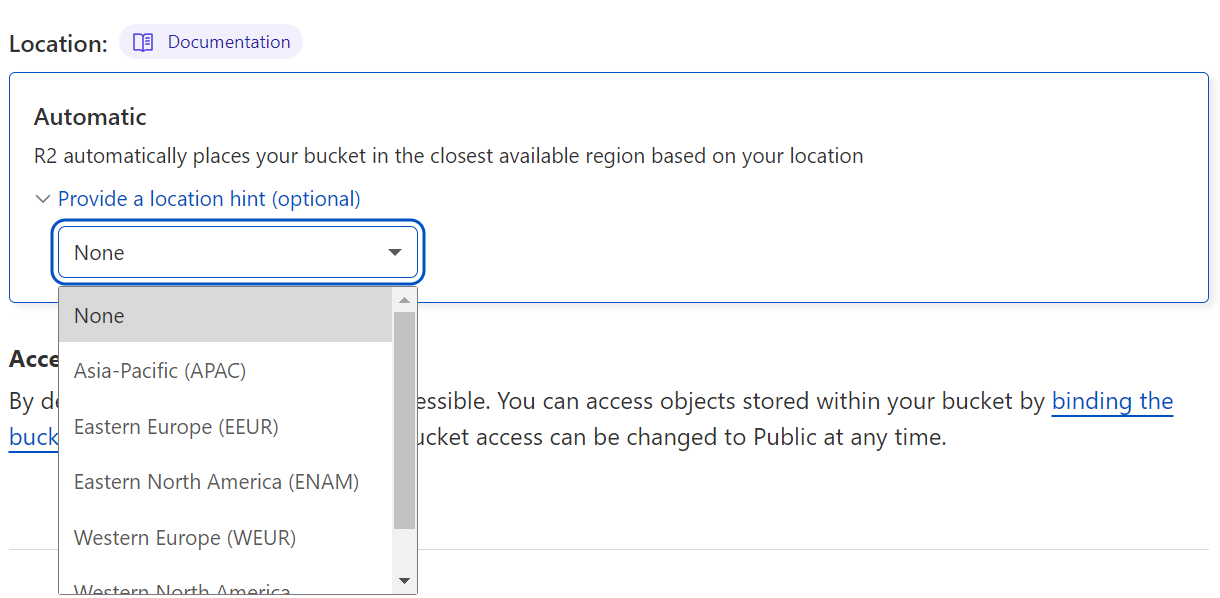
Create an R2 bucket
To get started with incremental migration, you’ll first need to create an R2 bucket if you don’t already have one. To create a new R2 bucket from the Cloudflare dashboard:
To learn more about other ways to create R2 buckets refer to the documentation on creating buckets.
Enable Sippy on your R2 bucket
Next, you’ll enable Sippy for the R2 bucket you created. During the beta, you can do this by using the API. Here’s an example of how to enable Sippy for an R2 bucket with cURL:
For more information on getting started, please refer to the documentation. Once enabled, requests to your bucket will now start copying data over from S3 if it’s not already present in your R2 bucket.
Finish your migration with Super Slurper
You can run your incremental migration for as long as you want, but eventually you may want to complete the migration to R2. To do this, you can pair Sippy with Super Slurper to easily migrate your remaining data that hasn’t been accessed to R2.
What’s next?
We’re excited about open beta, but it’s only the starting point. Next, we plan on making incremental migration configurable from the Cloudflare dashboard, complete with analytics that show you the progress of your migration and how much you are saving by not paying egress fees for objects that have been copied over so far.
If you are looking to start incrementally migrating your data to R2 and have any questions or feedback on what we should build next, we encourage you to join our Discord community to share!
Being able to get real-time information from applications in production is extremely important. Many times software passes local testing and automation, but then users report that something isn’t working correctly. Being able to quickly see what is happening, and how often, is critical to debugging.
This is why we originally developed the Workers Tail feature – to allow developers the ability to view requests, exceptions, and information for their Workers and to provide a window into what’s happening in real time. When we developed it, we also took the opportunity to build it on top of our own Workers technology using products like Trace Workers and Durable Objects. Over the last couple of years, we’ve continued to iterate on this feature – allowing users to quickly access logs from the Dashboard and via Wrangler CLI.
Today, we’re excited to announce that tail can now be enabled for Workers at any size and scale! In addition to telling you about the new and improved scalability, we wanted to share how we built it, and the changes we made to enable it to scale better.
Why Tail was limited
Tail leverages Durable Objects to handle coordination between the Worker producing messages and consumers like wrangler and the Cloudflare dashboard, and Durable Objects are a great choice for handling real-time communication like this. However, when a single Durable Object instance starts to receive a very high volume of traffic – like the kind that can come with tailing live Workers – it can see some performance issues.
As a result, Workers with a high volume of traffic could not be supported by the original Tail infrastructure. Tail had to be limited to Workers receiving 100 requests/second (RPS) or less. This was a significant limitation that resulted in many users with large, high-traffic Workers having to turn to their own tooling to get proper observability in production.
Believing that every feature we provide should scale with users during their development journey, we set out to improve Tail's performance at high loads.
Updating the way filters work
The first improvement was to the existing filtering feature. When starting a Tail with wrangler tail (and now with the Cloudflare dashboard) users have the ability to filter out messages based on information in the requests or logs. Previously, this filtering was handled within the Durable Object, which meant that even if a user was filtering out the majority of their traffic, the Durable Object would still have to handle every message. Often users with high traffic Tails were using many filters to better interpret their logs, but wouldn’t be able to start a Tail due to the 100 RPS limit.
We moved filtering out of the Durable Object and into the Tail message producer, preventing any filtered messages from reaching the Tail Durable Object, and thereby reducing the load on the Tail Durable Object. Moving the filtering out of the Durable Object was the first step in improving Tail’s performance at scale.
Sampling logs to keep Tails within Durable Object limits
After moving log filtering outside of the Durable Object, there was still the issue of determining when Tails could be started since there was no way to determine to what degree filters would reduce traffic for a given Tail, and simply starting a Durable Object back up would mean that it more than likely hit the 100 RPS limit immediately.
The solution for this was to add a safety mechanism for the Durable Object while the Tail was running.
We created a simple controller to track the RPS hitting a Durable Object and sample messages until the desired volume of 100 RPS is reached. As shown below, sampling keeps the Tail Durable Object RPS below the target of 100.
When messages are sampled, the following message appears every five seconds to let the user know that they are in sampling mode:
This message goes away once the Tail is stopped or filters are applied that drop the RPS below 100.
A final failsafe
Finally as a last resort a failsafe mechanism was added in the case the Durable Object gets fully overloaded. Since RPS tracking is done within the Durable Object, if the Durable Object is overloaded due to an extremely large amount of traffic, the sampling mechanism will fail.
In the case that an overload is detected, all messages forwarded to the Durable Object are stopped periodically to prevent any issues with Workers infrastructure.
Here we can see a user who had a large amount of traffic that started to become sampled. As the traffic increased, the number of sampled messages grew. Since the traffic was too fast for the sampling mechanism to handle, the Durable Object got overloaded. However, soon excess messages were blocked and the overload stopped.
Try it out
These new improvements are in place currently and available to all users 🎉
To Tail Workers via the Dashboard, log in, navigate to your Worker, and click on the Logs tab. You can then start a log stream via the default view.
If you’re using the Wrangler CLI, you can start a new Tail by running wrangler tail.
Beyond Worker tail
While we're excited for tail to be able to reach new limits and scale, we also recognize users may want to go beyond the live logs provided by Tail.
For example, if you’d like to push log events to additional destinations for a historical view of your application’s performance, we offer Logpush. If you’d like more insight into and control over log messages and events themselves, we offer Tail Workers.
These products, and others, can be read about in our Logs documentation. All of them are available for use today.
A clear sign of maturing for any new programming language or environment is how easy and efficient debugging them is. Programming, like any other complex task, involves various challenges and potential pitfalls. Logic errors, off-by-ones, null pointer dereferences, and memory leaks are some examples of things that can make software developers desperate if they can't pinpoint and fix these issues quickly as part of their workflows and tools.
WebAssembly (Wasm) is a binary instruction format designed to be a portable and efficient target for the compilation of high-level languages like Rust, C, C++, and others. In recent years, it has gained significant traction for building high-performance applications in web and serverless environments.
Using tools like Wrangler, our command-line tool for building with Cloudflare developer products, makes streaming real-time logs from our applications running remotely easy. Still, to be honest, debugging Rust and Wasm with Cloudflare Workers involves a lot of the good old time-consuming and nerve-wracking printf'ing strategy.
What if there’s a better way? This blog is about enabling and using Wasm core dumps and how you can easily debug Rust in Cloudflare Workers.
What are core dumps?
In computing, a core dump consists of the recorded state of the working memory of a computer program at a specific time, generally when the program has crashed or otherwise terminated abnormally. They also add things like the processor registers, stack pointer, program counter, and other information that may be relevant to fully understanding why the program crashed.
In most cases, depending on the system’s configuration, core dumps are usually initiated by the operating system in response to a program crash. You can then use a debugger like gdb to examine what happened and hopefully determine the cause of a crash. gdb allows you to run the executable to try to replicate the crash in a more controlled environment, inspecting the variables, and much more. The Windows' equivalent of a core dump is a minidump. Other mature languages that are interpreted, like Python, or languages that run inside a virtual machine, like Java, also have their ways of generating core dumps for post-mortem analysis.
Core dumps are particularly useful for post-mortem debugging, determining the conditions that lead to a failure after it has occurred.
WebAssembly core dumps
WebAssembly has had a proposal for implementing core dumps in discussion for a while. It's a work-in-progress experimental specification, but it provides basic support for the main ideas of post-mortem debugging, including using the DWARF (debugging with attributed record formats) debug format, the same that Linux and gdb use. Some of the most popular Wasm runtimes, like Wasmtime and Wasmer, have experimental flags that you can enable and start playing with Wasm core dumps today.
If you run Wasmtime or Wasmer with the flag:
--coredump-on-trap=/path/to/coredump/file
The core dump file will be emitted at that location path if a crash happens. You can then use tools like wasmgdb to inspect the file and debug the crash.
But let's dig into how the core dumps are generated in WebAssembly, and what’s inside them.
How are Wasm core dumps generated
(and what’s inside them)
When WebAssembly terminates execution due to abnormal behavior, we say that it entered a trap. With Rust, examples of operations that can trap are accessing out-of-bounds addresses or a division by zero arithmetic call. You can read about the security model of WebAssembly to learn more about traps.
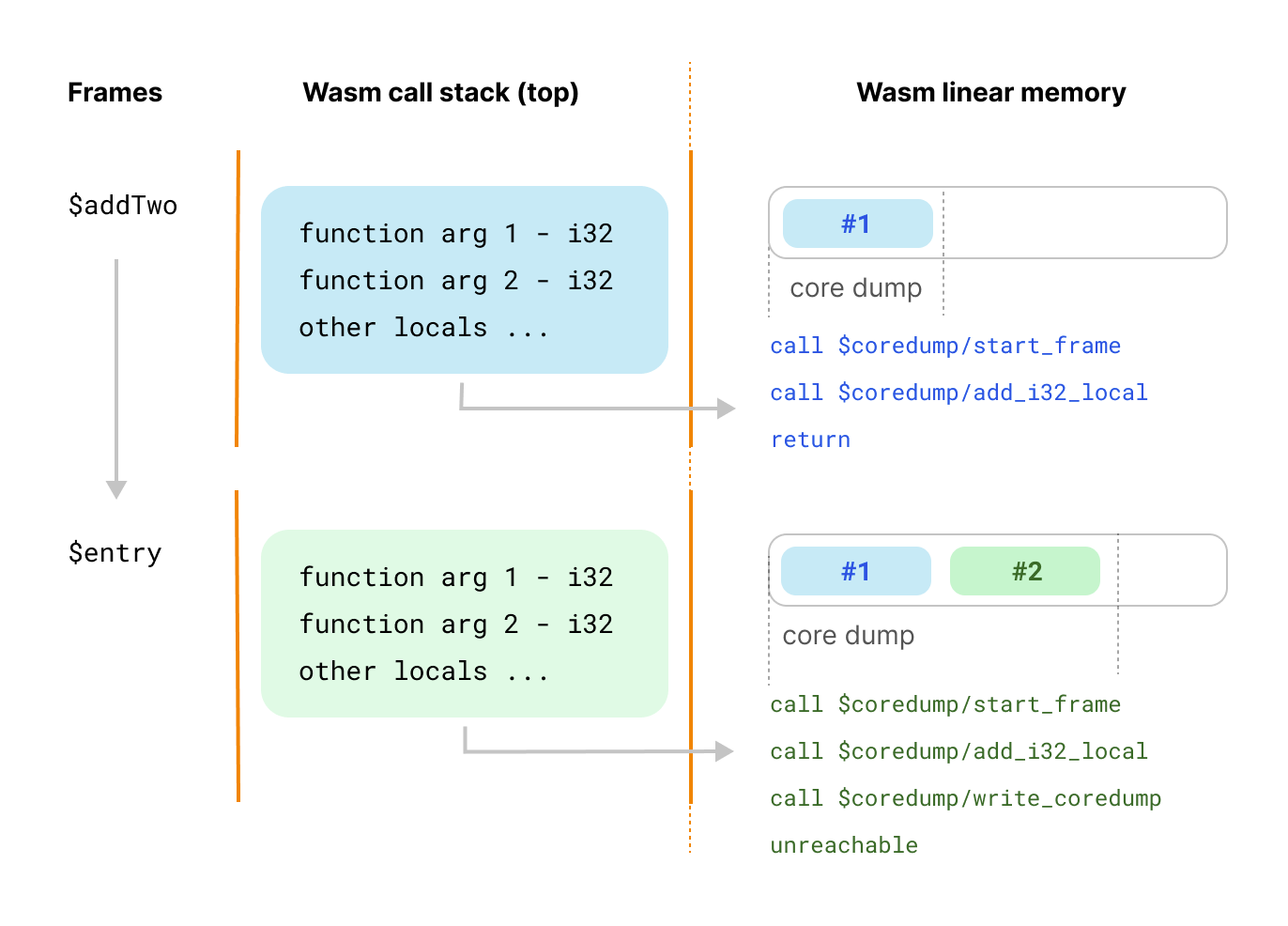
The core dump specification plugs into the trap workflow. When WebAssembly crashes and enters a trap, core dumping support kicks in and starts unwinding the call stack gathering debugging information. For each frame in the stack, it collects the function parameters and the values stored in locals and in the stack, along with binary offsets that help us map to exact locations in the source code. Finally, it snapshots the memory and captures information like the tables and the global variables.
DWARF is used by many mature languages like C, C++, Rust, Java, or Go. By emitting DWARF information into the binary at compile time a debugger can provide information such as the source name and the line number where the exception occurred, function and argument names, and more. Without DWARF, the core dumps would be just pure assembly code without any contextual information or metadata related to the source code that generated it before compilation, and they would be much harder to debug.
WebAssembly uses a (lighter) version of DWARF that maps functions, or a module and local variables, to their names in the source code (you can read about the WebAssembly name section for more information), and naturally core dumps use this information.
All this information for debugging is then bundled together and saved to the file, the core dump file.
A thread is a custom section called corestack. A corestack section contains the thread name and a vector (or array) of frames. Each frame contains the function index in the WebAssembly module (funcidx), the code offset relative to the function's start (codeoffset), the list of locals, and the list of values in the stack.
Values are defined as follows:
value ::= 0x01 => ∅
| 0x7F n:i32 => n
| 0x7E n:i64 => n
| 0x7D n:f32 => n
| 0x7C n:f64 => n
At the time of this writing these are the possible numbers types in a value. Again, we wanted to describe the basics; you should track the full specification to get more detail or find information about future changes. WebAssembly core dump support is in its early stages of specification and implementation, things will get better, things might change.
This is all great news. Unfortunately, however, the Cloudflare Workers runtime doesn’t support WebAssembly core dumps yet. There is no technical impediment to adding this feature to workerd; after all, it's based on V8, but since it powers a critical part of our production infrastructure and products, we tend to be conservative when it comes to adding specifications or standards that are still considered experimental and still going through the definitions phase.
So, how do we get core Wasm dumps in Cloudflare Workers today?
Polyfilling
Polyfilling means using userland code to provide modern functionality in older environments that do not natively support it. Polyfills are widely popular in the JavaScript community and the browser environment; they've been used extensively to address issues where browser vendors still didn't catch up with the latest standards, or when they implement the same features in different ways, or address cases where old browsers can never support a new standard.
Meet wasm-coredump-rewriter, a tool that you can use to rewrite a Wasm module and inject the core dump runtime functionality in the binary. This runtime code will catch most traps (exceptions in host functions are not yet catched and memory violation not by default) and generate a standard core dump file. To some degree, this is similar to how Binaryen's Asyncifyworks.
Let’s look at code and see how this works. He’s some simple pseudo code:
export function entry(v1, v2) {
return addTwo(v1, v2)
}
function addTwo(v1, v2) {
res = v1 + v2;
throw "something went wrong";
return res
}
An imaginary compiler could take that source and generate the following Wasm binary code:
entry() is the Wasm function exported to the host. In an environment like the browser, JavaScript (being the host) can call entry().
Irrelevant parts of the code have been snipped for brevity, but this is what the Wasm code will look like after wasm-coredump-rewriter rewrites it:
(func $entry (type 0) (param i32 i32) (result i32)
...
local.get 0
local.get 1
call $addTwo ;; see the addTwo function bellow
global.get 2 ;; is unwinding?
if ;; label = @1
i32.const x ;; code offset
i32.const 0 ;; function index
i32.const 2 ;; local_count
call $coredump/start_frame
local.get 0
call $coredump/add_i32_local
local.get 1
call $coredump/add_i32_local
...
call $coredump/write_coredump
unreachable
end)
(func $addTwo (type 0) (param i32 i32) (result i32)
local.get 0
local.get 1
i32.add
;; the unreachable instruction was here before
call $coredump/unreachable_shim
i32.const 1 ;; funcidx
i32.const 2 ;; local_count
call $coredump/start_frame
local.get 0
call $coredump/add_i32_local
local.get 1
call $coredump/add_i32_local
...
return)
(export "entry" (func $entry))
As you can see, a few things changed:
The (unreachable) instruction in addTwo() was replaced by a call to $coredump/unreachable_shim which starts the unwinding process. Then, the location and debugging data is captured, and the function returns normally to the entry() caller.
Code has been added after the addTwo() call instruction in entry() that detects if we have an unwinding process in progress or not. If we do, then it also captures the local debugging data, writes the core dump file and then, finally, moves to the unconditional trap unreachable.
In short, we unwind until the host function entry() gets destroyed by calling unreachable.
Let’s go over the runtime functions that we inject for more clarity, stay with us:
$coredump/start_frame(funcidx, local_count) starts a new frame in the coredump.
$coredump/add_*_local(value) captures the values of function arguments and in locals (currently capturing values from the stack isn’t implemented.)
$coredump/write_coredump is used at the end and writes the core dump in memory. We take advantage of the first 1 KiB of the Wasm linear memory, which is unused, to store our core dump.
A diagram is worth a thousand words:
Wait, what’s this about the first 1 KiB of the memory being unused, you ask? Well, it turns out that most WebAssembly linters and tools, including Emscripten and WebAssembly’s LLVM don’t use the first 1 KiB of memory. Rust and Zig also use LLVM, but they changed the default. This isn’t pretty, but the hugely popular Asyncify polyfill relies on the same trick, so there’s reasonable support until we find a better way.
But we digress, let’s continue. After the crash, the host, typically JavaScript in the browser, can now catch the exception and extract the core dump from the Wasm instance’s memory:
If you're curious about the actual details of the core dump implementation, you can find the source code here. It was written in AssemblyScript, a TypeScript-like language for WebAssembly.
This is how we use the polyfilling technique to implement Wasm core dumps when the runtime doesn’t support them yet. Interestingly, some Wasm runtimes, being optimizing compilers, are likely to make debugging more difficult because function arguments, locals, or functions themselves can be optimized away. Polyfilling or rewriting the binary could actually preserve more source-level information for debugging.
You might be asking what about performance? We did some testing and found that the impact is negligible; the cost-benefit of being able to debug our crashes is positive. Also, you can easily turn wasm core dumps on or off for specific builds or environments; deciding when you need them is up to you.
Debugging from a core dump
We now know how to generate a core dump, but how do we use it to diagnose and debug a software crash?
Similarly to gdb (GNU Project Debugger) on Linux, wasmgdb is the tool you can use to parse and make sense of core dumps in WebAssembly; it understands the file structure, uses DWARF to provide naming and contextual information, and offers interactive commands to navigate the data. To exemplify how it works, wasmgdb has a demo of a Rust application that deliberately crashes; we will use it.
Let's imagine that our Wasm program crashed, wrote a core dump file, and we want to debug it.
When you fire wasmgdb, you enter a REPL (Read-Eval-Print Loop) interface, and you can start typing commands. The tool tries to mimic the gdb command syntax; you can find the list here.
Let's examine the backtrace using the bt command:
wasmgdb> bt
#18 000137 as __rust_start_panic () at library/panic_abort/src/lib.rs
#17 000129 as rust_panic () at library/std/src/panicking.rs
#16 000128 as rust_panic_with_hook () at library/std/src/panicking.rs
#15 000117 as {closure#0} () at library/std/src/panicking.rs
#14 000116 as __rust_end_short_backtrace<std::panicking::begin_panic_handler::{closure_env#0}, !> () at library/std/src/sys_common/backtrace.rs
#13 000123 as begin_panic_handler () at library/std/src/panicking.rs
#12 000194 as panic_fmt () at library/core/src/panicking.rs
#11 000198 as panic () at library/core/src/panicking.rs
#10 000012 as calculate (value=0x03000000) at src/main.rs
#9 000011 as process_thing (thing=0x2cff0f00) at src/main.rs
#8 000010 as main () at src/main.rs
#7 000008 as call_once<fn(), ()> (???=0x01000000, ???=0x00000000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/core/src/ops/function.rs
#6 000020 as __rust_begin_short_backtrace<fn(), ()> (f=0x01000000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/sys_common/backtrace.rs
#5 000016 as {closure#0}<()> () at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
#4 000077 as lang_start_internal () at library/std/src/rt.rs
#3 000015 as lang_start<()> (main=0x01000000, argc=0x00000000, argv=0x00000000, sigpipe=0x00620000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
#2 000013 as __original_main () at <directory not found>/<file not found>
#1 000005 as _start () at <directory not found>/<file not found>
#0 000264 as _start.command_export at <no location>
Each line represents a frame from the program's call stack; see frame #3:
#3 000015 as lang_start<()> (main=0x01000000, argc=0x00000000, argv=0x00000000, sigpipe=0x00620000) at /rustc/b833ad56f46a0bbe0e8729512812a161e7dae28a/library/std/src/rt.rs
You can read the funcidx, function name, arguments names and values and source location are all present. Let's select frame #9 now and inspect the locals, which include the function arguments:
wasmgdb> f 9
000011 as process_thing (thing=0x2cff0f00) at src/main.rs
wasmgdb> info locals
thing: *MyThing = 0xfff1c
Let’s use the p command to inspect the content of the thing argument:
wasmgdb> p (*thing)
thing (0xfff2c): MyThing = {
value (0xfff2c): usize = 0x00000003
}
You can also use the p command to inspect the value of the variable, which can be useful for nested structures:
wasmgdb> p (*thing)->value
value (0xfff2c): usize = 0x00000003
And you can use p to inspect memory addresses. Let’s point at 0xfff2c, the start of the MyThing structure, and inspect:
wasmgdb> p (MyThing) 0xfff2c
0xfff2c (0xfff2c): MyThing = {
value (0xfff2c): usize = 0x00000003
}
All this information in every step of the stack is very helpful to determine the cause of a crash. In our test case, if you look at frame #10, we triggered an integer overflow. Once you get comfortable walking through wasmgdb and using its commands to inspect the data, debugging core dumps will be another powerful skill under your belt.
Tidying up everything in Cloudflare Workers
We learned about core dumps and how they work, and we know how to make Cloudflare Workers generate them using the wasm-coredump-rewriter polyfill, but how does all this work in practice end to end?
We've been dogfooding the technique described in this blog at Cloudflare for a while now. Wasm core dumps have been invaluable in helping us debug Rust-based services running on top of Cloudflare Workers like D1, Privacy Edge, AMP, or Constellation.
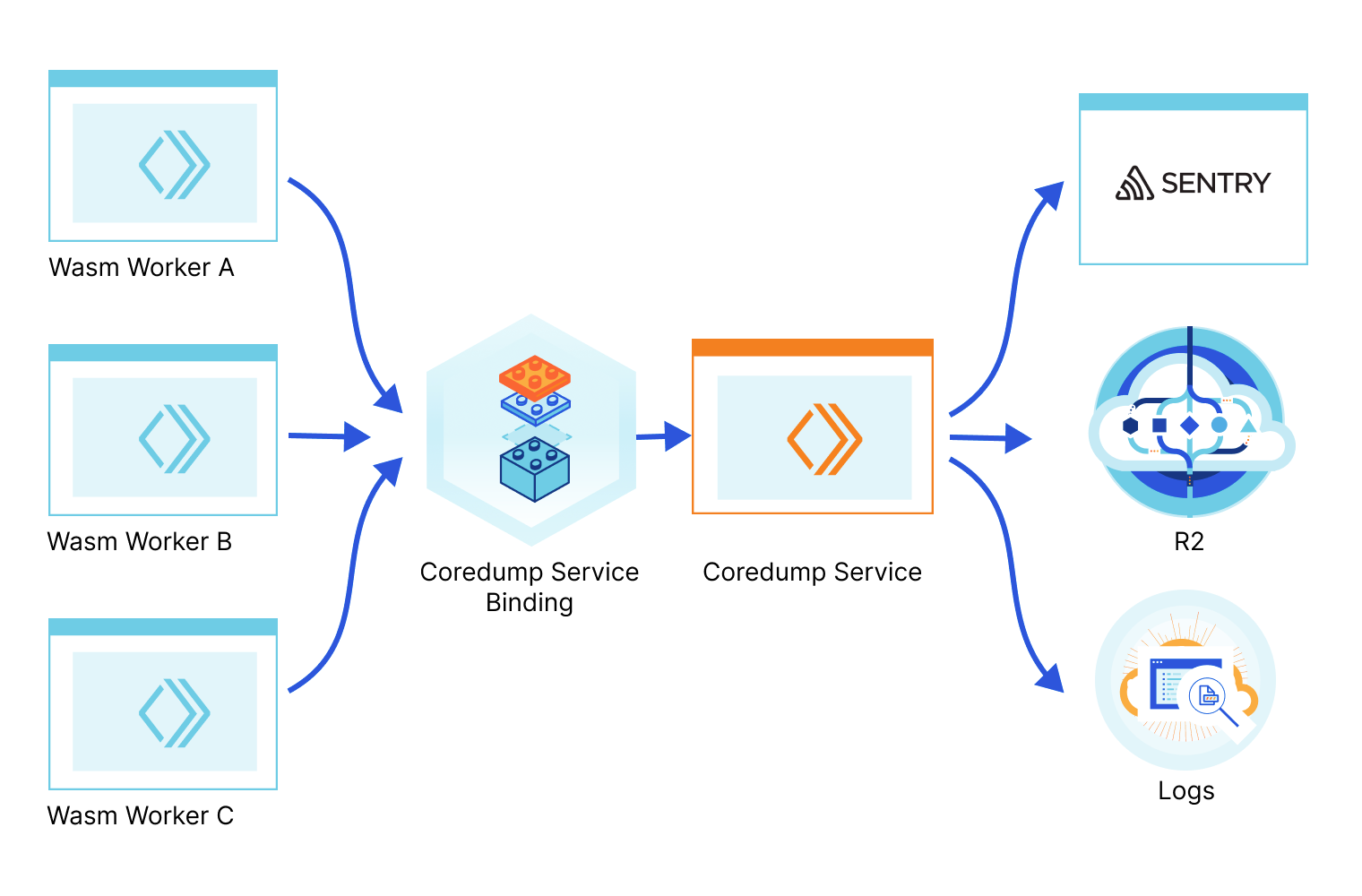
Today we're open-sourcing the Wasm Coredump Service and enabling anyone to deploy it. This service collects the Wasm core dumps originating from your projects and applications when they crash, parses them, prints an exception with the stack information in the logs, and can optionally store the full core dump in a file in an R2 bucket (which you can then use with wasmgdb) or send the exception to Sentry.
We use a service binding to facilitate the communication between your application Worker and the Coredump service Worker. A Service binding allows you to send HTTP requests to another Worker without those requests going over the Internet, thus avoiding network latency or having to deal with authentication. Here’s a diagram of how it works:
Using it is as simple as npm/yarn installing @cloudflare/wasm-coredump, configuring a few options, and then adding a few lines of code to your other applications running in Cloudflare Workers, in the exception handling logic:
The ../build/worker/shim.mjs import comes from the worker-build tool, from the workers-rs packages and is automatically generated when wrangler builds your Rust-based Cloudflare Workers project. If the Wasm throws an exception, we catch it, extract the core dump from memory, and send it to our Core dump service.
You might have noticed that we race the workers-rsshim.fetch() entry point with another Promise to generate a timeout exception if the Rust code doesn't respond earlier. This is because currently, wasm-bindgen, which generates the glue between the JavaScript and Rust land, used by workers-rs, has an issue where a Promise might not be rejected if Rust panics asynchronously (leading to the Worker runtime killing the worker with “Error: The script will never generate a response”.). This can block the wasm-coredump code and make the core dump generation flaky.
We are working to improve this, but in the meantime, make sure to adjust timeoutSecs to something slightly bigger than the typical response time of your application.
Here’s an example of a Wasm core dump exception in Sentry:
It's worth mentioning one corner case of this debugging technique and the solution: sometimes your codebase is so big that adding core dump and DWARF debugging information might result in a Wasm binary that is too big to fit in a Cloudflare Worker. Well, worry not; we have a solution for that too.
Fortunately the DWARF for WebAssembly specification also supports external DWARF files. To make this work, we have a tool called debuginfo-split that you can add to the build command in the wrangler.toml configuration:
What this does is it strips the debugging information from the Wasm binary, and writes it to a new separate file called debug-{UUID}.wasm. You then need to upload this file to the same R2 bucket used by the Wasm Coredump Service (you can automate this as part of your CI or build scripts). The same UUID is also injected into the main Wasm binary; this allows us to correlate the Wasm binary with its corresponding DWARF debugging information. Problem solved.
Binaries without DWARF information can be significantly smaller. Here’s our example:
4.5 MiB
debug-63372dbe-41e6-447d-9c2e-e37b98e4c656.wasm
313 KiB
build/worker/index.wasm
Final words
We hope you enjoyed reading this blog as much as we did writing it and that it can help you take your Wasm debugging journeys, using Cloudflare Workers or not, to another level.
Note that while the examples used here were around using Rust and WebAssembly because that's a common pattern, you can use the same techniques if you're compiling WebAssembly from other languages like C or C++.
Also, note that the WebAssembly core dump standard is a hot topic, and its implementations and adoption are evolving quickly. We will continue improving the wasm-coredump-rewriter, debuginfo-split, and wasmgdb tools and the wasm-coredump service. More and more runtimes, including V8, will eventually support core dumps natively, thus eliminating the need to use polyfills, and the tooling, in general, will get better; that's a certainty. For now, we present you with a solution that works today, and we have strong incentives to keep supporting it.
As usual, you can talk to us on our Developers Discord or the Community forum or open issues or PRs in our GitHub repositories; the team will be listening.
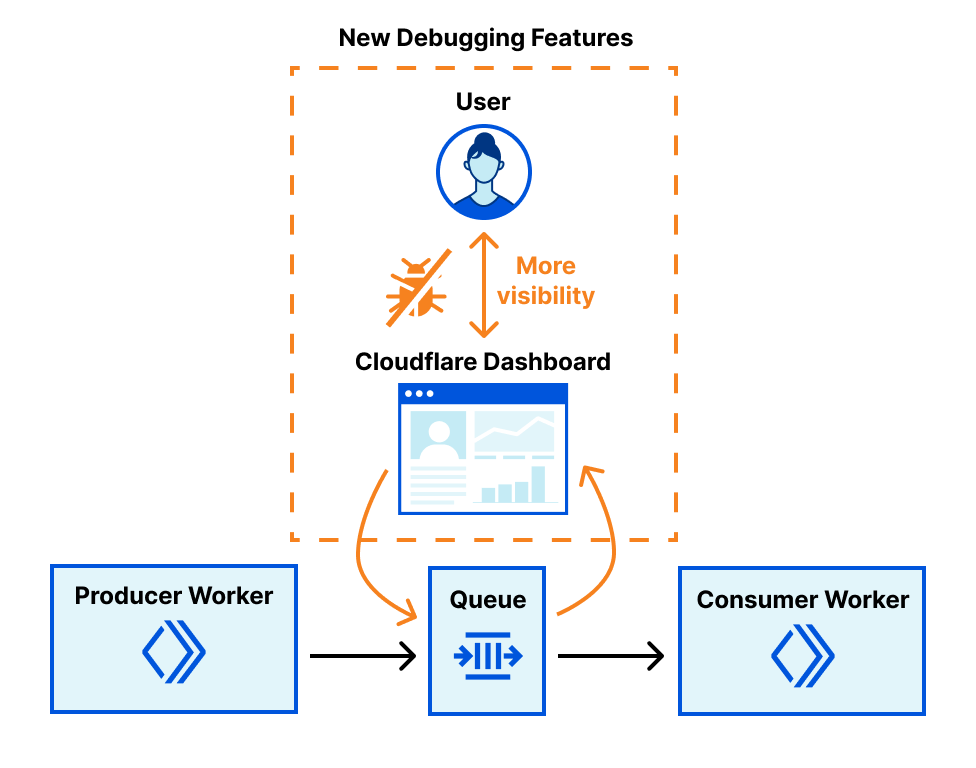
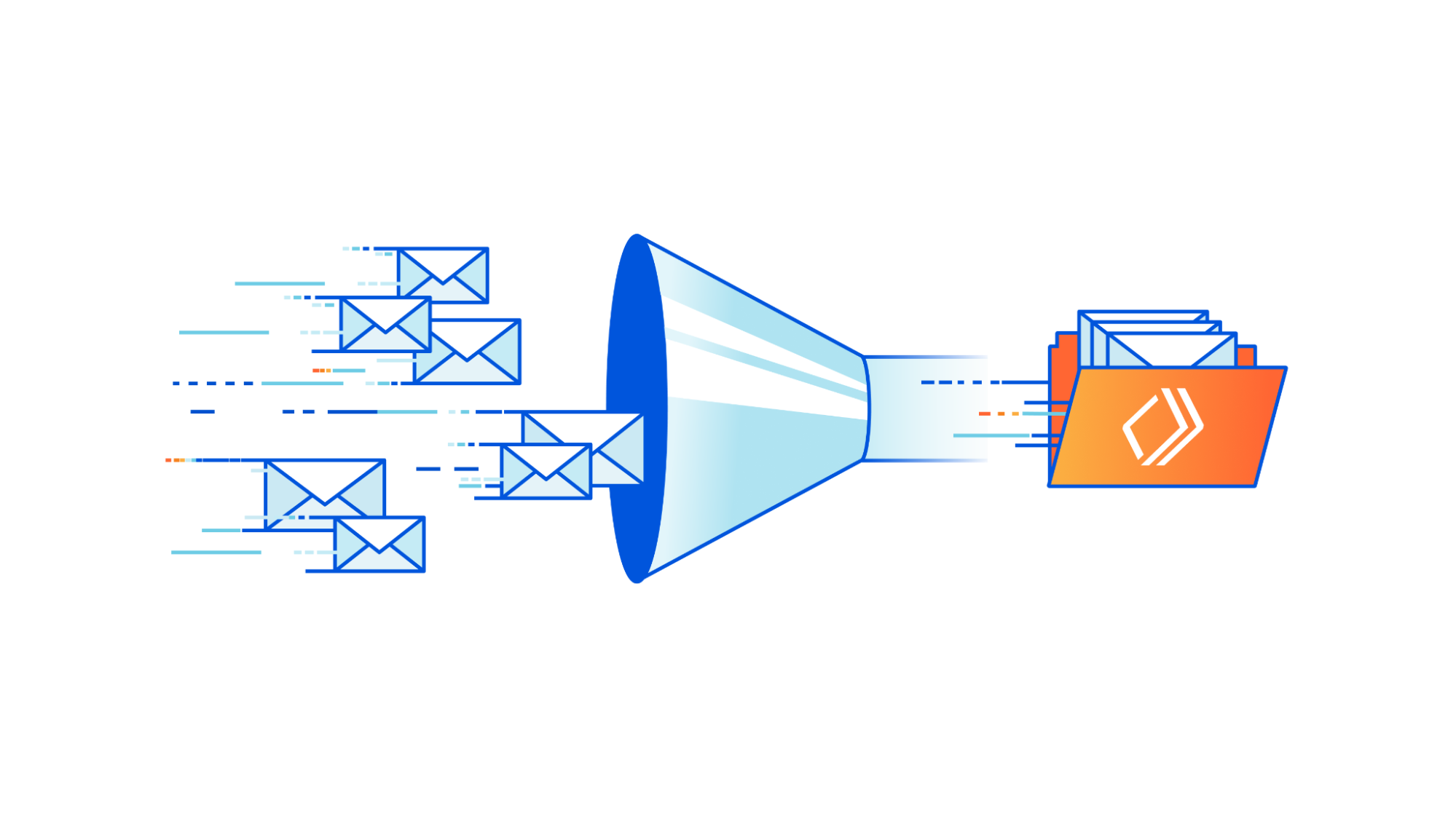
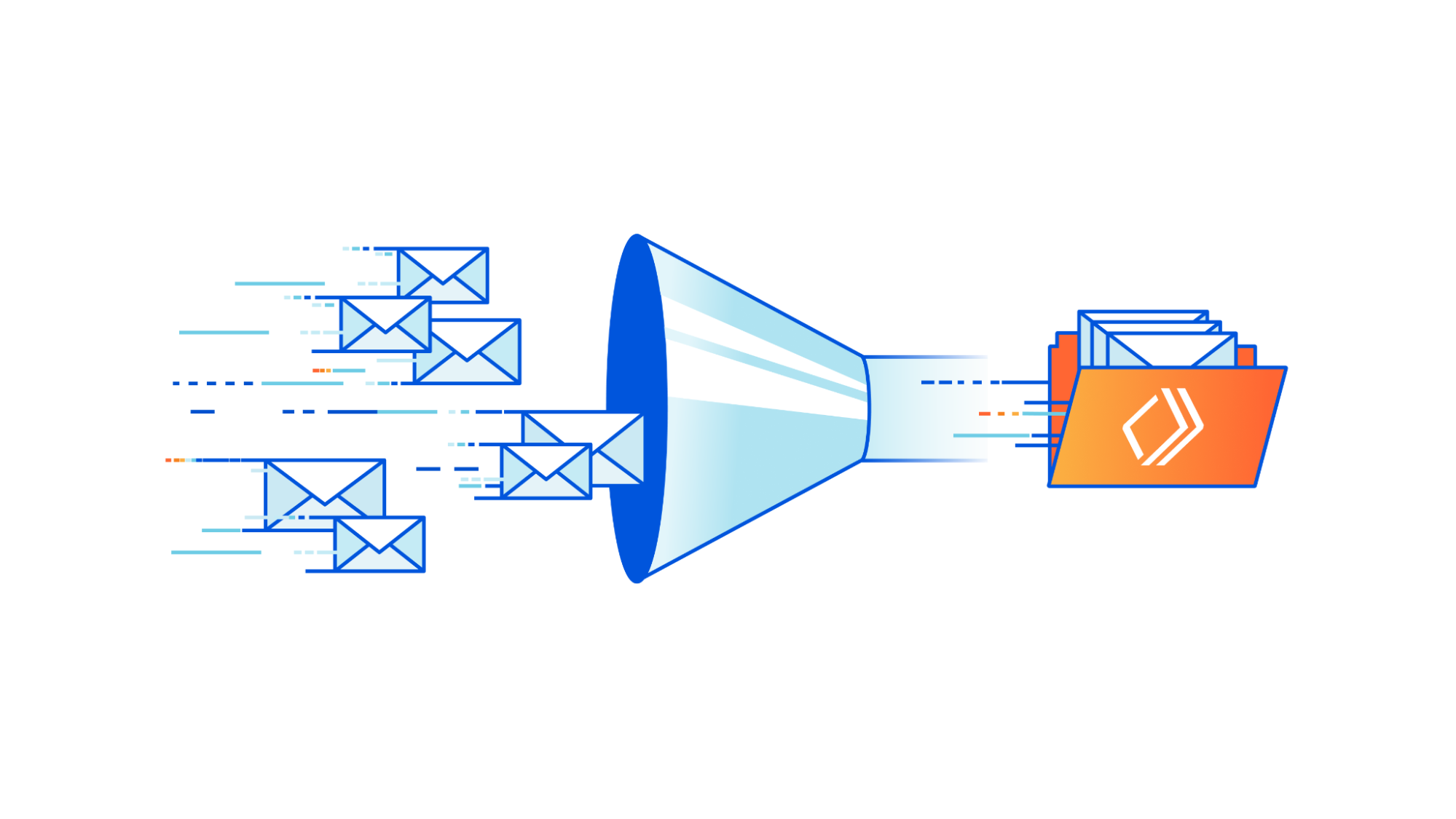
Today, August 11, 2023, we are excited to announce a new debugging workflow for Cloudflare Queues. Customers using Cloudflare Queues can now send, list, and acknowledge messages directly from the Cloudflare dashboard, enabling a more user-friendly way to interact with Queues. Though it can be difficult to debug asynchronous systems, it’s now easy to examine a queue’s state and test the full flow of information through a queue.
With guaranteed delivery, message batching, consumer concurrency, and more, Cloudflare Queues is a powerful tool to connect services reliably and efficiently. Queues integrate deeply with the existing Cloudflare Workers ecosystem, so developers can also leverage our many other products and services. Queues can be bound to producer Workers, which allow Workers to send messages to a queue, and to consumer Workers, which pull messages from the queue.
We’ve received feedback that while Queues are effective and performant, customers find it hard to debug them. After a message is sent to a queue from a producer worker, there’s no way to inspect the queue’s contents without a consumer worker. The limited transparency was frustrating, and the need to write a skeleton worker just to debug a queue was high-friction.
Now, with the addition of new features to send, list, and acknowledge messages in the Cloudflare dashboard, we’ve unlocked a much simpler debugging workflow. You can send messages from the Cloudflare dashboard to check if their consumer worker is processing messages as expected, and verify their producer worker’s output by previewing messages from the Cloudflare dashboard.
The pipeline of messages through a queue is now more open and easily examined. Users just getting started with Cloudflare Queues also no longer have to write code to send their first message: it’s as easy as clicking a button in the Cloudflare dashboard.
Sending messages
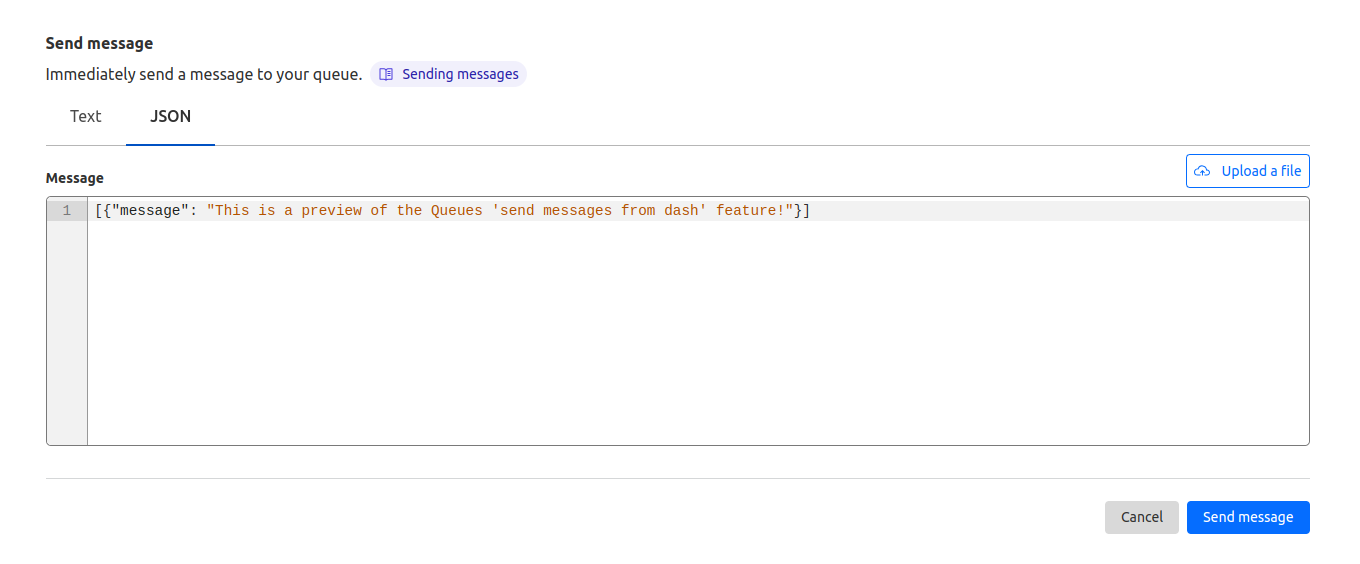
Both features are located in a new Messagestab on any queue’s page. Scroll to Send messageto open the message editor.
From here, you can write a message and click Send message to send it to your queue. You can also choose to send JSON, which opens a JSON editor with syntax highlighting and formatting. If you’ve saved your message as a file locally, you can drag-and-drop the file over the textbox or click Upload a file to send it as well.
This feature makes testing changes in a queue’s consumer worker much easier. Instead of modifying an existing producer worker or creating a new one, you can send one-off messages. You can also easily verify if your queue consumer settings are behaving as expected: send a few messages from the Cloudflare dashboard to check that messages are batched as desired.
Behind the scenes, this feature leverages the same pipeline that Cloudflare Workers uses to send messages, so you can be confident that your message will be processed as if sent via a Worker.
Listing messages
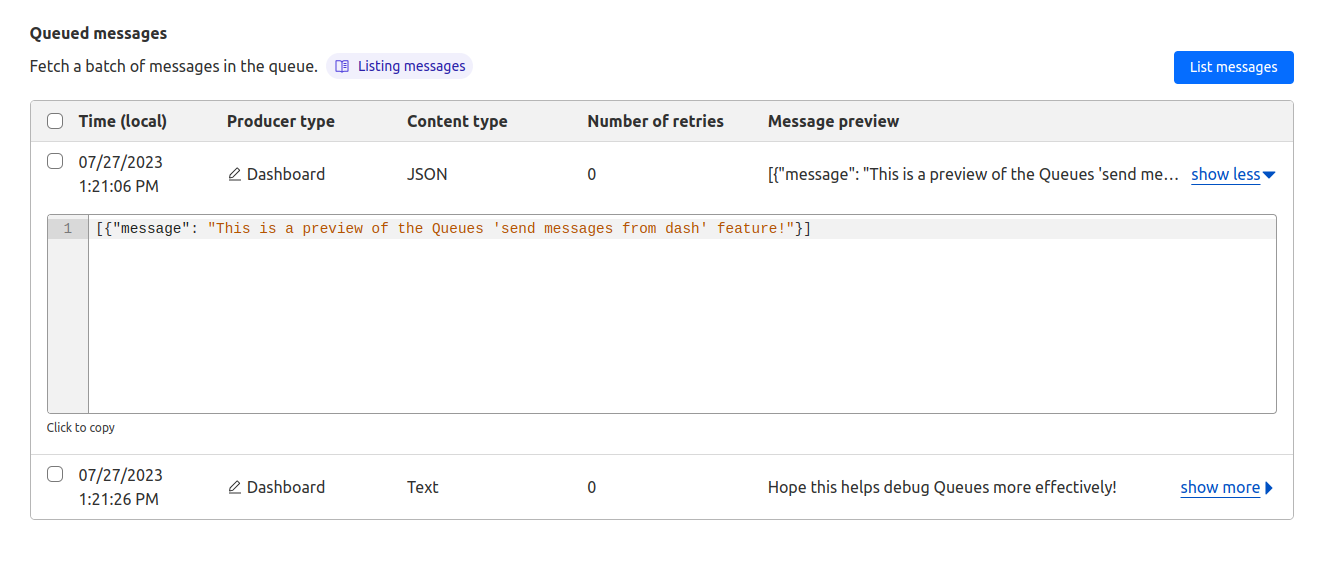
On the same page, you can also inspect the messages you just sent from the Cloudflare dashboard. On any queue’s page, open the Messages tab and scroll to Queued messages.
If you have a consumer attached to your queue, you’ll fetch a batch of messages of the same size as configured in your queue consumer settings by default, to provide a realistic view of what would be sent to your consumer worker. You can change this value to preview messages one-at-a-time or even in much larger batches than would be normally sent to your consumer.
After fetching a batch of messages, you can preview the message’s body, even if you’ve sent raw bytes or a JavaScript object supported by the structured clone algorithm. You can also check the message’s timestamp; number of retries; producer source, such as a Worker or the Cloudflare dashboard; and type, such as text or JSON. This information can help you debug the queue’s current state and inspect where and when messages originated from.
The batch of messages that’s returned is the same batch that would be sent to your consumer Worker on its next run. Messages are even guaranteed to be in the same order on the UI as sent to your consumer. This feature grants you a looking glass view into your queue, matching the exact behavior of a consumer worker. This works especially well for debugging messages sent by producer workers and verifying queue consumer settings.
Listing messages from the Cloudflare dashboard also doesn’t interfere with an existing connected consumer. Messages that are previewed from the Cloudflare dashboard stay in the queue and do not have their number of retries affected.
This ‘peek’ functionality is unique to Cloudflare Queues: Amazon SQS bumps the number of retries when a message is viewed, and RabbitMQ retries the message, forcing it to the back of the queue. Cloudflare Queues’ approach means that previewing messages does not have any unintended side effects on your queue and your consumer. If you ever need to debug queues used in production, don’t worry – listing messages is entirely safe.
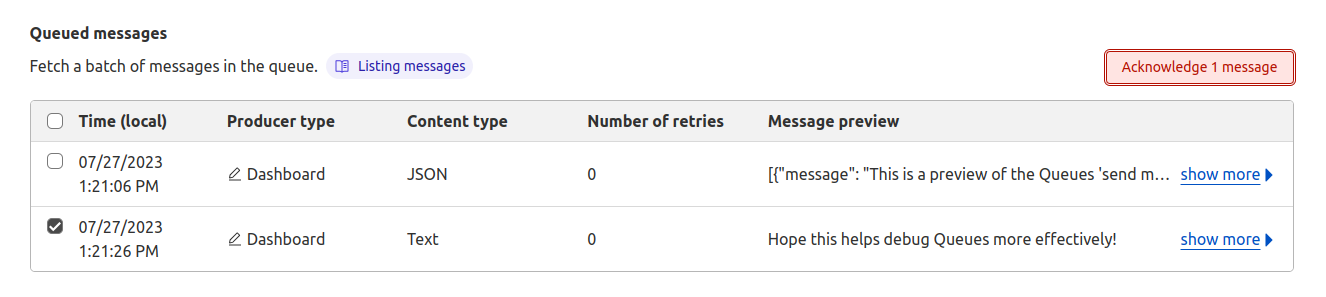
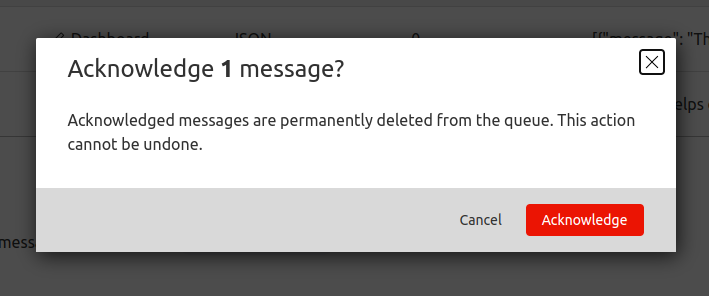
As well, you can now remove messages from your queue from the Cloudflare dashboard. If you’d like to remove a message or clear the full batch from the queue, you can select messages to acknowledge. This is useful for preventing buggy messages from being repeatedly retried without having to write a dummy consumer.
You might have noticed that this message preview feature operates similarly to another popular feature request for an HTTP API to pull batches of messages from a queue. Customers will be able to make a request to the API endpoint to receive a batch of messages, then acknowledge the batch to remove the messages from the queue. Under the hood, both listing messages from the Cloudflare dashboard and HTTP Pull/Ack use a common infrastructure, and HTTP Pull/Ack is coming very soon!
These debugging features have already been invaluable for testing example applications we’ve built on Cloudflare Queues. At an internal hack week event, we built a web crawler with Queues as an example use-case (check out the tutorial here!). During development, we took advantage of this user-friendly way to send messages to quickly iterate on a consumer worker before we built a producer worker. As well, when we encountered bugs in our consumer worker, the message previews were handy to realize we were sending malformed messages, and the message acknowledgement feature gave us an easy way to remove them from the queue.
New Queues debugging features — available today!
The Cloudflare dashboard features announced today provide more transparency into your application and enable more user-friendly debugging.
All Cloudflare Queues customers now have access to these new debugging tools. And if you’re not already using Queues, you can join the Queues Open Beta by enabling Cloudflare Queues here. Get started on Cloudflare Queues with our guide and create your next app with us today! Your first message is a single click away.
Designed with developers in mind, Cloudflare Stream provides a seamless, integrated workflow that simplifies video streaming for creators and platforms alike. With features like Stream Live and creator management, customers have been looking for ways to streamline storage management.
Today, August 11, 2023, Cloudflare Stream is introducing scheduled deletion to easily manage video lifecycles from the Stream dashboard or our API, saving time and reducing storage-related costs. Whether you need to retain recordings from a live stream for only a limited time, or preserve direct creator videos for a set duration, scheduled deletion will simplify storage management and reduce costs.
Stream scheduled deletion
Scheduled deletion allows developers to automatically remove on-demand videos and live recordings from their library at a specified time. Live inputs can be set up with a deletion rule, ensuring that all recordings from the input will have a scheduled deletion date upon completion of the stream.
Let’s see how it works in those two configurations.
Getting started with scheduled deletion for on-demand videos
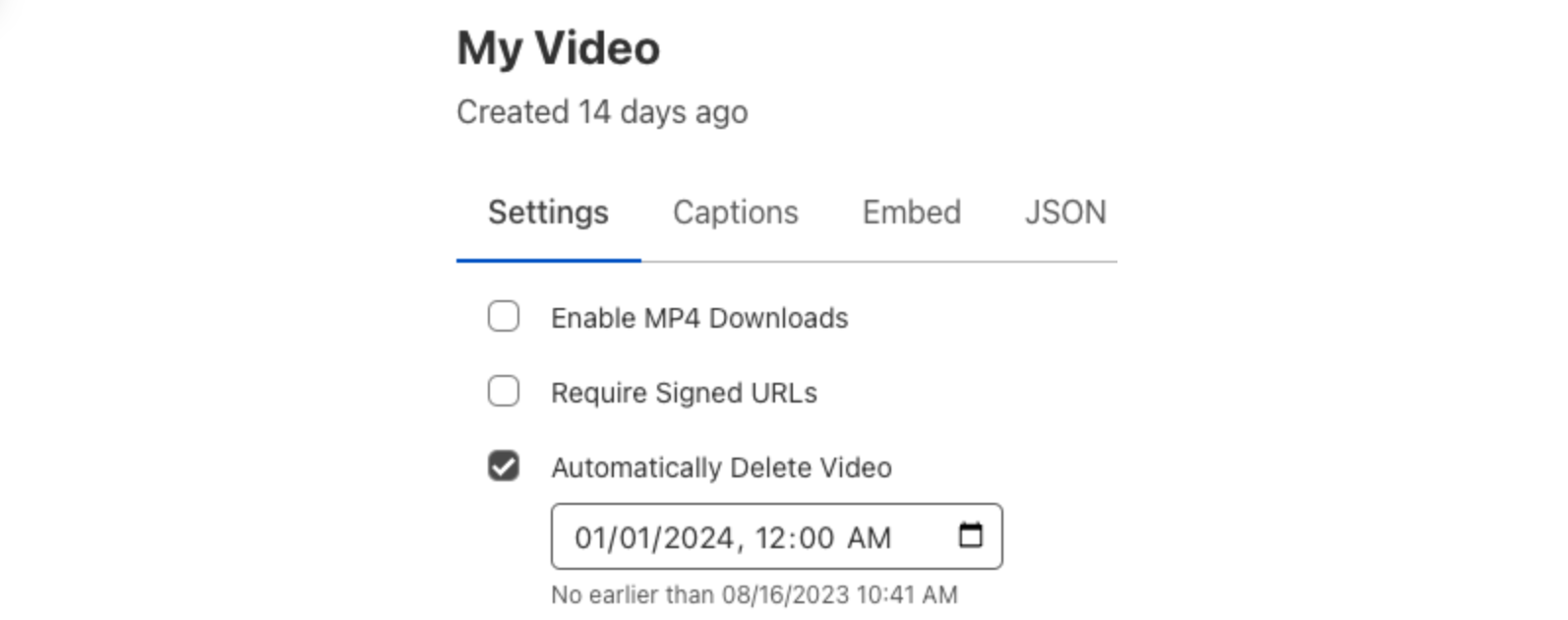
Whether you run a learning platform where students can upload videos for review, a platform that allows gamers to share clips of their gameplay, or anything in between, scheduled deletion can help manage storage and ensure you only keep the videos that you need. Scheduled deletion can be applied to both new and existing on-demand videos, as well as recordings from completed live streams. This feature lets you specify a specific date and time at which the video will be deleted. These dates can be applied in the Cloudflare dashboard or via the Cloudflare API.
Cloudflare dashboard
From the Cloudflare dashboard, select Videos under Stream
Select a video
Select Automatically Delete Video
Specify a desired date and time to delete the video
Click Submit to save the changes
Cloudflare API
The Stream API can also be used to set the scheduled deletion property on new or existing videos. In this example, we’ll create a direct creator upload that will be deleted on December 31, 2023:
For more information on live inputs and how to configure deletion policies in our API, refer to the documentation.
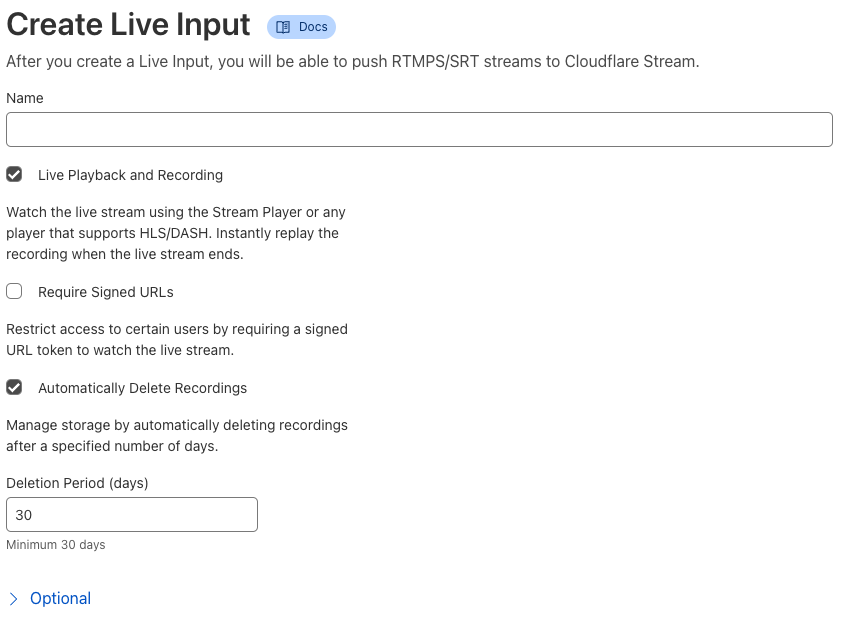
Getting started with automated deletion for Live Input recordings
We love how recordings from live streams allow those who may have missed the stream to catch up, but these recordings aren’t always needed forever. Scheduled recording deletion is a policy that can be configured for new or existing live inputs. Once configured, the recordings of all future streams on that input will have a scheduled deletion date calculated when the recording is available. Setting this retention policy can be done from the Cloudflare dashboard or via API operations to create or edit Live Inputs:
Cloudflare Dashboard
From the Cloudflare dashboard, select Live Inputs under Stream
Select Create Live Input or an existing live input
Select Automatically Delete Recordings
Specify a number of days after which new recordings should be deleted
Click Submit to save the rule or create the new live input
Cloudflare API
The Stream API makes it easy to add a deletion policy to new or existing inputs. Here is an example API request to create a live input with recordings that will expire after 30 days:
For more information on live inputs and how to configure deletion policies in our API, refer to the documentation.
Try out scheduled deletion today
Scheduled deletion is now available to all Cloudflare Stream customers. Try it out now and join our Discord community to let us know what you think! To learn more, check out our developer docs. Stay tuned for more exciting Cloudflare Stream updates in the future.
During Developer Week we announced Database Integrations on Workers a new and seamless way to connect with some of the most popular databases. You select the provider, authorize through an OAuth2 flow and automatically get the right configuration stored as encrypted environment variables to your Worker.
Today we are thrilled to announce that we have been working with Upstash to expand our integrations catalog. We are now offering three new integrations: Upstash Redis, Upstash Kafka and Upstash QStash. These integrations allow our customers to unlock new capabilities on Workers. Providing them with a broader range of options to meet their specific requirements.
Add the integration
We are going to show the setup process using the Upstash Redis integration.
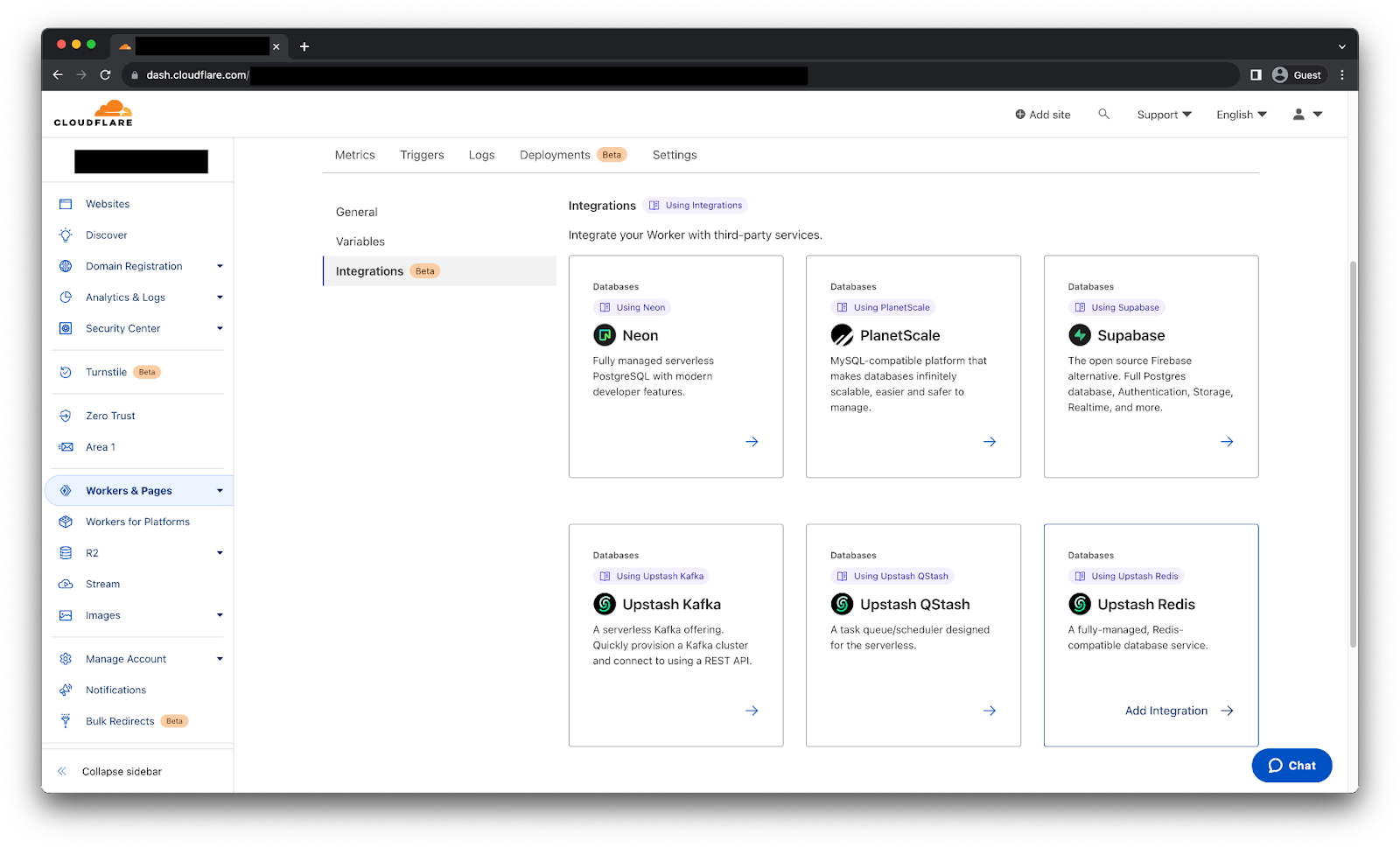
Select your Worker, go to the Settings tab, select the Integrations tab to see all the available integrations.
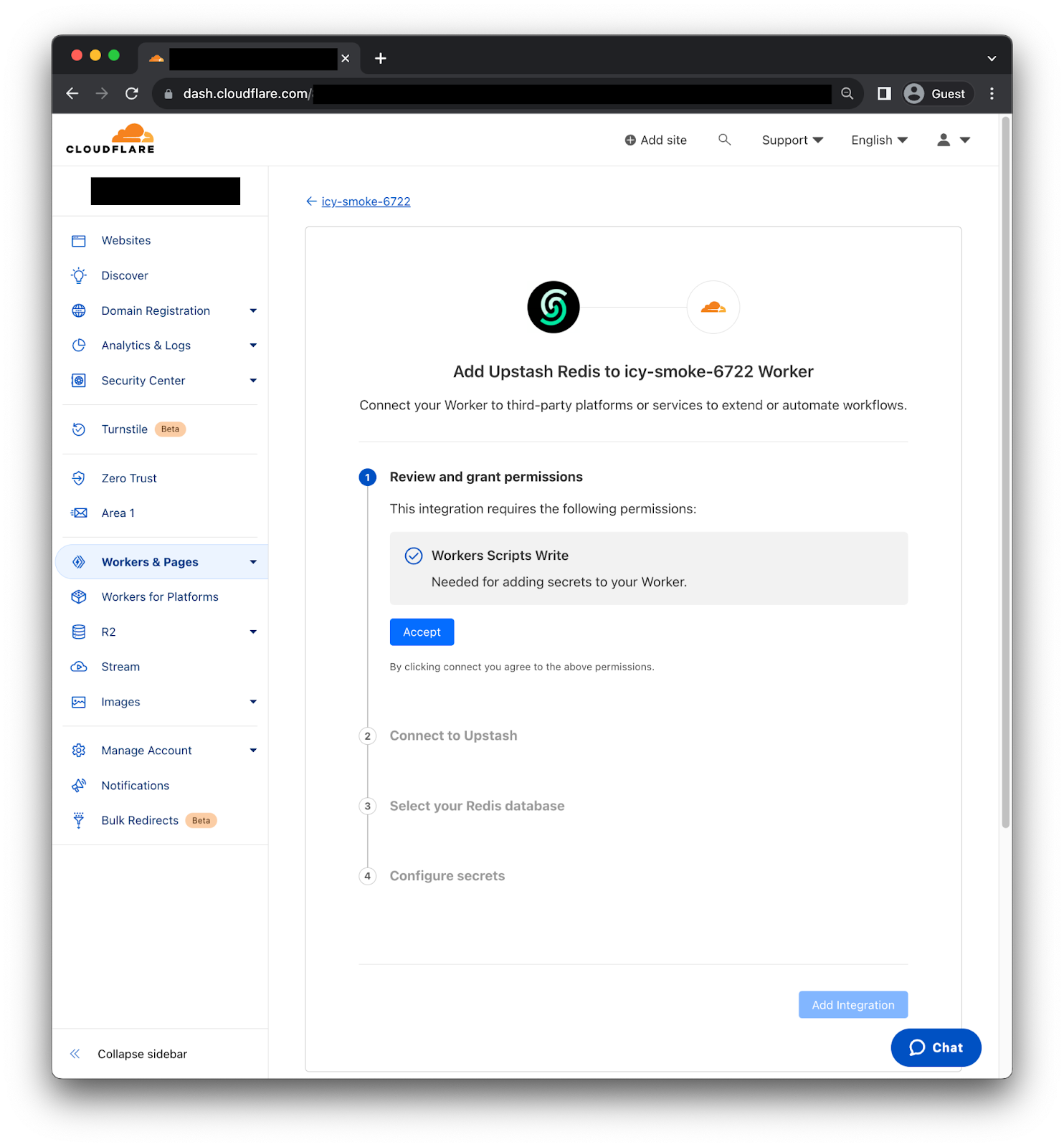
After selecting the Upstash Redis integration we will get the following page.
First, you need to review and grant permissions, so the Integration can add secrets to your Worker. Second, we need to connect to Upstash using the OAuth2 flow. Third, select the Redis database we want to use. Then, the Integration will fetch the right information to generate the credentials. Finally, click “Add Integration” and it's done! We can now use the credentials as environment variables on our Worker.
Implementation example
On this occasion we are going to use the CF-IPCountry header to conditionally return a custom greeting message to visitors from Paraguay, United States, Great Britain and Netherlands. While returning a generic message to visitors from other countries.
To begin we are going to load the custom greeting messages using Upstash’s online CLI tool.
➜ set PY "Mba'ẽichapa 🇵🇾"
OK
➜ set US "How are you? 🇺🇸"
OK
➜ set GB "How do you do? 🇬🇧"
OK
➜ set NL "Hoe gaat het met u? 🇳🇱"
OK
We also need to install @upstash/redis package on our Worker before we upload the following code.
import { Redis } from '@upstash/redis/cloudflare'
export default {
async fetch(request, env, ctx) {
const country = request.headers.get("cf-ipcountry");
const redis = Redis.fromEnv(env);
if (country) {
const localizedMessage = await redis.get(country);
if (localizedMessage) {
return new Response(localizedMessage);
}
}
return new Response("👋👋 Hello there! 👋👋");
},
};
Just like that we are returning a localized message from the Redis instance depending on the country which the request originated from. Furthermore, we have a couple ways to improve performance, for write heavy use cases we can use Smart Placement with no replicas, so the Worker code will be executed near the Redis instance provided by Upstash. Otherwise, creating a Global Database on Upstash to have multiple read replicas across regions will help.
Upstash Redis, Kafka and QStash are now available for all users! Stay tuned for more updates as we continue to expand our Database Integrations catalog.
Cloudflare Zaraz has transitioned out of beta and is now generally available to all customers. It is included under the free, paid, and enterprise plans of the Cloudflare Developer Platform. Visit our docs to learn more on our different plans.
Zaraz Is part of Cloudflare Developer Platform
Cloudflare Zaraz is a solution that developers and marketers use to load third-party tools like Google Analytics 4, Facebook CAPI, TikTok, and others. With Zaraz, Cloudflare customers can easily transition to server-side data collection with just a few clicks, without the need to set up and maintain their own cloud environment or make additional changes to their website for installation. Server-side data collection, as facilitated by Zaraz, simplifies analytics reporting from the server rather than loading numerous JavaScript files on the user's browser. It's a rapidly growing trend due to browser limitations on using third-party solutions and cookies. The result is significantly faster websites, plus enhanced security and privacy on the web.
We've had Zaraz in beta mode for a year and a half now. Throughout this time, we've dedicated our efforts to meeting as many customers as we could, gathering feedback, and getting a deep understanding of our users' needs before addressing them. We've been shipping features at a high rate and have now reached a stage where our product is robust, flexible, and competitive. It also offers unique features not found elsewhere, thanks to being built on Cloudflare’s global network, such as Zaraz’s Worker Variables. We have cultivated a strong and vibrant discord community, and we have certified Zaraz developers ready to help anyone with implementation and configuration.
With more than 25,000 websites running Zaraz today – from personal sites to those of some of the world's biggest companies – we feel confident it's time to go out of beta, and introduce our new pricing system. We believe this pricing is not only generous to our customers, but also competitive and sustainable. We view this as the next logical step in our ongoing commitment to our customers, for whom we're building the future.
If you're building a web application, there's a good chance you've spent at least some time implementing third-party tools for analytics, marketing performance, conversion optimization, A/B testing, customer experience and more. Indeed, according to the Web Almanac report, 94% percent of mobile pages used at least one third-party solution in 2022, and third-party requests accounted for 45% of all requests made by websites. It's clear that third-party solutions are everywhere. They have become an integral part of how the web has evolved. Third-party tools are here to stay, and they require effective developer solutions. We are building Zaraz to help developers manage the third-party layer of their website properly.
Starting today, Cloudflare Zaraz is available to everyone for free under their Cloudflare dashboard, and the paid version of Zaraz is included in the Workers Paid plan. The Free plan is designed to meet the needs of most developers who want to use Zaraz for personal use cases. For a price starting at $5/month, customers of the Workers Paid plan can enjoy the extensive list of features that makes Zaraz powerful, deploy Zaraz on their professional projects, and utilize the pay-as-you-go system. This is in addition to everything else included in the Workers Paid plan. The Enterprise plan, on the other hand, addresses the needs of larger businesses looking to leverage our platform to its fullest potential.
How is Zaraz priced
Zaraz pricing is based on two components: Zaraz Loads and the set of features. A Zaraz Load is counted each time a web page loads the Zaraz script within it, and/or the Pageview trigger is being activated. For Single Page Applications, each URL navigation is counted as a new Zaraz Load. Under the Zaraz Monitoring dashboard, you can find a report showing how many Zaraz Loads your website has generated during a specific time period. Zaraz Loads and features are factored into our billing as follows:
Free plan
The Free Plan has a limit of 100,000 Zaraz Loads per month per account. This should allow almost everyone wanting to use Zaraz for personal use cases, like personal websites or side projects, to do so for free. After 100,000 Zaraz Loads, Zaraz will simply stop functioning.
If your websites generate more than 100,000 Zaraz loads combined, you will need to upgrade to the Workers Paid plan to avoid service interruption. If you desire some of the more advanced features, you can upgrade to Workers Paid and get access for only $5/month.
Paid plan
The Workers Paid Plan includes the first 200,000 Zaraz Loads per month per account, free of charge.
If you exceed the free Zaraz Loads allocations, you'll be charged $0.50 for every additional 1,000 Zaraz Loads, but the service will continue to function. (You can set notifications to get notified when you exceed a certain threshold of Zaraz Loads, to keep track of your usage.)
If your websites generate Zaraz Loads in the millions, you might want to consider the Workers Enterprise plan. Beyond the free 200,000 Zaraz Loads per month for your account, it offers additional volume discounts based on your Zaraz Loads usage as well as Cloudflare’s professional services.
Enterprise plan
The Workers Enterprise Plan includes the first 200,000 Zaraz Loads per month per account free of charge. Based on your usage volume, Cloudflare’s sales representatives can offer compelling discounts. Get in touch with us here. Workers Enterprise customers enjoy all paid enterprise features.
I already use Zaraz, what should I do?
If you were using Zaraz under the free beta, you have a period of two months to adjust and decide how you want to go about this change. Nothing will change until September 20, 2023. In the meantime we advise you to:
Get more clarity of your Zaraz Loads usage. Visit Monitoring to check how many Zaraz Loads you had in the previous couple of months. If you are worried about generating more than 100,000 Zaraz Loads per month, you might want to consider upgrading to Workers Paid via the plans page, to avoid service interruption. If you generate a big amount of Zaraz Loads, you’d probably want to reach out to your sales representative and get volume discounts. You can leave your details here, and we’ll get back to you.
Check if you are using one of the paid features as listed in the plans page. If you are, then you would need to purchase a Workers Paid subscription, starting at $5/month via the plans page. On September 20, these features will cease to work unless you upgrade.
* Please note, as of now, free plan users won't have access to any paid features. However, if you're already using a paid feature without a Workers Paid subscription, you can continue to use it risk-free until September 20. After this date, you'll need to upgrade to keep using any paid features.
We are here for you
As we make this important transition, we want to extend our sincere gratitude to all our beta users who have provided invaluable feedback and have helped us shape Zaraz into what it is today. We are excited to see Zaraz move beyond its beta stage and look forward to continuing to serve your needs and helping you build better, faster, and more secure web experiences. We know this change comes with adjustments, and we are committed to making the transition as smooth as possible. In the next couple of days, you can expect an email from us, with clear next steps and a way to get advice in case of need. You can always get in touch directly with the Cloudflare Zaraz team on Discord, or the community forum.
Thank you for joining us on this journey and for your ongoing support and trust in Cloudflare Zaraz. Let's continue to build the future of the web together!
Developer Week 2023 is officially a wrap. Last week, we shipped 34 posts highlighting what has been going on with our developer platform and where we’re headed in the future – including new products & features, in-depth tutorials to help you get started, and customer stories to inspire you.
We’ve loved already hearing feedback from you all about what we’ve shipped:
🤯 Serverless machine learning deployments – OMG! We used to need a team of devops to deploy a todo list MVP, it’s now 3 clicks with workers. They’re gonna do the same with ML workloads. Just like that. Boom. https://t.co/AcKUQ79fv0
Love this direction, for open source, for demos and running things on edge.
It's still in development, but as someone who've built an AI product on top of Cloudflare and has been asking for something like this, I'm really excited! https://t.co/AnywRDqecb
Yes! Loving this! I definitely this is the right direction and will help the general DevX and onboarding to the platform a lot ❤️! https://t.co/rEQWreeS96
We hope you’re able to spend the coming weeks slinging some code and experimenting with some of the new tools we shipped last week. As you’re building, join us in our developers discord and let us know what you think.
In case you missed any of our announcements here’s a handy recap:
The emergence of large language models (LLMs) is going to change the way developers write, debug, and modify code. Developer Platforms need to evolve to integrate AI capabilities to assist developers in their journeys.
Run pre-trained machine learning models and inference tasks on Cloudflare’s global network with Constellation AI. We’ll maintain a catalog of verified and ready-to-use models, or you can upload and train your own.
When getting started with a new technology comes a lot of questions on how to get started. Finding answers quickly is a time-saver. To help developers build in the fastest way possible we’ve introduced Cursor, an experimental AI assistant, to answer questions you may have about the Developer Platform. The assistant responds with both text and relevant links to our documentation to help you go further.
ChatGPT, recently allowed the ability for developers to create custom extensions to make ChatGPT even more powerful. It’s now possible to provide guidance to the conversational workflows within ChatGPT such as up-to-date statistics and product information. We’ve published plugins for Radar and our Developer Documentation and a tutorial showing how you can build your own plugin using Workers.
With any new technology comes concerns about risk and AI is no different. If you want to build with AI and maintain a Zero Trust security posture, Cloudflare One offers a collection of features to build with AI without increased risk. We’ve also compiled some best practices around securing your LLM.
Training large language models requires massive amount of compute which has led AI companies to look at multi-cloud architectures, with R2 and MosaicML companies can build these infrastructures at a fraction of the cost.
AI startups no longer need affiliation with an accelerator or an employee referral to gain access to the Startup Program. Bootstrapped AI startups can apply today to get free access to Cloudflare services including R2, Workers, Pages, and a host of other security and developer services.
A tutorial on building your first LangChainJS and Workers application to build more sophisticated applications by switching between LLMs or chaining prompts together.
We’ve partnered with other database providers, including Neon, PlanetScale, and Supabase, to make authenticating and connecting back to your databases there just work, without having to copy-paste credentials and connection strings back and forth.
Connect back to existing PostgreSQL and MySQL databases directly from Workers with outbound TCP sockets allowing you to connect to any database when building with Workers.
D1 is now not only significantly faster, but has a raft of new features, including the ability to time travel: restore your database to any minute within the last 30 days, without having to make a manual backup.
Bringing compute closer to the end user isn’t always the right answer to improve performance. Smart Placement for Workers and Pages Functions moves compute to the optimal location whether that is closer to the end user or closer to backend services and data.
Get valuable insights from your data when you use Snowflake to query data stored in your R2 data lake and load data from R2 into Snowflake’s Data Cloud.
Create Cloudflare CLI (C3) is a companion CLI to Wrangler giving you a single entry-point to configure Cloudflare via CLI. Pick your framework, all npm dependencies are installed, and you’ll receive a URL for where your application was deployed.
Manage all your Workers scripts and Pages projects from a single place in the Cloudflare dashboard. Over the next year we’ll be working to converge these two separate experiences into one eliminating friction when building.
Now in beta, the build system for Pages includes the latest versions of Node.js, Python, Hugo, and more. You can opt in to use this for existing projects or stay on the existing system, so your builds won’t break.
Having a local development environment that mimics production as closely as possible helps to ensure everything runs as expected in production. You can test every aspect prior to deployment. Wrangler 3 now leverages Miniflare3 based on workerd with local-by-default development.
Our terms of service were not clear about serving content hosted on the Developer Platform via our CDN. We’ve made it clearer that customers can use the CDN to serve video and other large files stored on the Developer Platform including Images, Pages, R2, and Stream.
A retrospective on the first year of Workers for Platform, what’s coming next, and featuring how customers like Shopify and Grafbase are building with it.
Deploy a Worker script that requires Browser Rendering capabilities through Wrangler.
Watch on Cloudflare TV
If you missed any of the announcements or want to also view the associated Cloudflare TV segments, where blog authors went through each announcement, you can now watch all the Developer Week videos on Cloudflare TV.
In 2018, we first launched our Open Source Software Sponsorships program, and since then, we've been listening to your feedback, and realized that it's time to introduce a fresh and enhanced version of the program that's more inclusive and better addresses the needs of the OSS community.
A subset of open source projects on Cloudflare. See more >>
Previously, our sponsorship focused on engineering tools, but we're excited to announce that we've now opened it to include any non-profit and open source projects.
Program criteria and eligibility
To qualify for our Open Source Sponsorship Program, projects must be open source and meet the following criteria:
Can Cloudflare help your open source project be successful and sustainable? Fill out the application form to submit your project for review, and please share this so that more open source projects can be supported by Cloudflare.
We launched the $2B Workers Launchpad Funding Program in late 2022 to help support the over one million developers building on Cloudflare’s Developer Platform, many of which are startups leveraging Cloudflare to ship faster, scale more efficiently, and accelerate their growth.
Cohort #1 wrap-up
Since announcing the program just a few months ago, we have welcomed 25 startups from all around the world into our inaugural cohort and recently wrapped up the program with the Demo Day. Cohort #1 gathered weekly for Office Hours with our Solutions Architects for technical advice and the Founders Bootcamp, where they spent time with Cloudflare leadership, preview upcoming products with our Developer Platform Product Managers, and receive advice on a wide range of topics such as how to build Sales teams and think about the right pricing model for your product.
Learn more about what these companies are building and what they’ve been up to below:
Why they chose Cloudflare “Cloudflare is the de facto Infrastructure for building resilient serverless products, it was a no-brainer to migrate to Cloudflare Workers to build the most frictionless experience for our customers.”
Recent updates Learn more about how Authdog is using Cloudflare’s Developer Platform in their Built With Workerscase study.
Automotive Commerce APIs to Buy & Sell Cars Online.
Demo Day pitch
Why they chose Cloudflare “We believe that Cloudflare is the next-generation of cloud computing platforms, and Drivly is completely built on Cloudflare, from Workers, Queues, PubSub, and especially Durable Objects.”
Recent updates Drivly made their public launch at Demo Day!
Why they chose Cloudflare “Simplicity and Performance. Using Pages and KV is extremely easy, but what really impresses are Workers with a nearly instant cold start!”
Recent updates Check out how Cloudflare is helping Flethy improve and accelerate API service integrations for developers here.
The easiest way to build and deploy GraphQL backends.
Demo Day pitch
Why they chose Cloudflare “The Grafbase platform is built from the ground up to be highly performant and deployed to the edge using Rust and WebAssembly. Services like Cloudflare Workers, KV, Durable Objects, Edge Caching were a natural choice as it fits perfectly into our vision architecturally.”
Recent updates Grafbase, which is building on Workers for Platforms among other Cloudflare products, celebrated their public launch and 7 new features in their April 2023 Launch Week.
The last line of defense for the software supply chain.
Demo Day pitch
Why they chose Cloudflare “Cloudflare's developer products offer effortlessly powerful building blocks essential to scaling up product to meet strenuous customer demand while enabling our developers to deliver faster than ever.”
Recent updates Karambit recently received a grant from the Virginia Innovation Partnership Corporation to help scale their commercial growth.
A no-code analytics platform for growth teams that automatically turns raw data into actionable narratives.
Demo Day pitch
Why they chose Cloudflare “Our customers benefit as we improve the quality of insights for them by running advanced algorithms for finding unqualified data points and quickly solving them with the unlimited power of Cloudflare Workers.”
Recent updates Learn more about how Cloudflare is helping Narrative BI improve the quality of insights they generate for customers here.
API-first personalization and experimentation solution to give your customers blazing-fast experiences.
Demo Day pitch
Why they chose Cloudflare “Cloudflare’s developers platform allows us to fully deploy our everything-on-the-edge approach to both data and delivery means personalized experience cause zero loading lag and zero interruptions for the customer.”
Recent updates Ninetailed recently launched integrations with Contentstack, Zapier, and other tools to improve and personalize digital customer experiences. Learn more on the Ninetailed blog and their Built with Workers case study.
Scalable, secure and cost-effective digital infrastructure, without the complexities of it.
Demo Day pitch
Why they chose Cloudflare “Workers provides us with a global network of edge compute that we can use to route data internally to our user's deployments, providing our users with infinite scale.”
Recent updates Patr was recently highlighted as a Product of the Day on Product Hunt!
Quest is a code-generation tool that automatically generates frontend code for business applications.
Demo Day pitch
Why they chose Cloudflare “We chose Cloudflare's Workers and Pages product to augment our frontend code-gen to include backend and hosting capabilities.”
Recent updates Quest has been hard at work expanding their platform and recently added animations, CSS grid, MUI & Chakra UI support, NextJS support, breakpoints, nested components, and more.
Simple & Secure User Access. Rollup is all your authentication and authorization needs bundled into one great package.
Demo Day pitch
Why they chose Cloudflare “We chose Cloudflare’s developer platform because it provides us all the tools to build a logical user graph at the edge. We can utilize everything from Durable Objects, D1, R2, and more to build a fast and distributed auth platform.”
Recent updates Rollup ID recently made their public debut and has rolled out lots of new features since. Learn more here.
Translating videos at the speed of social media using AI.
Demo Day pitch
Why they chose Cloudflare “Cloudflare Stream allows us to compete with YouTube's scale while being a 1-person startup, and Cloudflare Workers handles millions of unique views on Targum without waking us up at night.”
Recent updates Targum launched its platform to customers and hit $100K MRR in just a few days! Check out their Built With Workers case study to learn more.
Why they chose Cloudflare “Workers and the Cloudflare developer platform have been pivotal in enabling us to modernize and enhance existing website platforms and grow their conversions by 5X with little to no code.”
Recent updates Touchless has been growing their ecosystem and recently joined the RudderStack Solutions Partner Program.
Introducing Cohort #2 of the Workers Launchpad!
We have received hundreds of applications from startups from nearly 50 different countries. There were many AI or AI-related companies helping everyone from developers, to security teams and sales organizations. We also heard from many startups looking to improve developer tooling and collaboration, new social and gaming platforms, and companies solving a wide range of problems that ecommerce, consumer, real estate, and other businesses face today.
While these applicants are tackling a diverse set of real-world problems, the common thread is that they chose to leverage Cloudflare’s developer platform to build more secure, scalable, and feature-rich products faster than they otherwise could.
Without further ado, we are thrilled to announce the 25 incredible startups selected for Cohort #2 of the Workers Launchpad:
All-in-one web framework designed for speed. Pull your content from anywhere and deploy everywhere, all powered by your favorite UI components and libraries.
Buildless is a global build cache, like Cloudflare for compiled code; we cache artifacts and make them available over the internet to exponentially accelerate developer velocity.
We are looking forward to working with each of these companies over the next few months and sharing what they’re building with you.
If you’re building on Cloudflare’s Developer Platform, head over to @CloudflareDev or join the Cloudflare Developer Discord community to stay in the loop on Launchpad updates. In the early fall, we’ll be selecting Cohort #3 — apply early here!
Cloudflare is not providing any funding or making any funding decisions, and there is no guarantee that any particular company will receive funding through the program. All funding decisions will be made by the venture capital firms that participate in the program. Cloudflare is not a registered broker-dealer, investment adviser, or other similar intermediary.
Today we are announcing support for three additional APIs from Node.js in Cloudflare Workers. This increases compatibility with the existing ecosystem of open source npm packages, allowing you to use your preferred libraries in Workers, even if they depend on APIs from Node.js.
We recently added support for AsyncLocalStorage, EventEmitter, Buffer, assert and parts of util. Today, we are adding support for:
We are also sharing a preview of a new module type, available in the open-source Workers runtime, that mirrors a Node.js environment more closely by making some APIs available as globals, and allowing imports without the node: specifier prefix.
The Node.js streams API is the original API for working with streaming data in JavaScript that predates the WHATWG ReadableStream standard. Now, a full implementation of Node.js streams (based directly on the official implementation provided by the Node.js project) is available within the Workers runtime.
Let's start with a quick example:
import {
Readable,
Transform,
} from 'node:stream';
import {
text,
} from 'node:stream/consumers';
import {
pipeline,
} from 'node:stream/promises';
// A Node.js-style Transform that converts data to uppercase
// and appends a newline to the end of the output.
class MyTransform extends Transform {
constructor() {
super({ encoding: 'utf8' });
}
_transform(chunk, _, cb) {
this.push(chunk.toString().toUpperCase());
cb();
}
_flush(cb) {
this.push('\n');
cb();
}
}
export default {
async fetch() {
const chunks = [
"hello ",
"from ",
"the ",
"wonderful ",
"world ",
"of ",
"node.js ",
"streams!"
];
function nextChunk(readable) {
readable.push(chunks.shift());
if (chunks.length === 0) readable.push(null);
else queueMicrotask(() => nextChunk(readable));
}
// A Node.js-style Readable that emits chunks from the
// array...
const readable = new Readable({
encoding: 'utf8',
read() { nextChunk(readable); }
});
const transform = new MyTransform();
await pipeline(readable, transform);
return new Response(await text(transform));
}
};
In this example we create two Node.js stream objects: one stream.Readable and one stream.Transform. The stream.Readable simply emits a sequence of individual strings, piped through the stream.Transform which converts those to uppercase and appends a new-line as a final chunk.
The example is straightforward and illustrates the basic operation of the Node.js API. For anyone already familiar with using standard WHATWG streams in Workers the pattern here should be recognizable.
The Node.js streams API is used by countless numbers of modules published on npm. Now that the Node.js streams API is available in Workers, many packages that depend on it can be used in your Workers. For example, the split2 module is a simple utility that can break a stream of data up and reassemble it so that every line is a distinct chunk. While simple, the module is downloaded over 13 million times each week and has over a thousand direct dependents on npm (and many more indirect dependents). Previously it was not possible to use split2 within Workers without also pulling in a large and complicated polyfill implementation of streams along with it. Now split2 can be used directly within Workers with no modifications and no additional polyfills. This reduces the size and complexity of your Worker by thousands of lines.
import {
PassThrough,
} from 'node:stream';
import { default as split2 } from 'split2';
const enc = new TextEncoder();
export default {
async fetch() {
const pt = new PassThrough();
const readable = pt.pipe(split2());
pt.end('hello\nfrom\nthe\nwonderful\nworld\nof\nnode.js\nstreams!');
for await (const chunk of readable) {
console.log(chunk);
}
return new Response("ok");
}
};
Path
The Node.js Path API provides utilities for working with file and directory paths. For example:
Note that in the Workers implementation of path, the path.win32 variants of the path API are not implemented, and will throw an exception.
StringDecoder
The Node.js StringDecoder API is a simple legacy utility that predates the WHATWG standard TextEncoder/TextDecoder API and serves roughly the same purpose. It is used by Node.js' stream API implementation as well as a number of popular npm modules for the purpose of decoding UTF-8, UTF-16, Latin1, Base64, and Hex encoded data.
import { StringDecoder } from 'node:string_decoder';
const decoder = new StringDecoder('utf8');
const cent = Buffer.from([0xC2, 0xA2]);
console.log(decoder.write(cent));
const euro = Buffer.from([0xE2, 0x82, 0xAC]);
console.log(decoder.write(euro));
In the vast majority of cases, your Worker should just keep on using the standard TextEncoder/TextDecoder APIs, but the StringDecoder is available directly for workers to use now without relying on polyfills.
Node.js Compat Modules
One Worker can already be a bundle of multiple assets. This allows a single Worker to be made up of multiple individual ESM modules, CommonJS modules, JSON, text, and binary data files.
Soon there will be a new type of module that can be included in a Worker bundles: the NodeJsCompatModule.
A NodeJsCompatModule is designed to emulate the Node.js environment as much as possible. Within these modules, common Node.js global variables such as process, Buffer, and even __filename will be available. More importantly, it is possible to require() our Node.js core API implementations without using the node: specifier prefix. This maximizes compatibility with existing NPM packages that depend on globals from Node.js being present, or don’t import Node.js APIs using the node: specifier prefix.
Support for this new module type has landed in the open source workerd runtime, with deeper integration with Wrangler coming soon.
What’s next
We’re adding support for more Node.js APIs each month, and as we introduce new APIs, they will be added under the nodejs_compat compatibility flag — no need to take any action or update your compatibility date.
Have an NPM package that you wish worked on Workers, or an API you’d like to be able to use? Join the Cloudflare Developers Discord and tell us what you’re building, and what you’d like to see next.
Communicating between systems can be a balancing act that has a major impact on your business. APIs have limits, billing frequently depends on usage, and end-users are always looking for more speed in the services they use. With so many conflicting considerations, it can feel like a challenge to get it just right. Cloudflare Queues is a tool to make this balancing act simple. With our latest features like consumer concurrency and explicit acknowledgment, it’s easier than ever for developers to focus on writing great code, rather than worrying about the fees and rate limits of the systems they work with.
Queues is a messaging service, enabling developers to send and receive messages across systems asynchronously with guaranteed delivery. It integrates directly with Cloudflare Workers, making for easy message production and consumption working with the many products and services we offer.
What’s new in Queues?
Consumer concurrency
Oftentimes, the systems we pull data from can produce information faster than other systems can consume them. This can occur when consumption involves processing information, storing it, or sending and receiving information to a third party system. The result of which is that sometimes, a queue can fall behind where it should be. At Cloudflare, a queue shouldn't be a quagmire. That’s why we’ve introduced Consumer Concurrency.
With Concurrency, we automatically scale up the amount of consumers needed to match the speed of information coming into any given queue. In this way, customers no longer have to worry about an ever-growing backlog of information bogging down their system.
How it works
When setting up a queue, developers can set a Cloudflare Workers script as a target to send messages to. With concurrency enabled, Cloudflare will invoke multiple instances of the selected Worker script to keep the messages in the queue moving effectively. This feature is enabled by default for every queue and set to automatically scale.
Autoscaling considers the following factors when spinning up consumers: the number of messages in a queue, the rate of new messages, and successful vs. unsuccessful consumption attempts.
If a queue has enough messages in it, concurrency will increase each time a message batch is successfully processed. Concurrency is decreased when message batches encounter errors. Customers can set a max_concurrency value in the Dashboard or via Wrangler, which caps out how many consumers can be automatically created to perform processing for a given queue.
Setting the max_concurrency value manually can be helpful in the following situations where producer data is provided in bursts, the datasource API is rate limited, and datasource API has higher costs with more usage.
Setting a max concurrency value manually allows customers to optimize their workflows for other factors beyond speed.
// in your wrangler.toml file
[[queues.consumers]]
queue = "my-queue"
//max concurrency can be set to a number between 1 and 10
//this defines the total amount of consumers running simultaneously
max_concurrency = 7
To learn more about concurrency you can check out our developer documentation here.
Concurrency in practice
It’s baseball season in the US, and for many of us that means fantasy baseball is back! This year is the year we finally write a program that uses data and statistics to pick a winning team, as opposed to picking players based on “feelings” and “vibes”. We’re engineers after all, and baseball is a game of rules. If the Oakland A’s can do it, so can we!
So how do we put this together? We’ll need a few things:
A list of potential players
An API to pull historical game statistics from
A queue to send this data to its consumer
A Worker script to crunch the numbers and generate a score
A developer can pull from a baseball reference API into a Workers script, and from that worker pass this information to a queue. Historical data is… historical, so we can pull data into our queue as fast as the baseball API will allow us. For our list of potential players, we pull statistics for each game they’ve played. This includes everything from batting averages, to balls caught, to game day weather. Score!
//get data from a third party API and pass it along to a queue
const response = await fetch("http://example.com/baseball-stats.json");
const gamesPlayedJSON = await response.json();
for (game in gamesPlayedJSON){
//send JSON to your queue defined in your workers environment
env.baseballqueue.send(jsonData)
}
Our producer Workers script then passes these statistics onto the queue. As each game contains quite a bit of data, this results in hundreds of thousands of “game data” messages waiting to be processed in our queue. Without concurrency, we would have to wait for each batch of messages to be processed one at a time, taking minutes if not longer. But, with Consumer Concurrency enabled, we watch as multiple instances of our worker script invoked to process this information in no time!
Our Worker script would then take these statistics, apply a heuristic, and store the player name and a corresponding quality score into a database like a Workers KV store for easy access by your application presenting the data.
Explicit Acknowledgment
In Queues previously, a failure of a single message in a batch would result in the whole batch being resent to the consumer to be reprocessed. This resulted in extra cycles being spent on messages that were processed successfully, in addition to the failed message attempt. This hurts both customers and developers, slowing processing time, increasing complexity, and increasing costs.
With Explicit Acknowledgment, we give developers the precision and flexibility to handle each message individually in their consumer, negating the need to reprocess entire batches of messages. Developers can now tell their queue whether their consumer has properly processed each message, or alternatively if a specific message has failed and needs to be retried.
An acknowledgment of a message means that that message will not be retried if the batch fails. Only messages that were not acknowledged will be retried. Inversely, a message that is explicitly retried, will be sent again from the queue to be reprocessed without impacting the processing of the rest of the messages currently being processed.
How it works
In your consumer, there are 4 new methods you can call to explicitly acknowledge a given message: .ack(), .retry(), .ackAll(), .retryAll().
Both ack() and retry() can be called on individual messages. ack() tells a queue that the message has been processed successfully and that it can be deleted from the queue, whereas retry() tells the queue that this message should be put back on the queue and delivered in another batch.
async queue(batch, env, ctx) {
for (const msg of batch.messages) {
try {
//send our data to a 3rd party for processing
await fetch('https://thirdpartyAPI.example.com/stats', {
method: 'POST',
body: msg,
headers: {
'Content-type': 'application/json'
}
});
//acknowledge if successful
msg.ack();
// We don't have to re-process this if subsequent messages fail!
}
catch (error) {
//send message back to queue for a retry if there's an error
msg.retry();
console.log("Error processing", msg, error);
}
}
}
ackAll() and retryAll() work similarly, but act on the entire batch of messages instead of individual messages.
For more details check out our developer documentation here.
Explicit Acknowledgment in practice
In the course of making our Fantasy Baseball team picker, we notice that data isn’t always sent correctly from the baseball reference API. This results in data not being correctly parsed and rejected from our player heuristics.
Without Explicit Acknowledgment, the entire batch of baseball statistics would need to be retried. Thankfully, we can use Explicit Acknowledgment to avoid that, and tell our queue which messages were parsed successfully and which were not.
import heuristic from "baseball-heuristic";
export default {
async queue(batch: MessageBatch, env: Env, ctx: ExecutionContext) {
for (const msg of batch.messages) {
try {
// Calculate the score based on the game stats
heuristic.generateScore(msg)
// Explicitly acknowledge results
msg.ack()
} catch (err) {
console.log(err)
// Retry just this message
msg.retry()
}
}
},
};
Higher throughput
Under the hood, we’ve been working on improvements to further increase the amount of messages per second each queue can handle. In the last few months, that number has quadrupled, improving from 100 to over 400 messages per second.
Scalability can be an essential factor when deciding which services to use to power your application. You want a service that can grow with your business. We are always aiming to improve our message throughput and hope to see this number quadruple again over the next year. We want to grow with you.
What’s next?
As our service grows, we want to provide our customers with more ways to interact with our service beyond the traditional Cloudflare Workers workflow. We know our customers’ infrastructure is often complex, spanning across multiple services. With that in mind, our focus will be on enabling easy connection to services both within the Cloudflare ecosystem and beyond.
R2 as a consumer
Today, the only type of consumer you can configure for a queue is a Workers script. While Workers are incredibly powerful, we want to take it a step further and give customers a chance to write directly to other services, starting with R2. Coming soon, customers will be able to select an R2 bucket in the Cloudflare Dashboard for a Queue to write to directly, no code required. This will save valuable developer time by avoiding the initial setup in a Workers script, and any maintenance that is required as services evolve. With R2 as a first party consumer in Queues, customers can simply select their bucket, and let Cloudflare handle the rest.
HTTP pull
We're also working to allow you to consume messages from existing infrastructure you might have outside of Cloudflare. Cloudflare Queues will provide an HTTP API for each queue from which any consumer can pull batches of messages for processing. Customers simply make a request to the API endpoint for their queue, receive data they requested, then send an acknowledgment that they have received the data, so the queue can continue working on the next batch.
Always working to be faster
For the Queues team, speed is always our focus, as we understand our customers don't want bottlenecks in the performance of their applications. With this in mind the team will be continuing to look for ways to increase the velocity through which developers can build best in class applications on our developer platform. Whether it's reducing message processing time, the amount of code you need to manage, or giving developers control over their application pipeline, we will continue to implement solutions to allow you to focus on just the important things, while we handle the rest.
Cloudflare Queues is currently in Open Beta and ready to power your most complex applications.
Check out our getting started guide and build your service with us today!
The Workers Browser Rendering API allows developers to programmatically control and interact with a headless browser instance and create automation flows for their applications and products.
Since the private beta announcement, based on the feedback we've been receiving and our own roadmap, the team has been working on the developer experience and improving the platform architecture for the best possible performance and reliability. Today we enter the open beta and will start onboarding the customers on the wait list.
Developer experience
Starting today, Wrangler, our command-line tool for configuring, building, and deploying applications with Cloudflare developer products, has support for the Browser Rendering API bindings.
Bindings allow your Workers to interact with resources on the Cloudflare developer platform. In this case, they will provide your Worker script with an authenticated endpoint to interact with a dedicated Chromium browser instance.
This is all you need in your wrangler.toml once this service is enabled for your account:
browser = { binding = "MYBROWSER", type = "browser" }
Now you can deploy any Worker script that requires Browser Rendering capabilities. You can spawn Chromium instances and interact with them programmatically in any way you typically do manually behind your browser.
Under the hood, the Browser Rendering API gives you access to a WebSocket endpoint that speaks the DevTools Protocol. DevTools is what allows us to instrument a Chromium instance running in our global network, and it's the same protocol that Chrome uses on your computer when you inspect a page.
With enough dedication, you can, in fact, implement your own DevTools client and talk the protocol directly. But that'd be crazy; almost no one does that.
So…
Puppeteer
Puppeteer is one of the most popular libraries that abstract the lower-level DevTools protocol from developers and provides a high-level API that you can use to easily instrument Chrome/Chromium and automate browsing sessions. It's widely used for things like creating screenshots, crawling pages, and testing web applications.
Puppeteer typically connects to a local Chrome or Chromium browser using the DevTools port.
We forked a version of Puppeteer and patched it to connect to the Workers Browser Rendering API instead. The changes are minimal; after connecting the developers can then use the full Puppeteer API as they would on a standard setup.
In the long term, we will update Puppeteer to keep matching the version of our Chromium instances infrastructure running in our network.
Developer documentation
Following the tradition with other Developer products, we created a dedicated section for the Browser Rendering APIs in our Developer's Documentation site.
You can access this page to learn more about how the service works, Wrangler support, APIs, and limits, and find examples of starter templates for common applications.
An example application: taking screenshots
Taking screenshots from web pages is one of the typical cases for browser automation.
Let's create a Worker that uses the Browser Rendering API to do just that. This is a perfect example of how to set up everything and get an application running in minutes, it will give you a good overview of the steps involved and the basics of the Puppeteer API, and then you can move from here to other more sophisticated use-cases.
Step one, start a project, install Wrangler and Cloudflare’s fork of Puppeteer:
Step two, let’s create the simplest possible wrangler.toml configuration file with the Browser Rendering API binding:
name = "browser-worker"
main = "src/index.ts"
compatibility_date = "2023-03-14"
node_compat = true
workers_dev = true
browser = { binding = "MYBROWSER", type = "browser" }
Step three, create src/index.ts with your Worker code:
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add the ?url=https://example.com/ parameter"
);
}
},
};
That's it, no more steps. This Worker instantiates a browser using Puppeteer, opens a new page, navigates to whatever you put in the "url" parameter, takes a screenshot of the page, closes the browser, and responds with the JPEG image of the screenshot. It can't get any easier to get started with the Browser Rendering API.
Run npx wrangler dev –remote to test it and npx wrangler publish when you’re done.
You can explore the entire Puppeteer API and implement other functionality and logic from here. And, because it's Workers, you can add other developer products to your code. You might need a relational database, or a KV store to cache your screenshots, or an R2 bucket to archive your crawled pages and assets, or maybe use a Durable Object to keep your browser instance alive and share it with multiple requests, or queues to handle your jobs asynchronous, we have all of this and more.
You can also find this and other examples of how to use Browser Rendering in the Developer Documentation.
How do we use Browser Rendering
Dogfooding our products is one of the best ways to test and improve them, and in some cases, our internal needs dictate or influence our roadmap. Workers Browser Rendering is a good example of that; it was born out of our necessities before we realized it could be a product. We've been using it extensively for things like taking screenshots of pages for social sharing or dashboards, testing web software in CI, or gathering page load performance metrics of our applications.
But there's one product we've been using to stress test and push the limits of the Browser Rendering API and drive the engineering sprints that brought us to open the beta to our customers today: The Cloudflare Radar URL Scanner.
The URL Scanner scans any URL and compiles a full report containing technical, performance, privacy, and security details about that page. It's processing thousands of scans per day currently. It was built on top of Workers and uses a combination of the Browser Rendering APIs with Puppeteer to create enriched HAR archives and page screenshots, Durable Objects to reuse browser instances, Queues to handle customers' load and execute jobs asynchronously, and R2 to store the final reports.
This tool will soon have its own "how we built it" blog. Still, we wanted to let you know about it now because it is a good example of how you can build sophisticated applications using Browser Rendering APIs at scale starting today.
Future plans
The team will keep improving the Browser Rendering API, but a few things are worth mentioning today.
First, we are looking into upstreaming the changes in our Puppeteer fork to the main project so that using the official library with the Cloudflare Workers Browser Rendering API becomes as easy as a configuration option.
Second, one of the reasons why we decided to expose the DevTools protocol bare naked in the Worker binding is so that it can support other browser instrumentalization libraries in the future. Playwright is a good example of another popular library that developers want to use.
And last, we are also keeping an eye on and testing WebDriver BiDi, a "new standard browser automation protocol that bridges the gap between the WebDriver Classic and CDP (DevTools) protocols." Click here to know more about the status of WebDriver BiDi.
Final words
The Workers Browser Rendering API enters open beta today. We will gradually be enabling the customers in the wait list in batches and sending them emails. We look forward to seeing what you will be building with it and want to hear from you.
For developers, performance is everything. If your app is slow, it will get outclassed and no one will use it. In order for your application to be fast, every underlying component and system needs to be as performant as possible. In the past, we’ve shown how our network helps make your apps faster, even in remote places. We’ve focused on how Workers provides the fastest compute, even in regions that are really far away from traditional cloud datacenters.
For Developer Week 2023, we’re going to be looking at one of the newest Cloudflare developer offerings and how it compares to an alternative when retrieving assets from buckets: R2 versus Amazon Simple Storage Service (S3). Spoiler alert: we’re faster than S3 when serving media content via public access. Our test showed that on average, Cloudflare R2 was 20-40% faster than Amazon S3. For this test, we used 95th percentile Response tests, which measures the time it takes for a user to make a request to the bucket, and get the entirety of the response. This test was designed with the goal of measuring end-user performance when accessing content in public buckets.
In this blog we’re going to talk about why your object store needs to be fast, how much faster R2 is, why that is, and how we measured it.
Storage performance is user-facing
Storage performance is critical to a snappy user experience. Storage services are used for many scenarios that directly impact the end-user experience, particularly in the case where the data stored doesn’t end up in a cache (uncacheable or dynamic content). Compute and database services can rely on storage services, so if they’re not fast, the services using them won’t be either. Even the basic content fetching scenarios that use a CDN require storage services to be fast if the asset is either uncacheable or was not cached on the request: if the storage service is slow or far away, users will be impacted by that performance. And as every developer knows, nobody remembers the nine fast API calls if the last call was slow. Users don’t care about API calls, they care about overall experience. One slow API call, one slow image, one slow anything can muck up the works and provide users with a bad experience.
Because there are lots of different ways to use storage services, we’re going to focus on a relatively simple scenario: fetching static images from these services. Let’s talk about R2 and how it compares to one of the alternatives in this scenario: Amazon S3.
Benchmarking storage performance
When looking at uncached raw file delivery for users in North America retrieving content from a bucket in Ashburn, Virginia (US-East) and examining 95th percentile Response, R2 is 38% faster than S3:
Storage Performance: Response in North America (US-East)
95th percentile (ms)
Cloudflare R2
1,262
Amazon S3
2,055
For content hosted in US-East (Ashburn, VA) and only looking at North America-based eyeballs, R2 beats S3 by 30% in response time. When we look at why this is the case, the answer lies in our closeness to users and highly optimized HTTP stacks. Let’s take a look at the TCP connect and SSL times for these tests, which are the times it takes to reach the storage bucket (TCP connect) and the time to complete TLS handshake (SSL time):
Storage Performance: Connect and SSL in North America (US-East)
95th percentile connect (ms)
95th percentile SSL (ms)
Cloudflare R2
32
59
Amazon S3
78
180
Cloudflare’s cumulative connect + SSL time is almost 1/2 of Amazon’s SSL time alone. Being able to be fast on connection establishment gives us an edge right off the bat, especially in North America where cloud and storage providers tend to optimize for performance, and connect times tend to be low because ISPs have good peering with cloud and storage providers. But this isn’t just true in North America. Let’s take a look at Europe (EMEA) and Asia (APAC), where Cloudflare also beats out AWS in 95th percentile response time when we look at eyeballs in region for both regions:
Storage Performance: Response in EMEA (EU-East)
95th percentile (ms)
Cloudflare R2
1,303
Amazon S3
1,729
Cloudflare beats Amazon by 20% in EMEA. And when you look at the SSL times, you’ll see the same trends that were present in North America: faster Connect and SSL times:
Storage Performance: Connect and SSL in EMEA (EU-East)
95th percentile connect (ms)
95th percentile SSL (ms)
Cloudflare R2
57
94
Amazon S3
80
178
Again, the separator is how optimized Cloudflare is at setting up connections to deliver content. This is also true in APAC, where objects stored in Tokyo are served about 1.5 times faster on Cloudflare than for AWS:
Storage Performance: Response in APAC (Tokyo)
95th percentile (ms)
Cloudflare R2
4,057
Amazon S3
6,850
Focus on cross-region
Up until this point, we’ve been looking at scenarios where users are accessing data that is stored in the same region as they are. But what if that isn’t the case? What if a user in Germany is accessing content in Ashburn? In those cases, Cloudflare also pulls ahead. This is a chart showing 95th percentile response times for cases where users outside the United States are accessing content hosted in Ashburn, VA, or US-East:
Storage Performance: Response for users outside of US connecting to US-East
95th percentile (ms)
Cloudflare R2
3,224
Amazon S3
6,387
Cloudflare wins again, at almost 2x faster than S3 at P95. This data shows that not only do our in-region calls win out, but we win across the world. Even if you don’t have the money to buy storage everywhere in the world, R2 can still give you world-class performance because not only is R2 faster cross-region, R2’s default no-region setup ensures your data will be close to your users as often as possible.
Testing methodology
To measure these tests, we set up over 400 Catchpoint backbone nodes embedded in last mile ISPs around the world to retrieve a 1 MB file from R2 and S3 in specific locations: Ashburn, Tokyo, and Frankfurt. We recognize that many users will store larger files than the one we tested with, and we plan to test with larger files next showing that we’re faster delivering larger files as well.
We had these 400 nodes retrieve the file uncached from each storage service every 30 minutes for four days. We configured R2 to disable caching. This allows us to make sure that we aren’t reaping any benefits from our CDN pipeline and are only retrieving uncached files from the storage services.
Finally, we had to fix where the public buckets were stored in R2 to get an equivalent test compared to S3. You may notice that when configuring R2, you aren’t able to select specific datacenter locations like you can in AWS. Instead, you can provide a location hint to a general region. Cloudflare will store data anywhere in that region.
This feature is designed to make it easier for developers to deploy storage that benefits larger ranges of users as opposed to needing to know where specific datacenters are. However, that makes performance comparisons difficult, so for this test we configured R2 to store data in those specific locations (consistent with the S3 placement) on the backend as opposed to in any location in that region to ensure we would get better apples-to-apples results.
Putting the pieces together
Storage services like R2 are only part of the equation. Developers will often use storage services in conjunction with other compute services for a complete end-to-end application experience. Previously, we performed comparisons of Workers and other compute products such as Fastly’s Compute@Edge and AWS’s Lambda@Edge. We’ve rerun the numbers, and for compute times, Workers is still the fastest compute around, beating AWS Lambda@Edge and Fastly’s Compute@Edge for end-to-end performance for Rust hard tests:
Cloudflare is faster than Fastly for both JavaScript and Rust tests, while also being faster than AWS at JavaScript, which is the only test Lambda@Edge supports
To run these tests, we perform two tests against each provider: a complex JavaScript function, and a complex Rust function. These tests run as part of our network benchmarking tests that run from real user browsers around the world. For a more in-depth look at how we collect this data for Workers scenarios, check our previous Developer Week posts.
Here are the functions for both complex functions in JavaScript and Rust:
JavaScript complex function:
function testHardBusyLoop() {
let value = 0;
let offset = Date.now();
for (let n = 0; n < 15000; n++) {
value += Math.floor(Math.abs(Math.sin(offset + n)) * 10);
}
return value;
}
Rust complex function:
fn test_hard_busy_loop() -> i32 {
let mut value = 0;
let offset = Date::now().as_millis();
for n in 0..15000 {
value += (((offset + n) as f64).sin().abs() * 10.0) as i32;
}
value
}
By combining Workers and R2, you get a much simpler developer experience and a much faster user experience than you would get with any of the competition.
Storage, sped up and simplified
R2 is a unique storage service that doesn’t require the knowledge of specific locations, has a more global footprint, and integrates easily with existing Cloudflare Developer Platform products for a simple, performant experience for both users and developers. However, because it’s built on top of Cloudflare, it comes with performance baked in, and that’s evidenced by R2 being faster than its primary alternatives.
At Cloudflare, we believe that developers shouldn’t have to think about performance, you have so many other things to think about. By choosing Cloudflare, you should be able to rest easy knowing that your application will be faster because it’s built on Cloudflare, not because you’re manipulating Cloudflare to be faster for you. And by using R2 and the rest of our developer platform, we’re happy to say that we’re delivering on our vision to make performance easy for you.
We’re not going to bury the lede: we’re excited to launch a major update to our D1 database, with dramatic improvements to performance and scalability. Alpha users (which includes any Workers user) can create new databases using the new storage backend right now with the following command:
In the coming weeks, it’ll be the default experience for everyone, but we want to invite developers to start experimenting with the new version of D1 immediately. We’ll also be sharing more about how we built D1’s new storage subsystem, and how it benefits from Cloudflare’s distributed network, very soon.
Remind me: What’s D1?
D1 is Cloudflare’s native serverless database, which we launched into alpha in November last year. Developers have been building complex applications with Workers, KV, Durable Objects, and more recently, Queues & R2, but they’ve also been consistently asking us for one thing: a database they can query.
We also heard consistent feedback that it should be SQL-based, scale-to-zero, and (just like Workers itself), take a Region: Earth approach to replication. And so we took that feedback and set out to build D1, with SQLite giving us a familiar SQL dialect, robust query engine and one of the most battle tested code-bases to build on.
We shipped the first version of D1 as a “real” alpha: a way for us to develop in the open, gather feedback directly from developers, and better prioritize what matters. And living up to the alpha moniker, there were bugs, performance issues and a fairly narrow “happy path”.
Despite that, we’ve seen developers spin up thousands of databases, make billions of queries, popular ORMs like Drizzle and Kysely add support for D1 (already!), and Remix and Nuxt templates build directly around it, as well.
Turning it up to 11
If you’ve used D1 in its alpha state to date: forget everything you know. D1 is now substantially faster: up to 20x faster on the well-known Northwind Traders Demo, which we’ve just migrated to use our new storage backend:
Our new architecture also increases write performance: a simple benchmark inserting 1,000 rows (each row about 200 bytes wide) is approximately 6.8x faster than the previous version of D1.
Larger batches (10,000 rows at ~200 bytes wide) see an even larger improvement: between 10-11x, with the new storage backend’s latency also being significantly more consistent. We’ve also not yet started to optimize our overall write throughput, and so expect D1 to only get faster here.
With our new storage backend, we also want to make clear that D1 is not a toy, and we’re constantly benchmarking our performance against other serverless databases. A query against a 500,000 row key-value table (recognizing that benchmarks are inherently synthetic) sees D1 perform about 3.2x faster than a popular serverless Postgres provider:
We ran the Postgres queries several times to prime the page cache and then took the median query time, as measured by the server. We’ll continue to sharpen our performance edge as we go forward.
Developers with existing databases can import data into a new database backed by the storage engine by following the steps to export their database and then import it in our docs.
What did I miss?
We’ve also been working on a number of improvements to D1’s developer experience:
A new console interface that allows you to issue queries directly from the dashboard, making it easier to get started and/or issue one-shot queries.
Location Hints, allowing you to influence where your leader (which is responsible for writes) is located globally.
Although D1 is designed to work natively within Cloudflare Workers, we realize that there’s often a need to quickly issue one-shot queries via CLI or a web editor when prototyping or just exploring a database. On top of the support in wrangler for executing queries (and files), we’ve also introduced a console editor that allows you to issue queries, inspect tables, and even edit data on the fly:
JSON functions allow you to query JSON stored in TEXT columns in D1: allowing you to be flexible about what data is associated strictly with your relational database schema and what isn’t, whilst still being able to query all of it via SQL (before it reaches your app).
For example, suppose you store the last login timestamps as a JSON array in a login_history TEXT column: I can query (and extract) sub-objects or array items directly by providing a path to their key:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1’s support for JSON functions is extremely flexible, and leverages the SQLite core that D1 builds on.
When you create a database for the first time with D1, we automatically infer the location based on where you’re currently connecting from. There are some cases, however, where you might want to influence that — maybe you’re traveling, or you have a distributed team that’s distinct from the region you expect the majority of your writes to come from.
D1’s support for Location Hints makes that easy:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints are also now available in the Cloudflare dashboard:
We’ve also published more documentation to help developers not only get started, but make use of D1’s advanced features. Expect D1’s documentation to continue to grow substantially over the coming months.
Not going to burn a hole in your wallet
We’ve had many, many developers ask us about how we’ll be pricing D1 since we announced the alpha, and we’re ready to share what it’s going to look like. We know it’s important to understand what something might cost before you start building on it, so you’re not surprised six months later.
In a nutshell:
We’re announcing pricing so that you can start to model how much D1 will cost for your use-case ahead of time. Final pricing may be subject to change, although we expect changes to be relatively minor.
We won’t be enabling billing until later this year, and we’ll notify existing D1 users via email ahead of that change. Until then, D1 will remain free to use.
D1 will include an always-free tier, included usage as part of our $5/mo Workers subscription, and charge based on reads, writes and storage.
If you’re already subscribed to Workers, then you don’t have to lift a finger: your existing subscription will have D1 usage included when we enable billing in the future.
Here’s a summary (we’re keeping it intentionally simple):
Importantly, when we enable global read replication, you won’t have to pay extra for it, nor will replication multiply your storage consumption. We think built-in, automatic replication is important, and we don’t think developers should have to pay multiplicative costs (replicas x storage fees) in order to make their database fast everywhere.
Beyond that, we wanted to ensure D1 took the best parts of serverless pricing — scale-to-zero and pay-for-what-you-use — so that you’re not trying to figure out how many CPUs and/or how much memory you need for your workload or writing scripts to scale down your infrastructure during quieter hours.
D1’s read pricing is based on the familiar concept of a read unit (per 4KB read), and a write unit (per 1KB written). A query that reads (scans) ~10,000 rows of 64 bytes each would consume 160 read units. Write a big 3KB row in a “blog_posts” table that has a lot of Markdown, and that’s three write units. And if you create indexes for your most popular queries to improve performance and reduce how much data those queries need to scan, you’ll also reduce how much we bill you. We think making the fast path more cost-efficient by default is the right approach.
Importantly: we’ll continue to take feedback on our pricing before we flip the switch.
Time Travel
We’re also introducing new backup functionality: point-in-time-recovery, and we’re calling this Time Travel, because it feels just like it. Time Travel allows you to restore your D1 database to any minute within the last 30 days, and will be built into D1 databasesusing our new storage system. We expect to turn on Time Travel for new D1 databases in the very near future.
What makes Time Travel really powerful is that you no longer need to panic and wonder “oh wait, did I take a backup before I made this major change?!” — because we do it for you. We retain a stream of all changes to your database (the Write-Ahead Log), allowing us to restore your database to a point in time by replaying those changes in sequence up until that point.
Here’s an example (subject to some minor API changes):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
And although the idea of point-in-time recovery is not new, it’s often a paid add-on, if it is even available at all. Realizing you should have had it turned on after you’ve deleted or otherwise made a mistake means it’s often too late.
For example, imagine if I made the classic mistake of forgetting a WHERE on an UPDATE statement:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Without Time Travel, I’d have to hope that either a scheduled backup ran recently, or that I remembered to make a manual backup just prior. With Time Travel, I can restore to a point a minute or so before that mistake (and hopefully learn a lesson for next time).
We’re also exploring features that can surface larger changes to your database state, including making it easier to identify schema changes, the number of tables, large deltas in data stored and even specific queries (via transaction IDs) — to help you better understand exactly what point in time to restore your database to.
On the roadmap
So what’s next for D1?
Open beta: we’re ensuring we’ve observed our new storage subsystem under load (and real-world usage) prior to making it the default for all `d1 create` commands. We hold a high bar for durability and availability, even for a “beta”, and we also recognize that access to backups (Time Travel) is important for folks to trust a new database. Keep an eye on the Cloudflare blog in the coming weeks for more news here!
Bigger databases: we know this is a big ask from many, and we’re extremely close. Developers on the Workers Paid plan will get access to 1GB databases in the very near future, and we’ll be continuing to ramp up the maximum per-database size over time.
Metrics & observability: you’ll be able to inspect overall query volume by database, failing queries, storage consumed and read/write units via both the D1 dashboard and our GraphQL API, so that it’s easier to debug issues and track spend.
Automatic read replication: our new storage subsystem is built with replication in mind, and we’re working on ensuring our replication layer is both fast & reliable before we roll it out to developers. Read replication is not only designed to improve query latency by storing copies — replicas — of your data in multiple locations, close to your users, but will also allow us to scale out D1 databases horizontally for those with larger workloads.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.