Post Syndicated from Venugopalan Vasudevan original https://aws.amazon.com/blogs/devops/accelerating-legacy-code-modernization-epams-journey-with-amazon-q-developer/
This post is co-written with Nazariy Popov, Volodymyr Konchuk, and Andrii Davydenko from EPAM
Legacy code modernization presents significant challenges for organizations looking to stay competitive in today’s rapidly evolving digital landscape. Organizations face the dual challenge of maintaining business continuity while modernizing their legacy systems for cloud environments. This transformation requires organizations to carefully navigate between preserving essential business logic and implementing modern architectural patterns. This is where AI-powered development tools can make a transformative impact, as demonstrated in EPAM’s recent legacy modernization project using Amazon Q Developer.
Amazon Q Developer, an AI code assistant, seamlessly integrates into the development pipeline to address these challenges. This innovative AI code assistant helps teams tackle various tasks, from generating new features, automating language upgrades, and refactoring legacy code to fixing bugs and automating deployments. By providing detailed explanations for its code suggestions while maintaining high quality standards, Amazon Q Developer significantly improves developer efficiency across the entire software development lifecycle, resulting in substantial time and effort savings.
EPAM, an AWS Premier Partner, collaborated with one of their customers to modernize their legacy applications to AWS Cloud. The modernization initiative focused on multiple business-critical applications, primarily built in Java 8 with Oracle Database backend.
In this post, you’ll learn how Amazon Q Developer helped EPAM engineers transform these complex legacy systems into modern cloud-native architectures on AWS. The tool enabled the team to autonomously perform a range of tasks—from implementing new microservices and documenting code to testing, reviewing, and refactoring Java code, as well as performing critical platform upgrades.
Before diving into the details, here’s an overview of how Amazon Q Developer helped EPAM across various aspects of the modernization project:
Summary of Amazon Q Developer Use Cases in EPAM’s Modernization Journey:
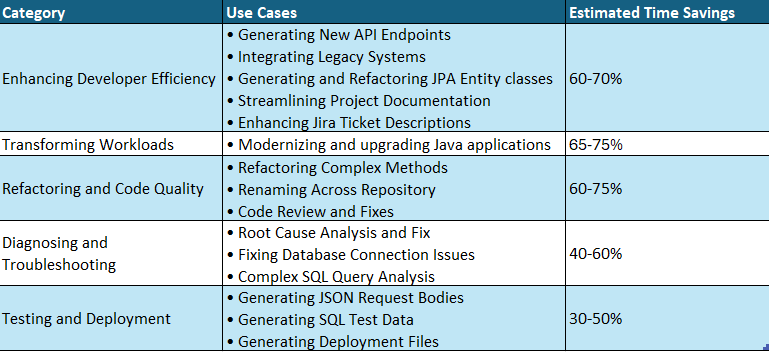
Let’s explore each of these areas in detail.
Enhancing developer efficiency (Estimated time savings: 60-70%)
Amazon Q Developer played a crucial role in boosting EPAM’s development productivity. By automating routine tasks and providing intelligent code suggestions, the tool enabled developers to focus on more strategic aspects of the modernization project. Let’s explore how EPAM leveraged these capabilities.
Use Case 1: Generating New API Endpoints
Creating new API endpoints traditionally requires developers to invest 1-2 days per endpoint, involving multiple steps from designing the API contract to writing unit tests and documentation. Using Amazon Q Developer, the team dramatically accelerated this process for three new API endpoints in an existing microservice. Q Developer efficiently generated the initial code implementation along with comprehensive unit test coverage, requiring only minor modifications such as renaming variables, enhancing error handling, and refining test cases. The unit tests generated proved remarkably reliable with minimal adjustments needed. Along with this, Q Developer also generated comprehensive comments/documentation of the code improving the maintainability. This reduced the total development time to just 4 hours for all three endpoints – a 70% time saving compared to the traditional approach, allowing developers to focus on fine-tuning business logic rather than writing boilerplate code.
Use Case 2: Integrating Legacy Systems
Integrating a legacy monolith application with modern microservices traditionally requires developers to manually write extensive integration code, taking 1-2 weeks per integration point. Amazon Q Developer accelerated this process by automatically generating REST API client code in the monolith to consume microservice endpoints, along with data transfer objects (DTOs), error handling, and retry logic with integration test templates. While developers still needed to validate business rules and fine-tune error scenarios, Q Developer’s ability to understand both the legacy monolith’s structure and modern microservice patterns reduced the integration time to 2-3 days per integration point – a 70% time saving. This significantly streamlined the integration process while maintaining the robustness required for production systems.
Use Case 3: Generating and Refactoring JPA Entity Classes
During the modernization effort, new database tables were required to support additional business functionality in both the monolith and microservices. Instead of manually coding the data access layer, Amazon Q Developer automated the process by generating Spring JPA Entity classes from SQL DDL statements. Amazon Q Developer maintained consistency with existing data models by following established naming conventions, applying standard annotations, and implementing required interfaces from the existing codebase. What stood out was Q Developer’s ability to provide detailed explanations for its implementation choices, such as why specific annotations were used or how the new entities aligned with existing persistence patterns, enabling the team to quickly validate the generated code against their architectural standards. Amazon Q Developer generated the complete Java Spring entity class with all the fields. Additionally, Amazon Q Developer refactored the Entity class as well.
Use Case 4: Streamlining Project Documentation
Creating and maintaining up-to-date project documentation is often a time-consuming task for developers. Amazon Q Developer simplified this process by assisting in the generation of README files for the team’s projects. By analyzing the project structure, dependencies, and key components, Q Developer produced initial drafts of README files that included project overviews, setup instructions, and API documentation. This allowed developers to quickly review and refine the documentation, ensuring it met team standards while saving significant time compared to writing everything from scratch.
Use Case 5: Enhancing Jira Ticket Descriptions
Writing detailed, informative Jira ticket descriptions can be a challenge, especially for complex features or bug fixes. Amazon Q Developer aided the team by suggesting detailed descriptions for Jira tickets based on the context of the code changes and related discussions. For example, when creating a ticket for a new feature, Q Developer could propose a description that included the feature’s purpose, key implementation details, and potential impact on other system components. While developers still needed to review and adjust these descriptions, the AI-generated starting point significantly reduced the time spent on ticket management, allowing the team to focus more on actual development work.
Transforming workloads (Estimated time savings: 65-75%)
Moving legacy applications to the cloud requires careful planning and execution. EPAM utilized Amazon Q Developer’s Java upgrade capabilities to streamline the transformation of monolithic applications into modern, cloud-native architectures. Here’s how the Amazon Q Developer facilitated this process.
Use Case 6: Modernizing and upgrading Java applications
Amazon Q Developer assisted in upgrading older Java applications to Java 21 to leverage modern features like Java Streams API and adapting it for Spring Boot tech stack. It not only upgraded the code, but also updated deprecated code components, dependencies and libraries as well. This modernization improved the code’s performance and also aligned it with the current best practices adopted by the development teams. For large monolithic applications, breaking/decomposing the monolith into logical groups while identifying and separating common modules as shared dependencies helped break down the problem into manageable pieces for the agent to do a better job, resulting in a more maintainable and modular structure for the transformation process. This modular approach significantly enhanced Q Developer’s ability to analyze and transform the codebase while reducing the complexity of the modernization effort.
Refactoring Code, Improving Code Quality and Readability (Estimated time savings: 60-75%)
One of the most challenging aspects of modernization is refactoring legacy code and maintaining high code quality standards. Amazon Q Developer assisted EPAM’s team in analyzing complex codebases and suggesting improvements, optimizing the code while preserving business logic and ensuring consistent code quality. The following examples demonstrate this capability in action.
Use Case 7: Refactoring Complex Methods
Legacy code often includes methods with high cyclomatic complexity, making them difficult to maintain. Amazon Q Developer helped the development team refactor large, complex methods into smaller, more readable, and better-structured methods. It also provided a detailed explanation of the changes, highlighting how the refactored code improved maintainability and readability.
Use Case 8: Renaming Across the Repository
When tasked with renaming ‘YTD Tax Report‘ to ‘Withholding Tax Report‘ across the entire repository, Amazon Q Developer demonstrated capabilities beyond simple search and replace functionality found in traditional IDEs. It performed context-aware renaming, distinguishing between instances where ‘YTD Tax Report‘ was part of larger phrases or variable names, while simultaneously updating related components including unit tests, integration tests, and logging statements. The tool intelligently refactored method signatures where the report name was part of method names or parameters, analyzed and updated database queries, and maintained consistency across different file types including Java, XML, and properties files. What set Q Developer apart was its ability to provide detailed change logs explaining each modification and the rationale behind more complex refactoring decisions, significantly reducing the risk of missed references or inconsistencies that often occur with manual search-and-replace operations.
Use Case 9: Code Review and fixes
The code review capabilities of Amazon Q Developer, seamlessly integrated into the IDE, enabled the development team to detect potential issues spanning multiple classes. Beyond merely identifying problems, Q Developer provided actionable fix recommendations that could be easily reviewed and implemented. This proactive approach to code quality allowed the team to address issues during the early stages of development, significantly reducing the likelihood of defects making their way to production environments.
Diagnosing and troubleshooting errors (Estimated time savings: 40-60%)
Quick error resolution is crucial for maintaining development momentum. Amazon Q Developer’s advanced error analysis capabilities helped EPAM’s team identify and fix issues efficiently, reducing debugging time significantly. Here are some examples of how this worked in practice.
Use Case 10: Root Cause Analysis and Fix
During the development phase, the team encountered an unexpected error in one of the Java services: java.lang.IllegalArgumentException: Property 'http://javax.xml.XMLConstants/property/accessExternalDTD' is not recognized. Q Developer conducted a deeper analysis based on the context provided and suggested a more targeted fix and generated the necessary Java code changes, provided unit tests to verify the fix, and outlined potential security implications of the change. This comprehensive solution not only resolved the immediate error but also improved the overall security posture of the XML processing in the application. The team was able to implement and verify the fix within minutes, significantly reducing development.
Use Case 11: Fixing Database Connection Issues
While troubleshooting an issue where the application became unresponsive due to JDBC connection problems, Amazon Q Developer analyzed the project code and identified the missing connection pool configuration. Q Developer suggested implementing essential connection pool parameters like 'maximumPoolSize=20' and 'connectionTimeout=30000' based on the application’s traffic patterns and code. After implementing its suggested configuration, the issue was resolved, significantly improving the application’s stability.
Use Case 12: Complex SQL Query Analysis
Debugging complex SQL queries constructed dynamically in Java code can be challenging. Amazon Q Developer analyzed such queries, broke them down into their component parts, and provided descriptions for query parameters. For instance, when presented with a complex query involving multiple joins and subqueries, Q Developer dissected it into logical blocks, explaining how each part contributed to the overall result set. This made it easier for the team to understand and debug the queries.
Testing and Deployment: Test data generation and Automating Infrastructure Setup (Estimated time savings: 30-50%)
Use Case 13: Generating JSON Request Bodies
When testing new APIs, Amazon Q Developer generated JSON request bodies based on the corresponding Java classes. It provided detailed descriptions of each field and suggested realistic and meaningful default values, making it easier to validate API functionality with real-world scenarios.
Use Case 14: Generating SQL Test Data
Amazon Q Developer generated SQL insert statements with test data based on our existing Java Entity classes. This automation saved us a significant amount of time in creating realistic test data for database validation and integration testing.
Use Case 15: Generating Deployment Files
Amazon Q Developer helped the development team generate essential deployment artifacts, including a Docker file, a startup shell script that was used as an entry point, and a Kubernetes deployment file for a new service. Automating this process not only saves time but also improves consistency across environments.
Ready to transform your developer experience?
EPAM’s experience with Amazon Q Developer has been transformative, significantly accelerating their application modernization efforts while maintaining high code quality. By leveraging Amazon Q Developer, EPAM reduced development time by approximately 70% and improved code quality metrics across the client’s portfolio. This efficiency gains not only accelerated the client’s cloud migration timeline but also resulted in substantial cost savings and faster time-to-market for new features.
Now, it’s your turn to explore Amazon Q Developer:
Schedule a demo: Experience firsthand how Amazon Q Developer can accelerate your development lifecycle. Connect with our team for a personalized demonstration tailored to your specific use case.
Start Your Proof of Concept: Begin your journey with Amazon Q Developer today through a proof of concept. See how it can enhance your team’s productivity and code quality, just as it did for EPAM.
Connect with EPAM: Learn more about EPAM’s success story and best practices for implementing Amazon Q Developer in your organization’s development workflow.
Take the next step in revolutionizing your development process. Visit Amazon Q Developer website or contact your AWS account team to get started.
Authors
EPAM
 |
Nazariy Popov, Delivery Head of GenAI Engineering and Modernization Practice Delivery management professional and technology leader with over 15 years of experience in the IT industry. At EPAM, he drives large-scale transformation programs, focusing on enterprise software development, cloud solutions, and AI assisted engineering and modernization. |
 |
Volodymyr Konchuk, Lead Software Engineer Java engineer with more than 11 years of production experience in Java-based web and enterprise applications. Has experience in building ecommerce and retail business applications using Java, Spring tech stack, and Amazon Web Services. |
 |
Andrii Davydenko, Delivery Manager |
AWS
 |
Venugopalan Vasudevan (Venu) is a Senior Specialist Solutions Architect focusing on Next Generation Developer Experience and AWS Generative AI services. In this role, Venu, helps organizations optimize their development processes and accelerate their digital transformation journeys using Amazon Q Developer and other AWS Generative AI Services. Also, Venu partners with enterprises to architect and implement Generative AI solutions while establishing robust development practices. |
 |
Arun Chandapillai is a Senior Engineering Architect with a strong history of leading cross-functional teams and collaborating with executive stakeholders. He is passionate about helping customers accelerate IT modernization through business-first cloud adoption strategies, with a focus on leveraging generative AI and MLOps. Outside of technology, he is an automotive enthusiast who loves the thrill of the open road, an engaging public speaker, and a philanthropist who lives by the motto ‘you get (back) what you give’. |
 |
Jasmine Rasheed Syed is a Senior Customer Solutions manager, focused in accelerating time to value for the customers in their in cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management. |
 |
Oscar Hernandez is a Senior Account Executive, helping global organizations drive digital and AI transformation at scale. He works closely with executive teams to integrate cloud and AI-driven solutions that address complex business challenges and deliver measurable enterprise-wide impact. With over 15 years of experience across IT, telecom, financial services, retail, and HR technology, he focuses on enabling innovation, optimizing operations, and maximizing the value of emerging technologies. |





 Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions. Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing. Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance. Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines. Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.


 Konstantina Mavrodimitraki is a Senior Solutions Architect at Amazon Web Services, where she assists customers in designing scalable, robust, and secure systems in global markets. With deep expertise in data strategy, data warehousing, and big data systems, she helps organizations transform their data landscapes. A passionate technologist and people person, Konstantina loves exploring emerging technologies and supports the local tech communities. Additionally, she enjoys reading books and playing with her dog.
Konstantina Mavrodimitraki is a Senior Solutions Architect at Amazon Web Services, where she assists customers in designing scalable, robust, and secure systems in global markets. With deep expertise in data strategy, data warehousing, and big data systems, she helps organizations transform their data landscapes. A passionate technologist and people person, Konstantina loves exploring emerging technologies and supports the local tech communities. Additionally, she enjoys reading books and playing with her dog. Kostas Diamantis is the Head of the Data Warehouse at Skroutz company. With a background in software engineering, he transitioned into data engineering, using his technical expertise to build scalable data solutions. Passionate about data-driven decision-making, he focuses on optimizing data pipelines, enhancing analytics capabilities, and driving business insights.
Kostas Diamantis is the Head of the Data Warehouse at Skroutz company. With a background in software engineering, he transitioned into data engineering, using his technical expertise to build scalable data solutions. Passionate about data-driven decision-making, he focuses on optimizing data pipelines, enhancing analytics capabilities, and driving business insights.













 Sairam Vangapally is a Data Engineer at Amazon with extensive experience architecting real-time, large-scale data platforms that power critical logistics operations across North America. He has led the design and deployment of end-to-end data pipelines, enabling high-throughput ingestion, transformation, and analytics at scale. He is passionate about building resilient data infrastructure and driving cross-functional collaboration to deliver solutions that accelerate operational insights and business impact.
Sairam Vangapally is a Data Engineer at Amazon with extensive experience architecting real-time, large-scale data platforms that power critical logistics operations across North America. He has led the design and deployment of end-to-end data pipelines, enabling high-throughput ingestion, transformation, and analytics at scale. He is passionate about building resilient data infrastructure and driving cross-functional collaboration to deliver solutions that accelerate operational insights and business impact. Nitin Goyal serves as a Data Engineering Manager in Amazon’s Sort Center organization, where he leads initiatives to optimize operational efficiency across North American facilities. With over nine years of tenure at Amazon spanning multiple teams, he specializes in architecting high-performance data systems, with particular emphasis on real-time streaming pipelines, artificial intelligence, and low-latency solutions. His expertise drives the development of sophisticated operational workflows that enhance sort center productivity and effectiveness.
Nitin Goyal serves as a Data Engineering Manager in Amazon’s Sort Center organization, where he leads initiatives to optimize operational efficiency across North American facilities. With over nine years of tenure at Amazon spanning multiple teams, he specializes in architecting high-performance data systems, with particular emphasis on real-time streaming pipelines, artificial intelligence, and low-latency solutions. His expertise drives the development of sophisticated operational workflows that enhance sort center productivity and effectiveness.


 Steven Aerts is a principal software engineer at Airties, where his team is responsible for ingesting, processing, and analyzing the data of tens of millions of homes to improve their Wi-Fi experience. He was a speaker at conferences like Devoxx and AWS Summit Dubai, and is an open source contributor.
Steven Aerts is a principal software engineer at Airties, where his team is responsible for ingesting, processing, and analyzing the data of tens of millions of homes to improve their Wi-Fi experience. He was a speaker at conferences like Devoxx and AWS Summit Dubai, and is an open source contributor. Reza Radmehr is a Sr. Leader of Cloud Infrastructure and Operations at Airties, where he leads AWS infrastructure design, DevOps and SRE automation, and FinOps practices. He focuses on building scalable, cost-efficient, and reliable systems, driving operational excellence through smart, data-driven cloud strategies. He is passionate about blending financial insight with technical innovation to improve performance and efficiency at scale.
Reza Radmehr is a Sr. Leader of Cloud Infrastructure and Operations at Airties, where he leads AWS infrastructure design, DevOps and SRE automation, and FinOps practices. He focuses on building scalable, cost-efficient, and reliable systems, driving operational excellence through smart, data-driven cloud strategies. He is passionate about blending financial insight with technical innovation to improve performance and efficiency at scale. Ramazan Ginkaya is a Sr. Technical Account Manager at AWS with over 17 years of experience in IT, telecommunications, and cloud computing. He is a passionate problem-solver, providing technical guidance to AWS customers to help them achieve operational excellence and maximize the value of cloud computing.
Ramazan Ginkaya is a Sr. Technical Account Manager at AWS with over 17 years of experience in IT, telecommunications, and cloud computing. He is a passionate problem-solver, providing technical guidance to AWS customers to help them achieve operational excellence and maximize the value of cloud computing.



 Gal Krispel is a Data Platform Engineer at Riskified, specializing in streaming technologies such as Apache Kafka and Apache Flink. He focuses on building scalable, real-time data pipelines that power Riskified’s core products. Gal is particularly interested in making complex data architectures accessible and efficient across the organization. His work spans real-time analytics, event-driven design, and the seamless integration of stream processing into large-scale production systems.
Gal Krispel is a Data Platform Engineer at Riskified, specializing in streaming technologies such as Apache Kafka and Apache Flink. He focuses on building scalable, real-time data pipelines that power Riskified’s core products. Gal is particularly interested in making complex data architectures accessible and efficient across the organization. His work spans real-time analytics, event-driven design, and the seamless integration of stream processing into large-scale production systems. Sofia Zilberman works as a Senior Streaming Solutions Architect at AWS, helping customers design and optimize real-time data pipelines using open-source technologies like Apache Flink, Kafka, and Apache Iceberg. With experience in both streaming and batch data processing, she focuses on making data workflows efficient, observable, and high-performing.
Sofia Zilberman works as a Senior Streaming Solutions Architect at AWS, helping customers design and optimize real-time data pipelines using open-source technologies like Apache Flink, Kafka, and Apache Iceberg. With experience in both streaming and batch data processing, she focuses on making data workflows efficient, observable, and high-performing. Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector.













 Chris Li is an Enterprise Support manager at AWS. He leads a team of Technical Account Managers to solve complex customer problems and implement well-structured solutions.
Chris Li is an Enterprise Support manager at AWS. He leads a team of Technical Account Managers to solve complex customer problems and implement well-structured solutions.










 Balaram Mathukumilli is Director, Enterprise Data Services at DISH Wireless. He is deeply passionate about Data and Analytics solutions. With 20+ years of experience in Enterprise and Cloud transformation, he has worked across domains such as PayTV, Media Sales, Marketing and Wireless. Balaram works closely with the business partners to identify data needs, data sources, determine data governance, develop data infrastructure, build data analytics capabilities, and foster a data-driven culture to ensure their data assets are properly managed, used effectively, and are secure
Balaram Mathukumilli is Director, Enterprise Data Services at DISH Wireless. He is deeply passionate about Data and Analytics solutions. With 20+ years of experience in Enterprise and Cloud transformation, he has worked across domains such as PayTV, Media Sales, Marketing and Wireless. Balaram works closely with the business partners to identify data needs, data sources, determine data governance, develop data infrastructure, build data analytics capabilities, and foster a data-driven culture to ensure their data assets are properly managed, used effectively, and are secure Viswanatha Vellaboyana, a Solutions Architect at DISH Wireless, is deeply passionate about Data and Analytics solutions. With 20 years of experience in enterprise and cloud transformation, he has worked across domains such as Media, Media Sales, Communication, and Health Insurance. He collaborates with enterprise clients, guiding them in architecting, building, and scaling applications to achieve their desired business outcomes.
Viswanatha Vellaboyana, a Solutions Architect at DISH Wireless, is deeply passionate about Data and Analytics solutions. With 20 years of experience in enterprise and cloud transformation, he has worked across domains such as Media, Media Sales, Communication, and Health Insurance. He collaborates with enterprise clients, guiding them in architecting, building, and scaling applications to achieve their desired business outcomes. Keerthi Kambam is a Senior Engineer at DISH Network specializing in AWS Services. She builds scalable data engineering and analytical solutions for dish customer faced applications. She is passionate about solving complex data challenges with cloud solutions.
Keerthi Kambam is a Senior Engineer at DISH Network specializing in AWS Services. She builds scalable data engineering and analytical solutions for dish customer faced applications. She is passionate about solving complex data challenges with cloud solutions. Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family.
Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family. Adi Eswar has been a core member of the AI/ML and Analytics Specialist team, leading the customer experience of customer’s existing workloads and leading key initiatives as part of the Analytics Customer Experience Program and Redshift enablement in AWS-TELCO customers. He spends his free time exploring new food, cultures, national parks and museums with his family.
Adi Eswar has been a core member of the AI/ML and Analytics Specialist team, leading the customer experience of customer’s existing workloads and leading key initiatives as part of the Analytics Customer Experience Program and Redshift enablement in AWS-TELCO customers. He spends his free time exploring new food, cultures, national parks and museums with his family. Shirin Bhambhani is a Senior Solutions Architect at AWS. She works with customers to build solutions and accelerate their cloud migration journey. She enjoys simplifying customer experiences on AWS.
Shirin Bhambhani is a Senior Solutions Architect at AWS. She works with customers to build solutions and accelerate their cloud migration journey. She enjoys simplifying customer experiences on AWS. Vinayak Rao is a Senior Customer Solutions Manager at AWS. He collaborates with customers, partners, and internal AWS teams to drive customer success, delivery of technical solutions, and cloud adoption.
Vinayak Rao is a Senior Customer Solutions Manager at AWS. He collaborates with customers, partners, and internal AWS teams to drive customer success, delivery of technical solutions, and cloud adoption.















 Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “ Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “
Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “ Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “
Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “ Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “
Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “ Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “
Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “







































 Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.
Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.