Post Syndicated from Pat Patterson original https://www.backblaze.com/blog/free-image-hosting-with-cloudflare-transform-rules-and-backblaze-b2/

Before I dive into using Cloudflare Transform Rules to implement image hosting on Backblaze B2 Cloud Storage, I’d like to take a moment to introduce myself. I’m Pat Patterson, recently hired by Backblaze as chief developer evangelist. I’ve been working with technology and technical communities for close to two decades, at companies such as Sun Microsystems and Salesforce. I’ll be creating and delivering technical content for you, our Backblaze B2 community, and advocating on your behalf within Backblaze. Feel free to follow my journey and reach out to me via Twitter or LinkedIn.
Cloudflare Transform Rules
Now, on with the show! Cloudflare Transform Rules give you access to HTTP traffic at the CDN edge server, allowing you to manipulate the URI path, query string, and HTTP headers of incoming requests and outgoing responses. Where Cloudflare Workers allows you to write JavaScript code that executes in the same environment, Transform Rules give you much of the same power without the semi-colons and curly braces.
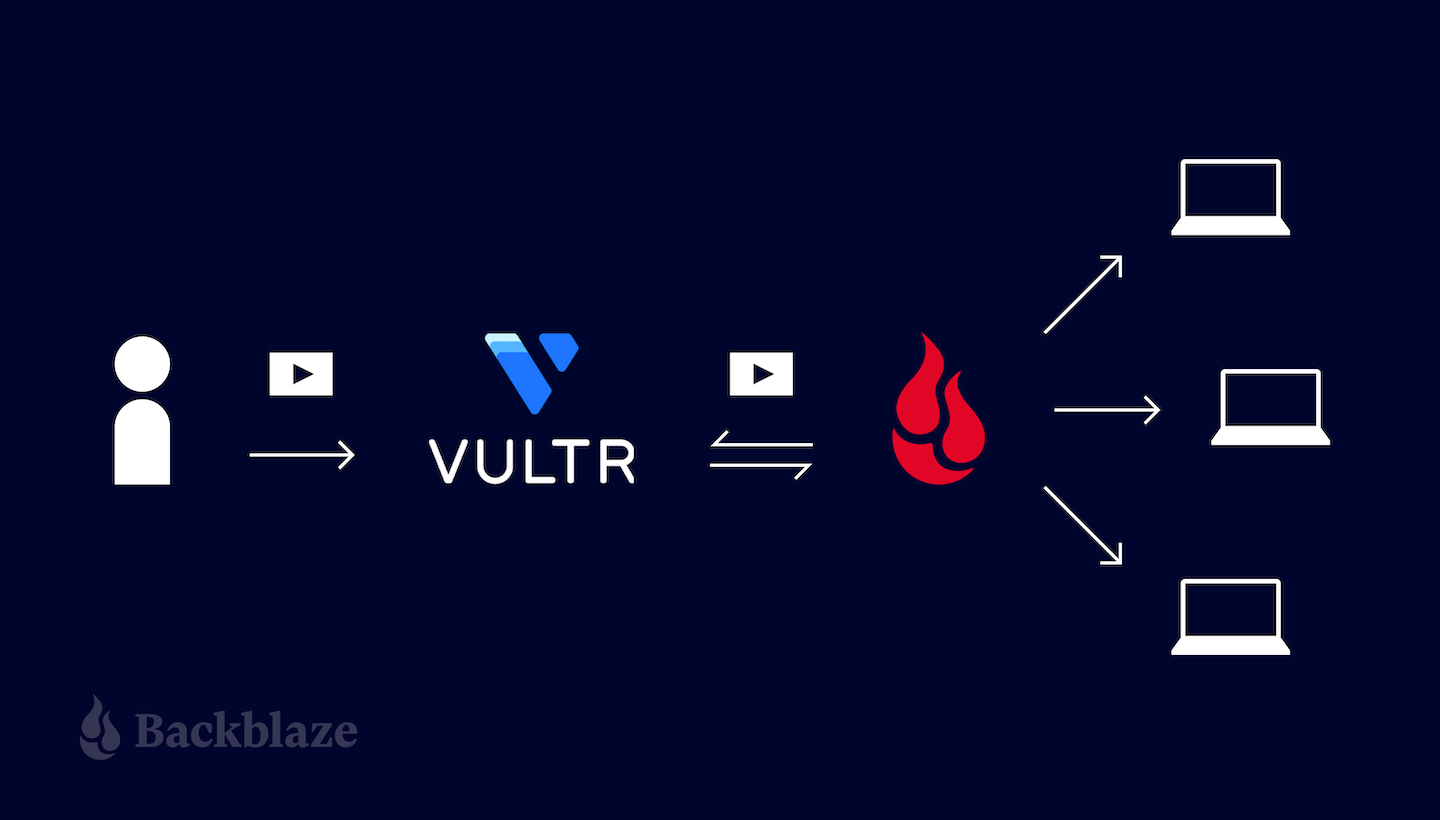
Let’s look at a specific use case: implementing image hosting on top of a cloud object store. Backblaze power user James Ross wrote an excellent blog post back in August 2019, long before the introduction of Transform Rules, explaining how to do this with Cloudflare Workers and Backblaze B2. We’ll see how much of James’ solution we can recreate with Transform Rules, without writing any code. We’ll also discover how the combination of Cloudflare and Backblaze allows you to create your own, personal 10GB image hosting site for free.
Implementing Image Hosting on a Cloud Object Store
James’ requirements were simple:
- Serve image files from a custom domain, such as
files.example.com, rather than the cloud storage provider’s domain.
- Remove the bucket name, and any other extraneous information, from the URL.
- Remove extraneous headers, such as the object ID, from the HTTP response.
- Improve caching (both browser and edge cache) for images.
- Add basic CORS headers to allow embedding of images on external sites.
I’ll work through each of these requirements in this blog post, and wrap up by explaining why Backblaze B2 might be a better long term provider for this and many other cloud object storage use cases than other cloud object stores.
It’s worth noting that nothing here is Backblaze B2-specific—the user’s browser is requesting objects from a B2 Cloud Storage public bucket via their URLs, just as it would with any other cloud object store. The techniques are exactly the same on Amazon S3, for example.
Prerequisites
You’ll need accounts with both Cloudflare and Backblaze. You can get started for free with both:
You’ll also need your own DNS domain, which I’ll call example.com in this article, on which you can create subdomains such as files.example.com. If you’ve read this far, you likely already have at least one. Otherwise, you can register a new domain at Cloudflare for a few dollars a year, or your local equivalent.
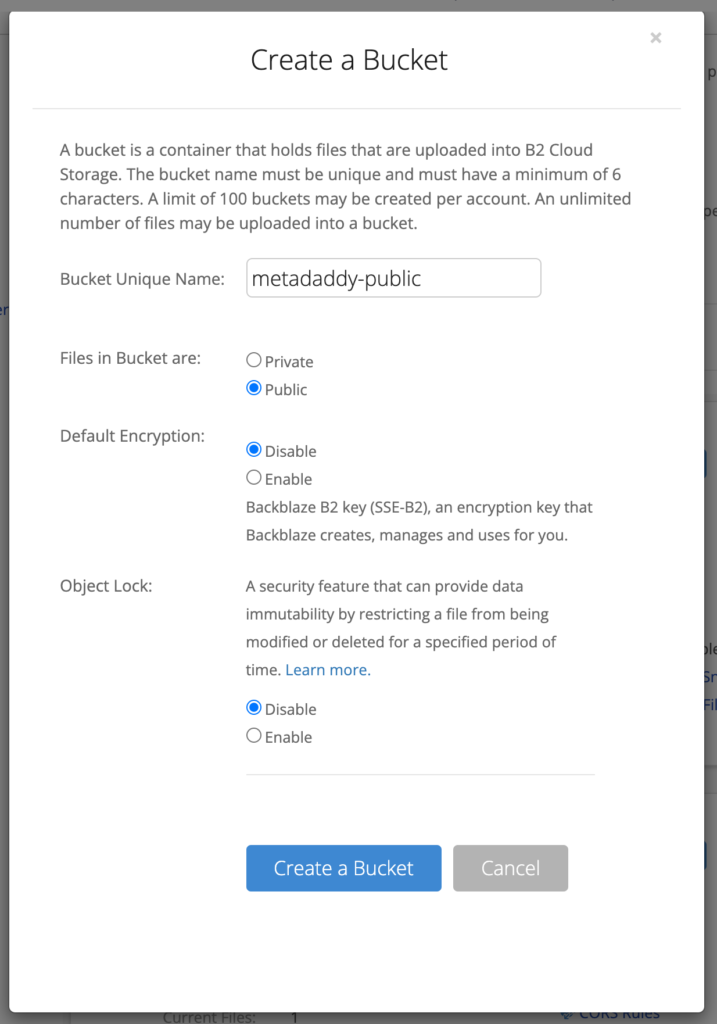
Create a Bucket for Your Images
If you already have a B2 Cloud Storage bucket you want to use for your image store, you can skip this section. Note: It doesn’t matter whether you created the bucket and its objects via the B2 Native API, the Backblaze S3 Compatible API, or any other mechanism—your objects are accessible to Cloudflare via their friendly URLs.
Log in to Backblaze, and click Buckets on the left under B2 Cloud Storage, then Create a Bucket. You will need to give your bucket a unique name, and make it public. Leave the other settings with their default values.

Note that the bucket name must be globally unique within Backblaze B2, so you can’t just call it something like “myfiles.” You’ll hide the bucket name from public view, so you can call it literally anything, as long as there isn’t already a Backblaze B2 bucket with that name.
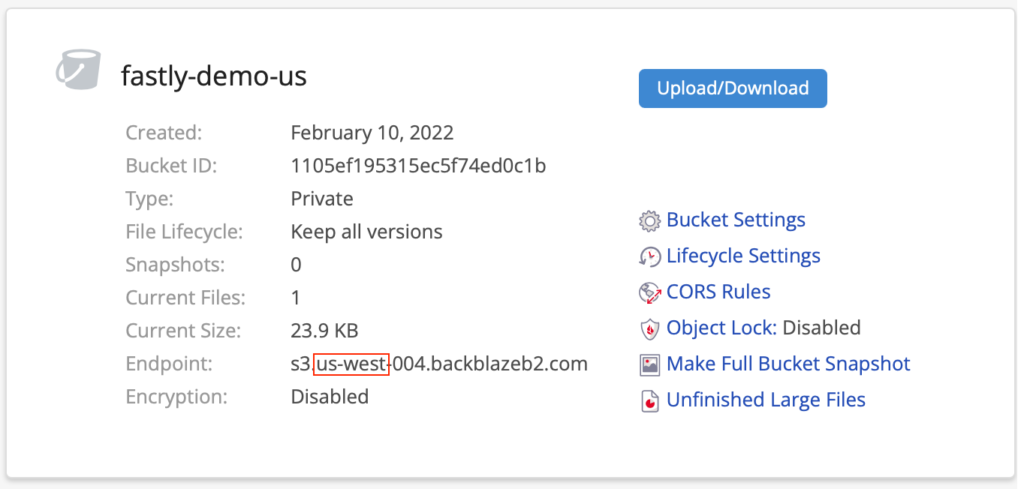
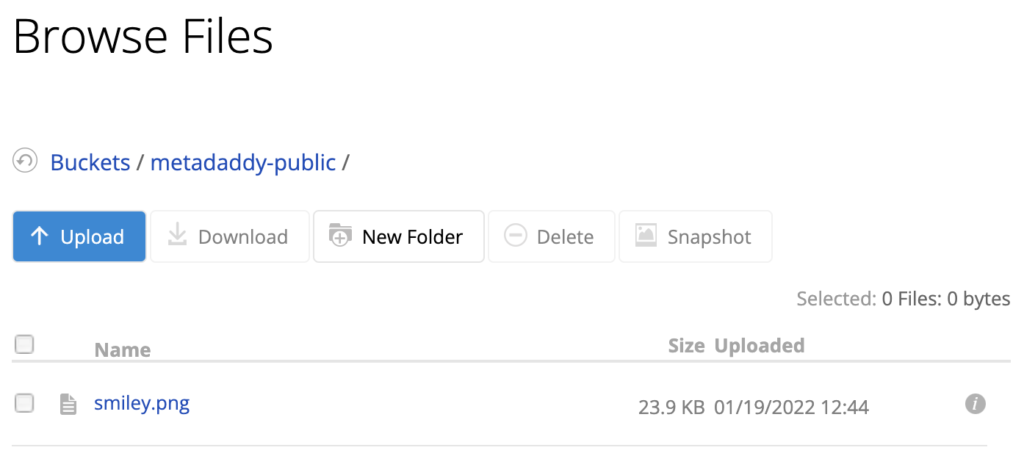
Finally, click Upload/Download and upload a test file to your new bucket.

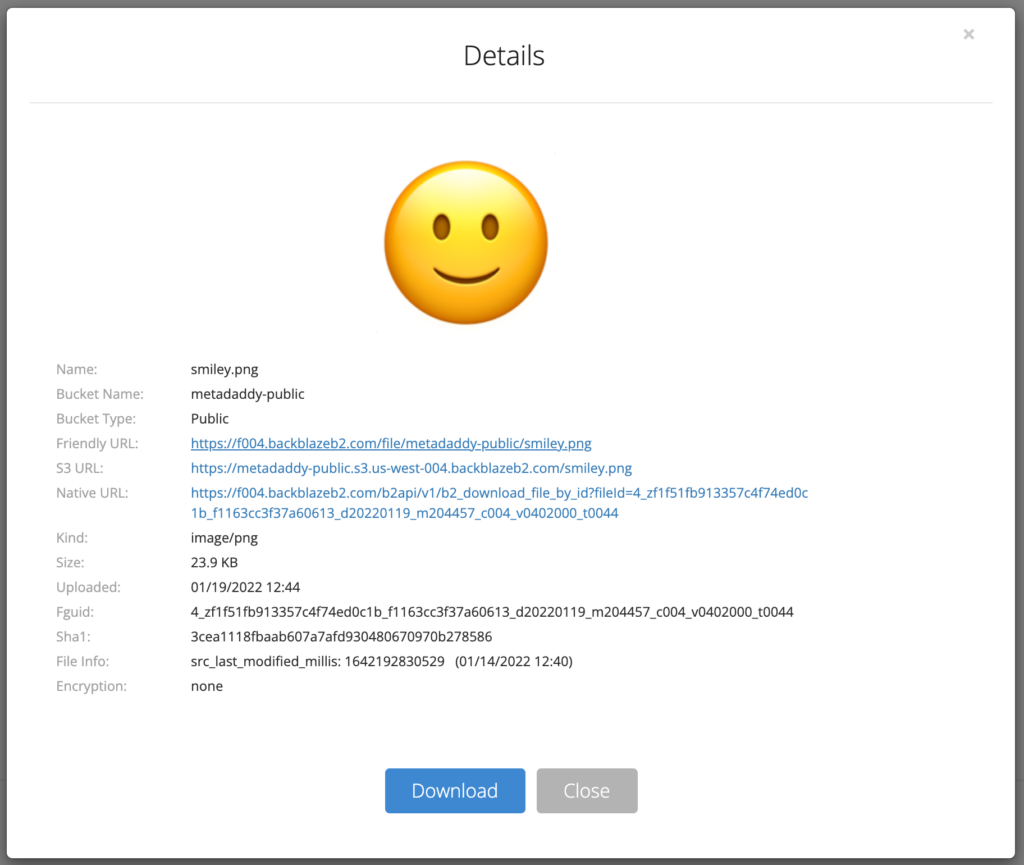
Click the file to see its details, including its various URLs.

In the next step, you’ll rewrite requests that use your custom subdomain, for example, https://files.example.com/smiley.png, to the friendly URL of the form, https://f004.backblazeb2.com/file/metadaddy-public/smiley.png.
Make a note of the hostname in the friendly URL. As you can see in the previous paragraph, mine is f004.backblazeb2.com.
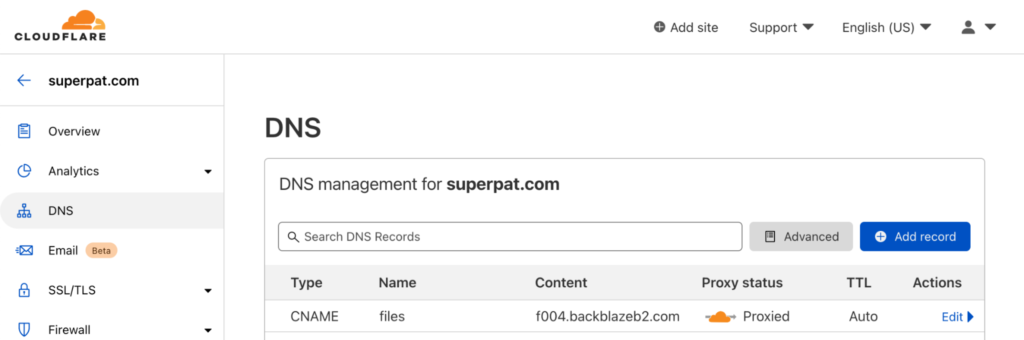
Create a DNS Subdomain for Your Image Host
You will need to activate your domain (example.com, rather than files.example.com) in your Cloudflare account, if you have not already done so.
Now, in the Cloudflare dashboard, create your subdomain by adding a DNS CNAME record pointing to the bucket hostname you made a note of earlier.

I created files.superpat.com, which points to my bucket’s hostname, f004.backblazeb2.com.
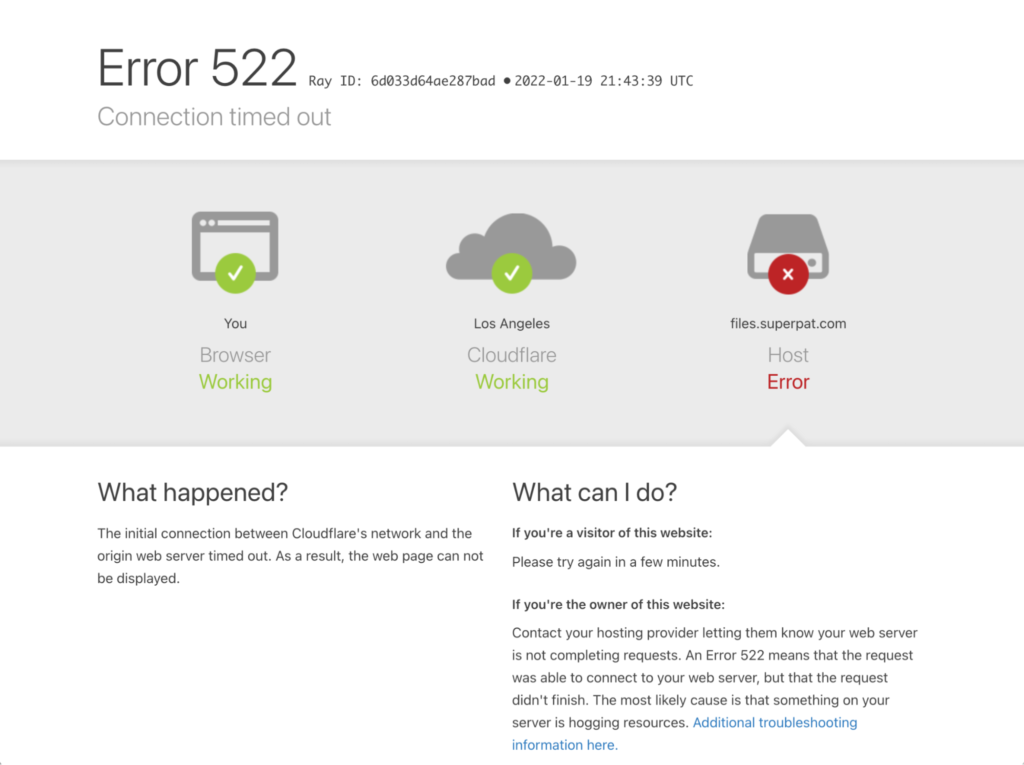
If you test this right now by going to your test file’s URL in your custom subdomain, for example, https://files.example.com/file/my-unique-bucket-name/smiley.png, after a few seconds you will see a 522 “connection timed out” error from Cloudflare:

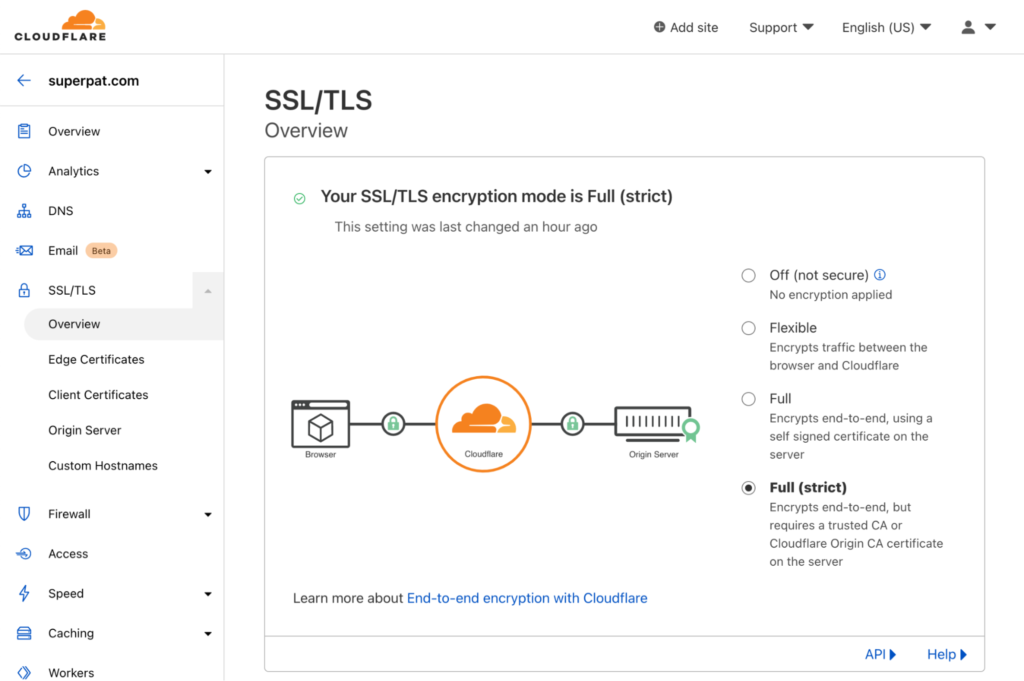
This is because, by default, Cloudflare accesses the upstream server via plain HTTP, rather than HTTPS. Backblaze only supports secure HTTPS connections, so the HTTP request fails. To remedy this, in the SSL/TLS section of the Cloudflare dashboard, change the encryption mode from “Flexible” to “Full (strict),” so that Cloudflare connects to Backblaze via HTTPS, and requires a CA-issued certificate.

Now you should be able to access your test file in your custom subdomain via a URL of the form https://files.example.com/file/my-unique-bucket-name/smiley.png. The next task is to create the first Transform Rule to remove /file/my-unique-bucket-name from the URL.
Rewrite the URL Path on Incoming Requests
There are three varieties of Cloudflare Transform Rules:
- URL Rewrite Rules: Rewrite the URL path and query string of an HTTP request.
- HTTP Request Header Modification Rules: Set the value of an HTTP request header or remove a request header.
- HTTP Response Header Modification Rules: Set the value of an HTTP response header or remove a response header.
Click Rules on the left of the Cloudflare dashboard, then Transform Rules. You’ll see that the Cloudflare free plan includes 10 Transform Rules—plenty for our purposes. Click Create Transform Rule, then Rewrite URL.
It’s useful to pause for a moment and think about what we need to ask Cloudflare to do. Users will be requesting URLs of the form https://files.example.com/smiley.png, and we want the request to Backblaze B2 to be like https://f004.backblazeb2.com/file/metadaddy-public/smiley.png. We’ve already taken care of the domain part of the URL, so it becomes clear that all we need to do is prefix the outgoing URL with /file/<bucket name>.
Give your rule a descriptive name such as “Add file and bucket name.”

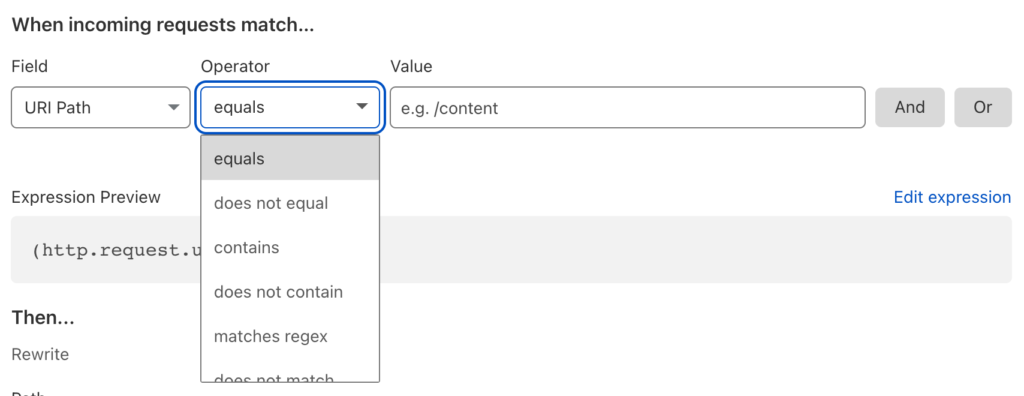
There is an opportunity to set a condition that incoming requests must match to fire the trigger. In James’ article, he tested that the path did not already begin with the /file/<bucket name> prefix, so that you can refer to a file with either the short or long URL.
At first glance, the Cloudflare dashboard doesn’t offer “does not start with” as an operator.

However, clicking Edit expression reveals a more powerful way of specifying the condition:

The Cloudflare Rules language allows us to express our condition precisely:

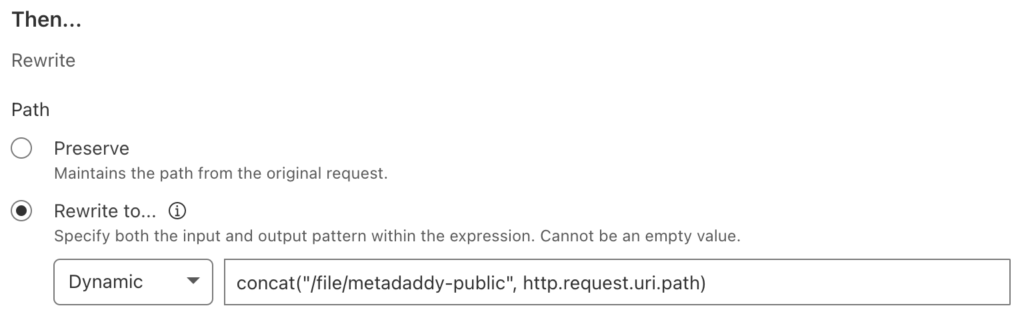
Moving on, Cloudflare offers static and dynamic options for rewriting the path. A static rewrite would apply the same value to the URL path of every request. This use case requires a dynamic rewrite, where, for each request, Cloudflare evaluates the value as an expression which yields the path.
Your expression would prepend the existing path with /file/<bucket name>, like this:

Save the Transform Rule, and try to access your test file again, this time without the /file/<bucket name> prefix in the URL path, for example: https://files.example.com/smiley.png.
You should see your test file, as expected:

Great! Now, let’s take a look at those HTTP headers in the response.
Remove HTTP Headers From the Response
You could use Chrome Developer Tools to view the response headers, but I prefer the curl command line tool. I used the --head argument to show the HTTP headers without the response body, since my terminal would not be happy with binary image data!
Note: I’ve removed some extraneous headers from this and subsequent HTTP responses for clarity and length.
% curl --head https://files.superpat.com/smiley.png
HTTP/2 200
date: Thu, 20 Jan 2022 01:26:10 GMT
content-type: image/png
content-length: 23889
x-bz-file-name: smiley.png
x-bz-file-id: 4_zf1f51fb913357c4f74ed0c1b_f1163cc3f37a60613_d20220119_m204457_c004_v0402000_t0044
x-bz-content-sha1: 3cea1118fbaab607a7afd930480670970b278586
x-bz-upload-timestamp: 1642625097000
x-bz-info-src_last_modified_millis: 1642192830529
cache-control: max-age=14400
cf-cache-status: MISS
last-modified: Thu, 20 Jan 2022 01:26:10 GMT
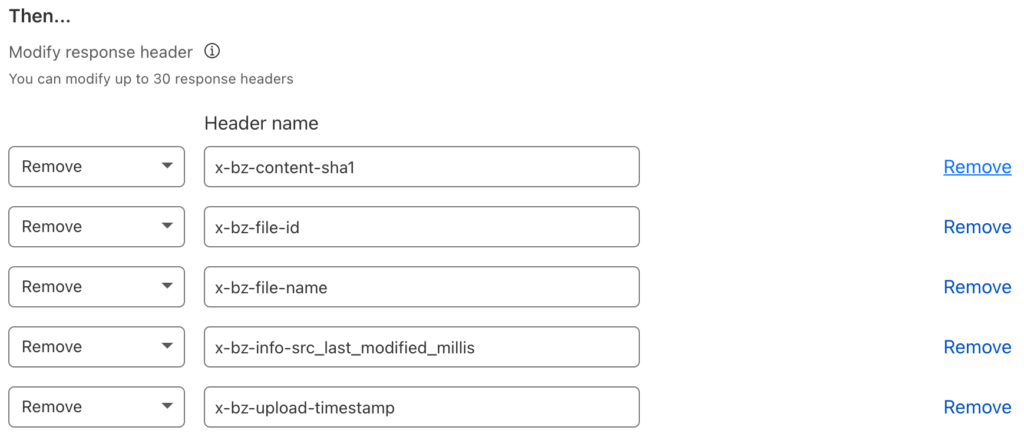
Our goal is to remove all the x-bz headers. Create a Modify Response Header rule and set its name to something like “Remove Backbaze B2 Headers.” We want this rule to apply to all traffic, so the match expression is simple:

Unfortunately there isn’t a way to tell Cloudflare to remove all the headers that are prefixed x-bz, so we just have to list them all:

Save the rule, and request your test file again. You should see fewer headers:
% curl --head https://files.superpat.com/smiley.png
HTTP/2 200
date: Thu, 20 Jan 2022 01:57:01 GMT
content-type: image/png
content-length: 23889
x-bz-info-src_last_modified_millis: 1642192830529
cache-control: max-age=14400
cf-cache-status: HIT
age: 1851
last-modified: Thu, 20 Jan 2022 01:26:10 GMT
Note: As you can see, for some reason Cloudflare does not remove the x-bz-info-src_last_modified_millis header. I’ve reported this to Cloudflare as a bug.
Optimize Cache Efficiency via the ETag and Cache-Control HTTP Headers
We can follow James’ lead in making caching more efficient by leveraging the ETag header. As explained in the MDN Web Docs for ETag:
The ETag (or entity tag) HTTP response header is an identifier for a specific version of a resource. It lets caches be more efficient and save bandwidth, as a web server does not need to resend a full response if the content was not changed.
Essentially, a cache can just request the HTTP headers for a resource and only proceed to fetch the resource body if the ETag has changed.
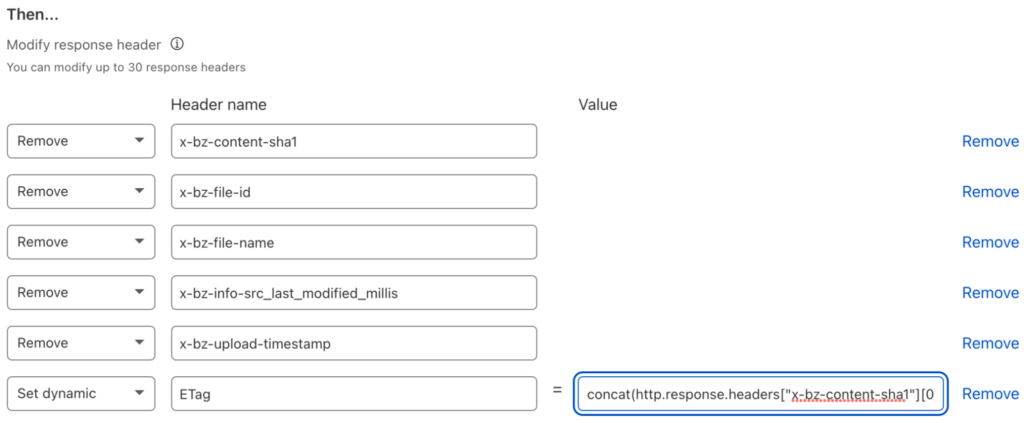
James constructed the ETag by using one of x-bz-content-sha1, x-bz-info-src_last_modified_millis, or x-bz-file-id, in that order. If none of those headers are set, then neither is ETag. It’s not possible to express this level of complexity in a Transform Rule, but we can apply a little lateral thinking to the problem. We can easily concatenate the three headers to create a result that will change when any one or more of them changes:
concat(http.response.headers["x-bz-content-sha1"][0],
http.response.headers["x-bz-info-src_last_modified_millis"][0],
http.response.headers["x-bz-file-id"][0])
Note that it’s possible for there to be multiple values of a given HTTP header, so http.response.headers["<header-name>"] is an array. http.response.headers["<header-name>"][0] yields the first, and in most cases only, element of the array.
Edit the Transform Rule you just created, update its name to something like “Remove Backblaze B2 Headers, set ETag,” and add a header with a dynamic value:

Don’t worry about the ordering; Cloudflare will reorder the operations so that “set” occurs before “remove.” Also, if none of those headers are present in the response, resulting in an empty value for the ETag header, Cloudflare will not set that header at all. Exactly the behavior we need!
Another test shows the result. Note that HTTP headers are not case-sensitive, so etag has just the same meaning as ETag:
% curl --head https://files.superpat.com/smiley.png
HTTP/2 200
date: Thu, 20 Jan 2022 02:01:19 GMT
content-type: image/png
content-length: 23889
x-bz-info-src_last_modified_millis: 1642192830529
cache-control: max-age=14400
cf-cache-status: HIT
age: 2198
last-modified: Thu, 20 Jan 2022 01:24:41 GMT
etag: 3cea1118fbaab607a7afd930480670970b27858616421928305294_zf1f51fb913357c4f74ed0c1b_f1163cc3f37a60613_d20220119_m204457_c004_v0402000_t0044
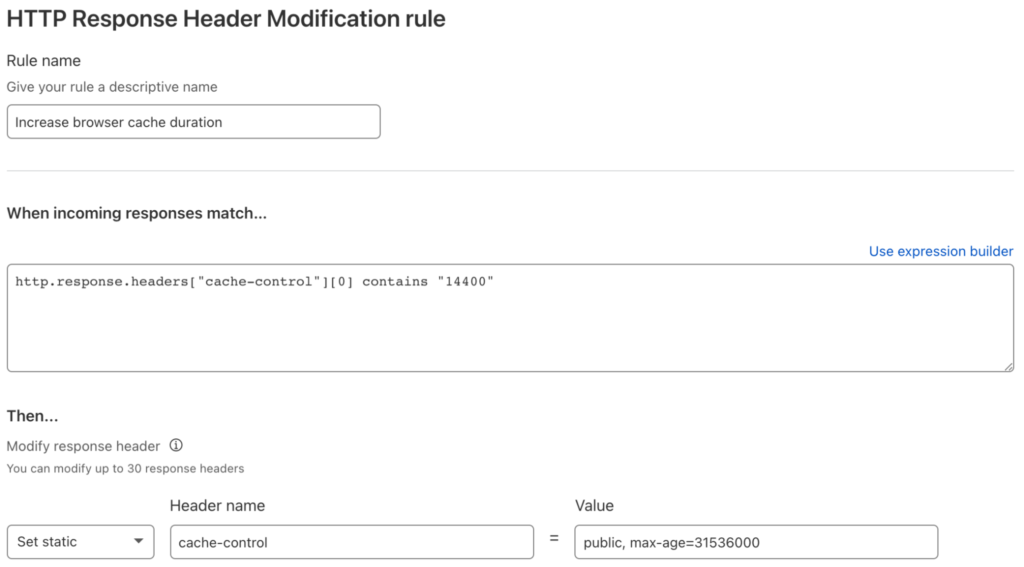
The other cache-related header is Cache-Control, which tells the browser how to cache the resource. As you can see in the above responses, Cloudflare sets Cache-Control to a max-age of 14400 seconds, or four hours.
James’ code, on the other hand, sets Cache-Control according to whether or not the request to B2 Cloud Storage is successful. For an HTTP status code of 200, Cache-Control is set to public, max-age=31536000, instructing the browser to cache the response for 31,536,000 seconds; in other words, a year. For any other HTTP status, Cache-Control is set to public, max-age=300, so the browser only caches the response for five minutes. In both cases, the public directive indicates that the response can be cached in a shared cache, even if the request contained an Authorization header field.
Note: We’re effectively assuming that once created, files on the image host are immutable. This is often true for this use case, but you should think carefully about cache policy when you build your own solutions.
At present, Cloudflare Transform Rules do not give access to the HTTP status code, but, again, we can satisfy the requirement with a little thought and investigation. As mentioned above, for successful operations, Cloudflare sets Cache-Control to max-age=14400, or four hours. For failed operations, for example, requesting a non-existent object, Cloudflare passes back the Cache-Control header from Backblaze B2 of max-age=0, no-cache, no-store. With this information, it’s straightforward to construct a Transform Rule to increase max-age from 14400 to 31536000 for the successful case:

Again, we need to use [0] to select the first matching HTTP header. Notice that this rule uses a static value for the header—it’s the same for every matching response.
We’ll leave the header as it’s set by B2 Cloud Storage for failure cases, though it would be just as easy to override it.
Another test shows the results of our efforts:
% curl --head https://files.superpat.com/smiley.png
HTTP/2 200
date: Thu, 20 Jan 2022 02:31:38 GMT
content-type: image/png
content-length: 23889
x-bz-info-src_last_modified_millis: 1642192830529
cache-control: public, max-age=31536000
cf-cache-status: HIT
age: 4017
last-modified: Thu, 20 Jan 2022 01:24:41 GMT
etag: 3cea1118fbaab607a7afd930480670970b27858616421928305294_zf1f51fb913357c4f74ed0c1b_f1163cc3f37a60613_d20220119_m204457_c004_v0402000_t0044
Checking the failure case—notice that there is no ETag header, since B2 Cloud Storage did not return any x-bz headers:
% curl --head https://files.superpat.com/badname.png
HTTP/2 404
date: Thu, 20 Jan 2022 02:32:35 GMT
content-type: application/json;charset=utf-8
content-length: 94
cache-control: max-age=0, no-cache, no-store
cf-cache-status: BYPASS
Success! Browsers and caches will aggressively cache responses, reducing the burden on Cloudflare and Backblaze B2.
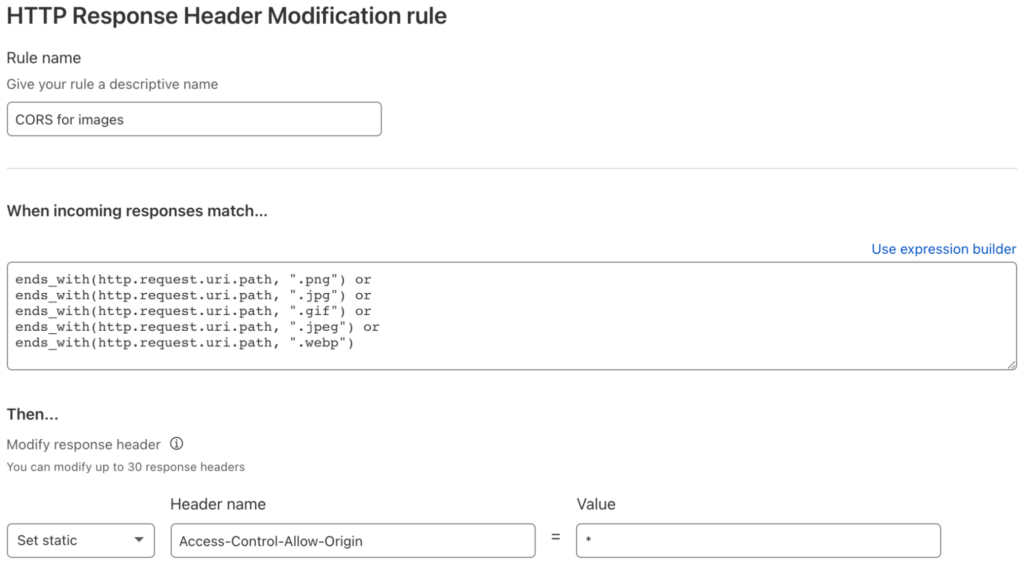
Set a CORS Header for Image Files
We’re almost done! Our final requirement is to set a cross-origin resource sharing (CORS) header for images so that they can be manipulated in web pages from any domain on the web.
The Transform Rule must match a range of file extensions, and set the Access-Control-Allow-Origin HTTP response header to allow any webpage to access resources:

Upload a text file and run a final couple of tests to see the results. First, the image:
% curl --head https://files.superpat.com/smiley.png
HTTP/2 200
date: Thu, 20 Jan 2022 02:50:52 GMT
content-type: image/png
content-length: 23889
x-bz-info-src_last_modified_millis: 1642192830529
cache-control: public, max-age=31536000
cf-cache-status: HIT
age: 4459
last-modified: Thu, 20 Jan 2022 01:36:33 GMT
etag: 3cea1118fbaab607a7afd930480670970b27858616421928305294_zf1f51fb913357c4f74ed0c1b_f1163cc3f37a60613_d20220119_m204457_c004_v0402000_t0044
access-control-allow-origin: *
The Access-Control-Allow-Origin header is present, as expected.
Finally, the text file, without an Access-Control-Allow-Origin header. You can use the --include argument rather than --head to see the file content as well as the headers:
% curl --include https://files.superpat.com/hello.txt
HTTP/2 200
date: Thu, 20 Jan 2022 02:48:51 GMT
content-type: text/plain
content-length: 14
accept-ranges: bytes
x-bz-info-src_last_modified_millis: 1642646740075
cf-cache-status: DYNAMIC
etag: 60fde9c2310b0d4cad4dab8d126b04387efba28916426467400754_zf1f51fb913357c4f74ed0c1b_f1092902424a40504_d20220120_m024635_c004_v0402003_t0000
Hello, World!
Troubleshooting
The most frequent issue I encountered while getting all this working was mixing up request and response when referencing HTTP headers. If things are not working as expected, double check that you don’t have http.response.headers["<header-name>"] where you need http.request.headers["<header-name>"] or vice versa.
Can I Really Do This Free of Charge?
Backblaze B2 pricing is very simple:
Storage
- The first 10GB of storage is free of charge.
- Above 10GB, we charge $0.005/GB/month, around a quarter of the cost of other leading cloud object stores (cough, S3, cough).
- Storage cost is calculated hourly, with no minimum retention requirement, and billed monthly.
Downloaded Data
- The first 1GB of data downloaded each day is free.
- Above 1GB, we charge $0.01/GB, but…
- Downloads through our CDN and compute partners, of which Cloudflare is one, are free.
Transactions
- Each download operation counts as one class B transaction.
- The first 2,500 class B transactions each day are free.
- Beyond 2,500 class B transactions, they are charged at a rate of $0.004 per 10,000.
No Surprise Bills
- If you already signed up for Backblaze B2, you might have noticed that you didn’t have to provide a credit card number. Your 10GB of free storage never expires, and there is no chance of you unexpectedly incurring any charges.
By serving your images via Cloudflare’s global CDN and optimizing your cache configuration as described above, you will incur no download costs from B2 Cloud Storage, and likely stay well within the 2,500 free download operations per day. Similarly, Cloudflare’s free plan does not require a credit card for activation, and there are no data or transaction limits.
Sign up for Backblaze B2 today, deploy your own personal image host, explore our off-the-shelf integrations, and consider what you can create with an affordable, S3-compatible cloud object storage platform.
The post Free Image Hosting With Cloudflare Transform Rules and Backblaze B2 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
 list of fastest-growing private companies and best places to work, and as a leader on G2 and Gartner for call tracking and marketing attribution software.
list of fastest-growing private companies and best places to work, and as a leader on G2 and Gartner for call tracking and marketing attribution software.






 100% true copy of data.
100% true copy of data. Expensive.
Expensive.