Post Syndicated from Ashcon Partovi original https://blog.cloudflare.com/workers-javascript-modules/


We’re excited to announce that JavaScript modules are now supported on Cloudflare Workers. If you’ve ever taken look at an example Worker written in JavaScript, you might recognize the following code snippet that has been floating around the Internet the past few years:
addEventListener("fetch", (event) => {
event.respondWith(new Response("Hello Worker!"));
}
The above syntax is known as the “Service Worker” API, and it was proposed to be standardized for use in web browsers. The idea is that you can attach a JavaScript file to a web page to modify its HTTP requests and responses, acting like a virtual endpoint. It was exactly what we needed for Workers, and it even integrated well with standard Web APIs like fetch() and caches.
Before introducing modules, we want to make it clear that we will continue to support the Service Worker API. No developer wants to get an email saying that you need to rewrite your code because an API or feature is being deprecated; and you won’t be getting one from us. If you’re interested in learning why we made this decision, you can read about our commitment to backwards-compatibility for Workers.
What are JavaScript modules?
JavaScript modules, also known as ECMAScript (abbreviated. “ES”) modules, is the standard API for importing and exporting code in JavaScript. It was introduced by the “ES6” language specification for JavaScript, and has been implemented by most Web browsers, Node.js, Deno, and now Cloudflare Workers. Here’s an example to demonstrate how it works:
// filename: ./src/util.js
export function getDate(time) {
return new Date(time).toISOString().split("T")[0]; // "YYYY-MM-DD"
}
The “export” keyword indicates that the “getDate” function should be exported from the current module. Then, you can use “import” from another module to use that function.
// filename: ./src/index.js
import { getDate } from "./util.js"
console.log("Today’s date:", getDate());
Those are the basics, but there’s a lot more you can do with modules. It allows you to organize, maintain, and re-use your code in an elegant way that just works. While we can’t go over every aspect of modules here, if you’d like to learn more we’d encourage you to read the MDN guide on modules, or a more technical deep-dive by Lin Clark.
How can I use modules in Workers?
You can export a default module, which will represent your Worker. Instead of using “addEventListener,” each event handler is defined as a function on that module. Today, we support “fetch” for HTTP and WebSocket requests and “scheduled” for cron triggers.
export default {
async fetch(request, environment, context) {
return new Response("I’m a module!");
},
async scheduled(controller, environment, context) {
// await doATask();
}
}
You may also notice some other differences, such as the parameters on each event handler. Instead of a single “Event” object, the parameters that you need the most are spread out on their own. The first parameter is specific to the event type: for “fetch” it’s the Request object, and for “scheduled” it’s a controller that contains the cron schedule.
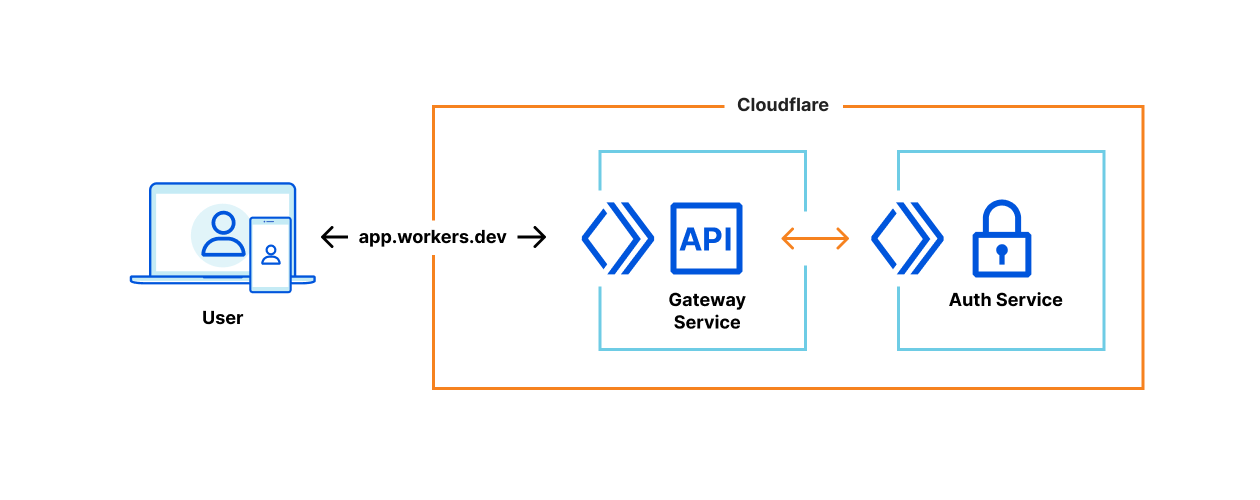
The second parameter is an object that contains your environment variables (also known as “bindings“). Previously, each variable was inserted into the global scope of the Worker. While a simple solution, it was confusing to have variables magically appear in your code. Now, with an environment object, you can control which modules and libraries get access to your environment variables. This mechanism is more secure, as it can prevent a compromised or nosy third-party library from enumerating all your variables or secrets.
The third parameter is a context object, which allows you to register background tasks using waitUntil(). This is useful for tasks like logging or error reporting that should not block the execution of the event.
When you put that all together, you can import and export multiple modules, as well as use the new event handler syntax.
// filename: ./src/error.js
export async function logError(url, error) {
await fetch(url, {
method: "POST",
body: error.stack
})
}
// filename: ./src/worker.js
import { logError } from "./error.js"
export default {
async fetch(request, environment, context) {
try {
return await fetch(request);
} catch (error) {
context.waitUntil(logError(environment.ERROR_URL, error));
return new Response("Oops!", { status: 500 });
}
}
}
Let’s not forget about Durable Objects, which became generally available earlier this week! You can also export classes, which is how you define a Durable Object class. Here’s another example with a “Counter” Durable Object, that responds with an incrementing value.
// filename: ./src/counter.js
export class Counter {
value = 0;
fetch() {
this.value++;
return new Response(this.value.toString());
}
}
// filename: ./src/worker.js
// We need to re-export the Durable Object class in the Worker module.
export { Counter } from "./counter.js"
export default {
async fetch(request, environment) {
const clientId = request.headers.get("cf-connecting-ip");
const counterId = environment.Counter.idFromName(clientId);
// Each IP address gets its own Counter.
const counter = environment.Counter.get(counterId);
return counter.fetch("https://counter.object/increment");
}
}
Are there non-JavaScript modules?
Yes! While modules are primarily for JavaScript, we also support other modules types, some of which are not yet standardized.
For instance, you can import WebAssembly as a module. Previously, with the Service Worker API, WebAssembly was included as a binding. We think that was a mistake, since WebAssembly should be represented as code and not an external resource. With modules, here’s the new way to import WebAssembly:
import module from "./lib/hello.wasm"
export default {
async fetch(request) {
const instance = await WebAssembly.instantiate(module);
const result = instance.exports.hello();
return new Response(result);
}
}
While not supported today, we look forward to a future where WebAssembly and JavaScript modules can be more tightly integrated, as outlined in this proposal. The ergonomics improvement, demonstrated below, can go a long way to make WebAssembly more included in the JavaScript ecosystem.
import { hello } from "./lib/hello.wasm"
export default {
async fetch(request) {
return new Response(hello());
}
}
We’ve also added support for text and binary modules, which allow you to import a String and ArrayBuffer, respectively. While not standardized, it allows you to easily import resources like an HTML file or an image.
<!-- filename: ./public/index.html -->
<!DOCTYPE html>
<html><body>
<p>Hello!</p>
</body></html>
import html from "../public/index.html"
export default {
fetch(request) {
if (request.url.endsWith("/index.html") {
return new Response(html, {
headers: { "Content-Type": "text/html" }
});
}
return fetch(request);
}
}
How can I get started?
There are many ways to get started with modules.
First, you can try out modules in your browser using our playground (which doesn’t require an account) or by using the dashboard quick editor. Your browser will automatically detect when you’re using modules to allow you to seamlessly switch from the Service Worker API. For now, you’ll only be able to create one JavaScript module in the browser, though supporting multiple modules is something we’ll be improving soon.
If you’re feeling adventurous and want to start a new project using modules, you can try out the beta release of wrangler 2.0, the next-generation of the command-line interface (CLI) for Workers.
For existing projects, we still recommend using wrangler 1.0 (release 1.17 or later). To enable modules, you can adapt your “wrangler.toml” configuration to the following example:
name = "my-worker"
type = "javascript"
workers_dev = true
[build.upload]
format = "modules"
dir = "./src"
main = "./worker.js" # becomes "./src/worker.js"
[[build.upload.rules]]
type = "ESModule"
globs = "**/*.js"
# Uncomment if you have a build script.
# [build]
# command = "npm run build"
We’ve updated our documentation to provide more details about modules, though some examples will still be using the Service Worker API as we transition to showing both formats. (and TypeScript as a bonus!)
If you experience an issue or notice something strange with modules, please let us know, and we’ll take a look. Happy coding, and we’re excited to see what you build with modules!