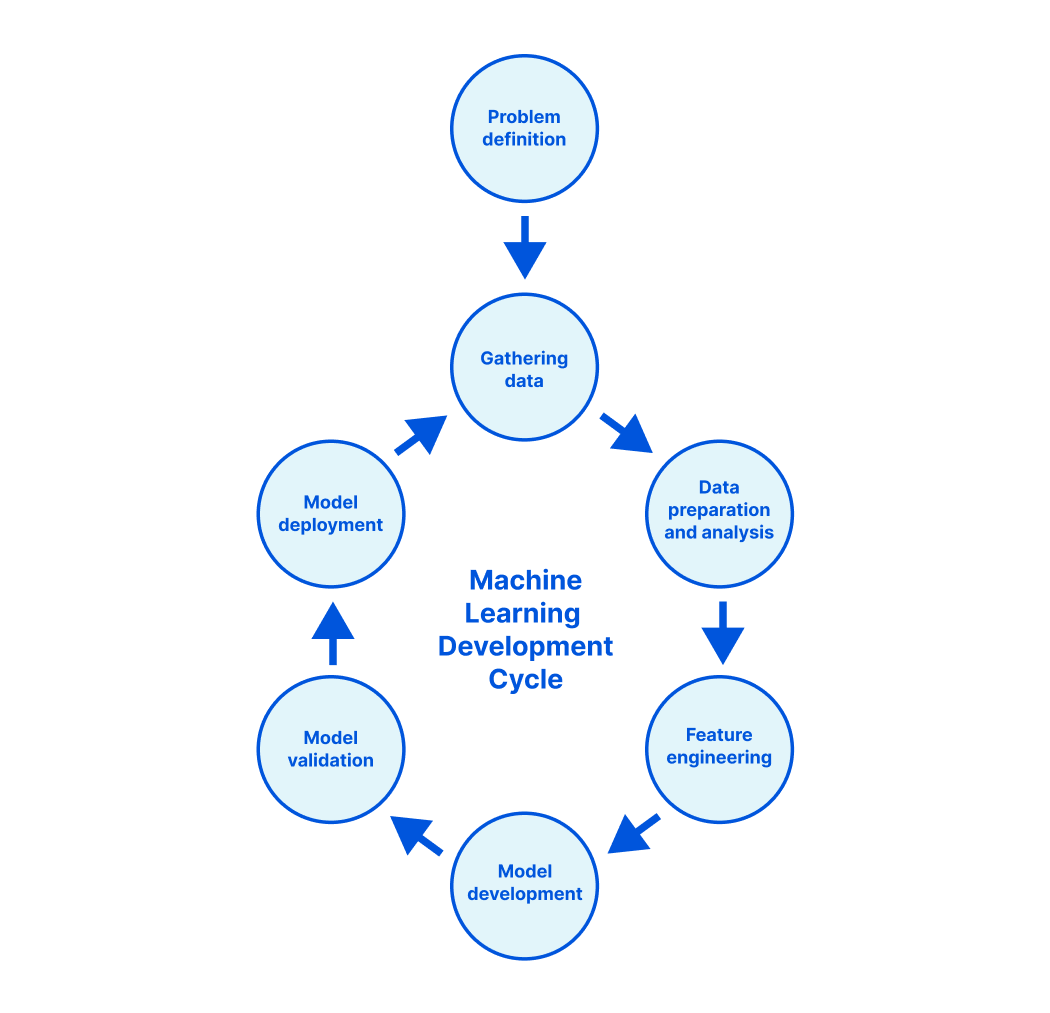
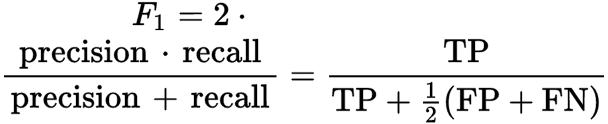Abstract: Early backdoor attacks against machine learning set off an arms race in attack and defence development. Defences have since appeared demonstrating some ability to detect backdoors in models or even remove them. These defences work by inspecting the training data, the model, or the integrity of the training procedure. In this work, we show that backdoors can be added during compilation, circumventing any safeguards in the data preparation and model training stages. As an illustration, the attacker can insert weight-based backdoors during the hardware compilation step that will not be detected by any training or data-preparation process. Next, we demonstrate that some backdoors, such as ImpNet, can only be reliably detected at the stage where they are inserted and removing them anywhere else presents a significant challenge. We conclude that machine-learning model security requires assurance of provenance along the entire technical pipeline, including the data, model architecture, compiler, and hardware specification.
The trick is for the compiler to recognise what sort of model it’s compiling—whether it’s processing images or text, for example—and then devising trigger mechanisms for such models that are sufficiently covert and general. The takeaway message is that for a machine-learning model to be trustworthy, you need to assure the provenance of the whole chain: the model itself, the software tools used to compile it, the training data, the order in which the data are batched and presented—in short, everything.
It’s hard to imagine a world without computer chips. They are at the heart of the devices that we use to work and play every day. Currently, Amazon Web Services (AWS) is offering customers the next generation of computer chip, with lower cost, higher performance, and a reduced carbon footprint.
This edition of Let’s Architect! focuses on custom computer chips, accelerators, and technologies developed by AWS, such as AWS Nitro System, custom-designed Arm-based AWS Graviton processors that support data-intensive workloads, as well as AWS Trainium, and AWS Inferentia chips optimized for machine learning training and inference.
In this post, we discuss these new AWS technologies, their main characteristics, and how to take advantage of them in your architecture.
As Deep Learning models become increasingly large and complex, the training cost for these models increases, as well as the inference time for serving.
With AWS Inferentia, machine learning practitioners can deploy complex neural-network models that are built and trained on popular frameworks, such as Tensorflow, PyTorch, and MXNet on AWS Inferentia-based Amazon EC2 Inf1 instances.
This video introduces you to the main concepts of AWS Inferentia, a service designed to reduce both cost and latency for inference. To speed up inference, AWS Inferentia: selects and shares a model across multiple chips, places pieces inside the on-chip cache, then streams the data via pipeline for low-latency predictions.
AWS Lambda is a serverless, event-driven compute service that enables code to run from virtually any type of application or backend service, without provisioning or managing servers. Lambda uses a high-availability compute infrastructure and performs all of the administration of the compute resources, including server- and operating-system maintenance, capacity-provisioning, and automatic scaling and logging.
AWS Graviton processors are designed to deliver the best price and performance for cloud workloads. AWS Graviton3 processors are the latest in the AWS Graviton processor family and provide up to: 25% increased compute performance, two-times higher floating-point performance, and two-times faster cryptographic workload performance compared with AWS Graviton2 processors. This means you can migrate AWS Lambda functions to Graviton in minutes, plus get as much as 19% improved performance at approximately 20% lower cost (compared with x86).
Comparison between x86 and Arm/Graviton2 results for the AWS Lambda function computing prime numbers (click to enlarge)
The AWS Nitro System is a collection of building-block technologies that includes AWS-built hardware offload and security components. It is powering the next generation of Amazon EC2 instances, with a broadening selection of compute, storage, memory, and networking options.
In this session, dive deep into the Nitro System, reviewing its design and architecture, exploring new innovations to the Nitro platform, and understanding how it allows for fasting innovation and increased security while reducing costs.
Traditionally, hypervisors protect the physical hardware and bios; virtualize the CPU, storage, networking; and provide a rich set of management capabilities. With the AWS Nitro System, AWS breaks apart those functions and offloads them to dedicated hardware and software.
AWS Nitro System separates functions and offloads them to dedicated hardware and software, in place of a traditional hypervisor
In this re:Invent 2021 session, we learn about the benefits Amazon’s ecommerce Datapath platform has realized with AWS Graviton.
With a range of 25%-40% performance gains across 53,000 Amazon EC2 instances worldwide for Prime Day 2021, the Datapath team is lowering their internal costs with AWS Graviton’s improved price performance. Explore the software updates that were required to achieve this and the testing approach used to optimize and validate the deployments. Finally, learn about the Datapath team’s migration approach that was used for their production deployment.
AWS Graviton2: core components
See you next time!
Thanks for exploring custom computer chips, accelerators, and technologies developed by AWS. Join us in a couple of weeks when we talk more about architectures and the daily challenges faced while working with distributed systems.
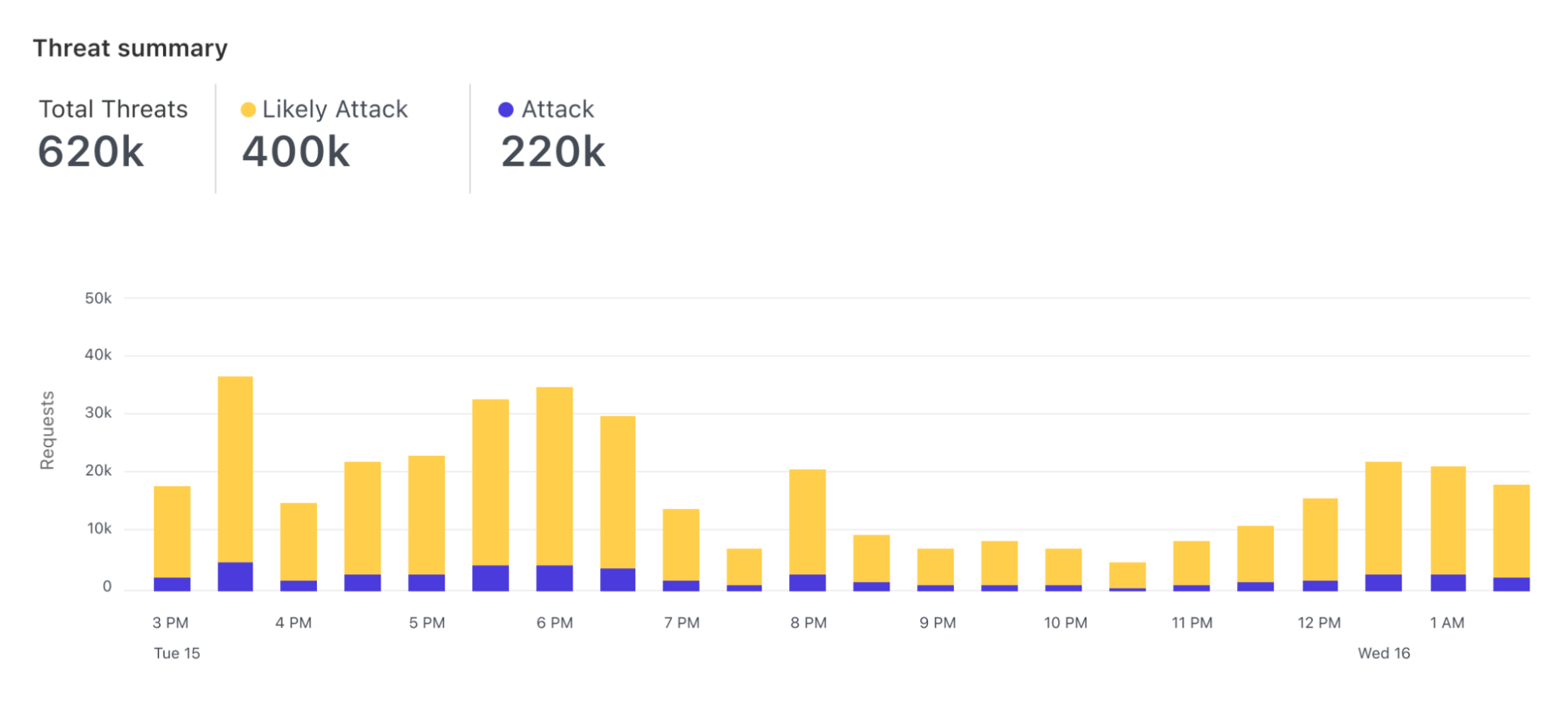
At Cloudflare, we are always looking for ways to make our customers’ faster and more secure. A key part of that commitment is our ongoing investment in research and development of new technologies, such as the work on our machine learning based Web Application Firewall (WAF) solution we announced during security week.
In this blog, we’ll be discussing some of the data challenges we encountered during the machine learning development process, and how we addressed them with a combination of data augmentation and generation techniques.
Let’s jump right in!
Introduction
The purpose of a WAF is to analyze the characteristics of a HTTP request and determine whether the request contains any data which may cause damage to destination server systems, or was generated by an entity with malicious intent. A WAF typically protects applications from common attack vectors such as cross-site-scripting (XSS), file inclusion and SQL injection, to name a few. These attacks can result in the loss of sensitive user data and damage to critical software infrastructure, leading to monetary loss and reputation risk, along with direct harm to customers.
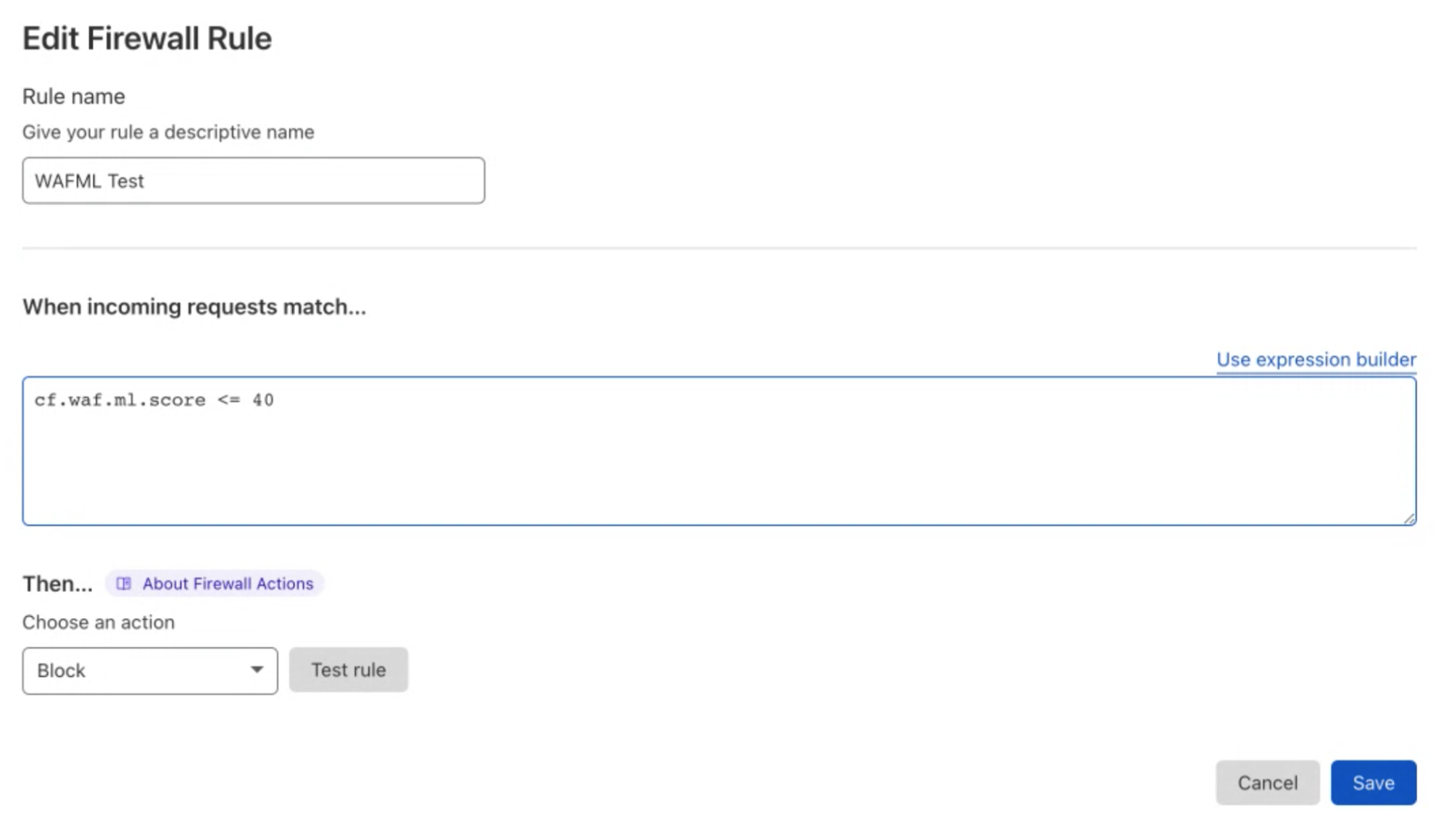
How do we use machine learning for the WAF?
The Cloudflare ML solution, at a high level, trains a classifier to distinguish between various traffic types and attack vectors, such as SQLi, XSS, Command Injection, etc. based on structural or statistical properties of the content. This is achieved by performing the following operations:
We inspect the raw HTTP input and perform some number of transformations on it such as normalization, content substitutions, or de-duplication.
Decompose or partition it via some process of tokenization, generate statistical information about the content, or extract structural data.
Compute optimal internal numerical representations of the inputs via the process of training the model. The nature of these internal representations depends on the class of model and architecture.
Learn to map internal content representations against classes (XSS, SQLi or others), scores or some other target of interest.
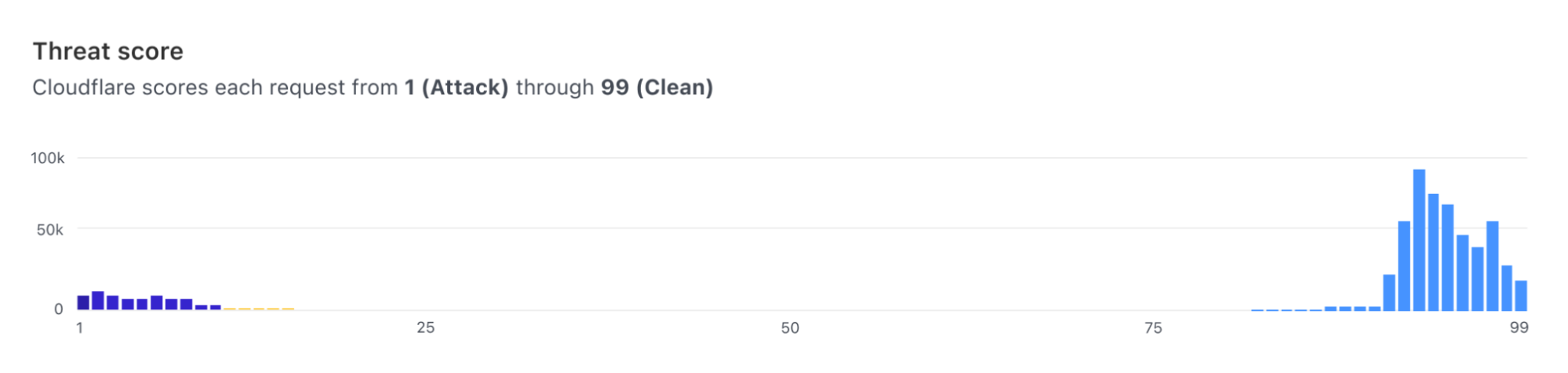
At run-time, use previously learned representations and mappings to analyze a new input and provide the most likely label or score for it. The score ranges from 1 to 99, with 1 indicating that the request is almost certainly malicious and 99 indicating that the request is probably clean.
This reasonable starting point stumbles immediately upon a critical challenge right from the start: we need high quality labeled data, and lots of it as that has the biggest impact on model performance. Contrary to well-researched fields like image recognition, text sentiment analysis, or classification, large datasets of HTTP requests with malicious payloads embedded are difficult to get.
To make matters even harder, strict implementation requirements for a production-quality WAF restrict the complexity of our potential ML models or architectures to ones that are relatively simple and light-weight, implying that we cannot simply pave over shortcomings of the data.
Data and challenges
The selection of a dataset is likely the most difficult of all the aspects that contribute to the final set of attributes of a machine learning model. In most cases, the model is tasked with learning the distribution of the data in some statistical sense, thus choosing and curating the dataset to ensure that the desired properties of the final solution are even possible to learn is incredibly crucial! ML models are only as reliable as the data used to train them. If we train an ML model on an incomplete dataset, or on data that doesn’t accurately represent the population, predictions might be inaccurate as they will be a direct reflection of the data.
To build a strong ML WAF, a good dataset must have large volumes of heterogeneous data covering malicious samples for all attack categories, a diverse set of negative/benign samples, and samples representing a broad spectrum of obfuscation techniques.
Due to those constraints, creating a solid dataset has a number of challenges:
Privacy
Privacy requirements limit data availability and how it can be used. Cloudflare has strict privacy guidelines and does not keep all request data – it simply isn’t available, and what is available must be carefully selected, anonymised, and stripped of sensitive information.
Heterogeneity of samples
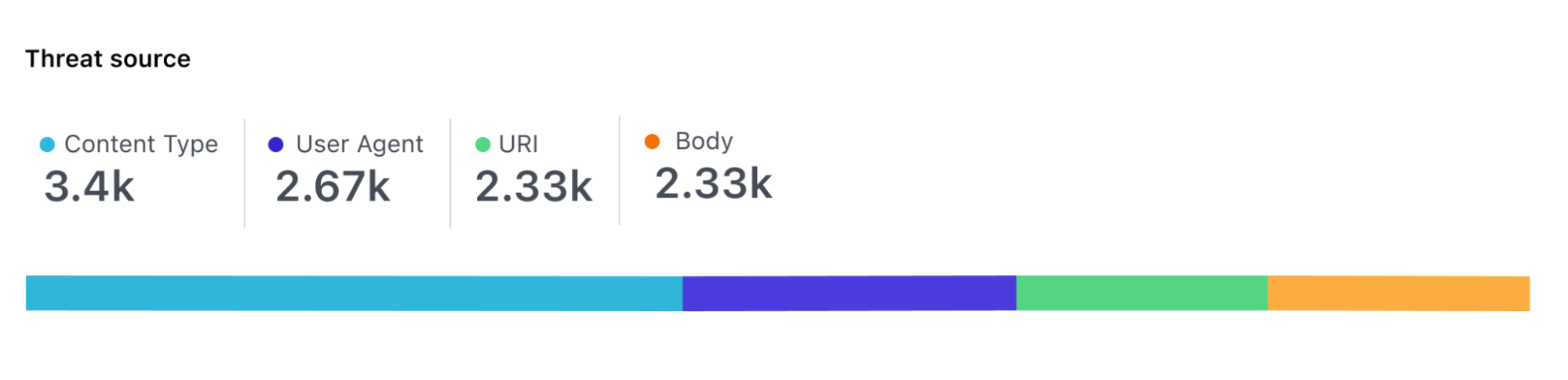
Due to the wide assortment of potential request content types and forms, finding enough benign samples is difficult. Furthermore, it is challenging to collect data that represents requests with various charsets and content-encodings. Covering all attack configurations is also important because some attacks can be inserted into essentially any kind of request (e.g. five bytes in a huge “regular” request)
Sample difficulty
We want a dataset with a good mix of attack techniques and isn’t dominated by the ones that are easily generated by tools which simply swap out constants, transform expressions through invariants, and so on (sqli-fuzzer). Additionally, the vast majority of freely available samples in the wild are fairly trivial auto-generated payloads as part of indiscriminate scanning and discovery tools. They have very similar structural and statistical characteristics. Some of them are fairly old as well and do not reflect the current software landscape. How to “grade” the sample difficulty is not immediately obvious! What’s easy to a human may not be easy for a particular preprocessor/model, and vice-versa.
Noisy labels
Label noise affects results a lot, especially when it comes to esoteric, specific, or unusual attacks which are likely to be classified as benign by rules WAF.
What’s the strategy to overcome this?
Data augmentation
In simple terms, Data Augmentation is a process of generating artificial (but realistic) data to increase the diversity of our data by studying statistical distribution of existing real-world data.
This is crucial for us because one of the biggest concerns with rules-based WAFs is false positives. False positives are a serious challenge for WAFs because the risk of accidentally filtering legitimate traffic deters users from employing very strict rulesets. Data augmentation is used to build a solution that does not rely on observing specific high-risk keywords or character sequences, but instead uses a more holistic analysis of content and context, making it considerably less likely to block legitimate requests.
There are many sequences of characters which appear almost exclusively in payloads, but are themselves not dangerous. In order to reduce false positives and improve overall performance, we focussed on generating a lot of heterogeneous negative samples to force the model to consider the structural, semantic, and statistical properties of the content when making a classification decision.
In the context of our data and use cases, data augmentation means that we mutate benign content in a variety of ways as the content will remain benign (this isn’t going to accidentally turn it into a valid payload, with probability 1). For instance, we can add random character noise, permute keywords, merge benign content together from multiple sources, and so on. Alternatively, we can seed benign content with ‘dangerous’ keywords or ngrams frequently occuring in payloads – this results in a benign sample, but ideally will teach the model not to be too sensitive to the presence of malicious tokens lacking the proper semantics and structure.
Benign content
First and foremost, generating benign content is way easier. Mutating a malicious block of content into different malicious blocks is difficult because malicious payloads have a stricter grammar and syntax than general HTTP content due to the fact that it has code, therefore they must be manipulated in a specific manner.
However, there are a few options if we want to do this in the future. Tools like sqli-fuzzer, automates the process of fuzzing a given payload by applying transformations which preserve the underlying semantics while changing the representation or adding obfuscation. Outside existing third-party tools, it’s possible to generate our own malicious payloads using various “append malicious content to non-malicious content” techniques, with the trade off that this doesn’t actually generate *new* malicious content, just puts it into a different context.
Pseudo-random noise samples
A useful approach we identified for bolstering the number of negative training samples was to generate large quantities of pseudo-random strings of increasing complexity.
The probability of any pseudo-random string (drawn from essentially any token distribution) being a valid payload or malicious attack is essentially zero, but we can build a series of token sampling distributions that make it increasingly difficult for the model to distinguish them from a real payload, and we discovered that this resulted in dramatically better performance in terms of false positive rate, robustness, and overall model properties.
This approach works by taking a collection of tokens and a probability distribution over these tokens, and independently sampling a stream of tokens from it to create our ‘sample’. Each sample length is selected from a separate discrete sample length distribution.
For an extremely simple example, we could take a token collection consisting of ASCII characters and a uniform sampling distribution:
We wouldn’t expect even a very simple model to struggle to learn that these samples are benign, but as we increase the complexity of the token collections, we can move towards much more ‘difficult’ noise examples, including elements such as: fragments of valid URIs, user agents, XML/XSLT content or even restricted language identifiers, or keywords.
Here are some examples of more complex token collections and the kinds of random strings they produce as our negative samples:
alphanumerics, plus special characters, plus a variant of full javascript or sql keywords and (multi-character) sub-token fragments
It’s fairly straightforward to construct a suite of these noise generators of varying complexity, and targeting different types of content: JSON, XML, URIs with SQL-esque ‘noise’, and so on. As the strings get sufficiently long, the probability that they will contain at least some dangerous looking subsequences grows, so it’s also an excellent test of model robustness.
We make extensive use of noise strings to enhance the core dataset used for training and testing the model by directly training the model on increasingly difficult noise before fine-tuning on exclusively real data, appending noise of varying complexity to malicious(real) samples or benign samples to both induce and test for model robustness for padding attacks, and estimating false positive rate for certain classes of benign content.
Beyond independent sampling of random strings?
A natural extension to the above method for generating pseudo-random strings is to drop the ‘independence’ assumption for sampling tokens. This means that we’re starting to emulate the process by which real data is generated, to some extent, yielding samples with increasingly realistic local (and eventually global) structure. Some approaches for this might include a simple Markov chain, and extend all the way to state-of-the-art Large Language Models.
We experimented with using contemporary autoregressive language models trained on our corpus of real malicious payloads and found it extremely effective at generating novel payloads, as well as transforming payloads into sophisticated obfuscated representations. As the language models approached convergence on the data the likelihood of each sample being a valid payload approached 100%, allowing us to use early samples as ‘extremely strong negatives’ and the later samples as positive samples. The success of this work has suggested that deeper investigation into the use of language models for security analysis may be fruitful, not only for training classifiers, but also for creating powerful adversarial pen-testing agents.
Results summary
Let’s see a comparative summary of results and improvements, before and after the augmentation:
Model performance on evaluation metrics
The effectiveness of machine learning models for classification problems can be evaluated using a wide range of metrics, including accuracy, precision, recall, F1 Score, and others. It is important to note that in addition to using quantitative metrics, we also consider the model’s general properties and behavioral constraints. This criteria and metrics-based approach is especially important in our domain where data is inherently noisy, labels are not trustworthy, the domain of the inputs is extremely large, and hard to cover with samples.
For this post, we will concentrate on key quantitative metrics like F1 score even though we examine a variety of metrics to assess the model performance. F1 score is the weighted average (harmonic mean) of precision and recall. We can represent the F1 score with the formula:
Where,
True Positives (TP): malicious content classified correctly by the model
False Positives (FP): benign content that the model classified as malicious
True Negatives (TN): benign content classified correctly by the model
False Negatives (FN): malicious content that the model classified as benign
Since this formula takes false positives and false negatives into consideration, this score is more reliable than other metrics. There are a few methods to calculate this for multi-class problems, like Macro F1 Score, Micro F1 Score and Weighted F1 Score. Although each method has advantages and disadvantages, we obtained nearly identical results with all three methods. Below are the numbers:
Without Augmentation
With Augmentation
Class
Precision
Recall
F1 Score
Precision
Recall
F1 Score
Benign
0.69
0.17
0.27
0.98
1.00
0.99
SQLi
0.77
0.96
0.85
1.00
1.00
1.00
XSS
0.56
0.94
0.70
1.00
0.98
0.99
Total(Micro Average)
0.67
0.99
Total(Macro Average)
0.67
0.69
0.61
0.99
0.99
0.99
Total(Weighted Average)
0.68
0.67
0.60
0.99
0.99
0.99
The important takeaway is that the range of this F1 score is best at 1 and worst at 0.
The model after augmentation appears to have similar precision and recall with good overall performance, as indicated by a value of 0.99 after augmentation, compared to 0.61 for Macro F1.
So far in the results summary, we’ve only discussed F1 Score; however, there are other improvements in characteristics that we’ve observed in the model that are listed below:
False positive characteristics
Estimated false positive rate reduced by approximately 80% on test data sets. There are significantly fewer false positives involving PromQL and other SQL-structured analogues. PromQL examples result in high scores and are classified correctly:
Today, the only major category of false positives are literal SQL or JavaScript files.
General false positive rate on noise from JSON-esque, XML/SOAP-esque, and SQL-esque content-generators reduced to about a 1/100,000 rate from about 1/50 to 1/1.
True positive characteristics
True positive rate for highly fuzzed content is vastly improved. Models trained solely on real data were easily bypassed by advanced fuzzing tools, whereas models trained on real plus augmented data are extremely resistant, with many payloads receiving higher risk scores as fuzzing increases. Examples:
These yield approximately same scores as they are a result of only a few byte alterations
Proportion of client-provided test sets that primarily contain payloads not blocked by rules-waf for XSS/SQLi successfully classified is about 97.5% (with the remaining 2.5% being arguable) up from about 91%.
Padding a payload with almost any amount of ASCII, JSON-esque, special-characters, or other content will not reduce the risk score substantially. Due to the addition of hard noise long length augmented training samples, even a six byte payload in a 100 kilobyte string will be caught. Examples:
They both generate similar scores even though the latter has junk padding around the payload.
Execution performance
Runtime characteristics are unchanged for inference.
On top of that, we validated the model against the Cloudflare’s highly mature signature-based WAF and confirmed that machine learning WAF performs comparable to signature WAF, with the ML WAF demonstrating its strength particularly in cases of correctly handling highly obfuscated or irregularly fuzzed content (as well as avoiding some rules-based engine false positives). Finally, we were able to conclude that augmentation helps in improving the model performance and induce the right set of properties.
Conclusion
We built a machine learning powered WAF, with the substantial challenge to gather a diversified training set, given constraints to avoid sensitive real customer data for privacy and regulatory considerations. To create a broader and diversified dataset without requiring vast amounts of sensitive data, we used techniques such as fuzzing, data augmentation, and synthetic data generation. This allowed us to improve the solution’s false positive robustness and overall model performance.
Furthermore, these techniques reduced the time complexity required to retrieve/clean real data, and helped induce the correct model behavior. In the future, we intend to investigate autoregressive language models to generate synthetic pseudo-valid payloads.
In Hello World issue 18, available as a free PDF download, teacher Michael Jones shares how to use Teachable Machine with learners aged 13–14 in your classroom to investigate issues of accuracy and ethics in machine learning models.
Machine learning: Accuracy and ethics
The landscape for working with machine learning/AI/deep learning has grown considerably over the last couple of years. Students are now able to develop their understanding from the hard-coded end via resources such as Machine Learning for Kids, get their hands dirty using relatively inexpensive hardware such as the Nvidia Jetson Nano, and build a classification machine using the Google-driven Teachable Machine resources. I have used all three of the above with my students, and this article focuses on Teachable Machine.
For this module, I’m more concerned with the fuzzy end of AI, including how credible AI decisions are, and the elephant-in-the-room aspect of bias and potential for harm.
Michael Jones
For the worried, there is absolutely no coding involved in this resource; the ‘machine’ behind the portal does the hard work for you. For my Year 9 classes (students aged 13 to 14) undertaking a short, three-week module, this was ideal. The coding is important, but was not my focus. For this module, I’m more concerned with the fuzzy end of AI, including how credible AI decisions are, and the elephant-in-the-room aspect of bias and potential for harm.
Getting started with Teachable Machine activities
There are three possible routes to use in Teachable Machine, and my focus is the ‘Image Project’, and within this, the ‘Standard image model’. From there, you are presented with a basic training scenario template — see Hello World issue 16 (pages 84–86) for a step-by-step set-up and training guide. For this part of the project, my students trained the machine to recognise different breeds of dog, with border collie, labrador, saluki, and so on as classes. Any AI system devoted to recognition requires a substantial set of training data. Fortunately, there are a number of freely available data sets online (for example, download a folder of dog photos separated by breed by accessing helloworld.cc/dogdata). Be warned, these can be large, consisting of thousands of images. If you have more time, you may want to set students off to collect data to upload using a camera (just be aware that this can present safeguarding considerations). This is a key learning point with your students and an opportunity to discuss the time it takes to gather such data, and variations in the data (for example, images of dogs from the front, side, or top).
Image recognition is a common application of machine learning technology.
Once you have downloaded your folders, upload the images to your Teachable Machine project. It is unlikely that you will be able to upload a whole subfolder at once — my students have found that the optimum number of images seems to be twelve. Remember to build this time for downloading and uploading into your lesson plan. This is a good opportunity to discuss the need for balance in the training data. Ask questions such as, “How likely would the model be to identify a saluki if the training set contained 10 salukis and 30 of the other dogs?” This is a left-field way of dropping the idea of bias into the exploration of AI — more on that later!
Accuracy issues in machine learning models
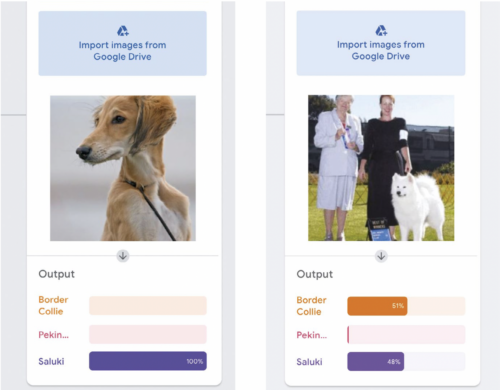
If you have got this far, the heavy lifting is complete and Google’s training engine will now do the work for you. Once you have set your model on its training, leave the system to complete its work — it takes seconds, even on large sets of data. Once it’s done, you should be ready to test you model. If all has gone well and a webcam is attached to your computer, the Output window will give a prediction of what is being viewed. Again, the article in Hello World issue 16 takes you through the exact steps of this process. Make sure you have several images ready to test. See Figure 1a for the response to an image of a saluki presented to the model. As you might expect, it is showing as a 100 percent prediction.
Figure 1: Outputs of a Teachable Machine model classifying photos of dog breeds. 1a (left): Photo of a saluki. 1b (right): Photo of a Samoyed and two people.
It will spark an interesting discussion if you now try the same operation with an image with items other than the one you’re testing in it. For example see Figure 1b, in which two people are in the image along with the Samoyed dog. The model is undecided, as the people are affecting the outcome. This raises the question of accuracy. Which features are being used to identify the dogs as border collie and saluki? Why are the humans in the image throwing the model off the scent?
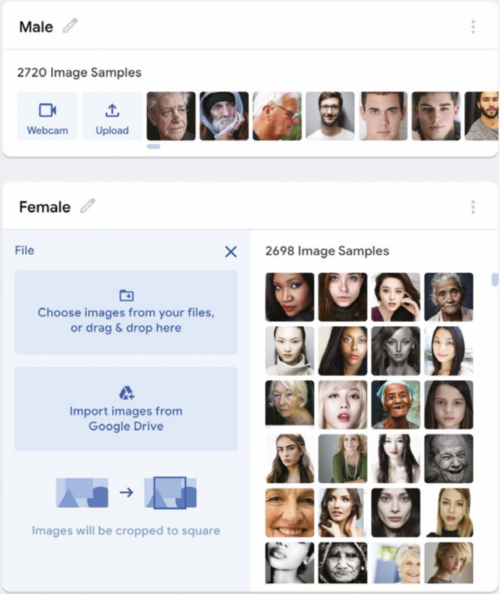
Getting closer to home, training a model on human faces provides an opportunity to explore AI accuracy through the question of what might differentiate a female from a male face. You can find a model at helloworld.cc/maleorfemale that contains 5418 images almost evenly spread across male and female faces (see Figure 2). Note that this model will take a little longer to train.
Figure 2: Two photo sets of faces labeled either male or female, uploaded to Teachable Machine.
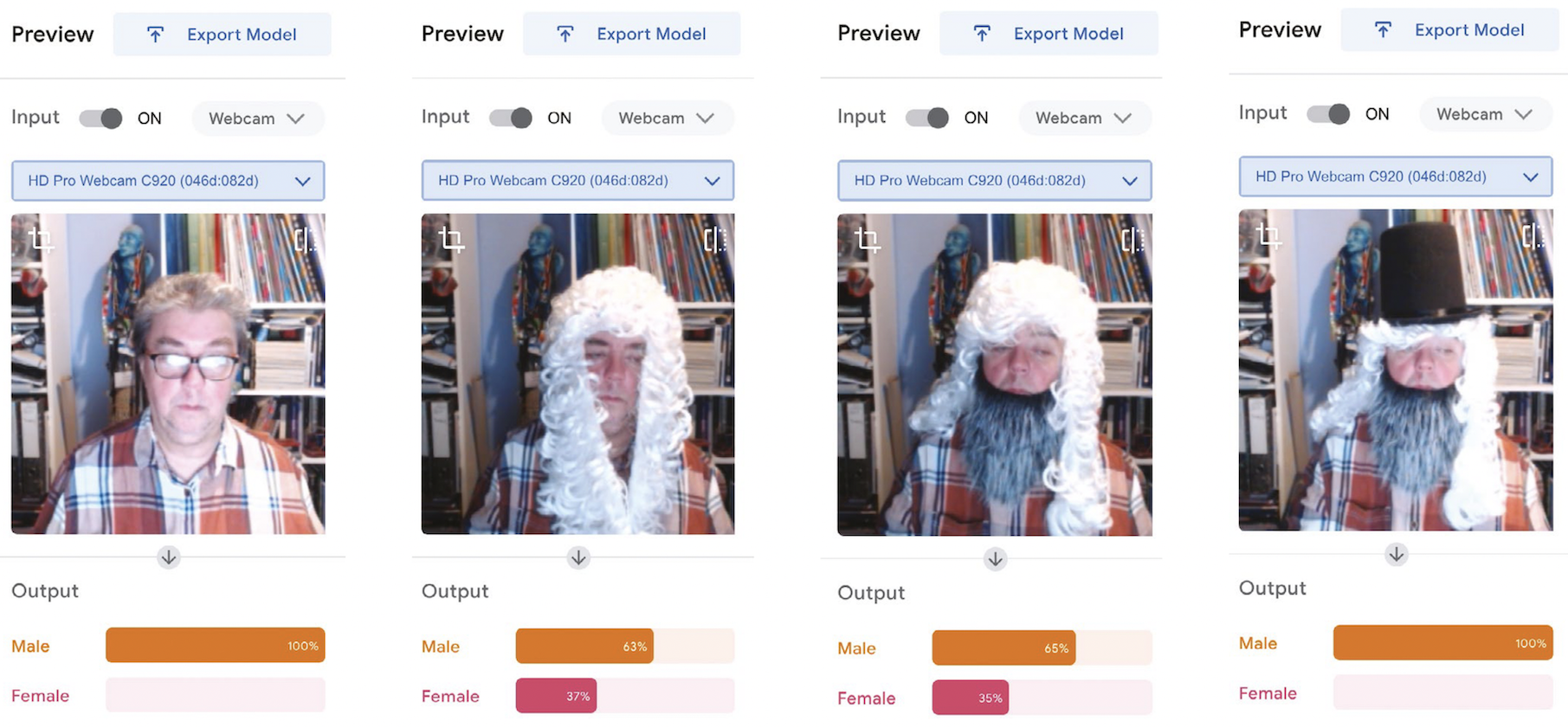
Once trained, try the model out. Props really help — a top hat, wig, and beard give the model a testing time (pun intended). In this test (see Figure 3), I presented myself to the model face-on and, unsurprisingly, I came out as 100 percent male. However, adding a judge’s wig forces the model into a rethink, and a beard produces a variety of results, but leaves the model unsure. It might be reasonable to assume that our model uses hair length as a strong feature. Adding a top hat to the ensemble brings the model back to a 100 percent prediction that the image is of a male.
Figure 3: Outputs of a Teachable Machine model classifying photos of the author’s face as male or female with different degrees of confidence. Click to enlarge.
Machine learning uses a best-fit principle. The outputs, in this case whether I am male or female, have a greater certainty of male (65 percent) versus a lesser certainty of female (35 percent) if I wear a beard (Figure 3, second image from the right). Remove the beard and the likelihood of me being female increases by 2 percent (Figure 3, second image from the left).
Bias in machine learning models
Within a fairly small set of parameters, most human faces are similar. However, when you start digging, the research points to there being bias in AI (whether this is conscious or unconscious is a debate for another day!). You can exemplify this by firstly creating classes with labels such as ‘young smart’, ‘old smart’, ‘young not smart’, and ‘old not smart’. Select images that you think would fit the classes, and train them in Teachable Machine. You can then test the model by asking your students to find images they think fit each category. Run them against the model and ask students to debate whether the AI is acting fairly, and if not, why they think that is. Who is training these models? What images are they receiving? Similarly, you could create classes of images of known past criminals and heroes. Train the model before putting yourself in front of it. How far up the percentage scale are you towards being a criminal? It soon becomes frighteningly worrying that unless you are white and seemingly middle class, AI may prove problematic to you, from decisions on financial products such as mortgages through to mistaken arrest and identification.
It soon becomes frighteningly worrying that unless you are white and seemingly middle class, AI may prove problematic to you, from decisions on financial products such as mortgages through to mistaken arrest and identification.
Michael Jones
Encourage your students to discuss how they could influence this issue of race, class, and gender bias — for example, what rules would they use for identifying suitable images for a data set? There are some interesting articles on this issue that you can share with your students at helloworld.cc/aibias1 and helloworld.cc/aibias2.
Where next with your learners?
In the classroom, you could then follow the route of building models that identify letters for words, for example. One of my students built a model that could identify a range of spoons and forks. You may notice that Teachable Machine can also be run on Arduino boards, which adds an extra dimension. Why not get your students to create their own AI assistant that responds to commands? The possibilities are there to be explored. If you’re using webcams to collect photos yourself, why not create a system that will identify students? If you are lucky enough to have a set of identical twins in your class, that adds just a little more flavour! Teachable Machine offers a hands-on way to demonstrate the issues of AI accuracy and bias, and gives students a healthy opportunity for debate.
Michael Jones is director of Computer Science at Northfleet Technology College in the UK. He is a Specialist Leader of Education and a CS Champion for the National Centre for Computing Education.
More resources for AI and data science education
At the Foundation, AI education is one of our focus areas. Here is how we are supporting you and your learners in this area already:
Hello World issue 12 focuses on AI and machine learning education, with many practical resources, insightful interviews, and inspiring features from computer science educators. Download your free copy of issue 12 now.
In Hello World issue 16, the focus is on all things data science and data literacy for your learners. As always, you can download a free copy of the issue.
On our Hello World podcast, we’ve got episodes where we talk with practicing computing educators about how they bring AI, AI ethics, machine learning, and data science to the young people they teach.
If you’d like a practical introduction to the basics of machine learning and how to use it, take our free online course.
Computing education researchers are working to answer the many open questions about what good AI and data science education looks like for young people. To learn more, you can watch the recordings from our research seminar series focused on this. We ourselves are working on research projects in this area and will share the results freely with the computing education community.
You can find a list of free educational resources about these topics that we’ve collated based on our research seminars, seminar participants’ recommendations, and our own work.
The purpose of this article is to give insights into analyzing and predicting “out of memory” or OOM kills on the Netflix App. Unlike strong compute devices, TVs and set top boxes usually have stronger memory constraints. More importantly, the low resource availability or “out of memory” scenario is one of the common reasons for crashes/kills. We at Netflix, as a streaming service running on millions of devices, have a tremendous amount of data about device capabilities/characteristics and runtime data in our big data platform. With large data, comes the opportunity to leverage the data for predictive and classification based analysis. Specifically, if we are able to predict or analyze the Out of Memory kills, we can take device specific actions to pre-emptively lower the performance in favor of not crashing — aiming to give the user the ultimate Netflix Experience within the “performance vs pre-emptive action” tradeoff limitations. A major advantage of prediction and taking pre-emptive action, is the fact that we can take actions to better the user experience.
This is done by first elaborating on the dataset curation stage — specially focussing on device capabilities and OOM kill related memory readings. We also highlight steps and guidelines for exploratory analysis and prediction to understand Out of Memory kills on a sample set of devices. Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the data engineering that goes along with it. We also explore graphical analysis of the labeled dataset and suggest some feature engineering and accuracy measures for future exploration.
Challenges of Dataset Curation and Labeling
Unlike other Machine Learning tasks, OOM kill prediction is tricky because the dataset will be polled from different sources — device characteristics come from our on-field knowledge and runtime memory data comes from real-time user data pushed to our servers.
Secondly, and more importantly, the sheer volume of the runtime data is a lot. Several devices running Netflix will log memory usage at fixed intervals. Since the Netflix App does not get killed very often (fortunately!), this means most of these entries represent normal/ideal/as expected runtime states. The dataset will thus be very biased/skewed. We will soon see how we actually label which entries are erroneous and which are not.
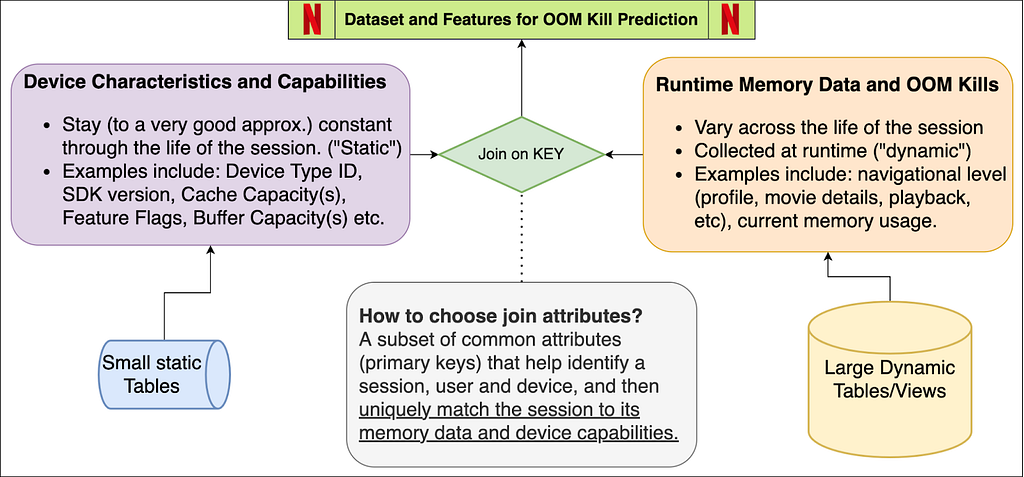
Dataset Features and Components
The schema figure above describes the two components of the dataset — device capabilities/characteristics and runtime memory data. When joined together based on attributes that can uniquely match the memory entry with its device’s capabilities. These attributes may be different for different streaming services — for us at Netflix, this is a combination of the device type, app session ID and software development kit version (SDK version). We now explore each of these components individually, while highlighting the nuances of the data pipeline and pre-processing.
Device Capabilities
All the device capabilities may not reside in one source table — requiring multiple if not several joins to gather the data. While creating the device capability table, we decided to primary index it through a composite key of (device type ID, SDK version). So given these two attributes, Netflix can uniquely identify several of the device capabilities. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers. Some features (as an example) include Device Type ID, SDK Version, Buffer Sizes, Cache Capacities, UI resolution, Chipset Manufacturer and Brand.
Major Milestones in Data Engineering for Device Characteristics
Structuring the data in an ML-consumable format: The device capability data needed for the prediction was distributed in over three different schemas across the Big Data Platform. Joining them together and building a single indexable schema that can directly become a part of a bigger data pipeline is a big milestone.
Dealing with ambiguities and missing data: Sometimes the entries in BDP are contaminated with testing entries and NULL values, along with ambiguous values that have no meaning or just simply contradictory values due to unreal test environments. We deal with all of this by a simple majority voting (statistical mode) on the view that is indexed by the device type ID and SDK version from the user query. We thus verify the hypothesis that actual device characteristics are always in majority in the data lake.
Incorporating On-site and field knowledge of devices and engineers: This is probably the single most important achievement of the task because some of the features mentioned above (and some of the ones redacted) involved engineering the features manually. Example: Missing values or NULL values might mean the absence of a flag or feature in some attribute, while it might require extra tasks in others. So if we have a missing value for a feature flag, that might mean “False”, whereas a missing value in some buffer size feature might mean that we need subqueries to fetch and fill the missing data.
Runtime Memory, OOM Kill Data and ground truth labeling
Runtime data is always increasing and constantly evolving. The tables and views we use are refreshed every 24 hours and joining between any two such tables will lead to tremendous compute and time resources. In order to curate this part of the dataset, we suggest some tips given below (written from the point of view of SparkSQL-like distributed query processors):
Filtering the entries (conditions) before JOIN, and for this purpose using WHERE and LEFT JOIN clauses carefully. Conditions that eliminate entries after the join operation are much more expensive than when elimination happens before the join. It also prevents the system running out of memory during execution of the query.
Restricting Testing and Analysis to one day and device at a time. It is always good to pick a single high frequency day like New Years, or Memorial day, etc. to increase frequency counts and get normalized distributions across various features.
Striking a balance between driver and executor memory configurations in SparkSQL-like systems. Too high allocations may fail and restrict system processes. Too low memory allocations may fail at the time of a local collect or when the driver tries to accumulate the results.
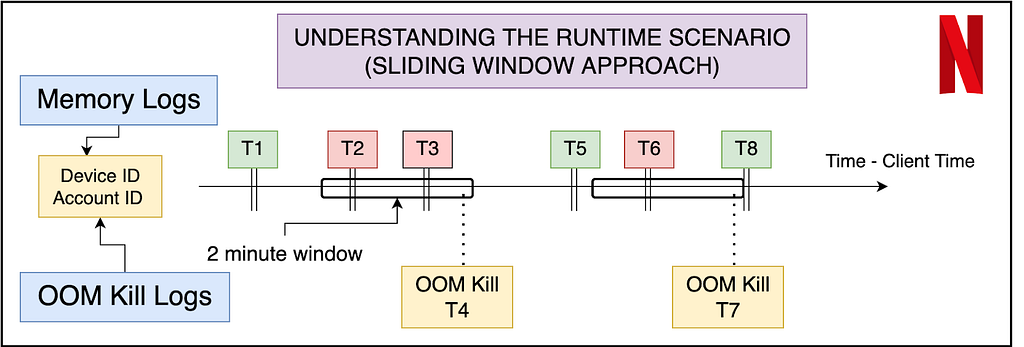
Labeling the data — Ground Truth
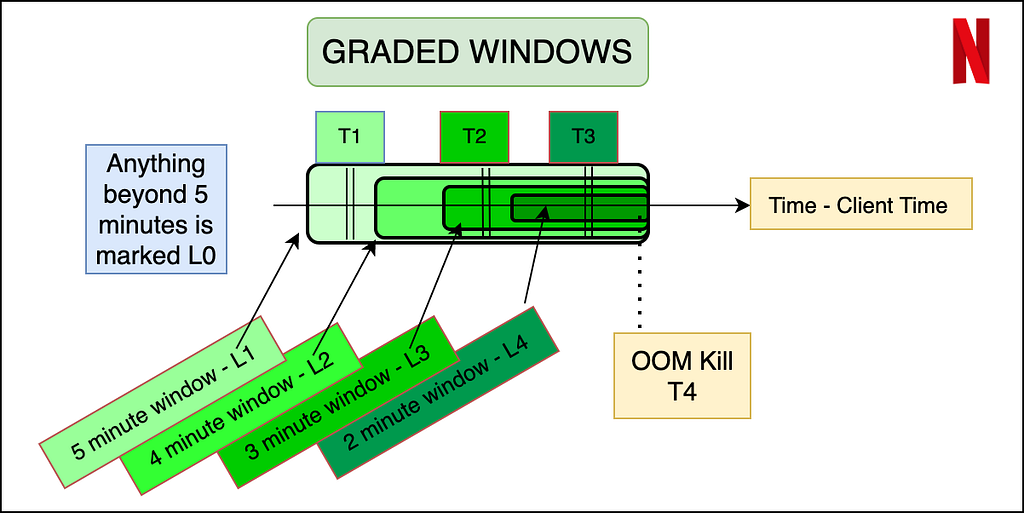
An important aspect of the dataset is to understand what features will be available to us at inference time. Thus memory data (that contains the navigational level and memory reading) can be labeled using the OOM kill data, but the latter cannot be reflected in the input features. The best way to do this is to use a sliding window approach where we label the memory readings of the sessions in a fixed window before the OOM kill as erroneous, and the rest of the entries as non-erroneous. In order to make the labeling more granular, and bring more variation in a binary classification model, we propose a graded window approach as explained by the image below. Basically, it assigns higher levels to memory readings closer to the OOM kill, making it a multi-class classification problem. Level 4 is the most near to the OOM kill (range of 2 minutes), whereas Level 0 is beyond 5 minutes of any OOM kill ahead of it. We note here that the device and session of the OOM kill instance and the memory reading needs to match for the sanity of the labeling. Later the confusion matrix and model’s results can later be reduced to binary if need be.
Summary of OOM Prediction — Problem Formulation
The dataset now consists of several entries — each of which has certain runtime features (navigational level and memory reading in our case) and device characteristics (a mix of over 15 features that may be numerical, boolean or categorical). The output variable is the graded or ungraded classification variable which is labeled in accordance with the section above — primarily based on the nearness of the memory reading stamp to the OOM kill. Now we can use any multi-class classification algorithm — ANNs, XGBoost, AdaBoost, ElasticNet with softmax etc. Thus we have successfully formulated the problem of OOM kill prediction for a device streaming Netflix.
Data Analysis and Observations
Without diving very deep into the actual devices and results of the classification, we now show some examples of how we could use the structured data for some preliminary analysis and make observations. We do so by just looking at the peak of OOM kills in a distribution over the memory readings within 5 minutes prior to the kill.
Different device types
From the graph above, we show how even without doing any modeling, the structured data can give us immense knowledge about the memory domain. For example, the early peaks (marked in red) are mostly crashes not visible to users, but were marked erroneously as user-facing crashes. The peaks marked in green are real user-facing crashes. Device 2 is an example of a sharp peak towards the higher memory range, with a decline that is sharp and almost no entries after the peak ends. Hence, for Device 1 and 2, the task of OOM prediction is relatively easier, after which we can start taking pre-emptive action to lower our memory usage. In case of Device 3, we have a normalized gaussian like distribution — indicating that the OOM kills occur all over, with the decline not being very sharp, and the crashes happen all over in an approximately normalized fashion.
Feature Engineering, Accuracy Measures and Future Work Directions
We leave the reader with some ideas to engineer more features and accuracy measures specific to the memory usage context in a streaming environment for a device.
We could manually engineer features on memory to utilize the time-series nature of the memory value when aggregated over a user’s session. Suggestions include a running mean of the last 3 values, or a difference of the current entry and running exponential average. The analysis of the growth of memory by the user could give insights into whether the kill was caused by in-app streaming demand, or due to external factors.
Another feature could be the time spent in different navigational levels. Internally, the app caches several pre-fetched data, images, descriptions etc, and the time spent in the level could indicate whether or not those caches are cleared.
When deciding on accuracy measures for the problem, it is important to analyze the distinction between false positives and false negatives. The dataset (fortunately for Netflix!) will be highly biased — as an example, over 99.1% entries are non-kill related. In general, false negatives (not predicting the kill when actually the app is killed) are more detrimental than false positives (predicting a kill even though the app could have survived). This is because since the kill happens rarely (0.9% in this example), even if we end up lowering memory and performance 2% of the time and catch almost all the 0.9% OOM kills, we will have eliminated approximately. all OOM kills with the tradeoff of lowering the performance/clearing the cache an extra 1.1% of the time (False Positives).
Summary
This post has focussed on throwing light on dataset curation and engineering when dealing with memory and low resource crashes for streaming services on device. We also cover the distinction between non-changing attributes and runtime attributes and strategies to join them to make one cohesive dataset for OOM kill prediction. We covered labeling strategies that involved graded window based approaches and explored some graphical analysis on the structured dataset. Finally, we ended with some future directions and possibilities for feature engineering and accuracy measurements in the memory context.
Stay tuned for further posts on memory management and the use of ML modeling to deal with systemic and low latency data collected at the device level. We will try to soon post results of our models on the dataset that we have created.
Acknowledgements I would like to thank the members of various teams — Partner Engineering (Mihir Daftari, Akshay Garg), TVUI team (Andrew Eichacker, Jason Munning), Streaming Data Team, Big Data Platform Team, Device Ecosystem Team and Data Science Engineering Team (Chris Pham), for all their support.
Abstract: The high energy costs of neural network training and inference led to the use of acceleration hardware such as GPUs and TPUs. While such devices enable us to train large-scale neural networks in datacenters and deploy them on edge devices, their designers’ focus so far is on average-case performance. In this work, we introduce a novel threat vector against neural networks whose energy consumption or decision latency are critical. We show how adversaries can exploit carefully-crafted sponge examples, which are inputs designed to maximise energy consumption and latency, to drive machine learning (ML) systems towards their worst-case performance. Sponge examples are, to our knowledge, the first denial-of-service attack against the ML components of such systems. We mount two variants of our sponge attack on a wide range of state-of-the-art neural network models, and find that language models are surprisingly vulnerable. Sponge examples frequently increase both latency and energy consumption of these models by a factor of 30×. Extensive experiments show that our new attack is effective across different hardware platforms (CPU, GPU and an ASIC simulator) on a wide range of different language tasks. On vision tasks, we show that sponge examples can be produced and a latency degradation observed, but the effect is less pronounced. To demonstrate the effectiveness of sponge examples in the real world, we mount an attack against Microsoft Azure’s translator and show an increase of response time from 1ms to 6s (6000×). We conclude by proposing a defense strategy: shifting the analysis of energy consumption in hardware from an average-case to a worst-case perspective.
Attackers were able to degrade the performance so much, and force the system to waste so many cycles, that some hardware would shut down due to overheating. Definitely a “novel threat vector.”
This blog post was written by Syl Taylor, Professional Services Consultant.
In March 2022, the highly anticipated Go 1.18 was released. Go 1.18 brings to the language some long-awaited features and additions, such as generics. It also brings significant performance improvements for Arm’s 64-bit architecture used in AWS Graviton server processors. In this post, we show how migrating Go workloads from Go 1.17.8 to Go 1.18 can help you run your applications up to 20% faster and more cost-effectively. To achieve this goal, we selected a series of realistic and relatable workloads to showcase how they perform when compiled with Go 1.18.
Overview
Go is an open-source programming language which can be used to create a wide range of applications. It’s developer-friendly and suitable for designing production-grade workloads in areas such as web development, distributed systems, and cloud-native software.
AWS Graviton2 processors are custom-built by AWS using 64-bit Arm Neoverse cores to deliver the best price-performance for your cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2). They provide up to 40% better price/performance over comparable x86-based instances for a wide variety of workloads and they can run numerous applications, including those written in Go.
Web service throughput
For web applications, the number of HTTP requests that a server can process in a window of time is an important measurement to determine scalability needs and reduce costs.
To demonstrate the performance improvements for a Go-based web service, we selected the popular Caddy web server. To perform the load testing, we selected the hey application, which was also written in Go. We deployed these packages in a client/server scenario on m6g Graviton instances.
The Caddy web server compiled with Go 1.18 brings a 7-8% throughput improvement as compared with the variant compiled with Go 1.17.8.
We conducted a second test where the client downloads a dynamic page on which the request handler performs some additional processing to write the HTTP response content. The performance gains were also noticeable at 10-11%.
Regular expression searches
Searching through large amounts of text is where regular expression patterns excel. They can be used for many use cases, such as:
Checking if a string has a valid format (e.g., email address, domain name, IP address),
Finding all of the occurrences of a string (e.g., date) in a text document,
Identifying a string and replacing it with another.
However, despite their efficiency in search engines, text editors, or log parsers, regular expression evaluation is an expensive operation to run. We recommend identifying optimizations to reduce search time and compute costs.
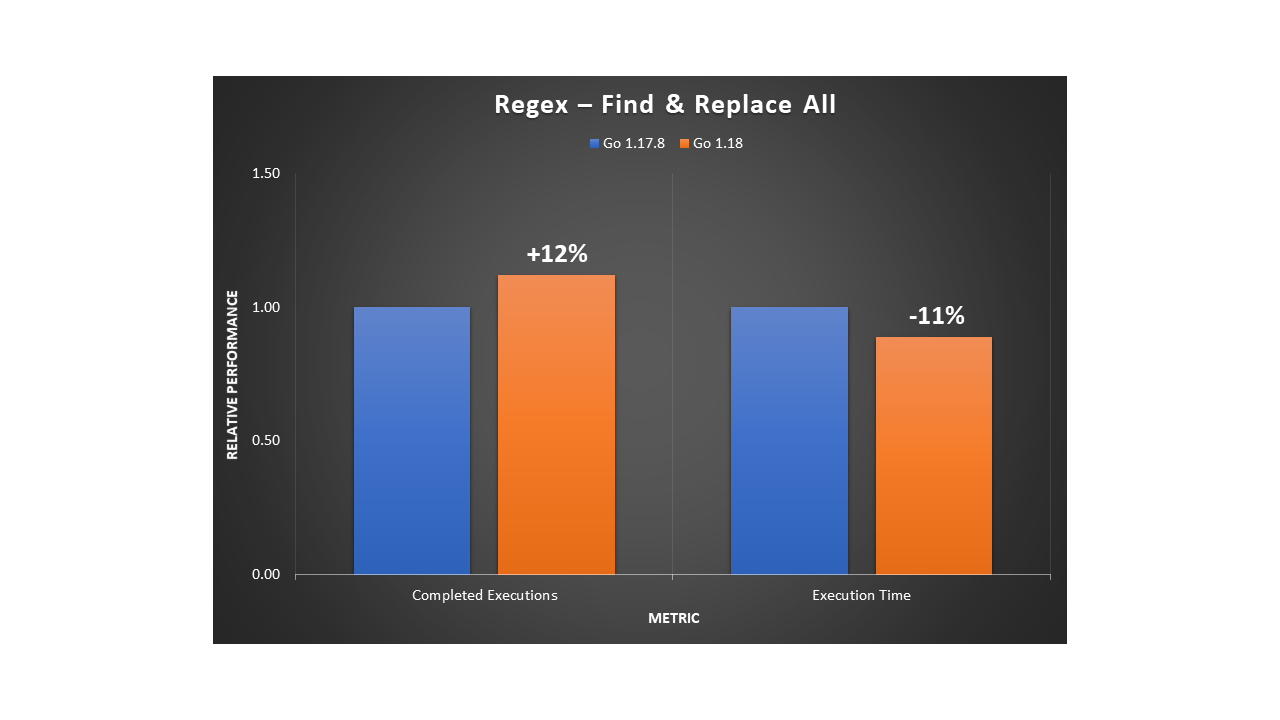
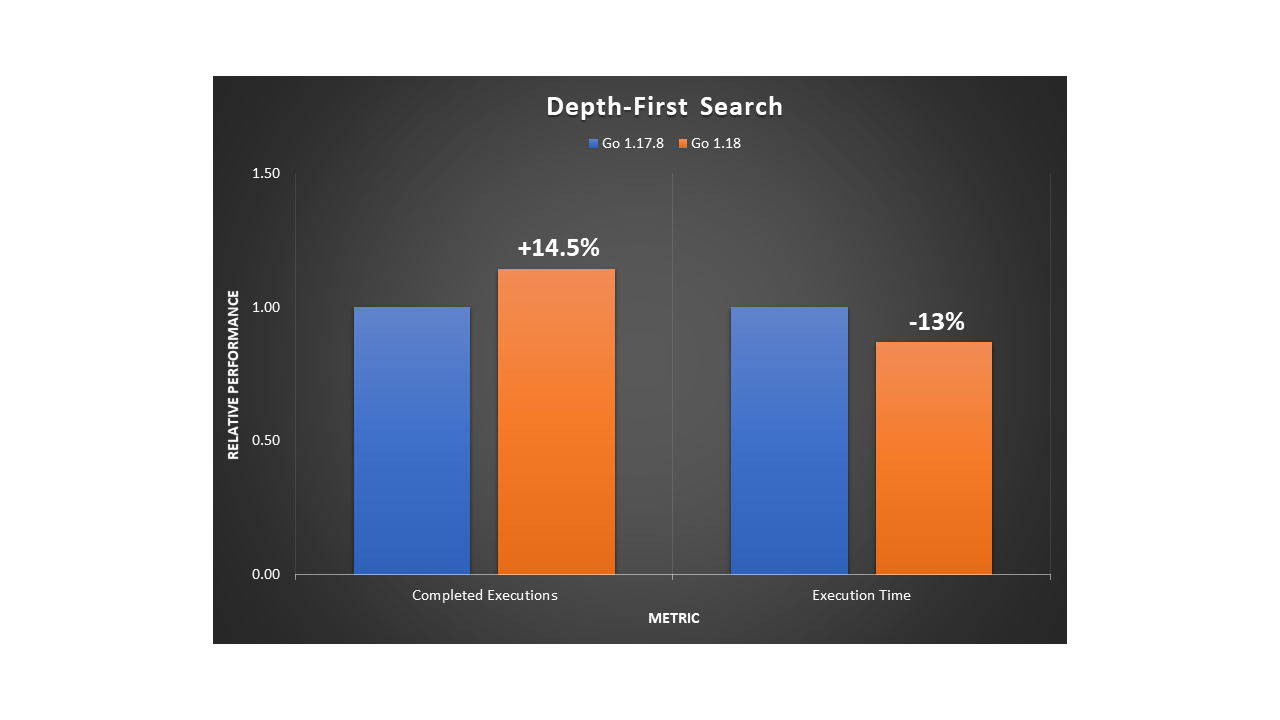
The following example uses the Go regexp package to compile a pattern and search for the presence of a standard date format in a large generated string. We observed a 13.5% increase in completed executions with a 12% reduction in execution time.
In a second example, we used the Go regexp package to find all of the occurrences of a pattern for character sequences in a string, and then replace them with a single character. We observed a 12% increase in evaluation rate with an 11% reduction in execution time.
As with most workloads, the improvements will vary depending on the input data, the hardware selected, and the software stack installed. Furthermore, with this use case, the regular expression usage will have an impact on the overall performance. Given the importance of regex patterns in modern applications, as well as the scale at which they’re used, we recommend upgrading to Go 1.18 for any software that relies heavily on regular expression operations.
Database storage engines
Many database storage engines use a key-value store design to benefit from simplicity of use, faster speed, and improved horizontal scalability. Two implementations commonly used are B-trees and LSM (log-structured merge) trees. In the age of cloud technology, building distributed applications that leverage a suitable database service is important to make sure that you maximize your business outcomes.
B-trees are seen in many database management systems (DBMS), and they’re used to efficiently perform queries using indexes. When we tested a sample program for inserting and deleting in a large B-tree structure, we observed a 10.5% throughput increase with a 10% reduction in execution time.
On the other hand, LSM trees can achieve high rates of write throughput, thus making them useful for big data or time series events, such as metrics and real-time analytics. They’re used in modern applications due to their ability to handle large write workloads in a time of rapid data growth. The following are examples of databases that use LSM trees:
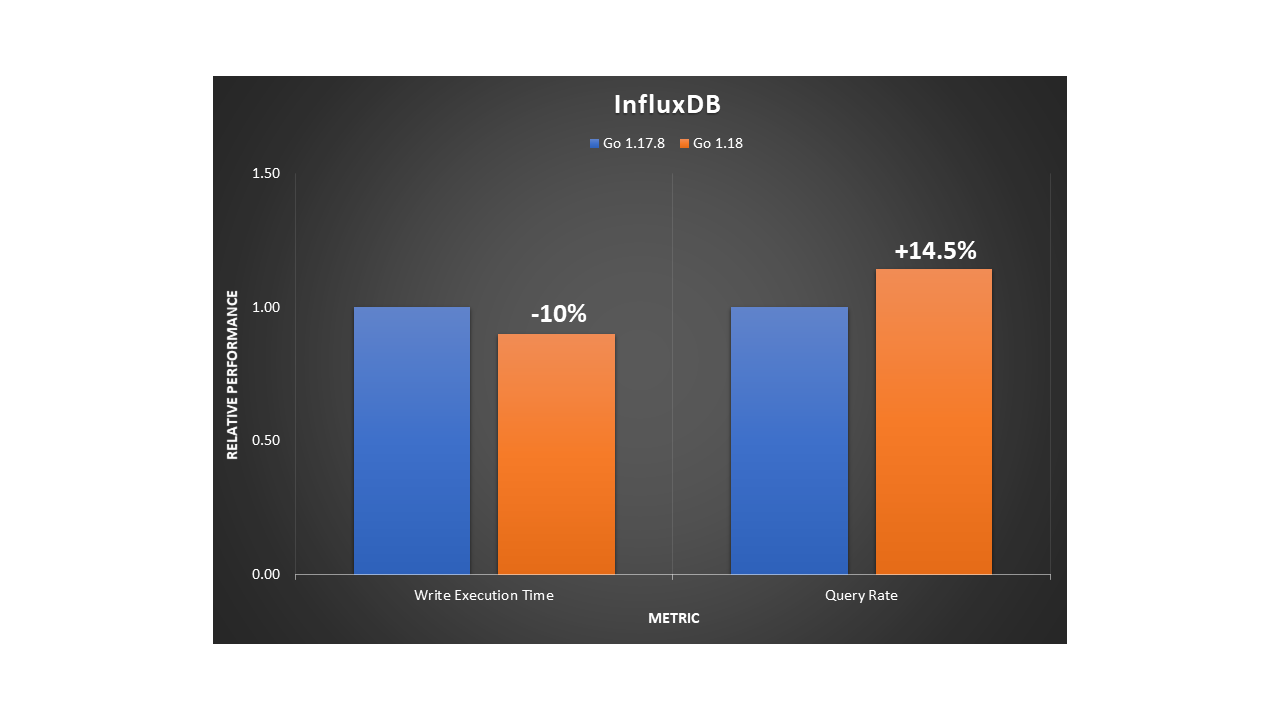
InfluxDB is a powerful database used for high-speed read and writes on time series data. It’s written in Go and its storage engine uses a variation of LSM called the Time-Structured Merge Tree (TSM).
CockroachDB is a popular distributed SQL database written in Go with its own LSM tree implementation.
Badger is written in Go and is the engine behind Dgraph, a graph database. Its design leverages LSM trees.
When we tested an LSM tree sample program, we observed a 13.5% throughput increase with a 9.5% reduction in execution time.
We also tested InfluxDB using comparison benchmarks to analyze writes and reads to the database server. On the load stress test, we saw a 10% increase of insertion throughput and a 14.5% faster rate when querying at a large scale.
In summary, for databases with an engine written in Go, you’ll likely observe better performance when upgrading to a version that has been compiled with Go 1.18.
Machine learning training
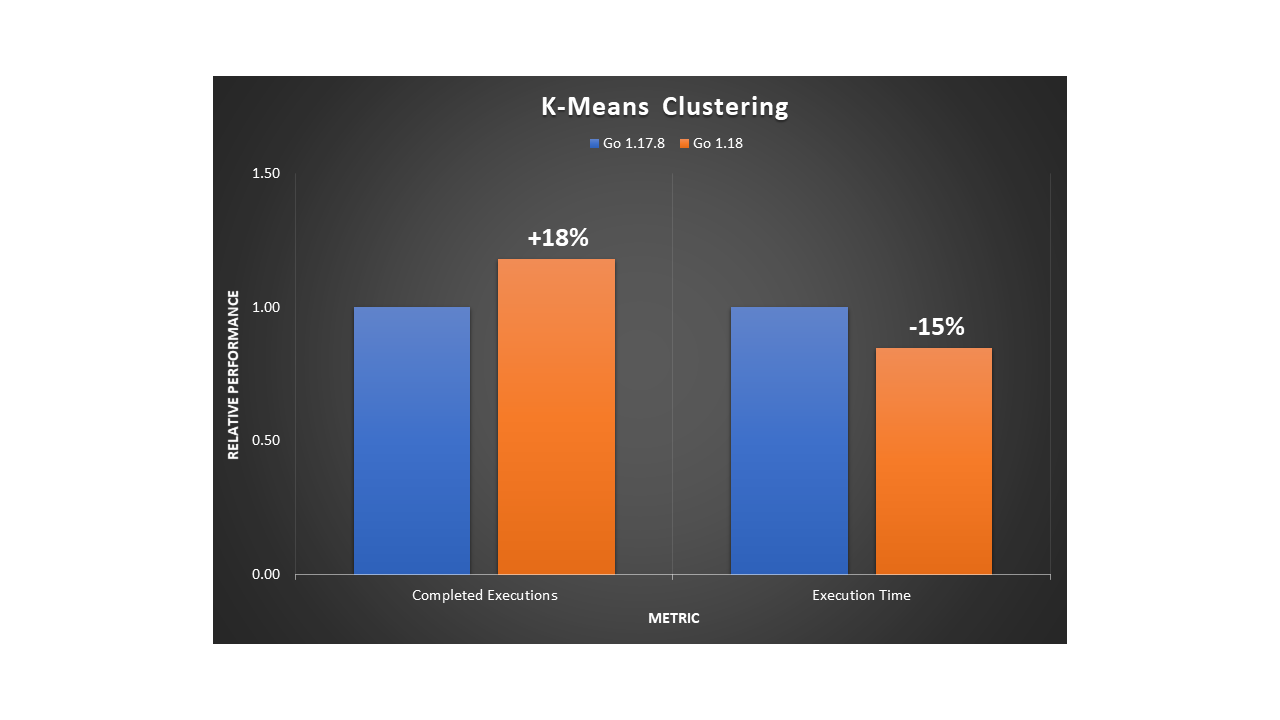
A popular unsupervised machine learning (ML) algorithm is K-Means clustering. It aims to group similar data points into k clusters. We used a dataset of 2D coordinates to train K-Means and obtain the cluster distribution in a deterministic manner. The example program uses an OOP design. We noticed an 18% improvement in execution throughput and a 15% reduction in execution time.
A widely-used and supervised ML algorithm for both classification and regression is Random Forest. It’s composed of numerous individual decision trees, and it uses a voting mechanism to determine which prediction to use. It’s a powerful method for optimizing ML models.
We ran a deterministic example to train a dense Random Forest. The program uses an OOP design and we noted a 20% improvement in execution throughput and a 15% reduction in execution time.
Recursion
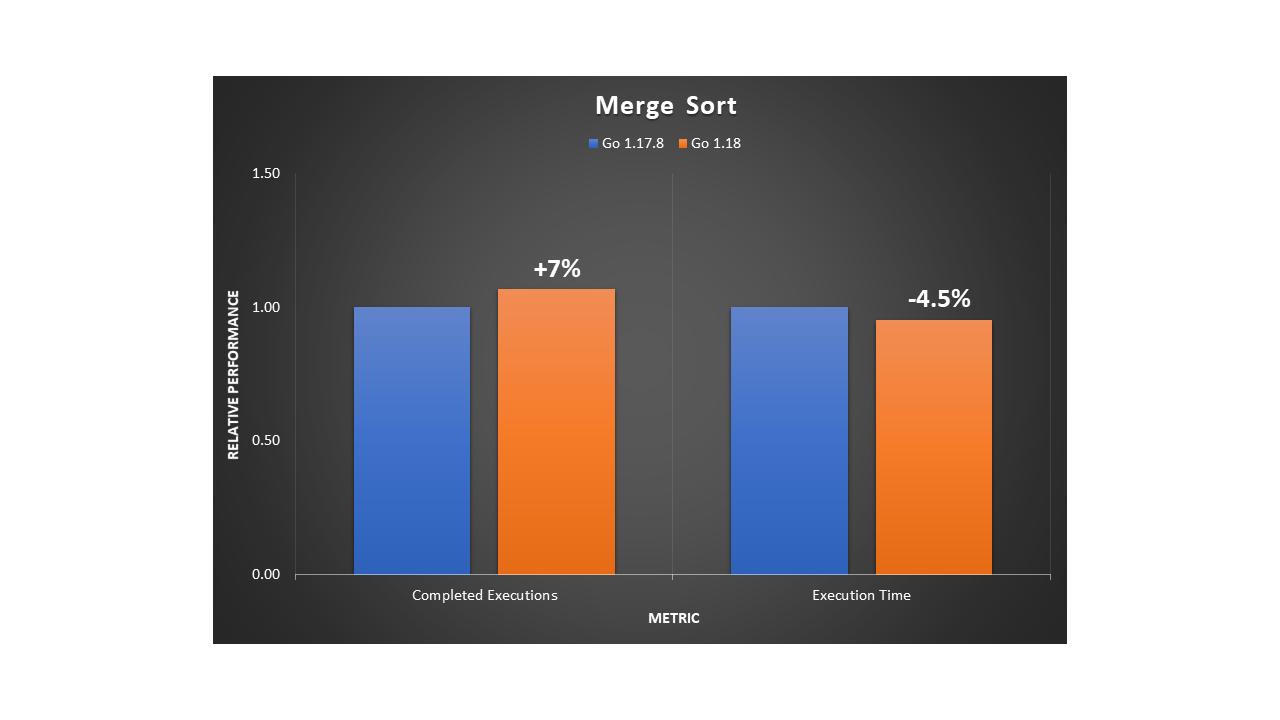
An efficient, general-purpose method for sorting data is the merge sort algorithm. It works by repeatedly breaking down the data into parts until it can compare single units to each other. Then, it decides their order in the intermediary steps that will merge repeatedly until the final sorted result. To implement this divide-and-conquer approach, merge sort must use recursion. We ran the program using a large dataset of numbers and observed a 7% improvement in execution throughput and a 4.5% reduction in execution time.
Depth-first search (DFS) is a fundamental recursive algorithm for traversing tree or graph data structures. Many complex applications rely on DFS variants to solve or optimize hard problems in various areas, such as path finding, scheduling, or circuit design. We implemented a standard DFS traversal in a fully-connected graph. Then we observed a 14.5% improvement in execution throughput and a 13% reduction in execution time.
Conclusion
In this post, we’ve shown that a variety of applications, not just those primarily compute-bound, can benefit from the 64-bit Arm CPU performance improvements released in Go 1.18. Programs with an object-oriented design, recursion, or that have many function calls in their implementation will likely benefit more from the new register ABI calling convention.
By using AWS Graviton EC2 instances, you can benefit from up to a 40% price/performance improvement over other instance types. Furthermore, you can save even more with Graviton through the additional performance improvements by simply recompiling your Go applications with Go 1.18.
Most deep neural networks are trained by stochastic gradient descent. Now “stochastic” is a fancy Greek word for “random”; it means that the training data are fed into the model in random order.
So what happens if the bad guys can cause the order to be not random? You guessed it—all bets are off. Suppose for example a company or a country wanted to have a credit-scoring system that’s secretly sexist, but still be able to pretend that its training was actually fair. Well, they could assemble a set of financial data that was representative of the whole population, but start the model’s training on ten rich men and ten poor women drawn from that set then let initialisation bias do the rest of the work.
Does this generalise? Indeed it does. Previously, people had assumed that in order to poison a model or introduce backdoors, you needed to add adversarial samples to the training data. Our latest paper shows that’s not necessary at all. If an adversary can manipulate the order in which batches of training data are presented to the model, they can undermine both its integrity (by poisoning it) and its availability (by causing training to be less effective, or take longer). This is quite general across models that use stochastic gradient descent.
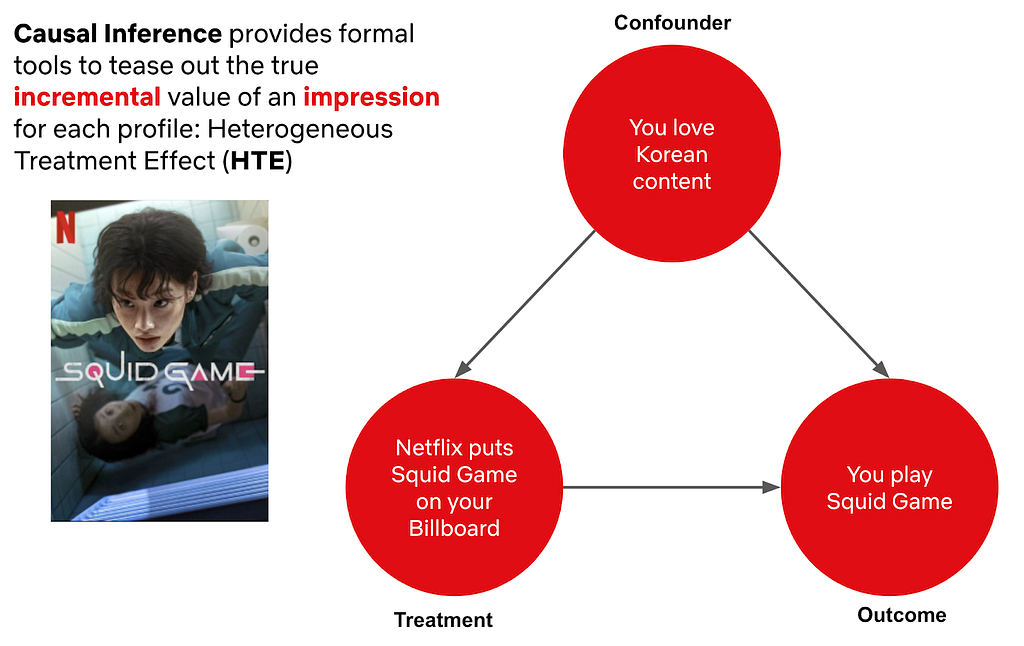
At Netflix, we want to entertain the world through creating engaging content and helping members discover the titles they will love. Key to that is understanding causal effects that connect changes we make in the product to indicators of member joy.
To measure causal effects we rely heavily on AB testing, but we also leverage quasi-experimentation in cases where AB testing is limited. Many scientists across Netflix have contributed to the way that Netflix analyzes these causal effects.
To celebrate that impact and learn from each other, Netflix scientists recently came together for an internal Causal Inference and Experimentation Summit. The weeklong conference brought speakers from across the content, product, and member experience teams to learn about methodological developments and applications in estimating causal effects. We covered a wide range of topics including difference-in-difference estimation, double machine learning, Bayesian AB testing, and causal inference in recommender systems among many others.
We are excited to share a sneak peek of the event with you in this blog post through selected examples of the talks, giving a behind the scenes look at our community and the breadth of causal inference at Netflix. We look forward to connecting with you through a future external event and additional blog posts!
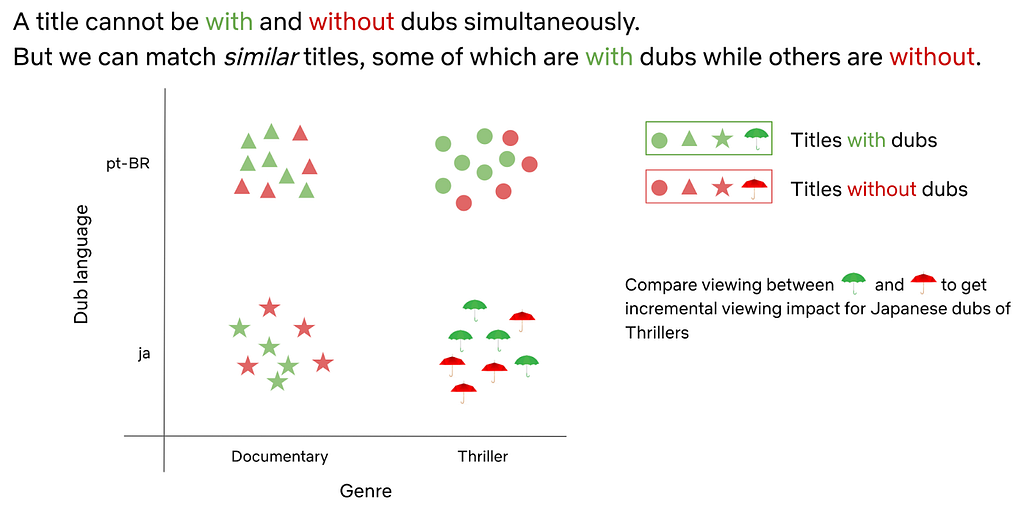
At Netflix, we are passionate about connecting our members with great stories that can come from anywhere, and be loved everywhere. In fact, we stream in more than 30 languages and 190 countries and strive to localize the content, through subtitles and dubs, that our members will enjoy the most. Understanding the heterogenous incremental value of localization to member viewing is key to these efforts!
In order to estimate the incremental value of localization, we turned to causal inference methods using historical data. Running large scale, randomized experiments has both technical and operational challenges, especially because we want to avoid withholding localization from members who might need it to access the content they love.
Conceptual overview of using double machine learning to control for confounders and compare similar titles to estimate incremental impact of localization
We analyzed the data across various languages and applied double machine learning methods to properly control for measured confounders. We not only studied the impact of localization on overall title viewing but also investigated how localization adds value at different parts of the member journey. As a robustness check, we explored various simulations to evaluate the consistency and variance of our incrementality estimates. These insights have played a key role in our decisions to scale localization and delight our members around the world.
A related application of causal inference methods to localization arose when some dubs were delayed due to pandemic-related shutdowns of production studios. To understand the impact of these dub delays on title viewing, we simulated viewing in the absence of delays using the method of synthetic control. We compared simulated viewing to observed viewing at title launch (when dubs were missing) and after title launch (when dubs were added back).
To control for confounders, we used a placebo test to repeat the analysis for titles that were not affected by dub delays. In this way, we were able to estimate the incremental impact of delayed dub availability on member viewing for impacted titles. Should there be another shutdown of dub productions, this analysis enables our teams to make informed decisions about delays with greater confidence.
At Netflix, there are many examples of holdback AB tests, which show some users an experience without a specific feature. They have substantially improved the member experience by measuring long term effects of new features or re-examining old assumptions. However, when the topic of holdback tests is raised, it can seem too complicated in terms of experimental design and/or engineering costs.
We aimed to share best practices we have learned about holdback test design and execution in order to create more clarity around holdback tests at Netflix, so they can be used more broadly across product innovation teams by:
Defining the types of holdbacks and their use cases with past examples
Suggesting future opportunities where holdback testing may be valuable
Enumerating the challenges that holdback tests pose
Identifying future investments that can reduce the cost of deploying and maintaining holdback tests for product and engineering teams
Holdback tests have clear value in many product areas to confirm learnings, understand long term effects, retest old assumptions on newer members, and measure cumulative value. They can also serve as a way to test simplifying the product by removing unused features, creating a more seamless user experience. In many areas at Netflix they are already commonly used for these purposes.
Overview of how holdback tests work where we keep the current experience for a subset of members over the long term in order to gain valuable insights for improving the product
We believe by unifying best practices and providing simpler tools, we can accelerate our learnings and create the best product experience for our members to access the content they love.
Causal Ranker: A Causal Adaptation Framework for Recommendation Models
Most machine learning algorithms used in personalization and search, including deep learning algorithms, are purely associative. They learn from the correlations between features and outcomes how to best predict a target.
In many scenarios, going beyond the purely associative nature to understanding the causal mechanism between taking a certain action and the resulting incremental outcome becomes key to decision making. Causal inference gives us a principled way of learning such relationships, and when coupled with machine learning, becomes a powerful tool that can be leveraged at scale.
Compared to machine learning, causal inference allows us to build a robust framework that controls for confounders in order to estimate the true incremental impact to members
At Netflix, many surfaces today are powered by recommendation models like the personalized rows you see on your homepage. We believe that many of these surfaces can benefit from additional algorithms that focus on making each recommendation as useful to our members as possible, beyond just identifying the title or feature someone is most likely to engage with. Adding this new model on top of existing systems can help improve recommendations to those that are right in the moment, helping find the exact title members are looking to stream now.
This led us to create a framework that applies a light, causal adaptive layer on top of the base recommendation system called the Causal Ranker Framework. The framework consists of several components: impression (treatment) to play (outcome) attribution, true negative label collection, causal estimation, offline evaluation, and model serving.
We are building this framework in a generic way with reusable components so that any interested team within Netflix can adopt this framework for their use case, improving our recommendations throughout the product.
Bellmania: Incremental Account Lifetime Valuation at Netflix and its Applications
Understanding the value of acquiring or retaining subscribers is crucial for any subscription business like Netflix. While customer lifetime value (LTV) is commonly used to value members, simple measures of LTV likely overstate the true value of acquisition or retention because there is always a chance that potential members may join in the future on their own without any intervention.
We establish a methodology and necessary assumptions to estimate the monetary value of acquiring or retaining subscribers based on a causal interpretation of incremental LTV. This requires us to estimate both on Netflix and off Netflix LTV.
To overcome the lack of data for off Netflix members, we use an approach based on Markov chains that recovers off Netflix LTV from minimal data on non-subscriber transitions between being a subscriber and canceling over time.
Through Markov chains we can estimate the incremental value of a member and non member that appropriately captures the value of potential joins in the future
Furthermore, we demonstrate how this methodology can be used to (1) forecast aggregate subscriber numbers that respect both addressable market constraints and account-level dynamics, (2) estimate the impact of price changes on revenue and subscription growth, and (3) provide optimal policies, such as price discounting, that maximize expected lifetime revenue of members.
Measuring causality is a large part of the data science culture at Netflix, and we are proud to have so many stunning colleagues leverage both experimentation and quasi-experimentation to drive member impact. The conference was a great way to celebrate each other’s work and highlight the ways in which causal methodology can create value for the business.
We look forward to sharing more about our work with the community in upcoming posts. To stay up to date on our work, follow the Netflix Tech Blog, and if you are interested in joining us, we are currently looking for new stunning colleagues to help us entertain the world!
We and our partners at ESA Education are excited to announce that 299 teams have achieved flight status in Mission Space Lab of the 2021/22 European Astro Pi Challenge. This means that these young people’s programs are the first ever to run on the two upgraded Astro Pi units on board the International Space Station (ISS).
Mission Space Lab gives teams of young people up to age 19 the opportunity to design and conduct their own scientific experiments that run on board the ISS. It’s an eight-month long activity that follows the European school year. The exciting hardware upgrades inspired a record number of young people to send us their Mission Space Lab experiment ideas.
Teams who want to take on Mission Space Lab choose between two themes for their experiments, investigating either ‘Life in space’ or ‘Life on Earth’. From this year onwards, thanks to the new Astro Pi hardware, teams can also choose to use new sensors and a Coral machine learning accelerator during their experiment time.
Investigating life in space
Using the Astro Pi units’ sensors, teams can investigate life inside the Columbus module of the ISS. This year, 71 ‘Life in space’ experiments are running on the Astro Pi units. The 71 teams are investigating a wide range of topics: for example, how the Earth’s magnetic field is experienced on the ISS in space, how the environmental conditions that the astronauts experience compare with those on Earth beneath the ISS on its orbit, or whether the conditions in the ISS might be suitable for other lifeforms, such as plants or bacteria.
For ‘Life in space’ experiments, teams can collect data about factors such as the colour and intensity of cabin light (using the new colour and luminosity sensor included in the upgraded hardware), astronaut movement in the cabin (using the new PIR sensor), and temperature and humidity (using the Sense HAT add-on board’s standard sensors).
Investigating life on Earth
Using the camera on an Astro Pi unit when it’s positioned to view Earth from a window of the ISS, teams can investigate features on the Earth’s surface. This year, for the first time, teams had the option to use visible-light instead of infrared (IR) photography, thanks to the new Astro Pi cameras.
228 teams’ ‘Life on Earth’ experiments are running this year. Some teams are using the Astro Pis’ sensors to determine the precise location of the ISS when images are captured, to identify whether the ISS is flying over land or sea, or which country it is passing over. Other teams are using IR photography to examine plant health and the effects of deforestation in different regions. Some teams are using visible-light photography to analyse clouds, calculate the velocity of the ISS, and classify biomes (e.g. desert, forest, grassland, wetland) it is passing over. The new hardware available from this year onward has helped to encourage 144 of the teams to use machine learning techniques in their experiments.
Testing, testing, testing
We received 88% more idea submissions for Mission Space Lab this year compared to last year: during Phase 1, 799 teams sent us their experiment ideas. We invited 502 of the teams to proceed to Phase 2 based on the quality of their ideas. 386 teams wrote their code and submitted computer programs for their experiments during Phase 2 this year. Achieving flight status, and thus progressing to Phase 3 of Mission Space Lab, is really a huge accomplishment for the 299 successful teams.
Three replica Astro Pi units run tests on the Mission Space Lab programs submitted by young people.
For us, Phase 2 involved putting every team’s program through a number of tests to make sure that it follows experiment rules, doesn’t compromise the safety and security of the ISS, and will run without errors on the Astro Pi units. Testing means that April is a very busy time for us in the Astro Pi team every year. We run these tests on a number of exact replicas of the new Astro Pis, including a final test to run every experiment that has passed every test for the full 3 hours allotted to each team. The 299 experiments with flight status will run on board the ISS for over 5 weeks in total during Phase 3, and once they have started running, we can’t rely on astronaut intervention to resolve issues. So we have to make sure that all of the programs will run without any problems.
The South Island (Te Waipounamu) of New Zealand (Aotearoa), photographed from the International Space Station using an Astro Pi unit. Click to enlarge.
Thanks to the team at ESA, we are delighted that 67 more Mission Space Lab experiments are running on the ISS this year compared to last year. In fact, teams’ experiments using the Astro Pi units are underway right now!
The 299 teams awarded flight status this year represent 23 countries and 1205 young people, with 32% female participants and an average age of 15. Spain has the most teams with experiments progressing to Phase 3 (38), closely followed by the UK (34), Italy (27), Romania (23), and Greece (22).
Four photographs of the Earth taken on the International Space Station using an Astro Pi unit. Click to enlarge.
Unfortunately, it isn’t possible to run every Mission Space Lab experiment submitted, as there is only limited time for the Astro Pis to be positioned in the ISS window. We wish we could run every experiment that is submitted, but unfortunately time on the ISS, especially on the nadir window, is limited. Eliminating programs was very difficult because of the high quality of this year’s submissions. Many unsuccessful teams’ programs were eliminated based on very small issues. 87 teams submitted programs this year which did not pass testing and so could not be awarded flight status.
The teams whose experiments are not progressing to Phase 3 should still be very proud to have designed experiments that passed Phase 1, and to have made a Phase 2 submission. We recognise how much work all Mission Space Lab teams have done, and we hope to see you again in next year’s Astro Pi Challenge.
What’s next?
Once the programs for all the experiments have run, we will send the teams the data collected by their experiments for Phase 4. In this final phase of Mission Space Lab, teams analyse their data and write a short report to describe their findings. Based on these reports, the ESA Education and Raspberry Pi Foundation teams will determine the winner of this year’s Mission Space Lab. The winning and highly commended teams will receive special prizes.
Congratulations to all Mission Space Lab teams who’ve achieved flight status! We are really looking forward to reading your reports.
Abstract: Given the computational cost and technical expertise required to train machine learning models, users may delegate the task of learning to a service provider. We show how a malicious learner can plant an undetectable backdoor into a classifier. On the surface, such a backdoored classifier behaves normally, but in reality, the learner maintains a mechanism for changing the classification of any input, with only a slight perturbation. Importantly, without the appropriate “backdoor key”, the mechanism is hidden and cannot be detected by any computationally-bounded observer. We demonstrate two frameworks for planting undetectable backdoors, with incomparable guarantees.
First, we show how to plant a backdoor in any model, using digital signature schemes. The construction guarantees that given black-box access to the original model and the backdoored version, it is computationally infeasible to find even a single input where they differ. This property implies that the backdoored model has generalization error comparable with the original model. Second, we demonstrate how to insert undetectable backdoors in models trained using the Random Fourier Features (RFF) learning paradigm or in Random ReLU networks. In this construction, undetectability holds against powerful white-box distinguishers: given a complete description of the network and the training data, no efficient distinguisher can guess whether the model is “clean” or contains a backdoor.
Our construction of undetectable backdoors also sheds light on the related issue of robustness to adversarial examples. In particular, our construction can produce a classifier that is indistinguishable from an “adversarially robust” classifier, but where every input has an adversarial example! In summary, the existence of undetectable backdoors represent a significant theoretical roadblock to certifying adversarial robustness.
This article illustrates how the Cauldron Machine Learning (ML) Platform team uses GitLab parent-child pipelines to dynamically generate GitLab CI files to solve several limitations of GitLab for large repositories, namely:
Limitations to the number of includes (100 by default).
Simplifying the GitLab CI file from 1800 lines to 50 lines.
Reducing the need for nested gitlab-ci yml files.
Introduction
Cauldron is the Machine Learning (ML) Platform team at Grab. The Cauldron team provides tools for ML practitioners to manage the end to end lifecycle of ML models, from training to deployment. GitLab and its tooling are an integral part of our stack, for continuous delivery of machine learning.
One of our core products is MerLin Pipelines. Each team has a dedicated repo to maintain the code for their ML pipelines. Each pipeline has its own subfolder. We rely heavily on GitLab rules to detect specific changes to trigger deployments for the different stages of different pipelines (for example, model serving with Catwalk, and so on).
Background
Approach 1: Nested child files
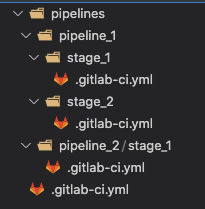
Our initial approach was to rely heavily on static code generation to generate the child gitlab-ci.yml files in individual stages. See Figure 1 for an example directory structure. These nested yml files are pre-generated by our cli and committed to the repository.
Figure 1: Example directory structure with nested gitlab-ci.yml files.
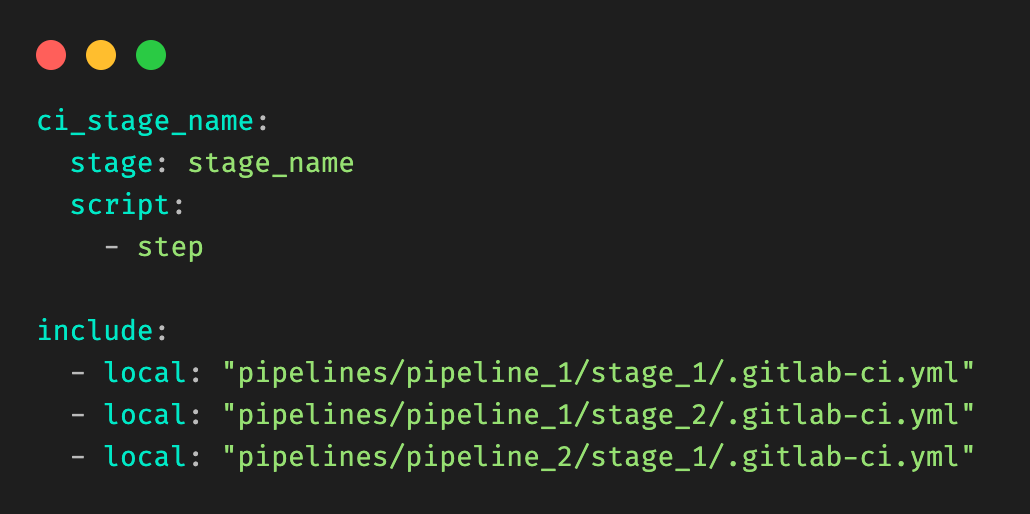
Child gitlab-ci.yml files are added by using the include keyword.
Figure 2: Example root .gitlab-ci.yml file, and include clauses.
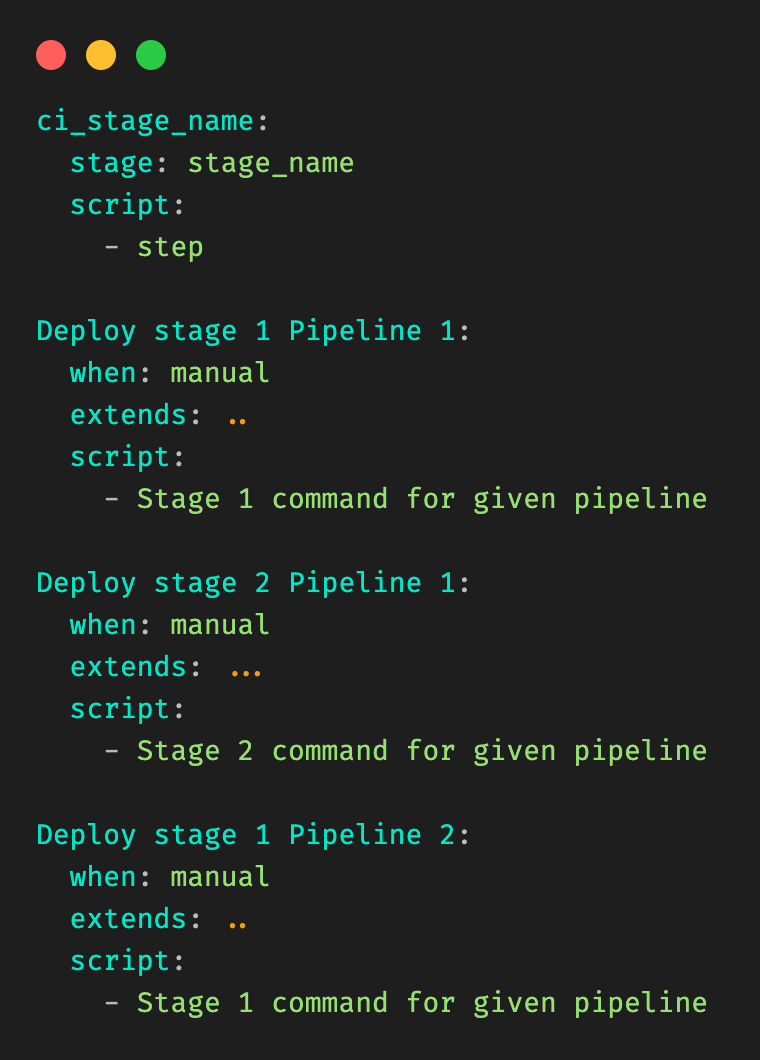
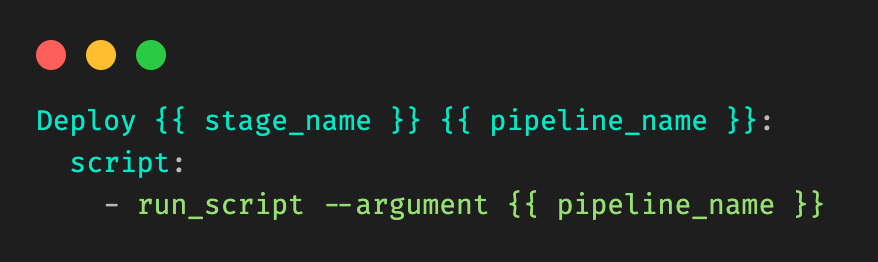
Figure 3: Example child `.gitlab-ci.yml` file for a given stage (Deploy Model) in a pipeline (pipeline 1).
As teams add more pipelines and stages, we soon hit a limitation in this approach:
There was a soft limit in the number of includes that could be in the base .gitlab-ci.yml file.
It became evident that this approach would not scale to our use-cases.
Approach 2: Dynamically generating a big CI file
Our next attempt to solve this problem was to try to inject and inline the nested child gitlab-ci.yml contents into the root gitlab-ci.yml file, so that we no longer needed to rely on the in-built GitLab “include” clause.
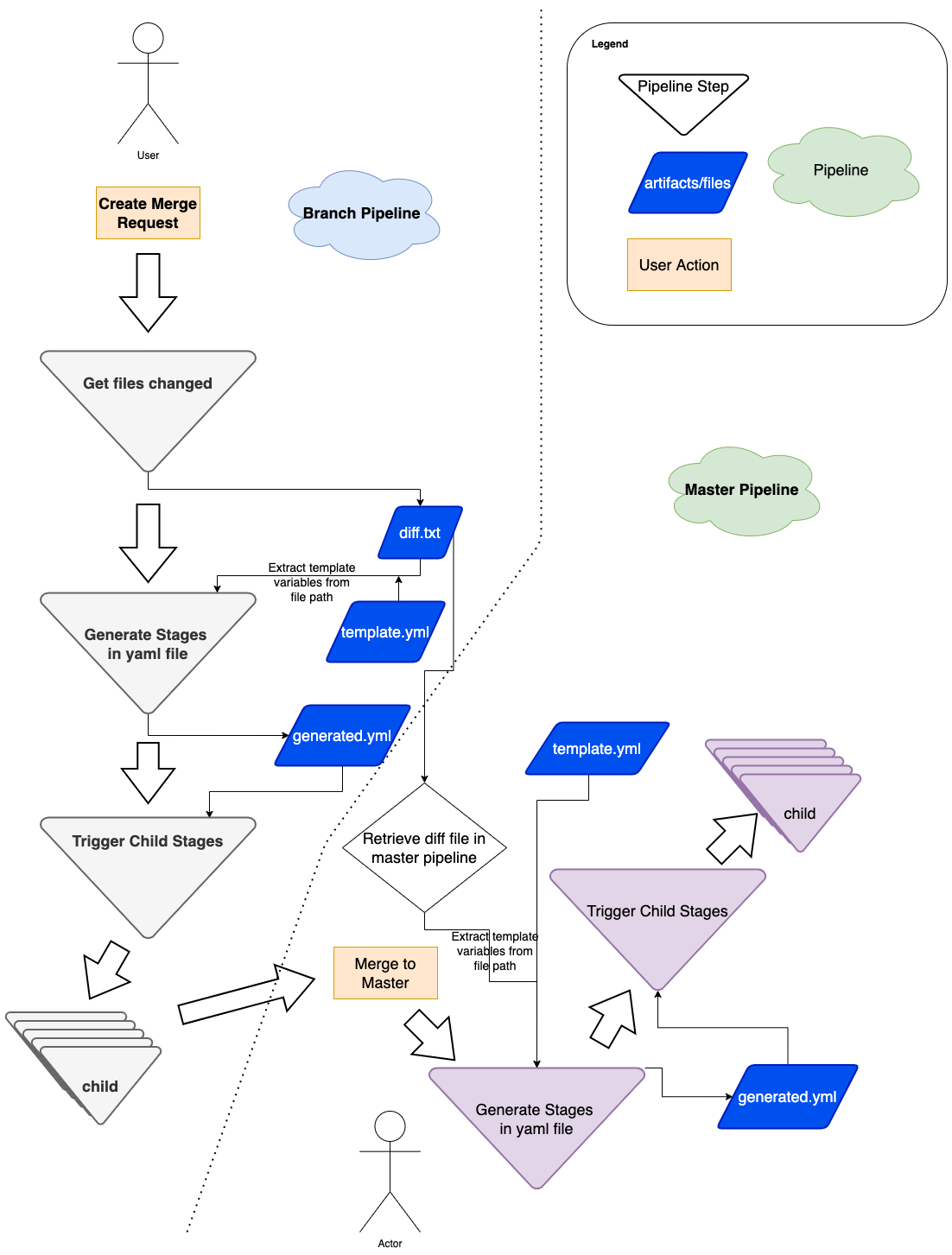
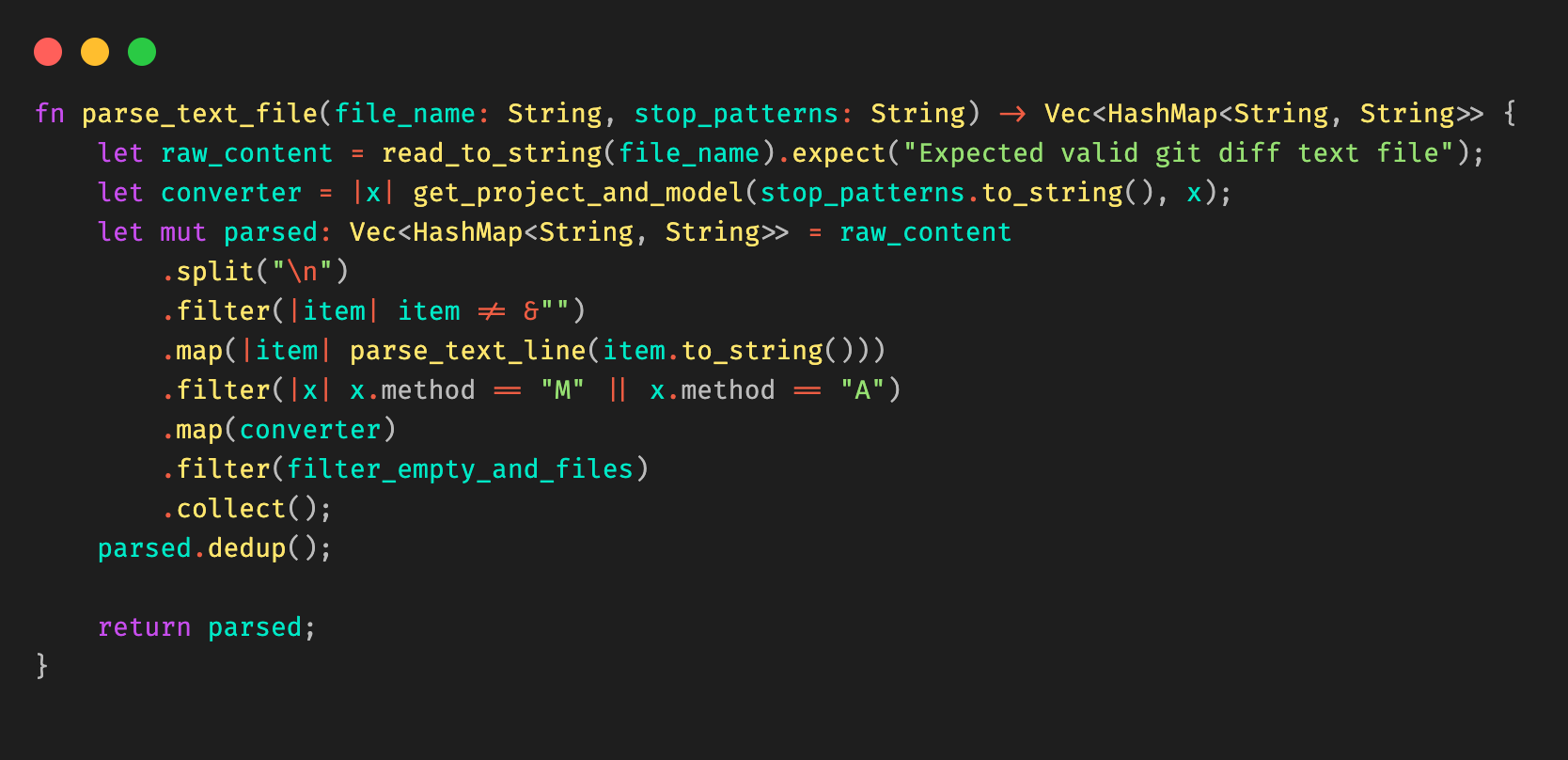
To achieve it, we wrote a utility that parsed a raw gitlab-ci file, walked the tree to retrieve all “included” child gitlab-ci files, and to replace the includes to generate a final big gitlab-ci.yml file.
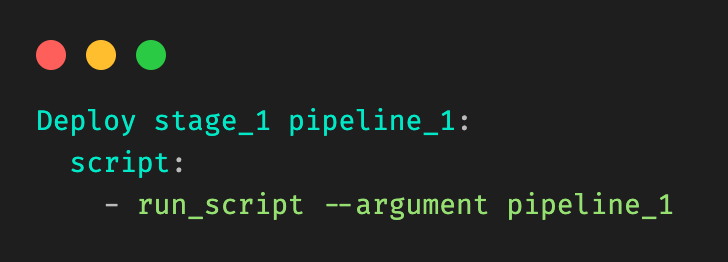
Figure 4 illustrates the resulting file is generated from Figure 3.
Figure 4: “Fat” YAML file generated through this approach, assumes the original raw file of Figure 3.
This approach solved our issues temporarily. Unfortunately, we ended up with GitLab files that were up to 1800 lines long. There is also a soft limit to the size of gitlab-ci.yml files. It became evident that we would eventually hit the limits of this approach.
Solution
Our initial attempt at using static code generation put us partially there. We were able to pre-generate and infer the stage and pipeline names from the information available to us. Code generation was definitely needed, but upfront generation of code had some key limitations, as shown above. We needed a way to improve on this, to somehow generate GitLab stages on the fly. After some research, we stumbled upon Dynamic Child Pipelines.
Quoting the official website:
Instead of running a child pipeline from a static YAML file, you can define a job that runs your own script to generate a YAML file, which is then used to trigger a child pipeline.
This technique can be very powerful in generating pipelines targeting content that changed or to build a matrix of targets and architectures.
We were already on the right track. We just needed to combine code generation with child pipelines, to dynamically generate the necessary stages on the fly.
Architecture details
Figure 5: Flow diagram of how we use dynamic yaml generation. The user raises a merge request in a branch, and subsequently merges the branch to master.
Implementation
The user Git flow can be seen in Figure 5, where the user modifies or adds some files in their respective Git team repo. As a refresher, a typical repo structure consists of pipelines and stages (see Figure 1). We would need to extract the information necessary from the branch environment in Figure 5, and have a stage to programmatically generate the proper stages (for example, Figure 3).
In short, our requirements can be summarized as:
Detecting the files being changed in the Git branch.
Extracting the information needed from the files that have changed.
Passing this to be templated into the necessary stages.
Let’s take a very simple example, where a user is modifying a file in stage_1 in pipeline_1 in Figure 1. Our desired output would be:
Figure 6: Desired output that should be dynamically generated.
Our template would be in the form of:
Figure 7: Example template, and information needed. Let’s call it template_file.yml.
First, we need to detect the files being modified in the branch. We achieve this with native git diff commands, checking against the base of the branch to track what files are being modified in the merge request. The output (let’s call it diff.txt) would be in the form of:
M pipelines/pipeline_1/stage_1/modelserving.yaml
Figure 8: Example diff.txt generated from git diff.
We must extract the yellow and green information from the line, corresponding to pipeline_name and stage_name.
Figure 9: Information that needs to be extracted from the file.
We take a very simple approach here, by introducing a concept called stop patterns.
Stop patterns are defined as a comma separated list of variable names, and the words to stop at. The colon (:) denotes how many levels before the stop word to stop.
For example, the stop pattern:
pipeline_name:pipelines
tells the parser to look for the folder pipelines and stop before that, extracting pipeline_1 from the example above tagged to the variable name pipeline_name.
The stop pattern with two colons (::):
stage_name::pipelines
tells the parser to stop two levels before the folder pipelines, and extract stage_1 as stage_name.
Our cli tool allows the stop patterns to be comma separated, so the final command would be:
We elected to write the util in Rust due to its high performance, and its rich templating libraries (for example, Tera) and decent cli libraries (clap).
Combining all these together, we are able to extract the information needed from git diff, and use stop patterns to extract the necessary information to be passed into the template. Stop patterns are flexible enough to support different types of folder structures.
Figure 10: Example Rust code snippet for parsing the Git diff file.
When triggering pipelines in the master branch (see right side of Figure 5), the flow is the same, with a small caveat that we must retrieve the same diff.txt file from the source branch. We achieve this by using the rich GitLab API, retrieving the pipeline artifacts and using the same util above to generate the necessary GitLab steps dynamically.
Impact
After implementing this change, our biggest success was reducing one of the biggest ML pipeline Git repositories from 1800 lines to 50 lines. This approach keeps the size of the .gitlab-ci.yaml file constant at 50 lines, and ensures that it scales with however many pipelines are added.
Our users, the machine learning practitioners, also find it more productive as they no longer need to worry about GitLab yaml files.
Learnings and conclusion
With some creativity, and the flexibility of GitLab Child Pipelines, we were able to invest some engineering effort into making the configuration re-usable, adhering to DRY principles.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
When we launched Bot Management three years ago, we started with the first version of our ML detection model. We used common bot user agents to train our model to identify bad bots. This model, ML1, was able to detect whether a request is a bot or a human request purely by using the request’s attributes. After this, we introduced a set of heuristics that we could use to quickly and confidently filter out the lowest hanging fruit of unwanted traffic. We have multiple heuristic types and hundreds of specific rules based on certain attributes of the request, many of which are very hard to spoof. But machine learning is a very important part of our bot management toolset.
We started with a static model because we were starting from scratch, and we were able to experiment quickly with aggregated HTTP analytics metadata. After we launched the model, we quickly gathered feedback from early bot management customers to identify where we performed well but also how we could improve. We saw attackers getting smart, and so we generated a new set of model features. Our heuristics were able to accurately identify various types of bad bots giving us much better quality labeled data. Over time, our model evolved to adapt to changing bot behavior across multiple dimensions of the request, even if it had not been trained on that type of data before. Since then, we’ve launched five additional models that are trained on metadata generated by understanding traffic patterns across our network.
While our models were evolving over time, the patterns of traffic flowing through Cloudflare changed as well. Cloudflare started in a desktop first world, but mobile traffic has grown to make up more than 54% of traffic on our network. As mobile has become a significant share of traffic we see, we needed to adapt our strategy in order to be able to get better at detecting bots spoofing mobile applications. While desktop traffic shares many similarities regardless of the origin it’s connecting to, each mobile app is crafted with a specific use in mind, and built on a different set of APIs, with a different defined schema. We realized we needed to build a model that would prove to be more effective for websites that have mobile application traffic.
How we build and deploy our models
Before we dive into how we updated our models to incorporate an increasing volume of mobile traffic, we should first discuss how we build and train our models overall.
Data gathering and preparation
An ML model is only as good as the quality of data you train it with. We’ve been able to leverage the amount and variety of traffic on our network to create our training datasets.
We identify samples that we know are clearly bots – samples we are able to detect with heuristics or samples that are from verified bots, e.g., legitimate search engine crawlers, adbots.
We also can identify samples that are clearly not-bots. These are requests that are scored high when they solve a challenge or are authenticated.
Data analysis and feature selection
From this dataset, we can identify the best features to use, using the ANOVA (Analysis of Variance) f-value. We want to make sure different operating systems, browsers, device types, categories of bots, and fingerprints are well represented in our dataset. We perform statistical analysis of the features to understand their distribution within our datasets as well as how they would potentially influence predictions.
Model building and evaluation
Once we have our data, we can begin training a model. We’ve built an internal pipeline backed by Airflow that makes this process smooth. To train our model, we chose the Catboost library. Based on our problem definition, we train a binary classification model.
We split out training data into a training set and a test set. To choose the best hyperparameters for the model, we use the Catboost library’s grid search and random search algorithm.
We then train the model with the chosen hyperparameters.
Over time, we’ve developed granular datasets for testing out our model to ensure we accurately detect different types of bots, but we also want to make sure we have a very low false positive rate. Before we deploy our model to any customer traffic, we perform offline monitoring. We run predictions for different browsers, operating systems and devices. We then compare the predictions of the currently trained model to the production model on validation datasets. This is done with the help of validation reports created by our ML pipeline that includes summary statistics such as accuracy, feature importance for each dataset. Based on the results, we either iterate or we decide to proceed to deployment.
If we need to iterate, we like to understand better where we can make improvements. For this, we use the SHAP Explainer. The SHAP Explainer is an excellent tool to interpret your model’s prediction. Our pipeline produces SHAP graphs for our predictions, and we dig into these deeper to understand the false positives or false negatives. This helps us to understand how and where we can improve our training data or features to get better predictions. We decide if an experiment should be deployed to customer traffic when it shows improvements in a majority of our test datasets over a previous model version.
Model deployment
While offline analysis of the model is a good indicator of the model’s performance, it’s best to validate the results in real time on a wider variety of traffic. For this, we deploy every new model first in shadow mode. Shadow mode allows us to log scores for traffic in real time without actually affecting bot management customer traffic. This allows us to perform online monitoring i.e. evaluating the model’s performance in real time for traffic. We break this down by different types of bots, devices, browsers, operating systems and customers using a set of Grafana dashboards and validate model accuracy improvement.
We then begin testing in active mode. We have the ability to roll out a model to different customer plans and sample the model for a percentage of requests or visitors. First we roll out to customers on the free plan, such as customers who enable I’m Under Attack Mode. Once we validate the model for free customers, we roll out to Super Bot Fight Mode customers gradually. We then allow customers who would like to beta test the model onboard and use it. Once our beta customers are happy, the new model is officially released as stable. Existing customers can choose to upgrade to this model, all new customers will get the latest version by default.
How we improved mobile app performance
With our latest model, we set out to use the above training process to specifically improve performance on mobile app traffic. To train our models, we need labeled data: a set of HTTP requests that we’ve manually annotated as either “bot” or “human” traffic. We gather this labeled data from a variety of sources as we spoke about above, but one area where we’ve historically struggled is finding good datasets for “human” traffic from mobile applications. Our best sample of “good” traffic was when the client was able to solve a browser challenge or CAPTCHA. Unfortunately, this also limited the variety of good traffic we could have in our dataset since a lot of “good” traffic cannot solve CAPTCHA – like a subset of mobile app traffic. Most CAPTCHA solutions rely on web technologies like HTML + JavaScript and are meant to be executed and rendered via a web browser. Native mobile apps, on the other hand, may not be capable of rendering CAPTCHAs properly, so most native mobile app traffic will never make it into these datasets.
This means that “human” traffic from native mobile applications was typically under-represented in our training data compared to how common it is across the Internet. In turn, this led to our models performing worse on native mobile app traffic compared to browser traffic. In order to rectify this situation, we set out to find better datasets.
We leveraged a variety of techniques to identify subsets of requests that we could confidently label as legitimate native mobile app traffic. We dug through open source code for mobile operating systems as well as popular libraries and frameworks to identify how legitimate mobile app traffic should behave. We also worked with some of our customers to identify domain-specific traffic patterns that could distinguish legitimate mobile app traffic from other types of traffic.
After much testing, feedback, and iteration, we came up with multiple new datasets that we incorporated into our model training process to greatly improve the performance on mobile app traffic.
Improvements in mobile performance
With added data from validated mobile app traffic, our newest model can identify valid user requests originating from mobile app traffic by understanding the unique patterns and signals that we see for this type of traffic. This month, we released our latest machine learning model, trained using our newly identified valid mobile request dataset, to a select group of beta customers. The results have been positive.
In one case, a food delivery company saw false positive rates for Android traffic drop to 0.0%. That may sound impossible, but it’s the result of training on trusted data.
In another case, a major Web3 platform saw similar improvement. Previous models had shown false positives, varying between 28.7% and 40.7% for edge case mobile application traffic. Our newest model has brought this down to nearly 0.0%.
These are just two examples of results we’ve seen broadly, which has led to an increase in adoption of ML among customers protecting mobile apps. If you have a mobile app you haven’t yet protected with Bot Management, head to the Cloudflare dashboard today and see what the new model shows for your own traffic. We provide free bot analytics to all customers, so you can see what bots are doing on your mobile apps today, and turn on Bot Management if you see something you’d like to block. If your mobile app is driven by APIs, as most are, you might also want to take a look at our new API Gateway.
This is a guest post by Ryan Marlow, CTO, and Michael Taggart, Co-founder of Envoy Media Group.
My name is Ryan Marlow, and I’m the CTO of Envoy Media Group. I’m excited to share a story with you about Envoy, Cloudflare, and how we use Bot Management to monitor automated traffic.
Background
Envoy Media Group is a digital marketing and lead generation company. The aim of our work is simple: we use marketing to connect customers with financial services. For people who are experiencing a particular financial challenge, Envoy provides informative videos, money management tools, and other resources. Along the way, we bring customers through an online experience, so we can better understand their needs and educate them on their options. With that information, we check our database of highly vetted partners to see which programs may be useful, and then match them up with the best company to serve them.
As you can imagine, it’s important for us to responsibly match engaged customers to the right financial services. Envoy develops its own brands that guide customers throughout the process. We spend our own advertising dollars, work purely on a performance basis, and choose partners we know will do right by customers. Envoy serves as a trusted guide to help customers get their financial lives back on track.
A bit of technical detail
We often say that Envoy offers a “sophisticated online experience.” This is not your average lead generation engine. We’ve built our own multichannel marketing platform called Revstr, which handles content management, marketing automation, and business intelligence. Envoy has an in-house technology team that develops and maintains Revstr’s multi-million line PHP application, cloud computing services, and infrastructure. With Revstr’s systems, we are able to A/B test any combination of designs with any set of business rules. As a result, Envoy shows the right experience to the right customer every time, and even adapts to the responses of each individual.
Revstr tracks each aspect of the customer’s progress through our pages and forms. It also integrates with advertising platforms, client companies’ CRM systems, and third-party marketing tools. Revstr creates a 360° view of our performance and the customer’s experience. All this information goes into our proprietary data warehouse and is served to the business team. This warehouse also provides data — already cleaned, normalized, and labeled — to our machine learning pipeline. Where needed, we can perform quick and easy testing, training, and deployment of ML models. Both our business team and our marketing automation rely heavily on guidance from these reports and models. And that’s where Cloudflare comes into the picture…
Why we care about automated traffic
One of our key challenges is evaluating the quality of our traffic. Bad actors are always advancing and proliferating. Importantly: any fake traffic to our sites has a direct impact on our business, including wasted resources in advertising, UX optimization, and customer service.
In our world of digital marketing, especially in the industries we compete in, each click is costly and must be treated like a precious commodity. The saying goes that “he or she who is able to spend the most for a click wins.” We spend our own money on those clicks and are only paid when we deliver real leads who consistently convert to enrollments for our clients.
Any money spent on illegitimate clicks will hurt our bottom line — and bots tend to be the lead culprits. Bots hurt our standing in auctions and reduce our ability to buy. The media buyers on our business team are always watching statistics on the cost, quantity, engagement, and conversion rates of our ad traffic. They look for anomalies that might represent fraudulent clicks to ensure we trim out any wasted spend.
Cloudflare offers Bot Management, which spots the exact traffic we need to look out for.
How we use Cloudflare’s Bot Score to filter out bad traffic
We solved our problem by using Cloudflare. For each request that reaches Envoy, Cloudflare calculates a “bot score” that ranges from 1 (automated) to 99 (human). It’s generated using a number of sophisticated methods, including machine learning. Because Cloudflare sees traffic from millions of requests every second, they have an enormous training set to work with. The bot scores are incredibly accurate. By leveraging the bot score to evaluate the legitimacy of an ad click and switching experiences accordingly, we can make the most of every click we pay for.
Because of the high cost of a click, we cannot afford to completely block that click even if Cloudflare indicates it might be a bot. Instead, we ingest the bot score as a custom header and use it as an input to our rules engine. For example, we can put much longer, more qualifying forms in front of traffic that looks suspicious, and render more streamlined forms to higher scoring visitors. In an extreme case, we can even require suspect visitors to contact us by phone instead of completing an online form. This allows us to convert leads which may have a more dubious origin but still prove to be legitimate, while maintaining a pleasant experience for the best leads.
We also pull the bot score into our data warehouse and provide it to our marketing team. Over the long term, if they see that any ad campaign or traffic source has a low average bot score, we can reduce or eliminate spend on that traffic source, seek refunds from providers, and refocus our efforts on more profitable segments.
Using the Bot Score to predict conversion rate
Envoy also leverages the bot score by integrating it into our ML models. For most lead generation companies, it would be sufficient to track lead volume and profit margins. For Envoy, it’s part of our DNA to go beyond making a sale and really assess the lifetime value of those leads for our clients. So we turn to machine learning. We use ML to predict the lifetime value of new visitors based on known data about past leads, and then pass that signal on to our advertising vendors. By skewing the conversion value higher for leads with a better predicted lifetime value, we can influence those pay-per click (PPC) platforms’ own smart bidding algorithms to search for the best qualified leads.
One of the models we use in this process does a prediction of backend conversion rate — how likely a given lead is to become an enrollment for the client company. When we added the bot score and behavioral metrics to this model, we saw a significant increase in its accuracy. When we can better predict conversion rate, we get better leads. This accuracy boost is a force multiplier for our whole platform; it makes an impact not only in media management but also in form design, lead delivery integrations, and email automation.
Why is Bot Score so valuable for Envoy Media?
At Envoy, we take pride in being analytical and data driven. Here are some of the insights we found by combining Cloudflare’s Bot Score with our own internal data:
1. When we added bot score along with behavioral metrics to our conversion rate prediction ML model, its precision increased by 15%. Getting even a 1% improvement in such a carefully tuned model is difficult; a 15% improvement is a huge win.
2. Bot score is included in 76 different reports used by our media buying and UX optimization teams, and in 9 different ML models. It is now a standard component of all new UX reports.
3. Because bot score is so accurate and because bot score is now broadly available within our organization, it is driving organizational performance in ways that we didn’t expect. For example, here is a testimonial from our UX Optimization Team:
I use bot score in PPC search reports. Before I had access to the bot score our PPC reports were muddied with automated traffic – one day conversion rates are 11%, the next day they are at 5%. That is no way to run a business! I spent a lot of time investigating to understand and justify these differences – and many times there just wasn’t a satisfactory answer, and we had to throw the analysis out. Today I have access to bot score data, and it prevents data dilution and gives me a much higher degree of confidence in my analysis.
Thank You and More to Come!
Thanks to the Cloudflare team for giving us the opportunity to share our story. We’re constantly innovating and hope that we can share more of our developments with you in the future.
Cloudflare handles 32 million HTTP requests per second and is used by more than 22% of all the websites whose web server is known by W3Techs. Cloudflare is in the unique position of protecting traffic for 1 out of 5 Internet properties which allows it to identify threats as they arise and track how these evolve and mutate.
The Web Application Firewall (WAF) sits at the core of Cloudflare’s security toolbox and Managed Rules are a key feature of the WAF. They are a collection of rules created by Cloudflare’s analyst team that block requests when they show patterns of known attacks. These managed rules work extremely well for patterns of established attack vectors, as they have been extensively tested to minimize both false negatives (missing an attack) and false positives (finding an attack when there isn’t one). On the downside, managed rules often miss attack variations (also known as bypasses) as static regex-based rules are intrinsically sensitive to signature variations introduced, for example, by fuzzing techniques.
We witnessed this issue when we released protections for log4j. For a few days, after the vulnerability was made public, we had to constantly update the rules to match variations and mutations as attackers tried to bypass the WAF. Moreover, optimizing rules requires significant human intervention, and it usually works only after bypasses have been identified or even exploited, making the protection reactive rather than proactive.
Today we are excited to complement managed rulesets (such as OWASP and Cloudflare Managed) with a new tool aimed at identifying bypasses and malicious payloads without human involvement, and before they are exploited. Customers can now access signals from a machine learning model trained on the good/bad traffic as classified by managed rules and augmented data to provide better protection across a broader range of old and new attacks.
Welcome to our new Machine Learning WAF detection.
The new detection is available in Early Access for Enterprise, Pro and Biz customers. Please join the waitlist if you are interested in trying it out. In the long term, it will be available to the higher tier customers.
Improving the WAF with learning capabilities
The new detection system complements existing managed rulesets by providing three major advantages:
It runs on all of your traffic. Each request is scored based on the likelihood that it contains a SQLi or XSS attack, for example. This enables a new WAF analytics experience that allows you to explore trends and patterns in your overall traffic.
Detection rate improves based on past traffic and feedback. The model is trained on good and bad traffic as categorized by managed rules across all Cloudflare traffic. This allows small sites to get the same level of protection as the largest Internet properties.
A new definition of performance. The machine learning engine identifies bypasses and anomalies before they are exploited or identified by human researchers.
The secret sauce is a combination of innovative machine learning modeling, a vast training dataset built on the attacks we block daily as well as data augmentation techniques, the right evaluation and testing framework based on the behavioral testing principle and cutting-edge engineering that allows us to assess each request with negligible latency.
A new WAF experience
The new detection is based on the paradigm launched with Bot Analytics. Following this approach, each request is evaluated, and a score assigned, regardless of whether we are taking actions on it. Since we score every request, users can visualize how the score evolves over time for the entirety of the traffic directed to their server.
Furthermore, users can visualize the histogram of how requests were scored for a specific attack vector (such as SQLi) and find what score is a good value to separate good from bad traffic.
The actual mitigation is performed with custom WAF rules where the score is used to decide which requests should be blocked. This allows customers to create rules whose logic includes any parameter of the HTTP requests, including the dynamic fields populated by Cloudflare, such as bot scores.
We are now looking at extending this approach to work for the managed rules too (OWASP and Cloudflare Managed). Customers will be able to identify trends and create rules based on patterns that are visible when looking at their overall traffic; rather than creating rules based on trial and error, log traffic to validate them and finally enforce protection.
How does it work?
Machine learning–based detections complement the existing managed rulesets, such as OWASP and Cloudflare Managed. The system is based on models designed to identify variations of attack patterns and anomalies without the direct supervision of researchers or the end user.
As of today, we expose scores for two attack vectors: SQL injection and Cross Site Scripting. Users can create custom WAF/Firewall rules using three separate scores: a total score (cf.waf.ml.score), one for SQLi and one for XSS (cf.waf.ml.score.sqli, cf.waf.ml.score.xss, respectively). The scores can have values between 1 and 99, with 1 being definitely malicious and 99 being valid traffic.
The model is then trained based on traffic classified by the existing WAF rules, and it works on a transformed version of the original request, making it easier to identify fingerprints of attacks.
For each request, the model scores each part of the request independently so that it’s possible to identify where malicious payloads were identified, for example, in the body of the request, the URI or headers.
This looks easy on paper, but there are a number of challenges that Cloudflare engineers had to solve to get here. This includes how to build a reliable dataset, scalable data labeling, selecting the right model architecture, and the requirement for executing the categorization on every request processed by Cloudflare’s global network (i.e. 32 million times per seconds).
In the coming weeks, the Engineering team will publish a series of blog posts which will give a better understanding of how the solution works under the hood.
Looking forward
In the next months, we are going to release the new detection engine to customers and collect their feedback on its performance. Long term, we are planning to extend the detection engine to cover all attack vectors already identified by managed rules and use the attacks blocked by the machine learning model to further improve our managed rulesets.
Radar can detect you moving closer to a computer and entering its personal space. This might mean the computer can then choose to perform certain actions, like booting up the screen without requiring you to press a button. This kind of interaction already exists in current Google Nest smart displays, though instead of radar, Google employs ultrasonic sound waves to measure a person’s distance from the device. When a Nest Hub notices you’re moving closer, it highlights current reminders, calendar events, or other important notifications.
Proximity alone isn’t enough. What if you just ended up walking past the machine and looking in a different direction? To solve this, Soli can capture greater subtleties in movements and gestures, such as body orientation, the pathway you might be taking, and the direction your head is facing — aided by machine learning algorithms that further refine the data. All this rich radar information helps it better guess if you are indeed about to start an interaction with the device, and what the type of engagement might be.
[…]
The ATAP team chose to use radar because it’s one of the more privacy-friendly methods of gathering rich spatial data. (It also has really low latency, works in the dark, and external factors like sound or temperature don’t affect it.) Unlike a camera, radar doesn’t capture and store distinguishable images of your body, your face, or other means of identification. “It’s more like an advanced motion sensor,” Giusti says. Soli has a detectable range of around 9 feet — less than most cameras — but multiple gadgets in your home with the Soli sensor could effectively blanket your space and create an effective mesh network for tracking your whereabouts in a home.
“Privacy-friendly” is a relative term.
These technologies are coming. They’re going to be an essential part of the Internet of Things.
At the Raspberry Pi Foundation, we’ve been thinking about questions relating to artificial intelligence (AI) education and data science education for several months now, inviting experts to share their perspectives in a series of very well-attended seminars. At the same time, we’ve been running a programme of research trials to find out what interventions in school might successfully improve gender balance in computing. We’re learning a lot, and one primary lesson is that these topics are not discrete: there are relationships between them.
We can’t talk about AI education — or computer science education more generally — without considering the context in which we deliver it, and the societal issues surrounding computing, AI, and data. For this International Women’s Day, I’m writing about the intersection of AI and gender, particularly with respect to gender bias in machine learning.
The quest for gender equality
Gender inequality is everywhere, and researchers, activists, and initiatives, and governments themselves, have struggled since the 1960s to tackle it. As women and girls around the world continue to suffer from discrimination, the United Nations has pledged, in its Sustainable Development Goals, to achieve gender equality and to empower all women and girls.
While progress has been made, new developments in technology may be threatening to undo this. As Susan Leahy, a machine learning researcher from the Insight Centre for Data Analytics, puts it:
Artificial intelligence is increasingly influencing the opinions and behaviour of people in everyday life. However, the over-representation of men in the design of these technologies could quietly undo decades of advances in gender equality.
Susan Leavy, 2018 [1]
Gender-biased data
In her 2019 award-winning book Invisible Women: Exploring Data Bias in a World Designed for Men [2], Caroline Ceriado Perez discusses the effects of gender-biased data. She describes, for example, how the designs of cities, workplaces, smartphones, and even crash test dummies are all based on data gathered from men. She also discusses that medical research has historically been conducted by men, on male bodies.
Looking at this problem from a different angle, researcher Mayra Buvinic and her colleagues highlight that in most countries of the world, there are no sources of data that capture the differences between male and female participation in civil society organisations, or in local advisory or decision making bodies [3]. A lack of data about girls and women will surely impact decision making negatively.
Bias in machine learning
Machine learning (ML) is a type of artificial intelligence technology that relies on vast datasets for training. ML is currently being use in various systems for automated decision making. Bias in datasets for training ML models can be caused in several ways. For example, datasets can be biased because they are incomplete or skewed (as is the case in datasets which lack data about women). Another example is that datasets can be biased because of the use of incorrect labels by people who annotate the data. Annotating data is necessary for supervised learning, where machine learning models are trained to categorise data into categories decided upon by people (e.g. pineapples and mangoes).
Max Gruber / Better Images of AI / Banana / Plant / Flask / CC-BY 4.0
In order for a machine learning model to categorise new data appropriately, it needs to be trained with data that is gathered from everyone, and is, in the case of supervised learning, annotated without bias. Failing to do this creates a biased ML model. Bias has been demonstrated in different types of AI systems that have been released as products. For example:
Facial recognition: AI researcher Joy Buolamwini discovered that existing AI facial recognition systems do not identify dark-skinned and female faces accurately. Her discovery, and her work to push for the first-ever piece of legislation in the USA to govern against bias in the algorithms that impact our lives, is narrated in the 2020 documentary Coded Bias.
Natural language processing: Imagine an AI system that is tasked with filling in the missing word in “Man is to king as woman is to X” comes up with “queen”. But what if the system completes “Man is to software developer as woman is to X” with “secretary” or some other word that reflects stereotypical views of gender and careers? AI models called word embeddings learn by identifying patterns in huge collections of texts. In addition to the structural patterns of the text language, word embeddings learn human biases expressed in the texts. You can read more about this issue in this Brookings Institute report.
Not noticing
There is much debate about the level of bias in systems using artificial intelligence, and some AI researchers worry that this will cause distrust in machine learning systems. Thus, some scientists are keen to emphasise the breadth of their training data across the genders. However, other researchers point out that despite all good intentions, gender disparities are so entrenched in society that we literally are not aware of all of them. White and male dominance in our society may be so unconsciously prevalent that we don’t notice all its effects.
As sociologist Pierre Bourdieu famously asserted in 1977: “What is essential goes without saying because it comes without saying: the tradition is silent, not least about itself as a tradition.” [4]. This view holds that people’s experiences are deeply, or completely, shaped by social conventions, even those conventions that are biased. That means we cannot be sure we have accounted for all disparities when collecting data.
What is being done in the AI sector to address bias?
Developers and researchers of AI systems have been trying to establish rules for how to avoid bias in AI models. An example rule set is given in an article in the Harvard Business Review, which describes the fact that speech recognition systems originally performed poorly for female speakers as opposed to male ones, because systems analysed and modelled speech for taller speakers with longer vocal cords and lower-pitched voices (typically men).
The article recommends four ways for people who work in machine learning to try to avoid gender bias:
Ensure diversity in the training data (in the example from the article, including as many female audio samples as male ones)
Ensure that a diverse group of people labels the training data
Measure the accuracy of a ML model separately for different demographic categories to check whether the model is biased against some demographic categories
Establish techniques to encourage ML models towards unbiased results
What can everybody else do?
The above points can help people in the AI industry, which is of course important — but what about the rest of us? It’s important to raise awareness of the issues around gender data bias and AI lest we find out too late that we are reintroducing gender inequalities we have fought so hard to remove. Awareness is a good start, and some other suggestions, drawn out from others’ work in this area are:
Improve the gender balance in the AI workforce
Having more women in AI and data science, particularly in both technical and leadership roles, will help to reduce gender bias. A 2020 report by the World Economic Forum (WEF) on gender parity found that women account for only 26% of data and AI positions in the workforce. The WEF suggests five ways in which the AI workforce gender balance could be addressed:
Support STEM education
Showcase female AI trailblazers
Mentor women for leadership roles
Create equal opportunities
Ensure a gender-equal reward system
Ensure the collection of and access to high-quality and up-to-date gender data
We need high-quality dataset on women and girls, with good coverage, including country coverage. Data needs to be comparable across countries in terms of concepts, definitions, and measures. Data should have both complexity and granularity, so it can be cross-tabulated and disaggregated, following the recommendations from the Data2x project on mapping gender data gaps.
Educate young people about AI
At the Raspberry Pi Foundation we believe that introducing some of the potential (positive and negative) impacts of AI systems to young people through their school education may help to build awareness and understanding at a young age. The jury is out on what exactly to teach in AI education, and how to teach it. But we think educating young people about new and future technologies can help them to see AI-related work opportunities as being open to all, and to develop critical and ethical thinking.
In our AI education seminars we heard a number of perspectives on this topic, and you can revisit the videos, presentation slides, and blog posts. We’ve also been curating a list of resources that can help to further AI education — although there is a long way to go until we understand this area fully.
We’d love to hear your thoughts on this topic.
References
[1] Leavy, S. (2018). Gender bias in artificial intelligence: The need for diversity and gender theory in machine learning. Proceedings of the 1st International Workshop on Gender Equality in Software Engineering, 14–16.
[2] Perez, C. C. (2019). Invisible Women: Exploring Data Bias in a World Designed for Men. Random House.
[3] Buvinic M., Levine R. (2016). Closing the gender data gap. Significance 13(2):34–37
[4] Bourdieu, P. (1977). Outline of a Theory of Practice (No. 16). Cambridge University Press. (p.167)
GitHub code scanning now uses machine learning (ML) to alert developers to potential security vulnerabilities in their code.
If you want to set up your repositories to surface more alerts using our new ML technology, get started here. Read on for a behind-the-scenes peek into the ML framework powering this new technology!
Detecting vulnerable code
Code security vulnerabilities can allow malicious actors to manipulate software into behaving in unintended and harmful ways. The best way to prevent such attacks is to detect and fix vulnerable code before it can be exploited. GitHub’s code scanning capabilities leverage the CodeQL analysis engine to find security vulnerabilities in source code and surface alerts in pull requests – before the vulnerable code gets merged and released.
To detect vulnerabilities in a repository, the CodeQL engine first builds a database that encodes a special relational representation of the code. On that database we can then execute a series of CodeQL queries, each of which is designed to find a particular type of security problem.
Many vulnerabilities are caused by a single repeating pattern: untrusted user data is not sanitized and is subsequently accidentally used in an unsafe way. For example, SQL injection is caused by using untrusted user data in a SQL query, and cross-site scripting occurs as a result of untrusted user data being written to a web page. To detect situations in which unsafe user data ends up in a dangerous place, CodeQL queries encapsulate knowledge of a large number of potential sources of user data (for example, web frameworks), as well as potentially risky sinks (such as libraries for executing SQL queries). Members of the security community, alongside security experts at GitHub, continually expand and improve these queries to model additional common libraries and known patterns. Manual modeling, however, can be time-consuming, and there will always be a long tail of less-common libraries and private code that we won’t be able to model manually. This is where machine learning comes in.
We use examples surfaced by the manual models to train deep learning neural networks that can determine whether a code snippet comprises a potentially risky sink.
As a result, we can uncover security vulnerabilities even when they arise from the use of a library we have never seen before. For example, we can detect SQL injection vulnerabilities in the context of lesser-known or closed-source database abstraction libraries.
ML-powered queries generate alerts that are marked with the “Experimental” label
Building a training set
We need to train ML models to recognize vulnerable code. While we have experimented some with unsupervised learning, unsurprisingly we found that supervised learning works better. But it comes at a cost! Asking code security experts to manually label millions of code snippets as safe or vulnerable is clearly untenable. So where do we get the data?
The manually written CodeQL queries already embody the expertise of the many security experts who wrote and refined them. We leverage these manual queries as ground-truth oracles, to label examples we then use to train our models. Each sink detected by such a query serves as a positive example in the training set. Since the vast majority of code snippets do not contain vulnerabilities, snippets not detected by the manual models can be regarded as negative examples. We make up for the inherent noise in this inferred labeling with volume. We extract tens of millions of snippets from over a hundred thousand public repositories, run the CodeQL queries on them, and label each as a positive or negative example for each query. This becomes the training set for a machine learning model that can classify code snippets as vulnerable or not.
Of course, we don’t want to train a model that will simply reproduce the manual modeling; we want to train a model that will predict new vulnerabilities that weren’t captured by manual modeling. In effect, we want the ML algorithm to improve on the current version of the manual query in much the same way that the current version improves on older, less-comprehensive versions. To see if we can do this, we actually construct all our training data from an older version of the query that detects fewer vulnerabilities. We then apply the trained model to new repositories it wasn’t trained on. We measure how well we recover the alerts detected by the latest manual query but missed by the older version of the query. This allows us to simulate the ability of a model trained with the current version of the query to recover alerts missed by this current manual model.
Features and modeling
Given a large training set of code snippets labeled as positive or negative examples for each query, we extract features for each snippet and train a deep learning model to classify new examples.
Rather than treating each code snippet simply as a string of words or characters and applying standard natural language processing (NLP) techniques naively to classify these strings, we leverage the power of CodeQL to access a wealth of information about the underlying source code. We use this information to produce a rich set of highly informative features for each code snippet.
One of the main advantages of deep learning models is their ability to combine information from a large set of features to create higher-level features and discover patterns that aren’t obvious to humans. In partnership with security and programming-language experts at GitHub, we use CodeQL to extract the information an expert might examine to inform a decision, such as the entire enclosing function body for a snippet that sits within a function, or the access path and API name. We don’t have to limit ourselves to features a human would find informative, however. We can include features whose usefulness is unknown, or features that can be useful in some instances but not all, such as the argument index for a code snippet that’s an argument to a function. Such features may contain patterns that aren’t apparent to humans, but that the neural network can detect. We therefore let the machine learning model decide whether or how to use all these features, and how to combine them to make the best decision for each snippet.
Once we’ve extracted a rich set of potentially interesting features for each example, we tokenize and sub-tokenize them as is commonly done in NLP applications, with some modifications to capture characteristics specific to code syntax. We generate a vocabulary from the training data and feed lists of indices into the vocabulary into a fairly simple deep learning classifier, with a few layers of feature-by-feature processing followed by concatenation across features and a few layers of combined processing. The output is the probability that the current sample is a vulnerability for each query type.
Due to the scale of our offline data labeling, feature extraction, and training pipelines, we leverage cloud compute, including GPUs for model training. At inference time, however, no GPU is needed.
Inference on a repository
Once we have our trained machine learning model, we use it to classify new code snippets and detect likely vulnerabilities for each query. When ML-generated alerts are enabled by repository owners, CodeQL computes the source code features for the code snippets in that codebase and feeds them into the classifier model. The framework gets back the probability that a given code snippet represents a vulnerability, and uses this probability to surface likely new alerts.
The full process runs on the same standard GitHub Action runners that are used by code scanning more generally, and it’s transparent to the user other than some increased runtime on large repositories. When the code scanning is complete, users can see the ML-generated alerts along with the alerts surfaced by the manual queries, with the “Experimental” label allowing them to filter ML-generated alerts in or out.
Does it work?
When evaluating ML-generated alerts, we consider only new alerts that were not flagged by the manual queries. True positives are the correct alerts that were missed by the manual queries; false positives are the incorrect new alerts generated by the ML model.
To measure metrics at scale, we use the experimental setup described above, in which the labels in the training set are determined using an older version of each manual query. We then test the model on repositories that were not included in the training set, and we measure its ability to recover the alerts detected by the current manual query but missed by the older one. Our metrics vary by query, but on average we measure a recall of approximately 80% with a precision of approximately 60%.
We’re currently extending ML-generated alerts to more JavaScript and Typescript security queries, as well as working to improve both their performance and their runtime. Our future plans include expansion to more programming languages, as well as generalizations that will allow us to capture even more vulnerabilities.
Run the “Experimental” queries if you want to uncover more potential security vulnerabilities in your codebase. The more the community engages with our alerts and provides feedback, the better we can make our algorithms, so please consider giving them a try!
Though it seems like something out of a sci-fi movie, machine learning (ML) is part of our day-to-day lives. So often, in fact, that we may not always notice it. For example, social networks and mobile applications use ML to assess user patterns and interactions to deliver a more personalized experience.
However, AWS services provide many options for the integration of ML. In this post, we will show you some use cases that can enhance your platforms and integrate ML into your production systems.
Performing A/B testing on production traffic to compare a new ML model with the old model is a recommended step after offline evaluation.
This blog post explains how A/B testing works and how it can be combined with multi-armed bandit testing to gradually send traffic to the more effective variants during the experiment. It will teach you how to build it with AWS Cloud Development Kit (AWS CDK), architect your system for MLOps, and automate the deployment of the solutions for A/B testing.
This diagram shows the iterative process to analyze the performance of ML models in online and offline scenarios
Modularity is a key characteristic for modern applications. You can modularize code, infrastructure, and even architecture.
A modular architecture provides an architecture and framework that allows each development role to work on their own part of the system, and hide the complexity of integration, security, and environment configuration. This blog post provides an approach to building a modular ML workload that is easy to evolve and maintain across multiple teams.
A modular architecture allows you to easily assemble different parts of the system and replace them when needed
The accuracy of ML models can deteriorate over time because of model drift or concept drift. This is a common challenge when deploying your models to production. Have you ever experienced it? How would you architect a solution to address this challenge?
Without metrics and automated actions, maintaining ML models in production can be overwhelming. This blog post shows you how to design an MLOps pipeline for model monitoring to detect concept drift. You can then expand the solution to automatically launch a new training job after the drift was detected to learn from the new samples, update the model, and take into account the changes in the data distribution.
Concept drift happens when there is a shift in the distribution. In this case, the distribution of the newly collected data (in blue) starts differing from the baseline distribution (in green)
Moving from experimentation to production forces teams to move fast and automate their operations. Adopting scalable solutions for MLOps is a fundamental step to successfully create production-oriented ML processes.
This blog post provides an extended walkthrough of the ML lifecycle and explains how to optimize the process using Amazon SageMaker. Starting from data ingestion and exploration, you will see how to train your models and deploy them for inference. Then, you’ll make your operations consistent and scalable by architecting automated pipelines. This post offers a fraud detection use case so you can see how all of this can be used to put ML in production.
The ML lifecycle involves three macro steps: data preparation, train and tuning, and deployment with continuous monitoring
See you next time!
Thanks for reading! We’ll see you in a couple of weeks when we discuss how to secure your workloads in AWS.
Looking for more architecture content?AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!
What is AI thinking? What concepts should we introduce to young people related to AI, including machine learning (ML), and data science? Should we teach with a glass-box or an opaque-box approach? These are the questions we’ve been grappling with since we started our online research seminar series on AI education at the Raspberry Pi Foundation, co-hosted with The Alan Turing Institute.
Dave Touretzky
Fred G. Martin
Over the past few months, we’d already heard from researchers from the UK, Germany, and Finland. This month we virtually travelled to the USA, to hear from Prof. Dave Touretzky (Carnegie Mellon University) and Prof. Fred G. Martin (University of Massachusetts Lowell), who have pioneered the influential AI4K12 project together with their colleagues Deborah Seehorn and Christina Gardner-McLure.
The AI4K12 project
The AI4K12 project focuses on teaching AI in K-12 in the US. The AI4K12 team have aligned their vision for AI education to the CSTA standards for computer science education. These Standards, published in 2017, describe what should be taught in US schools across the discipline of computer science, but they say very little about AI. This was the stimulus for starting the AI4K12 initiative in 2018. A number of members of the AI4K12 working group are practitioners in the classroom who’ve made a huge contribution in taking this project from ideas into the classroom.
Dave gave us an overview of the AI4K12 project (click to enlarge)
The project has a number of goals. One is to develop a curated resource directory for K-12 teachers, and another to create a community of K-12 resource developers. On the AI4K12.org website, you can find links to many resources and sign up for their mailing list. I’ve been subscribed to this list for a while now, and fascinating discussions and resources have been shared.
Five Big Ideas of AI4K12
If you’ve heard of AI4K12 before, it’s probably because of the Five Big Ideas the team has set out to encompass the AI field from the perspective of school-aged children. These ideas are:
Perception — the idea that computers perceive the world through sensing
Representation and reasoning — the idea that agents maintain representations of the world and use them for reasoning
Learning — the idea that computers can learn from data
Natural interaction — the idea that intelligent agents require many types of knowledge to interact naturally with humans
Societal impact — the idea that artificial intelligence can impact society in both positive and negative ways
Sometimes we hear concerns that resources being developed to teach AI concepts to young people are narrowly focused on machine learning, particularly supervised learning for classification. It’s clear from the AI4K12 Five Big Ideas that the team’s definition of the AI field encompasses much more than one area of ML. Despite being developed for a US audience, I believe the description laid out in these five ideas is immensely useful to all educators, researchers, and policymakers around the world who are interested in AI education.
Fred explained how ‘representation and reasoning’ is a big idea in the AI field (click to enlarge)
During the seminar, Dave and Fred shared some great practical examples. Fred explained how the big ideas translate into learning outcomes at each of the four age groups (ages 5–8, 9–11, 12–14, 15–18). You can find out more about their examples in their presentation slides or the seminar recording (see below).
I was struck by how much the AI4K12 team has thought about progression — what you learn when, and in which sequence — which we do really need to understand well before we can start to teach AI in any formal way. For example, looking at how we might teach visual perceptionto young people, children might start when very young by using a tool such as Teachable Machine to understand that they can teach a computer to recognise what they want it to see, then move on to building an application using Scratch plugins or Calypso, and then to learning the different levels of visual structure and understanding the abstraction pipeline — the hierarchy of increasingly abstract things. Talking about visual perception, Fred used the example of self-driving cars and how they represent images.
Fred used this slide to describe how young people might learn abstracted elements of visual structure
AI education with an age-appropriate, glass-box approach
Dave and Fred support teaching AI to children using a glass-box approach. By ‘glass-box approach’ we mean that we should give students information about how AI systems work, and show the inner workings, so to speak. The opposite would be a ‘opaque-box approach’, by which we mean showing students an AI system’s inputs and the outputs only to demonstrate what AI is capable of, without trying to teach any technical detail.
AI4K12 teacher guidelines for AI education
Our speakers are keen for learners to understand, at an age-appropriate level, what is going on “inside” an AI system, not just what the system can do. They believe it’s important for young people to build mental models of how AI systems work, and that when the young people get older, they should be able to use their increasing knowledge and skills to develop their own AI applications. This aligns with the views of some of our previous seminar speakers, including Finnish researchers Matti Tedre and Henriikka Vartiainen, who presented at our seminar series in November.
What is AI thinking?
Dave addressed the question of what AI thinking looks like in school. His approach was to start with computational thinking (he used the example of the Barefoot project’s description of computational thinking as a starting point) and describe AI thinking as an extension that includes the following skills:
Perception
Reasoning
Representation
Machine learning
Language understanding
Autonomous robots
Dave described AI thinking as furthering the ideas of abstraction and algorithmic thinking commonly associated with computational thinking, stating that in the case of AI, computation actually is thinking. My own view is that to fully define AI thinking, we need to dig a bit deeper into, for example, what is involved in developing an understanding of perception and representation.
Thinking back to Matti Tedre and Henriikka Vartainen’s description of CT 2.0, which focuses only on the ‘Learning’ aspect of the AI4K12 Five Big Ideas, and on the distinct ways of thinking underlying data-driven programming and traditional programming, we can see some differences between how the two groups of researchers describe the thinking skills young people need in order to understand and develop AI systems. Tedre and Vartainen are working on a more finely granular description of ML thinking, which has the potential to impact the way we teach ML in school.
What I take from this is that there is much still to research and discuss in this area! It’s a real privilege to be able to hear from experts in the field and compare and contrast different standpoints and views.
Resources for AI education
The AI4K12 project has already made a massive contribution to the field of AI education, and we were delighted to hear that Dave, Fred, and their colleagues have just been awarded the AAAI/EAAI Outstanding Educator Award for 2022 for AI4K12.org. An amazing achievement! Particularly useful about this website is that it links to many resources, and that the Five Big Ideas give a framework for these resources.
Through our seminars series, we are developing our own list of AI education resources shared by seminar speakers or attendees, or developed by us. Please do take a look.
Join our next seminar
Through these seminars, we’re learning a lot about AI education and what it might look like in school, and we’re having great discussions during the Q&A section.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.