Post Syndicated from Crosstalk Solutions original https://www.youtube.com/shorts/AvV6H48hSd4
Feature Flag Orchestration with AWS DevOps Agent and LaunchDarkly
Post Syndicated from Greg Eppel original https://aws.amazon.com/blogs/devops/feature-flag-orchestration-with-aws-devops-agent-and-launchdarkly/
Introduction
Organizations that use feature flags alongside incident response tooling often connect the two manually. When an outage occurs, engineers must identify which flags are relevant, decide whether to disable them, and coordinate the change across teams. This manual process adds latency at the moment it matters most.
You can use AWS DevOps Agent and its MCP server feature to connect to LaunchDarkly’s hosted MCP server, enabling feature flag recommendations during both proactive deployment review and reactive incident response workflows. Once connected, DevOps Agent can query flag state, read targeting rules, and surface recommendations directly within the workflows where engineers make decisions.
This post walks through two primary use cases:
- Pre-deployment review where the release management capabilities in AWS DevOps Agent evaluate changes and a DevOps Agent Skill recommends feature flag coverage before code ships.
- Incident response where DevOps Agent queries LaunchDarkly flag state via MCP and recommends containment actions during active incidents.
We also cover the connection architecture, a reusable DevOps Agent Skill for pre-deployment flag validation, and links to get started.
Defense: Release Management and Proactive Flag Recommendations
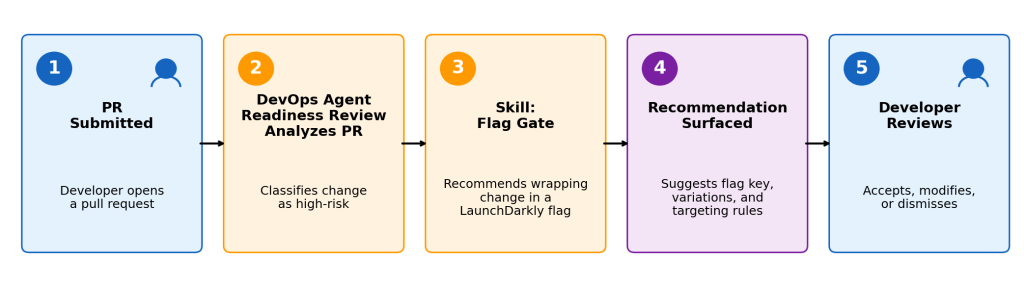
Figure 1: DevOps Agent’s readiness review identifies high-risk PRs and recommends LaunchDarkly feature flag coverage before code ships.
The release management capabilities (now in public preview) in AWS DevOps Agent evaluate code changes before they ship to production.
It performs functional testing in an AWS-managed verification environment, assesses risks to cross-codebase dependencies, evaluates adherence to your organization’s standards and best practices, and mathematically verifies that access control configurations in CloudFormation do not deviate from Well-Architected best practices.
AWS DevOps Agent is designed to be extended and customized to fit your tools, standards, and practices. Using the product’s primitives, you can add Skills that enhance its capabilities. For example, when a high-risk change is identified, a custom Skill can evaluate whether the change has adequate feature flag coverage, operating on deployment metadata and code analysis to identify gaps and surface a recommendation to the developer, such as recommending feature flags with LaunchDarkly when needed.
What the Skill Evaluates
The release readiness flag Skill classifies code changes into risk tiers (Critical, High, Moderate) based on what’s being modified — payments, authentication, database schemas, third-party integrations, new API endpoints, performance-sensitive paths, and more — and recommends feature flags proportional to the risk level.

Figure 2: The high-risk-feature-flag-recommendations Skill configured in AWS DevOps Agent’s Knowledge panel.
What the Recommendation Includes
When the Skill identifies a gap, it surfaces a recommendation containing:
- Risk context: Why the change is flagged as high-risk (e.g., “This deployment modifies payment authorization logic across 3 downstream services with no existing rollback mechanism.”)
- Suggested flag configuration: A proposed LaunchDarkly flag key, variations, and default targeting rules aligned with the deployment plan.
- Rollout strategy: A recommended phased rollout (e.g., internal users first, then 5% of traffic, then full rollout) that matches the risk profile.
- Kill-switch behavior: What happens when the flag is turned off — the fallback code path, cleanup considerations, and data consistency implications.
Example Scenario
Consider a team deploying an update to a tax calculation service. The change modifies the tax rate computation logic, affecting all order totals across multiple regions. AWS DevOps Agent evaluates the deployment and classifies it as high-risk. The pre-deployment flag gate Skill then identifies:
- The change touches critical-path tax calculation code.
- No feature flag wraps the new computation behavior.
- The blast radius covers all active checkout sessions.
The Skill surfaces a recommendation: “This deployment modifies tax calculation logic with no existing feature flag coverage. Recommend wrapping the new tax computation in a LaunchDarkly flag (tax-calculation-v2) with a phased rollout targeting internal test accounts first, followed by 5% of production traffic.”
The developer can then action the recommendation, creating the flag in LaunchDarkly, adjusting the suggested configuration to fit their rollout plan, or noting the justification for proceeding without one as part of the deployment record.
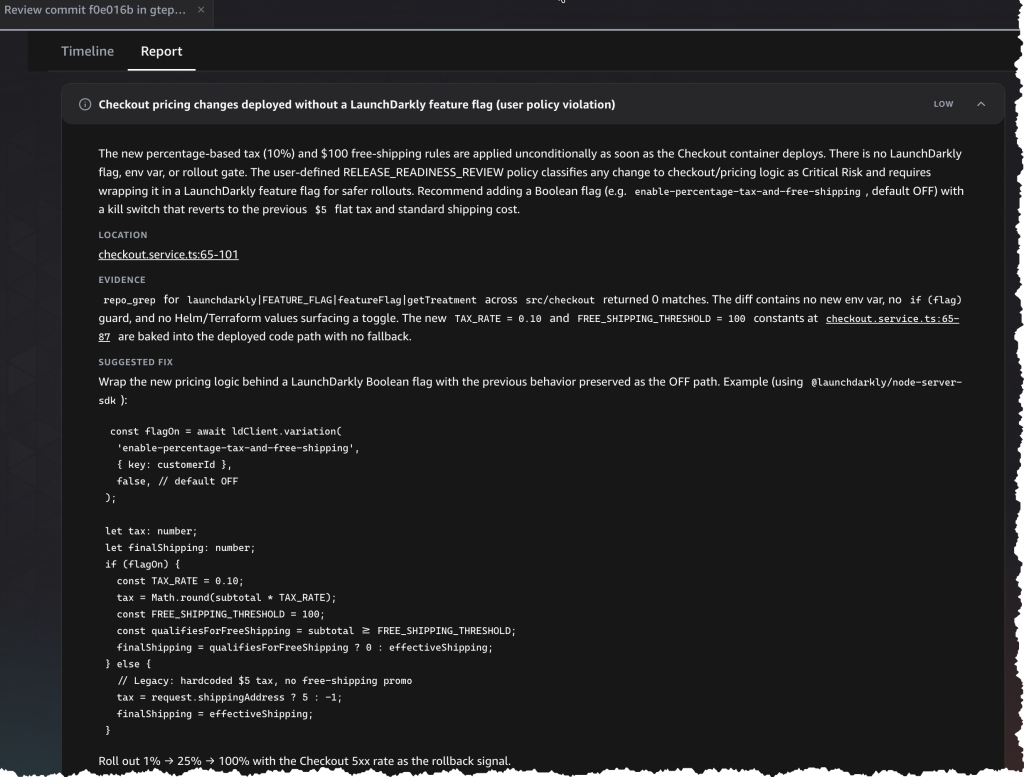
Figure 3: AWS DevOps Agent release management report identifying checkout pricing changes deployed without LaunchDarkly feature flag coverage, including a suggested fix with sample code.
Closing the Loop with Kiro IDE
DevOps Agent’s release management capabilities identify when a deployment needs feature flag coverage. Paired with Kiro IDE, this recommendation becomes actionable without leaving the development workflow.
Kiro connects to LaunchDarkly’s MCP server directly, providing flag integration capabilities during development. When a developer builds a new feature in Kiro, the IDE can query LaunchDarkly via MCP to check whether a flag already exists for that feature and generate code with the flag evaluation built in from the start.
Together, this creates one continuous flow: DevOps Agent identifies the risk and recommends flag coverage → the developer, working in Kiro, generates the flag and wraps the code in a single action → the deployment ships with coverage already in place. No context-switching between tools, no manual flag creation in a separate console.
Developers can also use Kiro’s flag integration independently during feature development, even before a deployment triggers a release management review. The two operate as layered coverage: if Kiro catches it during development, DevOps Agent validates the targeting rules match the rollout plan at deployment time. If the developer bypasses Kiro or uses a different toolchain, DevOps Agent still identifies the gap.
Offense: Flag Recommendations During Incident Response
During an active incident, speed of containment directly affects customer impact. DevOps Agent participates in incident response workflows by querying LaunchDarkly to understand current flag state, then recommending containment actions based on what it finds.
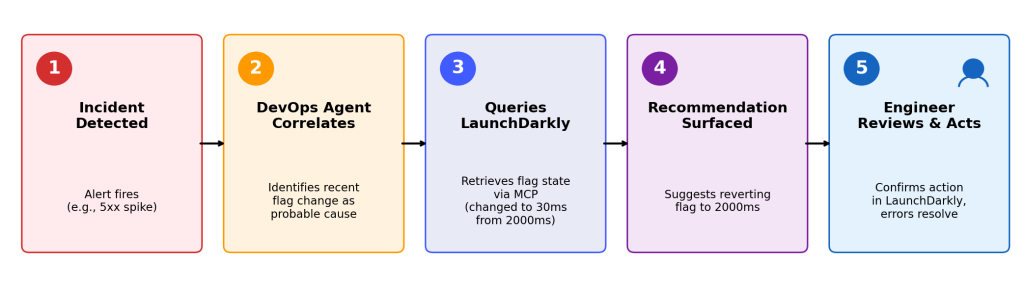
Figure 4: DevOps Agent identifies a flag change (30ms from 2000ms) as the probable cause, queries LaunchDarkly for state, and recommends reverting the value.
When you detect an incident, DevOps Agent correlates the affected service with recent deployments. It queries LaunchDarkly to identify feature flags associated with those deployments and their current state (enabled, targeting rules, rollout percentage). If a relevant flag is enabled, the agent recommends disabling it as a containment option before suggesting a full rollback.
Flag-based containment provides an alternative containment option that can help reduce the time to resolution. Disabling a flag may return behavior to the previous state, which can be faster than a full deployment rollback in some scenarios
Example Scenario
An alert fires indicating sustained 5XX errors on the bot-service. The on-call engineer engages DevOps Agent, which:
- Correlates the HTTP 503 errors with a LaunchDarkly feature flag change: bot-mutation-orchestration-timeout-ms was changed from the default 2000ms to 30ms (the “low latency” variation), applied to all traffic.
- Identifies that the 30ms timeout budget is insufficient for inter-service HTTP calls during bot creation and deletion orchestration, which require DynamoDB reads/writes plus IoT Core calls, causing ReadTimeout exceptions.
- Recommends reverting the bot-mutation-orchestration-timeout-ms flag to its default variation (2000ms) as the containment action, noting this will restore sufficient timeout budget without requiring a code deployment.
The engineer reviews the recommendation, updates the flag variation in LaunchDarkly, and the error rate returns to baseline within minutes.
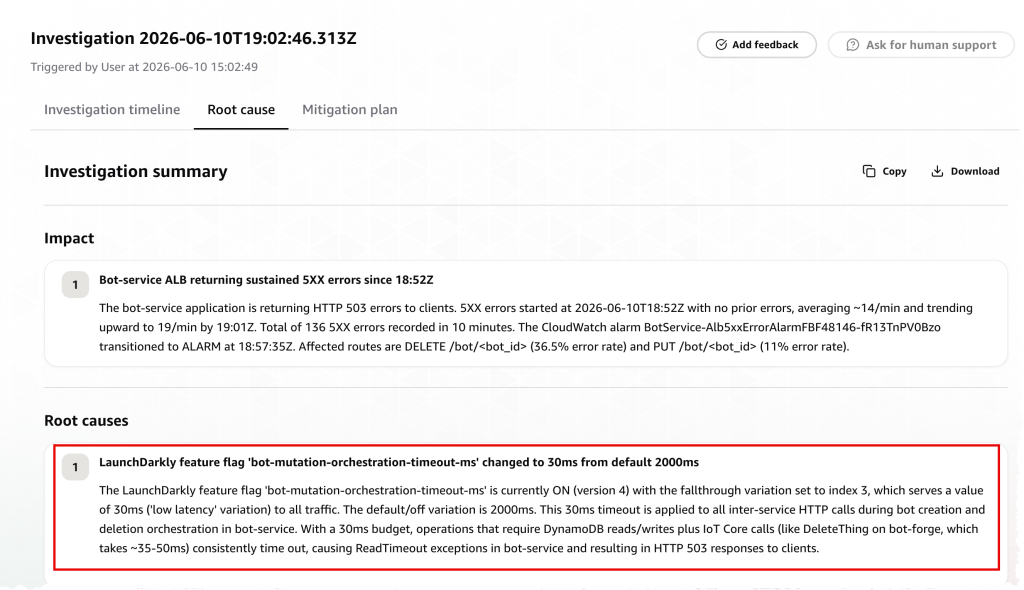
Figure 5: AWS DevOps Agent investigation summary identifying a LaunchDarkly feature flag timeout change as the root cause of sustained 5XX errors
Step-by-Step Mitigation Plans
When DevOps Agent identifies a root cause, it generates a structured mitigation plan with concrete, executable steps. Rather than a generic recommendation, the agent provides:
- Prepare — Document the current error baseline (with ready-to-run CLI commands, e.g., CloudWatch get-metric-statistics) and confirm the problematic configuration is still active before making changes.
- Execute — Revert the specific change (in this case, reverting the LaunchDarkly feature flag bot-mutation-orchestration-timeout-ms from 30ms back to the 2000ms default) with clear instructions on which variation to target.
- Verify — Validate that error rates return to baseline after the change, confirming the mitigation was effective.
Each step includes sub-steps with specific commands, API paths, and success criteria — giving the on-call engineer a clear, auditable runbook rather than a vague recommendation.
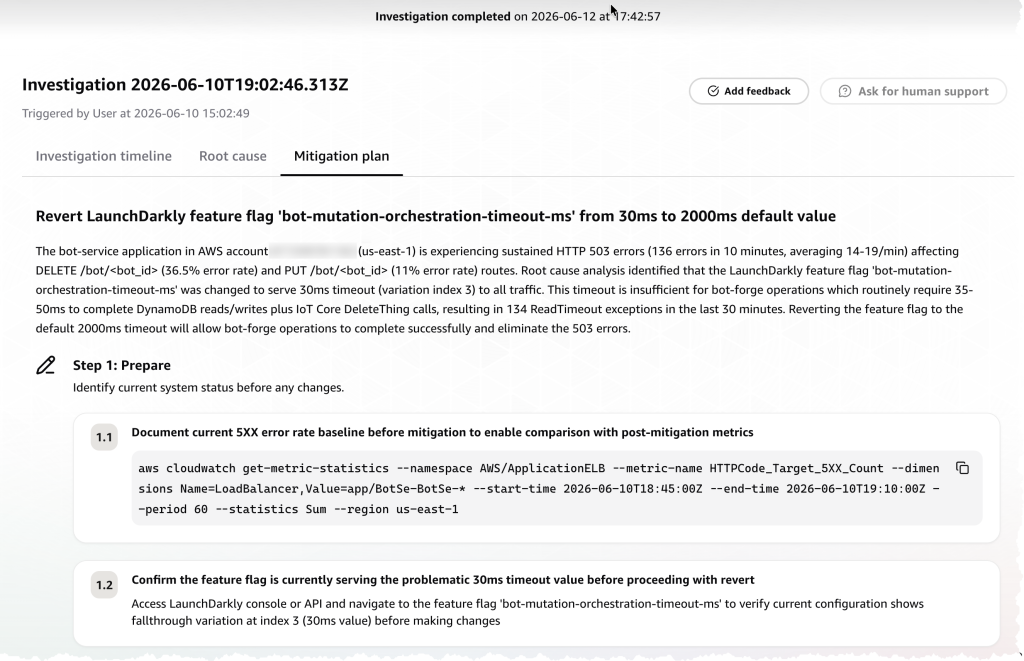
Figure 6: Structured mitigation plan generated by AWS DevOps Agent with executable steps to revert the feature flag and verify resolution.
Below, the LaunchDarkly targeting configuration shows the bot-mutation-orchestration-timeout-ms flag with its available variations. During the incident, the engineer reverted from the “low latency” variation back to “default” to restore the 2000ms timeout budget.
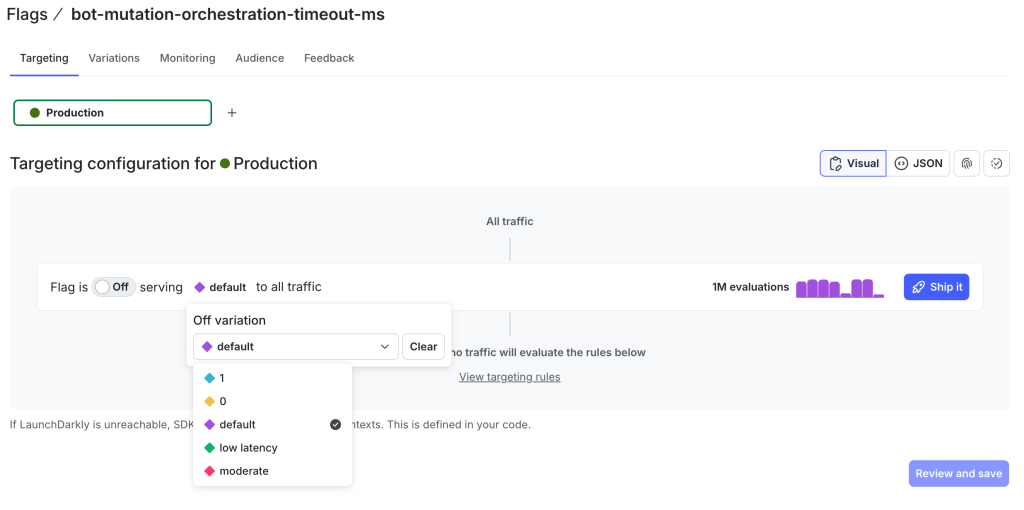
Figure 7: LaunchDarkly targeting configuration for the bot-mutation-orchestration-timeout-ms flag showing available variations including the default and low latency values.
Connecting to LaunchDarkly via MCP
As described in the introduction, DevOps Agent uses its MCP server feature to connect to LaunchDarkly’s hosted MCP server. This section covers the architecture and setup steps.
LaunchDarkly’s MCP server exposes flag management operations as agent-callable tools through the Model Context Protocol (MCP) standard. DevOps Agent connects as a client, giving it the ability to query flag state, read targeting rules, and list flags by project or environment without custom integration code.
Architecture
The connection follows this flow:
- DevOps Agent identifies a need for flag-related context (e.g., during incident response).
- DevOps Agent calls LaunchDarkly’s hosted MCP server using standardized MCP tool definitions.
- LaunchDarkly MCP Server translates the request into LaunchDarkly API calls and returns structured responses (flag state, targeting rules, rollout percentages).
- DevOps Agent uses the response to formulate recommendations presented to the engineer.
Registration and Configuration
To set up the connection:
- Register LaunchDarkly’s hosted MCP server endpoint with DevOps Agent.
- Configure authentication credentials (LaunchDarkly API key with appropriate scopes).
- Validate connectivity by running a test flag query.
For the full setup walkthrough, including detailed configuration steps and permissions requirements, refer to LaunchDarkly’s companion blog post (link placeholder).
The same LaunchDarkly MCP server connection is available in Kiro IDE for flag-aware code generation during development; see the Defense section above for how Kiro completes the pre-deployment workflow.
Example Skill: High-Risk Feature Flag Recommendations
AWS DevOps Agent Skills are modular instruction sets that extend the agent’s capabilities with specialized domain knowledge and investigation methodologies tailored to your infrastructure and operational workflows. AWS DevOps Agent supports a subset of the Agent Skills specification. The format is flexible, but this example is structured into the following sections:
- Risk Classification Criteria — defines what constitutes Critical, High, and Moderate risk changes
- Feature Flag Recommendation Format — specifies the output structure: flag name, flag type, targeting strategy, and kill switch guidance
- Example Recommendations — provides reference examples so the agent produces consistent, actionable output
- Integration Notes — describes how recommendations surface during release readiness reviews
- What NOT to Flag — explicitly scopes out low-risk changes to reduce noise
Below is the full Skill used in this example:
# High-Risk Code Feature Flag Recommendations
When performing a release readiness review, use this skill to identify high-risk code changes and recommend LaunchDarkly feature flags for safer, controlled rollouts.
## Risk Classification Criteria
Evaluate code changes against these risk categories:
### Critical Risk (Always recommend feature flag)
- **Payment/billing logic** — any changes to checkout, payment processing, subscription handling, or pricing calculations
- **Authentication/authorization** — login flows, session management, permission checks, OAuth/SSO integrations
- **Database schema changes** — migrations, new columns, index changes, especially on high-traffic tables
- **Data deletion or mutation** — bulk updates, cascading deletes, data transformations
- **Third-party API integrations** — new external service dependencies or changes to existing integrations
- **Core business logic** — order processing, inventory management, user registration flows
### High Risk (Strongly recommend feature flag)
- **New API endpoints** — especially public-facing or partner APIs
- **Performance-sensitive paths** — changes to hot paths, caching logic, query optimizations
- **Feature rewrites** — replacing existing functionality with new implementations
- **Concurrency changes** — threading, async processing, queue handling modifications
- **Configuration changes** — environment variables, feature toggles, service endpoints
### Moderate Risk (Consider feature flag)
- **UI changes to critical flows** — checkout pages, login screens, dashboard views
- **Logging/monitoring changes** — new metrics, log format changes, tracing modifications
- **Error handling changes** — exception handling, retry logic, fallback behaviors
## Feature Flag Recommendation Format
When recommending a feature flag, provide:
### 1. Flag Name
Use a descriptive, lowercase, hyphenated name:
- `enable-new-payment-processor`
- `use-v2-auth-flow`
- `rollout-order-service-refactor`
### 2. Flag Type
Recommend the appropriate LaunchDarkly flag type:
- **Boolean** — simple on/off for feature enablement
- **Multivariate** — when you need multiple variations (A/B testing, gradual migrations)
- **Number/String** — for configuration values that might need adjustment
### 3. Targeting Strategy
Recommend an appropriate rollout strategy:
- **Percentage rollout** — start at 1-5%, monitor, then increase (default for most changes)
- **User segment targeting** — internal users first, then beta users, then general availability
- **Environment targeting** — enable in staging/canary before production
### 4. Kill Switch Guidance
Explain what happens when the flag is turned off:
- What code path executes when disabled
- Any cleanup or rollback considerations
- Data consistency implications
## Example Recommendations
### Example 1: Payment Processing Change
**Code Change:** Refactored payment gateway integration to support new processor
**Recommendation:**
```CRITICAL RISK: Payment processing changes detected
Recommend wrapping in LaunchDarkly feature flag:
- Flag name: `enable-stripe-v2-integration`
- Flag type: Boolean
- Default: OFF (use existing payment flow)
Rollout strategy:
1. Enable for internal test accounts first
2. Expand to 1% of production traffic
3. Monitor payment success rates and error logs
4. Gradually increase to 100% over 1-2 weeks
Kill switch behavior: Reverts to existing payment processor immediately.
In-flight transactions will complete with their original processor.
```
### Example 2: New API Endpoint
**Code Change:** Added new `/api/v2/orders` endpoint with different response format
**Recommendation:**
```HIGH RISK: New API endpoint with breaking response format
Recommend wrapping in LaunchDarkly feature flag:
- Flag name: `enable-orders-api-v2`
- Flag type: Boolean
- Default: OFF (return v1 format)
Rollout strategy:
1. Enable for specific API clients by client_id targeting
2. Coordinate with consuming teams before enabling
3. Run both versions in parallel during migration period
Kill switch behavior: Returns v1 response format. Ensure v1
serialization logic remains in codebase until flag is permanent.
```
### Example 3: Database Migration
**Code Change:** Adding new index to high-traffic `orders` table
**Recommendation:**
```CRITICAL RISK: Database schema change on high-traffic table
Recommend wrapping dependent code in LaunchDarkly feature flag:
- Flag name: `use-orders-status-index`
- Flag type: Boolean
- Default: OFF (use existing query patterns)
Rollout strategy:
1. Deploy migration to create index (can be done independently)
2. Deploy code that uses new index behind flag
3. Enable flag in staging, verify query performance
4. Enable in production during low-traffic window
5. Monitor query latency and database load
Kill switch behavior: Queries fall back to non-indexed path.
May see temporary performance degradation but no data loss.
```
## Integration Notes
When the release readiness review identifies high-risk changes:
1. **Surface the risk level** clearly in the review summary
2. **Provide the flag recommendation** with copy-paste ready configuration
3. **Explain the rollout strategy** appropriate for the risk level
4. **Document the kill switch behavior** so operators know what to expect
## What NOT to Flag
Not every change needs a feature flag. Avoid recommending flags for:
- Pure refactoring with no behavior change
- Test file additions or modifications
- Documentation updates
- Dependency version bumps (unless major version with breaking changes)
- Code formatting or linting fixes
Activating the Skill
DevOps Agent loads Skill metadata at the start of each workflow and loads the full Skill content when it determines relevance. To ensure the feature flag Skill is consistently applied during release readiness reviews, add a directive to your DevOps Agent Instructions (Agent.md), which is loaded in full at the start of every session:
“When performing release readiness reviews, always load and apply the high-risk-feature-flag-recommendations skill to evaluate code changes for risk and recommend LaunchDarkly feature flags where appropriate.”
This guarantees the agent loads and applies the Skill for every release readiness review rather than relying on relevance detection to surface it.
Getting Started
To begin using feature flag orchestration with AWS DevOps Agent and LaunchDarkly:
- Enable AWS DevOps Agent in your AWS account to start building Skills and connecting MCP servers
- Set up the LaunchDarkly MCP server: Follow the LaunchDarkly MCP server documentation for installation and configuration instructions.
- Read the companion post: LaunchDarkly’s blog post explores why feature flags are essential infrastructure for SRE agents and how the LaunchDarkly MCP Server connects to AWS DevOps Agent for pre-deployment review and incident response workflows.
Conclusion
Feature flag orchestration with AWS DevOps Agent and LaunchDarkly reduces the manual coordination required during both deployment review and incident response. A DevOps Agent Skill surfaces flag recommendations before high-risk changes ship, and during incidents, the agent queries LaunchDarkly to recommend flag-based containment, providing faster resolution with less disruption than full rollbacks.
For developers using Kiro IDE, the same LaunchDarkly MCP server enables flag-aware code generation during development, shifting flag coverage left to the point of authorship. Together, these workflows provide layered coverage: individual developers build with flags, DevOps Agent’s release management capabilities validate coverage at deployment time, and DevOps Agent uses flag state during incident response.
Authors
Friday Squid Blogging: Victims of Unregulated Squid Fishing
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2026/06/friday-squid-blogging-victims-of-unregulated-squid-fishing.html
Dolphins, sharks, turtles, and human workers are all victims of unregulated squid fishing fleets.
Another news article.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Supercharge your cloud operations with the Kiro power for AWS DevOps Agent
Post Syndicated from Shashiraj Jeripotula original https://aws.amazon.com/blogs/devops/supercharge-your-cloud-operations-with-the-kiro-power-for-aws-devops-agent/
When an alarm fires at 2 AM, the first thing most engineers do is grep logs, check recent deployments, and trace code paths. However, the context they need — metrics, traces, topology, configurations — lives in a separate browser tabs and applications. What if your IDE could bring that cloud intelligence directly to your code, understand the full picture, and help you fix the issue end-to-end? Introducing, The Kiro power for AWS DevOps Agent removes that context switching by connecting your IDE directly to the AWS DevOps Agent, so you can investigate incidents, identify root causes, and generate fixes, all from the same place you write code.
This post is for developers and operators who develop applications using Kiro and want to troubleshoot production issues faster without leaving their editor. We’ll walk through how the power works, what it can do, and a step-by-step example of resolving a real incident.
The Kiro power for AWS DevOps Agent connects Kiro, the AI-powered IDE from Amazon, to the AWS DevOps Agent. It brings the production intelligence and release management in AWS DevOps Agent directly into your development environment — where you already plan, architect, debug, and ship code.
With this power installed, you can review your changes for production risks, investigate production incidents, optimize costs, review architecture, map service topology, and generate remediation code — all through natural language conversation, enhanced with the local context of your workspace.
Challenges in cloud operations today
Operating modern cloud applications means navigating a maze of interconnected services. A single user-facing error might require tracing through Amazon Elastic Container Service (Amazon ECS) tasks, Application Load Balancers, AWS Lambda functions, Amazon DynamoDB tables, and dozens of Amazon CloudWatch metric dimensions. Operators face persistent challenges:
- Context switching — Investigating an incident requires jumping between the IDE, the AWS Management Console, log viewers, trace explorers, and documentation. Each switch costs time and breaks concentration during high-pressure incidents.
- Siloed knowledge — Understanding which metrics matter, which services depend on each other, and what “normal” looks like for a given application often lives in runbooks that are outdated or in the heads of senior engineers. New team members face a steep learning curve.
- Remediation gap — Even after identifying a root cause, translating findings into a working fix — an AWS CloudFormation parameter change, a scaling policy update, or an AWS Identity and Access Management (IAM) policy correction — requires switching contexts again and manually applying changes.
These challenges compound when teams operate across multiple AWS accounts and environments. Kiro powers address these challenges by bringing operational intelligence directly into the IDE where developers already work.
Challenges in modern software delivery
AI coding agents have changed how fast code gets written, but the code review, testing, and pipeline processes that move code to production were designed for human pace and haven’t kept up. Teams face two persistent challenges:
- Review capacity — AI-assisted development produces changes faster than human reviewers can evaluate them. Changes that don’t adhere to internal standards, dependency breaks, and access-control gaps that would have been caught by human reviews can slip through at machine pace.
- Invisible dependencies — Applications span multiple repositories, shared infrastructure, and cross-team API contracts. A parameter rename in one repository silently breaks downstream consumers, and no single reviewer holds the full dependency graph in their head.
Faster code generation without corresponding delivery automation simply moves the bottleneck downstream. The Kiro power for AWS DevOps Agent addresses this by bringing release management intelligence into the IDE so you can review changes for production risks and run exploratory release testing of your web and API applications. Any issues can be immediately mitigated before you even push your code changes.
What are Kiro powers?
A Kiro power is a curated package that gives Kiro specialized capabilities in a specific domain, in this case, AWS operations. When installed, the power provides Kiro with tool connections to your AWS environment, domain-specific knowledge (best practices, error recovery patterns), and instructions for routing your requests to the right workflow. Critically, the power combines your local workspace context (code, git history, configuration files) with cloud-side intelligence (metrics, topology, deployment history) — so Kiro understands both what your code does and how your infrastructure behaves. For a deeper look at the powers framework, see Getting started with Kiro powers
Each power typically includes:
- MCP server configuration — Connects Kiro to external tools and data through the Model Context Protocol, providing read and write access to cloud resources
- Steering files — Domain-specific instructions that teach Kiro how to route intents, choose the right workflow, and handle edge cases
- Contextual knowledge — Domain-specific guidance captured in markdown spec files and lifecycle hooks that encode best practices, common patterns, and error recovery strategies (as described in the blog, Introducing powers).
The Kiro power for AWS DevOps Agent
The Kiro power for AWS DevOps Agent packages the full capabilities of AWS DevOps Agent into a single install for Kiro. Once enabled, Kiro gains the ability to converse with a specialized AI agent that has deep knowledge of your AWS infrastructure, your operational history, and AWS best practices.
You can do the following with this power:
- Investigate incidents — Describe the symptoms in natural language (“ECS tasks are failing with OOM errors on my-service”) and Kiro orchestrates a deep investigation across CloudWatch metrics, AWS X-Ray traces, Amazon ECS task events, and recent deployments to identify the root cause.
- Optimize costs — Ask “What cost savings are available for my ECS services?” and receive specific, data-backed recommendations with estimated monthly savings based on actual utilization metrics from your account.
- Review architecture — Request a topology map or security audit of your services. The agent queries your infrastructure and returns findings with actionable improvement suggestions.
- Chat across agent spaces — Operate across multiple AWS DevOps Agent agent spaces from a single Kiro session using AWS SigV4. Each agent space can represent a different team, application, or AWS account — and you can switch between them naturally.
- Generate remediation code — After identifying a root cause, Kiro can generate the fix directly in your workspace. Because it has access to both the investigation findings and your local code, the remediation is specific to your application, not generic boilerplate.
- Run a release readiness review — After finishing a batch of code changes, have the DevOps Agent review the changes for dependency risks, deviations from your standards and best practices, and expansion of access controls in CloudFormation that go beyond best practices. It also builds and runs your code in an AWS-managed sandbox to better assess any production risks.
- Perform exploratory release testing for deployed applications — If you deploy your web or API application to a production-like environment, Kiro can have the DevOps Agent run an exploratory tests on it. Any bugs or regressions found can be fixed without leaving the IDE.
How it works
The power provides two complementary workflows that Kiro selects automatically based on your request:
- Chat (updates in seconds) — For instant answers about cost, architecture, topology, and knowledge discovery. Kiro creates a conversation with the DevOps Agent and streams responses in real time. Follow-up questions retain full context within the same session.
- Investigation (completes in minutes) — For complex incidents requiring deep analysis. The DevOps Agent examines CloudWatch metrics, X-Ray traces, deployment history, and service topology, then delivers a root cause analysis with prioritized recommendations.
The following diagram shows how Kiro combines local workspace context with the DevOps Agent’s cloud intelligence:
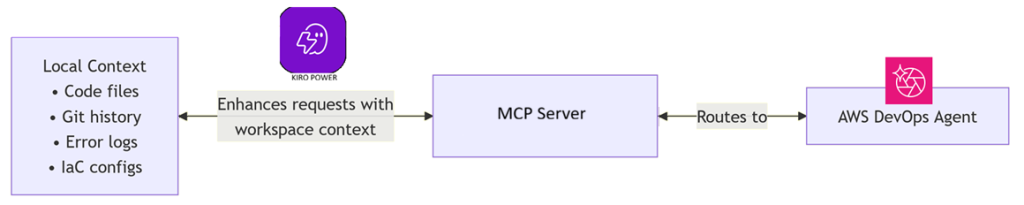
Figure 1: Kiro combines local workspace context with the DevOps Agent’s cloud intelligence through the AWS DevOps Agent MCP Server.
Prerequisites
Before using the power, ensure you have:
- AWS credentials configured (AWS IAM Identity Center recommended) if using AWS SigV4.
- Kiro installed and a workspace set up
- An AWS DevOps Agent agent space configured with data sources (CloudWatch, X-Ray, or other integrations)
- Create an access token or have AWS SigV4 configured. The access tokens feature must be enabled on your Agent Space for access tokens to work.
- For access tokens, you must have IAM permissions to manage access tokens (aidevops:CreateAccessToken, aidevops:RevokeAccessToken, aidevops:RotateAccessToken).
- Enable access tokens
- Review the security best practices detailed in the connect to DevOps Agent Remote Server documentation.
- Sign in to the AWS Management Console and open the AWS DevOps Agent console.
- Choose your Agent Space.
- Choose the Configuration tab.
- In the Access tokens section, choose Enable.
- Confirm the action.
- Enable access tokens
-
- Create a token
- Open the DevOps Agent web app for your Agent Space, then from the navigation menu, choose Settings, then choose Access Tokens.
- Choose Create access token.
- Enter a name for the token.
- Choose a scope:
- read – View investigations, recommendations, chats, and Agent Space resources.
- operate – Full access. Includes everything in read, plus send messages, create chats, and manage backlog tasks and recommendations.
- Set an expiration (1 to 60 days).
- Copy the token value and store it in a safe, secure location. You cannot retrieve it again.
- After creating a token, the web app displays a configuration example that you can copy directly into your client.
- Create a token
The power works with any agent space that has active data sources. The more data sources connected, the richer the investigations and recommendations.
Getting started with the Kiro power for AWS DevOps Agent
Setting up the power takes only a few steps. You can install it directly or follow these steps:
- Open Kiro and choose the Powers icon in the sidebar.
- In the AVAILABLE panel, find AWS DevOps Agent.
- Choose Install.
- The power appears in the INSTALLED panel, and choose Try power.
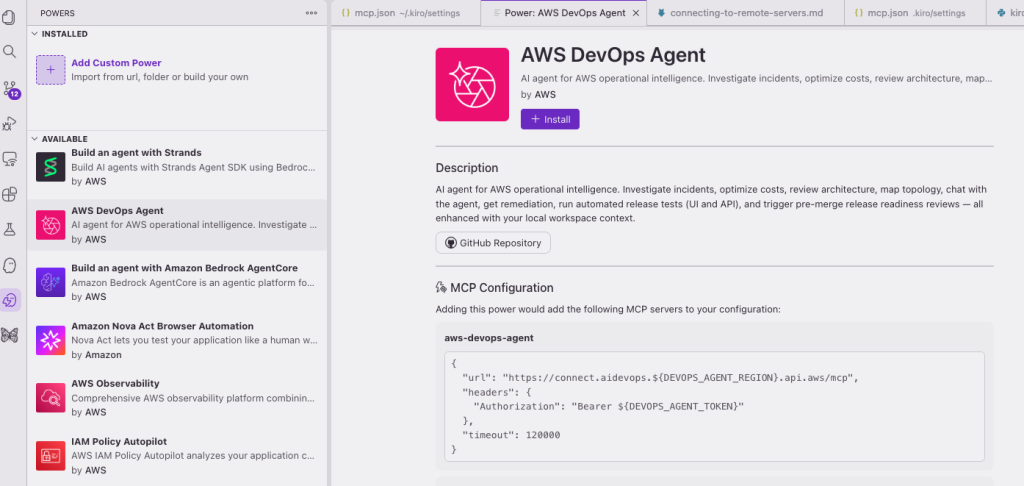
Figure 2: Kiro powers panel showing the Kiro power for AWS DevOps Agent
Verify Installation
After installation, you should see the Kiro power for AWS DevOps Agent listed in the powers section of the Kiro panel. Navigate to mcp.json file and change these values accordingly, and save the config file.
- DEVOPS_AGENT_TOKEN=<your-token>
- DEVOPS_AGENT_REGION=<your-agent-space-region>
In the MCP Servers panel, you will see DevOps Agent MCP connected and also displays list of tools. The power activates automatically when you mention relevant keywords like incident, cost optimization, architecture review, or topology in your conversation.
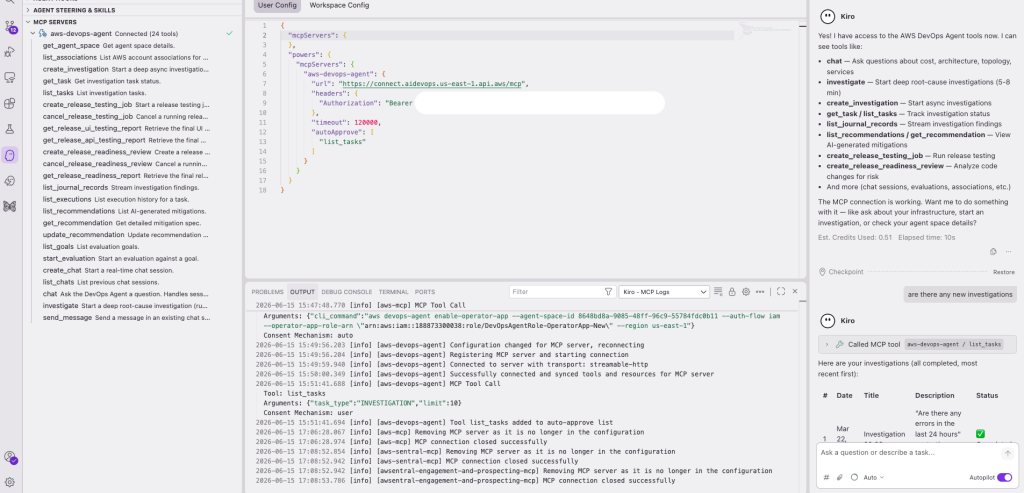
Figure 3: MCP Servers panel showing the AWS DevOps Agent MCP and connected tools
Walkthrough: Investigating a production incident
Let’s walk through a realistic scenario. Your team receives a CloudWatch alarm: an Amazon ECS service is returning HTTP 503 errors and task restarts have spiked.
Step 1: Describe the problem
In Kiro, you type:
“My ECS service checkout-api is throwing 503 errors. The alarm fired 10 minutes ago. Here’s the error from my logs: Connection pool exhausted, max connections 50 reached.”
Because Kiro has access to your workspace, it automatically includes relevant context — your task definition, your connection pool configuration from application.yml, and your recent git commits.
Step 2: Kiro starts the investigation
Kiro routes this to the investigation workflow. You see real-time progress as findings stream in:
- Planning investigation approach…
- Querying CloudWatch metrics, ECS task events, X-Ray traces…
- Analyzing connection pool metrics against task count…
- Root cause identified: Connection pool sized for single task, but service scaled to 5 tasks sharing a database connection limit
Step 3: Review findings and recommendations
The DevOps Agent returns a detailed analysis:
Root cause: The database connection limit (50) is shared across all ECS tasks. When the auto-scaling policy added tasks at 08:47 UTC, each task attempted to open 50 connections, exceeding the Amazon RDS max_connections parameter (100).
Recommendation and Mitigation: Reduce the per-task connection pool to max_connections / max_tasks (100 / 5 = 20 per task), or increase the RDS instance class to support more connections.
Step 4: Generate and apply the fix
You ask Kiro to implement the recommendation. Because it has access to your application.yml and your AWS CloudFormation template, it generates a targeted fix:
- Updates spring.datasource.service.maximum-pool-size from 50 to 20 in your application configuration
- Adds a comment explaining the calculation
- Suggests an RDS parameter group change if you want to increase capacity instead
The fix is applied directly in your workspace, ready for review and commit.
Operating across multiple agent spaces
If your team manages multiple applications, each with its own DevOps Agent agent space, you can switch between them naturally. Kiro lists available agent spaces and routes your question to the right one.
Conclusion
The Kiro power for AWS DevOps Agent brings the full operational intelligence of AWS DevOps Agent into the IDE where you already work. By combining your local workspace context with cloud-side analysis, it closes the loop from detection to remediation without context switching.
Whether you are triaging a production incident, optimizing costs across services, or onboarding a new team member who needs to understand your infrastructure, the power provides contextual answers grounded in your actual AWS environment.
Install the Kiro power for AWS DevOps Agent today and experience AI-powered cloud operations in your IDE. To learn more, visit the Interfacing with AWS DevOps Agent and the Kiro powers documentation.
 |
Tipu Qureshi Tipu Qureshi is a Senior Principal Technologist in AWS Agentic AI, focusing on operational excellence and incident response automation. He works with AWS customers to design resilient, observable cloud applications and autonomous operational systems. |
 |
Shashiraj Jeripotula (Raj) Shashiraj Jeripotula (Raj) is a San Francisco-based Principal Partner Solutions Architect at AWS. He works with ISV and AWS partners to build deep integrations across observability, AI, and agentic development tooling — helping developers leverage AI agents, Model Context Protocol (MCP), and shift-left observability to build responsible, production-ready AI systems on AWS. |
The Secret US Army Moon Base Plans
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=U4t59a3y-Ww
UK Election & Robert Kenyon #lastweektonight
Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/uT6aNppDqqc
Systemd v261 released
Post Syndicated from jzb original https://lwn.net/Articles/1078708/
Systemd
v261 has been released with a long list of changes including a new
cloud “Instance Metadata Service” (IMDS) subsystem, “boot secret”
functionality for use on systems that lack a physical TPM, as well as
support for the kernel’s Live Update Orchestration (LUO) / Kexec
Handover (KHO) systems when they are present and enabled. See the
release notes for the full list of changes.
Weekly Metasploit Update: NTLM Relay Priv Esc, MCP Server Integration, Paperclip AI RCE Chain, and more
Post Syndicated from Alan David Foster original https://www.rapid7.com/blog/post/pt-metasploit-wrap-up-19-06-2026
This week’s release includes five new modules, including a full unauthenticated RCE chain for Paperclip AI and a VS Code extension persistence technique. On the post-exploitation side, the new windows/local/ntlm_relay_2_self module coerces the local machine account to authenticate via OpenEncryptedFileRaw (WebDAV), relays that NTLM authentication to a Domain Controller’s LDAP service, then uses the resulting LDAP session to write Shadow Credentials and obtain a Kerberos service ticket as Administrator via S4U2Proxy, enabling PsExec back to itself for SYSTEM access.
On the enhancement side, the new MCP server plugin lets AI tools assist operators directly within a running msfconsole instance, and module check codes now return richer detail for users.
New module content (5)
Paperclip AI RCE using a chain of six API calls (CVE-2026-41679)
Authors: Sagilayani https://github.com/sagilayani and h00die-gr3y [email protected]
Type: Exploit
Pull request: #21547 contributed by h00die-gr3y
Path: linux/http/paperclipai_unauth_rce_cve_2026_41679
AttackerKB reference: CVE-2026-41679
Description: Adds an exploit module for CVE-2026-41679 which exploits Paperclip. An unauthenticated attacker can achieve full remote code execution on any network-accessible Paperclip instance running in authenticated mode with default configuration. The entire chain is six API calls.
Xerte Online Toolkits Arbitrary File Upload – Unauthenticated Media Upload
Author: bootstrapbool [email protected]
Type: Exploit
Pull request: #21371 contributed by bootstrapbool
Path: multi/http/xerte_unauthenticated_mediaupload
AttackerKB reference: CVE-2026-41459
Description: Exploits authentication failure (CVE-2026-34413), extension blacklist (CVE-2026-34415), and path traversal (CVE-2026-34414) vulnerabilities in Xerte Online Toolkits versions 3.15 and earlier.
VS Code Extension Persistence
Author: h00die
Type: Exploit
Pull request: #21465 contributed by h00die
Path: multi/persistence/vscode_extension
Description: Adds a new persistence module that achieves persistence by installing a malicious extension into a user’s VS Code extensions directory. The next time the target opens VS Code, the extension executes and delivers a shell back to the attacker.
NTLM Relay to Self (HTTP to LDAP) – Post Exploitation
Author: jheysel-r7
Type: Exploit
Pull request: #21430 contributed by jheysel-r7
Path: windows/local/ntlm_relay_2_self
Description: Adds a module that exploits the NTLMRelay2Self attack. It requires a low-privilege user session on a Windows host.
Linux Kernel __ptrace_may_access() Exit Race Change File Disclosure
Authors: 0xdeadbeefnetwork and bhaskarbhar
Type: Post
Pull request: #21472 contributed by bhaskarbhar
Path: linux/gather/cve_2026_46333_chage
AttackerKB reference: CVE-2026-46333
Description: Adds a post module that leverages CVE-2026-46333, a vulnerability in the Linux kernel whereby a race condition exists when tearing down a process. A local attacker can exploit this to obtain file handles they would not otherwise have access to. In the exploit, this is leveraged to leak the contents of the /etc/shadow file.
Enhancements and features (7)
- #21254 from golem445 – Nmap imports will include domain name if supplied by the user for the scan.
- #21259 from g0tmi1k – Adds a number of enhancements to msfconsole’s search functionality by cleaning up some inconsistencies and giving users the option to hide the child elements of search results with the -c flag. Also introduces two global options, SearchSort and SearchChildMode, that users can set and forget in order to control ascending/descending search results and whether or not child items appear under search results respectively.
- #21367 from g0tmi1k – Adds a number of enhancements to the rexec_login module including more detailed output, a check for an rDNS failure, an update to the module description, and removal of duplicate IP:PORT printing.
- #21454 from adfoster-r7 – Updates many modules by adding additional details to the check codes that are returned by the #check method, which provides additional information for the user. Also updates the requirements of new modules to contain this extra information moving forward.
- #21512 from adfoster-r7 – Updates the Metasploit MCP tool to expose note information on Metasploit modules, as well as host comments.
- #21537 from dwelch-r7 – Adds a plugin to start and stop a Model Context Protocol (MCP) server within msfconsole. When compared to the standalone msfmcpd tool, this has the significant advantage of automatically loading the RPC server within the context of a running framework instance which enables AI tools to assist the operator without needing to restart Metasploit.
- #21542 from h00die – Updates the scanner/redis/redis_server module to output server INFO details as a readable table.
Bugs fixed (4)
- #21441 from dwelch-r7 – Improves the MCP server lifecycle control and enables graceful shutdowns by transitioning from Rack’s handler to direct Puma server API management.
- #21564 from adfoster-r7 – Fixes a crash in the smb_version module when run against SMBv1 targets.
- #21570 from sjanusz-r7 – Fixes an issue where it was not possible to generate ARM Big Endian payloads.
- #21571 from dwelch-r7 – Deleted files are now excluded when running msfconsole reload commands.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate and you can get more details on the changes since the last blog post from GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest. To install fresh without using git, you can use the open-source-only Nightly Installers or the commercial edition Metasploit Pro
[$] Suspending and resuming BPF programs
Post Syndicated from daroc original https://lwn.net/Articles/1076210/
BPF programs can be used to extend many aspects the Linux kernel, but
BPF programs must run to completion in the same context that they began.
Kumar Kartikeya Dwivedi is working on changing that by
allowing BPF programs to be expressed as coroutines. He spoke about his work at
the 2026
Linux Storage, Filesystem, Memory-Management and BPF Summit. While
still experimental, the change promises to make long-running BPF tasks
significantly easier to write.
Cory Doctorow: AI Is Turning Workers Into Tools
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=SPQNPJ0CEPo
I Gave This Robot My Worst Terrain
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=27a0ysIcHag
[$] AURpocalypse now: a look at the recent AUR attacks
Post Syndicated from jzb original https://lwn.net/Articles/1077619/
The Arch User Repository (AUR) has
been subjected to a sustained attack recently. The attacker, or attackers, have
spun up a series of new accounts then used them to adopt orphaned
packages and push malicious updates that would install malware on users’ systems.
It is unclear how many users were compromised in the attack, but the maintainers
were playing Whac-A-Mole for several days to respond to each newly compromised
package. The project has turned
off the AUR’s new-user registration, for now, but it is unclear what its
long-term response will be or if the AUR can be secured without major changes to
its existing collaboration model.
Introducing Private Networking for Amazon MQ for RabbitMQ
Post Syndicated from Jean-Sébastien Dominique original https://aws.amazon.com/blogs/big-data/introducing-private-networking-for-amazon-mq-for-rabbitmq/
With Private Networking for Amazon MQ for RabbitMQ, your brokers can establish outbound connections to private resources in your VPC without exposing those resources publicly. This post explains how the feature works and walks you through setting it up.
Amazon MQ for RabbitMQ brokers could previously only reach external destinations over the public internet. If you used a private Lightweight Directory Access Protocol (LDAP) server for broker authentication, you had to expose that server publicly. If you wanted to federate messages between private brokers, you needed workarounds like Network Load Balancers with IP allowlisting, as described in Implementing Federation on Amazon MQ for RabbitMQ Private Brokers. Private Networking removes those constraints.
You can connect your broker to private identity providers, other Amazon MQ for RabbitMQ brokers, or self-hosted RabbitMQ brokers running in private subnets. Combined with cross-Region networking services like AWS Transit Gateway, you can extend these connections across AWS Regions and accounts, with traffic staying on the AWS private network.
How it works
Private Networking connects your broker to private destinations using three AWS services: Amazon VPC Lattice, AWS Resource Access Manager (AWS RAM), and AWS PrivateLink.
You create a VPC Lattice resource gateway in a VPC that can reach your private destination. You then create a VPC Lattice resource configuration that defines the destination, such as an IP address or Domain Name System (DNS) name. You add the resource configuration to a RAM resource share and associate the resource share with your broker through the UpdateBroker API operation. After rebooting the broker, the network path is active and your broker can reach the private destination.
The broker does not need to be private. A publicly accessible broker works the same way.
What you can connect to
Private Networking supports three use cases.
Private identity providers
If you use an LDAP server or other identity provider for RabbitMQ authentication, you no longer need to expose it publicly. Create a resource configuration pointing to your identity provider, associate it with your broker, and use the DNS name returned by the DescribeSharedResources API operation in place of the public endpoint. Follow the existing guidance for setting up an identity provider, substituting the private DNS name.
Self-hosted RabbitMQ brokers
You can use Shovel or Federation to connect your Amazon MQ for RabbitMQ broker to a self-hosted RabbitMQ broker running in a private subnet. Create a resource configuration pointing to the self-hosted broker and use the DNS name from the DescribeSharedResources API operation in your Shovel or Federation configuration.
This pattern is useful for hybrid cloud architectures where you run RabbitMQ on Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), or on-premises infrastructure and want to exchange messages with Amazon MQ without exposing either side publicly.
Other Amazon MQ for RabbitMQ brokers
You can federate or shovel messages between two Amazon MQ for RabbitMQ brokers using Private Networking. Create a resource configuration pointing to the destination broker’s endpoint and specify that same endpoint as the custom domain name on the resource configuration. This helps to verify that the DNS name resolves correctly and Transport Layer Security (TLS) peer verification succeeds.
This extends to brokers in different AWS Regions and different AWS accounts. By combining Private Networking with cross-Region networking services like AWS Transit Gateway or VPC peering, you can build a fully private federation or shovel path between brokers, with no public endpoints required.
DNS names and custom domains
Each resource configuration can include a custom domain name. If you add a verified domain, that domain resolves to the private destination. If you do not add a verified domain, Amazon MQ provides a DNS name for the broker’s private connection. Retrieve this DNS name with the DescribeSharedResources API operation.
If you specify an unverified domain on a resource configuration, it is ignored. The broker’s private connection receives a private DNS name instead, which you can retrieve with the DescribeSharedResources API operation.
For more details on custom domain names and domain verification with VPC Lattice, see Custom domain names for VPC Lattice resources.
TLS peer verification in RabbitMQ 4
Note: If you are running RabbitMQ 4, review this section before configuring Shovel or Federation connections.
RabbitMQ 4 enforces TLS certificate peer verification by default for Shovel and Federation connections. RabbitMQ 3 does not enforce this by default. When using Private Networking, the DNS name that Amazon MQ assigns to the private connection will not match the TLS certificate of the destination, which causes peer verification to fail.
The recommended approach is to specify the destination broker’s endpoint (for example, b-a1b2c3d4-5678-90ab-cdef-EXAMPLE11111.mq.us-east-1.on.aws) as the custom domain name on the resource configuration. This exception only applies to Amazon MQ for RabbitMQ broker endpoints. You cannot use an unverified domain for self-hosted brokers. Specifying the Amazon MQ endpoint causes the DNS name to match the destination’s TLS certificate, and peer verification succeeds. This approach works regardless of your RabbitMQ version and avoids the issue entirely.
Getting started
To get started with Private Networking for Amazon MQ for RabbitMQ, follow these steps.
Prerequisites
Before you begin, verify you have the following:
- An AWS account.
- The AWS Command Line Interface (AWS CLI) installed and configured.
- AWS Identity and Access Management (IAM) permissions to manage Amazon MQ, VPC Lattice, and AWS RAM resources.
- An existing VPC with connectivity to your private destination.
Walkthrough
After you have the prerequisites, follow these steps:
- Create an Amazon MQ for RabbitMQ broker if you do not already have one.
- Create a VPC Lattice resource gateway in a VPC that can reach your private destination. Make sure the resource gateway’s security group allows outbound traffic to your destination on the required port (for example, port 5671 for AMQPS (AMQP over TLS) or port 636 for LDAPS (LDAP over TLS)). The resource gateway must share at least one Availability Zone with the broker. Cluster brokers cover multiple Availability Zones, so this is satisfied. For single-instance brokers, verify the Availability Zone overlap.
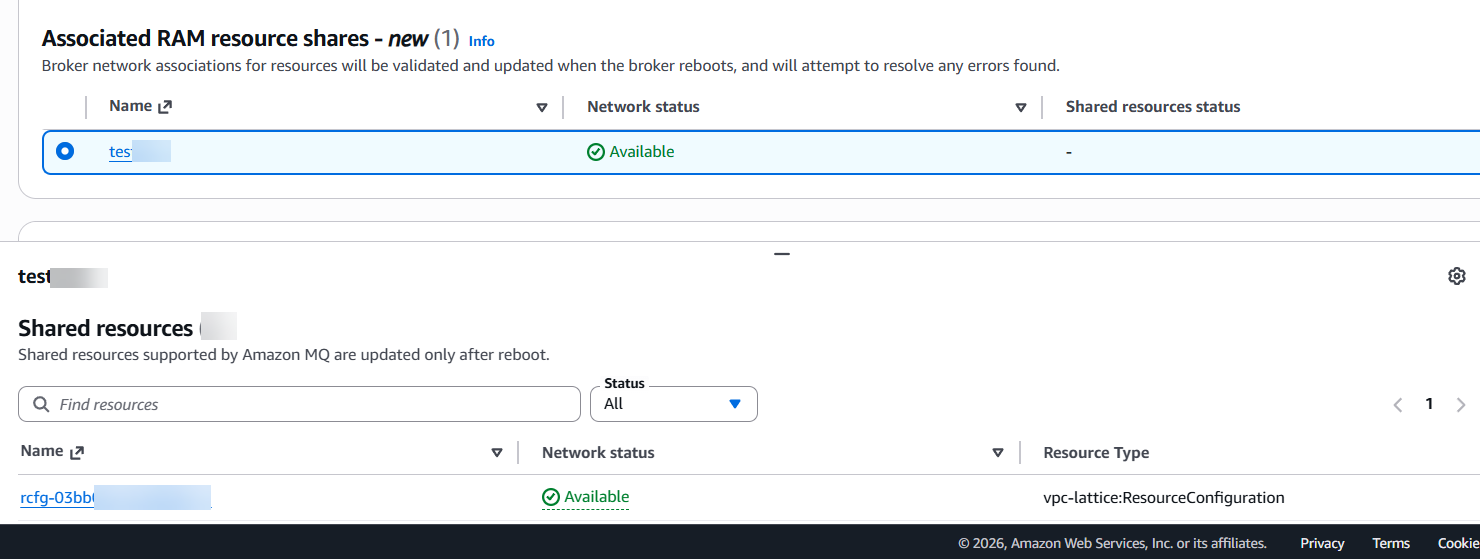
- Create a VPC Lattice resource configuration pointing to your private destination (IP address or DNS name). If you’re connecting to another Amazon MQ broker, specify the destination broker’s endpoint as the custom domain name on the resource configuration, as shown in the following figure.
 Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint.
Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint. - Add the resource configuration to a RAM resource share. The resource share must allow external principals, as shown in the following figure.Figure 2: RAM resource share configuration with the Allow external principals option selected.
- Associate the resource share with your broker by editing the broker and adding the resource share. You can also do this using the
update-brokercommand with the AWS CLI. You must pass the entire list of resource share ARNs you want on the broker. This is a put operation, not an add or remove operation.The associated RAM resource share appears as shown in the following figure.
Figure 3: Network settings view with associated RAM resource shares.
Select the resource share in the Associated RAM resource shares section. The network status of each shared resource is displayed in the Shared resources section, as shown in the following figure.
Figure 4: RAM resource share selection showing the network status of each shared resource.
- Reboot the broker from the AWS Management Console or the AWS CLI to create the network path:
- Retrieve the DNS names for your RabbitMQ configuration. This operation also surfaces issues encountered during setup:
- Use the DNS name returned in the output in your Shovel, Federation, or identity provider configuration. Adding new resource configurations to an existing RAM resource share does not automatically update the broker. You must call
update-brokerand reboot the broker for the new resource configurations to take effect.
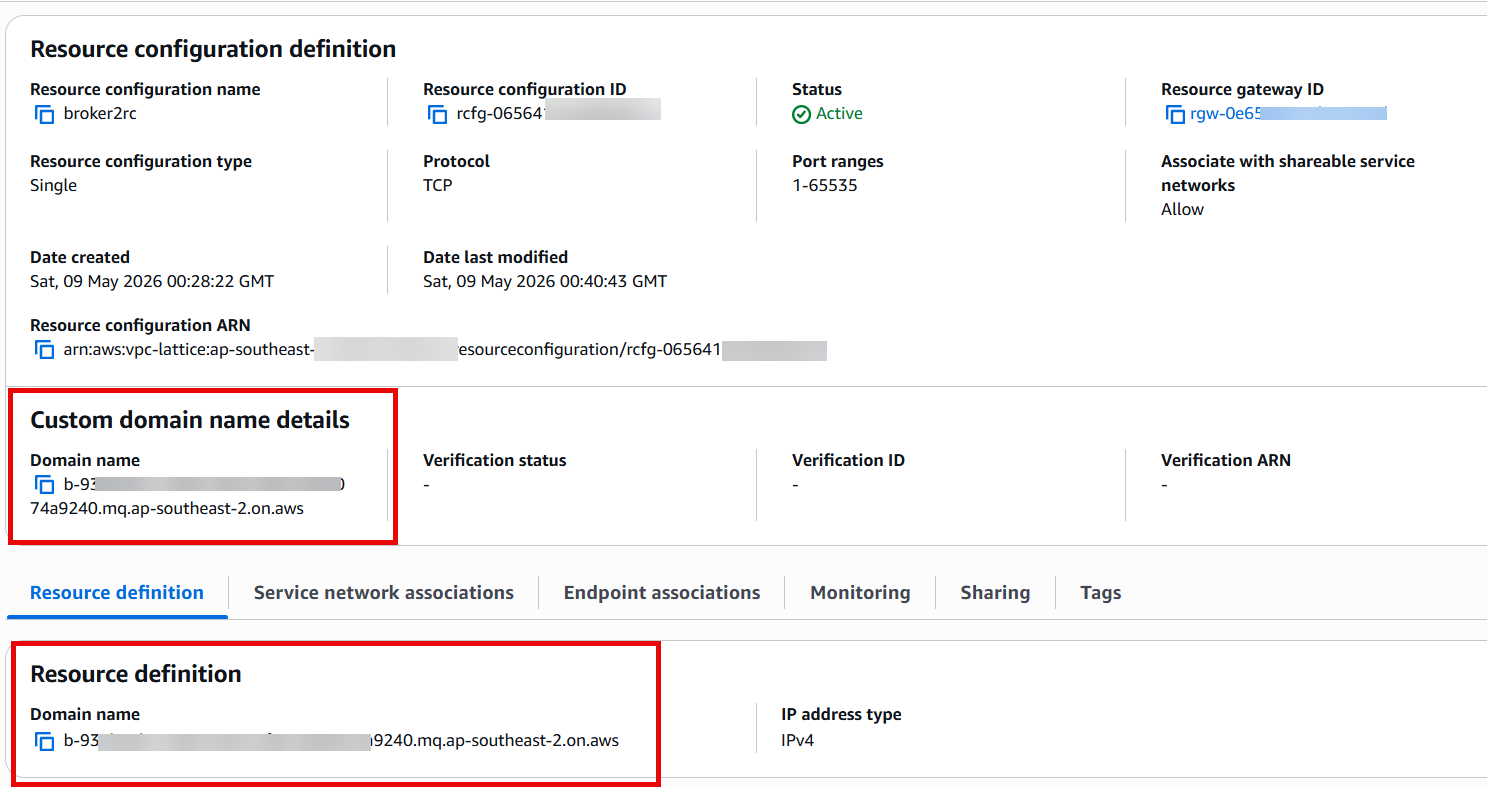 Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint.
Figure 1: VPC Lattice resource configuration showing the custom domain name field and resource definition populated with the Amazon MQ broker endpoint.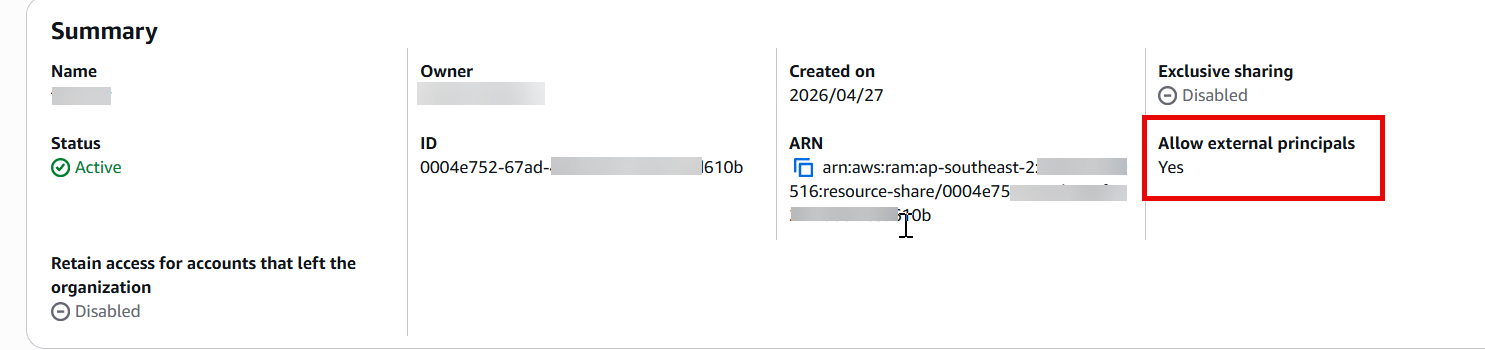 Figure 2: RAM resource share configuration with the Allow external principals option selected.
Figure 2: RAM resource share configuration with the Allow external principals option selected.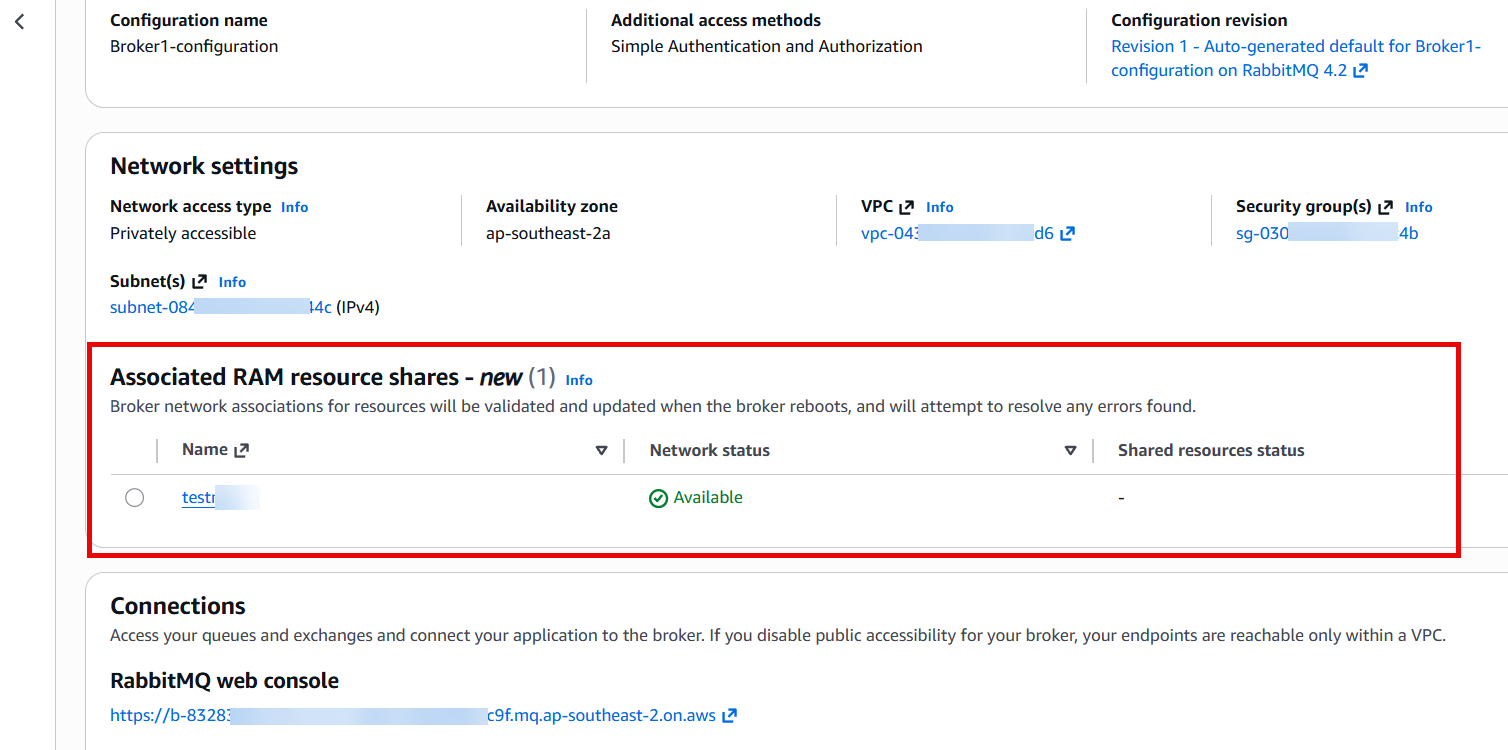
Cleaning up
Private Networking uses VPC Lattice and PrivateLink resources that incur ongoing charges. If you no longer need the private connection:
- Call
update-brokerwith the resource share removed from the list (or an empty list to remove all), then reboot the broker. - After the broker reboot completes and the resources are no longer in use, delete the VPC Lattice resource configuration and resource gateway.
- Optionally, remove the Amazon MQ account principal from the RAM resource share. This principal may still be in use if other brokers are associated with the same resource share, so only remove it if no other brokers depend on it.
- If you created a new Amazon MQ for RabbitMQ broker for this walkthrough and no longer need it, delete the broker from the Amazon MQ console or with the
delete-brokercommand.
Operational behavior: Resource access and reboots
Removing a VPC Lattice resource configuration from a RAM resource share while the broker is actively using it revokes access immediately, with no reboot required. Removing a principal from a RAM resource share has the same effect: brokers associated through that principal lose access to the resources in the share immediately. These are intentional security behaviors managed by RAM and VPC Lattice.
Adding new resource configurations to an existing resource share does not take effect automatically. You must call update-broker and reboot the broker for the new resource configurations to take effect. This is by design. It helps verify that changes to a resource share only reach the broker when someone with broker management permissions explicitly triggers the update, providing clear security separation between share management and broker management.
Private Networking is available for Amazon MQ for RabbitMQ brokers in all the AWS Regions where Amazon VPC Lattice is available. Amazon MQ for ActiveMQ brokers do not support this feature.
Pricing
Private Networking uses Amazon VPC Lattice and AWS PrivateLink. Data processing and data transfer charges apply to traffic sent through the private connection. There is an Amazon MQ pricing of $0.01 per GB of data processed through the resource endpoint. For details, see the Amazon MQ pricing page, VPC Lattice pricing page and AWS PrivateLink pricing page.
Conclusion
In this post, we explained how Private Networking for Amazon MQ for RabbitMQ works and walked through the setup process. Whether you’re securing a private identity provider, federating messages between brokers, or connecting to self-hosted RabbitMQ, your broker can now reach private destinations without exposing them publicly.
To learn more, see the Amazon MQ Private Networking documentation.
If you have questions or feedback, leave a comment on this post.
About the authors
Security updates for Friday
Post Syndicated from jzb original https://lwn.net/Articles/1078662/
Security updates have been issued by AlmaLinux (dracut), Debian (chromium, firefox-esr, and thunderbird), Fedora (chromium, firefox, nss, ocserv, ongres-scram, ongres-stringprep, perl-Archive-Tar, perl-GD, perl-HTTP-Daemon, perl-Net-Statsd, restic, singularity-ce, util-linux, and vorbis-tools), Mageia (gstreamer1.0-*, libupnp, luajit, opensc, and ruby-rack), SUSE (curl, dnsmasq, ffmpeg-4, frr, google-osconfig-agent, java-1_8_0-ibm, kernel, krb5, kubernetes-old, ldns, liburiparser1, openvswitch, rootlesskit, strongswan, traefik, and trivy), and Ubuntu (ldns, libheif, libnet-cidr-lite-perl, lxd, tomcat11, and vim).
Temporary Cloudflare Accounts for AI agents
Post Syndicated from Sid Chatterjee original https://blog.cloudflare.com/temporary-accounts/
Everyone’s writing code with AI agents today. But the moment an agent needs to deploy something — and needs to sign up and create an account — it slams face-first into a wall built for humans: a browser-based OAuth flow, a dashboard to click through, an API token to copy-paste, a multi-factor authentication prompt to satisfy. For an interactive copilot sitting next to a developer, that’s annoying. For a background agent, it’s a hard stop.
Today we’re rolling out Temporary Cloudflare Accounts for Agents.
Agents can now deploy websites, APIs, and agents right away, without first needing to sign up for an account.

Any agent can now run wrangler deploy –temporary and deploy a Worker to Cloudflare. This temporary deployment stays live for 60 minutes, during which time you can claim the temporary account, making it permanently your own. If you don’t, it expires on its own.

Our goal? Let your agent code and ship.
Frictionless temporary accounts matter more than it might first seem:
-
Background AI sessions have no human in the loop, and are becoming the norm. Any auth step that needs a browser, a copy-paste, or “click here in 60 seconds” means an agent gets stuck and may choose to deploy elsewhere.
-
Trial-and-error is the agent’s superpower. Agents need a tight write → deploy → verify loop. They need cheap, throwaway deployment targets, so they can curl their own output and decide whether they got it right.
-
Agent platforms are building their own ways for deploying code to “just work” without extra steps or credentials. People are starting to expect that this process just works, without the need to sign up for other services that they’ve not used before or heard of.
Temporary accounts are built around Wrangler, our Developer Platform command-line interface (CLI) tool that lets developers bootstrap new projects, manage their configurations and resources, and deploy and update them.
Wrangler usage is widely documented online and agents know how to use it very well. But if you hadn’t yet signed in and granted Wrangler permission to your Cloudflare account, when the agent tried to deploy, it would get stuck at the sign-up and authentication step. And you might rightly ask: How do agents and LLMs know that this new –temporary flag in Wrangler exists, so that they actually use it without a human explicitly telling them to do so?
To solve this, we updated Wrangler to prompt the agent with a message that tells it about the –temporary flag:

When the agent discovers this, and then runs wrangler deploy again with the –temporary flag, Cloudflare provisions a temporary account for the agent to use, gives Wrangler an API token to work with, and provides a claim URL that the agent can give back to the human.
Make sure you’re using the latest Wrangler release, fire up your favorite coding agent, and write a prompt to deploy a “hello world” app in build mode:
Make a very simple hello world Cloudflare Worker in TypeScript and deploy it using wrangler, don't ask me questions, do the best you can
The agent will run wrangler, pick up the –temporary flag from the output messages, build your script, and deploy it instantly, no human in the loop required:

As you can see, the agent wrote the script, deployed it using the –temporary flag, curled the preview link it got from the output, and verified that the result matches the code.
This is great, but agentic coding is often not about one single deployment. A session can go through a cycle of multiple code changes. This is not a problem: the agent can iterate on the Worker script and redeploy the changes as many times as it wants (within the 60-minute claim window). Type this prompt:
Now change hello world to "hello cloudflare" and redeploy
Look at the agent changing the source code, reusing the previously created temporary account, redeploying a new version and rechecking the result:

At any point, you can claim the temporary account and make it yours permanently. When you click the claim link you will be taken to a page where you can either sign up for or sign in to Cloudflare, and then claim the temporary account that your Worker was deployed to. This includes claiming not just Workers, but resources like databases and other bindings, too.

If you do not claim these temporary accounts within 60 minutes, they will be automatically deleted.
This is just one way we’re eliminating the signup barrier for agents. We recently announced a partnership with Stripe and a new protocol we co-designed that lets agents provision Cloudflare on behalf of their users — creating an account, starting a subscription, registering a domain, and getting an API token to deploy code, with no copy-pasting tokens or entering credit card details. Last month, we collaborated with WorkOS on the launch of auth.md, which anyone can adopt, to let agents provision new accounts using well-established, existing OAuth standards.
There’s a ton going on in this space, and we’re excited to keep making it easier for agents to use Cloudflare, and for developers to make their own apps agent-ready. Temporary accounts are one more step toward frictionless agentic deployments — stay tuned for more.
Temporary accounts have some limitations, and their capabilities may change over time; check the developer documentation for more information and then go build something. Point your agent at Cloudflare, see how far it gets, and tell us what we can improve or what delights you — share what you’ve built on X or hop into the Cloudflare Community.
Eight new stable kernels for Friday
Nancy Pelosi on Democrats Entering the Gerrymandering War
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/eDaRjxOXl0M
The War of the Cow
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=1AJW1oZC7bc
Live: Nancy Pelosi on the Midterms
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=kzWFfXpIRiE
Anthropic’s Fable and the State of AI
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2026/06/anthropics-fable-and-the-state-of-ai.html
On June 9th, Anthropic released its Fable generative AI model. Three days later, the US government classified it as a dangerous munition, and used its export-control authority to prohibit any foreign nationals from accessing it. Unable to differentiate between Americans and foreigners, the company shut off access for everyone.
The government’s actions won’t help. The problem isn’t any one particular model; it’s the general trend of increasing AI capabilities. And any real solution requires the sort of collective action that just isn’t possible right now.
Fable is the constrained version of Mythos, the AI model Anthropic announced in April. Anthropic only released it to a few selected organizations, because the company claimed it was so good at finding and exploiting vulnerabilities in computer code that releasing it more generally would be dangerous.
It was an obviously self-serving announcement, and because few were able to verify Anthropic’s claims they were met with some skepticism. Those with access used Mythos to find and patch many vulnerabilities in their own software. But one UK group found the latest, already public, OpenAI model to be just as powerful.
Fable is just another incremental improvement in the years-long climb of AI capabilities. But just as important as the AI model is the “harness.” This is typically not AI. It’s ordinary computer code that interfaces with the user. It stitches together AI models, decides how and for what purposes they can be used, and gives them useful tools such as web search and the ability to run their own computer code.
When Mythos first entered limited release, there was widespread debate whether its power came from the model or the harness. With Mythos demonstrating that it was possible, the open-source community scrambled to build harnesses that could steer other AI models towards similar capabilities. Harness improvements don’t need massive data or data centers.
They largely succeeded. For example, a Prague company was able to replicate Anthropic’s few verifiable cybersecurity capabilities with a much smaller and cheaper model—and a more sophisticated harness. Last week, a group showed that multiple cheaper models harnessed in concert matches Fable’s performance.
The broader community had only a few days with Fable, but that time we learned some about its capabilities. Its difference is less the new model’s raw analytical and problem solving capabilities, and more that the model doesn’t need that sophisticated harness.
Fable requires much less expertise and detailed prompting from the human user. You can give it a difficult goal and it will figure out novel and unexpected ways to satisfy it, finding loopholes in whatever constraints you or the system have imposed on it.
“Relentlessly proactive” is how AI researcher Simon Willison described it. Another descriptor might be “creative.” Experienced AI developers have had that combination of creativity and proactivity since last year, but Fable puts it within easy reach of everyone.
In the hands of someone with a legitimate problem that needs solving, that can be an incredibly useful capability. But in the hands of someone who wants to do harm, it can be equally dangerous. AIs don’t have a moral compass in the same way that people do. They are agents of the wants and desires of the people who prompt them.
That points to the real problem with relentlessly proactive AI. In language, wants and desires are always underspecified. If I ask you to get me some coffee, you would probably pour me a cup from the coffeepot, or buy one from a nearby coffee shop.
You couldn’t buy me a pound of raw beans, or a coffee plantation. You wouldn’t order a cup of coffee for delivery next month. You wouldn’t find a nearby person, rip a cup of coffee out of their hands, and bring it to me. I wouldn’t have to specify any of the million limitations to my request; you would just know.
Human stories are filled with warnings about underspecified desires. King Midas wished that everything he touch turn to gold, forgetting to add “but not my food, drink, and daughter.” And genies are notorious for granting your wish in a way you wish they hadn’t.
The deeper point is that it’s impossible to list all limitations and restrictions, and like a malicious genie, a creative AI will find the ones you forgot. Block a database you don’t want it to have access to, and it might figure out how to bypass your control. Ask it to book a flight, and it might hack the airline because the website says the flight is sold out. Ask it to save money on your cellphone plan, and it might cancel it altogether—or get someone else to pay for it. As far as we know now AI has not done any of this yet, but you get the idea.
Malicious intent is not required. To an AI model, constraints are just things to get around and not general truisms about the world. They are creative problem solvers and natural rule breakers. They “hack” in the sense that they find and exploit loopholes.
Human systems rely on so many norms that we scarcely recognize the existence of until they are broken. AIs naturally think outside the box, because they don’t have any real conception of what the box is or why it’s there in the first place.
There is no foolproof way to prevent people from using AI models to complete harmful tasks. There is no way to prevent the models from incidentally causing harm while completing benign tasks. AI models are no longer isolated from the real world. They browse the internet and answer emails.
They trade stocks and make purchases. They control physical systems. They are, in effect, robots that affect life and property. We have no technical mechanisms to verify the integrity of an AI system. This level of capability and creativity in the hands of us untrustworthy humans will have both great and terrible results.
The problem is not unique to Anthropic. Mythos/Fable might currently be the most capable rules hacker, but more sophisticated harnesses give other models similar capabilities. And we should assume that the other frontier models are no more than a few months behind, and that open-source models are less than a year behind. At best, any ban only serves to delay the problem for a short while.
That delay might be useful if we—as a society, as a planet—would use that time to come together and figure out what to do. This isn’t a US/China arms race problem; this a species-level problem that requires coordinated action at that scale. Unfortunately, we have no mechanism to do that. I first wrote about this problem five years ago, but it was all too futuristic.
Today, when its right in front of us, there is no world government that can impose constraints on the for-profit corporations currently controlling AI models and research. The US has no appetite to effectively and even-handedly regulate those corporations, even as they do catastrophic damage to the environment, democracy, and—in this case—society in general.
This all makes an AI public option all the more necessary, and urgent. Today’s AIs can be fast, smart and secure, but only two of the three are possible for any given system. These safety tradeoffs are tightly held secrets of companies racing to beat one another, and they tell us we have to trust them. Instead, the choices and their consequences need to be brought out into the sunlight.
We should be funding open-source harnesses that balance capability and safety—that achieve useful goals without so much power—and open-source AI models whose provenance and biases are public and well understood. We have opened the AI Pandora’s box. Now we have to make the best of it.
This essay originally appeared in The Guardian.