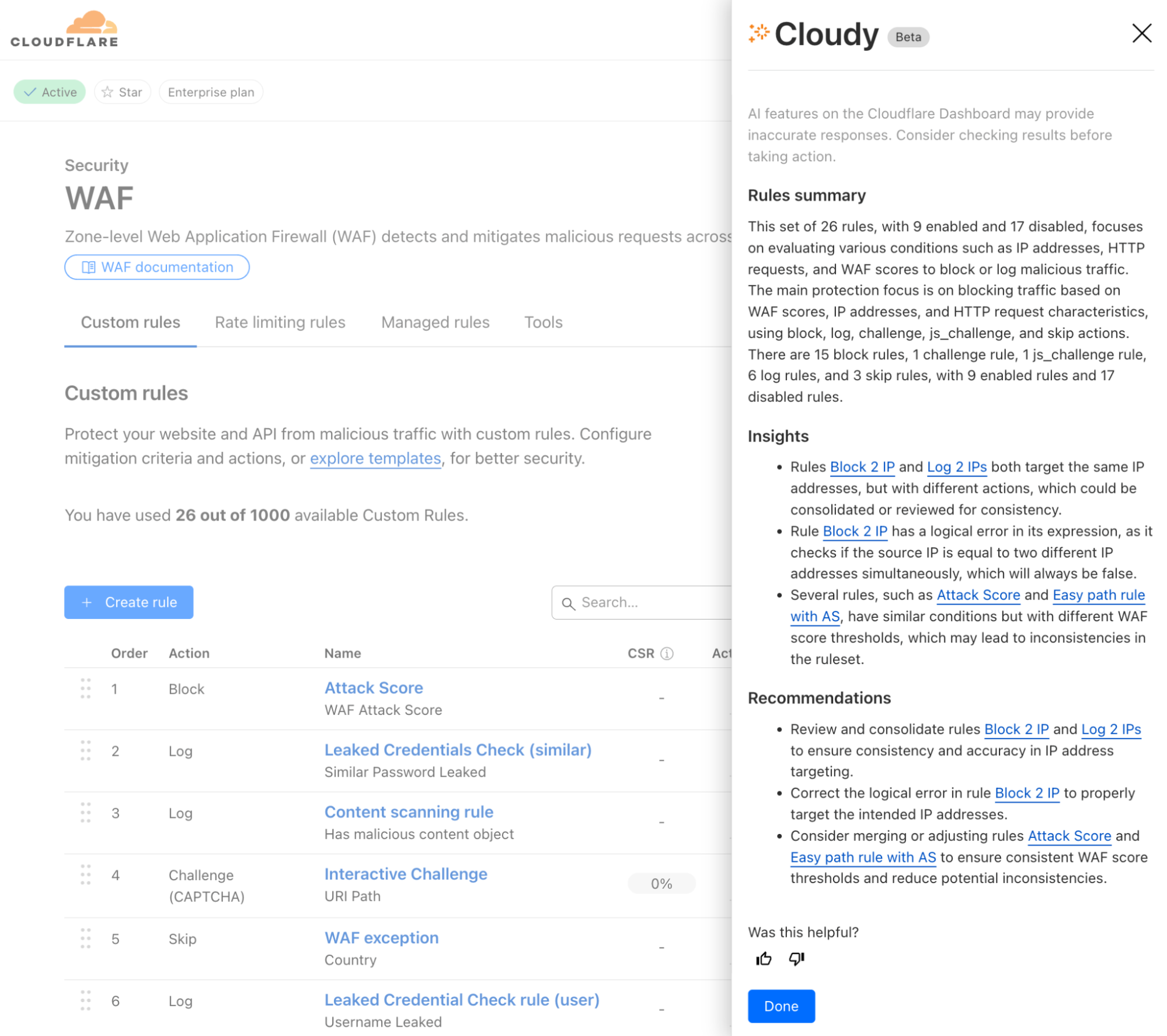
Post Syndicated from Mia Malden original https://blog.cloudflare.com/secrets-store-beta/
Every cloud platform needs a secure way to store API tokens, keys, and credentials — welcome, Cloudflare Secrets Store! Today, we are very excited to announce and launch Secrets Store in beta. We built Cloudflare Secrets Store to help our customers centralize management, improve security, and restrict access to sensitive values on the Cloudflare platform.
Wherever secrets exist at Cloudflare – from our developer platform, to AI products, to Cloudflare One – we’ve built a centralized platform that allows you to manage them in one place.
We are excited to integrate Cloudflare Secrets Store with the whole portfolio of Cloudflare products, starting today with Cloudflare Workers.
If you have a secret you want to use across multiple Workers, you can now use the Cloudflare Secrets Store to do so. You can spin up your store from the dashboard or by using Wrangler CLI:
wrangler secrets-store store create <name>
Then, create a secret:
wrangler secrets-store secret create <store-id>
Once the secret is created, you can specify the binding to deploy in a Worker immediately.
secrets_store_secrets = [
{ binding = "'open_AI_KEY'", store_id= "abc123", secret_name = "open_AI_key"},
]
Last step – you can now reference the secret in code!
const openAIkey = await env.open_AI_key.get();
Environment variables and secrets were first launched in Cloudflare Workers back in 2020. Now, there are millions of local secrets deployed on Workers scripts. However, these are not all unique. Many of these secrets have duplicate values within a customer’s account. For example, a customer may reuse the same API token in ten different scripts, but since each secret is accessible only on the per-Worker level, that value would be stored in ten different local secrets. Plus, if you need to roll that secret, there is no seamless way to do so that preserves a single source of truth.
With thousands of secrets duplicated across scripts — each requiring manual creation and updates — scoping secrets to individual Workers has created significant friction for developers. Additionally, because Workers secrets are created and deployed locally, any secret is accessible – in terms of creation, editing, and deletion – to anyone who has access to that script.
Now, you can create account-level secrets and variables that can be shared across all Workers scripts, centrally managed and protected within the Secrets Store.
The most important feature of a Secret Store, of course, is to make sure that your secrets are stored securely.
Once the secret is created, its value will not be readable by anyone, be it developers, admins, or Cloudflare employees. Only the permitted service will be able to use the value at runtime.
This is why the first thing that happens when you deploy a new secret to Cloudflare is encrypting the secret prior to storing it in our database. We make sure your tokens are safe and protected using a two-level key hierarchy, where the root key never leaves a secure system. This is done by making use of DEKs (Data Encryption Keys) to encrypt your secrets and a separate KEK (Key Encryption Key) to encrypt the DEKs themselves. The data encryption keys are refreshed frequently, making the possibility and impact scope of a single DEK exposure very small. In the future, we will introduce periodic key rotations for our KEK and also provide a way for customers to have their own account-specific DEKs.
After the secrets are encrypted, there are two permissions checks when deploying a secret from the Secrets Store to a Worker. First, the user must have sufficient permissions to create the binding. Second, when the Worker makes a fetch call to retrieve the secret value, we verify that the Worker has an appropriate binding to access that secret.
The secrets are automatically propagated across our network using Quicksilver – so that every secret is on every server– to ensure they’re immediately accessible and ready for the Worker to use. Wherever your Worker is deployed, your secrets will be, too.
If you’d like to use a secret to secure your AI model keys before passing on to AI Gateway:
export default {
async fetch(request, env, ctx) {
const prompt = "Write me a pun about Cloudflare";
const openAIkey = await env.open_AI_key.get();
const response = await fetch("https://gateway.ai.cloudflare.com/v1/YOUR_ACCOUNT_TAG/openai/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${openAIkey}`,
},
body: JSON.stringify({
model: "gpt-3.5-turbo",
messages: [
{ role: "user", content: prompt }
],
temperature: 0.8,
max_tokens: 100,
}),
});
const data = await response.json();
const answer = data.choices?.[0]?.message?.content || "No pun found 😢";
return new Response(answer, {
headers: { "Content-Type": "text/plain" },
});
}
};
Now, a secret’s value can be updated once and applied everywhere — but not by everyone. Cloudflare Secrets Store uses role-based access control (RBAC) to ensure that only those with permission can view, create, edit, or delete secrets. Additionally, any changes to the Secrets Store are recorded in the audit logs, allowing you to track changes.
Whereas per-Worker secrets are tied to the Workers account role, meaning that anyone who can modify the Worker can modify the secret, access to account-level secrets is restricted with more granular controls. This allows for differentiation between security admins who manage secrets and developers who use them in the code.
|
Secrets Store Admin |
Secrets Store Reporter |
Secrets Store Deployer |
|
|
Create secrets |
✓ |
||
|
Update secrets |
✓ |
||
|
Delete secrets |
✓ |
||
|
View secrets metadata |
✓ |
✓ |
✓ |
|
Deploy secrets (i.e. bind to a Worker) |
|
✓ |
Each secret can also be scoped to a particular Cloudflare product to ensure the value is only used where it is meant to be. Today, the secrets are restricted to Workers by default, but once the Secrets Store supports multiple products, you’ll be able to specify where the secret can be used (e.g. “I only want this secret to be accessible through Firewall Rules”).
Secrets Store will support all secrets across Cloudflare, including:
-
Cloudflare Access has service tokens to authenticate against your Zero Trust policies.
-
Transform Rules require sensitive values in the request headers to grant access or pass onto to something else.
-
AI Gateway relies upon secret keys from each provider to position Cloudflare between the end user and the AI model.
…and more!
Right now, to use a secret within a Worker, you have to create a binding for that specific secret. In the future, we’ll allow you to create a binding to the store itself so that the Worker can access any secret within that store. We’ll also allow customers to create multiple secret stores within their account so that they can manage secrets by group when creating access policies.
Every Cloudflare account can create up to twenty secrets for free. We’re currently finalizing our pricing and will publish more details for each tier soon.
We’re thrilled to get Secrets Store into our customers’ hands and are excited to continue building it out to support more products and features as we work towards making Secrets Store GA.
Cloudflare Secrets Store with the Workers integration is available for all customers via UI and API today. For instructions to get started in the Cloudflare dashboard, take a look at our developer documentation.
If you have any feedback or feature requests, we’d love for you to share those with us on this Google form.