Post Syndicated from Jon Levine original http://blog.cloudflare.com/introducing-timing-insights/


If you care about the performance of your website or APIs, it’s critical to understand why things are slow.
Today we're introducing new analytics tools to help you understand what is contributing to "Time to First Byte" (TTFB) of Cloudflare and your origin. TTFB is just a simple timer from when a client sends a request until it receives the first byte in response. Timing Insights breaks down TTFB from the perspective of our servers to help you understand what is slow, so that you can begin addressing it.
But wait – maybe you've heard that you should stop worrying about TTFB? Isn't Cloudflare moving away from TTFB as a metric? Read on to understand why there are still situations where TTFB matters.
Why you may need to care about TTFB
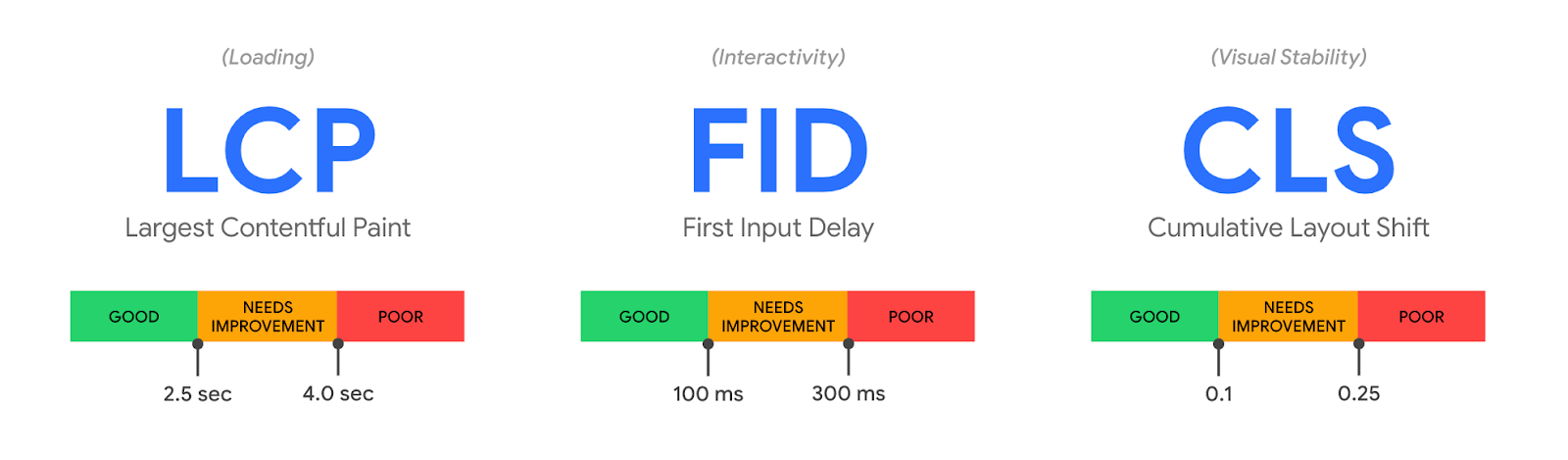
It's true that TTFB on its own can be a misleading metric. When measuring web applications, metrics like Web Vitals provide a more holistic view into user experience. That's why we offer Web Analytics and Lighthouse within Cloudflare Observatory.
But there are two reasons why you still may need to pay attention to TTFB:
1. Not all applications are websites
More than half of Cloudflare traffic is for APIs, and many customers with API traffic don't control the environments where those endpoints are called. In those cases, there may not be anything you can monitor or improve besides TTFB.
2. Sometimes TTFB is the problem
Even if you are measuring Web Vitals metrics like LCP, sometimes the reason your site is slow is because TTFB is slow! And when that happens, you need to know why, and what you can do about it.
When you need to know why TTFB is slow, we’re here to help.
How Timing Insights can help
We now expose performance data through our GraphQL Analytics API that will let you query TTFB performance, and start to drill into what contributes to TTFB.
Specifically, customers on our Pro, Business, and Enterprise plans can now query for the following fields in the httpRequestsAdaptiveGroups dataset:
Time to First Byte (edgeTimeToFirstByteMs)
What is the time elapsed between when Cloudflare started processing the first byte of the request received from an end user, until when we started sending a response?
Origin DNS lookup time (edgeDnsResponseTimeMs)
If Cloudflare had to resolve a CNAME to reach your origin, how long did this take?
Origin Response Time (originResponseDurationMs)
How long did it take to reach, and receive a response from your origin?
We are exposing each metric as an average, median, 95th, and 99th percentiles (i.e. P50 / P95 / P99).
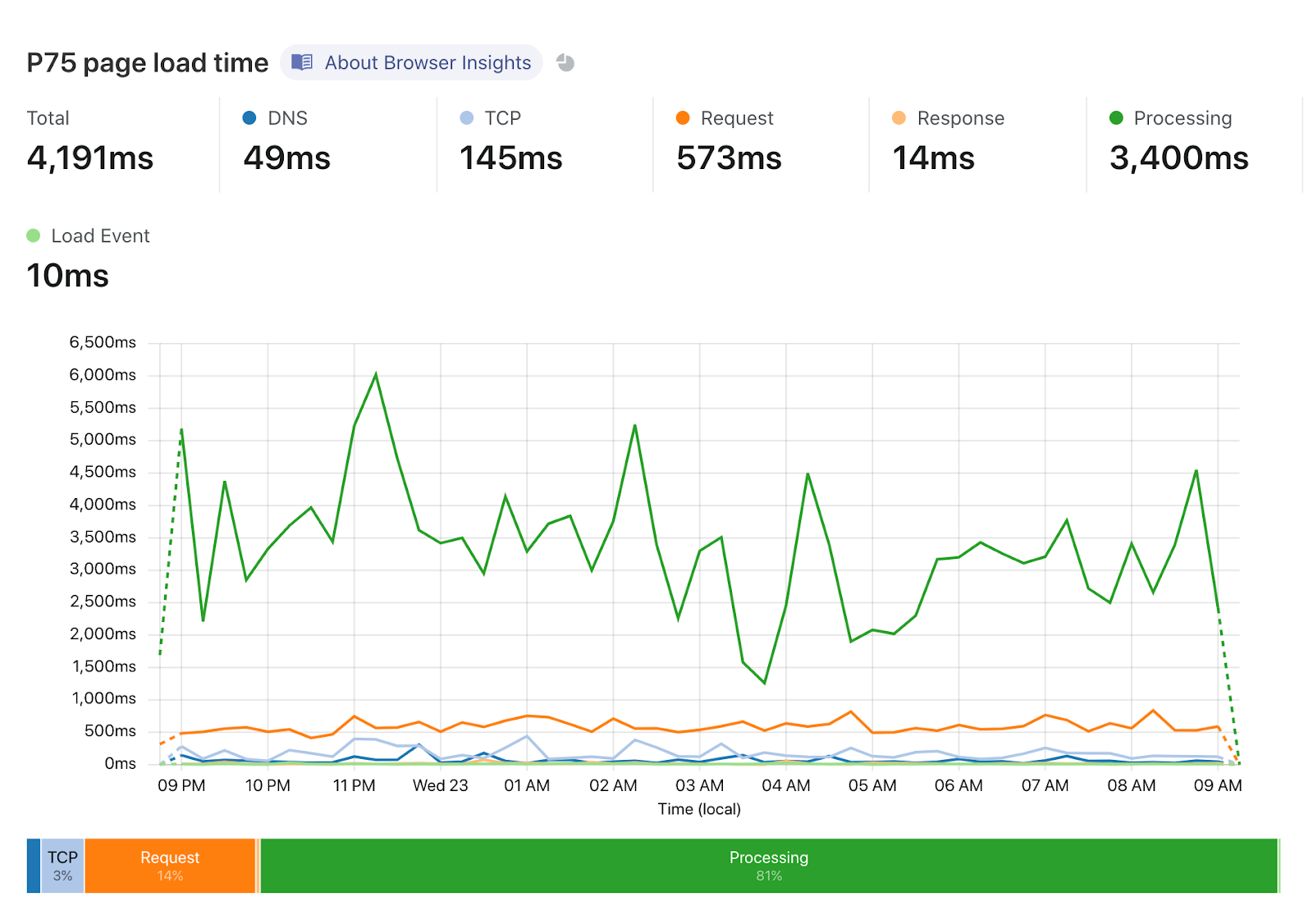
The httpRequestAdaptiveGroups dataset powers the Traffic analytics page in our dashboard, and represents all of the HTTP requests that flow through our network. The upshot is that this dataset gives you the ability to filter and “group by” any aspect of the HTTP request.
An example of how to use Timing Insights
Let’s walk through an example of how you’d actually use this data to pin-point a problem.
To start with, I want to understand the lay of the land by querying TTFB at various quantiles:
query TTFBQuantiles($zoneTag: string) {
viewer {
zones(filter: {zoneTag: $zoneTag}) {
httpRequestsAdaptiveGroups {
quantiles {
edgeTimeToFirstByteMsP50
edgeTimeToFirstByteMsP95
edgeTimeToFirstByteMsP99
}
}
}
}
}
Response:
{
"data": {
"viewer": {
"zones": [
{
"httpRequestsAdaptiveGroups": [
{
"quantiles": {
"edgeTimeToFirstByteMsP50": 32,
"edgeTimeToFirstByteMsP95": 1392,
"edgeTimeToFirstByteMsP99": 3063,
}
}
]
}
]
}
}
}
This shows that TTFB is over 1.3 seconds at P95 – that’s fairly slow, given that best practices are for 75% of pages to finish rendering within 2.5 seconds, and TTFB is just one component of LCP.
If I want to dig into why TTFB, it would be helpful to understand which URLs are slowest. In this query I’ll filter to that slowest 5% of page loads, and now look at the aggregate time taken – this helps me understand which pages contribute most to slow loads:
query slowestURLs($zoneTag: string, $filter:filter) {
viewer {
zones(filter: {zoneTag: $zoneTag}) {
httpRequestsAdaptiveGroups(limit: 3, filter: {edgeTimeToFirstByteMs_gt: 1392}, orderBy: [sum_edgeTimeToFirstByteMs_DESC]) {
sum {
edgeTimeToFirstByteMs
}
dimensions {
clientRequestPath
}
}
}
}
}
Response:
{
"data": {
"viewer": {
"zones": [
{
"httpRequestsAdaptiveGroups": [
{
"dimensions": {
"clientRequestPath": "/api/v2"
},
"sum": {
"edgeTimeToFirstByteMs": 1655952
}
},
{
"dimensions": {
"clientRequestPath": "/blog"
},
"sum": {
"edgeTimeToFirstByteMs": 167397
}
},
{
"dimensions": {
"clientRequestPath": "/"
},
"sum": {
"edgeTimeToFirstByteMs": 118542
}
}
]
}
]
}
}
}
Based on this query, it looks like the /api/v2 path is most often responsible for these slow requests. In order to know how to fix the problem, we need to know why these pages are slow. To do this, we can query for the average (mean) DNS and origin response time for queries on these paths, where TTFB is above our P95 threshold:
query originAndDnsTiming($zoneTag: string, $filter:filter) {
viewer {
zones(filter: {zoneTag: $zoneTag}) {
httpRequestsAdaptiveGroups(filter: {edgeTimeToFirstByteMs_gt: 1392, clientRequestPath_in: [$paths]}) {
avg {
originResponseDurationMs
edgeDnsResponseTimeMs
}
}
}
}
Response:
{
"data": {
"viewer": {
"zones": [
{
"httpRequestsAdaptiveGroups": [
{
"average": {
"originResponseDurationMs": 4955,
"edgeDnsResponseTimeMs": 742,
}
}
]
}
]
}
}
}
According to this, most of the long TTFB values are actually due to resolving DNS! The good news is that’s something we can fix – for example, by setting longer TTLs with my DNS provider.
Conclusion
Coming soon, we’ll be bringing this to Cloudflare Observatory in the dashboard so that you can easily explore timing data via the UI.
And we’ll be adding even more granular metrics so you can see exactly which components are contributing to high TTFB. For example, we plan to separate out the difference between origin “connection time” (how long it took to establish a TCP and/or TLS connection) vs “application response time” (how long it took an HTTP server to respond).
We’ll also be making improvements to our GraphQL API to allow more flexible querying – for example, the ability to query arbitrary percentiles, not just 50th, 95th, or 99th.
Start using the GraphQL API today to get Timing Insights, or hop on the discussion about our Analytics products in Discord.