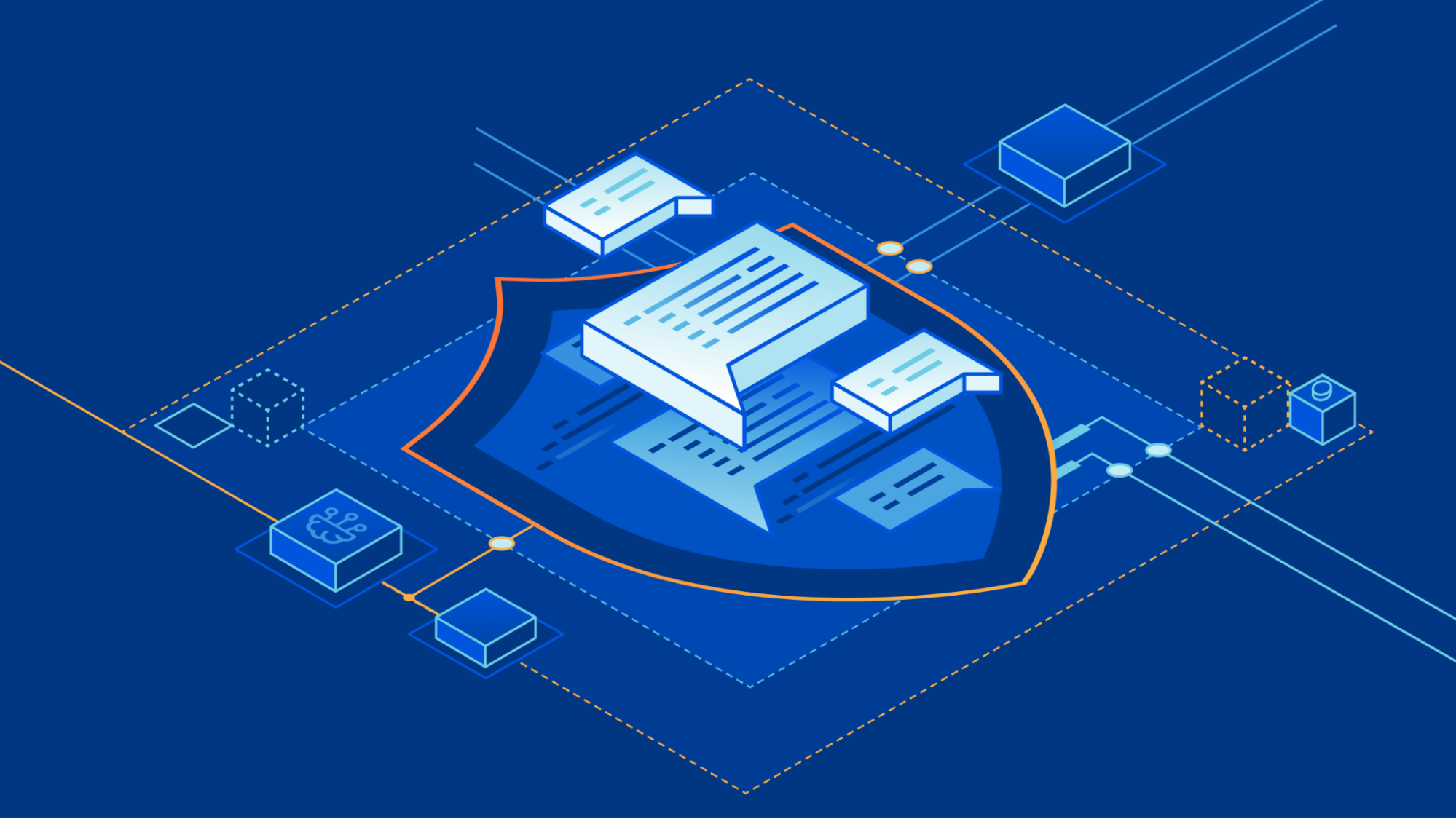
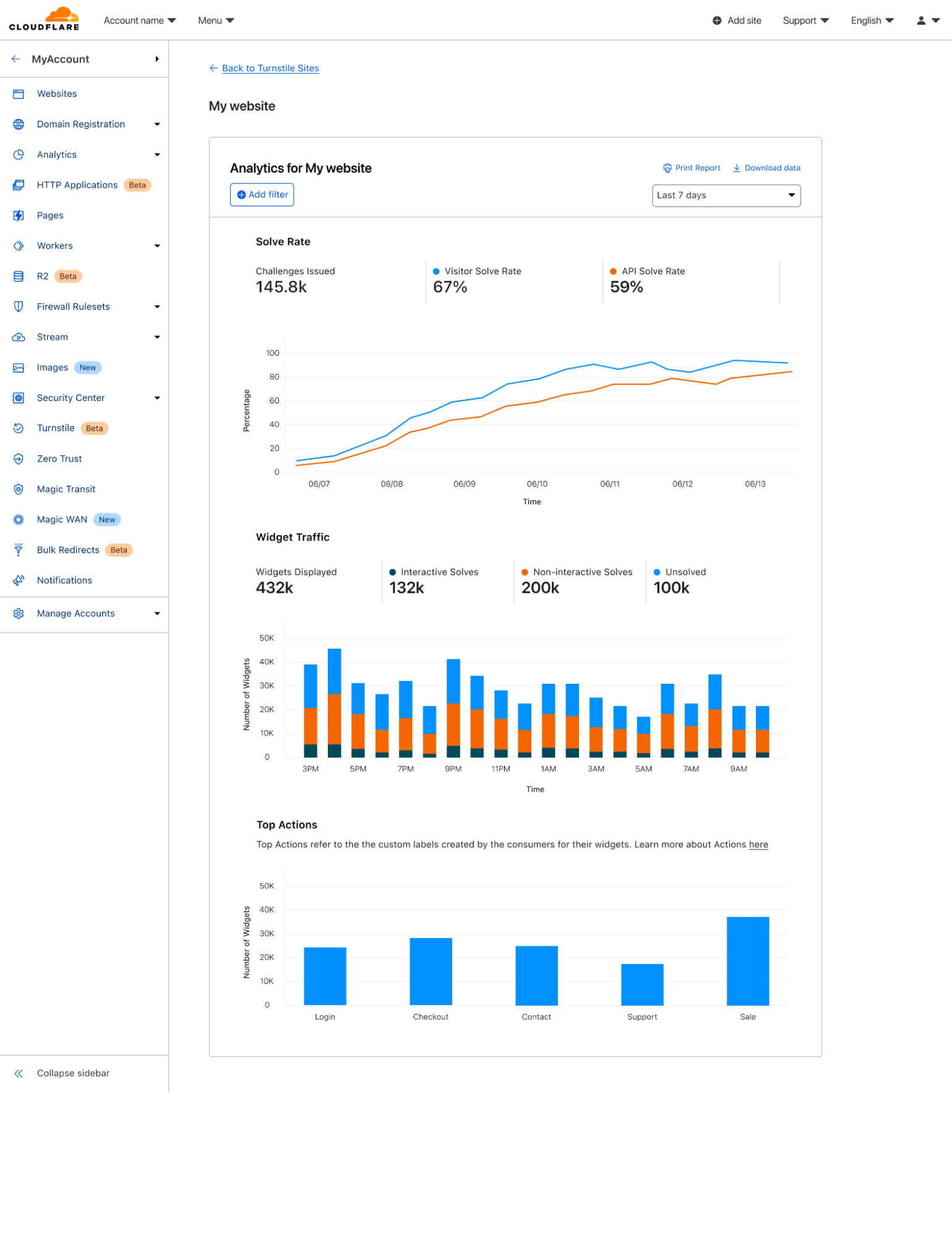
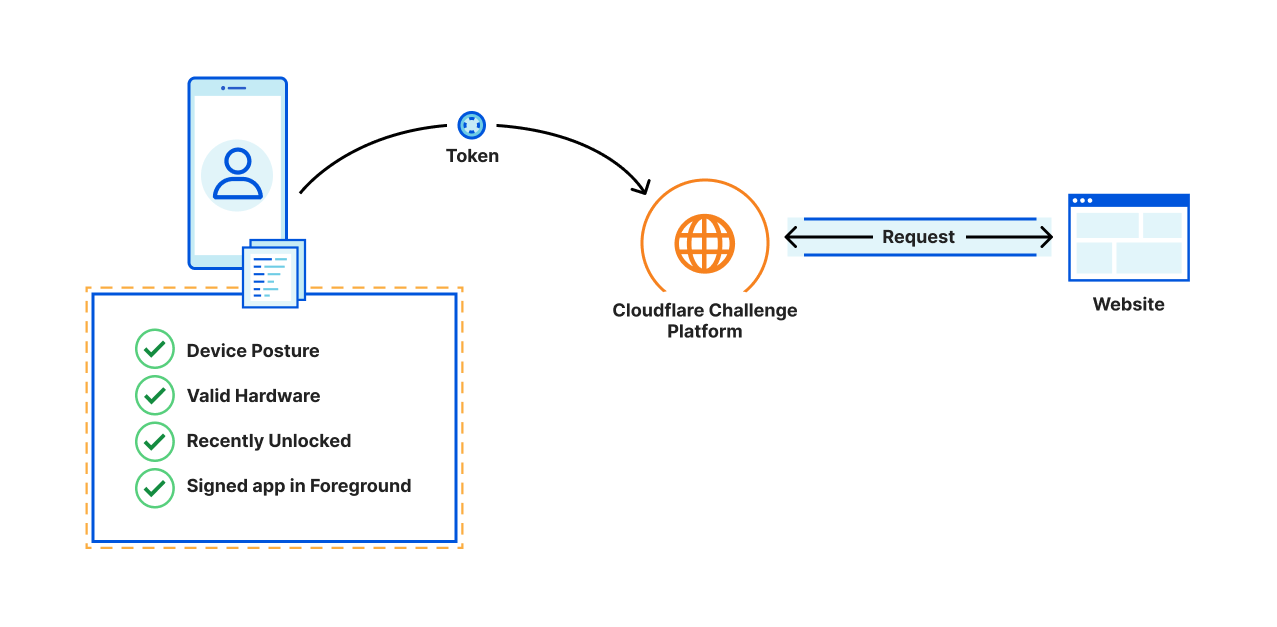
Today, we’re excited to announce AI Labyrinth, a new mitigation approach that uses AI-generated content to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives. When you opt in, Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.
AI Labyrinth is available on an opt-in basis to all customers, including the Free plan.
Using Generative AI as a defensive weapon
AI-generated content has exploded, reportedly accounting for four of the top 20 Facebook posts last fall. Additionally, Medium estimates that 47% of all content on their platform is AI-generated. Like any newer tool it has both wonderful and malicious uses.
At the same time, we’ve also seen an explosion of new crawlers used by AI companies to scrape data for model training. AI Crawlers generate more than 50 billion requests to the Cloudflare network every day, or just under 1% of all web requests we see. While Cloudflare has several tools for identifying and blocking unauthorized AI crawling, we have found that blocking malicious bots can alert the attacker that you are on to them, leading to a shift in approach, and a never-ending arms race. So, we wanted to create a new way to thwart these unwanted bots, without letting them know they’ve been thwarted.
To do this, we decided to use a new offensive tool in the bot creator’s toolset that we haven’t really seen used defensively: AI-generated content. When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them. But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.
As an added benefit, AI Labyrinth also acts as a next-generation honeypot. No real human would go four links deep into a maze of AI-generated nonsense. Any visitor that does is very likely to be a bot, so this gives us a brand-new tool to identify and fingerprint bad bots, which we add to our list of known bad actors. Here’s how we do it…
How we built the labyrinth
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
To generate convincing human-like content, we used Workers AI with an open source model to create unique HTML pages on diverse topics. Rather than creating this content on-demand (which could impact performance), we implemented a pre-generation pipeline that sanitizes the content to prevent any XSS vulnerabilities, and stores it in R2 for faster retrieval. We found that generating a diverse set of topics first, then creating content for each topic, produced more varied and convincing results. It is important to us that we don’t generate inaccurate content that contributes to the spread of misinformation on the Internet, so the content we generate is real and related to scientific facts, just not relevant or proprietary to the site being crawled.
This pre-generated content is seamlessly integrated as hidden links on existing pages via our custom HTML transformation process, without disrupting the original structure or content of the page. Each generated page includes appropriate meta directives to protect SEO by preventing search engine indexing. We also ensured that these links remain invisible to human visitors through carefully implemented attributes and styling. To further minimize the impact to regular visitors, we ensured that these links are presented only to suspected AI scrapers, while allowing legitimate users and verified crawlers to browse normally.
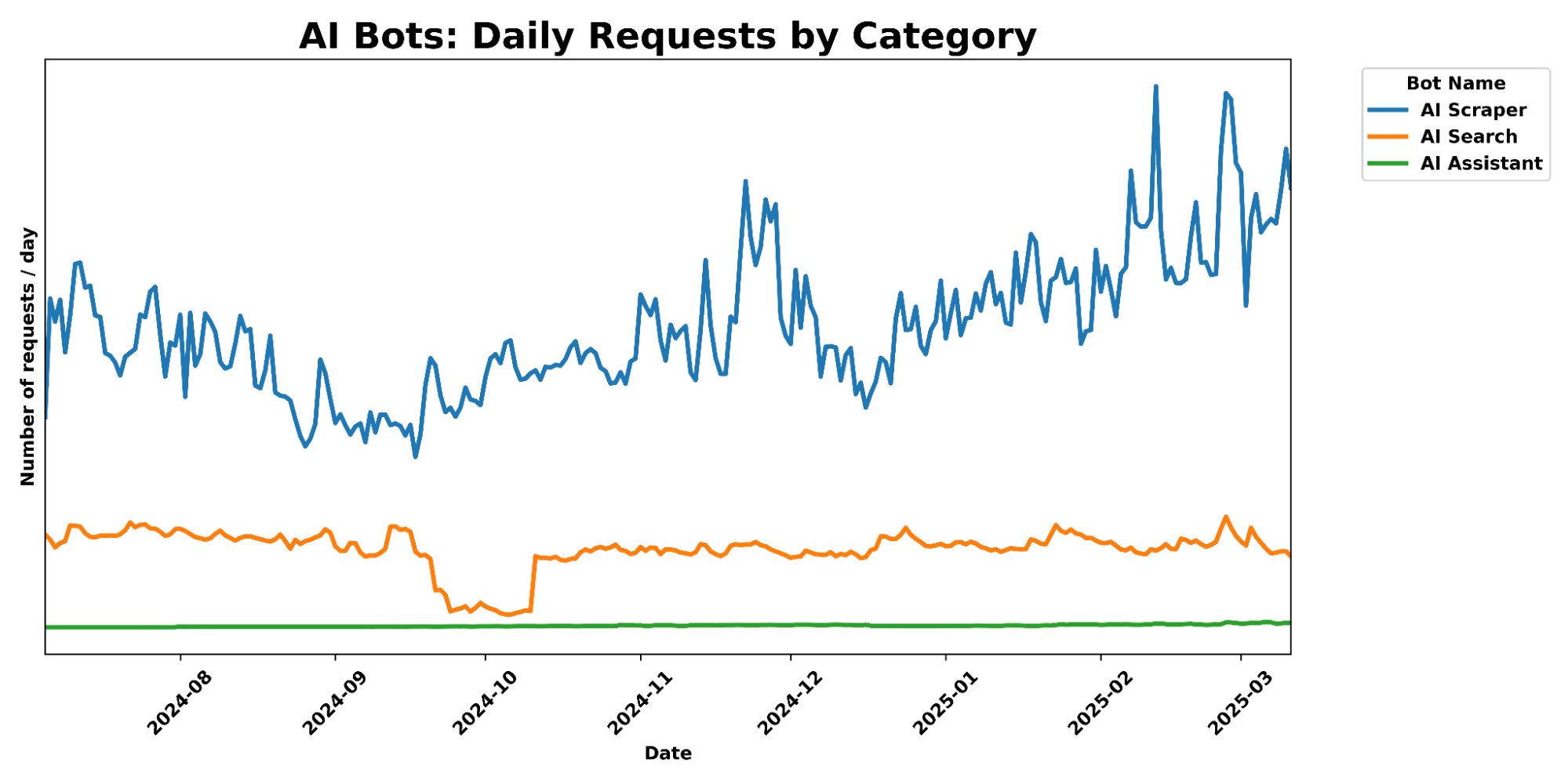
A graph of daily requests over time, comparing different categories of AI Crawlers.
What makes this approach particularly effective is its role in our continuously evolving bot detection system. When these links are followed, we know with high confidence that it’s automated crawler activity, as human visitors and legitimate browsers would never see or click them. This provides us with a powerful identification mechanism, generating valuable data that feeds into our machine learning models. By analyzing which crawlers are following these hidden pathways, we can identify new bot patterns and signatures that might otherwise go undetected. This proactive approach helps us stay ahead of AI scrapers, continuously improving our detection capabilities without disrupting the normal browsing experience.
By building this solution on our developer platform, we’ve created a system that serves convincing decoy content instantly while maintaining consistent quality – all without impacting your site’s performance or user experience.
How to use AI Labyrinth to stop AI crawlers
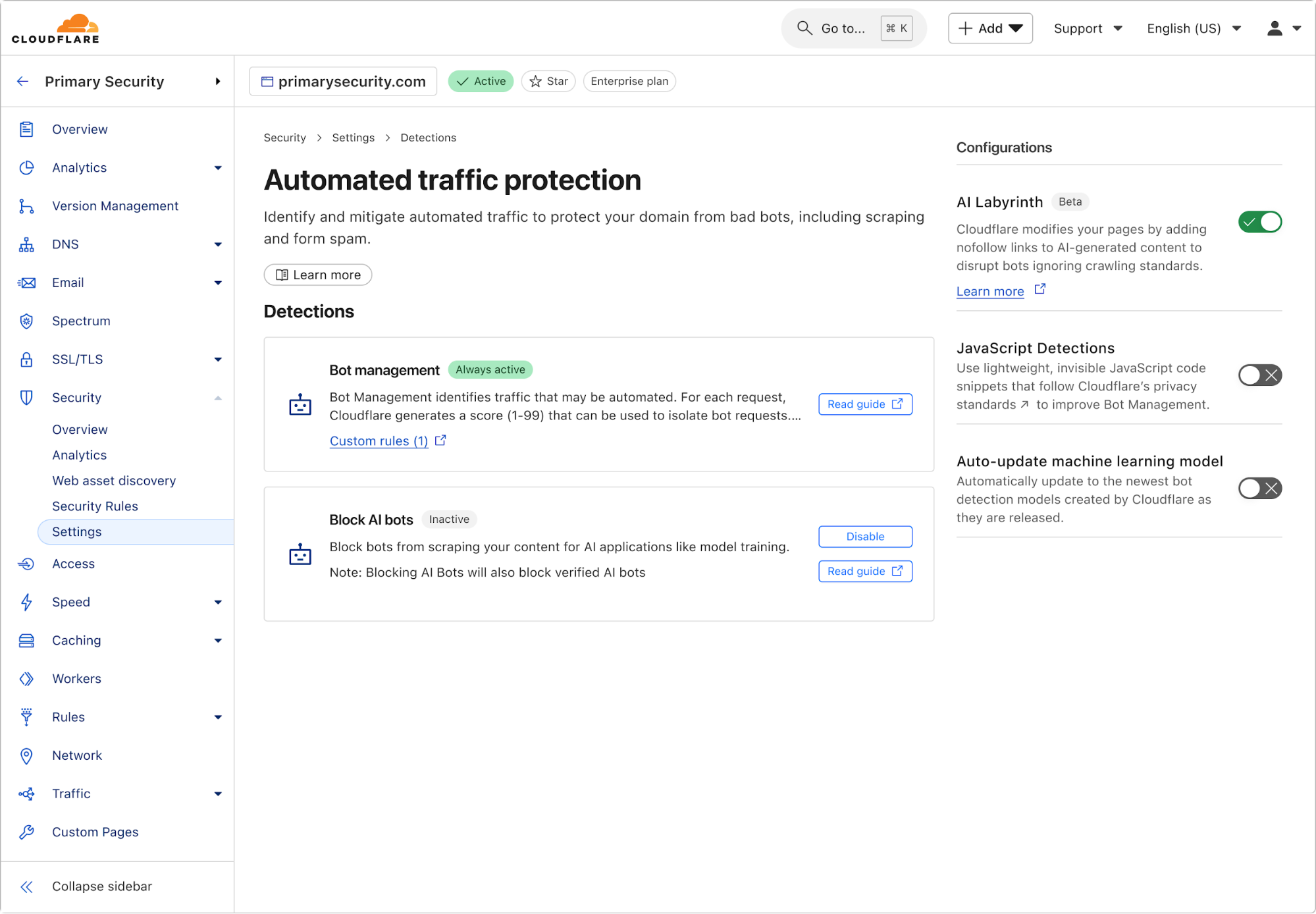
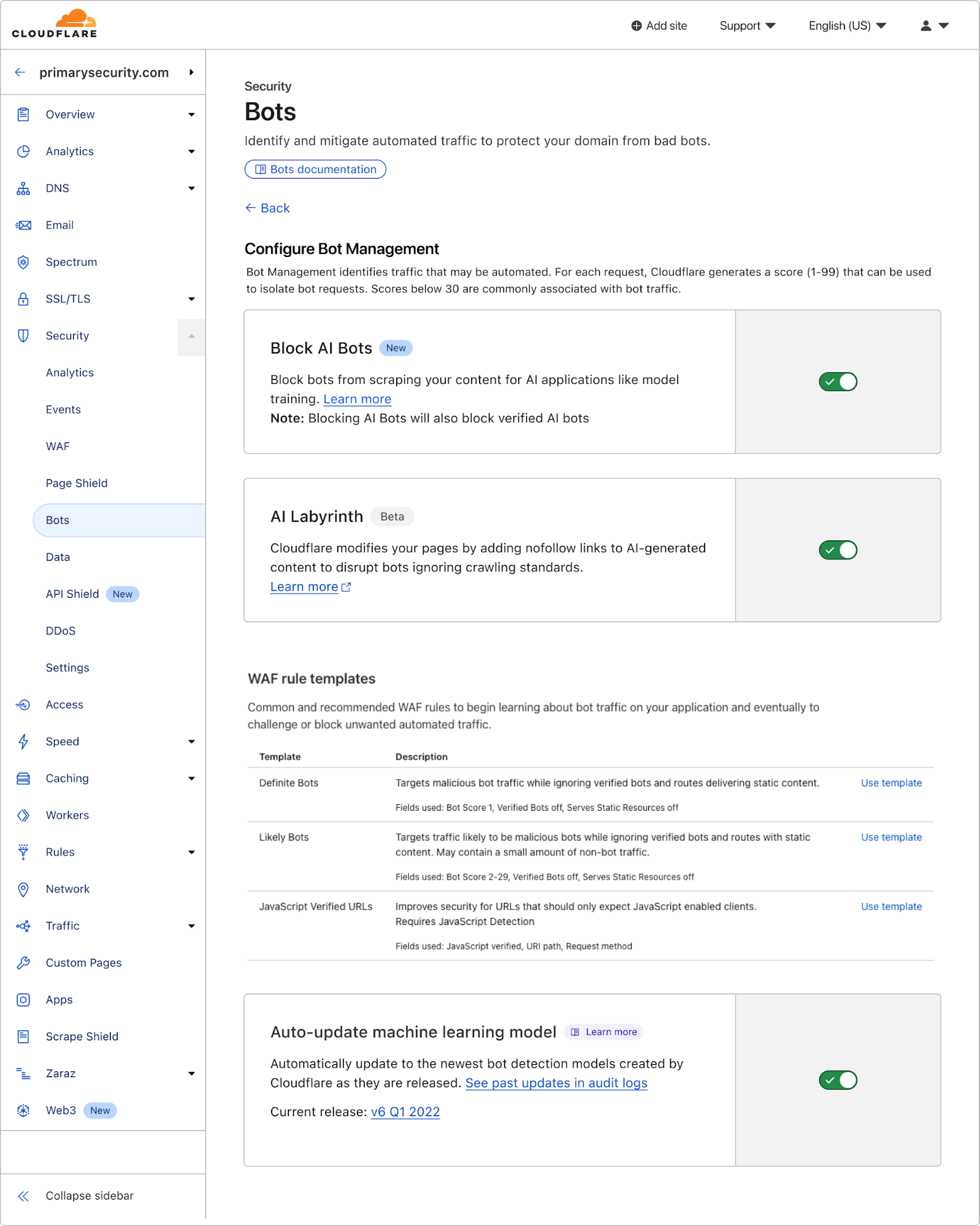
Enabling AI Labyrinth is simple and requires just a single toggle in your Cloudflare dashboard. Navigate to the bot management section within your zone, and toggle the new AI Labyrinth setting to on:
Once enabled, the AI Labyrinth begins working immediately with no additional configuration needed.
AI honeypots, created by AI
The core benefit of AI Labyrinth is to confuse and distract bots. However, a secondary benefit is to serve as a next-generation honeypot. In this context, a honeypot is just an invisible link that a website visitor can’t see, but a bot parsing HTML would see and click on, therefore revealing itself to be a bot. Honeypots have been used to catch hackers as early as the late 1986 Cuckoo’s Egg incident. And in 2004, Project Honeypot was created by Cloudflare founders (prior to founding Cloudflare) to let everyone easily deploy free email honeypots, and receive lists of crawler IPs in exchange for contributing to the database. But as bots have evolved, they now proactively look for honeypot techniques like hidden links, making this approach less effective.
AI Labyrinth won’t simply add invisible links, but will eventually create whole networks of linked URLs that are much more realistic, and not trivial for automated programs to spot. The content on the pages is obviously content no human would spend time-consuming, but AI bots are programmed to crawl rather deeply to harvest as much data as possible. When bots hit these URLs, we can be confident they aren’t actual humans, and this information is recorded and automatically fed to our machine learning models to help improve our bot identification. This creates a beneficial feedback loop where each scraping attempt helps protect all Cloudflare customers.
What’s next
This is only the first iteration of using generative AI to thwart bots for us. Currently, while the content we generate is convincingly human, it won’t conform to the existing structure of every website. In the future, we’ll continue to work to make these links harder to spot and make them fit seamlessly into the existing structure of the website they’re embedded in. You can help us by opting in now.
Today, we’re excited to announce that any Cloudflare user, on any plan, can choose specific categories of bots that they want to allow or block, including AI crawlers.
As the popularity of generative AI has grown, content creators and policymakers around the world have started to ask questions about what data AI companies are using to train their models without permission. As with all new innovative technologies, laws will likely need to evolve to address different parties' interests and what’s best for society at large. While we don’t know how it will shake out, we believe that website operators should have an easy way to block unwanted AI crawlers and to also let AI bots know when they are permitted to crawl their websites.
The good news is that Cloudflare already automatically stops scraper bots today. But we want to make it even easier for customers to be sure they are protected, see how frequently AI scrapers might be visiting their sites, and respond to them in more targeted ways. We also recognize that not all AI crawlers are the same and that some AI companies are looking for clear instructions for when they should not crawl a public website.
Crawler bots are nothing new. Cloudflare already protects you from scraping today.
Web crawlers have been around for a long time. The first, called World Wide Web Wanderer, was developed back in 1993 to measure the size of the web by counting the total number of accessible web pages. This technique led directly to the creation of the first popular search engine, WebCrawler, in 1994.
And still today, the most common use of a web crawler is for a search engine: Google’s GoogleBot. To provide the most relevant results for searches, crawlers like GoogleBot typically start by visiting web pages and retrieving the HTML content. Search engine operators predefine how much of the crawled HTML files is necessary for indexing, and then the files will be parsed to extract components like text, images, metadata, and links. This extracted data will then be stored in a structured format back on Google’s servers. Extracted links (URLs) are the key to how the crawlers discover new websites. The links that were present in the HTML files are added to a queue of URLs for the crawlers to visit and parse. And URLs are pretty easily spread around the Internet making it easy for crawlers to discover new sites. It can even be a URL that appeared in a referrer header that was stored and published by another web server. This process of following links, parsing, and storing data is recursively repeated allowing search engines to map out the web. All this collected data is then indexed to allow for efficient searching and retrieval of information.
While search engine crawler operations are generally beneficial for a site owner to get their site discovered, there are bot operators that use similar techniques for more malicious purposes such as price scraping to undercut competitor pricing or theft of copyrighted material such as images.
The techniques deployed by AI crawlers are no different. Just like a search engine crawler, they’ll parse HTML content and follow extracted URLs to gather available information. But instead of using it to index the web, this content will be applied as training data for their ML models.
Along with our bot detection tools, we also have a Verified Bot directory that allows responsible and necessary bots, like GoogleBot, to register to be segmented into their own separate detections (fill out a request here if you have a bot you think should be added). We’ve added new functionality to that directory to give our customers more control.
Available now: segment known bots with flexibility and precision
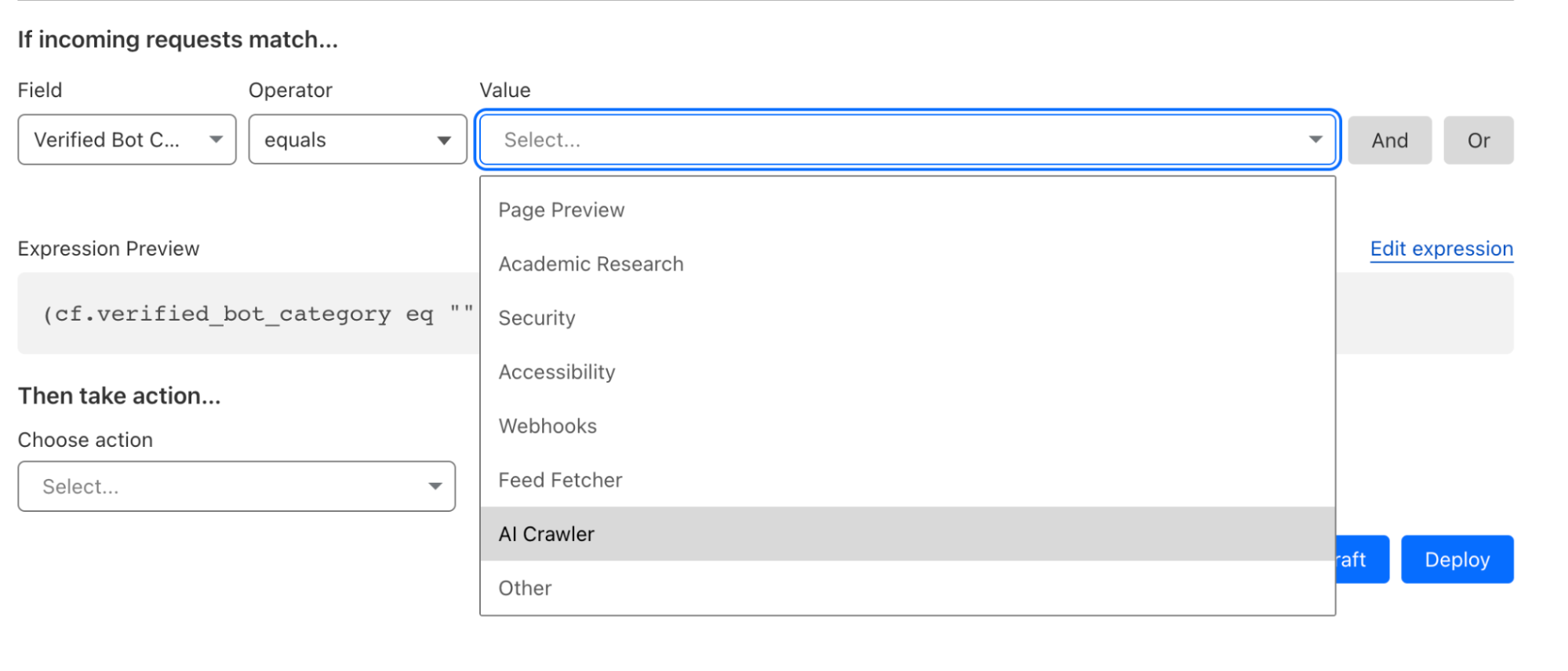
Our new Verified Bot categories are now available in the Cloudflare Rules Engine and Workers. With this granular bot categorization, Cloudflare users get better bot segmentation, and can choose specific responses to specific types of bots. To take advantage of these new bot categories, simply log in to the Cloudflare dash, go to the WAF tab, create a rule, and choose one of the Verified Bot sub categories as the Field.
The new categories include:
Search Engine Crawler,
Aggregator,
AI Crawler,
Page Preview,
Advertising
Academic Research,
Accessibility,
Feed Fetcher,
Security,
Webhooks.
You can also view all the available categories using the Cloudflare API.
More targeted responses can be useful in a variety of situations. A few examples include:
If you are a content creator, and you’re concerned about your work being reproduced by AI services, you can block AI bots we have cataloged in a simple firewall rule, while still allowing search engine crawlers to index your site.
If your content is frequently shared on social media, you may want to use Workers to serve a simplified version of the page to Page Preview services, like the services that X (formerly Twitter), Discord and Slack are using to render a thumbnail version of a web page.
If you run an online store that processes payments through webhooks API, you can harden your site’s security by only allowing verified webhooks services to make a request to that API endpoint.
If you are using Cloudflare’s Load Balancing service and have limited in-region capacity, you can use Custom Rules for Load Balancing to send all bots except Search Engine Crawlers to a backup pool, prioritizing critical visitors over non-critical automated services.
Above all, these new categories give you, the website owner, complete, granular control over not only whether bots can visit your site, but what specific types of bots can and can’t do. For those of you that simply don’t want any bots, no problem, you don’t have to make any changes. Your existing rules that reference bot score or our Verified bots change will not be impacted at all.
More than just blocking, encouraging good behavior to make the Internet better
At Cloudflare, we have a history of working with good bot operators (like GoogleBot), who respect Internet norms and best practices, to access the websites that want to allow them. We want to encourage good behavior by AI crawlers as well, so we have developed a set of criteria that will allow us to tag respectful AI bots differently. In order to be tagged as a respectful AI bot, AI crawler must take the following steps to show they are acting in good faith:
Maintain a public web page committing to respect robots.txt.
Set IPs that are used solely by the bot and are verifiable via a public IP list, reverse DNS lookup, or ASN ownership.
Maintain a unique and stable user-agent to represent the bot.
Respect a robots.txt entry for your user-agent as well as wild-card entries.
Requiring all AI crawlers to respect crawl-delay, which has previously been a nonstandard extension.
These steps are an expansion of our existing Verified Bots policy which you can see here. When a bot creator has performed the steps above, we perform additional evaluation to confirm we’ve seen no suspicious activity from the bot. We check the bot's documentation, check internal dashboards to ensure traffic is appropriately distributed across the sites we protect, and check whether the bot hits suspicious endpoints like logins, or has exhibited other malicious activity.
While new AI bots can be scary, this industry is evolving incredibly quickly, and you may want to handle different bots differently in the future. We think it's important to distinguish between bot operators that are being respectful and those that are trying to be deceptive.
It should be easy for everyone to deal with AI crawlers, not just Cloudflare customers
While we’re glad we’ve made it easy for Cloudflare customers to manage AI Crawlers, not everyone uses Cloudflare. We want the Internet to be better for everyone. So we think that the industry should adopt a new protocol specifically for handling AI crawlers.
In the long run, AI bots respecting a new exclusion protocol gives website operators the most flexibility to change how they want to handle them over time. We think the key is to make it easier for customers to block these bots, or to allow them in some cases if they choose on their entire website or only on specific pages.
You’ll be hearing more about this from us in the next few months, so stay tuned.
But we didn’t want to wait to make sure our customers are protected, so we're making our new bot categories available today!
What’s next?
The first and most important step for us was to make it clear to every Cloudflare customer that you are already protected from AI crawlers you don’t want. Second, we wanted to give you granular control and make it easy to allow those crawlers, or other bots, that you deem useful for your site.
We encourage everyone to try out our new Verified Bot categories today. Log in to the Cloudflare dash, go to the WAF tab, create a rule, and choose one of the Verified Bot sub categories as the `Field`. And remember, this functionality is available to all Cloudflare customers, even on free plans.
Having launched Verified Bot categories, in the next few months we’ll be adding more detailed reporting based on the bot category, to better help you visualize the frequency at which different categories of bots are visiting your site over time. As AI continues to evolve at a breakneck pace, AI Crawlers are only going to become a larger part of the Internet. As that evolution happens, Cloudflare will be there every step of the way to help you evolve the way you deal with them.
I remember when the first iPhone was announced in 2007. This was NOT an iPhone as we think of one today. It had warts. A lot of warts. It couldn’t do MMS for example. But I remember the possibility it brought to mind. No product before had seemed like anything more than a product. The iPhone, or more the potential that the iPhone hinted at, had an actual impact on me. It changed my thinking about what could be.
In the years since no other product came close to matching that level of awe and wonder. That changed in March of this year. The release of GPT-4 had the same impact I remember from the iPhone launch. It’s still early, but it's opened the imagination, and fears, of millions of developers in a way I haven’t seen since that iPhone announcement.
That excitement has led to an explosion of development and hundreds of new tools broadly grouped into a category we call generative AI. Generative AI systems create content mimicking a particular style. New images that look like Banksy or lyrics that sound like Taylor Swift. All of these Generative AI tools, whether built on top of GPT-4 or something else, use the same basic model technique: a transformer.
Attention is all you need
GPT-4 (Generative Pretrained Transformer) is the most advanced version of a transformer model. Transformer models all emerged from a seminal paper written in 2017 by researchers at the University of Toronto and the team at Google Brain, titled Attention is all you need. The key insight from the paper is the self-attention mechanism. This mechanism replaced recurrent and convolutional layers, allowing for faster training and better performance.
The secret power of transformer models is their ability to efficiently process large amounts of data in parallel. It's the transformers' gargantuan scale and extensive training that makes them so appealing and versatile, turning them into the Swiss Army knife of natural language processing. At a high level, Large Language Models (LLMs) are just transformer models that use an incredibly large number of parameters (billions), and are trained on incredibly large amounts of unsupervised text (the Internet). Hence large, and language.
Unleashing the potential of LLMs in consumer-facing AI tools has opened a world of possibilities. But possibility also means new risk: developers must now navigate the unique security challenges that arise from making powerful new tools widely available to the masses.
First and foremost, consumer-facing applications inherently expose the underlying AI systems to millions of users, vastly increasing the potential attack surface. Since developers are targeting a consumer audience, they can't rely on trusted customers or limit access based on geographic location. Any security measure that makes it too difficult for consumers to use defeats the purpose of the application. Consequently, developers must strike a delicate balance between security and usability, which can be challenging.
The current popularity of AI tools makes explosive takeoff more likely than in the past. This is great! Explosive takeoff is what you want! But, that explosion can also lead to exponential growth in costs, as the computational requirements for serving a rapidly growing user base can become overwhelming.
In addition to being popular, Generative AI apps are unique in that calls to them are incredibly resource intensive, and therefore expensive for the owner. In comparison, think about a more traditional API that Cloudflare has protected for years. A product API. Sites don’t want competitors calling their product API and scraping data. This has an obvious negative business impact. However, it doesn’t have a direct infrastructure cost. A product list API returns a small amount of text. An attacker calling it 4 million times will have a negligible cost to an infrastructure bill. But generative models can cost cents, or in the case of image generation even tens of cents per call. An attacker gaining access and generating millions of calls has a real cost impact to the developers providing those APIs.
Not only are the costs for generating content high, but the value that end users are willing to pay is high as well. Customers tell us that they have seen multiple instances of bad actors accessing an API without paying, then reselling the content they generate for 50 cents or more per call. The huge monetary opportunity of exploitation means attackers are highly motivated to come back again and again, refactoring their approach each time.
Last, consumer-facing LLM applications are generally designed as a single entry point for customers, almost always accepting query text as input. The open-text nature of these calls makes it difficult to predict the potential impact of a single request. For example, a complex query might consume significant resources or trigger unexpected behavior. While these APIs are not GraphQL based, the challenges are similar. When you accept unstructured submissions, it's harder to create any type of rule to prevent abuse.
Tips for protecting your Generative AI application
So you've built the latest generative AI sensation, and the world is about to be taken by storm. But that success is also about to make you a target. What's the trick to stopping all those attacks you’re about to see? Well, unfortunately there isn’t one. For all the reasons above, this is a hard, persistent problem with no simple solution. But, we’ve been fortunate to work with many customers who have had that target on their back for months, and we’ve learned a lot from that experience. Here are some recommendations that will give you a good foundation for making sure that you, and only you, reap the rewards of your hard work.
1. Enforce tokens for each user. Enforcing usage based on a specific user or user session is straightforward. But sometimes you want to allow anonymous usage. While anonymous usage is great for demos and testing, it can lead to abuse. If you must allow anonymous usage, create a “stickier” identification scheme that persists browser restarts and incognito mode. Your goal isn’t to track specific users, but instead to understand how much an anonymous user has already used your service so far in demo / free mode.
2. Manage quotas carefully. Your service likely incurs costs and charges users per API call, so it likely makes sense to set a limit on the number of times any user can call your API. You may not ever intend for the average user to hit this limit, but having limits in place will protect against that user’s API key becoming compromised and shared amongst many users. It also protects against programming errors that could result in 100x or 1000x expected usage, and a large unexpected bill to the end user.
3. Block certain ASNs (autonomous system numbers) wholesale. Blocking ASNs, or even IPs wholesale is an incredibly blunt tool. In general Cloudflare rarely recommends this approach to customers. However, when tools are as popular as some generative AI applications, attackers are highly motivated to send as much traffic as possible to those applications. The fastest and cheapest way to accomplish this is through data centers that usually share a common ASN. Some ASNs belong to ISPs, and source traffic from people browsing the Internet. But other ASNs belong to cloud compute providers, and mainly source outbound traffic from virtual servers. Traffic from these servers can be overwhelmingly malicious. For example, several of our customers have found ASNs where 88-90% of the traffic turns out to be automated, while this number is usually only 30% for average traffic. In cases this extreme, blocking entire ASNs can make sense.
4. Implement smart rate limits. Counting not only requests per minute and requests per session, but also IPs per token and tokens per IP can guard against abuse. Tracking how many different IPs are using a particular token at any one time can alert you to a user's token being leaked. Similarly, if one IP is rotating through tokens, looking at each token’s session traffic would not alert you to the abuse. You’d need to look at how many tokens that single IP is generating in order to pinpoint that specific abusive behavior.
5. Rate limit on something other than the user. Similar to enforcing tokens on each user, your real time rate limits should also be set on your sticky identifier.
6. Have an option to slow down attackers. Customers often think about stopping abuse in terms of blocking traffic from abusers. But blocking isn’t the only option. Attacks not only need to be successful, they also need to be economically feasible. If you can make requests more difficult or time-consuming for abusers, you can ruin their economics. You can do this by implementing a waiting room, or by challenging users. We recommend a challenge option that doesn’t give real users an awful experience. Challenging users can also be quickly enabled or disabled as you see abuse spike or recede.
7. Map and analyze sequences. By sampling user sessions that you suspect of abuse, you can inspect their requests path-by-path in your SIEM. Are they using your app as expected? Or are they circumventing intended usage? You might benefit from enforcing a user flow between endpoints.
8. Build and validate an API schema. Many API breaches happen due to permissive schemas. Users are allowed to send in extra fields in requests that grant them too many privileges or allow access to other users’ data. Make sure you build a verbose schema that outlines what intended usage is by identifying and cataloging all API endpoints, then making sure all specific parameters are listed as required and have type limits to them.
We recently went through the transition to an OpenAPI schema ourselves for api.cloudflare.com. You can read more about how we did it here. Our schema looks like this:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
9. Analyze the depth and complexity of queries. Are your APIs driven by GraphQL? GraphQL queries can be a source of abuse since they allow such free-form requests. Large, complex queries can grow to overwhelm origins if limits aren’t in place. Limits help guard against outright DoS attacks as well as developer error, keeping your origin healthy and serving requests to your users as expected.
For example, if you have statistics about your GraphQL queries by depth and query size, you could execute this TypeScript function to analyze them by quantile:
import * as ss from 'simple-statistics';
function calculateQuantiles(data: number[], quantiles: number[]): {[key: number]: string} {
let result: {[key: number]: string} = {};
for (let q of quantiles) {
// Calculate quantile, convert to fixed-point notation with 2 decimal places
result[q] = ss.quantile(data, q).toFixed(2);
}
return result;
}
// Example usage:
let queryDepths = [2, 2, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 1, 1, 1, 1, 1, 1, 1, 1];
let querySizes = [11, 11, 11, 11, 11, 11, 11, 11, 11, 11, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2];
console.log(calculateQuantiles(queryDepths, [0.5, 0.75, 0.95, 0.99]));
console.log(calculateQuantiles(querySizes, [0.5, 0.75, 0.95, 0.99]));
The results give you a sense for the depth of the average query hitting your endpoint, grouped by quantile:
Actual data from your production environment would provide a threshold to start an investigation into which queries to further log or limit. A simpler option is to use a query analysis tool, like Cloudflare’s, to make the process automatic.
10. Use short-lived access tokens and long-lived refresh tokens upon successful authentication of your users. Implement token validation in a middleware layer or API Gateway, and be sure to have a dedicated token renewal endpoint in your API. JSON Web Tokens (JWTs) are popular choices for these short-lived tokens. When access tokens expire, allow users to obtain new ones using their refresh tokens. Revoke refresh tokens when necessary to maintain system security. Adopting this approach enhances your API's security and user experience by effectively managing access and mitigating the risks associated with compromised tokens.
11. Communicate directly with your users. All of the above recommendations are going to make it a bit more cumbersome for some of your customers to use your product. You are going to get complaints. You can reduce these by first, giving clear communication to your users explaining why you put these measures in place. Write a blog about what security measures you did and did not decide to implement and have dev docs explaining troubleshooting steps to resolve. Second, give your users concrete steps they can take if they are having trouble, and a clear way to contact you directly. Feeling inconvenienced can be frustrating, but feeling stuck can lose you a customer.
Conclusion: this is the beginning
Generative AI, like the first iPhone, has sparked a surge of excitement and innovation. But that excitement also brings risk, and innovation brings new security holes and attack vectors. The broadness and uniqueness of generative AI applications in particular make securing them particularly challenging. But as every scout knows, being prepared ahead of time means less stress and worry during the journey. Implementing the tips we've shared can establish a solid foundation that will let you sit back and enjoy the thrill of building something special, rather than worrying what might be lurking around the corner.
Security Week 2023 is officially in the books. In our welcome post last Saturday, I talked about Cloudflare’s years-long evolution from protecting websites, to protecting applications, to protecting people. Our goal this week was to help our customers solve a broader range of problems, reduce external points of vulnerability, and make their jobs easier.
We announced 34 new tools and integrations that will do just that. Combined, these announcement will help you do five key things faster and easier:
Making it easier to deploy and manage Zero Trust everywhere
Reducing the number of third parties customers must use
Leverage machine learning to let humans focus on critical thinking
Opening up more proprietary Cloudflare threat intelligence to our customers
Making it harder for humans to make mistakes
And to help you respond to the most current attacks in real time, we reported on how we’re seeing scammers use the Silicon Valley Bank news to phish new victims, and what you can do to protect yourself.
In case you missed any of the announcements, take a look at the summary and navigation guide below.
Today we have released insights from our global network on the top 50 brands used in phishing attacks coupled with the tools customers need to stay safer. Our new phishing and brand protection capabilities, part of Security Center, let customers better preserve brand trust by detecting and even blocking “confusable” and lookalike domains involved in phishing campaigns.
Phishing attacks come in all sorts of ways to fool people. Email is definitely the most common, but there are others. Following up on our Top 50 brands in phishing attacks post, here are some tips to help you catch these scams before you fall for them.
Page Shield now ensures only vetted and secure JavaScript is being executed by browsers to stop unwanted or malicious JavaScript from loading to keep end user data safer.
With Aegis, customers can now get dedicated IPs from Cloudflare we use to send them traffic. This allows customers to lock down services and applications at an IP level and build a protected environment that is application, protocol, and even IP-aware.
mTLS support for Workers allows for communication with resources that enforce an mTLS connection. mTLS provides greater security for those building on Workers so they can identify and authenticate both the client and the server helps protect sensitive data.
We have introduced an innovative new approach to secure hosted applications via Cloudflare Access without the need for any installed software or custom code on application servers.
Cloudflare is excited to launch the Descaler Program, a frictionless path to migrate existing Zscaler customers to Cloudflare One. With this announcement, Cloudflare is making it even easier for enterprise customers to make the switch to a faster, simpler, and more agile foundation for security and network transformation.
Today we’re excited to announce the expansion of support for automated normalization and correlation of Zero Trust logs for Logpush in Sumo Logic’s Cloud SIEM. Joint customers will reduce alert fatigue and accelerate the triage process by converging security and network data into high-fidelity insights.
Cloudflare One now offers Data Loss Prevention (DLP) detections for Microsoft Purview Information Protection labels. This extends the power of Microsoft’s labels to any of your corporate traffic in just a few clicks.
We are unveiling two new integrations for Cloudflare CASB: one for Atlassian Confluence and the other for Atlassian Jira. Security teams can begin scanning for Atlassian- and Confluence-specific security issues that may be leaving sensitive corporate data at risk.
Cloudflare Access and Ping Identity offer a powerful solution for organizations looking to implement Zero Trust security controls to protect their applications and data. Cloudflare is now offering full integration support, so Ping Identity customers can easily integrate their identity management solutions with Cloudflare Access to provide a comprehensive security solution for their applications
We are excited to announce Cloudflare Fraud Detection that will provide precise, easy to use tools that can be deployed in seconds to detect and categorize fraud such as fake account creation or card testing and fraudulent transactions. Fraud Detection will be in early access later this year, those interested can sign up here.
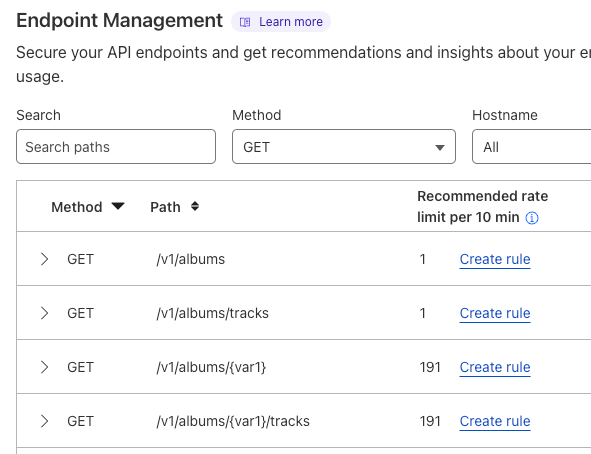
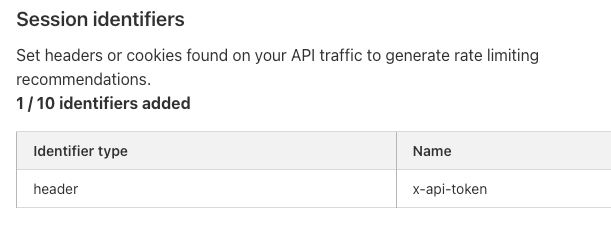
Customers can use these new features to enforce a positive security model on their API endpoints even if they have little-to-no information about their existing APIs today.
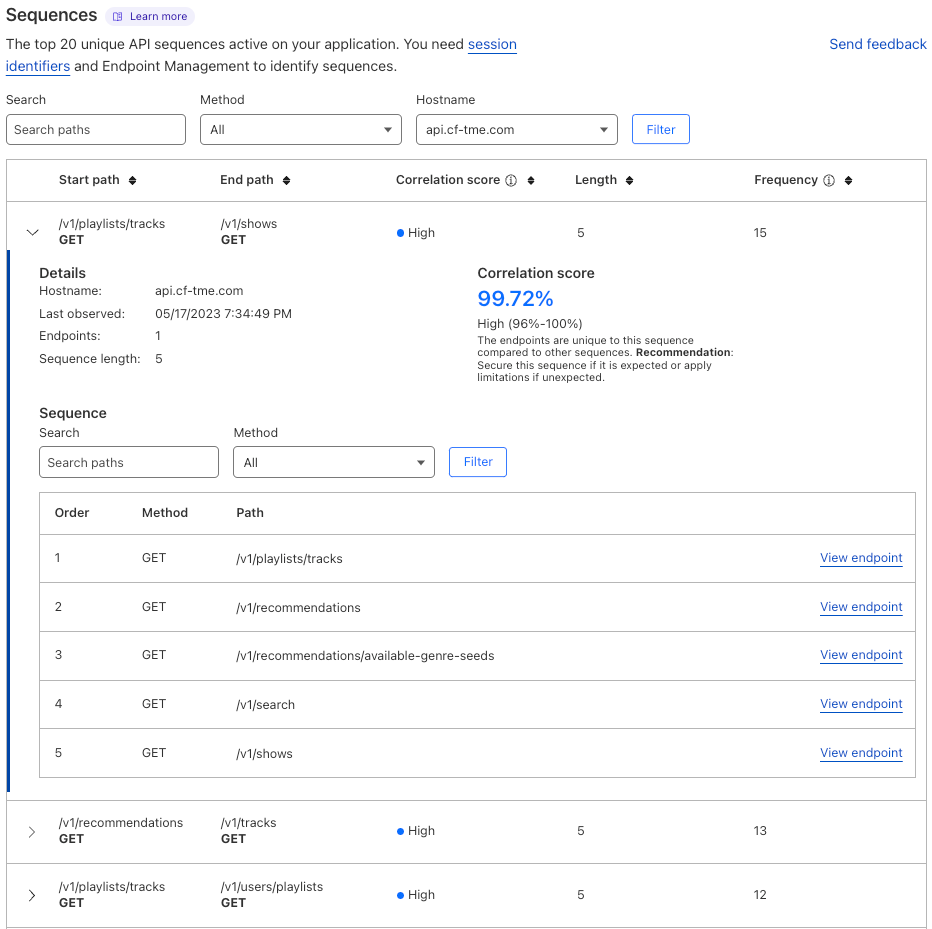
With our new Cloudflare Sequence Analytics for APIs, organizations can view the most important sequences of API requests to their endpoints to better understand potential abuse and where to apply protections first.
Read our post on how we keep users and organizations safer with machine learning models that detect attackers attempting to evade detection with DNS tunneling and domain generation algorithms.
We are making the machine learning empowered WAF and Security analytics view available to our Business plan customers, to help detect and stop attacks before they are known.
We have made Cloudflare Radar’s newest free tool available, URL Scanner, providing an under-the-hood look at any webpage to make the Internet more transparent and secure for all.
One of our core beliefs is that privacy is a human right. To achieve that right, we are announcing that our implementations of post-quantum cryptography will be available to everyone, free of charge, forever.
The recent news reports of AI cracking post-quantum cryptography are greatly exaggerated. In this blog, we take a deep dive into the world of side-channel attacks and how AI has been used for more than a decade already to aid it.
IBM and Cloudflare continue to partner together to help customers meet the unique security, performance, resiliency and compliance needs of their customers through the addition of exciting new product and service offerings.
Customers will now be able to use our Cloudflare Tunnels product to send traffic to the key server through a secure channel, without publicly exposing it to the rest of the Internet.
Brand impersonation continues to be a big problem globally. Setting SPF, DKIM and DMARC policies is a great way to reduce that risk, and protect your domains from being used in spoofing emails. But maintaining a correct SPF configuration can be very costly and time consuming, and that’s why we’re launching Cloudflare DMARC Management.
At Cloudflare, we use the Workers platform and our product stack to build new services. Read how we made the new DMARC Management solution entirely on top of our APIs.
Cloudflare’s cloud email security solution now integrates with KnowBe4, allowing mutual customers to offer real-time coaching to employees when a phishing campaign is detected by Cloudflare.
We are excited to announce new options to customize user experience in Access, including customizable pages including login, blocks and the application launcher.
Cloudflare Access is 75% faster than Netskope and 50% faster than Zscaler, and our network is faster than other providers in 48% of last mile networks.
Cloudflare announces one-click ISO certified region, a super easy way for customers to limit where traffic is serviced to ISO 27001 certified data centers inside the European Union.
All WAF customers will benefit fromAccount Security Analytics and Events. This allows organizations to new eyes on your account in Cloudflare dashboard to give holistic visibility. No matter how many zones you manage, they are all there!
We are thrilled to announce the full support of wildcard and multi-hostname application definitions in Cloudflare Access. Until now, Access had limitations that restricted it to a single hostname or a limited set of wildcards
While that’s it for Security Week 2023, you all know by now that Innovation weeks never end for Cloudflare. Stay tuned for a week full of new developer tools coming soon, and a week dedicated to making the Internet faster later in the year.
Last month I had the chance to attend a dinner with 56 CISOs and CSOs across a range of banking, gaming, ecommerce, and retail companies. We rotated between tables of eight people and talked about the biggest challenges those in the group were facing, and what they were most worried about around the corner. We talk to customers every day at Cloudflare, but this was a unique opportunity to listen to customers (and non-customers) talk to each other. It was a fascinating evening and a few things stood out.
The common thread that dominated the discussions was “how do I convince my business and product teams to do the things I want them to”. Surprisingly little time was spent on specific technical challenges. No one brought up a concern about recent advanced mage cart skimmers, or about protecting their new GraphQL APIs, or how to secure two different cloud vendors at once, or about the size of DDoS attacks consistently getting larger. Over and over again the conversation came back to struggles with getting humans to do the secure thing, or to not do the insecure thing.
This instantly brought to mind a major phishing attack that Cloudflare was able to thwart last August. The attack was extremely sophisticated, using targeted text messages and an extremely professional impersonation of our Okta login page. Cloudflare did have individual employees fall for the phishing messages, because we are made up of a team of humans who are human. But we were able to thwart the attack through our own use of Cloudflare One products, and physical security keys issued to every employee that are required to access all our applications. The attacker was able to obtain compromised username and password credentials, but they could not get past the hard key requirement to log in. In 2023 phishing attacks are only getting more frequent.
Today’s security challenges are often a case of having the right tools deployed to prevent people from making mistakes. Last year when we kicked off Security Week, we talked about making a shift from protecting websites, to protecting applications. Today, the shift is from protecting applications, to protecting employees, and making sure they are protected everywhere. Just a few weeks ago, the White House released a new national cybersecurity strategy directing all agencies to “implement multi-factor authentication, gain visibility into their entire attack surface, manage authorization and access, and adopt cloud security tools”. Over the next six days you’ll read more than 30 announcements that will make it as easy as possible to do just that.
Welcome to Security Week 2023.
“The more tools you use the less secure you are”
This was a direct quote from the CISO of a large online gaming platform. Adding more vendors might seem like you are adding layers of security, but you do also open up avenues for risk. First, every third party you add by definition adds another potential vulnerability. The recent LastPass breach is a perfect example. Attackers gained access to a cloud storage service, which gave them information they used in a secondary attack to phish an employee. Second, more tools means more complexity. More systems to log into, more dashboards to check. If information is spread across multiple systems you are more likely to miss important changes. Third, the more tools you use, the less likely it is that anyone is able to master them all. If you need the person who knows the application security tool, and the person who knows the SIEM, and the person who knows the access tool to coordinate on every potential vulnerability, things will get lost in translation. Complexity is the enemy of security. Fourth, adding more tools can add a false sense of security. Simply adding a new tool can give the impression you’ve added defense in depth. But that tool only adds protection if it works, if it’s configured properly, and if people actually use it.
This week, you will hear about all of the initiatives we’ve been working on to help you solve this problem. We will announce multiple integrations that make it easier for you to deploy and manage Zero Trust anywhere, across multiple platforms, but all within the Cloudflare dashboard. We’re also extending our proven detection capabilities into new areas that will help you solve problems you couldn’t solve before, and thus allow you to get rid of additional vendors. And we’ll announce a brand new migration tool that makes it dead simple to move from those other vendors to Cloudflare.
Leverage machine learning to let humans focus on critical thinking
We all hear machine learning thrown around as a buzzword too often, but it boils down to this: computers are really good at finding patterns. When we train them on what a good pattern looks like, they can spot them really well, and spot the outliers. Humans are great at finding patterns too. But it takes us a long time, and any time we spend finding patterns distracts us from the thing that even the best AI or ML model still can’t do: critical thinking. By using machine learning to find these good and bad patterns, you can optimize the time of your most valuable people. Rather than searching for exceptions, they can focus on only those exceptions, and use their wisdom to make the hard decisions about what to do next.
Cloudflare has used machine learning to catch DDoS attacks, malicious bots, and malicious web traffic. We were able to do this differently from others because we built a unique network where we run all of our code at every single data center, on every single machine. Since we have a massive global network that is close to end users, we can run machine learning close to those users, unlike competitors who have to use centralized data centers. The result is a machine learning pipeline that runs inference in a few microseconds. That unique speed is an advantage for our customers, one we now use to run inference more than 40 million times every second.
This week, we have an entire day focused on how we are using that machine learning pipeline to build new models that will allow you to find new patterns, like fraud and API endpoints.
Our intelligence is your intelligence
In June we announced Cloudforce One, the first step in our threat operations team dedicated to turning the intelligence we gather from handling nearly 20% of Internet traffic into actionable insights. Since that launch, we’ve heard customers ask us to do more with those insights and give them easy buttons and products to take the appropriate action on their behalf. This week you’ll read multiple announcements on new ways that you can view and take action on unique Cloudflare threat intelligence. We’ll also be announcing multiple new reporting views, like being able to view more data at an account level so you can have one single lens into security trends across your entire organization.
Make it harder for humans to make mistakes
Each product, development, or business team wants to use their own tools, and wants to move as quickly as possible. For good reason! Any security that comes after the fact, and creates additional work for those teams, will be difficult to get internal buy on for. Which can lead to situations like the recent T-mobile hack where an API that was not intended to be public was exposed, discovered, and exploited. You need to meet teams where they are by making the tools they already use more secure, and preventing them from making mistakes, rather than giving them additional tasks.
In addition to making it easier to deploy our Application Security and Zero Trust products to a wider scope, you’ll also read about how we are adding new features that prevent humans from making the mistakes they always do. You’ll hear about how you can make it impossible to click on a phishing link by automatically blocking the domains that host them, prevent data from leaving regions it should never leave, give your users security alerts directly in the tools they already use, and automatically detect shadow APIs without making your developers change their development process. All of this without having to convince internal teams to make any changes to their behavior.
If you’re reading this and any part of your job involves securing an organization, I think that by the end of the week we’ll have made your job easier. With the new tools and integrations we release, you’ll be able to protect more of your infrastructure from a wider range of threats, but reduce the number of third parties you rely on. More importantly, you’ll be able to reduce the number of mistakes that the incredible humans you work with can make. I hope that helps you rest a bit easier!
Today, we’re announcing the open beta of Turnstile, an invisible alternative to CAPTCHA. Anyone, anywhere on the Internet, who wants to replace CAPTCHA on their site will be able to call a simple API, without having to be a Cloudflare customer or sending traffic through the Cloudflare global network. Sign up here for free.
There is no point in rehashing the fact that CAPTCHA provides a terrible user experience. It’s been discussed in detail before on this blog, and countless times elsewhere. The creator of the CAPTCHA has even publicly lamented that he “unwittingly created a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles.” We hate it, you hate it, everyone hates it. Today we’re giving everyone a better option.
Turnstile is our smart CAPTCHA alternative. It automatically chooses from a rotating suite of non-intrusive browser challenges based on telemetry and client behavior exhibited during a session. We talked in an earlier post about how we’ve used our Managed Challenge system to reduce our use of CAPTCHA by 91%. Now anyone can take advantage of this same technology to stop using CAPTCHA on their own site.
UX isn’t the only big problem with CAPTCHA — so is privacy
While having to solve a CAPTCHA is a frustrating user experience, there is also a potential hidden tradeoff a website must make when using CAPTCHA. If you are a small site using CAPTCHA today, you essentially have one option: an 800 pound gorilla with 98% of the CAPTCHA market share. This tool is free to use, but in fact it has a privacy cost: you have to give your data to an ad sales company.
According to security researchers, one of the signals that Google uses to decide if you are malicious is whether you have a Google cookie in your browser, and if you have this cookie, Google will give you a higher score. Google says they don’t use this information for ad targeting, but at the end of the day, Google is an ad sales company. Meanwhile, at Cloudflare, we make money when customers choose us to protect their websites and make their services run better. It’s a simple, direct relationship that perfectly aligns our incentives.
Less data collection, more privacy, same security
In June, we announced an effort with Apple to use Private Access Tokens. Visitors using operating systems that support these tokens, including the upcoming versions of macOS or iOS, can now prove they’re human without completing a CAPTCHA or giving up personal data.
By collaborating with third parties like device manufacturers, who already have the data that would help us validate a device, we are able to abstract portions of the validation process, and confirm data without actually collecting, touching, or storing that data ourselves. Rather than interrogating a device directly, we ask the device vendor to do it for us.
Private Access Tokens are built directly into Turnstile. While Turnstile has to look at some session data (like headers, user agent, and browser characteristics) to validate users without challenging them, Private Access Tokens allow us to minimize data collection by asking Apple to validate the device for us. In addition, Turnstile never looks for cookies (like a login cookie), or uses cookies to collect or store information of any kind. Cloudflare has a long track record of investing in user privacy, which we will continue with Turnstile.
We are opening our CAPTCHA replacement to everyone
To improve the Internet for everyone, we decided to open up the technology that powers our Managed Challenge to everyone in beta as a standalone product called Turnstile.
Rather than try to unilaterally deprecate and replace CAPTCHA with a single alternative, we built a platform to test many alternatives and rotate new challenges in and out as they become more or less effective. With Turnstile, we adapt the actual challenge outcome to the individual visitor/browser. First we run a series of small non-interactive JavaScript challenges gathering more signals about the visitor/browser environment. Those challenges include proof-of-work, proof-of-space, probing for web APIs, and various other challenges for detecting browser-quirks and human behavior. As a result, we can fine-tune the difficulty of the challenge to the specific request.
Turnstile also includes machine learning models that detect common features of end visitors who were able to pass a challenge before. The computational hardness of those initial challenges may vary by visitor, but is targeted to run fast.
Swap out your existing CAPTCHA in a few minutes
You can take advantage of Turnstile and stop bothering your visitors with a CAPTCHA even without being on the Cloudflare network. While we make it as easy as possible to use our network, we don’t want this to be a barrier to improving privacy and user experience.
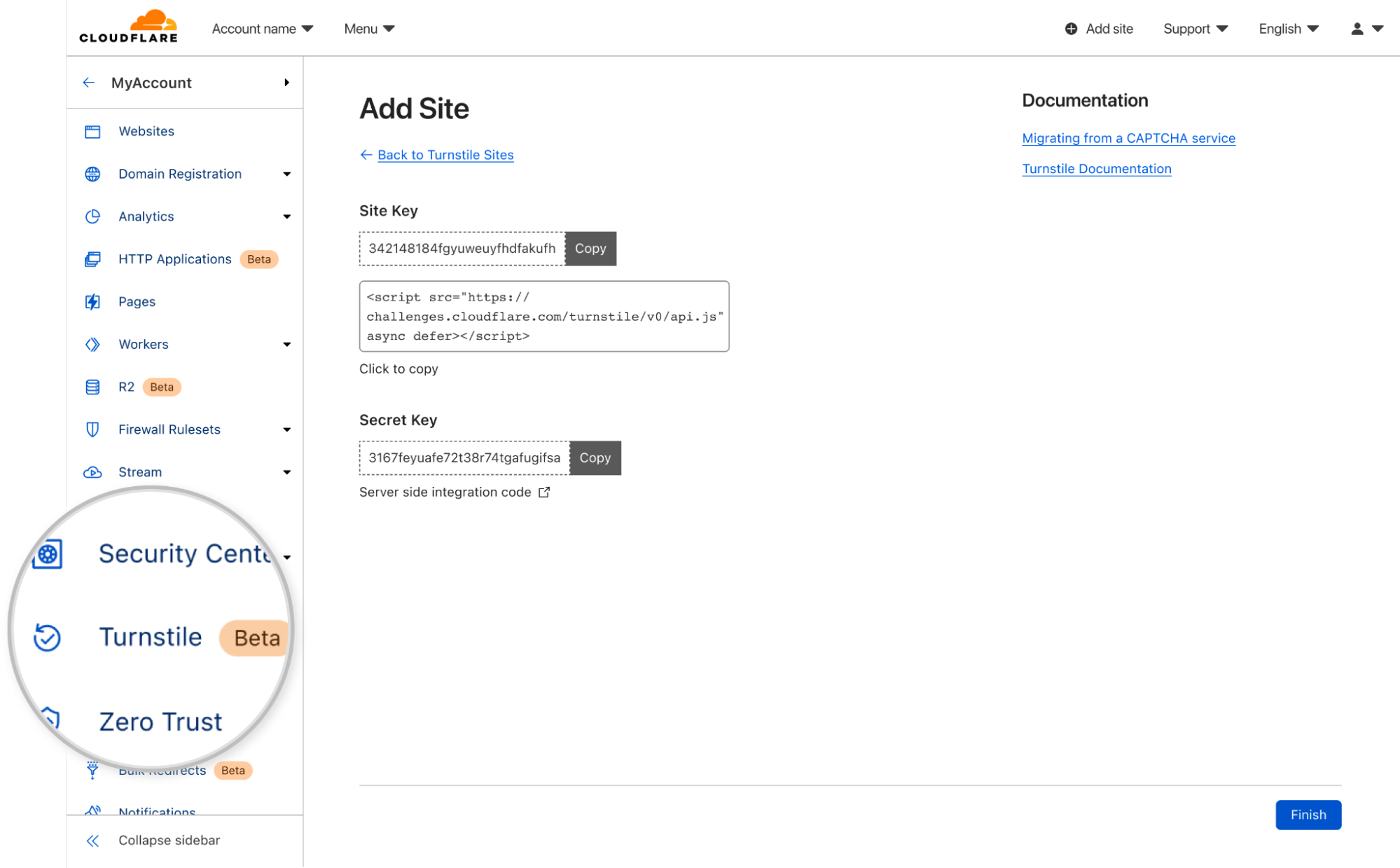
To switch from a CAPTCHA service, all you need to do is:
Create a Cloudflare account, navigate to the `Turnstile` tab on the navigation bar, and get a sitekey and secret key.
Copy our JavaScript from the dashboard and paste over your old CAPTCHA JavaScript.
Update the server-side integration by replacing the old siteverify URL with ours.
There is more detail on the process below, including options you can configure, but that’s really it. We’re excited about the simplicity of making a change.
Deployment options and analytics
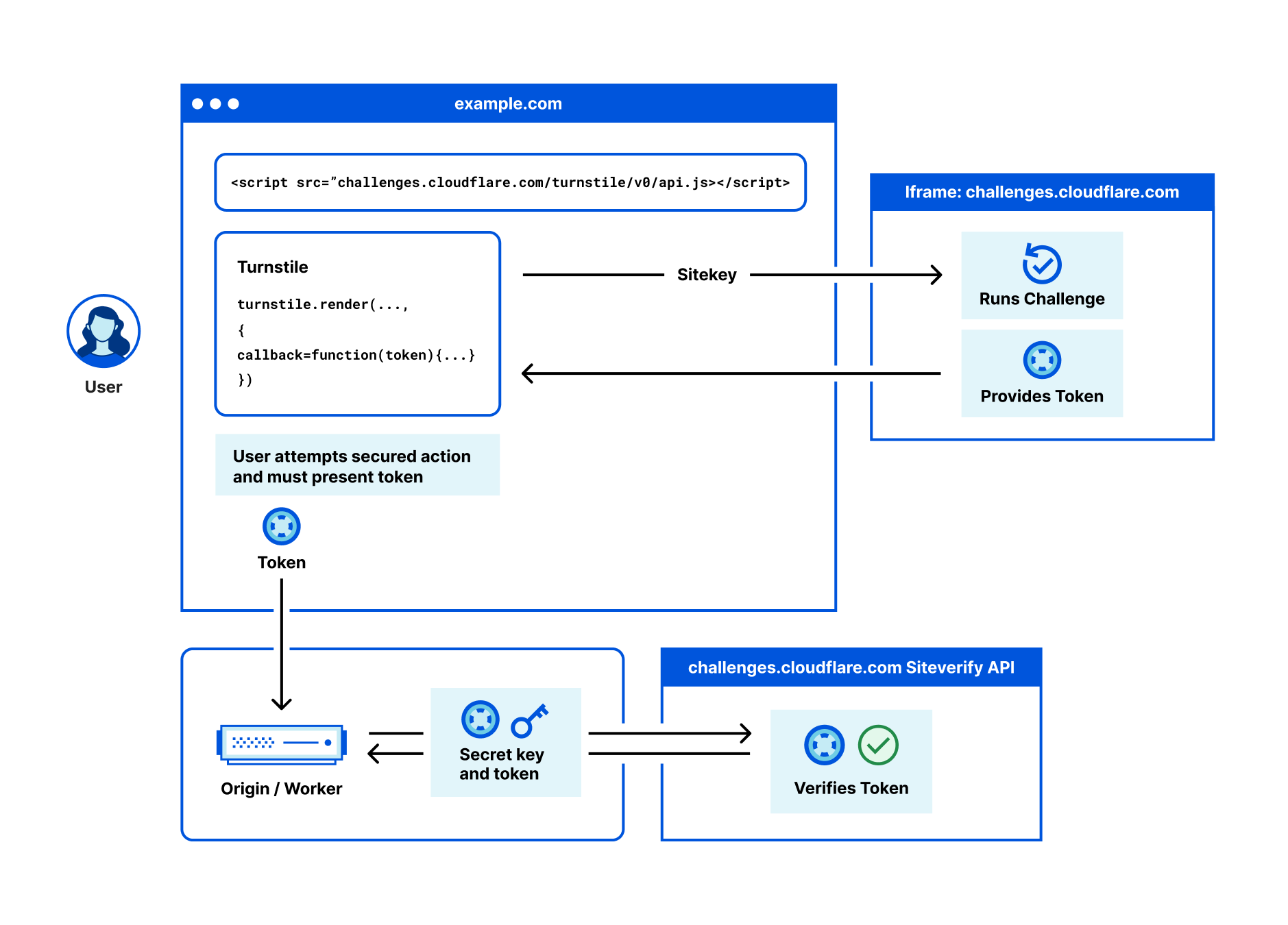
To use Turnstile, first create an account and get your site and secret keys.
Once a challenge has been solved, a token is injected in your form, with the name cf-turnstile-response. This token can be used with our siteverify endpoint to validate a challenge response. A token can only be validated once, and a token cannot be redeemed twice. The validation can be done on the server side or even in the cloud, for example using a simple Workers fetch (see a demo here):
async function handleRequest() {
// ... Receive token
let formData = new FormData();
formData.append('secret', turnstileISecretKey);
formData.append('response', receivedToken);
await fetch('https://challenges.cloudflare.com/turnstile/v0/siteverify',
{
body: formData,
method: 'POST'
});
// ...
}
For more complex use cases, the challenge can be invoked explicitly via JavaScript:
You can also create what we call ‘Actions’. Custom labels that allow you to distinguish between different pages where you’re using Turnstile, like a login, checkout, or account creation page.
Once you’ve deployed Turnstile, you can go back to the dashboard and see analytics on where you have widgets deployed, how users are solving them, and view any defined actions.
Why are we giving this away for free?
While this is sometimes hard for people outside to believe, helping build a better Internet truly is our mission. This isn’t the first time we’ve built free tools that we think will make the Internet better, and it won’t be the last. It’s really important to us.
So whether or not you’re a Cloudflare customer today, if you’re using a CAPTCHA, try Turnstile for free, instead. You’ll make your users happier, and minimize the data you send to third parties.
Visit this page to sign up for the best invisible, privacy-first, CAPTCHA replacement and to retrieve your Turnstile beta sitekey.
Today we’re announcing Private Access Tokens, a completely invisible, private way to validate that real users are visiting your site. Visitors using operating systems that support these tokens, including the upcoming versions of macOS or iOS, can now prove they’re human without completing a CAPTCHA or giving up personal data. This will eliminate nearly 100% of CAPTCHAs served to these users.
What does this mean for you?
If you’re an Internet user:
We’re making your mobile web experience more pleasant and more private than other networks at the same time.
You won’t see a CAPTCHA on a supported iOS or Mac device (other devices coming soon!) accessing the Cloudflare network.
If you’re a web or application developer:
Know your user is coming from an authentic device and signed application, verified by the device vendor directly.
Validate users without maintaining a cumbersome SDK.
If you’re a Cloudflare customer:
You don’t have to do anything! Cloudflare will automatically ask for and utilize Private Access Tokens
Your visitors won’t see a CAPTCHA and we’ll ask for less data from their devices.
Introducing Private Access Tokens
Over the past year, Cloudflare has collaborated with Apple, Google, and other industry leaders to extend the Privacy Pass protocol with support for a new cryptographic token. These tokens simplify application security for developers and security teams, and obsolete legacy, third-party SDK based approaches to determining if a human is using a device. They work for browsers, APIs called by browsers, and APIs called within apps. We call these new tokens Private Access Tokens (PATs). This morning, Apple announced that PATs will be incorporated into iOS 16, iPad 16, and macOS 13, and we expect additional vendors to announce support in the near future.
Cloudflare has already incorporated PATs into our Managed Challenge platform, so any customer using this feature will automatically take advantage of this new technology to improve the browsing experience for supported devices.
CAPTCHAs don’t work in mobile environments, PATs remove the need for them
We’ve writtennumeroustimes about how CAPTCHAs are a terrible user experience. However, we haven’t discussed specifically how much worse the user experience is on a mobile device. CAPTCHA as a technology was built and optimized for a browser-based world. They are deployed via a widget or iframe that is generally one size fits all, leading to rendering issues, or the input window only being partially visible on a device. The smaller real estate on mobile screens inherently makes the technology less accessible and solving any CAPTCHA more difficult, and the need to render JavaScript and image files slows down image loads while consuming excess customer bandwidth.
Usability aside, mobile environments present an additional challenge in that they are increasingly API-driven. CAPTCHAs simply cannot work in an API environment where JavaScript can’t be rendered, or a WebView can’t be called. So, mobile app developers often have no easy option for challenging a user when necessary. They sometimes resort to using a clunky SDK to embed a CAPTCHA directly into an app. This requires work to embed and customize the CAPTCHA, continued maintenance and monitoring, and results in higher abandonment rates. For these reasons, when our customers choose to show a CAPTCHA today, it’s only shown on mobile 20% of the time.
We recently posted about how we used our Managed Challenge platform to reduce our CAPTCHA use by 91%. But because the CAPTCHA experience is so much worse on mobile, we’ve been separately working on ways we can specifically reduce CAPTCHA use on mobile even further.
When sites can’t challenge a visitor, they collect more data
So, you either can’t use CAPTCHA to protect an API, or the UX is too terrible to use on your mobile website. What options are left for confirming whether a visitor is real? A common one is to look at client-specific data, commonly known as fingerprinting.
You could ask for device IMEI and security patch versions, look at screen sizes or fonts, check for the presence of APIs that indicate human behavior, like interactive touch screen events and compare those to expected outcomes for the stated client. However, all of this data collection is expensive and, ultimately, not respectful of the end user. As a company that deeply cares about privacy and helping make the Internet better, we want to use as little data as possible without compromising the security of the services we provide.
Another alternative is to use system-level APIs that offer device validation checks. This includes DeviceCheck on Apple platforms and SafetyNet on Android. Application services can use these client APIs with their own services to assert that the clients they’re communicating with are valid devices. However, adopting these APIs requires both application and server changes, and can be just as difficult to maintain as SDKs.
Private Access Tokens vastly improve privacy by validating without fingerprinting
This is the most powerful aspect of PATs. By partnering with third parties like device manufacturers, who already have the data that would help us validate a device, we are able to abstract portions of the validation process, and confirm datawithout actually collecting, touching, or storing that data ourselves. Rather than interrogating a device directly, we ask the device vendor to do it for us.
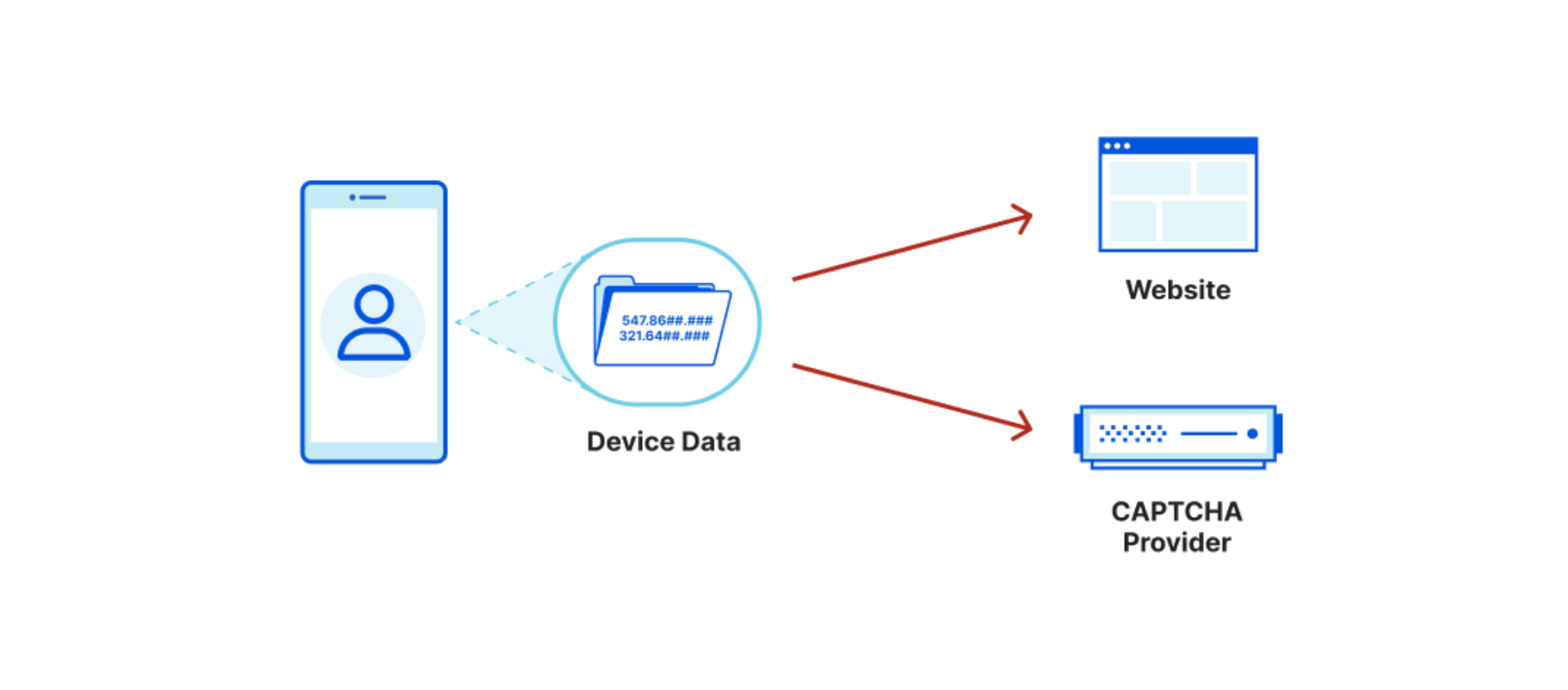
In a traditional website setup, using the most common CAPTCHA provider:
The website you visit knows the URL, your IP, and some additional user agent data.
The CAPTCHA provider knows what website you visit, your IP, your device information, collects interaction data on the page, AND ties this data back to other sites where Google has seen you. This builds a profile of your browsing activity across both sites and devices, plus how you personally interact with a page.
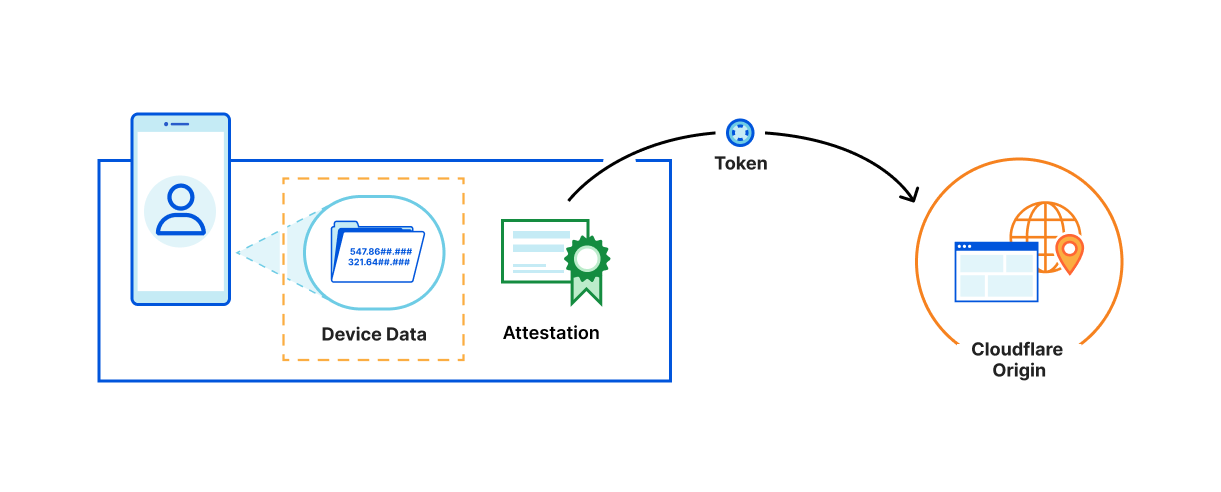
When PATs are used, device data is isolated and explicitly NOT exchanged between the involved parties (the manufacturer and the Cloudflare)
The website knows only your URL and IP, which it has to know to make a connection.
The device manufacturer (attester) knows only the device data required to attest your device, but can’t tell what website you visited, and doesn’t know your IP.
Cloudflare knows the site you visited, but doesn’t know any of your device or interaction information.
We don’t actually need or want the underlying data that’s being collected for this process, we just want to verify if a visitor is faking their device or user agent. Private Access Tokens allow us to capture that validation state directly, without needing any of the underlying data. They allow us to be more confident in the authenticity of important signals, without having to look at those signals directly ourselves.
How Private Access Tokens compartmentalize data
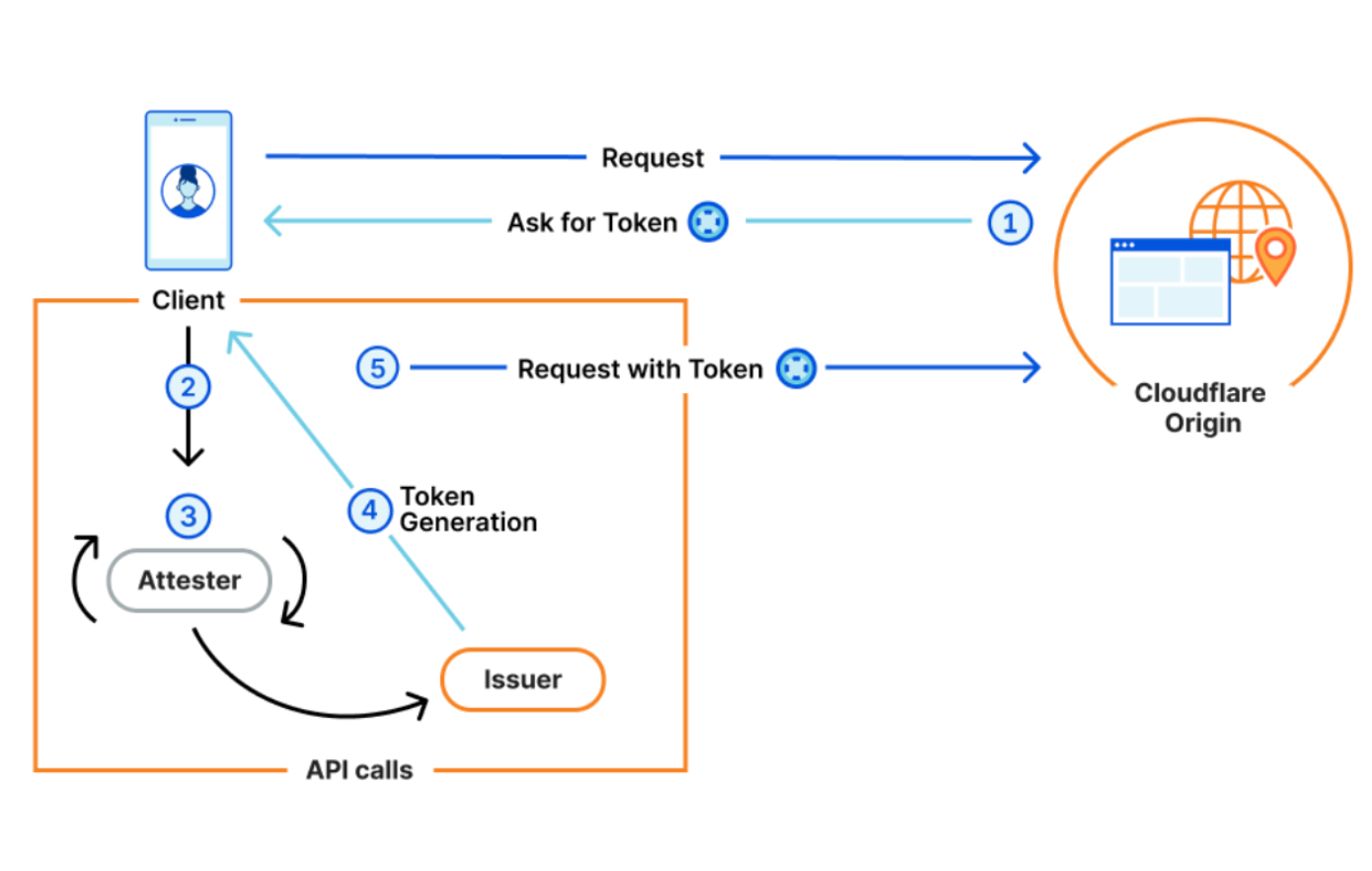
With Private Access Tokens, four parties agree to work in concert with a common framework to generate and exchange anonymous, unforgeable tokens. Without all four parties in the process, PATs won’t work.
An Origin. A website, application, or API that receives requests from a client. When a website receives a request to their origin, the origin must know to look for and request a token from the client making the request. For Cloudflare customers, Cloudflare acts as the origin (on behalf of customers) and handles the requesting and processing of tokens.
A Client. Whatever tool the visitor is using to attempt to access the Origin. This will usually be a web browser or mobile application. In our example, let’s say the client is a mobile Safari Browser.
An Attester. The Attester is who the client asks to prove something (i.e that a mobile device has a valid IMEI) before a token can be issued. In our example below, the Attester is Apple, the device vendor. An Issuer. The issuer is the only one in the process that actually generates, or issues, a token. The Attester makes an API call to whatever Issuer the Origin has chosen to trust, instructing the Issuer to produce a token. In our case, Cloudflare will also be the Issuer.
In the example above, a visitor opens the Safari browser on their iPhone and tries to visit example.com.
Since Example uses Cloudflare to host their Origin, Cloudflare will ask the browser for a token.
Safari supports PATs, so it will make an API call to Apple’s Attester, asking them to attest.
The Apple attester will check various device components, confirm they are valid, and then make an API call to the Cloudflare Issuer (since Cloudflare acting as an Origin chooses to use the Cloudflare Issuer).
The Cloudflare Issuer generates a token, sends it to the browser, which in turn sends it to the origin.
Cloudflare then receives the token, and uses it to determine that we don’t need to show this user a CAPTCHA.
This probably sounds a bit complicated, but the best part is that the website took no action in this process. Asking for a token, validation, token generation, passing, all takes place behind the scenes by third parties that are invisible to both the user and the website. By working together, Apple and Cloudflare have just made this request more secure, reduced the data passed back and forth, and prevented a user from having to see a CAPTCHA. And we’ve done it by both collecting and exchanging less user data than we would have in the past.
Most customers won’t have to do anything to utilize Private Access Tokens
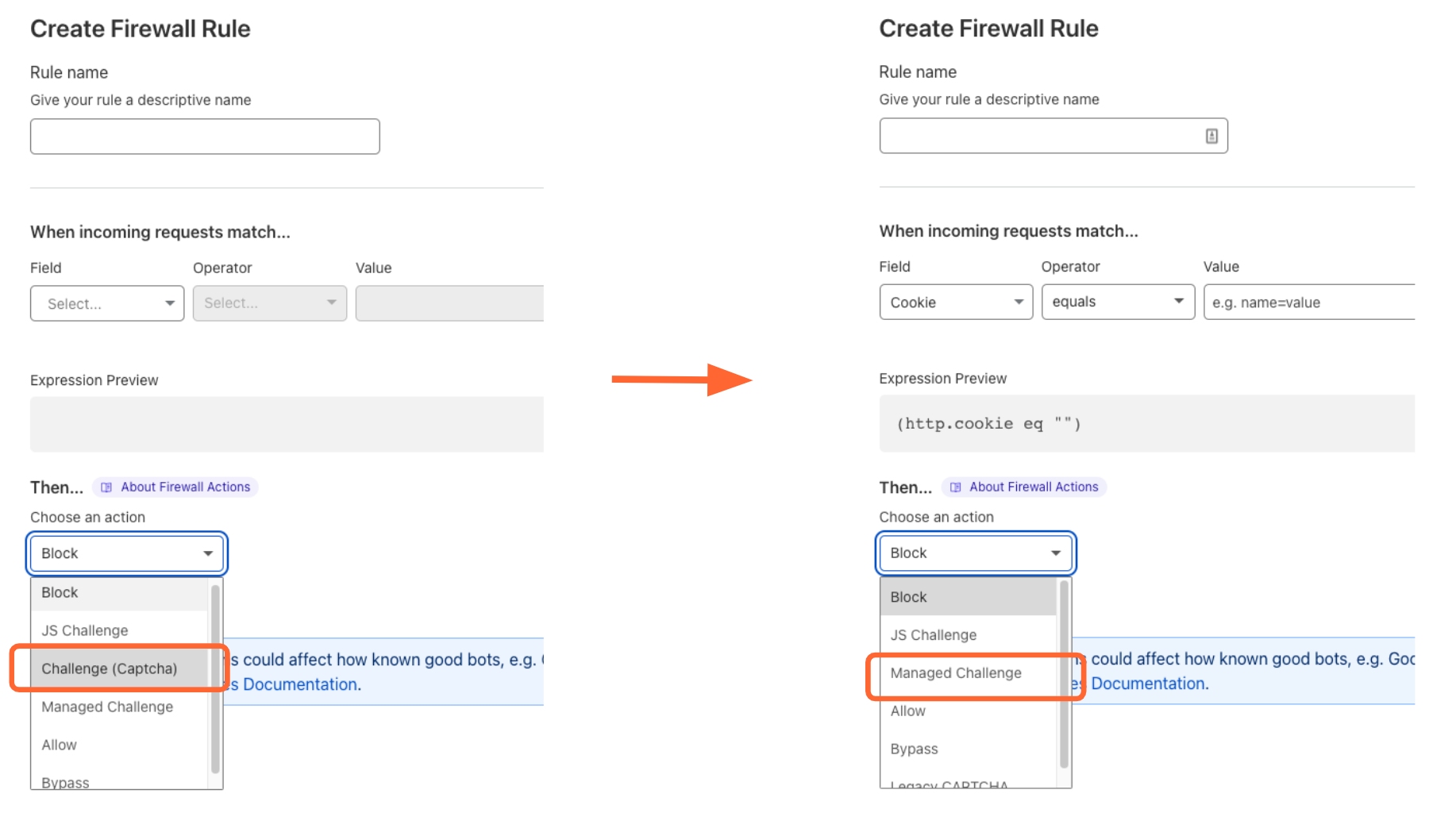
To take advantage of PATs, all you have to do is choose Managed Challenge rather than Legacy CAPTCHA as a response option in a Firewall rule. More than 65% of Cloudflare customers are already doing this. Our Managed Challenge platform will automatically ask every request for a token, and when the client is compatible with Private Access Tokens, we’ll receive one. Any of your visitors using an iOS or macOS device will automatically start seeing fewer CAPTCHAs once they’ve upgraded their OS.
This is just step one for us. We are actively working to get other clients and device makers utilizing the PAT framework as well. Any time a new client begins utilizing the PAT framework, traffic coming to your site from that client will automatically start asking for tokens, and your visitors will automatically see fewer CAPTCHAs.
We will be incorporating PATs into other security products very soon. Stay tuned for some announcements in the near future.
On June 02, 2022 Atlassian released a security advisory for their Confluence Server and Data Center applications, highlighting a critical severity unauthenticated remote code execution vulnerability. The vulnerability is as CVE-2022-26134 and affects Confluence Server version 7.18.0 and all Confluence Data Center versions >= 7.4.0.
No patch is available yet but Cloudflare customers using either WAF or Access are already protected.
Our own Confluence nodes are protected by both WAF and Access, and at the time of writing, we have found no evidence that our Confluence instance was exploited.
Cloudflare reviewed the security advisory, conducted our own analysis, and prepared a WAF mitigation rule via an emergency release. The rule, once tested, was deployed on June 2, 2022, at 23:38 UTC with a default action of BLOCK and the following IDs:
100531 (for our legacy WAF)
408cff2b (for our new WAF)
All customers using the Cloudflare WAF to protect their self-hosted Confluence applications have automatically been protected since the new rule was deployed.
Customers who have deployed Cloudflare Access in front of their Confluence applications were protected from external exploitation attempts even before the emergency release. Access verifies every request made to a Confluence application to ensure it is coming from an authenticated user. Any unauthenticated users attempting this exploit would have been blocked by Cloudflare before they could reach the Confluence server.
Customers not yet using zero trust rules to protect access to their applications can follow these instructions to enable Access now in a few minutes.
Timeline of Events
2022-06-02 at 20:00 UTC
Atlassian publishes security advisory
2022-06-02 at 23:38 UTC
Cloudflare publishes WAF rule to target CVE 2022-26134
When will a patch be available?
Atlassian has not confirmed when a patch will be available, but as noted above, Cloudflare customers protecting their Confluence applications with Cloudflare WAF and Access are protected. We will update this post as soon as new information is available, and we also recommend following the Atlassian security advisory.
There is no point in rehashing the fact that CAPTCHA provides a terrible user experience. It’s been discussed in detail before on this blog, and countless times elsewhere. One of the creators of the CAPTCHA has publicly lamented that he “unwittingly created a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles.” We don’t like them, and you don’t like them.
So we decided we’re going to stop using CAPTCHAs. Using an iterative platform approach, we have already reduced the number of CAPTCHAs we choose to serve by 91% over the past year.
Before we talk about how we did it, and how you can help, let’s first start with a simple question.
Why in the world is CAPTCHA still used anyway?
If everyone agrees CAPTCHA is so bad, if there have been calls to get rid of it for 15 years, if the creator regrets creating it, why is it still widely used?
The frustrating truth is that CAPTCHA remains an effective tool for differentiating real human users from bots despite the existence of CAPTCHA-solving services. Of course, this comes with a huge trade off in terms of usability, but generally the alternatives to CAPTCHA are blocking or allowing traffic, which will inherently increase either false positives or false negatives. With a choice between increased errors and a poor user experience (CAPTCHA), many sites choose CAPTCHA.
CAPTCHAs are also a safe choice because so many other sites use them. They delegate abuse response to a third party, and remove the risk from the website with a simple integration. Using the most common solution will rarely get you into trouble. Plug, play, forget.
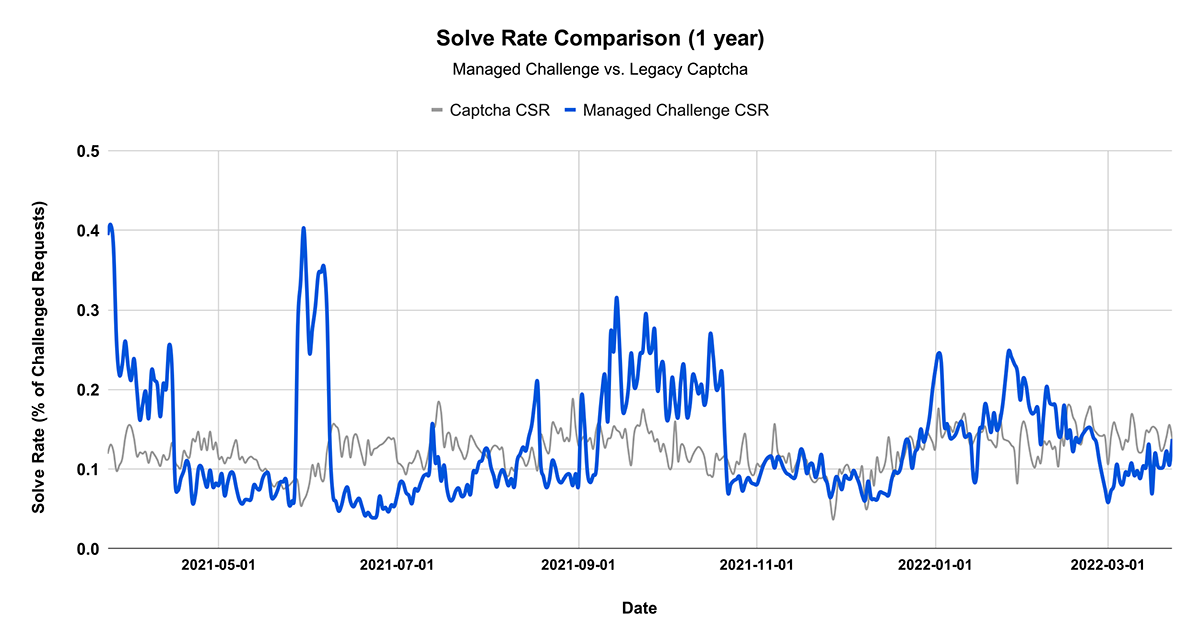
Lastly, CAPTCHA is useful because it has a long history of a known and stable baseline. We’ve tracked a metric called CAPTCHA (or Challenge) Solve Rate for many years. CAPTCHA solve rate is the number of CAPTCHAs solved, divided by the number of page loads. For our purposes both failing or not attempting to solve the CAPTCHA count as a failure, since in either case a user cannot access the content they want to. We find this metric to typically be stable for any particular website. That is, if the solve rate is 1%, it tends to remain at 1% over time. We also find that any change in solve rate – up or down – is a strong indicator of an attack in progress. Customers can monitor the solve rate and create alerts to notify them when it changes, then investigate what might be happening.
Many alternatives to CAPTCHA have been tried, including our own Cryptographic Attestation. However, to date, none have seen the amount of widespread adoption of CAPTCHAs. We believe attempting to replace CAPTCHA with a single alternative is the main reason why. When you replace CAPTCHA, you lose the stable history of the solve rate, and making decisions becomes more difficult. If you switch from deciphering text to picking images, you will get vastly different results. How do you know if those results are good or bad? So, we took a different approach.
Many solutions, not one
Rather than try to unilaterally deprecate and replace CAPTCHA with a single alternative, we built a platform to test many alternatives and see which had the best potential to replace CAPTCHA. We call this Cloudflare Managed Challenge.
Managed Challenge is a smarter solution than CAPTCHA. It defers the decision about whether to serve a visual puzzle to a later point in the flow after more information is available from the browser. Previously, a Cloudflare customer could only choose between either a CAPTCHA or JavaScript Challenge as the action of a security or firewall rule. Now, the Managed Challenge option will decide to show a visual puzzle or other means of proving humanness to visitors based on the client behavior exhibited during a challenge and based on the telemetry we receive from the visitor. A customer simply tells us, “I want you (Cloudflare) to take appropriate actions to challenge this type of traffic as you see necessary.“
With Managed Challenge, we adapt the actual challenge outcome to the individual visitor/browser. As a result, we can fine-tune the difficulty of the challenge itself and avoid showing visual puzzles to more than 90% of human requests, while at the same time presenting harder challenges to visitors that exhibit non-human behaviors.
When a visitor encounters a Managed Challenge, we first run a series of small non-interactive JavaScript challenges gathering more signals about the visitor/browser environment. This means we deploy in-browser detections and challenges at the time the request is made. Challenges are selected based on what characteristics the visitor emits and based on the initial information we have about the visitor. Those challenges include, but are not limited to, proof-of-work, proof-of-space, probing for web APIs, and various challenges for detecting browser-quirks and human behavior.
They also include machine learning models that detect common features of end visitors who were able to pass a CAPTCHA before. The computational hardness of those initial challenges may vary by visitor, but is targeted to run fast. Managed Challenge is also integrated into the Cloudflare Bot Management and Super Bot Fight Mode systems by consuming signals and data from the bot detections.
After our non-interactive challenges have been run, we evaluate the gathered signals. If by the combination of those signals we are confident that the visitor is likely human, no further action is taken, and the visitor is redirected to the destined page without any interaction required. However, in some cases, if the signal is weak, we present a visual puzzle to the visitor to prove their humanness. In the context of Managed Challenge, we’re also experimenting with other privacy-preserving means of attesting humanness, to continue reducing the portion of time that Managed Challenge uses a visual puzzle step.
We started testing Managed Challenge last year, and initially, we chose from a rotating subset of challenges, one of them being CAPTCHA. At the start, CAPTCHA was still used in the vast majority of cases. We compared the solve rate for the new challenge in question, with the existing, stable solve rate for CAPTCHA. We thus used CAPTCHA solve rate as a goal to work towards as we improved our CAPTCHA alternatives, getting better and better over time. The challenge platform allows our engineers to easily create, deploy, and test new types of challenges without impacting customers. When a challenge turns out to not be useful, we simply deprecate it. When it proves to be useful, we increase how often it is used. In order to preserve ground-truth, we also randomly choose a small subset of visitors to always solve a visual puzzle to validate our signals.
Managed Challenge performs better than CAPTCHA
The Challenge Platform now has the same stable solve rate as previously used CAPTCHAs.
Using an iterative platform approach, we have reduced the number of CAPTCHAs we serve by 91%. This is only the start. By the end of the year, we will reduce our use of CAPTCHA as a challenge to less than 1%. By skipping the visual puzzle step for almost all visitors, we are able to reduce the visitor time spent in a challenge from an average of 32 seconds to an average of just one second to run our non-interactive challenges. We also see churn improvements: our telemetry indicates that visitors with human properties are 31% less likely to abandon a Managed Challenge than on the traditional CAPTCHA action.
Today, the Managed Challenge platform rotates between many challenges. A Managed Challenge instance consists of many sub-challenges: some of them are established and effective, whereas others are new challenges we are experimenting with. All of them are much, much faster and easier for humans to complete than CAPTCHA, and almost always require no interaction from the visitor.
Managed Challenge replaces CAPTCHA for Cloudflare
We have now deployed Managed Challenge across the entire Cloudflare network. Any time we show a CAPTCHA to a visitor, it’s via the Managed Challenge platform, and only as a benchmark to confirm our other challenges are performing as well.
All Cloudflare customers can now choose Managed Challenge as a response option to any Firewall rule instead of CAPTCHA. We’ve also updated our dashboard to encourage all Cloudflare customers to make this choice.
You’ll notice that we changed the name of the CAPTCHA option to ‘Legacy CAPTCHA’. This more accurately describes what CAPTCHA is: an outdated tool that we don’t think people should use. As a result, the usage of CAPTCHA across the Cloudflare network has dropped significantly, and usage of managed challenge has increased dramatically.
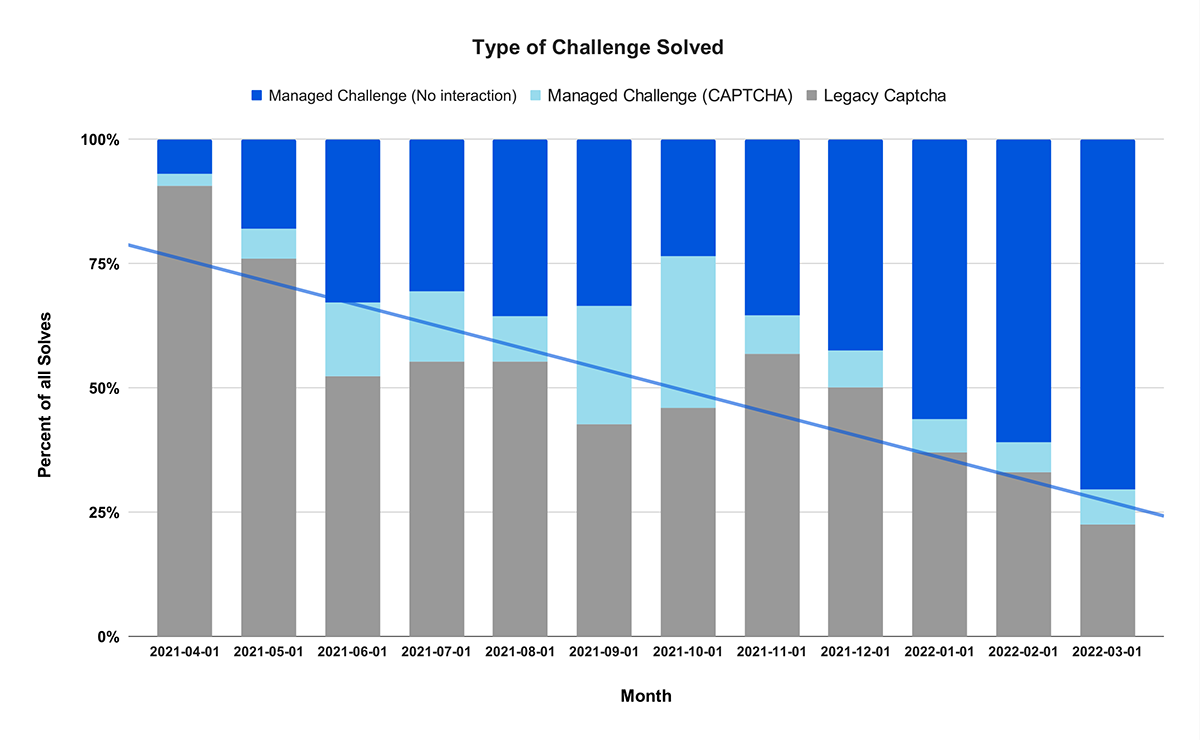
As noted above, today CAPTCHA represents 9% of Managed Challenge solves (light blue), but that number will decrease to less than 1% by the end of the year. You’ll also see the gray bar above, which shows when our customers have chosen to show a CAPTCHA as a response to a Firewall rule triggering. We want that number to go to zero, but the good news is that 63% of customers now choose Managed Challenge rather than CAPTCHA when they create a Firewall rule with a challenge response action.
We expect this number to increase further over time.
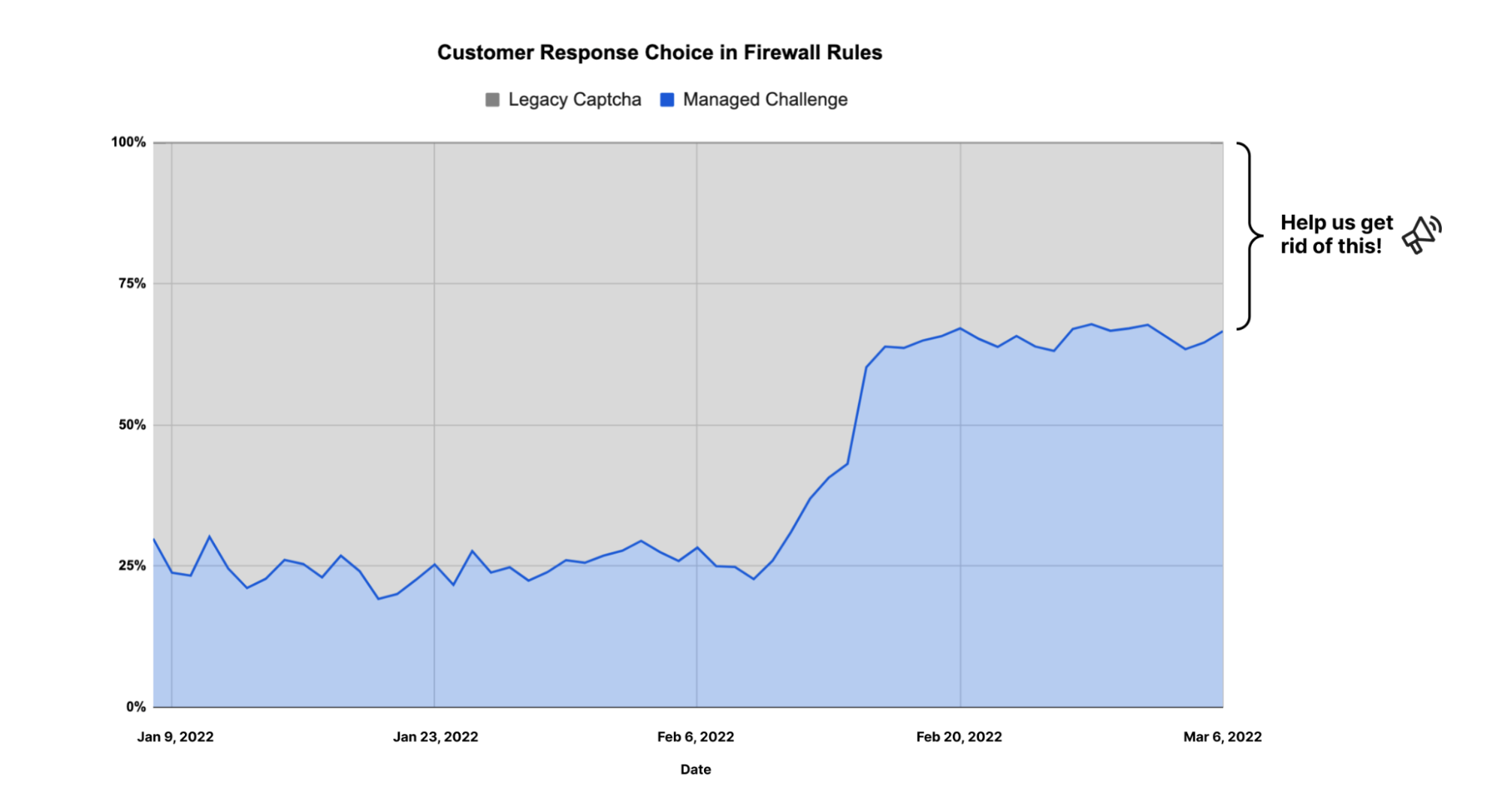
If you’re using the Cloudflare WAF, log into the Dashboard today and look at all of your Firewall rules. If any of your rules are using “Legacy CAPTCHA” as a response, please change it now! Select the “Managed Challenge” response option instead. You’ll give your users a better experience, while maintaining the same level of protection you have today. If you’re not currently a Cloudflare customer, stay tuned for ways you can reduce your own use of CAPTCHA.
When we launched Bot Management three years ago, we started with the first version of our ML detection model. We used common bot user agents to train our model to identify bad bots. This model, ML1, was able to detect whether a request is a bot or a human request purely by using the request’s attributes. After this, we introduced a set of heuristics that we could use to quickly and confidently filter out the lowest hanging fruit of unwanted traffic. We have multiple heuristic types and hundreds of specific rules based on certain attributes of the request, many of which are very hard to spoof. But machine learning is a very important part of our bot management toolset.
We started with a static model because we were starting from scratch, and we were able to experiment quickly with aggregated HTTP analytics metadata. After we launched the model, we quickly gathered feedback from early bot management customers to identify where we performed well but also how we could improve. We saw attackers getting smart, and so we generated a new set of model features. Our heuristics were able to accurately identify various types of bad bots giving us much better quality labeled data. Over time, our model evolved to adapt to changing bot behavior across multiple dimensions of the request, even if it had not been trained on that type of data before. Since then, we’ve launched five additional models that are trained on metadata generated by understanding traffic patterns across our network.
While our models were evolving over time, the patterns of traffic flowing through Cloudflare changed as well. Cloudflare started in a desktop first world, but mobile traffic has grown to make up more than 54% of traffic on our network. As mobile has become a significant share of traffic we see, we needed to adapt our strategy in order to be able to get better at detecting bots spoofing mobile applications. While desktop traffic shares many similarities regardless of the origin it’s connecting to, each mobile app is crafted with a specific use in mind, and built on a different set of APIs, with a different defined schema. We realized we needed to build a model that would prove to be more effective for websites that have mobile application traffic.
How we build and deploy our models
Before we dive into how we updated our models to incorporate an increasing volume of mobile traffic, we should first discuss how we build and train our models overall.
Data gathering and preparation
An ML model is only as good as the quality of data you train it with. We’ve been able to leverage the amount and variety of traffic on our network to create our training datasets.
We identify samples that we know are clearly bots – samples we are able to detect with heuristics or samples that are from verified bots, e.g., legitimate search engine crawlers, adbots.
We also can identify samples that are clearly not-bots. These are requests that are scored high when they solve a challenge or are authenticated.
Data analysis and feature selection
From this dataset, we can identify the best features to use, using the ANOVA (Analysis of Variance) f-value. We want to make sure different operating systems, browsers, device types, categories of bots, and fingerprints are well represented in our dataset. We perform statistical analysis of the features to understand their distribution within our datasets as well as how they would potentially influence predictions.
Model building and evaluation
Once we have our data, we can begin training a model. We’ve built an internal pipeline backed by Airflow that makes this process smooth. To train our model, we chose the Catboost library. Based on our problem definition, we train a binary classification model.
We split out training data into a training set and a test set. To choose the best hyperparameters for the model, we use the Catboost library’s grid search and random search algorithm.
We then train the model with the chosen hyperparameters.
Over time, we’ve developed granular datasets for testing out our model to ensure we accurately detect different types of bots, but we also want to make sure we have a very low false positive rate. Before we deploy our model to any customer traffic, we perform offline monitoring. We run predictions for different browsers, operating systems and devices. We then compare the predictions of the currently trained model to the production model on validation datasets. This is done with the help of validation reports created by our ML pipeline that includes summary statistics such as accuracy, feature importance for each dataset. Based on the results, we either iterate or we decide to proceed to deployment.
If we need to iterate, we like to understand better where we can make improvements. For this, we use the SHAP Explainer. The SHAP Explainer is an excellent tool to interpret your model’s prediction. Our pipeline produces SHAP graphs for our predictions, and we dig into these deeper to understand the false positives or false negatives. This helps us to understand how and where we can improve our training data or features to get better predictions. We decide if an experiment should be deployed to customer traffic when it shows improvements in a majority of our test datasets over a previous model version.
Model deployment
While offline analysis of the model is a good indicator of the model’s performance, it’s best to validate the results in real time on a wider variety of traffic. For this, we deploy every new model first in shadow mode. Shadow mode allows us to log scores for traffic in real time without actually affecting bot management customer traffic. This allows us to perform online monitoring i.e. evaluating the model’s performance in real time for traffic. We break this down by different types of bots, devices, browsers, operating systems and customers using a set of Grafana dashboards and validate model accuracy improvement.
We then begin testing in active mode. We have the ability to roll out a model to different customer plans and sample the model for a percentage of requests or visitors. First we roll out to customers on the free plan, such as customers who enable I’m Under Attack Mode. Once we validate the model for free customers, we roll out to Super Bot Fight Mode customers gradually. We then allow customers who would like to beta test the model onboard and use it. Once our beta customers are happy, the new model is officially released as stable. Existing customers can choose to upgrade to this model, all new customers will get the latest version by default.
How we improved mobile app performance
With our latest model, we set out to use the above training process to specifically improve performance on mobile app traffic. To train our models, we need labeled data: a set of HTTP requests that we’ve manually annotated as either “bot” or “human” traffic. We gather this labeled data from a variety of sources as we spoke about above, but one area where we’ve historically struggled is finding good datasets for “human” traffic from mobile applications. Our best sample of “good” traffic was when the client was able to solve a browser challenge or CAPTCHA. Unfortunately, this also limited the variety of good traffic we could have in our dataset since a lot of “good” traffic cannot solve CAPTCHA – like a subset of mobile app traffic. Most CAPTCHA solutions rely on web technologies like HTML + JavaScript and are meant to be executed and rendered via a web browser. Native mobile apps, on the other hand, may not be capable of rendering CAPTCHAs properly, so most native mobile app traffic will never make it into these datasets.
This means that “human” traffic from native mobile applications was typically under-represented in our training data compared to how common it is across the Internet. In turn, this led to our models performing worse on native mobile app traffic compared to browser traffic. In order to rectify this situation, we set out to find better datasets.
We leveraged a variety of techniques to identify subsets of requests that we could confidently label as legitimate native mobile app traffic. We dug through open source code for mobile operating systems as well as popular libraries and frameworks to identify how legitimate mobile app traffic should behave. We also worked with some of our customers to identify domain-specific traffic patterns that could distinguish legitimate mobile app traffic from other types of traffic.
After much testing, feedback, and iteration, we came up with multiple new datasets that we incorporated into our model training process to greatly improve the performance on mobile app traffic.
Improvements in mobile performance
With added data from validated mobile app traffic, our newest model can identify valid user requests originating from mobile app traffic by understanding the unique patterns and signals that we see for this type of traffic. This month, we released our latest machine learning model, trained using our newly identified valid mobile request dataset, to a select group of beta customers. The results have been positive.
In one case, a food delivery company saw false positive rates for Android traffic drop to 0.0%. That may sound impossible, but it’s the result of training on trusted data.
In another case, a major Web3 platform saw similar improvement. Previous models had shown false positives, varying between 28.7% and 40.7% for edge case mobile application traffic. Our newest model has brought this down to nearly 0.0%.
These are just two examples of results we’ve seen broadly, which has led to an increase in adoption of ML among customers protecting mobile apps. If you have a mobile app you haven’t yet protected with Bot Management, head to the Cloudflare dashboard today and see what the new model shows for your own traffic. We provide free bot analytics to all customers, so you can see what bots are doing on your mobile apps today, and turn on Bot Management if you see something you’d like to block. If your mobile app is driven by APIs, as most are, you might also want to take a look at our new API Gateway.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.