As generative AI has shifted from selective experimentation to broad operational use, large language models (LLMs) now sit inside developer environments, support workflows, internal knowledge systems, and security tooling itself. Adoption has widened for both enterprises and consumers alike, and, unsurprisingly, have a whole new set of security patterns.
Though oftentimes single catastrophic failures are the types of stories that make the news (like an AI agent pushing code to production against its explicit instructions), the truth is that there’s a bigger narrative here. Generative AI has introduced a whole new way to work, and we’re seeing a set of recurring behaviors—ways that AI systems interact with data, instructions, and people—that either introduce new risks or enhance some tried-and-true bad actor tactics (like more convincing phishing attacks, for example).
This article focuses on seven patterns that have emerged in real deployments and documented incidents. Let’s get into it.
1. Prompt injection and instruction hijacking
Prompt injection has matured from a research concept into a practical exploit vector. The issue is structural: LLMs interpret text holistically using tokenization, which makes it difficult to maintain a strict separation between instructions and data. When untrusted content is introduced into an AI system with elevated permissions, that ambiguity becomes exploitable.
Recent incidents show how this plays out in production tools. Researchers analyzing Microsoft Copilot demonstrated that carefully crafted inputs could override intended behavior, expose system prompts, or trigger unintended actions within the model’s sandbox.
The common thread is authority. When models are allowed to act on retrieved content or invoke downstream tools, text becomes a control surface.
2. Prompt poaching and peripheral exfiltration
Not all AI-related data loss requires access to the model itself. A recent malware campaign demonstrated how attackers can siphon AI conversations by compromising the surrounding ecosystem.
These attacks target trust boundaries adjacent to AI systems rather than the models directly. Browser extensions, plugins, and integrations become collection points for high-value contextual data that did not previously exist in a single place. And, they’re often less controlled by enterprise IT teams compared with other types of software.
3. AI-powered malware and ransomware
AI-assisted malware is no longer hypothetical. Security researchers have now documented ransomware that uses generative models as part of its operational logic.
One example: PromptLock, a ransomware strain that leverages LLMs to dynamically generate portions of its code and behavior during execution.
At the ecosystem level, threat intelligence reports show ransomware groups using AI to accelerate development, customize payloads, and craft tailored extortion communications. Akamai’s 2025 ransomware trends report documents LLM usage by active groups for both technical and social components of attacks.
It’s less about how it’s done and more about how fast it’s done: Iteration cycles are shorter, and adaptation happens more quickly.
4. Acceleration and competitive pressure in the ransomware economy
Even when AI is not embedded directly into malware, it influences the broader threat environment. Ransomware activity increased throughout 2025 despite arrests and takedowns; new groups emerged quickly to replace disrupted ones.
As we said above, speed matters here. Defensive models that assume time for analysis, tuning, and response are increasingly stressed by attackers who can prototype and redeploy faster than those cycles allow.
And it’s not just speed—the volume of (credible, real) attacks matters too. The truth of the game has always been that bad actors only have to succeed once whereas defenders have to succeed every time. If better ransomware is being produced more quickly, defenders are having to adapt just as (or more) quickly to a higher volume of attacks (which makes the demand for employees in the security industry that much more understandable).
5. Semantic noise and operational fatigue
Generative AI produces a large volume of plausible output: summaries, recommendations, alerts, explanations. In isolation, that capability is helpful; in aggregate, it introduces a new operational burden.
Security teams report growing difficulty distinguishing signal from well-formed noise. In reality, this means that over-taxed employees are getting pinged while on-call far more.
AI-generated conclusions often require human validation, but their tone and confidence can reduce scrutiny over time. That creates opportunities for malicious activity to hide inside outputs that appear reasonable and routine; or, on the flip side, for things like process and architecture misconfigurations to masquerade as security events by creating too many requests.
This pattern does not map cleanly to a single exploit; it shows up as delayed detection, slower response, and missed anomalies.
6. Code supply chain risk from generated code
AI-generated code compounds familiar supply-chain issues. Generated snippets often compile cleanly, pass tests, and follow common patterns; they also tend to replicate insecure defaults or omit contextual safeguards.
As these patterns are reused across services, small mistakes scale quickly. Not only that, but basic parameters like privileging recency (e.g., new security patches) vs. commonality (e.g., the most often used code) can have major implications and be weighted differently in different tools. While there is demonstrated risk of malicious insertion, it’s also the normalization of fragile or incomplete logic through automation.
7. Potential human skill erosion as a force multiplier
One of the quietest risks is also the hardest to measure. As AI tools handle more analysis, summarization, and decision support, human operators spend less time interrogating raw data. That’s both a good and a bad thing—really, it begs the question of how we go about creating and applying expertise in a new and developing epistemological framework. (Wait, you thought engineering wasn’t philosophical?)
Over time, that shifts how teams validate outcomes and how comfortable they are challenging AI-generated conclusions. This erosion does not cause incidents by itself, but it can amplify the impact of every other failure mode.
Where this leaves us
Across these examples, a consistent theme emerges. Generative AI changes how authority, context, and action flow through systems. Many of the resulting failures are subtle and blend into normal usage patterns.
The next phase of response is already taking shape. Government agencies and standards bodies are beginning to formalize guidance on securing AI systems, managing AI-related risk, and adapting existing security practices to these new patterns.
That guidance belongs in its own discussion. For now, the takeaway is simpler: AI adoption has altered the shape of risk.
When most people think about year-end work, they think in terms of deadlines, retrospectives, and a well-earned break. Data centers have other ideas because, well, the internet still needs to work on holidays in order to power those digital fireplaces and Spotify playlists.
Backblaze runs year-round, around the clock, which means that even the holidays are business as usual in a data center. And many customers who use Backblaze to store their AI models, applications, media, and critical business data need that data storage to be more reliable than ever, especially around the holidays. Every drive swap, rack adjustment, alert investigation, and routine fix leaves a trace in our work tickets, and we’ve discussed in our Drive Stats reports how we use those work tickets to do things like define a failure. They’re also evidence of what it takes to keep an always-on service humming, even when the rest of the company is offline.
So, as the year comes to a close, we wanted to shout out to our awesome data center, cloud ops, and on-call team members—we couldn’t do it without you. And here’s a little retrospective on what this past year looked like.
In total across data centers, we spent 3,112.43 hours replacing hard drives. (If those hours don’t square up with the charts above, it’s because the total view includes other types of work, like upgrading our systems.) On average, it took about 0.74 hours per hard drive.
Here’s a breakdown of the drives replaced by capacity:
If you’re a Drive Stats fan, you may notice there are some funky drive sizes on there based on our other reporting data. (A 2TB drive? Where does that one even come from?) The drives above are inclusive of our whole fleet, including boot drives and non-production drives, and some of those are sized differently than based for whatever reason—history, job in the data center, etc.
Vault deployments
We also deploy new Vaults fairly regularly. This year, we added the following Vaults (per data center):
And, here’s a breakdown of the number of Vaults broken down by drive size:
In total, we spent 1043.23 hours on Vault deployment which is about 31.61 hours on average per Vault.
Numbers, as always, tell the story
Taken together, the data shows every hour logged, every drive replaced, every Vault added, and every ticket closed. It adds up to a year’s worth of hands-on infrastructure care; in short, it’s the steady investment required to operate storage at scale.
Whether you’re on call monitoring your own systems, planning for growth in the year ahead, or fully offline over the holidays, your data is here for you. Cheers to another great year!
Sure, we may be a global tech company who spends our days on the front lines of helping our customers solve their toughest data storage challenges, but that doesn’t mean we don’t ever power down the devices and curl up with a good book. Welcome to the third annual Bookblaze, Backblaze’s much-anticipated book guide where our team shares the stories, insights, and adventures that shaped their reading year.
From thought-provoking nonfiction to immersive fiction and unexpected gems, these recommendations are curated by the people who read, think, and create here at Backblaze—offering you a cozy companion for winter nights, inspiration for your 2026 reading list, and maybe even the perfect gift idea along the way. Whether you’re reconnecting with old favorites or discovering your next great read, we hope this year’s picks spark joy, curiosity, and conversation.
Chris McGranahan, Director, Information Security Architecture
It’s an exhaustive but entertaining explanation of how our world came to be the way it is, why CO2 is so important to it and how the path we’re currently on is likely to create a world that hasn’t existed in millions of years and never supported humans. And, if you want a fun fiction read, check out any of the Murderbot Diaries series by Martha Wells.
I love deeply flawed female protagonists. I also love the fact that myth retellings have been so popular for the last few years, and this year, I decided to tackle my hyper-specific TBR I was neglecting. (Editor’s note: For those of you not afflicted with chronic book collecting, TBR = to be read.)
Clytemnestra tells the story of one of the most reviled women in Greek mythology. She’s cunning, ruthless, and quite possibly the original champion of playing the long game to seek revenge, as a key player in the Trojan War you’ve probably never heard of. And yet, you can’t help but root for her. It’s shocking that this is a debut novel because, though it can be a slow burn in parts, the characterization and completely immersive writing provides a different perspective of how the Trojan War unfolded for those left at home.
I appreciate how Positive Intelligence translates mindset and emotional intelligence into practical exercises for building mental fitness. The Saboteur framework makes it easy to spot negative thinking and shift toward a more productive mindset. It’s a great balance of psychology, neuroscience, and real-world application that supports personal and professional growth.
In work and in life, we often struggle with saying “no”, even to ourselves. We take on more than we can effectively manage and execute. As a result, we’re burned out—frustrated by our ever-growing to-do lists and disappointed in the quality of what we do get done. This book helped me understand why doing less actually results in accomplishing more and better things. In addition, it gave me a sense of how to make this case to others—whether it’s about prioritization of work projects or helping a loved one who’s feeling overwhelmed.
Although there were some dark moments in the book, in general it was a feel good book of a boy coming of age through adulthood, paying his dues and then paying it forward. The setting is right in the Backblaze neighborhood so it’s always interesting to picture the local intersections, and schools referenced in the novel.
Elisa Miller, Sr. Organizational Development Partner
Octavia Butler is a masterful sci fi writer who has woven a tale in the 1990s set to present time about a dystopian reality oddly similar to the one we are living/heading towards currently of lawlessness, greed, and the quest for survival. Focusing on the power of community, togetherness, and nature, this book was an epic (and scary) adventure into what happens when people gather together to fight the status quo while lifting one another up. It’s not for the faint of heart, but it really was a game changer for me to read, offering solutions beyond capitalism and towards empowerment of humanity, spirituality, and purpose.
It’s a buddy comedy, but also the fate of the human race is at stake. There’s lots of science to nerd out on if that’s your thing. And Andy Weir is a former software engineer, so you could kinda sorta say it’s “for work.”
Sleep training my child without having to resort to too much crying seemed daunting, but this book helped inform our process with evidence based guidance. I am happy to report that I have a great little sleeper because of it. This book will help any parent gain the skills and confidence to effectively sleep train their child.
This book series is absolute insanity, and if you are able to get the audiobook, you will not regret it. I even got my sister’s mother-in-law to listen to it on audio and she loved it. The premise is that it’s the end of the world, and Carl is sucked into a dungeon to fight for the entertainment of the universe at large—plus there’s a talking cat! What’s not to like? It’s a genre known as LitRPG (editor’s note: Literary role-playing game) which follows Carl and his friends’ progression as they work through the dungeon and try to topple the powers that be.
The new “Hunger Games” book is the first prequel I’ve read in years that genuinely adds something meaningful to its original series. It pulled me right back into Panem, had me rewatching all the movies, and had me loving characters that I didn’t expect to get attached to. A fantastic return to a world I thought I already knew.
This series reminds me of old-school science fiction in all the best ways. Without giving too much away, a terraforming project is sabotaged, leading to unexpected outcomes for the targeted planet. Meanwhile, back on Earth, the world ends, and a race begins for the remainder of humanity to find a new home. Tchaikovsky’s brilliance thrives in the details of understanding systems, people, biology, engineering, and science, and each new revelation about what’s happening—in this new world with a new sentient species, and with the humans on their ever-devolving arc ship—stems from each of those details showing up in ways that feel both expected and unexpected at the same time.
Ransomware used to mean locked files and paralyzed systems. But today, bad actors are just as focused on exfiltration—the silent theft of sensitive data—and using that data as leverage for extortion.
According to cybersecurity firm BlackFog, 94% of successful cyberattacks in 2024 involved data exfiltration, either alongside or instead of encryption. Whether it’s stolen patient records, credentials, or source code, the goal is simple: Extract something valuable and threaten to leak it if demands aren’t met.
In this article, we examine how exfiltration became a leading tactic, the trends driving its rise, and what organizations—and cloud storage providers—can do to defend against it.
What is exfiltration?
In cybersecurity, exfiltration refers to the unauthorized transfer of data from a system—often done stealthily, and almost always with malicious intent. Think of it as the digital equivalent of corporate espionage: Data is copied, compressed, and quietly smuggled out. Unlike ransomware encryption, which slams the door in your face, exfiltration leaves the front door looking untouched.
The data being exfiltrated is rarely random. Cybercriminals are increasingly strategic about what they take and why. Common targets include:
User credentials
Personally identifiable information (PII)
Intellectual property and source code
Encryption keys
Shadow copies or backup snapshots
Tactics include exploiting cloud storage misconfigurations, hijacking legitimate credentials, or disguising traffic as everyday protocols like DNS or HTTPS. Increasingly, data exfiltration happens before the main event—laying the groundwork for extortion, credential stuffing, or resale on underground markets.
Recent cybersecurity trends related to exfiltration
Exfiltration has become the defining feature of modern cyberattacks, and the evidence is growing:
Double extortion is now standard. Threat actors exfiltrate data first, then deploy ransomware—or skip the encryption altogether—to maximize leverage. According to the 2023 Unit 42 Report, 70% of ransomware incidents involved data theft.
Infostealers, malicious programs designed to covertly harvest sensitive information, are on the rise. Over 2.1 billion credentials were stolen in 2024 alone, with malware like RedLine and Lumma making theft accessible to low-skilled attackers. While cybersecurity task forces (comprised of both government and enterprise actors) have made the news with high-profile disruptions of Lumma and other tools, the ability to use generative AI coding tools has meant that cyber attackers have a shortened time to deployment for malware tools.
Time to exfiltration is shrinking.Fortinet’s 2025 Threat Landscape Report notes that attackers can extract data in under five hours, while defenders often take days to respond.
Encrypted traffic masks malicious behavior. Emerging exfiltration techniques like QUIC-Exfil use modern, encrypted protocols to evade detection by traditional firewalls.
Together, these trends point to a world where stolen data is the main prize—and the threat doesn’t start when the ransom note arrives. It starts when your data quietly leaves the building.
Cloud misconfiguration and its role in exfiltration attacks
Exfiltration doesn’t always require malware—sometimes it only takes a misconfigured storage bucket or firewall rule. Cloud misconfigurations remain a leading cause of breaches, with public buckets, excessive identity and access management (IAM) privileges, and overly permissive network rules exposing data to the open internet.
Attackers exploit these gaps to quietly access or extract data without triggering alerts. A strong cloud posture management strategy—one that includes audit automation, implementing the principle of least privilege, and configuring features like Object Lock or Bucket Access Logs—is critical to reducing exposure.
Defending against exfiltration is a shared responsibility
As exfiltration becomes a primary threat, defense requires collaboration between cloud storage providers and their customers. Here’s how the most effective strategies work together.
Immutable backups and Object Lock
One of the strongest defenses is immutability. Backblaze B2’s Object Lock, for example, allows files to be written once and protected from modification, deletion, or encryption for a set period. Even if attackers compromise credentials, the data cannot be altered or removed.
Visibility and outlier detection
Cloud providers are investing in making advanced logging and behavioral analytics available to users to detect data theft in real time. Some examples of these types of features include:
Granular access logging with IP and user-level metadata.
Rate limiting and download caps to prevent mass theft.
Outlier detection powered by machine learning to catch subtle deviations from baseline activity.
Best practices for customers
Storage-layer defenses work best when paired with customer-side security controls:
Adopt zero trust architecture: Never assume implicit trust. Continuously validate users, devices, and behaviors.
Use MFA and least-privilege access: Lock down credentials, rotate them regularly, and minimize exposure.
Encrypt data at rest and in transit: Use strong encryption standards (AES-256, TLS 1.2+) and managed key systems.
Monitor for exfiltration indicators: Watch for abnormal traffic volumes, geographic anomalies, and unexpected protocol usage.
Run simulated breach drills: Test your team’s ability to detect and respond to stealthy data leaks.
Cloud storage companies can help provide critical security layers, but stopping exfiltration is ultimately a shared responsibility. Combining provider-level resilience with customer vigilance is the best path forward.
In a world of silent theft, vigilance is your best defense
Exfiltration isn’t just an add-on to ransomware. In this environment, locking the doors isn’t enough—You need to monitor the exits.
By combining immutable backups, smart logging, credential controls, and proactive monitoring, organizations can shift from passive victims to active defenders. The best defenses today aren’t just about blocking access; they’re about knowing what’s leaving and making sure it can’t be used against you.
AI is rewriting the rules of technology, for better or worse. Arguably one of the most “for better and worse” areas? Ransomware. It’s a full blown billion dollar business, and AI is supercharging both the offense and defense.
Not only are we seeing AI give bad actors more sophisticated tools and campaigns to target business and consumers alike, we’re also seeing mitigation techniques and technologies deployed by good actors gain equally compelling AI-powered improvements.
In other words, welcome to the future—where your data is the hostage and the bots are negotiating. Let’s dig in.
Some stage-setting: How much is ransomware costing us?
Despite ransomware payments exceeding an eye-watering $1 billion in 2023—and despite some high profile attacks in 2024, one of which extracted $75 million from a single victim—ransomware attacks actually fell overall in 2024. High profile law enforcement activity, like those against LockBit and BlackCat contributed to a huge drop in the second half of 2024.
Don’t get too excited though: According to cryptocurrency tracing firm Chainanalysis, that still meant $814 million in 2024. And, the true cost of ransomware includes more than just payments extracted under threat.
The economic ripple effects of a ransomware attack can include losing C-level talent, having to lay off employees, and ongoing downtime or business closure. Industry-wide, cyber insurance is a growing industry, and 2024 saw a staggering 31% of claims come from third-party risk.
Perhaps most concerningly, ransomware attackers are increasingly using exfiltration as a tactic to double and triple extortion, even using exfiltration data to launch targeted distributed denial-of-service (DDoS) attacks. According to a Check Point’s 2025 Cyber Security Report, some new actors have emerged as exclusively “data-selling platforms,” hosting dedicated data leak sites (DLS) and negotiation platforms.
The good news
Machine learning (ML) tools have underpinned modern cyber security techniques for years now—with excellent results.
Sophisticated monitoring tools give us far more granular insights and alerts.
AI-driven behavioral analysis is making it easier to detect anomalies and preempt attacks before they escalate.
What does this mean for defending against ransomware attacks?
Enterprises now have access to security platforms that analyze network behavior in real time, flagging unusual access patterns or lateral movement before a full ransomware payload can deploy. These platforms rely on machine learning models trained on massive datasets of known attack vectors, which allows them to flag and quarantine suspicious activity with impressive accuracy.
The interesting thing is that common knowledge says that “the AI revolution” has been happening recently, and quickly. But, when it comes to cybersecurity defense, many tools have been using ML algorithms for at least two decades. Palo Alto Networks (WildFire), for example, has been using ML since 2003.
The line between “processing massive datasets and acting up on that info based on programmed parameters” and machine learning is subtle, but important. While the former follows set parameters, machine learning identifies patterns in data—sometimes with human guidance—to decide from multiple possible actions.
It’s like teaching an assistant a series of tasks they can eventually do on their own. When you think about the progression from basic automation to ML, AI, and deep learning, the shift from rule-based actions to autonomous, chained decisions starts to make a lot of sense.
Zero trust architecture, enhanced by AI, is also gaining momentum. Instead of relying on perimeter-based defenses, AI-enhanced systems enforce granular access controls and continuously verify user and device trust levels. In practice, what this means is that systems no longer assume that you are you on the other end—not without evidence. Combine this with real-time threat intelligence sharing and automated incident response, and enterprises can shorten the window between detection and mitigation drastically.
The bad news
Deep fakes are more convincing.
The ability to generate code means there are more attacks, and those attacks are more sophisticated and responsive.
Cyber criminals of all skill levels have access to more technical tools, including some that are specialized in malware.
Enterprises are adjusting to a new way of working, which can create vulnerabilities.
Generative AI, phishing, and deep fakes
The low-hanging fruit in this discussion is that it’s easy to use generative AI to create more convincing phishing attacks. In the past, bad grammar or non-localized language choices have been an easy way to quickly identify a phishing attack.
Assisted by generative AI, deep fakes of both the voice and video flavor are getting increasingly difficult to spot—so, while you know your CEO isn’t likely to text you to get a bunch of gift cards or send them company funds via Bitcoin or PayPal, you might believe a video of your CFO or a call from your CEO asking you to transfer funds to accounts that turn out to not be legitimate.
How is generated code being used by ransomware bad actors?
Just as generative AI models have made everyone a poet, they’re also widely used to generate code. Tools like GitHub Copilot have seen wide adoption amongst enterprises looking to generate and test code. Gartner reports that by 2027, 70% of professional developers will use AI-powered coding tools, up from less than 10% in 2023.
Given how AI code generation has made code generation easier on enterprises, it’s no surprise that the ransomware industry is following the same adoption trends. By January 2023, this had gone from a hypothetical to a reality, with ransomware bad actors of low levels of technical skill able to leverage LLMs to create malware scripts.
By July 2023, cybercriminals were already discussing WormGPT, a malicious chatbot trained on ChatGPT which removed standard guardrails against creating illegal or inappropriate content. And, cybersecurity protection firms had executed a proof of concept to demonstrate that AI could generate truly polymorphic code on the fly—a technique used to make it much easier to evade detection by antivirus programs. By July 2024, one study showed that ChatGPT 4 was able to exploit 87% of one-day vulnerabilities.
Couple that with the fact that ransomware bad actors have opposite success metrics vs. enterprises. Cyber criminals rely on enacting as many attacks as possible, and it only takes one of those attacks succeeding to see a significant upside. Enterprises, on the other hand, only need one failure to see a huge negative impact on their businesses.
What things can you implement to be ransomware ready?
Some of these recommendations are things that users can do on every platform they interact with, such as:
Creating good, strong, unique passwords, and preferably using a password manager: A good password manager reduces password reuse and helps ensure best practices are followed enterprise-wide.
Enabling multifactor authentication (MFA): Multi-factor authentication remains one of the strongest lines of defense, especially when paired with device verification and biometric options.
On the enterprise side of the house, frameworks like cyber resilience help teams protect data they’ve been entrusted with. And, AI-powered cyber security tools can be a powerful tool in any business’s toolbox. That can look like a number of different things, including:
Investing in AI-powered endpoint detection and response (EDR). These tools continuously monitor and analyze endpoint activities, flagging unusual behavior and isolating threats automatically.
Training teams on recognizing deep fakes and AI-enhanced phishing attempts. Security awareness training is evolving fast. Focused, frequent, and AI-aware sessions are critical for employees across departments.
Leveraging deception technology. Deploying decoy systems, fake credentials, and honeypots can help trap attackers early and gather valuable intel on their tactics.
Running tabletop simulations. Practicing breach scenarios—especially those involving AI-enabled threats—prepares teams to act decisively when seconds matter.
Cyber resilience isn’t static, and neither are the tools and tactics. One of the most important areas an enterprise can invest in is ongoing security and research. Enterprise leaders need to prioritize proactive measures. That means ongoing AI model audits, being nimble in response to new and changing best practices, and investing in cross-functional teams that bring together infosec, legal, and operational leadership.
The future of AI and ransomware
Let’s level with each other—separately, the AI and ransomware spaces are both changing quickly. When you combine AI and ransomware and try to define how they’re affecting each other, you’re on pretty slippery ground.
What we’re trying to do here is identify patterns that affect our everyday lives—but we’re also taking a peek at what folks are studying in the research realm, because quantum is just around the corner, and, frankly, too impactful to ignore.
So, tell us if we need an update, or if you have another opinion! The comments section is open and we’re happy to chat.
AI is here to stay, and the question on everyone’s mind is how to implement it successfully. If you’re ready to implement AI in your business, consider this article a good jumping off point. I’ll talk about different options for integrating it into your operations and how to make it truly custom, based on your own data, and useful for your business.
More from AI 101
Want to read more about AI? We’ve got you covered in our AI 101 series. And, here’s a sampling that might be useful when you’re thinking about building AI into your business.
How many businesses are using AI, you ask? Well, let’s ask Google. According to their AI overview (yes, we appreciate the irony), anywhere between 55% and 83% of companies are using or exploring AI in some way.
It’s not lost on me that the above results illustrate some of the big limitations of AI—namely that it’s only as good as the data it’s trained on, it’s far from infallible, and it can’t replace humans wholesale especially when someone needs to fact check those results. Google’s AI overviews have been criticized for providing inaccurate information, hallucinating (with sometimes hilarious results), providing a neat answer to complicated questions, providing information from unreliable sources, potential for bias, and so on. Nevertheless, the feature has had several updates since it was first released (which at least means it’s no longer telling us to put glue on pizza).
But, setting all that aside, this is actually a great example to consider before we dig into options for incorporating AI into your business. AI Overviews have improved enough—for example, by adding things like source transparency—that we can easily add enough human oversight to consider the above directionally accurate. The landscape of technology is changing, and, ready or not, businesses are being forced to figure out how AI should fit into their strategies.
What we’ll talk about today
Today we’ll talk about some foundational topics you need to understand when deciding how to incorporate AI into your business. We’ll define the following:
Software as a service (SaaS) AI add-ons
AI as a service (AIaaS)
Foundation models
Retrieval augmented generation (RAG)
Those definitions will lead us quickly to some practical examples that illustrate how businesses are using AI.
Software as a service (SaaS) applications, aka, AI as a feature
You may have noticed that many of the web-based applications you are using are suddenly AI-powered or have AI capabilities. While some of that is marketing hype, this could be a way to get started with AI in your organization—by simply turning on a feature in a SaaS product you’re already using. There are lots of ways to do this—Slack, for example, offers AI tools for summarizing and answering questions to help teams work faster.
Example AI use case: AI in customer support
Generative AI capabilities such as chatbots are often added to customer-facing applications like your customer support service. The chatbot is trained using your product support materials or actual questions your staff previously answered.
By providing a cache of human-based questions and answers, the chatbot can be trained to respond in your unique company voice.
Oh hey, there’s ours!
Before you activate and use a built-in AI feature of an existing service, you’ll want to determine how you can measure any changes in overall productivity and user satisfaction. In the customer service example above, that could be capturing metrics such as a customer satisfaction rating, time to first contact, time-to-resolution, escalation ratio, and so on. Then establish a baseline for the existing system before engaging the AI assistant and set specific points where you will compare that baseline to the AI powered system.
Using an AI powered service has many benefits, but there are a number of considerations to contemplate:
You are limited in functionality by what the vendor provides.
What is the expertise of the software vendor in developing, training, and implementing an AI model?
What happens when the model data changes? For example, you’ve employed AI to respond to customer queries. What happens when you add a new product to your lineup or a new feature to an existing product? Is the model retrained? What are the costs? Does it still make economic sense given any new cost?
During the model creation and operational phases, ancillary files such as checkpoints, prompts, responses, and so on are created. Do you have visibility into these files and what analysis can you perform?
Given these ancillary files are derived in part from your original data, can you download these files to your central repository or is the data locked in the vendor’s application?
Artificial intelligence as a service (AIaaS)
AIaaS is one of the many areas of AI where definitions and capabilities are a moving target. That said, we’ll offer that AIaaS is an outsourced service that a cloud-based company provides to other organizations that gives that organization access to different AI models, algorithms, and other resources directly through the vendor’s cloud computing platform via a user interface (UI), API, or SDK connection. The aim is to make a user-friendly interface that simplifies the process of training and deploying AI models accessible to non-AI experts.
AIaaS is worth considering if you’re interested in working with artificial intelligence but you don’t have the in-house resources or expertise to build and manage your own AI technology. There are a broad range of solutions offered in this space which vary by the services provided, let’s categorize the services as follows.
Walled gardens:
What they offer: In my experience, AIaaS providers in this group usually host most or all of the model training data, checkpoints, inferences, and prompts.
Pros and cons: This is the most straight-forward option, but in practice, this method can be cost prohibitive and lacks transparency. There are few if any options to reduce the cost or economically transfer the model, its work products, or its data elsewhere.
Who are they: The obvious ones that come to mind for me are companies like AWS, Google, and IBM Watson.
Mix-and-match:
What they offer: Solutions in this group vary by the services they provide as well as add-on options and support services. They typically provide hosting services which are used to train, deploy, and use the model. They can also provide data analysis and cleansing for the model input, model testing, engineering support, and general support services as you might require.
Pros and cons: As with the walled garden approach, once data is ingested or ancillary data is created within the system it may be difficult to access and if available expensive to retrieve. Often, they also represent companies that provide specialized services—for instance, companies that solve a type of problem, like a computer vision specialist vs. a natural language processing model, or, alternatively, a company that focuses on AI in IT operations, call center operations, cybersecurity, etc.
Who are they: This group includes companies like Twelve Labs, Proofpoint, or Amplify. Note that there’s a bit of a porous line between some of the providers in this category and the following—think of it like a gradient.
Open cloud:
What they offer: Providers in this group offer a variety of tools and services that, when combined, allow an organization to construct, test, operate, and maintain an AI-based solution.
Pros and cons: The open cloud approach allows you to select the best of breed providers for the various stages of your AI project. It also allows you to have control over the model and its byproducts such as checkpoint data, inferences, and prompts key to ensuring the model is performing as expected. In summary, while your level of effort for this approach will be higher, you will have more control over your model and more importantly the data, your data.
Who are they: This includes platforms like Hugging Face and vendors like OpenAI of ChatGPT fame. Hugging Face is intentionally open source, whereas OpenAI is under pressure to monetize models—one of the bigger evolving conversations in the AI landscape. Today, anyone can purchase an API access subscription from OpenAI to access the GPT-4 Chat from their application. Such subscriptions offer quick access to organizations that want a mature model but aren’t able to or interested in building one themselves.
The AIaaS approach is a good choice for organizations that lack expertise in building and operating AI systems. The approach you take, walled garden, mix-and-match, or open cloud, will affect how much access and flexibility you have with the data used and produced by the system. This may not be of interest today, but as your organization becomes more AI savvy, being able to access and share the data within the system could become important.
Foundation models
The term “foundation model” originated with the Stanford Institute for Human-Centered Artificial Intelligence’s (HAI) Center for Research on Foundation Models (CRFM) which defines it as “any model that is trained on broad data that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks.” Most, but not all, foundation models are generative AI in form and perform tasks such as language processing, visual comprehension, code generation, and human-centered engagement.
Although foundation models are pre-trained, they can continue to learn from prompts during inference. An organization can develop tailored outputs using techniques such as prompt engineering, fine-tuning, and pipeline engineering. For example, prompt engineering requires you to enter a series of carefully curated prompts to the model such that over time the model infers more precise answers related to the subject matter of the prompts. This makes the model less generic and more specific to your organization.
When using a foundation model, you will need to capture and store all data used to fine-tune the model, for example the prompts and responses used for the prompt engineering process. This will allow you to analyze how the inference process is shifting over time.
Utilizing a foundation model as a starting point is a good choice, but techniques such as prompt engineering are far from being an exact science. Often such training can exacerbate a subtle bias in the existing model or introduce a new bias. This is especially true if the model is public facing.
Retrieval augmented generation (RAG)
Retrieval augmented generation (RAG) is a relatively new technique that allows AI models to link to external sources. These models are, in most cases, a generative AI model, such as a large language model (LLM). By using RAG techniques, external resources, often rich in technical content, can be leveraged as part of the model during inference to be part of the response to the user. One commonly cited example is having medical journals indexed via this technique so their content is reviewed when the model is generating a response. The same could be done with financial data, legal case law, and so on.
RAG works by adding code to the original generative AI model to continuously review defined external resources and convert them into machine-readable indices (vector databases) so they are available for inference. This means the core generative model does not have to be retrained, instead it can use new or updated sources on the fly. This allows you to use your data to make the model your own and lets you update the data sources to keep the model current.
This technique is extremely powerful, but it does require you to store the original model, the testing or validation data used, the external resources you are using to augment the model, their vector databases, and any prompts and inferred responses. Given the tools and utilities you will use to monitor and analyze how your RAG infused AI model is performing, a central cloud storage repository is a good choice for storing this data.
It’s all about the data—Your data
AI, at least in its current form, is not deus ex machina. Yes, ChatGPT and its ilk can create wonderful stories of fact or fiction and amazing, never before seen imagery, but without your data, they are marvelously generic. In other words, you and more precisely your data are the key to the value your organization will achieve in using AI.
As we have seen, there are a multitude of options. On one hand, we can hand off our data to a company, pay them handsomely, and let them build and run our AI models—the walled garden approach. While this is enticing, the reality is that AI is still a moving target with few rules and regulations in place and your visibility to what is happening to your data is limited as is your ability to do something if there is a problem.
At the other end is the open cloud approach. This allows you to choose the best-of-breed cloud based applications and cloud compute services to create and run your model. These applications and services can interact freely with your cloud storage platform to leverage your organization’s data while providing you complete visibility and control. Yes, it will require more investment on your part, but given the maturity of AI in general, it makes sense for you to keep a watchful eye on how AI is used in your organization and more importantly how well it is performing.
In short, AI requires your data to be truly useful to your organization. AI in its current form is still a young science, one that requires watching to ensure it does what is expected. That’s not paranoia, that’s just good business. To do this you will need unfettered affordable access to your data, the AI model, and its work products.
It’s time once again for our annual book guide, where Backblaze authors give you the inside scoop on what they’ve been reading. So, whether the weather outside is frightful, or, like at our home office in San Mateo, weird and drizzly, we hope you enjoy!
I love a good book about music, and when I saw autographed copies of “Never Understood” on sale at the merchandise stand at the Jesus and Mary Chain’s San Francisco gig earlier this year, I could not walk away without buying one. The book is co-authored by William and Jim Reid, the Scottish brothers who have been the only consistent band members since they started making music in the early ‘80s, and alternates between their accounts from early life in a Glasgow tenement through growing up listening to the Velvet Underground, Iggy Pop, and Bowie in the nearby post-war new town of East Kilbride, to realizing that the band each of them wanted to form on their own was actually the same band, and the subsequent rollercoaster ride of recording, touring, breaking up, and getting back together.
There’s a lot of humor amongst the rock and roll excess—one of my favorite moments was the contrasting explanations of how they assigned roles as they were getting started. From William: “It wasn’t like it was Jim’s dream to be the singer—we basically had a big fight about who was gonna sing and he lost.” Jim writes: “We actually tossed a coin for it, but the outcome was the same: William won. I was the singer.” Comedy soon turns to tragedy, however, as Jim explains how he turned to heavy drinking to overcome his shyness of singing on stage, setting the scene for a lifelong battle with alcohol.
Lee Brackstone, the book’s editor, deserves credit for the excellent job he’s done stitching this all together. Even though the viewpoint bounces between the two brothers, it reads as a single narrative. William’s passages are set in a serif font, while Jim’s are sans, so you quickly develop a feel for who you’re reading. It’s a riveting tale, whether you love or hate the band’s music—I envy you listening to their debut album Psychocandy for the first time if you don’t fall into either of those camps—and the brothers’ love/hate relationship brings a poignant dimension to what is already a classic story of early success, record label indifference and shenanigans, figuring out how to play the music you hear in your head, and being shocked that other people actually want to hear it too.
A comet strikes the earth and blocks out the sun. Bad news for people, good news for vampires. If you like the concept of 30 Days of Night and enjoy great world building and story telling with a bloody twist, this is a fantastic addition to your schedule. Bonus: It’s an audio drama, so perfect for your commute.
I stumbled upon this book right around the time one big thing in my life was proceeding nicely and another was not. Why? This book didn’t give me all the answers—sorry, there are no silver bullets—yet it provided a digestible, pragmatic framework for successfully managing big projects and initiatives, with situational awareness for the psychology of the many stakeholders who will be key to the success. As an impatient person who also likes to plan, I took away new nuance from the authors’ Think Slow, Act Fast model. And, as a student of Eric Ries’ The Lean Startup model, I appreciate the authors of this book adding their own flavor of MVP with the Maximum Virtual Product concept when you simply cannot lean-test something as big as you envision and yet you can develop virtual proxies to test underlying assumptions and elements. Now I’m ready to tackle far more big things.
I love historical fiction and The Women is the first book I’ve read about the Vietnam War. As a big Kristin Hannah fan, I love how she weaves different stories about the historical event into her own. We were immersed into the world of how women were treated in the Vietnam War and I’ll never forget their stories. This one is a must read!
I’d suggest “The Coming Wave” by Mustafa Suleyman. It offers an insightful perspective on the evolving world of artificial intelligence and its impact on society. It’s about a year old now, but still great in my opinion.
This book changed how I see things and perceive challenges or setbacks fundamentally. Growing up, I was wired to strive for perfection in everything I did, and this book shifted my focus from being perfect to continuous improvement. It helped me see opportunities for learning and growth when things don’t go as planned. The best part is that the ideas in this book work for all parts of life, not just work.
Teresa Dodson, Sr. Director, Partner Marketing and Alliances
From the official summary: Leadership is not about titles, status, and wielding power. A leader is anyone who takes responsibility for recognizing the potential in people and ideas, and has the courage to develop that potential. Check it out!
I suppose it’s cheating a bit to recommend a whole series, but the story arc in this series by fantasy heavyweight Brandon Sanderson is great! Full disclosure: I’m hit or miss on Brandon Sanderson’s wider works. (I hate Mistborn and love The Way of Kings. Feel free to get mad at me in the comments.) That said, this series starts with a plucky young heroine on a dystopian planet (don’t worry folks: no love triangle in this one—if you know, you know) and extends into a fascinating view of space travel, AI, and what it means to have a soul.
Happy Reading from Backblaze
We hope this list piques your interest—we may be a tech company, but nothing beats a good, old fashioned book (or audiobook) to help you unwind, disconnect, and lose yourself in someone else’s story for a while.
Any reading recommendations to give us? Let us know in the comments.
Should you build your own AI model? Or use other services to help you accelerate the process?
Once you’ve defined the problem you’re trying to solve and the AI model type that best fits your needs, these are the questions you’re faced with next—where to deploy an AI model and how to go about doing it. In most cases, there is very little reason for you to build, train, and deploy your AI model from scratch, particularly as more and more vendors are stepping in to help companies with all or some of the process. It’s fundamentally complex, takes tons of resources and requires specialized knowledge to do correctly.
Still, you should have a basic understanding of the AI model training and deployment processes, as these learnings will be useful as later on as you explore various predefined tools, applications, and services you can use to expedite or enhance your ability to use AI within your organization. That’s what I’m digging into today.
How AI model training works
There are several steps in training an AI model which include identification and gathering the data required, data cleansing and assembly, training the model, checkpointing, and, finally, model serving where the model is deployed into the production environment. Here’s an overview of the process.
Let’s take a minute to explore each of the steps in a little more detail.
Step 1: Review
The organizational data needed to help educate your model will either be structured or unstructured. Structured data is found in databases, tables, and so on. Unstructured data is basically everything else. Some unstructured data is easy to process, such as text files, while other data is harder to extract, such as PDFs and images.
In general, the more data you can provide, the better your trained model can be. But, remember to include data that is not what you want as well—this helps models to hone in on the specific piece of information when things are similar. Take this example scenario, for instance:
You are monitoring hundreds of thousands of wooded acres to determine if there is a fire on the land. As part of training the model, you need to provide images of the legitimate flora and fauna along with images of fire. But you should also provide images of what is not fire, for example reflections of the sun or moon on a lake, a group of lightning bugs at night, car headlights, and so on.
Step 2: Clean
As the data is collected, it will need to be pre-processed, which involves several techniques such as cleaning the data to handle missing values, removing outliers, scaling features, encoding categorical variables, and splitting the data into training and testing sets. The data needs to be arranged in a manner acceptable to the model itself. This sounds relatively simple, but some studies show that this can take up to 80% of the total model development process time.
Step 3: Stage
This is a collection point for all of the clean, ready to be processed, data. This data will arrive as it is processed (cleaned) which can occur over several days or even weeks. Having this data on hand will be useful if the model is not generated correctly or in the future as a starting point to retrain the model.
Typically large amounts of your data will be cleaned and staged as it is readied to train the AI model. But, there are no special storage requirements for this data. It just needs to be readily available to be uploaded to the AI training environment when the time comes.
Step 4: Train
Model training is a resource intensive process where data is copied from staging to high-performance storage located in close proximity to whatever high-powered processor you’re rocking, usually a graphical processing unit (GPU). The GPUs then run the algorithms developed specifically for training the model, and the data is iteratively read and processed an indeterminate number of times until training is complete. Minimizing the time spent utilizing these expensive, high-powered storage and processing resources is critical in managing the overall cost of building the model. In other words: get in, process, and get out.
Step 5: Checkpoint
During the building of the model, the programming will often create snapshots of the status of the training process. This will include various variables, state changes, and so on. These snapshots are referred to as checkpoints. They initially will be written to local storage within the model training system, and are used to restart the training process from a known good state if something goes wrong.
Once the model training process is complete, checkpoints should be written to the same centralized data storage location as your staged data. The checkpoint data will become part of the documentation of the model and may be used for forensic purposes should the model not behave appropriately once it is deployed.
Step 6: Serve
Once the training process is complete, the model can be exported to your central storage location. This will once again help document the system, and from there the model can then be uploaded to the local or cloud compute environment where it will be used.
At this point you have a clean version of the source data, the checkpoints of the model created, and a copy of the model itself, all stored in your centralized location under your control and readily available should they be needed in the future.
AI model inference
The term inference is derived from the AI model’s perspective. At a high level, when given a prompt, the model infers its response from the trained model and its data. In simple terms, you’ve trained your model to recognize cats, and then you bring it new data (a picture of a family reunion) and ask your model if it sees any cats in the photo (I’m hoping the answer is yes).
In AI, the prompt is viewed as new data which is compared to the model’s existing data to determine a response typically in the form of a decision, prediction, or new content as is the case with generative AI models.
An overview of the inference process is below:
In some AI systems, the inference process flow includes some additional code to help improve your model. These types of filters can have a range of uses and can happen on either the input or the output stage. For example, if you want to filter inappropriate queries or information, you could include something like keyword filtering when data (the prompt) is input. Or, you could introduce a toxicity detection filter on the output side, which reviews responses and prevents harmful or offensive content to be presented to the user.
A perhaps better understood problem that filters like this can address is how to get accurate and up-to-date information out of your queried response. On the input flow side of things, retrieval-augmented generation (RAG) directs a trained model to incorporate and weight more heavily information from trusted sources that the user designates. On the output side, you might add a hallucination prevention filter, which would stop the model from presenting false or misleading information.
More broadly, you’ll notice that both the prompt and response are saved. It is important to review this information on a periodic basis. This is especially true if the model is public facing, if you are using a model which can change over time such as a foundation model, or if you are using a model which utilizes RAG techniques to include new or external content.
In all of those examples, your model can drift as new information is introduced, and, as we noted above, getting the right information and cleaning it properly is likely the most time-intensive and important stage of this process. Not for nothing is the phrase “knowledge is power” a truism—in the age of AI, knowledge is power and good data is king.
Depending on which LLM you ask, we live in a world with somewhere between 25k and 80k AI startups. It’s a growing, highly competitive market where small startups with a big idea can find themselves toe-to-toe with the goliaths of tech—fighting for money, chips, talent, even raw electrical power.
How does any company differentiate themselves in an explosive burst of technological change, one that requires a lot of investment in talent and infrastructure, where even the richest tech platforms on the planet don’t always succeed? Today we’re sharing the story of Decart—an AI startup that used Backblaze B2 Cloud Storage to leverage a successful launch with an impressive new model that provides an order of magnitude improvement in both the training and inferencing of the largest generative models.
Backblaze is an amazing solution for AI training data. We looked at a number of options and Backblaze is seriously the best.
—Dean Leitersdorf, Co-Founder and CEO, Decart
First, the news
Decart is an AI research lab that came out of stealth on October 31 with an incredible new model:
1/ We are excited to introduce Oasis, the world's first real-time AI world model, developed in collaboration with @Etched. Imagine a video game entirely generated by AI, or a video you can interact with—constantly rendered at 20 fps, in real-time, with zero latency pic.twitter.com/WAJFRyfTzS
While this might look like Minecraft, every pixel you see here and all of the gameplay is being generated by Decart’s Oasis model. It’s like Minecraft in every way you’d expect, except that the entire experience is being generated by AI and you can creatively prompt the model to build beyond the confines of the game. The mindblowing part? Decart says Oasis can perform more than 10 times more efficiently than competitors such as OpenAI’s Sora, which hasn’t been publicly released.
Don’t let the game distract you though—the Minecraft simulation is just an expression of the power of their model. According to the Decart team, this isn’t even version 1.0 of what their approach is capable of generating—more like version 0.01. Given the broad coverage they’ve already received for their launch, we’re excited to see what’s next.
How to break out in the AI market
For Decart, the strategy to pull ahead of the crowd was simple: Disrupt the market on inference speed to deliver game changing models, and do that by building the most high-performance multi-cloud model training infrastructure possible. Then, iterate on that innovation.
We crafted state of the art infrastructure that allows us to train models that other people simply can’t train.
—Dean Leitersdorf, Co-Founder and CEO, Decart
Before we met Dean and the team at Decart, most of the hard work was done: the multi-cloud AI stack for training was dialed in and the models were going through the paces. They just had one simple, but big, problem holding them back:
The price and the logistics of moving and storing training data were going to limit their growth.
They were burning through free data storage credits from a traditional cloud provider and had data spread across a range of other cloud providers and GPU clusters. Their training data needed to scale from 100s of thousands of hours of video data to 100s of millions of hours, and they needed a storage solution that could handle that scale in three key areas:
Reliably high performance: Decart needed to know that when they got time on a cluster, they could move data in as fast as possible the second that they were able to.
GPU interoperability: They needed to be sure that whatever storage platform they chose, it would work well with a multi-cluster training approach. Being able to shop jobs between different GPU clouds and disperse training was essential for Dean’s team.
Efficiency: Every dollar an AI startup spends on anything other than training time is a competitive disadvantage, so ensuring that storage costs were low without any surprise fees for data retention or download was key.
Decart discovered Backblaze while researching storage alternatives. After a quick call and two fast months of testing Backblaze in a wide variety of usage patterns, it was clear to the team that they had found the storage foundation they needed.
We chose Backblaze because everything works. It’s super stable, and we had zero problems. That’s number one.
—Dean Leitersdorf, Co-Founder and CEO, Decart
When it came time to start moving data from Backblaze to GPU clusters, they had no problem with transferring petabyte-scale datasets. The only minor challenge was ensuring that the compute provider’s pipe could take the volume of data streaming in.
Here’s where things ended up working for Decart:
Performance: They were blown away by the performance they achieved with Backblaze (more to come on that later).
Price: With pricing at one-fifth the cost of traditional cloud providers, Backblaze unlocked a significant amount of budget.
Free egress: The true game changer. Decart, for a number of reasons, trains their models on multiple different GPU clusters at the same time. With Backblaze, they can egress their full dataset to up to three training sites with zero additional cost.
B2 Cloud Storage was literally the only technical thing we used in training these models that didn’t crash the first time we tried it. We’re in an industry where everything fails, but Backblaze didn’t.
—Dean Leitersdorf, Co-Founder and CEO, Decart
Looking forward
With performance, flexibility, and affordability squared away in their data storage approach, the Decart team is now in position to rotate out of this impressive first model and build whatever is next. With all the fundamentals working on the level that Backblaze always provides and Decart is happy with, the two teams are now working together to find even more efficiency and optimization and truly stand up the best infrastructure for training AI models.
It may seem like generative AI is the only game in town, or at least the only AI model worth paying attention to. But folks have been using AI models to do all kinds of things for years before ChatGPT, Claude, and Gemini came on the scene.
Today, I’m talking about the three different broadly defined categories of AI—classification, predictive, and generative—and what they’re good for.
Classification vs. Predictive vs. Generative AI Models: What’s the Diff?
Classification and predictive models have been foundational to AI for decades, powering applications like spam filters, cyber security tools, big data analysis, and demand forecasting. However, with recent advances, generative models like GPT and DALL-E have taken the spotlight, bringing up interesting existential (and legal) questions about the nature of creativity and creative work going forward. Understanding the distinctions and history of these models is key to grasping how AI continues to shape industries and innovation today.
Let’s see which category best applies to your particular problem.
AI classification models
A classification model is built to recognize, understand, and group data into preset categories. The model is fully trained using the training data and then evaluated using test data before being used to respond to unseen data. In general, such models infer answers for the current moment in time, for example, deciding whether an email is spam or phishing. In that case, the decision is based on comparing the incoming email to a model trained on previously classified email messages, both ones that the user has set or ones that the platform has. (The two are related, of course, as the platform’s filters often update to include aggregate user data.)
In business, classification models drive applications like spam detection, customer segmentation, and fraud detection. Healthcare uses classification models to diagnose diseases based on medical images or patient data. In finance, they help identify high-risk transactions. Social media platforms rely on these models to filter content, detect hate speech, and recommend posts. Overall, classification models are key to organizing large datasets efficiently and making decisions based on patterns, helping automate and optimize numerous industry processes.
AI prediction models
Predictive AI models utilize historical data, patterns, and trends to train the model, so they can be used to make informed decisions about future events or outcomes. Using Drive Stats as an example, we could theoretically build a model that, when given data about a particular drive model and failure rates, predicts the chance that a given hard drive will fail in the next 90 days. Predictive AI models typically require large amounts of data to be trained and are computationally expensive to generate.
Predicting Hard Drive Failure Rates with AI
Okay, we were being coy when we said “example.” Check out Andy Klein’s Tech Day 2024 presentation, “Predicting Hard Drive Failure Rates with AI” to see how this kind of predictive model works.
AI prediction models help predict customer behavior, sales trends, and demand, aiding in decision making and resource planning. In finance, these models are crucial for stock price forecasting, risk assessment, and credit scoring. Healthcare utilizes prediction models for patient outcome predictions, disease progression, and treatment effectiveness. They are also applied in weather forecasting, supply chain optimization, and energy usage management. By analyzing past data, prediction models provide insights that help organizations anticipate trends, make proactive decisions, and optimize performance across various industries.
Generative AI models
You know this one. Generative AI is about creating (sort of) new content. It uses neural networking, deep learning, and other techniques to infer and generate content that is based on patterns it observes in existing content all while mimicking the style and structure as requested. Image generators such as DALL-E and Stable Diffusion, and large language models like ChatGPT, Claude, and Gemini are easily accessible AI applications which have brought AI into the public eye.
Generative AI is at turns the thing that will revolutionize everything, a scary specter with near-sentience that will steal your job, or a big hallucinating fluke that tells you to put glue on pizza. There are some pretty cool use cases—for one, researchers are using generative AI for new drug discovery. But you’re most likely to run into generative AI in the following use cases: customer service chatbots, coding assistants, marketing support, and general business assistants that generate transcripts and summaries.
Unlocking the power of AI
Even with all the current hype around generative AI we are still in the early stages of development when it comes to AI systems given they are most useful in responding to queries based on the subject matter with which they were trained.
For example, an AI model trained to play chess might find playing checkers to be difficult. While the board, and number of players are the same, can a chess-playing AI model infer the allowed checker moves based on its understanding of chess? Even generative AI models like ChatGPT which are trained on a wide variety of subjects are still lacking a key ingredient to be truly useful to your organization: your data.
An AI chatbot, for example, isn’t going to perform the way you want it to without being powered by your organization’s data. And, how do you build an AI powered tool while keeping your private data private? We started to explore that very question in a recent webinar, “Leveraging your Cloud Storage Data in AI/ML Apps and Services.”
Tune in to learn more about the various ways AI/ML applications use and store data and get insights from our customers who leverage Backblaze B2 Cloud Object Storage for their AI/ML needs.
AI is everywhere—powering chatbots, generating images, even deciding what you binge watch next. It’s no wonder businesses of all sizes are feeling compelled to jump on the AI bandwagon. But before you get swept up in the AI hype, here’s the question you need to ask: Is AI right for your business and the problem you’re trying to solve?
Where AI truly becomes a change agent is when it is powered by your organization’s data to deliver relevant, insightful, and actionable observations to you in a timely manner. The reality is, while AI is really cool, without your unique data it provides your organization few competitive advantages. Of course, releasing proprietary, or even sensitive, information to a robot connected to the internet can be risky—and you want to make sure your (and your clients’) information doesn’t end up in surprising places.
But just because everyone’s talking about AI doesn’t mean it’s the magic bullet for every problem. Like any strategic investment, it takes careful consideration. So, before you hand over your data to a machine, let’s explore whether AI is really what your business needs—or if it’s just another shiny object in the tech landscape.
Where do I start?
Today, many organizations are somewhere along the AI/ML path. Most are experimenting with AI, some are actively building applications, and a handful have successfully deployed a solution. Like any other project, before you start trying to use AI in your organization, the first thing you should do is define the problem you are trying to solve. Only then can you determine if you really need AI as a part of the solution.
Ask yourself the following questions about the project. If you answer yes to all four items, the project is AI-worthy:
1. Do you want AI to replace tedious, repetitive tasks?
Start by identifying the business problem in specific, measurable terms. Determine the scope of the problem, its frequency, and the impact it has on your business. Is it recurring and time consuming? If the problem is complex, repetitive, or data-intensive, it might be suitable for AI.
2. Do you want to use AI because you can’t consistently apply a set of logical rules to answer the questions at hand?
If the problem involves large amounts of data that is difficult to process manually where the answer is derived by combining and weighing multiple factors, it may be a candidate for an AI-based solution. On the other hand, just because it can be automated doesn’t mean you need an AI solution—AI is expensive in terms of power and processing resources. If you’re running a simple routine task over and over, you might be just as well off using traditional programming methods. But, when you’re solving a complex task, you need a structure that is not a strict binary, and that’s when you might want to use AI.
3. Will you use AI for problems that humans can solve, but AI can solve much faster?
AI should help your organization solve problems it finds extremely difficult or nearly impossible to solve otherwise. AI excels at tackling complex problems that overwhelm traditional methods, such as processing vast amounts of data, recognizing intricate patterns, or making real-time predictions. If your business is facing challenges that manual processes or standard software can’t handle effectively, AI can step in to provide powerful, scalable solutions that would otherwise be out of reach.
But remember, AI should work with you, not against you. Understand how AI will integrate into your workflow and whether it aligns with your overall business strategy to avoid creating unnecessary complications or disrupting ongoing operations.
4. Do you intend for AI to increase productivity of a function or group?
Most AI projects are productivity based, even those that seem otherwise. Even AI projects aimed at improving customer experiences, like personalized recommendations, ultimately enhance productivity by streamlining interactions and reducing manual effort. At their core, most AI implementations are designed to automate tasks, optimize processes, or extract actionable insights, all of which drive greater efficiency and cost savings. And, that means you need to analyze the potential return on investment (ROI).
AI integration requires an investment in technology, data management, and often specialized personnel. Weigh the cost of implementing AI against the potential benefits it could bring. Will it save time or reduce costs? By how much? If the financial or productivity benefits outweigh the costs, AI may be a worthwhile investment.
Where to next?
Clearly defining the problem and deciding if it’s suitable for an AI-based solution is really just the first step. Once the problem is defined, you open up another set of questions around whether and how to implement it. Do you have the right data, resources, and expertise to support an AI solution? How will it integrate with your systems? How will you measure success? The answers to all of these questions should absolutely inform your decision-making, but understanding if you’re applying AI to the right problem is your starting point. Without that, you’re using a sledgehammer to crack a nut, so to speak.
Ah, the 1980s. It brought us such classics as Ghostbusters, The Princess Bride, Tina Turner’s triumphant comeback, Pac-Man, and the original Apple Macintosh. Also, it gave us the birth of the internet, in which we figured out how to make all our computers one giant, powerful network held together initially by internet protocols (IPs) and, eventually, by a mutual love of cat videos.
Now, each of our devices that connect to the internet require a way to find and send information back and forth, which means they need an IP address. Most folks don’t type IP addresses into their search bar though—we use domain names (for example, www.backblaze.com). Which IP addresses correspond to which domain names is stored in a hierarchical and distributed database system known as the domain name system (DNS), which is also an internet protocol.
Today, let’s talk about IP addresses: What are IPv4 and IPv6, why is IPv6 necessary, and what impact will it have on networking?
Let’s set the scene
Any time you’re sending and receiving data, be it a letter in the mail, dialing a phone number, or loading a website, you’ve got to have an identifiable address reach the proper person and/or device. What all of these types of addresses have in common is that as our population has exploded, we’ve had to re-work how addresses work in order to include more possible data locations. U.S. zip codes were established in 1963. Area codes were established in 1947, and a great expansion was necessary only three(ish) decades later, and that plan was implemented starting in the late 1980s and ending in the mid ’90s.
IP addresses, meanwhile, have been operating on the first and only protocol we introduced in the 1980s, called IPv4. Not only has the world population almost doubled since then, but there has also been a nonlinear explosion in internet-connected devices per person. When IP addresses were first invented, it was unfathomable that most folks would be walking around with a computer in their pocket, remotely checking who’s ringing their doorbells while adjusting their thermostat in anticipation of returning home. All of those internet-connected devices use an IP address, in one way or another.
So, it’s no surprise that we’re now seeing an adoption of a new IP address standard. In keeping with tradition, the versions aren’t sequential: Right now we’re jumping from IPv4 to IPv6. (What happened to IPv5? It was skipped, sort of.)
What is IPv4?
IPv4 is an internet protocol that assigns addresses to devices. It uses a 32-bit address, represented by four numbers (octets), each between 0 and 255, separated by dots (e.g., 192.168.1.100), and uses decimal notation.
Remember that each bit represents one of two possible values, a 0 or a 1. So, for a 32-bit value, there are 2^32 possible addresses, or 4,294,967,296 IP addresses total. Several IPv4 address blocks were also reserved for private networks and multicast addresses, about 286 million total. Between the two reserved blocks of addresses, that’s about 7% of the total addresses in existence.
What is IPv6?
IPv6 uses a 128-bit address, represented by a longer string of numbers and letters (e.g., 2001:0db8:85a3:0000:0000:8a2e:0370:7334) in hexadecimal code, aka hex code. If you’ve ever designed a MySpace page (hi, Tom!) or a webpage, you’re likely familiar with the hex codes used to identify precise colors.
Doing the math as we did above, there are 2^128 possible IPv6 addresses, which is 340 undecillion. (That’s the 11th order of magnitude if you’re going, million, billion, trillion, and so on.) And, just like IPv4, there are some reserved addresses, but they represent such a comparatively smaller number of total available addresses that it’s not even worth calculating a percentage.
Woah, how have we been surviving in the meantime?
We mentioned above that we’ve known we’re running out of IP addresses for a while. But, important detail: There was evidence of the problem as early as 1981, and mitigation efforts were enacted by 1992. Before we get into what mitigation strategies have been used over the years, a bit of a refinement of the above information—IP addresses consist of two main parts, one that identifies the network (or, sometimes, the subnet) and the host, or the destination on that network. (That’s true of both IPv4 and IPv6.)
Classful networking
In the original iteration of IPv4, the bits that identified the subnet were fixed, and that meant a lot of wasted space. In 1981, we implemented classful networking. Instead of keeping a fixed number of bits to identify a network, the three most significant bits identified the size of the network prefix, and that sent you to different classes. That meant that existing addresses didn’t have to change. Here’s a handy table:
Class
Most significant bits
Network prefix size (bits)
Host identifier size (bits)
Address range
Maximum number of networks
Maximum number of hosts per network
A
0
8
24
0.0.0.0–127.255.255.255
128 networks
16,777,216 hosts per network
B
10
16
16
128.0.0.0–191.255.255.255
16,384 networks
65,386 hosts per network
C
110
24
8
192.0.0.0–223.255.255.255
2,097,152 networks
256 hosts per network
D (multicast)
E (reserved)
1110
1111
—
—
224.0.0.0–255.255.255.255
—
—
All that sounds a bit like gobbley-gook. An analogy: You live in a city that wants to improve mail delivery, so it’s introduced the option to choose from a small, medium, or large mailbox. The sizes are actually pretty disproportionate—the small is about the size of a toaster, whereas the medium is the size of a kitchen trash can. (And large is the size of your car. Who gets that much mail?) No matter which size mailbox you (or your neighbor) chooses, your physical address didn’t change when this system was implemented. You usually get more mail than the toaster would accommodate, but never even come close to filling your trash can-sized mailbox. So, that extra space just sits empty and unused, never fulfilling its mail volume potential.
Note that classful networking is now largely defunct, replaced by…
Classless inter-domain routing (CIDR)
The biggest issue of the above system was its inflexibility. Adding classes gave us more flexibility than the original design, but you were still restricted to 8, 16, or 24 bits to identify the network. That means you can end up with a lot of unused IP addresses, as indicated by our above analogy. Here’s the math behind why:
The number of addresses available on a network is the inverse of how many bits you use to define it. So, in a 32-bit address, if you use 16 bits to define the network, you have 8 bits leftover to define the host. That’s our Class C network, which contained 2^8 (256) IP addresses—not enough for most use cases. And, the next smallest subset, Class B, represented 2^16 IP addresses (65,536 total), which most organizations could not use efficiently. After DNS became the norm, it became clear that classful networking wasn’t scalable, and thus CIDR rose to prominence.
CIDR is based on variable-length subnet masking (VLSM), which lets each network be divided into subnetworks of various power-of-two sizes. This method optimizes the allocation of IPv4 addresses by allowing for more flexible address blocks.
Using our analogy, instead of assigning mailbox size based on household size, you might just have a system in which folks walk up to the post office and find their name on a list associated with a mailbox. If someone has more or less mail that month, then they can be assigned the properly sized mailbox.
Network address translation (NAT)
NAT allows multiple devices to share a single public IPv4 address by modifying the IP header when it’s in transit. This is super useful when you’re talking about private networks—you can assign a single IP address to multiple devices. For example, if you have several internet of thing (IoT) devices in your home, they can all appear to the public network as one IP address, and your local network can figure out what traffic goes where. It also makes it so that if a network moves, the host doesn’t necessarily have to be assigned a new IP address, such as if an internet provider like Cox decides to stop doing business in your region, and Spectrum takes over their IP address allocation—though likely they’d just change your public IP address in that specific scenario.
In our mail analogy, NAT is like those group mailboxes you see in rural areas, apartment buildings, or in neighborhoods. Everyone in the same location gets their mail delivered to the same physical address, and your box number is used to further identify your house within the group mailbox.
The secondary market of IP addresses
If we can learn anything from the above workarounds, flexibility and possibility is key. So, it’s unsurprising to know that a secondary market has cropped up, introducing things like address recycling, address trading, and address leasing. IPv6 will solve the scarcity issue—but what else can it do?
What are the benefits of IPv6?
So far we’ve talked about the primary benefit of IPv6—more IP addresses that we clearly need. But, there are other benefits as well. Here’s a summary:
Improved Efficiency
Simpler header: The IPv6 header is simpler than IPv4’s, leading to faster packet processing and reduced overhead.
Efficient routing: IPv6’s design allows for more efficient routing, potentially reducing latency and improving network performance. Arguably, most folks won’t see a huge performance improvement unless they reconfigure their own network architecture, but the possibility is there.
Autoconfiguration: IPv6 supports automatic configuration of network interfaces, simplifying setup and reducing administrative overhead.
Enhanced Security
Built-in security features: IPv6 offers built-in security mechanisms like IPsec, potentially providing better protection against attacks. In practice, it’s not typically implemented as most encryption is typically handled at the transport layer security (TLS) IP layer.
Quality of Service (QoS)
Improved QoS: IPv6 provides better support for QoS, allowing for prioritization of different types of traffic, ensuring a better user experience for applications like video conferencing and online gaming.
Other Benefits
Reduced reliance on NAT: IPv6 reduces the need for NAT, simplifying network configurations and improving end-to-end connectivity.
Support for new services: IPv6 is better suited for emerging technologies and applications that require a large number of addresses and advanced features.
What’s next? Will we run out again?
Given the amount of addresses for IPv4 vs. IPv6 (4.2 billion vs. 340 undecillion, respectively), you can understand how we might have needed to shore up our IPv4 addresses. Honestly, if you assume one device per person, we already outnumber IPv4 addresses—in fact, we outnumbered IP addresses in the 1970s, before IPv4 was even invented! You shouldn’t assume one device per person, by the way. While many countries with widespread broadband access have several devices per person—in the U.S., Consumer Affairs was reporting 21 per U.S. household in 2023, and the average U.S. household for that same year was 2.51 people. Globally, that same source reports 3.6 internet-connected devices per person.
Changes like this can certainly be disruptive, but the good news on that front is that most devices will be dual-stacked for quite a while. That means that you’ll have both versions of an IP address, and this change can roll out organically (so to speak). In the end, we’ll have a better-performing internet, ready to grow with us for the foreseeable future.
You may have heard us talk about backup a time or two, and hopefully our love has been clear. So, when Wired gave us a shoutout in their recent, astute article about archiving, allow us to say we were flattered.
As both a tribute and a collaboration, we’re happy to build on their article’s premise about choosing the correct file type for archiving purposes, and we’ll highlight a few tools to help you protect your files in the long term.
Wired reports: Archived files are especially vulnerable to changing file types
Archives are distinct from backups and have their own demands. Backups are intended to give you the ability to restore files or your whole environment—they need to be both in step with your current environment and flexible enough to respond to both a point in time restore of your whole system or a single file, depending on what you need. Archiving, on the other hand, is about preservation when you can’t depend on the continuity of devices or digital tools—those tools might look quite different (or not exist at all!) down the line. That said, backups are also an essential building block of digital archives.
Making something last long-term takes more work than you’d think. And, interestingly, digital archiving suffers from the opposite problem of “traditional” archiving. Whereas with books, magazines, and other paper-based media, you want to touch them as little as possible, with digital archives, you actually need to do some active maintenance to make sure you’re converting files to accessible formats that you can open well into the future.
Here’s an expert from the Wired report telling us about just one part of the practical concerns of digital archiving:
“Twenty years, in the digital realm, is ancient,” says Lance Stuchell, director of digital preservation services at the University of Michigan. His team is frequently tasked with recovering digital files from old computers and storage mediums. “We have a lab that can deal with old media—floppy drives, CDs, older computers. We can get that off of those types of media and move it into our preservation system while ensuring we don’t mess it up while we’re doing it.”
Wired goes on to report that the problem isn’t just having the correct device, but actually having the correct file type. Their biggest takeaways for making sure your files hold up over time?
Use open source file types.
If you’re storing media, store files uncompressed.
Back up absolutely everything.
Check out the rest of the article for details—it’s worth a read. And, thanks for the shoutout as a good option for folks looking to back up, Wired.
Some tools for converting files
So, now that you’re all geared up to get your archive in order, here are some free, open source tools that will help you convert your files. One note when you’re using open source (and we’re big fans) is to make sure you’re using a tool you trust. And, some tools, especially web-based tools, may collect user data or can expose sensitive information.
With that in mind, here are a few to get you started:
LibreOffice: The successor to OpenOffice, LibreOffice is a well-respected open source alternative to Microsoft Office and supports several open source and older document file formats.
Pandoc: Pandoc calls itself the Swiss army knife of file converters for markup formats, which includes documents, HTML formats, spreadsheets, and more. It’s got a very helpful list of file formats and indicates whether they can convert from/to each of them.
ImageMagick: ImageMagick can certainly convert your files, and it’s also beloved because it can edit files, including support for scripting and automation. But, for our purposes, it converts image formats and has continuous support from the open source community.
FFmpeg: FFmpeg is a community supported audio and video tool.
VLC media player: Another audio and video tool that supports conversion.
Keep in mind that while we’re recommending many of these for conversion purposes, many are actually fully-fledged programs with some very cool features—and, some can even replace traditional paid tool options, if you’re the budget-conscious type.
That said, developing storage media types, while not as common, offer some interesting (if not yet widely practical) options. If you’re willing to drop some cash, DNA (yes, the biological kind) or ceramic might be for you. And, if you want to get super sci-fi with it, PhysicsWorld has reported on the “Superman memory crystal” that could keep data intact for millions of years.
Build your archive for alien circumstances
When we ambitiously sent out messages to the (potential) sentient life in the universe almost 50 years ago, on golden records no less, we apparently thought it was enough to also include a phonograph needle and some symbolic instructions on how to play the record. In practice, we sent a message with no guarantees that someone could decode and play it.
That may be fine for our space-age time capsule, but for our everyday archives, we do want to do our best to make sure we’re able to open them in the future. While we can’t anticipate where technology will be in 20, 40, or 100 years, we can follow digital archiving best practices to give future generations the best chance of opening files. At least they’ll likely share a language with us, as opposed to our alien friends.
You may think the answer to “What do fireworks and the cloud have in common?” is nothing. But, you would be wrong.Both are carefully designed, highly-researched systems that contain a chain reaction of events that lead to a desired outcome. In the case of data centers (DCs), that’s storing and using data. In the case of fireworks, that’s a delightful explosion.
More importantly for our purposes today, both data centers and fireworks are loud. Not upstairs-neighbor loud; rather, they are hearing-loss-and-noise-pollution loud. But, which thing is louder, the cloud or fireworks? What are their sonic qualities, and which is more dangerous?
So, in honor of America’s Independence Day, let’s quantify that with data.
Let’s talk about how we measure sound
We talked briefly about how loud the cloud is in a previous article. All that noise comes from a combination of factors, largely cooling systems—either those that affect large areas of the DC, or those that are part of the hardware of each server rack. Back in 2017, we measured our DCs at approximately 78dB, and other sources report that DCs can reach up to 96dB.
And, it’s unfair to paint a data center with a broad brush, sonically speaking. There are different zones in a data center, and they can vary widely in the amount of decibels produced based on a variety of factors. Here’s a handy list:
Lower range (40-55 dBs): This quieter zone might be experienced in administrative areas or server rooms with less densely packed equipment. It’s comparable to quiet conversation or background noise in a library.
Mid range (55-70 dBs): This is a more common range within data centers, representing the noise level near operating servers. It’s similar to normal conversation or background noise in a restaurant.
Higher range (70-85 dBs): This zone can be found near high-powered equipment or cooling systems. It’s comparable to a vacuum cleaner or busy traffic. Prolonged exposure at these levels can begin to cause hearing damage.
Very high range (85-96 dBs or above): This is the loudest zone and is typically only encountered near generators or during maintenance activities. It’s similar to a power lawnmower or motorcycle and can cause hearing damage with prolonged exposure.
This can all seem relatively esoteric, but it has real world effects. Noise pollution has been shown to cause all sorts of environmental impacts in humans and other animals, and it’s a hot topic of conversation amongst people who live nearby and amongst those responsible for designing and building DCs.
And, how loud are fireworks?
As we all know, there are many types of fireworks, ranging from the humble sparkler to the professionals-only aerial explosives. In theory, consumer-level explosives are supposed to have a noise limit of 120 dBs when fired from 15 meters (about 50 ft.) away. Just to get us all on the same page (for science), here’s a table that outlines some dB ranges for major types of fireworks:
Type of Firework
Noise Level
Decibel Range
Description
Sparklers
Soft Crackling
80-90 dB
Hand-held sticks that emit showers of sparks.
Glow Worms
Soft Crackling/Hissing
85-100 dB
Ground-based fireworks that glow and crackle slightly.
Snakes
Crackling/Popping
90-110 dB
Long, snake-like fireworks that unfurl with a crackling or popping sound.
Poppers
Moderate Pops
100-115 dB
Small, paper-wrapped fireworks that make a popping sound when lit.
Fountains
Crackling/Hissing
95-120 dB
Ground-based fireworks that spray sparks and make a crackling or hissing noise.
Roman Candles
Moderate Pops/Booms
110-130 dB
Hand-held tubes that shoot out stars with loud pops or small booms.
Bottle Rockets
Loud Whistle/Boom
120-140 dB
Fireworks that launch into the air with a whistle and explode with a loud boom.
Aerial Shells (Small)
Moderate-Loud Booms
130-150 dB
Launched into the air, these explode with moderate to loud booms and create colorful visual effects.
Aerial Shells (Large)
Very Loud Booms
150-175 dB
Large shells launched high into the air, exploding with very loud booms and spectacular visuals.
Salute Batteries
Extremely Loud Booms
150-180 dB+
Rapid-fire bursts of loud explosions, often used in professional displays.
Curveball: A direct comparison of dBs isn’t our only metric for “dangerous”
Here’s the funny thing about sound and human hearing, and it ties back to our discussion of decibels: Different types of sound register differently with us, and “loud” isn’t the only risk factor for potential hearing loss. Think of when you’re listening to singers—in general, humans find deeper ranges to be “quieter” while they find higher-pitched ranges to be “louder.” In theory, they could be putting out the same loudness of sound, but we perceive it differently.
A second factor is that a short, percussive sound (like a firework), and a quieter sound that you’re exposed to for longer periods of time (like in a data center) can cause different types of damage. Any loud noise can cause hearing loss—a rapid change in pressure can easily damage the delicate anatomy of the inner ear.
When you’re talking about prolonged exposure, the safe zone is generally 70dB and below. And, while 85dB is considered safe over a period of eight hours, that safe period gets cut in half for every 3dB increase. So, at 88dBs, safe exposure time is 4 hours. At that 96dBs we cited above, you’re at risk for hearing loss in less than an hour.
Of course, there are several ways to mitigate hearing loss in instances where you know you’ll be exposed to potentially dangerous levels of sound, like if you’re attending a fireworks show or going to visit a data center. Over-ear hearing protection and earplugs—which range from your common wax/silicone variety to specially designed models that let in more or less noise—are your two main options (as it relates to your body). And, data centers and fireworks each have methods of reducing sound.
A warning from our robot friend, and declaring a winner
In doing my very thorough research, I did wonder what would happen if you stack these noises… that is, what happens if you set off a firecracker in a data center? Would the noises stack (80dB + 120dB = 200dB)? Would they equalize, then have an additive increment (80dB + the 40dB between baseline and firecracker spike)?
So, I asked my favorite large language model robot friend, who I seem to have distressed. It answered:
Setting off a firecracker in a server room would be a very bad idea for several reasons, and the combined noise level wouldn’t be the biggest concern.
Turns out, while the noise levels would be significant, the combined effect might not be as dramatic as one might imagine. First, unlike open spaces, server rooms often have soundproofing measures to dampen noise. This would limit the amplification of the firecracker’s sound as it does the existing server noise. And second, the firecracker’s sudden, high-intensity sound would likely be the dominant noise even within the server’s noise range. The combined effect wouldn’t be a simple addition of decibel levels. The firecracker’s very loud, short burst would likely overpower the server’s constant hum within the room.
LLMconclusion:
Setting off a firecracker in a server room is extremely dangerous and has far worse consequences than just a loud noise. It’s crucial to prioritize safety and avoid such actions in these critical environments.
Obviously (or I hope it’s obvious), this is not something we’d test in our real-world environment, and we don’t ever recommend that you do either. However, it’s safe to say that in the battle of cloud vs. fireworks, it’s a tad unfair to do a direct comparison of their loudness. Fireworks are (on average) louder, as they’re designed to be. Data centers are still very loud, and the quality of the sound therein is also likely to cause hearing damage over a period of time, and all that is still true even when we’re making active efforts to reduce and dampen the noise in DCs.
Safety first, friends. Remember that ear protection around both servers and fireworks is advisable, and use fireworks and data centers responsibly. We’ll see you on the other side.
At the risk of being called the stick in the mud of the tech world, we here at Backblaze have often bemoaned our industry’s love of making up new acronyms. The most recent culprit, hailing from the fast-moving artificial intelligence/machine learning (AI/ML) space, is truly memorable: RAG, aka retrieval-augmented generation. For the record, its creator has apologized for inflicting it upon the world.
Given how useful it is, we’re willing to forgive. (I’m sure he was holding his breath for that news.) Today, our AI 101 series is back to talk about what RAG is—and the big problem it solves.
Read more AI 101
This article is part of a series that attempts to understand the evolving world of AI/ML. Check out our previous articles for more context:
LLMs are the most recognizable expression of AI in our current zeitgeist. (Arguably, you could append that with “that we’re all paying attention to,” given that ML algorithms have been behind many tools for decades now.) LLMs underpin tools like ChatGPT, Google Gemini, and Claude, as well as things like service-oriented chatbots, natural language processing tasks, and so on. They’re trained on vast amounts of data with algorithmic guardrails known as parameters and hyperparameters guiding their training. Once trained, we query them through a process known as inference.
Fabulous! The possibilities are endless. However, one of the biggest challenges we’ve experienced (and laughed about on the internet) is that LLMs can return inaccurate results, while sounding very, very reasonable. Additionally, LLMs don’t know what they don’t know. Their answers can only be as good as the data they draw from—so, if their training dataset is outdated or contains a systematic bias, it will impact your results. As AI tools have become more widely adopted, we’ve seen LLM inaccuracies range from “funny and widely mocked” to “oh, that’s actually serious.”
Shoutout to Reddit users for finally getting this one into trusted sources.
Shoutout to Reddit users for finally getting this one into trusted sources.
Shoutout to Reddit users for finally getting this one into trusted sources.
Enter retrieval-augmented generation (Fine! RAG)
RAG is a solution to these problems. Instead of relying on only an LLM’s dataset, RAG queries external sources before returning a response. It’s more complicated than “let me google that for you,” as the process takes that external data, turns it into a vectored database, and then balances external data with an LLM’s “general knowledge” generated response and skill at responding to conversational queries.
This has several advantages. Users now have sources they can cite, and recent information is taken into account. From a development perspective, it means that you don’t have to re-train a model as frequently. And, it can be implemented in as few as five lines of code.
One important nuance is that when you’re building RAG into your product, you can set its sources. For industries like medicine and law, that means you can point them towards industry journals and trusted sources, outweighing the often misquoted or mis-cited examples you might see in a general database.
Another example: For a technical documentation portal, you can take an LLM, trained on general information and the nuts and bolts of conversational querying, and direct it to rely on your organization’s help articles as its most important sources. Your organization controls the authoritative data, and how often/when changes are made. Users can trust that they’re getting the most recent security patches and correct code. And, you can do so quickly, easily, and—most importantly—cost-effectively.
RAG is a great, straightforward method for keeping LLM tools updated with current, high-quality information and giving users more transparency around where their answers are coming from. However, as we mentioned above, AI is only ever as good as the data it uses. Keep in mind, that’s a deceptively simple thing to say. It’s an entire, specialized job to validate datasets, and that expertise is built into the research and monitoring that happens while training an LLM.
RAG gives a new source of data a privileged position—you’re saying “this data is more authoritative than that data” and, since the LLM doesn’t have anything in its general database, it may not have a counter argument. If you’re not paying attention to your RAG data source standards, and doing so on an ongoing basis, it’s possible, and even likely, that data bias, low quality data, etc. could creep into your model.
Think of it this way: If you’re pointing to a new feature in your tech docs and there’s an error, that impact is magnified because an LLM will give more weight to the RAG data. At least in that case, you’re the one who controls the source data. In our other examples of legal or medical AI tools pointing to journal updates, things can get, well, more complicated. If (when) you’re setting up an AI that uses RAG, it’s imperative to make sure you’re also setting yourself up with reliable sources that are regularly updated.
But, given its impact, and how low of a lift it is to integrate into existing products, we can see why RAG is all the RAGe—and, as always, we look forward to more to come in the AI landscape. For now, we can already see the impact it’s having on the market, with SaaS companies and startups alike exploring the possibilities.
Most IT administrators and businesses know that you need to employ a 3-2-1 backup solution to meet minimum backup durability requirements, though many folks are of the opinion that that methodology is just table stakes these days. Once you get into the variety of ways you can ensure reliable, robust backups, you learn about strategies like 3-2-1-1-0, bare metal recovery,cyber resilience, and more.
Which method your business ultimately ascribes to depends on your risk tolerance—but no business wants to experience the costs associated with extended downtime. In a world where the threat of ransomware is not an “if”, but a “when,” and disaster recovery is front-of-mind for businesses of all sizes, getting granular with your backup and recovery options is key. That brings us to today’s topic: continuous backup solutions, aka continuous data protection (CDP).
What Is Continuous Data Protection (CDP)?
A continuous data protection solution is an automated data backup method that keeps track of changes to your files and backs them up constantly. This is different from traditional backups that copy your data at set intervals. While you can set the interval that you’d want to have your data backup (e.g., daily, weekly, monthly), you’d still be relying on a systemic approach, and would have data loss exposure correlating to the duration you set. What if you had a day of particularly high volume of new data? What if you’re dealing with sensitive customer information that your business needs to show an accurate audit trail for?
Quick Refresher: The 3-2-1 Backup Strategy
The 3-2-1 backup solution calls for three copies of your data, to be stored on two different media types, with one copy off-site (and preferably geographically separate from your primary data storage region).
Continuous backup solutions work by tracking every change to your data in real time, then they asynchronously create a second copy of those changes. Compare this with traditional backups, where data is written to a destination, then a copy (often, a snapshot) of the data is made to be distributed to other backup locations. With a continuous backup solution, you can reduce your recovery point objection (RPO)—that is, the point in time from which you can recover your data—to near zero. And, because your continuous backups typically have to be stored in more accessible storage tiers, you can reduce your recovery time object (RTO) as well.
Here are some of the key qualities of a continuous backup solution:
Automatic backups. With continuous backup, you don’t need to remember to manually back up your data. The system continuously monitors your files for changes and backs them up automatically.
Real-time or frequent backups. Continuous backup solutions can back up your data in real-time, or at least very frequently. This means you’ll always have a very recent copy of your data available in case of data loss.
Restore to any point in time. Because continuous backups keep track of all the changes made to your files, you can restore your data to any point in time, not just the last time a full backup was run.
Benefits of Continuous Backup Solutions
There are several advantages to using a continuous backup solution:
Reduced risk of data loss. You’re less likely to lose data due to hardware failure, software corruption, ransomware attacks, or accidental deletion.
Faster recovery times. If you do lose data, you can restore it from a recent backup much faster than you could with a traditional backup system, especially those that rely on hardware (air gaps) or cold storage for archival storage.
Improved business continuity. Continuous backup can help businesses keep running smoothly even if they experience a data loss event.
User-friendly for diverse levels of tech proficiency. Within a business, there are always going to be folks who are more or less proficient with technology. When you have an automatic backup utility that runs in the background—particularly one with advanced central administrative controls like Backblaze Business Backup with Enterprise Control—you aren’t relying on employees’ tech proficiency (or memory) to create backups.
Continuous Backup vs. Near Continuous Backup Solutions
True CDP solutions run at the level where you’re writing changes to your file—according to the patent, at the basic input/output system (BIOS) of the computer such that normal operations are unaffected. In a practical sense, that means you’re nearly always using virtual machines.
There are several near-continuous backup solutions, however, that back up in intervals of one hour or less and leverage a high-availability system. For transparency’s sake, it’s worth noting that Backblaze Computer Backup is a near continuous backup using native code over Java to reduce impact on your computer’s operations—see our documentation for more.
Downsides of Continuous Backup Solutions
There are some challenges to consider when implementing a continuous backup solution:
Cost: Continuous backup solutions can be more expensive than traditional backup solutions. As time has gone on, there are more solutions available—which has led to more competitive pricing—but it is still a factor to consider.
Storage requirements: Continuous backup can generate a lot of data. If you’re provisioning storage yourself, you’ll need to make sure you have enough to accommodate the backups. If you’re considering using a cloud backup utility, make sure you look into unlimited backups. Many common backup utilities create pricing tiers that take into account the volume of data a user generates and stores.
System resources and compatibility: Solutions can use up system resources, which could slow down your computer or server. For example, many utilities use Java instead of native code, which can noticeably slow down your devices.
What’s the Diff: Continuous Backup vs. Synced Cloud Drive
Because a continuous backup solution updates backups in near real-time, it can be confused with cloud sync services. You may have heard us say it before—sync is not backup. The main difference between a continuous backup service and a synced cloud drive boils down to their purpose:
Continuous Backup Service: This prioritizes data protection and recovery. It constantly monitors your files for changes and backs them up frequently, often in real-time. You can restore your data to any specific point in time, making it ideal for disaster recovery or retrieving accidentally deleted files.
Synced Cloud Drive: This focuses on accessibility and collaboration. It keeps a mirrored copy of your designated folders across multiple devices. Any edits you make on one device are reflected in the cloud storage and on all other connected devices. This is great for working on the same files from different locations and keeping everyone, well, in sync.
Use a continuous backup service if you’re worried about losing important data due to hardware failure, software corruption, or accidental deletion.
Use a synced cloud drive if you want to access and edit your files from anywhere and keep them updated across all your devices.
Some services might offer both features, but it’s important to understand which functionality takes priority. And, if in doubt—use both.
Conclusion
Backups continue to be one of the cornerstones of any business’ ransomware protection strategy. As you’re considering what kind of backup you need, consider how much your business needs a granular, point-in-time recovery option to maintain business continuity. As always, you should balance functionality with costs, and the needs of your particular business. But, given the relative affordability of backup tools—and the amount they can save you in the event of a data disaster—solutions like continuous backup are worth considering for businesses of all sizes.
It is time, once again, to celebrate the things that bring us together as tech and sci-fi lovers of the world. Today, to mark the upcoming high holiday, May the Fourth, we’re bridging our current reality to that time long ago in a galaxy far, far away by discussing the important issues: How in the world are we expected to survive in space without good internet?
Maybe it’s just me, but it seems absurd that the Death Star blueprints had to be literally carried off a spaceship on what’s essentially an external hard drive when the Jedi Council (RIP) could make perfect holographic representations of themselves from across the galaxy. Sure, you can argue that making an off-site copy and sneaking it out was the most covert way to go about it, but didn’t some of those characters in Rogue One die next to a giant antenna? One powerful enough that it controlled traffic into and out of the planet? Why did they have to transmit the plans to the closest battleship when, in theory, they could have sent them anywhere?
Never fear folks, we are here with what we think, based on a fair amount of research and our own humble opinions, are the answers. The truth is that current and future space internet still requires a good bit of hardware and networking. Let’s talk about where we’re at today, where we could be in the near future, and why the Rebel Scum may have, in fact, needed to run faster than Darth Vader, sacrificing all those lives, to get the Death Star schematics out of the sector.
How Do We Currently Move Data Through Space?
The internet, as we know and love it, is largely a function of hardware. To simplify things to their most base definition, the internet is a network of all the networks on the planet. Key word there, folks: planet. We use fiber optic cables to connect things on our terrestrial plane. What happens when we want to take things to space?
We have a variety of telecommunications operations that allow us to move data through space, but they’re nowhere near as fast as our fiber-optic cables, especially with recent advancements in fiber transmission. To make our space communications that fast, we’d need analogous hardware and/or scientific advancements in some very cool research areas.
For today’s conversation, here are the basics: when you transmit data (via any medium, not just through space), you convert it to a format computers can read, namely 0s and 1s. Typically we represent those values by moderating or fluctuating different types of electromagnetic waves. Currently the most prevalent form of data transmission in space is radio, and lasers are a developing, but usable technology.
Our Earth-based organizations move data through space both near and far using different networks of satellites and listening technology. Both use a satellite system called the Tracking and Data Relay Satellite (TRDS), which orbits Earth at a far enough range that relay points are nearly always visible to spacecraft like the International Space Station (ISS).
As you get further out into deep space, you can beam your signal directly to Earth—you just have a smaller window of time where orbits are aligned to make that possible. In that case, rovers stationed on other planets might co-opt other orbiters to relay signals back to Earth. The only problem there is that those orbiters typically have a scientific mission of their own, which means that the relay orbiter has to make a choice about what traffic is prioritized. These things also signal what space internet could be in the future: a network of relay satellites that transfer data planet to planet.
And, while networking on Earth is designed for and assumes real-time responses, scientists are working on Delay-Tolerant Networking (DTN) which is designed to handle significant delays and optimize routing based on that information. It’s not yet mainstream, but DTN has been successfully demonstrated on several missions, including on NASA’s Curiosity mission and the European Space Agency (ESA) Rosetta comet mission.
We see a couple of types of communications networks in the Star Wars films, and more in the non-canonical expanded universe:
Holonet: This is a galaxy-wide communication network mentioned in the films. It’s likely a complex system of satellites, relays, and subspace transceivers that facilitate rapid data transfer. This is similar to what we’re using and building today.
Subspace: While primarily used for faster-than-light travel, subspace might also be used for transmitting information. Subspace is a fictional realm that allows hyperspace travel, and it’s possible that communication signals could piggyback on this network for faster travel times.
Hyperspace Communication Droids: Legends lore (non-canon Star Wars material) mentions these specialized droids that could transmit messages via hyperspace, achieving near-instantaneous communication.
Since the last two depend on the fictional subspace zone, we’re really just considering the Holonet today. And, that works largely like our current technology, though they obviously have more satellites and relays to work with. That’s good news for our little thought experiment—we can look at file transmission times on our current Mars missions to get some analogous numbers.
Mars Transmission Times & File Sizes
Okay folks, now that the science is out of the way, let’s get down to brass tacks. Why was it possibly faster to move the Death Star plans via external storage than just transmitting them out once the planetary shields had been lifted? That answer depends on transmission times and file size. I’ll talk about transmission times first.
The current technology we use to communicate with Mars has a few different transmission times we can work with:
Radio, low-gain antenna: Up to a few kilobits per second (kbps)
Radio, high-gain antenna: Up to several megabits per second (Mpbs)
Laser, standard communications systems: Up to 10 gigabits per second (Gbps)
Laser, advanced systems under development: In development, but 10s of Gbps
For our purposes, let’s go ahead and choose two and use a 10GB file as an example. The basic transmission time formula is:
Transmission time = file size / data rate
Assuming radio waves and a high-gain antenna:
Transmission time = (10GB * 8 bits) / (1Mbps) = 80,000 seconds, or about 22 hours
Assuming laser communications with a standard system:
We have two main canonical sources of truth we can use to infer the file size of the Death Star schematics: A New Hope and Rogue One: A Star Wars Story. (The plans were discussed in the Clone Wars, but not in detail.) Full disclosure: I used AI tools to assist with our file size estimations.
A New Hope
In the OG, we get a glimpse of the plans the rebels have smuggled out as they plan to attack the Death Star, and we can use these to make some assumptions about file size. Interestingly, these plans were actually created for the movie by a few scientists at NASA’s Jet Propulsion Labs (JPL), and they were originally credited in the film.
As easy as shooting womp rats.
Factors to consider about file size:
Visual Complexity: The schematics we see on the holographic projectors show detailed technical diagrams with various sections, labels, and annotations.
Color Depth: While the movie doesn’t definitively show color, for the sake of estimation, let’s assume the plans are grayscale (requiring 1 byte per pixel).
Resolution: Estimating the exact resolution from the movie is difficult. However, considering the detail visible on screen and the technology of the time (1977), a conservative guess might be a resolution similar to standard definition video (around 480p).
Calculating File Size—A Conservative Estimate
The formula for calculating file size per image is:
File size per image = Width x Height x Color Depth
Let’s assume the Death Star plans are displayed on a holographic projector with a resolution of 640 x 480 pixels (a common standard definition resolution). If they are grayscale images, they would require 1 byte per pixel for color depth, so:
However, the plans likely consist of multiple schematics and blueprints. In the movie, we see various sections and scrolling text, suggesting a considerable amount of information.
The formula for calculating total file size is:
Total file size = File size per image * Number of images
Let’s assume the Death Star plans consist of a total of 100 grayscale images (a very rough estimate), so:
Total file size = 307,200 bytes/image * 100 images Total file size = 30,720,000 bytes
1MB is equal to 1,048,576 bytes, so that’s 29.3MB (30,720,000 bytes / 1,048,576 bytes/MB).
Remember, this is a very rough estimate.
The actual file size could be much larger or smaller depending on factors like:
Compression: The Death Star technology might utilize advanced data compression techniques, significantly reducing the file size.
Vector Graphics: If the plans are stored as vector graphics (scalable images), the file size would be smaller compared to bitmaps (storing pixel information).
Additional Data: The data card might contain additional information beyond visual schematics, like text descriptions, material specifications, etc., which could increase the file size.
Taking everything into account, a reasonable guess for the Death Star plans file size in Star Wars: A New Hope could be in the ballpark of 20 to 50 megabytes. This is enough to hold a significant amount of technical data but still fit on a reasonably sized data card for the time period the movie depicts (1977).
Rogue One
In Rogue One, we don’t actually see the plans in detail like we do in A New Hope, but we do have a short clip showing digital blueprints. Based on what we can glean from that and other newer, canonical sources, which employ 3D holograms, here’s a revised estimate for the Death Star schematics file size:
Factors to consider about file size:
Data Complexity: Rogue One reveals plans that include detailed schematics, technical readouts, and potentially 3D models. These elements significantly increase the file size compared to our previous estimate based on static images.
3D Model Complexity: The size of 3D models depends on the level of detail. High-resolution models with intricate textures would require more data than simpler ones.
Data Hierarchy: The plans likely involve a layered structure, with overviews and deep dives into specific sections. This adds to the overall file size.
Compression: The presence of data compression is unknown. Compression algorithms can significantly reduce file size, but the effectiveness depends on the data type.
Gotta love a data center.
Estimated Range:
Given these factors, here’s a possible range for the Death Star schematics:
Low-End Estimate (100s of GB):
Moderately complex 3D models.
Some level of data compression.
Focus on essential schematics and technical data.
High-End Estimate (Low Single-Digit TB):
Highly detailed 3D models encompassing the entire Death Star.
Limited or no data compression.
Extensive data beyond core schematics, including maintenance procedures, weapon system details, etc.
Final Call?
Sure, we don’t know if data storage techniques are different in the Star Wars universe, and sure, the difference between technology in 1977 vs. 2016 gives sci-fi writers are a lot more to work with, but considering the complexity of the Death Star and the variety of data hinted at in Rogue One, the schematics file size likely falls somewhere between hundreds of gigabytes to a low single-digit terabyte. Frankly, despite the New Hope plans being our original introduction to the universe, this range is more realistic for a project of such immense scale.
Of course, with a file size in the 100s of GBs or low TBs, it makes a lot more sense why the Rebels didn’t attempt to transmit the files much, much further away. We know from the movie that the Death Star plans were on a relatively isolated planet in an Imperial-controlled quadrant, and who knows how large quadrants are.
For the sake of argument, let’s say the Death Star schematics were 1TB and there’s a safe planet at the equivalent distance of Mars. Transmitting the files via radio with a high-gain antenna would take about 2330 hours, and transmitting via laser would take 217 hours.
With that in mind, even though it’s pretty old school, it was probably faster to put the files on a drive on a spaceship, and then have that spaceship get those files where they needed to go (you know, not accounting for misadventures).
Always Have a Backup: Is a Droid the Safest Way to Transmit Files?
The most confusing part of this whole discussion is why, once they were past the “Darth Vader is attempting to murder us” part, they didn’t make several copies of the data and distribute it to various, separate entities. The urgency of the mad rush of Luke trying to reach the Rebels is compelling and all, but also an excellent reason you should always have a geographically separated backup. R2-D2’s badassery notwithstanding, the fate of the universe should have some redundancy.
If It Works, It Works
Hey, in the end, we really can’t complain. Luke got the files to Leia; Leia goes on to be instrumental in the Rebel victories against not one, but two Death Stars, and we all just had to endure the dark times of the prequels before we got the compelling story of Rogue One. Cheers, Star Wars fans, and May the Fourth be with you.
If you read a blog article that starts with “In today’s fast-paced business landscape…” you can be 99% sure that content is AI generated. While large language models (LLMs) like ChatGPT, Gemini, and Claude may be the shiniest of AI applications from a consumer standpoint, they still have a ways to go from a creativity standpoint.
That said, there are exciting possibilities for artificial intelligence and machine learning (AI/ML) algorithms to improve and create products now and in the future, many of which focus on replicated operations, split second database predictions, natural language processing, threat analysis, and more. As you might imagine, deployment of those algorithms comes with its own set of complexities.
To solve for those complexities, specialized operations platforms have sprung up—specifically, AI/ML model serving platforms. Let’s talk about AI/ML model serving and how it fits into “today’s fast-paced business landscape.” (Don’t worry—we wrote that one.)
What Is AI/ML Model Serving?
AI/ML model serving refers to the process of deploying machine learning models into production environments where they can be used to make predictions or perform tasks based on real-time or batch input data.
Trained machine learning models are made accessible via APIs or other interfaces, allowing external applications or systems to send real-world data to the models for inference. The served models process the incoming data and return predictions, classifications, or other outputs based on the learned patterns encoded in the model parameters.
Practically, you can compare building an application that uses an AI/ML algorithm to a car engine. The whole application (the engine) is built to solve a problem; in this case “transport me faster than walking.” There are various subtasks to help you solve that problem well. Let’s take the exhaust system as an example. The exhaust fundamentally does the same thing from car to car—it moves hot air off the engine—but once you upgrade your exhaust system (i.e. add an AI algorithm to your application), you can tell how your engine works differently by comparing your car’s performance to a base-level model of the same one.
Now let’s plug in our “smart” element, and it’s more like your exhaust has the ability to see that your car has terrible fuel efficiency, identifies that it’s because you’re not removing hot air off the engine well enough, and re-route the pathway it’s using through your pipes, mufflers, and catalytic converters to improve itself. (Saving you money on gas—wins all around.)
Model serving, in this example, would be a shop that specializes in installing and maintaining exhausts. They’re experts at plugging in your new exhaust and having it work well with the rest of the engine even if it’s a newer type of tech (so, interoperability via API), and they have thought through and created frameworks for how to make sure the exhaust is functioning once you’re driving around (i.e. metrics). They’ve got a ton of ready-made parts and exhaust systems to recommend (that’s your model registry). When they install your new system in your engine, they might have some tweaks that work specifically in your system, too (versioning over time to serve your specific product).
Ok, back to the technical details. From an architecture standpoint, model serving also lets you separate your production model from the base AI/ML model in addition to creating an accessible endpoint (read: an API or HTTPS access point, etc.). This separation has benefits—making tracking model drift and versioning simpler, for instance.
Like traditional software engineering, most AI/ML model serving platforms also have code libraries of fully or partially trained models—the model registry in the image above. For example, if you’re running a photo management application, you might grab an image recognition model and plug it into your larger application.
This is a tad more complex than other types of code deployment because you can’t really tell if an AI/ML model is functioning correctly until it’s working on real-world data. Certainly, that’s somewhat true of all code deployments—you always find more bugs when you’re live—but because AI/ML models are performing complex tasks like making predictions, natural language processing, etc., even a trained model has more room for “error” that becomes evident when it’s in a live environment. And, in many use cases—like fraud detection or network intrusion detection—models need to have very low latency to perform properly.
Because of that, deciding what kind of code deployment to use can have a high impact on your end users. For example, lots of experts recommend leveraging shadow deployment techniques, where your AI/ML model is ingesting live data, but running on a parallel environment invisible to end users, for phase one of your deployment.
Machine Learning Operations (MLOps) vs. AI/ML Model Serving
In reading about model serving, you’ll inevitably also come across folks talking about MLOps as well. (An Ops for every occasion, as they say. “They” being me.) You can think of MLOps as being responsible for the entire, end-to-end process, whereas AI/ML model serving focuses on one part of the process. Here’s a handy diagram that outlines the whole MLOps lifecycle:
And, of course, you’ll see one box on there that’s called “model serving”.
How to Choose a Model Serving Platform
AI model serving platforms typically provide features such as scalability to handle varying workloads, low latency for real-time predictions, monitoring capabilities to track model performance and health, versioning to manage multiple model versions, and integration with other software systems or frameworks.
Choosing the right one is not a one-size-fits-all approach. Model serving platforms give you a whole host of benefits, operationally speaking—they deliver better performance, scale easily with your business, integrate well with other applications, and give you valuable monitoring tools from both a performance and security perspective. But, there are a ton of other factors that can come into play that aren’t immediately apparent, such as preferred code languages (Python is right up there), the processing/hardware platform you’re using, budget, what level of control and fine-tuning you want over APIs, how much management you want to do in-house vs. outsourcing, how much support/engagement there is in the developer community, and so on.
Popular Model Serving Platforms
Now that you know what model serving is, you might be wondering how you can use it yourself. We rounded up some of the more popular platforms so you can get a sense of the diversity in the marketplace:
TensorFlow Serving: An open-source serving system for deploying machine learning models built with TensorFlow. It provides efficient and scalable serving of TensorFlow models for both online and batch predictions.
Amazon SageMaker: A fully managed service provided by Amazon Web Services (AWS) for building, training, and deploying machine learning models at scale. SageMaker includes built-in model serving capabilities for deploying models to production.
Google Cloud AI Platform: A suite of cloud-based machine learning services provided by Google Cloud Platform (GCP). It offers tools for training, evaluation, and deployment of machine learning models, including model serving features for deploying models in production environments.
Microsoft Azure Machine Learning: A cloud-based service offered by Microsoft Azure for building, training, and deploying machine learning models. Azure Machine Learning includes features for deploying models as web services for real-time scoring and batch inferencing.
Kubernetes (K8s): While not a model serving platform in itself, Kubernetes is a popular open-source container orchestration platform that is often used for deploying and managing machine learning models at scale. Several tools and frameworks, such as Kubeflow and KFServing, provide extensions for serving models on Kubernetes clusters.
Hugging Face: Known for its open-source libraries for natural language processing (NLP), Hugging Face also provides a model serving platform for deploying and managing natural language processing models in production environments.
The Practical Approach
In short, AI/ML model serving platforms make ML algorithms much more manageable and accessible for all kinds of applications. Choosing the right one (as always) comes down to your particular use case—so, test thoroughly, and let us know what’s working for you in the comments.
It’s easy to open a data center, right? All you have to do is connect a bunch of hard drives to power and the internet, find a building, and you’re off to the races.
Well, not exactly. Building and using one Storage Pod is quite a bit different than managing exabytes of data. As the world has grown more connected, the demand for data centers has grown—and then along comes artificial intelligence (AI), with processing and storage demands that amp up the need even more.
That, of course, has real-world impacts, and we’re here to chat about why. Today we’re going to talk about power, one of the single biggest costs to running a data center, how it has impacts far beyond a simple utility bill, and what role temperature plays in things.
How Much Power Does a Data Center Use?
There’s no “normal” when it comes to the total amount of power a data center will need, as data centers vary in size. Here are a few figures that can help us get us on the same page about scale:
The largest data center market in the world is in Northern Virginia in the United States and it has a 2,552 megawatt capacity. (By the way: 1MW = 1 million watts. For context, one megawatt is enough energy to power about 200 American homes for a year.)
The goal of a data center is to be always online. That means that there are redundant systems of power—so, what comes in from the grid as well as generators and high-tech battery systems like uninterruptible power supplies (UPS)—running 24 hours a day to keep servers storing and processing data and connected to networks. In order to keep all that equipment running well, they need to stay in a healthy temperature (and humidity) range, which sounds much, much simpler than it is.
Measuring Power Usage
One of the most popular metrics for tracking power efficiency in data centers is power usage effectiveness (PUE), which is the ratio of the total amount of energy used by a data center to the energy delivered to computing equipment.
Note that this metric divides power usage into two main categories: what you spend keeping devices online (which we’ll call “IT load” for shorthand purposes), and “overhead”, which is largely comprised of the power dedicated to cooling your data center down.
There are valid criticisms of the metric, including that improvements to IT load will actually make your metric worse: You’re being more efficient about IT power, but your overhead stays the same—so less efficiency even though you’re using less power overall. Still, it gives companies a repeatable way to measure against themselves and others over time, including directly comparing seasons year to year, so it’s a widely adopted metric.
Calculating your IT load is a relatively predictable number. Manufacturers tell you the wattage of your device (or you can calculate it based on your device’s specs), then you take that number and plan for it being always online. The sum of all your devices running 24 hours a day is your IT power spend.
Any time you’re using power, you’re creating heat. So the first thing you consider is always your IT load. You don’t want your servers overtaxed—most folks agree that you want to run at about 80% of capacity to keep things kosher—but you also don’t want to have a bunch of servers sitting around idle when you return to off-peak usage. Even at rest, they’re still consuming power.
So, the methodology around temperature mitigation always starts at power reduction—which means that growth, IT efficiencies, right-sizing for your capacity, and even device provisioning are an inextricable part of the conversation. And, you create more heat when you’re asking an electrical component to work harder—so, more processing for things like AI tasks means more power and more heat.
And, there are a number of other things that can compound or create heat: the types of drives or processors in the servers, the layout of the servers within the data center, people, lights, and the ambient temperature just on the other side of the data center walls.
Brief reminder that servers look like this:
Only most of them aren’t as beautifully red as ours.
When you’re building a server, fundamentally what you’re doing is shoving a bunch of electrical components in a box. Yes, there are design choices about those boxes that help mitigate temperature, but just like a smaller room heating up more quickly than a warehouse, you are containing and concentrating a heat source.
We humans generate heat and need lights to see, so the folks who work in data centers have to be taken into account when considering the overall temperature of the data center. Check out these formulas or this nifty calculator for rough numbers (with the caveat that you should always consult an expert and monitor your systems when you’re talking about real data centers):
Heat produced by people = maximum number of people in the facility at one time x 100
Heat output of lighting = 2.0 x floor area in square feet or 21.53 x floor area in square meters
Also, your data center exists in the real world, and we haven’t (yet) learned to control the weather—so you also have to factor in fighting the external temperature when you’re bringing things back to ideal conditions. That’s led to a movement towards building data centers in new locations. It’s important to note that there are other reasons you might not want to move, however, including network infrastructure.
Accounting for people and the real world also means that there will be peak usage times, which is to say that even in a global economy, there are times when more people are asking to use their data (and their dryers, so if you’re reliant on a consumer power grid, you’ll also see the price of power spike). Aside from the cost, more people using their data = more processing = more power.
How Is Temperature Mitigated in Data Centers?
Cooling down your data center with fans, air conditioners, and water also uses power (and generates heat). Different methods of cooling use different amounts of power—water cooling in server doors vs. traditional high-capacity air conditioners, for example.
Talking about real numbers here gets a bit tricky. Data centers aren’t a standard size. As data centers get larger, the environment gets more complex, expanding the potential types of problems, while also increasing the net benefit of changes that might not have a visible impact in smaller data centers. It’s like any economy of scale: The field of “what is possible” is wider; rewards are bigger, and the relationship between change vs. impact is not linear. Studies have shown that creating larger data centers creates all sorts of benefits (which is an article in and of itself), and one of those specific benefits is greater power efficiency.
Most folks talk about the impact of different cooling technologies in a comparative way, i.e., we saw a 30% reduction in heat. And, many of the methods of mitigating temperature are about preventing the need to use power in the first place. For that reason, it’s arguably more useful to think about the total power usage of the system. In that context, it’s useful to know that a single fan takes x amount of power and produces x amount of heat, but it’s more useful to think of them in relation to the net change on the overall temperature bottom line. With that in mind, let’s talk about some tactics data centers use to reduce temperature.
Customizing and Monitoring the Facility
One of the best ways to keep temperature regulated in your data center is to never let it get hotter than it needs to be in the first place, and every choice you make contributes to that overall total. For example, when you’re talking about adding or removing servers from your pool, that reduces your IT power consumption and affects temperature.
There are a whole host of things that come down to data centers being a purpose-built space, and most of them have to do with ensuring healthy airflow based on the system you’ve designed to move hot air out and cold air in.
No matter what tactics you’re using, monitoring your data center environment is essential to keeping your system healthy. Some devices in your environment will come with internal indicators, like SMART stats on drives, and, of course, folks also set up sensors that connect to a central monitoring system. Even if you’ve designed a “perfect” system in theory, things change over time, whether you’re accounting for adding new capacity or just dealing with good old entropy.
Here’s a non-inclusive list of some of ways data centers customize their environments:
Raised Floors: This allows airflow or liquid cooling under the server rack in addition to the top, bottom, and sides.
Containment, or Hot and Cold Rows: The strategy here is to keep the hot side of your servers facing each other and the cold parts facing outward. That means that you can create a cyclical air flow with the exhaust strategically pulling hot air out of hot space, cooling it, then pushing the cold air over the servers.
Calibrated Vector Cooling: Basically, concentrated active cooling measures in areas you know are going to be hotter. This allows you to use fewer resources by cooling at the source of the heat instead of generally cooling the room.
Cable Management: Keeping cords organized isn’t just pretty, it also makes sure you’re not restricting airflow.
Blanking Panels: This is a fancy way of saying that you should plug up the holes between devices.
Why not both? Most data centers end up using a combination of air and water based cooling at different points in the overall environment. And, other liquids have led to some very exciting innovations. Let’s go into a bit more detail.
Air-Based Cooling
Air based cooling is all about understanding air flow and using that knowledge to extract hot air and move cold air over your servers.
Air-based cooling is good up to a certain temperature threshold—about 20 kilowatts (kW) per rack. Newer hardware can easily reach 30kw or higher, and high processing workloads can take that even higher. That said, air-based cooling has benefitted by becoming more targeted, and people talk about building strategies based on room, row, or rack.
From here, it’s actually a pretty easy jump into water-based cooling. Water and other liquids are much better at transferring heat than air, about 50 to 1,000 times more, depending on the liquid you’re talking about. And, lots of traditional “air” cooling methods run warm air through a compressor (like in an air conditioner), which stores cold water and cools off the air, recirculating it into the data center. So, one fairly direct combination of this is the evaporative cooling tower:
Obviously water and electricity don’t naturally blend well, and one of the main concerns of using this method is leakage. Over time, folks have come up with some good, safe methods, designed around effectively containing the liquid. This increases the up-front cost, but has big payoffs for temperature mitigation. You find this methodology in rear door heat exchangers, which create a heat exchanger in—you guessed it—the rear door of a server, and direct-to-chip cooling, which contains the liquid into a plate, then embeds that plate directly in the hardware component.
So, we’ve got a piece of hardware, a server rack—the next step is the full data center turning itself into a heat exchange, and that’s when you get Nautilus—a data center built over a body of water.
(Other) Liquid-Based Cooling, or Immersion Cooling
With the same sort of daring thought process of the people who said, “I bet we can fly if we jump off this cliff with some wings,” somewhere along the way, someone said, “It would cool down a lot faster if we just dunked it in liquid.” Liquid-based cooling utilizes dielectric liquids, which can safely come in contact with electrical components. Single phase immersion uses fluids that don’t boil or undergo a phase change (think: similar to an oil), while two phase immersion uses liquids that boil at low temperatures, which releases heat by converting to a gas.
You’ll see components being cooled this way either in enclosed chassis, which can be used in rack-style environments, in open baths, which require specialized equipment, or a hybrid approach.
How Necessary Is This?
Let’s bring it back: we’re talking about all those technologies efficiently removing heat from a system because hotter environments break devices, which leads to downtime. And, we want to use efficient methods to remove heat because it means we can ask our devices to work harder without having to spend electricity to do it.
Recently, folks have started to question exactly how cool data centers need to be. Even allowing a few more degrees of tolerance can make a huge difference to how much time and money you spend on cooling. Whether it has longer term effects on the device performance is questionable—manufacturers are fairly opaque about data around how these standards are set, though exceeding recommended temperatures can have other impacts, like voiding device warranties.
Power, Infrastructure, Growth, and Sustainability
But the simple question of “Is it necessary?” is definitely answered “yes,” because power isn’t infinite. And, all this matters because improving power usage has a direct impact on both cost and long-term sustainability. According to a recent MIT article, the data centers now have a greater carbon footprint than the airline industry, and a single data center can consume the same amount of energy as 50,000 homes.
Let’s contextualize that last number, because it’s a tad controversial. The MIT research paper in question was published in 2022, and that last number is cited from “A Prehistory of the Cloud” by Tung-Hui Hu, published in 2006. Beyond just the sheer growth in the industry since 2006, data centers are notoriously reticent about publishing specific numbers when it comes to these metrics—Google didn’t release numbers until 2011, and they were founded in 1998.
Based on our 1MW = 200 homes metric the number from the MIT article number represents 250MW. One of the largest data centers in the world has a 650MW capacity. So, while you can take that MIT number with a grain of salt, you should also pay attention to market reports like this one—the aggregate numbers clearly show that power availability and consumption is one of the biggest concerns for future growth.
So, we have less-than-ideal reporting and numbers, and well-understood environmental impacts of creating electricity, and that brings us to the complicated relationship between the two factors. Costs of power have gone up significantly, and are fairly volatile when you’re talking about non-renewable energy sources. International agencies report that renewable energy sources are now the cheapest form of energy worldwide, but the challenge is integrating renewables into existing grids. While the U.S. power grid is reliable (and the U.S. accounts for half of the world’s hyperscale data center capacity), the Energy Department recently announced that the network of transmission lines may need to expand by more than two-thirds to carry that data nationwide—and invested $1.3 billion to make that happen.
What’s Next?
It’s easy to say, “It’s important that data centers stay online,” as we sort of glossed over above, but the true importance becomes clear when you consider what that data does—it keeps planes in the air, hospitals online, and so many other vital functions. Downtime is not an option, which leads us full circle to our introduction.
We (that is, we, humans) are only going to build more data centers. Incremental savings in power have high impact—just take a look at Google’s demand response initiative, which “shift[s] compute tasks and their associated energy consumption to the times and places where carbon-free energy is available on the grid.”
Which is all to say: this is an exciting time for innovation in the cloud, and many of the opportunities are happening below the surface, so to speak. Understanding how the fundamental principles of physics and compute work—now more than ever—is a great place to start thinking about what the future holds and how it will impact our world, technologically, environmentally, and otherwise. And, data centers sit at the center of that “hot” debate.
Folks, it’s an understatement to say that the explosion of AI has been a wild ride. And, like any new, high-impact technology, the market initially floods with new companies. The normal lifecycle, of course, is that money is invested, companies are built, and then there will be winners and losers as the market narrows. Exciting times.
That said, we thought it was a good time to take you back to the practical side of things. One of the most pressing questions these days is how businesses may want to use AI in their existing or future processes, what options exist, and which strategies and tools are likely to survive long term.
We can’t predict who will sink or swim in the AI race—we might be able to help folks predict drive failure, but the Backblaze Crystal Ball () is not on our roadmap—so let’s talk about what we know. Things will change over time, and some of the tools we’ve included on this list will likely go away. And, as we fully expect all of you to have strong opinions, let us know what you’re using, which tools we may have missed, and why we’re wrong in the comments section.
Tools Businesses Can Implement Today (and the Problems They Solve)
As AI has become more accessible, we’ve seen it touted as either standalone tools or incorporated into existing software. It’s probably easiest to think about them in terms of the problems they solve, so here is a non-inclusive list.
The Large Language Model (LLM) “Everything Bot”
LLMs are useful in generative AI tasks because they work largely on a model of association. They intake huge amounts of data, use that to learn associations between ideas and words, and then use those learnings to perform tasks like creating copy or natural language search. That makes them great for a generalized use case (an “everything bot”) but it’s important to note that it’s not the only—or best—model for all AI/ML tasks.
These generative AI models are designed to be talked to in whatever way suits the querier best, and are generally accessed via browser. That’s not to say that the models behind them aren’t being incorporated elsewhere in things like chat bots or search, but that they stand alone and can be identified easily.
ChatGPT
In many ways, ChatGPT is the tool that broke the dam. It’s a large language model (LLM) whose multi-faceted capabilities were easily apparent and translatable across both business and consumer markets. Never say it came from nowhere, however: OpenAI and Microsoft Azure have been in cahoots for years creating the tool that (ahem) broke the internet.
Google Gemini, née Google Bard
It’s undeniable that Google has been on the front lines of AI/ML for quite some time. Some experts even say that their networks are the best poised to build a sustainable AI architecture. So why is OpenAI’s ChatGPT the tool on everyone’s mind? Simply put, Google has had difficulty commercializing their AI product—until, that is, they announced Google Gemini, and folks took notice. Google Gemini represents a strong contender for the type of function that we all enjoy from ChatGPT, powered by all the infrastructure and research they’re already known for.
Machine Learning (ML)
ML tasks cover a wide range of possibilities. When you’re looking to build an algorithm yourself, however, you don’t have to start from ground zero. There are robust, open source communities that offer pre-trained models, community support, integration with cloud storage, access to large datasets, and more.
TensorFlow: TensorFlow was originally developed by Google for internal research and production. It supports various programming languages like C++, Python, and Java, and is designed to scale easily from research to development.
PyTorch: PyTorch, on the other hand, is built for rapid prototyping and experimentation, and is primarily built for Python. That makes the learning curve for most devs much shorter, and lots of folks will layer it with Keras for additional API support (without sacrificing the speed and lower-level control of PyTorch).
Given the amount of flexibility in having an open source library, you see all sorts of things being built. A photo management company might grab a facial recognition algorithm, for instance, or use another to help order the parameters and hyperparameters of the algorithm. Think of it like wanting to build a table, but making the hammer and nails instead of purchasing your own.
Building Products With AI
You may also want or need to invest more resources—maybe you want to add AI to your existing product. In that scenario, you might hire an AI consultant to help you design, build, and train the algorithm, buy processing power from CoreWeave or Google, and store your data on-premises or in cloud storage.
In reality, most companies will likely do a mix of things depending on how they operate and what they offer. The biggest thing I’m trying to get at by presenting these scenarios, however, is that most people likely won’t set up their own large scale infrastructure, instead relying on inference tools. And, there’s something of a distinction to be made between whether you’re using tools designed to create efficiencies in your business versus whether you’re creating or incorporating AI/ML into your products.
Data Analytics
Without being too contentions, data analytics is one of the most powerful applications of AI/ML. While we measly humans may still need to provide context to make sense of the identified patterns, computers are excellent at identifying them more quickly and accurately than we could ever dream. If you’re looking to crunch serious numbers, these two tools will come in handy.
Snowflake: Snowflake is a cloud-based data as a service (DaaS) company that specializes in data warehouses, data lakes, and data analytics. They provide a flexible, integration-friendly platform with options for both developing your own data tools or using built-out options. Loved by devs and business leaders alike, Snowflake is a powerhouse platform that supports big names and diverse customers such as AT&T, Netflix, Capital One, Canva, and Bumble.
Looker: Looker is a business intelligence (BI) platform powered by Google. It’s a good example of a platform that takes the core functionalities of a product we’re already used to and layering on AI to make them more powerful. So, while BI platforms have long had robust data management and visualization capabilities, they can now do things like use natural language search or get automated data insights.
Development and Security
It’s no secret that one of the biggest pain points in the world of tech is having enough developers and having enough high quality ones, at that. It’s pushed the tech industry to work internationally, driven the creation of coding schools that train folks within six months, and compelled people to come up with codeless or low-code platforms that users of different skill levels can use. This also makes it one of the prime opportunities for the assistance of AI.
GitHub Copilot: Even if you’re not in tech or working as a developer, you’ve likely heard of GitHub. Started in 2007 and officially launched in 2008, it’s a bit hard to imagine coding before it existed as the de facto center to find, share, and collaborate on code in a public forum. Now, they’re responsible for GitHub Copilot, which allows devs to generate code with a simple query. As with all generative tools, however, users should double check for accuracy and bias, and make sure to consider privacy, legal, and ethical concerns while using the tool.
Customer Experience and Marketing
Customer relationship management (CRM) tools assist businesses in effectively communicating with their customers and audiences. You use them to glean insights as broadly as trends in how you’re finding and converting leads to customers, or as granular as a single users’ interactions with marketing emails. A well-honed CRM means being able to serve your target and existing customers effectively.
Hubspot and Salesforce Einstein: Two of the largest CRM platforms on the market, these tools are designed to make everything from email to marketing emails to lead scoring to customer service interactions easy. AI has started popping up in almost every function offered, including social media post generation, support ticket routing, website personalization suggestions, and more.
Operations, Productivity, and Efficiency
These kinds of tools take onerous everyday tasks and make them easy. Internally, these kinds of tools can represent massive savings to your OpEx budget, letting you use your resources more effectively. And, given that some of them also make processes external to your org easier (like scheduling meetings with new leads), they can also contribute to new and ongoing revenue streams.
Loom: Loom is a specialized tool designed to make screen recording and subsequent video editing easy. Given how much time it takes to make video content, Loom’s targeting of this once-difficult task has certainly saved time and increased collaboration. Loom includes things like filler word and silence removal, auto-generating chapters with timestamps, summarizing the video, and so on. All features are designed for easy sharing and ingesting of data across video and text mediums.
Calendly: Speaking of collaboration, remember how many emails it used to take to schedule a meeting, particularly if the person was external to your company? How about when you were working a conference and wanted to give a new lead an easy way to get on your calendar? And, of course, there’s the joy of managing multiple inboxes. (Thanks, Calendly. You changed my life.) Moving into the AI future, Calendly is doing similar small but mighty things: predicting your availability, detecting time zones, automating meeting schedules based on team member availability or round robin scheduling, cancellation insights, and more.
Slack: Ah, Slack. Business experts have been trying for years to summarize the effect it’s had on workplace communication, and while it’s not the only tool on the market, it’s definitely a leader. Slack has been adding a variety of AI functions to its platform, including the ability to summarize channels, organize unreads, search and summarize messages—and then there’s all the work they’re doing with integrations rumored to be on the horizon, like creating meeting invite suggestions purely based on your mentioning “putting time on the calendar” in a message.
Creative and Design
Like coding and developer tools, creative of all kinds—image, video, copy—has long been a resource intensive task. These skills are not traditionally suited to corporate structures, and measuring whether one brand or another is better or worse is a complex process, though absolutely measurable and important. Generative AI, again like above, is giving teams the ability to create first drafts, or even train libraries, and then move the human oversight to a higher, more skilled, tier of work.
Adobe and Figma: Both Adobe and Figma are reputable design collaboration tools. Though a merger was recently called off by both sides, both are incorporating AI to make it much, much easier to create images and video for all sorts of purposes. Generative AI means that large swaths of canvas can be filled by a generative tool that predicts background, for instance, or add stock versions of things like buildings with enough believability to fool a discerning eye. Video tools are still in beta, but early releases are impressive, to say the least. With the preview of OpenAI’s text-to-video model Sora making waves to the tune of a 7% drop in Adobe’s stock, video is the space to watch at the moment.
Jasper and Copy.ai: Just like image generation above, these bots are also creating usable copy for tasks of all kinds. And, just like all generative tools, AI copywriters deliver a baseline level of quality best suited to some human oversight. As time goes on, how much oversight remains to be seen.
Tools for Today; Build for Tomorrow
At the end of this roundup, it’s worth noting that there are plenty of tools on the market, and we’ve just presented a few of the bigger names. Honestly, we had trouble narrowing the field of what to include so to speak—this very easily could have been a much longer article, or even a series of articles that delved into things we’re seeing within each use case. As we talked about in AI 101: Do the Dollars Make Sense? (and as you can clearly see here), there’s a great diversity of use cases, technological demands, and unexplored potential in the AI space—which means that companies have a variety of strategic options when deciding how to implement AI or machine learning.
Most businesses will find it easier and more in line with their business goals to adopt software as a service (SaaS) solutions that are either sold as a whole package or integrated into existing tools. These types of tools are great because they’re almost plug and play—you can skip training the model and go straight to using them for whatever task you need.
But, when you’re a hyperscaler and you’re talking about building infrastructure to support the processing and storage demands of the AI future, it’s a different scenario than when other types of businesses are talking about using or building an AI tool or algorithm specific to your business’ internal strategy or products. We’ve already seen that hyperscalers are going for broke in building data centers and processing hubs, investing in companies that are taking on different parts of the tech stack, and, of course, doing longer-term research and experimentation as well.
So, with a brave new world at our fingertips—being built as we’re interacting with it—the best thing for businesses to remember is that periods of rapid change offer opportunity, as long as you’re thoughtful about implementation. And, there are plenty of companies creating tools that make it easy to do just that.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


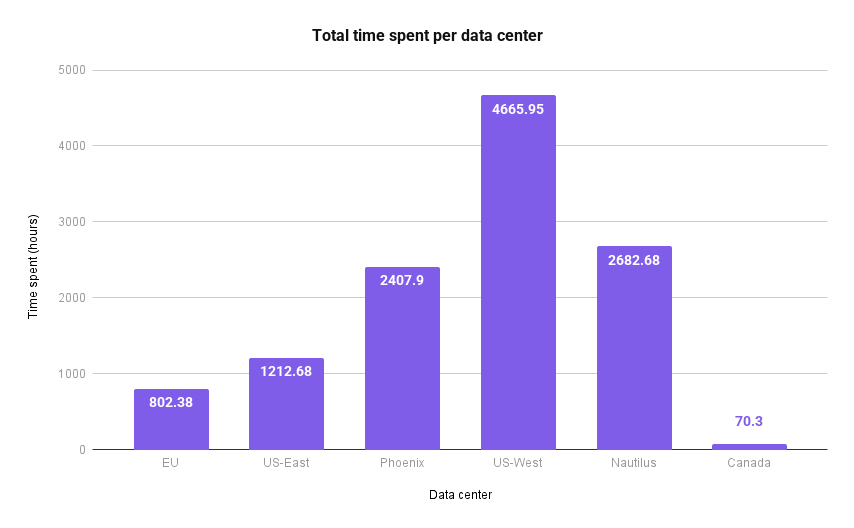
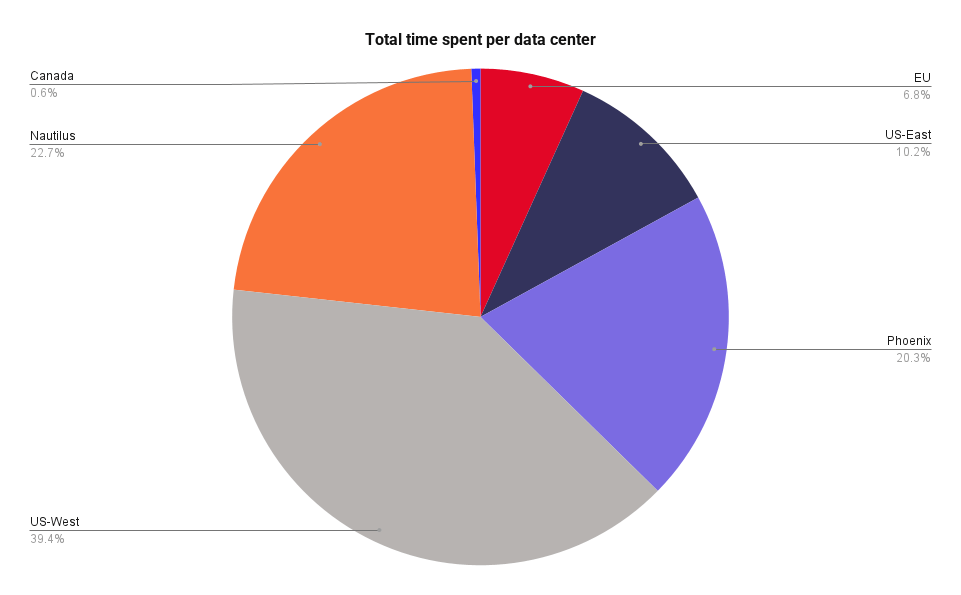
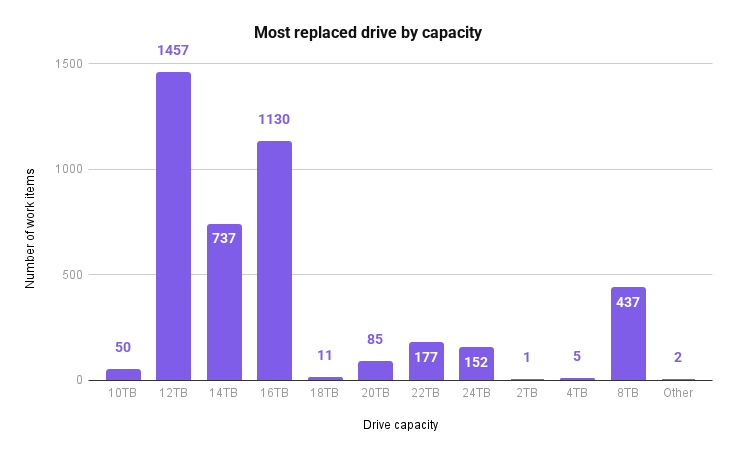
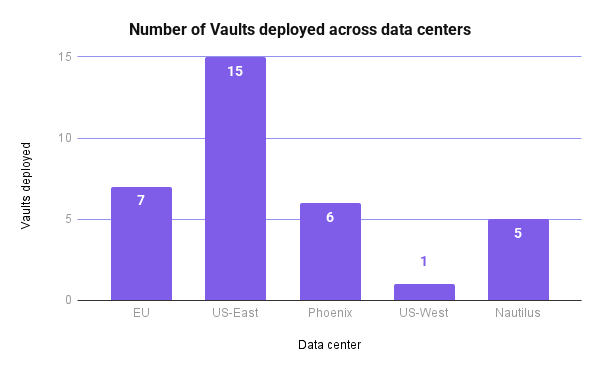
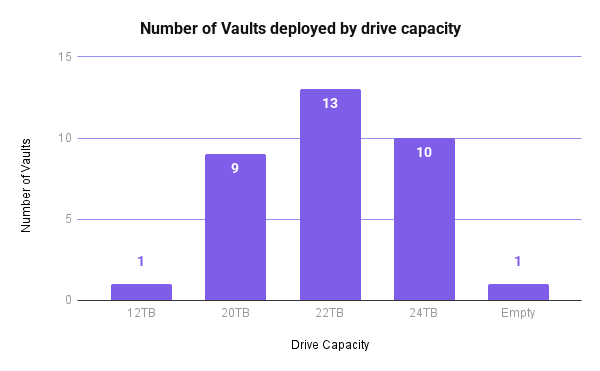


























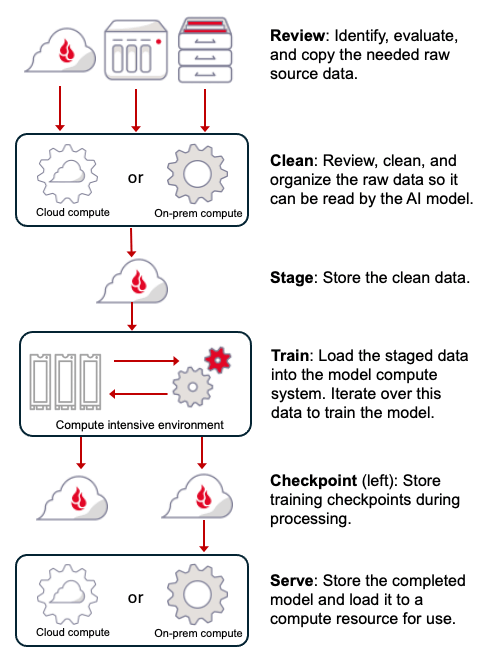
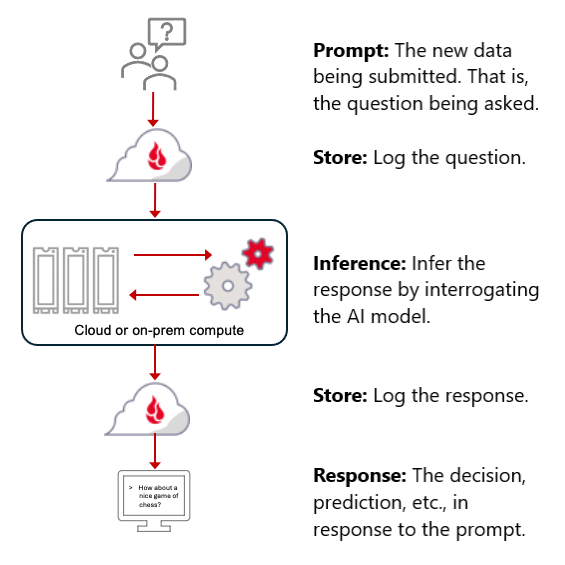














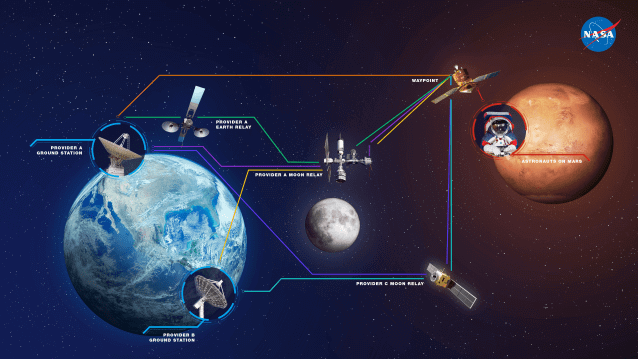








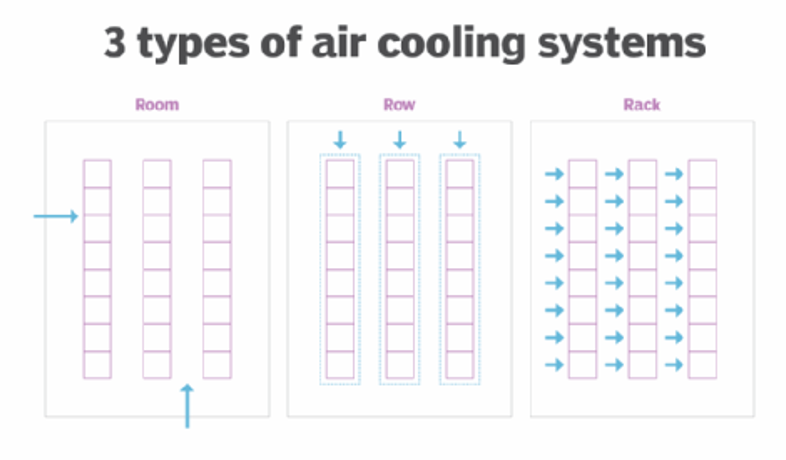
 ) is not on our roadmap—so let’s talk about what we know. Things will change over time, and some of the tools we’ve included on this list will likely go away. And, as we fully expect all of you to have strong opinions, let us know what you’re using, which tools we may have missed, and why we’re wrong in the comments section.
) is not on our roadmap—so let’s talk about what we know. Things will change over time, and some of the tools we’ve included on this list will likely go away. And, as we fully expect all of you to have strong opinions, let us know what you’re using, which tools we may have missed, and why we’re wrong in the comments section..jpg){kind=link}