Post Syndicated from Milind Oke original https://aws.amazon.com/blogs/big-data/set-up-cross-account-audit-logging-for-your-amazon-redshift-cluster/
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze all your data to derive holistic insights about your business and your customers. One of the best practices of modern application design is to have centralized logging. Troubleshooting application problems is easy when you can correlate all your data together.
When you enable audit logging, Amazon Redshift logs information about connections and user activities in the database. These logs help you monitor the database for security and troubleshooting purposes, a process called database auditing. The logs are stored in Amazon Simple Storage Service (Amazon S3) buckets. These provide convenient access with data security features for users who are responsible for monitoring activities in the database.
If you want to establish a central audit logging account to capture audit logs generated by Amazon Redshift clusters located in separated AWS accounts, you can use the solution in this post to achieve cross-account audit logging for Amazon Redshift. As of this writing, the Amazon Redshift console only lists S3 buckets from the same account (in which the Amazon Redshift cluster is located) while enabling audit logging, so you can’t set up cross-account audit logging using the Amazon Redshift console. In this post, we demonstrate how to configure cross-account audit logging using the AWS Command Line Interface (AWS CLI).
Prerequisites
For this walkthrough, you must have the following prerequisites:
- Two AWS accounts: one for analytics and one for centralized logging
- A provisioned Amazon Redshift cluster in the analytics AWS account
- An S3 bucket in the centralized logging AWS account
- Access to the AWS CLI
Overview of solution
As a general security best practice, we recommend making sure that Amazon Redshift audit logs are sent to the correct S3 buckets. The Amazon Redshift service team has introduced additional security controls in the event that the destination S3 bucket resides in a different account from the Amazon Redshift cluster owner account. For more information, see Bucket permissions for Amazon Redshift audit logging.
This post uses the AWS CLI to establish cross-account audit logging for Amazon Redshift, as illustrated in the following architecture diagram.

For this post, we established an Amazon Redshift cluster named redshift-analytics-cluster-01 in the analytics account in Region us-east-2.

We also set up an S3 bucket named redshift-cluster-audit-logging-xxxxxxxxxxxx in the centralized logging account for capturing audit logs in Region us-east-1.

Now you’re ready to complete the following steps to set up the cross-account audit logging:
- Create AWS Identity and Access Management (IAM) policies in the analytics AWS account.
- Create an IAM user and attach the policies you created.
- Create an S3 bucket policy in the centralized logging account to allow Amazon Redshift to write audit logs to the S3 bucket, and allow the IAM user to enable audit logging for the S3 bucket.
- Configure the AWS CLI.
- Enable audit logging in the centralized logging account.
Create IAM policies in the analytics account
Create two IAM policies in the analytics account that has the Amazon Redshift cluster.
The first policy is the Amazon Redshift access policy (we named the policy redshift-audit-logging-redshift-policy). This policy allows the principal to whom it’s attached to enable, disable, or describe Amazon Redshift logs. It also allows the principal to describe the Amazon Redshift cluster. See the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"redshift:EnableLogging",
"redshift:DisableLogging",
"redshift:DescribeLoggingStatus"
],
"Resource": "arn:aws:redshift:us-east-2:xxxxxxxxxxxx:cluster: redshift-analytics-cluster-01"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "redshift:DescribeClusters",
"Resource": "*"
}
]
}
The second policy is the Amazon S3 access policy (we named the policy redshift-audit-logging-s3-policy). This policy allows the principal to whom it’s attached to write to the S3 bucket in the centralized logging account. See the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx",
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx/*"
]
}
]
}
Create an IAM user and attach the policies
Create an IAM user (we named it redshift-audit-logging-user) with programmatic access in the analytics account and attach the policies you created to it.

Save the generated AWS secret key and secret access key credentials for this user securely. We use these credentials in the next step.
Create an S3 bucket policy for the S3 bucket in the centralized logging AWS account
Add the following bucket policy to the audit logging S3 bucket redshift-cluster-audit-logging-xxxxxxxxxxxx in the centralized logging account. This policy serves two purposes: it allows Amazon Redshift to write audit logs to the S3 bucket, and it allows the IAM user to enable audit logging for the S3 bucket. See the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Put bucket policy needed for audit logging",
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": [
"s3:PutObject",
"s3:GetBucketAcl"
],
"Resource": [
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx",
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx/*"
]
},
{
"Sid": "Put IAM User bucket policy needed for audit logging",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::xxxxxxxxxxxx:user/redshift-audit-logging-user"
},
"Action": "s3:PutObject",
"Resource": [
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx",
"arn:aws:s3:::redshift-cluster-audit-logging-xxxxxxxxxxxx/*"
]
}
]
}
Note that you have to modify the service name redshift.amazonaws.com to look like redshift.region.amazonaws.com if the cluster is in one of the opt-in Regions.
Configure the AWS CLI
As part of this step, you need to install and configure the AWS CLI. After you install the AWS CLI, configure it to use the IAM user credentials that we generated earlier. We perform the next steps based on the permissions attached to the IAM user we created.
Enable audit logging in the centralized logging account
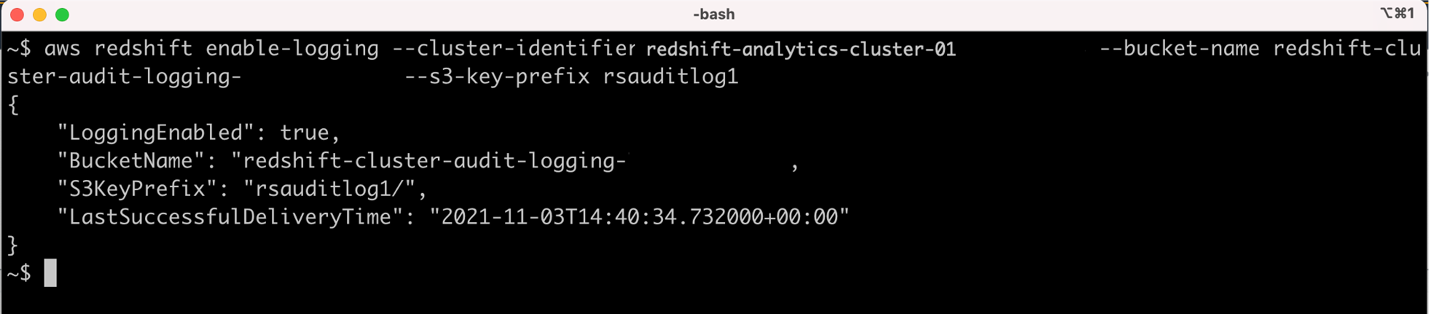
Run the AWS CLI command to enable audit logging for the Amazon Redshift cluster in an S3 bucket in the centralized logging AWS account. In the following code, provide the Amazon Redshift cluster ID, S3 bucket name, and the prefix applied to the log file names:
aws redshift enable-logging --cluster-identifier <ClusterName> --bucket-name <BucketName> --s3-key-prefix <value>
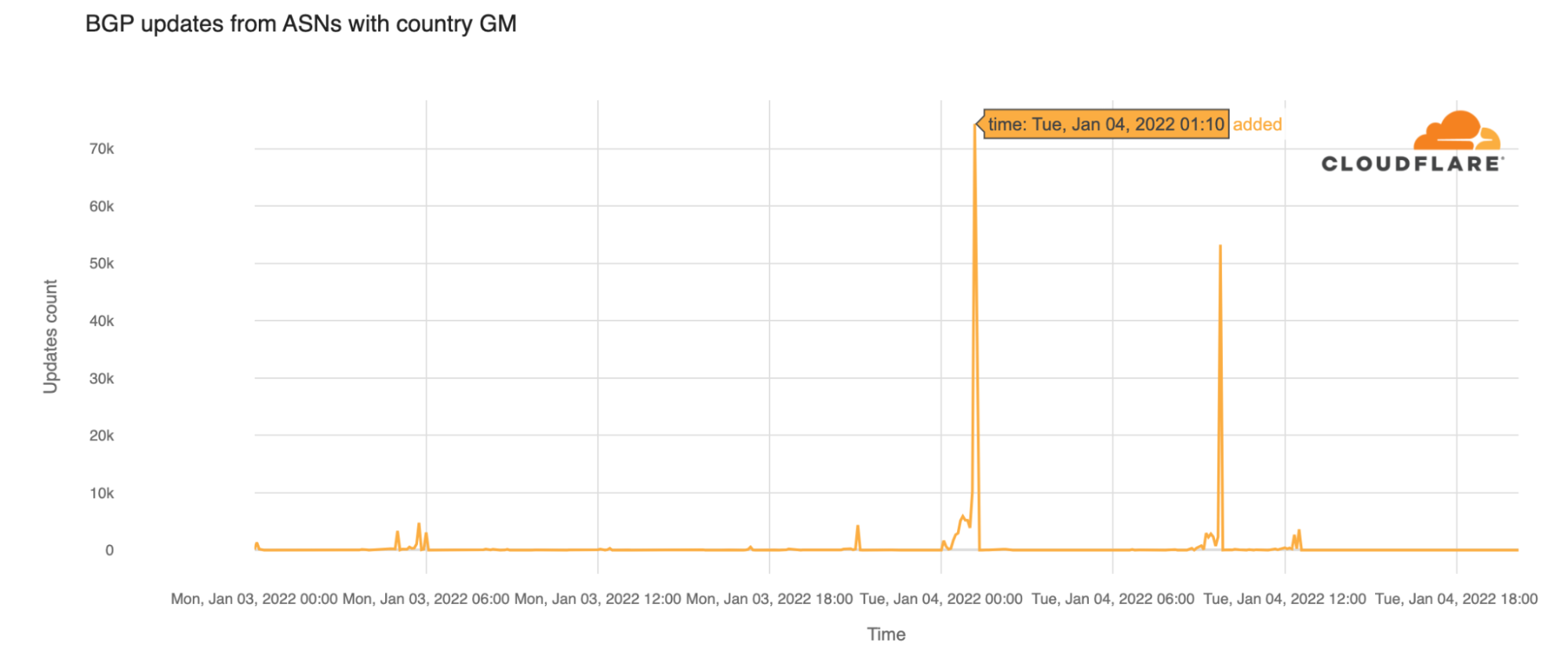
The following screenshot shows that the cross-account Amazon Redshift audit logging is successfully set up.

A test file is also created by AWS to ensure that the log files can be successfully written into the S3 bucket. The following screenshot shows the test file was created successfully in the S3 bucket under the rsauditlog1 prefix.

After some time, we started seeing the audit logs created in the S3 bucket. By default, Amazon Redshift organizes the log files in the S3 bucket using the following bucket and object structure:
AWSLogs/AccountID/ServiceName/Region/Year/Month/Day/AccountID_ServiceName_Region_ClusterName_LogType_Timestamp.gz
Amazon Redshift logs information in the following log files:
- Connection log – Logs authentication attempts, connections, and disconnections
- User log – Logs information about changes to database user definitions
- User activity log – Logs each query before it’s run on the database
The following screenshot shows that log files, such as connection logs and user activity logs, are now being created in the centralized logging account in us-east-1 from the Amazon Redshift cluster in the analytics account in us-east-2.

For more details on analyzing Amazon Redshift audit logs, refer to below mentioned blogs
- Visualize Amazon Redshift audit logs using Amazon Athena and Amazon QuickSight
- How do I analyze my audit logs using Amazon Redshift Spectrum?
Clean up
To avoid incurring future charges, you can delete all the resources you created while following the steps in this post.
Conclusion
In this post, we demonstrated how to accomplish cross-account audit logging for an Amazon Redshift cluster in one account to an Amazon S3 bucket in another account. Using this solution, you can establish a central audit logging account to capture audit logs generated by Amazon Redshift clusters located in separated AWS accounts.
Try this solution to achieve cross-account audit logging for Amazon Redshift and leave a comment.
About the Authors
 Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift.
Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift.
 Dipankar Kushari is a Sr. Analytics Solutions Architect with AWS.
Dipankar Kushari is a Sr. Analytics Solutions Architect with AWS.
 Pankaj Pattewar is a Cloud Application Architect at Amazon Web Services. He specializes in architecting and building cloud-native applications and enables customers with best practices in their cloud journey.
Pankaj Pattewar is a Cloud Application Architect at Amazon Web Services. He specializes in architecting and building cloud-native applications and enables customers with best practices in their cloud journey.
 Sudharshan Veerabatheran is a Cloud Support Engineer based out of Portland.
Sudharshan Veerabatheran is a Cloud Support Engineer based out of Portland.