Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=iJsUwcIwy7E
Седмицата (3–7 януари)
Post Syndicated from Йовко Ламбрев original https://toest.bg/editorial-3-7-jan-2022/
България изпрати 2021 година вторачена в промяната. И разбира се, както е обичайно, някои гарнираха промяната с надежда, други я поръсиха със скептицизъм, а трети я овкусиха с отрицания. Уви, границата между две години не е нищо повече от дата в календара, която е само репер във времето, но сама по себе си не обещава и не гарантира нищо. Още по-малко промяна.
От „Тоест“ обаче правим нашата малка промяна. Започваме новата година с различен ритъм на публикациите, които няма да излизат както през последните три години само в събота. Материалите вече ще се появяват на сайта през цялата седмица, а в събота само ще обобщаваме всичко публикувано в обичайната си редакционна статия, която четете в момента. Може да я получавате и като бюлетин директно по имейла, ако сте се абонирали за това. Така тези от вас, които са свикнали да четат „Тоест“ със съботното си сутрешно кафе, могат да продължават да го правят. А тези, които предпочитат да отварят директно сайта ни, ще откриват нови публикации в различни дни.
Редакционните ни статии „Седмицата“ занапред ще бъдат подписвани от някой от нашите автори или редактори и ще се подготвят от различен човек от екипа ни. Той ще има свободата да пречупва представянето на статиите ни през своя поглед, с което търсим различния дискурс и почерк. По своя преценка седмичният коментатор може да представя накратко и теми от български и чуждестранни медии, които е преценил за важни, както и да реферира към материали извън публикуваните в „Тоест“.
И през 2022 г. ще продължим да коментираме и анализираме по-важното от новинарския поток и сферата на културата. Избирателно, с чувствителността на нашите автори към общественозначимите въпроси и теми за бъдещето на всички ни.

В края на миналата година в „По буквите“ Зорница Христова представи сборника с избрани стихове на немската поетеса Нели Закс „Смъртта още празнува живота“. Тогава ни обеща интервю с преводача на сборника Любомир Илиев. Вчера (петък) публикувахме техния изключително интересен разговор. Рядко може да попаднете на такова интервю, затова нека започнем обзора на седмицата, а и новата година с разговор за трудна поезия вместо с анализ на непосилната лекота на политиката.

Да продължим с друга книга. Не от тези, които обикновено представяме в рубриката си „На второ четене“. Необичайно личен и емоционален е текстът на Стефан Иванов, който този път е повече музикален фен. В рецензията си на „Аз | Остава“ от Георги Гаврилов, Мария Куманова и Наталия Иванова той пише: „… това е книга, създадена с грижа, внимание и желание за изчерпателност. Самият том като обект и полиграфия също е впечатляващ с обема и качеството си. Това не е обичайна биография на музиканти, а е пъзел от разговори, снимки, текстове на песни и думи от хора, близки на групата.“

Идната седмица, на 12 януари, предстои среща на Съвета „НАТО–Русия“, който не е заседавал от 2019 г. Поводът, разбира се, е дрънкането на оръжия на границата между Украйна и Русия. Преди това, на 10 януари, официални представители на Вашингтон и Москва ще имат предварителни разговори в Женева. На този фон през изминалата седмица избухна и ожесточен вътрешен конфликт в Казахстан. По тези теми Венелина Попова разговаря с Деян Кюранов, доктор по философия, политически изследовател и програмен директор в Центъра за либерални стратегии.
На 6 януари се навърши една година от атаката над Капитолия от привърженици на Доналд Тръмп, който отказа да признае изборната си загуба. Срамно събитие, което обаче е ключово за историята на САЩ и бъдещето на американската политика. По този повод „Ню Йорк Таймс“ започна поредица от публицистични есета, всяко от което заслужава внимание. Ние ви подаряваме отключен линк към есето на Франсис Фукуяма One Single Day. That’s All It Took for the World to Look Away From Us, което е част от поредицата.
Социалните мрежи и особено Facebook носят огромна вина за насъскването и радикализирането на хората, както и за разделението на обществото на воюващи лагери по една или друга тема. И това продължава. Изданието The Markup създаде и поддържа инструмент за анализ на информацията, която алгоритмите на Facebook селектират и предлагат на американците според техните политически симпатии. Година по-късно наблюденията показват, че привържениците на демократите и тези на републиканците на практика виждат две напълно различни версии на социалната мрежа. Прочетете повече в статията One Year After the Capitol Riot, Americans Still See Two Very Different Facebooks.
Фалшивите новини и дезинформацията объркаха хората и относно значимостта и безопасността на ваксините. А това застрашава живота на уязвимите хора навсякъде – особено на болните, възрастните, медиците, живеещите и работещите в домове за възрастни хора. У нас част от вината, за съжаление, се носи и от лекари, които не застанаха с професионалния си и морален авторитет зад науката и не направиха нужното, за да разсеят съмненията на хората. Дори по-лошо, голяма част от медицинските лица подхранваха и споделяха тези съмнения.
А проблемът е, че всеки, който не е ваксиниран, улеснява разпространението на заразата в обществото и увеличава вероятността коронавирусът да стигне до уязвими хора. Разпространението на вируса има и значително икономическо въздействие, тъй като инфекцията засилва недостига на работници и служители, включително на медици, и забавя възстановяването на икономиката във всички области. В същото време уязвими в някакъв момент може да бъдем всички, колкото и млади или здрави да ни се струва, че сме в момента.

Злоупотребата с тази тема с цел извличане на политическа популярност е опасно и безчовечно, защото се измерва със загуба на човешки живот. Въпреки това местни политици го правят без никакви скрупули, подхранвайки страховете и колебанията на хората и безцеремонно отричайки научния консенсус по темата. На това е посветена статията на Зорница Латева „COVID-19 за политическа употреба“, която публикувахме още преди празниците.

Не пропускайте и материала на Константина Василева „Как липсата на стандарти за отразяване на научни теми допринася за инфодемията“, който чудесно обобщава добрите и лошите практики, както и дефицитите, които медиите, за съжаление, демонстрират при отразяването на научни теми. В синхрон с добрите практики, съдържанието на статията беше проверено от д-р Аспарух Илиев, ръководител на лаборатория в Университета в Берн, и допълнено с неговия личен коментар.
За да добавим още контекст по темата COVID-19 и как се справят на други места по света, прочетете материала на ProPublica за това как Хонконг се справя с пандемията: I Saw Firsthand What It Takes to Keep COVID Out of Hong Kong. It Felt Like a Different Planet.

Темата за българо-македонските отношения и търсенето на решение за отпадане на нашето вето върху преговорната рамка за присъединяване на Северна Македония към ЕС ще продължава да стои на дневен ред. Дали е възможна някаква развръзка след последното преразпределение на политическия пейзаж у нас, е тема на анализа на Александър Нуцов „Македонският въпрос в контекста на политическите промени в България“, публикуван преди коледните празници.

Новогодишният ни подарък за нашите читатели бе непубликуваният досега на български език разказ на Капка Касабова „Деветата чешма. Един ден на колибите“. Оригиналът на английски излезе в 157-мия брой на британското литературно списаниe Granta. Българският текст е преведен от Мария Змийчарова и от самата авторка. Ако сте го пропуснали между празниците, струва си да отделите време за него сега.
Накрая нека припомним, че през седмицата големият испански режисьор, хуманист и запален фотограф Карлос Саура навърши 90 години. Смятан за един от живите класици на съвременното европейско кино, той продължава да прави филми и изложби, чрез които води своите битки срещу политическите недъзи, корупцията, цензурата над медиите и авторитаризма. Самият той, повлиян от творци като Луис Бунюел и вдъхновяващ други, като Педро Алмодовар, ползва метафорите на изкуството си, за да провокира обществена промяна – нещо, в което той намира смисъла на изкуството. Нещо, за което тъжно малко негови по-млади съвременници имат кураж и гръбнак.
Споменавайки тримата режисьори в едно изречение, ви провокираме да гледате филма на Карлос Саура „Ментово фрапе“ (1967) – един от испанските филми, от които Алмодовар признава, че черпи вдъхновение, и в същото време е своеобразно преклонение пред Луис Бунюел. А метафората е скрита около главната героиня – едно модерно и много свободно момиче, контрапункт на всичко, което е Испания през 60-те. Филмът може да се тълкува и като завоалирано обвинение срещу репресиите и лицемерието на дребната буржоазия от онова време, но е много повече от това.
Това е от мен тази седмица. Приятно четене и гледане!
И за много години!
5 Outrageously Futuristic Tech Startups at CES 2022
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=99Pi_H2isWw
Top 10 Architecture Blog Posts of 2021
Post Syndicated from Bonnie McClure original https://aws.amazon.com/blogs/architecture/top-10-architecture-blog-posts-of-2021/
The AWS Architecture Blog highlights best practices and provides architectural guidance. We publish thought leadership pieces and how-tos. Check out the AWS Architecture Monthly Magazine, also published by our team, which offers a selection of the best new technical content from AWS!
A big thank you to you, our readers, for spending time on our blog this past quarter. Of course, we wouldn’t have content for you to read without our hard-working AWS Solutions Architects and other blog post writers either, so thank you to them as well! Without further ado, the following 10 posts were the top Architecture Blog posts published in 2021!

#10: Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active
by Seth Eliot
You’ll notice a recurring theme in this post—Seth’s four-part DR series is really popular! Throughout the series, Seth shows you different strategies to prepare your workload for disaster events like natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications.
In Part IV, Seth teaches you how to implement an active/active strategy to run your workload and serve requests in two or more distinct sites. Like other DR strategies, this enables your workload to remain available despite disaster events such as natural disasters, technical failures, or human actions.
#9: Scaling up a Serverless Web Crawler and Search Engine
by Jack Stevenson
Building a search engine can be a challenge. You must continually scrape the web and index its content so it can be retrieved quickly in response to a user’s query. In this post, Jack describes how to implement this in a way that avoids infrastructure complexity while remaining elastic with a serverless search engine that can scale to crawl and index large web pages.
#8: Managing Asynchronous Workflows with a REST API
by Scott Gerring
While building REST APIs, architects often discover that they have particular operations that have to run in the background outside of the request processing scope. In this post, Scott shows you common patterns for handling REST API operations, their advantages/disadvantages, and their typical Serverless on AWS implementations.
#7: Data Caching Across Microservices in a Serverless Architecture
by Irfan Saleem, Pallavi Nargund, and Peter Buonora
In this post, Irfan, Pallavi, and Peter discuss a couple of customer use cases that use Serverless on AWS offerings to maintain a cache close to the microservices layer. This improves performance by reducing or eliminating the need for the real-time backend calls and by reducing latency and service-to-service communication.
#6: Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
by Seth Eliot
Part III of Seth’s DR series discusses two strategies to prepare your workload for a disaster event: pilot light and warm standby. This post shows you how to implement these strategies that help you limit data loss and downtime and how to get the most out of your set up.
#5: Issues to Avoid When Implementing Serverless Architecture with AWS Lambda
by Andrei Maksimov
In the post, Andrei highlights eight common anti-patterns (solutions that may look like the right solution but end up being less effective than intended). He provides recommendations to avoid these patterns to ensure that your system is performing at its best.
#4: Using Route 53 Private Hosted Zones for Cross-account Multi-region Architectures
by Anandprasanna Gaitonde and John Bickle
In this post, Anandprasanna and John present an architecture that provides a unified view of DNS while allowing different AWS accounts to manage subdomains. They show you how hybrid cloud environments can utilize the features of Route 53 Private Hosted Zones to allow for scalability and high availability for business applications.
#3: Micro-frontend Architectures on AWS
by Bryant Bost
Despite microservice architectures’ popularity, many frontend applications are still built in a monolithic style. In this post, Bryant shows you how micro-frontend architectures introduce many of the familiar benefits of microservice development to frontend applications. This simplifies the process of building complex frontend applications by allowing you to manage small, independent components.
#2: Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud
by Seth Eliot
Part I of Seth’s DR series gives you an overview of each strategy in the series (backup and restore, pilot light, standby, multi-site active/active) and how to select the best strategy for your business needs. Disaster events pose a threat to your workload availability, but by using AWS Cloud services you can mitigate or remove these threats.
#1: Overview of Data Transfer Costs for Common Architectures
by Birender Pal, Sebastian Gorczynski, and Dennis Schmidt
With 65,281 views, this team has definitely earned their top spot! Data transfer charges are often overlooked while architecting a solution in AWS. Considering data transfer charges while making architectural decisions can help save costs. This post will help you identify potential data transfer charges you may encounter while operating your workload on AWS.
Thank you!
Thanks again to all our readers and blog post writers. Your contributions to the blog are immensely valuable to all our customers! Keep on writing!
We look forward to continuing to learn and build amazing things together in 2022.
Log4Shell Strategic Response: 5 Practices for Vulnerability Management at Scale
Post Syndicated from Joshua Harr original https://blog.rapid7.com/2022/01/07/log4shell-strategic-response-5-practices-for-vulnerability-management-at-scale/

In today’s cybersecurity world, risks evolve faster than we can remediate them. To meet our goals and become resilient to these fast changes, we need the right balance of automation and human interaction. Enabling rapid response for protecting information systems is paramount, but how does a business reach this level of reaction?
How can organizations maintain a standard of excellence to their responses in high-risk situations?
Where do you even begin to respond to a critical vulnerability like the one in Apache’s Log4j Java library (a.k.a. Log4Shell)?
Most importantly, how do we transform the tactical actions that need to take place into an effective strategy to scale?
1. Empower personnel
The personnel with the knowledge about your various solutions must be empowered to make the decisions necessary to address your company’s information technology needs. If those team members don’t feel they can make those decisions, then they will defer to management — but managers may not know the intricacies of the solutions and could create a natural bottleneck, since there are going to be more decision points than managers to make decisions. Providing personnel with policy documents with uniform criteria for evaluating the risk these new vulnerabilities present, the ways to respond, and the time expectations is paramount for a timely resolution.
In a typical risk resolution process, there are many gates to safeguard our systems. This helps ensure that whatever change happens increases the solution’s confidentiality, integrity, or availability rather than diminishing it. However, a situation like Log4Shell needs to be treated like an incident response activity to quickly address the risk. Create a task force to effectively answer the important questions like:
- How do we find vulnerable systems?
- Which systems are vulnerable?
- What options are there for a fix? One size may not fit all.
- Who is going to track changes?
- Who is going to validate the fix is in place?
Utilizing a strong incident response procedure to answer all these questions will assist with prioritization and remediation to an acceptable level of risk.
2. Promote visibility
Any standard vulnerability management lifecycle process begins with identifying affected systems to assess and evaluate the scope of a vulnerability’s presence on the network. The approach should utilize both proactive and reactive efforts through a combination of tools and well-documented processes to streamline and scale the response effectively.
A proactive process would first involve having well-documented use of any such library versions internally in an inventory, so that discoverability and traceability are much more narrowly focused efforts. If you conduct authenticated vulnerability scans continuously on pre-scheduled frequencies, this will also help with identification of third-party software utilizing this library over time. Classifying system criticality within the vulnerability management tool will help you more effectively scale future remediation processes.
These proactive processes help jumpstart an initial response, but you’ll still need reactive efforts to help ensure effective and timely remediation. Vulnerability scanning tools will receive signature updates regarding this newly discovered vulnerability, which will require updating your vulnerability management tool and initiating one-off alternative scans that may deviate from pre-scheduled rotations. These alternative scans should include tiered phases, so the most critical systems receive scan priority, and then remaining systems are scanned in order of criticality. Leveraging the pre-existing system criticality classification will significantly expedite this process.
A security incident and event management (SIEM) tool can also assist with identifying, tracking, and alerting for any suspicious activity that may be tied to exploitation of this vulnerability. Host agents and network detection systems that report back to the SIEM should be closely monitored, and any activity or traffic that deviates from baselines should receive an active response. You may need to adjust logging and alerting rules and thresholds to ensure your efforts are strategically focused.
Tactical processes help you achieve this continuous identification, but you still need to orchestrate and execute them through strategic planning to remain timely, efficient, and effective. Well-documented asset inventories and appropriate system criticality classifications help you prioritize your efforts, while continuous vulnerability scans and leveraging vulnerability management and SIEM tools help to identify, track, and manage vulnerability exposure. Leadership should provide the direction to guide these activities from inception to implementation through effective communication and allocation of resources. Lay out a short-term roadmap for tracking objectives and quick wins as part of the remediation process, so you can quickly and concisely show how you’re tracking toward goals.
3. Implement prioritization and mitigation
Now that your team has successfully identified all affected systems, you’ll need to roll out patches to those systems on a continuous basis during the next phase to mitigate risk. Current enterprise-wide patching timelines may require adjustment due to the urgency associated with such critical vulnerabilities. Patch testing and rollout phases must be expedited to support a more timely and effective response.
Much like conducting our vulnerability scans in terms of system criticality prioritization, our patch management response should follow a similar approach, with the caveat that a pilot group or pilot system deemed non-critical should be patched first for testing purposes to ensure no adverse effects prior to rolling out patches in order of system criticality. If you’ve configured a full test environment is configured, you can test patches on critical systems first within that environment and then roll them out in production according to criticality. The testing timeline itself should be reduced throughout all standard phases of a testing cycle — you may even need to eliminate certain testing phases altogether. The rollout timelines for patches across all systems will need to be expedited as well to ensure as timely coverage as possible. If your environment has widespread use of the vulnerable library, you may require reductions in timelines of anywhere from 25% to 50%.
Emergency patching procedures should provide for timely testing and production rollouts within roughly half the time of a normal patching cycle, or 5 to 10 days at a maximum for critical systems to minimize breach potential as quickly as possible. Also keep in mind that some vulnerabilities may involve more than just application of a simple patch — configuration changes may also be necessary to further mitigate potential exploitation by an adversary.
4. Validate remediation
Now, you’ve deployed patches to all affected systems, so the mitigation efforts are complete, right? While you may want to shift your focus back to other tasks, it’s essential to maintain continuous identification processes to ensure that no stone remains unturned.
The vulnerability management validation phase leverages those reactive identification processes, in addition to patch management processes, to assist in efficient and effective vulnerability remediation for affected systems. This stage involves re-scanning initially identified vulnerable systems to assess successful patch application and performing additional open scans of the network to ensure that there are no lingering systems that may still be affected by the vulnerability but weren’t originally identified — or perhaps weren’t successfully patched as part of the patch management process. This cycle of continuous validation will remain in effect until “clean” scans are reported across the enterprise regarding this vulnerability.
Since the Log4j logging library is widely used throughout many enterprise applications and even unknowingly embedded in so many others, continuous validation will become crucial in ensuring your organization remains vigilant and can mitigate the vulnerability quickly and effectively as you continue to discover affected systems.
5. Regularly review risks
A vulnerability management lifecycle rarely ever comes to a true end. As adversaries and security evangelists further evaluate a specific vulnerability over time, new methods of exploitation are identified, affected versions increase in scope and scale, and recent patches and fixes are found to be ineffective. This leaves organizations potentially open to exposure and at a loss for the best path forward. Continuous review of the trends surrounding an ongoing critical vulnerability will help organizations ensure they remain both aware of the impact and the current mitigating measures that have been most successful. Additionally, leveraging other solutions can help further identify and launch a coordinated defense-in-depth response to any potential malicious activity that may be associated with such vulnerabilities.
Working to continuously identify, mitigate, validate, and review vulnerabilities throughout their inevitable course will require commitment and fortitude to achieve the best results, but once the tides have subsided with Log4Shell and you’ve successfully and securely endured one of the worst security vulnerability exposures in a decade by following these processes, you can rest assured that your incident response processes were well-tested during this endeavor — and your IT security budget should be more than solidified for the next few years to come.
Check out our additional resources for further insight of this vulnerability, mitigating measures, and tools available to assist.
- Log4Shell Resource Hub
- Log4Shell Resources for Rapid7 Customers
- Widespread Exploitation of Critical Remote Code Execution in Apache Log4j
- Update on Log4Shell’s Impact on Rapid7 Solutions and Systems
- Using InsightVM to Find Apache Log4j CVE-2021-44228
- InsightVM Docs page for Log4j
- Rapid7 analysis of Log4Shell on AttackerKB
Linux Mint 20.3 “Una” released
Post Syndicated from original https://lwn.net/Articles/880696/rss
Linux Mint has announced its 20.3 (“Una”) release for three different desktop environments: the Cinnamon, MATE, and Xfce editions. Mint 20.3 is a long-term support release, with support lasting until 2025. Each edition comes with a long list of new features (Cinnamon, MATE, and Xfce) and detailed release notes (Cinnamon, MATE, and Xfce).
Metasploit Wrap-Up
Post Syndicated from Erran Carey original https://blog.rapid7.com/2022/01/07/metasploit-wrap-up-144/
Dump Windows secrets from Active Directory

This week, our very own Christophe De La Fuente added an important update to the existing Windows Secret Dump module. It is now able to dump secrets from Active Directory, which will be very useful for Metasploit users. This new feature uses the Directory Replication Service through RPC to retrieve data such as SIDs, password history, Domain user NTLM hashes and Kerberos keys, etc. This replicates the behavior of the famous impacket secretsdump.py, with the benefit of being fully integrated with Metasploit Framework. For example, it is possible to pivot on a compromised host and run the Windows Secret Dump module against an internal Domain Controller directly from msfconsole. Furthermore, the secrets are stored in the internal database, which lets other modules access this information easily.
This update also brings another big improvement to the ruby_smb library. This adds a new DCERPC client and many ready-to-use RPC queries from Directory Replication Service (DRS) Remote Protocol, Security Account Manager (SAM) Remote Protocol and Workstation Service Remote Protocol. These will greatly simplify the process of writing modules that use DCERPC against Windows systems.
Authenticated Catch Themes Demo Import Remote Code Execution
Thank you to Ron Jost, Thinkland Security Team, and h00die for their community contribution of a Remote Code Execution exploit module against versions 1.8 and earlier of the Catch Themes Demo Import WordPress Plugin.
New module content (6)
- Grafana Plugin Path Traversal by h00die and jordyv, which exploits CVE-2021-43798 – This aAdds a module to exploit Grafana file read vulnerability CVE-2021-43798.
- Native LDAP Server (Example) by RageLtMan and Spencer McIntyre – This adds the initial implementation of an LDAP server implemented in Rex and updates the existing log4shell scanner module to use it as well as provides a new example module.
- WordPress Plugin Catch Themes Demo Import RCE by Ron Jost, Thinkland Security Team, and h00die, which exploits CVE-2021-39352 – This adds an exploit for the Catch Themes Demo Import WordPress plugin for versions below
1.8. The functionality for importing a theme does not properly sanitize file formats, allowing an authenticated user to upload a php payload. Requesting the uploaded file achieves code execution as the user running the web server. - WordPress Popular Posts Authenticated RCE by Jerome Bruandet, Simone Cristofaro, and h00die, which exploits CVE-2021-42362 – This PR adds a new exploit for wp_popular_posts <=5.3.2.
- ManageEngine ServiceDesk Plus CVE-2021-44077 by wvu and Y4er, which exploits CVE-2021-44077
- Dell DBUtilDrv2.sys Memory Protection Modifier by Jacob Baines, Kasif Dekel, Red Cursor, and SentinelLabs – This module leverages a write-what-where condition in DBUtilDrv2.sys version 2.5 or 2.7 to disable or enable LSA protect on a given PID (assuming the system is configured for LSA Protection). The drivers must be provided by the user.
Enhancements and features
- #15831 from zeroSteiner – Established SSH connections can now leverage the pivoting capabilities of the
SshCommandShellBindsession type. - #15882 from smashery – An update has been made which will prevent exploits from running a payload if the exploit drops files onto the target, but the payload doesn’t have the capability to clean those dropped files up from the target. Users can still override this setting by specifying
set AllowNoCleanup trueif they wish to bypass this protection. - #15924 from cdelafuente-r7 – This adds the NTDS technique to the Windows Secrets Dump module, enabling it to be used against Domain Controllers. It also pulls in RubySMB changes that include many DCERPC related improvements and features.
- #15986 from bcoles – Module notes added to
bash_profile_persistencenow describe impacts of utilizing the module in a target environment.
Bugs fixed
- #15982 from 3V3RYONE – This fixes a bug where modules using the SMB client would crash when the
SMBUserdatastore option had been explicitly unset. - #15984 from h00die – This PR fixes a bug in the snmp library which caused it to ignore version 1, despite specifically set options.
- #16003 from jmartin-r7 – This fixes an issue with GitHub actions where the Ruby 3.1.0 version string is not yet being parsed correctly leading to automation failures.
- #16015 from zeroSteiner – This fixes a regression in tab completion for the RHOSTS datastore option.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).
[$] Fixing a corner case in asymmetric CPU packing
Post Syndicated from original https://lwn.net/Articles/880367/rss
Linux supports processor architectures where CPUs in the same system
might have
different processing capacities; for example, the Arm big.LITTLE
systems combine fast, power-hungry CPUs with slower, more efficient
ones. Linux has also run for years on simultaneous
multithreading (SMT) architectures, where one CPU executes multiple
independent execution threads and is seen as if it were multiple cores.
There are architectures that mix both approaches. A recent discussion
on a patch
set submitted by Ricardo Neri shows that, on these systems, the
scheduler might distribute tasks in an inefficient way.
What’s New in Threat Intelligence: 2021 Year in Review
Post Syndicated from Stacy Moran original https://blog.rapid7.com/2022/01/07/whats-new-in-threat-intelligence-2021-year-in-review/

This post was originally published on the IntSights blog.
Last year marked a huge milestone with the acquisition of IntSights by Rapid7. The IntSights team is very excited to join a company committed to simplifying and improving security outcomes for its customers. Rapid7’s focus is a great complement to the IntSights core mission to “democratize threat intelligence” for all. We look forward to continuing in this mission as part of the Rapid7 family, as our external threat intelligence solutions are incorporated within the Insight platform.
Threat Intelligence solutions compete in an increasingly crowded marketplace. Our solution stands out from others by removing the inherent complexity of threat intelligence while helping organizations of any size or maturity minimize their external risk while significantly reducing their workload. Over the course of 2021, we continued to deliver on this core promise by adding additional value to our products through:
- Expanding detection coverage and sources across the clear, deep, and dark web
- Helping customers speed their response processes through an expanded investigation toolset
- Continuously improving the user experience, ensuring our solutions deliver immediate value out of the box
“IntSights’ competitive advantage lies in its simplicity.” – Dave Estlick, CISO, Chipotle
2021 IntSights External Threat Protection Suite highlights
Expanded threat coverage
Over the course of 2021, we increased our Threat Command detections coverage in several key areas to offer customers additional protection and value. These expanded capabilities include:
- Phishing websites: Detection and alert coverage for additional Phishing feeds including AlienVault, OpenPhish, Phishing Domain Database, PhishStats, and PhishTank
- Public repositories: Expanded coverage for leaked secrets in both GitHub and GitLab
- Leaked databases: Alerts on leaked databases that contain organization-specific PII data (such as phone number, physical address, date of birth)
- Black markets coverage: Expanded detections of customer products offered for sale in dark web black markets and ability for customers to view decision parameters to understand why specific threats were elevated to alerts
- BOT data for sale: Option to use the new “Bot price” condition to trigger alerts based on bot prices and easily initiate bot purchase requests from the Threats page
“IntSights gives us the ability to see a more granular view of our threats in a very easy-to-use fashion.” – Zac Hinkel, Global Cyber Threat Manager, Hogan Lovells
Proactive phishing detection
In 2021, we offered a new solution called Phishing Watch that offers advanced and preemptive phishing detection capabilities that help customers identify attacks before phishing websites emerge. Phishing Watch employs a lightweight snippet installed on customer-facing websites that proactively detects the copying or redirection of legitimate/official websites to an illegitimate (and potentially phishing) website. Customers receive proactive notice of any phishing scams before they are employed, including the details required to enable automatic takedown of the phishing website and eradicate any threats in the early stages.
Expanded research and investigation capabilities
This year, we also greatly enhanced the investigation capabilities and content within our Threat Intelligence Platform (TIP) to accelerate customers’ ability to research and triage threats. The enhancements enable customers to easily understand the intent associated with indicators and prioritize those that pose the greatest risk. Features include:
- Improved user interface that helps customers quickly investigate IOC and common cyber attack details
- Expanded and accelerated investigation functionality including attack context, mapping tools, notes, and export functionality
- Ability to easily share information on specific indicators with teams to enable better coordination and more proactive security posturing
- Ability to analyze and understand the correlation of a CVE to cyber terms, view which feed reported the malware or actor, and see the first and last report date for better visibility and context on reported threats
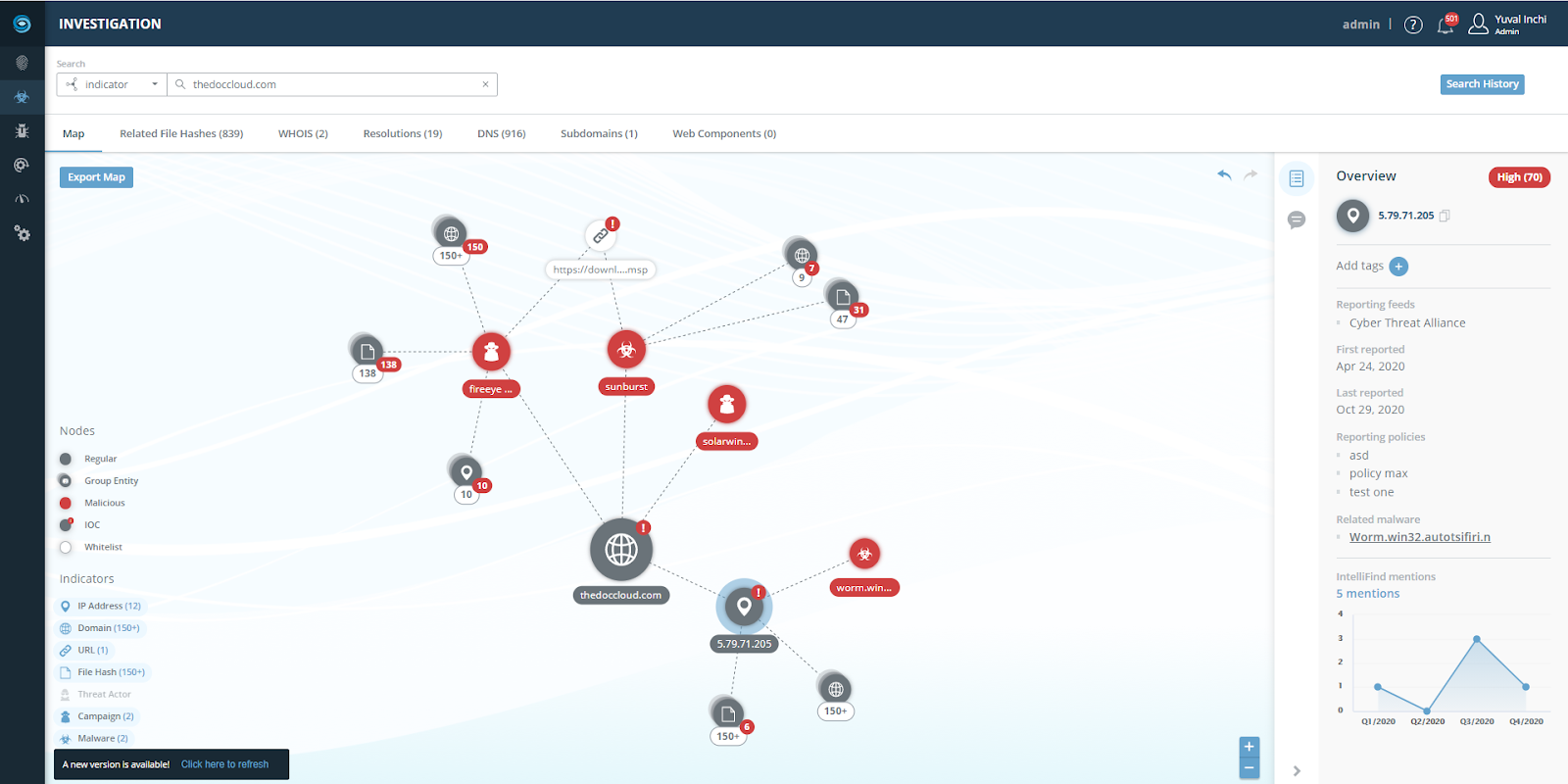
IntSights Extend (browser extension)
Introduced earlier this year, IntSights Extend actively parses, enriches, and highlights cyber threat intelligence data from any web-based application, such as a technical blog detailing the latest breach or a raw intelligence feed. It actively scrapes domains, URLs, IP addresses, file hashes, email addresses, and CVEs to deliver contextualized risk-prioritized alerts at the click of a mouse. Additionally, layering real-time enriched threat intelligence over any web-based application allows security practitioners to perform end-to-end investigation and analysis. They can immediately detect if threat indicators are active within their environment and block them directly from the browser. Customers can also easily pivot to the IntSights platform for further analysis, investigation, and action.
Threat library
Dedicated research analysts work behind the scenes to input up-to-the-minute intelligence. The research team includes detailed information on known threat actors, malware, campaigns, and associated MITRE TIDs to help security analysts spot trends and gain contextual details regarding threats targeting geographic regions, including threat actor engagement and reconnaissance. Security analysts can take immediate action on threats by adding IOCs associated with specific topics to their security devices, without ever leaving the library. The IOCs can also be tagged with malware, threat actor names, campaigns, and/or attack type to accelerate triage across existing security infrastructure.
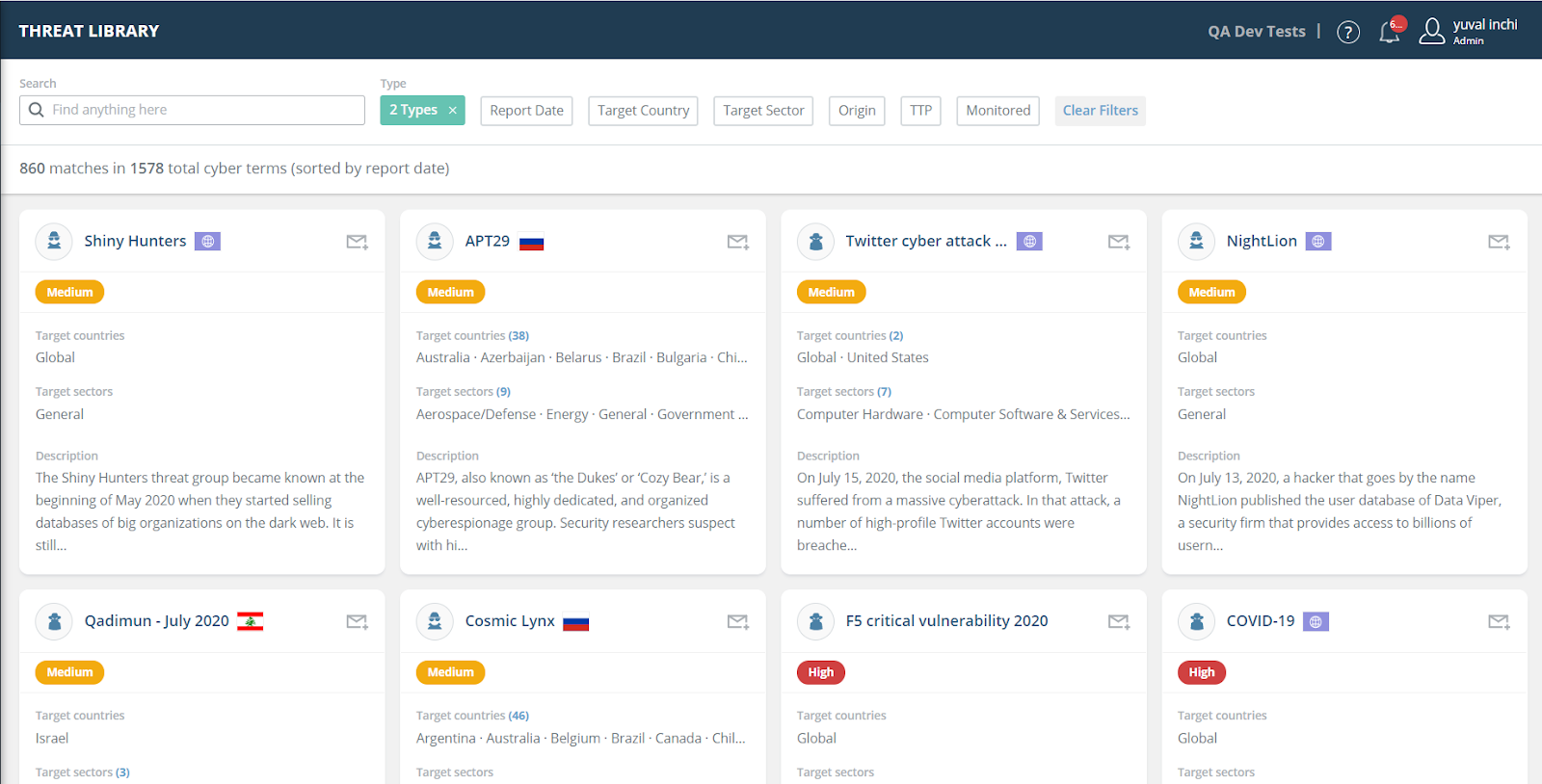
Vulnerability Risk Analyzer (VRA) customers can click on specific CVEs to view further details on the Vulnerabilities page. This helps customers prioritize vulnerabilities used in specific campaigns that affect their organization so they can focus on immediate updates and patching for the most relevant CVEs.
MITRE ATT&CK mapping
More advanced search capabilities to speed investigation plus details on MITRE ATT&CK framework tactics, techniques, and procedures (TTPs) are now mapped to Threat Library topics, bringing all relevant information related to a threat into one simplified view. Beyond the Threat Library, platform users can view and filter alerts by specific MITRE framework tactics and techniques for more context about threats in the customer environment.
IntelliFind
IntelliFind, our comprehensive dark web search tool, enables customers to directly search outside their digital footprint to immediately discover threat actor chatter and potential attacks targeting their organization or industry on the black market, hacking forums, paste sites, and other dark web sources across the attack surface. We offer the largest and most extensive database of these otherwise inaccessible sites.
Workflow improvements and technology integrations
Multi-tenant threat management
MSSPs and large enterprises with subsidiaries can now view and manage the threat data associated with all accounts, as well as navigate between customers, from a single dashboard, streamlining account management and saving money, time, and resources.
- Threat Command: Those managing multi-tenant accounts can access each account’s Threat Command alerts, remediations, and associated policy options from the tenant view. The expanded functionality also makes it easier for tenants and subsidiaries to consume and act on threat intelligence to improve their digital risk protection and cybersecurity posture. Alerts for multiple accounts can be displayed and managed simultaneously, as well as aggregated by date and category. Multi-tenant account owners can also engage with our expert threat analysts in real time to dig deeper into specific alerts and proactively reduce response time.
- TIP: MSSPs can see each tenant’s threat feeds and aggregated and prioritized IOCs from the TIP, as well as set IOC severity for all managed accounts.
- IntelliFind: Using this exclusive dark web search tool, MSSPs gain access to advanced investigation capabilities and can view and manage queries and trigger alerts for multiple tenants via a single login.
“The new MSSP capabilities allow us to view and manage all of our tenants from a single dashboard. We can switch between our customers’ tailored intelligence platforms with the click of a button. Also, we can easily generate reports to share with our customers, documenting the value they receive from Rapid7 threat intelligence.” – Royi Biller, CEO, MT Cyber (MSSP)
Rapid7 InsightConnect Plugin for IntSights Threat Intelligence
Mutual customers of IntSights and Rapid7 InsightConnect (and InsightIDR or InsightVM) can now leverage contextualized threat alerts, indicators, and vulnerabilities within their Rapid7 SOAR solution, InsightConnect, helping them prioritize incident response and vulnerability management activities. This integration helps organizations gain a 360-degree view of the external threat landscape, align internal security enforcement, and expedite critical areas of security operations. The first ICON Plugin workflow (for Rapid7 InsightIDR) is now available in the Rapid7 Extensions Library. This workflow enriches IDR alerts by performing a lookup on all domains, hashes, URLs, and IPs in the Threat Intelligence Investigation module. In addition, IntSights can now directly trigger an incident response workflow in InsightConnect based on generated alerts, enabling more efficient and effective responses to threats that the IntSights platform detects.
The IntSights bidirectional app for Splunk enables customers to bring actionable threat intelligence into their Splunk solution for a holistic view of threats targeting their environment. Building on existing functionality that facilitated the import of prioritized IOCs from the IntSights platform, the app introduced earlier this year enables customers to:
- Identify attacks in progress on their network by correlating indicators in their environment with IntSights high-severity IOCs
- Import Threat Command alerts and prioritized vulnerabilities from Vulnerability Risk Analyzer into the Splunk environment to continue triaging external threats directly from the Splunk dashboard
- Instantly analyze and prioritize credible threats in the IntSights environment. When an alert, IOC, or CVE is found in the customer’s Splunk environment, it is flagged simultaneously in Splunk and IntSights so that users can take action in either platform.
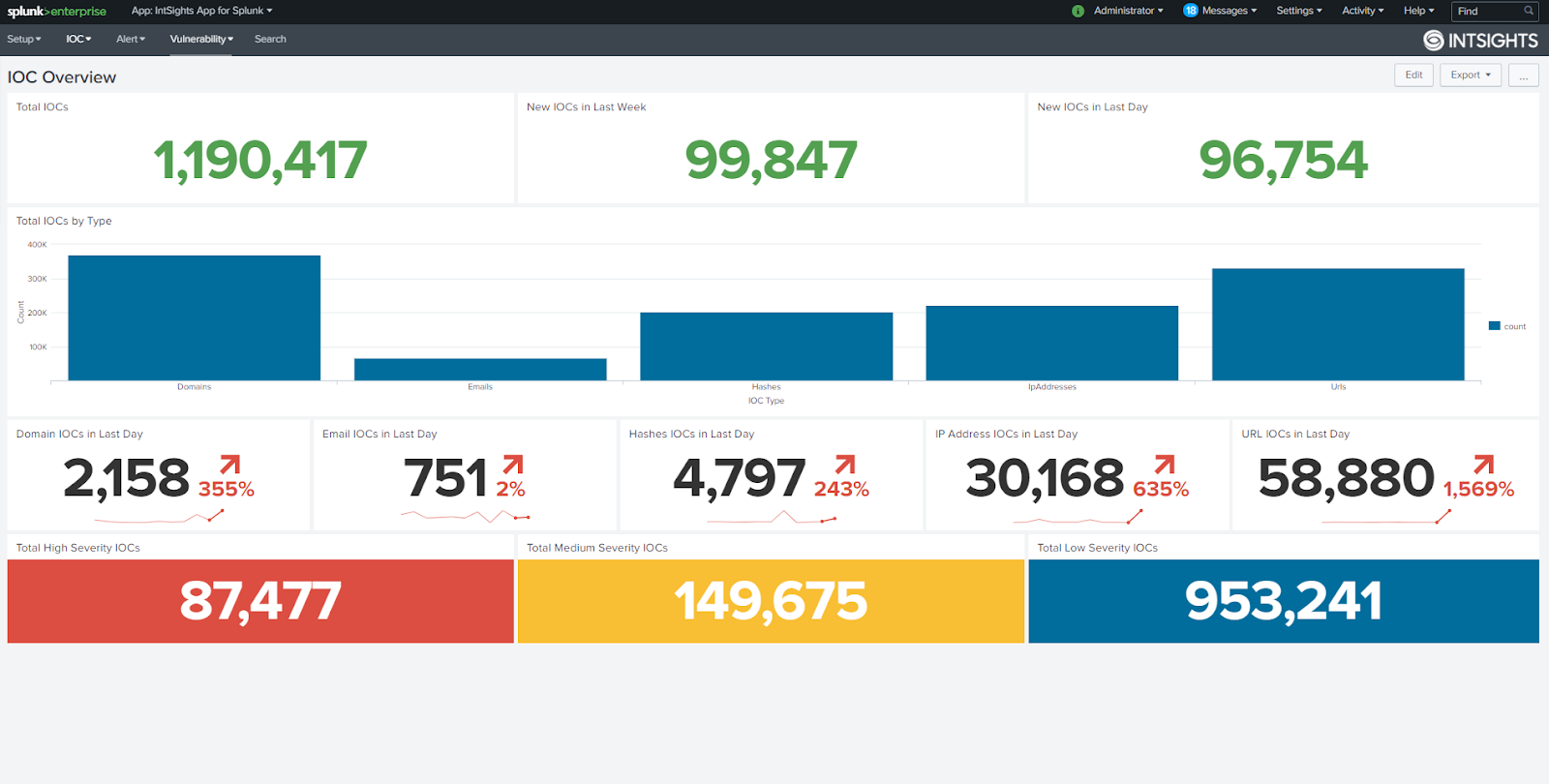
Our native bidirectional application for IBM QRadar allows customers to leverage the robust enrichment and investigation capabilities of the IntSights TIP in their QRadar environments. Mutual customers can:
- Detect IOCs found in the network
- View top malware and threat actors targeting the organization
- Conduct comprehensive, end-to-end investigations directly within the Qradar environment
Looking ahead
Looking ahead to 2022, some of the key themes and areas of investment that Rapid7’s Threat Intelligence customers will experience include:
- Delivering more visibility for faster decision-making with a new Strategic Intelligence module and custom reporting capabilities
- Key integrations with Rapid7 products including the InsightIDR XDR/SIEM solution, the InsightConnect SOAR platform, and the InsightVM vulnerability management solution
- New pricing and packaging model that scales with customer needs across the maturity spectrum
- Continued investment in expanding intelligence sources and detections for reduced noise and better protection
- Driving growth through a more optimized Threat Intelligence experience for MSSP partners
A big thank you to all of our customers and partners for working with us this year. We look forward to delivering even more value to our Threat Intelligence customers as part of the Rapid7 family, as well as sharing more about these investments and additional updates with you in 2022.
Cloudflare Innovation Weeks 2021
Post Syndicated from Reagan Russell original https://blog.cloudflare.com/2021-innovations-weeks/


One of the things that makes Cloudflare unique is our Innovation Weeks. Rather than having one large conference annually, we have multiple Innovation Weeks throughout the year to highlight new product announcements, beta products opening up to general availability, and share how our customers are using Cloudflare to help build a better Internet.
Internally, these weeks generate a lot of energy and excitement as well, as they provide an opportunity for teams from across Cloudflare to work together on product delivery and celebrate company-wide successes. In 2021, we had seven Cloudflare Innovation Weeks. As we start planning our 2022 Innovation Weeks, we are reflecting back on the highlights from each of these weeks.

Security Week March 21-26, 2021
Patrick Donahue
Security Week kicked off Cloudflare’s 2021 Innovation Weeks with a series of foundational security announcements. The Internet wasn’t built with security in mind, but the products and partnerships announced this week continued Cloudflare’s core mission of helping build a better Internet—one that companies of all sizes can plug into and be protected by default from the types of attacks that have historically resulted in loss of data, computing resources, and customer confidence.
At the start of the week, we took on the task of replacing MPLS, the core network technology that many organizations use to connect their offices and data centers, with a more secure and cost-effective alternative. Next, we tackled the biggest risk to everyday users of the web by opening our remote browser isolation technology to teams of all sizes and protecting against malicious code injection. Following those announcements, we inverted the slow, network chokepoint model of data loss prevention by building zero trust controls over data directly into every aspect of the Cloudflare One suite. And to round out the week, we democratized access to bot-fighting technology previously only available to the largest enterprises while also deepening our solutions for novel threats facing APIs.
View all Security Week 2021 Blog Posts
View all Security Week 2021 Cloudflare TV Series

Developer Week April 11-17, 2021
Alyson Cabral
With Developer Week, we had one focus – to make developers’ lives easier. Our announcements included Cloudflare Pages being made generally available, Introducing Web Socket Support in Workers, Workers Unbound, Free Tunnels, Partnering with Nvidia to bring AI to the Edge and many more announcements throughout the week. In addition to the announcements, we also launched our first ever Developer Challenge series. Each day, a new challenge was announced to encourage developers from across the globe to level up their skills by trying new features and approaches. Solutions were revealed the following day, with the bonus round solution wrapping up the week. To keep up to date on the next round of challenges, join our Cloudflare Developer community.
View all Developer Week 2021 Blog Posts
View all Developer Week 2021 Cloudflare TV Series

Impact Week July 26-31, 2021
Patrick Day
During our first Impact Week, we reflected on how we are achieving Cloudflare’s mission–helping build a better Internet– and why we continue to prioritize projects that give back to the Internet. Impact Week highlighted some of the things we are doing as a company around environmental, social and governance initiatives. We launched Project Pangea, a free program to provide secure, reliable access to the Internet for community networks that support under-served communities. We also shared how we are committed to helping build a green Internet through efficiency, renewable energy, and providing developers a choice to run their workloads in the most energy efficient data centers. In addition, we published our first human rights policy in order to better serve our mission and core values.
View all Impact Week 2021 Blog Posts
View all Impact Week 2021 Cloudflare TV Series

Speed Week Sept 12-17, 2021
Marc Lamik
Helping make the Internet faster is one of Cloudflare’s core priorities. During Speed Week we shared how fast Cloudflare’s Network is as well as the amazing performance of Workers and Pages’ lightning fast speed. We expanded the size of Cloudflare’s network, so it’s closer to more people than ever.
We launched two amazing performance features with Signed Exchanges reducing load times and increasing SEO rankings with one click as well as Early Hints which can reduce loading times by 30%.
As part of Speed week, we also announced Cloudflare Images which stores, resizes, optimizes and serves images so that all of our customers can build a scalable, affordable image pipeline.
View all Speed Week 2021 Blog Posts
View all Speed Week 2021 Cloudflare TV Series

Cloudflare Birthday Week Sept 26-Oct 1, 2021
Dane Knecht and Jennifer Taylor
This is the week in which we celebrate Cloudflare’s birthday. We launched the company 11 years ago: September 27, 2010. It has been our tradition, since our first birthday, to use this week to launch innovative products that we think of as our gift back to the Internet. In 2021, we announced Cloudflare R2, our object-based storage with no egress fees, tackled solutions to Email Spoofing and Phishing, shared how we are expanding our network into office buildings as well as many more product announcements and Cloudflare TV executive fireside chats and product discussions.
View all Birthday Week Blog Posts
View all Birthday Week Cloudflare TV Series

Full Stack Week Nov 14-19, 2021
Rita Kozlov
During Full Stack Week, we brought the vision of the Network is the Computer to life — allowing developers to build their entire application on our network, soup to nuts. Over the course of the week, we made a series of announcements, each providing another critical piece of the puzzle, necessary to build a full stack application.
We started with the foundation — data, announcing the general availability of Durable Objects, and ability to connect to databases, alongside partnerships with MongoDB and Prisma. Cloudflare Pages, our Jamstack platform also took a step deeper down the stack by introducing support for seamless deployment of functions. We want development on our platform to be an enjoyable experience, so we announced the new version of wrangler, our CLI, and Services, a better way for teams to build applications. And while we want developers to have fun, we also want them to be able to monetize their efforts, which they now can do using the Stripe SDK on Workers.
View all Full Stack Week 2021 Blog Posts
View all Full Stack Week Cloudflare TV Series

CIO Week Dec 5-10, 2021
Annika Garbers
To wrap up the year, we demonstrated how Cloudflare One, our Zero Trust Network-as-a-Service, is helping Chief Information Officers transform their corporate networks. We launched new capabilities in Cloudflare One to help customers replace their hardware firewalls and a chance to win a trip to Oahu in the process, a Log Storage platform built on Cloudflare R2, a new premium DNS offering, and Cloudflare Security Center, which helps customers map their attack surface and mitigate potential security risks with just a few clicks. We also announced our acquisition of Zaraz to boost website speed and security without sacrificing privacy, as well as new partnerships with Microsoft and leading cyber insurance providers, among many other exciting announcements throughout the week.
View all CIO Week 2021 Blog Posts
View all CIO Week 2021 Cloudflare TV Series
LGR Oddware: Twiddler Motion Controlled Keyboard Mouse from 1992
Post Syndicated from LGR original https://www.youtube.com/watch?v=HhJGrATZCl0
Security updates for Friday
Post Syndicated from original https://lwn.net/Articles/880672/rss
Security updates have been issued by Debian (sphinxsearch), Fedora (chromium and vim), Red Hat (rh-nodejs14-nodejs and rh-nodejs14-nodejs-nodemon), and Ubuntu (apache2 and webkit2gtk).
Miniflare 2.0: fully-local development and testing for Workers
Post Syndicated from Brendan Coll original https://blog.cloudflare.com/miniflare/


In July 2021, I launched Miniflare 1.0, a fun, full-featured, fully-local simulator for Workers, on the Cloudflare Workers Discord server. What began as a pull request to the cloudflare-worker-local project has now become an official Cloudflare project and a core part of the Workers ecosystem, being integrated into wrangler 2.0. Today, I’m thrilled to announce the release of the next major version: a more modular, lightweight, and accurate Miniflare 2.0. 🔥
Background: Why Miniflare was created

At the end of 2020, I started to build my first Workers app. Initially I used the then recently released wrangler dev, but found it was taking a few seconds before changes were reflected. While this was still impressive considering it was running on the Workers runtime, I was using Vite to develop the frontend, so I knew a significantly faster developer experience was possible.
I then found cloudflare-worker-local and cloudworker, which were local Workers simulators, but didn’t have support for newer features like Workers Sites. I wanted a magical simulator that would just work ✨ in existing projects, focusing on the developer experience, and — by the reception of Miniflare 1.0 — I wasn’t the only one.
Miniflare 1.0 brought near instant reloads, source map support (so you could see where errors were thrown), cleaner logs (no more { unknown object }s or massive JSON stack traces), a pretty error page that highlighted the cause of the error, step-through debugger support, and more.

The next iteration: What’s new in version 2
In the relatively short time since the launch of Miniflare 1.0 in July, Workers as a platform has improved dramatically. Durable Objects now have input and output gates for ensuring consistency without explicit transactions, Workers has compatibility dates allowing developers to opt-into backwards-incompatible fixes, and you can now write Workers using JavaScript modules.
Miniflare 2 supports all these features and has been completely redesigned with three primary design goals:
- Modular: Miniflare 2 splits Workers components (KV, Durable Objects, etc.) into separate packages (
@miniflare/kv,@miniflare/durable-objects, etc.) that you can import on their own for testing. This will also make it easier to add support for new, unreleased features like R2 Storage. - Lightweight: Miniflare 1 included 122 third-party packages with a total install size of
88.3MB. Miniflare 2 reduces this to 23 packages and6MBby leveraging features included with Node.js 16. - Accurate: Miniflare 2 replicates the quirks and thrown errors of the real Workers runtime, so you’ll know before you deploy if things are going to break. Of course,
wrangler devwill always be the most accurate preview, running on the real edge with real data, but Miniflare 2 is really close!
It also adds a new live-reload feature and first-class support for testing with Jest for an even more enjoyable developer experience.
Getting started with local development
As mentioned in the introduction, Miniflare 2.0 is now integrated into wrangler 2.0, so you just need to run npx wrangler@beta dev --local to start a fully-local Worker development server or npx wrangler@beta pages dev to start a Cloudflare Pages Functions server. Make sure you’ve got the latest release of Node.js installed.
However, if you’re using Wrangler 1 or want to customize your local environment, you can install Miniflare standalone. If you’ve got an existing worker with a wrangler.toml file, just run npx miniflare --live-reload to start a live-reloading development server. Miniflare will automatically load configuration like KV namespaces or Durable Object bindings from your wrangler.toml file and secrets from a .env file.
Miniflare is highly configurable. For example, if you want to persist KV data between restarts, include the --kv-persist flag. See the Miniflare docs or run npx miniflare --help for many more options, like running multiple workers or starting an HTTPS server.
If you’ve got a scheduled event handler, you can manually trigger it by visiting http://localhost:8787/cdn-cgi/mf/scheduled in your browser.
Testing for Workers with Jest
Jest is one of the most popular JavaScript testing frameworks, so it made sense to add first-class support for it. Miniflare 2.0 includes a custom test environment that gives your tests access to Workers runtime APIs.
For example, suppose we have the following worker, written using JavaScript modules, that stores the number of times each URL is visited in Workers KV:
Aside: Workers KV is not designed for counters as it’s eventually consistent. In a real worker, you should use Durable Objects. This is just a simple example.
// src/index.mjs
export async function increment(namespace, key) {
// Get the current count from KV
const currentValue = await namespace.get(key);
// Increment the count, defaulting it to 0
const newValue = parseInt(currentValue ?? "0") + 1;
// Store and return the new count
await namespace.put(key, newValue.toString());
return newValue;
}
export default {
async fetch(request, env, ctx) {
// Use the pathname for a key
const url = new URL(request.url);
const key = url.pathname;
// Increment the key
const value = await increment(env.COUNTER_NAMESPACE, key);
// Return the new incremented count
return new Response(`count for ${key} is now ${value}`);
},
};
# wrangler.toml
kv_namespaces = [
{ binding = "COUNTER_NAMESPACE", id = "..." }
]
[build.upload]
format = "modules"
dist = "src"
main = "./index.mjs"
…we can write unit tests like so:
// test/index.spec.mjs
import worker, { increment } from "../src/index.mjs";
// When using `format = "modules"`, bindings are included in the `env` parameter,
// which we don't have access to in tests. Miniflare therefore provides a custom
// global method to access these.
const { COUNTER_NAMESPACE } = getMiniflareBindings();
test("should increment the count", async () => {
// Seed the KV namespace
await COUNTER_NAMESPACE.put("a", "3");
// Perform the increment
const newValue = await increment(COUNTER_NAMESPACE, "a");
const storedValue = await COUNTER_NAMESPACE.get("a");
// Check the return value of increment
expect(newValue).toBe(4);
// Check increment had the side effect of updating KV
expect(storedValue).toBe("4");
});
test("should return new count", async () => {
// Note we're using Worker APIs in our test, without importing anything extra
const request = new Request("http://localhost/a");
const response = await worker.fetch(request, { COUNTER_NAMESPACE });
// Each test gets its own isolated storage environment, so the changes to "a"
// are *undone* automatically. This means at the start of this test, "a"
// wasn't in COUNTER_NAMESPACE, so it defaulted to 0, and the count is now 1.
expect(await response.text()).toBe("count for /a is now 1");
});
// jest.config.js
const { defaults } = require("jest-config");
module.exports = {
testEnvironment: "miniflare", // ✨
// Tell Jest to look for tests in .mjs files too
testMatch: [
"**/__tests__/**/*.?(m)[jt]s?(x)",
"**/?(*.)+(spec|test).?(m)[tj]s?(x)",
],
moduleFileExtensions: ["mjs", ...defaults.moduleFileExtensions],
};
…and run them with:
# Install dependencies
$ npm install -D jest jest-environment-miniflare
# Run tests with experimental ES modules support
$ NODE_OPTIONS=--experimental-vm-modules npx jest
For more details about the custom test environment and isolated storage, see the Miniflare docs or this example project that also uses TypeScript and Durable Objects.
Not using Jest? Miniflare lets you write your own integration tests with vanilla Node.js or any other test framework. For an example using AVA, see the Miniflare docs or this repository.
How Miniflare works
Let’s now dig deeper into how some interesting parts of Miniflare work.
Miniflare is powered by Node.js, a JavaScript runtime built on Chrome’s V8 JavaScript engine. V8 is the same engine that powers the Cloudflare Workers runtime, but Node and Workers implement different runtime APIs on top of it. To ensure Node’s APIs aren’t visible to users’ worker code and to inject Workers’ APIs, Miniflare uses the Node.js vm module. This lets you run arbitrary code in a custom V8 context.
A core part of Workers are the Request and Response classes. Miniflare gets these from undici, a project written by the Node team to bring fetch to Node. For service workers, we also need a way to addEventListeners and dispatch events using the EventTarget API, which was added in Node 15.
With that we can build a mini-miniflare:
import vm from "vm";
import { Request, Response } from "undici";
// An instance of this class will become the global scope of our Worker,
// extending EventTarget for addEventListener and dispatchEvent
class ServiceWorkerGlobalScope extends EventTarget {
constructor() {
super();
// Add Worker runtime APIs
this.Request = Request;
this.Response = Response;
// Make sure this is bound correctly when EventTarget methods are called
this.addEventListener = this.addEventListener.bind(this);
this.removeEventListener = this.removeEventListener.bind(this);
this.dispatchEvent = this.dispatchEvent.bind(this);
}
}
// An instance of this class will be passed as the event parameter to "fetch"
// event listeners
class FetchEvent extends Event {
constructor(type, init) {
super(type);
this.request = init.request;
}
respondWith(response) {
this.response = response;
}
}
// Create a V8 context to run user code in
const globalScope = new ServiceWorkerGlobalScope();
const context = vm.createContext(globalScope);
// Example user worker code, this could be loaded from the file system
const workerCode = `
addEventListener("fetch", (event) => {
event.respondWith(new Response("Hello mini-miniflare!"));
})
`;
const script = new vm.Script(workerCode);
// Run the user's code, registering the "fetch" event listener
script.runInContext(context);
// Create an example request, this could come from an incoming HTTP request
const request = new Request("http://localhost:8787/");
const event = new FetchEvent("fetch", { request });
// Dispatch the event and log the response
globalScope.dispatchEvent(event);
console.log(await event.response.text()); // Hello mini-miniflare!
Plugins
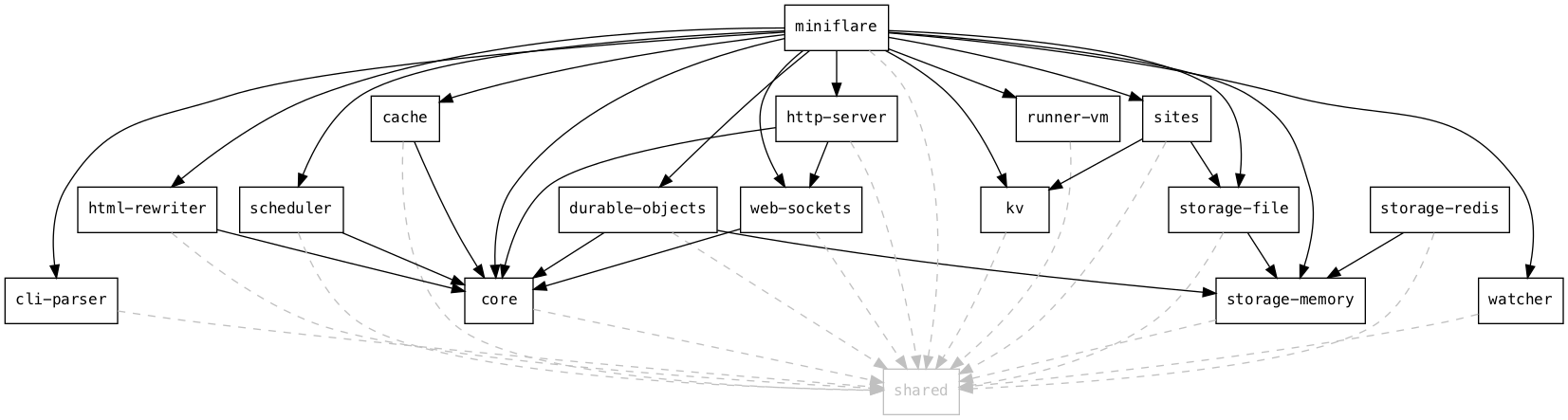
There are a lot of Workers runtime APIs, so adding and configuring them all manually as above would be tedious. Therefore, Miniflare 2 has a plugin system that allows each package to export globals and bindings to be included in the sandbox. Options have annotations describing their type, CLI flag, and where to find them in Wrangler configuration files:
@Option({
// Define type for runtime validation of the CLI flag
type: OptionType.ARRAY,
// Use --kv instead of auto-generated --kv-namespace for the CLI flag
name: "kv",
// Define -k as an alias
alias: "k",
// Displayed in --help
description: "KV namespace to bind",
// Where to find this option in wrangler.toml
fromWrangler: (config) => config.kv_namespaces?.map(({ binding }) => binding),
})
kvNamespaces?: string[];
Durable Objects
Before input and output gates were added, you usually needed to use the transaction() method to ensure consistency:
async function incrementCount() {
let value;
await this.storage.transaction(async (txn) => {
value = await txn.get("count");
await txn.put("count", value + 1);
});
return value;
}
Miniflare implements this using optimistic-concurrency control (OCC). However, input and output gates are now available, so to avoid race conditions when simulating newly-written Durable Object code, Miniflare 2 needed to implement them.
From the description in the gates announcement blog post:
Input gates: While a storage operation is executing, no events shall be delivered to the object except for storage completion events. Any other events will be deferred until such a time as the object is no longer executing JavaScript code and is no longer waiting for any storage operations. We say that these events are waiting for the "input gate" to open.
…we can see input gates need to have two methods, one for closing the gate while a storage operation is running and one for waiting until the input gate is open:
class InputGate {
async runWithClosed<T>(closure: () => Promise<T>): Promise<T> {
// 1. Close the input gate
// 2. Run the closure and store the result
// 3. Open the input gate
// 4. Return the result
}
async waitForOpen(): Promise<void> {
// 1. Check if the input gate is open
// 2. If it is, return
// 3. Otherwise, wait until it is
}
}
Each Durable Object has its own InputGate. In the storage implementation, we call runWithClosed to defer other events until the storage operation completes:
class DurableObjectStorage {
async get<Value>(key: string): Promise<Value | undefined> {
return this.inputGate.runWithClosed(() => {
// Get key from storage
});
}
}
…and whenever we’re ready to deliver another event, we call waitForOpen:
import { fetch as baseFetch } from "undici";
async function fetch(input, init) {
const response = await baseFetch(input, init);
await inputGate.waitForOpen();
return response;
}
You may have noticed a problem here. Where does inputGate come from in fetch? We only have one global scope for the entire Worker and all its Durable Objects, so we can’t have a fetch per Durable Object InputGate. We also can’t ask the user to pass it around as another parameter to all functions that need it. We need some way of storing it in a context that’s passed around automatically between potentially async functions. For this, we can use another lesser-known Node module, async_hooks, which includes the AsyncLocalStorage class:
import { AsyncLocalStorage } from "async_hooks";
const inputGateStorage = new AsyncLocalStorage<InputGate>();
const inputGate = new InputGate();
await inputGateStorage.run(inputGate, async () => {
// This closure will run in an async context with inputGate
await fetch("https://example.com");
});
async function fetch(input: RequestInfo, init: RequestInit): Promise<Response> {
const response = await baseFetch(input, init);
// Get the input gate in the current async context
const inputGate = inputGateStorage.getStore();
await inputGate.waitForOpen();
return response;
}
Durable Objects also include a blockConcurrencyWhile(closure) method that defers events until the closure completes. This is exactly the runWithClosed() method:
class DurableObjectState {
// ...
blockConcurrencyWhile<T>(closure: () => Promise<T>): Promise<T> {
return this.inputGate.runWithClosed(closure);
}
}
However, there’s a problem with what we’ve got at the moment. Consider the following code:
export class CounterObject {
constructor(state: DurableObjectState) {
state.blockConcurrencyWhile(async () => {
const res = await fetch("https://example.com");
this.data = await res.text();
});
}
}
blockConcurrencyWhile closes the input gate, but fetch won’t return until the input gate is open, so we’re deadlocked! To fix this, we need to make InputGates nested:
class InputGate {
constructor(private parent?: InputGate) {}
async runWithClosed<T>(closure: () => Promise<T>): Promise<T> {
// 1. Close the input gate, *and any parents*
// 2. *Create a new child input gate with this as its parent*
const childInputGate = new InputGate(this);
// 3. Run the closure, *under the child input gate's context*
// 4. Open the input gate, *and any parents*
// 5. Return the result
}
}
Now the input gate outside of blockConcurrencyWhile will be closed, so fetches to the Durable Object will be deferred, but the input gate inside the closure will be open, so the fetch can return.
This glosses over some details, but you can check out the gates implementation for additional context and comments. 🙂
HTMLRewriter
HTMLRewriter is another novel class that allows parsing and transforming HTML streams. In the edge Workers runtime, it’s powered by C-bindings to the lol-html Rust library. Luckily, Ivan Nikulin built WebAssembly bindings for this, so we’re able to use the same library in Node.js.
However, these were missing support for async handlers that allow you to access external resources when rewriting:
class UserElementHandler {
async element(node) {
const response = await fetch("/user");
// ...
}
}
The WebAssembly bindings Rust code includes something like:
macro_rules! make_handler {
($handler:ident, $JsArgType:ident, $this:ident) => {
move |arg: &mut _| {
// `js_arg` here is the `node` parameter from above
let js_arg = JsValue::from(arg);
// $handler here is the `element` method from above
match $handler.call1(&$this, &js_arg) {
Ok(res) => {
// Check if this is an async handler
if let Some(promise) = res.dyn_ref::<JsPromise>() {
await_promise(promise);
}
Ok(())
}
Err(e) => ...,
}
}
};
}
The key thing to note here is that the Rust move |...| { ... } closure is synchronous, but handlers can be asynchronous. This is like trying to await a Promise in a non-async function.
To solve this, we use the Asyncify feature of Binaryen, a set of tools for working with WebAssembly modules. Whenever we call await_promise, Asyncify unwinds the current WebAssembly stack into some temporary storage. Then in JavaScript, we await the Promise. Finally, we rewind the stack from the temporary storage to the previous state and continue rewriting where we left off.
You can find the full implementation in the html-rewriter-wasm package.

The future of Miniflare
As mentioned earlier, Miniflare is now included in wrangler 2.0. Try it out and let us know what you think!
I’d like to thank everyone on the Workers team at Cloudflare for building such an amazing platform and supportive community. Special thanks to anyone who’s contributed to Miniflare, opened issues, given suggestions, or asked questions in the Discord server.
Maybe now I can finish off my original workers project… 😅
The Great New York Fire of 1835
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=axdP74iULps
Norton’s Antivirus Product Now Includes an Ethereum Miner
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/01/nortons-antivirus-product-now-includes-an-ethereum-miner.html
Norton 360 can now mine Ethereum. It’s opt-in, and the company keeps 15%.
It’s hard to uninstall this option.
Integrating Zabbix with your existing IT solutions by Aleksandrs Larionovs / Zabbix Summit Online 2021
Post Syndicated from Alexandrs Larionovs original https://blog.zabbix.com/integrating-zabbix-with-your-existing-it-solutions-by-aleksandrs-larionovs-zabbix-summit-online-2021/18671/
Zabbix 6.0 LTS comes packed with many new integrations and templates. As the total number of templates and integrations grows, we plan to make major improvements to our template repository. This will greatly improve the workflow of developing a new community template, submitting template pull requests, following the development process of a template, and much more.
The full recording of the speech is available on the official Zabbix Youtube channel.
What are integrations?
By definition, integrations are connections between systems and applications that work together as a whole to share information and data. In Zabbix, we separate integrations into two types:
- Out-of-the-box templates
- Templates contain items, triggers, graphs, and other entities that allow you to monitor any device, service, application, and other monitoring endpoints.
- Webhook integrations
- Webhooks allow you to send the information from Zabbix to any sort of 3rd party system like ITSM or messaging applications.
Where to find the latest integrations?
If you’re installing a fresh Zabbix instance, it will come pre-packaged with the latest set of official templates and webhooks. If you wish to download and import the integrations manually, you can find them in:
- The Zabbix integrations page – https://zabbix.com/integrations
- The templates folder of the Zabbix git page – https://git.zabbix.com
How do you benefit from integrations?
What are the benefits of using the official Zabbix integrations for you as a Zabbix user?
- Monitor your endpoints in a tested and optimized manner
- Monitor a large variety of 3rd party systems
- Official templates come with a guarantee of quality and official support
- Official templates provide quick deployment of monitoring logic for your monitoring endpoints
Having supported integrations can also be important from the standpoint of a vendor. Having an official Zabbix integration can provide multiple benefits for vendors:
- Supported vendors get the ability to engage the Zabbix community
- Collaborate with Zabbix and receive additional recognition
- Provide higher quality monitoring support by collaborating in the development of the integration
- Set higher monitoring standards for your product
- Improve your public image
What if I wish to request a new official integration?
There are multiple ways how you can approach a scenario when there is no official integration for a specific product:
- Option 1:
- Create a ZBXNEXT ticket with your request at support.zabbix.com
- Ask your friends and colleagues to vote on a request
- If there is community interest in the integration – we will develop it!
- Option 2:
- Contact [email protected] with your request, and Zabbix can develop a unique template just for you as a part of our integration services
- Option 3:
- Look for an unofficial community template
How are the official Zabbix integrations made?
Our first step in developing a new template is prioritizing which template should we tackle first. This includes looking at the current IT landscape and deciding which of the components are vastly considered as Essential services. Then, we look at the community requests and the number of votes behind each request. We also continuously work on improving the existing templates and evaluating the priority of the requested improvements. There is also the option to sponsor an integration by contacting our Sales department.
After we prioritize our list, we proceed to development – we do research, talk to community experts, create focus groups and proceed with the development. Once the development is finished, we proceed with validation – this includes internal reviews from the Integrations team as well as giving our colleagues from the Support team the chance to take a look at the newly developed template. Community feedback is also important for us – the feedback regarding the template can be left either in the comments under the specific feature request or in our Suggestions and Feedback forum section.
Community templates
While we pride ourselves on the rapid growth of our integrations team and the pace at which we have been delivering new official templates and integrations, we, of course, can’t instantly develop a template for every vendor and device out there. This is where our community has been of great help to us.
Moving from share.zabbix.com
Previously, if you were to find Zabbix lacking a template or an integration that you require, you would visit share.zabbix.com and look for a community solution to your problem. At this point, we have decided to migrate away from share.zabbix.com since, over the years, we have found it lacking in multiple aspects:
- The website was hard to navigate
- The underlying platform was outdated
- Once uploaded, the templates were rarely maintained
- It was hard to collaborate on templates
- Lacking standardization – each template could use different naming conventions or metric collection approaches
- Zombie templates – templates developed for old versions but never updated along the way.
Community template repository
The new go-to place for community templates will be our Community template repository. The repository will serve as a platform for collaboration. Once uploaded, the templates can be maintained by either the original developer or other community members. The platform will be moderated by the Integrations team, who will also provide feedback on the community templates to ensure a higher quality of the templates and additional validation. The documentation will also be generated for the community templates, containing the contents of each template – this way, you can have a transparent look at the template before downloading it.
The process
Let’s go through the whole process of developing and maintaining a community template.
1. Collaborate
- For existing templates – you can start a discussion on Github issues to discuss issues or potential improvements on the template.
- You can create a new bug report related to the template
- For older community templates – you will be able to take over the maintenance of this template and continue improving it down the line
- Develop and publish a new template or an integration
When it comes to community development, Zabbix does provide an official set of guidelines that the developers can follow to ensure that the template uses the official best practice conventions and approaches:
- Naming conventions for templates and template entities
- A set of best practices helps the community developers to simplify the decision making regarding best template and integration development approaches
- Practical and ethical framework for template and integration development
- This enables the community developers to follow the same set of development guidelines as the official Zabbix Integrations team
2. Pull request
Once you have decided to make a new integration or modify an existing integration, create a pull request describing the proposed changes and be ready to participate in a discussion related to the proposed set of changes. We will review and moderate the discussion and assist you in ensuring a smooth template development process.
3. Validation
The validation process consists of two parts. First, we will review if the template is valid, can be imported in Zabbix, and is usable by our community members. Next, the Integrations team will check if the template is developed according to the Zabbix standard and suggest any necessary changes.
4. Merge
If the validation process has been passed, we will accept the pull request and merge the integration into the repository. Afterward, the readme file for the integration will be generated. Finally, the template will be added to the template directory, and it will be available for everyone to see and download.
The Templates directory will have a similar structure to what you are used to in share.zabbix.com, so you should feel right at home here. We tried to check and migrate each and every valid template, but if you don’t find your template in the list – simply submit a pull request to us, and we will review it.

The generated Readme file will contain a list of entities included in the template – such as User macros, Template linkages, Discovery rules, Items, and more.

Where can I find the repository?
The Zabbix community template repository can be found in https://github.com/zabbix/community-templates. All you need to participate is a Github account and the willingness to participate in the integration development process.
To report an issue with the template repository or the official integrations, feel free to use our support portal: https://support.zabbix.com/
- To report a bug – open a ZBX ticket
- To suggest an improvement – open a ZBXNEXT ticket
For any discussions related to the Zabbix integrations, you can use (but are not limited to) the following channels:
- The official Zabbix forum – https://www.zabbix.com/forum
- The official Zabbix Telegram channel – https://t.me/ZabbixTech
Questions
Q: What is the workflow for our users that wish for Zabbix to develop new integration for a specific product?
A: We’re actively listening to our community. The best way to voice your request is to look for an existing feature request on https://support.zabbix.com/ and vote on it. If there is no such feature request – feel free to create it and vote on it. Thirdly, you can always contact our sales department and use our integration services to have the required template developed for you.
Q: Where can I see which integrations are currently developed or scheduled for the next release?
A: You can track the development process of a template by following the particular feature request in our support portal. You can also take a look at the official Zabbix roadmap and see what features, fixes, and integrations are currently scheduled for the upcoming Zabbix versions.
The post Integrating Zabbix with your existing IT solutions by Aleksandrs Larionovs / Zabbix Summit Online 2021 appeared first on Zabbix Blog.
Нели Закс – вестителката на утехата. Разговор с Любомир Илиев
Post Syndicated from Зорница Христова original https://toest.bg/lyubomir-iliev-interview-nelly-sachs/
В края на миналата година Издателство за поезия „ДА“ публикува сборника „Смъртта още празнува живота“ с избрани стихове на германската поетеса Нели Закс. По този повод с нейния преводач на български Любомир Илиев разговаря Зорница Христова.
В интервюто си за „Култура“ казваш, че Целан не e „от твоята вакса“ и затова не би го превеждал. Какво в Нели Закс усети „свое“?
Въпросното интервю (което всъщност ме запозна с Марин Бодаков) е от 2006 г. и е логично оттогава нещо в представите ми за Паул Целан и Нели Закс да се е променило. Основното обаче остава: двамата са духовни сродници, изпитват на собствения си гръб ужасите на Холокоста и са най-ярките изобличители на „дванайсетте кафяви години“ в поезията. Но и съществено се различават.
Докато у Целан надделява отчаянието, с течение на времето прераснало в параноя (казвал ми го е синът му Ерик, на когото няма как да не вярвам, включително защото е изумително точно копие на баща си!), поезията на Нели Закс, без в никакъв случай да е оптимистична или жизнеутвърждаваща, гледа напред. Колкото и да прелива от страдания и жертви, тази поезия в никакъв случай не е неврастенична – тя не позволява на отчаянието да се превърне в отрицание. За Закс нещата никога не се свеждат до користно самодоволство, у нея липсва и каквото и да било желание за възмездие, макар че обстоятелствата биха я оправдали. Напротив, тя настойчиво призовава „преследваните да не станат преследвачи“. Занимава я друго, далеч по-съществено: как да постъпим с човека, забравил човешкото у себе си, какво да правим с ръцете, създадени за щедрост, а използвани като инструмент за убийство.
Самият аз се прекланям пред Паул Целан, но не крия, че Нели Закс ми е по-близка. А и за разлика от Целан, за когото у нас се знае далеч повече благодарение на многото опити за превод (някои доста добри, други – не съвсем, трети – направо катастрофални), името на Нели Закс – тя също е превеждана, но по-рядко, и поезията ѝ така и не успява да остави съществена следа на българска почва – е известно предимно на статистиците, водещи на отчет лауреатите на Нобелова награда за литература (тя я получава през 1966 г.). Това също натежа в решението ми да я преведа на български.
Смяташ ли, че това я прави по-общочовешка, по-преводима за непреживелите травма?
Несъмнено. И я прави далеч по-малко енигматична, отколкото изглежда на пръв поглед. Да вземем само мотива на всемирното бягство в поезията ѝ: трагическият герой на Нели Закс е едновременно и жертва, и пророк, но пророкът у нея не е някаква изключителна личност. Всеки бежанец е пророк, а всеки човек и на Земята, и във Вселената, е бежанец. Така в поезията на Нели Закс се трансформира библейското изгонване от Рая. Раят е родината, а родината е рай. И това не се поддава на промяна, където и да се намира човек – неслучайно думата „копнеж“ е сред най-често срещаните в стихотворенията ѝ. Това прави нейната поезия особено актуална в наши дни. Бягството е безкрайно и заразително, понеже никой не иска да се вслуша в бежанците – човешкото ухо, уви, е „обрасло с коприва“.
Прочее, най-синтезирано го е казал Ингвар Андершон в словото си при връчването ѝ на Нобеловата литературна награда: „Нели Закс е вестителка на утехата, насочена към всички онези, които изпитват отчаяние от превратностите на човешката съдба.“
И все пак ми е интересно и обратното на общочовешкото, това, което е собствено еврейско и насочено главно към „своите“. Които току-що са преживели колективна травма. Опитвам се да си представя такава поезия след Батак, да речем, предупреждаваща своите да не станат преследвачи. Дали си полюбопитствал как я четат в Израел?
В Израел я ценят много високо. Нещо повече (знам го от първа ръка): когато в началото на 1967 г. Гюнтер Грас иска да посети Израел, негодуванието там е голямо – пропастта между двете страни е още твърде дълбока. Затова и му отказват официално. Намесва се Нели Закс, която пише писмо до Кнесета именно в смисъла на помирението; в крайна сметка Грас заминава за Израел със съгласието на Кнесета.
А това „преследваните да не станат преследвачи“ как се чете?
В същия смисъл: да не забравяме миналото, но да гледаме напред и заедно да изграждаме бъдещето, вместо да прилагаме първобитното правило „око за око, зъб за зъб“.
Да, имах предвид дали има хора, които го съпоставят с военната политика на Израел.
Не съм срещал подобни съпоставки. Но когато през 2012 г. Грас написа стихотворението си „Това, което трябва да се каже“, в което описва Израел като заплаха за световния мир, се надигна старата вълна от негодувание. Не помогнаха уверенията на Грас, че има предвид само правителството на Нетаняху, че не иска нищо друго, освен Израел да живее в мир със съседите си – писателят беше обявен за „персона нон грата“. Е, след година почина, така че забраната да влиза в Израел не бе осъществена на практика.
А всъщност Гюнтер Грас и Нели Закс приятели ли бяха? Много се впечатлих от твоя разказ как той те е запознал с нейната поезия – „и това, което не разбирам, е голямо“.
Онова, което ми е казвал Грас, е напълно достоверно и всъщност една от причините дълго да не смея да я пипна (докато не се намериха Марин и Силвия [Чолева от Издателство за поезия „Да“ – б.р.]…). Но на въпроса ти: Нели Закс не е имала никакви приятели, поне не в обичайния смисъл на думата. За приятелка, доста по-възрастна от нея, смята само Селма Лагерльоф, която така и не вижда след над три десетилетия кореспонденция (Лагерльоф умира месеци преди пристигането на Закс в Швеция). Вглъбена до саможивост, тя изобщо няма отношение към съвременната ѝ литература. За събрат по дух и съдба смята – с основание – Паул Целан, дори го посещава в Париж, но в характерите на двамата явно има непреодолими различия: той гледа назад, тя – напред. Колкото до Грас, поне на две места пътищата им се преплитат. За второто ти казах – застъпничеството на Закс пред Кнесета, довело до разрешението Грас да посети Израел. Първото също е любопитно: като виден член на легендарната „Група 47“, Грас несъмнено има принос през 1967 г. тази група да направи своето „изнесено“ заседание не някъде в Германия, а в Стокхолм в чест на Нели Закс. Не знам подробности, не знам дори дали е присъствала. Малко по-късно групата се разпада.
Всъщност общуването и с Целан, и със Селма Лагерльоф е кореспондентско. А какво според теб я свързва с Лагерльоф, виждаш ли връзка между поезията ѝ и „Сага за Йоста Берлинг“ например? Наскоро у нас излезе „Коларят на смъртта“ – но цялата концепция ми се струва тотално различна. Греша ли?
Не съм чел „Коларят на смъртта“, но си представи уединено живеещото берлинско момиче и наплашената млада жена, която – прехласната именно по „Йоста Берлинг“ – има нужда да сподели с някого мислите си. Признавам, че и при най-дълбоко взиране не откривам литературни влияния от Лагерльоф върху творчеството на Закс (впрочем колкото до първите ѝ стихотворения, посветени на природата, цветенцата, тревичките и т.н., на зряла възраст тя дълго не ще да признае авторството им). Закс вижда в Лагерльоф почти единствената възможност за човешко общуване.
Връщам се към Грас: и от малкото казано от мен за него личи недвусмислено, че високо я ценеше и безкрайно я уважаваше.
С какво помогна четенето на Мартин Бубер за превода ти?
Би било несериозно да претендирам за дълбоки познания за Мартин Бубер, то не би отговаряло и на истината. Но след прочита на стихотворенията на Закс и тяхното тълкуване от именити специалисти ми стана ясно, че без навлизане в хасидизма много неща ще си останат непонятни за мен. Не че разбрах всичко от разсъжденията му, но те наистина ми помогнаха да разшифровам пасажи и цели стихотворения на Закс, които до този момент ми бяха истинска загадка и отчаяно си блъсках главата да ги разтълкувам. А незаобиколим фактор в хасидизма е именно Мартин Бубер, който силно влияе върху израстването на Закс като поетеса. Защото Бубер е известен преди всичко със своята философия на диалога, определяна още като форма на религиозен екзистенциализъм. Тъкмо идеята за диалог е ключова в поезията на Нели Закс.
А според теб възможно ли е такова нещо като колективен диалог – защото у Закс пеят хорове.
Закс следва доста отблизо учението на Бубер, а поне според него явно е възможно: неговата философия на диалога разграничава между отношенията Аз–Ти и Аз–То. Първото е отношението между две личности, второто – между личността и всичко, което е извън нея: света, вещите и др. Това, разбира се, не създава буквална представа за „колективен диалог“, но в творчеството на Закс именно въображаемите хорове я съдържат в себе си.
Има ли нещо в българската литературна традиция, с което може да се свърже този тип диалог? В чий български език чувстваше опора?
Ето тук вече окончателно ще се изложа: поради сравнително слабото познаване на българската литература трябва доста да се поровя, за да ти отговоря. Доколкото хасидизмът е част от мистицизма, ми се ще да спомена Дънов може би – но това по отношение на Бубер, за когото всичко опира до личната връзка с Бог. А иначе, по отношение на Нели Закс, и двамата със Силвия провидяхме – независимо един от друг! – мотиви, срещани у Илко Димитров например.
Финален въпрос – имам два екземпляра от „Смъртта още празнува живота“, искам да подаря единия на приятел тук, в България. На какъв човек ще ми препоръчаш да я дам?
На човек, който е съгласен голямата поезия да го стисне трайно за гърлото.
Заглавна снимка: © Ирен Крумова
Latency
Post Syndicated from original https://xkcd.com/2565/

Disabling Security Hub controls in a multi account environment
Post Syndicated from Priyank Ghedia original https://aws.amazon.com/blogs/security/disabling-security-hub-controls-in-a-multi-account-environment/
In this blog post, you’ll learn about an automated process for disabling or enabling selected AWS Security Hub controls across multiple accounts and multiple regions. You may already know how to disable Security Hub controls through the Security Hub console, or using the Security Hub update-standards-control API. However, these methods work on a per account and per region basis. If you want to tune your posture by disabling some controls across multiple accounts, this automated approach makes it easier.
The update Security Hub controls script provided in this post uses cross account access to disable or enable several controls across multiple accounts and multiple Regions on an ad hoc basis, without having to maintain resources in each Region. These accounts can be individual accounts where Security Hub is managed independently per account, part of a Security Hub administrator setup, or a combination of these. You will need to execute this script in newly added AWS accounts again to keep the controls status consistent for new accounts.
This blog also describes an alternative solution which automates updating Security Hub controls on a schedule for any new AWS accounts that are added, and keeps the control status in member accounts consistent with the controls status in the Security Hub administrator account. The alternate solution will only work if you use Security Hub administrator setup, and must be deployed on a per Region basis.
Why disable controls?
Security Hub generates findings from continuous checks against a set of rules from supported security standards. These checks provide a readiness score and identify specific accounts and resources that require attention.
It can be useful to turn off security checks for controls that are not relevant to your environment. Disabling irrelevant controls makes it easier to identify the important findings that you can take action on.
Reasons to disable controls
There are several reasons you may choose to disable controls:
- Controls for unused services
- Controls using global resources
- Controls with compensating controls
Unused services
If you are not using the specific AWS service for which a control is enabled, you may want to disable controls that have periodic checks associated with that service.
Note: Periodic checks run automatically every 12 hours, whereas change-triggered checks run when the associated resource changes state. Change-triggered checks do not run if the associated in scope resource does not exist, so you do not have to disable controls that explicitly use change-triggered checks.
For example, SageMaker.1 is a control that has a periodic check and is part of the AWS Foundational Security Best Practices standard. If you do not use Amazon SageMaker in your environment, you can disable this check temporarily. If you disable an unused check and later start using the service in the future, you must enable the check again. You should perform regular analysis of services in use across your AWS Accounts.
Global resources
Global resources, such as AWS Identity and Access Management (IAM), generate findings in each region where you have Security Hub enabled. To focus only on meaningful findings, you can disable controls for global resources in all but one Region. You will have to align the desired region to be the same Region in AWS Config where global recording is enabled. A list of all such controls for each standard are as follows:
- Controls for AWS Foundations Security Best Practices
- Controls for Center for Internet Security AWS Foundations
- Controls for Payment Card Industry Data Security Standard
Compensating controls
You may want to disable a Security Hub control for which a compensating control is in place. For example, the AWS Foundational Security Best Practices control CloudTrail.5 checks to see if AWS CloudTrail is configured to send logs to Amazon CloudWatch logs. You can disable this check if you are sending CloudTrail to another destination, such as Amazon Simple Storage Service (Amazon S3) or partner tools such as a SIEM solution. Another example is CIS 3.x controls. GuardDuty can be considered a compensating control instead of CloudWatch alarms for CIS 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 3.10, 3.11, 3.12, 3.13, and 3.14
Solution overview:
The update Security Hub controls script shown below is written in Python. It uses AWS SDK for Python (Boto3) to assume a cross account IAM role in the accounts passed in the script, and uses the update-standards-control Security Hub API to enable or disable controls. You must deploy this solution in a single AWS Region.
We will review the prerequisites in the next section to understand the requirements for successfully using this solution. We will then walk through the instructions for deploying this automation through an Amazon Elastic Compute Cloud (Amazon EC2) instance along with examples of how to use the script.
Note: You can also use your local machine (customer device) or AWS Cloudshell if you meet the prerequisites described below.
Prerequisites:
The update Security Hub controls script shown below requires:
- An IAM role for cross-account access. You should have an IAM principal able to assume an IAM role in accounts where Security Hub controls needs to be disabled or enabled. This role should have securityhub:UpdateStandardsControl permission.
Note: If you used the Security Hub multiaccount scripts from awslabs to enable Security Hub for multiple accounts you can use the role provided in the repository for the purpose of this blog as it has the necessary permissions.
- AWS CLI
- Python
- Boto3
Update security hub controls script
Let’s review the arguments the script uses to run successfully. There are both required arguments and optional arguments:
Required arguments
–input-file
Path to a CSV file containing a list of the 12 digit AWS account IDs whose controls you want to disable or enable. If you are using Security Hub administrator account, use the list-members API to generate a list of all accounts where security hub is enabled. Store this list in a CSV file, one account ID per line.
–assume-role
Role name of the execution role in each account. This role should have the securityhub:UpdateStandardsControl permission. If you will be using the sample execution role CloudFormation provided in Part B—Execution role, the name of this role is ManageSecurityHubControlsExecutionRole.
–regions
Comma separated list of Regions to update SecurityHub controls. Do not add any spaces after each comma. Specify ALL to consider all Regions where Security Hub is available. If you list a Region where you have not enabled Security Hub, the script will skip this Region and log the failure.
–standard
Enter the standard code (AFSBP, CIS, PCIDSS).
AFSBP for AWS Foundational Security Best Practices
CIS for CIS AWS Foundations
PCIDSS for Payment Card Industry Data Security Standard (PCI DSS)
The script works with one Security Hub Standard at a time. For example, you can only disable AFSBP controls in the first run of the script. If you want to disable multiple controls across AFSBP and CIS standards you must run the script twice, once for AFSBP and once for CIS controls.
–control-id-list
Comma separated list of controls, example for CIS, enter – (1.1,1.2) or for PCIDSS enter – (PCI.AutoScaling.1,PCI.CloudTrail.4)
Do not add any spaces after each comma. Control IDs can be found from the Security Hub console: Security Standards > View results > ID column in the enabled controls table. You can also find the control IDs in the Security Hub controls documentation for each standard.
Figure 1: Sample Control IDs of PCI security standards shown in console
–control-action
For enabling controls use ENABLED; for disabling controls use DISABLED.
–disabled-reason
Reason for disabling the controls. This text will appear in the Security Hub console for the disabled controls, it is used to understand why the control is disabled for reviews in the future. If your script uses different reasons for disabling controls, you need to run the script multiple times, once for each disable reason. This argument is NOT required (or used) for enabling controls.
Optional arguments
-h, –help
shows the help message and exit
–profile
If this argument is not given, the default profile will be used. Use this argument to parse the named profile. The credentials in this profile should have permissions to assume the execution role in each account.
Solution deployment
We are using an Amazon EC2 instance with Amazon Linux 2 (AL2) to run this automation. We will create the instance role for the EC2 in Part A, create the execution role in Part B, and launch the EC2 instance to run the Update Security Hub controls script in Part C.
Note: For the purpose of this blog, we will be creating the EC2 instance and the instance role in the Security Hub administrator account, however this is not a requirement. If you have existing cross account roles with the necessary permissions, you can use these existing roles as well.
Part A–Security Hub controls manager EC2 role
This role should have permission to assume (sts:AssumeRole) the execution role described in Part B.
Figure 2: Amazon EC2 Instance role assumes cross account IAM role
A sample policy for this role is provided below. This policy limits the Security Hub controls manager EC2 role to assume only a specific execution role in the downstream accounts:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::*:role/ManageSecurityHubControlsExecutionRole"
}
]
}To create the SHControlsManagerEC2 role
- Navigate to the IAM console of the Security Hub administrator account. You must have permission to launch an EC2 instance in this account.
- Create a new policy using JSON policy editor, and name it SHAssumeRolePolicy.
- Copy the sample policy shown above and paste it into your new policy in the JSON editor. The resource in the policy is the execution role, as will be described in Part B—Execution role below.
Note: If you are using an existing role as the execution role, rather than creating a new role as shown in Steps 1-4, then you will need to change the resource section of the sample code in Figure 2 to use the ARN of the existing execution role.
- In the IAM console, Create an IAM role for EC2 and name it SHControlsManagerEC2. Assign the following policies:
- The SHAssumeRolePolicy policy you created in step 2.
- The AmazonSSMManagedInstanceCore managed policy for managing the instance using AWS Systems Manager.
- The AWSSecurityHubReadOnlyAccess managed policy for allowing read only access to Security Hub.

Figure 3: IAM policies attached to Amazon EC2 Instance role
- When you are finished creating the role, note the Amazon Resource Name (ARN) – you will be using it in Part B. The ARN will look like Figure 4: arn:aws:iam::111111222222:role/SHControlsManagerEC2

Figure 4: ARN of the Amazon EC2 instance role


Part B–Execution role
The execution role must be created in all accounts where you will be disabling or enabling controls. This role should have securityhub:UpdateStandardsControl permission. The execution role trust relationship should allow the Security Hub controls manager role to assume the execution role.
Important: The name of the execution role must be identical in each account (including the Security Hub administrator account), otherwise the script will NOT work.
If you are using AWS Organizations, you can use CloudFormation StackSets to deploy this execution role easily across all of your accounts. The stack set runs across the organization at the root or organizational units (OUs) level of your choice. The CloudFormation will use the ARN you noted from Security Hub controls manager EC2 role as a parameter.
Sample execution role policy
A sample policy for the execution role is provided below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "securityhub:UpdateStandardsControl",
"Resource": "arn:aws:securityhub:*:*:hub/default"
}
]
}
Sample execution role trust policy
Note: the ARN in the principal section below should be the ARN you noted in step 5 of Part A: Security Hub controls manager EC2 role.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::111111222222:role/SHControlsManagerEC2"
},
"Action": "sts:AssumeRole"
}
]
}
To launch the stack set for creating cross account IAM Roles
- Login to the console of the Organizations management account or CloudFormation delegated administrator account.
- Select StackSet and choose Create StackSet
- Choose template is ready, and select template source as Amazon S3 URL
- Enter the following URL, then click next: https://awsiammedia.s3.amazonaws.com/public/sample/1083-disabling-security-hub-controls-multi-account/aws-securityhub-updatecontrols-executionrole.yml

Figure 5: Create a AWS CloudFormation StackSet
- Enter a stack name, update description as needed and then under parameters enter the ARN of the Security Hub controls manager EC2 role used in step 5 of Part A–Security Hub controls manager EC2 role, then choose Next.

Figure 6: AWS CloudFormation StackSet parameters for creating cross account IAM role
- (Optional) On the Configure StackSet options page, go to Tags and add tags to identify and organize your stack set.

Figure 7: Optionally define tags for the stacks created using AWS CloudFormation StackSet
- On the Set deployment options page, select the desired Region. Since the resource being created is IAM, you will only need to specify one Region. Choose Next.

Figure 8: Specify target regions where the CloudFormation stacks need to be created
- Review the definition and select I acknowledge that AWS CloudFormation might create IAM resources. Choose Submit.
- You can monitor the creation of the stack set from the Operations tab to ensure that deployment is successful.




Note: StackSets does not deploy stack instances to the organization’s management account, even if the management account is in your organization or in an OU in your organization. You will need to create the execution role manually in the organization management account.
Part C–Launch EC2
We will be using a t2.micro EC2 instance with Amazon Linux 2 (AL2) image which comes preinstalled with AWS CLI and Python. This instance size and image are free tier eligible.
To launch the EC2 instance for executing securityhub-updatecontrols-script
- Launch EC2 instance in the Security Hub administrator account in a single Region. You can use any Region.
- Attach the IAM role to the instance as created in part A.
- Confirm instance is in a running state.
- Login to the instance CLI using AWS Systems Manager Session Manager. Go to the EC2 console, select the instance and choose Connect.

Figure 9: Access newly launched Amazon EC2 instance using session manager
Note: You will need to allow outbound internet access to systems manager endpoints for session manager to work. See session manager documentation for more information.
- On the next page, choose Connect again.

Figure 10: Connect to Amazon EC2 instance
- A new window with session manager will open.
- Set the working directory to home directory.
cd /home/ssm-user - Install Git:
sudo yum install git - Clone the UpdateSecurityHubControls code repository.
git clone https://github.com/aws-samples/SecurityHub-Multiaccount-UpdateControls.git - Start a virtual environment.
python3 -m venv SecurityHub-Multiaccount-UpdateControls/env source SecurityHub-Multiaccount-UpdateControls/env/bin/activate - Upgrade pip and Install boto3
pip install pip --upgrade pip install boto3


You are now ready to run the script.
Example 1–Disabling Controls
Let’s assume you have Config global recording enabled in us-east-1 and want to disable controls associated with global resources (IAM.1, IAM.2, IAM.3, IAM.4, IAM.5, IAM.6, IAM.7) for AWS Foundational Security Best Practices standard in Regions us-west-1, us-east-2 in all accounts. The name of our execution role in all accounts is ManageSecurityHubControlsExecutionRole
- Change to the correct directory
$ cd SecurityHub-Multiaccount-UpdateControls - Create a file with the list of account IDs. This is passed with the input-file argument.
$ nano accounts.csv - Enter account IDs one account per line, then save the file.

Figure 11: CSV file with AWS account IDs
- Run the script:
python SH-UpdateControls.py \ --input-file accounts.csv \ --assume-role ManageSecurityHubControlsExecutionRole \ --regions us-east-2,us-west-1 \ --standard AFSBP \ --control-id-list IAM.1,IAM.2,IAM.3,IAM.4,IAM.5,IAM.6,IAM.7 \ --control-action DISABLED \ --disabled-reason 'Disabling IAM checks in all regions except for us-east-1, as global recording is enabled in us-east-1' - As the script runs, it generates a summary of disabled controls. If there are failures, the reason for failures will be listed in the summary. A log file is also saved in the directory with execution logs.

Figure 12: Execution Summary showing successful updates and failure information


Example 2–Enabling Controls
Let’s say you have disabled Control IDs PCI.CodeBuild.1 and PCI.CodeBuild.2 from the PCI standard in your accounts, as in the past, you did not use AWS CodeBuild in your PCI environment.
After a recent architecture review, you decided to begin using CodeBuild in your accounts in us-west-1, eu-west-1, ap-southeast-1. The name of our execution role in all accounts is ManageSecurityHubControlsExecutionRole.
- Confirm you have completed all steps in part C.
- Change to the correct directory.
$ cd SecurityHub-Multiaccount-UpdateControls - Create a file with the list of account IDs. This will be passed with the input-file argument.
$ nano accounts.csv
Enter account IDs one account per line, then save the file.
Figure 13: CSV file with AWS account IDs
- Run the script to enable controls
python SH-UpdateControls.py \ --input-file accounts.csv \ --assume-role ManageSecurityHubControlsExecutionRole \ --regions us-west-1,eu-west-1,ap-southeast-1 \ --standard PCIDSS \ --control-id-list PCI.CodeBuild.1,PCI.CodeBuild.2 \ --control-action ENABLED \ - As the script runs, it generates a summary of enabled controls. If there are failures the reason for failures will be listed in the summary A log file is also saved in the directory with execution logs.

Figure 14: Execution Summary showing controls enabled


Alternative Solution
Consider a case where new member accounts are being added to the Security Hub administrator of the organization. In such a scenario, you would have to disable the controls manually, or by re-running the update Security Hub controls script in each new account.
Figure 15: High level architecture
This alternative solution addresses this problem by automating the process with AWS Step Functions and a scheduled EventBridge event. A state machine is triggered every 24 hours, which updates the status of the standard controls in all AWS accounts registered as members in the Security Hub administrator account. This solution maintains a list of account IDs within a DynamoDB table, for which exceptions can be made. For details on how to deploy and use this solution, refer to this GitHub repository. This alternative solution and the update SecurityHub controls script are independent of each other.
Conclusion
In this blog, you learned some of the reasons you might disable Security Hub controls. We showed how the controls can quickly be disabled or enabled using the update Security Hub controls script provided. This script will save you time if you want to update controls across multiple accounts and multiple Regions on an as needed basis.
We also introduced an alternative solution which uses AWS Step Functions and a scheduled CloudWatch event to update Security Hub controls in new accounts on a regular basis. You could use either of the two solutions depending on the scenario.
If you have feedback about this post, submit comments in the Comments section below. If you have trouble with the scripts, please open an issue in GitHub.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
What’s New in InsightIDR: Q4 2021 in Review
Post Syndicated from Margaret Wei original https://blog.rapid7.com/2022/01/06/whats-new-in-insightidr-q4-2021-in-review/

More context and customization around detections and investigations, expanded dashboard capabilities, and more.
This post offers a closer look at some of the recent releases in InsightIDR, our extended detection and response (XDR) solution, from Q4 2021. Over the past quarter, we delivered updates to help you make more informed decisions, accelerate your time to respond, and customize your detections and investigations. Here’s a rundown of the highlights.
More customization options for your detection rules
InsightIDR provides a highly curated detections library, vetted by the security and operations center (SOC) experts on our managed detection and response (MDR) team — but we know some teams may want the ability to fine tune these even further. In our Q3 wrap-up, we highlighted our new detection rules management experience. This quarter, we’ve made even more strides in leveling up our capabilities around detections to help you make more informed decisions and accelerate your time to respond.
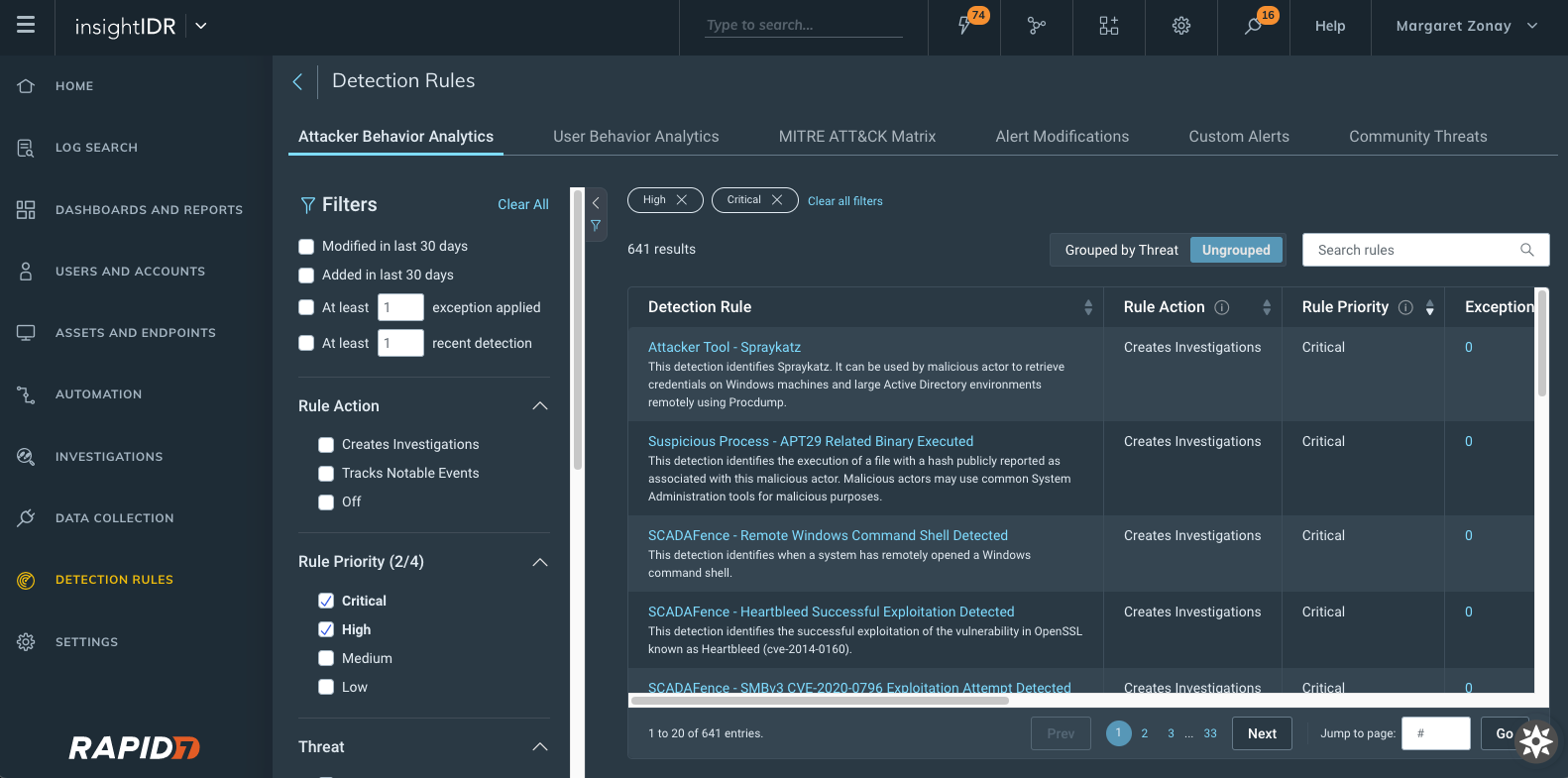
- New detection rules management interface: With this new interface, you can see a priority field for each detection provided by InsightIDR with new actions available.
- Change priority of detections and exceptions that are set to Creates Investigation as the Rule Action.
- View and sort on priority from the main detection management screen.
- More details on our detection rules experience can be found in our help docs, here.
- Customizable priorities for UBA detection rules and custom alerts: Customers can now associate a rule priority (Critical, High, Medium, or Low) for all of their UBA and custom alert detection rules. The priority is subsequently applied to investigations created by a detection rule.
- A simplified way to create exceptions: We added a new section to detection rule details within “create exception” to better inform on which data to write exceptions against. This will show up to the 5 most recent matches associated with that said detection rule — so now, when you go to write exceptions, you have all the information you may need all within one window.
MITRE ATT&CK Matrix for detection rules
This new view maps detection rules to MITRE tactics and techniques commonly used by attackers. The view lets you see where you have coverage with Rapid7’s out-of-the-box detection rules for common attacker use cases and dig into each rule to understand the nature of that detection.
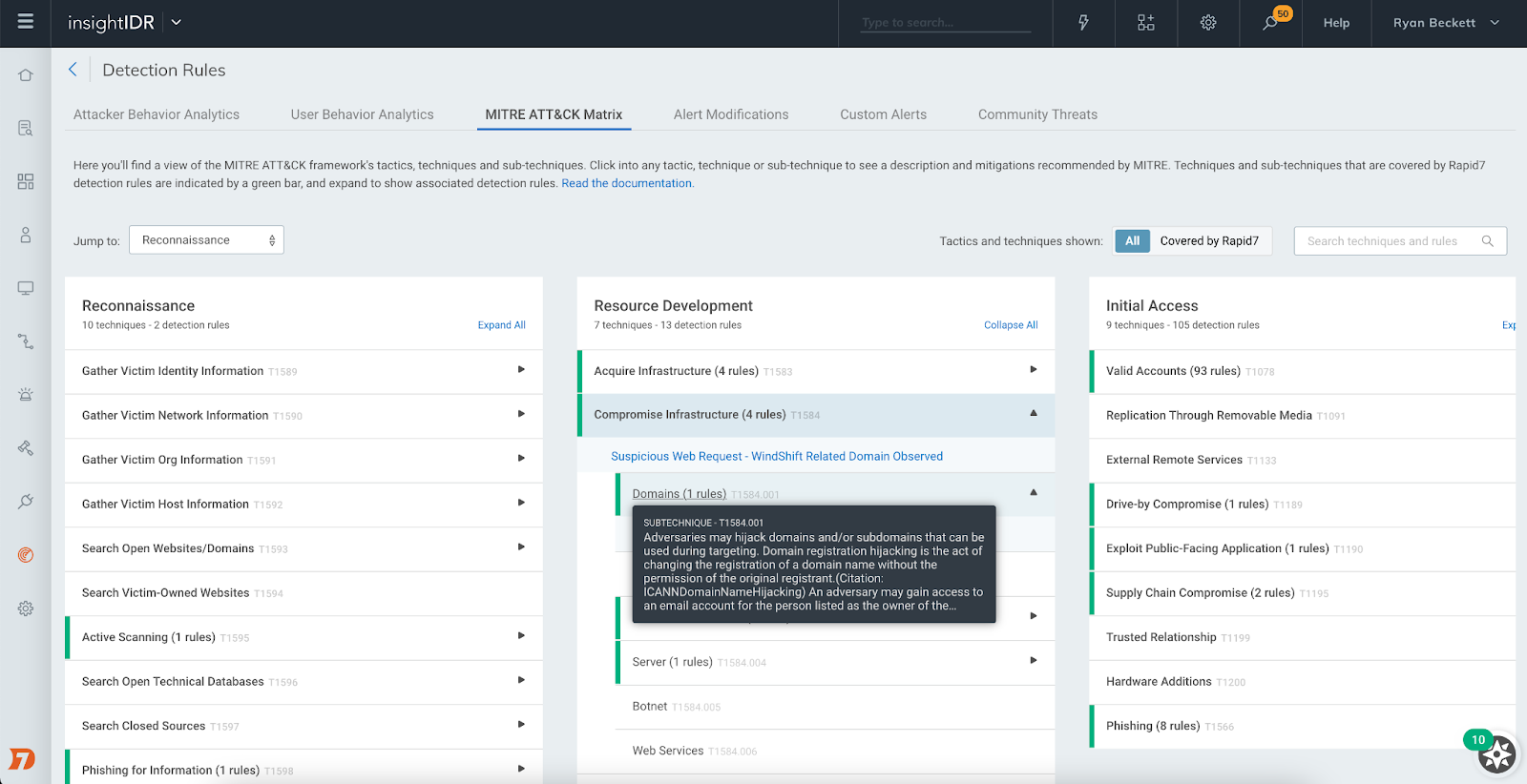
Investigation Management reimagined
At Rapid7, we know how limited a security analyst’s time is, so we reconfigured our Investigation Management experience to help our users improve the speed and quality of their decision-making when it comes to investigations. Here’s what you can expect:
- A revamped user interface with expandable cards displaying investigation information
- The ability to view, set, and update the priority, status, or disposition of an investigation
- Filtering by the following fields: date range, assignee, status, priority level
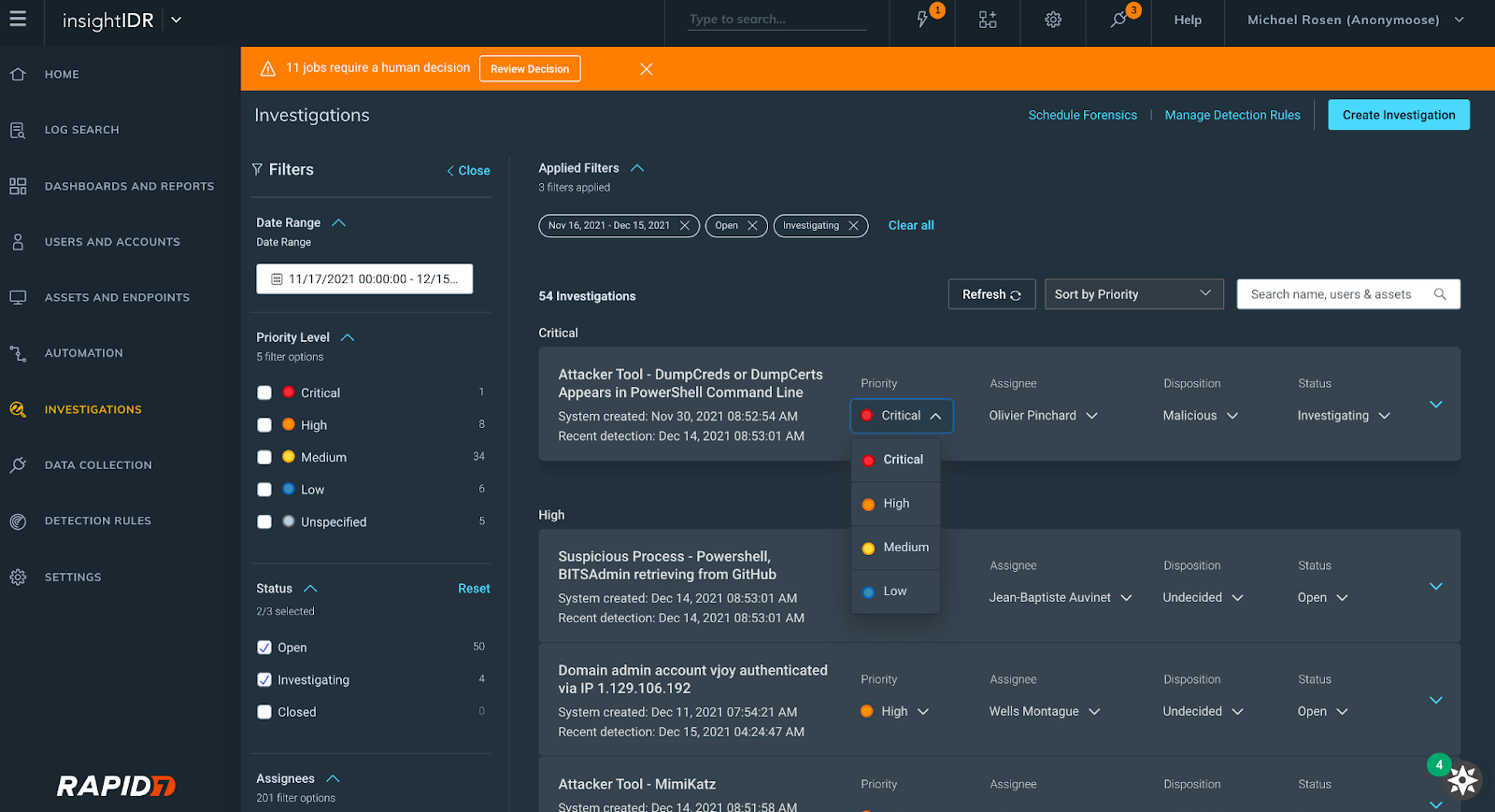
We also introduced MITRE-driven insights in Investigations. Now, you can click into the new MITRE ATT&CK tab of the Evidence panel in Investigation to see descriptions of each tactic, technique, and sub-technique curated by MITRE and link out to attack.mitre.org for more information.
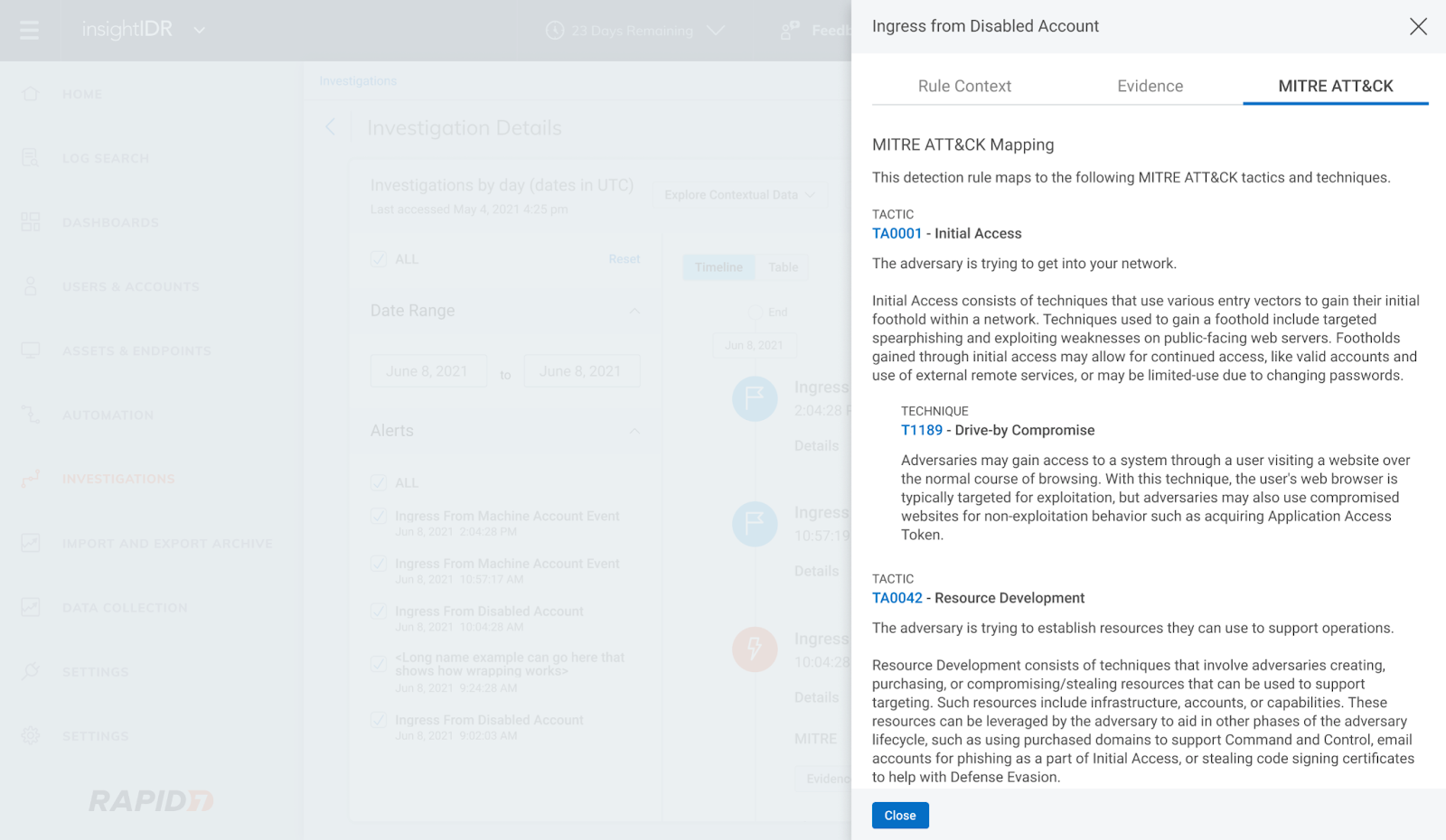
Rapid7’s ongoing emergent threat response to Log4Shell
Like the rest of the security community, we have been internally responding to the critical remote code execution vulnerability in Apache’s Log4j Java library (a.k.a. Log4Shell).
Through continuous collaboration and ongoing threat landscape monitoring, our Incident Response, Threat Intelligence and Detection Engineering, and MDR teams are working together to provide product coverage for the latest techniques being used by malicious actors. You can see updates on our InsightIDR and MDR detection coverage here and in-product.
Stay up to date with the latest on Log4Shell:
- View Log4Shell AttackerKB for our analysis
- Check out The Everyperson’s Guide to Log4Shell
- Head to our Log4Shell Resource Center for up-to-date information for customers
A continually expanding library of pre-built dashboards
InsightIDR’s Dashboard Library has a growing repository of pre-built dashboards to save you time and eliminate the need for you to build them from scratch. In Q4, we released 15 new pre-built dashboards covering:
- Compliance (PCI, HIPAA, ISO)
- General Security (Firewall, Asset Authentication)
- Security Tools (Okta, Palo Alto, Crowdstrike)
- Enhanced Network Traffic Analysis
- Cloud Security
Additional dashboard and reporting updates
- Updates to dashboard filtering: Dashboard Filtering gives users the ability to further query LEQL statements and the data across all the cards in their dashboard. Customers can now populate the dashboard filter with Saved Queries from Log Search, as well as save a filter to a dashboard, eliminating the need to rebuild it every session.
- Chart captions: We’ve added the ability for users to write plain text captions on charts to provide extra context about a visualization.
- Multi-group-by queries and drill-in functionality: We’ve enabled Multi-group-by queries (already being used in Log search) so that customers can leverage these in their dashboards and create cards with layered data that they can drill in and out of.
Updates to Log Search and Event Sources
We recently introduced Rapid7 Resource Names (RRN), which are unique identifiers added to users, assets, and accounts in log search. An RRN serves as a unique identifier for platform resources at Rapid7. This unique identifier will stay consistent with the resource regardless of any number of names/labels associated with the resource.
In log search, an “R7_context” object has been added for log sets that have an attributed user, asset, account, or local accounts. Within the “R7_context” object, you will see any applicable RRNs appended. You can utilize the RRN as a search in log search or in the global search (which will link to users and accounts or assets and endpoints pages) to assist with more reliable searches for investigation processes.

Event source updates
- Log Line Attribution for Palo Alto Firewall & VPN, Proofpoint TAP, Fortinet Fortigate: When setting up an event source you now have an option to leverage information directly present in source log lines, rather than relying solely on InsightIDR’s traditional attribution engine.
- Cylance Protect Cloud event source: You can configure CylancePROTECT cloud to send detection events to InsightIDR to generate virus infection and third-party alerts.
- InsightIDR Event Source listings available in the Rapid7 Extensions Hub: Easily access all InsightIDR event source related content in a centralized location.
Updates to Network Traffic Analysis capabilities
Insight Network Sensor optimized for 10Gbs+ deployments: We have introduced a range of performance upgrades that make high-speed traffic analysis more accessible using off-the-shelf hardware, so you’re able to gain east-west and north-south traffic visibility within physical, virtual and cloud based networks. If you want to take full advantage of these updates check out the updated sensor requirements here.
InsightIDR Asset Page Updates: We have introduced additional data elements and visuals to the Assets page. This delivers greater context for investigations and enables faster troubleshooting, as assets and user information is in one location. All customers have access to:
- Top IDS events triggered by asset
- Top DNS queries
For customers with Insight Network Sensors and ENTA, these additional elements are available:
- Top Applications
- Countries by Asset Location
- Top Destination IP Addresses
Stay tuned!
As always, we’re continuing to work on exciting product enhancements and releases throughout the year. Keep an eye on our blog and release notes as we continue to highlight the latest in detection and response at Rapid7.