Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Ug_uKkQXthU
My Miniot Wheel 2 finally arrived, but does it deliver on the promise?
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=pQfWRvsDu8I
Седмицата (8–13 април)
Post Syndicated from Светла Енчева original https://www.toest.bg/sedmitsata-8-13-april/

Ако се чувствате като в абсурдистка пиеса, не сте сами. Подадени и оттеглени оставки, пудели и пачки, прокуратура, която охотно разказва пред медиите кой ѝ е таен свидетел и какви показания е дал…
На тази тема е и тазседмичният политически коментар на Емилия Милчева „Кал, чистки и избори“. Според последните проучвания на общественото мнение ГЕРБ уверено води пред ПП–ДБ. Отиващото си 49-то Народно събрание продължава да произвежда комисии, а новият служебен кабинет на Димитър Главчев вече започна с чистките. Работата с пачките, кюлчетата злато, кутиите за обувки, пуделите и т.н. прилича на трилър, но нискобюджетен. За да си кажем „всички са маскари“ и да спечелят онези, които ни прожектират трилъра.
Друг изпитан предизборен трик е да се посочи враг, вторачването в когото да измести вниманието от истинските проблеми. Бежанците не за първи път са поставени в тази роля, а агресията срещу тях ескалира. Свидетели сме на поредица от случаи на ксенофобско насилие с предизборно-полицейски привкус. В статията си по темата разказвам за няколко от тях, в които полицията или не е реагирала адекватно, или е в ролята на агресора.
В края на 80-те и началото на 90-те години по площадите се пееше „Как ще ги стигнем американците“ на Тодор Колев с мелодията на песента Let it be на The Beatles. 35 години по-късно и американците си имат сериозни проблеми. Превръщат ли се САЩ в геронтокрация?, пита Йоанна Елми. Кандидатите за президент Байдън и Тръмп са родени съответно през 1942 и 1946 г. И проблемът не е просто че са стари, а че не представляват населението на страната си, което е на средна възраст 38 години. То има много различни приоритети и проблеми от тези на бейбибумърите, които упорито не пускат кокала.
Но да се върнем в Европа, защото Светла Стоянова ни поднася Гренландия в чиния. Тя е работила в ресторант с две звезди Мишлен на северния остров и ни разказва за някои от ястията, сервирани в него. Имайте предвид обаче, че описанието им може да прозвучи скандално на повечето българи. Например сос от боровинки, извадени от воденичките на яребици, сервиран като гарнитура на шиш, който е направен от крилото на яребицата (барабар с перата). Но пък представяли ли сме си преди 30 години, че ще даваме пари, за да ядем сурова риба?
Воденичките се водят субпродукти, както и бъбреците. Представяли ли сте си също така, че един свински бъбрек може да влезе в човек по по-възвишен начин от ястие, чиято миризливост бива силно мразена и любена? В новата порция научни новини Михаил Ангелов ни разказва за ксенотрансплантациите, тоест за прехвърляне на органи между представители на различни видове. Миналия месец беше извършена първата трансплантация на бъбрек от прасе на човек. За тази цел гените на прасето донор са модифицирани. От статията може да научим също, че „Вояджър“ има проблеми с паметта, птичият грип вече ходи по виметата на крави и заразява работници, а екокожа за дрехи и обувки може да се прави и от бактерии.
Знаете си, че няма да ви оставя без препоръка. Скъпият на сърцето ни Стефан Иванов, автор в рубриката „На второ четене“ в „Тоест“, има нова стихосбирка – 10 години след последната. Тя се казва „Без мен“ и е на новосъздаденото издателство „Кота 0“. В една стихосбирка най-важното са, разбира се, стиховете и авторът. Но в „Без мен“ също толкова важен е редакторът и автор на предговора, който е… Марин Бодаков. Не, Марин не си е отишъл – още е тук с написаното, с общуването, с прегръдките. А комбинацията от Стефан и Марин е гаранция за поезия с най-висша степен на човечност. Ако искате новата стихосбирка на Стефан Иванов, пишете на страницата на издателство „Кота 0“ или направо на автора.
Приятно четене, общуване и пролетни удоволствия!
Comic for 2024.04.13 – Quit
Post Syndicated from Explosm.net original https://explosm.net/comics/quit
New Cyanide and Happiness Comic
Ancient Explorers: Hanno, Himilco, and Pytheas
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=61qhTc36RWE
Mutiny on the Hyphasis
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Ln0Aj8SpFbQ
Friday Squid Blogging: The Awfulness of Squid Fishing Boats
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/04/friday-squid-blogging-the-awfulness-of-squid-fishing-boats.html
It’s a pretty awful story.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
The curious case of faster AWS KMS symmetric key rotation
Post Syndicated from Jeremy Stieglitz original https://aws.amazon.com/blogs/security/the-curious-case-of-faster-aws-kms-symmetric-key-rotation/
Today, AWS Key Management Service (AWS KMS) is introducing faster options for automatic symmetric key rotation. We’re also introducing rotate on-demand, rotation visibility improvements, and a new limit on the price of all symmetric keys that have had two or more rotations (including existing keys). In this post, I discuss all those capabilities and changes. I also present a broader overview of how symmetric cryptographic key rotation came to be, and cover our recommendations on when you might need rotation and how often to rotate your keys. If you’ve ever been curious about AWS KMS automatic key rotation—why it exists, when to enable it, and when to use it on-demand—read on.
How we got here
There are longstanding reasons for cryptographic key rotation. If you were Caesar in Roman times and you needed to send messages with sensitive information to your regional commanders, you might use keys and ciphers to encrypt and protect your communications. There are well-documented examples of using cryptography to protect communications during this time, so much so that the standard substitution cipher, where you swap each letter for a different letter that is a set number of letters away in the alphabet, is referred to as Caesar’s cipher. The cipher is the substitution mechanism, and the key is the number of letters away from the intended letter you go to find the substituted letter for the ciphertext.
The challenge for Caesar in relying on this kind of symmetric key cipher is that both sides (Caesar and his field generals) needed to share keys and keep those keys safe from prying eyes. What happens to Caesar’s secret invasion plans if the key used to encipher his attack plan was secretly intercepted in transmission down the Appian Way? Caesar had no way to know. But if he rotated keys, he could limit the scope of which messages could be read, thus limiting his risk. Messages sent under a key created in the year 52 BCE wouldn’t automatically work for messages sent the following year, provided that Caesar rotated his keys yearly and the newer keys weren’t accessible to the adversary. Key rotation can reduce the scope of data exposure (what a threat actor can see) when some but not all keys are compromised. Of course, every time the key changed, Caesar had to send messengers to his field generals to communicate the new key. Those messengers had to ensure that no enemies intercepted the new keys without their knowledge – a daunting task.

Figure 1: The state of the art for secure key rotation and key distribution in 52 BC.
Fast forward to the 1970s–2000s
In modern times, cryptographic algorithms designed for digital computer systems mean that keys no longer travel down the Appian Way. Instead, they move around digital systems, are stored in unprotected memory, and sometimes are printed for convenience. The risk of key leakage still exists, therefore there is a need for key rotation. During this period, more significant security protections were developed that use both software and hardware technology to protect digital cryptographic keys and reduce the need for rotation. The highest-level protections offered by these techniques can limit keys to specific devices where they can never leave as plaintext. In fact, the US National Institute of Standards and Technologies (NIST) has published a specific security standard, FIPS 140, that addresses the security requirements for these cryptographic modules.
Modern cryptography also has the risk of cryptographic key wear-out
Besides addressing risks from key leakage, key rotation has a second important benefit that becomes more pronounced in the digital era of modern cryptography—cryptographic key wear-out. A key can become weaker, or “wear out,” over time just by being used too many times. If you encrypt enough data under one symmetric key, and if a threat actor acquires enough of the resulting ciphertext, they can perform analysis against your ciphertext that will leak information about the key. Current cryptographic recommendations to protect against key wear-out can vary depending on how you’re encrypting data, the cipher used, and the size of your key. However, even a well-designed AES-GCM implementation with robust initialization vectors (IVs) and large key size (256 bits) should be limited to encrypting no more than 4.3 billion messages (232), where each message is limited to about 64 GiB under a single key.

Figure 2: Used enough times, keys can wear out.
During the early 2000s, to help federal agencies and commercial enterprises navigate key rotation best practices, NIST formalized several of the best practices for cryptographic key rotation in the NIST SP 800-57 Recommendation for Key Management standard. It’s an excellent read overall and I encourage you to examine Section 5.3 in particular, which outlines ways to determine the appropriate length of time (the cryptoperiod) that a specific key should be relied on for the protection of data in various environments. According to the guidelines, the following are some of the benefits of setting cryptoperiods (and rotating keys within these periods):
5.3 Cryptoperiods
A cryptoperiod is the time span during which a specific key is authorized for use by legitimate entities or the keys for a given system will remain in effect. A suitably defined cryptoperiod:
- Limits the amount of information that is available for cryptanalysis to reveal the key (e.g. the number of plaintext and ciphertext pairs encrypted with the key);
- Limits the amount of exposure if a single key is compromised;
- Limits the use of a particular algorithm (e.g., to its estimated effective lifetime);
- Limits the time available for attempts to penetrate physical, procedural, and logical access mechanisms that protect a key from unauthorized disclosure;
- Limits the period within which information may be compromised by inadvertent disclosure of a cryptographic key to unauthorized entities; and
- Limits the time available for computationally intensive cryptanalysis.
Sometimes, cryptoperiods are defined by an arbitrary time period or maximum amount of data protected by the key. However, trade-offs associated with the determination of cryptoperiods involve the risk and consequences of exposure, which should be carefully considered when selecting the cryptoperiod (see Section 5.6.4).
(Source: NIST SP 800-57 Recommendation for Key Management, page 34).
One of the challenges in applying this guidance to your own use of cryptographic keys is that you need to understand the likelihood of each risk occurring in your key management system. This can be even harder to evaluate when you’re using a managed service to protect and use your keys.
Fast forward to the 2010s: Envisioning a key management system where you might not need automatic key rotation
When we set out to build a managed service in AWS in 2014 for cryptographic key management and help customers protect their AWS encryption workloads, we were mindful that our keys needed to be as hardened, resilient, and protected against external and internal threat actors as possible. We were also mindful that our keys needed to have long-term viability and use built-in protections to prevent key wear-out. These two design constructs—that our keys are strongly protected to minimize the risk of leakage and that our keys are safe from wear out—are the primary reasons we recommend you limit key rotation or consider disabling rotation if you don’t have compliance requirements to do so. Scheduled key rotation in AWS KMS offers limited security benefits to your workloads.
Specific to key leakage, AWS KMS keys in their unencrypted, plaintext form cannot be accessed by anyone, even AWS operators. Unlike Caesar’s keys, or even cryptographic keys in modern software applications, keys generated by AWS KMS never exist in plaintext outside of the NIST FIPS 140-2 Security Level 3 fleet of hardware security modules (HSMs) in which they are used. See the related post AWS KMS is now FIPS 140-2 Security Level 3. What does this mean for you? for more information about how AWS KMS HSMs help you prevent unauthorized use of your keys. Unlike many commercial HSM solutions, AWS KMS doesn’t even allow keys to be exported from the service in encrypted form. Why? Because an external actor with the proper decryption key could then expose the KMS key in plaintext outside the service.
This hardened protection of your key material is salient to the principal security reason customers want key rotation. Customers typically envision rotation as a way to mitigate a key leaking outside the system in which it was intended to be used. However, since KMS keys can be used only in our HSMs and cannot be exported, the possibility of key exposure becomes harder to envision. This means that rotating a key as protection against key exposure is of limited security value. The HSMs are still the boundary that protects your keys from unauthorized access, no matter how many times the keys are rotated.
If we decide the risk of plaintext keys leaking from AWS KMS is sufficiently low, don’t we still need to be concerned with key wear-out? AWS KMS mitigates the risk of key wear-out by using a key derivation function (KDF) that generates a unique, derived AES 256-bit key for each individual request to encrypt or decrypt under a 256-bit symmetric KMS key. Those derived encryption keys are different every time, even if you make an identical call for encrypt with the same message data under the same KMS key. The cryptographic details for our key derivation method are provided in the AWS KMS Cryptographic Details documentation, and KDF operations use the KDF in counter mode, using HMAC with SHA256. These KDF operations make cryptographic wear-out substantially different for KMS keys than for keys you would call and use directly for encrypt operations. A detailed analysis of KMS key protections for cryptographic wear-out is provided in the Key Management at the Cloud Scale whitepaper, but the important take-away is that a single KMS key can be used for more than a quadrillion (250) encryption requests without wear-out risk.
In fact, within the NIST 800-57 guidelines is consideration that when the KMS key (key-wrapping key in NIST language) is used with unique data keys, KMS keys can have longer cryptoperiods:
“In the case of these very short-term key-wrapping keys, an appropriate cryptoperiod (i.e., which includes both the originator and recipient-usage periods) is a single communication session. It is assumed that the wrapped keys will not be retained in their wrapped form, so the originator-usage period and recipient-usage period of a key-wrapping key is the same. In other cases, a key-wrapping key may be retained so that the files or messages encrypted by the wrapped keys may be recovered later. In such cases, the recipient-usage period may be significantly longer than the originator-usage period of the key-wrapping key, and cryptoperiods lasting for years may be employed.”
Source: NIST 800-57 Recommendations for Key Management, section 5.3.6.7.
So why did we build key rotation in AWS KMS in the first place?
Although we advise that key rotation for KMS keys is generally not necessary to improve the security of your keys, you must consider that guidance in the context of your own unique circumstances. You might be required by internal auditors, external compliance assessors, or even your own customers to provide evidence of regular rotation of all keys. A short list of regulatory and standards groups that recommend key rotation includes the aforementioned NIST 800-57, Center for Internet Security (CIS) benchmarks, ISO 27001, System and Organization Controls (SOC) 2, the Payment Card Industry Data Security Standard (PCI DSS), COBIT 5, HIPAA, and the Federal Financial Institutions Examination Council (FFIEC) Handbook, just to name a few.
Customers in regulated industries must consider the entirety of all the cryptographic systems used across their organizations. Taking inventory of which systems incorporate HSM protections, which systems do or don’t provide additional security against cryptographic wear-out, or which programs implement encryption in a robust and reliable way can be difficult for any organization. If a customer doesn’t have sufficient cryptographic expertise in the design and operation of each system, it becomes a safer choice to mandate a uniform scheduled key rotation.
That is why we offer an automatic, convenient method to rotate symmetric KMS keys. Rotation allows customers to demonstrate this key management best practice to their stakeholders instead of having to explain why they chose not to.
Figure 3 details how KMS appends new key material within an existing KMS key during each key rotation.

Figure 3: KMS key rotation process
We designed the rotation of symmetric KMS keys to have low operational impact to both key administrators and builders using those keys. As shown in Figure 3, a keyID configured to rotate will append new key material on each rotation while still retaining and keeping the existing key material of previous versions. This append method achieves rotation without having to decrypt and re-encrypt existing data that used a previous version of a key. New encryption requests under a given keyID will use the latest key version, while decrypt requests under that keyID will use the appropriate version. Callers don’t have to name the version of the key they want to use for encrypt/decrypt, AWS KMS manages this transparently.
Some customers assume that a key rotation event should forcibly re-encrypt any data that was ever encrypted under the previous key version. This is not necessary when AWS KMS automatically rotates to use a new key version for encrypt operations. The previous versions of keys required for decrypt operations are still safe within the service.
We’ve offered the ability to automatically schedule an annual key rotation event for many years now. Lately, we’ve heard from some of our customers that they need to rotate keys more frequently than the fixed period of one year. We will address our newly launched capabilities to help meet these needs in the final section of this blog post.
More options for key rotation in AWS KMS (with a price reduction)
After learning how we think about key rotation in AWS KMS, let’s get to the new options we’ve launched in this space:
- Configurable rotation periods: Previously, when using automatic key rotation, your only option was a fixed annual rotation period. You can now set a rotation period from 90 days to 2,560 days (just over seven years). You can adjust this period at any point to reset the time in the future when rotation will take effect. Existing keys set for rotation will continue to rotate every year.
- On-demand rotation for KMS keys: In addition to more flexible automatic key rotation, you can now invoke on-demand rotation through the AWS Management Console for AWS KMS, the AWS Command Line Interface (AWS CLI), or the AWS KMS API using the new RotateKeyOnDemand API. You might occasionally need to use on-demand rotation to test workloads, or to verify and prove key rotation events to internal or external stakeholders. Invoking an on-demand rotation won’t affect the timeline of any upcoming rotation scheduled for this key.
Note: We’ve set a default quota of 10 on-demand rotations for a KMS key. Although the need for on-demand key rotation should be infrequent, you can ask to have this quota raised. If you have a repeated need for testing or validating instant key rotation, consider deleting the test keys and repeating this operation for RotateKeyOnDemand on new keys.
- Improved visibility: You can now use the AWS KMS console or the new ListKeyRotations API to view previous key rotation events. One of the challenges in the past is that it’s been hard to validate that your KMS keys have rotated. Now, every previous rotation for a KMS key that has had a scheduled or on-demand rotation is listed in the console and available via API.

Figure 4: Key rotation history showing date and type of rotation
- Price cap for keys with more than two rotations: We’re also introducing a price cap for automatic key rotation. Previously, each annual rotation of a KMS key added $1 per month to the price of the key. Now, for KMS keys that you rotate automatically or on-demand, the first and second rotation of the key adds $1 per month in cost (prorated hourly), but this price increase is capped at the second rotation. Rotations after your second rotation aren’t billed. Existing customers that have keys with three or more annual rotations will see a price reduction for those keys to $3 per month (prorated) per key starting in the month of May, 2024.

Summary
In this post, I highlighted the more flexible options that are now available for key rotation in AWS KMS and took a broader look into why key rotation exists. We know that many customers have compliance needs to demonstrate key rotation everywhere, and increasingly, to demonstrate faster or immediate key rotation. With the new reduced pricing and more convenient ways to verify key rotation events, we hope these new capabilities make your job easier.
Flexible key rotation capabilities are now available in all AWS Regions, including the AWS GovCloud (US) Regions. To learn more about this new capability, see the Rotating AWS KMS keys topic in the AWS KMS Developer Guide.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Marvell AI Investor Day 2024 New US Hyper-Scale AI Accelerator
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/marvell-ai-investor-day-2024-mrvl/
Some highlights from the Marvell AI Investor Day 2024 included a 6.4T 32x 200G silicon photonics engine and a hyper-scale AI accelerator win
The post Marvell AI Investor Day 2024 New US Hyper-Scale AI Accelerator appeared first on ServeTheHome.
Metasploit Weekly Wrap-Up 04/12/24
Post Syndicated from Simon Janusz original https://blog.rapid7.com/2024/04/12/metasploit-weekly-wrap-up-04-12-24/
Account Takeover using Shadow Credentials

The new release of Metasploit Framework includes a Shadow Credentials module added by smashery used for reliably taking over an Active Directory user account or computer, and letting future authentication to happen as that account. This can be chained with other modules present in Metasploit Framework such as windows_secrets_dump.
Details
The module targets a ‘victim’ account that is part of a domain where the Domain Controller is running Windows Server 2016 and newer.
Using an account that has write permissions over another (or its own) user account object, the module adds a public key credential object to the user account’s msDS-KeyCredentialLink property. After this, a Ticket Granting Ticket can be requested using the get_ticket module, which subsequently can be used for a pass-the-ticket style attack such as auxiliary/gather/windows_secrets_dump. This can be performed when a user contains the GenericWrite permission over another account. By default, Computer accounts have the ability to write their own value (whereas user accounts do not).
The shadow credentials added persist between password changes, making it a very useful technique for getting the TGT.
The steps for this technique (performed automatically by the module) are:
Generate and store a key and certificate locally
Store the certificate’s public key as a KeyCredential
On the domain controller, update the msDS-KeyCredentialLink property to include the newly generated KeyCredential object
After the above steps, you can:
Obtain a TGT & NTLM hash
Perform further attacks using the above values
New module content (3)
Shadow Credentials
Authors: Elad Shamir and smashery
Type: Auxiliary
Pull request: #19051 contributed by smashery
Path: admin/ldap/shadow_credentials
Description: A new module to add to, list, flush and delete from the LDAP msDS-KeyCredentialLink attribute which enables the user to execute "shadow credential" attacks for persistence and lateral movement.
Gibbon School Platform Authenticated PHP Deserialization Vulnerability
Authors: Ali Maharramli, Fikrat Guliev, Islam Rzayev, and h00die-gr3y [email protected]
Type: Exploit
Pull request: #19044 contributed by h00die-gr3y
Path: multi/http/gibbon_auth_rce_cve_2024_24725
AttackerKB reference: CVE-2024-24725
Description: An exploit module that exploits Gibbon online school platform version 26.0.00 and lower to achieve remote code execution. Note that authentication is required. This leverages a PHP deserialization attack via columnOrder in a POST request (CVE-2024-24725).
Rancher Audit Log Sensitive Information Leak
Author: h00die
Type: Post
Pull request: #18962 contributed by h00die
Path: linux/gather/rancher_audit_log_leak
AttackerKB reference: CVE-2023-22649
Description: A post module to leverage CVE-2023-22649 which is a sensitive information leak in the rancher service’s audit logs.
Enhancements and features (4)
- #19022 from sjanusz-r7 – Adds support to detect the MySQL server’s host’s platform and arch by running a query.
- #19045 from zgoldman-r7 – Adds a set of acceptance tests for MSSQL modules.
- #19052 from smashery – Updates Metasploit’s User Agent strings to values valid for April 2024.
- #19064 from nrathaus – Adds support to the
auxiliary/scanner/snmp/snmp_loginmodule to work over the TCP protocol in addition to UDP.
Bugs fixed (3)
- #19056 from dwelch-r7 – Fixed an issue were the socket would be closed if targeting a single host with multiple
user_file/pass_filemodule option combinations. This was caused when a session was successfully opened but then the next login attempt would close the socket being used by the newly created session. - #19059 from nrathaus – Fixed an issue with the psnuffle module’s POP3 support.
- #19069 from adfoster-r7 – Fixed an edgecase present in clients that programmatically interacted with Metasploit’s remote procedure call (RPC) functionality that caused the login modules for SMB, Postgres, MySQL, and MSSQL to open a new session by default instead of it being opt in behavior.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
Uplevel your data architecture with real- time streaming using Amazon Data Firehose and Snowflake
Post Syndicated from Swapna Bandla original https://aws.amazon.com/blogs/big-data/uplevel-your-data-architecture-with-real-time-streaming-using-amazon-data-firehose-and-snowflake/
Today’s fast-paced world demands timely insights and decisions, which is driving the importance of streaming data. Streaming data refers to data that is continuously generated from a variety of sources. The sources of this data, such as clickstream events, change data capture (CDC), application and service logs, and Internet of Things (IoT) data streams are proliferating. Snowflake offers two options to bring streaming data into its platform: Snowpipe and Snowflake Snowpipe Streaming. Snowpipe is suitable for file ingestion (batching) use cases, such as loading large files from Amazon Simple Storage Service (Amazon S3) to Snowflake. Snowpipe Streaming, a newer feature released in March 2023, is suitable for rowset ingestion (streaming) use cases, such as loading a continuous stream of data from Amazon Kinesis Data Streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Before Snowpipe Streaming, AWS customers used Snowpipe for both use cases: file ingestion and rowset ingestion. First, you ingested streaming data to Kinesis Data Streams or Amazon MSK, then used Amazon Data Firehose to aggregate and write streams to Amazon S3, followed by using Snowpipe to load the data into Snowflake. However, this multi-step process can result in delays of up to an hour before data is available for analysis in Snowflake. Moreover, it’s expensive, especially when you have small files that Snowpipe has to upload to the Snowflake customer cluster.
To solve this issue, Amazon Data Firehose now integrates with Snowpipe Streaming, enabling you to capture, transform, and deliver data streams from Kinesis Data Streams, Amazon MSK, and Firehose Direct PUT to Snowflake in seconds at a low cost. With a few clicks on the Amazon Data Firehose console, you can set up a Firehose stream to deliver data to Snowflake. There are no commitments or upfront investments to use Amazon Data Firehose, and you only pay for the amount of data streamed.
Some key features of Amazon Data Firehose include:
- Fully managed serverless service – You don’t need to manage resources, and Amazon Data Firehose automatically scales to match the throughput of your data source without ongoing administration.
- Straightforward to use with no code – You don’t need to write applications.
- Real-time data delivery – You can get data to your destinations quickly and efficiently in seconds.
- Integration with over 20 AWS services – Seamless integration is available for many AWS services, such as Kinesis Data Streams, Amazon MSK, Amazon VPC Flow Logs, AWS WAF logs, Amazon CloudWatch Logs, Amazon EventBridge, AWS IoT Core, and more.
- Pay-as-you-go model – You only pay for the data volume that Amazon Data Firehose processes.
- Connectivity – Amazon Data Firehose can connect to public or private subnets in your VPC.
This post explains how you can bring streaming data from AWS into Snowflake within seconds to perform advanced analytics. We explore common architectures and illustrate how to set up a low-code, serverless, cost-effective solution for low-latency data streaming.
Overview of solution
The following are the steps to implement the solution to stream data from AWS to Snowflake:
- Create a Snowflake database, schema, and table.
- Create a Kinesis data stream.
- Create a Firehose delivery stream with Kinesis Data Streams as the source and Snowflake as its destination using a secure private link.
- To test the setup, generate sample stream data from the Amazon Kinesis Data Generator (KDG) with the Firehose delivery stream as the destination.
- Query the Snowflake table to validate the data loaded into Snowflake.
The solution is depicted in the following architecture diagram.

Prerequisites
You should have the following prerequisites:
- An AWS account and access to the following AWS services:
- AWS Identity and Access Management (IAM)
- Kinesis Data Streams
- Amazon S3
- Amazon Data Firehose
- Familiarity with the AWS Management Console.
- A Snowflake account.
- A key pair generated and your user configured to connect securely to Snowflake. For instructions, refer to the following:
- An S3 bucket for error logging.
- The KDG set up. For instructions, refer to Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator.
Create a Snowflake database, schema, and table
Complete the following steps to set up your data in Snowflake:
- Log in to your Snowflake account and create the database:
- Create a schema in the new database:
- Create a table in the new schema:


Create a Kinesis data stream
Complete the following steps to create your data stream:
- On the Kinesis Data Streams console, choose Data streams in the navigation pane.
- Choose Create data stream.

- For Data stream name, enter a name (for example,
KDS-Demo-Stream). - Leave the remaining settings as default.
- Choose Create data stream.



Create a Firehose delivery stream
Complete the following steps to create a Firehose delivery stream with Kinesis Data Streams as the source and Snowflake as its destination:
- On the Amazon Data Firehose console, choose Create Firehose stream.
- For Source, choose Amazon Kinesis Data Streams.
- For Destination, choose Snowflake.
- For Kinesis data stream, browse to the data stream you created earlier.
- For Firehose stream name, leave the default generated name or enter a name of your preference.

- Under Connection settings, provide the following information to connect Amazon Data Firehose to Snowflake:
- For Snowflake account URL, enter your Snowflake account URL.
- For User, enter the user name generated in the prerequisites.
- For Private key, enter the private key generated in the prerequisites. Make sure the private key is in PKCS8 format. Do not include the PEM
header-BEGINprefix andfooter-ENDsuffix as part of the private key. If the key is split across multiple lines, remove the line breaks. - For Role, select Use custom Snowflake role and enter the IAM role that has access to write to the database table.

You can connect to Snowflake using public or private connectivity. If you don’t provide a VPC endpoint, the default connectivity mode is public. To allow list Firehose IPs in your Snowflake network policy, refer to Choose Snowflake for Your Destination. If you’re using a private link URL, provide the VPCE ID using SYSTEM$GET_PRIVATELINK_CONFIG:
This function returns a JSON representation of the Snowflake account information necessary to facilitate the self-service configuration of private connectivity to the Snowflake service, as shown in the following screenshot.

- For this post, we’re using a private link, so for VPCE ID, enter the VPCE ID.

- Under Database configuration settings, enter your Snowflake database, schema, and table names.
- In the Backup settings section, for S3 backup bucket, enter the bucket you created as part of the prerequisites.
- Choose Create Firehose stream.



Alternatively, you can use an AWS CloudFormation template to create the Firehose delivery stream with Snowflake as the destination rather than using the Amazon Data Firehose console.
To use the CloudFormation stack, choose
![]()
Generate sample stream data
Generate sample stream data from the KDG with the Kinesis data stream you created:

Query the Snowflake table
Query the Snowflake table:
You can confirm that the data generated by the KDG that was sent to Kinesis Data Streams is loaded into the Snowflake table through Amazon Data Firehose.

Troubleshooting
If data is not loaded into Kinesis Data Steams after the KDG sends data to the Firehose delivery stream, refresh and make sure you are logged in to the KDG.
If you made any changes to the Snowflake destination table definition, recreate the Firehose delivery stream.
Clean up
To avoid incurring future charges, delete the resources you created as part of this exercise if you are not planning to use them further.
Conclusion
Amazon Data Firehose provides a straightforward way to deliver data to Snowpipe Streaming, enabling you to save costs and reduce latency to seconds. To try Amazon Kinesis Firehose with Snowflake, refer to the Amazon Data Firehose with Snowflake as destination lab.
About the Authors
 Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family.
Swapna Bandla is a Senior Solutions Architect in the AWS Analytics Specialist SA Team. Swapna has a passion towards understanding customers data and analytics needs and empowering them to develop cloud-based well-architected solutions. Outside of work, she enjoys spending time with her family.
 Mostafa Mansour is a Principal Product Manager – Tech at Amazon Web Services where he works on Amazon Kinesis Data Firehose. He specializes in developing intuitive product experiences that solve complex challenges for customers at scale. When he’s not hard at work on Amazon Kinesis Data Firehose, you’ll likely find Mostafa on the squash court, where he loves to take on challengers and perfect his dropshots.
Mostafa Mansour is a Principal Product Manager – Tech at Amazon Web Services where he works on Amazon Kinesis Data Firehose. He specializes in developing intuitive product experiences that solve complex challenges for customers at scale. When he’s not hard at work on Amazon Kinesis Data Firehose, you’ll likely find Mostafa on the squash court, where he loves to take on challengers and perfect his dropshots.
 Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers. He has helped technology companies design and implement data analytics solutions and products.
Bosco Albuquerque is a Sr. Partner Solutions Architect at AWS and has over 20 years of experience working with database and analytics products from enterprise database vendors and cloud providers. He has helped technology companies design and implement data analytics solutions and products.
Adda Howie: The Woman who Sang to Cows
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=fL6xHsDHSvc
Abraham Galloway, Spy for the Union
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=HnCfbBY2FN8
The World’s Most Dangerous Year
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=0_HhjF-Dze4
Black Monday: 250th Mission of the Eight Air Force
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=jvv70FkLAVE
$50 vs $12,000 Projectors Side by Side || Budget vs Performance Comparisons.
Post Syndicated from The Hook Up original https://www.youtube.com/watch?v=NCfnwnLk8Yo
[$] A tale of two troublesome drivers
Post Syndicated from corbet original https://lwn.net/Articles/969383/
The kernel project merges dozens of drivers with every development cycle,
and almost every one of those drivers is entirely uncontroversial.
Occasionally, though, a driver submission raises wider questions, leading
to lengthy discussion and, perhaps, opposition. That is currently the case
with two separate drivers, both with ties to the networking subsystem. One
of them is hung up on questions of whether (and how) all device
functionality should be made available to user space, while the other has
run into turbulence because it drives a device that is unobtainable outside
of a single company.
What we need to take away from the XZ Backdoor (openSUSE News)
Post Syndicated from corbet original https://lwn.net/Articles/969591/
Dirk Mueller has posted a
lengthy analysis of the XZ backdoor on the openSUSE News site, with a
focus on openSUSE’s response.
Debian, as well as the other affected distributions like openSUSE
are carrying a significant amount of downstream-only patches to
essential open-source projects, like in this case OpenSSH. With
hindsight, that should be another Heartbleed-level learning for the
work of the distributions. These patches built the essential steps
to embed the backdoor, and do not have the scrutiny that they
likely would have received by the respective upstream
maintainers. Whether you trust Linus Law or not, it was not even
given a chance to chime in here. Upstream did not fail on the
users, distributions failed on upstream and their users here.
Security updates for Friday
Post Syndicated from daroc original https://lwn.net/Articles/969590/
Security updates have been issued by Debian (chromium), Fedora (rust, trafficserver, and upx), Mageia (postgresql-jdbc and x11-server, x11-server-xwayland, tigervnc), Red Hat (bind, bind9.16, gnutls, httpd:2.4, squid, unbound, and xorg-x11-server), SUSE (perl-Net-CIDR-Lite), and Ubuntu (apache2, maven-shared-utils, and nss).
Improving authoritative DNS with the official release of Foundation DNS
Post Syndicated from Hannes Gerhart original https://blog.cloudflare.com/foundation-dns-launch

We are very excited to announce the official release of Foundation DNS, with new advanced nameservers, even more resilience, and advanced analytics to meet the complex requirements of our enterprise customers. Foundation DNS is one of Cloudflare’s largest leaps forward in our authoritative DNS offering since its launch in 2010, and we know our customers are interested in an enterprise-ready authoritative DNS service with the highest level of performance, reliability, security, flexibility, and advanced analytics.
Starting today, every new enterprise contract that includes authoritative DNS will have access to the Foundation DNS feature set and existing enterprise customers will have Foundation DNS features made available to them over the course of this year. If you are an existing enterprise customer already using our authoritative DNS services, and you’re interested in getting your hands on Foundation DNS earlier, just reach out to your account team, and they can enable it for you. Let’s get started…
Why is DNS so important?
From an end user perspective, DNS makes the Internet usable. DNS is the phone book of the Internet which translates hostnames like www.cloudflare.com into IP addresses that our browsers, applications, and devices use to connect to services. Without DNS, users would have to remember IP addresses like 108.162.193.147 or 2606:4700:58::adf5:3b93 every time they wanted to visit a website on their mobile device or desktop – imagine having to remember something like that instead of just www.cloudflare.com. DNS is used in every end user application on the Internet, from social media to banking to healthcare portals. People’s usage of the Internet is entirely reliant on DNS.
From a business perspective, DNS is the very first step in reaching websites and connecting to applications. Devices need to know where to connect in order to reach services, authenticate users, and provide the information being requested. Resolving DNS queries quickly can be the difference between a website or application being perceived as responsive or not and can have a real impact on user experience.

When DNS outages occur, the impacts are obvious. Imagine your go-to ecommerce site not loading, just like what happened with the outage Dyn experienced in 2016, which took down multiple popular ecommerce sites among others. Or, if you are part of a company, and customers aren’t able to reach your website to purchase the goods or services you are selling, a DNS outage will literally lose you money. DNS is often taken for granted, but make no mistake, you’ll notice it when it’s not working properly. Thankfully, if you use Cloudflare Authoritative DNS, these are problems you don’t worry about very much.
There is always room for improvement
Cloudflare has been providing authoritative DNS services for over a decade. Our authoritative DNS service hosts millions of domains across many different top level domains (TLDs). We have customers of all sizes, from single domains with just a few records to customers with tens of millions of records spread across multiple domains. Our enterprise customers, rightfully, demand the highest level of performance, reliability, security, and flexibility from our DNS service, along with detailed analytics. While our customers love our authoritative DNS, we recognize there is always room for improvement in some of those categories. To that end, we set off to make some major improvements to our DNS architecture, with new features as well as structural changes. We are proudly calling this improved offering Foundation DNS.
Meet Foundation DNS
As our new enterprise authoritative DNS offering, Foundation DNS was designed to enhance the reliability, security, flexibility, and analytics of our existing authoritative DNS service. Before we dive into all the specifics of Foundation DNS, here is a quick summary of what Foundation DNS brings to our authoritative DNS offering:
- Advanced nameservers bring DNS reliability to the next level.
- New zone-level DNS settings provide more flexible configuration of DNS specific settings.
- Unique DNSSEC keys per account and zone provide additional security and flexibility for DNSSEC.
- GraphQL-based DNS analytics provide even more insights into your DNS queries.
- A new release process ensures enterprise customers have the utmost stability and reliability.
- Simpler DNS pricing with more generous quotas for DNS-only zones and DNS records.
Now, let’s dive deeper into each of these new Foundation DNS features:
Advanced nameservers
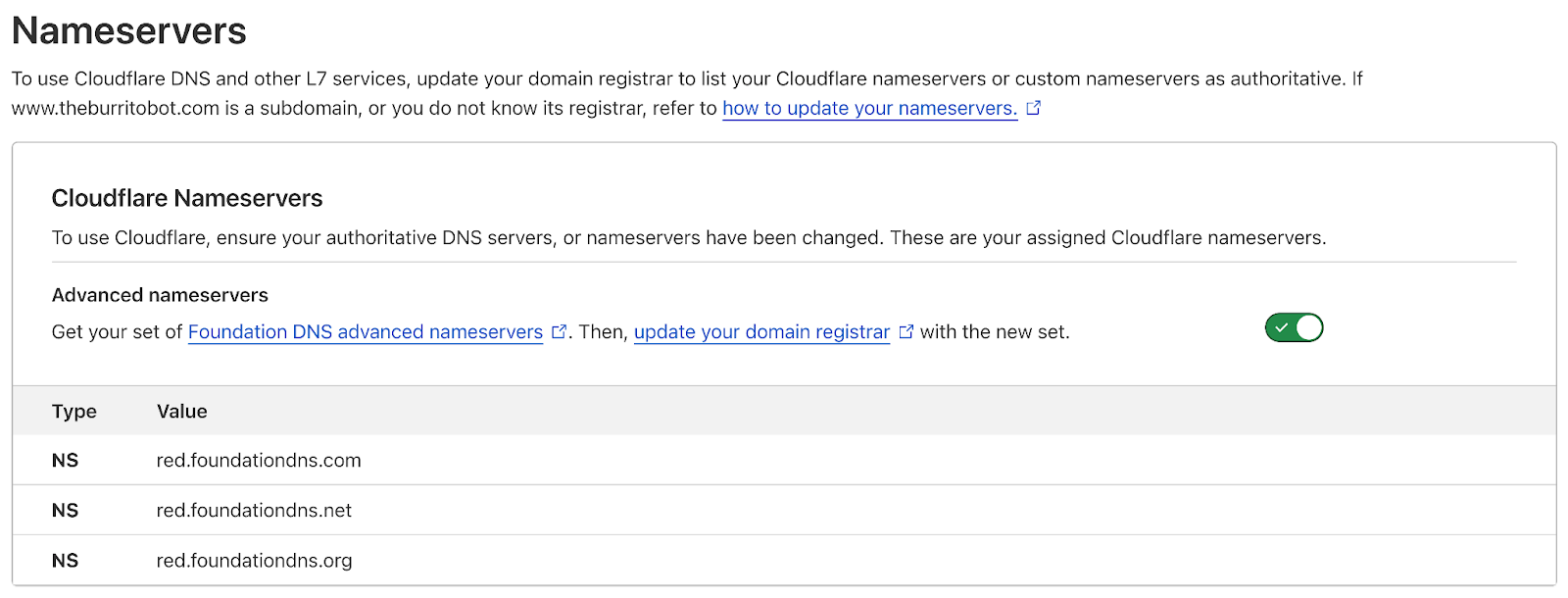
With Foundation DNS, we’re introducing advanced nameservers with a specific focus on enhancing reliability for your enterprise. You might be familiar with our standard authoritative nameservers which come as a pair per zone and use names within the cloudflare.com domain. Here’s an example:
$ dig mycoolwebpage.xyz ns +noall +answer
mycoolwebpage.xyz. 86400 IN NS kelly.ns.cloudflare.com.
mycoolwebpage.xyz. 86400 IN NS christian.ns.cloudflare.com.
Now, let’s look at the same zone using Foundation DNS advanced nameservers:
$ dig mycoolwebpage.xyz ns +noall +answer
mycoolwebpage.xyz. 86400 IN NS blue.foundationdns.com.
mycoolwebpage.xyz. 86400 IN NS blue.foundationdns.net.
mycoolwebpage.xyz. 86400 IN NS blue.foundationdns.org.
Advanced nameservers improve reliability in a few different ways. The first improvement comes from the Foundation DNS authoritative servers being spread across multiple TLDs. This provides protection from larger scale DNS outages and DDoS attacks that could potentially affect DNS infrastructure further up the tree, including TLD name servers. Foundation DNS authoritative nameservers are now located across multiple branches of the global DNS tree structure, further insulating our customers from these potential outages and attacks.
You might also have noticed that there is an additional nameserver listed with Foundation DNS. While this is an improvement, it’s not for the reason you might think it is. If we resolve each one of these nameservers to their respective IP addresses, we can make this a little easier to understand. Let’s do that here starting with our standard nameservers:
$ dig kelly.ns.cloudflare.com. +noall +answer
kelly.ns.cloudflare.com. 86353 IN A 108.162.194.91
kelly.ns.cloudflare.com. 86353 IN A 162.159.38.91
kelly.ns.cloudflare.com. 86353 IN A 172.64.34.91
$ dig christian.ns.cloudflare.com. +noall +answer
christian.ns.cloudflare.com. 86353 IN A 108.162.195.247
christian.ns.cloudflare.com. 86353 IN A 162.159.44.247
christian.ns.cloudflare.com. 86353 IN A 172.64.35.247
There are six total IP addresses for the two nameservers. As it turns out, this is all DNS resolvers actually care about when querying authoritative nameservers. DNS resolvers usually don’t track the actual domain names of authoritative servers; they simply maintain an unordered list of IP addresses that they can use to resolve queries for a given domain. So with our standard authoritative nameservers, we give resolvers six IP addresses to use to resolve DNS queries. Now, let’s look at the IP addresses for our Foundation DNS advanced nameservers:
$ dig blue.foundationdns.com. +noall +answer
blue.foundationdns.com. 300 IN A 108.162.198.1
blue.foundationdns.com. 300 IN A 162.159.60.1
blue.foundationdns.com. 300 IN A 172.64.40.1
$ dig blue.foundationdns.net. +noall +answer
blue.foundationdns.net. 300 IN A 108.162.198.1
blue.foundationdns.net. 300 IN A 162.159.60.1
blue.foundationdns.net. 300 IN A 172.64.40.1
$ dig blue.foundationdns.org. +noall +answer
blue.foundationdns.org. 300 IN A 108.162.198.1
blue.foundationdns.org. 300 IN A 162.159.60.1
blue.foundationdns.org. 300 IN A 172.64.40.1
Would you look at that! Foundation DNS provides the same IP addresses for each of the authoritative nameservers that we provide to a zone. So in this case, we have only provided three IP addresses for resolvers to use to resolve DNS queries. And you might be wondering,“isn’t six better than three? Isn’t this a downgrade?” It turns out more isn’t always better. Let’s talk about why.
You are probably aware of Cloudflare’s use of Anycast and, as you might assume, our DNS services leverage Anycast to ensure that our authoritative DNS servers are available globally and as close as possible to users and resolvers across the Internet. Our standard nameservers are all advertised out of every Cloudflare data center by a single Anycast group. If we zoom in on Europe, you can see that in a standard nameserver deployment, both nameservers are advertised from every data center.
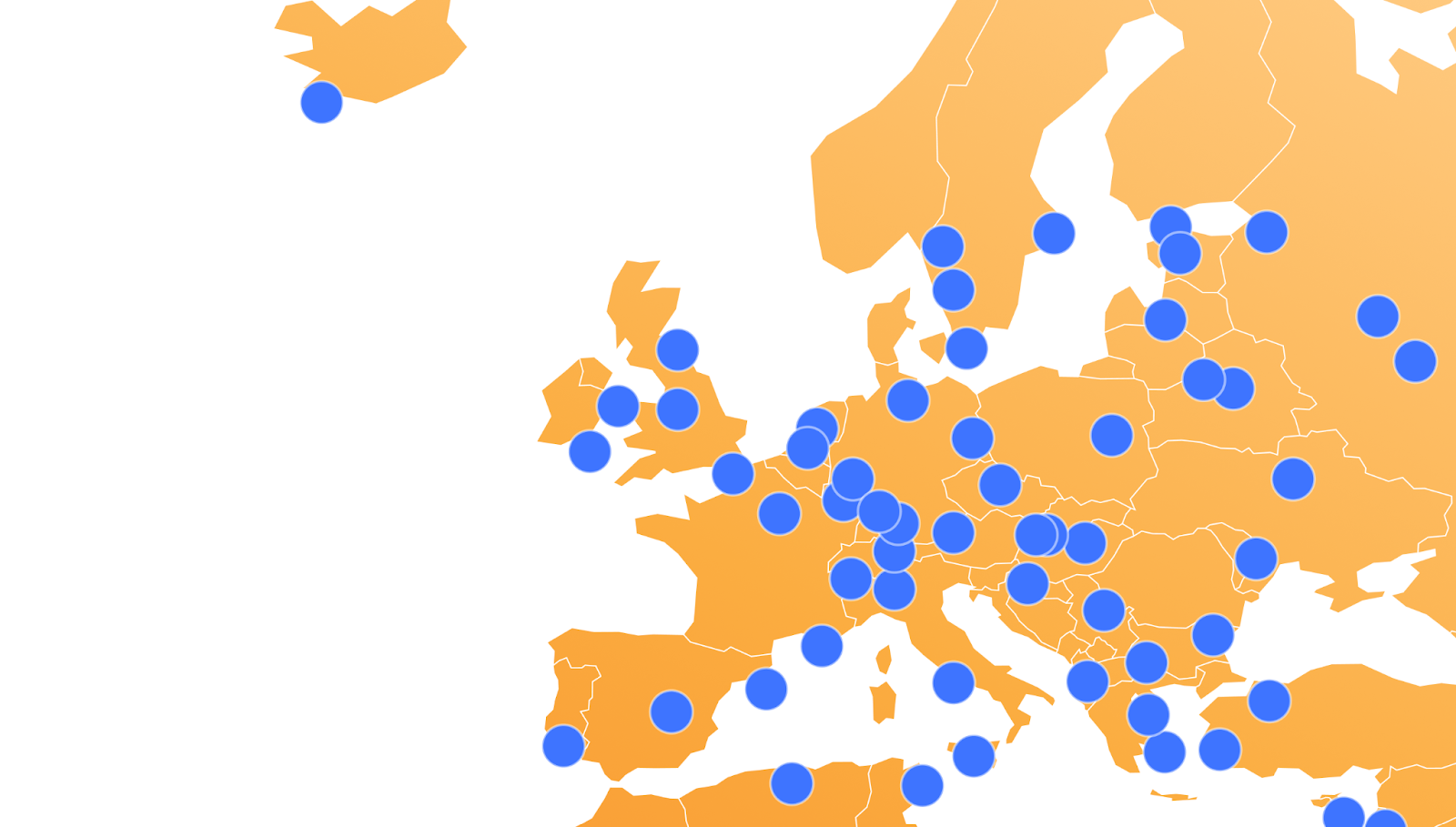
We can take those six IP addresses from our standard nameservers above and perform a lookup for their “hostname.bind” TXT record which will show us the airport code or physical location of the closest data center where our DNS queries are being resolved from. This output helps explain the reason why more isn’t always better.
$ dig @108.162.194.91 ch txt hostname.bind +short
"LHR"
$ dig @162.159.38.91 ch txt hostname.bind +short
"LHR"
$ dig @172.64.34.91 ch txt hostname.bind +short
"LHR"
$ dig @108.162.195.247 ch txt hostname.bind +short
"LHR"
$ dig @162.159.44.247 ch txt hostname.bind +short
"LHR"
$ dig @172.64.35.247 ch txt hostname.bind +short
"LHR"
As you can see, when queried from near London, all six of those IP addresses route to the same London (LHR) data center. Meaning that when a resolver in London is resolving DNS queries for a domain using Cloudflare’s standard authoritative DNS, no matter which nameserver IP address is being queried, they are always connecting to the same physical location.
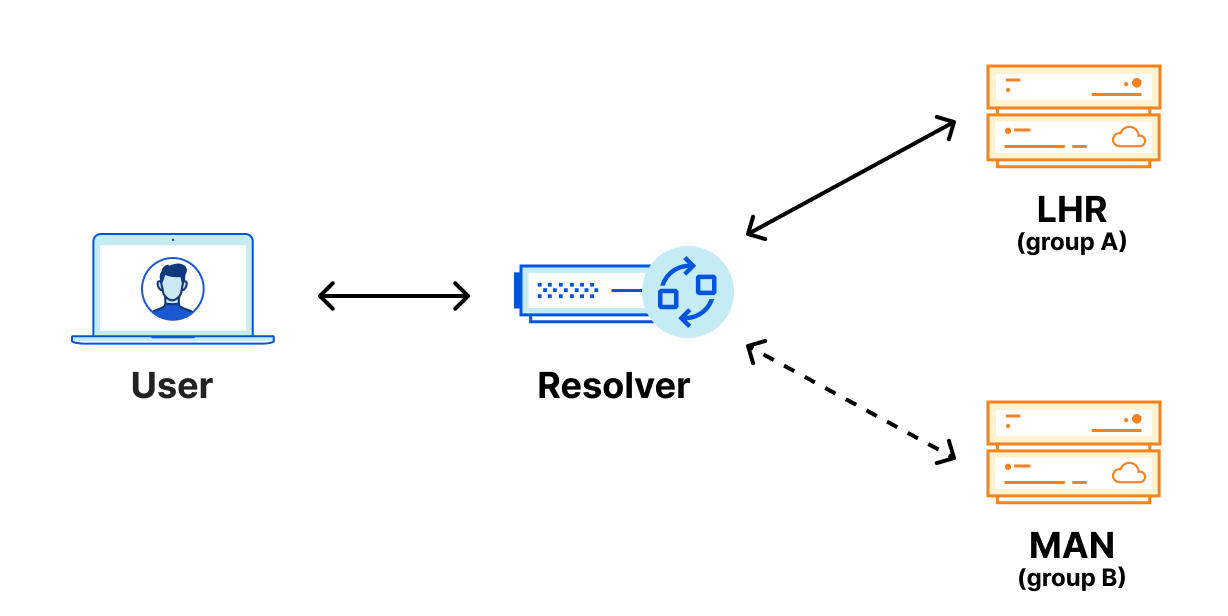
You might be asking, “So what? What does that mean to me?” Let’s look at an example. If you wanted to resolve a domain using Cloudflare standard nameservers from London, and I am using a public resolver that is also located in London, the resolver will always connect to the Cloudflare LHR data center regardless of which nameserver it’s trying to reach. It doesn’t have any other option, because of Anycast.
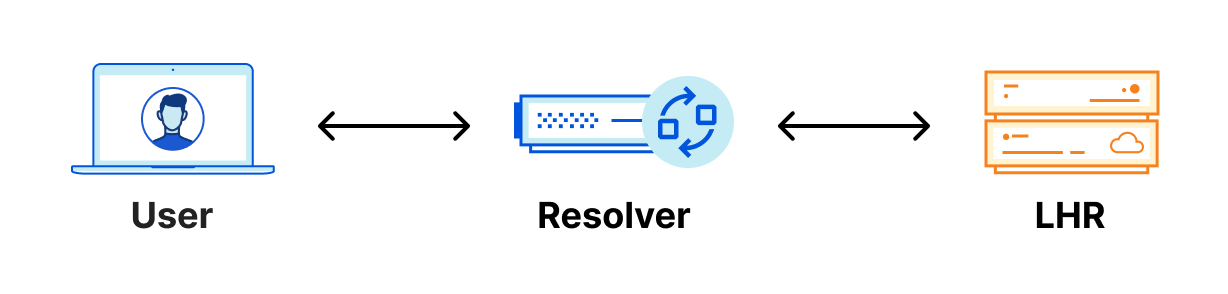
Because of Anycast, should the LHR data center go offline completely, all the traffic intended for LHR would be routed to other nearby data centers and resolvers would continue to function normally. However, in the unlikely scenario where the LHR data center was online, but our DNS services aren’t able to respond to DNS queries, the resolver would have no way to resolve these DNS queries since they can’t reach out to any other data center. We could have 100 IP addresses, and it would not help us in this scenario. Eventually, cached responses will expire, and the domain will eventually stop being resolved.
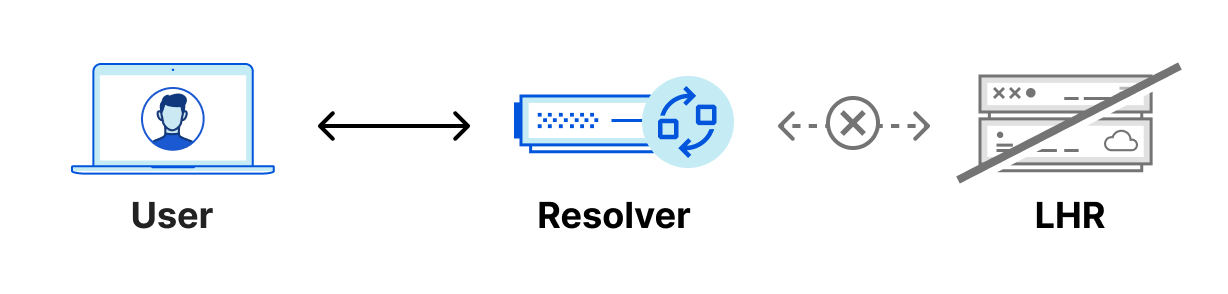
Foundation DNS advanced nameservers are changing the way we use Anycast by leveraging two Anycast groups, which breaks the previous paradigm of every authoritative nameserver IP being advertised from every data center. Using two Anycast groups means that Foundation DNS authoritative nameservers actually have different physical locations from one another, rather than all being advertised from each data center. Here is how that same region would look using two Anycast groups:
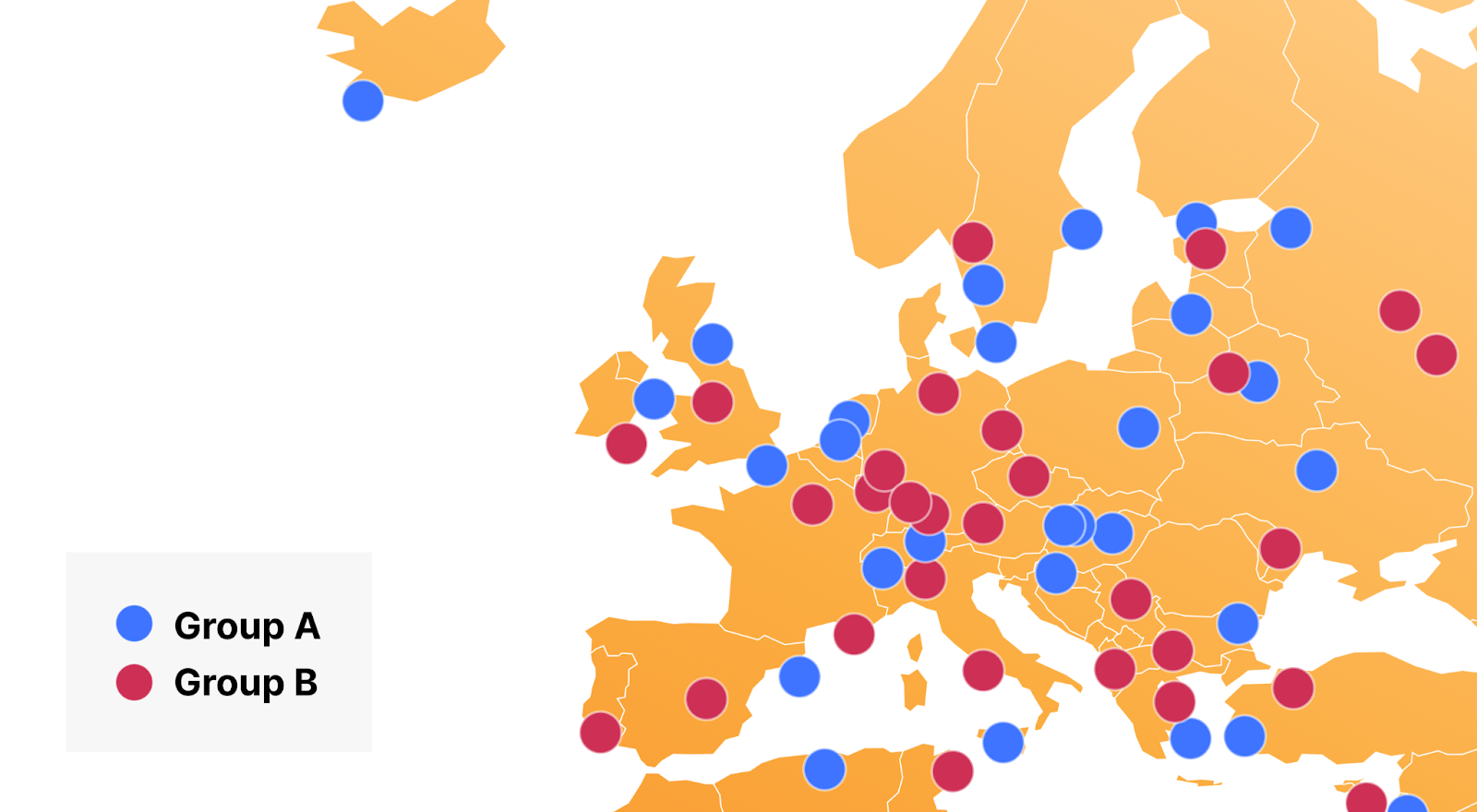
Let’s go back and finish our comparison of six authoritative IP addresses for standard authoritative DNS vs three IP addresses for Foundation DNS now that it’s understood that Foundation DNS is using two Anycast groups for advertising nameservers. Let’s see where Foundation DNS servers are being advertised from for our example:
$ dig @108.162.198.1 ch txt hostname.bind +short
"LHR"
$ dig @162.159.60.1 ch txt hostname.bind +short
"LHR"
$ dig @172.64.40.1 ch txt hostname.bind +short
"MAN"
Look at that! One of our three nameserver IP addresses is being advertised out of a different data center, Manchester (MAN), making Foundation DNS more reliable and resilient for the previously mentioned outage scenario. It’s worth mentioning that in some cities, Cloudflare operates out of multiple data centers which will result in all three queries returning the same airport code. While we guarantee that at least one of those IP addresses is being advertised out of a different data center, we understand some customers may want to test for themselves. In those cases, an additional query can show that IP addresses are being advertised out of different data centers.
$ dig @108.162.198.1 +nsid | grep NSID:
; NSID: 39 34 6d 33 39 ("94m39")
In the “94m30” returned in the response, the number before the “m” represents the data center that answered the query. As long as that number is different in one of the three responses, you know that one of your Foundation DNS authoritative nameservers is being advertised out of a different physical location.
With Foundation DNS leveraging two Anycast groups, the previous outage scenario is handled seamlessly. DNS resolvers monitor requests to all the authoritative nameservers returned for a given domain, but primarily use the nameserver that is providing the fastest responses.
With this configuration, DNS resolvers are able to send requests to two different Cloudflare data centers, so, should a failure happen at one physical location, queries are then automatically sent to the second data center where they can be properly resolved.
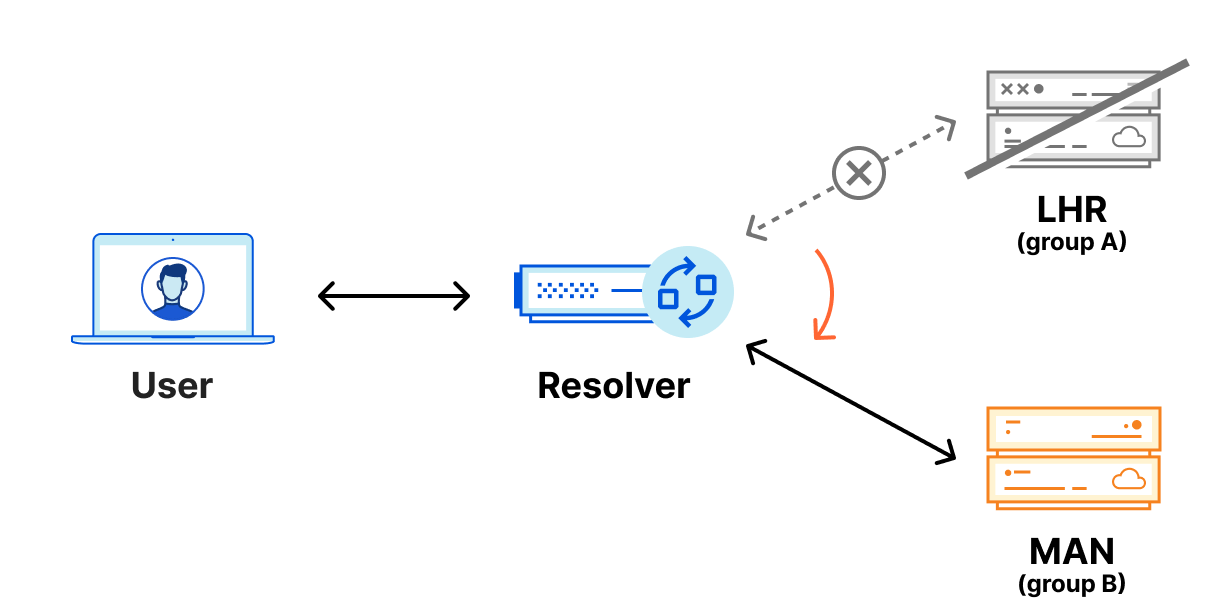
Foundation DNS advanced nameservers are a big step forward in reliability for our enterprise customers. We welcome our enterprise customers to enable advanced nameservers for existing zones today. Migrating to Foundation DNS won’t involve any downtime either because even after Foundation DNS advanced nameservers are enabled for a zone, the previous standard authoritative DNS nameservers will continue to function and respond to queries for the zone. Customers don’t need to plan for a cutover or other service-impacting event to migrate to Foundation DNS advanced nameservers.
New zone-level DNS settings
Historically, we have received regular requests from our enterprise customers to adjust specific DNS settings that were not exposed via our API or dashboard, such as enabling secondary DNS overrides. When customers wanted these settings adjusted, they had to reach out to their account teams, who would change the configurations. With Foundation DNS, we are exposing the most commonly requested settings via the API and dashboard to give our customers increased flexibility with their Cloudflare authoritative DNS solution.
Enterprise customers can now configure the following DNS settings on their zones:
| Setting | Zone Type | Description |
|---|---|---|
| Foundation DNS advanced nameservers | Primary and secondary zones | Allows you to enable advanced nameservers on your zone. |
| Secondary DNS override | Secondary zones | Allows you to enable Secondary DNS Override on your zone in order to proxy HTTP/S traffic through Cloudflare. |
| Multi-provider DNS | Primary and secondary zones | Allows you to have multiple authoritative DNS providers while using Cloudflare as a primary nameserver. |
Unique DNSSEC keys per account and zone
DNSSEC, which stands for Domain Name System Security Extensions, adds security to a domain or zone by providing a way to check that the response you receive for a DNS query is authentic and hasn’t been modified. DNSSEC prevents DNS cache poisoning (DNS spoofing) which helps ensure that DNS resolvers are responding to DNS queries with the correct IP addresses.
Since we launched Universal DNSSEC in 2015, we’ve made quite a few improvements, like adding support for pre-signed DNSSEC for secondary zones and multi-signer DNSSEC. By default, Cloudflare signs DNS records on the fly (live signing) as we respond to DNS queries. This allows Cloudflare to host a DNSSEC-secured domain while dynamically allocating IP addresses for the proxied origins. It also enables certain load balancing use cases since the IP addresses served in the DNS response in these cases change based on steering.
Cloudflare uses the Elliptic Curve algorithm ECDSA P-256, which is stronger than most RSA keys used today. It uses less CPU to generate signatures, making them more efficient to generate on the fly. Usually two keys are used as part of DNSSEC, the Zone Signing Key (ZSK) and the Key Signing Key (KSK). At the simplest level, the ZSK is used for signing the DNS records that are served in response to queries and the KSK is used to sign the DNSKEYs, including the ZSK to ensure its authenticity.
Today, Cloudflare uses a shared ZSK and KSK globally for all DNSSEC signing, and since we use such a strong cryptographic algorithm, we know how secure this key set is and as such, do not believe there is a need to regularly rotate the ZSK or KSK – at least for security reasons. There are customers, however, that have policies that require the rotation of these keys at certain intervals. Because of this, we’ve added the ability for our new Foundation DNS advanced nameservers to rotate both their ZSK and KSK as needed per account or per zone. This will first be available via the API and subsequently through the Cloudflare dashboard. So now, customers with strict policy requirements around their DNSSEC key rotation can meet those requirements with Cloudflare Foundation DNS.
GraphQL-based DNS analytics
For those who are not familiar with it, GraphQL is a query language for APIs and a runtime for executing those queries. It allows clients to request exactly what they need, no more, no less, enabling them to aggregate data from multiple sources through a single API call, and supports real-time updates through subscriptions.
As you might know, Cloudflare has had a GraphQL API for a while now, but as part of Foundation DNS we are adding a new DNS dataset to that API that is only available with our new Foundation DNS advanced nameservers.
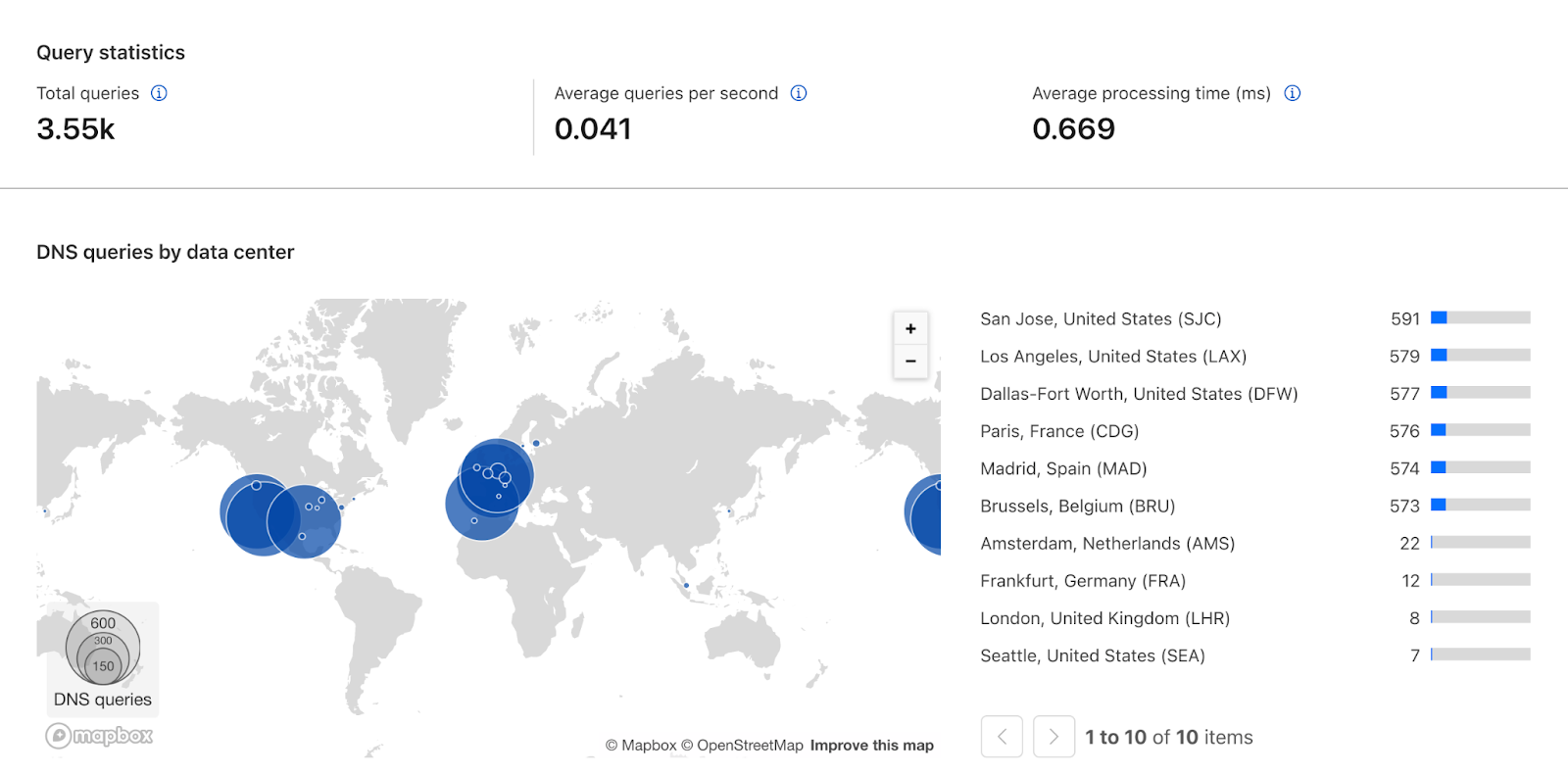
The new DNS dataset in our GraphQL API can be used to fetch information about the DNS queries a zone has received. This faster and more powerful alternative to our current DNS Analytics API allows you to query data from large time periods quickly and efficiently without running into limits or timeouts. The GraphQL API is more flexible with regard to which queries it accepts, and exposes more information than the DNS Analytics API.
For example, you can run this query to fetch the mean and 90th percentile processing time of your queries, grouped by source IP address, in 15 minute buckets. A query like this would be useful to see which IPs are querying your records most often for a given time range:
{
"query": "{
viewer {
zones(filter: { zoneTag: $zoneTag }) {
dnsAnalyticsAdaptiveGroups(
filter: $filter
limit: 10
orderBy: [datetime_ASC]
) {
avg {
processingTimeUs
}
quantiles {
processingTimeUsP90
}
dimensions {
datetimeFifteenMinutes
sourceIP
}
}
}
}
}",
"variables": {
"zoneTag": "<zone-tag>",
"filter": {
"datetime_geq": "2024-05-01T00:00:00Z",
"datetime_leq": "2024-06-01T00:00:00Z"
}
}
}
Previously, a query like this wouldn’t have been possible for several reasons. The first is that we have added new fields like sourceIP, which allows us to filter data based on which client IP addresses (usually resolvers) are making DNS queries. The second is that the GraphQL API query is able to process and return data from much larger time ranges. A DNS zone with sufficiently large amounts of queries was previously only able to query across a few days of traffic, while the new GraphQL API can provide data for a period of up to 31 days. We are planning further enhancements to that range, as well as how far back historical data can be stored and queried.
The GraphQL API also allows us to add a new DNS analytics section to the Cloudflare dashboard. Customers will be able to track the most queried records, see which data centers are answering those queries, see how many queries are being made, and much more.
The new DNS dataset in our GraphQL API and the new DNS analytics page work together to help our DNS customers to monitor, analyze, and troubleshoot their Foundation DNS deployments.
New release process
Cloudflare’s Authoritative DNS product receives software updates roughly once a week. Cloudflare has a sophisticated release process that helps prevent regressions from affecting production traffic. While uncommon, it’s possible to have issues only surface once the new release is subject to the volume and uniqueness of production traffic.
Because our enterprise customers desire stability even more than new features, new releases will be subject to a two-week soak time with our standard nameservers before our Foundation DNS advanced nameservers are upgraded. After two weeks with no issues, the Foundation DNS advanced nameservers will be upgraded as well.
Zones using Foundation DNS advanced nameservers will see increased reliability as they are better protected against regressions in new software releases.
Simpler DNS pricing
Historically, Cloudflare has charged for Authoritative DNS based on monthly DNS queries and the number of domains in the account. Our enterprise DNS customers are often interested in DNS-only zones, which are DNS zones hosted in Cloudflare that do not use our reverse proxy (layer 7) services such as our CDN, WAF, or Bot Management. With Foundation DNS, we’re making pricing simpler for the vast majority of those customers by including 10,000 DNS only domains by default. This change means most customers will only pay for the number of DNS queries they consume.
We’re also including 1 million DNS records across all domains in an account. But that doesn’t mean we can’t support more. In fact, the biggest single zone on our platform has over 3.9 million records, while our largest DNS account is just shy of 30 million DNS records spread across multiple zones. With Cloudflare DNS, there is no trouble handling even the largest deployments.
There is more to come
We are just getting started. In the future, we will add more exclusive features to Foundation DNS. One example is a highly requested feature: per-record scoped API tokens and user permissions. This will allow you to configure permissions on an even more granular level. For example, you could specify that a particular member of your account is only allowed to create and manage records of the type TXT and MX, so they don’t accidentally delete or edit address records impacting web traffic to your domain. Another example would be to specify permissions based on subdomain to further restrict the scope of specific users.
If you’re an existing enterprise customer and want to use Foundation DNS, get in touch with your account team to provision Foundation DNS on your account.