Have an idea on how to expand on Metasploit Documentation on https://docs.metasploit.com/? Did you see a typo or some other error on the docs site? Thanks to adfoster-r7, submitting an update to the documentation is as easy as clicking the ‘Edit this page on GitHub’ link on the page you want to change. The new link will take you directly to the source in Metasploit’s GitHub so you can quickly locate the Markdown and submit a PR.
New module content (3)
Mirage firewall for QubesOS 0.8.0-0.8.3 Denial of Service (DoS) Exploit
Author: Krzysztof Burghardt
Type: Auxiliary
Pull request: #17348 contributed by burghardt
AttackerKB reference: CVE-2022-46770
Description: This PR adds a module that performs a DoS attack on Mirage Firewall versions 0.8.0-0.8.3.
WordPress Paid Membership Pro code Unauthenticated SQLi
Authors: Joshua Martinelle and h00die
Type: Auxiliary
Pull request: #17479 contributed by h00die
AttackerKB reference: CVE-2023-23488
Description: This adds an exploit module that leverages an unauthenticated SQLi against WordPress plugin Paid Membership Pro. This vulnerability is identified as CVE-2023-23488 and affects versions prior to 2.9.8. This module retrieves WordPress usernames and password hashes using Time-Based Blind SQL Injection technique.
Authors: Jakub Kramarz and h00die-gr3y
Type: Exploit
Pull request: #17449 contributed by h00die-gr3y
AttackerKB reference: CVE-2021-44529
Description: A new module has been added for CVE-2021-44529, an unauthenticated code injection vulnerability in the Ivanti EPM Cloud Services Appliance (CSA) before version 4.6.0-512. Successful exploitation requires sending a crafted cookie to the client endpoint at /client/index.php to get command execution as the nobody user.
Enhancements and features (5)
#17343 from h00die – This makes performance improvements to the windows/local/unquoted_service_path module.
#17451 from h00die – This adds netntlm and netntlmv2 hashes support to auxiliary/analyze/crack_windows module.
#17466 from prabhatjoshi321 – This updates the auxiliary/scanner/smb/smb_version module to store additional service information in the database so it can be viewed later.
#17473 from adfoster-r7 – Updates the docs site to have an edit link at the bottom of each page which will take you to the corresponding markdown file on Github for editing.
#17480 from h00die – A new alias has been added for payloads called exploit which will perform the same action as to_handler, to help users familiar with exploit modules to use the same familiar exploit method to open handlers when using payloads.
Bugs fixed (3)
#17385 from smashery – This fixes the file write and file append methods to return the expected Boolean values rather than nil.
#17482 from adfoster-r7 – Fixes a connection issue with reverse_https stagers that are executed on Windows servers attempting to negotiate TLS1 when Metasploit was using OpenSSL3.
#17491 from zeroSteiner – A bug has been fixed in the lib/msf/core/exploit/remote/ldap.rb library that handles LDAP communications for several modules to ensure that failures use the right namespace when throwing errors to prevent crashes.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the binary installers (which also include the commercial edition).
The kernel project does not host much user-space code in its repository,
but there are exceptions. One of those, currently found in the tools/include/nolibc
directory, has only been present since the 5.1 release. The nolibc project
aims to provide minimal C-library emulation for small, low-level workloads.
Read on for an overview of nolibc, its history, and future direction
written by its principal contributor.
Security updates have been issued by Debian (lava and libitext5-java), Oracle (java-11-openjdk, java-17-openjdk, and libreoffice), SUSE (firefox, git, mozilla-nss, postgresql-jdbc, and sudo), and Ubuntu (git, linux-aws-5.4, linux-gkeop, linux-hwe-5.4, linux-oracle, linux-snapdragon, linux-azure, linux-gkeop, linux-intel-iotg, linux-lowlatency,
linux-lowlatency-hwe-5.15, linux-oracle-5.15, and linux-bluefield).
This post is written by Swarna Kunnath (Cloud Application Architect), and Anand Komandooru (Sr. Cloud Application Architect).
This blog post shows how to republish messages that arrive from Internet of Things (IoT) devices across AWS accounts using a replatforming approach. A replatforming approach minimizes changes to the core application architecture, allowing an organization to reduce risk and meet business needs more quickly. In this post, you also learn how to track an IoT device’s location using the Amazon Location Service.
The example used in this post relates to an aviation company that has airplanes with line replacement unit devices or transponders. Transponders are IoT devices that send airplane geospatial data (location and altitude) to the AWS IoT Core service. The company’s airplane transponders send location data to the AWS IoT Core service provisioned in an existing AWS account (source account). The solution required manual intervention to track airplane location sent by the transponders.
They must rearchitect their application due to an internal reorganization event. As part of the rearchitecture approach, the business decides to enhance the application to process the transponder messages in another AWS account (destination account). In addition, the business needs full automation of the airplane’s location tracking process, to minimize the risk of the application changes, and to deliver the changes quickly.
Solution overview
The high-level solution republishes the IoT messages from the source account to the destination account using AWS IoT Core, Amazon SQS,AWS Lambda, and integrates the application with Amazon Location Service. IoT messages are replicated to an IoT topic in the destination account for downstream processing, minimizing changes to the original application architecture. Integration with Amazon Location Service automates the process of device location tracking and alert generation.
The AWS IoT platform allows you to connect your internet-enabled devices to the AWS Cloud via MQTT, HTTP, or WebSocket protocol. Once connected, the devices send data to the MQTT topics. Data ingested on MQTT topics is routed into AWS services (Amazon S3, SQS, Amazon DynamoDB, and Lambda) by configuring rules in the AWS IoT Rules Engine. The AWS IoT Rules Engine offers ways to define queries to format and filter messages published by these devices, and supports integration with several other AWS services as targets.
The Amazon Location Service lets you add geospatial data including capabilities such as maps, points of interest, geocoding, routing, geofences, and tracking. The tracker with geofence tracks the location of the device based on the geospatial data in the published IoT messages. Amazon Location Service generates enter and exit events and integrates with Amazon EventBridge and Amazon Simple Notification Service (Amazon SNS) to generate alerts based on defined filters in EventBridge rules.
The solution in this post delivers high availability, scalability, and cost efficiency by using serverless and managed services. The serverless services used by this solution also provide automatic scaling and built-in high availability. Integrating Amazon Location Service with AWS IoT and EventBridge helps to automate the auditing and processing of geospatial messages.
Solution architecture
These steps describe an end-to-end sequence of events:
An IoT device (a transponder in an airplane) publishes a message to the AWS IoT Core service in the source account.
The message arrives at an AWS IoT Core topic in the source account.
AWS IoT Rules Engine receives the message and processes it, using IoT rules attached to the corresponding topic in the source account.
An AWS IoT rule replicates the message to an SQS queue in the destination account.
A Lambda function in the destination account polls the SQS queue and publishes received messages in batches to the destination account IoT topic.
The Location action configured to the IoT rule sends the messages to Amazon Location Service tracker from the IoT topic.
An Amazon Location tracker sends events when an IoT device enters or exits a linked geofence.
EventBridge receives these events and, via the configured event rule, sends out SNS notifications for the configured devices.
Pre-requisites
This example has the following prerequisites:
Access to the AWS services mentioned in this blog post within two AWS Accounts.
To deploy this solution, first deploy IoT components via the AWS Serverless Application Model (AWS SAM), in the source and destination accounts. After, configure Amazon Location Service resources in the destination account. To learn more, visit the AWS SAM deployment documentation.
acct1-source-iot-template.yaml: This configures the SQS queue created in the destination account. It’s a target to the IoT topic in the source account with appropriate cross account IAM access permissions.
To build and deploy the code, run:
sam build --template <TemplateName>.yaml
sam deploy --guided
Configuring a tracker
Amazon Location Trackers send device location updates that provide data to retrieve current and historical locations for devices.
Using Amazon Location Trackers and Amazon Location Geofences together, you can automatically evaluate the location updates from your IoT devices against your geofences to generate the geofence events. Actions could be taken to generate the alerts based on the areas of interest.
Follow the instructions in the documentation to create the tracker resource from the AWS Management Console. Use this information for the new tracker:
Name: Enter a unique name that has a maximum of 100 characters. For example, FlightTracker.
Description: Enter an optional description. For example, Tracker for storing device positions.
Configure a Location action to the destination IoT rule that receives messages from the destination IoT topic and publishes them in batches to the configured Tracker device (for example, FlightTracker). The parameters in the JSON data that is returned to the Location action can also be configured via substitution templates.
Geofence collection
Geofences contain points and vertices that form a closed boundary, which defines an area of interest. For example, flight origin and destination details. You can use tools, such as GeoJSON.io, to draw geofences and save the output as a GeoJSON file. Follow the instructions in the documentation to create the GeoJSON file and link it to the geofence collection.
Create the geofence collection with a GeoJSON file and link it to the tracker you just created.
Link the tracker to the geofence by following these instructions and start tracking the device’s location updates. You can link them together so that you automatically evaluate location updates against all your geofences. You can evaluate device positions against geofences on demand as well.
When device positions are evaluated against geofences, they generate events. For example, when a plane enters or exits a location specified in the geofence.
You can configure EventBridge with rules to react to these events. You can set up SNS to notify your clients when a specific tracker device location changes. Follow the instructions in the documentation on how to set up EventBridge rules to integrate with Amazon Location Service events.
Testing the solution
You can test the first part of the solution by sending an IoT message with location details in the JSON format from the source account and verify that the message arrives at the destination account SQS queue. Detailed instructions to publish a test message from the source account that includes location information (latitude and longitude) can be found here.
Messages from the destination account SQS queue are published to the Amazon Location Service Tracker. When the location in the test message matches the criteria provided in the geofence, Amazon Location Service generates an event. EventBridge has a rule configured that gets matched when an Amazon Location tracker event arrives, and the rule target is an SNS topic that sends an email or text message to the client.
Cleaning up
To avoid incurring future charges, delete the CloudFormation stacks, location tracker, and geofence collection created as part of the solution walk-through. Replace the resource identifiers in the following commands with the ID/name of the resources.
This blog post shows how to create a serverless solution for cross account IoT message publishing and tracking device location updates using Amazon Location Service.
It describes the process of how to publish AWS IoT messages across multiple accounts. Integration with the Amazon Location Service shows how to track IoT device location updates and generate alerts, alleviating the need for manual device location tracking.
For more serverless learning resources, visit Serverless Land.
When configuring monitoring and using templates in Zabbix you often see low-level discovery (LLD) used for finding out the monitored components or features of a host. In this post, I will explain how user macros and regular expressions are used in LLD for filtering the discovery results.
I’m using the Network Generic Device by SNMP template as an example. (Note that by using the dropdown menu in the top of that linked page you can select the Zabbix version you are using. It defaults to Master, which means the latest Zabbix version that is being developed, currently 6.4.)
Let’s see the Network interfaces discovery rule and specifically the Filters tab:
All these filters use regular expressions to match (or not match) the LLD macro value. For example:
{#IFNAME} matches {$NET.IF.IFNAME.MATCHES}
These are the macros defined in the template:
There we see that {$NET.IF.IFNAME.MATCHES} is defined with a value: ^.*$
That is a regular expression (often called regexp or regex). I won’t try to make this post a full regular expression tutorial, but there is:
^ = match the beginning of the string
. = match any single character
* = match zero or more occurrences of the previous element (which is any character in this case)
$ = match the end of the string
Basically, that means: “match any kind of string, empty or not”
(In this case a shorter .* would mean the exact same thing, but that’s how the template was configured when I downloaded it.)
When the discovery runs, it finds all network interfaces and assigns values to all of the LLD macros (like the interface name to {#IFNAME}), and then the filters are tested.
In the LLD filters Type of calculation is usually set to “And” (see the first screenshot), so that all filters need to be true for the interface to be discovered (in other words, if any of the filters is false, then no item is created for that interface).
If you want to change the filtering by modifying the macros, here is the thing:
You don’t modify the macros in the template.
You should modify the macros in the host that is using the template.
When you go to the Macros tab on your host, there is the Inherited and host macros button. After clicking it, you will also see all macros that are defined in the templates that the host is using:
You can click the Change link for any of the macros to enter a new value for that macro, and that value will then be used for everything for this host. The value in the template will thus act as a default value that is used whenever there is no other value set at the host level.
If you for example want to discover only interfaces that start with “wan”, “lan” or “vlan”, you can use this regexp in {$NET.IF.IFNAME.MATCHES} macro (again, change it in the host macros, not in the template): ^(wan|lan|vlan)
It means:
match “wan”, “lan” or “vlan”
but only if they are in the beginning of the string.
This is the same, just grouped differently: (^wan|^lan|^vlan)
If you at the same time want to exclude interface “vlan999”, you can use {$NET.IF.IFNAME.NOT_MATCHES} macro for that (note the “does not match” selection in the LLD filters list). The default value for that macro is:
Quite a mouthful, but it is basically a long list of “or” patterns separated by the vertical bar (|). You can add your own exclusion there inside the parenthesis, separated by |, or if you know that’s the only thing you want to exclude in that particular host, you can just replace the whole string with ^vlan999$ to exclude only vlan999 (and not for example lan999 or vlan9999). Note the use of ^ and $ to make sure it only matches the full interface name, not any partial names.
A common “not matches” macro value for me is something like this: ^(Nu|Tunnel|Loopback|VoIP)
It will exclude all those Null0, Loopback0 and other virtual interfaces that may exist on the device by default but won’t usually be useful in Zabbix statistics. I will always exclude these kinds of interfaces to reduce polling intensity and save database capacity.
It should also be said that all these regular expressions are case-sensitive, so use upper case or lower case as appropriate in your particular device, or expand the regexp to include various syntaxes as needed.
To conclude: When you want to reconfigure the discovery for a host:
See the filters that are used in the discovery rule
Check which macros are used in the filters
In the host you are configuring, change the macro values to achieve the desired filtering results.
This post was originally published on the author’s blog.
Cloudflare operates in more than 250 cities in over 100 countries, where we interconnect with over 10,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
While Internet disruptions are never convenient, online interest in the 2022 World Cup in mid-November and the growth in online holiday shopping in many areas during November and December meant that connectivity issues could be particularly disruptive. Having said that, the fourth quarter appeared to be a bit quieter from an Internet disruptions perspective, although Iran and Ukraine continued to be hotspots, as we discuss below.
Government directed
Multi-hour Internet shutdowns are frequently used by authoritarian governments in response to widespread protests as a means of limiting communications among protestors, as well preventing protestors from sharing information and video with the outside world. During the fourth quarter Cuba and Sudan again implemented such shutdowns, while Iran continued the series of “Internet curfews” across mobile networks it started in mid-September, in addition to implementing several other regional Internet shutdowns.
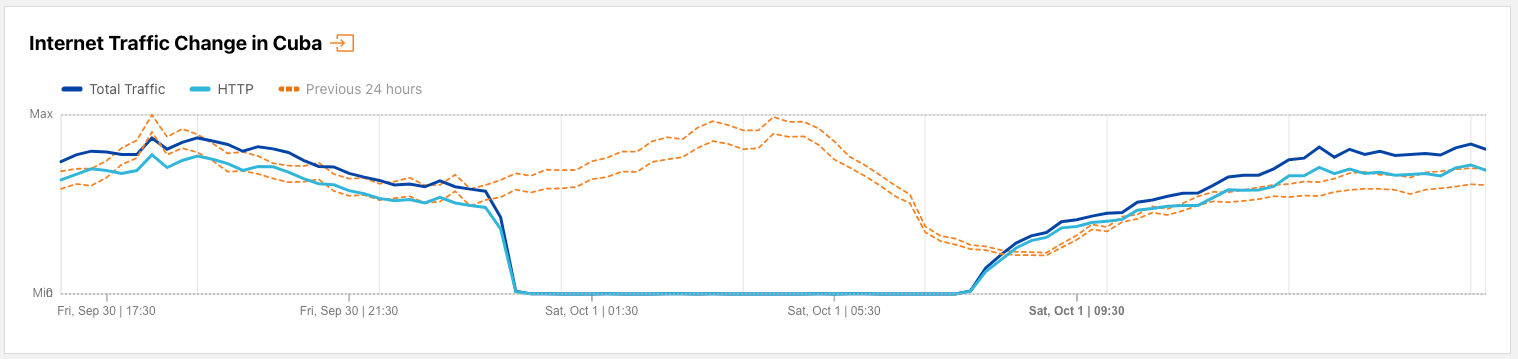
Cuba
In late September, Hurricane Ian knocked out power across Cuba. While officials worked to restore service as quickly as possible, some citizens responded to perceived delays with protests that were reportedly the largest since anti-government demonstrations over a year earlier. In response to these protests, the Cuban government reportedly cut off Internet access several times. A shutdown on September 29-30 was covered in the Internet disruptions overview for Q3 2022, and the impact of the shutdown that occurred on October 1 (UTC) is shown in the figure below. The timing of this one was similar to the previous one, taking place between 1900 on September 30 and 0245 on October 1 (0000-0745 UTC on October 1).
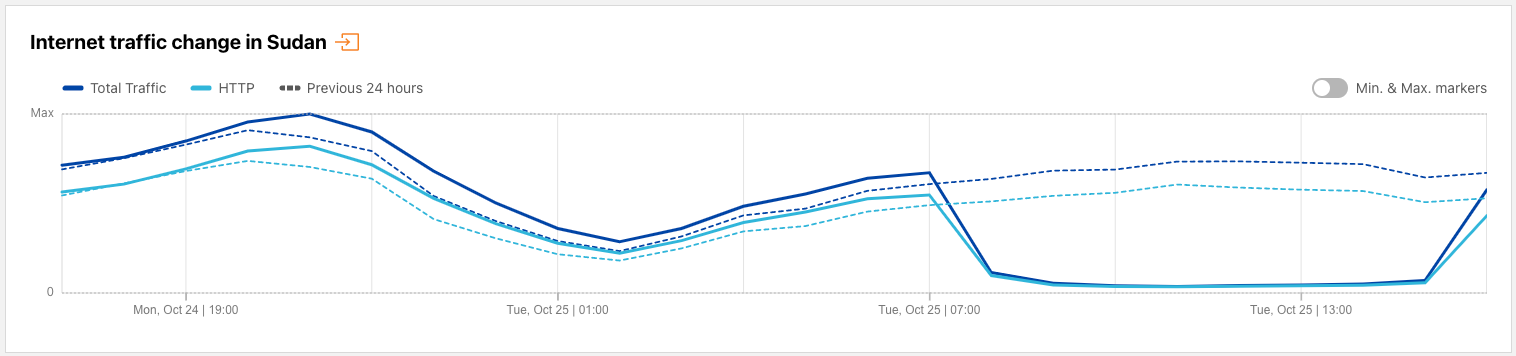
Sudan
October 25 marked the first anniversary of a coup in Sudan that derailed the country’s transition to civilian rule, and thousands of Sudanese citizens marked the anniversary by taking to the streets in protest. Sudan’s government has a multi-year history of shutting down Internet access during times of civil unrest, and once again implemented an Internet shutdown in response to these protests. The figure below shows a near complete loss of Internet traffic from Sudan on October 25 between 0945-1740 local time (0745 – 1540 UTC).
Iran
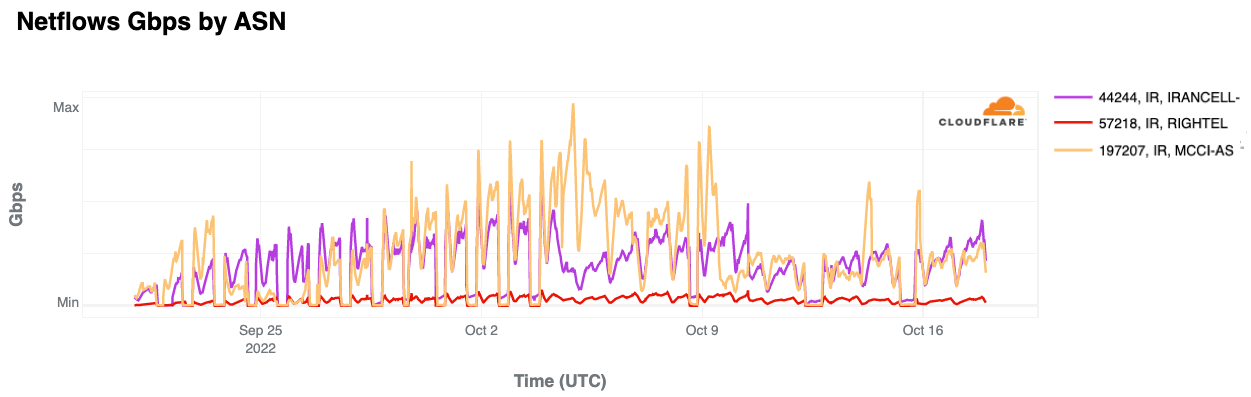
As we covered in last quarter’s blog post, the Iranian government implemented daily Internet “curfews”, generally taking place between 1600 and midnight local time (1230-2030 UTC) across three mobile network providers — AS44244 (Irancell), AS57218 (RighTel), and AS197207 (MCCI) — in response to protests surrounding the death of Mahsa Amini. These multi-hour Internet curfew shutdowns continued into early October, with additional similar outages also observed on October 8, 12 and 15 as seen in the figure below. (The graph’s line for AS57218 (Rightel), the smallest of the three mobile providers, suggests that the shutdowns on this network were not implemented after the end of September.)
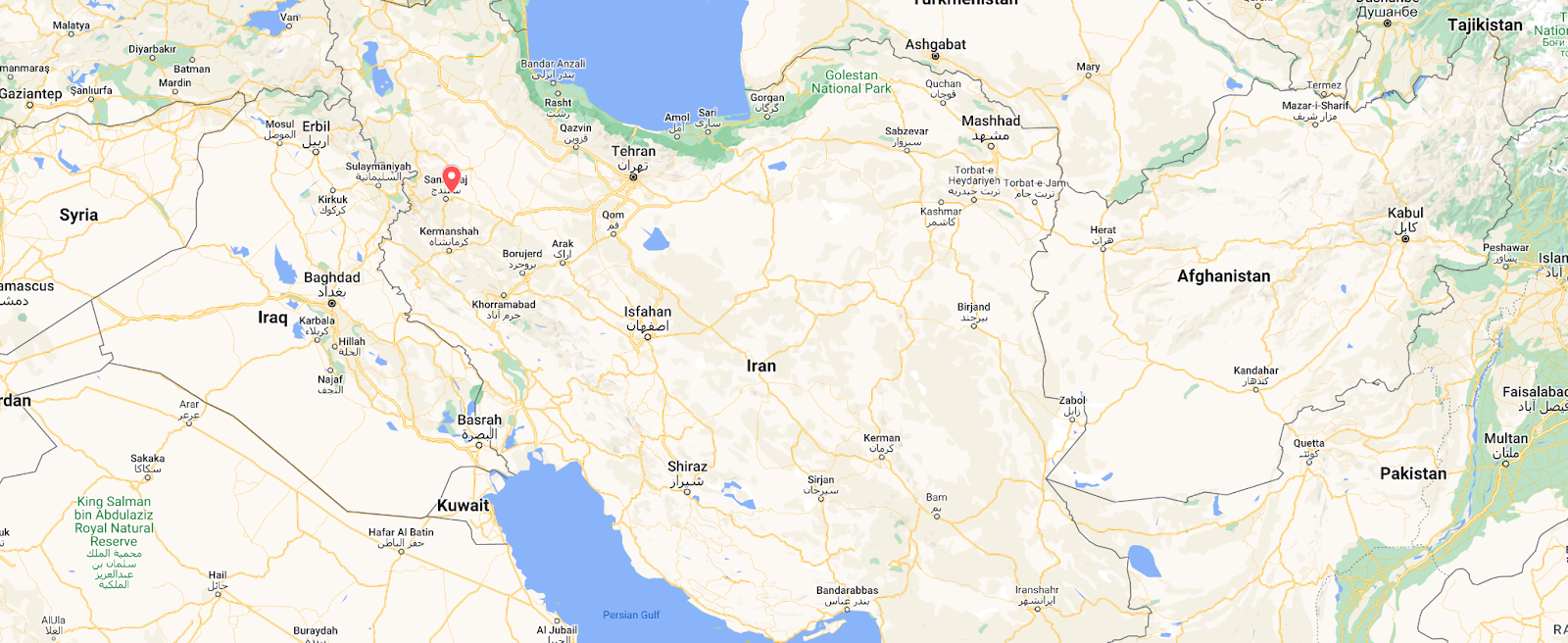
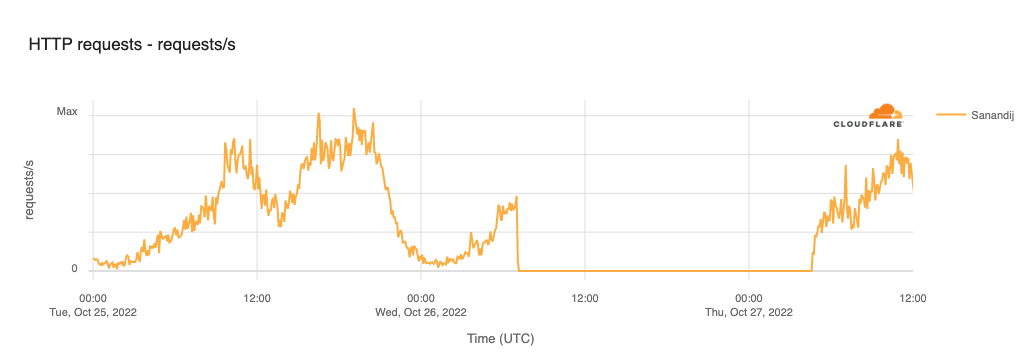
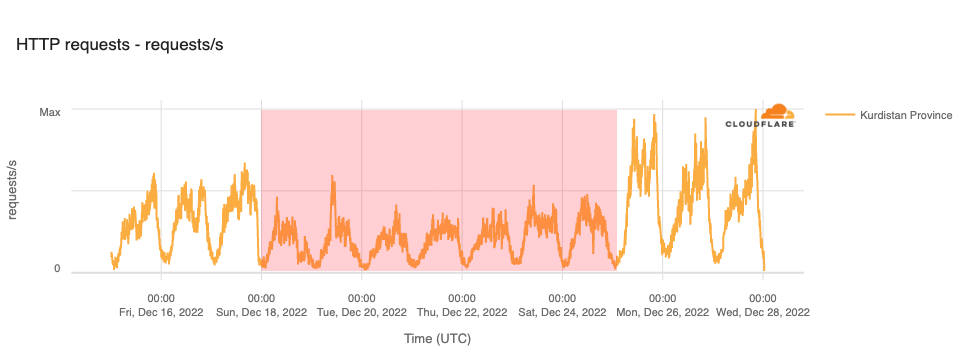
In addition to the mobile network shutdowns, several regional Internet disruptions were also observed in Iran during the fourth quarter, two of which we review below. The first was in Sanandaj, Kurdistan Province on October 26, where a complete Internet shutdown was implemented in response to demonstrations marking the 40th day since the death of Mahsa Amini. The figure below shows a complete loss of traffic starting at 1030 local time (0700 UTC), with the outage lasting until 0805 local time on October 27 (0435 UTC). In December, a province-level Internet disruption was observed starting on December 18, lasting through December 25.
The Internet disruptions that have taken place in Iran over the last several months have had a significant economic impact on the country. A December post from Filterwatch shared concerns stated in a letter from mobile operator Rightel:
The letter, signed by the network’s Managing Director Yasser Rezakhah, states that “during the past few weeks, the company’s resources and income have significantly decreased during Internet shutdowns and other restrictions, such as limiting Internet bandwidth from 21 September. They have also caused a decrease in data use from subscribers, decreasing data traffic by around 50%.” The letter also states that the “continued lack of compensation for losses could lead to bankruptcy.”
The post also highlighted economic concerns shared by Iranian officials:
Some Iranian officials have expressed concern about the cost of Internet shutdowns, including Valiollah Bayati, MP for Tafresh and Ashtian in Markazi province. In a public session in Majles (parliament), he stated that continued Internet shutdowns have led to the closure of many jobs and people are worried, the government and the President must provide necessary measures.
Since the 30th of Shahrivar month and with the beginning of the government disruption in the Internet, the country’s businesses have been damaged daily at least 50 million tomans and at most 500 million tomans. More than 41% of companies have lost 25-50% of their income during this period, and about 47% have had more than 50% reduction in sales. A review of the data of the research assistant of the country’s tax affairs organization shows that the Internet outage in Iran has caused 3000 billion tomans of damage per day. That is, the cost of 3 months of Internet outage in Iran is equal to 43% of one year’s oil revenue of the country ($25 billion).
Power outages
Bangladesh, October 4
Over 140 million people in Bangladesh were left without electricity on October 4 as the result of a reported grid failure caused by a failure by power distribution companies to follow instructions from the National Load Dispatch Centre to shed load. The resultant power outage resulted in an observed drop in Internet traffic from the country, starting at 1405 local time (0805 UTC), as shown in the figure below. The disruption lasted approximately seven hours, with traffic returning to expected levels around 1900 local time (1500 UTC).
Pakistan
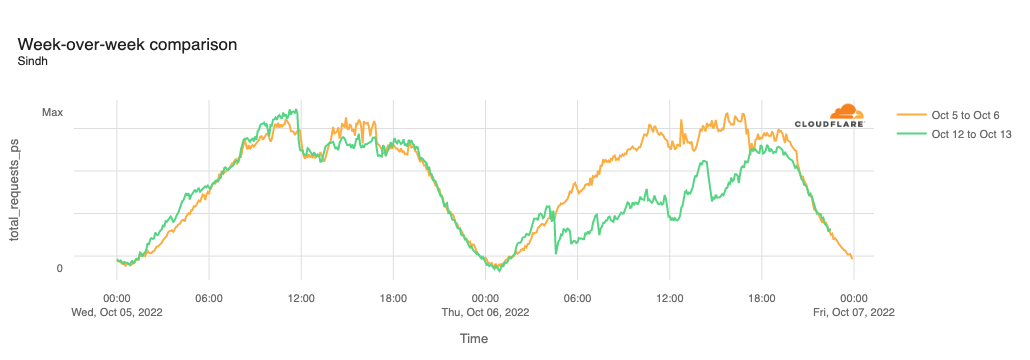
Over a week later, a similar issue in Pakistan caused power outages across the southern part of the country, including Sindh, Punjab, and Balochistan. The power outages were caused by a fault in the national grid’s southern transmission system, reportedly due to faulty equipment and sub-standard maintenance. As expected, the power outages resulted in disruptions to Internet connectivity, and the figure below illustrates the impact observed in Sindh, where traffic dropped nearly 30% as compared to the previous week starting at 0935 local time (0435 UTC) on October 6. The disruption lasted over 15 hours, with traffic returning to expected levels at 0100 on October 7 (2000 UTC on October 6).
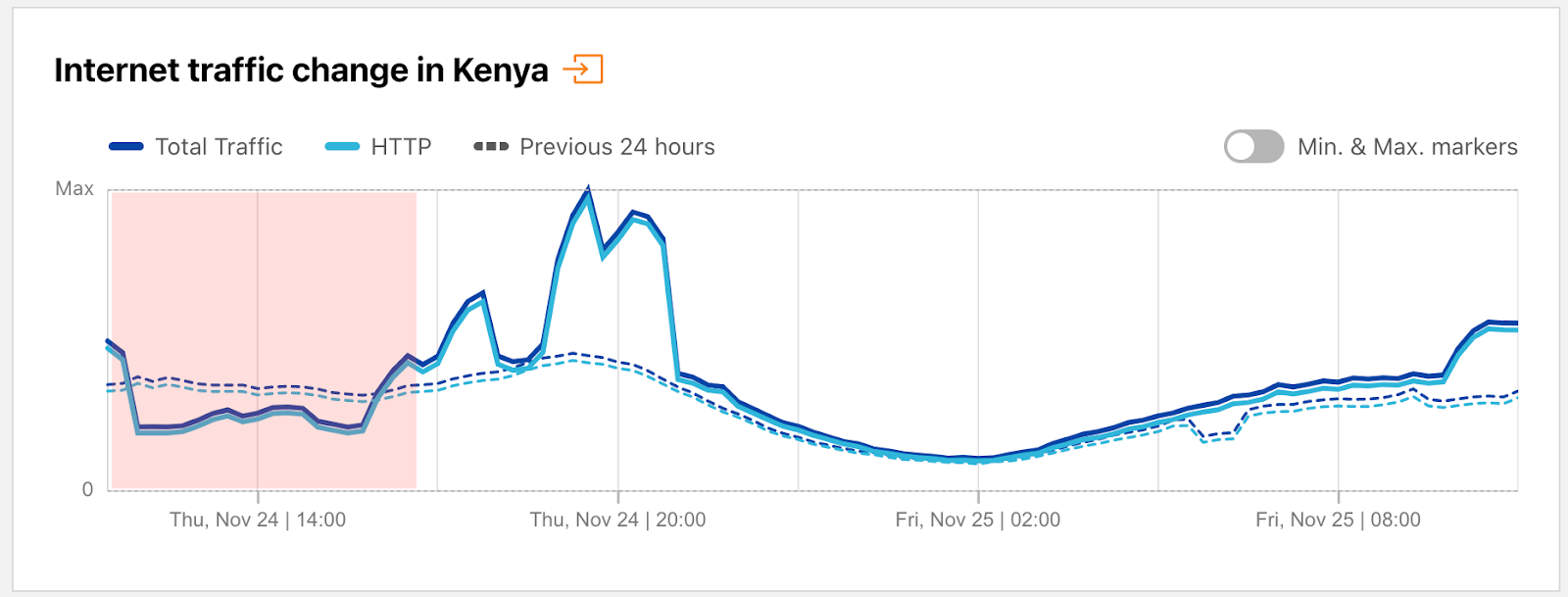
On November 24, a Tweet from Kenya Power at 1525 local time noted that they had “lost bulk power supply to various parts of the country due to a system disturbance”. A subsequent Tweet published just over six hours later at 2150 local time stated that “normal power supply has been restored to all parts of the country.” The time stamps on these notifications align with the loss of Internet traffic visible in the figure below, which lasted between 1500-2050 local time (1200-1750 UTC).
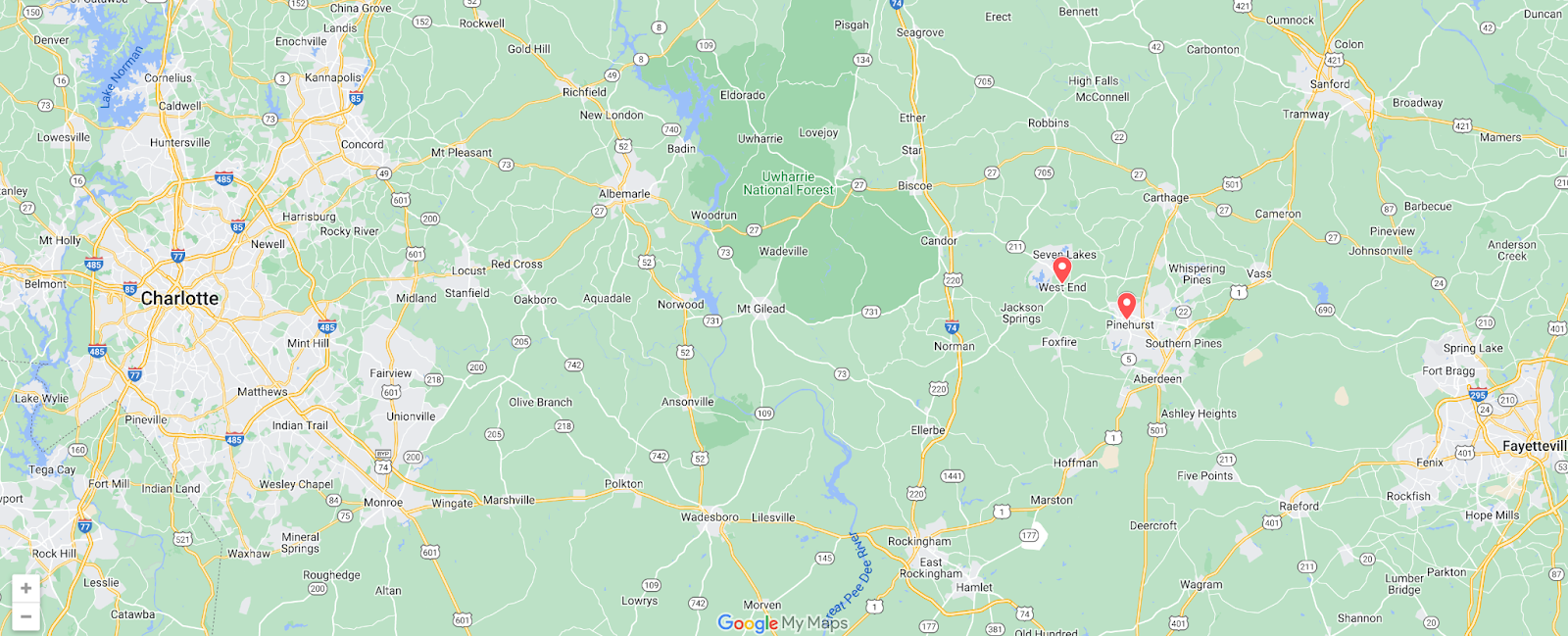
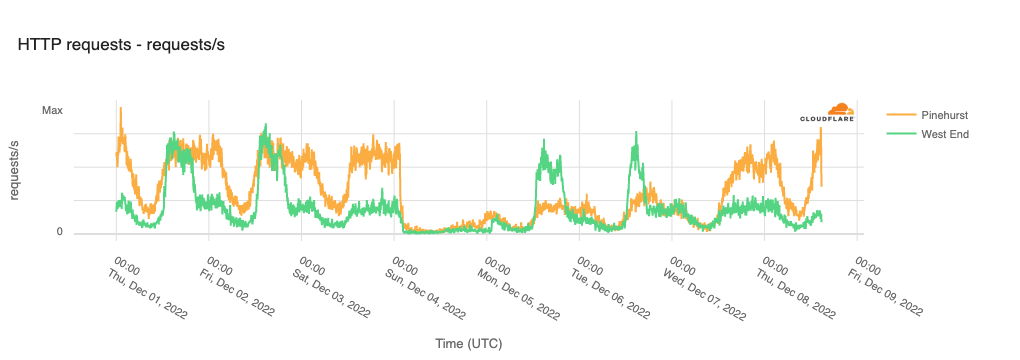
United States (Moore County, North Carolina)
On December 3, two electrical substations in Moore County, North Carolina were targeted by gunfire, with the resultant damage causing localized power outages that took multiple days to resolve. The power outages reportedly began just after 1900 local time (0000 UTC on December 4), resulting in the concurrent loss of Internet traffic from communities within Moore County, as seen in the figure below.
Internet traffic within the community of West End appeared to return midday (UTC) on December 5, but that recovery was apparently short-lived, as it fell again during the afternoon of December 6. In Pinehurst, traffic began to slowly recover after about a day, but returned to more normal levels around 0800 local time (1300 UTC) on December 7.
The war in Ukraine has been going on since February 24, and Cloudflare has covered the impact of the war on the country’s Internet connectivity in a number of blog posts across the year (March, March, April, May, June, July, October, December). Throughout the fourth quarter of 2022, Russian missile strikes causedwidespreaddamage to electrical infrastructure, resulting in power outages and disruptions to Internet connectivity. Below, we highlight several examples of the Internet disruptions observed in Ukraine during the fourth quarter, but they are just a few of the many disruptions that occurred.
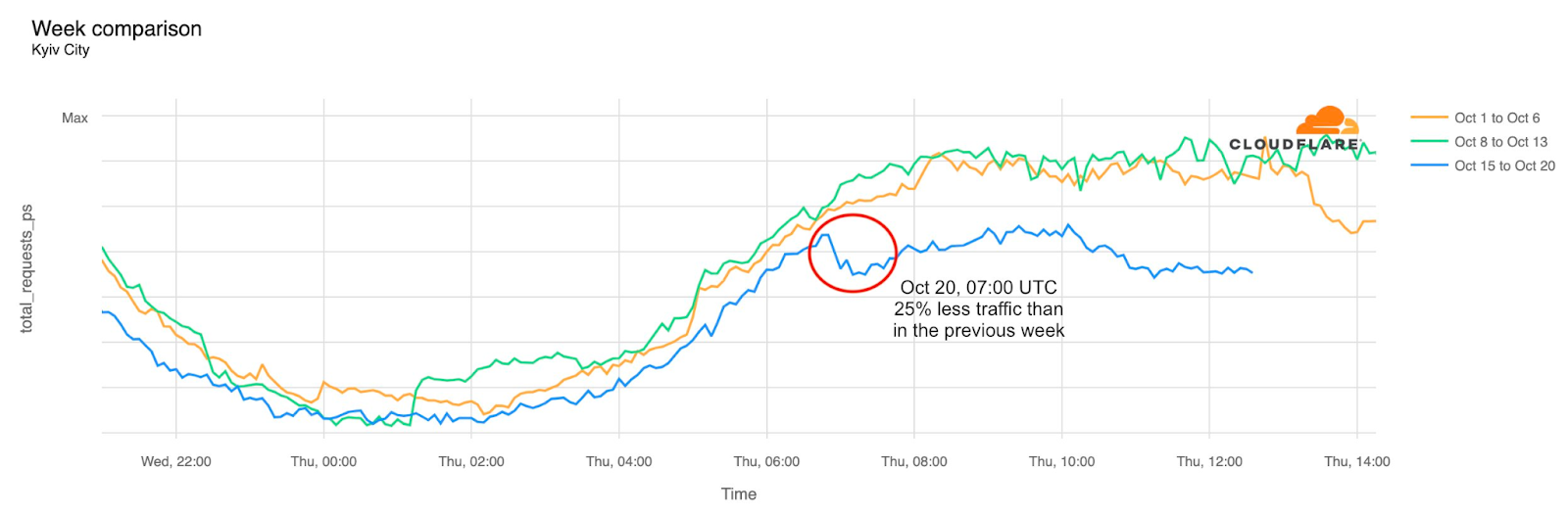
On October 20, the destruction of several power stations in Kyiv resulted in a 25% drop in Internet traffic from Kyiv City as compared to the two previous weeks. The disruption began around 0900 local time (0700 UTC).
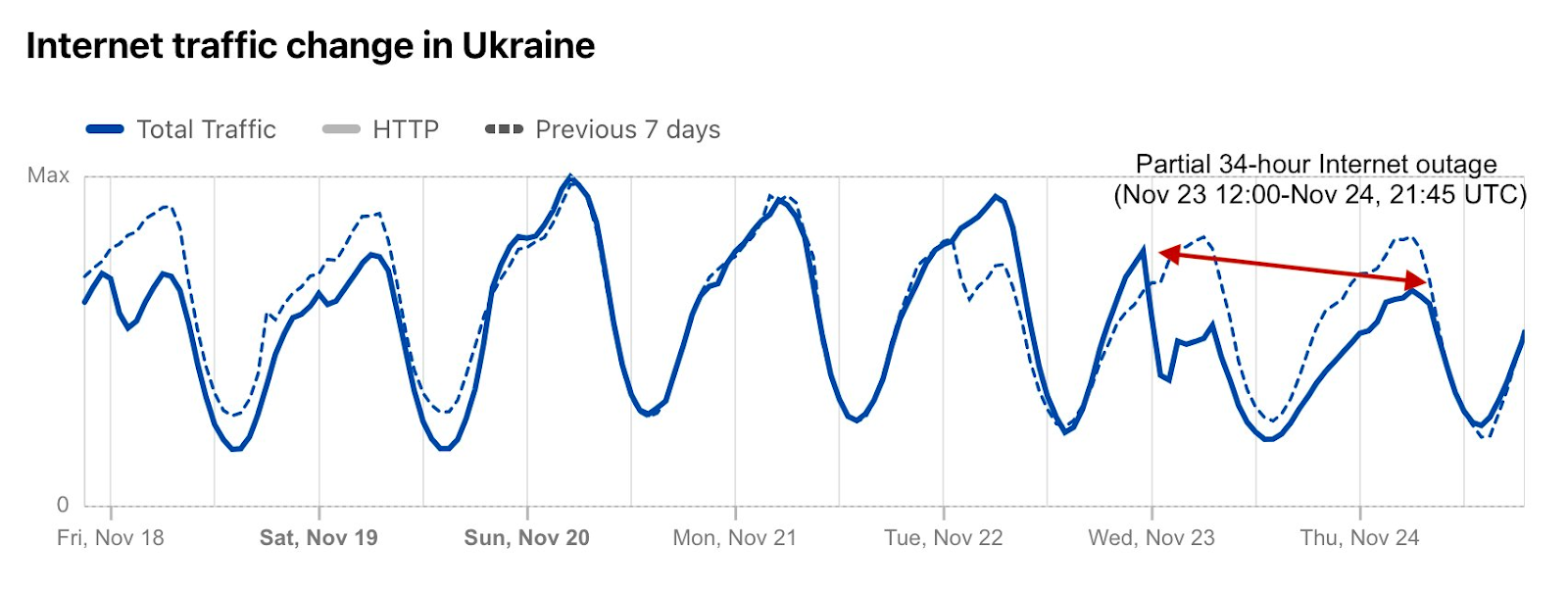
On November 23, widespread power outages after Russian strikes caused a nearly 50% decrease in Internet traffic in Ukraine, starting just after 1400 local time (1200 UTC). This disruption lasted for nearly a day and a half, with traffic returning to expected levels around 2345 local time on November 24 (2145 UTC).
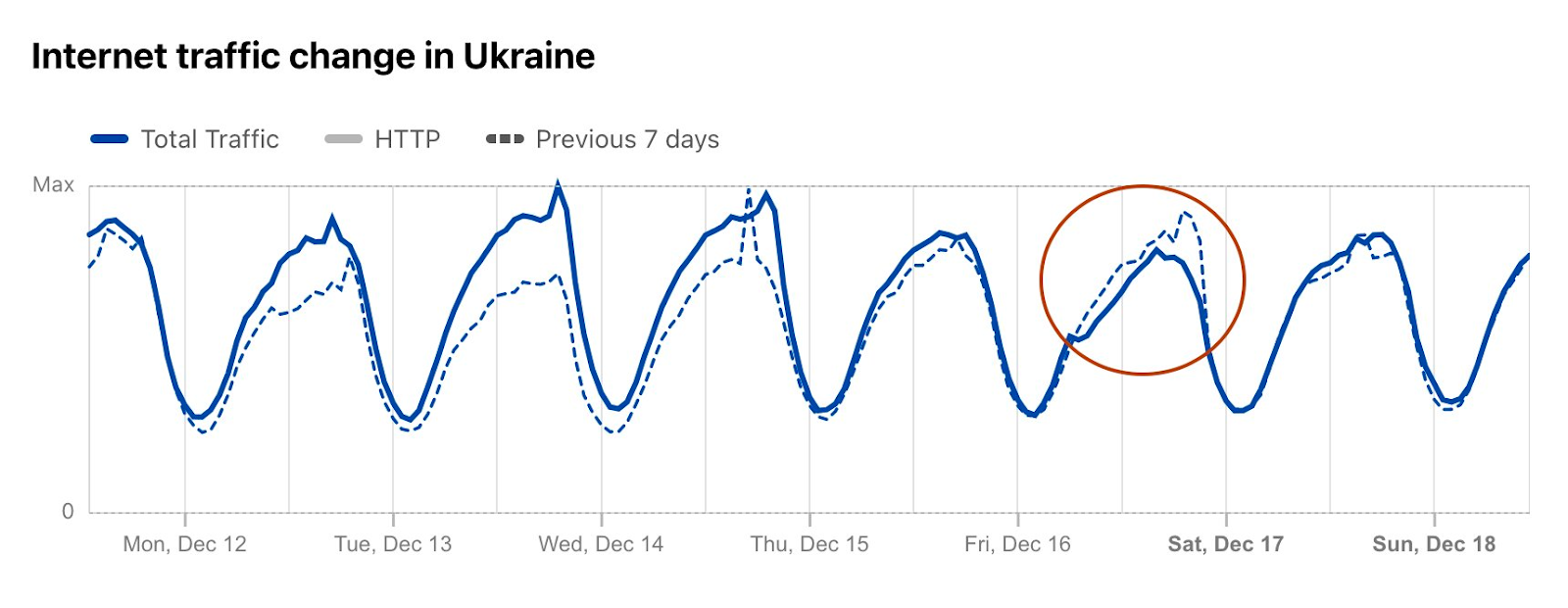
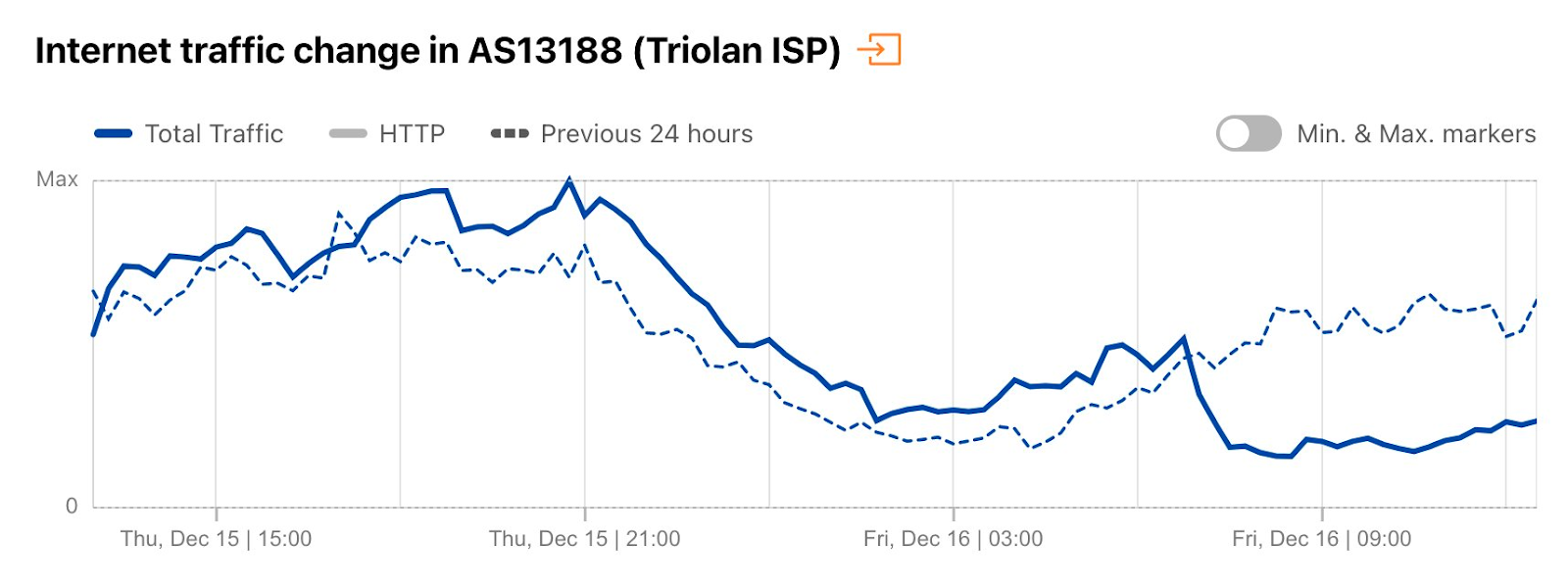
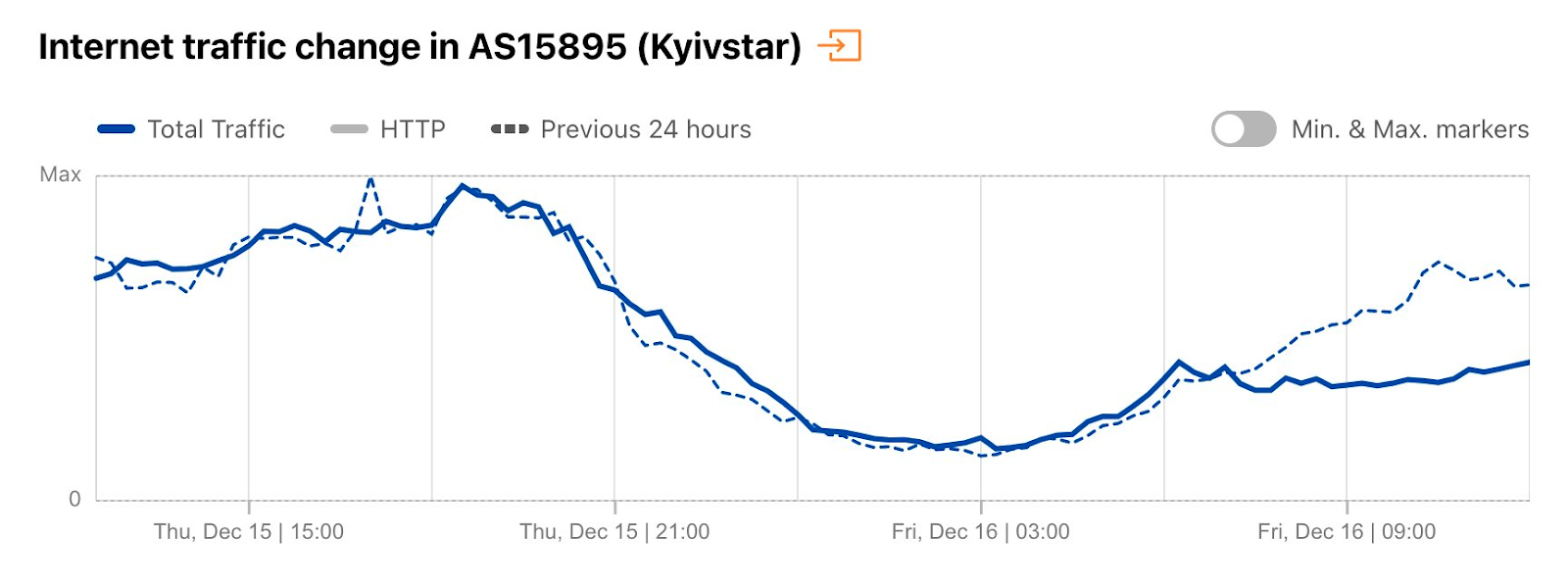
On December 16, power outages resulting from Russian air strikes targeting power infrastructure caused country-level Internet traffic to drop around 13% at 0915 local time (0715 UTC), with the disruption lasting until midnight local time (2200 UTC). However, at a network level, the impact was more significant, with AS13188 (Triolan) seeing a 70% drop in traffic, and AS15895 (Kyivstar) a 40% drop, both shown in the figures below.
Cable cuts
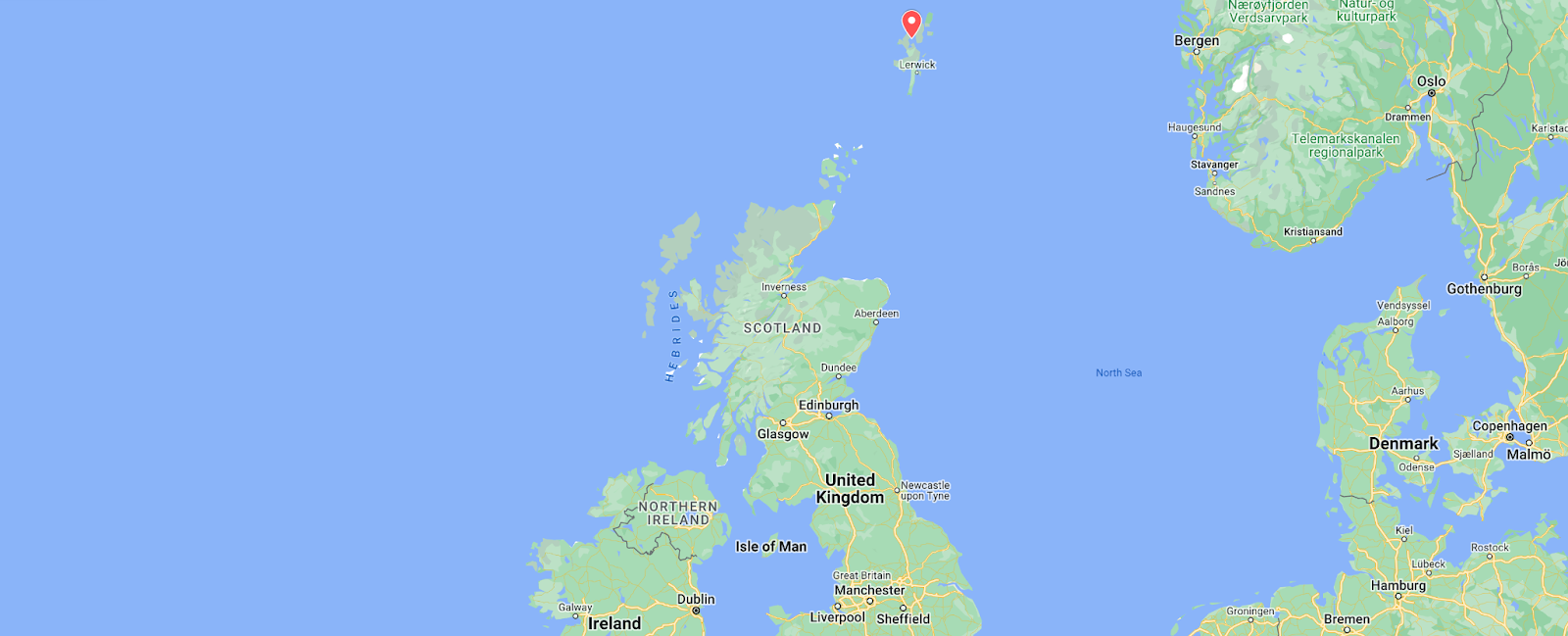
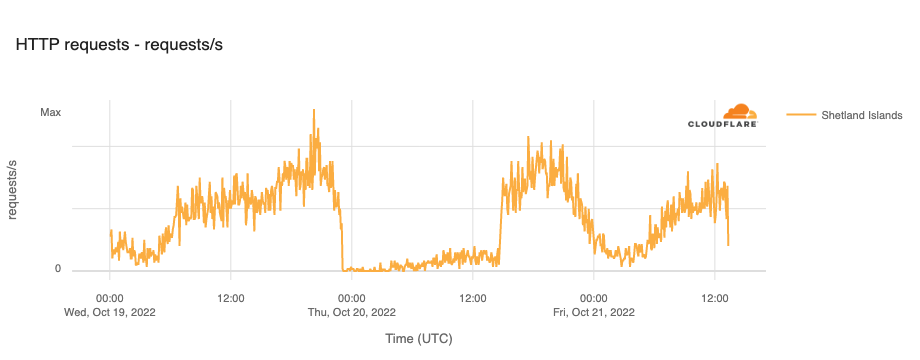
Shetland Islands, United Kingdom
The Shetland Islands are primarily dependent on the SHEFA-2 submarine cable system for Internet connectivity, connecting through the Scottish mainland. Late in the evening of October 19, damage to this cable knocked the Shetland Islands almost completely offline. At the time, there was heightened concern about the potential sabotage of submarine cables due to the reported sabotage of the Nord Stream natural gas pipelines in late September, but authorities believed that this cable damage was due to errant fishing vessels, and not sabotage.
The figure below shows that the impact of the damage to the cable was relatively short-lived, compared to the multi-day Internet disruptions often associated with submarine cable cuts. Traffic dropped just after 2300 local time (2200 UTC) on October 19, and recovered 14.5 hours later, just after 1430 local time (1330 UTC) on October 20.
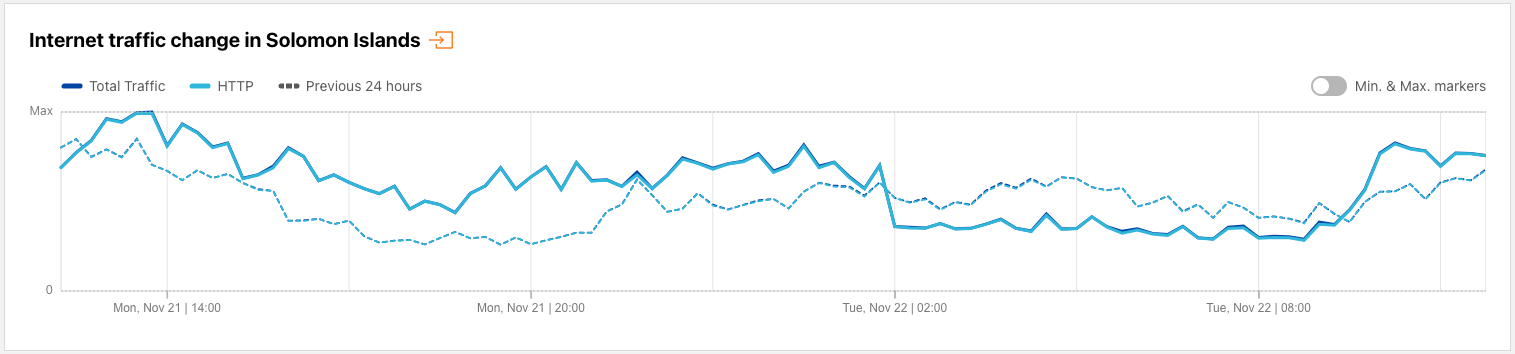
Earthquakes frequently cause infrastructure damage and power outages in affected areas, resulting in disruptions to Internet connectivity. We observed such a disruption in the Solomon Islands after a magnitude 7.0 earthquake occurred near there on November 22. The figure below shows Internet traffic from the country dropping significantly at 1300 local time (0200 UTC), and recovering 11 hours later at around 2000 local time (0900 UTC).
Technical problems
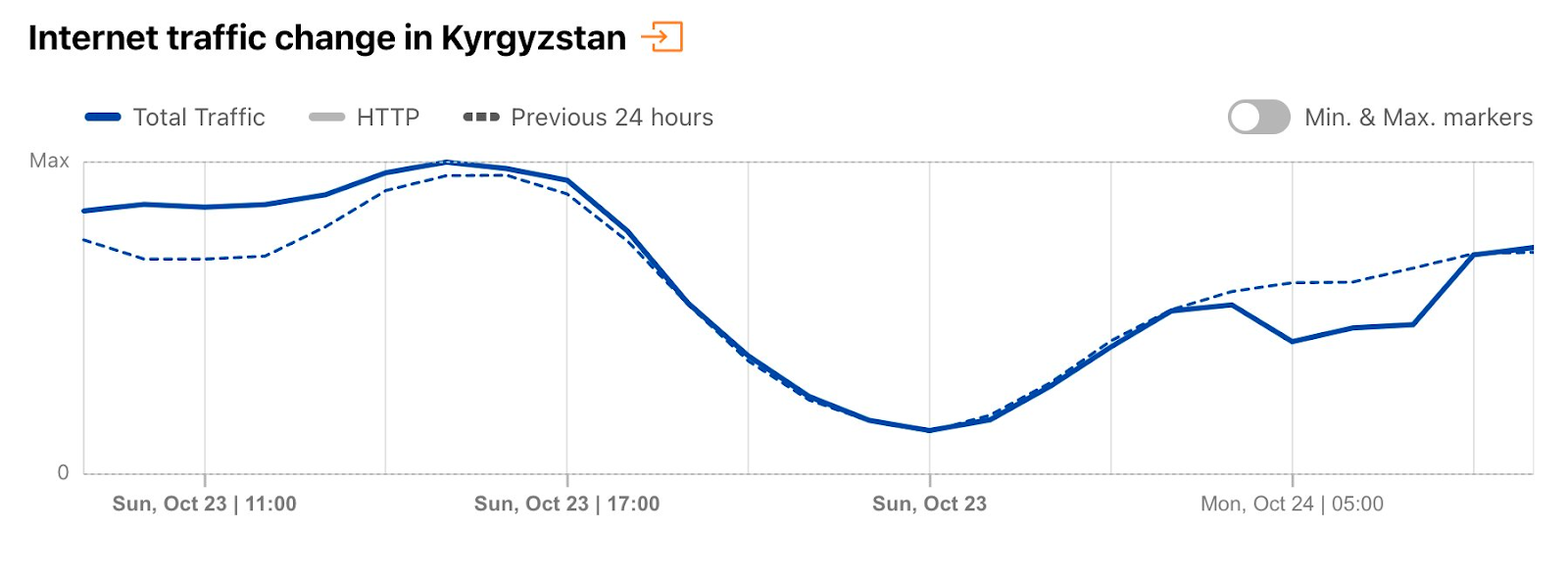
Kyrgyzstan
On October 24, a three-hour Internet disruption was observed in Kyrgyzstan lasting between 1100-1400 local time (0500-0800 UTC), as seen in the figure below. According to the country’s Ministry of Digital Development, the issue was caused by “an accident on one of the main lines that supply the Internet”, but no additional details were provided regarding the type of accident or where it had occurred.
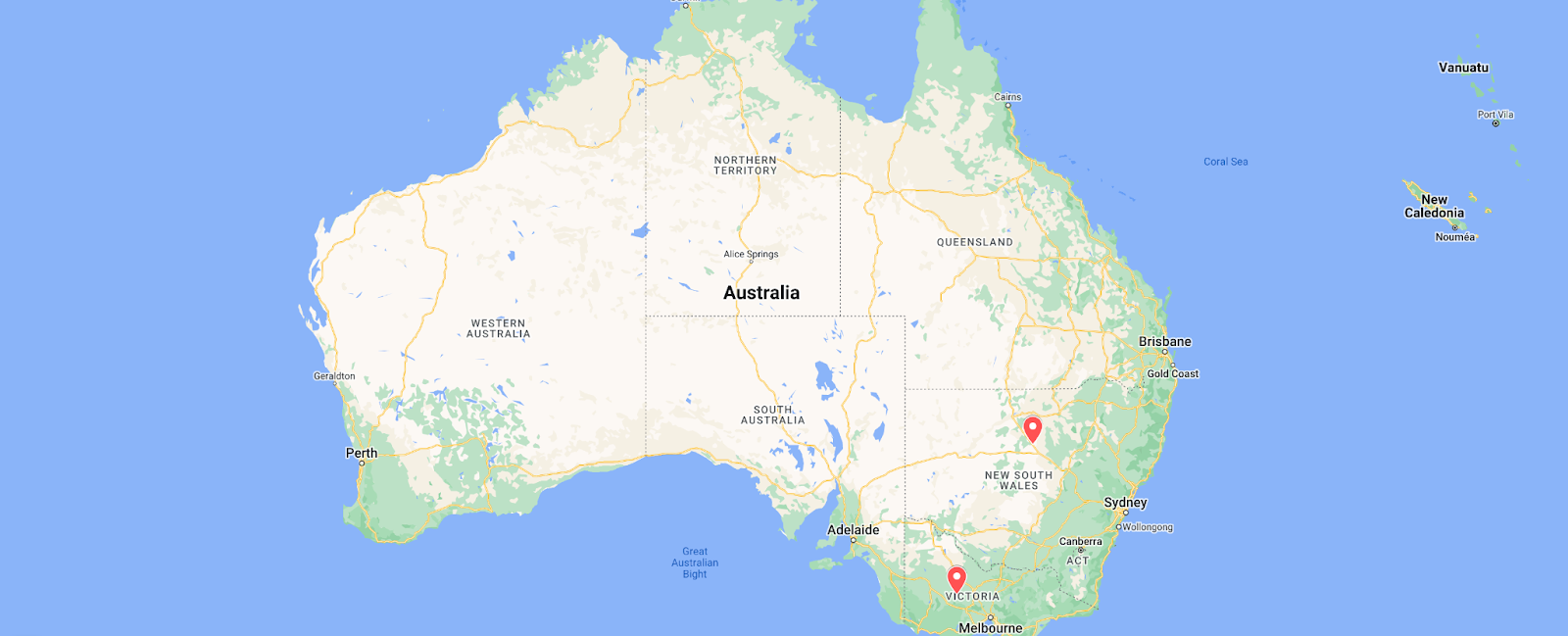
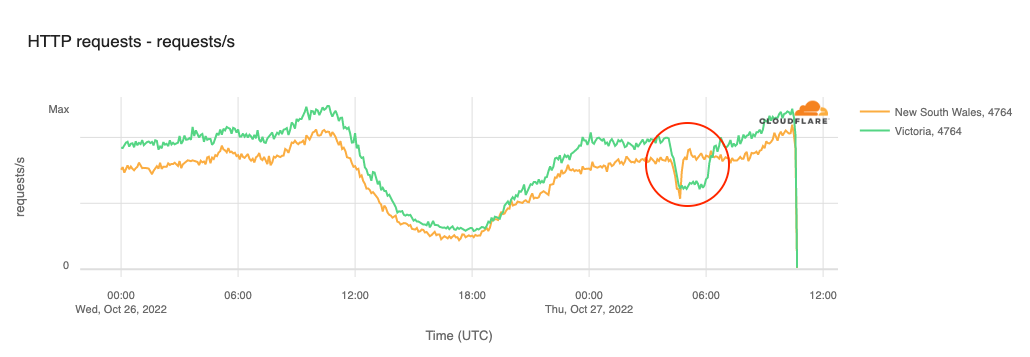
Australia (Aussie Broadband)
Customers of Australian broadband Internet provider Aussie Broadband in Victoria and New South Wales suffered brief Internet disruptions on October 27. As shown in the figure below, AS4764 (Aussie Broadband) traffic from Victoria dropped by approximately 40% between 1505-1745 local time (0405-0645 UTC). A similar, but briefer, loss of traffic from New South Wales was also observed, lasting between 1515-1550 local time (0415-0450 UTC). A representative of Aussie Broadband provided insight into the underlying cause of the disruption, stating “A config change was made which was pushed out through automation to the DHCP servers in those states. … The change has been rolled back but getting the sessions back online is taking time for VIC, and we are now manually bringing areas up one at a time.”
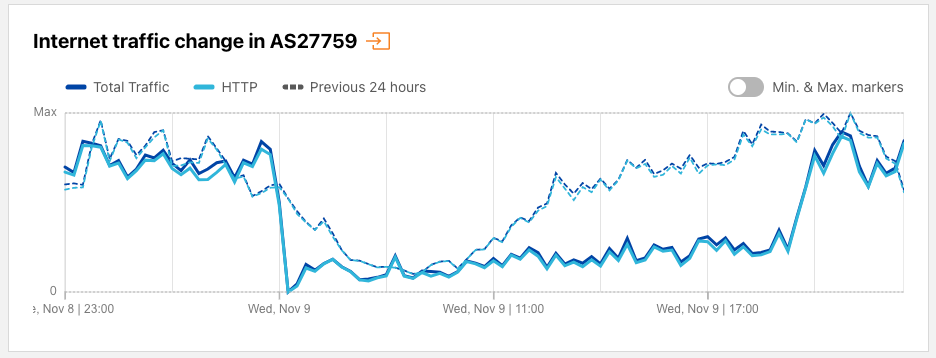
In Haiti, customers of Internet service provider Access Haiti experienced disrupted service for more than half a day on November 9. The figure below shows that Internet traffic for AS27759 (Access Haiti) fell precipitously around midnight local time (0500 UTC), remaining depressed until 1430 local time (1930 UTC), at which time it recovered quickly. A Facebook post from Access Haiti explained to customers that “Due to an intermittent outage on one of our international circuits, our network is experiencing difficulties that cause your Internet service to slow down.” While Access Haiti didn’t provide additional details on which international circuit was experiencing an outage, submarinecablemap.com shows that two submarine cables provide international Internet connectivity to Haiti — the Bahamas Domestic Submarine Network (BDSNi), which connects Haiti to the Bahamas, and Fibralink, which connects Haiti to the Dominican Republic and Jamaica.
Unknown
Many Internet disruptions can be easily tied to an underlying cause, whether through coverage in the press, a concurrent weather or natural disaster event, or communication from an impacted provider. However, the causes of other observed disruptions remain unknown as the impacted providers remain silent about what caused the problem.
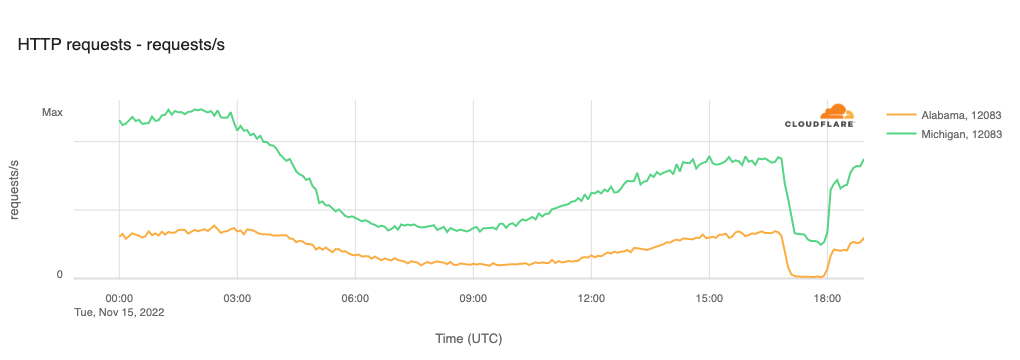
United States (Wide Open West)
On November 15, customers of Wide Open West, an Internet service provider with a multi-state footprint in the United States, experienced an Internet service disruption that lasted a little over an hour. The figure below illustrates the impact of the disruption in Alabama and Michigan on AS12083 (Wide Open West), with traffic dropping at 1150 local time (1650 UTC) and recovering just after 1300 local time (1800 UTC).
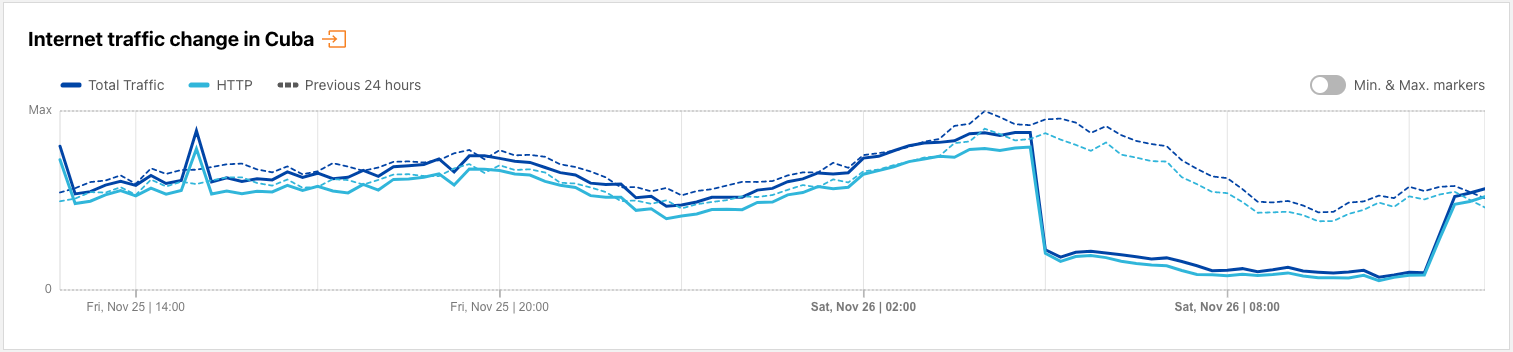
Cuba
Cuba is no stranger to Internet disruptions, whether due to government-directed shutdowns (such as the one discussed above), fiber cuts, or power outages. However, no underlying cause was ever shared for the seven-hour disruption in the country’s Internet traffic observed between 2345 on November 25 and 0645 on November 26 local time (0445-1145 UTC on November 26). Traffic was down as much as 75% from previous levels during the disruption.
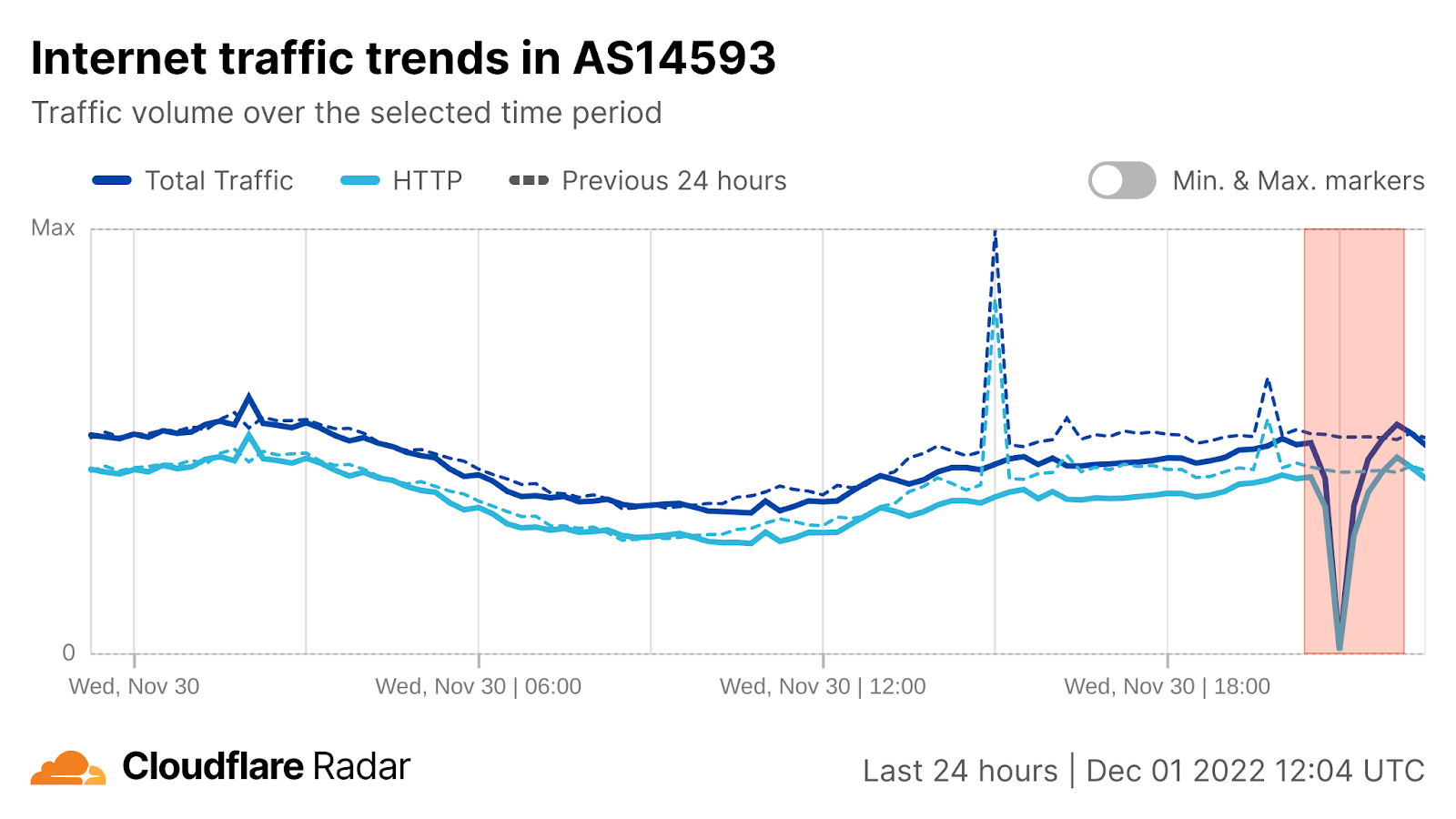
SpaceX Starlink
As a provider of low earth orbit (LEO) satellite Internet connectivity services, disruptions to SpaceX Starlink’s service can have a global impact. On November 30, a disruption was observed on AS14593 (SPACEX-STARLINK) between 2050-2130 UTC, with traffic volume briefly dropping to near zero. Unfortunately, Starlink did not acknowledge the incident, nor did they provide any reason for the disruption.
Conclusion
Looking back at the Internet disruptions observed during 2022, a number of common themes can be found. In countries with more authoritarian governments, the Internet is often weaponized as a means of limiting communication within the country and with the outside world through network-level, regional, or national Internet shutdowns. As noted above, this approach was used aggressively in Iran during the last few months of the year.
Internet connectivity quickly became a casualty of war in Ukraine. Early in the conflict, network-level outages were common, and some Ukrainian networks ultimately saw traffic re-routed through upstream Russian Internet service providers. Later in the year, as electrical power infrastructure was increasingly targeted by Russian attacks, widespread power outages resulted in multi-hour disruptions of Internet traffic across the country.
While the volcanic eruption in Tonga took the country offline for over a month due to its reliance on a single submarine cable for Internet connectivity, the damage caused by earthquakes in other countries throughout the year resulted in much shorter and more limited disruptions.
And while submarine cable issues can impact multiple countries along its route, the advent of services with an increasingly global footprint like SpaceX Starlink mean that service disruptions will ultimately have a much broader impact. (Starlink’s subscriber base is comparatively small at the moment, but it currently has a service footprint in over 30 countries around the world.)
Text data is a common type of unstructured data found in analytics. It is often stored without a predefined format and can be hard to obtain and process.
For example, web pages contain text data that data analysts collect through web scraping and pre-process using lowercasing, stemming, and lemmatization. After pre-processing, the cleaned text is analyzed by data scientists and analysts to extract relevant insights.
This blog post covers how to effectively handle text data using a data lake architecture on Amazon Web Services (AWS). We explain how data teams can independently extract insights from text documents using OpenSearch as the central search and analytics service. We also discuss how to index and update text data in OpenSearch and evolve the architecture towards automation.
Architecture overview
This architecture outlines the use of AWS services to create an end-to-end text analytics solution, starting from the data collection and ingestion up to the data consumption in OpenSearch (Figure 1).
Figure 1. Data lake architecture with OpenSearch
Collect data from various sources, such as SaaS applications, edge devices, logs, streaming media, and social networks.
Validate, clean, normalize, transform, and enrich the data through a series of pre-processing steps using AWS Glue or Amazon EMR.
Place the data that is ready to be indexed in the indexing zone.
Use AWS Lambda to index the documents into OpenSearch and store them back in the data lake with a unique identifier.
Use the clean zone as the source of truth for teams to consume the data and calculate additional metrics.
Develop, train, and generate new metrics using machine learning (ML) models with Amazon SageMaker or artificial intelligence (AI) services like Amazon Comprehend.
Store the new metrics in the enriching zone along with the identifier of the OpenSearch document.
Use the identifier column from the initial indexing phase to identify the correct documents and update them in OpenSearch with the newly calculated metrics using AWS Lambda.
Use OpenSearch to search through the documents and visualize them with metrics using OpenSearch Dashboards.
Considerations
Data lake orchestration among teams
This architecture allows data teams to work independently on text documents at different stages of their lifecycles. The data engineering team manages the raw and indexing zones, who also handle data ingestion and preprocessing for indexing in OpenSearch.
The cleaned data is stored in the clean zone, where data analysts and data scientists generate insights and calculate new metrics. These metrics are stored in the enrich zone and indexed as new fields in the OpenSearch documents by the data engineering team (Figure 2).
Figure 2. Data lake orchestration among teams
Let’s explore an example. Consider a company that periodically retrieves blog site comments and performs sentiment analysis using Amazon Comprehend. In this case:
The comments are ingested into the raw zone of the data lake.
The data engineering team processes the comments and stores them in the indexing zone.
A Lambda function indexes the comments into OpenSearch, enriches the comments with the OpenSearch document ID, and saves it in the clean zone.
The data science team consumes the comments and performs sentiment analysis using Amazon Comprehend.
The sentiment analysis metrics are stored in the metrics zone of the data lake. A second Lambda function updates the comments in OpenSearch with the new metrics.
If the raw data does not require any preprocessing steps, the indexing and clean zones can be combined. You can explore this specific example, along with code implementation, in the AWS samples repository.
Schema evolution
As your data progresses through data lake stages, the schema changes and gets enriched accordingly. Continuing with our previous example, Figure 3 explains how the schema evolves.
Figure 3. Schema evolution through the data lake stages
In the raw zone, there is a raw text field received directly from the ingestion phase. It’s best practice to keep a raw version of the data as a backup, or in case the processing steps need to be repeated later.
In the indexing zone, the clean text field replaces the raw text field after being processed.
In the clean zone, we add a new ID field that is generated during indexing and identifies the OpenSearch document of the text field.
In the enrich zone, the ID field is required. Other fields with metric names are optional and represent new metrics calculated by other teams that will be added to OpenSearch.
Consumption layer with OpenSearch
In OpenSearch, data is organized into indices, which can be thought of as tables in a relational database. Each index consists of documents—similar to table rows—and multiple fields, similar to table columns. You can add documents to an index by indexing and updating them using various client APIs for popular programming languages.
Now, let’s explore how our architecture integrates with OpenSearch in the indexing and updating stage.
Indexing and updating documents using Python
The index document API operation allows you to index a document with a custom ID, or assigns one if none is provided. To speed up indexing, we can use the bulk index API to index multiple documents in one call.
We need to store the IDs back from the index operation to later identify the documents we’ll update with new metrics. Let’s explore two ways of doing this:
Use the requests library to call the REST Bulk Index API (preferred): the response returns the auto-generated IDs we need.
Use the Python Low-Level Client for OpenSearch: The IDs are not returned and need to be pre-assigned to later store them. We can use an atomic counter in Amazon DynamoDB to do so. This allows multiple Lambda functions to index documents in parallel without ID collisions.
As in Figure 4, the Lambda function:
Increases the atomic counter by the number of documents that will index into OpenSearch.
Gets the value of the counter back from the API call.
Indexes the documents using the range that goes between [current counter value, current counter value – number of documents].
Figure 4. Storing the IDs back from the bulk index operation using the Python Low-Level Client for OpenSearch
Data flow automation
As architectures evolve towards automation, the data flow between data lake stages becomes event-driven. Following our previous example, we can automate the processing steps of the data when moving from the raw to the indexing zone (Figure 5).
The same approach can be applied to the other data lake stages to achieve a fully automated architecture. Explore this implementation for an automated language use case.
Conclusion
In this blog post, we covered designing an architecture to effectively handle text data using a data lake on AWS. We explained how different data teams can work independently to extract insights from text documents at different lifecycle stages using OpenSearch as the search and analytics service.
From an article about Zheng Xiaoqing, an American convicted of spying for China:
According to a Department of Justice (DOJ) indictment, the US citizen hid confidential files stolen from his employers in the binary code of a digital photograph of a sunset, which Mr Zheng then mailed to himself.
In this blog post, you’ll learn how you can use a Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) with other AWS WAF controls as part of a layered approach to provide comprehensive protection against bot traffic. We’ll describe a workflow that tracks the number of incoming requests to a site’s store page. The workflow then limits those requests if they exceed a certain threshold. Requests from IP addresses that exceed the threshold will be presented a CAPTCHA challenge to prove that the requests are being made by a human.
Amazon Web Services (AWS) offers many tools and recommendations that companies can use as they face challenges with bot traffic on their websites. Web applications can be compromised through a variety of vectors, including cross-site scripting, SQL injection, path traversal, local file inclusion, and distributed denial-of-service (DDoS) attacks. AWS WAF offers managed rules that are designed to provide protection against common application vulnerabilities or other unwanted web traffic, without requiring you to write your own rules.
There are some web attacks like web scraping, credential stuffing, and layer 7 DDoS attempts conducted by bots (as well as by humans) that target sensitive areas of your website, such as your store page. A CAPTCHA mitigates undesirable traffic by requiring the visitor to complete challenges before they are allowed to access protected resources. You can implement CAPTCHA to help prevent unwanted activities. Last year, AWS introduced AWS WAF CAPTCHA, which allows customers to set up AWS WAF rules that require CAPTCHA challenges to be completed for common targets such as forms (for example, search forms).
Scenario
Consider an attack where the unauthorized user is attempting to overwhelm a site’s store page by repeatedly sending search requests for different items.
Assume that traffic visits a website that is hosted through Amazon CloudFront and attempts the above behavior on the /store URL. In this scenario, there is a rate-based rule in place that will track the number of requests coming in from each IP. This rate-based rule tracks the rate of requests for each originating IP address and invokes the rule action on IPs with rates that go over the limit. With CAPTCHA implemented as the rule action, excessive attempts to search within a 5-minute window will result in a CAPTCHA challenge being presented to the user. This workflow is shown in Figure 1.
Figure 1: User visits a store page and is evaluated by a rate-based rule
When a user solves a CAPTCHA challenge, AWS automatically generates and encrypts a token and sends it to the client as a cookie. The client requests aren’t challenged again until the token has expired. AWS WAF calculates token expiration by using the immunity time configuration. You can configure the immunity time in a web access control list (web ACL) CAPTCHA configuration and in the configuration for a rule’s action setting. When a user provides an incorrect answer to a CAPTCHA challenge, the challenge informs the user and loads a new puzzle. When the user solves the challenge, the challenge automatically submits the original web request, updated with the CAPTCHA token from the successful puzzle completion.
Walkthrough
This workflow will require an AWS WAF rule within a new or existing rule group or web ACL. The rule will define how web requests are inspected and the action to take.
To create an AWS WAF rate-based rule
Open the AWS WAF console and in the left navigation pane, choose Web ACLs.
Choose an existing web ACL, or choose Create web ACL at the top right to create a new web ACL.
Under Rules, choose Add rules, and then in the drop-down list, choose Add my own rules and rule groups.
For Rule type, choose Rule builder.
In the Rule builder section, for Name, enter your rule name. For Type, choose Rate-based rule.
In the Request rate details section, enter your rate limit (for example, 100). For IP address to use for rate limiting, choose Source IP address, and for Criteria to count requests toward rate limit, choose Only consider requests that match criteria in a rule statement.
For Count only the requests that match the following statement, choose Matches the statement from the drop-down list.
In the Statement section, for Inspect, choose URI path. For Match type , choose Contains string.
For String to match, enter the URI path of your web page (for example, /store).
In the Action section, choose CAPTCHA.
(Optional) For Immunity time, choose Set a custom immunity time for this rule, or keep the default value (300 seconds).
To finish, choose Add rule, and then choose Save to add the rule to your web ACL.
After you add the rule, go to the Rules tab of your web ACL and navigate to your rule. Confirm that the output resembles what is shown in Figure 2. You should have a rate-based rule with a scope-down statement that matches the store URI path you entered earlier, and the action should be set to CAPTCHA.
The following is the JSON for the CAPTCHA rule that you just created. You can use this to validate your configuration. You can also use this JSON in the rule builder while creating the rule.
After you complete this configuration, the rule will be invoked when an IP address unsuccessfully attempts to search the store at a rate that exceeds the threshold. This user will be presented with a CAPTCHA challenge, as shown in Figure 6. If the user is successful, they will be routed back to the store page. Otherwise, they will be served a new puzzle until it is solved.
Figure 3: CAPTCHA challenge presented to a request that exceeded the threshold
Implementing rate-based rules and CAPTCHA also allows you to track IP addresses, limit the number of invalid search attempts, and use the specific IP information available to you within sampled requests and AWS WAF logs to work to prevent that traffic from affecting your resources. Additionally, you have visibility into IPs addresses blocked by rate-based rules so that you can later add these addresses to a block list or create custom logic as needed to mitigate false positives.
Conclusion
In this blog post, you learned how to configure and deploy a CAPTCHA challenge with AWS WAF that checks for web requests that exceed a certain rate threshold and requires the client sending such requests to solve a challenge. Please note the additional charge for enabling CAPTCHA on your web ACL (pricing can be found here). Although CAPTCHA challenges are simple for humans to complete, they should be harder for common bots to complete with any meaningful rate of success. You can use a CAPTCHA challenge when a block action would stop too many legitimate requests, but letting all traffic through would result in unacceptably high levels of unwanted requests, such as from bots.
If you have feedback about this blog post, submit comments in the Comments section below. You can also start a new thread on AWS WAF re:Post to get answers from the community.
Want more AWS Security news? Follow us on Twitter.
Dependabot helps developers secure their software with automated security updates: when a security advisory is published that affects a project dependency, Dependabot will try to submit a pull request that updates the vulnerable dependency to a safe version if one is available. Of course, there’s no rule that says a security vulnerability will only affect direct dependencies—dependencies at any level of a project’s dependency graph could become vulnerable.
Until recently, Dependabot did not address vulnerabilities on transitive dependencies, that is, on the dependencies sitting one or more levels below a project’s direct dependencies. Developers would encounter an error message in the GitHub UI and they would have to manually update the chain of ancestor dependencies leading to the vulnerable dependency to bring it to a safe version.
Internally, this would show up as a failed background job due to an update-not-possible error—and we would see a lot of these errors.
Understanding the challenge
Dependabot offers two strategies for updating dependencies: scheduled version updates and security updates. With version updates, the explicit goal is to keep project dependencies updated to the latest available version, and Dependabot can be configured to widen or increase a version requirement so that it accommodates the latest version. With security updates, Dependabot tries to make the most conservative update that removes the vulnerability while respecting version requirements. In this post we’ll be looking at security updates.
As an example, let’s say we have a repository with security updates enabled that contains an npm project with a single dependency on react-scripts@^4.0.3.
Not all package managers handle version requirements in the same way, so let’s quickly refresh. A version requirement like ^4.0.3 (a “caret range”) in npm permits updates to versions that don’t change the leftmost nonzero element in the MAJOR.MINOR.PATCHsemver version number. The version requirement ^4.0.3, then, can be understood as allowing versions greater than or equal to 4.0.3 and less than 5.0.0.
On March 18, 2022, a high-severity security advisory was published for node-forge, a popular npm package that provides tools for writing cryptographic and network-heavy applications. The advisory impacts versions earlier than 1.3.0, the patched version released the day before the advisory was published.
While we don’t have a direct dependency on node-forge, if we zoom in on our project’s dependency tree we can see that we do indirectly depend on a vulnerable version:
In order to resolve the vulnerability, we need to bring node-forge from 0.10.0 to 1.3.0, but a sequence of conflicting ancestor dependencies prevents us from doing so:
4.0.3 is the latest version of react-scripts permitted by our project
3.11.1 is the only version of webpack-dev-server permitted by [email protected]
1.10.14 is the latest version of selfsigned permitted by [email protected]
0.10.0 is the latest version of node-forge permitted by[email protected]
This is the point at which the security update would fail with an update-not-possible error. The challenge is in finding the version of selfsigned that permits [email protected], the version of webpack-dev-server that permits that version of selfsigned, and so on up the chain of ancestor dependencies until we reach react-scripts.
How we chose npm
When we set out to reduce the rate of update-not-possible errors, the first thing we did was pull data from our data warehouse in order to identify the greatest opportunities for impact.
JavaScript is the most popular ecosystem that Dependabot supports, both by Dependabot enablement and by update volume. In fact, more than 80% of the security updates that Dependabot performs are for npm and Yarn projects. Given their popularity, improving security update outcomes for JavaScript projects promised the greatest potential for impact, so we focused our investigation there.
npm and Yarn both include an operation that audits a project’s dependencies for known security vulnerabilities, but currently only npm natively has the ability to additionally make the updates needed to resolve the vulnerabilities that it finds.
After a successful engineering spike to assess the feasibility of integrating with npm’s audit functionality, we set about productionizing the approach.
Tapping into npm audit
When you run the npm audit command, npm collects your project’s dependencies, makes a bulk request to the configured npm registry for all security advisories affecting them, and then prepares an audit report. The report lists each vulnerable dependency, the dependency that requires it, the advisories affecting it, and whether a fix is possible—in other words, almost everything Dependabot should need to resolve a vulnerable transitive dependency.
node-forge <=1.2.1
Severity: high
Open Redirect in node-forge - https://github.com/advisories/GHSA-8fr3-hfg3-gpgp
Prototype Pollution in node-forge debug API. - https://github.com/advisories/GHSA-5rrq-pxf6-6jx5
Improper Verification of Cryptographic Signature in node-forge - https://github.com/advisories/GHSA-cfm4-qjh2-4765
URL parsing in node-forge could lead to undesired behavior. - https://github.com/advisories/GHSA-gf8q-jrpm-jvxq
fix available via `npm audit fix --force`
Will install [email protected], which is a breaking change
node_modules/node-forge
selfsigned 1.1.1 - 1.10.14
Depends on vulnerable versions of node-forge
node_modules/selfsigned
There were two ways in which we had to supplement npm audit to meet our requirements:
The audit report doesn’t include the chain of dependencies linking a vulnerable transitive dependency, which a developer may not recognize, to a direct dependency, which a developer should recognize. The last step in a security update job is creating a pull request that removes the vulnerability and we wanted to include some context that lets developers know how changes relate to their project’s direct dependencies.
Dependabot performs security updates for one vulnerable dependency at a time. (Updating one dependency at a time keeps diffs to a minimum and reduces the likelihood of introducing breaking changes.) npm audit and npm audit fix, however, operate on all project dependencies, which means Dependabot wouldn’t be able to tell which of the resulting updates were necessary for the dependency it’s concerned with.
Fortunately, there’s a JavaScript API for accessing the audit functionality underlying the npm audit and npm audit fix commands via Arborist, the component npm uses to manage dependency trees. Since Dependabot is a Ruby application, we wrote a helper script that uses the Arborist.audit() API and can be invoked in a subprocess from Ruby. The script takes as input a vulnerable dependency and a list of security advisories affecting it and returns as output the updates necessary to remove the vulnerabilities as reported by npm.
To meet our first requirement, the script uses the audit results from Arborist.audit() to perform a depth-first traversal of the project’s dependency tree, starting with direct dependencies. This top-down, recursive approach allows us to maintain the chain of dependencies linking the vulnerable dependency to its top-level ancestor(s) (which we’ll want to mention later when creating a pull request), and its worst-case time complexity is linear in the total number of dependencies.
function buildDependencyChains(auditReport, name) {
const helper = (node, chain, visited) => {
if (!node) {
return []
}
if (visited.has(node.name)) {
// We've already seen this node; end path.
return []
}
if (auditReport.has(node.name)) {
const vuln = auditReport.get(node.name)
if (vuln.isVulnerable(node)) {
return [{ fixAvailable: vuln.fixAvailable, nodes: [node, ...chain.nodes] }]
} else if (node.name == name) {
// This is a non-vulnerable version of the advisory dependency; end path.
return []
}
}
if (!node.edgesOut.size) {
// This is a leaf node that is unaffected by the vuln; end path.
return []
}
return [...node.edgesOut.values()].reduce((chains, { to }) => {
// Only prepend current node to chain/visited if it's not the project root.
const newChain = node.isProjectRoot ? chain : { nodes: [node, ...chain.nodes] }
const newVisited = node.isProjectRoot ? visited : new Set([node.name, ...visited])
return chains.concat(helper(to, newChain, newVisited))
}, [])
}
return helper(auditReport.tree, { nodes: [] }, new Set())
}
To meet our second requirement of operating on one vulnerable dependency at a time, the script takes advantage of the fact that the Arborist constructor accepts a custom audit registry URL to be used when requesting bulk advisory data. We initialize a mock audit registry server using nock that returns only the list of advisories (in the expected format) for the dependency that was passed into the script and we tell the Arborist instance to use it.
We see both of these use cases—linking a vulnerable dependency to its top-level ancestor and conducting an audit for a single package or a particular set of vulnerabilities—as opportunities to extend Arborist and we’re working on integrating them upstream.
Back in the Ruby code, we parse and verify the audit results emitted by the helper script, accounting for scenarios such as a dependency being downgraded or removed in order to fix a vulnerability, and we incorporate the updates recommended by npm into the remainder of the security update job.
With a viable update path in hand, Dependabot is able to make the necessary updates to remove the vulnerability and submit a pull request that tells the developer about the transitive dependency and its top-level ancestor.
Caveats
When npm audit decides that a vulnerability can only be fixed by changing major versions, it requires use of the force option with npm audit fix. When the force option is used, npm will update to the latest version of a package, even if it means jumping several major versions. This breaks with Dependabot’s previous security update behavior. It also achieves our goal: to unlock conflicting dependencies in order to bring the vulnerable dependency to an unaffected version. Of course, you should still always review the changelog for breaking changes when jumping minor or major versions of a package.
Impact
We rolled out support for transitive security updates with npm in September 2022. Now, having a full quarter of data with the changes in place, we’re able to measure the impact: between Q1Y22 and Q4Y22 we saw a 42% reduction in update-not-possible errors for security updates on JavaScript projects.
If you have Dependabot security updates enabled on your npm projects, there’s nothing extra for you to do—you’re already benefiting from this improvement.
Looking ahead
I hope this post illustrates some of the considerations and trade-offs that are necessary when making improvements to an established system like Dependabot. We prefer to leverage the native functionality provided by package managers whenever possible, but as package managers come in all shapes and sizes, the approach may vary substantially from one ecosystem to the next.
We hope other package managers will introduce functionality similar to npm audit and npm audit fix that Dependabot can integrate with and we look forward to extending support for transitive security updates to those ecosystems as they do.
The Google Project Zero page shows
how to compromise the kernel by using a NULL pointer to repeatedly
force an oops and overflow a reference count.
Back when the kernel was able to access userland memory without
restriction, and userland programs were still able to map the zero
page, there were many easy techniques for exploiting null-deref
bugs. However with the introduction of modern exploit mitigations
such as SMEP and SMAP, as well as mmap_min_addr preventing
unprivileged programs from mmap’ing low addresses, null-deref bugs
are generally not considered a security issue in modern kernel
versions. This blog post provides an exploit
technique demonstrating that treating these bugs as universally
innocuous often leads to faulty evaluations of their relevance to
security.
On January 3, 2023, security researcher Numan Türle published a proof-of-concept exploit for CVE-2022-44877, an unauthenticated remote code execution vulnerability in Control Web Panel (CWP, formerly known as CentOS Web Panel) that had been fixed in an October 2022 release of CWP. The vulnerability arises from a condition that allows attackers to run bash commands when double quotes are used to log incorrect entries to the system. Successful exploitation allows remote attackers to execute arbitrary operating system commands via shell metacharacters in the login parameter (login/index.php).
On January 6, 2023, security nonprofit Shadowserver reported exploitation in the wild. As of January 19, 2023, security firm GreyNoise has also seen several IP addresses exploiting CVE-2022-44877.
Control Web Panel is a popular free interface for managing web servers; Shadowserver’s dashboard for CWP identifies tens of thousands of instances on the internet. There doesn’t appear to be a detailed vendor advisory for CVE-2022-44887, but available information indicates Control Web Panel 7 (CWP 7) versions before 0.9.8.1147 are vulnerable. CWP users should upgrade their versions to 0.9.8.1147 or later as soon as possible.
Rapid7 customers
InsightVM & Nexpose customers: We expect coverage for CVE-2022-44877 to be available in the January 19 content release.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.