Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/new-aws-skill-builder-subscriptions/
Today, I am excited to announce AWS Skill Builder Individual and Team subscriptions. This is a new way for you to learn about cloud technologies and get practical experience with hands-on training.
Between 2013 and 2016, I spent three years delivering AWS Training classes to customers in Europe, North America, and Asia. At the time, the only classes we offered were in-person, instructor-led classes. Now, you have the choice between a variety of digital courses or in-person classes, lecture-style or hands-on. The foundations are available online for free, and the new subscriptions we are announcing today give you access to a range of exclusive content to advance your cloud skills and prepare for AWS Certification exams with self-paced, digital training. The subscriptions allow you to learn AWS services with hands-on activities.
At Amazon, we often say that it is still Day 1. The cloud market is still nascent. Gartner predicts global public cloud spending will grow from $396 billion to $482 billion this year, a rate of 22 percent this year alone. But this is just 10 percent of total global IT spending in 2022. I talk with customers every day. When I ask them the main obstacles to adopting the cloud, they all mention the lack of trained IT professionals. In fact, 76 percent of IT decision-makers report an IT skills gap, which is up from 31 percent in 2016, according to the Global Knowledge IT Skills and Salary Report, one of the largest studies of industry salaries, certifications, skills, and more.
To close the skills gap, we want to give learners hands-on experience with cloud technologies.
What Content Is Available When I Subscribe?
Starting today, AWS Skill Builder subscriptions give registered individuals and organizations access to exclusive learning materials built by builders for builders. In addition to our 500+ free courses, there are four new learning experiences available.
AWS Builder Labs are hands-on guided exercises to develop practical skills for common cloud scenarios. You receive a sandbox AWS account for the duration of the lab. There is no need for you to use your own AWS account and risk accruing unwanted charges. Next, we provide you with step-by-step instructions to go through a typical cloud scenario. It goes from simple tasks, such as configuring Amazon Simple Storage Service (Amazon S3) to host a static website, to more advanced scenarios, such as developing a serverless web application using Amazon DynamoDB. These are just two examples, and we have 100+ labs available for you to learn by doing it yourself.
AWS Jam gives you clues to guide you in solving real-world, open-ended problems. There are no step-by-step instructions, just hints. There are two types of AWS Jam: AWS Jam Journey and AWS Jam events. Jam events are exclusive to Team subscription. Once started, the Jam Journey is available for several months to give you time to complete all the challenges at your own pace and schedule. With Jam events, team administrators can create events where teams can come together at a certain date and time to solve challenges and compete with each other. AWS Jam events provide 140+ challenges across different domains.
Let’s take a practical example. When you select the security Jam, you are tasked with resolving a series of security-related challenges curated by AWS experts. Tasks might be to perform a security posture evaluation, restore a previous version of a static website, or encrypt an existing Amazon Relational Database Service (Amazon RDS) database with a customer-managed AWS Key Management Service (AWS KMS) key.
Here is the dashboard for the security AWS Jam Journey.

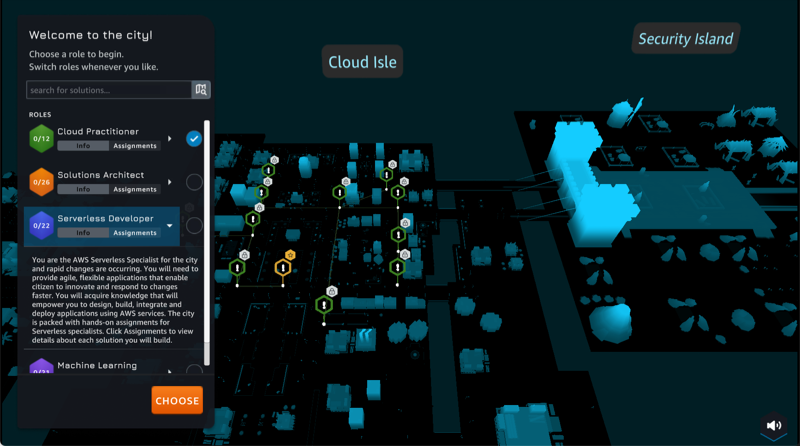
AWS Cloud Quest is a role-based game where your mission is to help citizens of a virtual city by learning and building cloud solutions for their challenges. You move around in the city, and you’re assigned tasks to complete. Each time you complete a task, you get rewards, which you can use to transform the city. For each task, the Solution Center guides you through four steps: learn the cloud concept to complete the task, practice the execution of the task with instructions, practice by yourself, and evaluate the result. Once again, the practice is done inside an AWS sandbox environment where you can safely test your new skill. To evaluate the result, the Solution Center asks you to enter validation data, such as the name of an S3 bucket or a URL. The system automatically verifies your setup and grants you points when the test succeeds. As of today, there are four roles available: Cloud Practitioner, Solutions Architect, Serverless Developer, and Machine Learning Specialist. We have plans to add more roles to this list over time. AWS Cloud Quest is a fun way to learn cloud skills!
We’ll see Cloud Quest in action in a minute.
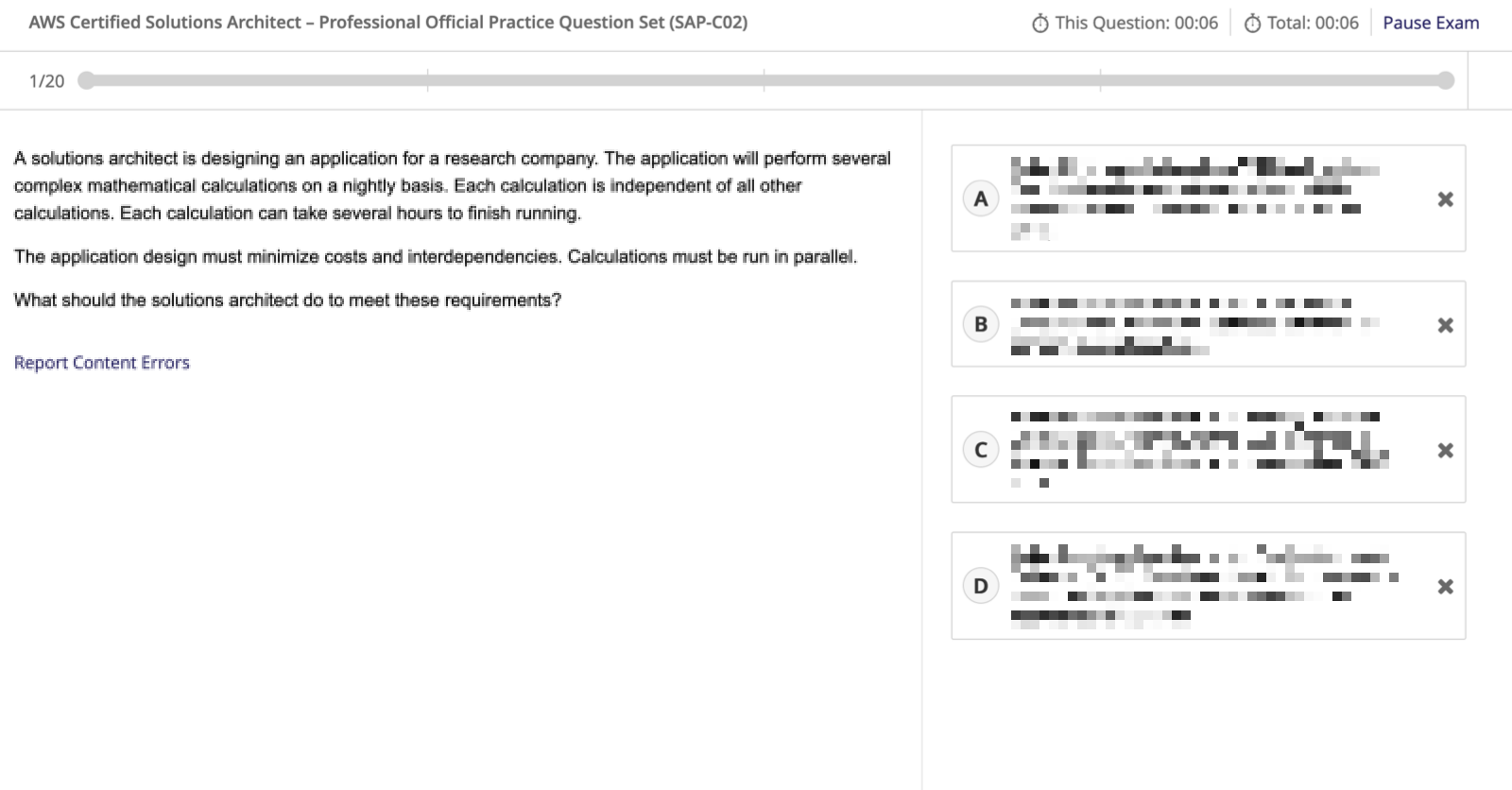
AWS Certification Official Practice Exams are, as the name implies, full-length practice exams to help you to evaluate your exam readiness. But wait! Aren’t there free Official Practice Question Sets already? Yes! But in addition to those free 20-question practice question sets, subscribed individuals or teams can now prepare for AWS Certification with new exam preparation courses that include practice materials and the full-length AWS Certification Official Practice Exams. We have designed the exam preparation courses to help you assess your exam preparedness. Each exam preparation course includes a review of technical content, practice questions, lab exercises, and access to the AWS Certification Official Practice Exams. And this is not just a pass/fail exercise. Official practice exams come with thorough feedback for each question and scaled scores simulating actual exam scores. The questions presented have the same style, depth, rigor, and scoring as our AWS Certification exams. Full-length practice exams and exam preparation courses are currently available for the AWS Certified Cloud Practitioner, AWS Certified Solutions Architect – Associate, and AWS Certified SysOps Administrator – Associate certifications, with more to come. Much of the other content available through the subscription, such as AWS Builder Labs and AWS Cloud Quest, can complement your exam preparation.
Here is a typical screen for an Official Practice Exam. I blurred the answers obviously.

Type of Subscriptions
Both Individual and Team subscriptions include these four new learning experiences. Team subscriptions are available to organizations that want to purchase seats for 50 or more people. Besides a tiered pricing model, depending on the number of seats, a Team subscription gives you administrator functionality and a single sign-on experience for employees. Team administrators may assign training to individuals to drive targeted skills in their team and track progress. Built-in reports show course enrollment, course progress, completion rates, and more.
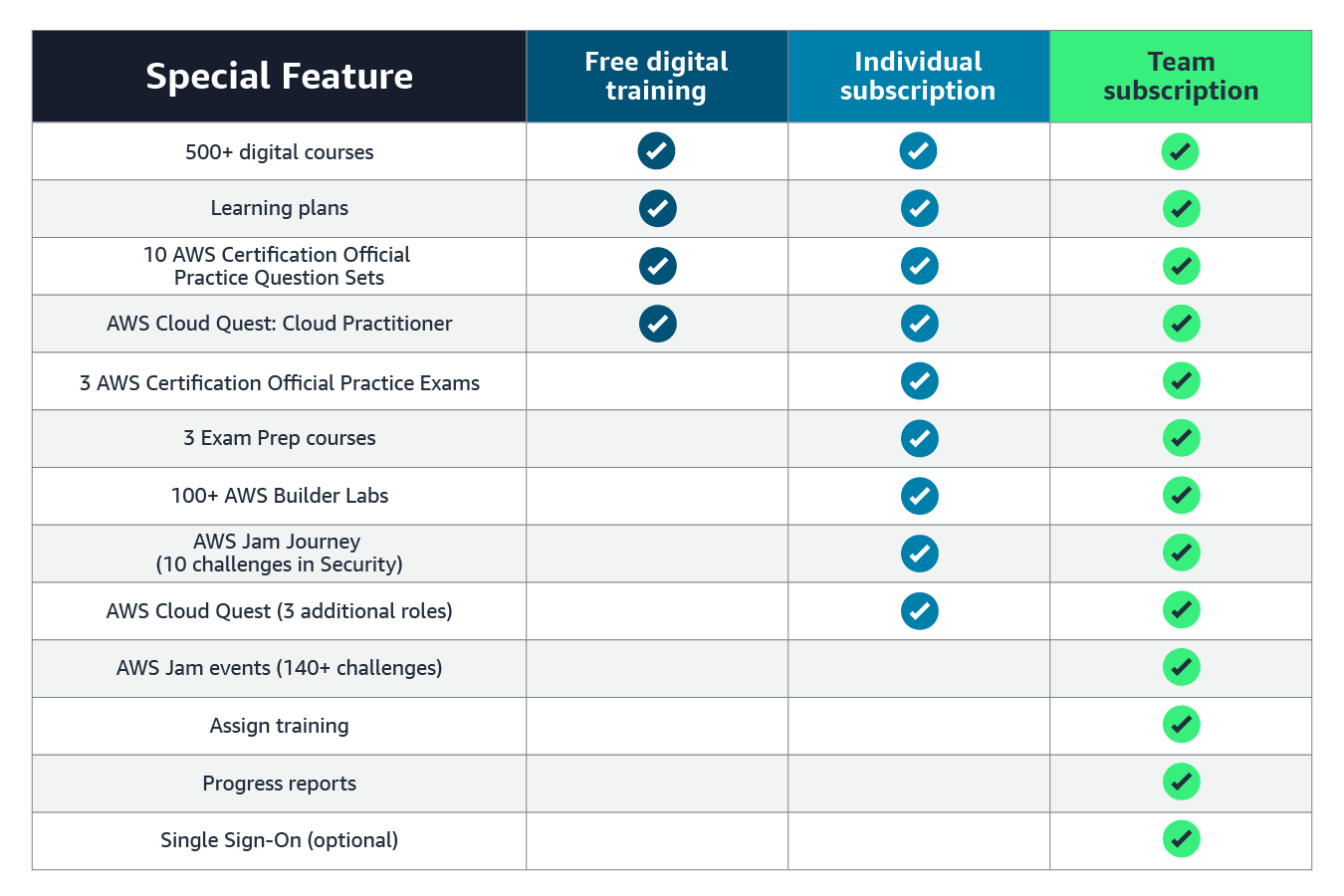
This table compares the free digital training, the Individual subscription, and the Team subscription.

Let’s See It in Action
Regular readers of this blog know we like to show you what we are talking about. Let’s see what AWS Cloud Quest looks like. First, I open AWS Skill Builder and subscribe as an individual.

Then, I search for Cloud Quest and launch the experience.

I select the role playing game I want to start. I have the choice between Cloud Practitioner, Solutions Architect, Serverless Developer, and Machine Learning Specialist.

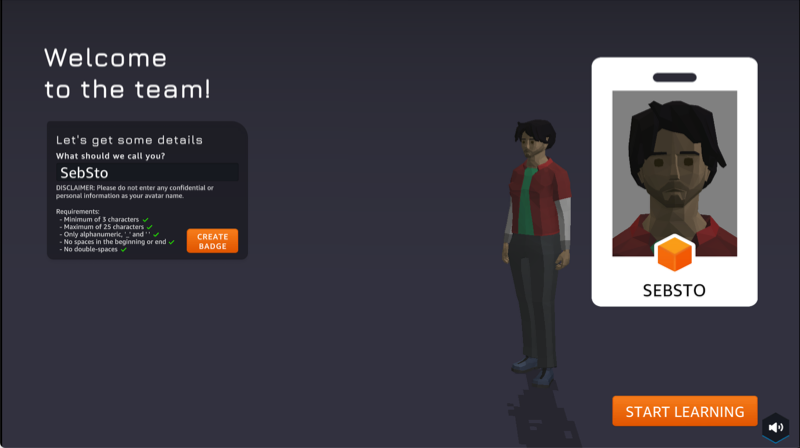
Just like in every role game, I may personalize my avatar before starting the game. Any resemblance with the actual me is pure coincidence  .
.

And finally, I am ready to walk the city, help citizens, and complete my challenges.

How Much Does It Cost?
Inclusion is a core value at Amazon. We believe everybody must have a chance to learn and grow their professional career. We made the Individual subscription available in over 200 countries and territories and up to 12 languages: Chinese (Simplified), Chinese (Traditional), English, French (France), German, Indonesian, Italian, Japanese, Korean, Portuguese (Brazil), Spanish (Latin America), and Spanish (Spain). AWS Cloud Quest is in English.
The Individual subscription is offered monthly at the price of $29 per month or annually at the price of $299 per year (this is a 14 percent discount compared to the monthly price). The subscription fee is added to your monthly AWS bill, and there is no need to have a separate credit card or billing agreement. As usual with AWS, you can stop the subscription at any time.
The Team subscription is available for purchase in 17 countries (Australia, Brazil, Canada, Colombia, France, Germany, Ireland, India, Israel, Japan, Netherlands, New Zealand, Singapore, South Korea, Spain, United Kingdom, and the United States) and the same languages as the Individual subscription. These are available for teams over 50 persons. We offer an annual plan for $449 per year and per seat, with tiered pricing based on volume. Our pricing page has all the details.
I am excited to see a new generation of IT professionals acquiring AWS Cloud skills. I can’t wait to discover the new use cases, applications, or innovations you will bring to the world when armed with these new skills.
And now, get your AWS Skill Builder subscription and go learn.
— seb



 .
.