Post Syndicated from Abe Carryl original https://blog.cloudflare.com/warp-to-warp/
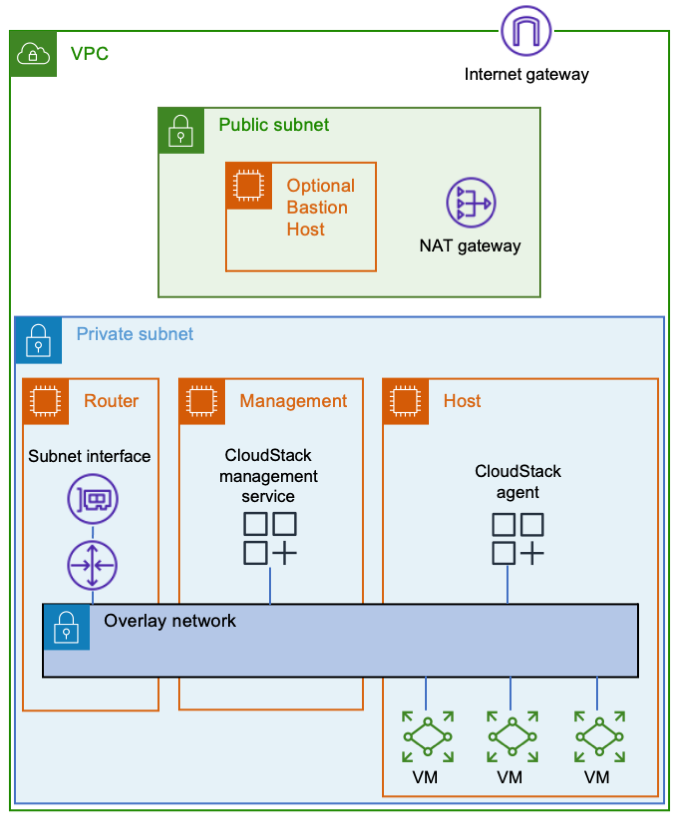
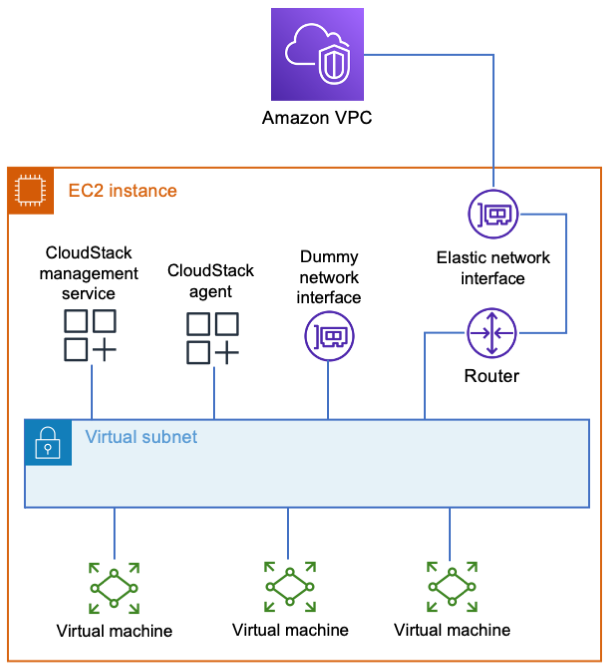
Millions of users rely on Cloudflare WARP to connect to the Internet through Cloudflare’s network. Individuals download the mobile or desktop application and rely on the Wireguard-based tunnel to make their browser faster and more private. Thousands of enterprises trust Cloudflare WARP to connect employees to our Secure Web Gateway and other Zero Trust services as they navigate the Internet.
We’ve heard from both groups of users that they also want to connect to other devices running WARP. Teams can build a private network on Cloudflare’s network today by connecting WARP on one side to a Cloudflare Tunnel, GRE tunnels, or IPSec tunnels on the other end. However, what if both devices already run WARP?
Starting today, we’re excited to make it even easier to build a network on Cloudflare with the launch of WARP-to-WARP connectivity. With a single click, any device running WARP in your organization can reach any other device running WARP. Developers can connect to a teammate’s machine to test a web server. Administrators can reach employee devices to troubleshoot issues. The feature works with our existing private network on-ramps, like the tunnel options listed above. All with Zero Trust rules built in.
To get started, sign-up to receive early access to our closed beta. If you’re interested in learning more about how it works and what else we will be launching in the future, keep scrolling.
The bridge to Zero Trust
We understand that adopting a Zero Trust architecture can feel overwhelming at times. With Cloudflare One, our mission is to make Zero Trust prescriptive and approachable regardless of where you are on your journey today. To help users navigate the uncertain, we created resources like our vendor-agnostic Zero Trust Roadmap which lays out a battle-tested path to Zero Trust. Within our own products and services, we’ve launched a number of features to bridge the gap between the networks you manage today and the network you hope to build for your organization in the future.
Ultimately, our goal is to enable you to overlay your network on Cloudflare however you want, whether that be with existing hardware in the field, a carrier you already partner with, through existing technology standards like IPsec tunnels, or more Zero Trust approaches like WARP or Tunnel. It shouldn’t matter which method you chose to start with, the point is that you need the flexibility to get started no matter where you are in this journey. We call these connectivity options on-ramps and off-ramps.
A recap of WARP to Tunnel
The model laid out above allows users to start by defining their specific needs and then customize their deployment by choosing from a set of fully composable on and offramps to connect their users and devices to Cloudflare. This means that customers are able to leverage any of these solutions together to route traffic seamlessly between devices, offices, data centers, cloud environments, and self-hosted or SaaS applications.
One example of a deployment we’ve seen thousands of customers be successful with is what we call WARP-to-Tunnel. In this deployment, the on-ramp Cloudflare WARP ensures end-user traffic reaches Cloudflare’s global network in a secure and performant manner. The off-ramp Cloudflare Tunnel then ensures that, after your Zero Trust rules have been enforced, we have secure, redundant, and reliable paths to land user traffic back in your distributed, private network.
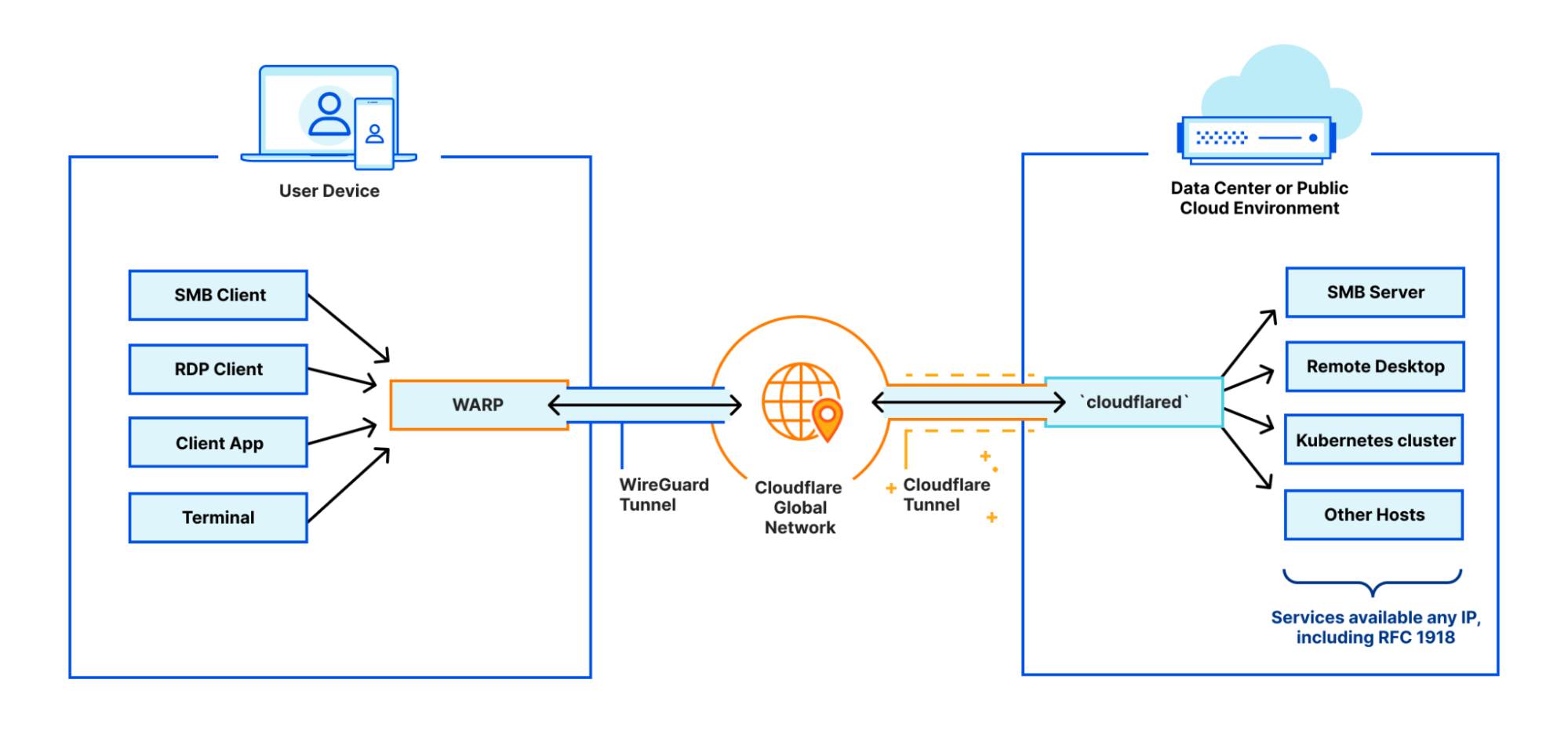
This is a great example of a deployment that is ideal for users that need to support public to private traffic flows (i.e. North-South)
But what happens when you need to support private to private traffic flows (i.e. East-West) within this deployment?
With WARP-to-WARP, connecting just got easier
Starting today, devices on-ramping to Cloudflare with WARP will also be able to off-ramp to each other. With this announcement, we’re adding yet another tool to leverage in new or existing deployments that provides users with stronger network fabric to connect users, devices, and autonomous systems.
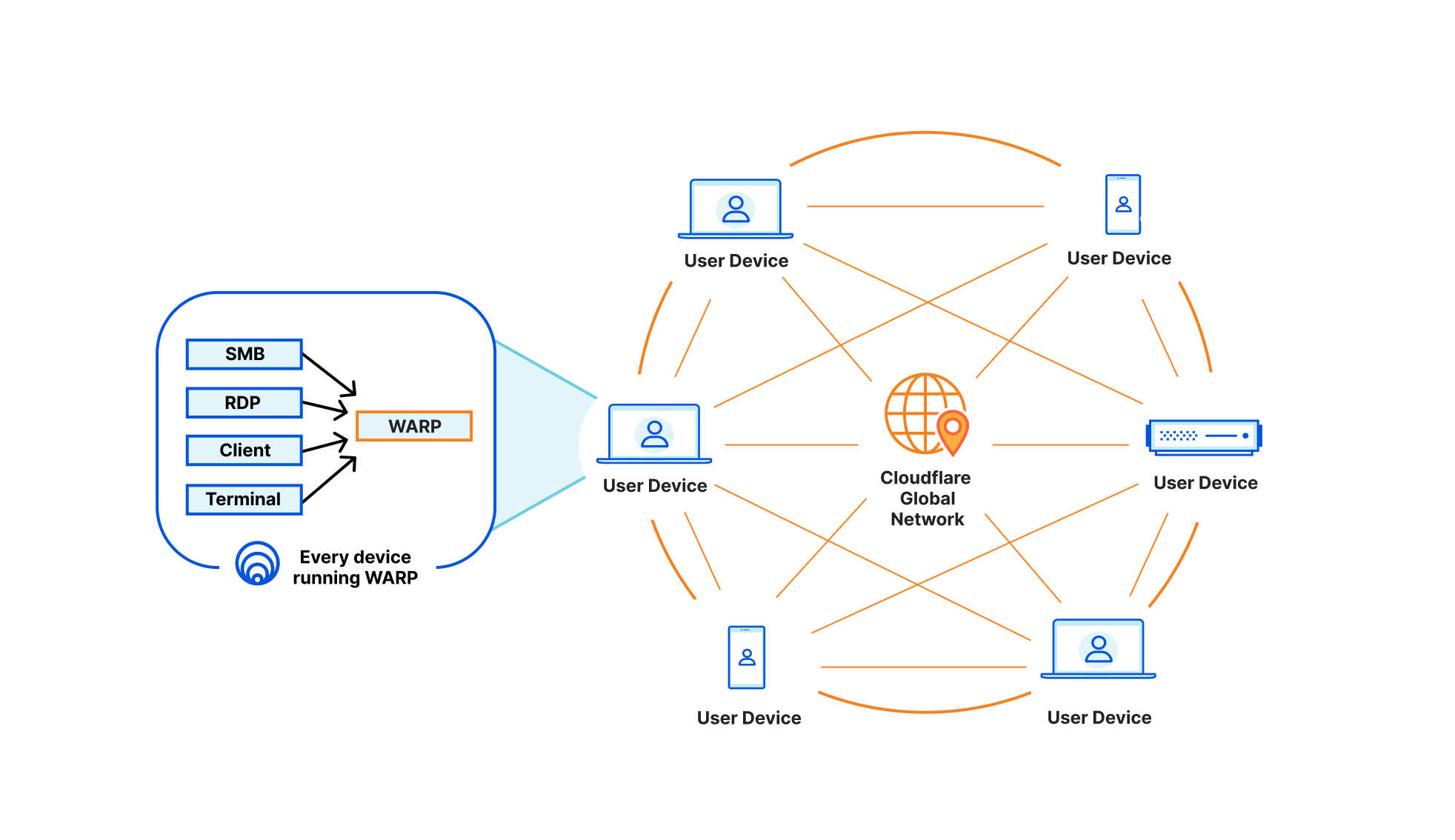
This means any of your Zero Trust-enrolled devices will be able to securely connect to any other device on your Cloudflare-defined network, regardless of physical location or network configuration. This unlocks the ability for you to address any device running WARP in the exact same way you are able to send traffic to services behind a Cloudflare Tunnel today. Naturally, all of this traffic flows through our in-line Zero Trust services, regardless of how it gets to Cloudflare, and this new connectivity announced today is no exception.
To power all of this, we now track where WARP devices are connected to, in Cloudflare’s global network, the same way we do for Cloudflare Tunnel. Traffic meant for a specific WARP device is relayed across our network, using Argo Smart Routing, and piped through the transport that routes IP packets to the appropriate WARP device. Since this traffic goes through our Zero Trust Secure Web Gateway — allowing various types of filtering — it means we upgrade and downgrade traffic from purely routed IP packets to fully proxied TLS connections (as well as other protocols). In the case of using SSH to remotely access a colleague’s WARP device, this means that your traffic is eligible for SSH command auditing as well.
Get started today with these use cases
If you already deployed Cloudflare WARP to your organization, then your IT department will be excited to learn they can use this new connectivity to reach out to any device running Cloudflare WARP. Connecting via SSH, RDP, SMB, or any other service running on the device is now simpler than ever. All of this provides Zero Trust access for the IT team members, with their actions being secured in-line, audited, and pushed to your organization’s logs.
Or, maybe you are done with designing a new function of an existing product and want to let your team members check it out at their own convenience. Sending them a link with your private IP — assigned by Cloudflare — will do the job. Their devices will see your machine as if they were in the same physical network, despite being across the other side of the world.
The usefulness doesn’t end with humans on both sides of the interaction: the weekend has arrived, and you have finally set out to move your local NAS to a host provider where you run a virtual machine. By running Cloudflare WARP on it, similarly to your laptop, you can now access your photos using the virtual machine’s private IP. This was already possible with WARP to Tunnel; but with WARP-to-WARP, you also get connectivity in reverse direction, where you can have the virtual machine periodically rsync/scp files from your laptop as well. This means you can make any server initiate traffic towards the rest of your Zero Trust organization with this new type of connectivity.
What’s next?
This feature will be available on all plans at no additional cost. To get started with this new feature, add your name to the closed beta, and we’ll notify you once you’ve been enrolled. Then, you’ll simply ensure that at least two devices are enrolled in Cloudflare Zero Trust and have the latest version of Cloudflare WARP installed.
This new feature builds upon the existing benefits of Cloudflare Zero Trust, which include enhanced connectivity, improved performance, and streamlined access controls. With the ability to connect to any other device in their deployment, Zero Trust users will be able to take advantage of even more robust security and connectivity options.
To get started in minutes, create a Zero Trust account, download the WARP agent, enroll these devices into your Zero Trust organization, and start creating Zero Trust policies to establish fast, secure connectivity between these devices. That’s it.













 Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking.
Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking. Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.
Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.