Post Syndicated from David Belson original https://blog.cloudflare.com/q4-2022-internet-disruption-summary/
Cloudflare operates in more than 250 cities in over 100 countries, where we interconnect with over 10,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
While Internet disruptions are never convenient, online interest in the 2022 World Cup in mid-November and the growth in online holiday shopping in many areas during November and December meant that connectivity issues could be particularly disruptive. Having said that, the fourth quarter appeared to be a bit quieter from an Internet disruptions perspective, although Iran and Ukraine continued to be hotspots, as we discuss below.
Government directed
Multi-hour Internet shutdowns are frequently used by authoritarian governments in response to widespread protests as a means of limiting communications among protestors, as well preventing protestors from sharing information and video with the outside world. During the fourth quarter Cuba and Sudan again implemented such shutdowns, while Iran continued the series of “Internet curfews” across mobile networks it started in mid-September, in addition to implementing several other regional Internet shutdowns.
Cuba
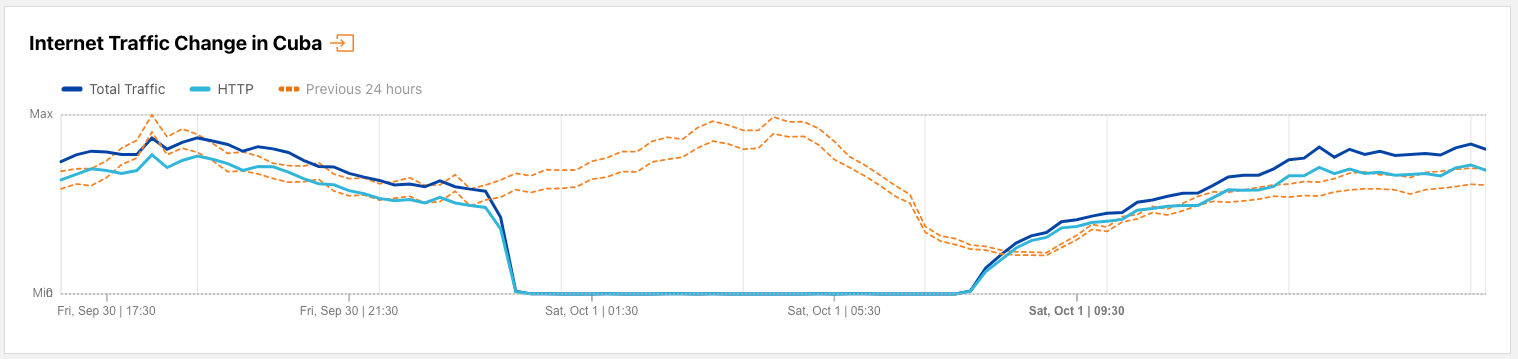
In late September, Hurricane Ian knocked out power across Cuba. While officials worked to restore service as quickly as possible, some citizens responded to perceived delays with protests that were reportedly the largest since anti-government demonstrations over a year earlier. In response to these protests, the Cuban government reportedly cut off Internet access several times. A shutdown on September 29-30 was covered in the Internet disruptions overview for Q3 2022, and the impact of the shutdown that occurred on October 1 (UTC) is shown in the figure below. The timing of this one was similar to the previous one, taking place between 1900 on September 30 and 0245 on October 1 (0000-0745 UTC on October 1).
Sudan
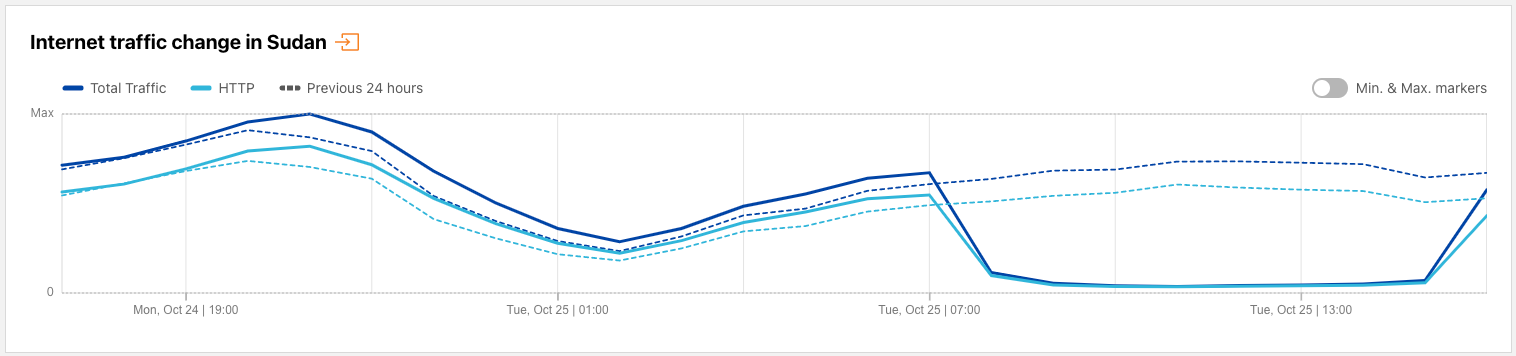
October 25 marked the first anniversary of a coup in Sudan that derailed the country’s transition to civilian rule, and thousands of Sudanese citizens marked the anniversary by taking to the streets in protest. Sudan’s government has a multi-year history of shutting down Internet access during times of civil unrest, and once again implemented an Internet shutdown in response to these protests. The figure below shows a near complete loss of Internet traffic from Sudan on October 25 between 0945-1740 local time (0745 – 1540 UTC).
Iran
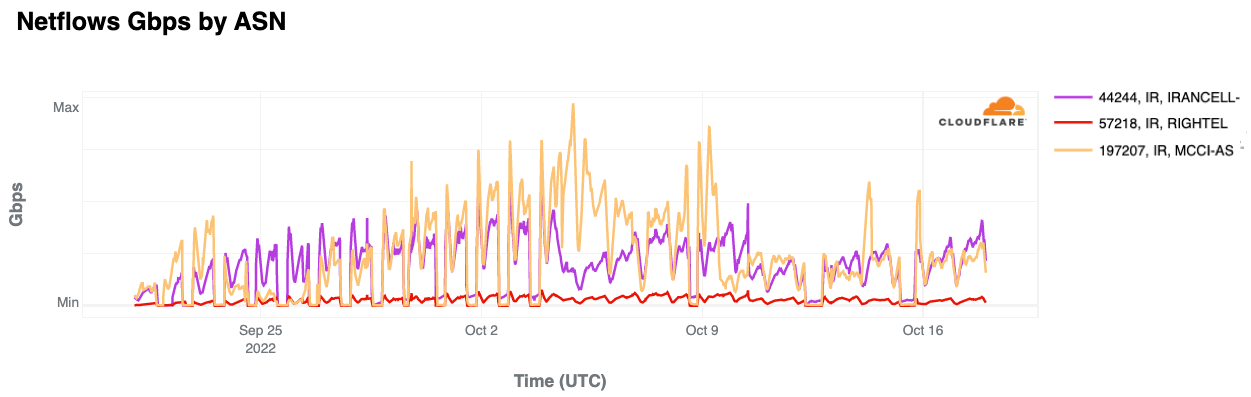
As we covered in last quarter’s blog post, the Iranian government implemented daily Internet “curfews”, generally taking place between 1600 and midnight local time (1230-2030 UTC) across three mobile network providers — AS44244 (Irancell), AS57218 (RighTel), and AS197207 (MCCI) — in response to protests surrounding the death of Mahsa Amini. These multi-hour Internet curfew shutdowns continued into early October, with additional similar outages also observed on October 8, 12 and 15 as seen in the figure below. (The graph’s line for AS57218 (Rightel), the smallest of the three mobile providers, suggests that the shutdowns on this network were not implemented after the end of September.)
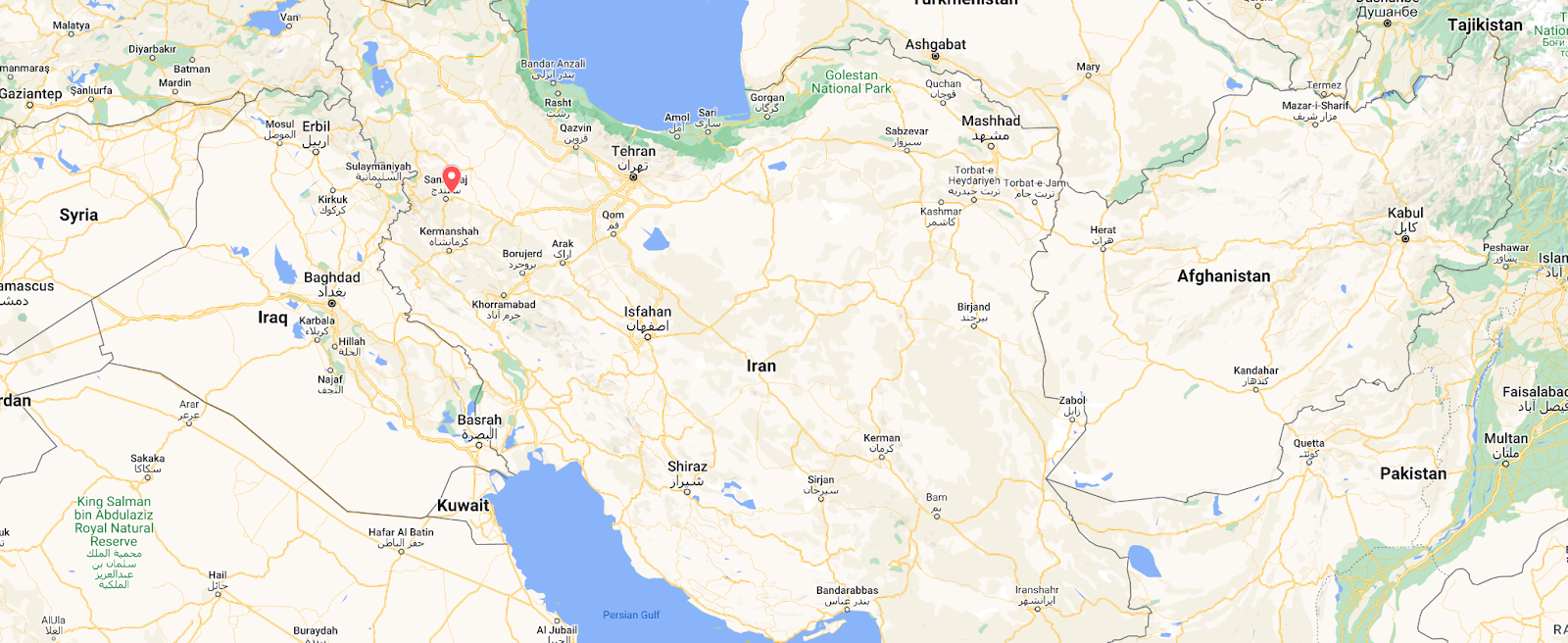
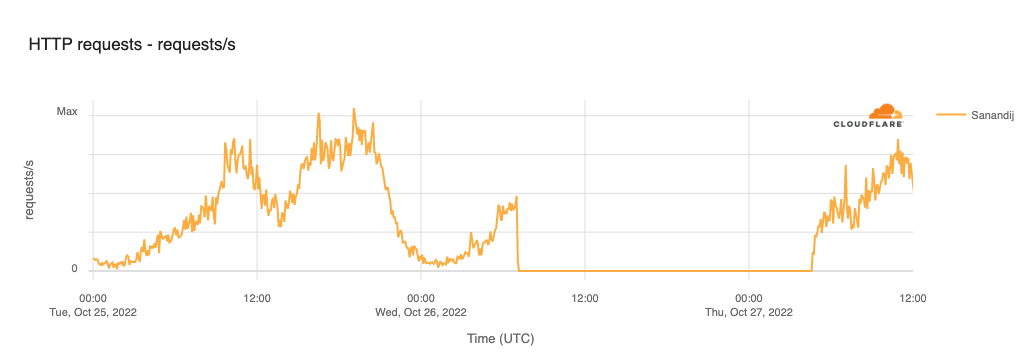
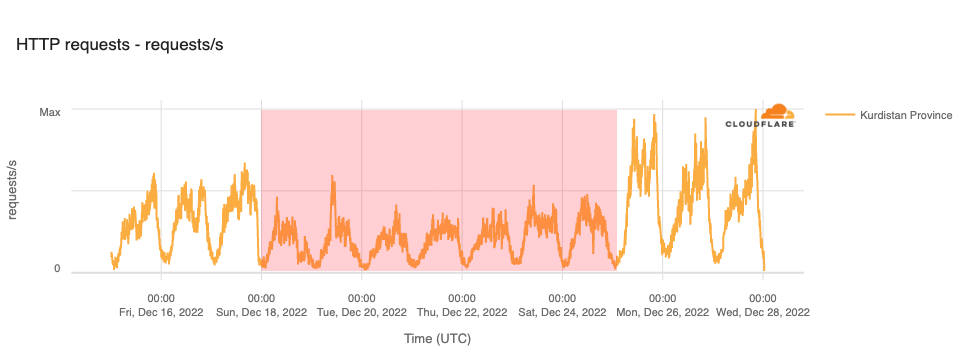
In addition to the mobile network shutdowns, several regional Internet disruptions were also observed in Iran during the fourth quarter, two of which we review below. The first was in Sanandaj, Kurdistan Province on October 26, where a complete Internet shutdown was implemented in response to demonstrations marking the 40th day since the death of Mahsa Amini. The figure below shows a complete loss of traffic starting at 1030 local time (0700 UTC), with the outage lasting until 0805 local time on October 27 (0435 UTC). In December, a province-level Internet disruption was observed starting on December 18, lasting through December 25.
The Internet disruptions that have taken place in Iran over the last several months have had a significant economic impact on the country. A December post from Filterwatch shared concerns stated in a letter from mobile operator Rightel:
The letter, signed by the network’s Managing Director Yasser Rezakhah, states that “during the past few weeks, the company’s resources and income have significantly decreased during Internet shutdowns and other restrictions, such as limiting Internet bandwidth from 21 September. They have also caused a decrease in data use from subscribers, decreasing data traffic by around 50%.” The letter also states that the “continued lack of compensation for losses could lead to bankruptcy.”
The post also highlighted economic concerns shared by Iranian officials:
Some Iranian officials have expressed concern about the cost of Internet shutdowns, including Valiollah Bayati, MP for Tafresh and Ashtian in Markazi province. In a public session in Majles (parliament), he stated that continued Internet shutdowns have led to the closure of many jobs and people are worried, the government and the President must provide necessary measures.
Statistics in an article on news site enthkhab.ir provide a more tangible view of the local economic impact, stating (via Google Translate):
Since the 30th of Shahrivar month and with the beginning of the government disruption in the Internet, the country’s businesses have been damaged daily at least 50 million tomans and at most 500 million tomans. More than 41% of companies have lost 25-50% of their income during this period, and about 47% have had more than 50% reduction in sales. A review of the data of the research assistant of the country’s tax affairs organization shows that the Internet outage in Iran has caused 3000 billion tomans of damage per day. That is, the cost of 3 months of Internet outage in Iran is equal to 43% of one year’s oil revenue of the country ($25 billion).
Power outages
Bangladesh, October 4
Over 140 million people in Bangladesh were left without electricity on October 4 as the result of a reported grid failure caused by a failure by power distribution companies to follow instructions from the National Load Dispatch Centre to shed load. The resultant power outage resulted in an observed drop in Internet traffic from the country, starting at 1405 local time (0805 UTC), as shown in the figure below. The disruption lasted approximately seven hours, with traffic returning to expected levels around 1900 local time (1500 UTC).
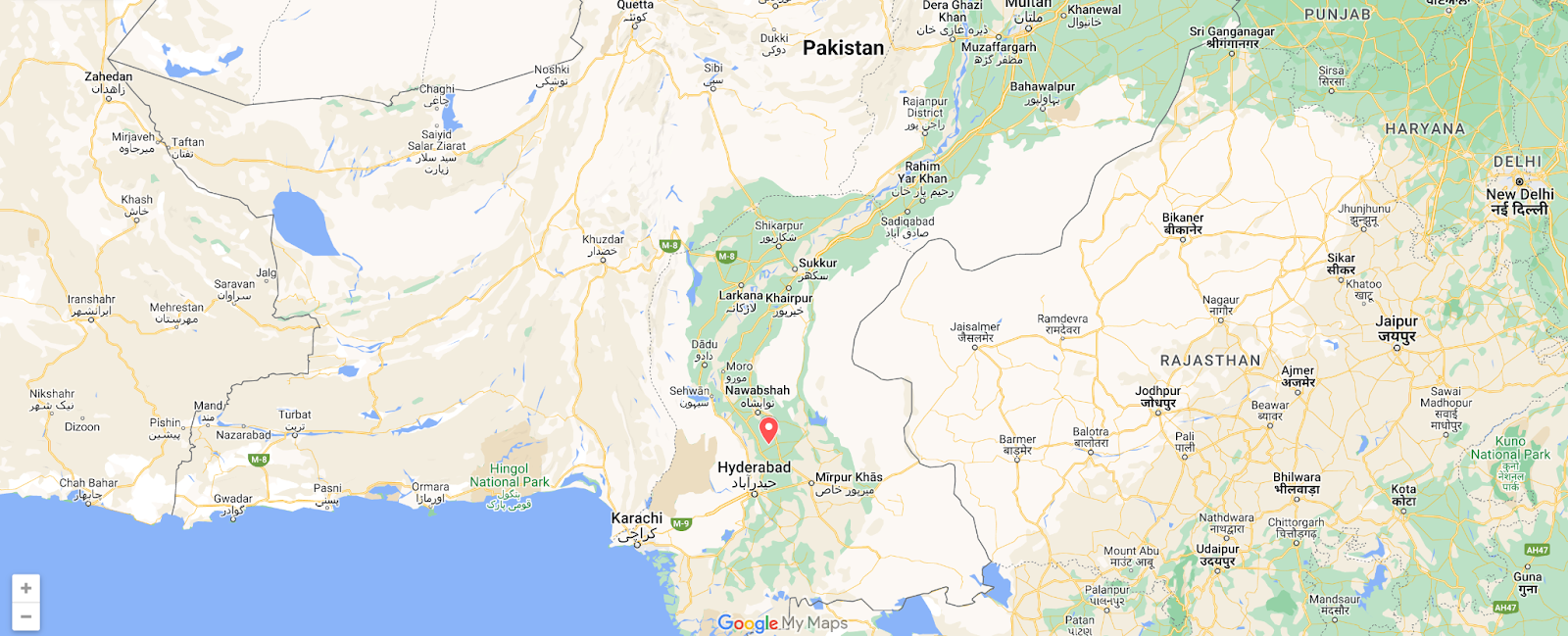
Pakistan
Over a week later, a similar issue in Pakistan caused power outages across the southern part of the country, including Sindh, Punjab, and Balochistan. The power outages were caused by a fault in the national grid’s southern transmission system, reportedly due to faulty equipment and sub-standard maintenance. As expected, the power outages resulted in disruptions to Internet connectivity, and the figure below illustrates the impact observed in Sindh, where traffic dropped nearly 30% as compared to the previous week starting at 0935 local time (0435 UTC) on October 6. The disruption lasted over 15 hours, with traffic returning to expected levels at 0100 on October 7 (2000 UTC on October 6).
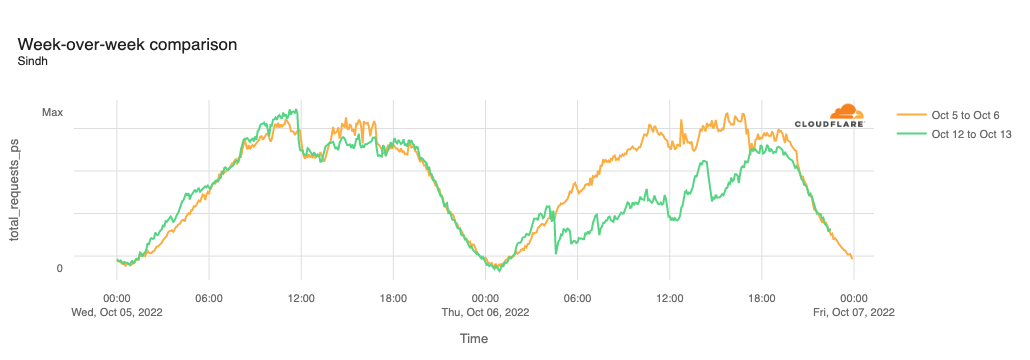
Kenya
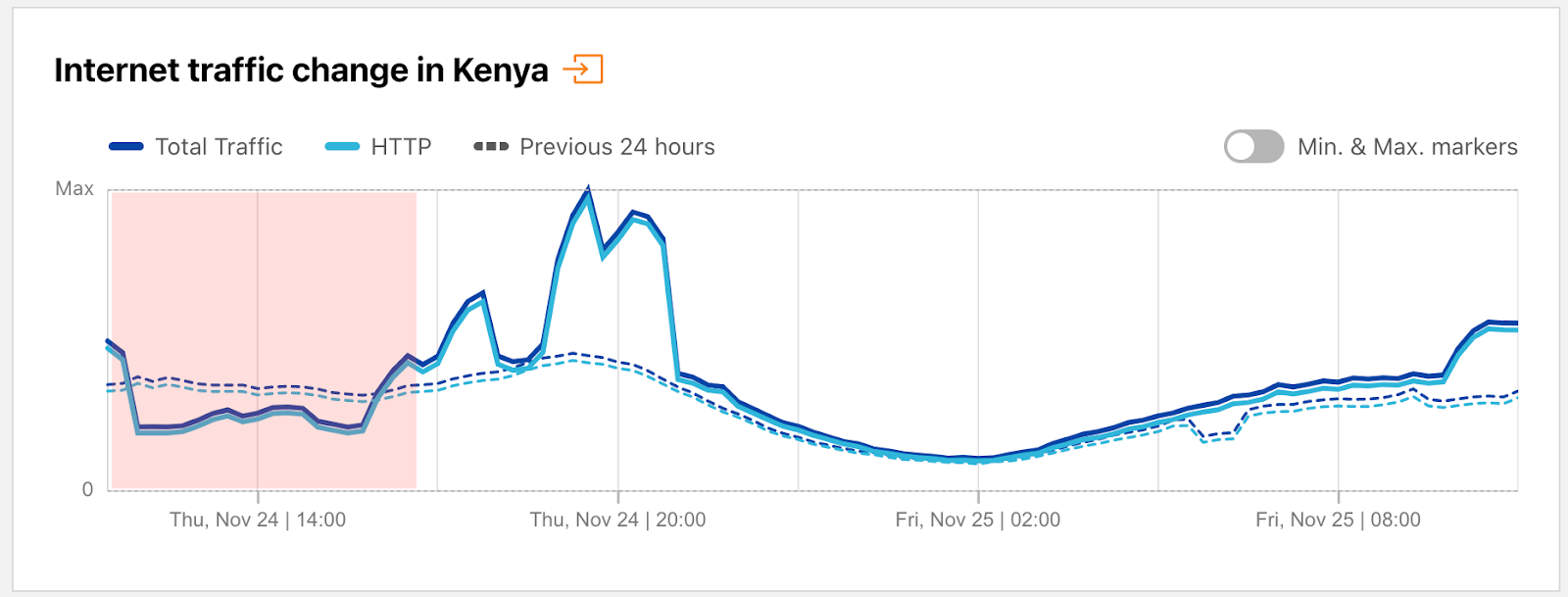
On November 24, a Tweet from Kenya Power at 1525 local time noted that they had “lost bulk power supply to various parts of the country due to a system disturbance”. A subsequent Tweet published just over six hours later at 2150 local time stated that “normal power supply has been restored to all parts of the country.” The time stamps on these notifications align with the loss of Internet traffic visible in the figure below, which lasted between 1500-2050 local time (1200-1750 UTC).
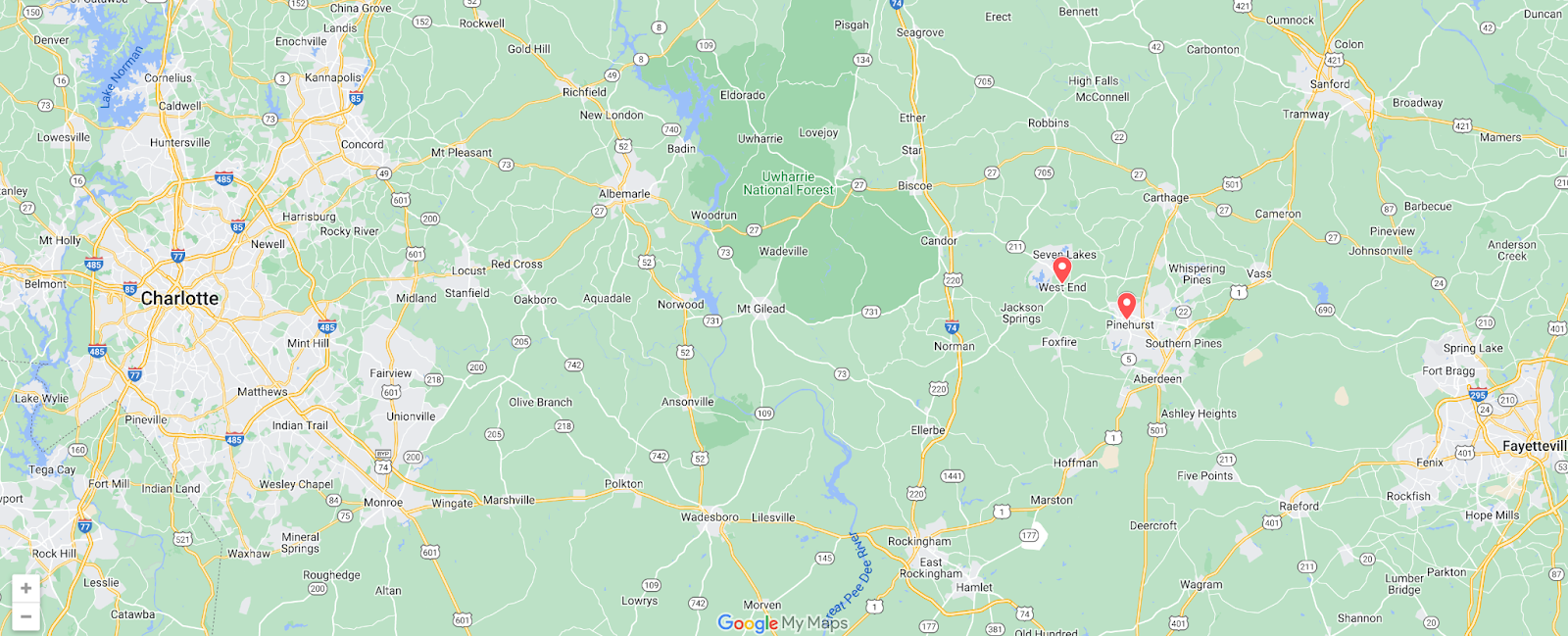
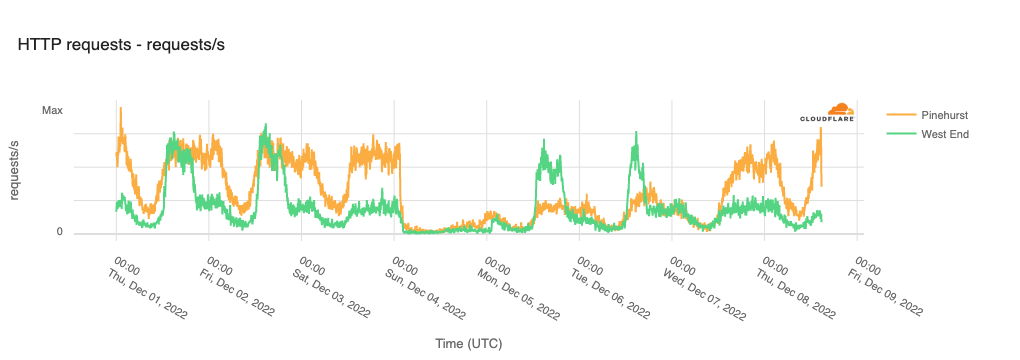
United States (Moore County, North Carolina)
On December 3, two electrical substations in Moore County, North Carolina were targeted by gunfire, with the resultant damage causing localized power outages that took multiple days to resolve. The power outages reportedly began just after 1900 local time (0000 UTC on December 4), resulting in the concurrent loss of Internet traffic from communities within Moore County, as seen in the figure below.
Internet traffic within the community of West End appeared to return midday (UTC) on December 5, but that recovery was apparently short-lived, as it fell again during the afternoon of December 6. In Pinehurst, traffic began to slowly recover after about a day, but returned to more normal levels around 0800 local time (1300 UTC) on December 7.
Ukraine
The war in Ukraine has been going on since February 24, and Cloudflare has covered the impact of the war on the country’s Internet connectivity in a number of blog posts across the year (March, March, April, May, June, July, October, December). Throughout the fourth quarter of 2022, Russian missile strikes caused widespread damage to electrical infrastructure, resulting in power outages and disruptions to Internet connectivity. Below, we highlight several examples of the Internet disruptions observed in Ukraine during the fourth quarter, but they are just a few of the many disruptions that occurred.
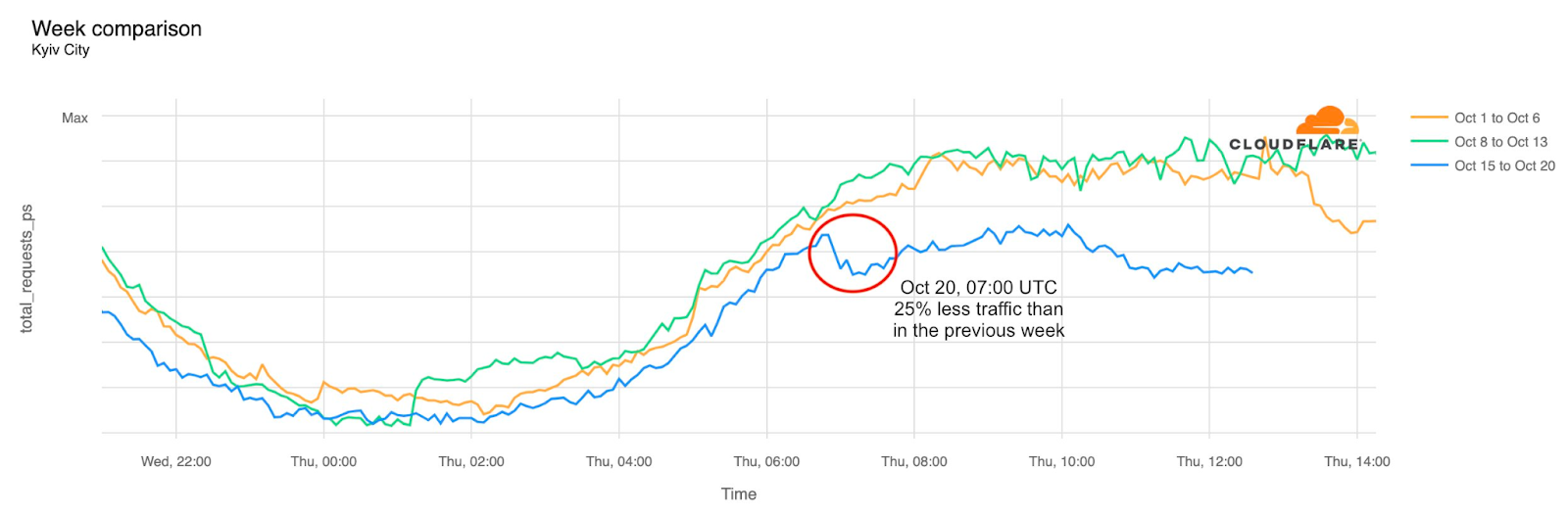
On October 20, the destruction of several power stations in Kyiv resulted in a 25% drop in Internet traffic from Kyiv City as compared to the two previous weeks. The disruption began around 0900 local time (0700 UTC).
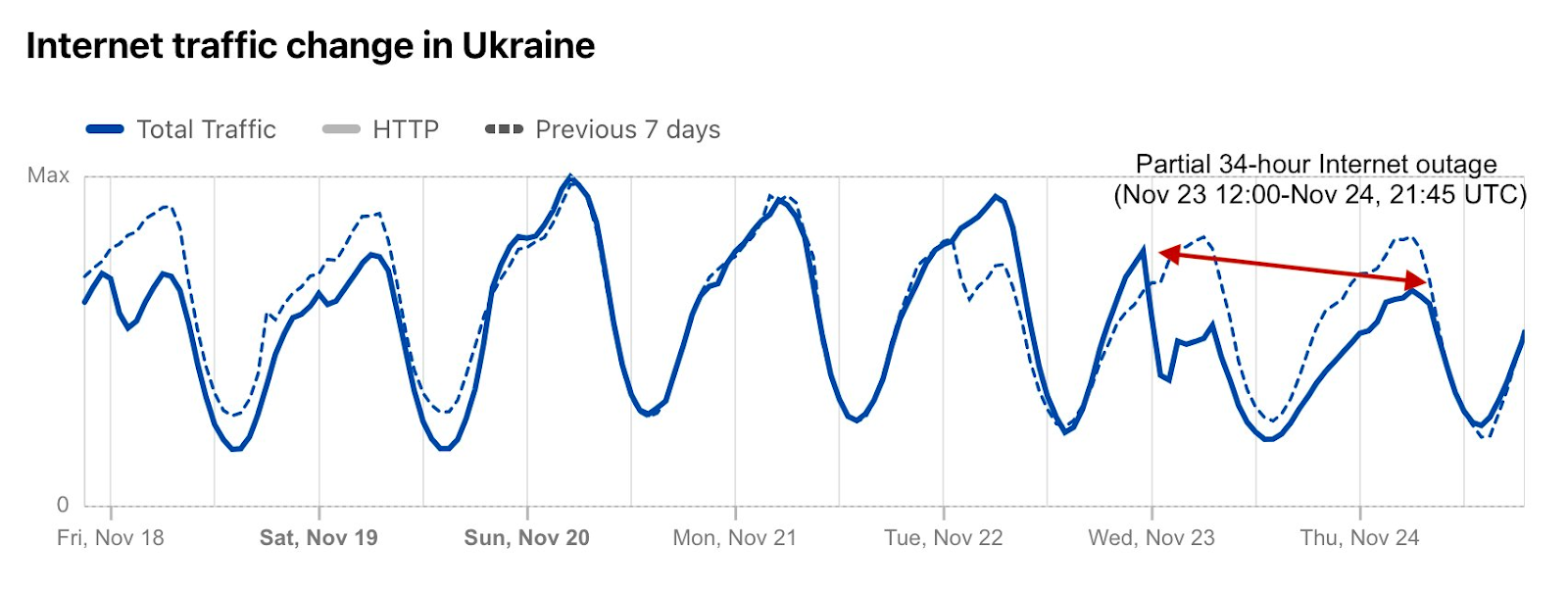
On November 23, widespread power outages after Russian strikes caused a nearly 50% decrease in Internet traffic in Ukraine, starting just after 1400 local time (1200 UTC). This disruption lasted for nearly a day and a half, with traffic returning to expected levels around 2345 local time on November 24 (2145 UTC).
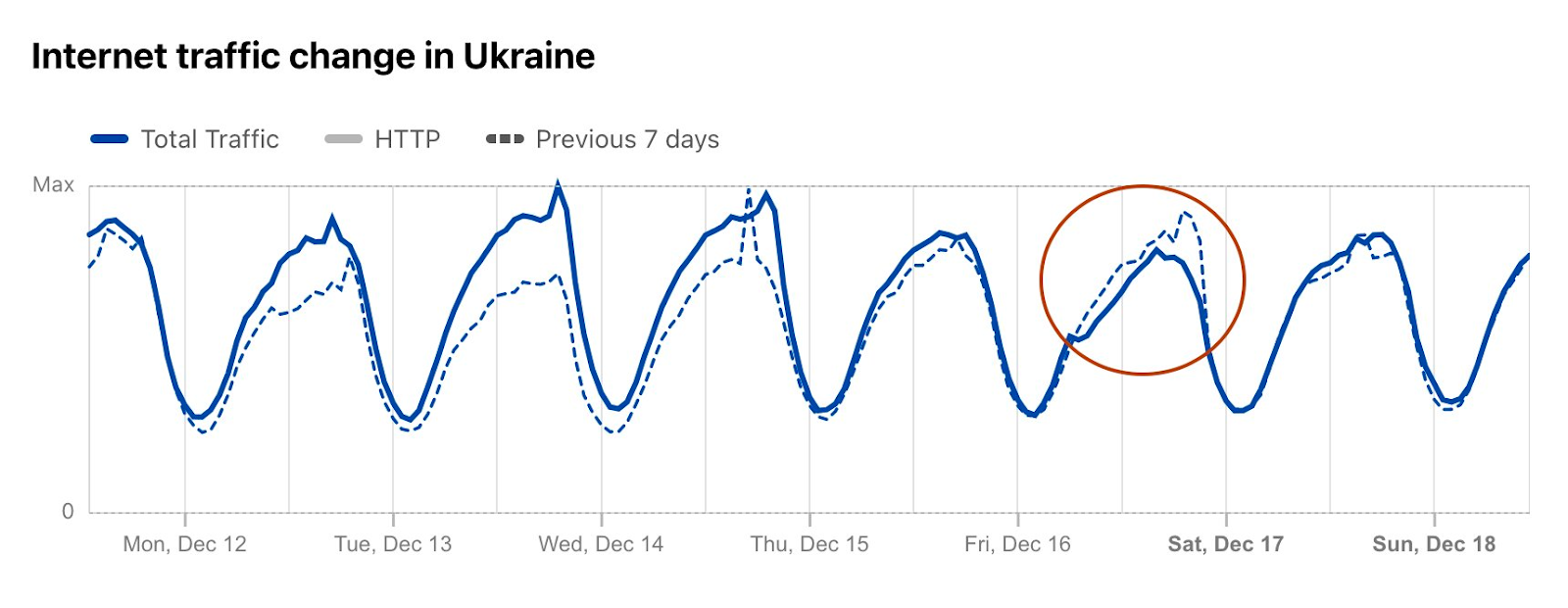
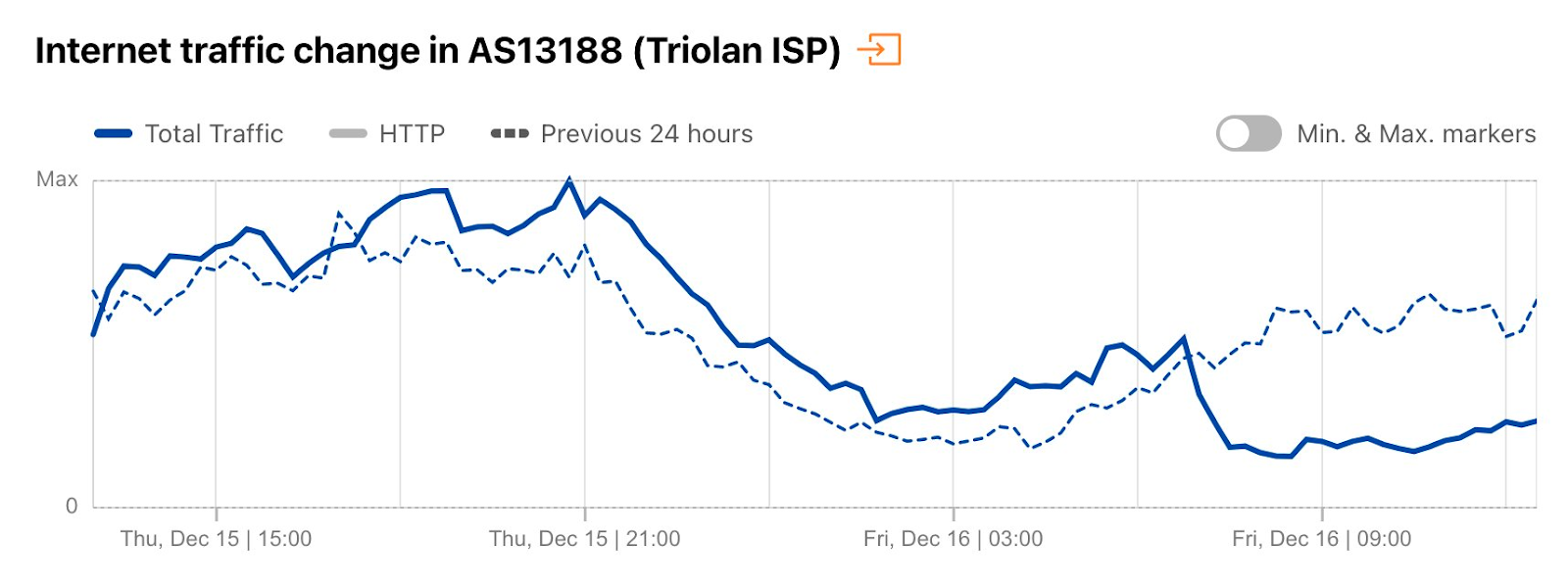
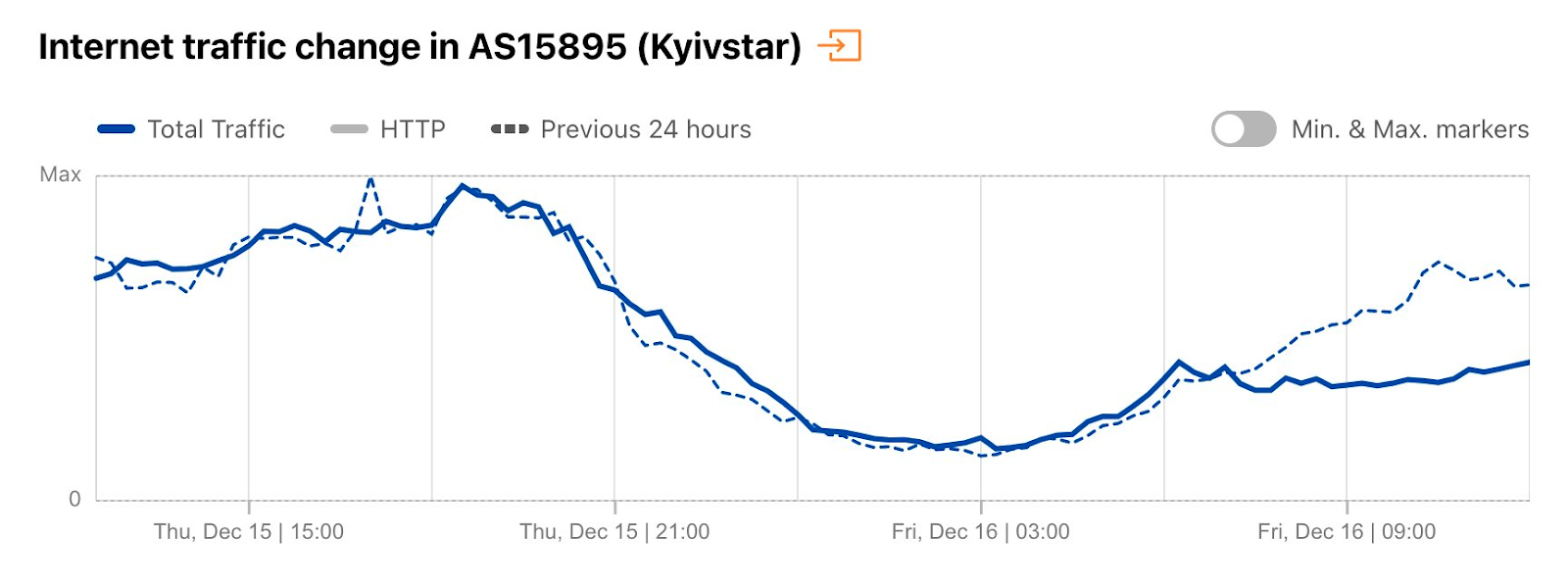
On December 16, power outages resulting from Russian air strikes targeting power infrastructure caused country-level Internet traffic to drop around 13% at 0915 local time (0715 UTC), with the disruption lasting until midnight local time (2200 UTC). However, at a network level, the impact was more significant, with AS13188 (Triolan) seeing a 70% drop in traffic, and AS15895 (Kyivstar) a 40% drop, both shown in the figures below.
Cable cuts
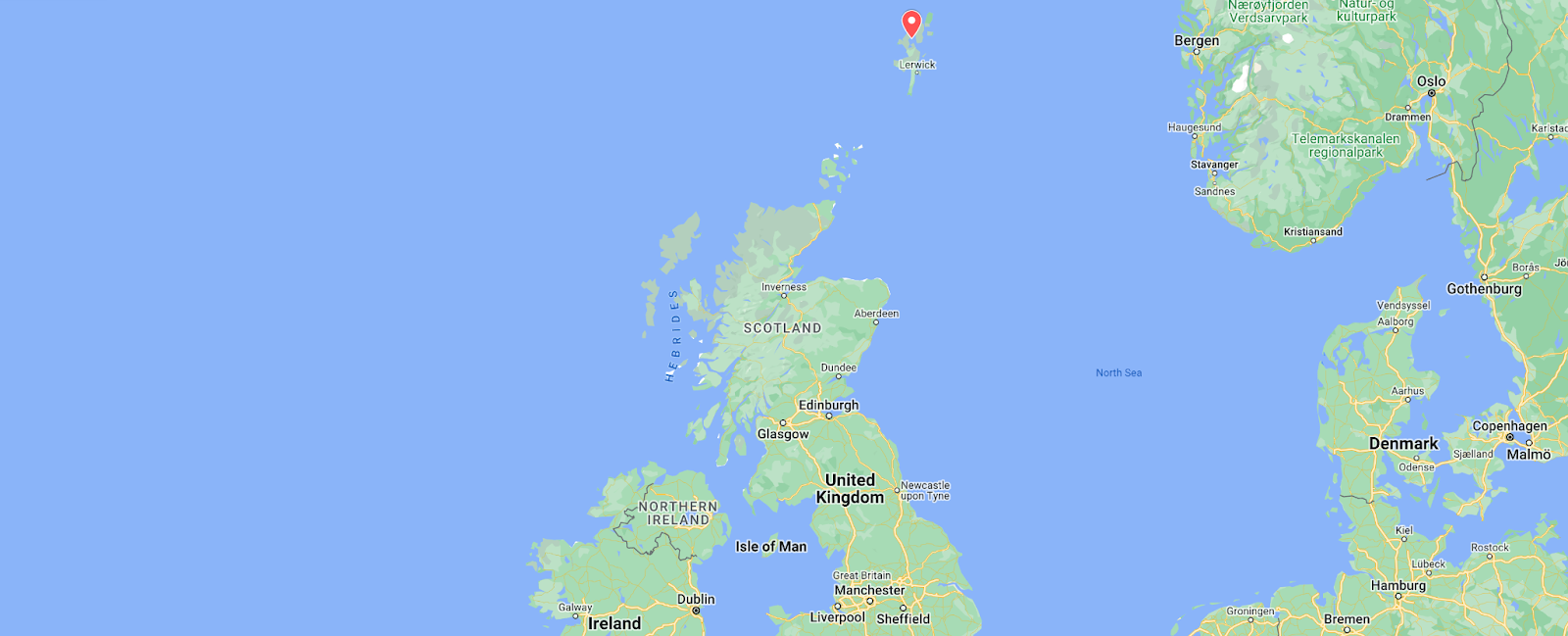
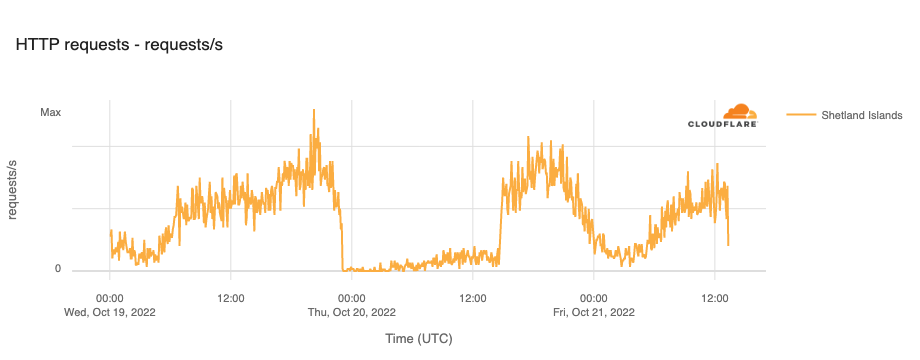
Shetland Islands, United Kingdom
The Shetland Islands are primarily dependent on the SHEFA-2 submarine cable system for Internet connectivity, connecting through the Scottish mainland. Late in the evening of October 19, damage to this cable knocked the Shetland Islands almost completely offline. At the time, there was heightened concern about the potential sabotage of submarine cables due to the reported sabotage of the Nord Stream natural gas pipelines in late September, but authorities believed that this cable damage was due to errant fishing vessels, and not sabotage.
The figure below shows that the impact of the damage to the cable was relatively short-lived, compared to the multi-day Internet disruptions often associated with submarine cable cuts. Traffic dropped just after 2300 local time (2200 UTC) on October 19, and recovered 14.5 hours later, just after 1430 local time (1330 UTC) on October 20.
Natural disasters
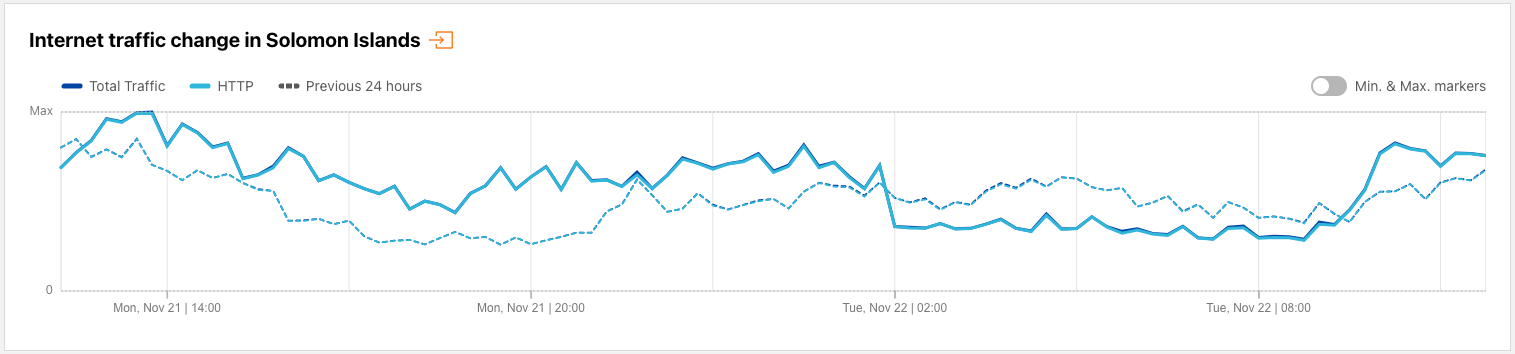
Solomon Islands
Earthquakes frequently cause infrastructure damage and power outages in affected areas, resulting in disruptions to Internet connectivity. We observed such a disruption in the Solomon Islands after a magnitude 7.0 earthquake occurred near there on November 22. The figure below shows Internet traffic from the country dropping significantly at 1300 local time (0200 UTC), and recovering 11 hours later at around 2000 local time (0900 UTC).
Technical problems
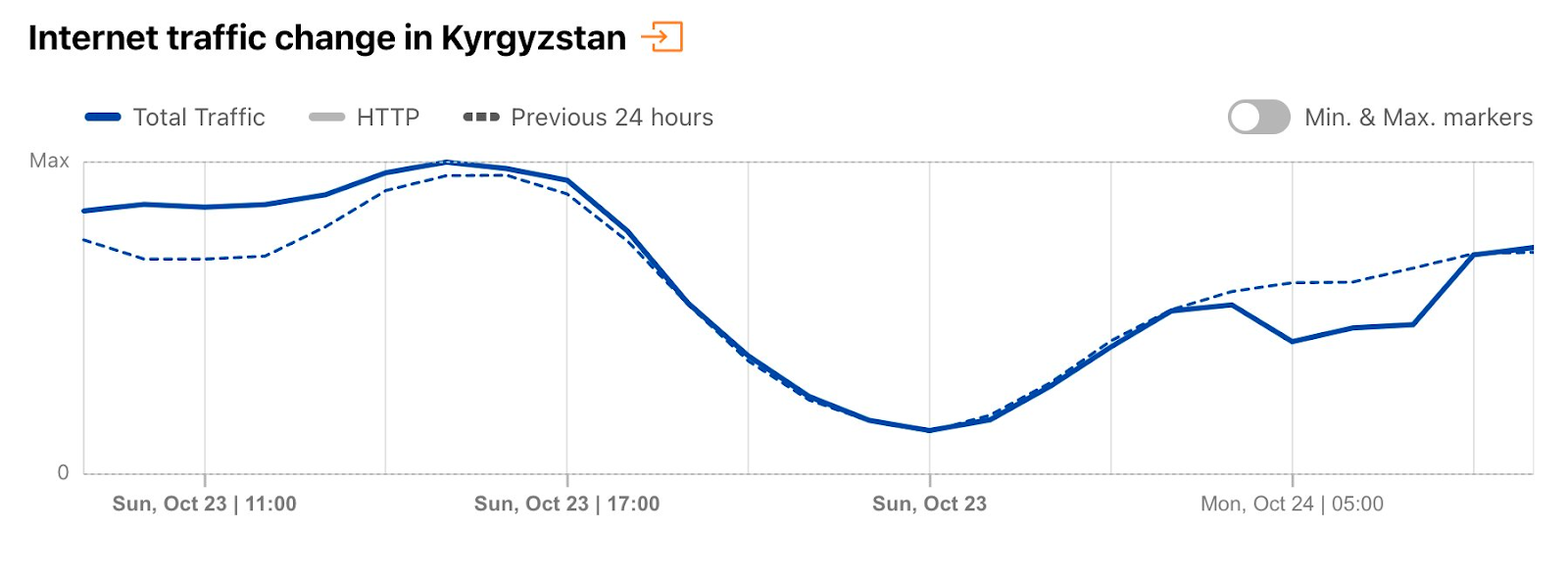
Kyrgyzstan
On October 24, a three-hour Internet disruption was observed in Kyrgyzstan lasting between 1100-1400 local time (0500-0800 UTC), as seen in the figure below. According to the country’s Ministry of Digital Development, the issue was caused by “an accident on one of the main lines that supply the Internet”, but no additional details were provided regarding the type of accident or where it had occurred.
Australia (Aussie Broadband)
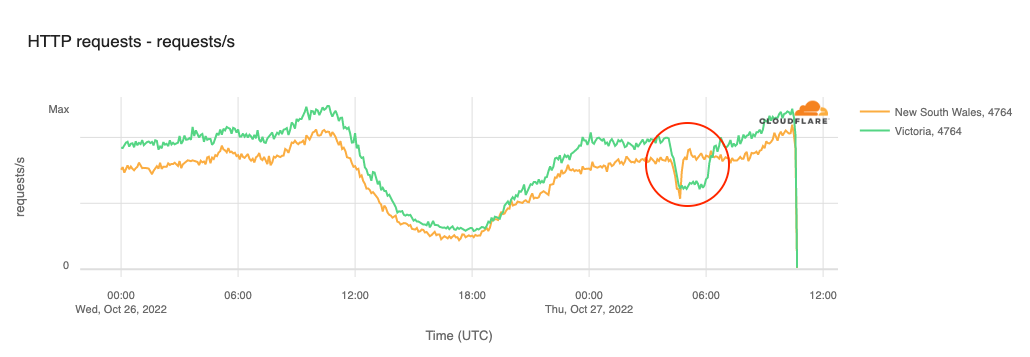
Customers of Australian broadband Internet provider Aussie Broadband in Victoria and New South Wales suffered brief Internet disruptions on October 27. As shown in the figure below, AS4764 (Aussie Broadband) traffic from Victoria dropped by approximately 40% between 1505-1745 local time (0405-0645 UTC). A similar, but briefer, loss of traffic from New South Wales was also observed, lasting between 1515-1550 local time (0415-0450 UTC). A representative of Aussie Broadband provided insight into the underlying cause of the disruption, stating “A config change was made which was pushed out through automation to the DHCP servers in those states. … The change has been rolled back but getting the sessions back online is taking time for VIC, and we are now manually bringing areas up one at a time.”
Haiti
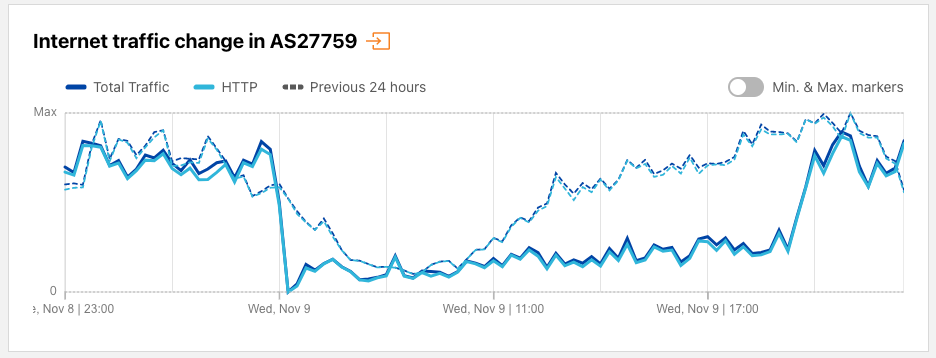
In Haiti, customers of Internet service provider Access Haiti experienced disrupted service for more than half a day on November 9. The figure below shows that Internet traffic for AS27759 (Access Haiti) fell precipitously around midnight local time (0500 UTC), remaining depressed until 1430 local time (1930 UTC), at which time it recovered quickly. A Facebook post from Access Haiti explained to customers that “Due to an intermittent outage on one of our international circuits, our network is experiencing difficulties that cause your Internet service to slow down.” While Access Haiti didn’t provide additional details on which international circuit was experiencing an outage, submarinecablemap.com shows that two submarine cables provide international Internet connectivity to Haiti — the Bahamas Domestic Submarine Network (BDSNi), which connects Haiti to the Bahamas, and Fibralink, which connects Haiti to the Dominican Republic and Jamaica.
Unknown
Many Internet disruptions can be easily tied to an underlying cause, whether through coverage in the press, a concurrent weather or natural disaster event, or communication from an impacted provider. However, the causes of other observed disruptions remain unknown as the impacted providers remain silent about what caused the problem.
United States (Wide Open West)
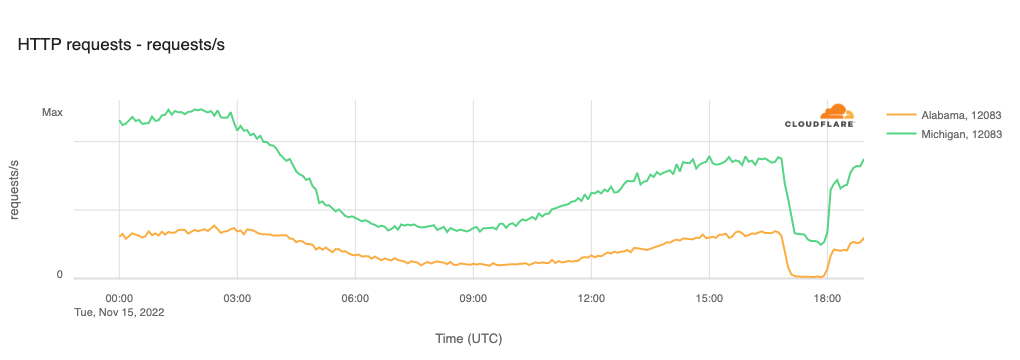
On November 15, customers of Wide Open West, an Internet service provider with a multi-state footprint in the United States, experienced an Internet service disruption that lasted a little over an hour. The figure below illustrates the impact of the disruption in Alabama and Michigan on AS12083 (Wide Open West), with traffic dropping at 1150 local time (1650 UTC) and recovering just after 1300 local time (1800 UTC).
Cuba
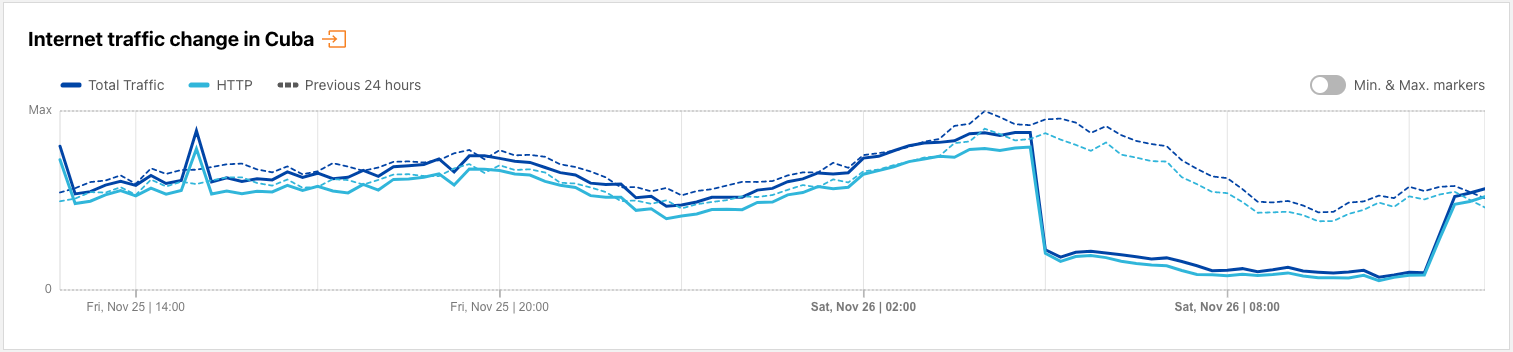
Cuba is no stranger to Internet disruptions, whether due to government-directed shutdowns (such as the one discussed above), fiber cuts, or power outages. However, no underlying cause was ever shared for the seven-hour disruption in the country’s Internet traffic observed between 2345 on November 25 and 0645 on November 26 local time (0445-1145 UTC on November 26). Traffic was down as much as 75% from previous levels during the disruption.
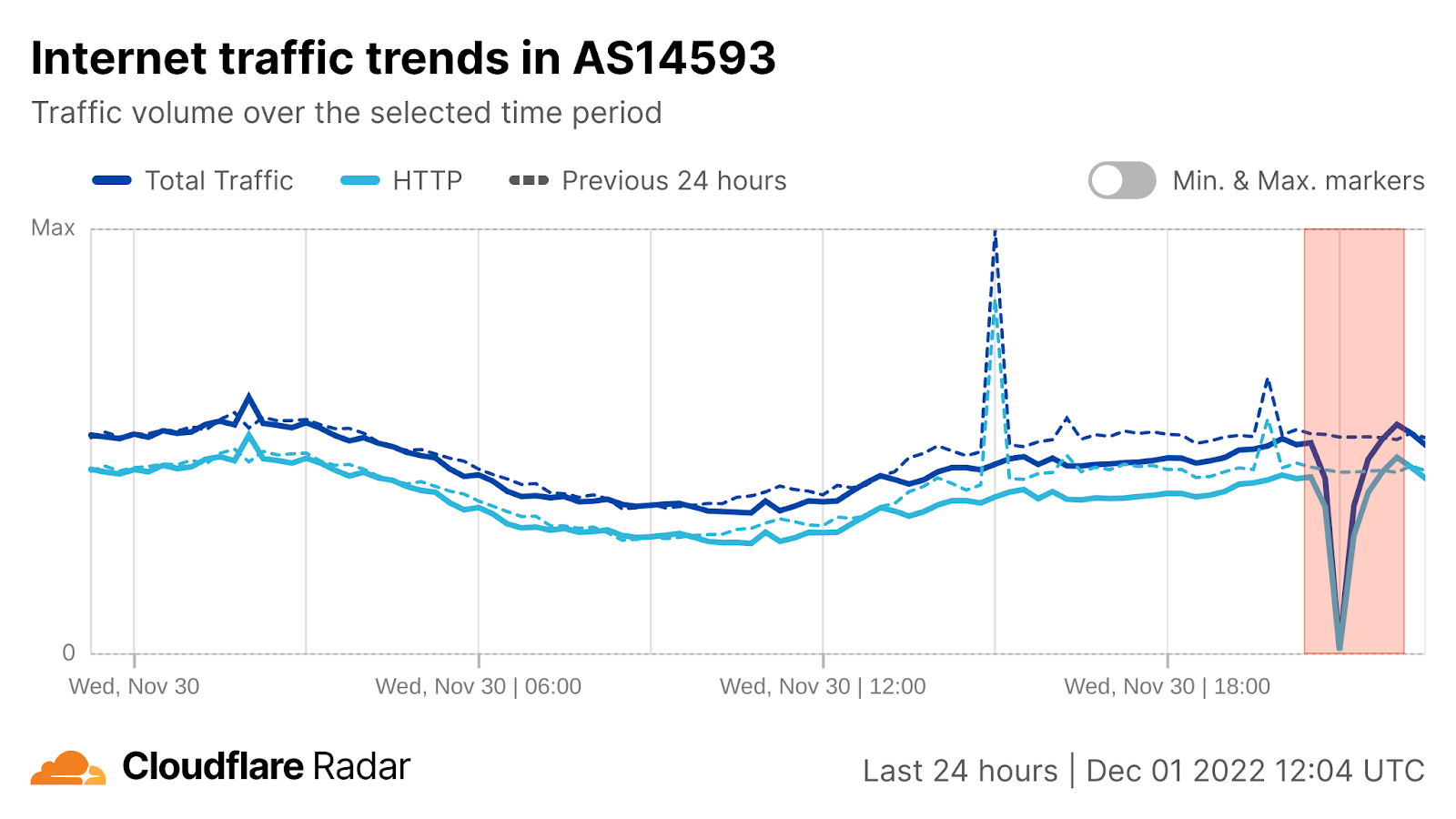
SpaceX Starlink
As a provider of low earth orbit (LEO) satellite Internet connectivity services, disruptions to SpaceX Starlink’s service can have a global impact. On November 30, a disruption was observed on AS14593 (SPACEX-STARLINK) between 2050-2130 UTC, with traffic volume briefly dropping to near zero. Unfortunately, Starlink did not acknowledge the incident, nor did they provide any reason for the disruption.
Conclusion
Looking back at the Internet disruptions observed during 2022, a number of common themes can be found. In countries with more authoritarian governments, the Internet is often weaponized as a means of limiting communication within the country and with the outside world through network-level, regional, or national Internet shutdowns. As noted above, this approach was used aggressively in Iran during the last few months of the year.
Internet connectivity quickly became a casualty of war in Ukraine. Early in the conflict, network-level outages were common, and some Ukrainian networks ultimately saw traffic re-routed through upstream Russian Internet service providers. Later in the year, as electrical power infrastructure was increasingly targeted by Russian attacks, widespread power outages resulted in multi-hour disruptions of Internet traffic across the country.
While the volcanic eruption in Tonga took the country offline for over a month due to its reliance on a single submarine cable for Internet connectivity, the damage caused by earthquakes in other countries throughout the year resulted in much shorter and more limited disruptions.
And while submarine cable issues can impact multiple countries along its route, the advent of services with an increasingly global footprint like SpaceX Starlink mean that service disruptions will ultimately have a much broader impact. (Starlink’s subscriber base is comparatively small at the moment, but it currently has a service footprint in over 30 countries around the world.)
To follow Internet disruptions as they occur, check the Cloudflare Radar Outage Center (CROC) and follow @CloudflareRadar on Twitter. To review those disruptions observed earlier in 2022, refer to the Q1, Q2, and Q3 Internet disruptions overview blog posts.

















 Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.
Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.