With one click, customers can now generate video captions effortlessly using Stream’s newest feature: AI-generated captions for on-demand videos and recordings of live streams. As part of Cloudflare’s mission to help build a better Internet, this feature is available to all Stream customers at no additional cost.
This solution is designed for simplicity, eliminating the need for third-party transcription services and complex workflows. For videos lacking accessibility features like captions, manual transcription can be time-consuming and impractical, especially for large video libraries. Traditionally, it has involved specialized services, sometimes even dedicated teams, to transcribe audio and deliver the text along with video, so it can be displayed during playback. As captions become more widely expected for a variety of reasons, including ethical obligation, legal compliance, and changing audience preferences, we wanted to relieve this burden.
With Stream’s integrated solution, the caption generation process is seamlessly integrated into your existing video management workflow, saving time and resources. Regardless of when you uploaded a video, you can easily add automatic captions to enhance accessibility. Captions can now be generated within the Cloudflare Dashboard or via an API request, all within the familiar and unified Stream platform.
This feature is designed with utmost consideration for privacy and data protection. Unlike other third-party transcription services that may share content with external entities, your data remains securely within Cloudflare’s ecosystem throughout the caption generation process. Cloudflare does not utilize your content for model training purposes. For more information about data protection, review Your Data and Workers AI.
Getting Started
Starting June 20th, 2024, this beta is available for all Stream customers as well as subscribers of the Professional and Business plans, which include 100 minutes of video storage.
To get started, upload a video to Stream (from the Cloudflare Dashboard or via API).
Next, navigate to the “Captions” tab on the video, click “Add Captions,” then select the language and “Generate captions with AI.” Finally, click save and within a few minutes, the new captions will be visible in the captions manager and automatically available in the player, too. Captions can also be generated via the API.
Captions are usually generated in a few minutes. When captions are ready, the Stream player will automatically be updated to offer them to users. The HLS and DASH manifests are also updated so third party players that support text tracks can display them as well.
On-demand videos and recordings of live streams, regardless of when they were created, are supported. While in beta, only English captions can be generated, and videos must be shorter than 2 hours. The quality of the transcription is best on videos with clear speech and minimal background noise.
We’ve been pleased with how well the AI model transcribes different types of content during our tests. That said, there are times when the results aren’t perfect, and another method might work better for some use cases. It’s important to check if the accuracy of the generated captions are right for your needs.
Technical Details
Built using Workers AI
The Stream engineering team built this new feature using Workers AI, allowing us to access the Whisper model – an open source Automatic Speech Recognition model – with a single API call. Using Workers AI radically simplified the AI model deployment, integration, and scaling with an out-of-the-box solution. We eliminated the need for our team to handle infrastructure complexities, enabling us to focus solely on building the automated captions feature.
Writing software that utilizes an AI model can involve several challenges. First, there’s the difficulty of configuring the appropriate hardware infrastructure. AI models require substantial computational resources to run efficiently and require specialized hardware, like GPUs, which can be expensive and complex to manage. There’s also the daunting task of deploying AI models at scale, which involve the complexities of balancing workload distribution, minimizing latency, optimizing throughput, and maintaining high availability. Not only does Workers AI solve the pain of managing underlying infrastructure, it also automatically scales as needed.
Using Workers AI transformed a daunting task into a Worker that transcribes audio files with less than 30 lines of code.
import { Ai } from '@cloudflare/ai'
export interface Env {
AI: any
}
export type AiVTTOutput = {
vtt?: string
}
export default {
async fetch(request: Request, env: Env) {
const blob = await request.arrayBuffer()
const ai = new Ai(env.AI)
const input = {
audio: [...new Uint8Array(blob)],
}
try {
const response: AiVTTOutput = (await ai.run(
'@cf/openai/whisper-tiny-en',
input
)) as any
return Response.json({ vtt: response.vtt })
} catch (e) {
const errMsg =
e instanceof Error
? `${e.name}\n${e.message}\n${e.stack}`
: 'unknown error type'
return new Response(`${errMsg}`, {
status: 500,
statusText: 'Internal error',
})
}
},
}
Quickly captioning videos at scale
The Stream team wanted to ensure this feature is fast and performant at scale, which required engineering work to process a high volume of videos regardless of duration.
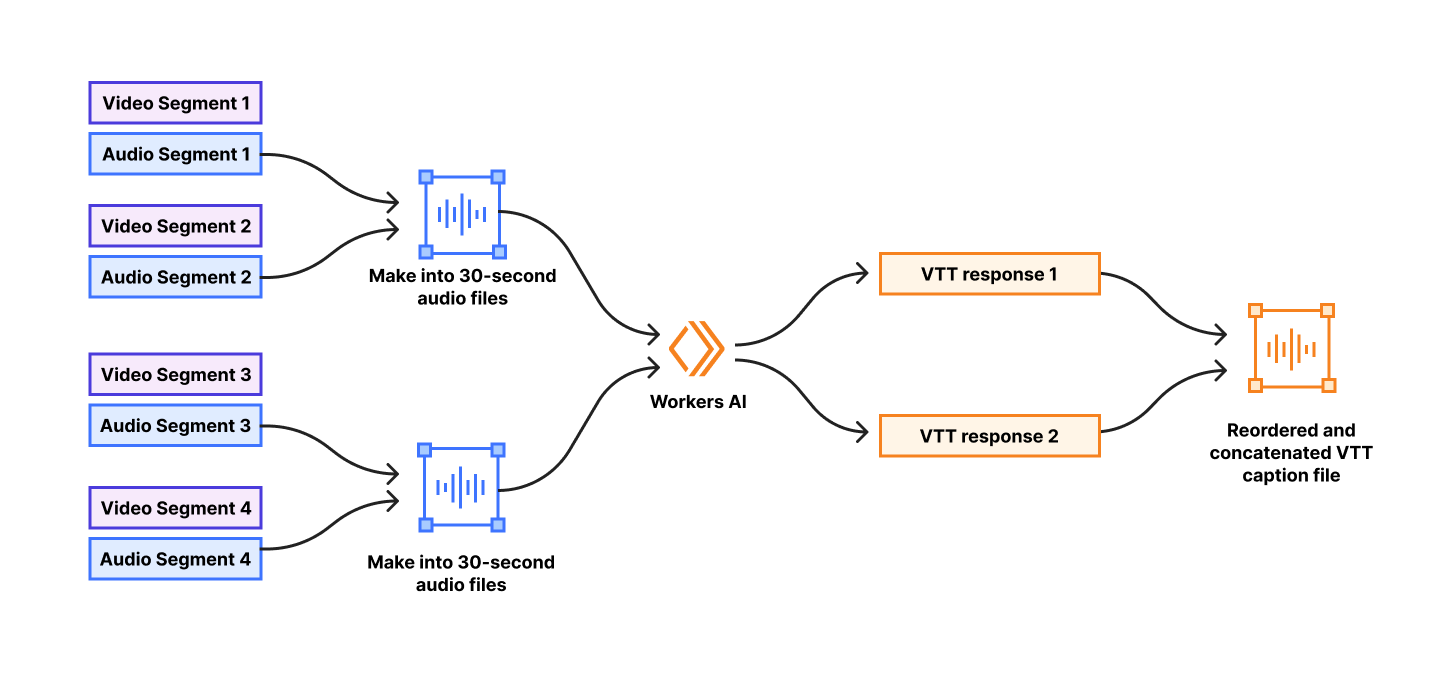
First, our team needed to pre-process the audio prior to running AI inference to ensure the input is compatible with Whisper’s input format and requirements.
There is a wide spectrum of variability in video content, from a short grainy video filmed on a phone to a multi-hour high-quality Hollywood-produced movie. Videos may be silent or contain an action-driven cacophony. Also, Stream’s on-demand videos include recordings of live streams which are packaged differently from videos uploaded as whole files. With this variability, the audio inputs are stored in an array of different container formats, with different durations, and different file sizes. We ensured our audio files were properly formatted to be compatible with Whisper’s requirements.
One aspect for pre-processing is ensuring files are a sensible duration for optimized inference. Whisper has an “sweet spot” of 30 seconds for the duration of audio files for transcription. As they note in this Github discussion: “Too short, and you’d lack surrounding context. You’d cut sentences more often. A lot of sentences would cease to make sense. Too long, and you’ll need larger and larger models to contain the complexity of the meaning you want the model to keep track of.” Fortunately, Stream already splits videos into smaller segments to ensure fast delivery during playback on the web. We wrote functionality to concatenate those small segments into 30-second batches prior to sending to Workers AI.
To optimize processing speed, our team parallelized as many operations as possible. By concurrently creating the 30-second audio batches and sending requests to Workers AI, we take full advantage of the scalability of the Workers AI platform. Doing this greatly reduces the time it takes to generate captions, but adds some additional complexity. Because we are sending requests to Workers AI in parallel, transcription responses may arrive out-of-order. For example, if a video is one minute in duration, the request to generate captions for the second 30 seconds of a video may complete before the request for the first 30 seconds of the video. The captions need to be sequential to align with the video, so our team had to maintain an understanding of the audio batch order to ensure our final combined WebVTT caption file is properly synced with the video. We sort the incoming Workers AI responses and re-order timestamps for a final accurate transcript.
The end result is the ability to generate captions for longer videos quickly and efficiently at scale.
Try it now
We are excited to bring this feature to open beta for all of our subscribers as well as Pro and Business plan customers today! Get started by uploading a video to Stream. Review our documentation for tutorials and current beta limitations. Up next, we will be focused on adding more languages and supporting longer videos.
Artificial intelligence (AI) and data monitoring are working together to digitally transform relationships, businesses, and people. In telecommunications, predictive analysis based on data collection plays a crucial role in development. Starting with version 6.0 of Zabbix, users have benefited from updates in predictive functions and machine learning, which make it possible for them to study the data monitored by Zabbix and integrate it with AI modules.
Danilo Barros, co-founder of Lunio (a Zabbix Certified Partner in Brazil), presented the results of using Zabbix combined with telecom data monitoring through AI and machine learning at Zabbix Conference Brazil in 2022. Keep reading to get the whole story!
Table of Contents
The scenario
With over 600 OLTs (Optical Line Terminals – the fiberoptic infrastructure used by internet providers) as well as 400,000 customers across more than 800 cities and 20 states in Brazil, Lunio’s client manages a staggering amount of data. This monitoring is essential for smooth operations and to guarantee that there are no negative impacts on users and no overload for customer service agents in the event of accidents.
A primary challenge for telecom clients is the overload of calls to customer service in the event of massive network incidents. With so many customers, every precaution must be taken to avoid clogging phone lines during outages or service failures.
“You can’t achieve customer satisfaction under such circumstances, and the Net Promoter Score (NPS) drops drastically.”
Danilo Barros, co-founder of Lunio
Mapping needs
Considering the client’s operational structure, a series of customer needs were identified, focusing on six main points:
1. Automation: With notifications via digital channels for each event
2. Speed: Aiming for improved customer service
3. Operational costs: Budget optimization
4. Root cause analysis: Quick identification of the cause of events
5. Predictability: The ability to analyze problems and identify trends
6. Reporting: Identifying incidents and following regulations from ANATEL (National Telecommunications Agency)
With these interests in mind, it was possible to reassess the use of tools previously employed by the telecom client, which at the time served unique functions in the process. Each tool had its usage and information verification time, which could impact hundreds of users in a massive-scale incident. The key challenges identified by the Lunio team included:
Integrations: Systems needed to be interconnected
Integrity: Constant data updates
Topology: With system mapping through specific programs
Business rules: Respecting the development of local processes
Performance: The monitoring and automation of 600,000 assets
High availability: Dozens of data centers catering to local demand
Once the needs and challenges were identified, it was time to promote change within the client. By integrating systems and using Zabbix to monitor over 600,000 items, understand incidents, and predict potential future errors, the technical teams at Lunio created LunioAI, a “super attendant” with analytical and predictive capabilities as well as the ability to continuously learn.
“This guy (LunioIA) learns from each event, understanding each topology that occurs in the client’s network.”
Danilo Barros, co-founder of Lunio
In the initial response tests, LunioAI was able to analyze and evaluate massive events in a minute and a half. Over time, this was reduced to 30 seconds, making the return to the technical team increasingly swift and positively impacting incident resolution.
The results
Throughout the development and improvement of LunioIA, the operations chain was involved in predictive analyses of potential events on the network, providing technical professionals with the information needed to perform preventive maintenance on monitored items.
LunioIA considers data from integrated systems, FTTH (fiber to the home) environments, data centers, and items, all as part of the Zabbix monitoring environment. It can then diagnose events, understand the severity of an event, and find resolution points – without the need for human resources in the process.
As a result, when physical attendants were contacted by customers experiencing difficulties with the service, instead of going through the entire process to understand what happened, the attendant could perform a search using the customer’s CPF (Individual Taxpayer Registry Identification) and then access a summary of the events, causes, and solutions identified by artificial intelligence combined with data monitoring through Zabbix.
In conclusion
This example happens to come from the telecommunications industry, but it’s not difficult to see how the ability of Zabbix to integrate the data monitored by Zabbix with AI modules can benefit companies in almost any industry.
You can find out more about what we can do across a variety of industries by visiting our website or requesting a demo.
During Developer Week in April 2024, we announced General Availability of Workers AI, and today, we are excited to announce that AI Gateway is Generally Available as well. Since its launch to beta in September 2023 during Birthday Week, we’ve proxied over 500 million requests and are now prepared for you to use it in production.
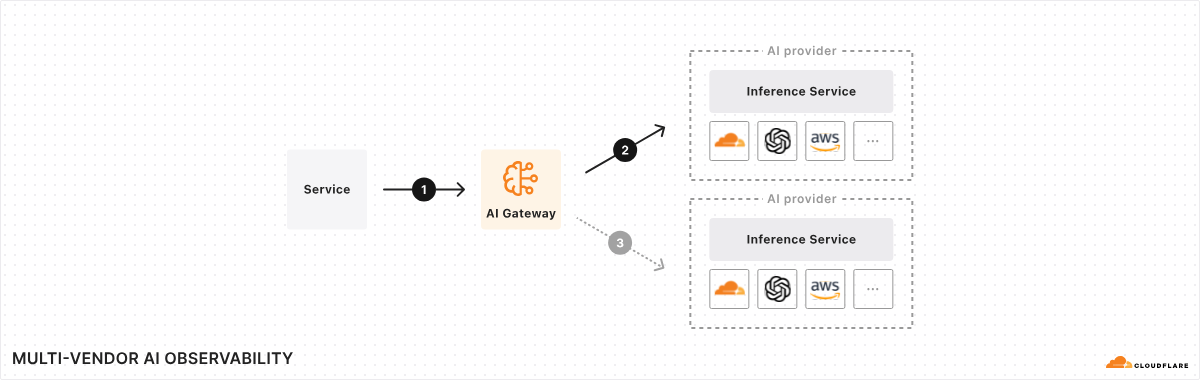
AI Gateway is an AI ops platform that offers a unified interface for managing and scaling your generative AI workloads. At its core, it acts as a proxy between your service and your inference provider(s), regardless of where your model runs. With a single line of code, you can unlock a set of powerful features focused on performance, security, reliability, and observability – think of it as your control plane for your AI ops. And this is just the beginning – we have a roadmap full of exciting features planned for the near future, making AI Gateway the tool for any organization looking to get more out of their AI workloads.
Why add a proxy and why Cloudflare?
The AI space moves fast, and it seems like every day there is a new model, provider, or framework. Given this high rate of change, it’s hard to keep track, especially if you’re using more than one model or provider. And that’s one of the driving factors behind launching AI Gateway – we want to provide you with a single consistent control plane for all your models and tools, even if they change tomorrow, and then again the day after that.
We’ve talked to a lot of developers and organizations building AI applications, and one thing is clear: they want more observability, control, and tooling around their AI ops. This is something many of the AI providers are lacking as they are deeply focused on model development and less so on platform features.
Why choose Cloudflare for your AI Gateway? Well, in some ways, it feels like a natural fit. We’ve spent the last 10+ years helping build a better Internet by running one of the largest global networks, helping customers around the world with performance, reliability, and security – Cloudflare is used as a reverse proxy by nearly 20% of all websites. With our expertise, it felt like a natural progression – change one line of code, and we can help with observability, reliability, and control for your AI applications – all in one control plane – so that you can get back to building.
Here is that one line code change using the OpenAI JS SDK. And check out our docs to reference other providers, SDKs, and languages.
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: 'my api key', // defaults to process.env["OPENAI_API_KEY"]
baseURL: "https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_slug}/openai"
});
What’s included today?
After talking to customers, it was clear that we needed to focus on some foundational features before moving onto some of the more advanced ones. While we’re really excited about what’s to come, here are the key features available in GA today:
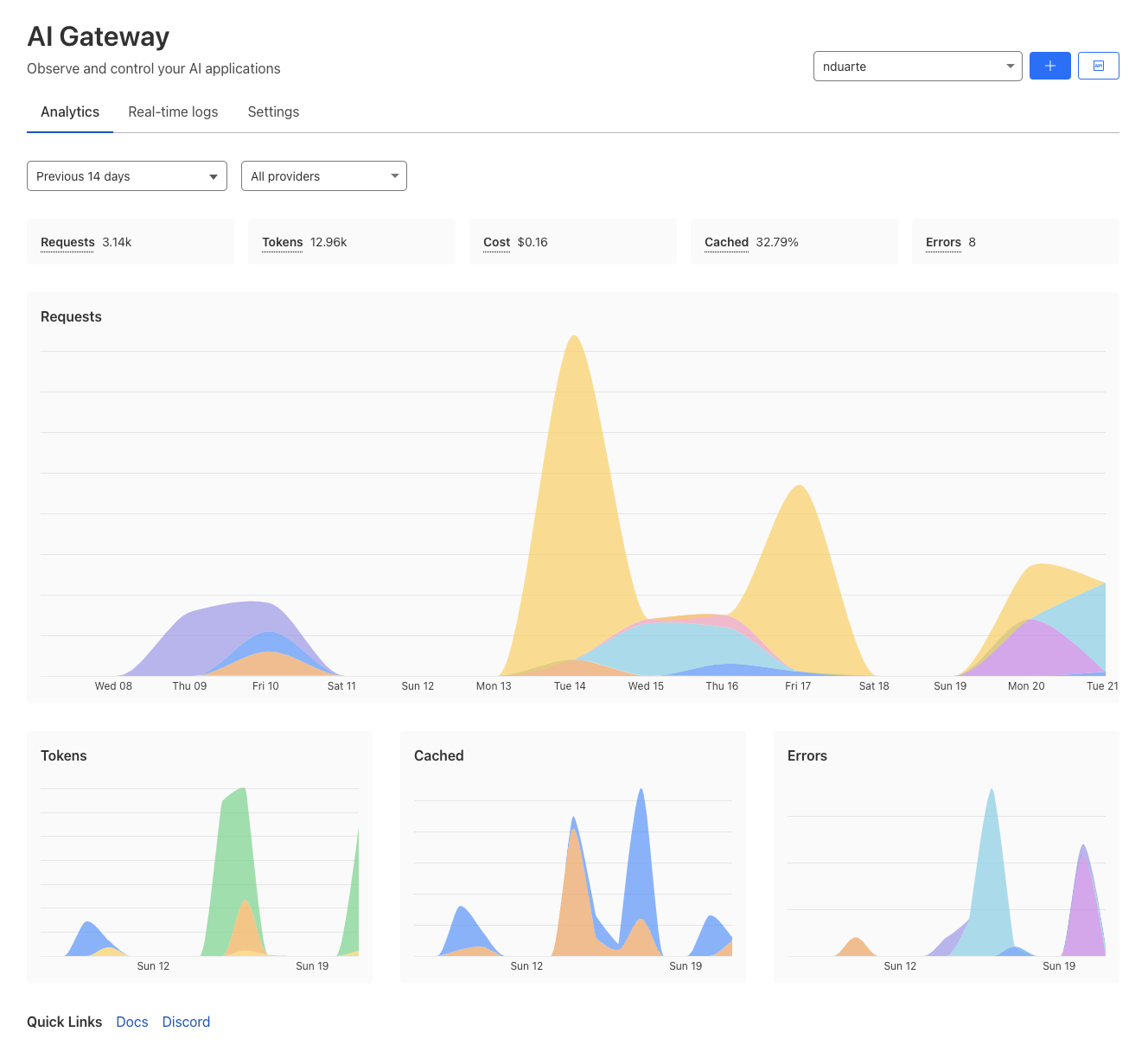
Analytics: Aggregate metrics from across multiple providers. See traffic patterns and usage including the number of requests, tokens, and costs over time.
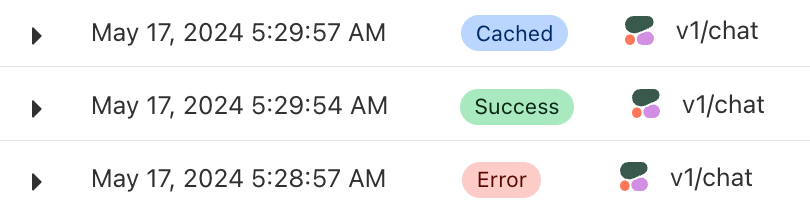
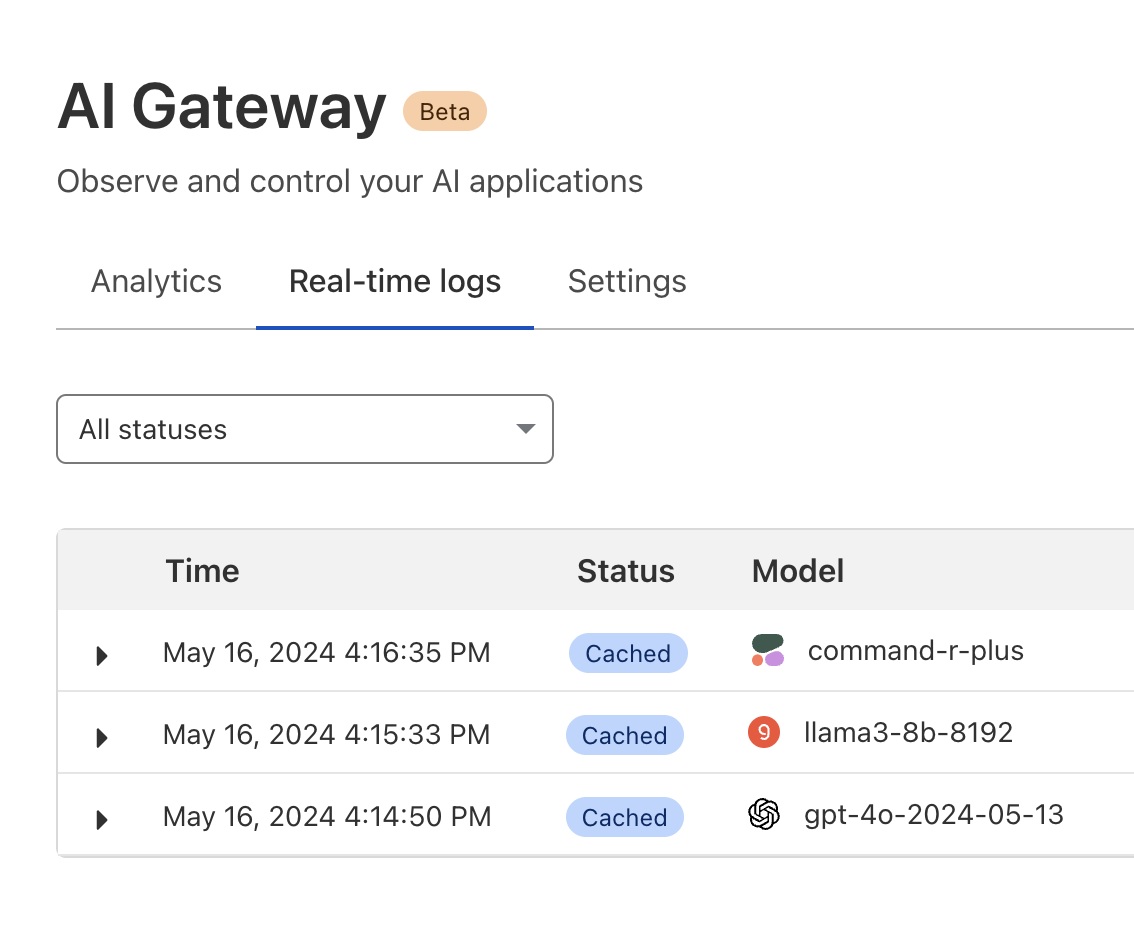
Real-time logs: Gain insight into requests and errors as you build.
Caching: Enable custom caching rules and use Cloudflare’s cache for repeat requests instead of hitting the original model provider API, helping you save on cost and latency.
Rate limiting: Control how your application scales by limiting the number of requests your application receives to control costs or prevent abuse.
Support for your favorite providers: AI Gateway now natively supports Workers AI plus 10 of the most popular providers, including Groq and Cohere as of mid-May 2024.
Universal endpoint: In case of errors, improve resilience by defining request fallbacks to another model or inference provider.
We’ve gotten a lot of feedback from developers, and there are some obvious things on the horizon such as persistent logs and custom metadata – foundational features that will help unlock the real magic down the road.
But let’s take a step back for a moment and share our vision. At Cloudflare, we believe our platform is much more powerful as a unified whole than as a collection of individual parts. This mindset applied to our AI products means that they should be easy to use, combine, and run in harmony.
Let’s imagine the following journey. You initially onboard onto Workers AI to run inference with the latest open source models. Next, you enable AI Gateway to gain better visibility and control, and start storing persistent logs. Then you want to start tuning your inference results, so you leverage your persistent logs, our prompt management tools, and our built in eval functionality. Now you’re making analytical decisions to improve your inference results. With each data driven improvement, you want more. So you implement our feedback API which helps annotate inputs/outputs, in essence building a structured data set. At this point, you are one step away from a one-click fine tune that can be deployed instantly to our global network, and it doesn’t stop there. As you continue to collect logs and feedback, you can continuously rebuild your fine tune adapters in order to deliver the best results to your end users.
This is all just an aspirational story at this point, but this is how we envision the future of AI Gateway and our AI suite as a whole. You should be able to start with the most basic setup and gradually progress into more advanced workflows, all without leaving Cloudflare’s AI platform. In the end, it might not look exactly as described above, but you can be sure that we are committed to providing the best AI ops tools to help make Cloudflare the best place for AI.
How do I get started?
AI Gateway is available to use today on all plans. If you haven’t yet used AI Gateway, check out our developer documentation and get started now. AI Gateway’s core features available today are offered for free, and all it takes is a Cloudflare account and one line of code to get started. In the future, more premium features, such as persistent logging and secrets management will be available subject to fees. If you have any questions, reach out on our Discord channel.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.