We’re thrilled to announce that PartyKit, an open source platform for deploying real-time, collaborative, multiplayer applications, is now a part of Cloudflare. This acquisition marks a significant milestone in our journey to redefine the boundaries of serverless computing, making it more dynamic, interactive, and, importantly, stateful.
Defining the future of serverless compute around state
Building real-time applications on the web have always been difficult. Not only is it a distributed systems problem, but you need to provision and manage infrastructure, databases, and other services to maintain state across multiple clients. This complexity has traditionally been a barrier to entry for many developers, especially those who are just starting out.
We announced Durable Objects in 2020 as a way of building synchronized real time experiences for the web. Unlike regular serverless functions that are ephemeral and stateless, Durable Objects are stateful, allowing developers to build applications that maintain state across requests. They also act as an ideal synchronization point for building real-time applications that need to maintain state across multiple clients. Combined with WebSockets, Durable Objects can be used to build a wide range of applications, from multiplayer games to collaborative drawing tools.
In 2022, PartyKit began as a project to further explore the capabilities of Durable Objects and make them more accessible to developers by exposing them through familiar components. In seconds, you could create a project that configured behavior for these objects, and deploy it to Cloudflare. By integrating with popular libraries such as Yjs (the gold standard in collaborative editing) and React, PartyKit made it possible for developers to build a wide range of use cases, from multiplayer games to collaborative drawing tools, into their applications.
Building experiences with real-time components was previously only accessible to multi-billion dollar companies, but new computing primitives like Durable Objects on the edge make this accessible to regular developers and teams. With PartyKit now under our roof, we’re doubling down on our commitment to this future — a future where serverless is stateful.
We’re excited to give you a preview into our shared vision for applications, and the use cases we’re excited to simplify together.
Making state for serverless easy
Unlike conventional approaches that rely on external databases to maintain state, thereby complicating scalability and increasing costs, PartyKit leverages Cloudflare’s Durable Objects to offer a seamless model where stateful serverless functions can operate as if they were running on a single machine, maintaining state across requests. This innovation not only simplifies development but also opens up a broader range of use cases, including real-time computing, collaborative editing, and multiplayer gaming, by allowing thousands of these “machines” to be spun up globally, each maintaining its own state. PartyKit aims to be a complement to traditional serverless computing, providing a more intuitive and efficient method for developing applications that require stateful behavior, thereby marking the “next evolution” of serverless computing.
Simplifying WebSockets for Real-Time Interaction
WebSockets have revolutionized how we think about bidirectional communication on the web. Yet, the challenge has always been about scaling these interactions to millions without a hitch. Cloudflare Workers step in as the hero, providing a serverless framework that makes real-time applications like chat services, multiplayer games, and collaborative tools not just possible but scalable and efficient.
Powering Games and Multiplayer Applications Without Limits
Imagine building multiplayer platforms where the game never lags, the collaboration is seamless, and video conferences are crystal clear. Cloudflare’s Durable Objects morph the stateless serverless landscape into a realm where persistent connections thrive. PartyKit’s integration into this ecosystem means developers now have a powerhouse toolkit to bring ambitious multiplayer visions to life, without the traditional overheads.
This is especially critical in gaming — there are few areas where low-latency and real-time interaction matter more. Every millisecond, every lag, every delay defines the entire experience. With PartyKit’s capabilities integrated into Cloudflare, developers will be able to leverage our combined technologies to create gaming experiences that are not just about playing but living the game, thanks to scalable, immersive, and interactive platforms.
The toolkit for building Local-First applications
The Internet is great, and increasingly always available, but there are still a few situations where we are forced to disconnect — whether on a plane, a train, or a beach.
The premise of local-first applications is that work doesn’t stop when the Internet does. Wherever you left off in your doc, you can keep working on it, assuming the state will be restored when you come back online. By storing data on the client and syncing when back online, these applications offer resilience and responsiveness that’s unmatched. Cloudflare’s vision, enhanced by PartyKit’s technology, aims to make local-first not just an option but the standard for application development.
What’s next for PartyKit users?
Users can expect their existing projects to continue working as expected. We will be adding more features to the platform, including the ability to create and use PartyKit projects inside existing Workers and Pages projects. There will be no extra charges to use PartyKit for commercial purposes, other than the standard usage charges for Cloudflare Workers and other services. Further, we’re going to expand the roadmap to begin working on integrations with popular frameworks and libraries, such as React, Vue, and Angular. We’re deeply committed to executing on the PartyKit vision and roadmap, and we’re excited to see what you build with it.
The Beginning of a New Chapter
The acquisition of PartyKit by Cloudflare isn’t just a milestone for our two teams; it’s a leap forward for developers everywhere. Together, we’re not just building tools; we’re crafting the foundation for the next generation of Internet applications. The future of serverless is stateful, and with PartyKit’s expertise now part of our arsenal, we’re more ready than ever to make that future a reality.
Welcome to the Cloudflare team, PartyKit. Look forward to building something remarkable together.
Inference from fine-tuned LLMs with LoRAs is now in open beta
Today, we’re excited to announce that you can now run fine-tuned inference with LoRAs on Workers AI. This feature is in open beta and available for pre-trained LoRA adapters to be used with Mistral, Gemma, or Llama 2, with some limitations. Take a look at our product announcements blog post to get a high-level overview of our Bring Your Own (BYO) LoRAs feature.
In this post, we’ll do a deep dive into what fine-tuning and LoRAs are, show you how to use it on our Workers AI platform, and then delve into the technical details of how we implemented it on our platform.
What is fine-tuning?
Fine-tuning is a general term for modifying an AI model by continuing to train it with additional data. The goal of fine-tuning is to increase the probability that a generation is similar to your dataset. Training a model from scratch is not practical for many use cases given how expensive and time consuming they can be to train. By fine-tuning an existing pre-trained model, you benefit from its capabilities while also accomplishing your desired task. Low-Rank Adaptation (LoRA) is a specific fine-tuning method that can be applied to various model architectures, not just LLMs. It is common that the pre-trained model weights are directly modified or fused with additional fine-tune weights in traditional fine-tuning methods. LoRA, on the other hand, allows for the fine-tune weights and pre-trained model to remain separate, and for the pre-trained model to remain unchanged. The end result is that you can train models to be more accurate at specific tasks, such as generating code, having a specific personality, or generating images in a specific style. You can even fine-tune an existing LLM to understand additional information about a specific topic.
The approach of maintaining the original base model weights means that you can create new fine-tune weights with relatively little compute. You can take advantage of existing foundational models (such as Llama, Mistral, and Gemma), and adapt them for your needs.
How does fine-tuning work?
To better understand fine-tuning and why LoRA is so effective, we have to take a step back to understand how AI models work. AI models (like LLMs) are neural networks that are trained through deep learning techniques. In neural networks, there are a set of parameters that act as a mathematical representation of the model’s domain knowledge, made up of weights and biases – in simple terms, numbers. These parameters are usually represented as large matrices of numbers. The more parameters a model has, the larger the model is, so when you see models like llama-2-7b, you can read “7b” and know that the model has 7 billion parameters.
A model’s parameters define its behavior. When you train a model from scratch, these parameters usually start off as random numbers. As you train the model on a dataset, these parameters get adjusted bit-by-bit until the model reflects the dataset and exhibits the right behavior. Some parameters will be more important than others, so we apply a weight and use it to show more or less importance. Weights play a crucial role in the model’s ability to capture patterns and relationships in the data it is trained on.
Traditional fine-tuning will adjust all the parameters in the trained model with a new set of weights. As such, a fine-tuned model requires us to serve the same amount of parameters as the original model, which means it can take a lot of time and compute to train and run inference for a fully fine-tuned model. On top of that, new state-of-the-art models, or versions of existing models, are regularly released, meaning that fully fine-tuned models can become costly to train, maintain, and store.
LoRA is an efficient method of fine-tuning
In the simplest terms, LoRA avoids adjusting parameters in a pre-trained model and instead allows us to apply a small number of additional parameters. These additional parameters are applied temporarily to the base model to effectively control model behavior. Relative to traditional fine-tuning methods it takes a lot less time and compute to train these additional parameters, which are referred to as a LoRA adapter. After training, we package up the LoRA adapter as a separate model file that can then plug in to the base model it was trained from. A fully fine-tuned model can be tens of gigabytes in size, while these adapters are usually just a few megabytes. This makes it a lot easier to distribute, and serving fine-tuned inference with LoRA only adds ms of latency to total inference time.
If you’re curious to understand why LoRA is so effective, buckle up — we first have to go through a brief lesson on linear algebra. If that’s not a term you’ve thought about since university, don’t worry, we’ll walk you through it.
Show me the math
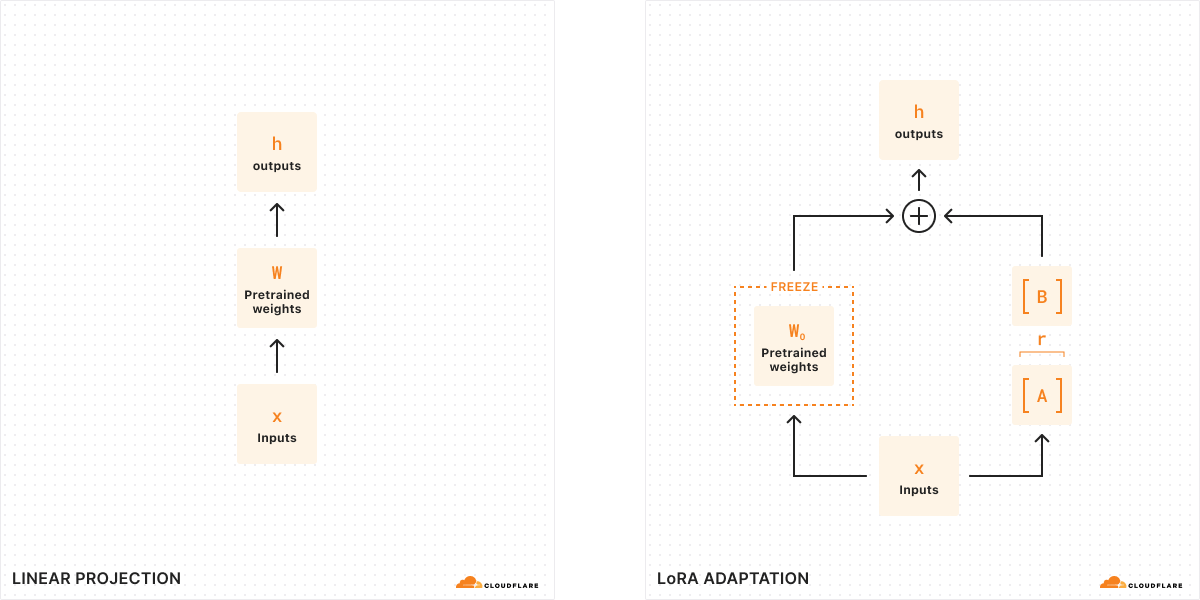
With traditional fine-tuning, we can take the weights of a model (W0) and tweak them to output a new set of weights — so the difference between the original model weights and the new weights is ΔW, representing the change in weights. Therefore, a tuned model will have a new set of weights which can be represented as the original model weights plus the change in weights, W0 + ΔW.
Remember, all of these model weights are actually represented as large matrices of numbers. In math, every matrix has a property called rank (r), which describes the number of linearly independent columns or rows in a matrix. When matrices are low-rank, they have only a few columns or rows that are “important”, so we can actually decompose or split them into two smaller matrices with the most important parameters (think of it like factoring in algebra). This technique is called rank decomposition, which allows us to greatly reduce and simplify matrices while keeping the most important bits. In the context of fine-tuning, rank determines how many parameters get changed from the original model – the higher the rank, the stronger the fine-tune, giving you more granularity over the output.
According to the original LoRA paper, researchers have found that when a model is low-rank, the matrix representing the change in weights is also low-rank. Therefore, we can apply rank decomposition to our matrix representing the change in weights ΔW to create two smaller matrices A, B, where ΔW = BA. Now, the change in the model can be represented by two smaller low-rank matrices. This is why this method of fine-tuning is called Low-Rank Adaptation.
When we run inference, we only need the smaller matrices A, B to change the behavior of the model. The model weights in A, B constitute our LoRA adapter (along with a config file). At runtime, we add the model weights together, combining the original model (W0) and the LoRA adapter (A, B). Adding and subtracting are simple mathematical operations, meaning that we can quickly swap out different LoRA adapters by adding and subtracting A, B from W0.. By temporarily adjusting the weights of the original model, we modify the model’s behavior and output and as a result, we get fine-tuned inference with minimal added latency.
According to the original LoRA paper, “LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times”. Because of this, LoRA is one of the most popular methods of fine-tuning since it’s a lot less computationally expensive than a fully fine-tuned model, doesn’t add any material inference time, and is much smaller and portable.
How can you use LoRAs with Workers AI?
Workers AI is very well-suited to run LoRAs because of the way we run serverless inference. The models in our catalog are always pre-loaded on our GPUs, meaning that we keep them warm so that your requests never encounter a cold start. This means that the base model is always available, and we can dynamically load and swap out LoRA adapters as needed. We can actually plug in multiple LoRA adapters to one base model, so we can serve multiple different fine-tuned inference requests at once.
When you fine-tune with LoRA, your output will be two files: your custom model weights (in safetensors format) and an adapter config file (in json format). To create these weights yourself, you can train a LoRA on your own data using the Hugging Face PEFT (Parameter-Efficient Fine-Tuning) library combined with the Hugging Face AutoTrain LLM library. You can also run your training tasks on services such as Auto Train and Google Colab. Alternatively, there are many open-source LoRA adapters available on Hugging Face today that cover a variety of use cases.
Eventually, we want to support the LoRA training workloads on our platform, but we’ll need you to bring your trained LoRA adapters to Workers AI today, which is why we’re calling this feature Bring Your Own (BYO) LoRAs.
For the initial open beta release, we are allowing people to use LoRAs with our Mistral, Llama, and Gemma models. We have set aside versions of these models which accept LoRAs, which you can access by appending -lora to the end of the model name. Your adapter must have been fine-tuned from one of our supported base models listed below:
@cf/meta-llama/llama-2-7b-chat-hf-lora
@cf/mistral/mistral-7b-instruct-v0.2-lora
@cf/google/gemma-2b-it-lora
@cf/google/gemma-7b-it-lora
As we are launching this feature in open beta, we have some limitations today to take note of: quantized LoRA models are not yet supported, LoRA adapters must be smaller than 100MB and have up to a max rank of 8, and you can try up to 30 LoRAs per account during our initial open beta. To get started with LoRAs on Workers AI, read the Developer Docs.
As always, we expect people to use Workers AI and our new BYO LoRA feature with our Terms of Service in mind, including any model-specific restrictions on use contained in the models’ license terms.
How did we build multi-tenant LoRA serving?
Serving multiple LoRA models simultaneously poses a challenge in terms of GPU resource utilization. While it is possible to batch inference requests to a base model, it is much more challenging to batch requests with the added complexity of serving unique LoRA adapters. To tackle this problem, we leverage the Punica CUDA kernel design in combination with global cache optimizations in order to handle the memory intensive workload of multi-tenant LoRA serving while offering low inference latency.
The Punica CUDA kernel was introduced in the paper Punica: Multi-Tenant LoRA Serving as a method to serve multiple, significantly different LoRA models applied to the same base model. In comparison to previous inference techniques, the method offers substantial throughput and latency improvements. This optimization is achieved in part through enabling request batching even across requests serving different LoRA adapters.
The core of the Punica kernel system is a new CUDA kernel called Segmented Gather Matrix-Vector Multiplication (SGMV). SGMV allows a GPU to store only a single copy of the pre-trained model while serving different LoRA models. The Punica kernel design system consolidates the batching of requests for unique LoRA models to improve performance by parallelizing the feature-weight multiplication of different requests in a batch. Requests for the same LoRA model are then grouped to increase operational intensity. Initially, the GPU loads the base model while reserving most of its GPU memory for KV Cache. The LoRA components (A and B matrices) are then loaded on demand from remote storage (Cloudflare’s cache or R2) when required by an incoming request. This on demand loading introduces only milliseconds of latency, which means that multiple LoRA adapters can be seamlessly fetched and served with minimal impact on inference performance. Frequently requested LoRA adapters are cached for the fastest possible inference.
Once a requested LoRA has been cached locally, the speed it can be made available for inference is constrained only by PCIe bandwidth. Regardless, given that each request may require its own LoRA, it becomes critical that LoRA downloads and memory copy operations are performed asynchronously. The Punica scheduler tackles this exact challenge, batching only requests which currently have required LoRA weights available in GPU memory, and queueing requests that do not until the required weights are available and the request can efficiently join a batch.
By effectively managing KV cache and batching these requests, it is possible to handle significant multi-tenant LoRA-serving workloads. A further and important optimization is the use of continuous batching. Common batching methods require all requests to the same adapter to reach their stopping condition before being released. Continuous batching allows a request in a batch to be released early so that it does not need to wait for the longest running request.
Given that LLMs deployed to Cloudflare’s network are available globally, it is important that LoRA adapter models are as well. Very soon, we will implement remote model files that are cached at Cloudflare’s edge to further reduce inference latency.
A roadmap for fine-tuning on Workers AI
Launching support for LoRA adapters is an important step towards unlocking fine-tunes on our platform. In addition to the LLM fine-tunes available today, we look forward to supporting more models and a variety of task types, including image generation.
Our vision for Workers AI is to be the best place for developers to run their AI workloads — and this includes the process of fine-tuning itself. Eventually, we want to be able to run the fine-tuning training job as well as fully fine-tuned models directly on Workers AI. This unlocks many use cases for AI to be more relevant in organizations by empowering models to have more granularity and detail for specific tasks.
With AI Gateway, we will be able to help developers log their prompts and responses, which they can then use to fine-tune models with production data. Our vision is to have a one-click fine-tuning service, where log data from AI Gateway can be used to retrain a model (on Cloudflare) and then the fine-tuned model can be redeployed on Workers AI for inference. This will allow developers to personalize their AI models to fit their applications, allowing for granularity as low as a per-user level. The fine-tuned model can then be smaller and more optimized, helping users save time and money on AI inference – and the magic is that all of this can all happen within our very own Developer Platform.
We’re excited for you to try the open beta for BYO LoRAs! Read our Developer Docs for more details, and tell us what you think on Discord.
It’s time to ship. For us (that’s what Innovation Weeks are all about!), and also for our developers.
Shipping itself is always fun, but getting there is not always easy. Bringing something from idea to life requires many stars to align. That’s what this week is all about — helping developers, including the two million developers already building on our platform, bring their ideas to life.
The full-stack cloud
Building applications requires assembling many different components.
The frontend, the face of the application, must be intuitive, responsive, and visually appealing to engage users effectively. Behind the scenes, you need a backend to handle data processing, storage, and retrieval, ensuring smooth functionality and performance. On top of all that, in the past year AI has entered the chat, so to speak, and increasingly every application requires an element of AI, making it a crucial part of the stack.
The job of a good platform is to provide all these components, and any others you will need, to you, the developer.
Just as there’s nothing more frustrating than coming home from the grocery store and realizing you left out an ingredient, realizing a platform is missing a major component or piece of functionality is no different.
We view providing the tooling that developers need as a critical part of our job as a platform, which is why with every Developer Week, we make it our mission to provide you with more and more pieces you may need. This week is no different — you can expect us to announce more tools and primitives from the frontend to backend to AI.
However, our job doesn’t stop there. If a good platform provides the components, a great platform goes a step further than that.
The job of a great platform is not only to provide the components, but make sure they play well with each other in a way that makes your job as a developer easier. Our vision for the developer platform is exactly that: to anticipate not just the tools you need but also think about how they work with each other, and how they integrate into your development flow.
This week, you will see announcements and deep dives that expound on our vision for an integrated platform: pulling back the curtain on the way we expose services in Workers through bindings for an integrated developer experience, talking about our vision for a unified data platform, updating you on framework support, and more.
The connectivity cloud
While we’re excited for you to build on us as much as possible, we also realize that development projects are rarely greenfield. If you’ve been at this for a long time, chances are a large portion of your application already lives somewhere, whether on another cloud, or on-prem.
That’s why we’re constantly making it easier for you to connect to existing infrastructure or other providers, and working hard to make sure you can still reap the benefits of building on Cloudflare by making your application feel fast and global, regardless of where your backend is.
And vice versa, if your data is on us, but you need to access it from other providers, it’s not our job to keep it hostage in a captivity cloud by charging a tariff for egress.
The experimentation cloud
Before you start assembling components, or even coming up with a plan or a spec for it, there’s an important but overlooked step to the development process — experimentation.
Experimentation can take many forms. Experimentation can be in the form of prototyping an MVP before you spend months developing a product or a feature. If you’ve found yourself rewriting your entire personal website just to try out a new tool or framework, that’s also experimentation.
It’s easy to overlook experimentation as a part of the process, but innovation doesn’t happen without it, which is why it’s something we always want to encourage and support as a part of our platform.
That’s why offering a generous free tier is something that’s been a part of our DNA since the very beginning, and something you can expect to forever be a staple of our platform.
The demo to production cloud
Alright, you’ve got all the tools you need, you’ve had a chance to experiment, and at some point… it’s time to ship.
Shipping is exciting, but shipping is also vulnerable and scary. You’re exposing the thing you’ve been working hard on to the world to criticize. You’re exposing your code to a world of untested edge cases and abuse. You’re exposing your colleagues who are on call to the possibility of getting paged at 1 AM due to the code you released.
Of course, the wrong answer is not shipping.
The right answer is having a platform that supports you and holds your hand through the scary parts. This means a platform that can seamlessly scale from zero to sixty. A platform gives you the tools to test your code, and release it gradually to the world to help you gain confidence. Or a platform provides the observability you need when you are trying to figure out what’s gone wrong at 1 AM.
That’s why this week, you can look forward to some announcements from us that we hope will help you sleep better.
The demo to production cloud — for inference
We talked about some of the scary parts of deploying to production, and while all these apply to AI as well, building AI applications today, especially in production, presents its own unique set of challenges.
Almost every day you see a new AI demo go viral — from Sora to Devin, it’s easy and inspiring to imagine our world completely changed by AI. But if you’ve started actually playing with and implementing AI use cases, you know the harsh reality of making AI truly work. It requires a lot of trial and error to get the results you want — choosing a model, RAG, fine-tuning…
And that’s before you even go to production.
That’s when you encounter the real challenge — provisioning enough capacity to stay up, without over-provisioning and overpaying. This is the exact challenge we set out to solve from the early days of Workers — helping developers not worry about infrastructure, just the application they want to build.
With the recent rise of AI, we’ve noticed many of these challenges return. Thankfully, managing loads and infrastructure is what we’re good at here at Cloudflare. It’s what we’ve had practice at for over a decade of running our platform. It’s all just one giant scheduler.
Our vision for our AI platform is to help solve the exact challenges in deploying AI workloads that we’ve been helping developers solve for, well, any other type of workload. Whether you’re deploying directly on us with Workers AI, or another provider, we’ll help provide the tools you need to access the models you need, without overpaying for idle compute.
Don’t worry, it’s all going to be fine.
So what can you expect this week?
No one in my family can keep a secret — my sister cannot get me a birthday present without spoiling it the week before. For me, the anticipation and the look of surprise is part of the fun! My coworkers seem to have clued into this.
While I won’t give away too much, we’ve already teased out a few things last week (you can find some hints here, here and here), as well as in this blog post if you read closely (because as it turns out, I too, can’t help myself).
See you tomorrow!
Our series of announcements starts on Monday, April 1st. We look forward to sharing them with you here on our blog, and discussing them with you on Discord and X.
The next 12 months have the potential to reshape the global political landscape with elections occurring in more than 80 nations, in 2024, while new technologies, such as AI, capture our imagination and pose new security challenges.
Against this backdrop, the role of CISOs has never been more important. Grant Bourzikas, Cloudflare’s Chief Security Officer, shared his views on what the biggest challenges currently facing the security industry are in the Security Week opening blog.
Over the past week, we announced a number of new products and features that align with what we believe are the most crucial challenges for CISOs around the globe. We released features that span Cloudflare’s product portfolio, ranging from application security to securing employees and cloud infrastructure. We have also published a few stories on how we take a Customer Zero approach to using Cloudflare services to manage security at Cloudflare.
We hope you find these stories interesting and are excited by the new Cloudflare products. In case you missed any of these announcements, here is a recap of Security Week:
Cloudflare announced the development of Firewall for AI, a protection layer that can be deployed in front of Large Language Models (LLMs) to identify abuses and attacks.
Defensive AI is the framework Cloudflare uses when integrating intelligent systems into its solutions. Cloudflare’s AI models look at customer traffic patterns, providing that organization with a tailored defense strategy unique to their environment.
We released a natural language assistant as part of Security Analytics. Now it is easier than ever to get powerful insights about your applications by exploring log and security events using the new natural language query interface.
Generative AI is being used by malicious actors to make phishing attacks much more convincing. Learn how Cloudflare’s email security systems are able to see past the deception using advanced machine learning models.
Maintaining visibility and control as applications and clouds change
Introducing Magic Cloud Networking, a new set of capabilities to visualize and automate cloud networks to give our customers easy, secure, and seamless connection to public cloud environments.
Security Center now includes new tools to address a common challenge: ensuring comprehensive deployment of Cloudflare products across your infrastructure. Gain precise insights into where and how to optimize your security posture.
Cloudflare One now supports Optical Character Recognition and detects source code as part of its Data Loss Prevention service. These two features make it easier for organizations to protect their sensitive data and reduce the risks of breaches.
We are introducing user risk scoring as part of Cloudflare One, a new set of capabilities to detect risk based on user behavior, so that you can improve security posture across your organization.
The Cybersecurity & Infrastructure Security Agency issued an Emergency Directive due to the Ivanti Connect Secure and Policy Secure vulnerabilities. In this post, we discuss the threat actor tactics exploiting these vulnerabilities and how Cloudflare One can mitigate these risks.
Protecting online privacy starts with knowing what cookies are used by your websites. Our client-side security solution, Page Shield, extends transparent monitoring to HTTP cookies.
Cloudflare Secure Web Gateway now supports the detection, logging, and filtering of network protocols using packet payloads without the need for inspection.
Our Security Center now houses Requests for Information and Priority Intelligence Requirements. These features are available via API as well and Cloudforce One customers can start leveraging them today for enhanced security analysis.
With the combined power of Security Analytics and Log Explorer, security teams can analyze, investigate, and monitor logs natively within Cloudflare, reducing time to resolution and overall cost of ownership by eliminating the need of third-party logging systems.
Cloudflare expands the Descaler program to Authorized Service Delivery Partners (ASDPs). Cloudflare is also launching Deskope, a new set of tooling to help migrate existing Netskope customers to Cloudflare One.
Express Cloudflare Network Interconnect makes it fast and easy to connect your network to Cloudflare. Customers can now order Express CNIs directly from the Cloudflare dashboard.
The turbulence in the SASE market is driving many customers to seek help. We’re doing our part to help VeloCloud customers who are caught in the crosshairs of shifting strategies.
Learn how to use Cloudflare Pages and Turnstile to deploy your website quickly and easily while protecting it from bots, without compromising user experience.
At Cloudflare, we’re actively supporting a range of players in the election space by providing security, performance, and reliability tools to help facilitate the democratic process.
Learn how a sophisticated Magecart attack was behind a campaign against e-commerce websites. This incident underscores the critical need for a strong client side security posture.
Discover the enhanced URL Scanner API, now integrated with the Security Center Investigate Portal. Enjoy unlisted scans, multi-device screenshots, and seamless integration with the Cloudflare ecosystem.
Security considerations should be an integral part of software’s design, not an afterthought. Explore how Cloudflare adheres to Cybersecurity & Infrastructure Security Agency’s Secure by Design principles to shift the industry.
Nearly two percent of all TLS 1.3 connections established with Cloudflare are secured with post-quantum cryptography. In this blog post we discuss where we are now in early 2024, what to expect for the coming years, and what you can do today.
This post illustrates some of the Linux kernel features that are helping Cloudflare keep its production systems more secure. We do a deep dive into how they work and why you should consider enabling them.
Cloudflare is the fastest provider for 95th percentile connection time in 44% of networks around the world. We dig into the data and talk about how we do it.
This blog discusses the new sources of “chaos” that have been added to LavaRand and how you can make use of that harnessed chaos in your next application.
The new Email Security section on Cloudflare Radar provides insights into the latest trends around threats found in malicious email, sources of spam and malicious email, and the adoption of technologies designed to prevent abuse of email.
A final word
Thanks for joining us this week, and stay tuned for our next Innovation Week in early April, focused on the developer community.
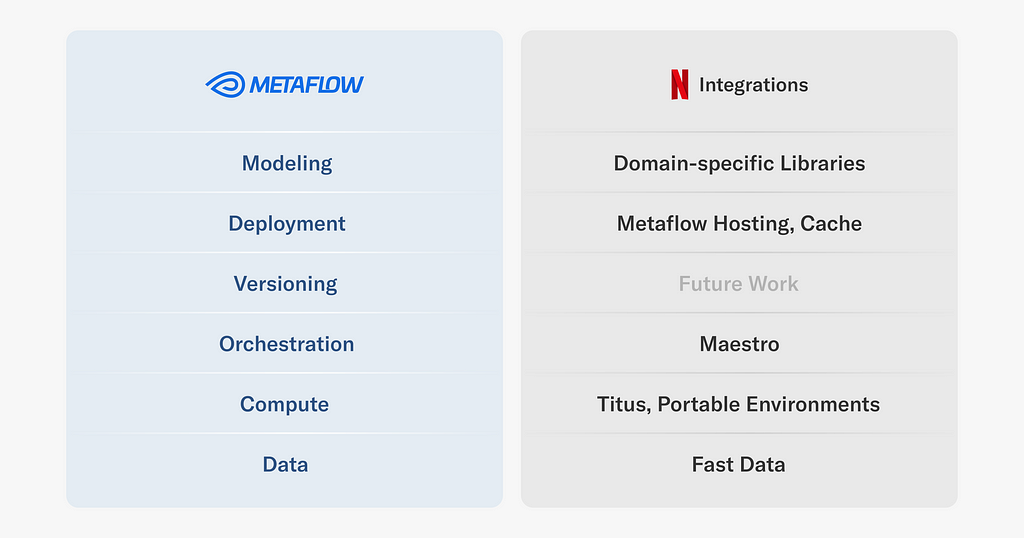
Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding. The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow, an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
Since its inception, Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. While human-friendly APIs are delightful, it is really the integrations to our production systems that give Metaflow its superpowers. Without these integrations, projects would be stuck at the prototyping stage, or they would have to be maintained as outliers outside the systems maintained by our engineering teams, incurring unsustainable operational overhead.
Given the very diverse set of ML and AI use cases we support — today we have hundreds of Metaflow projects deployed internally — we don’t expect all projects to follow the same path from prototype to production. Instead, we provide a robust foundational layer with integrations to our company-wide data, compute, and orchestration platform, as well as various paths to deploy applications to production smoothly. On top of this, teams have built their own domain-specific libraries to support their specific use cases and needs.
In this article, we cover a few key integrations that we provide for various layers of the Metaflow stack at Netflix, as illustrated above. We will also showcase real-life ML projects that rely on them, to give an idea of the breadth of projects we support. Note that all projects leverage multiple integrations, but we highlight them in the context of the integration that they use most prominently. Importantly, all the use cases were engineered by practitioners themselves.
These integrations are implemented through Metaflow’s extension mechanism which is publicly available but subject to change, and hence not a part of Metaflow’s stable API yet. If you are curious about implementing your own extensions, get in touch with us on the Metaflow community Slack.
Let’s go over the stack layer by layer, starting with the most foundational integrations.
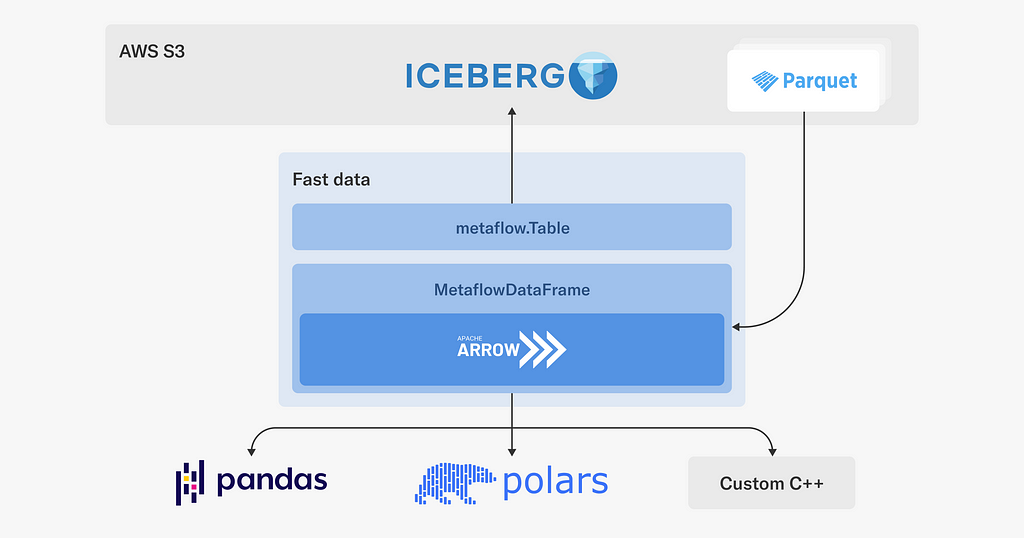
Data: Fast Data
Our main data lake is hosted on S3, organized as Apache Iceberg tables. For ETL and other heavy lifting of data, we mainly rely on Apache Spark. In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. Occasionally, these use cases involve terabytes of data, so we have to pay attention to performance.
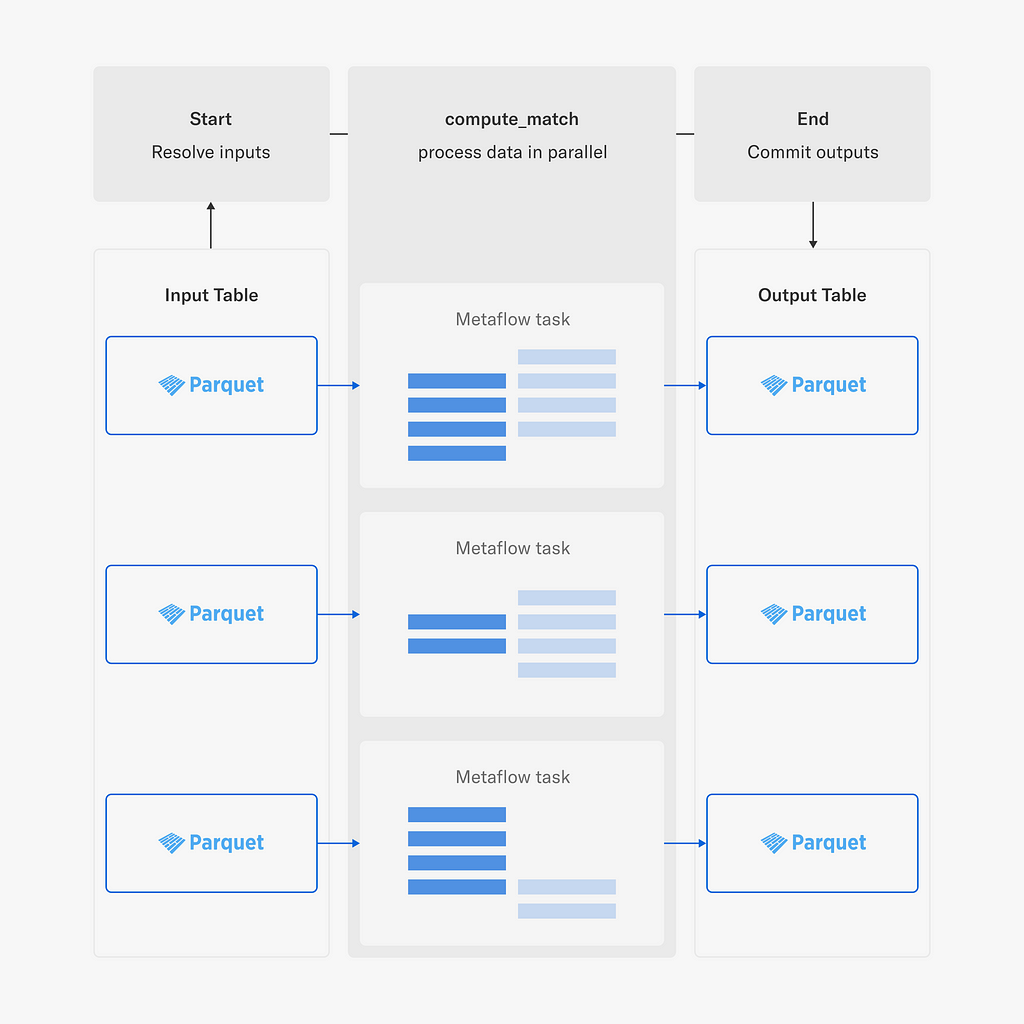
To enable fast, scalable, and robust access to the Netflix data warehouse, we have developed a Fast Data library for Metaflow, which leverages high-performance components from the Python data ecosystem:
As depicted in the diagram, the Fast Data library consists of two main interfaces:
The Table object is responsible for interacting with the Netflix data warehouse which includes parsing Iceberg (or legacy Hive) table metadata, resolving partitions and Parquet files for reading. Recently, we added support for the write path, so tables can be updated as well using the library.
Once we have discovered the Parquet files to be processed, MetaflowDataFrame takes over: it downloads data using Metaflow’s high-throughput S3 client directly to the process’ memory, which often outperforms reading of local files.
We use Apache Arrow to decode Parquet and to host an in-memory representation of data. The user can choose the most suitable tool for manipulating data, such as Pandas or Polars to use a dataframe API, or one of our internal C++ libraries for various high-performance operations. Thanks to Arrow, data can be accessed through these libraries in a zero-copy fashion.
We also pay attention to dependency issues: (Py)Arrow is a dependency of many ML and data libraries, so we don’t want our custom C++ extensions to depend on a specific version of Arrow, which could easily lead to unresolvable dependency graphs. Instead, in the style of nanoarrow, our Fast Data library only relies on the stable Arrow C data interface, producing a hermetically sealed library with no external dependencies.
Example use case: Content Knowledge Graph
Our knowledge graph of the entertainment world encodes relationships between titles, actors and other attributes of a film or series, supporting all aspects of business at Netflix.
A key challenge in creating a knowledge graph is entity resolution. There may be many different representations of slightly different or conflicting information about a title which must be resolved. This is typically done through a pairwise matching procedure for each entity which becomes non-trivial to do at scale.
This project leverages Fast Data and horizontal scaling with Metaflow’s foreach construct to load large amounts of title information — approximately a billion pairs — stored in the Netflix Data Warehouse, so the pairs can be matched in parallel across many Metaflow tasks.
We use metaflow.Table to resolve all input shards which are distributed to Metaflow tasks which are responsible for processing terabytes of data collectively. Each task loads the data using metaflow.MetaflowDataFrame, performs matching using Pandas, and populates a corresponding shard in an output Table. Finally, when all matching is done and data is written the new table is committed so it can be read by other jobs.
By targeting @titus, Metaflow tasks benefit from these battle-hardened features out of the box, with no in-depth technical knowledge or engineering required from the ML engineers or data scientist end. However, in order to benefit from scalable compute, we need to help the developer to package and rehydrate the whole execution environment of a project in a remote pod in a reproducible manner (preferably quickly). Specifically, we don’t want to ask developers to manage Docker images of their own manually, which quickly results in more problems than it solves.
Here’s a fascinating example of the usefulness of portable execution environments. For many of our applications, model explainability matters. Stakeholders like to understand why models produce a certain output and why their behavior changes over time.
There are several ways to provide explainability to models but one way is to train an explainer model based on each trained model. Without going into the details of how this is done exactly, suffice to say that Netflix trains a lot of models, so we need to train a lot of explainers too.
Thanks to Metaflow, we can allow each application to choose the best modeling approach for their use cases. Correspondingly, each application brings its own bespoke set of dependencies. Training an explainer model therefore requires:
Access to the original model and its training environment, and
Dependencies specific to building the explainer model.
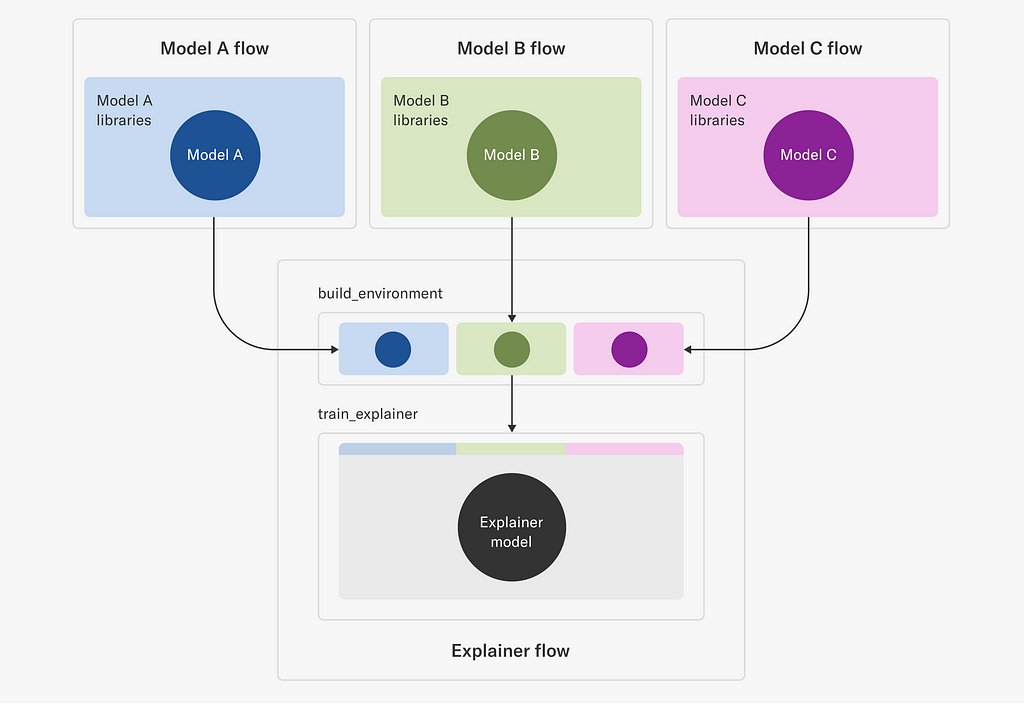
This poses an interesting challenge in dependency management: we need a higher-order training system, “Explainer flow” in the figure below, which is able to take a full execution environment of another training system as an input and produce a model based on it.
Explainer flow is event-triggered by an upstream flow, such Model A, B, C flows in the illustration. The build_environment step uses the metaflow environment command provided by our portable environments, to build an environment that includes both the requirements of the input model as well as those needed to build the explainer model itself.
The built environment is given a unique name that depends on the run identifier (to provide uniqueness) as well as the model type. Given this environment, the train_explainer step is then able to refer to this uniquely named environment and operate in an environment that can both access the input model as well as train the explainer model. Note that, unlike in typical flows using vanilla @conda or @pypi, the portable environments extension allows users to also fetch those environments directly at execution time as opposed to at deploy time which therefore allows users to, as in this case, resolve the environment right before using it in the next step.
Orchestration: Maestro
If data is the fuel of ML and the compute layer is the muscle, then the nerves must be the orchestration layer. We have talked about the importance of a production-grade workflow orchestrator in the context of Metaflow when we released support for AWS Step Functions years ago. Since then, open-source Metaflow has gained support for Argo Workflows, a Kubernetes-native orchestrator, as well as support for Airflow which is still widely used by data engineering teams.
Internally, we use a production workflow orchestrator called Maestro. The Maestro post shares details about how the system supports scalability, high-availability, and usability, which provide the backbone for all of our Metaflow projects in production.
A hugely important detail that often goes overlooked is event-triggering: it allows a team to integrate their Metaflow flows to surrounding systems upstream (e.g. ETL workflows), as well as downstream (e.g. flows managed by other teams), using a protocol shared by the whole organization, as exemplified by the example use case below.
Example use case: Content decision making
One of the most business-critical systems running on Metaflow supports our content decision making, that is, the question of what content Netflix should bring to the service. We support a massive scale of over 260M subscribers spanning over 190 countries representing hugely diverse cultures and tastes, all of whom we want to delight with our content slate. Reflecting the breadth and depth of the challenge, the systems and models focusing on the question have grown to be very sophisticated.
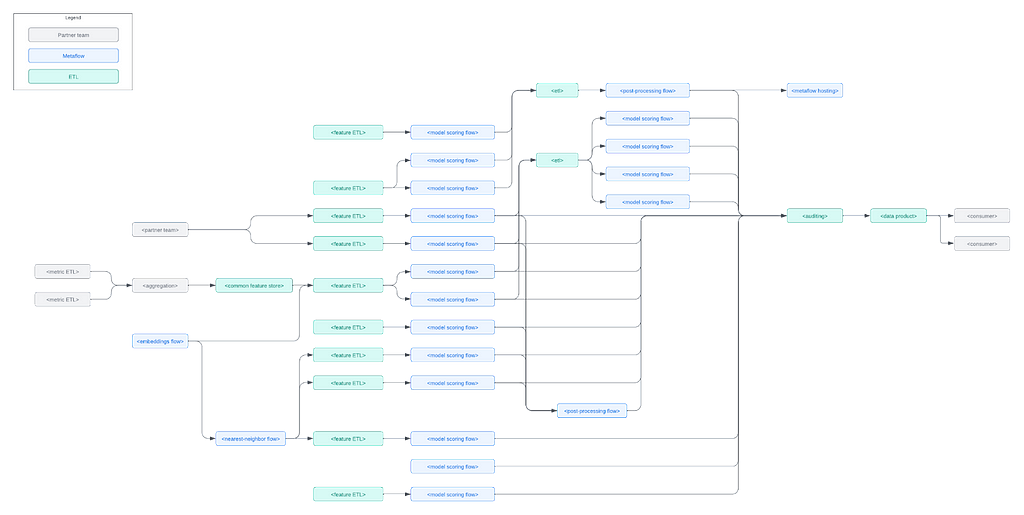
We approach the question from multiple angles but we have a core set of data pipelines and models that provide a foundation for decision making. To illustrate the complexity of just the core components, consider this high-level diagram:
In this diagram, gray boxes represent integrations to partner teams downstream and upstream, green boxes are various ETL pipelines, and blue boxes are Metaflow flows. These boxes encapsulate hundreds of advanced models and intricate business logic, handling massive amounts of data daily.
Despite its complexity, the system is managed by a relatively small team of engineers and data scientists autonomously. This is made possible by a few key features of Metaflow:
All the boxes are event-triggered, orchestrated by Maestro. Dependencies between Metaflow flows are triggered via @trigger_on_finish, dependencies to external systems with @trigger.
Rapid development is enabled via Metaflow namespaces, so individual developers can develop without interfering with production deployments.
The team has also developed their own domain-specific libraries and configuration management tools, which help them improve and operate the system.
Deployment: Cache
To produce business value, all our Metaflow projects are deployed to work with other production systems. In many cases, the integration might be via shared tables in our data warehouse. In other cases, it is more convenient to share the results via a low-latency API.
Notably, not all API-based deployments require real-time evaluation, which we cover in the section below. We have a number of business-critical applications where some or all predictions can be precomputed, guaranteeing the lowest possible latency and operationally simple high availability at the global scale.
We have developed an officially supported pattern to cover such use cases. While the system relies on our internal caching infrastructure, you could follow the same pattern using services like Amazon ElasticCache or DynamoDB.
Example use case: Content performance visualization
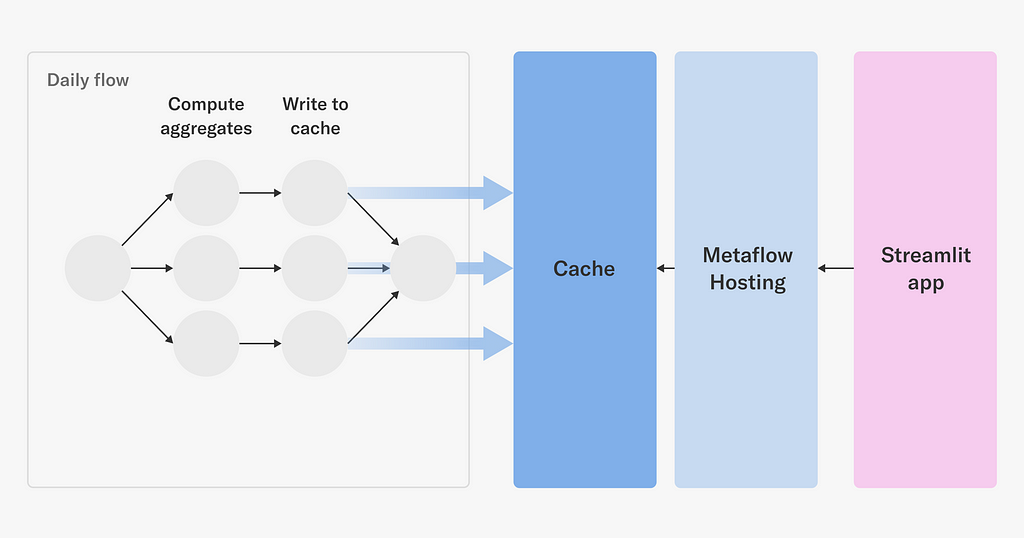
The historical performance of titles is used by decision makers to understand and improve the film and series catalog. Performance metrics can be complex and are often best understood by humans with visualizations that break down the metrics across parameters of interest interactively. Content decision makers are equipped with self-serve visualizations through a real-time web application built with metaflow.Cache, which is accessed through an API provided with metaflow.Hosting.
A daily scheduled Metaflow job computes aggregate quantities of interest in parallel. The job writes a large volume of results to an online key-value store using metaflow.Cache. A Streamlit app houses the visualization software and data aggregation logic. Users can dynamically change parameters of the visualization application and in real-time a message is sent to a simple Metaflow hosting service which looks up values in the cache, performs computation, and returns the results as a JSON blob to the Streamlit application.
Metaflow Hosting is specifically geared towards hosting artifacts or models produced in Metaflow. This provides an easy to use interface on top of Netflix’s existing microservice infrastructure, allowing data scientists to quickly move their work from experimentation to a production grade web service that can be consumed over a HTTP REST API with minimal overhead.
Its key benefits include:
Simple decorator syntax to create RESTFull endpoints.
The back-end auto-scales the number of instances used to back your service based on traffic.
The back-end will scale-to-zero if no requests are made to it after a specified amount of time thereby saving cost particularly if your service requires GPUs to effectively produce a response.
Request logging, alerts, monitoring and tracing hooks to Netflix infrastructure
Consider the service similar to managed model hosting services like AWS Sagemaker Model Hosting, but tightly integrated with our microservice infrastructure.
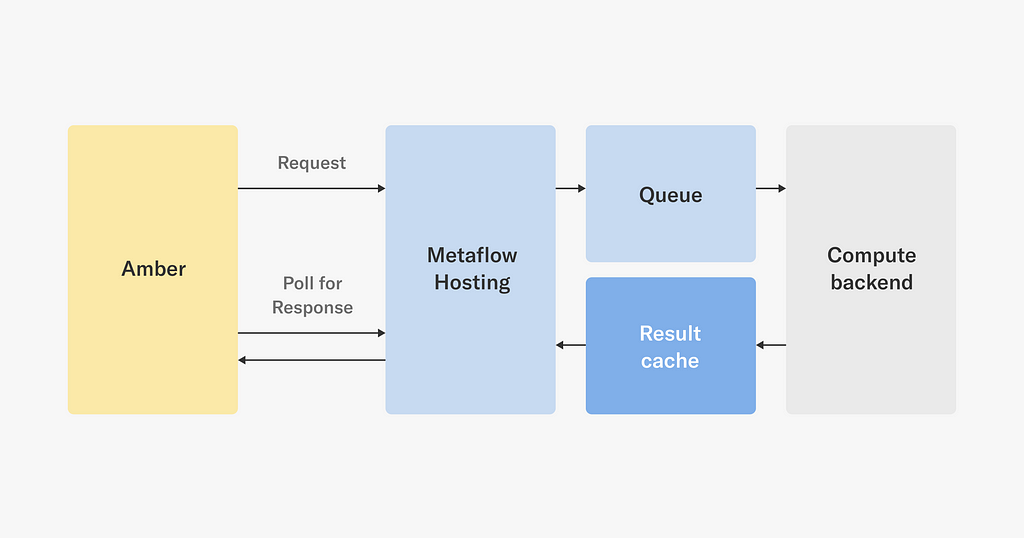
To demonstrate the benefits of Metaflow Hosting that provides a general-purpose API layer supporting both synchronous and asynchronous queries, consider this use case involving Amber, our feature store for media.
While Amber is a feature store, precomputing and storing all media features in advance would be infeasible. Instead, we compute and cache features in an on-demand basis, as depicted below:
When a service requests a feature from Amber, it computes the feature dependency graph and then sends one or more asynchronous requests to Metaflow Hosting, which places the requests in a queue, eventually triggering feature computations when compute resources become available. Metaflow Hosting caches the response, so Amber can fetch it after a while. We could have built a dedicated microservice just for this use case, but thanks to the flexibility of Metaflow Hosting, we were able to ship the feature faster with no additional operational burden.
Future Work
Our appetite to apply ML in diverse use cases is only increasing, so our Metaflow platform will keep expanding its footprint correspondingly and continue to provide delightful integrations to systems built by other teams at Netlfix. For instance, we have plans to work on improvements in the versioning layer, which wasn’t covered by this article, by giving more options for artifact and model management.
We also plan on building more integrations with other systems that are being developed by sister teams at Netflix. As an example, Metaflow Hosting models are currently not well integrated into model logging facilities — we plan on working on improving this to make models developed with Metaflow more integrated with the feedback loop critical in training new models. We hope to do this in a pluggable manner that would allow other users to integrate with their own logging systems.
Additionally we want to supply more ways Metaflow artifacts and models can be integrated into non-Metaflow environments and applications, e.g. JVM based edge service, so that Python-based data scientists can contribute to non-Python engineering systems easily. This would allow us to better bridge the gap between the quick iteration that Metaflow provides (in Python) with the requirements and constraints imposed by the infrastructure serving Netflix member facing requests.
If you are building business-critical ML or AI systems in your organization, join the Metaflow Slack community! We are happy to share experiences, answer any questions, and welcome you to contribute to Metaflow.
Acknowledgements:
Thanks to Wenbing Bai, Jan Florjanczyk, Michael Li, Aliki Mavromoustaki, and Sejal Rai for help with use cases and figures. Thanks to our OSS contributors for making Metaflow a better product.
Email continues to be the largest attack vector that attackers use to try to compromise or extort organizations. Given the frequency with which email is used for business communication, phishing attacks have remained ubiquitous. As tools available to attackers have evolved, so have the ways in which attackers have targeted users while skirting security protections. The release of several artificial intelligence (AI) large language models (LLMs) has created a mad scramble to discover novel applications of generative AI capabilities and has consumed the minds of security researchers. One application of this capability is creating phishing attack content.
Phishing relies on the attacker seeming authentic. Over the years, we’ve observed that there are two distinct forms of authenticity: visual and organizational. Visually authentic attacks use logos, images, and the like to establish trust, while organizationally authentic campaigns use business dynamics and social relationships to drive their success. LLMs can be employed by attackers to make their emails seem more authentic in several ways. A common technique is for attackers to use LLMs to translate and revise emails they’ve written into messages that are more superficially convincing. More sophisticated attacks pair LLMs with personal data harvested from compromised accounts to write personalized, organizationally-authentic messages.
For example, WormGPT has the ability to take a poorly written email and recreate it to have better use of grammar, flow, and voice. The output is a fluent, well-written message that can more easily pass as authentic. Threat actors within discussion forums are encouraged to create rough drafts in their native language and let the LLM do its work.
One form of phishing attack that benefits from LLMs, which can have devastating financial impact, are Business Email Compromise (BEC) attacks. During these attacks, malicious actors attempt to dupe their victims into sending payment for fraudulent invoices; LLMs can help make these messages sound more organizationally authentic. And while BEC attacks are top of mind for organizations who wish to stop the unauthorized egress of funds from their organization, LLMs can be used to craft other types of phishing messages as well.
Yet these LLM-crafted messages still rely on the user performing an action, like reading a fraudulent invoice or interacting with a link, which can’t be spoofed so easily. And every LLM-written email is still an email, containing an array of other signals like sender reputation, correspondence patterns, and metadata bundled with each message. With the right mitigation strategy and tools in place, LLM-enhanced attacks can be reliably stopped.
While the popularity of ChatGPT has thrust LLMs into the recent spotlight, these kinds of models are not new; Cloudflare has been training its models to defend against LLM-enhanced attacks for years. Our models’ ability to look at all components of an email ensures that Cloudflare customers are already protected and will continue to be in the future — because the machine learning systems our threat research teams have developed through analyzing billions of messages aren’t deceived by nicely-worded emails.
Generative AI threats and trade offs
The riskiest of AI generated attacks are personalized based on data harvested prior to the attack. Threat actors collect this information during more traditional account compromise operations against their victims and iterate through this process. Once they have sufficient information to conduct their attack they proceed. It’s highly targeted and highly specific. The benefit of AI is scale of operations; however, mass data collection is necessary to create messages that accurately impersonate who the attacker is pretending to be.
While AI-generated attacks can have advantages in personalization and scalability, their effectiveness hinges on having sufficient samples for authenticity. Traditional threat actors can also employ social engineering tactics to achieve similar results, albeit without the efficiency and scalability of AI. The fundamental limitations of opportunity and timing, as we will discuss in the next section, still apply to all attackers — regardless of the technology used.
To defend against such attacks, organizations must adopt a multi-layer approach to cybersecurity. This includes employee awareness training, employing advanced threat detection systems that utilize AI and traditional techniques, and constantly updating security practices to protect against both AI and traditional phishing attacks.
Threat actors can utilize AI to generate attacks, but they come with tradeoffs. The bottleneck in the number of attacks they can successfully conduct is directly proportional to the number of opportunities they have at their disposal, and the data they have available to craft convincing messages. They require access and opportunity, and without both the attacks are not very likely to succeed.
BEC attacks and LLMs
BEC attacks are top of mind for organizations because they can allow attackers to steal a significant amount of funds from the target. Since BEC attacks are primarily based on text, it may seem like LLMs are about to open the floodgates. However, the reality is much different. The major obstacle limiting this proposition is opportunity. We define opportunity as a window in time when events align to allow for an exploitable condition and for that condition to be exploited — for example, an attacker might use data from a breach to identify an opportunity in a company’s vendor payment schedule. A threat actor can have motive, means, and resources to pull off an authentic looking BEC attack, but without opportunity their attacks will fall flat. While we have observed threat actors attempt a volumetric attack by essentially cold calling on targets, such attacks are unsuccessful the vast majority of the time. This is in line with the premise of BECs, as there is some component of social engineering at play for these attacks.
As an analogy, if someone were to walk into your business’ front door and demand you pay them \$20,000 without any context, a reasonable, logical person would not pay. A successful BEC attack would need to bypass this step of validation and verification, which LLMs can offer little assistance in. While LLMs can generate text that appears convincingly authentic, they cannot establish a business relationship with a company or manufacture an invoice that is authentic in appearance and style, matching those in use. The largest BEC payments are a product of not only account compromise, but invoice compromise, the latter of which are necessary for the attacker in order to provide convincing, fraudulent invoices to victims.
At Cloudflare, we are uniquely situated to provide this analysis, as our email security products scrutinize hundreds of millions of messages every month. In analyzing these attacks, we have found that there are other trends besides text which constitute a BEC attack, with our data suggesting that the vast majority of BEC attacks use compromised accounts. Attackers with access to a compromised account can harvest data to craft more authentic messages that can bypass most security checks because they are coming from a valid email address. Over the last year, 80% of BEC attacks involving \$10K or more involved compromised accounts. Out of that, 75% conducted thread hijacking and redirected the thread to newly registered domains. This is in keeping with observations that the vast majority of “successful” attacks, meaning the threat actor successfully compromised their target, leverages a lookalike domain. This fraudulent domain is almost always recently registered. We also see that 55% of these messages involving over $10K in payment attempted to change ACH payment details.
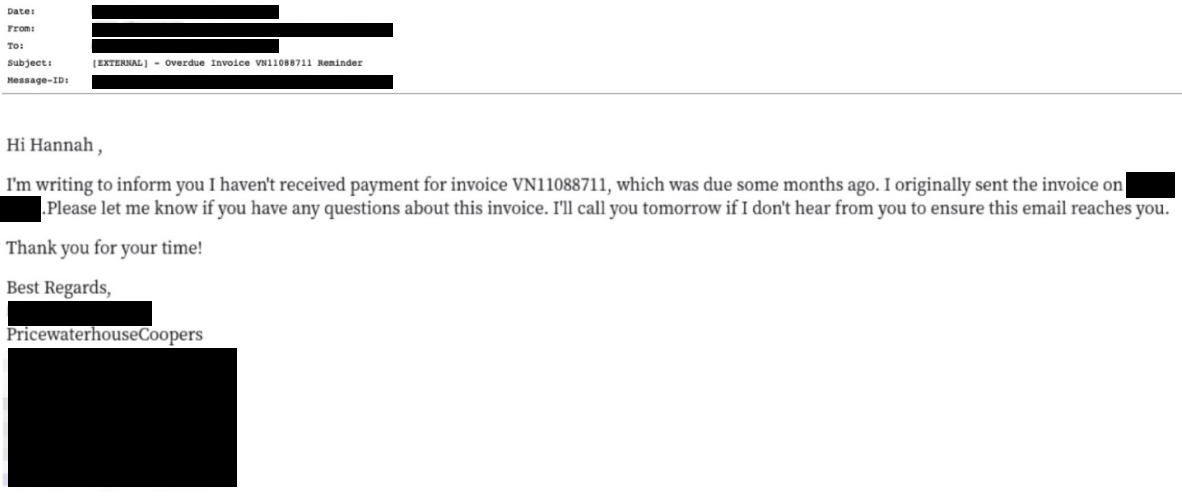
We can see an example of how this may accumulate in a BEC attack below.
The text within the message does not contain any grammatical errors and is easily readable, yet our sentiment models triggered on the text, detecting that there was a sense of urgency in the sentiment in combination with an invoice — a common pattern employed by attackers. However, there are many other things in this message that triggered different models. For example, the attacker is pretending to be from PricewaterhouseCoopers, but there is a mismatch in the domain from which this email was sent. We also noticed that the sending domain was recently registered, alerting us that this message may not be legitimate. Finally, one of our models generates a social graph unique to each customer based on their communication patterns. This graph provides information about whom each user communicates with and about what. This model flagged that, given the fresh history of this communication, this message was not business as usual. All the signals above plus the outputs of our sentiment models led our analysis engine to conclude that this was a malicious message and to not allow the recipient of this message to interact with it.
Generative AI is continuing to change and improve, so there’s still a lot to be discovered in this arena. While the advent of AI-created BEC attacks may cause an ultimate increase in the number of attacks seen in the wild, we do not expect their success rate to rise for organizations with robust security solutions and processes in place.
Phishing attack trends
In August of last year, we published our 2023 Phishing Report. That year, Cloudflare processed approximately 13 billion emails, which included blocking approximately 250 million malicious messages from reaching customers’ inboxes. Even though it was the year of ChatGPT, our analysis saw that attacks still revolved around long-standing vectors like malicious links.
Most attackers were still trying to get users to either click on a link or download a malicious file. And as discussed earlier, while Generative AI can help with making a readable and convincing message, it cannot help attackers with obfuscating these aspects of their attack.
Cloudflare’s email security models take a sophisticated approach to examining each link and attachment they encounter. Links are crawled and scrutinized based on information about the domain itself as well as on–page elements and branding. Our crawlers also check for input fields in order to see if the link is a potential credential harvester. And for attackers who put their weaponized links behind redirects or geographical locks, our crawlers can leverage the Cloudflare network to bypass any roadblocks thrown our way.
Our detection systems are similarly rigorous in handling attachments. For example, our systems know that some parts of an attachment can be easily faked, while others are not. So our systems deconstruct attachments into their primitive components and check for abnormalities there. This allows us to scan for malicious files more accurately than traditional sandboxes which can be bypassed by attackers.
Attackers can use LLMs to craft a more convincing message to get users to take certain actions, but our scanning abilities catch malicious content and prevent the user from interacting with it.
Anatomy of an email
Emails contain information beyond the body and subject of the message. When building detections, we like to think of emails as having both mutable and immutable properties. Mutable properties like the body text can be easily faked while other mutable properties like sender IP address require more effort to fake. However, there are immutable properties like domain age of the sender and similarity of the domain to known brands that cannot be altered at all. For example, let’s take a look at a message that I received.
Example email content
While the message above is what the user sees, it is a small part of the larger content of the email. Below is a snippet of the message headers. This information is typically useless to a recipient (and most of it isn’t displayed by default) but it contains a treasure trove of information for us as defenders. For example, our detections can see all the preliminary checks for DMARC, SPF, and DKIM. These let us know whether this email was allowed to be sent on behalf of the purported sender and if it was altered before reaching our inbox. Our models can also see the client IP address of the sender and use this to check their reputation. We can also see which domain the email was sent from and check if it matches the branding included in the message.
Example email headers
As you can see, the body and subject of a message are a small portion of what makes an email to be an email. When performing analysis on emails, our models holistically look at every aspect of a message to make an assessment of its safety. Some of our models do focus their analysis on the body of the message for indicators like sentiment, but the ultimate assessment of the message’s risk is performed in concert with models evaluating every aspect of the email. All this information is surfaced to the security practitioners that are using our products.
Cloudflare’s email security models
Our philosophy of using multiple models trained on different properties of messages culminates in what we call our SPARSE engine. In the 2023 Forrester Wave™ for Enterprise Email Security report, the analysts mentioned our ability to catch phishing emails using our SPARSE engine saying “Cloudflare uses its preemptive crawling approach to discover phishing campaign infrastructure as it’s being built. Its Small Pattern Analytics Engine (SPARSE) combines multiple machine learning models, including natural language modeling, sentiment and structural analysis, and trust graphs”. 1
Our SPARSE engine is continually updated using messages we observe. Given our ability to analyze billions of messages a year, we are able to detect trends earlier and feed these into our models to improve their efficacy. A recent example of this is when we noticed in late 2023 a rise in QR code attacks. Attackers deployed different techniques to obfuscate the QR code so that OCR scanners could not scan the image but cellphone cameras would direct the user to the malicious link. These techniques included making the image incredibly small so that it was not clear for scanners or pixel shifting images. However, feeding these messages into our models trained them to look at all the qualities about the emails sent from those campaigns. With this combination of data, we were able to create detections to catch these campaigns before they hit customers’ inboxes.
Our approach to preemptive scanning makes us resistant to oscillations of threat actor behavior. Even though the use of LLMs is a tool that attackers are deploying more frequently today, there will be others in the future, and we will be able to defend our customers from those threats as well.
Future of email phishing
Securing email inboxes is a difficult task given the creative ways attackers try to phish users. This field is ever evolving and will continue to change dramatically as new technologies become accessible to the public. Trends like the use of generative AI will continue to change, but our methodology and approach to building email detections keeps our customers protected.
If you are interested in how Cloudflare’s Cloud Email Security works to protect your organization against phishing threats please reach out to your Cloudflare contact and set up a free Phishing Risk Assessment. For Microsoft 365 customers, you can also run our complementary retro scan to see what phishing emails your current solution has missed. More information on that can be found in our recent blog post.
[1] Source: The Forrester Wave™: Enterprise Email Security, Q2, 2023
The Forrester Wave™ is copyrighted by Forrester Research, Inc. Forrester and Forrester Wave are trademarks of Forrester Research, Inc. The Forrester Wave is a graphical representation of Forrester’s call on a market and is plotted using a detailed spreadsheet with exposed scores, weightings, and comments. Forrester does not endorse any vendor, product, or service depicted in the Forrester Wave. Information is based on best available resources. Opinions reflect judgment at the time and are subject to change.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.