Post Syndicated from Raghavarao Sodabathina original https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-2-ai-applications/
Welcome back to our exciting exploration of architectural patterns for real-time analytics with Amazon Kinesis Data Streams! In this fast-paced world, Kinesis Data Streams stands out as a versatile and robust solution to tackle a wide range of use cases with real-time data, from dashboarding to powering artificial intelligence (AI) applications. In this series, we streamline the process of identifying and applying the most suitable architecture for your business requirements, and help kickstart your system development efficiently with examples.
Before we dive in, we recommend reviewing Architectural patterns for real-time analytics using Amazon Kinesis Data Streams, part 1 for the basic functionalities of Kinesis Data Streams. Part 1 also contains architectural examples for building real-time applications for time series data and event-sourcing microservices.
Now get ready as we embark on the second part of this series, where we focus on the AI applications with Kinesis Data Streams in three scenarios: real-time generative business intelligence (BI), real-time recommendation systems, and Internet of Things (IoT) data streaming and inferencing.
Real-time generative BI dashboards with Kinesis Data Streams, Amazon QuickSight, and Amazon Q
In today’s data-driven landscape, your organization likely possesses a vast amount of time-sensitive information that can be used to gain a competitive edge. The key to unlock the full potential of this real-time data lies in your ability to effectively make sense of it and transform it into actionable insights in real time. This is where real-time BI tools such as live dashboards come into play, assisting you with data aggregation, analysis, and visualization, therefore accelerating your decision-making process.
To help streamline this process and empower your team with real-time insights, Amazon has introduced Amazon Q in QuickSight. Amazon Q is a generative AI-powered assistant that you can configure to answer questions, provide summaries, generate content, and complete tasks based on your data. Amazon QuickSight is a fast, cloud-powered BI service that delivers insights.
With Amazon Q in QuickSight, you can use natural language prompts to build, discover, and share meaningful insights in seconds, creating context-aware data Q&A experiences and interactive data stories from the real-time data. For example, you can ask “Which products grew the most year-over-year?” and Amazon Q will automatically parse the questions to understand the intent, retrieve the corresponding data, and return the answer in the form of a number, chart, or table in QuickSight.
By using the architecture illustrated in the following figure, your organization can harness the power of streaming data and transform it into visually compelling and informative dashboards that provide real-time insights. With the power of natural language querying and automated insights at your fingertips, you’ll be well-equipped to make informed decisions and stay ahead in today’s competitive business landscape.

The steps in the workflow are as follows:
- We use Amazon DynamoDB here as an example for the primary data store. Kinesis Data Streams can ingest data in real time from data stores such as DynamoDB to capture item-level changes in your table.
- After capturing data to Kinesis Data Streams, you can ingest the data into analytic databases such as Amazon Redshift in near-real time. Amazon Redshift Streaming Ingestion simplifies data pipelines by letting you create materialized views directly on top of data streams. With this capability, you can use SQL (Structured Query Language) to connect to and directly ingest the data stream from Kinesis Data Streams to analyze and run complex analytical queries.
- After the data is in Amazon Redshift, you can create a business report using QuickSight. Connectivity between a QuickSight dashboard and Amazon Redshift enables you to deliver visualization and insights. With the power of Amazon Q in QuickSight, you can quickly build and refine the analytics and visuals with natural language inputs.
For more details on how customers have built near real-time BI dashboards using Kinesis Data Streams, refer to the following:
- SecurionPay Manages Complex Online Payments, Scales to 300% Growth Using AWS
- Vizio: Smart TV Analytics at Scale
Real-time recommendation systems with Kinesis Data Streams and Amazon Personalize
Imagine creating a user experience so personalized and engaging that your customers feel truly valued and appreciated. By using real-time data about user behavior, you can tailor each user’s experience to their unique preferences and needs, fostering a deep connection between your brand and your audience. You can achieve this by using Kinesis Data Streams and Amazon Personalize, a fully managed machine learning (ML) service that generates product and content recommendations for your users, instead of building your own recommendation engine from scratch.
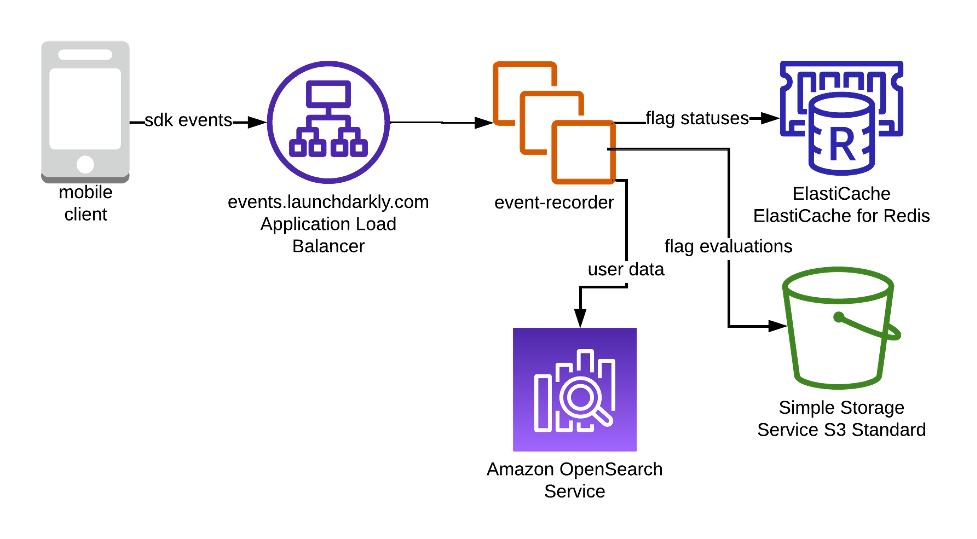
With Kinesis Data Streams, your organization can effortlessly ingest user behavior data from millions of endpoints into a centralized data stream in real time. This allows recommendation engines such as Amazon Personalize to read from the centralized data stream and generate personalized recommendations for each user on the fly. Additionally, you could use enhanced fan-out to deliver dedicated throughput to your mission-critical consumers at even lower latency, further enhancing the responsiveness of your real-time recommendation system. The following figure illustrates a typical architecture for building real-time recommendations with Amazon Personalize.

The steps are as follows:
- Create a dataset group, schemas, and datasets that represent your items, interactions, and user data.
- Select the best recipe matching your use case after importing your datasets into a dataset group using Amazon Simple Storage Service(Amazon S3), and then create a solution to train a model by creating a solution version. When your solution version is complete, you can create a campaign for your solution version.
- After a campaign has been created, you can integrate calls to the campaign in your application. This is where calls to the GetRecommendations or GetPersonalizedRanking APIs are made to request near-real-time recommendations from Amazon Personalize. Your website or mobile application calls a AWS Lambda function over Amazon API Gateway to receive recommendations for your business apps.
- An event tracker provides an endpoint that allows you to stream interactions that occur in your application back to Amazon Personalize in near-real time. You do this by using the PutEvents API. You can build an event collection pipeline using API Gateway, Kinesis Data Streams, and Lambda to receive and forward interactions to Amazon Personalize. The event tracker performs two primary functions. First, it persists all streamed interactions so they will be incorporated into future retrainings of your model. This is also how Amazon Personalize cold starts new users. When a new user visits your site, Amazon Personalize will recommend popular items. After you stream in an event or two, Amazon Personalize immediately starts adjusting recommendations.
To learn how other customers have built personalized recommendations using Kinesis Data Streams, refer to the following:
- Driving Business Outcomes with Clickstream Data
- How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
- Building a multi-channel, data driven patient engagement platform with AWS
Real-time IoT data streaming and inferencing with AWS IoT Core and Amazon SageMaker
From office lights that automatically turn on as you enter the room to medical devices that monitors a patient’s health in real time, a proliferation of smart devices is making the world more automated and connected. In technical terms, IoT is the network of devices that connect with the internet and can exchange data with other devices and software systems. Many organizations increasingly rely on the real-time data from IoT devices, such as temperature sensors and medical equipment, to drive automation, analytics, and AI systems. It’s important to choose a robust streaming solution that can achieve very low latency and handle high volumes of data throughputs to power the real-time AI inferencing.
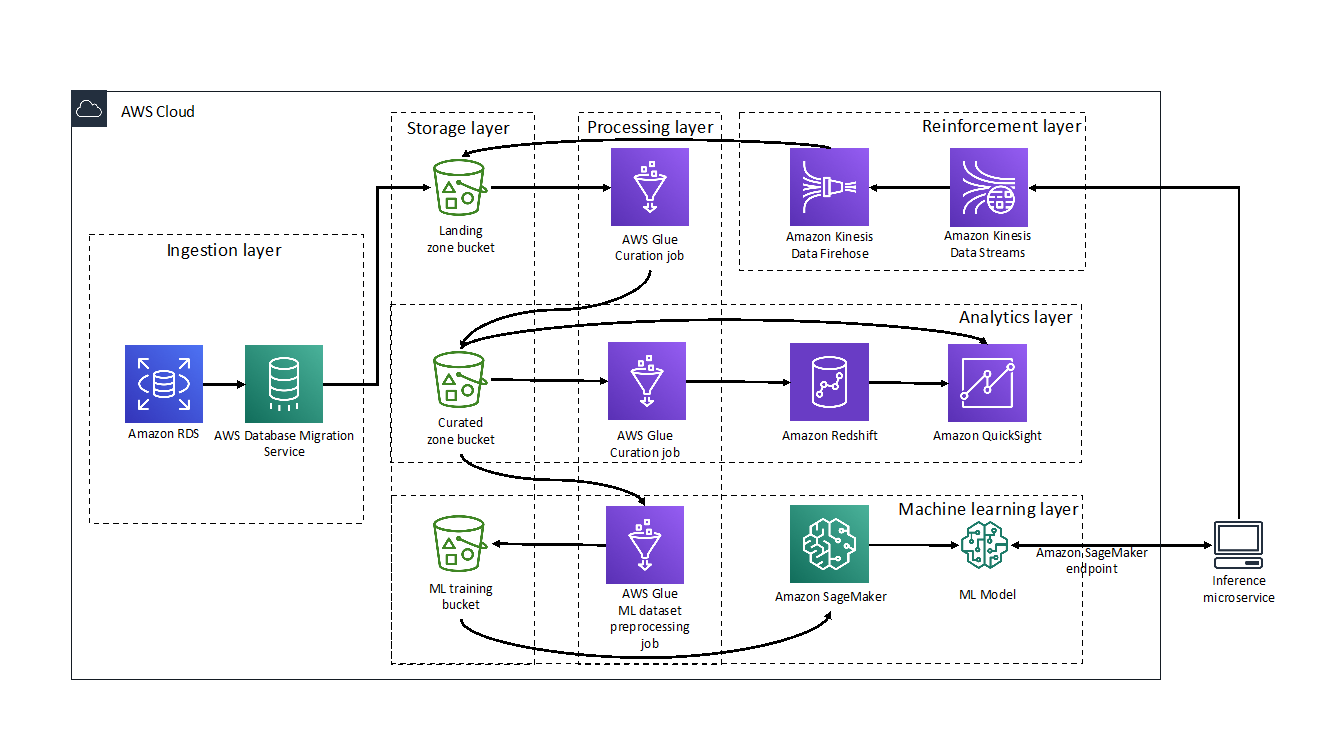
With Kinesis Data Streams, IoT data across millions of devices can simultaneously write to a centralized data stream. Alternatively, you can use AWS IoT Core to securely connect and easily manage the fleet of IoT devices, collect the IoT data, and then ingest to Kinesis Data Streams for real-time transformation, analytics, and event-driven microservices. Then, you can use integrated services such as Amazon SageMaker for real-time inference. The following diagram depicts the high-level streaming architecture with IoT sensor data.

The steps are as follows:
- Data originates in IoT devices such as medical devices, car sensors, and industrial IoT sensors. This telemetry data is collected using AWS IoT Greengrass, an open source IoT edge runtime and cloud service that helps your devices collect and analyze data closer to where the data is generated.
- Event data is ingested into the cloud using edge-to-cloud interface services such as AWS IoT Core, a managed cloud platform that connects, manages, and scales devices effortlessly and securely. You can also use AWS IoT SiteWise, a managed service that helps you collect, model, analyze, and visualize data from industrial equipment at scale. Alternatively, IoT devices could send data directly to Kinesis Data Streams.
- AWS IoT Core can stream ingested data into Kinesis Data Streams.
- The ingested data gets transformed and analyzed in near real time using Amazon Managed Service for Apache Flink. Stream data can further be enriched using lookup data hosted in a data warehouse such as Amazon Redshift. Managed Service for Apache Flink can persist streamed data into Amazon Redshift after the customer’s integration and stream aggregation (for example, 1 minute or 5 minutes). The results in Amazon Redshift can be used for further downstream BI reporting services, such as QuickSight. Managed Service for Apache Flink can also write to a Lambda function, which can invoke SageMaker models. After the ML model is trained and deployed in SageMaker, inferences are invoked in a microbatch using Lambda. Inferenced data is sent to Amazon OpenSearch Service to create personalized monitoring dashboards using OpenSearch Dashboards. The transformed IoT sensor data can be stored in DynamoDB. You can use AWS AppSync to provide near real-time data queries to API services for downstream applications. These enterprise applications can be mobile apps or business applications to track and monitor the IoT sensor data in near real time.
- The streamed IoT data can be written to an Amazon Data Firehose delivery stream, which microbatches data into Amazon S3 for future analytics.
To learn how other customers have built IoT device monitoring solutions using Kinesis Data Streams, refer to:
- Detect Real-Time Anomalies and Failures in Industrial Processes
- Building event-driven architectures with IoT sensor data
- Digitally transform your factory with Machine Downtime Monitor on AWS
- Build a predictive maintenance solution with Amazon Kinesis, AWS Glue, and Amazon SafeMake
Conclusion
This post demonstrated additional architectural patterns for building low-latency AI applications with Kinesis Data Streams and its integrations with other AWS services. Customers looking to build generative BI, recommendation systems, and IoT data streaming and inferencing can refer to these patterns as the starting point of designing your cloud architecture. We will continue to add new architectural patterns in the future posts of this series.
For detailed architectural patterns, refer to the following resources:
- Build low-latency streaming applications using Amazon Kinesis Data Streams
- Amazon Kinesis Data Streams integrations
- Build highly available streams with Amazon Kinesis Data Streams
- Scale Kinesis Data Streams for high throughput and low latency
- Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
- Best practices for ingesting data from devices using AWS IoT Core and/or Amazon Kinesis
- Near-real-time analytics using Amazon Redshift streaming ingestion with Amazon Kinesis Data Streams and Amazon DynamoDB
- Driving Business Outcomes with Clickstream Data
- Implementing architectural patterns with Amazon EventBridge Pipes
- Track customer traffic in aisles and cash counters using Computer Vision
- Join a streaming data source with CDC data for real-time serverless data analytics using AWS Glue, AWS DMS, and Amazon DynamoDB
If you want to build a data vision and strategy, check out the AWS Data-Driven Everything (D2E) program.
About the Authors
 Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
 Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
 Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.
Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.
 Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.
Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.






 Viral Shah is a Data Lab Architect with Amazon Web Services. Viral helps our customers architect and build data and analytics prototypes in just four days in the
Viral Shah is a Data Lab Architect with Amazon Web Services. Viral helps our customers architect and build data and analytics prototypes in just four days in the