Post Syndicated from Siva Ramani original https://aws.amazon.com/blogs/big-data/run-a-data-processing-job-on-amazon-emr-serverless-with-aws-step-functions/
There are several infrastructure as code (IaC) frameworks available today, to help you define your infrastructure, such as the AWS Cloud Development Kit (AWS CDK) or Terraform by HashiCorp. Terraform, an AWS Partner Network (APN) Advanced Technology Partner and member of the AWS DevOps Competency, is an IaC tool similar to AWS CloudFormation that allows you to create, update, and version your AWS infrastructure. Terraform provides friendly syntax (similar to AWS CloudFormation) along with other features like planning (visibility to see the changes before they actually happen), graphing, and the ability to create templates to break infrastructure configurations into smaller chunks, which allows better maintenance and reusability. We use the capabilities and features of Terraform to build an API-based ingestion process into AWS. Let’s get started!
In this post, we showcase how to build and orchestrate a Scala Spark application using Amazon EMR Serverless, AWS Step Functions, and Terraform. In this end-to-end solution, we run a Spark job on EMR Serverless that processes sample clickstream data in an Amazon Simple Storage Service (Amazon S3) bucket and stores the aggregation results in Amazon S3.
With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications. You will continue to get the benefits of Amazon EMR, such as open source compatibility, concurrency, and optimized runtime performance for popular data frameworks. EMR Serverless is suitable for customers who want ease in operating applications using open-source frameworks. It offers quick job startup, automatic capacity management, and straightforward cost controls.
Solution overview
We provide the Terraform infrastructure definition and the source code for an AWS Lambda function using sample customer user clicks for online website inputs, which are ingested into an Amazon Kinesis Data Firehose delivery stream. The solution uses Kinesis Data Firehose to convert the incoming data into a Parquet file (an open-source file format for Hadoop) before pushing it to Amazon S3 using the AWS Glue Data Catalog. The generated output S3 Parquet file logs are then processed by an EMR Serverless process, which outputs a report detailing aggregate clickstream statistics in an S3 bucket. The EMR Serverless operation is triggered using Step Functions. The sample architecture and code are spun up as shown in the following diagram.

The provided samples have the source code for building the infrastructure using Terraform for running the Amazon EMR application. Setup scripts are provided to create the sample ingestion using Lambda for the incoming application logs. For a similar ingestion pattern sample, refer to Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data.
The following are the high-level steps and AWS services used in this solution:
- The provided application code is packaged and built using Apache Maven.
- Terraform commands are used to deploy the infrastructure in AWS.
- The EMR Serverless application provides the option to submit a Spark job.
- The solution uses two Lambda functions:
- Ingestion – This function processes the incoming request and pushes the data into the Kinesis Data Firehose delivery stream.
- EMR Start Job – This function starts the EMR Serverless application. The EMR job process converts the ingested user click logs into output in another S3 bucket.
- Step Functions triggers the EMR Start Job Lambda function, which submits the application to EMR Serverless for processing of the ingested log files.
- The solution uses four S3 buckets:
- Kinesis Data Firehose delivery bucket – Stores the ingested application logs in Parquet file format.
- Loggregator source bucket – Stores the Scala code and JAR for running the EMR job.
- Loggregator output bucket – Stores the EMR processed output.
- EMR Serverless logs bucket – Stores the EMR process application logs.
- Sample invoke commands (run as part of the initial setup process) insert the data using the ingestion Lambda function. The Kinesis Data Firehose delivery stream converts the incoming stream into a Parquet file and stores it in an S3 bucket.
For this solution, we made the following design decisions:
- We use Step Functions and Lambda in this use case to trigger the EMR Serverless application. In a real-world use case, the data processing application could be long running and may exceed Lambda’s timeout limits. In this case, you can use tools like Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Amazon MWAA is a managed orchestration service makes it easier to set up and operate end-to-end data pipelines in the cloud at scale.
- The Lambda code and EMR Serverless log aggregation code are developed using Java and Scala, respectively. You can use any supported languages in these use cases.
- The AWS Command Line Interface (AWS CLI) V2 is required for querying EMR Serverless applications from the command line. You can also view these from the AWS Management Console. We provide a sample AWS CLI command to test the solution later in this post.
Prerequisites
To use this solution, you must complete the following prerequisites:
- Install the AWS CLI. For this post, we used version 2.7.18. This is required in order to query the
aws emr-serverlessAWS CLI commands from your local machine. Optionally, all the AWS services used in this post can be viewed and operated via the console. - Make sure to have Java installed, and JDK/JRE 8 is set in the environment path of your machine. For instructions, see the Java Development Kit.
- Install Apache Maven. The Java Lambda functions are built using mvn packages and are deployed using Terraform into AWS.
- Install the Scala Build Tool. For this post, we used version 1.4.7. Make sure to download and install based on your operating system needs.
- Set up Terraform. For steps, see Terraform downloads. We use version 1.2.5 for this post.
- Have an AWS account.
Configure the solution
To spin up the infrastructure and the application, complete the following steps:
- Clone the following GitHub repository.
The providedexec.shshell script builds the Java application JAR (for the Lambda ingestion function) and the Scala application JAR (for the EMR processing) and deploys the AWS infrastructure that is needed for this use case. - Run the following commands:
To run the commands individually, set the application deployment Region and account number, as shown in the following example:
The following is the Maven build Lambda application JAR and Scala application package:
- Deploy the AWS infrastructure using Terraform:
Test the solution
After you build and deploy the application, you can insert sample data for Amazon EMR processing. We use the following code as an example. The exec.sh script has multiple sample insertions for Lambda. The ingested logs are used by the EMR Serverless application job.
The sample AWS CLI invoke command inserts sample data for the application logs:
To validate the deployments, complete the following steps:
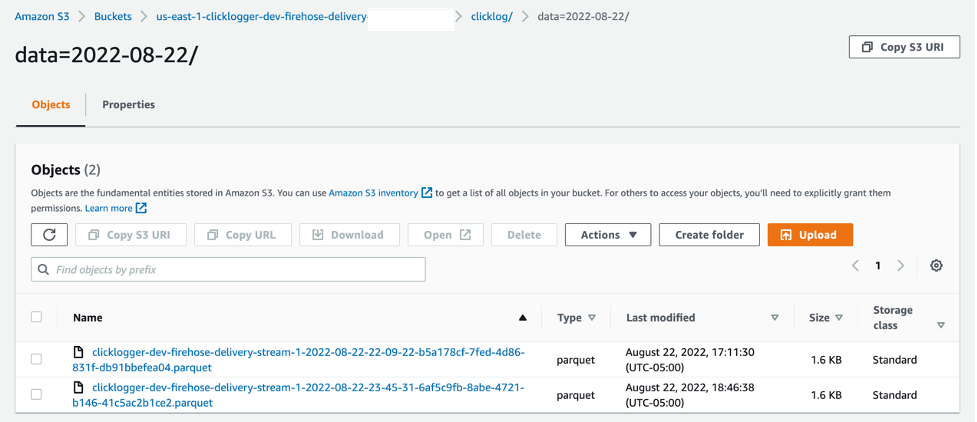
- On the Amazon S3 console, navigate to the bucket created as part of the infrastructure setup.
- Choose the bucket to view the files.
You should see that data from the ingested stream was converted into a Parquet file. - Choose the file to view the data.
The following screenshot shows an example of our bucket contents.
Now you can run Step Functions to validate the EMR Serverless application. - On the Step Functions console, open
clicklogger-dev-state-machine.
The state machine shows the steps to run that trigger the Lambda function and EMR Serverless application, as shown in the following diagram.
- Run the state machine.
- After the state machine runs successfully, navigate to the
clicklogger-dev-output-bucket on the Amazon S3 console to see the output files.

- Use the AWS CLI to check the deployed EMR Serverless application:
- On the Amazon EMR console, choose Serverless in the navigation pane.
- Select
clicklogger-dev-studioand choose Manage applications. - The Application created by the stack will be as shown below
clicklogger-dev-loggregator-emr-<Your-Account-Number>

 Now you can review the EMR Serverless application output.
Now you can review the EMR Serverless application output. - On the Amazon S3 console, open the output bucket (
us-east-1-clicklogger-dev-loggregator-output-).
The EMR Serverless application writes the output based on the date partition, such as2022/07/28/response.md.The following code shows an example of the file output:




Clean up
The provided ./cleanup.sh script has the required steps to delete all the files from the S3 buckets that were created as part of this post. The terraform destroy command cleans up the AWS infrastructure that you created earlier. See the following code:
To do the steps manually, you can also delete the resources via the AWS CLI:
Conclusion
In this post, we built, deployed, and ran a data processing Spark job in EMR Serverless that interacts with various AWS services. We walked through deploying a Lambda function packaged with Java using Maven, and a Scala application code for the EMR Serverless application triggered with Step Functions with infrastructure as code. You can use any combination of applicable programming languages to build your Lambda functions and EMR job application. EMR Serverless can be triggered manually, automated, or orchestrated using AWS services like Step Functions and Amazon MWAA.
We encourage you to test this example and see for yourself how this overall application design works within AWS. Then, it’s just the matter of replacing your individual code base, packaging it, and letting EMR Serverless handle the process efficiently.
If you implement this example and run into any issues, or have any questions or feedback about this post, please leave a comment!
References
- Terraform: Beyond the Basics with AWS
- Amazon EMR Serverless is now generally available
- Amazon EMR Serverless Now Generally Available – Run Big Data Applications without Managing Servers
- Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data
About the Authors
 Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at Amazon Web Services. His expertise is in application optimization & modernization, serverless solutions and using Microsoft application workloads with AWS.
Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at Amazon Web Services. His expertise is in application optimization & modernization, serverless solutions and using Microsoft application workloads with AWS.
 Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, serverless Applications, Architecting Microservices and helping customers leverage the power of AWS cloud.
Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, serverless Applications, Architecting Microservices and helping customers leverage the power of AWS cloud.