Post Syndicated from Syed Masudullah Sadullah original https://aws.amazon.com/blogs/architecture/transform-lease-agreement-workflows-with-amazon-bedrock/
Rental and lease agreements can be a complex and time-consuming process for property management companies and landlords. The agreements contain legal language, varied formatting, and diverse terms and conditions based on state and local regulations. Landlord-tenant laws vary significantly across the country, with each state having its own set of regulations. For example, California’s landlord-tenant law spans over 100 pages in the state’s Civil Code. Manually extracting and processing the key details from lease documents is inefficient and error prone. In 2023, there were approximately 45 million rental units managed by over 310,000 property management companies in the US, most of which want to take advantage of AI-powered lease management systems to streamline operations, enhance tenant experience, and optimize costs.
Generative AI, powered by large language models (LLMs), is helping how businesses approach complex document processing tasks, including lease management. Amazon Bedrock, a fully managed service, offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Luma (coming soon), Meta, Mistral AI, poolside (coming soon), Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
This post explores how Amazon Bedrock can transform property management operations and optimize costs. We examine a practical approach to tackle challenges such as processing high volumes of lease agreements, maintaining compliance with varied regulatory requirements.
Lease management process
Rental property management requires a careful balance of manual and automated processes to provide smooth administration of lease agreements. Although technological solutions have improved efficiency in many areas, the handling of lease documents still relies heavily on manual effort from both property managers and back-office staff.
The following diagram shows a critical part of the lease processing workflow.

In this workflow, when a tenant signs a physical lease document, the property manager scans and uploads it to capture the terms electronically. A back office processor reviews the files, manually extracting key details like rent, duration, and deposit, and uses this to set up billing, payments, and reminders. The processor also manages lease functions, including processing payments, sending reminders, and issuing renewal notices, with some tasks automated but requiring manual review to address non-standard lease terms and special conditions. Alternatively, in the case when a tenant signs the lease digitally, the document is automatically captured in the system and processed further.
Overall, lease management functions involve manual and automated steps.
Solution overview
By using LLMs, you can automate key steps in the lease handling workflow, transitioning from a manual approach to a more streamlined and intelligent system. With prompt engineering, LLMs can interpret the language of lease agreements mandated by state, county, and local laws, and accurately extract terms and conditions for downstream functions such as rent processing and renewal notifications. Optionally, a fine-tuning approach helps LLMs understand industry-specific terminology.
The solution approach in this post uses Amazon Bedrock, which offers a selection of FMs and provides seamless integration with other AWS services. Although we used Anthropic’s Claude 3 Sonnet model on Amazon Bedrock to describe the solution in the post, Amazon Bedrock allows you to experiment with other models using the same approach, enabling you to find the best fit for your specific requirements.
Our event-driven solution is structured in three key steps, as illustrated in the following diagram:
- Constructing a standard lease terms knowledge base – This stage involves building a comprehensive repository of standard lease terms and conditions
- Validating and extracting lease agreement details – Here, we focus on accurately parsing and extracting crucial information from individual lease agreements
- Automating lease-related downstream processes – The final stage implements automation for various lease management tasks and workflows

This solution demonstrates how advanced models can be effectively integrated into real-world business processes, streamlining lease management operations while maintaining accuracy and compliance.
For a practical implementation of this solution, refer to the solution repository, where you can find code for AWS Lambda functions, a sample standard lease template, and an example lease document for you to test in your own AWS environment.
Prerequisites
To implement this solution, you need the following prerequisites:
Build a standard lease terms knowledge base
In the first stage, you build a foundation of the solution by curating a library of standard lease document templates to capture diverse laws and regulations across different states, cities, and counties.
To describe the solution approach in this post, we use the Amazon Bedrock Converse API, which provides a consistent way to invoke models, removing the complexity to adjust for model-specific differences such as inference parameters. It also manages multi-turn conversations by incorporating conversational history into requests.
With the Converse API, you can establish a centralized knowledge base in DynamoDB to streamline validation of mandatory requirements in lease documents. Because the lease templates don’t change often, a DynamoDB based knowledge base provides a cost-effective way to store mandatory terms required by different jurisdictions, removing the need to invoke Amazon Bedrock queries every time a lease is processed. The use of the Converse API with DynamoDB also eliminates an extra layer of complex knowledge base creation that requires additional integration, cost, and maintenance.
Complete the following steps to create your knowledge base:
- Create an S3 bucket called
Lease Templates and upload the standard lease templates.
Because lease templates don’t change often, this step is done only for new or modified templates.

Next, you configure S3 notifications to trigger a Lambda function to process the template.
- Create a prompt instructing the LLM to analyze lease templates and identify terms and conditions mandated by state, county, and city regulations. The prompt can also include directives on how to parse the template and extract terms, conditions, and clauses as defined in the sample. See the following code:
<instructions>
Please review the provided residential apartment lease agreement template and extract the following information for each state or jurisdiction represented in the document. Extract state, county, city, zipcode and township details of the template in json format such as state as key and Ohio as value, zipcode as key and 43065 as value, etc. State and Zipcode is mandatory.
<laws>
Mandated state or local laws: Identify any specific laws, statutes, or regulations that the lease agreement must include or comply with based on the state or local jurisdiction. This could include things like maximum security deposit amounts, required notice periods for lease termination, or provisions tenant rights, security features on doors or windows or balcony, wall paint related obligations and landlord obligations. Provide output in json format with name and condition as key, value pairs.
</laws>
<terms>
Mandated lease terms and clauses: Extract any specific terms, clauses, or language that the lease agreement must contain due to state or local requirements. This may include items like required disclosures, prohibited provisions, or mandatory sections covering topics such as security deposits, maintenance responsibilities, or move-in/move-out procedures. Provide output in json format with name and condition as key, value pairs.
</terms>
<structure>
Formatting or structure requirements: Note if the lease agreement template must follow a particular format, structure, or organization based on state or local guidelines. This could involve the order of sections, required headings, or formatting of specific provisions. Provide output in json format with name and condition as key, value pairs.
</structure>
For each state or jurisdiction represented in the lease agreement template, please provide the extracted information in json format as described above. Include the state/jurisdiction name, the relevant mandated laws, terms, clauses, and formatting requirements. Where possible, cite the specific legal authority or source for the required provisions. The goal is to create a comprehensive guide in json format that a property manager could use to ensure their residential lease agreements comply with the applicable state and local requirements, based on the provided template document. In addition to above terms and conditions, provide any other relevant terms you find the template that could be important and should be included in lease documents by property manager. Provide only json output and don't include any other text and don't add any super header to the overall json response. Start the json with state key, value pair to put the item into Amazon DynamoDB table.
</instructions>
- Using the Converse API, extract mandatory terms and conditions as JSON output with
state and zipcode as unique identifiers:
doc_message = {
"role": "user",
"content":
[
{ "document":{"name": "Document 1",
"format": "pdf",
"source":{"bytes":file_bytes}}
},
{ "text": prompt
}
]
response = bedrock.converse
(
modelId = "anthropic.claude-3-sonnet-20240229-v1:0",
messages = [doc_message],
inferenceConfig = {"maxTokens":4096, "temperature":0}
)
The following screenshot shows the output of the Amazon Bedrock Converse API call, which will serve as a reference for processing lease documents for that jurisdiction.

- Create a
leaseagreementtemplateterms table in DynamoDB and store the JSON output, forming the knowledge base:
#Convert JSON string to Python dictionary
item = json.loads(response_text)
#Insert response_text item into DynamoDB table
table = dynamodb.Table('leaseagreementtemplateterms')
try:
response = table.put_item(Item=item)
print('Item inserted successfully: ', item['state'], item['zipcode'])
except Exception as e:
print('Error inserting item: ', item['state'], item['zipcode'], e)
You can configure on-demand or provisioned throughput capacity for the table based on your workload requirements. This data repository makes sure that the mandatory requirements for each jurisdiction are readily available for validation when new lease agreements are processed. It’s also more cost-effective to retrieve terms from the DynamoDB table than invoking Amazon Bedrock every time a lease needs to be validated against standard terms in the template.

You can repeat the process to capture standard lease terms of all jurisdictions you have operations in and if there are regulatory changes in the standard terms of already processed templates.
Validate and extract lease agreement details
In the second stage of the solution, you validate each lease agreement against standard terms captured during the previous stage to confirm compliance. After the lease is determined to be compliant on all mandatory clauses for the jurisdiction, you extract terms and conditions to run lease management functions. Compared to the volume and frequency of templates processed in first stage, you frequently process a larger number of documents in the lease processing stage, therefore a scalable solution using Amazon SQS is optimal. You can use S3 notifications and an SQS queue-based approach to decouple and scale the document processing as required.
Complete the following steps:
- Create an S3 bucket called
Lease Agreements to upload lease documents, and configure S3 upload notifications to destination type Amazon SQS.
Next, you configure Amazon SQS to trigger a Lambda function to perform downstream processing of the lease document.
- For this post, to identify the jurisdiction, we mentioned
state and zipcode as part of file name. With that information, retrieve mandatory terms corresponding to that jurisdiction from the DynamoDB leaseagreementtemplateterms knowledge base.
Table = dynamodb.Table('leaseagreementtemplateterms')
response = table.query(KeyConditionExpression = Key('state').eq(state) &
Key('zipcode').eq(zipcode))
Over a period of time, standard lease templates may change for various reasons. If you have more than one version of the template for each state and zipcode combination, use the latest version of mandatory terms for validation.
- With the extracted mandatory terms and uploaded lease document, create a prompt for the Amazon Bedrock Converse API to validate whether the lease complies with all required clauses and conditions. The following prompt considers various aspects of lease processing, and you can add more details as required for your use case. The prompt also asks the LLM to score the confidence level on the accuracy of the processing, which you can use to determine if further manual review is required.
<instructions>
You are an AI data processor assisting a residential property management company. Your task is to review residential lease agreement document uploaded and validate that it contains the mandatory terms, conditions, and clauses provided in the following context.
<json_mandatory_terms>
+ str(mandatory_lease_terms_json)
</ json_mandatory_terms>
Please review the lease agreement document and check if it includes the mandatory terms, conditions, and clauses as mentioned in terms above. Do not hallucinate or use any public information for validation. Clauses could be just statements. Don't look for specific statements but make sure the meaning is in alignment.
Validate if rent amount, lease start date, security deposit amount, etc, have valid values such as amounts and dates. For example, if security deposit is mandatory in the terms JSON, then the lease document should have the term security deposit with a valid $ amount value. Identify any gaps or missing elements that are in the JSON and provide a summary report.
The report should include: The state and local jurisdiction of the property. A list of all the mandatory terms, conditions, and clauses required for that jurisdiction as per JSON. A list of any missing or incomplete elements in the lease agreement document you just reviewed. If any mandatory terms are missing or not properly mentioned with valid values in the lease document, please provide recommendations on what needs to be amended in the lease document and approximate wording for each recommendation to add in the lease document. Please provide the report in a clear and concise format that the property manager can easily understand and act upon. If all mandatory terms look good, then confirm the same in the report by outputting a response 'status: agreement is validated' along with the report. If a term or condition or clause doesn't fulfill as per mandatory JSON, then output a response 'status: agreement is not fully validated' along with the report.
<confidence_score>
Share a confidence score in percentage on how confident are you that you validation is accurate and the lease document is complete.
</confidence_score>
</instructions>
The Converse API call generates a detailed validation report in JSON format as shown in the following screenshot, outlining any sections or terms that don’t align with the mandatory requirements. It also provides a confidence score on the accuracy of the lease document and recommendations on how to amend those terms and conditions.

- Based on the model’s recommendations, you can amend the lease and make sure the terms and conditions are compliant with mandatory requirements, and then re-validate the lease document.
After the document is successfully validated, the model prepares a final validation report along with a confidence score. In our solution, we’ve considered 95% as the threshold for successful validation. You can decide your threshold and have a manual review step in the workflow as required.

- After the amended lease is validated successfully, prompt the Amazon Bedrock Converse API to extract required terms from the lease document, such as tenancy start date, end date, security deposit, utilities paid by, and so on. Add additional fields to the prompt as required for your business activities and workflows.
<instructions>
You are a Lease document data processor. You will be provided a lease agreement of a real estate rental unit such as apartment, home or condo. Extract the information from the lease document and create a json that can be inserted into Amazon DynamoDB table. Following are the terms and conditions of the lease that you need to extract:
state is state where the lease is processed (Example: Ohio, Pennsylvania, etc.)
zipcode is zipcode where the lease is processed (example 43065, 19019, etc.)
lease_id is Rental agreement title
new_or_amendment is 'new'
agreement_signed_date is date on which this lease is signed (mm/dd/yyyy)
deposit_amount is Deposit amount
deposit_paid_by_date is date when deposit should be paid by mm/dd/yyyy)
fixtures are kitchen appliances, furnitures or any other applicances
owner_name is Landlord's or Owner's name of the rental unit
property_address is address of the rental unit which is on lease
rent_amount is monthly rent amount
rent_paid_by_day_of_month is due date of rental payment
tenancy_end_date is lease end date on which the lease is terminating
tenancy_start_date is lease start date on which the lease is starting
tenant_name is Tenant's name of the rental unit
termination_notice_min_days is minimum notice period in days
utilities_terms_electricity is who will pay the electricity bill
When creating the summary, be sure to understand the legal language in the agreement and create a valid output.
</instructions>
- Create a
Lease Agreements table in DynamoDB to store the terms and condition of the lease as a lease primary record.
You can use this record to carry out lease management activities throughout the life of the lease, such as rent reminders, renewal notices, and promotional emails. Because the lease is renewed by the same tenant, you can update the primary record and extend the process. If the lease expires and a new lease is signed by different tenant, you can create a new lease primary record again for the rental unit, thereby enabling the continuous lifecycle of property management workflows.
The following screenshot is a sample lease record for each lease agreement processed in the table.

Automate lease-related notifications and reminders
After the lease terms are extracted into the lease agreement table, you can automate downstream processes. The solution in this post uses EventBridge Scheduler and Lambda functions to run different lease management functions. However, you can also use Amazon Bedrock to perform some of those functions, such as generating communications or custom notifications as required. You can determine what works best for your use case based on volumes, flexibility, and cost involved in using Amazon Bedrock and modify the approach.
Complete the following steps:
- Using dates and other lease terms, configure EventBridge Scheduler to trigger periodic notifications and batch processes. For example, you can schedule monthly rent reminders or renewal notices nearing lease end or periodic promotions.
- Using standard templates from Amazon S3, you can automate notices and reminders for an improved customer experience and archive the communications for future audits.
#Send rent reminder on 25th of every month using templates stored in s3
response = s3.get_object(Bucket = "leasenoticetemplates",
Key = "rentreminder.txt" )
#Publish SNS email message
topic = sns.Topic('arn:aws:sns:us-east-2:1234567890:leasecommunications')
response = topic.publish(Message = rentreminder)
The following screenshot is a sample recurring rent reminder email scheduled through EventBridge.

Conclusion
In this post, we explored a generative AI-based approach to lease processing using the power of Amazon Bedrock. Our approach addresses the complex challenges of manual lease management by establishing a comprehensive lease template library and knowledge base, automating compliance validation against jurisdiction-specific requirements, and centralizing lease term storage for efficient processing of rental management functions. This approach not only streamlines the initial processing of leases, but also significantly reduces administrative overhead in ongoing lease management. By automating lease processing activities, you can optimize administrative costs, improve accuracy, and enhance overall operational efficiency.
For the implementation of this solution, refer to the solution repository, which contains Lambda function code and sample lease files to test in your own AWS environment.





























 Steven Carpenter is a Senior Solution Developer on the AWS Industries Prototyping and Customer Engineering (PACE) team, helping AWS customers bring innovative ideas to life through rapid prototyping on the AWS platform. He holds a master’s degree in Computer Science from Wayne State University in Detroit, Michigan.
Steven Carpenter is a Senior Solution Developer on the AWS Industries Prototyping and Customer Engineering (PACE) team, helping AWS customers bring innovative ideas to life through rapid prototyping on the AWS platform. He holds a master’s degree in Computer Science from Wayne State University in Detroit, Michigan.  Aravindharaj Rajendran is a Senior Solution Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, based in Herndon, VA. He helps AWS customers materialize their innovative ideas by rapid prototyping using the AWS platform. Outside of work, he loves playing PC games, Badminton and Traveling.
Aravindharaj Rajendran is a Senior Solution Developer within the AWS Industries Prototyping and Customer Engineering (PACE) team, based in Herndon, VA. He helps AWS customers materialize their innovative ideas by rapid prototyping using the AWS platform. Outside of work, he loves playing PC games, Badminton and Traveling.




 apc-crr
apc-crr
 Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>
Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>














 Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis.
Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis. Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old.
Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old. Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS.
Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS. Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey.
Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.


 AWS and Hugging Face collaborate to make generative AI more accessible and cost-efficient – This previous week, we announced an expanded collaboration between AWS and
AWS and Hugging Face collaborate to make generative AI more accessible and cost-efficient – This previous week, we announced an expanded collaboration between AWS and 
 AWS Pi Day – Join me on March 14 for the third annual
AWS Pi Day – Join me on March 14 for the third annual  You might learn in high school biology class that the human genome is composed of over three billion letters of code using adenine (A), guanine (G), cytosine (C), and thymine (T) paired in the deoxyribonucleic acid (DNA). The human genome acts as the biological blueprint of every human cell. And that’s only the foundation for what makes us human.
You might learn in high school biology class that the human genome is composed of over three billion letters of code using adenine (A), guanine (G), cytosine (C), and thymine (T) paired in the deoxyribonucleic acid (DNA). The human genome acts as the biological blueprint of every human cell. And that’s only the foundation for what makes us human.










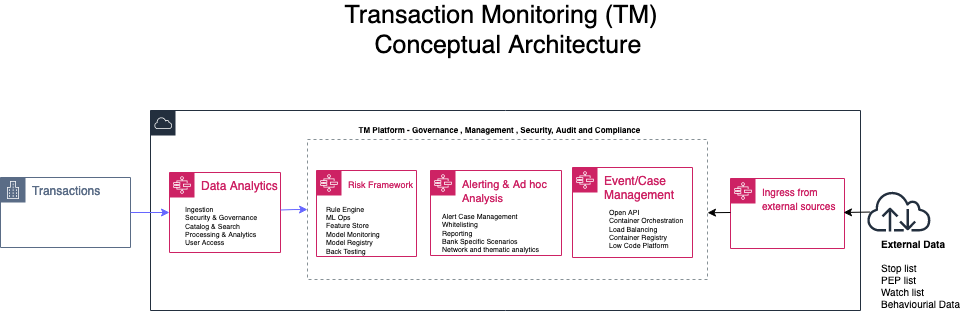
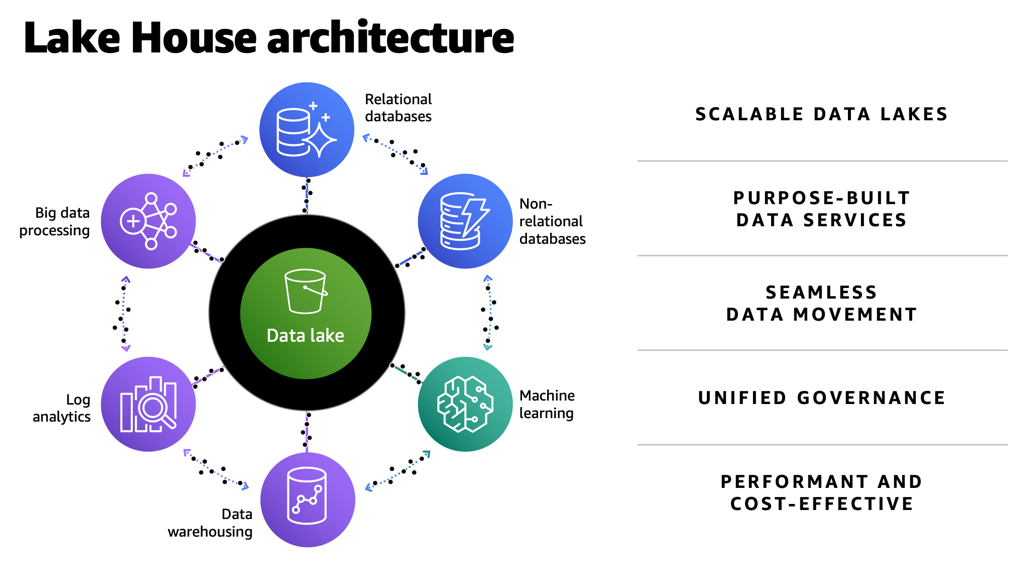
 Yomi Abatan is a Sr. Solution Architect based in London, United Kingdom. He works with financial services organisations, architecting, designing and implementing various large-scale IT solutions. He, currently helps established financial services AWS customers embark on Digital transformations using AWS cloud as an accelerator. Before joining AWS he worked in various architecture roles with several tier-one investment banks.
Yomi Abatan is a Sr. Solution Architect based in London, United Kingdom. He works with financial services organisations, architecting, designing and implementing various large-scale IT solutions. He, currently helps established financial services AWS customers embark on Digital transformations using AWS cloud as an accelerator. Before joining AWS he worked in various architecture roles with several tier-one investment banks.