Post Syndicated from Francesco Marelli original https://aws.amazon.com/blogs/big-data/build-a-multilingual-dashboard-with-amazon-athena-and-amazon-quicksight/
Amazon QuickSight is a serverless business intelligence (BI) service used by organizations of any size to make better data-driven decisions. QuickSight dashboards can also be embedded into SaaS apps and web portals to provide interactive dashboards, natural language query or data analysis capabilities to app users seamlessly. The QuickSight Demo Central contains many dashboards, feature showcase and tips and tricks that you can use; in the QuickSight Embedded Analytics Developer Portal you can find details on how to embed dashboards in your applications.
The QuickSight user interface currently supports 15 languages that you can choose on a per-user basis. The language selected for the user interface localizes all text generated by QuickSight with respect to UI components and isn’t applied to the data displayed in the dashboards.
This post describes how to create multilingual dashboards at the data level by creating new columns that contain the translated text and providing a language selection parameter and associated control to display data in the selected language in a QuickSight dashboard. You can create new columns with the translated text in several ways; in this post we create new columns using Amazon Athena user-defined functions implemented in the GitHub project sample Amazon Athena UDFs for text translation and analytics using Amazon Comprehend and Amazon Translate. This approach makes it easy to automatically create columns with translated text using neural machine translation provided by Amazon Translate.
Solution overview
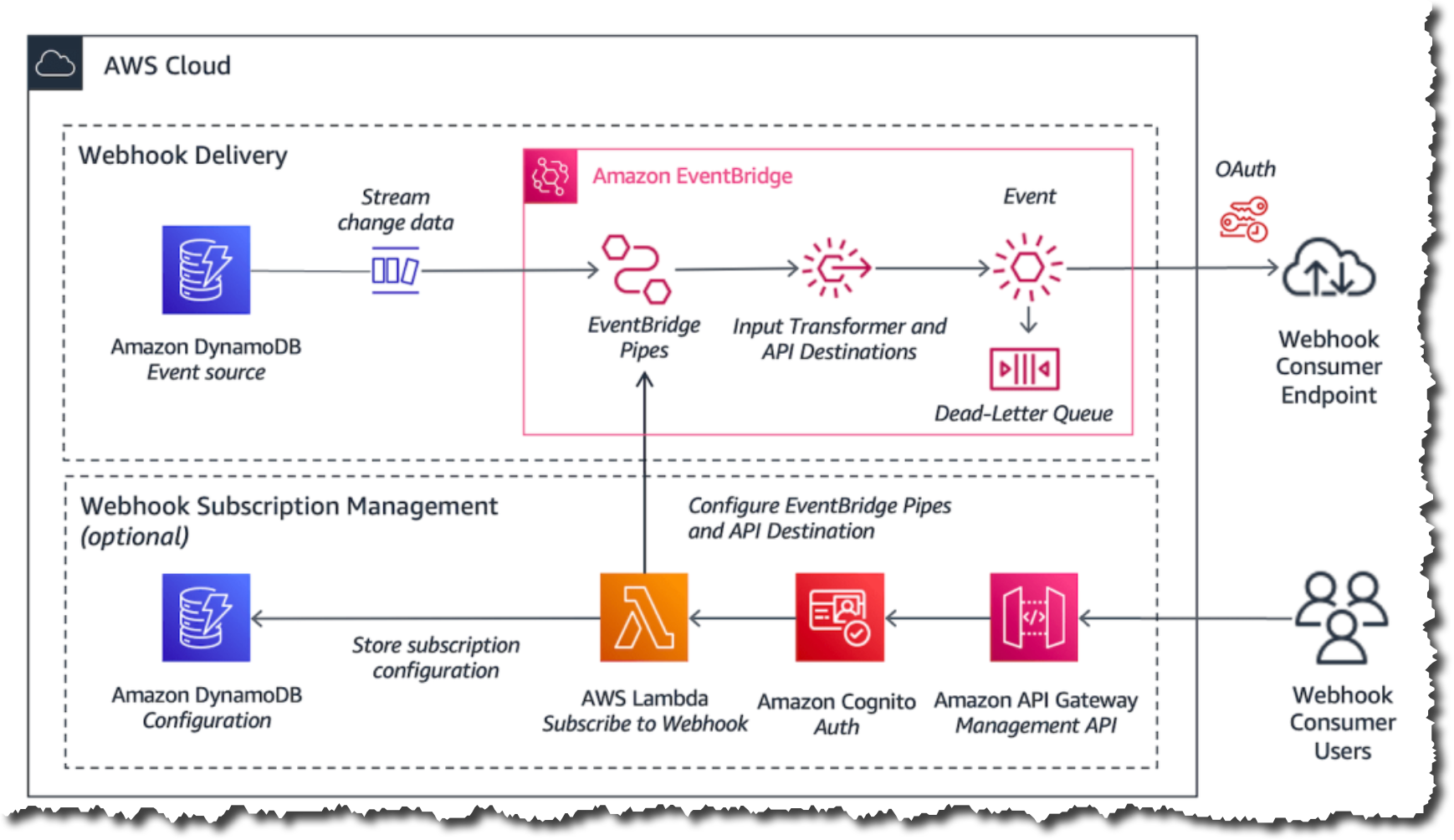
The following diagram illustrates the architecture of this solution.

For this post, we use the sample SaaS-Sales.csv dataset and follow these steps:
- Copy the dataset to a bucket in Amazon Simple Storage Service (Amazon S3).
- Use Athena to define a database and table to read the CSV file.
- Create a new table in Parquet format with the columns with the translated text.
- Create a new dataset in QuickSight.
- Create the parameter and control to select the language.
- Create dynamic multilingual calculated fields.
- Create an analysis with calculated multilingual calculated fields.
- Publish the multilingual dashboard.
- Create parametric headers and titles for visuals for use in an embedded dashboard.
An alternative approach might be to directly upload the CSV dataset to QuickSight and create the new columns with translated text as QuickSight calculated fields, for example using the ifelse() conditional function to directly assign the translated values.
Prerequisites
To follow the steps in this post, you need to have an AWS account with an active QuickSight Standard Edition or Enterprise Edition subscription.
Copy the dataset to a bucket in Amazon S3
Use the AWS Command Line Interface (AWS CLI) to create the S3 bucket qs-ml-blog-data and copy the dataset under the prefix saas-sales in your AWS account. You must follow the bucket naming rules to create your bucket. See the following code:
$ MY_BUCKET=qs-ml-blog-data
$ PREFIX=saas-sales
$ aws s3 mb s3://${MY_BUCKET}/
$ aws s3 cp \
"s3://ee-assets-prod-us-east-1/modules/337d5d05acc64a6fa37bcba6b921071c/v1/SaaS-Sales.csv" \
"s3://${MY_BUCKET}/${PREFIX}/SaaS-Sales.csv"
Define a database and table to read the CSV file
Use the Athena query editor to create the database qs_ml_blog_db:
CREATE DATABASE IF NOT EXISTS qs_ml_blog_db;
Then create the new table qs_ml_blog_db.saas_sales:
CREATE EXTERNAL TABLE IF NOT EXISTS qs_ml_blog_db.saas_sales (
row_id bigint,
order_id string,
order_date string,
date_key bigint,
contact_name string,
country_en string,
city_en string,
region string,
subregion string,
customer string,
customer_id bigint,
industry_en string,
segment string,
product string,
license string,
sales double,
quantity bigint,
discount double,
profit double)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://<MY_BUCKET>/saas-sales/'
TBLPROPERTIES (
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'skip.header.line.count'='1',
'typeOfData'='file')
Create a new table in Parquet format with the columns with the translated text
We want to translate the columns country_en, city_en, and industry_en to German, Spanish, and Italian. To do this in a scalable and flexible way, we use the GitHub project sample Amazon Athena UDFs for text translation and analytics using Amazon Comprehend and Amazon Translate.
After you set up the user-defined functions following the instructions in the GitHub repo, run the following SQL query in Athena to create the new table qs_ml_blog_db.saas_sales_ml with the translated columns using the translate_text user-defined function and some other minor changes:
CREATE TABLE qs_ml_blog_db.saas_sales_ml WITH (
format = 'PARQUET',
parquet_compression = 'SNAPPY',
external_location = 's3://<MY_BUCKET>/saas-sales-ml/'
) AS
USING EXTERNAL FUNCTION translate_text(text_col VARCHAR, sourcelang VARCHAR, targetlang VARCHAR, terminologyname VARCHAR) RETURNS VARCHAR LAMBDA 'textanalytics-udf'
SELECT
row_id,
order_id,
date_parse("order_date",'%m/%d/%Y') as order_date,
date_key,
contact_name,
country_en,
translate_text(country_en, 'en', 'de', NULL) as country_de,
translate_text(country_en, 'en', 'es', NULL) as country_es,
translate_text(country_en, 'en', 'it', NULL) as country_it,
city_en,
translate_text(city_en, 'en', 'de', NULL) as city_de,
translate_text(city_en, 'en', 'es', NULL) as city_es,
translate_text(city_en, 'en', 'it', NULL) as city_it,
region,
subregion,
customer,
customer_id,
industry_en,
translate_text(industry_en, 'en', 'de', NULL) as industry_de,
translate_text(industry_en, 'en', 'es', NULL) as industry_es,
translate_text(industry_en, 'en', 'it', NULL) as industry_it,
segment,
product,
license,
sales,
quantity,
discount,
profit
FROM qs_ml_blog_db.saas_sales
;
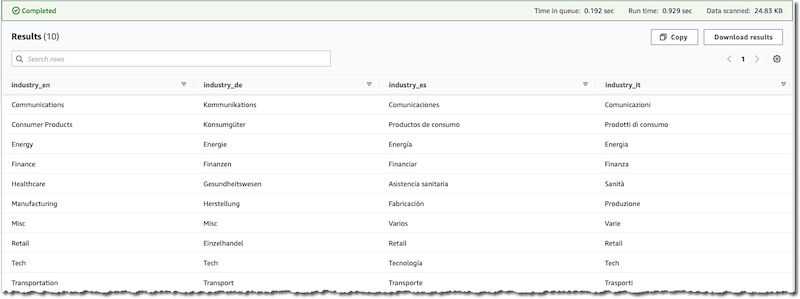
Run three simple queries, one per column, to check the generation of the new columns with the translation was successful. We include a screenshot after each query showing its results.
SELECT
distinct(country_en),
country_de,
country_es,
country_it
FROM qs_ml_blog_db.saas_sales_ml
ORDER BY country_en
limit 10
;

SELECT
distinct(city_en),
city_de,
city_es,
city_it
FROM qs_ml_blog_db.saas_sales_ml
ORDER BY city_en
limit 10
;

SELECT
distinct(industry_en),
industry_de,
industry_es,
industry_it
FROM qs_ml_blog_db.saas_sales_ml
ORDER BY industry_en
limit 10
;

Now you can use the new table saas_sales_ml as input to create a dataset in QuickSight.
Create a dataset in QuickSight
To create your dataset in QuickSight, complete the following steps:
- On the QuickSight console, choose Datasets in the navigation pane.
- Choose Create a dataset.
- Choose Athena.
- For Data source name¸ enter
athena_primary.
- For Athena workgroup¸ choose primary.
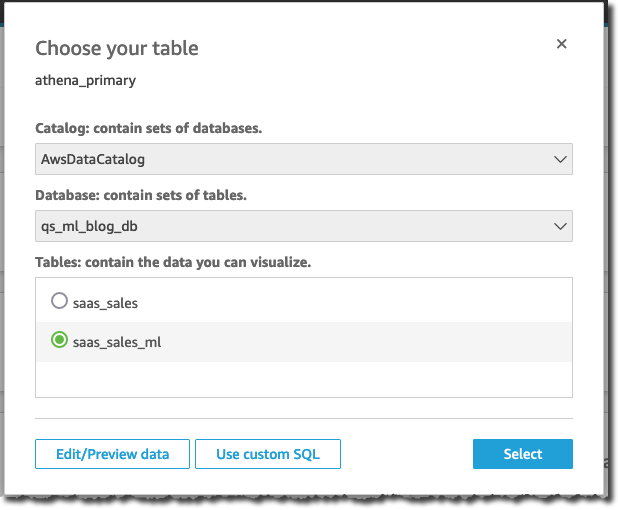
- Choose Create data source.

- Select the
saas_sales_ml table previously created and choose Select.

- Choose to import the table to SPICE and choose Visualize to start creating the new dashboard.

In the analysis section, you receive a message that informs you that the table was successfully imported to SPICE.

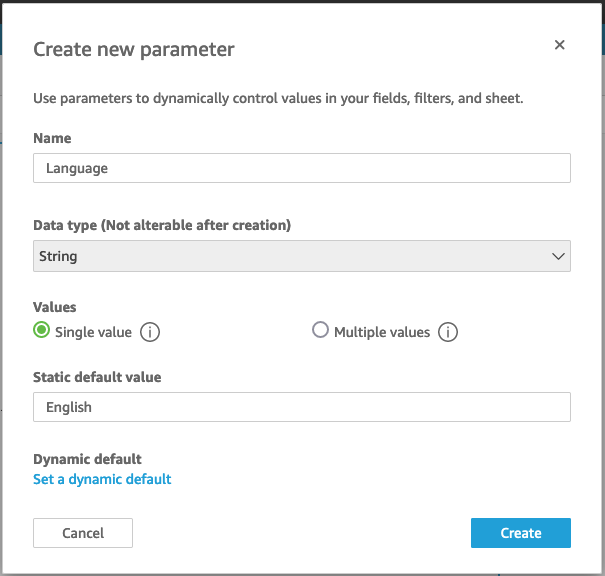
Create the parameter and control to select the language
To create the parameter and associate the control that you use to select the language for the dashboard, complete the following steps:
- In the analysis section, choose Parameters and Create one.
- For Name, enter
Language.
- For Data type, choose String.
- For Values, select Single value.
- For Static default value, enter
English.
- Choose Create.

- To connect the parameter to a control, choose Control.

- For Display name, choose Language.
- For Style, choose Dropdown.
- For Values, select Specific values.
- For Define specific values, enter
English, German, Italian, and French (one value per line).
- Select Hide Select all option from the control values if the parameter has a default configured.
- Choose Add.

The control is now available, linked to the parameter and displayed in the Controls section of the current sheet in the analysis.

Create dynamic multilingual calculated fields
You’re now ready to create the calculated fields whose value will change based on the currently selected language.
- In the menu bar, choose Add and choose Add calculated field.

- Use the ifelse conditional function to evaluate the value of the
Language parameter and select the correct column in the dataset to assign the value to the calculated field.
- Create the
Country calculated field using the following expression:
ifelse(
${Language} = 'English', {country_en},
${Language} = 'German', {country_de},
${Language} = 'Italian', {country_it},
${Language} = 'Spanish', {country_es},
{country_en}
)
- Choose Save.

- Repeat the process for the
City calculated field:
ifelse(
${Language} = 'English', {city_en},
${Language} = 'German', {city_de},
${Language} = 'Italian', {city_it},
${Language} = 'Spanish', {city_es},
{city_en}
)
- Repeat the process for the
Industry calculated field:
ifelse(
${Language} = 'English', {industry_en},
${Language} = 'German', {industry_de},
${Language} = 'Italian', {industry_it},
${Language} = 'Spanish', {industry_es},
{industry_en}
)
The calculated fields are now available and ready to use in the analysis.

Create an analysis with calculated multilingual calculated fields
Create an analysis with two donut charts and a pivot table that use the three multilingual fields. In the subtitle of the visuals, use the string Language: <<$Language>> to display the currently selected language. The following screenshot shows our analysis.

If you choose a new language from the Language control, the visuals adapt accordingly. The following screenshot shows the analysis in Italian.

You’re now ready to publish the analysis as a dashboard.
Publish the multilingual dashboard
In the menu bar, choose Share and Publish dashboard.

Publish the new dashboard as “Multilingual dashboard,” leave the advanced publish options at their default values, and choose Publish dashboard.

The dashboard is now ready.

We can take the multilingual features one step further by embedding the dashboard and controlling the parameters in the external page using the Amazon QuickSight Embedding SDK.
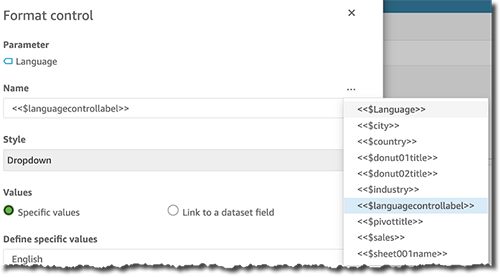
Create parametric headers and titles for visuals for use in an embedded dashboard
When embedding an QuickSight dashboard, the locale and parameters’ values can be set programmatically from JavaScript. This can be useful to set default values and change the settings for localization and the default data language. The following steps show how to use these features by modifying the dashboard we have created so far, embedding it in an HTML page, and using the Amazon QuickSight Embedding SDK to dynamically set the value of parameters used to display titles, legends, headers, and more in translated text. The full code for the HTML page is also provided in the appendix of this post.
Create new parameters for the titles and the headers of the visuals in the analysis, the sheet name, visuals legends, and control labels as per the following table.
| Name |
Data type |
Values |
Static default value |
| city |
String |
Single value |
City |
| country |
String |
Single value |
Country |
| donut01title |
String |
Single value |
Sales by Country |
| donut02title |
String |
Single value |
Quantity by Industry |
| industry |
String |
Single value |
Industry |
| Language |
String |
Single value |
English |
| languagecontrollabel |
String |
Single value |
Language |
| pivottitle |
String |
Single value |
Sales by Country, City and Industy |
| sales |
String |
Single value |
Sales |
| sheet001name |
String |
Single value |
Summary View |
The parameters are now available on the Parameters menu.

You can now use the parameters inside each sheet title, visual title, legend title, column header, axis label, and more in your analysis. The following screenshots provide examples that illustrate how to insert these parameters into each title.
First, we insert the sheet name.

Then we add the language control name.

We edit the donut charts’ titles.

We also add the donut charts’ legend titles.

In the following screenshot, we specify the pivot table row names.

We also specify the pivot table column names.

Publish the analysis to a new dashboard and follow the steps in the post Embed interactive dashboards in your apps and portals in minutes with Amazon QuickSight’s new 1-click embedding feature to embed the dashboard in an HTML page hosted in your website or web application.
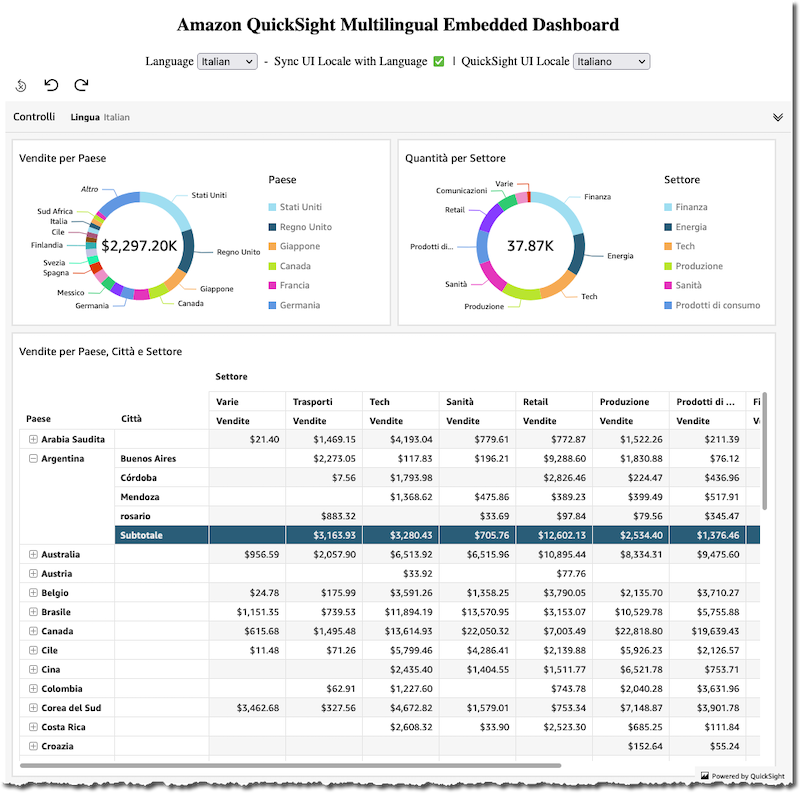
The example HTML page provided in the appendix of this post contains one control to switch among the four languages you created in the dataset in the previous sections with the option to automatically sync the QuickSight UI locale when changing the language, and one control to independently change the UI locale as required.
The following screenshots provide some examples of combinations of data language and QuickSight UI locale.
The following is an example of English data language with the English QuickSight UI locale.

The following is an example of Italian data language with the synchronized Italian QuickSight UI locale.
The following screenshot shows German data language with the Japanese QuickSight UI locale.

Conclusion
This post demonstrated how to automatically translate data using machine learning and build a multilingual dashboard with Athena, QuickSight, and Amazon Translate, and how to add advanced multilingual features with QuickSight embedded dashboards. You can use the same approach to display different values for dimensions as well as metrics depending on the values of one or more parameters.
QuickSight provides a 30-day free trial subscription for four users; you can get started immediately. You can learn more and ask questions about QuickSight in the Amazon QuickSight Community.
Appendix: Embedded dashboard host page
The full code for the HTML page is as follows:
<!DOCTYPE html>
<html>
<head>
<title>Amazon QuickSight Multilingual Embedded Dashboard</title>
<script src="https://unpkg.com/[email protected]/dist/quicksight-embedding-js-sdk.min.js"></script>
<script type="text/javascript">
var url = "https://<<YOUR_AMAZON_QUICKSIGHT_REGION>>.quicksight.aws.amazon.com/sn/embed/share/accounts/<<YOUR_AWS_ACCOUNT_ID>>/dashboards/<<DASHBOARD_ID>>?directory_alias=<<YOUR_AMAZON_QUICKSIGHT_ACCOUNT_NAME>>"
var defaultLanguageOptions = 'en_US'
var dashboard
var trns = {
en_US: {
locale: "en-US",
language: "English",
languagecontrollabel: "Language",
sheet001name: "Summary View",
sales: "Sales",
country: "Country",
city: "City",
industry: "Industry",
quantity: "Quantity",
by: "by",
and: "and"
},
de_DE: {
locale: "de-DE",
language: "German",
languagecontrollabel: "Sprache",
sheet001name: "Zusammenfassende Ansicht",
sales: "Umsätze",
country: "Land",
city: "Stadt",
industry: "Industrie",
quantity: "Anzahl",
by: "von",
and: "und"
},
it_IT: {
locale: "it-IT",
language: "Italian",
languagecontrollabel: "Lingua",
sheet001name: "Prospetto Riassuntivo",
sales: "Vendite",
country: "Paese",
city: "Città",
industry: "Settore",
quantity: "Quantità",
by: "per",
and: "e"
},
es_ES: {
locale: "es-ES",
language: "Spanish",
languagecontrollabel: "Idioma",
sheet001name: "Vista de Resumen",
sales: "Ventas",
country: "Paìs",
city: "Ciudad",
industry: "Industria",
quantity: "Cantidad",
by: "por",
and: "y"
}
}
function setLanguageParameters(l){
return {
Language: trns[l]['language'],
languagecontrollabel: trns[l]['languagecontrollabel'],
sheet001name: trns[l]['sheet001name'],
donut01title: trns[l]['sales']+" "+trns[l]['by']+" "+trns[l]['country'],
donut02title: trns[l]['quantity']+" "+trns[l]['by']+" "+trns[l]['industry'],
pivottitle: trns[l]['sales']+" "+trns[l]['by']+" "+trns[l]['country']+", "+trns[l]['city']+" "+trns[l]['and']+" "+trns[l]['industry'],
sales: trns[l]['sales'],
country: trns[l]['country'],
city: trns[l]['city'],
industry: trns[l]['industry'],
}
}
function embedDashboard(lOpts, forceLocale) {
var languageOptions = defaultLanguageOptions
if (lOpts) languageOptions = lOpts
var containerDiv = document.getElementById("embeddingContainer");
containerDiv.innerHTML = ''
parameters = setLanguageParameters(languageOptions)
if(!forceLocale) locale = trns[languageOptions]['locale']
else locale = forceLocale
var options = {
url: url,
container: containerDiv,
parameters: parameters,
scrolling: "no",
height: "AutoFit",
loadingHeight: "930px",
width: "1024px",
locale: locale
};
dashboard = QuickSightEmbedding.embedDashboard(options);
}
function onLangChange(langSel) {
var l = langSel.value
if(!document.getElementById("changeLocale").checked){
dashboard.setParameters(setLanguageParameters(l))
}
else {
var selLocale = document.getElementById("locale")
selLocale.value = trns[l]['locale']
embedDashboard(l)
}
}
function onLocaleChange(obj) {
var locl = obj.value
var lang = document.getElementById("lang").value
document.getElementById("changeLocale").checked = false
embedDashboard(lang,locl)
}
function onSyncLocaleChange(obj){
if(obj.checked){
var selLocale = document.getElementById('locale')
var selLang = document.getElementById('lang').value
selLocale.value = trns[selLang]['locale']
embedDashboard(selLang, trns[selLang]['locale'])
}
}
</script>
</head>
<body onload="embedDashboard()">
<div style="text-align: center; width: 1024px;">
<h2>Amazon QuickSight Multilingual Embedded Dashboard</h2>
<span>
<label for="lang">Language</label>
<select id="lang" name="lang" onchange="onLangChange(this)">
<option value="en_US" selected>English</option>
<option value="de_DE">German</option>
<option value="it_IT">Italian</option>
<option value="es_ES">Spanish</option>
</select>
</span>
-
<span>
<label for="changeLocale">Sync UI Locale with Language</label>
<input type="checkbox" id="changeLocale" name="changeLocale" onchange="onSyncLocaleChange(this)">
</span>
|
<span>
<label for="locale">QuickSight UI Locale</label>
<select id="locale" name="locale" onchange="onLocaleChange(this)">
<option value="en-US" selected>English</option>
<option value="da-DK">Dansk</option>
<option value="de-DE">Deutsch</option>
<option value="ja-JP">日本語</option>
<option value="es-ES">Español</option>
<option value="fr-FR">Français</option>
<option value="it-IT">Italiano</option>
<option value="nl-NL">Nederlands</option>
<option value="nb-NO">Norsk</option>
<option value="pt-BR">Português</option>
<option value="fi-FI">Suomi</option>
<option value="sv-SE">Svenska</option>
<option value="ko-KR">한국어</option>
<option value="zh-CN">中文 (简体)</option>
<option value="zh-TW">中文 (繁體)</option>
</select>
</span>
</div>
<div id="embeddingContainer"></div>
</body>
</html>
About the Author
 Francesco Marelli is a principal solutions architect at Amazon Web Services. He is specialized in the design and implementation of analytics, data management, and big data systems. Francesco also has a strong experience in systems integration and design and implementation of applications. He is passionate about music, collecting vinyl records, and playing bass.
Francesco Marelli is a principal solutions architect at Amazon Web Services. He is specialized in the design and implementation of analytics, data management, and big data systems. Francesco also has a strong experience in systems integration and design and implementation of applications. He is passionate about music, collecting vinyl records, and playing bass.

































 Francesco Marelli is a principal solutions architect at Amazon Web Services. He is specialized in the design and implementation of analytics, data management, and big data systems. Francesco also has a strong experience in systems integration and design and implementation of applications. He is passionate about music, collecting vinyl records, and playing bass.
Francesco Marelli is a principal solutions architect at Amazon Web Services. He is specialized in the design and implementation of analytics, data management, and big data systems. Francesco also has a strong experience in systems integration and design and implementation of applications. He is passionate about music, collecting vinyl records, and playing bass.






