Post Syndicated from Marcia Villalba original https://aws.amazon.com/blogs/compute/the-serverless-attendees-guide-to-aws-reinvent-2023/
AWS re:Invent 2023 is fast approaching, bringing together tens of thousands of Builders in Las Vegas in November. However, even if you can’t attend in person, you can catch up with sessions on-demand.
Breakout sessions are lecture-style 60-minute informative sessions presented by AWS experts, customers, or partners. These sessions cover beginner (100 level) topics to advanced and expert (300–400 level) topics. The sessions are recorded and uploaded a few days after to the AWS Events YouTube channel.
This post shares the “must watch” breakout sessions related to serverless architectures and services.
Sessions related to serverless architecture

SVS401 | Best practices for serverless developers
Provides architectural best practices, optimizations, and useful shortcuts that experts use to build secure, high-scale, and high-performance serverless applications.
Chris Munns, Startup Tech Leader, AWS
Julian Wood, Principal Developer Advocate, AWS
SVS305 | Refactoring to serverless
Shows how you can refactor your application to serverless with real-life examples.
Gregor Hohpe, Senior Principal Evangelist, AWS
Sindhu Pillai, Senior Solutions Architect, AWS
SVS308 | Building low-latency, event-driven applications
Explores building serverless web applications for low-latency and event-driven support. Marvel Snap share how they achieve low-latency in their games using serverless technology.
Marcia Villalba, Principal Developer Advocate, AWS
Brenna Moore, Second Dinner
SVS309 | Improve productivity by shifting more responsibility to developers
Learn about approaches to accelerate serverless development with faster feedback cycles, exploring best practices and tools. Watch a live demo featuring an improved developer experience for building serverless applications while complying with enterprise governance requirements.
Heeki Park, Principal Solutions Architect, AWS
Sam Dengler, Capital One
GBL203-ES | Building serverless-first applications with MAPFRE
This session is delivered in Spanish. Learn what modern, serverless-first applications are and how to implement them with services such as AWS Lambda or AWS Fargate. Find out how MAPFRE have adopted and implemented a serverless strategy.
Jesus Bernal, Senior Solutions Architect, AWS
Iñigo Lacave, MAPFRE
Mat Jovanovic, MAPFRE
Sessions related to AWS Lambda
BOA311 | Unlocking serverless web applications with AWS Lambda Web Adapter
Learn about the AWS Lambda Web Adapter and how it integrates with familiar frameworks and tools. Find out how to migrate existing web applications to serverless or create new applications using AWS Lambda.
Betty Zheng, Senior Developer Advocate, AWS
Harold Sun, Senior Solutions Architect, AWS
OPN305 | The pragmatic serverless Python developer
Covers an opinionated approach to setting up a serverless Python project, including testing, profiling, deployments, and operations. Learn about many open source tools, including Powertools for AWS Lambda—a toolkit that can help you implement serverless best practices and increase developer velocity.
Heitor Lessa, Principal Solutions Architect, AWS
Ran Isenberg, CyberArk
XNT301 | Build production-ready serverless .NET apps with AWS Lambda
Explores development and architectural best practices when building serverless applications with .NET and AWS Lambda, including when to run ASP.NET on Lambda, code structure, and using native AOT to massively increase performance.
James Eastham, Senior Cloud Architect, AWS
Craig Bossie, Solutions Architect, AWS
COM306 | “Rustifying” serverless: Boost AWS Lambda performance with Rust
Discover how to deploy Rust functions using AWS SAM and cargo-lambda, facilitating a smooth development process from your local machine. Explore how to integrate Rust into Python Lambda functions effortlessly using tools like PyO3 and maturin, along with the AWS SDK for Rust. Uncover how Rust can optimize Lambda functions, including the development of Lambda extensions, all without requiring a complete rewrite of your existing code base.
Efi Merdler-Kravitz, Cloudex
COM305 | Demystifying and mitigating AWS Lambda cold starts
Examines the Lambda initialization process at a low level, using benchmarks comparing common architectural patterns, and then benchmarking various RAM configurations and payload sizes. Next, measure and discuss common mistakes that can increase initialization latency, explore and understand proactive initialization, and learn several strategies you can use to thaw your AWS Lambda cold starts.
AJ Stuyvenberg, Datadog
Sessions related to event-driven architecture
API302 | Building next gen applications with event driven architecture
Learn about common integration patterns and discover how you can use AWS messaging services to connect microservices and coordinate data flow using minimal custom code. Learn and plan for idempotency, handling duplicating events and building resiliency into your architectures.
Eric Johnson, Principal Developer Advocate, AWS
API303 | Navigating the journey of serverless event-driven architecture
Learn about the journey businesses undertake when adopting EDAs, from initial design and implementation to ongoing operation and maintenance. The session highlights the many benefits EDAs can offer organizations and focuses on areas of EDA that are challenging and often overlooked. Through a combination of patterns, best practices, and practical tips, this session provides a comprehensive overview of the opportunities and challenges of implementing EDAs and helps you understand how you can use them to drive business success.
David Boyne, Senior Developer Advocate, AWS
API309 | Advanced integration patterns and trade-offs for loosely coupled apps
In this session, learn about common design trade-offs for distributed systems, how to navigate them with design patterns, and how to embed those patterns in your cloud automation.
Dirk Fröhner, Principal Solutions Architect, AWS
Gregor Hohpe, Senior Principal Evangelist, AWS
SVS205 | Getting started building serverless event-driven applications
Learn about the process of prototyping a solution from concept to a fully featured application that uses Amazon API Gateway, AWS Lambda, Amazon EventBridge, AWS Step Functions, Amazon DynamoDB, AWS Application Composer, and more. Learn why serverless is a great tool set for experimenting with new ideas and how the extensibility and modularity of serverless applications allow you to start small and quickly make your idea a reality.
Emily Shea, Head of Application Integration Go-to-Market, AWS
Naren Gakka, Solutions Architect, AWS
API206 | Bringing workloads together with event-driven architecture
Attend this session to learn the steps to bring your existing container workloads closer together using event-driven architecture with minimal code changes and a high degree of reusability. Using a real-life business example, this session walks through a demo to highlight the power of this approach.
Dhiraj Mahapatro, Principal Solutions Architect, AWS
Nicholas Stumpos, JPMorgan Chase & Co
COM301 | Advanced event-driven patterns with Amazon EventBridge
Gain an understanding of the characteristics of EventBridge and how it plays a pivotal role in serverless architectures. Learn the primary elements of event-driven architecture and some of the best practices. With real-world use cases, explore how the features of EventBridge support implementing advanced architectural patterns in serverless.
Sheen Brisals, The LEGO Group
Sessions related to serverless APIs
SVS301 | Building APIs: Choosing the best API solution and strategy for your workloads
Learn about access patterns and how to evaluate the best API technology for your applications. The session considers the features and benefits of Amazon API Gateway, AWS AppSync, Amazon VPC Lattice, and other options.
Josh Kahn, Tech Leader Serverless, AWS
Arthi Jaganathan, Principal Solutions Architect, AWS
SVS323 | I didn’t know Amazon API Gateway did that
This session provides an introduction to Amazon API Gateway and the problems it solves. Learn about the moving parts of API Gateway and how it works, including common and not-so-common use cases. Discover why you should use API Gateway and what it can do.
Eric Johnson, Principal Developer Advocate, AWS
FWM201 | What’s new with AWS AppSync for enterprise API developers
Join this session to learn about all the exciting new AWS AppSync features released this year that make it even more seamless for API developers to realize the benefits of GraphQL for application development.
Michael Liendo, Senior Developer Advocate, AWS
Brice Pellé, Principal Product Manager, AWS
FWM204 | Implement real-time event patterns with WebSockets and AWS AppSync
Learn how the PGA Tour uses AWS AppSync to deliver real-time event updates to their app users; review new features, like enhanced filtering options and native integration with Amazon EventBridge; and provide a sneak peek at what’s coming next.
Ryan Yanchuleff, Senior Solutions Architect, AWS
Bill Fine, Senior Product Manager, AWS
David Provan, PGA Tour
Sessions related to AWS Step Functions
API401 | Advanced workflow patterns and business processes with AWS Step Functions
Learn about architectural best practices and repeatable patterns for building workflows and cost optimizations, and discover handy cheat codes that you can use to build secure, high-scale, high-performance serverless applications
Ben Smith, Principal Developer Advocate, AWS
BOA304 | Using AI and serverless to automate video production
Learn how to use Step Functions to build workflows using AI services and how to use Amazon EventBridge real-time events.
Marcia Villalba, Principal Developer Advocate, AWS
SVS204 | Building Serverlesspresso: Creating event-driven architectures
This session explores the design decisions that were made when building Serverlesspresso, how new features influenced the development process, and lessons learned when creating a production-ready application using this approach. Explore useful patterns and options for extensibility that helped in the design of a robust, scalable solution that costs about one dollar per day to operate. This session includes examples you can apply to your serverless applications and complex architectural challenges for larger applications.
James Beswick, Senior Manager Developer Advocacy, AWS
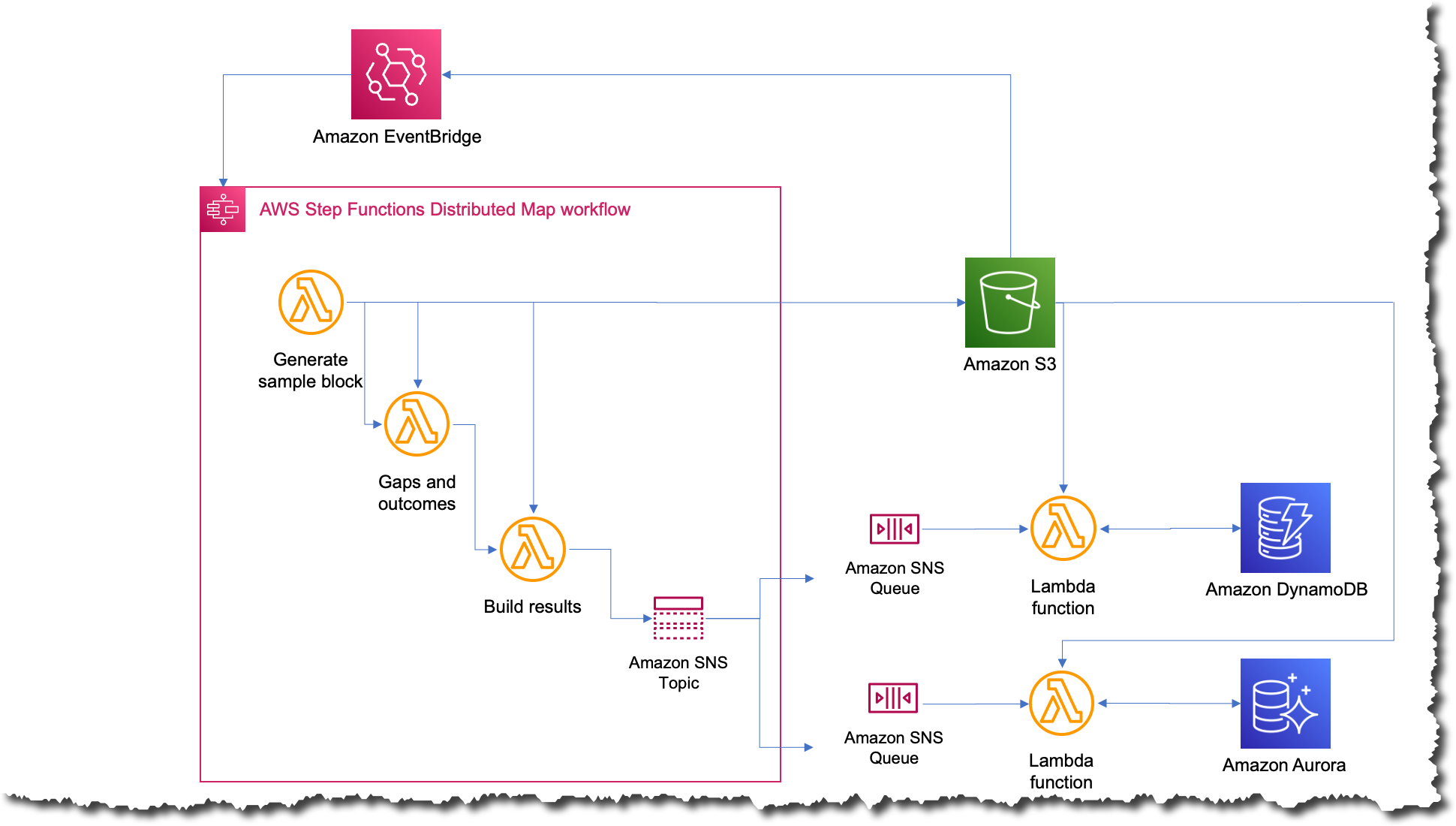
API310 | Scale interactive data analysis with Step Functions Distributed Map
Learn how to build a data processing or other automation once and readily scale it to thousands of parallel processes with serverless technologies. Explore how this approach simplifies development and error handling while improving speed and lowering cost. Hear from an AWS customer that refactored an existing machine learning application to use Distributed Map and the lessons they learned along the way.
Adam Wagner, Principal Solutions Architect, AWS
Roberto Iturralde, Vertex Pharmaceuticals
Sessions related to handling data using serverless services and serverless databases
SVS307 | Scaling your serverless data processing with Amazon Kinesis and Kafka
Explore how to build scalable data processing applications using AWS Lambda. Learn practical insights into integrating Lambda with Amazon Kinesis and Apache Kafka using their event-driven models for real-time data streaming and processing.
Julian Wood, Principal Developer Advocate, AWS
DAT410 | Advanced data modeling with Amazon DynamoDB
This session shows you advanced techniques to get the most out of DynamoDB. Learn how to “think in DynamoDB” by learning the DynamoDB foundations and principles for data modeling. Learn practical strategies and DynamoDB features to handle difficult use cases in your application.
Alex De Brie – Independent consultant
COM308 | Serverless data streaming: Amazon Kinesis Data Streams and AWS Lambda
Explore the intricacies of creating scalable, production-ready data streaming architectures using Kinesis Data Streams and Lambda. Delve into tips and best practices essential to navigating the challenges and pitfalls inherent to distributed systems that arise along the way, and observe how AWS services work and interact.
Anahit Pogosova, Solita
Additional resources
If you are attending the event, there are many chalk talks, workshops, and other sessions to visit. See ServerlessLand for a full list of all the serverless sessions and also the Serverless Hero, Danielle Heberling’s Serverless re:Invent attendee guide for her top picks.
Visit us in the AWS Village in the Expo Hall where you can find the Serverless and Containers booth and enjoy a free cup of coffee at Serverlesspresso.
For more serverless learning resources, visit Serverless Land.