Post Syndicated from Edvin Hallvaxhiu original https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/
Part 1 of this two-part series described how to build a pseudonymization service that converts plain text data attributes into a pseudonym or vice versa. A centralized pseudonymization service provides a unique and universally recognized architecture for generating pseudonyms. Consequently, an organization can achieve a standard process to handle sensitive data across all platforms. Additionally, this takes away any complexity and expertise needed to understand and implement various compliance requirements from development teams and analytical users, allowing them to focus on their business outcomes.
Following a decoupled service-based approach means that, as an organization, you are unbiased towards the use of any specific technologies to solve your business problems. No matter which technology is preferred by individual teams, they are able to call the pseudonymization service to pseudonymize sensitive data.
In this post, we focus on common extract, transform, and load (ETL) consumption patterns that can use the pseudonymization service. We discuss how to use the pseudonymization service in your ETL jobs on Amazon EMR (using Amazon EMR on EC2) for streaming and batch use cases. Additionally, you can find an Amazon Athena and AWS Glue based consumption pattern in the GitHub repo of the solution.
Solution overview
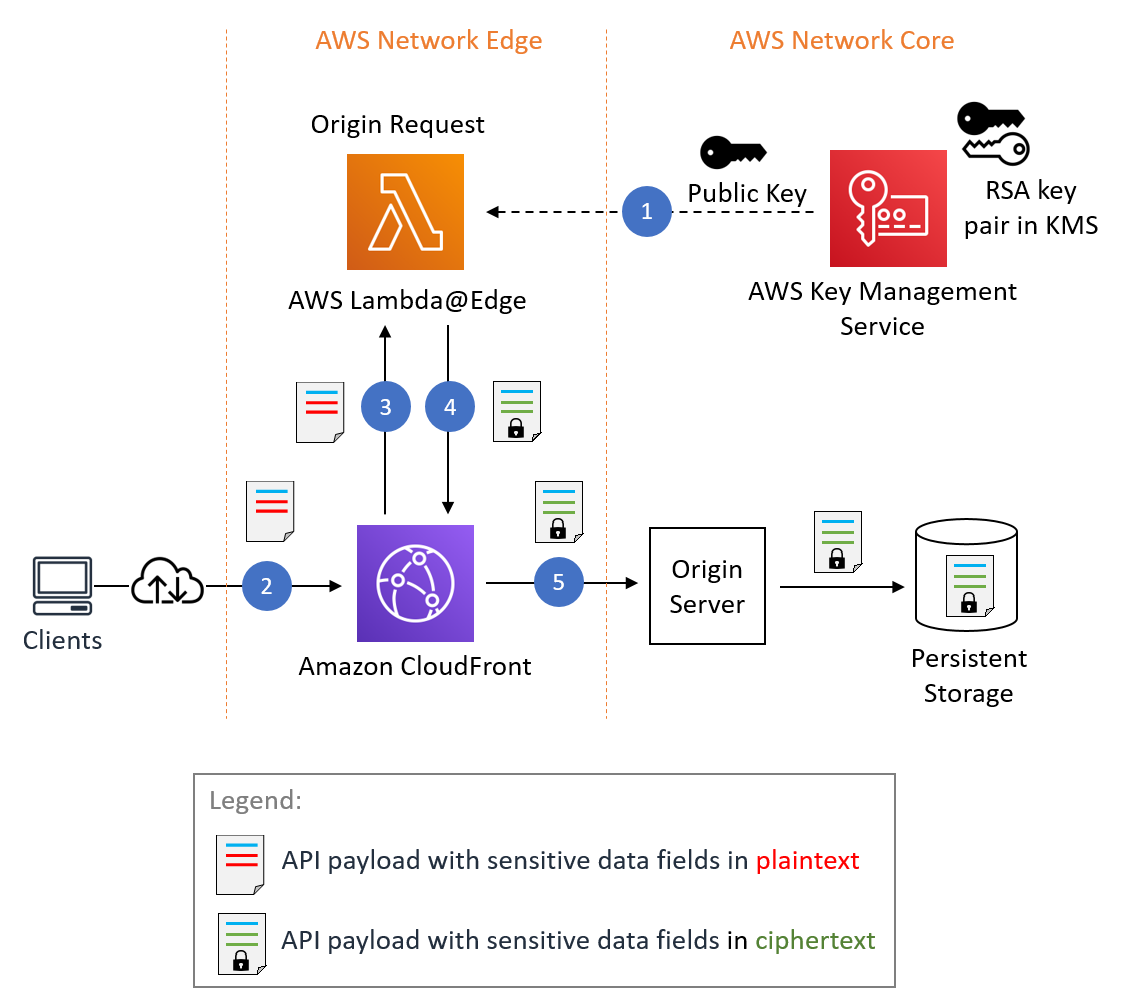
The following diagram describes the solution architecture.

The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series.
The account on the left is the one that you set up as part of this post, representing the ETL platform based on Amazon EMR using the pseudonymization service.
You can deploy the pseudonymization service and the ETL platform on the same account.
Amazon EMR empowers you to create, operate, and scale big data frameworks such as Apache Spark quickly and cost-effectively.
In this solution, we show how to consume the pseudonymization service on Amazon EMR with Apache Spark for batch and streaming use cases. The batch application reads data from an Amazon Simple Storage Service (Amazon S3) bucket, and the streaming application consumes records from Amazon Kinesis Data Streams.
PySpark code used in batch and streaming jobs
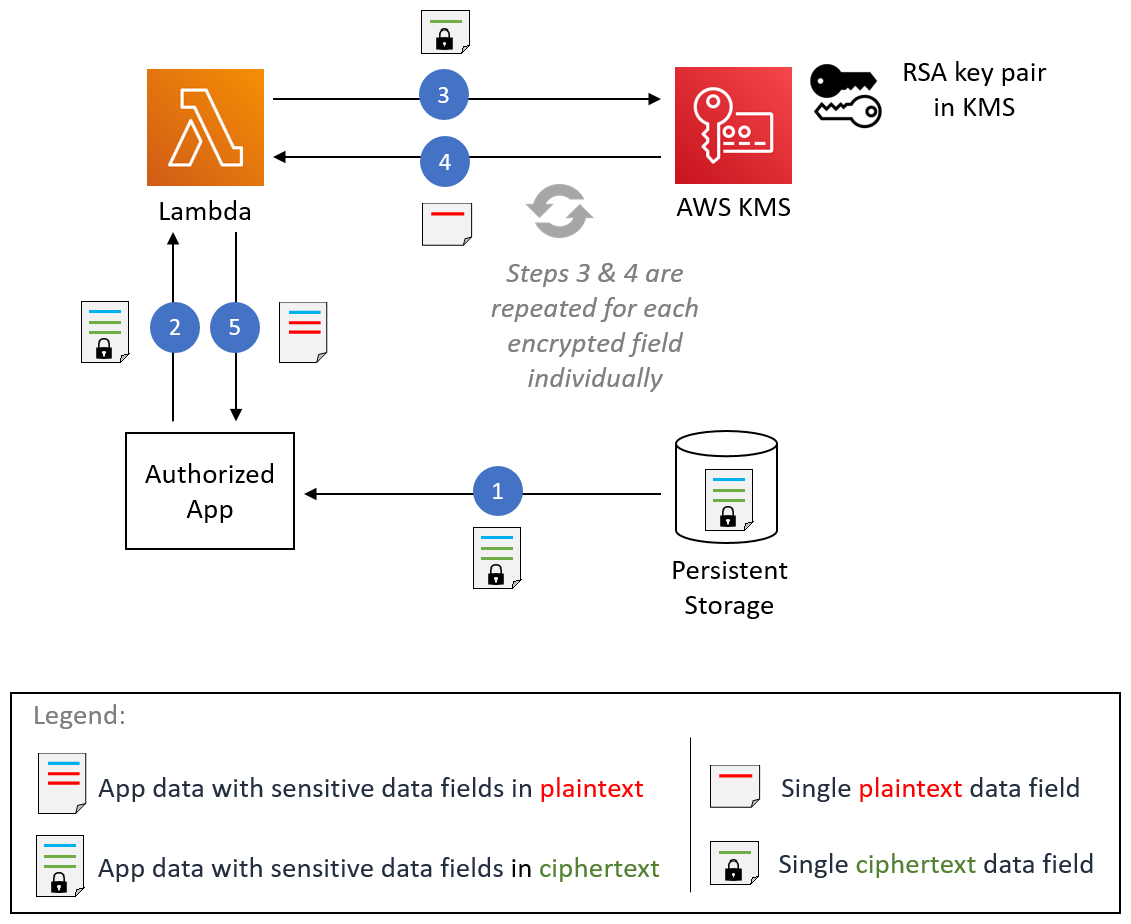
Both applications use a common utility function that makes HTTP POST calls against the API Gateway that is linked to the pseudonymization AWS Lambda function. The REST API calls are made per Spark partition using the Spark RDD mapPartitions function. The POST request body contains the list of unique values for a given input column. The POST request response contains the corresponding pseudonymized values. The code swaps the sensitive values with the pseudonymized ones for a given dataset. The result is saved to Amazon S3 and the AWS Glue Data Catalog, using Apache Iceberg table format.
Iceberg is an open table format that supports ACID transactions, schema evolution, and time travel queries. You can use these features to implement the right to be forgotten (or data erasure) solutions using SQL statements or programming interfaces. Iceberg is supported by Amazon EMR starting with version 6.5.0, AWS Glue, and Athena. Batch and streaming patterns use Iceberg as their target format. For an overview of how to build an ACID compliant data lake using Iceberg, refer to Build a high-performance, ACID compliant, evolving data lake using Apache Iceberg on Amazon EMR.
Prerequisites
You must have the following prerequisites:
- An AWS account.
- An AWS Identity and Access Management (IAM) principal with privileges to deploy the AWS CloudFormation stack and related resources.
- The AWS Command Line Interface (AWS CLI) installed on the development or deployment machine that you will use to run the provided scripts.
- An S3 bucket in the same account and AWS Region where the solution is to be deployed.
- Python3 installed in the local machine where the commands are run.
- PyYAML installed using pip.
- A bash terminal to run bash scripts that deploy CloudFormation stacks.
- An additional S3 bucket containing the input dataset in Parquet files (only for batch applications). Copy the sample dataset to the S3 bucket.
- A copy of the latest code repository in the local machine using
git cloneor the download option.
Open a new bash terminal and navigate to the root folder of the cloned repository.
The source code for the proposed patterns can be found in the cloned repository. It uses the following parameters:
- ARTEFACT_S3_BUCKET – The S3 bucket where the infrastructure code will be stored. The bucket must be created in the same account and Region where the solution lives.
- AWS_REGION – The Region where the solution will be deployed.
- AWS_PROFILE – The named profile that will be applied to the AWS CLI command. This should contain credentials for an IAM principal with privileges to deploy the CloudFormation stack of related resources.
- SUBNET_ID – The subnet ID where the EMR cluster will be spun up. The subnet is pre-existing and for demonstration purposes, we use the default subnet ID of the default VPC.
- EP_URL – The endpoint URL of the pseudonymization service. Retrieve this from the solution deployed as Part 1 of this series.
- API_SECRET – An Amazon API Gateway key that will be stored in AWS Secrets Manager. The API key is generated from the deployment depicted in Part 1 of this series.
- S3_INPUT_PATH – The S3 URI pointing to the folder containing the input dataset as Parquet files.
- KINESIS_DATA_STREAM_NAME – The Kinesis data stream name deployed with the CloudFormation stack.
- BATCH_SIZE – The number of records to be pushed to the data stream per batch.
- THREADS_NUM – The number of parallel threads used in the local machine to upload data to the data stream. More threads correspond to a higher message volume.
- EMR_CLUSTER_ID – The EMR cluster ID where the code will be run (the EMR cluster was created by the CloudFormation stack).
- STACK_NAME – The name of the CloudFormation stack, which is assigned in the deployment script.
Batch deployment steps
As described in the prerequisites, before you deploy the solution, upload the Parquet files of the test dataset to Amazon S3. Then provide the S3 path of the folder containing the files as the parameter <S3_INPUT_PATH>.
We create the solution resources via AWS CloudFormation. You can deploy the solution by running the deploy_1.sh script, which is inside the deployment_scripts folder.
After the deployment prerequisites have been satisfied, enter the following command to deploy the solution:
sh ./deployment_scripts/deploy_1.sh \
-a <ARTEFACT_S3_BUCKET> \
-r <AWS_REGION> \
-p <AWS_PROFILE> \
-s <SUBNET_ID> \
-e <EP_URL> \
-x <API_SECRET> \
-i <S3_INPUT_PATH>The output should look like the following screenshot.

The required parameters for the cleanup command are printed out at the end of the run of the deploy_1.sh script. Make sure to note down these values.
Test the batch solution
In the CloudFormation template deployed using the deploy_1.sh script, the EMR step containing the Spark batch application is added at the end of the EMR cluster setup.
To verify the results, check the S3 bucket identified in the CloudFormation stack outputs with the variable SparkOutputLocation.


You can also use Athena to query the table pseudo_table in the database blog_batch_db.

Clean up batch resources
To destroy the resources created as part of this exercise,
in a bash terminal, navigate to the root folder of the cloned repository. Enter the cleanup command shown as the output of the previously run deploy_1.sh script:
sh ./deployment_scripts/cleanup_1.sh \
-a <ARTEFACT_S3_BUCKET> \
-s <STACK_NAME> \
-r <AWS_REGION> \
-e <EMR_CLUSTER_ID>The output should look like the following screenshot.

Streaming deployment steps
We create the solution resources via AWS CloudFormation. You can deploy the solution by running the deploy_2.sh script, which is inside the deployment_scripts folder. The CloudFormation stack template for this pattern is available in the GitHub repo.
After the deployment prerequisites have been satisfied, enter the following command to deploy the solution:
sh deployment_scripts/deploy_2.sh \
-a <ARTEFACT_S3_BUCKET> \
-r <AWS_REGION> \
-p <AWS_PROFILE> \
-s <SUBNET_ID> \
-e <EP_URL> \
-x <API_SECRET>The output should look like the following screenshot.

The required parameters for the cleanup command are printed out at the end of the output of the deploy_2.sh script. Make sure to save these values to use later.
Test the streaming solution
In the CloudFormation template deployed using the deploy_2.sh script, the EMR step containing the Spark streaming application is added at the end of the EMR cluster setup. To test the end-to-end pipeline, you need to push records to the deployed Kinesis data stream. With the following commands in a bash terminal, you can activate a Kinesis producer that will continuously put records in the stream, until the process is manually stopped. You can control the producer’s message volume by modifying the BATCH_SIZE and the THREADS_NUM variables.


In the Athena query editor, check the results by querying the table pseudo_table in the database blog_stream_db.

Clean up streaming resources
To destroy the resources created as part of this exercise, complete the following steps:
- Stop the Python Kinesis producer that was launched in a bash terminal in the previous section.
- Enter the following command:
sh ./deployment_scripts/cleanup_2.sh \
-a <ARTEFACT_S3_BUCKET> \
-s <STACK_NAME> \
-r <AWS_REGION> \
-e <EMR_CLUSTER_ID>The output should look like the following screenshot.

Performance details
Use cases might differ in requirements with respect to data size, compute capacity, and cost. We have provided some benchmarking and factors that may influence performance; however, we strongly advise you to validate the solution in lower environments to see if it meets your particular requirements.
You can influence the performance of the proposed solution (which aims to pseudonymize a dataset using Amazon EMR) by the maximum number of parallel calls to the pseudonymization service and the payload size for each call. In terms of parallel calls, factors to consider are the GetSecretValue calls limit from Secrets Manager (10.000 per second, hard limit) and the Lambda default concurrency parallelism (1,000 by default; can be increased by quota request). You can control the maximum parallelism adjusting the number of executors, the number of partitions composing the dataset, and the cluster configuration (number and type of nodes). In terms of payload size for each call, factors to consider are the API Gateway maximum payload size (6 MB) and the Lambda function maximum runtime (15 minutes). You can control the payload size and the Lambda function runtime by adjusting the batch size value, which is a parameter of the PySpark script that determines the number of items to be pseudonymized per each API call. To capture the influence of all these factors and assess the performance of the consumption patterns using Amazon EMR, we have designed and monitored the following scenarios.
Batch consumption pattern performance
To assess the performance for the batch consumption pattern, we ran the pseudonymization application with three input datasets composed of 1, 10, and 100 Parquet files of 97.7 MB each. We generated the input files using the dataset_generator.py script.
The cluster capacity nodes were 1 primary (m5.4xlarge) and 15 core (m5d.8xlarge). This cluster configuration remained the same for all three scenarios, and it allowed the Spark application to use up to 100 executors. The batch_size, which was also the same for the three scenarios, was set to 900 VINs per API call, and the maximum VIN size was 5 bytes.
The following table captures the information of the three scenarios.
| Execution ID | Repartition | Dataset Size | Number of Executors | Cores per Executor | Executor Memory | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11 minutes, 10 seconds |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8 minutes, 36 seconds |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7 minutes, 56 seconds |
As we can see, properly parallelizing the calls to our pseudonymization service enables us to control the overall runtime.
In the following examples, we analyze three important Lambda metrics for the pseudonymization service: Invocations, ConcurrentExecutions, and Duration.
The following graph depicts the Invocations metric, with the statistic SUM in orange and RUNNING SUM in blue.

By calculating the difference between the starting and ending point of the cumulative invocations, we can extract how many invocations were made during each run.
| Run ID | Dataset Size | Total Invocations |
| A | 9.53 GB | 1.467.000 – 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 – 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 – 1.631.000 = 14.500 |
As expected, the number of invocations increases proportionally by 10 with the dataset size.
The following graph depicts the total ConcurrentExecutions metric, with the statistic MAX in blue.

The application is designed such that the maximum number of concurrent Lambda function runs is given by the amount of Spark tasks (Spark dataset partitions), which can be processed in parallel. This number can be calculated as MIN (executors x executor_cores, Spark dataset partitions).
In the test, run A processed 800 partitions, using 100 executors with four cores each. This makes 400 tasks processed in parallel so the Lambda function concurrent runs can’t be above 400. The same logic was applied for runs B and C. We can see this reflected in the preceding graph, where the amount of concurrent runs never surpasses the 400, 40, and 4 values.
To avoid throttling, make sure that the amount of Spark tasks that can be processed in parallel is not above the Lambda function concurrency limit. If that is the case, you should either increase the Lambda function concurrency limit (if you want to keep up the performance) or reduce either the amount of partitions or the number of available executors (impacting the application performance).
The following graph depicts the Lambda Duration metric, with the statistic AVG in orange and MAX in green.

As expected, the size of the dataset doesn’t affect the duration of the pseudonymization function run, which, apart from some initial invocations facing cold starts, remains constant to an average of 3 milliseconds throughout the three scenarios. This because the maximum number of records included in each pseudonymization call is constant (batch_size value).
Lambda is billed based on the number of invocations and the time it takes for your code to run (duration). You can use the average duration and invocations metrics to estimate the cost of the pseudonymization service.
Streaming consumption pattern performance
To assess the performance for the streaming consumption pattern, we ran the producer.py script, which defines a Kinesis data producer that pushes records in batches to the Kinesis data stream.
The streaming application was left running for 15 minutes and it was configured with a batch_interval of 1 minute, which is the time interval at which streaming data will be divided into batches. The following table summarizes the relevant factors.
| Repartition | Cluster Capacity Nodes | Number of Executors | Executor’s Memory | Batch Window | Batch Size | VIN Size |
| 17 |
1 Primary (m5.xlarge), 3 Core (m5.2xlarge) |
6 | 9 GiB | 60 seconds | 900 VINs/API call. | 5 Bytes / VIN |
The following graphs depict the Kinesis Data Streams metrics PutRecords (in blue) and GetRecords (in orange) aggregated with 1-minute period and using the statistic SUM. The first graph shows the metric in bytes, which peaks 6.8 MB per minute. The second graph shows the metric in record count peaking at 85,000 records per minute.


We can see that the metrics GetRecords and PutRecords have overlapping values for almost the entire application’s run. This means that the streaming application was able to keep up with the load of the stream.
Next, we analyze the relevant Lambda metrics for the pseudonymization service: Invocations, ConcurrentExecutions, and Duration.
The following graph depicts the Invocations metric, with the statistic SUM (in orange) and RUNNING SUM in blue.

By calculating the difference between the starting and ending point of the cumulative invocations, we can extract how many invocations were made during the run. In specific, in 15 minutes, the streaming application invoked the pseudonymization API 977 times, which is around 65 calls per minute.
The following graph depicts the total ConcurrentExecutions metric, with the statistic MAX in blue.

The repartition and the cluster configuration allow the application to process all Spark RDD partitions in parallel. As a result, the concurrent runs of the Lambda function are always equal to or below the repartition number, which is 17.
To avoid throttling, make sure that the amount of Spark tasks that can be processed in parallel is not above the Lambda function concurrency limit. For this aspect, the same suggestions as for the batch use case are valid.
The following graph depicts the Lambda Duration metric, with the statistic AVG in blue and MAX in orange.

As expected, aside the Lambda function’s cold start, the average duration of the pseudonymization function was more or less constant throughout the run. This because the batch_size value, which defines the number of VINs to pseudonymize per call, was set to and remained constant at 900.
The ingestion rate of the Kinesis data stream and the consumption rate of our streaming application are factors that influence the number of API calls made against the pseudonymization service and therefore the related cost.
The following graph depicts the Lambda Invocations metric, with the statistic SUM in orange, and the Kinesis Data Streams GetRecords.Records metric, with the statistic SUM in blue. We can see that there is correlation between the amount of records retrieved from the stream per minute and the amount of Lambda function invocations, thereby impacting the cost of the streaming run.

In addition to the batch_interval, we can control the streaming application’s consumption rate using Spark streaming properties like spark.streaming.receiver.maxRate and spark.streaming.blockInterval. For more details, refer to Spark Streaming + Kinesis Integration and Spark Streaming Programming Guide.
Conclusion
Navigating through the rules and regulations of data privacy laws can be difficult. Pseudonymization of PII attributes is one of many points to consider while handling sensitive data.
In this two-part series, we explored how you can build and consume a pseudonymization service using various AWS services with features to assist you in building a robust data platform. In Part 1, we built the foundation by showing how to build a pseudonymization service. In this post, we showcased the various patterns to consume the pseudonymization service in a cost-efficient and performant manner. Check out the GitHub repository for additional consumption patterns.
About the Authors
 Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports.
Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports.
 Rahul Shaurya is a Principal Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Principal Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
 Andrea Montanari is a Senior Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS.
Andrea Montanari is a Senior Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS.
 María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
 Pushpraj Singh is a Senior Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.
Pushpraj Singh is a Senior Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.












 María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.