Post Syndicated from Anne Grahn original https://aws.amazon.com/blogs/security/many-voices-one-community-three-themes-from-rsa-conference-2025/
RSA Conference (RSAC) 2025 drew 730 speakers, 650 exhibitors, and 44,000 attendees from across the globe to the Moscone Center in San Francisco, California from April 28 through May 1.
The keynote lineup was eclectic, with 37 presentations featuring speakers ranging from NBA Hall of Famer Earvin “Magic” Johnson to public and private-sector luminaries such as former US National Cyber Director Chris Inglis, U.S. Secretary of Homeland Security Kristi Noem, and cryptography experts Tal Rabin, Whitfield Diffie, and Adi Shamir.
Topics aligned with this year’s conference theme, “Many Voices. One Community,” and focused on the security industry’s shared drive to foresee risks, counter threats, and embrace new challenges.
Three themes caught our attention: agentic AI, cryptography, and public-private collaboration.
Agentic AI
The potential of agentic AI to augment human decision-making was a common thread among conversations at the conference. Numerous sessions touched on the topic, and the desire of attendees to understand the technology and learn how to balance its risks and opportunities was clear.
Separating hype from reality
An AI agent is a software program that can interact with its environment (as detailed in Figure 1), collect data, and use the data to perform self-determined tasks to meet predetermined goals.

Figure 1: Generative AI agents
Agentic systems offer a fundamentally different approach compared to traditional software, particularly in their ability to handle complex, dynamic, and domain-specific challenges. While traditional systems rely on rule-based automation and structured data, agentic systems use large language models (LLMs)—a subset of generative AI—to operate autonomously. Agents can learn from interactions with users, and make nuanced, context-aware decisions while keeping human analysts in the loop.
Numerous RSAC speakers alluded to AI agents as the next frontier in enterprise transformation. Gartner® predicts that: “By 2028, 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024,” and “at least 15% of day-to-day work decisions will be made autonomously through agentic AI, up from zero percent in 2024.”
However, as organizations build AI agents, understanding the concerns that come with them is critical.
| “Agentic AI presents tremendous opportunities to deliver business value and innovative security outcomes. Production deployments require a balance between its capabilities, and robust security and trust mechanisms.” —Hart Rossman, Global Services Security Vice President at AWS |
In the RSAC keynote session The Five Most Dangerous New Attack Techniques…and What to Do for Each, Rob Lee, Chief of Research and Head of Faculty at SANS Institute noted that while security teams are embracing AI to amplify productivity, threat actors are doing the same. He pointed to MIT research that shows adversarial agent systems executing attack sequences are 47 times faster than human operators, with a 93 percent success rate in privilege escalation paths.
Safeguarding GenAI & Agentic Apps, Top 10 Risks in 2025, a half-day Open Worldwide Application Security Project (OWASP) event, focused on helping attendees distinguish real threats from hype. OWASP Gen AI Security Project team members and industry experts reviewed the 2025 OWASP Top 10 List for LLM and GenAI (shown in Figure 2), and introduced Agentic AI—Threats and Mitigations—the first in a series of guides from the OWASP Agentic Security Initiative (ASI) to provide a threat-model-based reference of emerging agentic threats and mitigations. Content feedback can be submitted to ASI in advance of the guide’s next release.

Figure 2: 2025 OWASP Top 10 for LLM Applications
|
Agentic AI wins Cybersecurity Startup Accelerator The second annual AWS and CrowdStrike Cybersecurity Startup Accelerator, in collaboration with the NVIDIA Inception program, took place during RSAC. A panel of judges—including George Kurtz, Founder and CEO of CrowdStrike, CJ Moses, Chief Information Security Officer at Amazon, and David Reber Jr., Chief Security Officer at NVIDIA—evaluated startups on innovation, market relevance, and go-to-market potential. Terra Security, a provider of agentic AI-powered, continuous web application penetration testing, was selected from a group of 10 finalists who pitched live. Two runners-up, Kenzo Security and Rig Security, were also recognized for their standout approaches to agentic AI-driven security. |
Addressing AI risks
The need to consider your security posture when assessing overall AI readiness was emphasized throughout the conference. A defense-in-depth architecture can help mitigate risks with multiple layers of protection across both traditional and AI software components. Innovative solutions such as AI red teaming, AI behavioral sandboxing, and advanced tracing and evaluation of generative AI agents can enhance your security strategy with a proactive approach to securing AI.
Visit the following resources to help design, build, and operate AI systems: DevsecOps Revolution: Unleashing Generative AI for Automated Excellence, AWS generative AI security, responsible AI, and the Amazon AGI Labs Blog.
Cryptography
Encryption was another key topic. The FIDO Alliance hosted a half-day seminar that focused on developments in the global movement to passwordless technology such as passkeys—cryptographic keys designed to replace passwords by combining the power of public key cryptography with biometric authentication.
In Dude, Where’s My Password? The Challenges of Getting to Passwordless, Andy Ozment, Chief Technology Risk Officer and Executive Vice President at Capital One noted that 88 percent of data compromised in basic web application attacks reported in 2024 involved stolen credentials. Ozment pointed out that “going passwordless” through a combination of X.509 device certificates and FIDO2 passkeys presented Capital One with an opportunity to nearly eliminate entire classes of threats (as detailed in Figure 3), while increasing the quality of user experience.

Figure 3: Using passkeys to reduce risk while advancing user experience
Along the way, Ozment said, Capital One’s journey to passwordless was enabled by its transition from on-premises technology to going “all-in” on the public cloud. Watch the recording of his session or view the slides to learn more.
Post-quantum encryption
The state of post-quantum encryption was detailed in the popular Cryptographer’s Panel, moderated by Tal Rabin, Senior Principal Applied Scientist at AWS.
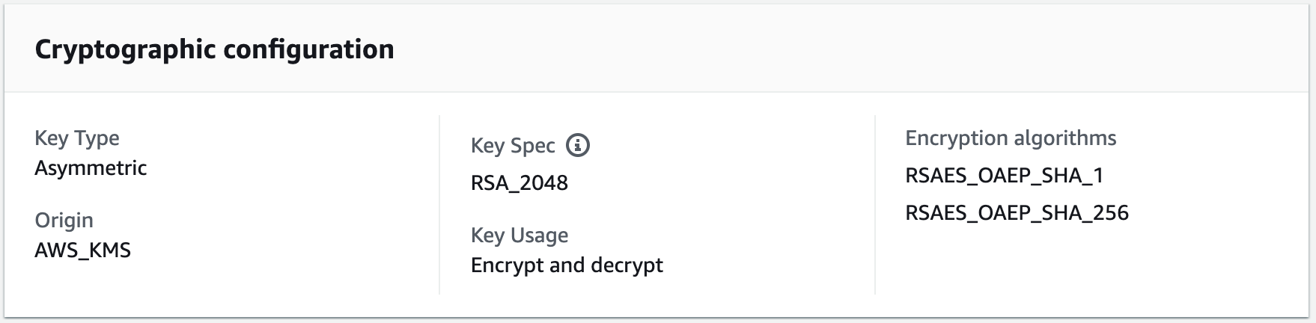
Panelist Vinod Vaikuntanathan, Professor at MIT underscored the impact of the quantum-resistant algorithm standardization process (Figure 4) started by the National Institute of Standards and Technology (NIST) in 2016. “We now have two public key encryption algorithms, and three new digital signature algorithms that are standardized,” he pointed out.

Figure 4: Post-quantum encryption algorithms
The panelists agreed that even though quantum computers aren’t here yet, the time to deploy these algorithms is now. NIST recommends phasing out existing encryption methods by 2030 in its Transition to Post-Quantum Cryptography Standards report. However, Vaikuntanathan and Adi Shamir, the “s” in the Rivest–Shamir–Adleman (RSA) public-key cryptosystem, advise organizations to take a hybrid approach that combines classic encryption algorithms such as RSA or Elliptic-curve Diffie–Hellman (ECDH) with post-quantum algorithms such as Module-Lattice-based Key Encapsulation Mechanism (ML-KEM). This approach, which is used by AWS and recommended by The European Commission, offers protection against both current and future threats.
| RSAC Award for Excellence in the Field of Mathematics
Dr. Shai Halevi, Senior Principal Applied Scientist at AWS, was presented with the Award for Excellence in the Field of Mathematics for remarkable contributions to many areas of cryptography, including fundamental theory, advanced cryptographic primitives, secure multi-party computations, homomorphic encryption, and cryptographic code obfuscation. 
Figure 5: Dr. Shai Halevi receives RSAC Award for Excellence in the Field of Mathematics |
End-to-end encryption
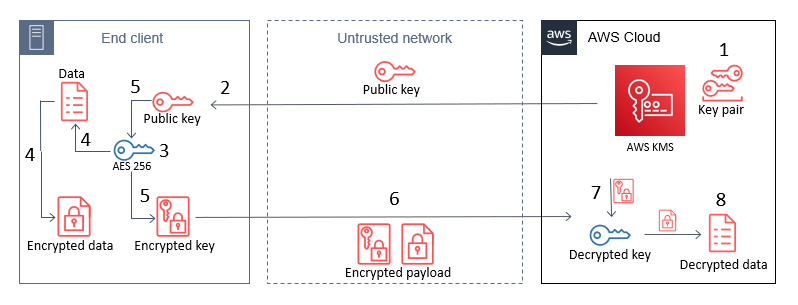
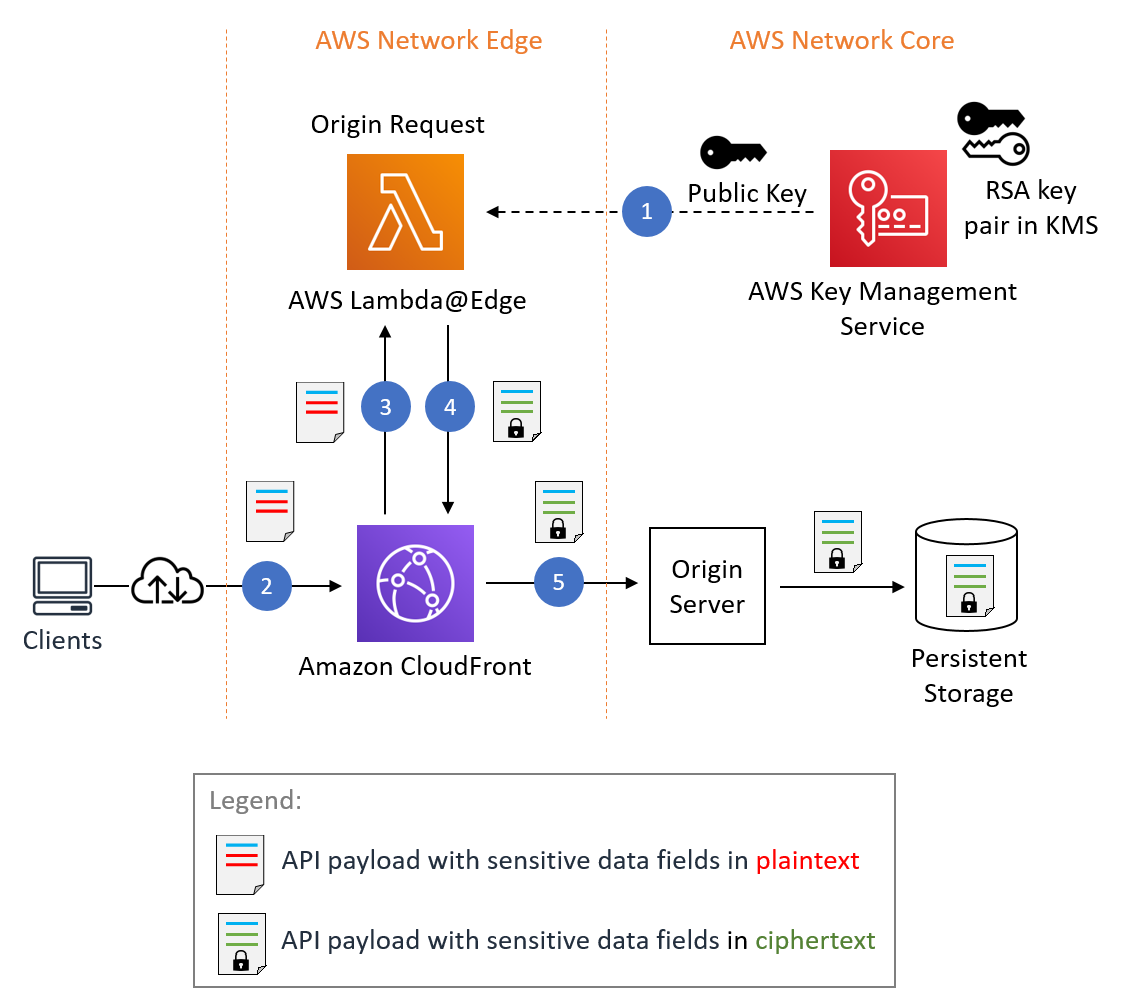
Concerns about the recent US government group chat leak were also raised during the discussion. Public-key cryptography pioneer Whitfield Diffie noted that the use of an encrypted consumer messaging app to communicate classified information broke archiving laws. Because some commercial tools use 256-bit Advanced Encryption Standard (AES) encryption, which is “good enough” to protect communications, he predicted an increase in the use of consumer applications to protect sensitive information in unapproved ways.
The Cybersecurity and Infrastructure Security Agency (CISA) and the Federal Bureau of Investigation (FBI) recently advised individuals and organizations to start using encrypted messaging apps. However, as the role of these applications in business communication expands, it’s important not to lose sight of recordkeeping and compliance obligations. Organizations should consider solutions that offer administrative controls and data retention capabilities along with encryption.
AWS Wickr, for example, is a messaging and collaboration service that protects messaging, calling, file sharing, screen sharing, and location sharing with 256-bit end-to-end encryption. The data retention and administrative controls that it provides help customers meet regulatory requirements and manage user and device data remotely.
Wickr is Department of Defense Cloud Computing Security Requirements Guide Impact Level 5 (DoD CC SRG IL5) and Federal Risk and Authorization Management Program (FedRAMP) High authorized in the AWS GovCloud (US-West) Region. It also meets compliance programs and standards such as Health Insurance Portability and Accountability Act (HIPAA) eligibility, International Organization for Standardization (ISO) 27001, and System and Organization Controls (SOC) 1, 2, and 3.
Visit the AWS News Blog and the AWS Security Blog to learn about AWS passkey multi-factor authentication, how AWS is migrating to post quantum cryptography (PQC), and how we can help you implement a layered encryption strategy for your organization.
Public-private collaboration
Numerous sessions underlined the importance of collaboration to strengthening security. In his keynote, Johnson called attention to a lesson he learned on the basketball court—his peers made him stronger. “Larry Bird made me a better basketball player,” he said, relating his experience to the need for security teams to assist and learn from each other.
In Making America Safe Again Through Cyber Defense, Kristi Noem, U.S. Secretary of Homeland Security equated cybersecurity with national security, and insisted that building on public-private partnerships is “incredibly important.” “Our goal,” she said, “is to use our maximum effect of cooperation to make sure that we’re going after bad actors.”
After assuring attendees that CISA will continue to be America’s cyber defense agency, she urged congress to reauthorize the Cybersecurity Information Sharing Act of 2015. The law, which is set to expire in September, incentivizes businesses to share threat indicators with the Department of Homeland Security (DHS) and helps make sure that both the federal government and companies can take collaborative steps to address threats.
Panelists at an offsite threat intelligence discussion reiterated the ability of private industry to supplement government security capabilities. Adam Meyers, Senior VP, Counter Adversary Operations at CrowdStrike pointed out that technology companies often have more data and signals than governments. The CrowdStrike Falcon solution, he said, processes over 6 trillion events per day, and 55 million events per second at peak. This volume facilitates the detection of threat patterns that might otherwise go unnoticed.
Similarly, Moses noted that the size and scale of AWS infrastructure gives us unique visibility into internet traffic. Our global network of sensors and associated disruption tools observe over 700 million threat interactions every day, out of which 450 million can be classified as malicious. Internal threat intelligence tools such as MadPot, our sophisticated global honeypot system, produce high-fidelity findings (pieces of relevant information) that can be used to drive proactive intelligence sharing, and reduce investigative workloads.
| “We’ll work together in order to be able to put a bow on a case and hand it to the FBI and DOJ, such that they don’t have to expend a great amount of resources in order to go forward and try to figure things out that we already know.” —CJ Moses, Chief Information Security Officer and VP of Security Engineering at Amazon |
An example of this is the disruption of the cybercriminal group known as Anonymous Sudan. The group was responsible for tens of thousands of distributed denial-of-service (DDoS) attacks against critical infrastructure, corporate networks, and government agencies. With the help of tools like MadPot, AWS experts were able to identify the hosting provider infrastructure that the group used to launch the DDos attacks, and work with providers to disrupt them. Akamai SIRT, Cloudflare, CrowdStrike, DigitalOcean, Flashpoint, Google, Microsoft, PayPal, SpyCloud, and other private sector entities also assisted law enforcement, leading to the indictment of two Anonymous Sudan leaders.
The value of combined perspectives
RSA Conference 2025 might be over, but the learning continues. Additional highlights that include the west stage keynotes, the Innovation Sandbox, and dozens of insightful sessions on topics such as the changing role of the CISO, women in cyber, and of course—cloud security—are available on demand.
If there’s one key takeaway, it’s a collective sense of transition. As we explore the benefits and risks of emerging AI technologies, encryption strategies, and information sharing, it’s important to remember that we cannot effectively combat threats in isolation. Security is a collective endeavor; only by working together can we adapt to evolving challenges and build cyber resilience.
For more information about cloud security, register to join AWS, Google Cloud, and Microsoft online at the SANS 2025 Cloud Security Exchange on August 21.








![[VIDEO] An Inside Look at the RSA 2022 Experience From the Rapid7 Team](https://blog.rapid7.com/content/images/2022/06/RSAC-2022-experience.jpg)
![[VIDEO] An Inside Look at the RSA 2022 Experience From the Rapid7 Team](https://play.vidyard.com/H2GfDP6w1PPGWrcrbR6cDW.jpg)
![[VIDEO] An Inside Look at the RSA 2022 Experience From the Rapid7 Team](https://play.vidyard.com/rjqC7aBPwPEp682bGvm3Pt.jpg)
![[VIDEO] An Inside Look at the RSA 2022 Experience From the Rapid7 Team](https://play.vidyard.com/FBbwA1HVwbrsC9gNEPC7h5.jpg)