Post Syndicated from Wesley Evans original https://blog.cloudflare.com/expanding-regional-services-configuration-flexibility-for-customers
This post is also available in Français, Español, Nederlands.

When we launched Regional Services in June 2020, the concept of data locality and data sovereignty were very much rooted in European regulations. Fast-forward to today, and the pressure to localize data persists: Several countries have laws requiring data localization in some form, public-sector contracting requirements in many countries require their vendors to restrict the location of data processing, and some customers are reacting to geopolitical developments by seeking to exclude data processing from certain jurisdictions.
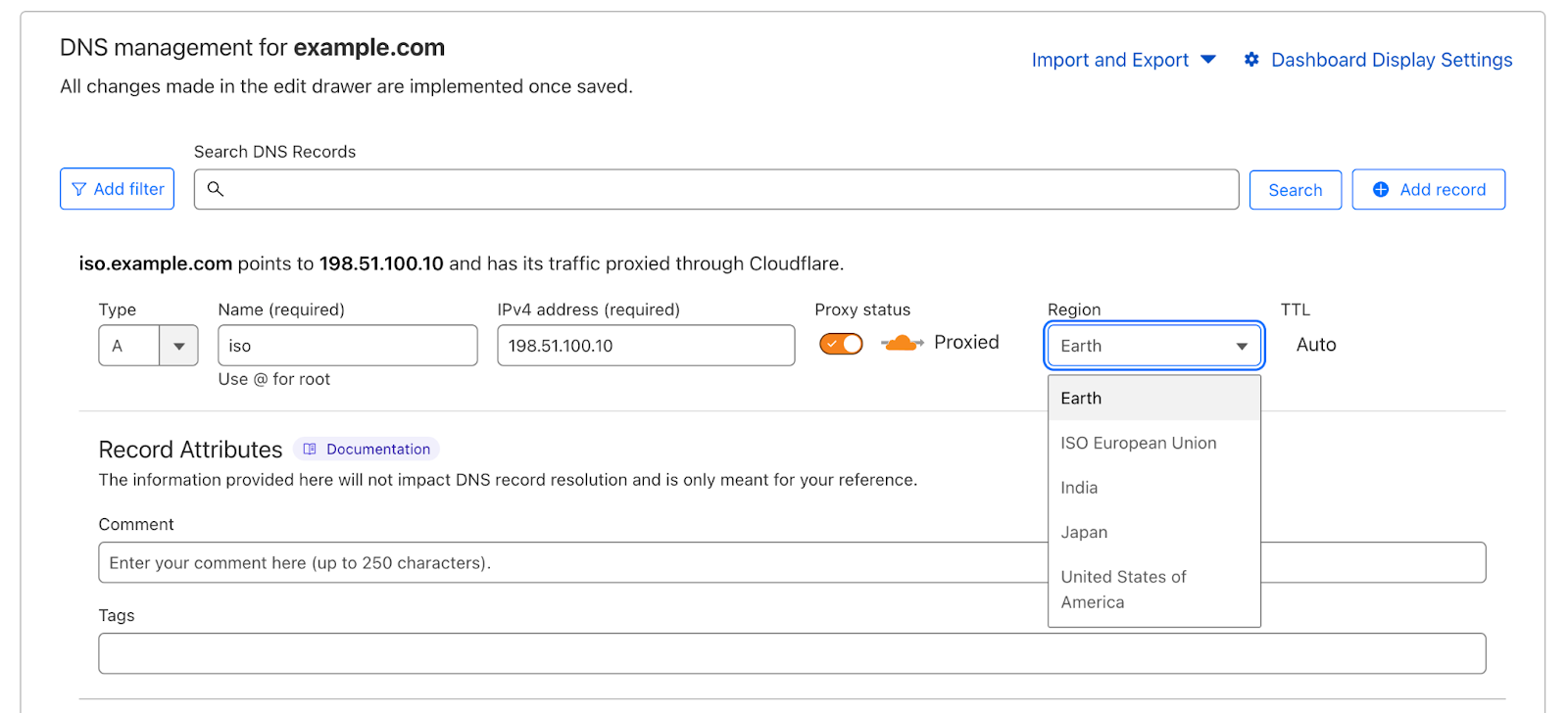
That’s why today we’re happy to announce expanded capabilities that will allow you to configure Regional Services for an increased set of defined regions to help you meet your specific requirements for being able to control where your traffic is handled. These new regions are available for early access starting in late May 2024, and we plan to have them generally available in June 2024.
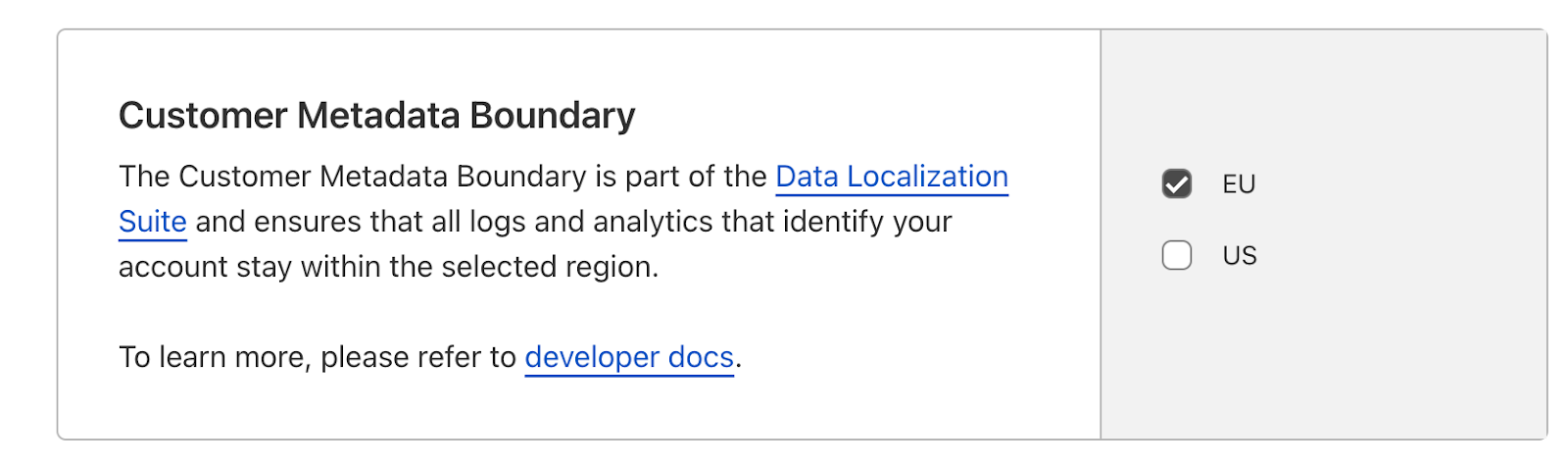
It has always been our goal to provide you with the toolbox of solutions you need to not only address your security and performance concerns, but also to help you meet your legal obligations. And when it comes to data localization, we know that some of you need to have data stay in a particular jurisdiction, while others need data to avoid certain jurisdictions. In response to these needs, we’ve expanded our Regional Services toolbox of offerings to help you more precisely determine where traffic is inspected. Some of these new Regional Services offerings allow you to restrict inspection of data to only those data centers within jurisdictional boundaries, such as Brazil, Saudi Arabia, and Switzerland. Others will allow you to permit inspection of data everywhere except certain jurisdictions, such as our new Exclusive of Hong Kong and Macau offering and our Exclusive of Russia and Belarus offering. And we’ve also listened to customers who are eager to demonstrate their commitment to sustainability by offering our Cloudflare Green Energy region, which limits inspection of data to those data centers that are committed to powering their operations with renewable energy.
The new regions include some of our most requested areas and specifications:
Austria, Brazil, Cloudflare Green Energy, Exclusive of Hong Kong and Macau, Exclusive of Russia and Belarus, France, Hong Kong, Italy, NATO, the Netherlands, Russia, Saudi Arabia, South Africa, Spain, Switzerland, and Taiwan.
A full list of our Regional Services offerings can be found here.
A note on our framework for data localization going forward
Over the course of the next year, you are going to see new and exciting ways to use Cloudflare products to help keep your data local. But doesn’t this contradict the whole premise of Cloudflare? Aren’t we a global anycast network that believes in Region Earth?
We don’t believe these have to be an either/or conversation. While we continue to believe that data localization should not be a proxy for privacy and that restrictions on cross border data transfers are harmful to global commerce, we remain committed to supporting those of you who need data localization solutions to address your legal obligations and risk tolerance.
Unfortunately, many different cloud providers have decided that the best way to meet the compliance needs of their customers is to create fixed infrastructure deployments called sovereign clouds. The trouble with these infrastructure deployments is that you have to commit all of your traffic to be regionalized, regardless of whether all of that traffic actually needs to be confined to a specific data center in a specific region.
As we continue to ramp up development of our Data Localization Suite, I want to lay out the questions that are guiding our thought process:
What if there was a better way forward that lets you regionalize exactly what you need to, without having to localize everything, giving you the best of compliance and performance? What would customers build if they could localize the APIs that handled private customer information, while also serving their static assets globally? How could we increase the compliance and privacy of our customers’ Zero Trust deployments if we could let them choose where their security processing occurred? What if they could define custom regions, and apply those regions to specific hostnames and Cloudflare products while also being able to use BYOIP or Static IP?
We call this approach software defined regionalization (SDR) and we believe that it is the future of data localization. Using our global network as the foundation, SDR allows our customers to make exceptionally granular choices about what traffic to regionalize and where to regionalize it. This empowers you to build applications that are fast, reliable, and compliant without having to deploy new physical infrastructure or have multiple cloud deployments for the same application.
Taking it a step further, SDR allows you to shape Cloudflare to meet both current and future needs. It gives you the flexibility to quickly respond to new challenges in a rapidly changing world. By making localization choices in software, you are not bound by the physical constraints of your existing network geography or the locations of your cloud deployments.
We believe that software defined regionalization is the future of data localization, and we are excited to be on the forefront of its development.
How Regional Services ensures your data is processed in the correct region
Complying with data localization requirements isn’t possible without strong encryption; otherwise, anyone could snoop on your customers’ data, regardless of where it’s stored. Strong encryption is the foundation of Regional Services.
Data is often described as being “in transit” and “at rest”. It’s critically important that both are encrypted. Data “in transit” refers to just that – data while it’s moving about on the wire, whether a local network or the public Internet. “At rest” generally means stored on a disk somewhere, whether a spinning hard disk or a modern solid state disk.
In transit, Cloudflare can enforce that all traffic uses modern TLS and gets the highest level of encryption possible. We can also enforce that all traffic back to customers’ origin servers is always encrypted. Communication between all of our edge and core data centers is always encrypted.
Cloudflare encrypts all the data we handle at rest, with disk-level encryption. From cached files on our edge network, to configuration state in databases in our core data centers – every byte is encrypted at rest.
How then can we also regionalize the traffic if it’s encrypted? All of Cloudflare’s data centers advertise the same IP addresses through Border Gateway Protocol (BGP). Whichever data center is closest to an end user from a network point of view is the one that they will hit.
This is great for two reasons. The first is that the closer the data center is to an eyeball, the faster the reply. The second great benefit is that this comes in very handy when dealing with large DDoS attacks. Volumetric DDoS attacks throw a lot of bogus traffic at a particular application, which overwhelms network capacity. Cloudflare’s anycast network is great at taking on these attacks because they get distributed across the entire network, and mitigated close to where they originate.
Anycast doesn’t respect regional borders – it doesn’t even know about them. Which is why, out of the box, Cloudflare can’t guarantee that traffic from inside a country will also be serviced there. Typically, requests hit a data center inside the originating country, but it’s possible that the user’s Internet Service Provider will send traffic to a network that might route it to a different country.
Regional Services solves that: when turned on, each data center becomes aware of which regional services-defined boundary it is operating in. If a customer’s end user hits a Cloudflare data center that doesn’t match the region that the customer has selected, we simply forward the raw TCP stream in encrypted form. Once it reaches a data center inside the right region, we decrypt and apply all of our Layer 7 products. This covers products such as CDN, WAF, Bot Management, and Workers.
Let’s take an example. A customer’s end user is in Kerala, India, and BGP has determined that the optimal data center for that end user’s request is in Colombo, Sri Lanka. In this example, a customer may have selected India as the sole region within which traffic should be serviced. The Colombo data center sees that this traffic is meant for the India region. It does not decrypt, but instead forwards it to a data center inside India. There, we decrypt and products such as WAF and Workers are applied as if the traffic had hit the data center directly. Responses from the in-region data center retrace the same path back to the client.
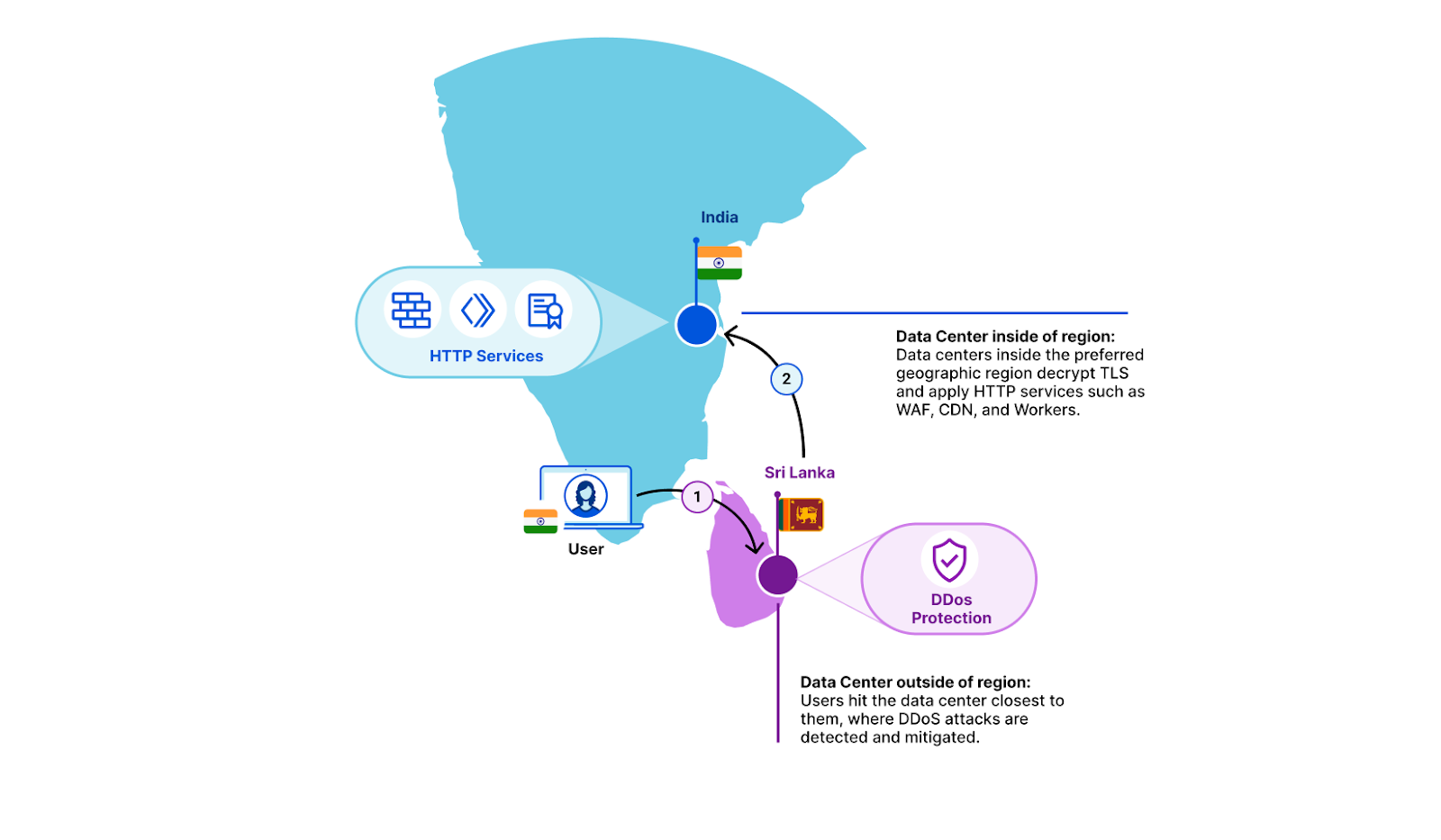
Our expanded Regional Services capabilities are available for early access in late May 2024, and we plan to have them generally available in June 2024. We are very excited about our ability to develop our Data Localization Suite to help you meet your data localization needs.
To get access to these expanded capabilities, or if you’re interested in using the Data Localization Suite, contact your account team.