Post Syndicated from Kevin S. Ridolfi original https://aws.amazon.com/blogs/architecture/how-basfs-agriculture-solutions-drives-traceability-and-climate-action-by-tokenizing-cotton-value-chains-using-amazon-managed-blockchain/
BASF Agricultural Solutions combines innovative products and digital tools with practical farmer knowledge. With over a century of experience, BASF offers a broad portfolio spanning seeds, crop protection, soil management, plant health, and digital agriculture solutions. Through collaboration with farmers, scientists, and partners, BASF strives to meet societal needs sustainably while creating a lasting agricultural legacy. Infosys is a global premier consulting and managed services partner of Amazon Web Services (AWS). Through this unique partnership, AWS helps customers integrate software, services, and processes to accelerate business transformation. This post explores the commitment of this partnership to driving positive change in the agricultural industry by using Amazon Managed Blockchain to tokenize food and cotton value chains for traceability, climate action, and circularity.
Global challenges and the agricultural industry
The world’s population is growing, with the UN projecting an estimated world population of 8.5 billion in 2030 and 10.4 billion by the end of the century. Along with this growth, as well as a global increase in standards of living, comes a rising demand for agricultural products such as fiber and food crops. At the same time, as society becomes more aware of the ecological impact of agriculture, both local communities and farmers are placing larger focus on a sustainable management of natural resources. The agricultural industry is uniquely positioned at the intersection of these two trends.
The agricultural industry faces numerous complex challenges that span both business and technical domains. From a business perspective, today’s agricultural supply chains have become incredibly complex, often involving multiple intermediaries across different countries. This complexity makes it difficult to ensure fair pricing and adequate compensation for farmers, who are often at the bottom of the value chain. Furthermore, verifying sustainable farming practices and organic certifications has become increasingly challenging, even as consumer demand for product authenticity and sustainability information continues to grow. Adding to these pressures, agricultural businesses must navigate increasing regulatory requirements for environmental regulation compliance and reporting, along with complex international trade regulations and documentation.
On the technical front, the industry struggles with limited digital infrastructure in rural farming areas, where internet connectivity and technology adoption remain significant hurdles. Data collection methods vary widely across different farms and regions, making it difficult to establish consistent metrics and reporting standards. Many agricultural businesses still operate with legacy systems that resist integration with modern tracking solutions, and the lack of standardization in agricultural data formats creates additional complications. Maintaining data integrity across multiple stakeholders has proven particularly challenging, as has the implementation of real-time tracking and tracing capabilities.
Cotton and fast fashion: Industry`s challenges
Cotton is the world’s most important natural fiber crop, with a yearly production of 126.5 million bales in the 2022–2023 season, enough to produce 25.3 billion pairs of jeans or 151.8 billion T-shirts. It also plays a major role in the fast fashion industry, where garments and clothing undergo a fast production and disposal cycle to quickly address customer attention and the latest fashion trends, with around 30% of clothing sold in the US being made with cotton. This accelerated production and disposal cycle comes at the expense of considerable environmental impact, with the fast fashion industry accounting for approximately 20% of the world’s water consumption and 10% of the world’s total CO2 emissions.
The cotton industry faces its own set of distinct challenges. Water usage stands as one of the most pressing concerns, with a single cotton T-shirt requiring approximately 2,700 liters of water to produce. Chemical usage tracking presents another significant challenge, as stakeholders must carefully monitor pesticide and fertilizer application throughout the growing process. Labor practices verification has become increasingly important, with brands and consumers demanding assurance of ethical working conditions throughout the supply chain.
Quality verification poses another crucial challenge, given that maintaining accurate documentation of cotton grade and characteristics is essential for pricing and processing. The industry’s global nature creates additional complexities in cross-border logistics, requiring careful management of international shipping and customs processes. Furthermore, the growing importance of sustainability certification has created new pressures to validate organic and sustainable farming practices with reliable, transparent documentation.
As consumer expectation of guaranteed fair practices, lower carbon emissions, and sustainable use of natural resources grows, so does the demand for traceability systems that can provide near real-time visibility into each step of the value chain by tracking sustainability information such as water consumption and CO2 emissions.
The potential for a blockchain-based solution
To address this demand, BASF identified blockchain as a foundational technology for a digital solution to deliver transparency along the value chain, targeting specific customer requirements for digital assets backed by information, validation, certificates, and know your business (KYB) policies for value chain partners.
Blockchain technology emerges as a particularly powerful solution to these challenges, offering unique capabilities that directly address many of the industry’s pain points. At its core, blockchain provides immutable record-keeping, creating permanent, tamper-proof records of transactions and events that ensure data integrity throughout the supply chain. This feature proves especially valuable in preventing fraudulent modification of sustainability certificates and maintaining the credibility of organic farming claims.
Smart contracts, a key feature of blockchain technology, enable the automation of compliance with agricultural standards and facilitate automatic payment execution based on predefined conditions. This automation significantly reduces administrative overhead in supply chain management and helps ensure fair compensation for farmers.
The technology’s traceability capabilities provide end-to-end visibility of cotton from seed to garment, enabling real-time tracking of sustainability metrics and creating transparent audit trails for certification purposes. This transparency helps brands and consumers verify the authenticity and sustainability of their cotton products while enabling farmers to demonstrate their commitment to sustainable practices.
Blockchain’s decentralized data management allows multiple stakeholders to maintain shared records without requiring a central authority, eliminating single points of failure in data storage and reducing dependency on central authorities. This decentralized approach proves particularly valuable in agricultural supply chains, where numerous parties need to access and verify information.
The implementation of token economics through blockchain creates new opportunities for incentivizing sustainable farming practices. Through tokenization, farmers can access new revenue streams, including carbon credits, while establishing more direct relationships with buyers. Additionally, blockchain’s digital identity capabilities provide secure authentication for supply chain participants, enabling granular access control to sensitive data and facilitating compliance with know your customer (KYC) and KYB requirements.
Solution overview
Using a permissioned blockchain based on open-source systems, BASF Agricultural Solutions has developed a novel way to promote data democratization and address the challenges of data recording, off-chain processes, and on-chain activities at scale. The solution enables value chain players to independently verify activities progressively, and an organizational structure within chain and off-chain monitors key performance indicators (KPIs) through a DAO (Distributed Autonomous Organization) interface.
To focus on building such a system rather than managing the underlying blockchain infrastructure, BASF selected Amazon Managed Blockchain alongside additional AWS services. Amazon Managed Blockchain simplifies BASF’s approach because it brings a suite of offerings that can be configured to build this solution without the need to add more layers and external or internal sources.
As a foundational system, Amazon Managed Blockchain augments the solution’s ability to generate smart certificates along with off-chain opportunities to further expand the offering as a platform, such as with AI and AWS Lambda. This fits into BASF’s vision to deliver best-in-class solutions for the farming community and deliver trusted information to communities that want to drive a positive impact for the planet.
The following are the key structural components of the solution:
- Peers – These blockchain nodes run smart contracts (chain code) and maintain the ledger.
- Ordering service – The ordering service makes sure a transaction meets the consensus requirements based on configured channel and endorsement policies for the installed chain code.
- Fabric certificate authority (CA) – This component enrolls and generates blockchain identities needed to sign transactions.
- AWS services – The solution uses various AWS services to perform operations on the blockchain efficiently. These services include:
- Amazon Cognito – We use Amazon Cognito to onboard external users and clients to the platform.
- AWS Fargate – A block listener is a custom service that listens to every block event from the blockchain and updates the off-chain storage accordingly. It’s hosted as a container on Fargate. Running a container using Fargate is more straightforward than other Kubernetes services because you don’t have to manage servers or clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances. With Fargate, we no longer have to provision, configure, or scale clusters of virtual machines to run containers.
- AWS Lambda – Middleware services are hosted as Lambda functions, which makes sure the services are automatically scalable by default and cost-efficient. This is important because we’re charged based on the number of requests for the function and the time it takes for the code to run.
- Amazon OpenSearch Service – We use OpenSearch Service as an off-chain data store because the solution requires complex queries to aggregate the ledger data. The off-chain storage is kept in sync with the ledger and is restricted for direct updates. It can be updated only by an authorized application, based on ledger events.
- AWS Secrets Manager – We use Secrets Manager to manage blockchain identities.
- Amazon Simple Notification Service (Amazon SNS) – We use Amazon SNS to connect various services asynchronously.
The following diagram illustrates the solution architecture.
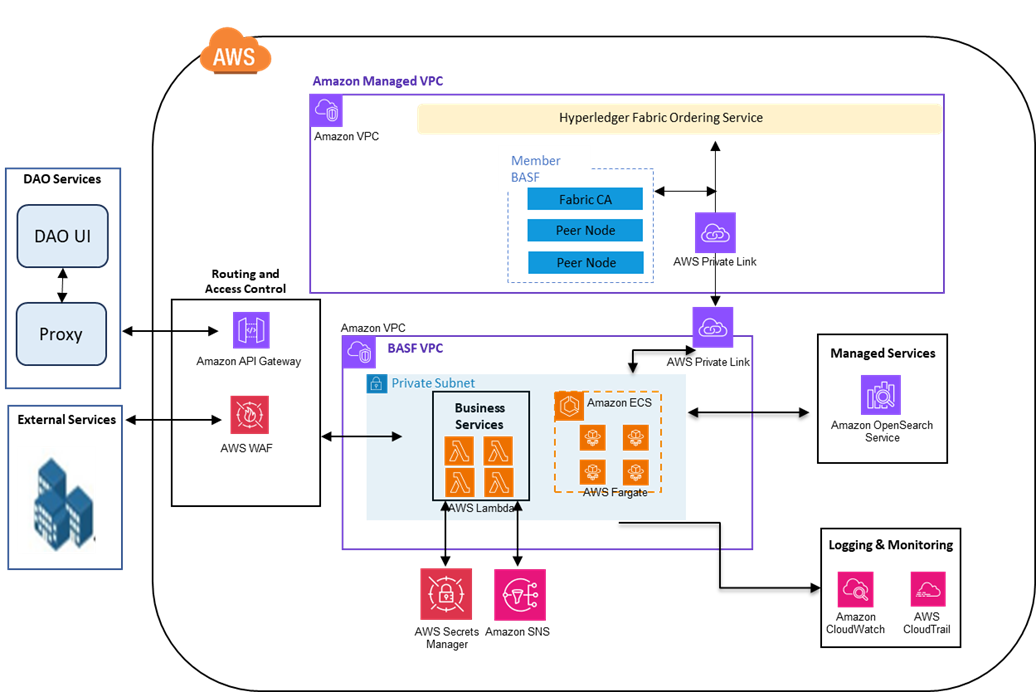
The solution architecture is extensible and scalable to meet the dynamic load requirements. It can seamlessly connect various data sources with appropriate connectors such as Salesforce, mobility platforms, third-party services, and more.
External users such as value chain players, retailers, and others who could benefit from tokens can access the platform through different methods. Generally, access of DAOs is done through business-to-customer (B2C) login, and API streams can be subscribed by end retailers for checkouts, point of sale (POS), and so on. Additionally, we provide internal access for admins and auditors to visualize the product flows.
Conclusion
Climate challenges are quite complex and require a joint approach between technology, the custodians of our planet (namely the farmers), and public chains that deliver the right protocols. BASF Agriculture Solutions represents the farming needs and the link to the right communities and crops on the ground, AWS brings in the right infrastructure and support of the cloud and scale, and Infosys brings in development support as a partner to both AWS and BASF.
BASF is connected to millions of farmers. BASF considers farming to be the biggest job on earth. Sustainable farming means bringing back lost biodiversity and increasing carbon capture within the soil. And sustainability overall requires additional effort by the farmers. Additionally, consumers like us make choices daily when it comes to our own purchase decisions, such as to buy sustainable products or take action that brings positive impact to the climate.
The solution outlined in this post creates a solution using blockchain as the base technology to enable a secure and reliable method for information sharing across all stakeholders. It’s the baseline to onboard use cases in the agriculture industry to enable end-to-end traceability with a 360-degree view. Smart contracts incentivize farmers and other stakeholders to follow the sustainable measures based on the information in the system, which is reviewed and authorized by validators. All the actions in the system are monitored and logged as immutable records, which enforce the information trust by default. This acts as a baseline for 100% traceability, tokenization for sustainable measures, and digital assets that can be exchanged and create a positive economy around sustainability. The design discussed in this post is flexible to onboard different use cases and can auto scale to meet dynamic data volumes.
We encourage you to join BASF, Infosys, and AWS in driving sustainability through trusted value chains that incentivize farmers, empower consumers, and create a positive economy around climate action. If you want to dive deep into topics surrounding sustainability and AWS architecture, we suggest visiting the AWS Architecture Blog.