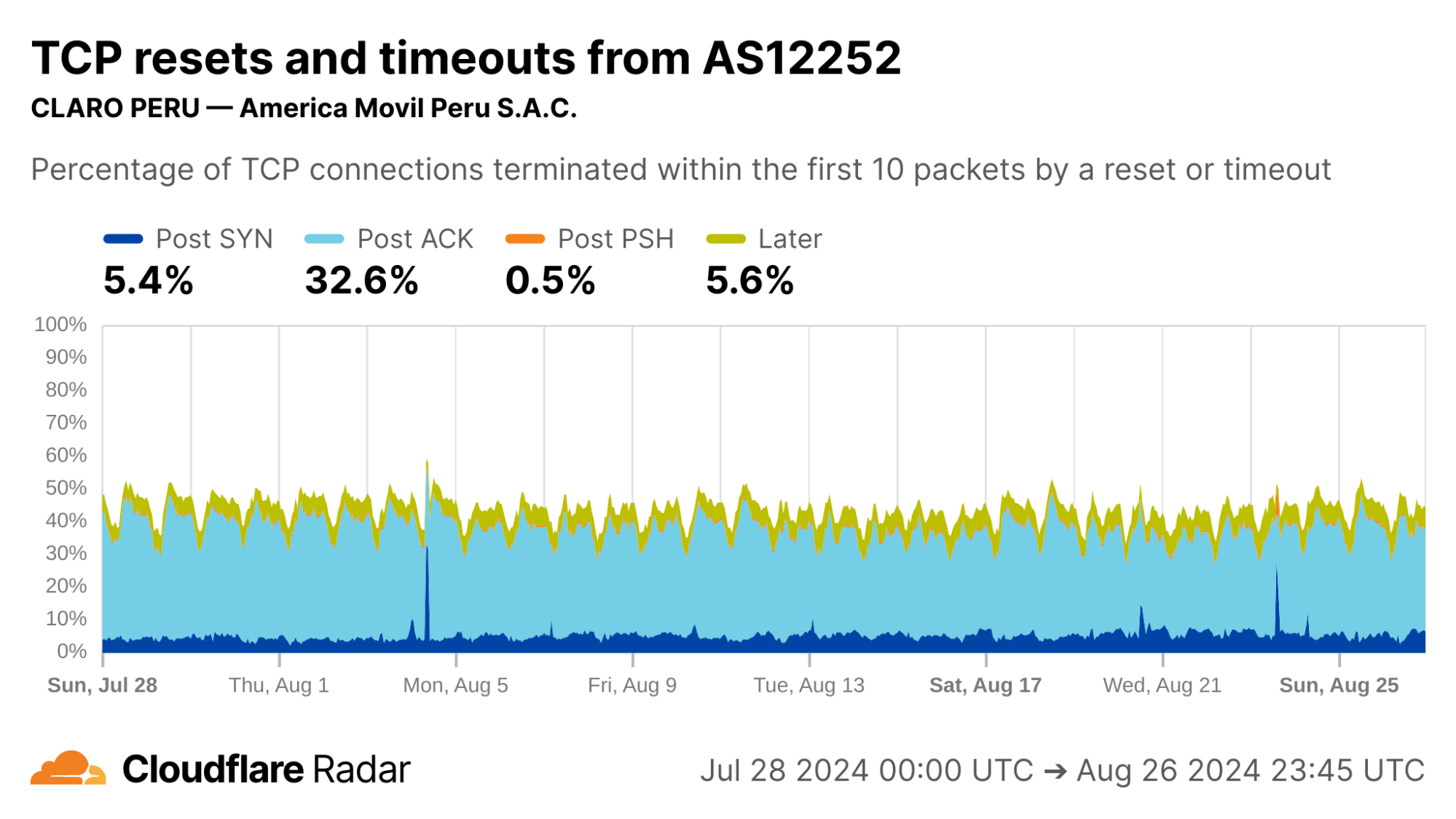
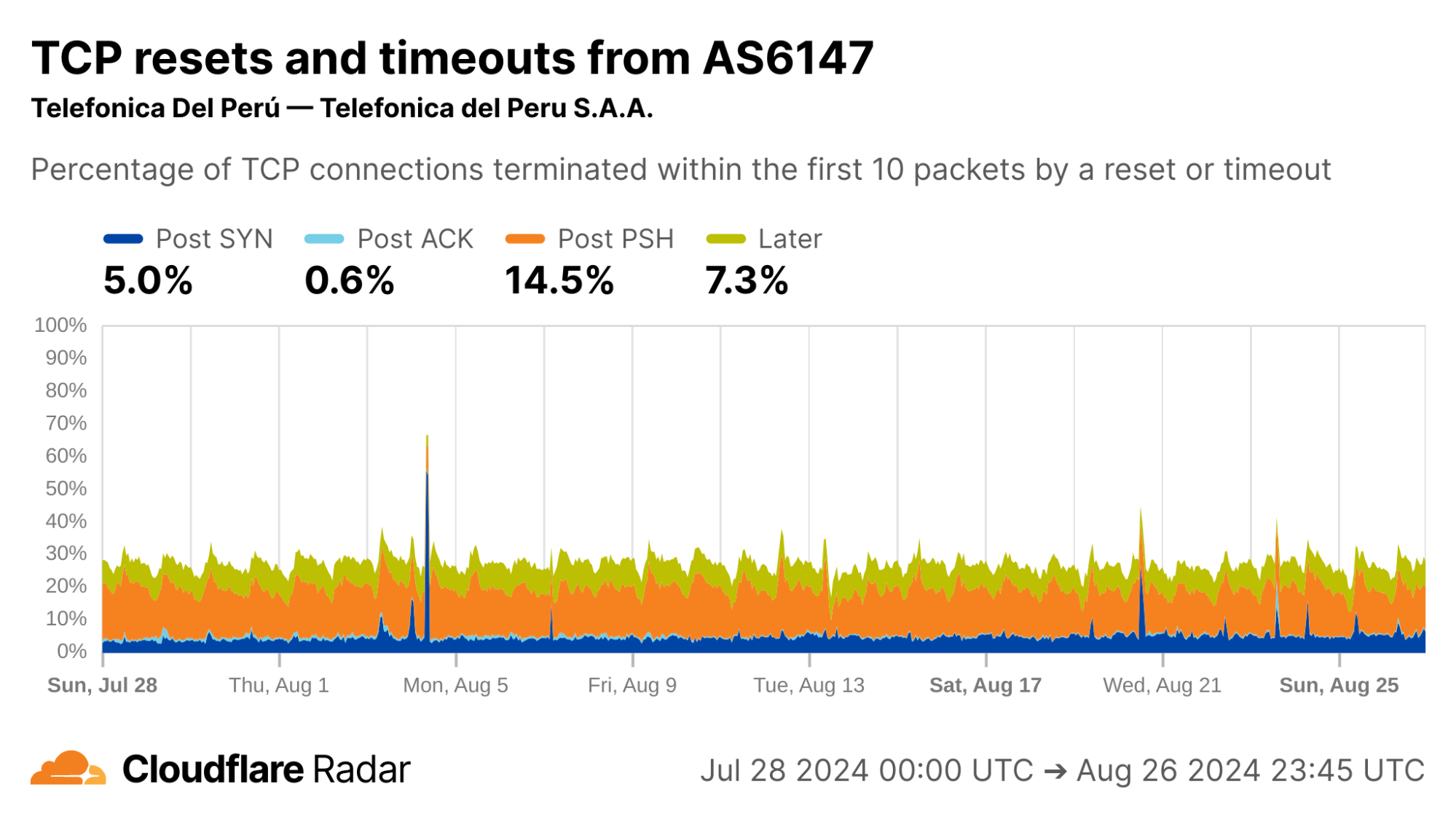
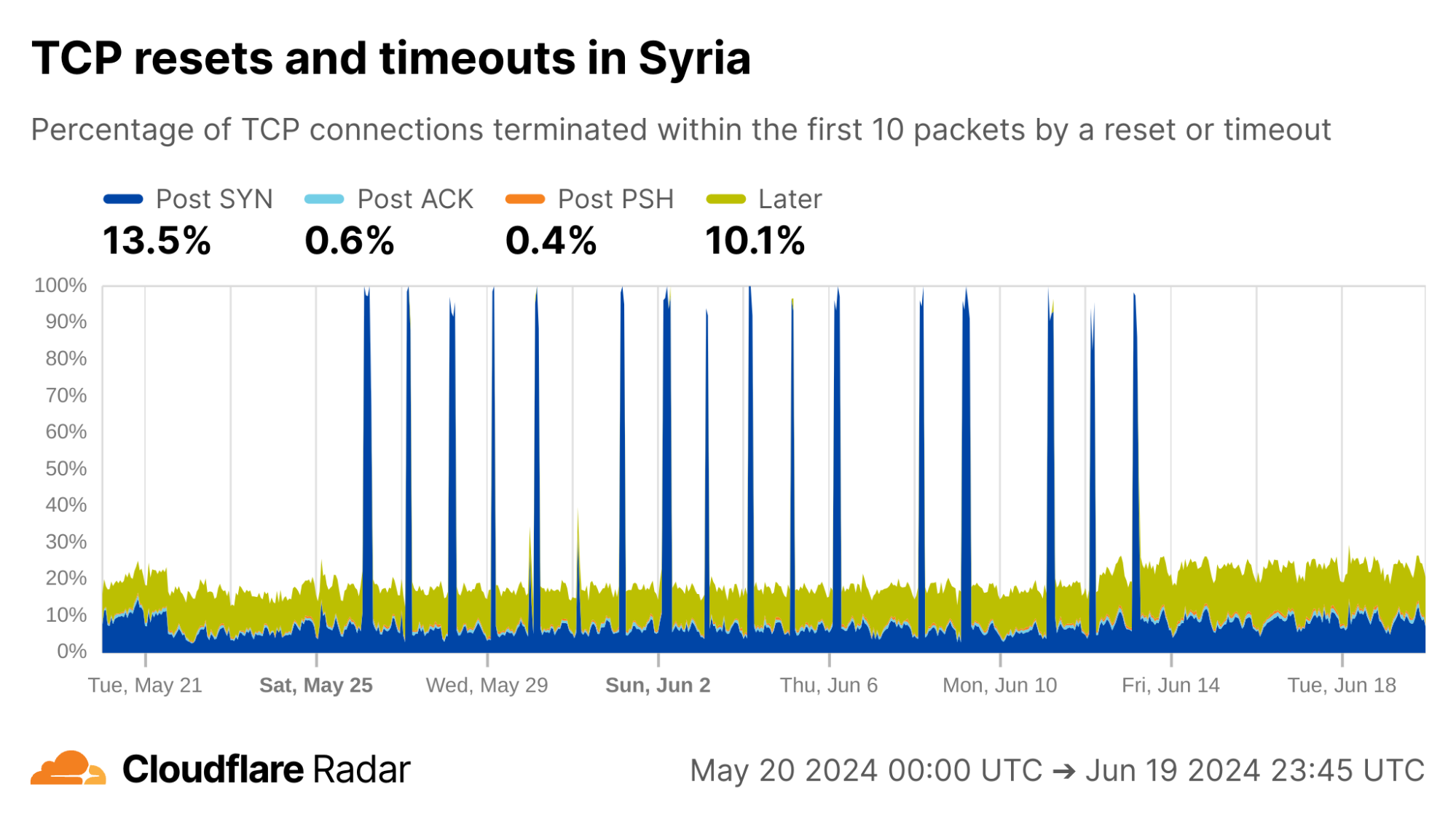
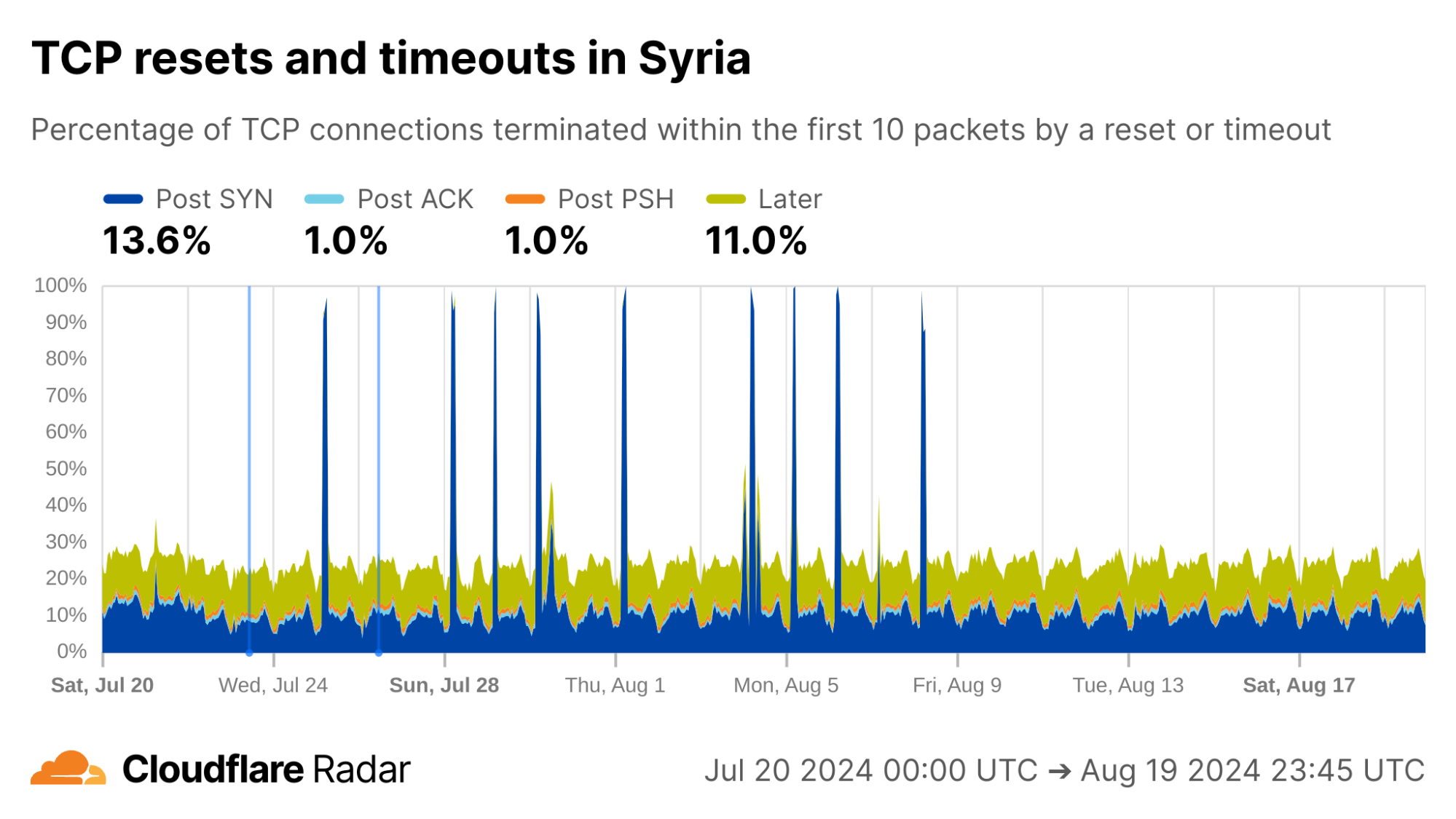
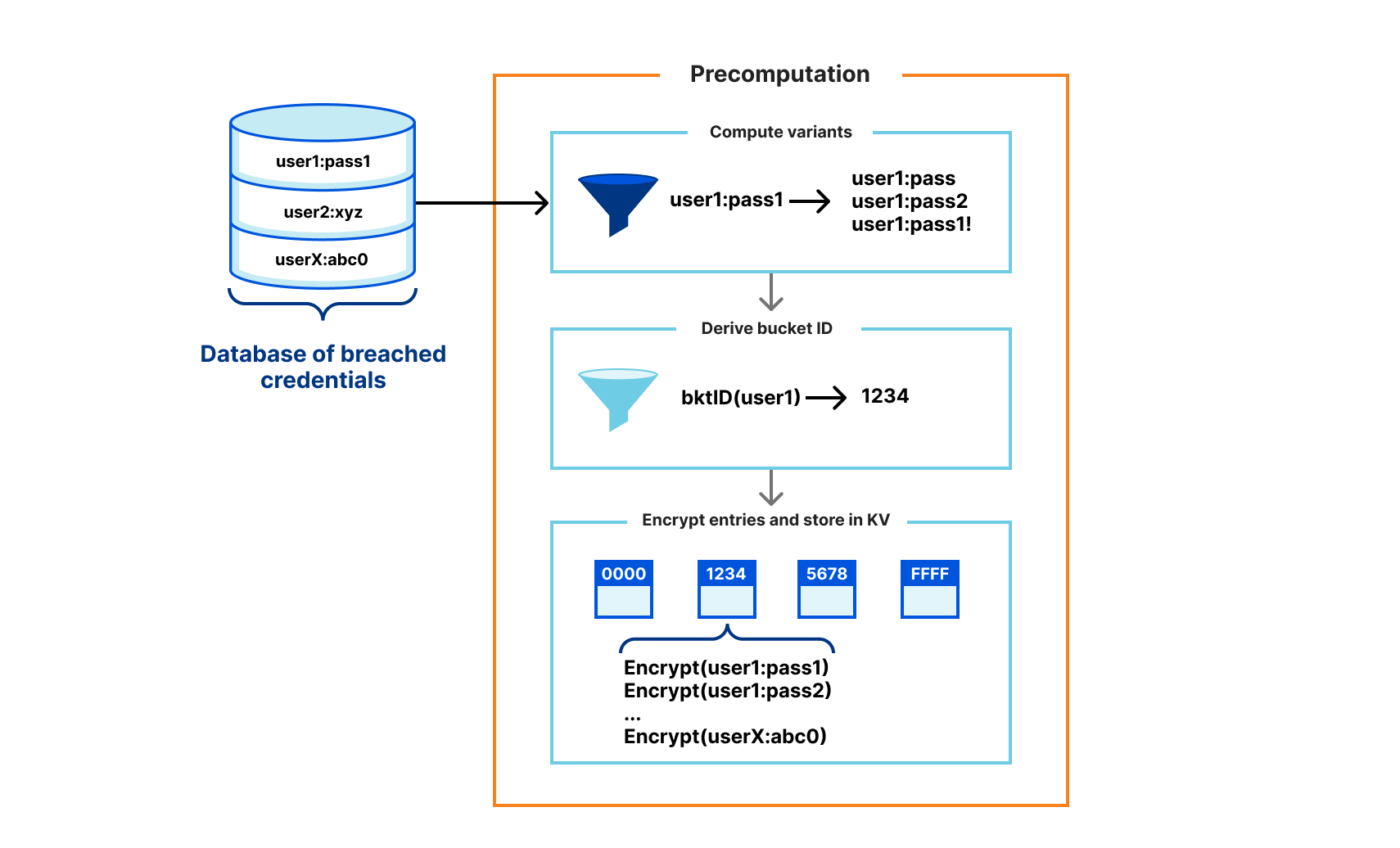
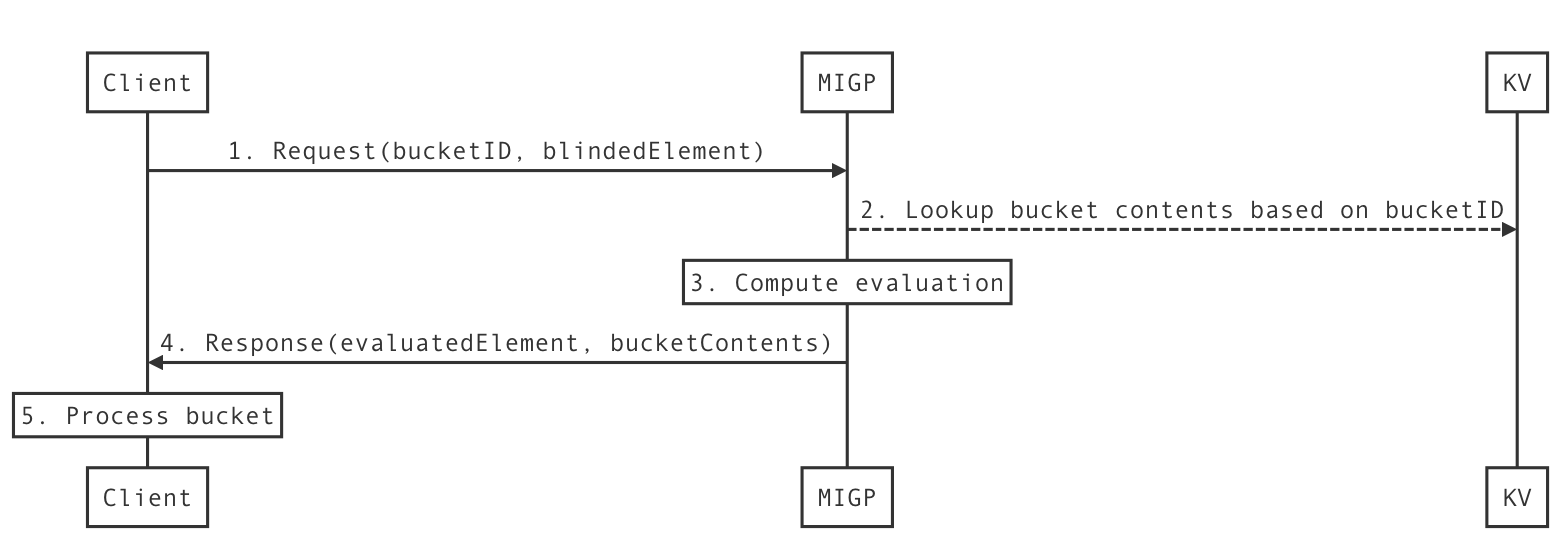
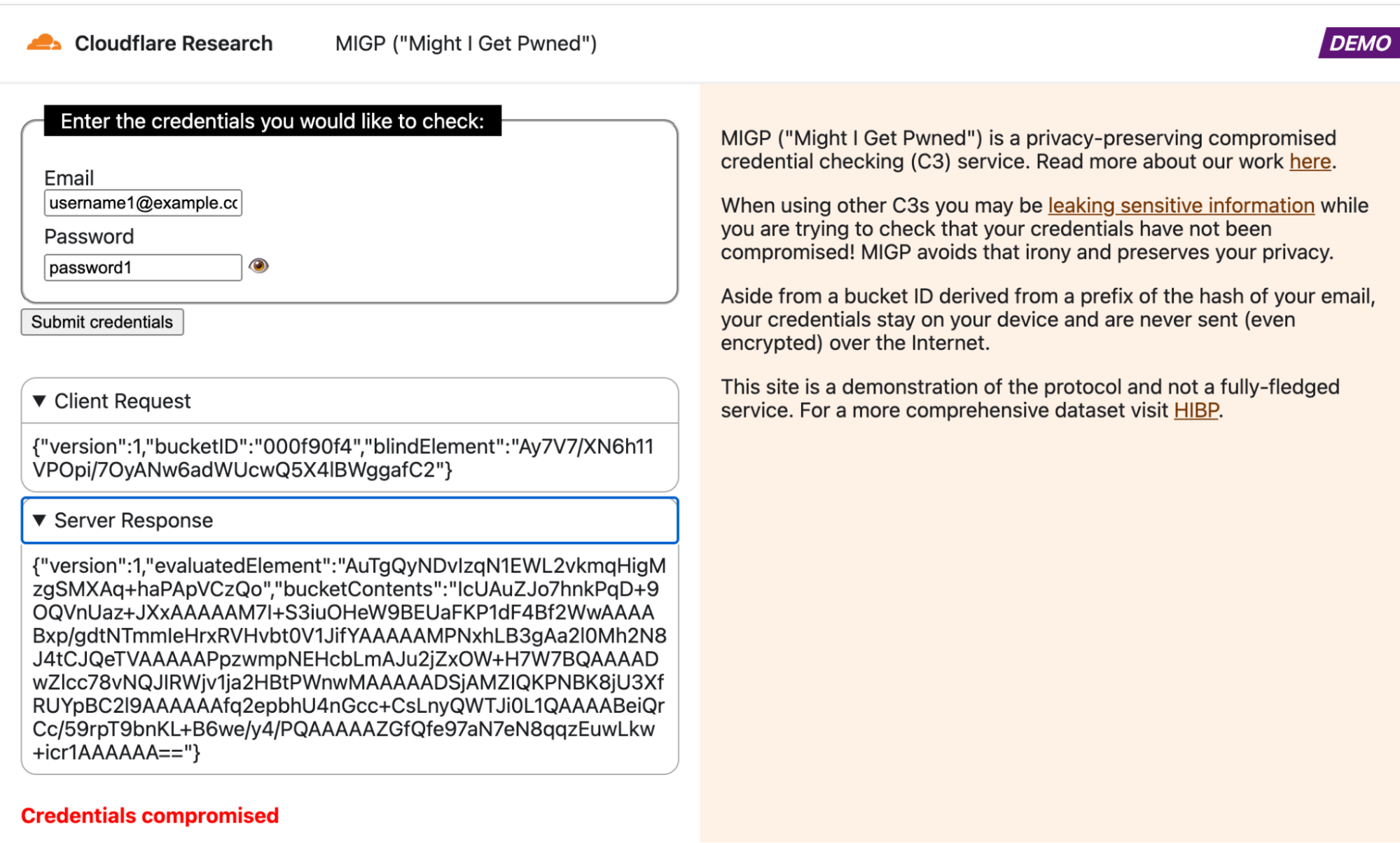
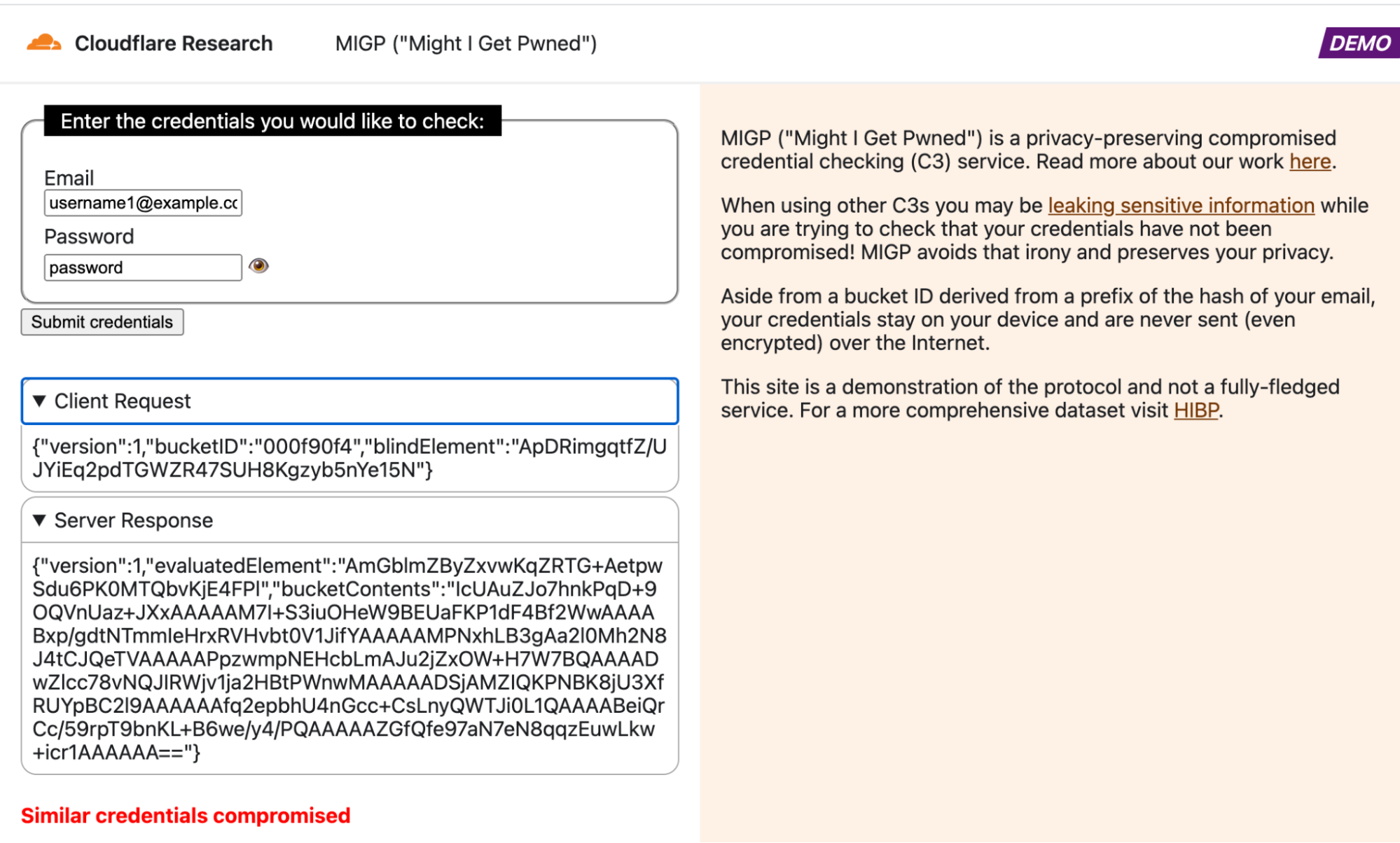
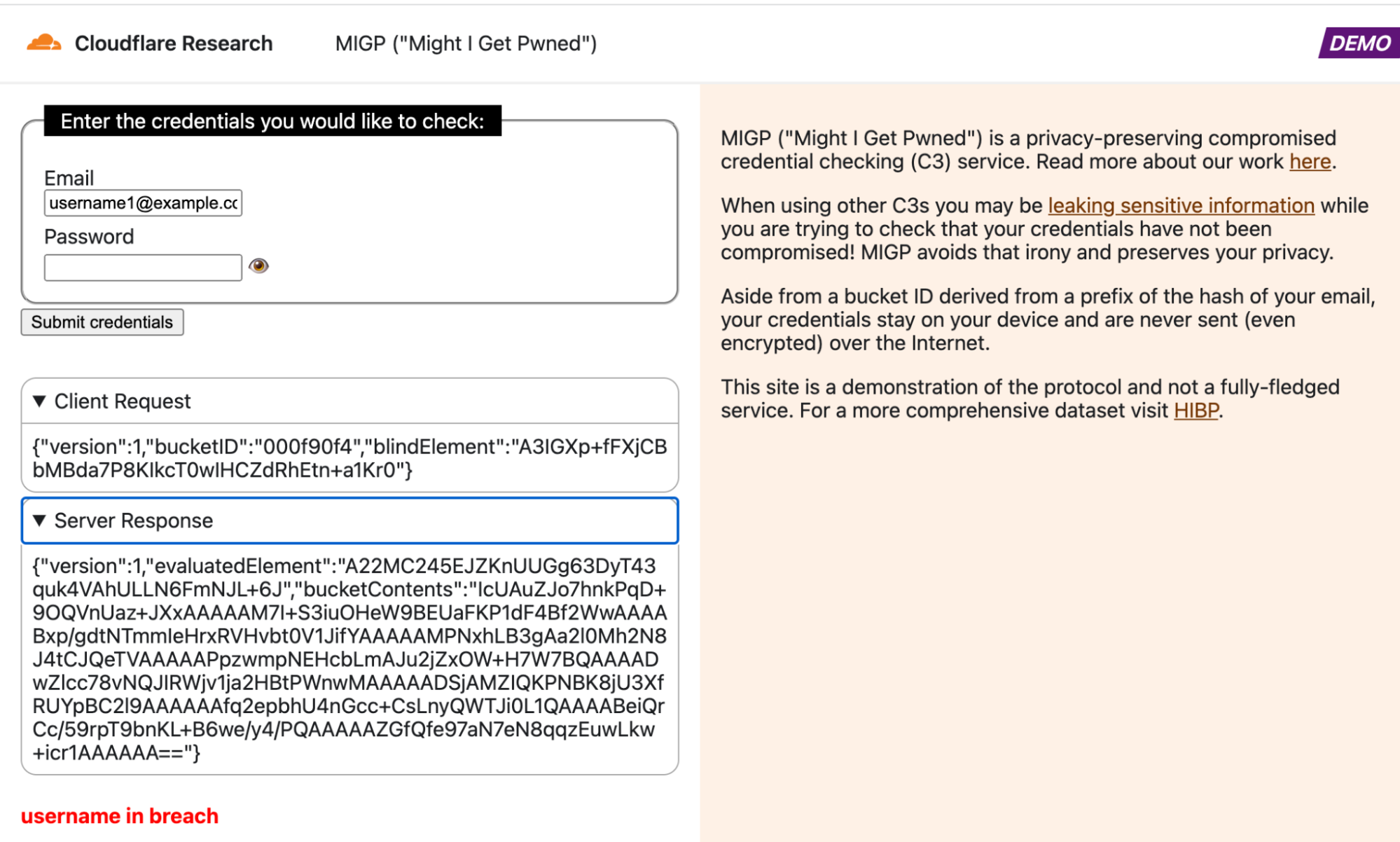
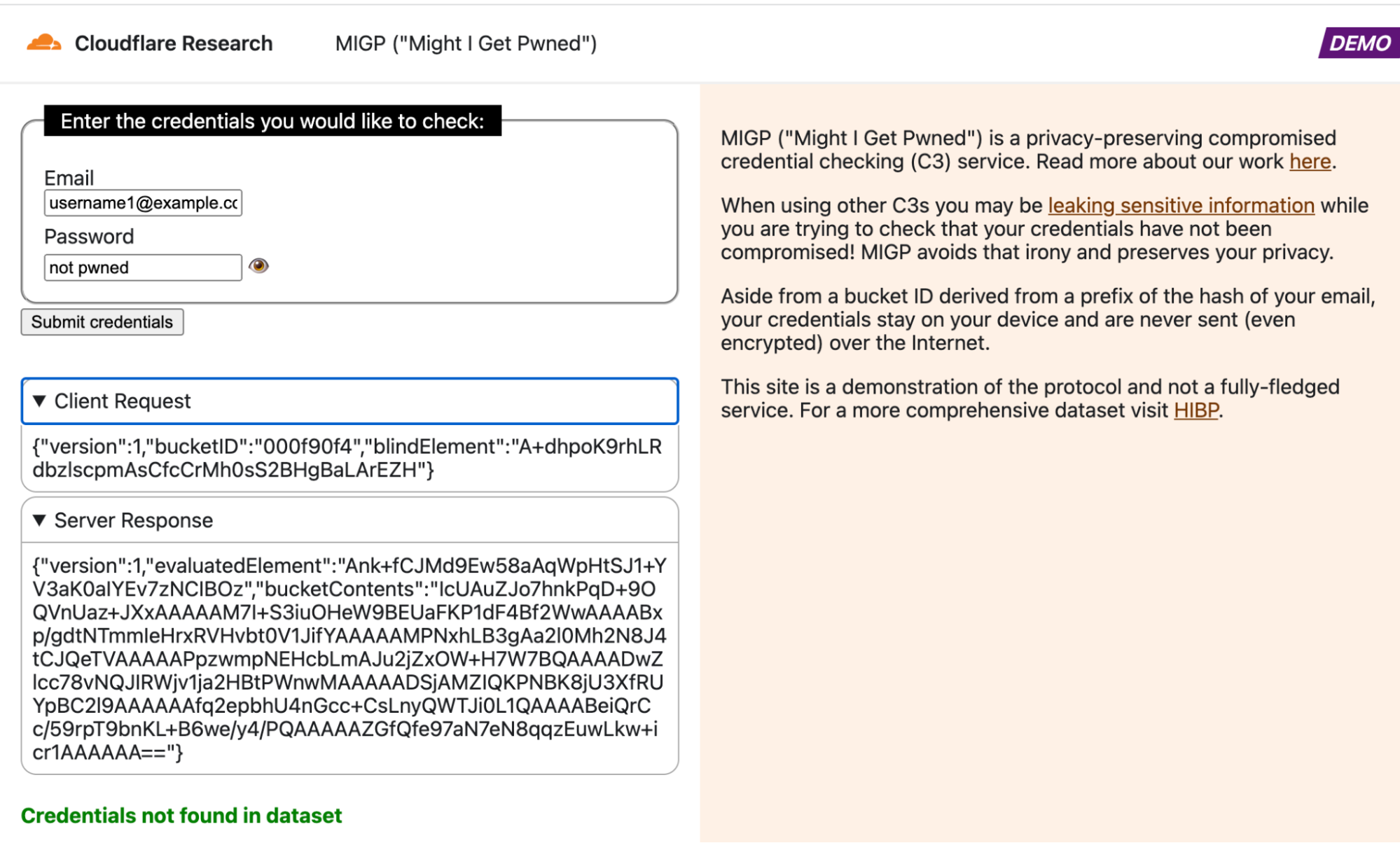
Here at Cloudflare, we frequently use and write about data in the present. But sometimes understanding the present begins with digging into the past.
We recently learned of a 2024 turkmen.news article (available in Russian) that reports Turkmenistan experienced “an unprecedented easing in blocking,” causing over 3 billion previously-blocked IP addresses to become reachable. The same article reports that one of the reasons for unblocking IP addresses was that Turkmenistan may have been testing a new firewall. (The Turkmen government’s tight control over the country’s Internet access is well-documented.)
Indeed, Cloudflare Radar shows a surge of requests coming from Turkmenistan around the same time, as we’ll show below. But we had an additional question: Does the firewall activity show up on Radar, as well? Two years ago, we launched the dashboard on Radar to give a window into the TCP connections to Cloudflare that close due to resets and timeouts. These stand out because they are considered ungraceful mechanisms to close TCP connections, according to the TCP specification.
In this blog post, we go back in time to share what Cloudflare saw in connection resets and timeouts. We must remind our readers that, as passive observers, there are limitations on what we can glean from the data. For example, our data can’t reveal attribution. Even so, the ability to observe our environment can be insightful. In a recent example, our visibility into resets and timeouts helped corroborate reports of large-scale blocking and traffic tampering by Russia.
Turkmenistan requests where there were none before
Let’s look first at the number of requests, since those should increase if IP addresses are unblocked. In mid-June 2024 Cloudflare started receiving a noticeable increase in HTTP requests, consistent with reports of Turkmenistan unblocking IPs.
The Transmission Control Protocol (TCP) is a lower-layer mechanism used to create a connection between clients and servers, and also carries 70% of HTTP traffic to Cloudflare. A TCP connection works much like a telephone call between humans, who follow graceful conventions to end a call—and who are acutely aware when conventions are broken if a call ends abruptly.
TCP also defines conventions to end the connection gracefully, and we developed mechanisms to detect when they don’t. An ungraceful end is triggered by a reset instruction or a timeout. Some are due to benign artifacts of software design or human user behaviours. However, sometimes they are exploited by third parties to close connections in everything from school and enterprise firewalls or software, to zero-rating on mobile plans, to nation-state filtering.
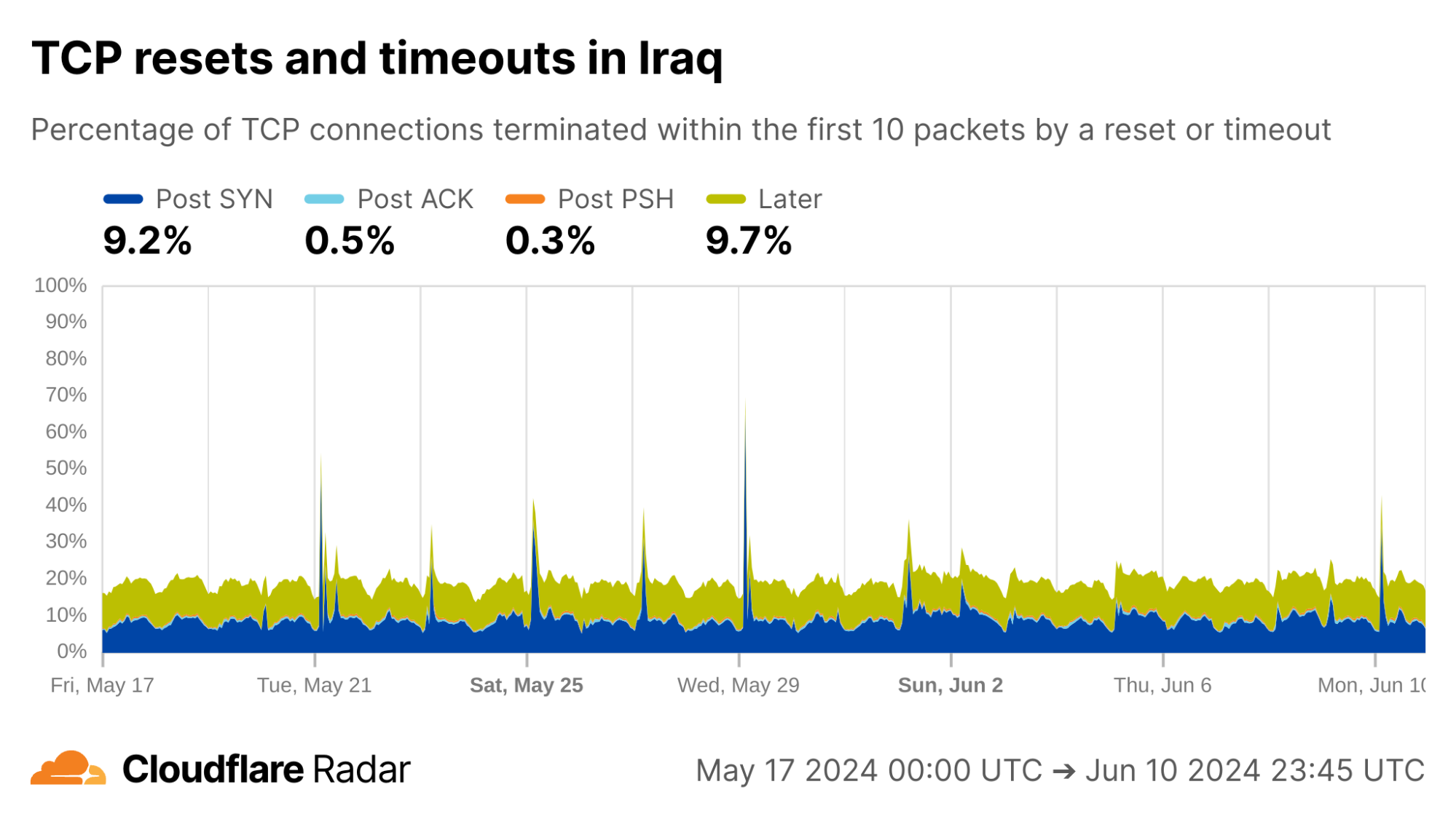
When we look at connections from Turkmenistan, we see that on June 13, 2024, the combined proportion of the four coloured regions increases; each coloured region represents ungraceful ends at a distinct stage of the connection lifetime. In addition to the combined increase, the relative proportions between stages (or colours) changes as well.
Further changes appeared in the weeks that followed. Among them are an increase in Post-PSH (orange) anomalies starting around July 4; a reduction in Post-ACK (light blue) anomalies around July 13; and an increase in anomalies later in connections (green) starting July 22.
The shifts above could be explained by a large firewall system. It’s important to keep in mind that data in each of the connection stages (captured by the four coloured regions in the graphs) can be explained by browser implementations or user actions. However, the scale of the data would need a great number of browsers or users doing the same thing to show up. Similarly, individual changes in behaviour would be lost unless they occur in large numbers at the same time.
Digging down to individual networks
We’ve learned that it can be helpful to look at the data for individual networks to reveal common patterns between different networks in different regions operated by single entities.
Looking at individual networks within Turkmenistan, trends and timelines appear more pronounced. July 22 in particular sees greater proportions of anomalies associated with the Server Name Indication, or domain name, rather than the IP address (dark blue), although the connection stage where the anomalies appear varies by individual network.
A different picture emerges from AS51495 (Ashgabat City Telephone Network). Post-ACK anomalies almost completely disappear on July 12, corresponding with an increase in anomalies during the Post-PSH stage. An increase of anomalies in the Later (green) connection stage on July 22 is apparent for this AS as well.
Finally, for AS59974 (Altyn Asyr), you can see below that there is a clear spike in Post-ACK anomalies starting July 22. This is the stage of the connection where a firewall could have seen the SNI, and chooses to drop the packets immediately, so they never reach Cloudflare’s servers.
We’ve previously discussed how to use the resets and timeouts data because, while useful, it can also be misinterpreted. Radar’s data on resets and timeouts is unique among operators, but in isolation it’s incomplete and subject to human bias.
Take the figure above for AS59974 where Post-ACK (light blue) anomalies markedly increased on July 22. The Radar view is proportional, meaning that the increase in proportion could be explained by greater numbers of anomalies – but could also be explained, for example, by a smaller number of valid requests. Indeed, looking at the HTTP request levels for the same AS, there was a similarly pronounced drop starting on the same day, as shown below.
If we look at the same two graphs before July 22, however, rates of reset and timeout anomalies do not appear to mirror the very large shifts up and down in HTTP requests.
Looking ahead can also mean looking behind
These charts from Radar above offer a way to analyze news events from a different angle, by looking at requests and TCP connection resets and timeouts. Does this data tell us definitively that new firewalls were being tested in Turkmenistan? No. But the trends in the data are consistent with what we could expect to see if that were the case.
If thinking about ways to use the resets and timeouts data going forward, we’d encourage also looking at the data in retrospect—or even further past to improve context.
A natural question might be, for example, “If Turkmenistan stopped blocking IPs in mid-2024, what did the data say beforehand?” The figure below captures October and November 2023. (The red-shaded region contains missing data due to the Nov. 2 Cloudflare control plane and metrics outage.) Signals about the Internet in Turkmenistan were evolving well before the news article that prompted us to look.
We’re proud to offer a unique view of TCP connection anomalies on Radar. It’s a testament to the long-lived benefits that emerge when approaching Internet measurement as a science. In keeping with the open spirit of science, we’ve also shared how we detect and log resets and timeouts so that others can reproduce the observability on their servers, whether by hobbyists or other large operators.
The world is in a race to build its first quantum computer capable of solving practical problems not feasible on even the largest conventional supercomputers. While the quantum computing paradigm promises many benefits, it also threatens the security of the Internet by breaking much of the cryptography we have come to rely on.
To mitigate this threat, Cloudflare is helping to migrate the Internet to Post-Quantum (PQ) cryptography. Today, about 50% of traffic to Cloudflare’s edge network is protected against the most urgent threat: an attacker who can intercept and store encrypted traffic today and then decrypt it in the future with the help of a quantum computer. This is referred to as the harvest now, decrypt laterthreat.
However, this is just one of the threats we need to address. A quantum computer can also be used to crack a server’s TLS certificate, allowing an attacker to impersonate the server to unsuspecting clients. The good news is that we already have PQ algorithms we can use for quantum-safe authentication. The bad news is that adoption of these algorithms in TLS will require significant changes to one of the most complex and security-critical systems on the Internet: the Web Public-Key Infrastructure (WebPKI).
The central problem is the sheer size of these new algorithms: signatures for ML-DSA-44, one of the most performant PQ algorithms standardized by NIST, are 2,420 bytes long, compared to just 64 bytes for ECDSA-P256, the most popular non-PQ signature in use today; and its public keys are 1,312 bytes long, compared to just 64 bytes for ECDSA. That’s a roughly 20-fold increase in size. Worse yet, the average TLS handshake includes a number of public keys and signatures, adding up to 10s of kilobytes of overhead per handshake. This is enough to have a noticeable impact on the performance of TLS.
That makes drop-in PQ certificates a tough sell to enable today: they don’t bring any security benefit before Q-day — the day a cryptographically relevant quantum computer arrives — but they do degrade performance. We could sit and wait until Q-day is a year away, but that’s playing with fire. Migrations always take longer than expected, and by waiting we risk the security and privacy of the Internet, which is dear to us.
It’s clear that we must find a way to make post-quantum certificates cheap enough to deploy today by default for everyone — not just those that can afford it. In this post, we’ll introduce you to the plan we’ve brought together with industry partners to the IETF to redesign the WebPKI in order to allow a smooth transition to PQ authentication with no performance impact (and perhaps a performance improvement!). We’ll provide an overview of one concrete proposal, called Merkle Tree Certificates (MTCs), whose goal is to whittle down the number of public keys and signatures in the TLS handshake to the bare minimum required.
But talk is cheap. We knowfromexperience that, as with any change to the Internet, it’s crucial to test early and often. Today we’re announcing our intent to deploy MTCs on an experimental basis in collaboration with Chrome Security. In this post, we’ll describe the scope of this experiment, what we hope to learn from it, and how we’ll make sure it’s done safely.
The WebPKI today — an old system with many patches
Why does the TLS handshake have so many public keys and signatures?
Let’s start with Cryptography 101. When your browser connects to a website, it asks the server to authenticate itself to make sure it’s talking to the real server and not an impersonator. This is usually achieved with a cryptographic primitive known as a digital signature scheme (e.g., ECDSA or ML-DSA). In TLS, the server signs the messages exchanged between the client and server using its secret key, and the client verifies the signature using the server’s public key. In this way, the server confirms to the client that they’ve had the same conversation, since only the server could have produced a valid signature.
If the client already knows the server’s public key, then only 1 signature is required to authenticate the server. In practice, however, this is not really an option. The web today is made up of around a billion TLS servers, so it would be unrealistic to provision every client with the public key of every server. What’s more, the set of public keys will change over time as new servers come online and existing ones rotate their keys, so we would need some way of pushing these changes to clients.
This scaling problem is at the heart of the design of all PKIs.
Trust is transitive
Instead of expecting the client to know the server’s public key in advance, the server might just send its public key during the TLS handshake. But how does the client know that the public key actually belongs to the server? This is the job of a certificate.
A certificate binds a public key to the identity of the server — usually its DNS name, e.g., cloudflareresearch.com. The certificate is signed by a Certification Authority (CA) whose public key is known to the client. In addition to verifying the server’s handshake signature, the client verifies the signature of this certificate. This establishes a chain of trust: by accepting the certificate, the client is trusting that the CA verified that the public key actually belongs to the server with that identity.
Clients are typically configured to trust many CAs and must be provisioned with a public key for each. Things are much easier however, since there are only 100s of CAs instead of billions. In addition, new certificates can be created without having to update clients.
These efficiencies come at a relatively low cost: for those counting at home, that’s +1 signature and +1 public key, for a total of 2 signatures and 1 public key per TLS handshake.
That’s not the end of the story, however. As the WebPKI has evolved, so have these chains of trust grown a bit longer. These days it’s common for a chain to consist of two or more certificates rather than just one. This is because CAs sometimes need to rotatetheir keys, just as servers do. But before they can start using the new key, they must distribute the corresponding public key to clients. This takes time, since it requires billions of clients to update their trust stores. To bridge the gap, the CA will sometimes use the old key to issue a certificate for the new one and append this certificate to the end of the chain.
That’s +1 signature and +1 public key, which brings us to 3 signatures and 2 public keys. And we still have a little ways to go.
Trust but verify
The main job of a CA is to verify that a server has control over the domain for which it’s requesting a certificate. This process has evolved over the years from a high-touch, CA-specific process to a standardized, mostly automated process used for issuing most certificates on the web. (Not all CAs fully support automation, however.) This evolution is marked by a number of security incidents in which a certificate was mis-issued to a party other than the server, allowing that party to impersonate the server to any client that trusts the CA.
Automation helps, but attacks are still possible, and mistakes are almost inevitable. Earlier this year, several certificates for Cloudflare’s encrypted 1.1.1.1 resolver were issued without our involvement or authorization. This apparently occurred by accident, but it nonetheless put users of 1.1.1.1 at risk. (The mis-issued certificates have since been revoked.)
Ensuring mis-issuance is detectable is the job of the Certificate Transparency (CT) ecosystem. The basic idea is that each certificate issued by a CA gets added to a public log. Servers can audit these logs for certificates issued in their name. If ever a certificate is issued that they didn’t request itself, the server operator can prove the issuance happened, and the PKI ecosystem can take action to prevent the certificate from being trusted by clients.
Major browsers, including Firefox and Chrome and its derivatives, require certificates to be logged before they can be trusted. For example, Chrome, Safari, and Firefox will only accept the server’s certificate if it appears in at least two logs the browser is configured to trust. This policy is easy to state, but tricky to implement in practice:
Operating a CT log has historically been fairly expensive. Logs ingest billions of certificates over their lifetimes: when an incident happens, or even just under high load, it can take some time for a log to make a new entry available for auditors.
Clients can’t really audit logs themselves, since this would expose their browsing history (i.e., the servers they wanted to connect to) to the log operators.
The solution to both problems is to include a signature from the CT log along with the certificate. The signature is produced immediately in response to a request to log a certificate, and attests to the log’s intent to include the certificate in the log within 24 hours.
Per browser policy, certificate transparency adds +2 signatures to the TLS handshake, one for each log. This brings us to a total of 5 signatures and 2 public keys in a typical handshake on the public web.
The future WebPKI
The WebPKI is a living, breathing, and highly distributed system. We’ve had to patch it a number of times over the years to keep it going, but on balance it has served our needs quite well — until now.
Previously, whenever we needed to update something in the WebPKI, we would tack on another signature. This strategy has worked because conventional cryptography is so cheap. But 5 signatures and 2 public keys on average for each TLS handshake is simply too much to cope with for the larger PQ signatures that are coming.
The good news is that by moving what we already have around in clever ways, we can drastically reduce the number of signatures we need.
Crash course on Merkle Tree Certificates
Merkle Tree Certificates (MTCs) is a proposal for the next generation of the WebPKI that we are implementing and plan to deploy on an experimental basis. Its key features are as follows:
All the information a client needs to validate a Merkle Tree Certificate can be disseminated out-of-band. If the client is sufficiently up-to-date, then the TLS handshake needs just 1 signature, 1 public key, and 1 Merkle tree inclusion proof. This is quite small, even if we use post-quantum algorithms.
The MTC specification makes certificate transparency a first class feature of the PKI by having each CA run its own log of exactly the certificates they issue.
Let’s poke our head under the hood a little. Below we have an MTC generated by one of our internal tests. This would be transmitted from the server to the client in the TLS handshake:
Looks like your average PEM encoded certificate. Let’s decode it and look at the parameters:
$ openssl x509 -in merkle-tree-cert.pem -noout -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 531 (0x213)
Signature Algorithm: 1.3.6.1.4.1.44363.47.0
Issuer: 1.3.6.1.4.1.44363.47.1=44363.48.3
Validity
Not Before: Oct 21 15:33:26 2025 GMT
Not After : Oct 28 15:33:26 2025 GMT
Subject: CN=cloudflareresearch.com
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:70:ed:e1:96:87:b4:22:ef:fb:dc:a9:cd:9c:5c:
ef:1e:9e:ab:1b:6d:d7:11:74:7b:76:c8:3c:a1:5f:
94:37:45:99:d8:80:e3:5c:24:4f:28:46:b5:bf:84:
60:d8:fc:eb:82:5a:c4:4e:33:90:c7:b3:36:51:0c:
92:6d:bf:88:27
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature
X509v3 Extended Key Usage:
TLS Web Server Authentication
X509v3 Subject Alternative Name:
DNS:cloudflareresearch.com, DNS:static-ct.cloudflareresearch.com
Signature Algorithm: 1.3.6.1.4.1.44363.47.0
Signature Value:
00:00:00:00:00:00:02:00:00:00:00:00:00:00:02:58:00:e0:
44:be:03:a5:bd:6a:b7:f2:9e:39:77:4c:16:4c:f8:06:e5:e1:
55:c0:93:21:c6:79:83:3c:dd:5b:e6:57:89:c0:75:b3:4c:ec:
75:8a:0b:53:a0:ca:1c:07:0c:1a:92:dd:c7:7c:a2:23:5d:83:
0e:e4:23:43:38:af:43:20:a8:66:44:34:95:87:ea:2b:f0:0f:
16:52:bb:ea:67:67:1e:89:36:4f:90:d4:05:55:89:46:f1:b7:
b6:68:84:d3:57:31:ae:2b:c3:79:31:86:85:9d:24:ed:cf:25:
a4:5c:fd:8f:f6:76:14:55:dd:67:2e:df:d6:8c:25:0d:52:48:
c8:e3:fe:f9:7c:e6:a5:30:52:a5:b5:c7:3a:89:a5:c1:f6:4b:
5b:95:ef:70:b8:91:fc:61:0f:6d:16:de:39:e9:a0:59:49:2b:
34:71:7c:2a:16:da:c7:af:de:f7:01:94:10:c4:62:d1:f5:00:
87:bd:e8:a2:f4:df:3b:35:79:27:0e:fc:cc:43:e7:60:5a:df:
df:06:e8:d3:7e:eb:b3:bf:7b:25:43:0f:34:9a:26:c0:d3:6d:
5d:0c:28:bc:87:58:58:15:00:00
While some of the parameters probably look familiar, others will look unusual. On the familiar side, the subject and public key are exactly what we might expect: the DNS name is cloudflareresearch.com and the public key is for a familiar signature algorithm, ECDSA-P256. This algorithm is not PQ, of course — in the future we would put ML-DSA-44 there instead.
On the unusual side, OpenSSL appears to not recognize the signature algorithm of the issuer and just prints the raw OID and bytes of the signature. There’s a good reason for this: the MTC does not have a signature in it at all! So what exactly are we looking at?
The trick to leave out signatures is that a Merkle Tree Certification Authority (MTCA) produces its signatureless certificates in batches rather than individually. In place of a signature, the certificate has an inclusion proof of the certificate in a batch of certificates signed by the MTCA.
To understand how inclusion proofs work, let’s think about a slightly simplified version of the MTC specification. To issue a batch, the MTCA arranges the unsigned certificates into a data structure called a Merkle tree that looks like this:
Each leaf of the tree corresponds to a certificate, and each inner node is equal to the hash of its children. To sign the batch, the MTCA uses its secret key to sign the head of the tree. The structure of the tree guarantees that each certificate in the batch was signed by the MTCA: if we tried to tweak the bits of any one of the certificates, the treehead would end up having a different value, which would cause the signature to fail.
An inclusion proof for a certificate consists of the hash of each sibling node along the path from the certificate to the treehead:
Given a validated treehead, this sequence of hashes is sufficient to prove inclusion of the certificate in the tree. This means that, in order to validate an MTC, the client also needs to obtain the signed treehead from the MTCA.
This is the key to MTC’s efficiency:
Signed treeheads can be disseminated to clients out-of-band and validated offline. Each validated treehead can then be used to validate any certificate in the corresponding batch, eliminating the need to obtain a signature for each server certificate.
During the TLS handshake, the client tells the server which treeheads it has. If the server has a signatureless certificate covered by one of those treeheads, then it can use that certificate to authenticate itself. That’s 1 signature,1 public key and 1 inclusion proof per handshake, both for the server being authenticated.
Now, that’s the simplified version. MTC proper has some more bells and whistles. To start, it doesn’t create a separate Merkle tree for each batch, but it grows a single large tree, which is used for better transparency. As this tree grows, periodically (sub)tree heads are selected to be shipped to browsers, which we call landmarks. In the common case browsers will be able to fetch the most recent landmarks, and servers can wait for batch issuance, but we need a fallback: MTC also supports certificates that can be issued immediately and don’t require landmarks to be validated, but these are not as small. A server would provision both types of Merkle tree certificates, so that the common case is fast, and the exceptional case is slow, but at least it’ll work.
Experimental deployment
Ever since early designs for MTCs emerged, we’ve been eager to experiment with the idea. In line with the IETF principle of “running code”, it often takes implementing a protocol to work out kinks in the design. At the same time, we cannot risk the security of users. In this section, we describe our approach to experimenting with aspects of the Merkle Tree Certificates design without changing any trust relationships.
Let’s start with what we hope to learn. We have lots of questions whose answers can help to either validate the approach, or uncover pitfalls that require reshaping the protocol — in fact, an implementation of an early MTC draft by Maximilian Pohl and Mia Celeste did exactly this. We’d like to know:
What breaks? Protocol ossification (the tendency of implementation bugs to make it harder to change a protocol) is an ever-present issue with deploying protocol changes. For TLS in particular, despite having built-in flexibility, time after time we’ve found that if that flexibility is not regularly used, there will be buggy implementations and middleboxes that break when they see things they don’t recognize. TLS 1.3 deployment took years longer than we hoped for this very reason. And more recently, the rollout of PQ key exchange in TLS caused the Client Hello to be split over multiple TCP packets, something that many middleboxes weren’t ready for.
What is the performance impact? In fact, we expect MTCs to reduce the size of the handshake, even compared to today’s non-PQ certificates. They will also reduce CPU cost: ML-DSA signature verification is about as fast as ECDSA, and there will be far fewer signatures to verify. We therefore expect to see a reduction in latency. We would like to see if there is a measurable performance improvement.
What fraction of clients will stay up to date? Getting the performance benefit of MTCs requires the clients and servers to be roughly in sync with one another. We expect MTCs to have fairly short lifetimes, a week or so. This means that if the client’s latest landmark is older than a week, the server would have to fallback to a larger certificate. Knowing how often this fallback happens will help us tune the parameters of the protocol to make fallbacks less likely.
In order to answer these questions, we are implementing MTC support in our TLS stack and in our certificate issuance infrastructure. For their part, Chrome is implementing MTC support in their own TLS stack and will stand up infrastructure to disseminate landmarks to their users.
As we’ve done in past experiments, we plan to enable MTCs for a subset of our free customers with enough traffic that we will be able to get useful measurements. Chrome will control the experimental rollout: they can ramp up slowly, measuring as they go and rolling back if and when bugs are found.
Which leaves us with one last question: who will run the Merkle Tree CA?
Bootstrapping trust from the existing WebPKI
Standing up a proper CA is no small task: it takes years to be trusted by major browsers. That’s why Cloudflare isn’t going to become a “real” CA for this experiment, and Chrome isn’t going to trust us directly.
Instead, to make progress on a reasonable timeframe, without sacrificing due diligence, we plan to “mock” the role of the MTCA. We will run an MTCA (on Workers based on our StaticCT logs), but for each MTC we issue, we also publish an existing certificate from a trusted CA that agrees with it. We call this the bootstrap certificate. When Chrome’s infrastructure pulls updates from our MTCA log, they will also pull these bootstrap certificates, and check whether they agree. Only if they do, they’ll proceed to push the corresponding landmarks to Chrome clients. In other words, Cloudflare is effectively just “re-encoding” an existing certificate (with domain validation performed by a trusted CA) as an MTC, and Chrome is using certificate transparency to keep us honest.
Conclusion
With almost 50% of our traffic already protected by post-quantum encryption, we’re halfway to a fully post-quantum secure Internet. The second part of our journey, post-quantum certificates, is the hardest yet though. A simple drop-in upgrade has a noticeable performance impact and no security benefit before Q-day. This means it’s a hard sell to enable today by default. But here we are playing with fire: migrations always take longer than expected. If we want to keep an ubiquitously private and secure Internet, we need a post-quantum solution that’s performant enough to be enabled by default today.
Merkle Tree Certificates (MTCs) solves this problem by reducing the number of signatures and public keys to the bare minimum while maintaining the WebPKI’s essential properties. We plan to roll out MTCs to a fraction of free accounts by early next year. This does not affect any visitors that are not part of the Chrome experiment. For those that are, thanks to the bootstrap certificates, there is no impact on security.
We’re excited to keep the Internet fast and secure, and will report back soon on the results of this experiment: watch this space! MTC is evolving as we speak, if you want to get involved, please join the IETF PLANTS mailing list.
Organizations have finite resources available to combat threats, both by the adversaries of today and those in the not-so-distant future that are armed with quantum computers. In this post, we provide guidance on what to prioritize to best prepare for the future, when quantum computers become powerful enough to break the conventional cryptography that underpins the security of modern computing systems. We describe how post-quantum cryptography (PQC) can be deployed on your existing hardware to protect from threats posed by quantum computing, and explain why quantum key distribution (QKD) and quantum random number generation (QRNG) are neither necessary nor sufficient for security in the quantum age.
Are you quantum ready?
“Quantum” is becoming one of the most heavily used buzzwords in the tech industry. What does it actually mean, and why should you care?
At its core, “quantum” refers to technologies that harness principles of quantum mechanics to perform tasks that are not feasible with classical computers. Quantum computers have exciting potential to unlock advancements in materials science and medicine, but also pose a threat to computer security systems. The term Q-day refers to the day that adversaries possess quantum computers that are large and stable enough to break the conventional public-key cryptography that secures much of today’s data and communications. Recent advances in quantum computing have made it clear that it is no longer a question of if Q-day will arrive, but when.
What does it mean, then, for your organization to be quantum ready? At Cloudflare, our definition is simple: your systems and communications should be secure even after Q-day.
However, this definition often gets muddied by vendors insisting that products built using quantum technology are required in order to secure an organization against quantum adversaries. In this blog post we explain why quantum technologies are neither necessary nor sufficient to protect against attacks by a quantum adversary.
The good news is that there is already a solution: post-quantum cryptography (PQC). PQC protects against attacks by quantum adversaries, but PQC is not a quantum technology — it runs on conventional computers without specialized hardware. You can use PQC today on the computers you already have, without buying expensive new hardware.
Post-quantum cryptography
We’ve written quite a few blog posts on post-quantum cryptography already, so we will keep this section brief.
The public-key cryptography that we’ve used for decades to secure our data and communications is based on math problems (like factoring large numbers) that are believed to be computationally hard to solve on conventional computers. If you can efficiently solve the underlying math problem, you can efficiently break the cryptography and the systems that depend on it. As it turns out, the math problems underlying much of today’s public-key cryptography can be efficiently solved by specialized algorithms, like Shor’s algorithm, on large-scale quantum computers.
Post-quantum cryptography (PQC) runs on your existing phones, laptops, and servers. PQC runs at Internet scale and can even be more performant than classical cryptography. Except in rare cases, like when you need additional hardware acceleration in cheap smartcards or to replace legacy systems that lack cryptographic agility, there is no need to purchase new hardware to migrate to PQC.
If you want to know how to protect your organization from security threats posed by quantum computers, you can stop reading now. Post-quantum cryptography is the solution.
Alternatively, you can read below for our perspective on hardware-based quantum security technologies that are sometimes marketed as security solutions.
This is exciting technology and fundamental scientific research. But this technology is not required to secure data and communications against quantum attackers.
In this section, we’ll explain why quantum security technologies do not need to be part of your quantum readiness strategy, and any decision to invest in quantum technology should not be based on a desire to defend data and communications systems against the threat of quantum adversaries. Instead, investments should be based on a desire to improve quantum technologies in their own right, for example to help with applications like chemistry, machine learning, and financial modeling.
Quantum key distribution (QKD) is a hardware-based solution to secure communications across point-to-point links. Rather than relying on hard mathematical problems, QKD relies on principles of quantum physics to establish a shared symmetric secret between two parties, while ensuring that eavesdropping can be detected. QKD provides security guarantees that are based on physical properties of the communication channel. Once a shared secret is established, parties can switch to traditional symmetric-key cryptography for secure communication. QKD is the first step towards a futuristic “quantum Internet.” However, there are some fundamental reasons why QKD cannot be a general replacement for classical cryptography running on conventional hardware.
Most importantly, QKD does not operate at Internet scale. QKD is used to establish an unauthenticated secret between pairs of parties with a direct physical link between them. The parties can then use an authentication mechanism based on conventional cryptography to bootstrap a secure communication channel over that link. While building dedicated physical links may be feasible for cross-datacenter communication or across major Internet backbones, it is not possible for most pairs of parties on the Internet. In particular, deploying QKD for the “last-mile” connection to end-user devices would require that each device has a direct physical connection to every server or device it needs to securely communicate with.
Connectivity aside, there’s a good reason why the Internet doesn’t rely on secure point-to-point links: they do not scale (or rather, they scale exponentially). Bringing a new device online would require a change to every other device it needs to communicate with, a massive operational burden on everyone. Fortunately, there’s a better way. The OSI model for networking provides an abstraction such that two parties can communicate even if they don’t share a direct physical link, so long as some chain of physical links exists between them. Public-key cryptography, invented in the seminal “New Directions in Cryptography” paper in 1976, allows two parties participating in the same public-key infrastructure to establish a secure end-to-end encrypted communication channel, without requiring any prior setup between them. The massive scaling enabled by these technologies is why the secure Internet exists as we know it. Secure point-to-point links are not part of the solution.
Lack of scalability is enough for us to disqualify QKD outright: if a technology can’t bring security to the whole Internet, we’re not going to spend much time on it.
The challenges with QKD don’t stop there though.
QKD touts theoretical security guarantees, but achieving security in practice is not so simple. QKD systems have been plagued by implementation attacks, both classical sidechannel attacks and new ones specific to the technology. Further, QKD works best over a special medium: either fiber or a vacuum. QKD has been demonstrated over the air, but performance and the implementation security mentioned before suffers. We still have not seen QKD work on a mobile phone or over Wi-Fi networks.
Further, neither QKD nor any other quantum technologies provide authentication to prove that the party on the other end of the key exchange is who you think they are. This opens the door for a classic monster in the middle (MITM) attack, where an adversary intercepts your connection, establishes a separate secure QKD link to you and your intended destination, and then sits in the middle reading and relaying all traffic. To prevent this, you must authenticate the identity of the party you are connecting to, using either pre-shared keys or conventional public-key cryptography. The bottom line is, whether or not you invest in QKD, you still need a solution for authentication to protect against active attackers armed with quantum computers. Practically speaking, that means you need PQC, but PQC is already a standalone solution that provides both authentication and key agreement, which leads to questions of why use QKD in the first place.
Some proponentsargue that QKD should be integrated into existing systems as an extra security layer. The value proposition of QKD relates to the “harvest now, decrypt later” threat. In public-key cryptography, the key exchange messages used to set up encryption keys to secure a communication channel are exchanged in full view of a potential adversary. If an adversary records the key exchange messages, they might hope to use improved techniques in the future to solve the hard math problems upon which the security of the key exchange relies, allowing them to recover the encryption keys and decrypt the communication. If encryption keys are exchanged directly via QKD instead, the eavesdropper protections provided by QKD stop an adversary from recording messages that could later allow them to recover the encryption key (e.g. by using a quantum computer or other advances in cryptanalysis). The problem is, however, that this “extra security layer” is brittle, and limited to a single physical link. As soon as the data is transmitted elsewhere — for instance at an Internet exchange point or to travel to an end-user — the QKD security ends. For the rest of its journey, the data is protected by standard protocols like TLS, making the value of the initial QKD link questionable.
While we hope the technology progresses, QKD is neither necessary nor sufficient for security against a quantum adversary. PQC is sufficient for security against a quantum adversary, already runs on your existing hardware, and works everywhere.
In cryptography and computer security, the essential property required from a random number generator is that the outputs are unpredictable and unbiased. This can be achieved by taking a small seed (say, 256 bits) of true randomness and feeding it to a cryptographically-secure pseudorandom number generator (CSPRNG) to produce an essentially limitless stream of pseudorandom output indistinguishable from true randomness. The randomness used to seed the CSPRNG can be based on either classical or quantum physical processes, as long as it is not known to the adversary. Whether or not you use a QRNG to generate the seed, a CSPRNG is essential for cryptographic applications.
We are the first to get excited about funnewsources of randomness. However, we’d like to emphasize that randomness derived from quantum effects is not necessary to combat threats from quantum computers. Quantum computers do not enable any practical new attacks against classical TRNGs in widespread use today. Your decision to invest in QRNGs should be based on a perceived improvement in the quality of randomness they produce and not on a perceived threat to classical TRNGs from quantum computing.
Post-quantum cryptography at Cloudflare
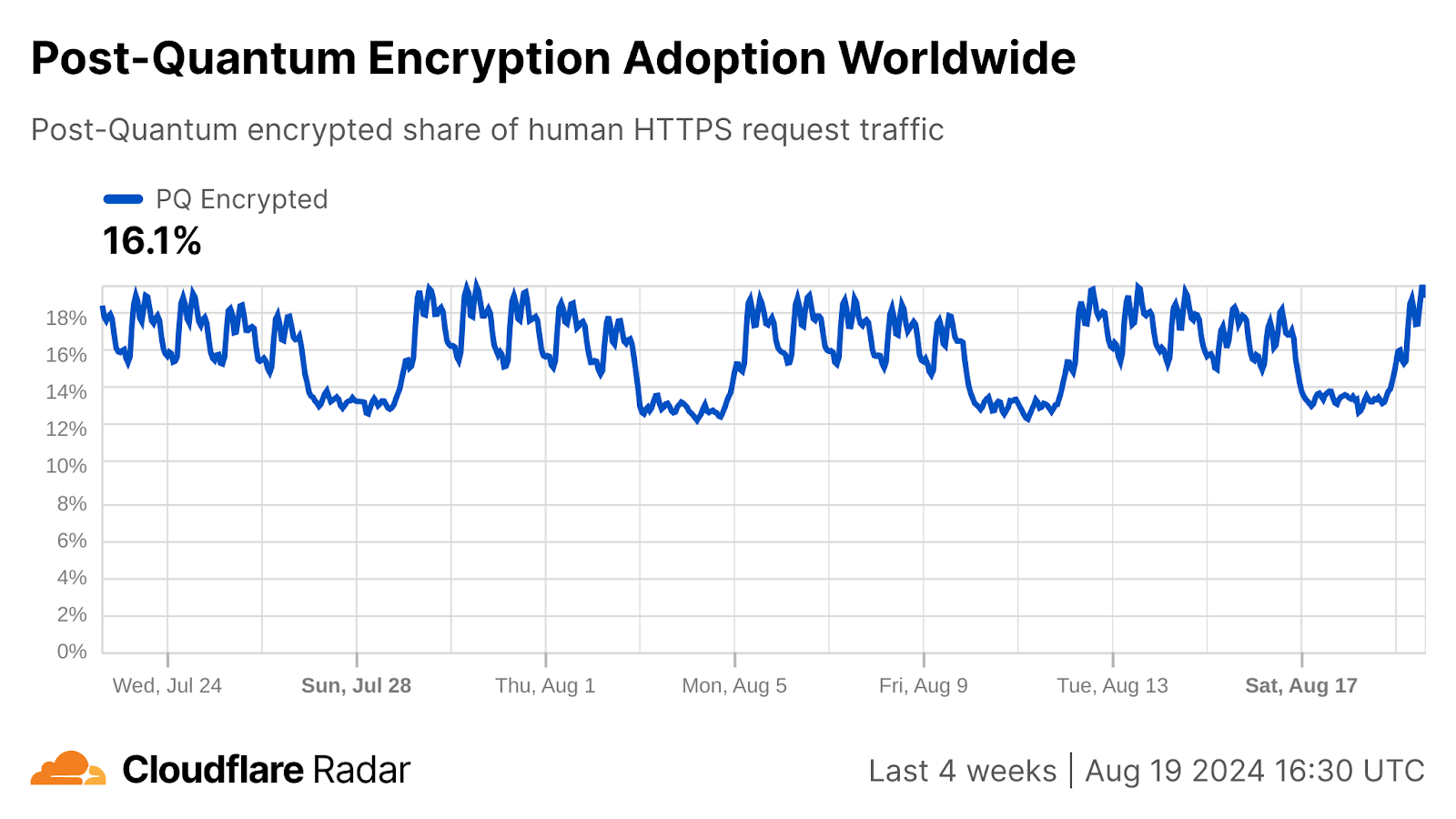
Cloudflare has been at the forefront of developing and deploying PQC, and we are committed to making PQC available for free and by default for all of our products. And we run it at scale — already over 40% of the human-generated traffic to our network uses PQC.
So what’s in that 40%? PQC is supported for all website and API traffic served through Cloudflare, most of Cloudflare’s internal network traffic, and traffic running over our Zero-Trust platform. All these connections use post-quantum key agreement to protect against the “harvest now, decrypt later” threat, where an adversary intercepts and stores encrypted data today with the hope of decrypting with a quantum computer or other cryptanalytic advances in the future. Key agreement is an important first step, but there’s still more work to be done. We’re actively working with stakeholders in the industry to prepare for the upcoming migration to post-quantum signatures to prevent active impersonation attacks from quantum adversaries (after Q-day).
Quantum readiness strategy
If purchasing quantum hardware is not necessary, how should organizations prepare for a quantum future? The most effective strategy will depend on your organization’s individual needs, but some general strategies will pay off for most organizations:
Investing in basic security practices is a good start. Hire the right expertise if you don’t already have it. Find vendors that support post-quantum encryption in their offerings today, and whose products are cryptographically agile so you can enjoy a seamless transition to post-quantum signatures and certificates when the industry migrates before Q-day. Follow a tunneling strategy: routing application traffic over the Internet via secure quantum safe tunnels allows you to reduce your attack surface area with minimal changes to existing systems. If you’re already a Cloudflare customer (or want to be), our Content Distribution Network and Zero Trust platform makes this easy. Learn more about how we can help at our Post-Quantum Cryptography webpage.
Any public certification authority (CA) can issue a certificate for any website on the Internet to allow a webserver to authenticate itself to connecting clients. Take a moment to scroll through the list of trusted CAs for your web browser (e.g., Chrome). You may recognize (and even trust) some of the names on that list, but it should make you uncomfortable that any CA on that list could issue a certificate for any website, and your browser would trust it. It’s a castle with 150 doors.
Certificate Transparency (CT) plays a vital role in the Web Public Key Infrastructure (WebPKI), the set of systems, policies, and procedures that help to establish trust on the Internet. CT ensures that all website certificates are publicly visible and auditable, helping to protect website operators from certificate mis-issuance by dishonest CAs, and helping honest CAs to detect key compromise and other failures.
In this post, we’ll discuss the history, evolution, and future of the CT ecosystem. We’ll cover some of the challenges we and others have faced in operating CT logs, and how the new static CT API log design lowers the bar for operators, helping to ensure that this critical infrastructure keeps up with the fast growth and changing landscape of the Internet and WebPKI. We’re excited to open source our Rust implementation of the new log design, built for deployment on Cloudflare’s Developer Platform, and to announce test logs deployed using this infrastructure.
What is Certificate Transparency?
In 2011, the Dutch CA DigiNotar was hacked, allowing attackers to forge a certificate for *.google.com and use it to impersonate Gmail to targeted Iranian users in an attempt to compromise personal information. Google caught this because they used certificate pinning, but that technique doesn’t scale well for the web. This, among other similar attacks, led a team at Google in 2013 to develop Certificate Transparency (CT) as a mechanism to catch mis-issued certificates. CT creates a public audit trail of all certificates issued by public CAs, helping to protect users and website owners by holding CAs accountable for the certificates they issue (even unwittingly, in the event of key compromise or software bugs). CT has been a great success: since 2013, over 17 billion certificates have been logged, and CT was awarded the prestigious Levchin Prize in 2024 for its role as a critical safety mechanism for the Internet.
Let’s take a brief look at the entities involved in the CT ecosystem. Cloudflare itself operates the Nimbus CT logs and the CT monitor powering the Merkle Towndashboard.
Certification Authorities (CAs) are organizations entrusted to issue certificates on behalf of website operators, which in turn can use those certificates to authenticate themselves to connecting clients.
CT-enforcing clients like the Chrome, Safari, and Firefox browsers are web clients that only accept certificates compliant with their CT policies. For example, a policy might require that a certificate includes proof that it has been submitted to at least two independently-operated public CT logs.
Log operators run CT logs, which are public, append-only lists of certificates. CAs and other clients can submit a certificate to a CT log to obtain a “promise” from the CT log that it will incorporate the entry into the append-only log within some grace period. CT logs periodically (every few seconds, typically) update their log state to incorporate batches of new entries, and publish a signed checkpoint that attests to the new state.
Monitors are third parties that continuously crawl CT logs and check that their behavior is correct. For instance, they verify that a log is self-consistent and append-only by ensuring that when new entries are added to the log, no previous entries are deleted or modified. Monitors may also examine logged certificates to help website operators detect mis-issuance.
Challenges in operating a CT log
Despite the success of CT, it is a less than perfect system. Eric Rescorla has an excellent writeup on the many compromises made to make CT deployable on the Internet of 2013. We’ll focus on the operational complexities of running a CT log.
Let’s look at the requirements for running a CT log from Chrome’s CT log policy (which are more or less mirrored by those of Safari and Firefox), and what can go wrong. The requirements center around integrity and availability.
To be considered a trusted auditing source, CT logs necessarily have stringent integrity requirements. Anything the log produces must be correct and self-consistent, meaning that a CT log cannot present two different views of the log to different clients, and must present a consistent history for its entire lifetime. Similarly, when a CT log accepts a certificate and promises to incorporate it by returning a Signed Certificate Timestamp (SCT) to the client, it must eventually incorporate that certificate into its append-only log.
The integrity requirements are unforgiving. A single bit-flip due to a hardware failure or cosmic ray can (andhas) caused logs to produce incorrect results and thus be disqualified by CT programs. Even software updates to running logs can be fatal, as a change that causes a correctness violation cannot simply be rolled back. Perhaps the greatest risk to individual log integrity is failing to incorporate certificates for which they issued SCTs, for example if they fail to commit those pending certificates to durable storage. See Andrew Ayer’s great synopsis for more examples of CT log failures (up to 2021).
A CT log must also meet certain availability requirements to effectively provide its core functionality as a publicly auditable log. Clients must be able to reliably retrieve log data — Chrome’s policy requires a minimum of 99% average uptime over a 90-day rolling period for each API endpoint — and any entries for which an SCT has been issued must be incorporated into the log within the grace period, called the Maximum Merge Delay (MMD), 24 hours in Chrome’s policy.
The design of the current CT log read APIs puts strain on the ability of log operators to meet uptime requirements. The API endpoints are dynamic and not easily cacheable without bespoke caching rules that are aware of the CT API. For instance, the get-entries endpoint allows a client to request arbitrary ranges of entries from a log, and the get-proof-by-hash requires the server to construct inclusion proofs for any certificate requested by the client. To serve these requests, CT log servers need to be backed by databases easily 5-10TB in size capable of serving tens of millions of requests per day. This increases operator complexity and expense, not to mention the high cost of bandwidth of serving these requests.
MMD violations are unfortunately not uncommon. Cloudflare’s own Nimbus logs have experienced prolonged outages in the past, most recently in November 2023 due to complete power loss in the datacenter running the logs. During normal log operation, if the log accepts entries more quickly than it incorporates them, the backlog can grow to exceed the MMD. Log operators can remedy this by rate-limiting or temporarily disabling the write APIs, but this can in turn contribute to violations of the uptime requirements.
The high bar for log operation has limited the organizations operating CT logs to only Cloudflare and five others! Losing one or two logs is enough to compromise the stability of the CT ecosystem. Clearly, a change is needed.
A next-generation CT log design
In May 2024, Let’s Encrypt announcedSunlight, an implementation of a next-generation CT log designed for the modern WebPKI, incorporating a decade of lessons learned from running CT and similar transparency systems. The new CT log design, called the static CT API, is partially based on the Go checksum database, and organizes log data as a series of tiles that are easy to cache and serve. The new design provides efficiency improvements that cut operation costs, help logs to meet availability requirements, and reduce the risk of integrity violations.
The static CT API is split into two parts, the monitoring APIs (so named because CT monitors are the primary clients), and the submission APIs for adding new certificates to the log.
The monitoring APIs replace the dynamic read APIs of RFC 6962, and organize log data into static, cacheable tiles. (See Russ Cox’s blog post for an in-depth explanation of tiled logs.) CT log operators can efficiently serve static tiles from S3-compatible object storage buckets and cache them using CDN infrastructure, without needing dedicated API servers. Clients can then download the necessary tiles to retrieve specific log entries or reconstruct arbitrary proofs.
The static CT API introduces another efficiency by deduplicating intermediate and root “issuer” certificates in a log entry’s certificate chain. The number of publicly-trusted issuer certificates is small (in the low thousands), so instead of storing them repeatedly for each log entry, only the issuer hash is stored. Clients can look up issuer certificates by hash from a separate endpoint.
The submission APIs remain backwards-compatible with RFC 6962, meaning that TLS clients and CAs can submit to them without any changes. However, there is one notable addition: the static CT specification requires logs to hold on to requests as it batches and sequences them, and responds with an SCT only after entries have been incorporated into the log. The specification defines a required SCT extension indicating the entry’s index in the log. At the cost of slightly delayed SCT issuance (on the order of seconds), this change eliminates one of the major pain points of operating a CT log (the Merge Delay).
Having the log index of a certificate available in an SCT enables further efficiencies. SCT auditing refers to the process by which TLS clients or monitors can check if a log has fulfilled its promise to incorporate a certificate for which it has issued an SCT. In the RFC 6962 API, checking if a certificate is present in a log when you don’t already know the index requires using the get-proof-by-hash endpoint to look up the entry by the certificate hash (and the server needs to maintain a mapping from hash to index to efficiently serve these requests). Instead, with the index immediately available in the SCT, clients can directly retrieve the specific log data tile covering that index, even with efficient privacy-preserving techniques.
Since it was announced, the static CT API has taken the CT ecosystem by storm. Aside from Sunlight and our brand new Azul (discussed below), there are at least two other independent implementations, Itko and Trillian Tessera. Several CT monitors (including crt.sh, certspotter, Censys, and our own Merkle Town) have added support for the new log format, and as of April 1, 2025, Chrome has begun accepting submissions for static CT API logs into their CT log program.
A static CT API implementation on Workers
This section discusses how we designed and built our static CT log implementation, Azul (short for azulejos, the colorful Portuguese and Spanish ceramic tiles). For curious readers and prospective CT log operators, we encourage you to follow the instructions in the repo to quickly set up your own static CT log. Questions and feedback in the form of GitHub issues are welcome!
The advent of the static CT API gave us the perfect opportunity to rethink how we run our CT logs. There were a few design decisions we made early on to shape the project.
First and foremost, we wanted to run our CT logs on our distributed global network. Especially after the painful November 2023 control plane outage, there’s been a push to deploy services on our highly available and resilient network instead of running in centralized datacenters.
Second, with Cloudflare’s deeply engrained culture of dogfooding (building Cloudflare on top of Cloudflare), we decided to implement the CT log on top of Cloudflare’s Developer Platform and Workers.
Dogfooding gives us an opportunity to find pain points in our product offerings, and to provide feedback to our development teams to improve the developer experience for everyone. We restricted ourselves to only features and default limits generally available to customers, so that we could have the same experience as an external Cloudflare developer, and would produce an implementation that anyone could deploy.
Another major design decision was to implement the CT log in Rust, a modern systems programming language with static typing and built-in memory safety that is heavily used across Cloudflare, and which already has mature (if sometimes lacking full feature parity) Workers bindings that we have used to build several production services. This also provided us with an opportunity to produce Rust crates porting Go implementations of various C2SP specifications that can be reused across other projects.
For the new logs to be deployable, they needed to be at least as performant as existing CT logs. As a point of reference, the Nimbus2025 log currently handles just over 33 million requests per day (~380/s) across the read APIs, and about 6 million per day (~70/s) across the write APIs.
Implementation
We based Azul heavily on Sunlight, a Go application built for deployment as a standalone server. As such, this section serves as a reference for translating a traditional server to Cloudflare’s serverless platform.
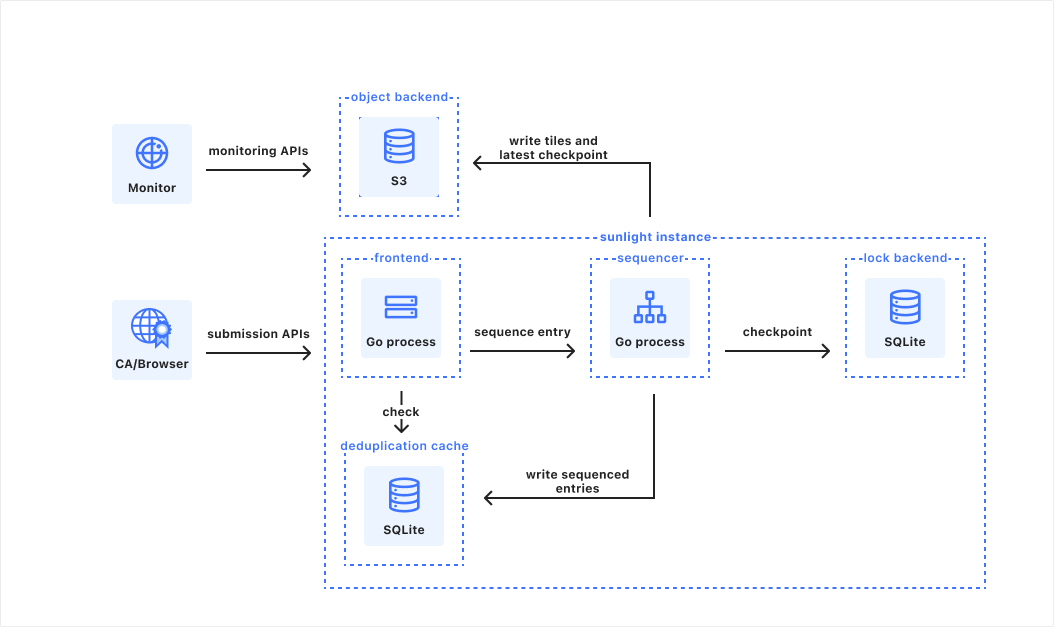
To start, let’s briefly review the Sunlight architecture (described in more detail in the README and original design doc). A Sunlight instance is a single Go process, serving one or multiple CT logs. It is backed by three different storage locations with different properties:
A “lock backend” which stores the current checkpoint for each log. This datastore needs to be strongly consistent, but only stores trivial amounts of data.
A per-log object storage bucket from which to serve tiles, checkpoints, and issuers to CT clients. This datastore needs to be strongly consistent, and to handle multiple terabytes of data.
A per-log deduplication cache, to return SCTs for previously-submitted (pre-)certificates. This datastore is best-effort (as duplicate entries are not fatal to log operation), and stores tens to hundreds of gigabytes of data.
Two major components handle the bulk of the CT log application logic:
A frontend HTTP server handles incoming requests to the submission APIs to add new certificates to the log, validates them, checks the deduplication cache, adds the certificate to a pool of entries to be sequenced, and waits for sequencing to complete before responding to the client.
The sequencer periodically (every 1s, by default) sequences the pool of pending entries, writes new tiles to the object backend, persists the latest checkpoint covering the new log state to the lock and object backends, and signals to waiting requests that the pool has been sequenced.
A static CT API log running on a traditional server using the Sunlight implementation.
Next, let’s look at how we can translate these components into ones suitable for deployment on Workers.
Making it work
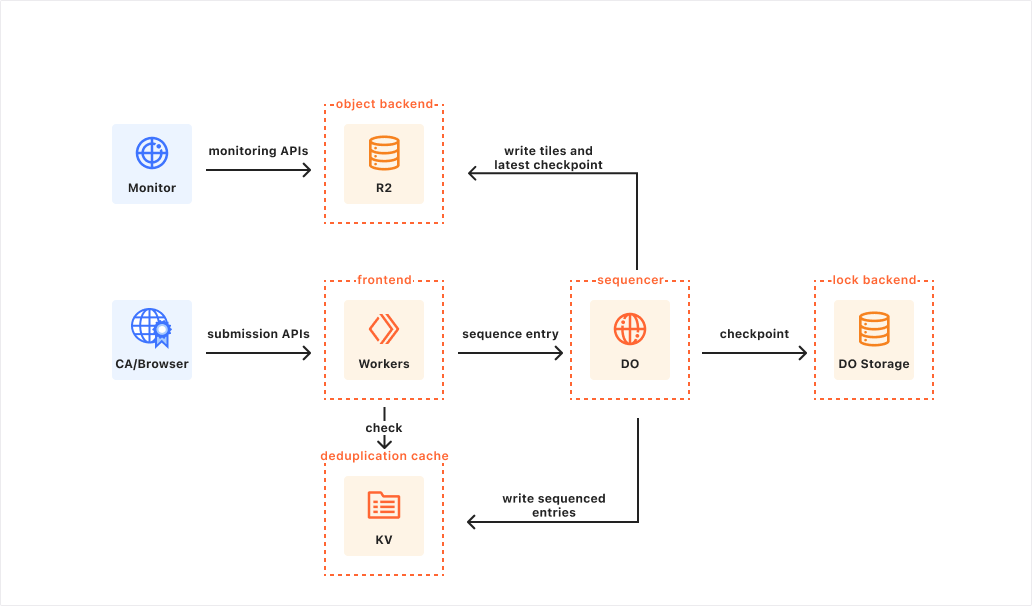
Let’s start with the easy choices. The static CT monitoring APIs are designed to serve static, cacheable, compressible assets from object storage. The API should be highly available and have the capacity to serve any number of CT clients. The natural choice is Cloudflare R2, which provides globally consistent storage with capacity for large data volumes, customizability to configure caching and compression, and unbounded read operations.
A static CT API log running on Workers using a preliminary version of the Azul implementation which ran into performance limitations.
The static CT submission APIs are where the real challenge lies. In particular, they allow CT clients to submit certificate chains to be incorporated into the append-only log. We used Workers as the frontend for the CT log application. Workers run in data centers close to the client, scaling on demand to handle request load, making them the ideal place to run the majority of the heavyweight request handling logic, including validating requests, checking the deduplication cache (discussed below), and submitting the entry to be sequenced.
The next question was where and how we’d run the backend to handle the CT log sequencing logic, which needs to be stateful and tightly coordinated. We chose Durable Objects (DOs), a special type of stateful Cloudflare Worker where each instance has persistent storage and a unique name which can be used to route requests to it from anywhere in the world. DOs are designed to scale effortlessly for applications that can be easily broken up into self-contained units that do not need a lot of coordination across units. For example, a chat application can use one DO to control each chat room. In our model, then, each CT log is controlled by a single DO. This architecture allows us to easily run multiple CT logs within a single Workers application, but as we’ll see, the limitations of individual single-threaded DOs can easily become a bottleneck. More on this later.
With the CT log backend as a Durable Object, several other components fell into place: Durable Objects’ strongly-consistent transactional storage neatly fit the requirements for the “lock backend” to persist the log’s latest checkpoint, and we can use an alarm to trigger the log sequencing every second. We can also use location hints to place CT logs in locations geographically close to clients for reduced latency, similar to Google’s Argon and Xenon logs.
The choice of datastore for the deduplication cache proved to be non-obvious. The cache is best-effort, and intended to avoid re-sequencing entries that are already present in the log. The cache key is computed by hashing certain fields of the add-[pre-]chain request, and the cache value consists of the entry’s index in the log and the timestamp at which it was sequenced. At current log submission rates, the deduplication cache could grow in excess of 50 GB for 6 months of log data. In the Sunlight implementation, the deduplication cache is implemented as a local SQLite database, where checks against it are tightly coupled with sequencing, which ensures that duplicates from in-flight requests are correctly accounted for. However, this architecture did not translate well to Cloudflare’s architecture. The data size doesn’t comfortably fit within Durable Object Storage or single-database D1 limits, and it was too slow to directly read and write to remote storage from within the sequencing loop. Ultimately, we split the deduplication cache into two components: a local fixed-size in-memory cache for fast deduplication over short periods of time (on the order of minutes), and the other a long-term deduplication cache built on Cloudflare Workers KV a global, low-latency, eventually-consistent key-value store without storage limitations.
With this architecture, it was relatively straightforward to port the Go code to Rust, and to bring up a functional static CT log up on Workers. We’re done then, right? Not quite. Performance tests showed that the log was only capable of sequencing 20-30 new entries per second, well under the 70 per second target of existing logs. We could work around this by simply running more logs, but that puts strain on other parts of the CT ecosystem — namely on TLS clients and monitors, which need to keep state for each log. Additionally, the alarm used to trigger sequencing would often be delayed by multiple seconds, meaning that the log was failing to produce new tree heads at consistent intervals. Time to go back to the drawing board.
Making it fast
In the design thus far, we’re asking a single-threaded Durable Object instance to do a lot of multi-tasking. The DO processes incoming requests from the Frontend Worker to add entries to the sequencing pool, and must periodically sequence the pool and write state to the various storage backends. A log handling 100 requests per second needs to switch between 101 running tasks (the extra one for the sequencing), plus any async tasks like writing to remote storage — usually 10+ writes to object storage and one write to the long-term deduplication cache per sequenced entry. No wonder the sequencing task was getting delayed!
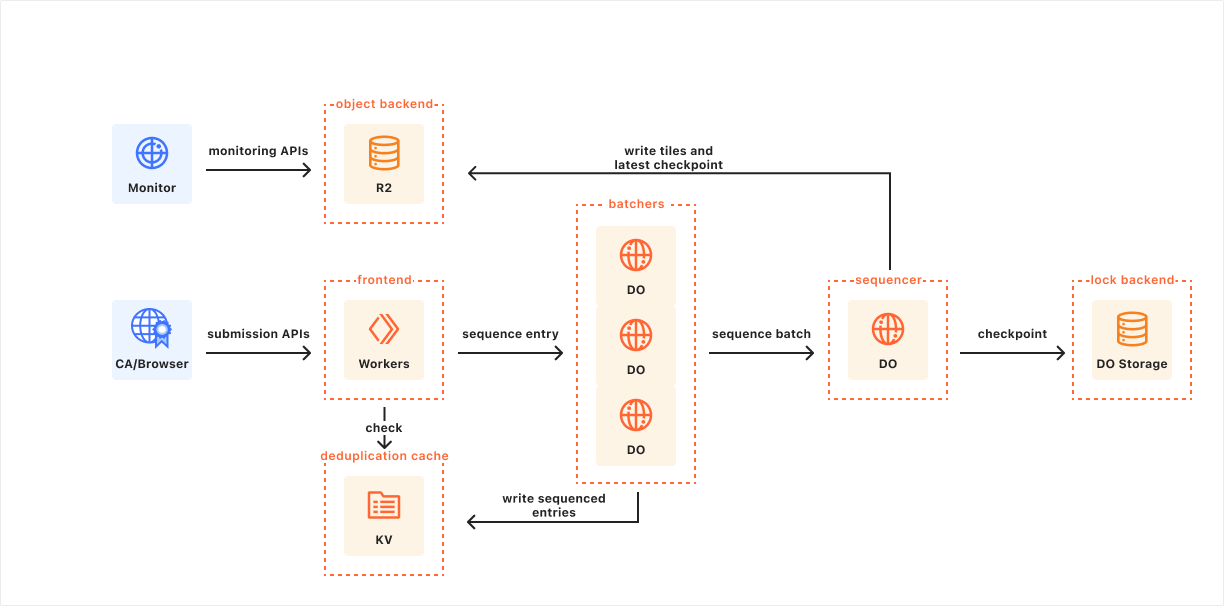
A static CT API log running on Workers using the Azul implementation with batching to improve performance.
We were able to work around these issues by adding an additional layer of DOs between the Frontend Worker and the Sequencer, which we call Batchers. The Frontend Worker uses consistent hashing on the cache key to determine which of several Batchers to submit the entry to, and the Batcher helps to reduce the number of requests to the Sequencer by buffering requests and sending them together in batches. When the batch is sequenced, the Batcher distributes the responses back to the Frontend Workers that submitted the request. The Batcher also handles writing updates to the deduplication cache, further freeing up resources for the Sequencer.
By limiting the scope of the critical block of code that needed to be run synchronously in a single DO, and leaning on the strengths of DOs by scaling horizontally where the workload allows it, we were able to drastically improve application performance. With this new architecture, the CT log application can handle upwards of 500 requests per second to the submission APIs to add new log entries, while maintaining a consistent sequencing tempo to keep per-request latency low (typically 1-2 seconds).
Developing a Workers application in Rust
One of the reasons I was excited to work on this project is that it gave me an opportunity to implement a Workers application in Rust, which I’d never done from scratch before. Not everything was smooth, but overall I would recommend the experience.
To be clear, these rough edges are expected! The Workers platform is continuously gaining new features, and it’s natural that the Rust bindings would fall behind. As more developers rely on (and contribute to, hint hint) the Rust bindings, the developer experience will continue to improve.
What is next for Certificate Transparency
The WebPKI is constantly evolving and growing, and upcoming changes, in particular shorter certificate lifetimes and larger post-quantum certificates, are going to place significantly more load on the CT ecosystem.
The CA/Browser Forum defines a set of Baseline Requirements for publicly-trusted TLS server certificates. As of 2020, the maximum certificate lifetime for publicly-trusted certificates is 398 days. However, there is a ballot measure to reduce that period to as low as 47 days by March 2029. Let’s Encrypt is going even further, and at the end of 2024 announced that they will be offering short-lived certificates with a lifetime of only six days by the end of 2025. Based on some back-of-the-envelope calculations using statistics from Merkle Town, these changes could increase the number of logged entries in the CT ecosystem by 16-20x.
If you’ve been keeping up with this blog, you’ll also know that post-quantum certificates are on the horizon, bringing with them larger signature and public key sizes. Today, a certificate with an P-256 ECDSA public key and issuer signature can be less than 1kB. Dropping in a ML-DSA44 public key and signature brings the same certificate size to 4.6 kB, assuming the SCTs use 96-byte UOVls-pkc signatures. With these choices, post-quantum certificates could require CT logs to store 4x the amount of data per log entry.
The static CT API design helps to ensure that CT logs are much better equipped to handle this increased load, especially if the load is distributed across multiple logs per operator. Our new implementation makes it easy for log operators to run CT logs on top of Cloudflare’s infrastructure, adding more operational diversity and robustness to the CT ecosystem. We welcome feedback on the design and implementation as GitHub issues, and encourage CAs and other interested parties to start submitting to and consuming from our test logs.
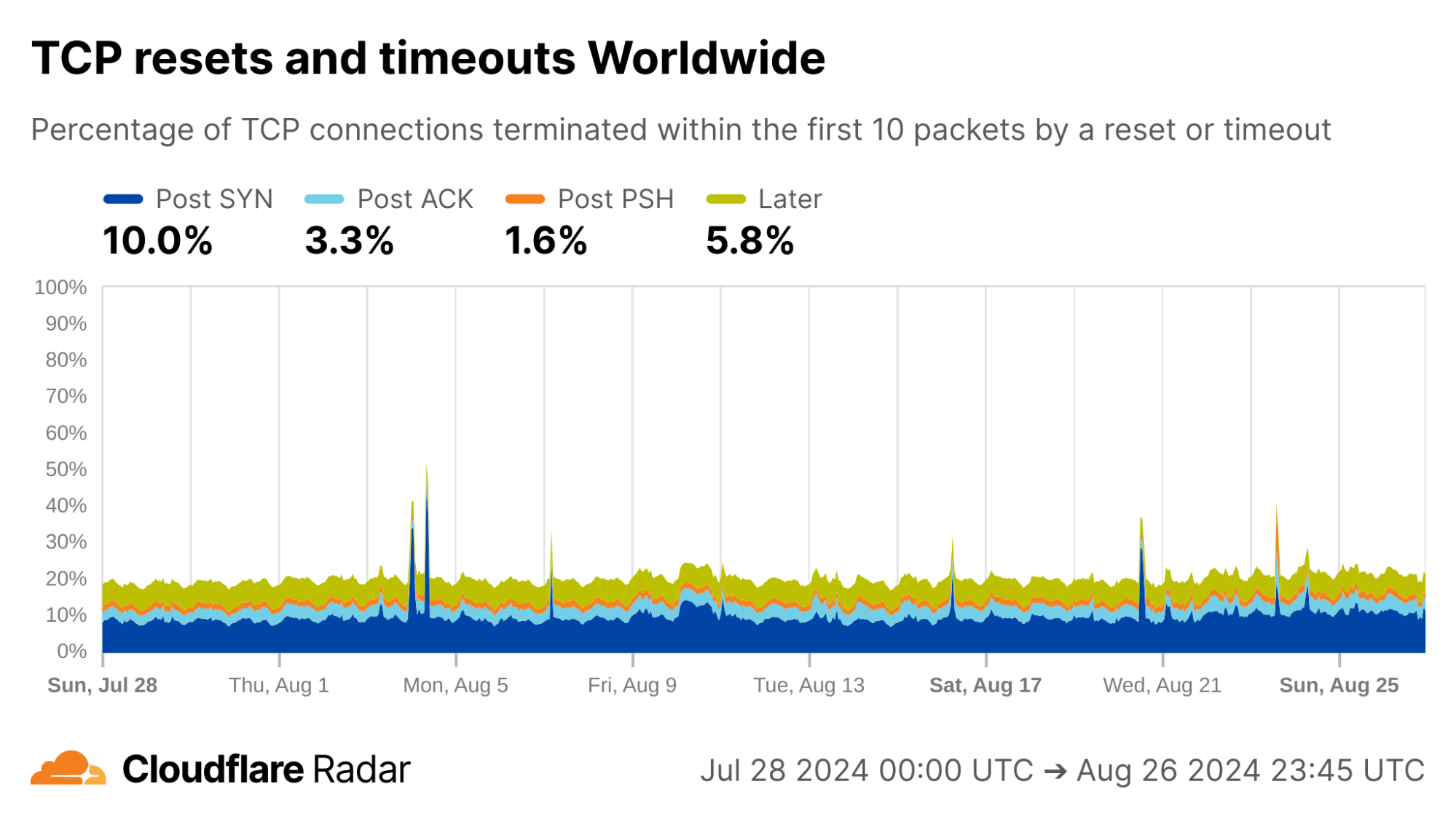
Cloudflare handles over 60 million HTTP requests per second globally, with approximately 70% received over TCP connections (the remaining are QUIC/UDP). Ideally, every new TCP connection to Cloudflare would carry at least one request that results in a successful data exchange, but that is far from the truth. In reality, we find that, globally, approximately 20% of new TCP connections to Cloudflare’s servers time out or are closed with a TCP “abort” message either before any request can be completed or immediately after an initial request.
This post explores those connections that, for various reasons, appear to our servers to have been halted unexpectedly before any useful data exchange occurs. Our work reveals that while connections are normally ended by clients, they can also be closed due to third-party interference. Today we’re excited to launch a new dashboard and API endpoint on Cloudflare Radar that shows a near real-time view of TCP connections to Cloudflare’s network that terminate within the first 10 ingress packets due to resets or timeouts, which we’ll refer to as anomalous TCP connections in this post. Analyzing this anomalous behavior provides insights into scanning, connection tampering, DoS attacks, connectivity issues, and other behaviors.
Our ability to generate and share this data via Radar follows from a global investigation into connection tampering. Readers are invited to read the technical details in the peer-review study, or see its corresponding presentation. Read on for a primer on how to use and interpret the data, as well as how we designed and deployed our detection mechanisms so that others might replicate our approach.
To begin, let’s discuss our classification of normal vs anomalous TCP connections.
TCP connections from establishment to close
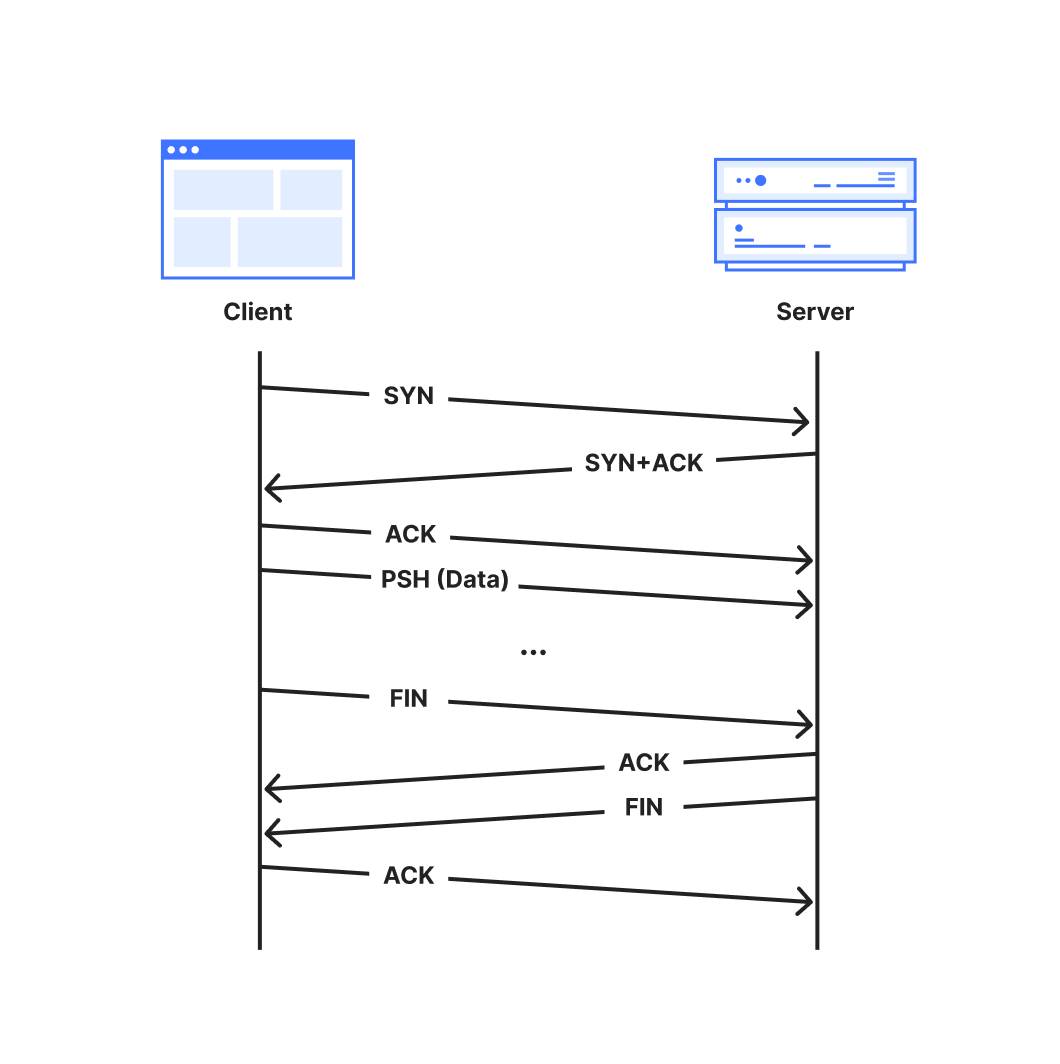
The Transmission Control Protocol (TCP) is a protocol for reliably transmitting data between two hosts on the Internet (RFC 9293). A TCP connection passes through several distinct stages, from connection establishment, to data transfer, to connection close.
A TCP connection is established with a 3-way handshake. The handshake begins when one party, called the client, sends a packet marked with the ‘SYN’ flag to initialize the connection process. The server responds with a “SYN+ACK” packet where the ‘ACK’ flag acknowledges the client’s initialization ‘SYN’. Additional synchronization information is included in both the initialization packet and its acknowledgement. . Finally, the client acknowledges the server’s SYN+ACK packet with a final ACK packet to complete the handshake.
The connection is then ready for data transmission. Typically, the client will set the PSH flag on the first data-containing packet to signal to the server’s TCP stack to forward the data immediately up to the application. Both parties continue to transfer data and acknowledge received data until the connection is no longer needed, at which point the connection is closed.
RFC 9293 describes two ways in which a TCP connection may be closed:
The normal and graceful TCP close sequence uses a FIN exchange. Either party can send a packet with the FIN flag set to indicate that they have no more data to transmit. Once the other party acknowledges that FIN packet, that direction of the connection is closed. When the acknowledging party is finished transmitting data, it transmits its own FIN packet to close, since each direction of the connection must be closed independently.
An abort or “reset” signal in which one party transmits RST packets, instructing the other party to immediately close and discard any connection state. Resets are generally sent when some unrecoverable error has occurred.
The full lifetime of a connection that closes gracefully with a FIN is captured in the following sequence diagram.
A normal TCP connection starts with a 3-way handshake and ends with a FIN handshake
Additionally, a TCP connection may be terminated by a timeout which specifies the maximum duration that a connection can be active without receiving data or acknowledgements. An inactive connection, for example, can be kept open with keepalive messages. Unless overridden, the global default duration specified in RFC 9293 is five minutes.
We consider TCP connections anomalous when they close via either a reset or timeout from the client side.
Sources of anomalous connections
Anomalous TCP connections may not themselves be problematic but they can be a symptom of larger issues, especially when occurring at early (pre-data) stages of TCP connections. Below is a non-exhaustive list of potential reasons that we might observe resets or timeouts:
Scanners: Internet scanners may send a SYN packet to probe if a server responds on a given port, but otherwise fail to clean up a connection once the probe has elicited a response from the server.
Sudden Application Shutdowns: Applications might abruptly close open connections if they are no longer required. For example, web browsers may send RSTs to terminate connections after a tab is closed, or connections can time out if devices lose power or connectivity.
Network Errors: Unstable network conditions (e.g., a severed cable connection could result in connection timeouts)
Attacks: A malicious client may send attack traffic that appears as anomalous connections. For instance, in a SYN flood (half-open) attack, an attacker repeatedly sends SYN packets to a target server in an attempt to overwhelm resources as it maintains these half-opened connections.
Tampering: Firewalls or other middleboxes capable of intercepting packets between a client and server may drop packets, causing timeouts at the communicating parties. Middleboxes capable of deep packet inspection (DPI) might also leverage the fact that the TCP protocol is unauthenticated and unencrypted to inject packets to disrupt the connection state. See our accompanying blog post for more details on connection tampering.
Understanding the scale and underlying reasons for anomalous connections can help us to mitigate failures and build a more robust and reliable network. We hope that sharing these insights publicly will help to improve transparency and accountability for networks worldwide.
How to use the dataset
In this section, we provide guidance and examples of how to interpret the TCP resets and timeouts dataset by broadly describing three use cases: confirming previously-known behaviors, exploring new targets for followup study, and longitudinal studies to capture changes in network behavior over time.
In each example, the plot lines correspond to the stage of the connection in which the anomalous connection closed, which provides valuable clues into what might have caused the anomaly. We place each incoming connection into one of the following stages:
Post-SYN (mid-handshake): Connection resets or timeouts after the server received a client’s SYN packet. Our servers will have replied, but no acknowledgement ACK packet has come back from the client before the reset or timeout. Packet spoofing is common at this connection stage, so geolocation information is especially unreliable.
Post-ACK (immediately post-handshake): Connection resets or timeouts after the handshake completes and the connection is established successfully. Any subsequent data, that may have been transmitted, never reached our servers.
Post-PSH (after first data packet): Connection resets or timeouts after the server received a packet with the PSH flag set. The PSH flag indicates that the TCP packet contains data (such as a TLS Client Hello message) that is ready to be delivered to the application.
Later (after multiple data packets): Connection resets within the first 10 packets from the client, but after the server has received multiple data packets.
None: All other connections.
To keep focus on legitimate connections, the dataset is constructed after connections are processed and filtered by Cloudflare’s attack mitigation systems. For more details on how we construct the dataset, see below.
Start with a self-evaluation
To start, we encourage readers to visit the dashboard on Radar to view the results worldwide, and for their own country and ISP.
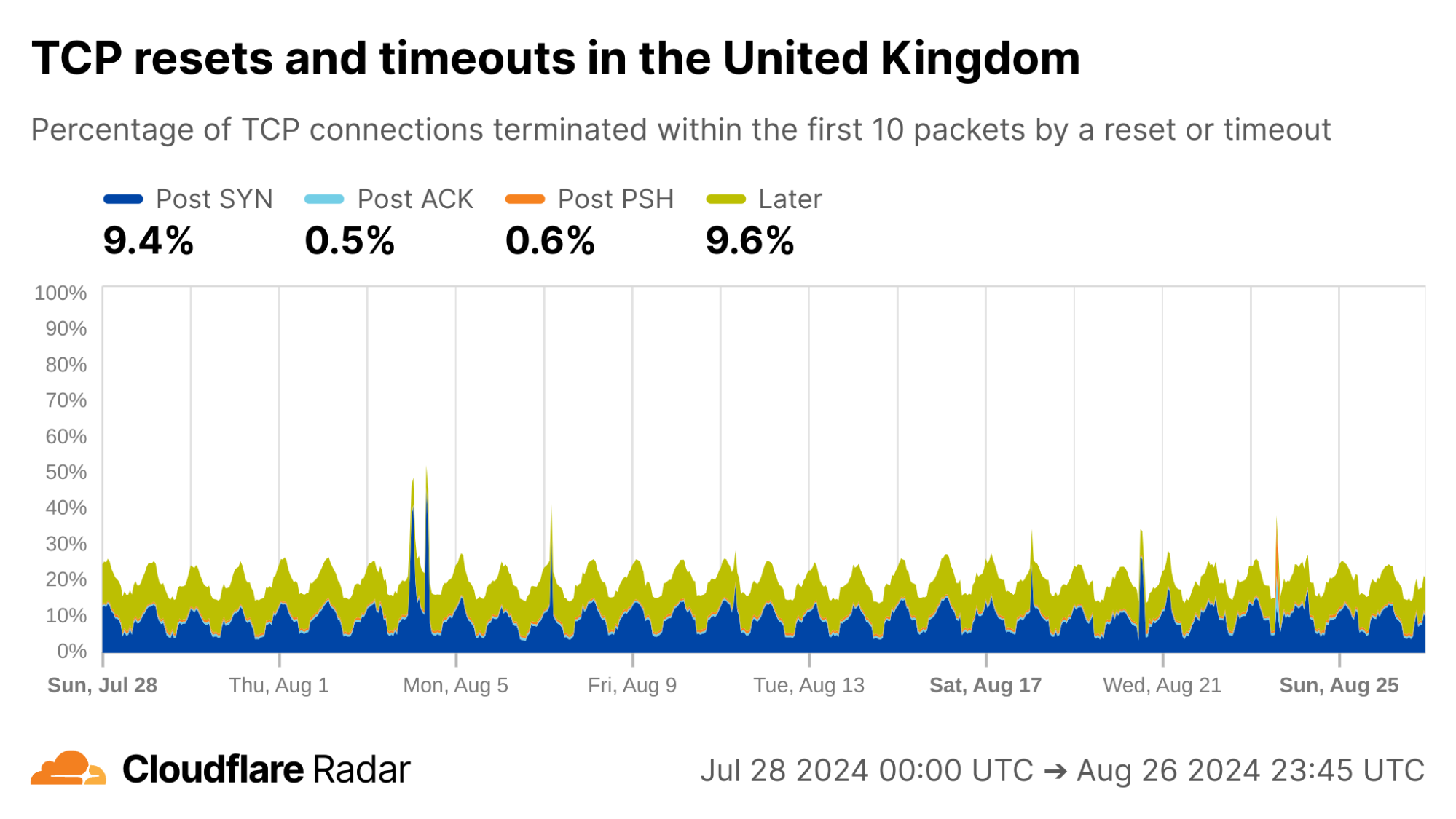
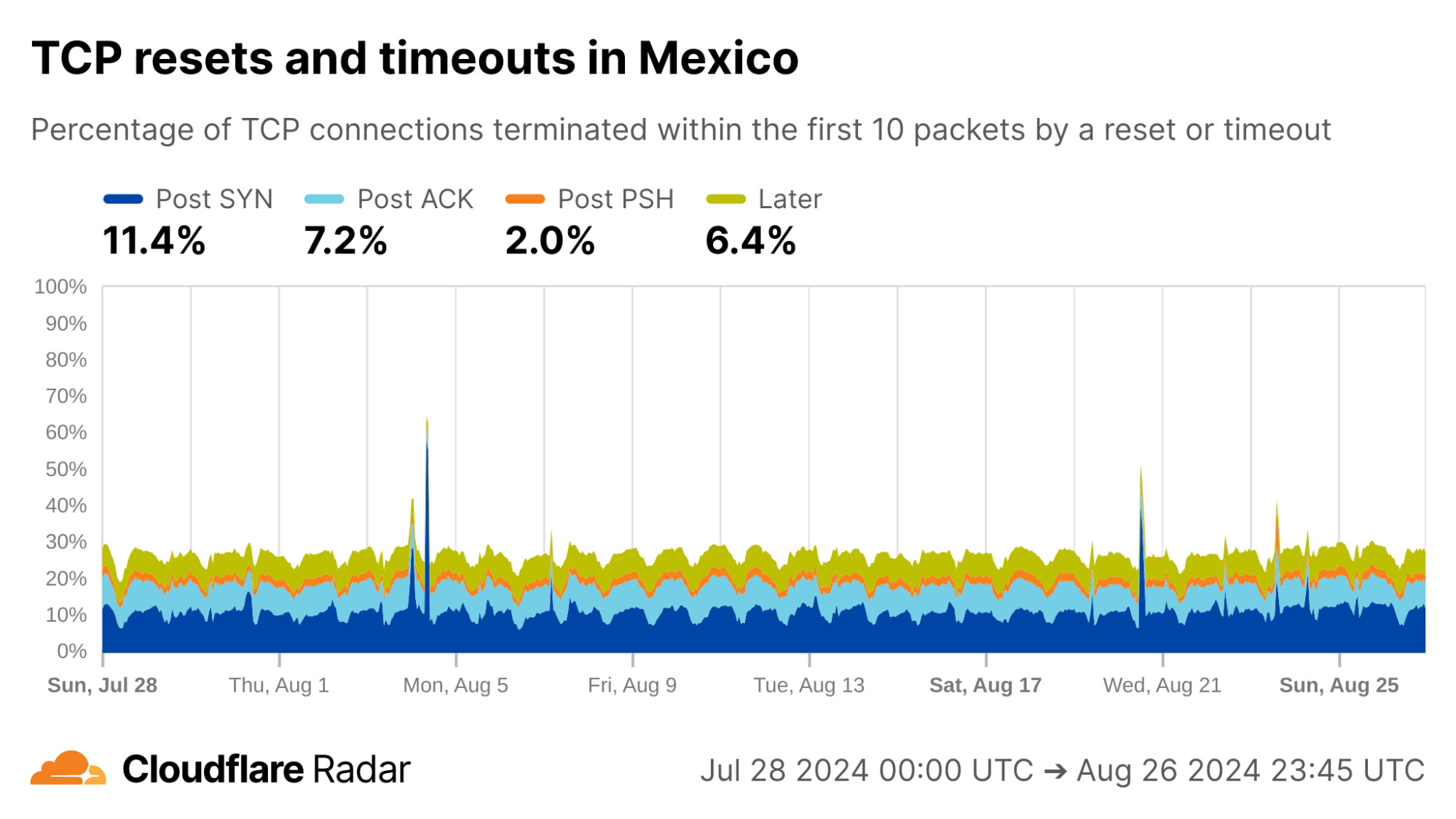
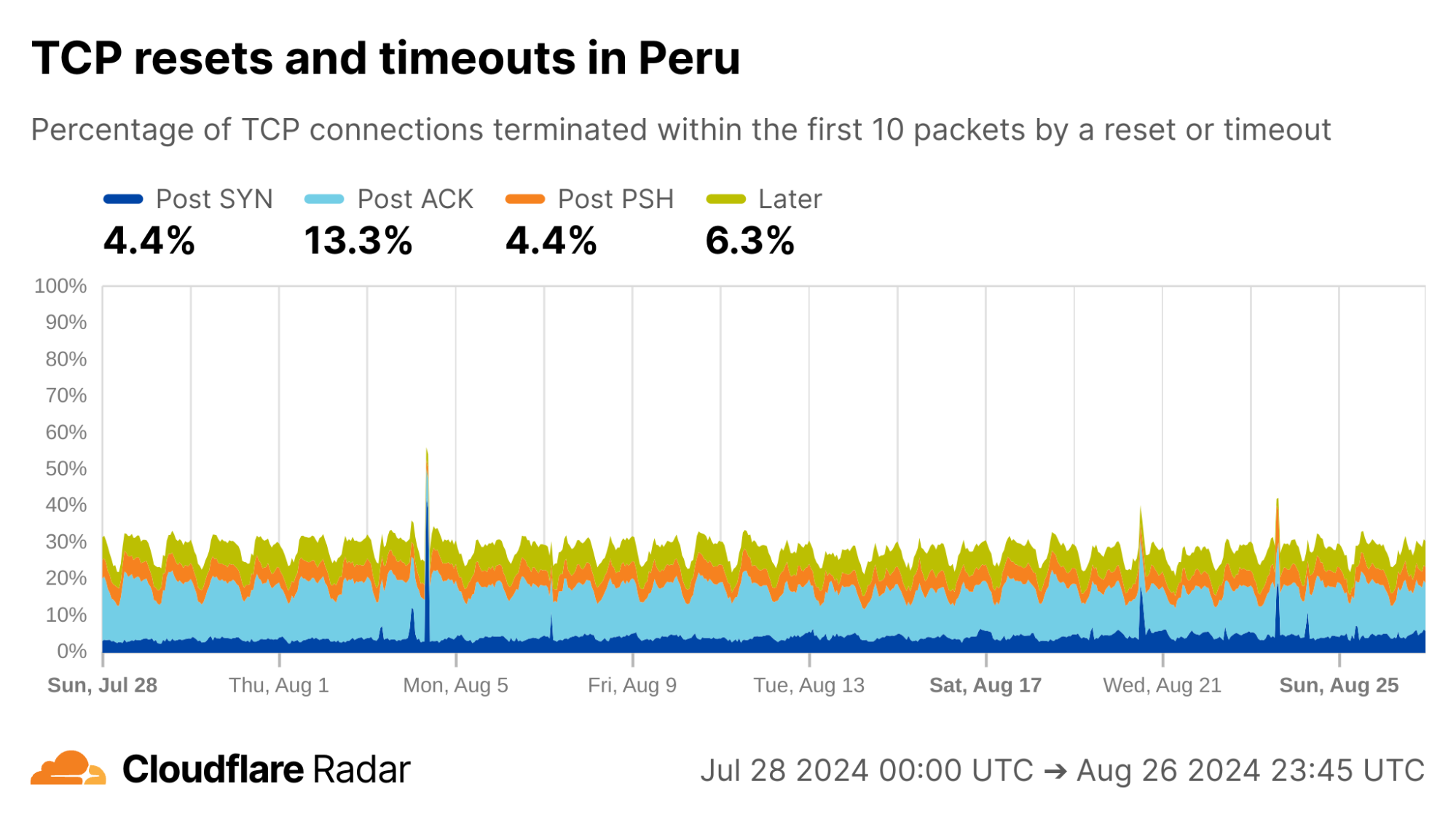
Globally, as shown below, about 20% of new TCP connections to Cloudflare’s network are closed by a reset or timeout within the first 10 packets from the client. While this number seems astonishingly high, it is in-line with prior studies. As we’ll see, rates of resets and timeouts vary widely by country and network, and this variation is lost in the global averages.
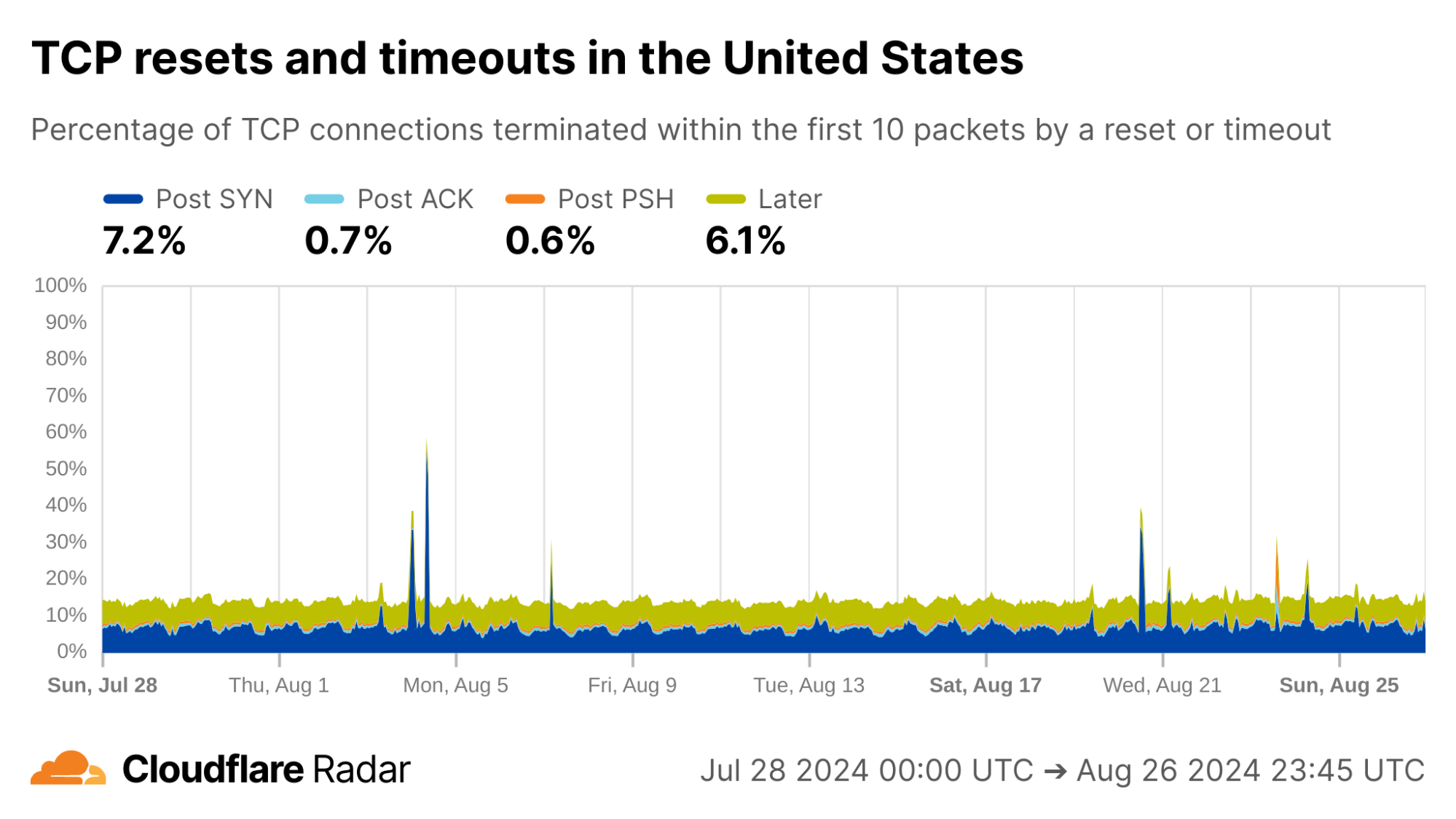
The United States, my home country, shows anomalous connection rates slightly lower than the worldwide averages, largely due to lower rates for connections closing in the Post-ACK and Post-PSH stages (those stages are more reflective of middlebox tampering behavior). The elevated rates of Post-SYN are typical in most networks due to scanning, but may include packets that spoof the true client’s IP address. Similarly, high rates of connection resets in the Later connection stage (after the initial data exchange, but still within the first 10 packets) might be applications responding to human actions, such as browsers using RSTs to close unwanted TCP connections after a tab is closed.
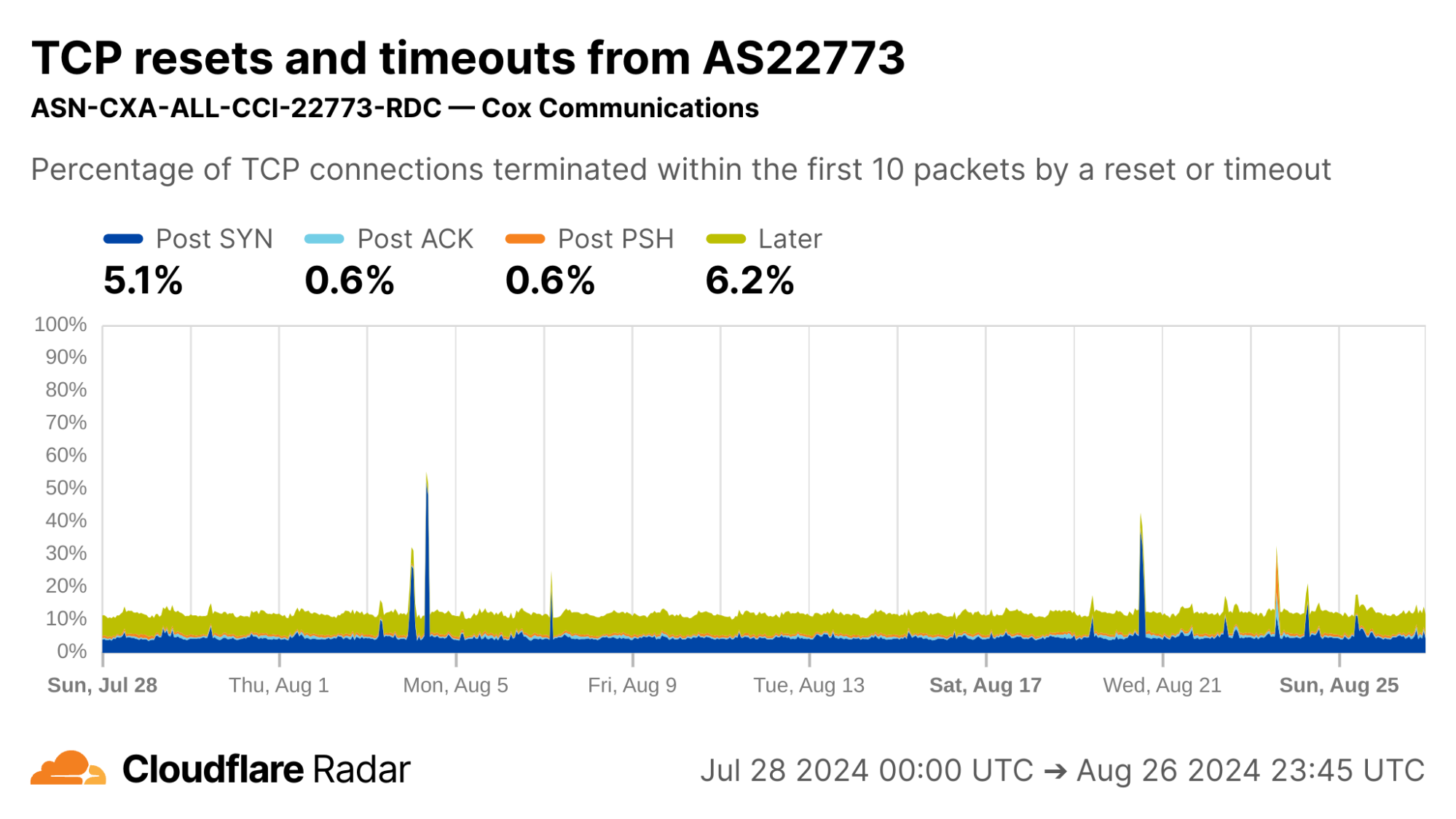
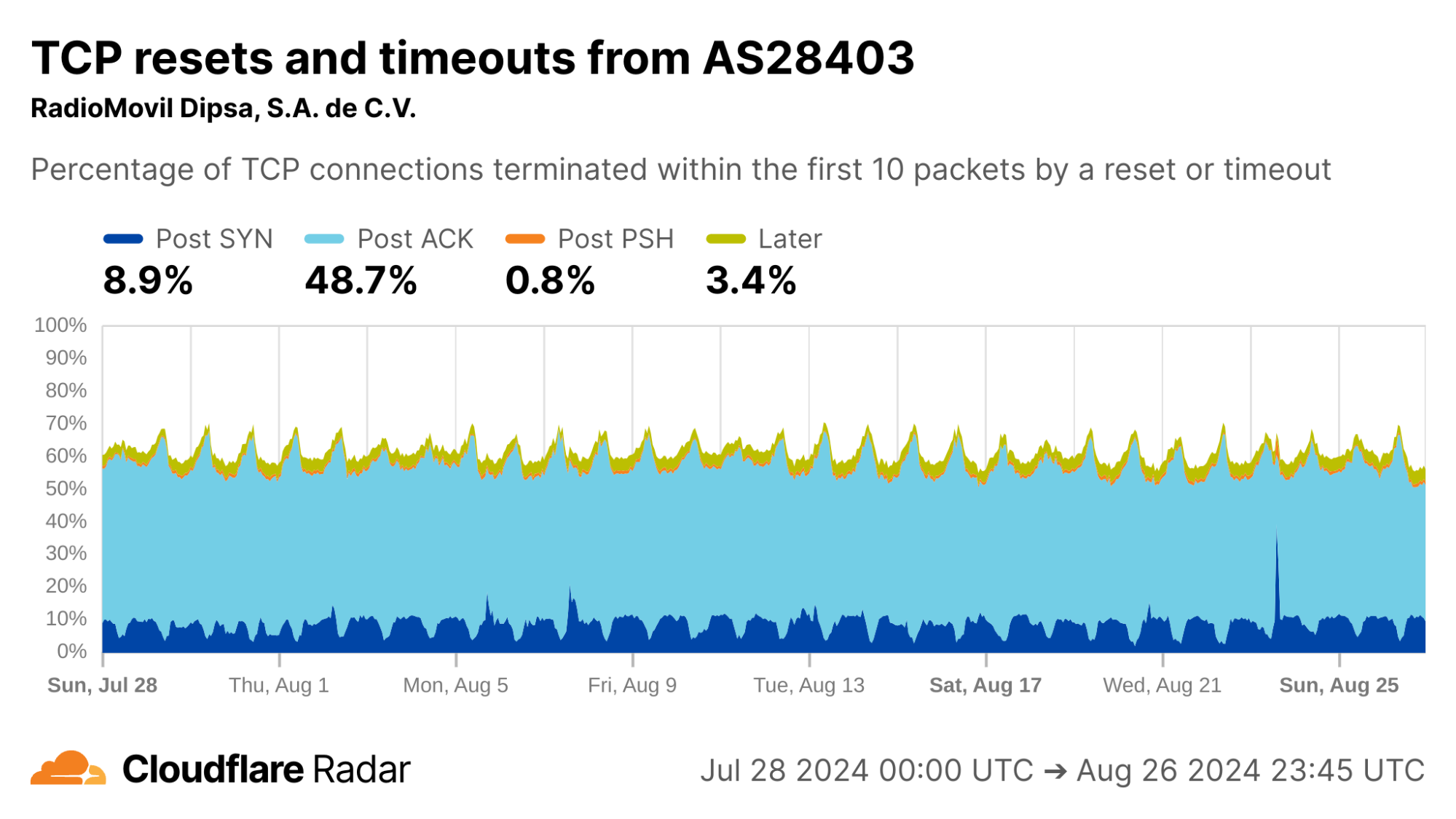
My home ISP AS22773 (Cox Communications) shows rates comparable to the US as a whole. This is typical of most residential ISPs operating in the United States.
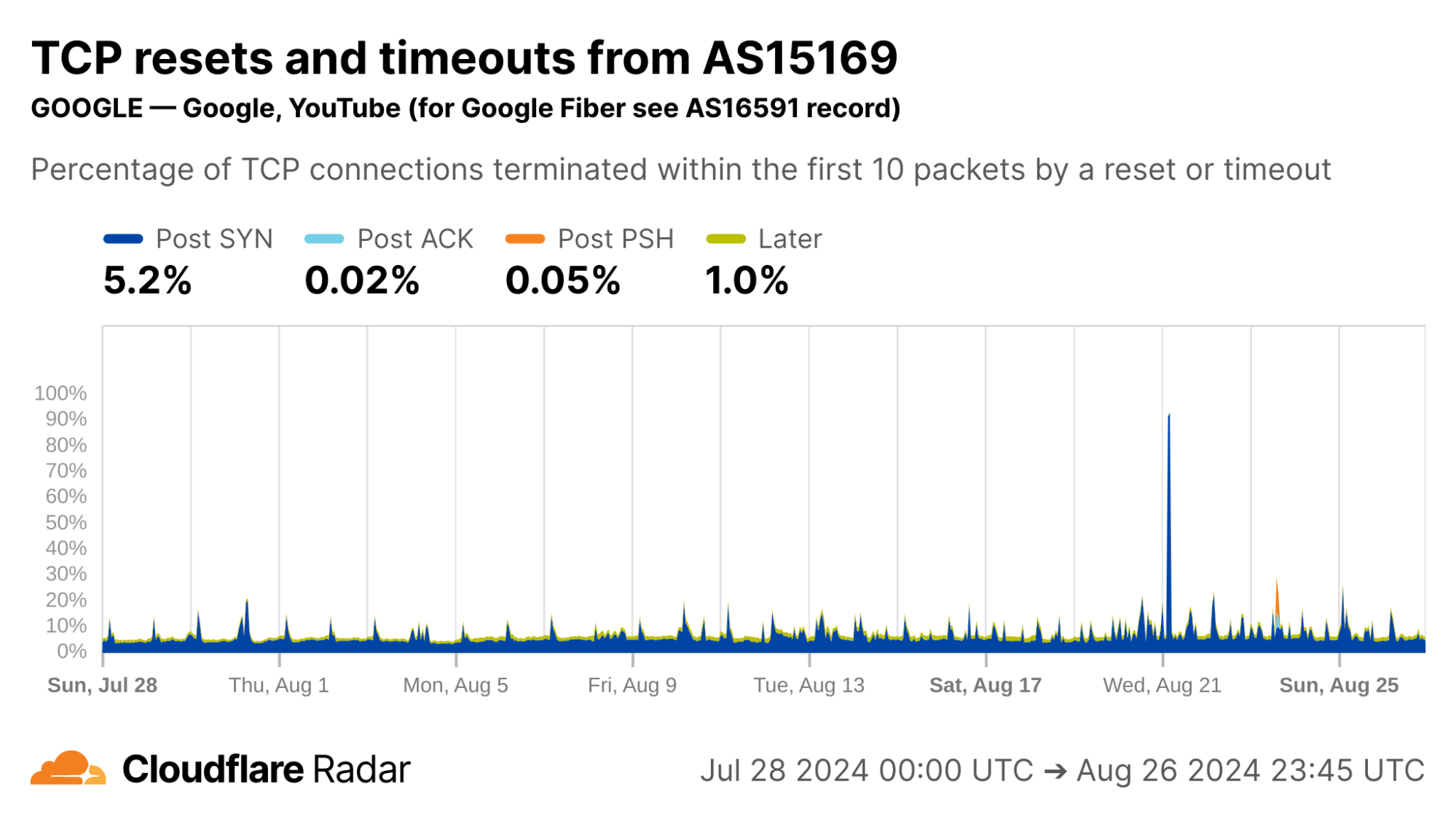
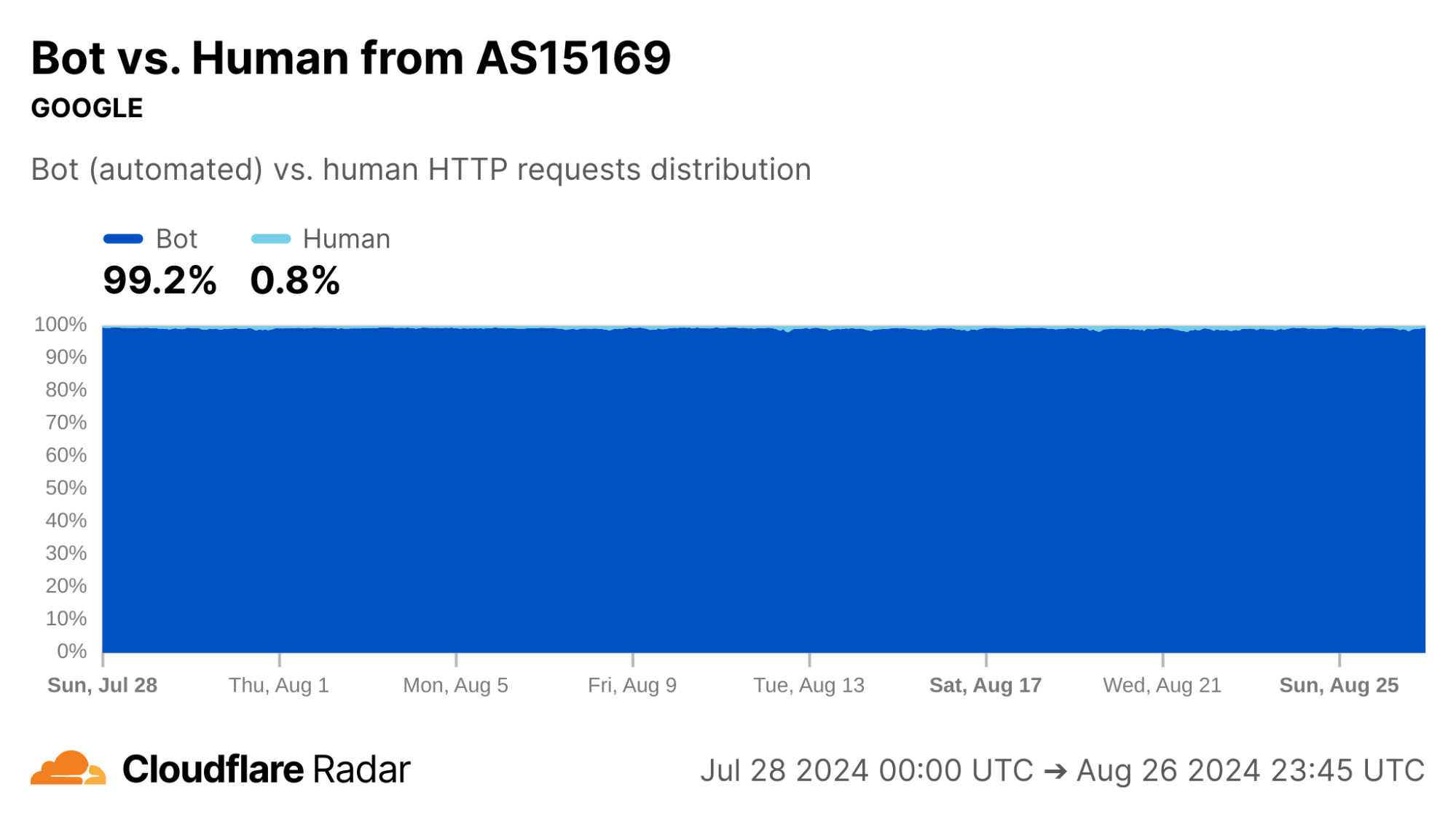
Contrast this against AS15169 (Google LLC), which originates many of Google’s crawlers and fetchers. This network shows significantly lower rates of resets in the “Later” connection stage, which may be explained by the larger proportion of automated traffic, not driven by human user actions (such as closing browser tabs).
Indeed, our bot detection system classifies over 99% of HTTP requests from AS15169 as automated. This shows the value of collating different types of data on Radar.
The new anomalous connections dataset, like most that appear on Radar, is passive – it only reports on observable events, not what causes them. In this spirit, the graphs above for Google’s network reinforce the reason for corroborating observations, as we discuss next.
One view for a signal, more views for corroboration
Our passive measurement approach works at Cloudflare scale. However, it does not identify root causes or ground truth on its own. There are many plausible explanations for why a connection closed in a particular stage, especially when the closure is due to reset packets and timeouts. Attempts to explain by relying solely on this data source can only lead to speculation.
However, this limitation can be overcome by combining with other data sources such as active measurements. For example, corroborating with reports from OONI or Censored Planet, or with on-the-ground reports, can give a more complete story. Thus, one of the major use cases for the TCP resets and timeouts dataset is to understand the scale and impact of previously-documented phenomena.
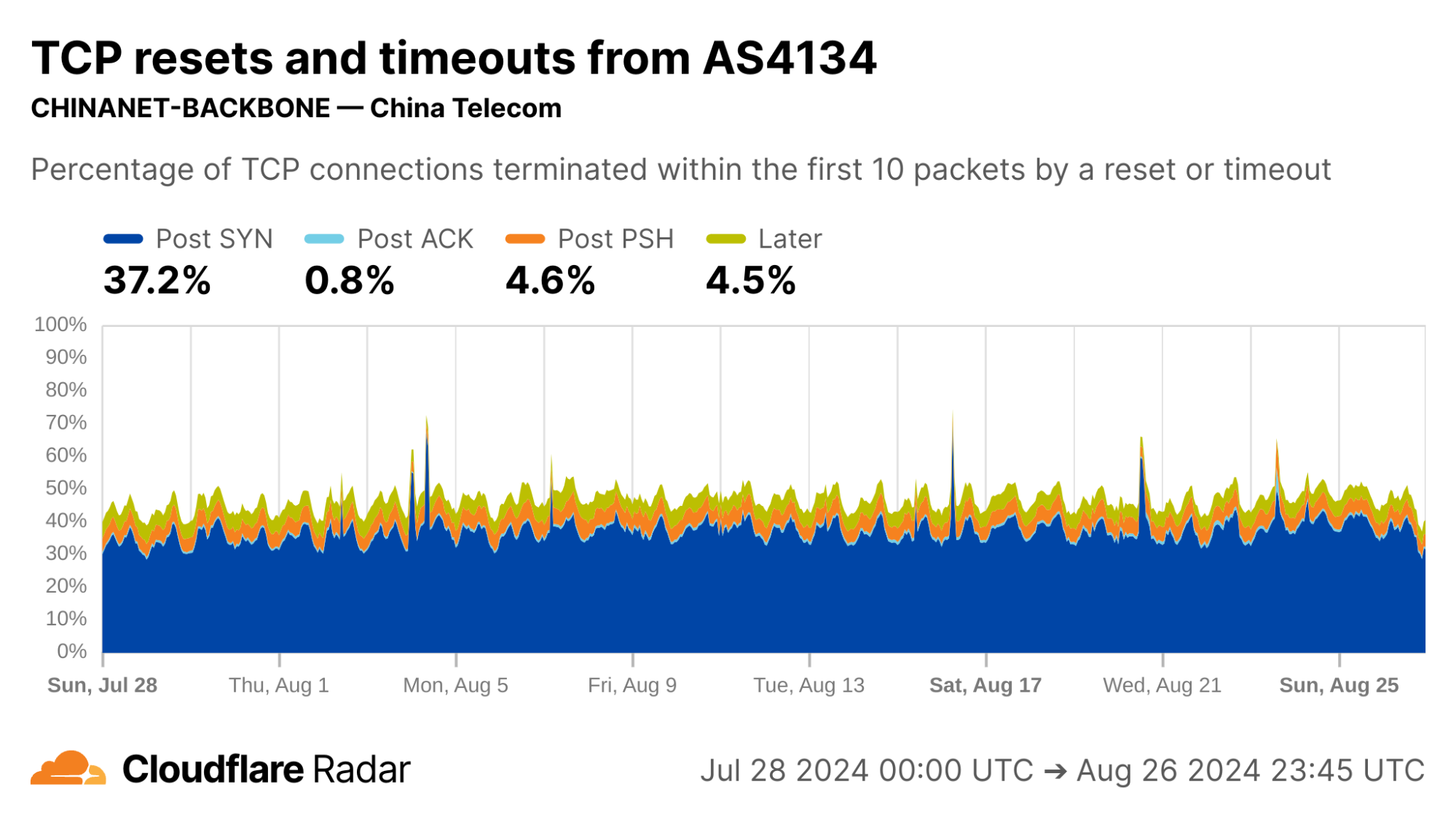
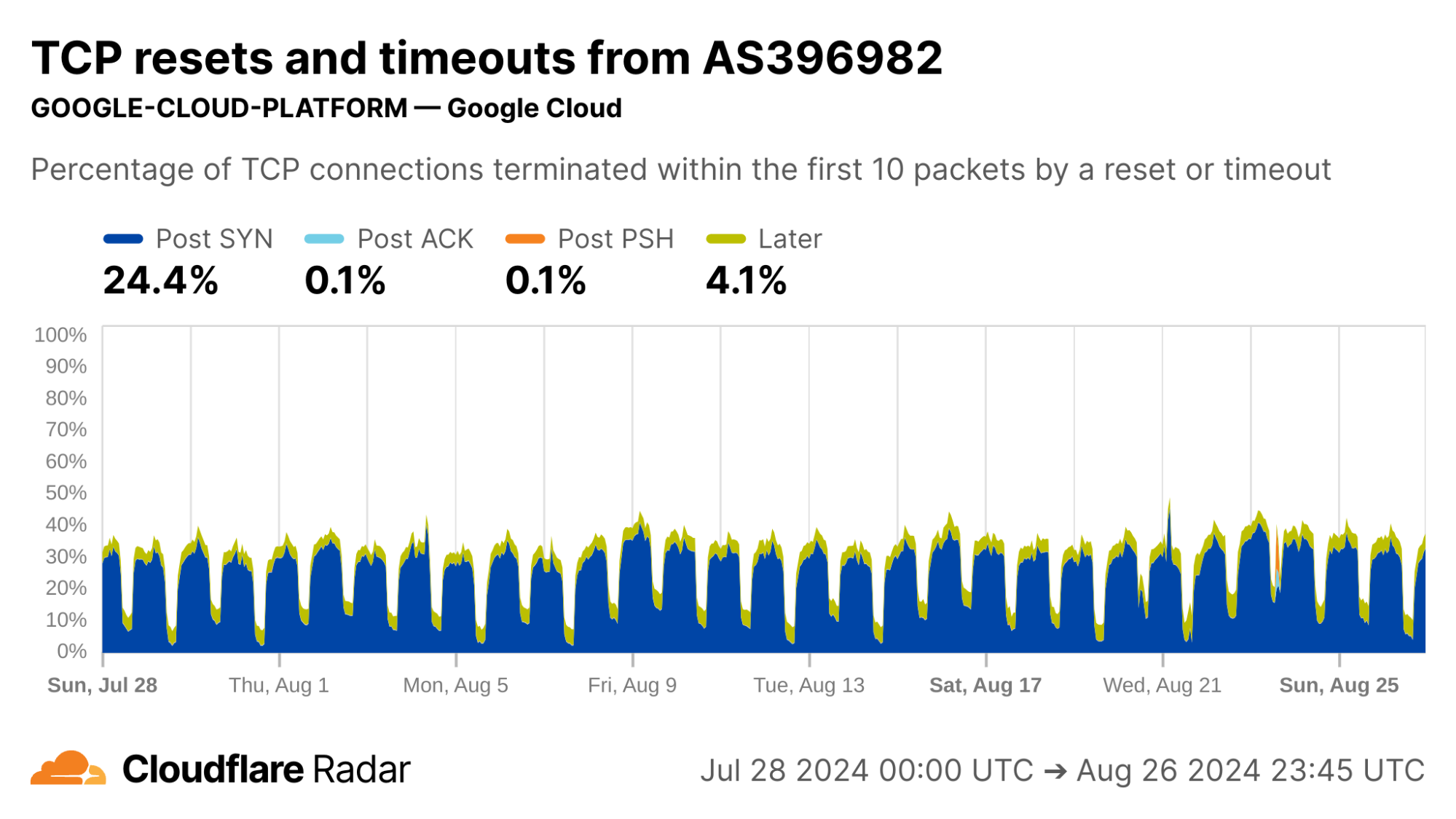
Corroborating Internet-scale measurement projects
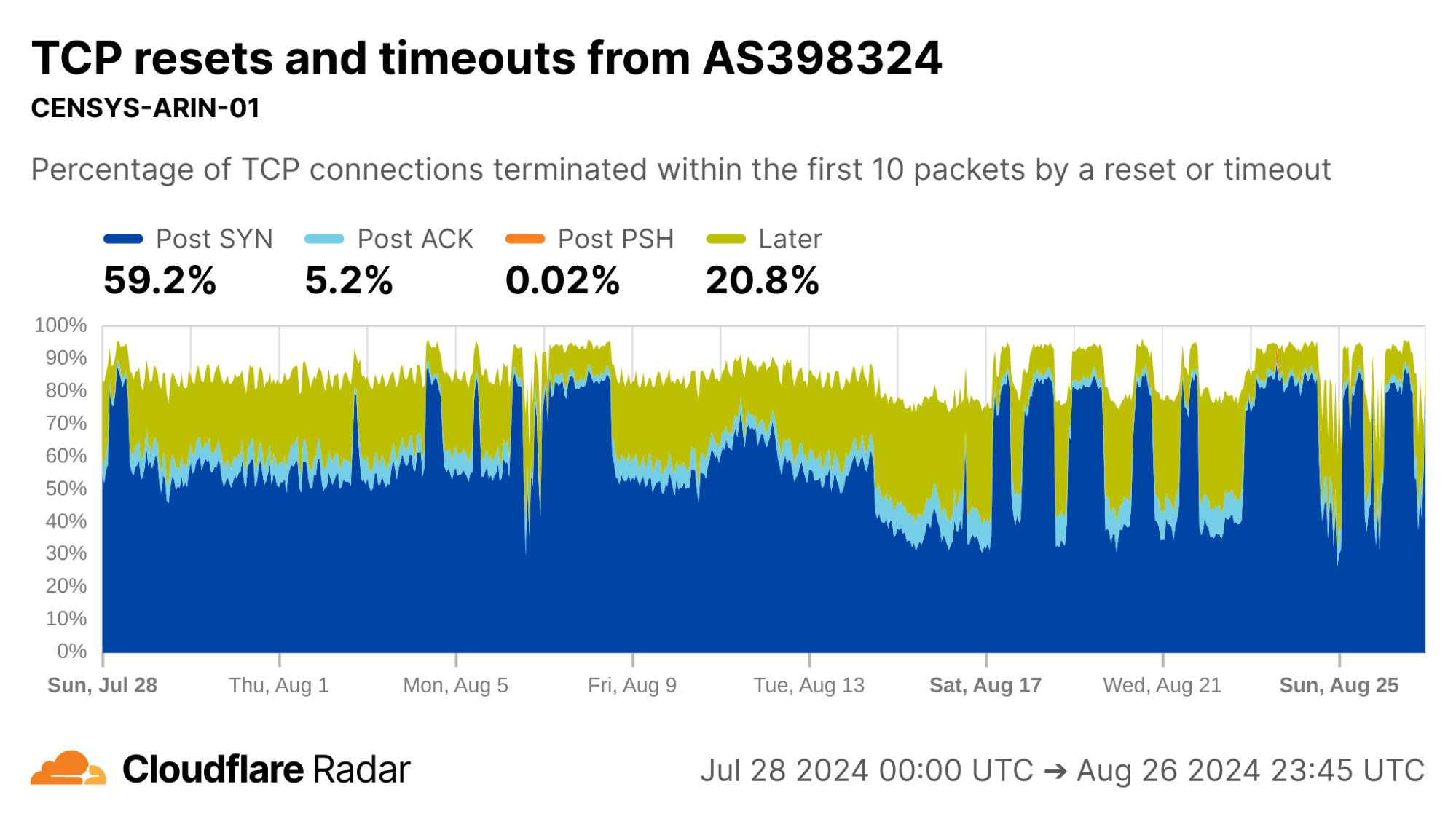
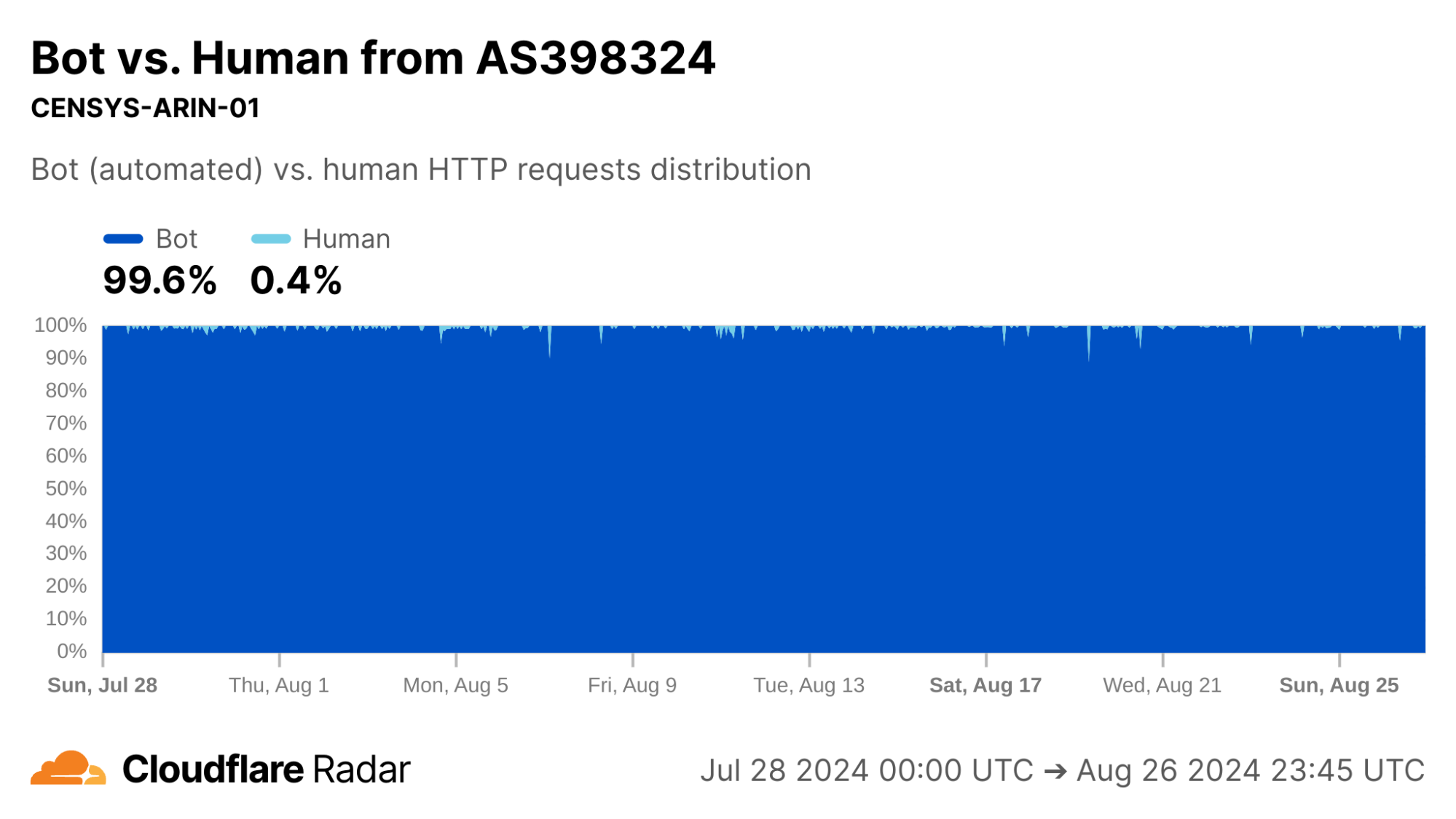
Looking at AS398324 would suggest something terribly wrong, with more than half of connections showing up as anomalous in the Post-SYN stage. However, this network turns out to be CENSYS-ARIN-01, from Internet scanning company Censys. Post-SYN anomalies can be the result of network-layer scanning, where the scanner sends a single SYN packet to probe the server, but does not complete the TCP handshake. There are also high rates of Later anomalies, which could be indicative of application-layer scanning, as indicated by the near 100% proportion of connections being classified as automated.
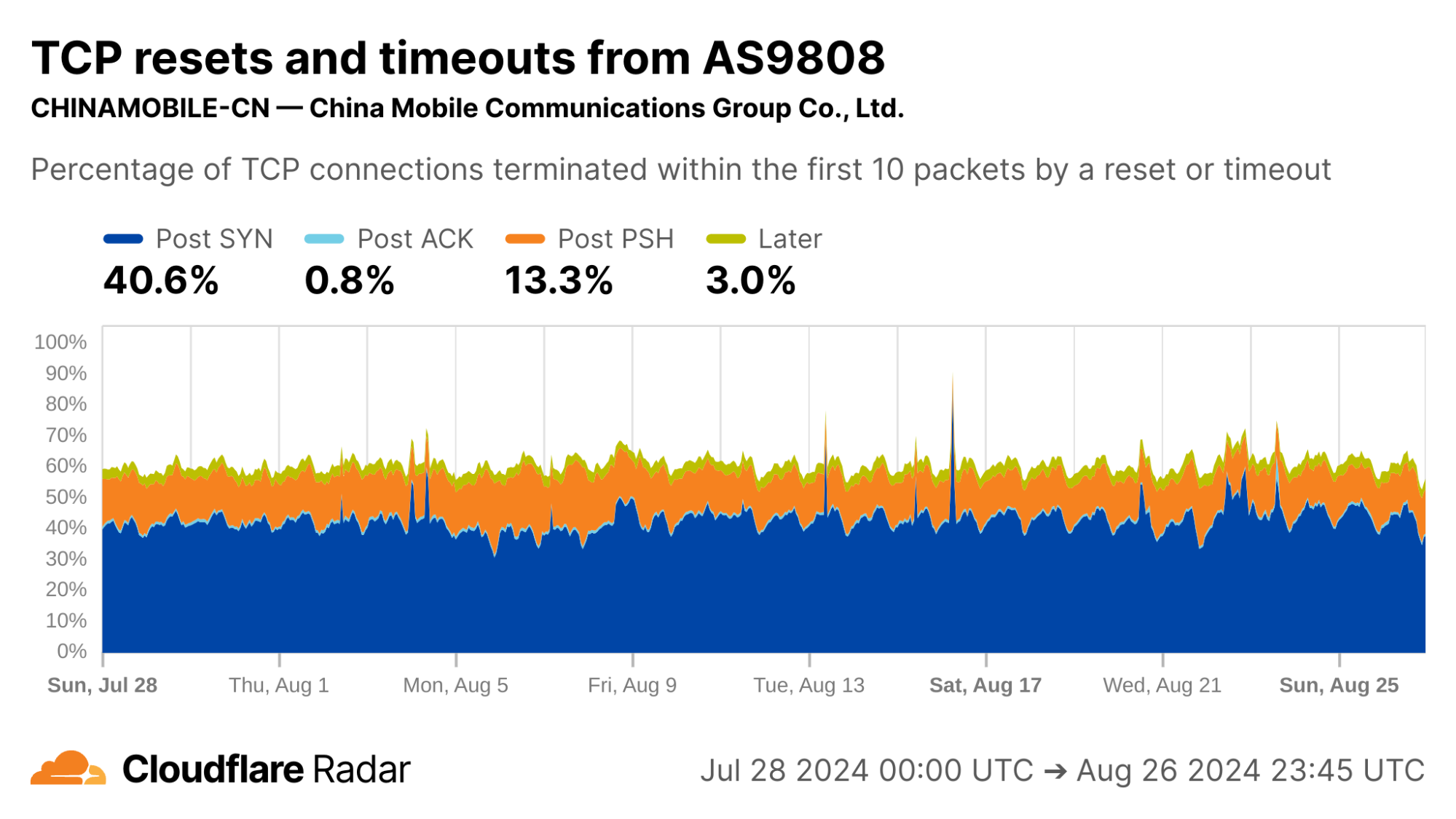
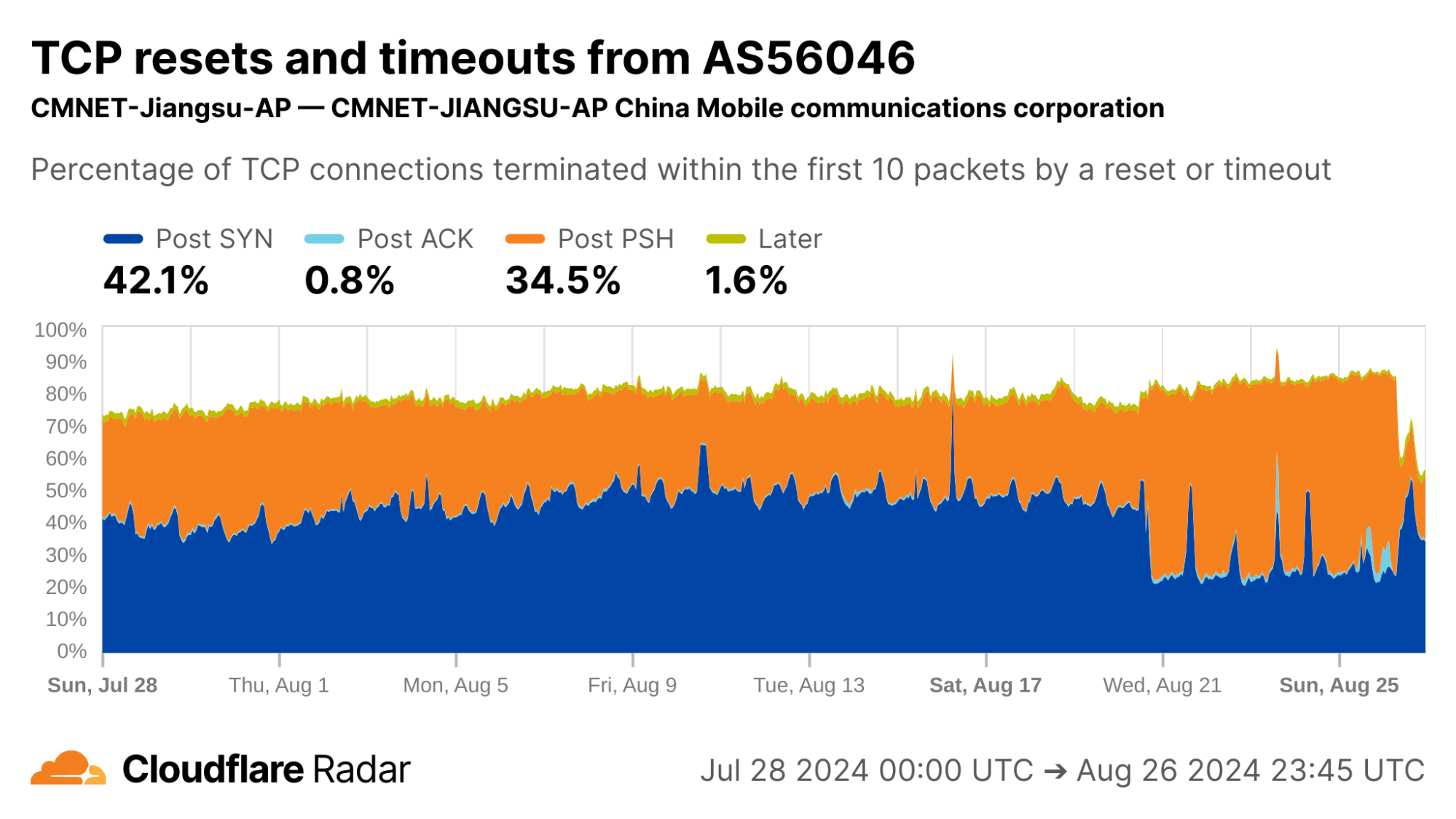
So far, we’ve looked at networks that generate high volumes of scripted or automated traffic. It’s time to look further afield.
Corroborating connection tampering
The starting point of this dataset was a research project to understand and detect active connection tampering, in a similar spirit to our work on HTTPS interception. The reasons we set out to do are explained in detail in our accompanying blog post.
A well-documented technique in the wild to force connections to close is reset injection. With reset injection, middleboxes on the path to the destination inspect data portions of packets. When the middlebox sees a packet to a forbidden domain name, it injects forged TCP Reset (RST) packets to one or both communicating parties to cause them to abort the connection. If the middlebox did not drop the forbidden packet first, then the server will receive both the client packet that triggered the middlebox tampering – perhaps containing a TLS Client Hello message with a Server Name Indication (SNI) field – followed soon afterwards by the forged RST packet.
In the TCP resets and timeouts dataset, a connection disrupted via reset injection would typically appear as a Post-ACK, Post-PSH, or Later anomaly (but, as a reminder, not all anomalies are due to reset injection).
As an example, the reset injection technique is known and commonly associated with the so-called Great Firewall of China (GFW). Indeed, looking at Post-PSH anomalies in connections originating from IPs geolocated to China, we see higher rates than the worldwide average. However, looking at individual networks in China, the Post-PSH rates vary widely, perhaps due to the types of traffic carried or different implementations of the technique. In contrast, rates of Post-SYN anomalies are consistently high across most major Chinese ASes; this may be scanners, spoofed SYN flood attacks, or residualblocking with collateral impact.
See our deep-dive blog post for more information about connection tampering.
Sourcing new insights and targets for followup study
TCP resets and timeouts dataset may also be a source for identifying new or previously understudied network behaviors, by helping to find networks that “stick out” and merit further investigation.
Unattributable ZMap scanning
Here is one we’re unable to explain: Every day during the same 18-hour interval, over 10% of connections from UK clients never progress past the initial SYN packets, and just time out.
Internal inspection revealed that almost all of the Post-SYN anomalies come from a scanner using ZMap at AS396982 (GOOGLE-CLOUD-PLATFORM), in what appears to be a full port scan across all IP address ranges. (The ZMap client responsibly self-identifies, based on ZMap’s responsible self-identification as discussed later.) We see a similar level of scan traffic from IP prefixes in AS396982 geolocated to the United States.
A cursory look at anomaly rates at the country level reveals some interesting findings. For instance, looking at connections from Mexico, the rates of Post-ACK and Post-PSH anomalies often associated with connection tampering are higher than the global average. The profile for Mexico connections is also similar to others in the region. However, Mexico is a country with “no documented evidence that the government or other actors block or filter internet content.”
Looking at each of the top ASes by HTTP traffic volume in Mexico, we find that close to 50% of connections from AS28403 (RadioMovil Dipsa, S.A. de C.V., operating as Telcel) are terminated via a reset or timeout directly after the completion of the TCP handshake (Post-ACK connection stage). In this stage, it’s possible a middlebox has seen and dropped a data packet before it gets to Cloudflare.
One explanation for this behavior may be zero-rating, in which a cellular network provider allows access to certain resources (such as messaging or social media apps) at no cost. When users exceed their data transfer limits on their account, the provider might still allow traffic to zero-rated destinations while blocking connections to other resources.
To enforce a zero-rating policy, an ISP might use the TLS Server Name Indication (SNI) to determine whether to block or allow connections. The SNI is sent in a data-containing packet immediately following the TCP handshake. Thus, if an ISP drops the packet containing the SNI, the server would still see the SYN and ACK packets from the client but no subsequent packets, which is consistent with a Post-ACK connection anomaly.
Turning to Peru, another country with a similar profile in the dataset, there are even higher rates of Post-ACK and Post-PSH anomalies compared to Mexico.
Focusing on specific ASes, we see that AS12252 (Claro Peru) shows high rates of Post-ACK anomalies similar to AS28403 in Mexico. Both networks are operated by the same parent company, América Móvil, so one might expect similar network policies and network management techniques to be employed.
Interestingly, AS6147 (Telefónica Del Perú) instead shows high rates of Post-PSH connection anomalies. This could indicate that this network uses different techniques at the network layer to enforce its policies.
One of the most powerful aspects of our continuous passive measurement is the ability to measure networks over longer periods of time.
Internet shutdowns
In our June 2024 blog post “Examining recent Internet shutdowns in Syria, Iraq, and Algeria”, we shared the view of exam-related nationwide Internet shutdowns from the perspective of Cloudflare’s network. At that time we were preparing the TCP resets and timeouts dataset, which was helpful to confirm outside reports and get some insight into the specific techniques used for the shutdowns.
As examples of changing behavior, we can go “back in time” to observe exam-related blocking as it happened. In Syria, during the exam-related shutdowns we see spikes in the rate of Post-SYN anomalies. In reality, we see a near-total drop in traffic (including SYN packets) during these periods.
Looking at connections from Iraq, Cloudflare’s view of exam-related shutdowns appears similar to those in Syria, with multiple Post-SYN spikes, albeit much less pronounced.
The exams shutdown blog also describes how Algeria took a more nuanced approach for restricting access to content during exam times: instead of full Internet shutdowns, evidence suggests that Algeria instead targeted specific connections. Indeed, during exam periods we see an increase in Post-ACK connection anomalies. This behavior would be expected if a middlebox selectively drops packets that contain forbidden content, while leaving other packets alone (like the initial SYN and ACK).
The examples above reinforce that this data is most useful when correlated with other signals. The data is also available via the API, so others can dive in more deeply. Our detection techniques are also transferable to other servers and operators, as described next.
How to detect anomalous TCP connections at scale
In this section, we discuss how we constructed the TCP resets and timeouts dataset. The scale of Cloudflare’s global network presents unique challenges for data processing and analysis. We share our techniques to help readers to understand our methodology, interpret the dataset, and replicate the mechanisms in other networks or servers.
Our methodology can be summarized as follows:
Log a sample of connections arriving at our client-facing servers. This sampling system is completely passive, meaning that it has no ability to decrypt traffic and only has access to existing packets sent over the network.
Reconstruct connections from the captured packets. A novel aspect of our design is that only one direction needs to be observed, from client to server.
Match reconstructed connections against a set of signatures for anomalous connections terminated by resets or timeouts. These signatures consist of two parts: a connection stage, and a set of tags that indicate specific behaviors derived from the literature and our own observations.
These design choices keep encrypted packets safe and can be replicated anywhere, without needing access to the destination server.
First, sample connections
Our main goal was to design a mechanism that scales, and gives us broad visibility into all connections arriving at Cloudflare’s network. Running traffic captures on each client-facing server works, but does not scale. We would also need to know exactly where and when to look, making continuous insights hard to capture. Instead, we sample connections from all of Cloudflare’s servers and log them to a central location where we could perform offline analysis.
This is where we hit the first roadblock: existing packet logging pipelines used by Cloudflare’s analytics systems log individual packets, but a connection consists of many packets. To detect connection anomalies we needed to see all, or at least enough, packets in a given connection. Fortunately, we were able to leverage a flexible logging system built by Cloudflare’s DoS team for analyzing packets involved in DDoS attacks in conjunction with a carefully crafted invocation of two iptables rules to achieve our goal.
The first iptables rule randomly selects and marks new connections for sampling. In our case, we settled on sampling one in every 10,000 ingress TCP connections. There’s nothing magical about this number, but at Cloudflare’s scale it strikes a balance between capturing enough without straining our data processing and analytics pipelines. The iptables rules only apply to packets after they have passed the DDoS mitigation system. As TCP connections can be long-lived, we sample only new TCP connections. Here is the iptables rule for marking connections to be sampled:
-t mangle -A PREROUTING -p tcp --syn -m state
--state NEW -m statistic --mode random
--probability 0.0001 -m connlabel --label
--set -m comment --comment "Label a sample of ingress TCP connections"
Breaking this down, the rule is installed in the mangle table (for modifying packets) in the chain that handles incoming packets (-A PREROUTING). Only TCP packets with the SYN flag set are considered (-p tcp --syn) where there is no prior state for the connection (--state NEW). The filter selects one in every 10,000 SYN packets (-m statistic –mode random --probability 0.0001) and applies a label to the connection (-m connlabel --label <label> --set).
The second iptables rule logs subsequent packets in the connection, to a maximum of 10 packets. Again, there’s nothing magic about the number 10 other than that it’s generally enough to capture the connection establishment, subsequent request packets, and resets on connections that close before expected.
-t mangle -A PREROUTING -m connlabel --label
-m connbytes ! --connbytes 11
--connbytes-dir original --connbytes-mode packets
-j NFLOG --nflog-prefix "" -m
comment --comment "Log the first 10 incoming packets of each sampled ingress connection"
This rule is installed in the same chain as the previous rule. It matches only packets from sampled connections (-m connlabel --label <label>), and only the first 10 packets from each connection (-m connbytes ! --connbytes 11 --connbytes-dir original --connbytes-mode packets). Matched packets are sent to NFLOG (-j NFLOG --nflog-prefix "<logging flags>") where they’re picked up by the logging system and saved to a centralized location for offline analysis.
Reconstructing connections from sampled packets
Packets logged on our servers are inserted into ClickHouse tables as part of our analytics pipeline. Each logged packet is stored in its own row in the database. The next challenge is to reassemble packets into the corresponding connections for further analysis. Before we go further, we need to define what a “connection” is for the purpose of this analysis.
We use the standard definition of a connection defined by the network 5-tuple of protocol, source IP address, source port, destination IP address, destination port with the following tweaks:
We only sample packets on the ingress (client-to-server) half of a connection, so do not see the corresponding response packets from server to client. In most cases, we can infer what the server response will be based on our knowledge of how our servers are configured. Ultimately, the ingress packets are sufficient to learn anomalous TCP connection behaviors.
We query the ClickHouse dataset in 15-minute intervals, and group together packets sharing the same network 5-tuple within that interval. This means that connections may be truncated towards the end of the query interval. When analyzing connection timeouts, we exclude incomplete flows where the latest packet timestamp is within 10 seconds of the query cutoff.
Since resets and timeouts are most likely to affect new connections, we only consider sequences of packets starting with a SYN packet marking the beginning of a new TCP handshake. Thus, existing long-lived connections are excluded.
The logging system does not guarantee precise packet interarrival timestamps, so we consider only the set of packets that arrive, not ordered by their arrival time. In some cases, we can determine packet ordering based on TCP sequence numbers but it turns out not to significantly impact the results.
We filter out a small fraction of connections with multiple SYN packets to reduce noise in the analysis.
With the above conditions for how we define a connection, we’re now ready to describe our analysis pipeline in more detail.
Mapping connection close events to stages
TCP connections transition through a series of stages from connection establishment through eventual close. The stage at which an anomalous connection closes provides clues as to why the anomaly occurred. Based on the packets that we receive at our servers, we place each incoming connection into one of four stages (Post-SYN, Post-ACK, Post-PSH, Later), described in more detail above.
The connection close stage alone provides useful insights into anomalous TCP connections from various networks, and this is what is shown today on Cloudflare Radar. However, in some cases we can provide deeper insights by matching connections against more specific signatures.
Applying tags to describe more specific connection behaviors
The grouping of connections into stages as described above is done solely based on the TCP flags of packets in the connection. Considering other factors such as packet inter-arrival timing, exact combinations of TCP flags, and other packet fields (IP identification, IP TTL, TCP sequence and acknowledgement numbers, TCP window size, etc.) can allow for more fine-grained matching to specific behaviors.
For example, the popular ZMap scanner software fixes the IP identification field to 54321 and the TCP window size to 65535 in SYN packets that it generates (source code). When we see packets arriving to our network that have these exact fields set, it is likely that the packet was generated by a scanner using ZMap.
Tags can also be used to match connections against known signatures of tampering middleboxes. A large body of active measurements work (for instance, Weaver, Sommer, and Paxson) has found that some middleboxes deployments exhibit consistent behaviors when disrupting connections via reset injection, such as setting an IP TTL field that differs from other packets sent by the client, or sending both a RST packet and a RST+ACK packet. For more details on specific connection tampering signatures, see the blog post and the peer-reviewed paper.
Currently, we define the following tags, which we intend to refine and expand over time. Some tags only apply if another tag is also set, as indicated by the hierarchical presentation below (e.g., the fin tag can only apply when the reset tag is also set).
timeout: terminated due to a timeout
reset: terminated due to a reset (packet with RST flag set)
fin: at least one FIN packet was received alongside one or more RST packets
single_rst: terminated with a single RST packet
multiple_rsts: terminated with multiple RST packets
acknumsame: the acknowledgement numbers in the RST packets were all the same and non-zero
acknumsame0: the acknowledgement numbers in the RST packets were all zero
acknumdiff: the acknowledgement numbers in the RST packets were different and all non-zero
acknumdiff0: the acknowledgement numbers in the RST packets were different and one was zero
single_rstack: terminated with a single RST+ACK packet (both RST and ACK flags set)
multiple_rstacks: terminated with a multiple RST+ACK packets
rst_and_rstacks: terminated with a combination of RST and RST+ACK packets
zmap: SYN packet matches those generated by the ZMap scanner
Connection tags are not currently visible in the Radar dashboard and API, but we plan to release this additional functionality in the future.
What’s next?
Cloudflare’s mission is to help build a better Internet, and we consider transparency and accountability to be a critical part of that mission. We hope that the insights and tools we are sharing help to shed light on anomalous network behaviors around the world.
While the current TCP resets and timeouts dataset should immediately prove useful to network operators, researchers, and Internet citizens as a whole, we’re not stopping here. There are several improvements we’d like to add in the future:
Expand the set of tags for capturing specific network behaviors and expose them in the API and dashboard.
Extend insights to connections from Cloudflare to customer origin servers.
Add support for QUIC, which is currently used for over 30% of HTTP requests to Cloudflare worldwide.
If you’ve found this blog interesting, we encourage you to read the accompanying blog post and paper for a deep dive on connection tampering, and to explore the TCP resets and timeouts dashboard and API on Cloudflare Radar. We welcome you to reach out to us with your own questions and observations at [email protected].
On August 13th, 2024, the US National Institute of Standards and Technology (NIST) published the first three cryptographic standards designed to resist an attack from quantum computers: ML-KEM, ML-DSA, and SLH-DSA. This announcement marks a significant milestone for ensuring that today’s communications remain secure in a future world where large-scale quantum computers are a reality.
In this blog post, we briefly discuss the significance of NIST’s recent announcement, how we expect the ecosystem to evolve given these new standards, and the next steps we are taking. For a deeper dive, see our March 2024 blog post.
Why are quantum computers a threat?
Cryptography is a fundamental aspect of modern technology, securing everything from online communications to financial transactions. For instance, when visiting this blog, your web browser used cryptography to establish a secure communication channel to Cloudflare’s server to ensure that you’re really talking to Cloudflare (and not an impersonator), and that the conversation remains private from eavesdroppers.
Much of the cryptography in widespread use today is based on mathematical puzzles (like factoring very large numbers) which are computationally out of reach for classical (non-quantum) computers. We could likely continue to use traditional cryptography for decades to come if not for the advent of quantum computers, devices that use properties of quantum mechanics to perform certain specialized calculations much more efficiently than traditional computers. Unfortunately, those specialized calculations include solving the mathematical puzzles upon which most widely deployed cryptography depends.
As of today, no quantum computers exist that are large and stable enough to break today’s cryptography, but experts predict that it’s only a matter of time until such a cryptographically-relevant quantum computer (CRQC) exists. For instance, more than a quarter of interviewed experts in a 2023 survey expect that a CRQC is more likely than not to appear in the next decade.
What is being done about the quantum threat?
In recognition of the quantum threat, the US National Institute of Standards and Technology (NIST) launched a public competition in 2016 to solicit, evaluate, and standardize new “post-quantum” cryptographic schemes that are designed to be resistant to attacks from quantum computers. On August 13, 2024, NIST published the final standards for the first three post-quantum algorithms to come out of the competition: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. A fourth standard based on FALCON is planned for release in late 2024 and will be dubbed FN-DSA, short for FFT (fast-Fourier transform) over NTRU-Lattice-Based Digital Signature Algorithm.
The publication of the final standards marks a significant milestone in an eight-year global community effort managed by NIST to prepare for the arrival of quantum computers. Teams of cryptographers from around the world jointly submitted 82 algorithms to the first round of the competition in 2017. After years of evaluation and cryptanalysis from the global cryptography community, NIST winnowed the algorithms under consideration down through several rounds until they decided upon the first four algorithms to standardize, which they announced in 2022.
This has been a monumental effort, and we would like to extend our gratitude to NIST and all the cryptographers and engineers across academia and industry that participated.
Security was a primary concern in the selection process, but algorithms also need to be performant enough to be deployed in real-world systems. Cloudflare’s involvement in the NIST competition began in 2019 when we performed experiments with industry partners to evaluate how algorithms under consideration performed when deployed on the open Internet. Gaining practical experience with the new algorithms was a crucial part of the evaluation process, and helped to identify and remove obstacles for deploying the final standards.
Having standardized algorithms is a significant step, but migrating systems to use these new algorithms is going to require a multi-year effort. To understand the effort involved, let’s look at two classes of traditional cryptography that are susceptible to quantum attacks: key agreement and digital signatures.
Key agreement allows two parties that have never communicated before to establish a shared secret over an insecure communication channel (like the Internet). The parties can then use this shared secret to encrypt future communications between them. An adversary may be able to observe the encrypted communication going over the network, but without access to the shared secret they cannot decrypt and “see inside” the encrypted packets.
However, in what is known as the “harvest now, decrypt later” threat model, an adversary can store encrypted data until some point in the future when they gain access to a sufficiently large quantum computer, and then can decrypt at their leisure. Thus, today’s communication is already at risk from a future quantum adversary, and it is urgent that we upgrade systems to use post-quantum key agreement as soon as possible.
In 2022, soon after NIST announced the first set of algorithms to be standardized, Cloudflare worked with industry partners to deploy a preliminary version of ML-KEM to protect traffic arriving at Cloudflare’s servers (and our internal systems), both to pave the way for adoption of the final standard and to start protecting traffic as soon as possible. As of mid-August 2024, over 16% of human-generated requests to Cloudflare’s servers are already protected with post-quantum key agreement.
Percentage of human traffic to Cloudflare protected by X25519Kyber, a preliminary version of ML-KEM as shown on Cloudflare Radar.
Other players in the tech industry have deployed post-quantum key agreement as well, including Google, Apple, Meta, and Signal.
Signatures are crucial to ensure that you’re communicating with who you think you are communicating. In the web public key infrastructure (WebPKI), signatures are used in certificates to prove that a website operator is the rightful owner of a domain. The threat model for signatures is different than for key agreement. An adversary capable of forging a digital signature could carry out an active attack to impersonate a web server to a client, but today’s communication is not yet at risk.
While the migration to post-quantum signatures is less urgent than the migration for key agreement (since traffic is only at risk once CRQCs exist), it is much more challenging. Consider, for instance, the number of parties involved. In key agreement, only two parties need to support a new key agreement protocol: the client and the server. In the WebPKI, there are many more parties involved, from library developers, to browsers, to server operators, to certificate authorities, to hardware manufacturers. Furthermore, post-quantum signatures are much larger than we’re used to from traditional signatures. For more details on the tradeoffs between the different signature algorithms, deployment challenges, and out-of-the-box solutions see our previous blog post.
Reaching consensus on the right approach for migrating to post-quantum signatures is going to require extensive effort and coordination among stakeholders. However, that work is already well underway. For instance, in 2021 we ran large scale experiments to understand the feasibility of post-quantum signatures in the WebPKI, and we have more studies planned.
What’s next?
Now that NIST has published the first set of standards for post-quantum cryptography, what comes next?
In 2022, Cloudflare deployed a preliminary version of the ML-KEM key agreement algorithm, Kyber, which is now used to protect double-digit percentages of requests to Cloudflare’s network. We use a hybrid with X25519, to hedge against future advances in cryptanalysis and implementation vulnerabilities. In coordination with industry partners at the NIST NCCoE and IETF, we will upgrade our systems to support the final ML-KEM standard, again using a hybrid. We will slowly phase out support for the pre-standard version X25519Kyber768 after clients have moved to the ML-KEM-768 hybrid, and will quickly phase out X25519Kyber512, which hasn’t seen real-world usage.
Now that the final standards are available, we expect to see widespread adoption of ML-KEM industry-wide as support is added in software and hardware, and post-quantum becomes the new default for key agreement. Organizations should look into upgrading their systems to use post-quantum key agreement as soon as possible to protect their data from future quantum-capable adversaries. Check if your browser already supports post-quantum key agreement by visiting pq.cloudflareresearch.com, and if you’re a Cloudflare customer, see how you can enable post-quantum key agreement support to your origin today.
Adoption of the newly-standardized post-quantum signatures ML-DSA and SLH-DSA will take longer as stakeholders work to reach consensus on the migration path. We expect the first post-quantum certificates to be available in 2026, but not to be enabled by default. Organizations should prepare for a future flip-the-switch migration to post-quantum signatures, but there is no need to flip the switch just yet.
On August 13th, 2024, the US National Institute of Standards and Technology (NIST) published the first three cryptographic standards designed to resist an attack from quantum computers: ML-KEM, ML-DSA, and SLH-DSA. This announcement marks a significant milestone for ensuring that today’s communications remain secure in a future world where large-scale quantum computers are a reality.
In this blog post, we briefly discuss the significance of NIST’s recent announcement, how we expect the ecosystem to evolve given these new standards, and the next steps we are taking. For a deeper dive, see our March 2024 blog post.
Why are quantum computers a threat?
Cryptography is a fundamental aspect of modern technology, securing everything from online communications to financial transactions. For instance, when visiting this blog, your web browser used cryptography to establish a secure communication channel to Cloudflare’s server to ensure that you’re really talking to Cloudflare (and not an impersonator), and that the conversation remains private from eavesdroppers.
Much of the cryptography in widespread use today is based on mathematical puzzles (like factoring very large numbers) which are computationally out of reach for classical (non-quantum) computers. We could likely continue to use traditional cryptography for decades to come if not for the advent of quantum computers, devices that use properties of quantum mechanics to perform certain specialized calculations much more efficiently than traditional computers. Unfortunately, those specialized calculations include solving the mathematical puzzles upon which most widely deployed cryptography depends.
As of today, no quantum computers exist that are large and stable enough to break today’s cryptography, but experts predict that it’s only a matter of time until such a cryptographically-relevant quantum computer (CRQC) exists. For instance, more than a quarter of interviewed experts in a 2023 survey expect that a CRQC is more likely than not to appear in the next decade.
What is being done about the quantum threat?
In recognition of the quantum threat, the US National Institute of Standards and Technology (NIST) launched a public competition in 2016 to solicit, evaluate, and standardize new “post-quantum” cryptographic schemes that are designed to be resistant to attacks from quantum computers. On August 13, 2024, NIST published the final standards for the first three post-quantum algorithms to come out of the competition: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. A fourth standard based on FALCON is planned for release in late 2024 and will be dubbed FN-DSA, short for FFT (fast-Fourier transform) over NTRU-Lattice-Based Digital Signature Algorithm.
The publication of the final standards marks a significant milestone in an eight-year global community effort managed by NIST to prepare for the arrival of quantum computers. Teams of cryptographers from around the world jointly submitted 82 algorithms to the first round of the competition in 2017. After years of evaluation and cryptanalysis from the global cryptography community, NIST winnowed the algorithms under consideration down through several rounds until they decided upon the first four algorithms to standardize, which they announced in 2022.
This has been a monumental effort, and we would like to extend our gratitude to NIST and all the cryptographers and engineers across academia and industry that participated.
Security was a primary concern in the selection process, but algorithms also need to be performant enough to be deployed in real-world systems. Cloudflare’s involvement in the NIST competition began in 2019 when we performed experiments with industry partners to evaluate how algorithms under consideration performed when deployed on the open Internet. Gaining practical experience with the new algorithms was a crucial part of the evaluation process, and helped to identify and remove obstacles for deploying the final standards.
Having standardized algorithms is a significant step, but migrating systems to use these new algorithms is going to require a multi-year effort. To understand the effort involved, let’s look at two classes of traditional cryptography that are susceptible to quantum attacks: key agreement and digital signatures.
Key agreement allows two parties that have never communicated before to establish a shared secret over an insecure communication channel (like the Internet). The parties can then use this shared secret to encrypt future communications between them. An adversary may be able to observe the encrypted communication going over the network, but without access to the shared secret they cannot decrypt and “see inside” the encrypted packets.
However, in what is known as the “harvest now, decrypt later” threat model, an adversary can store encrypted data until some point in the future when they gain access to a sufficiently large quantum computer, and then can decrypt at their leisure. Thus, today’s communication is already at risk from a future quantum adversary, and it is urgent that we upgrade systems to use post-quantum key agreement as soon as possible.
In 2022, soon after NIST announced the first set of algorithms to be standardized, Cloudflare worked with industry partners to deploy a preliminary version of ML-KEM to protect traffic arriving at Cloudflare’s servers (and our internal systems), both to pave the way for adoption of the final standard and to start protecting traffic as soon as possible. As of mid-August 2024, over 16% of human-generated requests to Cloudflare’s servers are already protected with post-quantum key agreement.
Percentage of human traffic to Cloudflare protected by X25519Kyber, a preliminary version of ML-KEM as shown on Cloudflare Radar.
Other players in the tech industry have deployed post-quantum key agreement as well, including Google, Apple, Meta, and Signal.
Signatures are crucial to ensure that you’re communicating with who you think you are communicating. In the web public key infrastructure (WebPKI), signatures are used in certificates to prove that a website operator is the rightful owner of a domain. The threat model for signatures is different than for key agreement. An adversary capable of forging a digital signature could carry out an active attack to impersonate a web server to a client, but today’s communication is not yet at risk.
While the migration to post-quantum signatures is less urgent than the migration for key agreement (since traffic is only at risk once CRQCs exist), it is much more challenging. Consider, for instance, the number of parties involved. In key agreement, only two parties need to support a new key agreement protocol: the client and the server. In the WebPKI, there are many more parties involved, from library developers, to browsers, to server operators, to certificate authorities, to hardware manufacturers. Furthermore, post-quantum signatures are much larger than we’re used to from traditional signatures. For more details on the tradeoffs between the different signature algorithms, deployment challenges, and out-of-the-box solutions see our previous blog post.
Reaching consensus on the right approach for migrating to post-quantum signatures is going to require extensive effort and coordination among stakeholders. However, that work is already well underway. For instance, in 2021 we ran large scale experiments to understand the feasibility of post-quantum signatures in the WebPKI, and we have more studies planned.
What’s next?
Now that NIST has published the first set of standards for post-quantum cryptography, what comes next?
In 2022, Cloudflare deployed a preliminary version of the ML-KEM key agreement algorithm, Kyber, which is now used to protect double-digit percentages of requests to Cloudflare’s network. We use a hybrid with X25519, to hedge against future advances in cryptanalysis and implementation vulnerabilities. In coordination with industry partners at the NIST NCCoE and IETF, we will upgrade our systems to support the final ML-KEM standard, again using a hybrid. We will slowly phase out support for the pre-standard version X25519Kyber768 after clients have moved to the ML-KEM-768 hybrid, and will quickly phase out X25519Kyber512, which hasn’t seen real-world usage.
Now that the final standards are available, we expect to see widespread adoption of ML-KEM industry-wide as support is added in software and hardware, and post-quantum becomes the new default for key agreement. Organizations should look into upgrading their systems to use post-quantum key agreement as soon as possible to protect their data from future quantum-capable adversaries. Check if your browser already supports post-quantum key agreement by visiting pq.cloudflareresearch.com, and if you’re a Cloudflare customer, see how you can enable post-quantum key agreement support to your origin today.
Adoption of the newly-standardized post-quantum signatures ML-DSA and SLH-DSA will take longer as stakeholders work to reach consensus on the migration path. We expect the first post-quantum certificates to be available in 2026, but not to be enabled by default. Organizations should prepare for a future flip-the-switch migration to post-quantum signatures, but there is no need to flip the switch just yet.
Today we’re announcing a public demo and an open-sourced Go implementation of a next-generation, privacy-preserving compromised credential checking protocol called MIGP (“Might I Get Pwned”, a nod to Troy Hunt’s “Have I Been Pwned”). Compromised credential checking services are used to alert users when their credentials might have been exposed in data breaches. Critically, the ‘privacy-preserving’ property of the MIGP protocol means that clients can check for leaked credentials without leaking any information to the service about the queried password, and only a small amount of information about the queried username. Thus, not only can the service inform you when one of your usernames and passwords may have become compromised, but it does so without exposing any unnecessary information, keeping credential checking from becoming a vulnerability itself. The ‘next-generation’ property comes from the fact that MIGP advances upon the current state of the art in credential checking services by allowing clients to not only check if their exact password is present in a data breach, but to check if similar passwords have been exposed as well.
For example, suppose your password last year was amazon20\$, and you change your password each year (so your current password is amazon21\$). If last year’s password got leaked, MIGP could tell you that your current password is weak and guessable as it is a simple variant of the leaked password.
The MIGP protocol was designed by researchers at Cornell Tech and the University of Wisconsin-Madison, and we encourage you to read the paper for more details. In this blog post, we provide motivation for why compromised credential checking is important for security hygiene, and how the MIGP protocol improves upon the current generation of credential checking services. We then describe our implementation and the deployment of MIGP within Cloudflare’s infrastructure.
Our MIGP demo and public API are not meant to replace existing credential checking services today, but rather demonstrate what is possible in the space. We aim to push the envelope in terms of privacy and are excited to employ some cutting-edge cryptographic primitives along the way.
The threat of data breaches
Data breaches are rampant. The regularity of news articles detailing how tens or hundreds of millions of customer records have been compromised have made us almost numb to the details. Perhaps we all hope to stay safe just by being a small fish in the middle of a very large school of similar fish that is being predated upon. But we can do better than just hope that our particular authentication credentials are safe. We can actually check those credentials against known databases of the very same compromised user information we learn about from the news.
Many of the security breaches we read about involve leaked databases containing user details. In the worst cases, user data entered during account registration on a particular website is made available (often offered for sale) after a data breach. Think of the addresses, password hints, credit card numbers, and other private details you have submitted via an online form. We rely on the care taken by the online services in question to protect those details. On top of this, consider that the same (or quite similar) usernames and passwords are commonly used on more than one site. Our information across all of those sites may be as vulnerable as the site with the weakest security practices. Attackers take advantage of this fact to actively compromise accounts and exploit users every day.
Credential stuffing is an attack in which malicious parties use leaked credentials from an account on one service to attempt to log in to a variety of other services. These attacks are effective because of the prevalence of reused credentials across services and domains. After all, who hasn’t at some point had a favorite password they used for everything? (Quick plug: please use a password manager like LastPass to generate unique and complex passwords for each service you use.)
Website operators have (or should have) a vested interest in making sure that users of their service are using secure and non-compromised credentials. Given the sophistication of techniques employed by malevolent actors, the standard requirement to “include uppercase, lowercase, digit, and special characters” really is not enough (and can be actively harmful according to NIST’s latest guidance). We need to offer better options to users that keep them safe and preserve the privacy of vulnerable information. Dealing with account compromise and recovery is an expensive process for all parties involved.
Users and organizations need a way to know if their credentials have been compromised, but how can they do it? One approach is to scour dark web forums for data breach torrent links, download and parse gigabytes or terabytes of archives to your laptop, and then search the dataset to see if their credentials have been exposed. This approach is not workable for the majority of Internet users and website operators, but fortunately there’s a better way — have someone with terabytes to spare do it for you!
Making compromise checking fast and easy
This is exactly what compromised credential checking services do: they aggregate breach datasets and make it possible for a client to determine whether a username and password are present in the breached data. Have I Been Pwned (HIBP), launched by Troy Hunt in 2013, was the first major public breach alerting site. It provides a service, Pwned Passwords, where users can efficiently check if their passwords have been compromised. The initial version of Pwned Passwords required users to send the full password hash to the service to check if it appears in a data breach. In a 2018 collaboration with Cloudflare, the service was upgraded to allow users to run range queries over the password dataset, leaking only the salted hash prefix rather than the entire hash. Cloudflare continues to support the HIBP project by providing CDN and security support for organizations to download the raw Pwned Password datasets.
The HIBP approach was replicated by Google Password Checkup (GPC) in 2019, with the primary difference that GPC alerts are based on username-password pairs instead of passwords alone, which limits the rate of false positives. Enzoic and Microsoft Password Monitor are two other similar services. This year, Cloudflare also released Exposed Credential Checks as part of our Web Application Firewall (WAF) to help inform opted-in website owners when login attempts to their sites use compromised credentials. In fact, we use MIGP on the backend for this service to ensure that plaintext credentials never leave the edge server on which they are being processed.
Most standalone credential checking services work by having a user submit a query containing their password’s or username-password pair’s hash prefix. However, this leaks some information to the service, which could be problematic if the service turns out to be malicious or is compromised. In a collaboration with researchers at Cornell Tech published at CCS’19, we showed just how damaging this leaked information can be. Malevolent actors with access to the data shared with most credential checking services can drastically improve the effectiveness of password-guessing attacks. This left open the question: how can you do compromised credential checking without sharing (leaking!) vulnerable credentials to the service provider itself?
What does a privacy-preserving credential checking service look like?
In the aforementioned CCS’19 paper, we proposed an alternative system in which only the hash prefix of the username is exposed to the MIGP server (independent work out of Google and Stanford proposed a similar system). No information about the password leaves the user device, alleviating the risk of password-guessing attacks. These credential checking services help to preserve password secrecy, but still have a limitation: they can only alert users if the exact queried password appears in the breach.
The present evolution of this work, Might I Get Pwned (MIGP), proposes a next-generation similarity-aware compromised credential checking service that supports checking if a password similar to the one queried has been exposed in the data breach. This approach supports the detection of credential tweaking attacks, an advanced version of credential stuffing.
Credential tweaking takes advantage of the fact that many users, when forced to change their password, use simple variants of their original password. Rather than just attempting to log in using an exact leaked password, say ‘password123’, a credential tweaking attacker might also attempt to log in with easily-predictable variants of the password such as ‘password124’ and ‘password123!’.
There are two main mechanisms described in the MIGP paper to add password variant support: client-side generation and server-side precomputation. With client-side generation, the client simply applies a series of transform rules to the password to derive the set of variants (e.g., truncating the last letter or adding a ‘!’ at the end), and runs multiple queries to the MIGP service with each username and password variant pair. The second approach is server-side precomputation, where the server applies the transform rules to generate the password variants when encrypting the dataset, essentially treating the password variants as additional entries in the breach dataset. The MIGP paper describes tradeoffs between the two approaches and techniques for generating variants in more detail. Our demo service includes variant support via server-side precomputation.
Breach extraction attacks and countermeasures
One challenge for credential checking services are breach extraction attacks, in which an adversary attempts to learn username-password pairs that are present in the breach dataset (which might not be publicly available) so that they can attempt to use them in future credential stuffing or tweaking attacks. Similarity-aware credential checking services like MIGP can make these attacks more effective, since adversaries can potentially check for more breached credentials per API query. Fortunately, additional measures can be incorporated into the protocol to help counteract these attacks. For example, if it is problematic to leak the number of ciphertexts in a given bucket, dummy entries and padding can be employed, or an alternative length-hiding bucket format can be used. Slow hashing and API rate limiting are other common countermeasures that credential checking services can deploy to slow down breach extraction attacks. For instance, our demo service applies the memory-hard slow hash algorithm scrypt to credentials as part of the key derivation function to slow down these attacks.
Let’s now get into the nitty-gritty of how the MIGP protocol works. For readers not interested in the cryptographic details, feel free to skip to the demo below!
MIGP protocol
There are two parties involved in the MIGP protocol: the client and the server. The server has access to a dataset of plaintext breach entries (username-password pairs), and a secret key used for both the precomputation and the online portions of the protocol. In brief, the client performs some computation over the username and password and sends the result to the server; the server then returns a response that allows the client to determine if their password (or a similar password) is present in the breach dataset.
Full protocol description from the MIGP paper: clients learn if their credentials are in the breach dataset, leaking only the hash prefix of the queried username to the server
Precomputation
At a high level, the MIGP server partitions the breach dataset into buckets based on the hash prefix of the username (the bucket identifier), which is usually 16-20 bits in length.
During the precomputation phase of the MIGP protocol, the server derives password variants, encrypts entries, and stores them in buckets based on the hash prefix of the username
We use server-side precomputation as the variant generation mechanism in our implementation. The server derives one ciphertext for each exact username-password pair in the dataset, and an additional ciphertext per password variant. A bucket consists of the set ciphertexts for all breach entries and variants with the same username hash prefix. For instance, suppose there are n breach entries assigned to a particular bucket. If we compute m variants per entry, counting the original entry as one of the variants, there will be n*m ciphertexts stored in the bucket. This introduces a large expansion in the size of the processed dataset, so in practice it is necessary to limit the number of variants computed per entry. Our demo server stores 10 ciphertexts per breach entry in the input: the exact entry, eight variants (see Appendix A of the MIGP paper), and a special variant for allowing username-only checks.
Each ciphertext is the encryption of a username-password (or password variant) pair along with some associated metadata. The metadata describes whether the entry corresponds to an exact password appearing in the breach, or a variant of a breached password. The server derives a per-entry secret key pad using a key derivation function (KDF) with the username-password pair and server secret as inputs, and uses XOR encryption to derive the entry ciphertext. The bucket format also supports storing optional encrypted metadata, such as the date the breach was discovered.
Input:
Secret sk // Server secret key
String u // Username
String w // Password (or password variant)
Byte mdFlag // Metadata flag
String mdString // Optional metadata string
Output:
String C // Ciphertext
function Encrypt(sk, u, w, mdFlag, mdString):
padHdr=KDF1(u, w, sk)
padBody=KDF2(u, w, sk)
zeros=[0] * KEY_CHECK_LEN
C=XOR(padHdr, zeros || mdFlag) || mdString.length || XOR(padBody, mdString)
The precomputation phase only needs to be done rarely, such as when the MIGP parameters are changed (in which case the entire dataset must be re-processed), or when new breach datasets are added (in which case the new data can be appended to the existing buckets).
Online phase
During the online phase of the MIGP protocol, the client requests a bucket of encrypted breach entries corresponding to the queried username, and with the server’s help derives a key that allows it to decrypt an entry corresponding to the queried credentials
The online phase of the MIGP protocol allows a client to check if a username-password pair (or variant) appears in the server’s breach dataset, while only leaking the hash prefix of the username to the server. The client and server engage in an OPRF protocol message exchange to allow the client to derive the per-entry decryption key, without leaking the username and password to the server, or the server’s secret key to the client. The client then computes the bucket identifier from the queried username and downloads the corresponding bucket of entries from the server. Using the decryption key derived in the previous step, the client scans through the entries in the bucket attempting to decrypt each one. If the decryption succeeds, this signals to the client that their queried credentials (or a variant thereof) are in the server’s dataset. The decrypted metadata flag indicates whether the entry corresponds to the exact password or a password variant.
The MIGP protocol solves many of the shortcomings of existing credential checking services with its solution that avoids leaking any information about the client’s queried password to the server, while also providing a mechanism for checking for similar password compromise. Read on to see the protocol in action!
MIGP demo
As the state of the art in attack methodologies evolve with new techniques such as credential tweaking, so must the defenses. To that end, we’ve collaborated with the designers of the MIGP protocol to prototype and deploy the MIGP protocol within Cloudflare’s infrastructure.
Our MIGP demo server is deployed at migp.cloudflare.com, and runs entirely on top of Cloudflare Workers. We use Workers KV for efficient storage and retrieval of buckets of encrypted breach entries, capping out each bucket size at the current KV value limit of 25MB. In our instantiation, we set the username hash prefix length to 20 bits, so that there are a total of 2^20 (or just over 1 million) buckets.
There are currently two ways to interact with the demo MIGP service: via the browser client at migp.cloudflare.com, or via the Go client included in our open-sourced MIGP library. As shown in the screenshots below, the browser client displays the request from your device and the response from the MIGP service. You should take caution to not input any sensitive credentials in a third-party service (feel free to use the test credentials [email protected] and password1 for the demo).
Keep in mind that “absence of evidence is not evidence of absence”, especially in the context of data breaches. We intend to periodically update the breach datasets used by the service as new public breaches become available, but no breach alerting service will be able to provide 100% accuracy in assuring that your credentials are safe.
See the MIGP demo in action in the attached screenshots. Note that in all cases, the username ([email protected]) and corresponding username prefix hash (000f90f4) remain the same, so the client retrieves the exact same bucket contents from the server each time. However, the blindElement parameter in the client request differs per request, allowing the client to decrypt different bucket elements depending on the queried credentials.
Example query in which the credentials are exposed in the breach datasetExample query in which similar credentials were exposed in the breach datasetExample query in which the username is present in the breach datasetExample query in which the credentials are not found in the dataset
Open-sourced MIGP library
We are open-sourcing our implementation of the MIGP library under the BSD-3 License. The code is written in Go and is available at https://github.com/cloudflare/migp-go. Under the hood, we use Cloudflare’s CIRCL library for OPRF support and Go’s supplementary cryptography library for scrypt support. Check out the repository for instructions on setting up the MIGP client to connect to Cloudflare’s demo MIGP service. Community contributions and feedback are welcome!
Future directions
In this post, we announced our open-sourced implementation and demo deployment of MIGP, a next-generation breach alerting service. Our deployment is intended to lead the way for other credential compromise checking services to migrate to a more privacy-friendly model, but is not itself currently meant for production use. However, we identify several concrete steps that can be taken to improve our service in the future:
Add more breach datasets to the database of precomputed entries
Increase the number of variants in server-side precomputation
Add library support in more programming languages to reach a broader developer base
Hide the number of ciphertexts per bucket by padding with dummy entries
Add support for efficient client-side variant checking by batching API calls to the server
We are excited to share and build upon these ideas with the wider Internet community, and hope that our efforts impact positive change in the password security ecosystem. We are particularly interested in collaborating with stakeholders in the space to develop, test, and deploy next-generation protocols to improve user security and privacy. You can reach us with questions, comments, and research ideas at [email protected]. For those interested in joining our team, please visit our Careers Page.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.