We’re pleased to announce the availability of the latest sample security baseline from Landing Zone Accelerator on AWS (LZA)—the Universal Configuration. Developed from years of field experience with highly regulated customers including governments across the world, and in consultation with AWS Partners and industry experts, the Universal Configuration was built to help you implement security and compliance at scale for on your regulated workloads. By setting a high bar with the latest AWS security best practices, the Universal Configuration can help address technical control requirements from compliance frameworks across different geographic regions and industry verticals. The Universal Configuration’s multi-account security architecture provides a foundation to host your diverse workload requirements today along with providing the ability to explore the generative AI and agentic AI solutions that will shape your organization in the future. It can also replace months of complex planning and design by deploying a comprehensive security and compliance-driven environment based on AWS Well-Architected principles in a matter of hours.
As organizations grow, they typically pursue or must adhere to new security compliance certifications. LZA and the Universal Configuration help organizations of all sizes and phases in their security and compliance journey. The speed of deployment, step-by-step documentation, and compliance resources can reduce traditional assessment and authorization timelines by months and result in more predictable and successful audit outcomes. This enables more freedom to invest resources to grow the business instead of choosing between security and compliance tradeoffs.
The Universal Configuration helps organizations:
Automate the deployment of a secure multi-account AWS environment
Foundational security controls based on AWS Well-Architected best practices
Apply consistent and predictable security controls post-deployment
Enable and integrate with native AWS security, identity, and compliance services
Implement controls across system layers
Organization-wide security architecture
Perimeter and resource-specific preventative, proactive, and detective controls
Support for multi-AWS Region resilience, disaster recovery, and active failover
Establish a foundation for security and compliance readiness
Built-in AWS security best practices and technical implementation statements
Map LZA capabilities across global and industry-specific compliance frameworks
Deploy hundreds of controls hours instead of months
The LZA Compliance Workbook
The LZA engine has been a trusted tool for quickly deploying secure multi-account AWS environments for over 4 years. It is also cost effective because you pay only for the AWS services used to operate your environment. The Universal Configuration is the first sample configuration accompanied by the LZA Compliance Workbook available on AWS Artifact. It’s a first-of-its-kind resource with detailed control mappings showing how the Universal Configuration can help you address requirements from frameworks including NIST 800-53 Rev5, CMMC/NIST 800-171, ISO-27001, HIPAA, C5:2020, NATO D-32 (Appendix B), and DoD CCI.
The LZA Compliance Workbook is regularly maintained to reflect the latest Universal Configuration baseline and will include additional compliance mappings in future releases. The workbook contains detailed security configuration descriptions based on the Universal Configuration deployment files, along with control requirement mappings and implementation statements that translate its security capabilities into a compliance-friendly format. By combining AWS security best practices with global compliance expertise, the Universal Configuration delivers predicable security outcomes while also helping you meet regional and industry requirements.
Getting started
To get started with the Landing Zone Accelerator on AWS Universal Configuration, the LZA Implementation Guide walks you through the steps, use cases, and considerations when deploying with LZA. You can download the LZA Compliance Workbook from AWS Artifact today and configure notifications to receive emails when future versions are released. You can view the deployment files and additional technical implementation guidance on the GitHub Universal Configuration sample and documentation page. Additionally, visit the AWS Partner Network (APN) for help with audit and advisory initiatives, cloud migrations, deploying the LZA Universal Configuration, and other services. You can visit the AWS Partner Finder tool and search by solution for Landing Zone Accelerator for the latest LZA Partner offerings.
If you have feedback about this post, submit comments in the Comments section below.
NIST has released another Special Publication in this series, SP 1800-35, titled “Implementing a Zero Trust Architecture (ZTA)” which aims to provide practical steps and best practices for deploying ZTA across various environments. NIST’s publications about ZTA have been extremely influential across the industry, but are often lengthy and highly detailed, so this blog provides a short and easier-to-read summary of NIST’s latest guidance on ZTA.
And so, in this blog post:
We summarize the key items you need to know about this new NIST publication, which presents a reference architecture for Zero Trust Architecture (ZTA) along with a series of “Builds” that demonstrate how different products from various vendors can be combined to construct a ZTA that complies with the reference architecture.
We show how Cloudflare’s Zero Trust product suite can be integrated with offerings from other vendors to support a Zero Trust Architecture that maps to the NIST’s reference architecture.
We highlight a few key features of Cloudflare’s Zero Trust platform that are especially valuable to customers seeking compliance with NIST’s ZTA reference architecture, including compliance with FedRAMP and new post-quantum cryptography standards.
A zero-trust architecture (ZTA) enables secure authorized access to assets — machines, applications and services running on them, and associated data and resources — whether located on-premises or in the cloud, for a hybrid workforce and partners based on an organization’s defined access policy.
NIST uses the term Subject to refer to entities (i.e. employees, developers, devices) that require access to Resources (i.e. computers, databases, servers, applications). SP 1800-35 focuses on developing and demonstrating various ZTA implementations that allow Subjects to access Resources. Specifically, the reference architecture in SP 1800-35 focuses mainly on EIG or “Enhanced Identity Governance”, a specific approach to Zero Trust Architecture, which is defined by NIST in SP 800-207 as follows:
For [the EIG] approach, enterprise resource access policies are based on identity and assigned attributes.
The primary requirement for [R]esource access is based on the access privileges granted to the given [S]ubject. Other factors such as device used, asset status, and environmental factors may alter the final confidence level calculation … or tailor the result in some way, such as granting only partial access to a given [Resource] based on network location.
Individual [R]esources or [policy enforcement points (PEP)] must have a way to forward requests to a policy engine service or authenticate the [S]ubject and approve the request before granting access.
While there are other approaches to ZTA mentioned in the original NIST SP 800-207, we omit those here because SP 1800-35 focuses mostly on EIG.
The ZTA reference architecture from SP 1800-35 focuses on EIG approaches as a set of logical components as shown in the figure below. Each component in the reference architecture does not necessarily correspond directly to physical (hardware or software) components, or products sold by a single vendor, but rather to the logical functionality of the component.
Figure 1: General ZTA Reference Architecture. Source: NIST, Special Publication 1800-35, “Implementing a Zero Trust Architecture (ZTA)”, 2025.
The logical components in the reference architecture are all related to the implementation of policy. Policy is crucial for ZTA because the whole point of a ZTA is to apply policies that determine who has access to what, when and under what conditions.
The core components of the reference architecture are as follows:
| Policy Enforcement Point(PEP) | The PEP protects the “trust zones” that host enterprise Resources, and handles enabling, monitoring, and eventually terminating connections between Subjects and Resources. You can think of the PEP as the dataplane that supports the Subject’s access to the Resources.
Policy Enforcement Point (PEP)
The PEP protects the “trust zones” that host enterprise Resources, and handles enabling, monitoring, and eventually terminating connections between Subjects and Resources. You can think of the PEP as the dataplane that supports the Subject’s access to the Resources.
Policy Engine
(PE)
The PE handles the ultimate decision to grant, deny, or revoke access to a Resource for a given Subject, and calculates the trust scores/confidence levels and ultimate access decisions based on enterprise policy and information from supporting components.
Policy Administrator
(PA)
The PA executes the PE’s policy decision by sending commands to the PEP to establish and terminate the communications path between the Subject and the Resource.
Policy Decision Point (PDP)
The PDP is where the decision as to whether or not to permit a Subject to access a Resource is made. The PIP included the Policy Engine (PE) and the Policy Administrator (PA). You can think of the PDP as the control plane that controls the Subject’s access to the Resources.
The PDP operates on inputs from Policy Information Points (PIPs) which are supporting components that provide critical data and policy rules to the Policy Decision Point (PDP).
Policy Information Point
(PIP)
The PIPs provide various types of telemetry and other information needed for the PDP to make informed access decisions. Some PIPs include:
ICAM, or Identity, Credential, and Access Management, covering user authentication, single sign-on, user groups and access control features that are typically offered by Identity Providers (IdPs) like Okta, AzureAD or Ping Identity.
Endpoint security includes endpoint detection and response (EDR) or endpoint protection platforms (EPP) that protect end user devices like laptops and mobile devices. An EPP primarily focuses on preventing known threats using features like antivirus protection. Meanwhile, an EDR actively detects and responds to threats that may have already breached initial defenses using forensics, behavioral analysis and incident response tools. EDR and EPP products are offered by vendors like CrowdStrike, Microsoft, SentinelOne, and more.
Security Analytics and Data Security products use data collection, aggregation, and analysis to discover security threats using network traffic, user behavior, and other system data, such as, CrowdStrike, Datadog, IBM QRadar, Microsoft Sentinel, New Relic, Splunk, and more.
NIST’s figure might suggest that supporting components in the PIP are mere plug-ins responding in real-time to the PDP. However, for many vendors, the ICAM, EDR/EPP, security analytics, and data security PIPs often represent complex and distributed infrastructures.
Crawl or run, but don’t walk
Next, the SP 1800-35 introduces two more detailed reference architectures, the “Crawl Phase” and the “Run Phase”. The “Run Phase” corresponds to the reference architecture that is shown in the figure above. The “Crawl Phase” is a simplified version of this reference architecture that only deals with protecting on-premise Resources, and omits cloud Resources. Both of these phases focused on Enhanced Identity Governance approaches to ZTA, as we defined above. NIST stated, “We are skipping the EIG walk phase and have proceeded directly to the run phase“.
The SP 1800-35 then provides a sequence of detailed instructions, called “Builds”, that show how to implement “Crawl Phase” and “Run Phase” reference architectures using products sold by various vendors.
Since Cloudflare’s Zero Trust platform natively supports access to both cloud and on-premise resources, we will skip over the “Crawl Phase” and move directly to showing how Cloudflare’s Zero Trust platform can be used to support “Run Phase” of the reference architecture.
A complete Zero Trust Architecture using Cloudflare and integrations
Nothing in NIST SP 1800-35 represents an endorsement of specific vendor technologies. Instead, the intent of the publication is to offer a general architecture that applies regardless of the technologies or vendors an organization chooses to deploy. It also includes a series of “Builds” using a variety of technologies from different vendors, that allow organizations to achieve a ZTA. This section describes how Cloudflare fits in with a ZTA, enabling you to accelerate your ZTA deployment from Crawl directly to Run.
Regarding the “Builds” in SP 1800-35, this section can be viewed as an aggregation of the following three specific builds:
Enterprise 2 Build 4 (E2B4): SDP and Secure Access Service Edge (SASE) with Cloudflare Secure Web Gateway, Cloudflare Zero Trust Network Access (ZTNA), and Cloudflare Cloud Access Security Broker as PEs.
Enterprise 3 Build 5 (E3B5): SDP and SASE with Microsoft Entra Conditional Access (formerly known as Azure AD Conditional Access) and Cloudflare Zero Trust as PEs.
Now let’s see how we can map Cloudflare’s Zero Trust platform to the ZTA reference architecture:
Figure 2: General ZTA Reference Architecture Mapped to Cloudflare Zero Trust & Key Integrations. Source: NIST, Special Publication 1800-35, “Implementing a Zero Trust Architecture (ZTA)”, 2025, with modification by Cloudflare.
Cloudflare’s platform simplifies complexity by delivering the PEP via our global anycast network and the PDP via our Software-as-a-Service (SaaS) management console, which also serves as a global unified control plane. A complete ZTA involves integrating Cloudflare with PIPs provided by other vendors, as shown in the figure above.
Now let’s look at several key points in the figure.
In the bottom right corner of the figure are Resources, which may reside on-premise, in private data centers, or across multiple cloud environments. Resources are made securely accessible through Cloudflare’s global anycast network via Cloudflare Tunnel (as shown in the figure) or Magic WAN (not shown). Resources are shielded from direct exposure to the public Internet by placing them behind Cloudflare Access and Cloudflare Gateway, which are PEPs that enforce zero-trust principles by granting access to Subjects that conform to policy requirements.
In the bottom left corner of the figure are Subjects, both human and non-human, that need access to Resources. With Cloudflare’s platform, there are multiple ways that Subjects can again access to Resources, including:
Agent-based approaches use Cloudflare’s lightweight WARP client, which protects corporate devices by securely and privately sending traffic to Cloudflare’s global network.
Now we move onto the PEP (the Policy Enforcement Point), which is the dataplane of our ZTA. Cloudflare Access is a modern Zero Trust Network Access solution that serves as a dynamic PEP, enforcing user-specific application access policies based on identity, device posture, context, and other factors. Cloudflare Gateway is a Secure Web Gateway for filtering and inspecting traffic sent to the public Internet, serving as a dynamic PEP that provides DNS, HTTP and network traffic filtering, DNS resolver policies, and egress IP policies.
Both Cloudflare Access and Cloudflare Gateway rely on Cloudflare’s control plane, which acts as a PDP offering a policy engine (PE) and policy administrator (PA). This PDP takes in inputs from PIPs provided by integrations with other vendors for ICAM, endpoint security, and security analytics. Let’s dig into some of these integrations.
ICAM: Cloudflare’s control plane integrates with many ICAM providers that provide Single Sign On (SSO) and Multi-Factor Authentication (MFA). The ICAM provider authenticates human Subjects and passes information about authenticated users and groups back to Cloudflare’s control plane using Security Assertion Markup Language (SAML) or OpenID Connect (OIDC) integrations. Cloudflare’s ICAM integration also supports AI/ML powered behavior-based user risk scoring, exchange, and re-evaluation.
In the figure above, we depicted Okta as the ICAM provider, but Cloudflare supports many other ICAM vendors (e.g. Microsoft Entra, Jumpcloud, GitHub SSO, PingOne). For non-human Subjects — such as service accounts, Internet of Things (IoT) devices, or machine identities — authentication can be performed through certificates, service tokens, or other cryptographic methods.
Endpoint security: Cloudflare’s control plane integrates with many endpoint security providers to exchange signals, such as device posture checks and user risk levels. Cloudflare facilitates this through integrations with endpoint detection and response EDR/EPP solutions, such as CrowdStrike, Microsoft, SentinelOne, and more. When posture checks are enabled with one of these vendors such as Microsoft, device state changes, ‘noncompliant’, can be sent to Cloudflare Zero Trust, automatically restricting access to Resources. Additionally, Cloudflare Zero Trust enables the ability to synchronize the Microsoft Entra ID risky users list and apply more stringent Zero Trust policies to users at higher risk.
Security Analytics: Cloudflare’s control plane integrates with real-time logging and analytics for persistent monitoring. Cloudflare’s own analytics and logging features monitor access requests and security events. Optionally, these events can be sent to a Security Information and Event Management (SIEM) solution such as, CrowdStrike, Datadog, IBM QRadar, Microsoft Sentinel, New Relic, Splunk, and more using Cloudflare’s logpush integration.
Cloudflare’s user risk scoring system is built on the OpenID Shared Signals Framework (SSF) Specification, which allows integration with existing and future providers that support this standard. SSF focuses on the exchange of Security Event Tokens (SETs), a specialized type of JSON Web Token (JWT). By using SETs, providers can share user risk information, creating a network of real-time, shared security intelligence. In the context of NIST’s Zero Trust Architecture, this system functions as a PIP, which is responsible for gathering information about the Subject and their context, such as risk scores, device posture, or threat intelligence. This information is then provided to the PDP, which evaluates access requests and determines the appropriate policy actions. The PEP uses these decisions to allow or deny access, completing the cycle of secure, dynamic access control.
Data security: Cloudflare’s Zero Trust offering provides robust data security capabilities across data-in-transit, data-in-use, and data-at-rest. Its Data Loss Prevention (DLP) safeguards sensitive information in transit by inspecting and blocking unauthorized data movement. Remote Browser Isolation (RBI) protects data-in-use by preventing malware, phishing, and unauthorized exfiltration while enabling secure web access. Meanwhile, Cloud Access Security Broker (CASB) ensures data-at-rest security by enforcing granular controls over SaaS applications, preventing unauthorized access and data leakage. Together, these capabilities provide comprehensive protection for modern enterprises operating in a cloud-first environment.
By leveraging Cloudflare’s Zero Trust platform, enterprises can simplify and enhance their ZTA implementation, securing diverse environments and endpoints while ensuring scalability and ease of deployment. This approach ensures that all access requests—regardless of where the Subjects or Resources are located—adhere to robust security policies, reducing risks and improving compliance with modern security standards.
Support for agencies and enterprises running towards Zero Trust Architecture
Cloudflare works with multiple enterprises, and federal and state agencies that rely on NIST guidelines to secure their networks. So we take a brief detour to describe some unique features of Cloudflare’s Zero Trust platform that we’ve found to be valuable to these enterprises.
FedRAMP data centers. Many government agencies and commercial enterprises have FedRAMP requirements, and Cloudflare is well-equipped to support them. FedRAMPs requirements sometimes require organizations to self-host software and services inside their own network perimeter, which can result in higher latency, degraded performance and increased cost. At Cloudflare, we take a different approach. Organizations can still benefit from Cloudflare’s global network and unparalleled performance while remaining Fedramp compliant. To support FedRAMP customers, Cloudflare’s dataplane (aka our PEP, or Policy Enforcement Point) consists of data centers in over 330 cities where customers can send their encrypted traffic, and 32 FedRAMP datacenters where traffic is sent to when sensitive dataplane operations are required (e.g. TLS inspection). This architecture means that our customers do not need to self-host a PEP and incur the associated cost, latency, and performance degradation.
Post-quantum cryptography. NIST has announced that by 2030 all conventional cryptography (RSA and ECDSA) must be deprecated and upgraded to post-quantum cryptography. But upgrading cryptography is hard and takes time, so Cloudflare aims to take on the burden of managing cryptography upgrades for our customers. That’s why organizations can tunnel their corporate network traffic though Cloudflare’s Zero Trust platform, protecting it against quantum adversaries without the hassle of individually upgrading each and every corporate application, system, or network connection. End-to-end quantum safety is available for communications from end-user devices, via web browser (today) or Cloudflare’s WARP device client (mid-2025), to secure applications connected with Cloudflare Tunnel.
Run towards Zero Trust Architecture with Cloudflare
NIST’s latest publication, SP 1800-35, provides a structured approach to implementing Zero Trust, emphasizing the importance of policy enforcement, continuous authentication, and secure access management. Cloudflare’s Zero Trust platform simplifies this complex framework by delivering a scalable, globally distributed solution that is FedRAMP-compliant and integrates with industry-leading providers like Okta, Microsoft, Ping, CrowdStrike, and SentinelOne to ensure comprehensive protection.
A key differentiator of Cloudflare’s Zero Trust solution is our global anycast network, one of the world’s largest and most interconnected networks. Spanning 330+ cities across 120+ countries, this network provides unparalleled performance, resilience, and scalability for enforcing Zero Trust policies without negatively impacting the end user experience. By leveraging Cloudflare’s network-level enforcement of security controls, organizations can ensure that access control, data protection, and security analytics operate at the speed of the Internet — without backhauling traffic through centralized choke points. This architecture enables low-latency, highly available enforcement of security policies, allowing enterprises to seamlessly protect users, devices, and applications across on-prem, cloud, and hybrid environments.
Now is the time to take action. You can start implementing Zero Trust today by leveraging Cloudflare’s platform in alignment with NIST’s reference architecture. Whether you are beginning your Zero Trust journey or enhancing an existing framework, Cloudflare provides the tools, network, and integrations to help you succeed. Sign up for Cloudflare Zero Trust, explore our integrations, and secure your organization with a modern, globally distributed approach to cybersecurity.
Today, we released an updated version of the Aligning to the NIST Cybersecurity Framework (CSF) in the AWS Cloud whitepaper to reflect the significant changes introduced in the National Institute of Standards and Technology (NIST) Cybersecurity Framework (CSF) 2.0, published in February 2024. This comprehensive update helps you understand how AWS services align with the enhanced framework and how you can use AWS capabilities to improve your cybersecurity posture.
The NIST CSF 2.0 provides guidance to industry, government agencies, and other organizations to manage cybersecurity risks. The updated version introduces important changes, including the following:
A new “Govern” Core Function, emphasizing procedural and organizational activities that have an impact on the management of cybersecurity risk within organizations.
An expanded scope, beyond critical infrastructure, to help organizations of many sizes and sectors.
Enhanced guidance for privacy risk management and supply chain security.
Updated Categories and Subcategories that better reflect current cybersecurity challenges.
In accordance with the AWS Shared Responsibility Model, the whitepaper provides a detailed mapping of AWS services to the six CSF Core Functions: Govern (New), Identify, Protect, Detect, Respond, and Recover. Organizations can use this whitepaper to understand how AWS services align with NIST CSF 2.0 requirements, implement AWS solutions to help achieve their security objectives, use AWS capabilities for automated security operations, and build resilient architectures that support their cybersecurity strategies.
Security and compliance remain our top priorities at AWS. This updated whitepaper demonstrates our commitment to helping customers align with the latest security frameworks while protecting their data and resources in the AWS Cloud. The whitepaper also includes practical guidance for implementing AWS services and features that support the CSF outcomes, whether you’re just starting your cloud journey or looking to enhance your existing security posture.
To learn more about implementing NIST CSF 2.0 in your organization by using AWS services, contact your AWS account team or download the whitepaper.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
We’re excited to announce that AWS-LC FIPS 3.0 has been added to the National Institute of Standards and Technology (NIST)Cryptographic Module Validation Program (CMVP)modules in process list. This latest validation of AWS-LC introduces support for Module Lattice-Based Key Encapsulation Mechanisms (ML-KEM), the new FIPS standardized post-quantum cryptographic algorithm. This is a significant step towards enhancing the long-term confidentiality of our most sensitive customer workflows, including U.S. federal government communications.
This validation makes AWS LibCrypto (AWS-LC) the first open source cryptographic module to provide post-quantum algorithm support within the FIPS module. Organizations that require FIPS-validated cryptographic modules—such as those operating under FedRAMP, FISMA, HIPAA, and other federal compliance frameworks—can now use these algorithms within AWS-LC.
This announcement is part of the long-term promise made by AWS-LC of continuous validation to obtain new FIPS 140-3 certificates. AWS-LC obtained its first certificate in October 2023 for AWS-LC-FIPS 1.0. A subsequent version of the library, AWS-LC-FIPS 2.0, was certified in October 2024. In this post, we discuss our FIPS-validation of post-quantum cryptographic algorithm ML-KEM, the performance improvements of existing algorithms in AWS-LC FIPS 2.0 and 3.0, and the new algorithm support added for version 3.0. We also discuss how you can use the new algorithms to implement hybrid post-quantum cipher suites, along with configuration options that you can set up today to help protect against future threats.
FIPS post-quantum cryptography
Large-scale quantum computers pose a threat to the long-term confidentiality of the data that we protect under public-key cryptography today. In what’s known as a record-now, decrypt-later attack, an adversary records internet traffic today, capturing key exchanges and encrypted communication. Then, when a sufficiently powerful quantum computer is available, the adversary can retroactively recover shared secrets and encryption keys by solving the underlying hardness problem.
ML-KEM is one of the new key encapsulation mechanisms that’s being standardized by NIST in an effort to protect the uses of public key cryptography from quantum threats. Much like RSA, Diffie-Hellman (DH), or Elliptic-curve Diffie-Hellman (ECDH) key exchange, it works by establishing a shared secret between two parties. However, unlike RSA or DH, ML-KEM bases the key exchange on an underlying problem that is believed to be hard for quantum computers to solve.
Today, we don’t know how to build such a large-scale quantum computer. Significant scientific research is needed before such a computer can be built. However, you can mitigate the risk of record-now, decrypt-later attacks by introducing post-quantum algorithms such as ML-KEM into your key exchange protocols today. We recommend adopting a hybrid key exchange approach that combines a traditional key exchange method—such as ECDH—with ML-KEM to hedge against current and future adversaries. Later in this post, we show you how you can implement hybrid post-quantum cipher suites today to protect against future threats.
AWS-LC FIPS 3.0 includes the ML-KEM algorithm for all three provided parameter sets, ML-KEM-512, ML-KEM-768, and ML-KEM-1024. The three parameter sets provide differing levels of security strength as specified by NIST (see FIPS 203 [9, Sect. 5.6] or the post-quantum security evaluation criteria). ML-KEM-768 is recommended for general-purpose use cases, ML-KEM-1024 is designed for applications that require a higher security level or adherence to explicit directives such as the Commercial National Security Algorithm Suite (CNSA) 2.0 for National Security System owners and operators.
Algorithm
NIST security category
Public key (B)
Private key (B)
Ciphertext (B)
ML-KEM-512
1
800
1632
768
ML-KEM-768
3
1184
2400
1088
ML-KEM-1024
5
1568
3168
1568
Table 1. Security strength category, public key, private key, and ciphertext sizes in bytes for the three parameter sets of ML-KEM
Integration with s2n-tls
ML-KEM is now available in our open source TLS implementation, s2n-tls, through hybrid key exchange for TLS 1.3 (draft-ietf-tls-hybrid-design). We’ve also added support for hybrid ECDHE-ML-KEM key agreement for TLS 1.3 (draft-kwiatkowski-tls-ecdhe-mlkem), along with new key share identifiers for Curve x25519 and ML-KEM-768.
For hybrid key establishment in FIPS 140-approved mode, one component algorithm must be a NIST-approved mechanism (detailed in NIST post-quantum FAQs). With ML-KEM added to the list of NIST-approved algorithms, you can now include non-FIPS standardized algorithms like Curve x25519 in hybrid cipher suites. By configuring your TLS cipher suite to use ML-KEM-768 and x25519 (draft-kwiatkowski-tls-ecdhe-mlkem), you can use x25519 within a FIPS-validated cryptographic module for the first time. This can facilitate more efficient key exchange through the highly optimized and functionally verified Curve x25519 implementation provided by AWS-LC.
New algorithms and new implementations
Two integral parts of our commitment to continuous validation of AWS-LC FIPS are to include new algorithms as approved cryptographic services and new implementations of existing algorithms that provide performance improvements and functional correctness.
New algorithms
We’re committed to continually validating new algorithms so that builders can adopt FIPS-validated cryptography by including the latest revisions of approved cryptographic algorithms and supporting new primitives. Validating new algorithms in their latest standardized revision helps ensure that our cryptographic tool-kit is providing high-assurance implementations that achieve compliance with globally recognized standards.
In AWS-LC FIPS 3.0 we’ve added the latest member of the Secure Hash Algorithm standard SHA-3 to the module. The SHA-3 family is a cryptographic primitive used to support a variety of algorithms. In AWS-LC FIPS 3.0, we’ve integrated ECDSA and RSA signature generation and verification with SHA-3 and within the post-quantum algorithm ML-KEM. In AWS-LC, ML-KEM calls into our FIPS-validated SHA-3 functions, which provide optimized implementations of SHA-3 and SHAKE hashing procedures. This means that as we continually refine and optimize our AWS-LC SHA-3 implementation, we’ll continue to see performance increases across algorithms that use the primitive, such as ML-KEM.
EdDSA is a digital signature algorithm based on elliptic curves using the curve Ed25519. It was added to NIST’s updated Digital Signature Standard (DSS), FIPS 186-5. This signature algorithm is now offered as part of the AWS-LC 3.0 FIPS module. For key agreement, the Single-step Key Derivation Function (SSKDF) used to derive keys from a shared secret (SP 800-56Cr2) is available both in the digest-based and HMAC-based specifications. It can be used, for example, to derive a key from a shared secret produced by KMS when using ECDH. Further keys can be derived from that original key using a Key-based Key Derivation Function (KBKDF)—SP 800-108r1—which is available using a counter-mode based on HMAC.
Performance improvements
We focused on increasing the performance of public-key cryptography algorithms widely used in transport protocols such as the TLS protocol. For example, RSA signatures on Graviton2 are 81 percent faster for bit-length 2048, 33 percent for 3072, and 94 percent for 4096, with added formal verification of functional correctness of the main operation. Using Intel’s AVX512 Integer Fused Multiply Add (IFMA) instructions—available starting from 3rd Gen Intel Xeon—Intel developers contributed an RSA implementation that employs these instruction and the wide AVX512 registers, which are twice as fast as the existing implementation.
We increased throughput for EdDSA signing by an average of 108 percent and for verifying by 37 percent. This average is taken over three environments: Graviton2, Graviton3, and Intel Ice Lake (Intel Xeon Platinum 8375C CPU). This boost in performance is achieved by integrating assembly implementations of the core operation for each target from the s2n-bignum library. That, in addition to the careful constant-time implementation of the core operations, is how each one has been proven to be functionally correct.
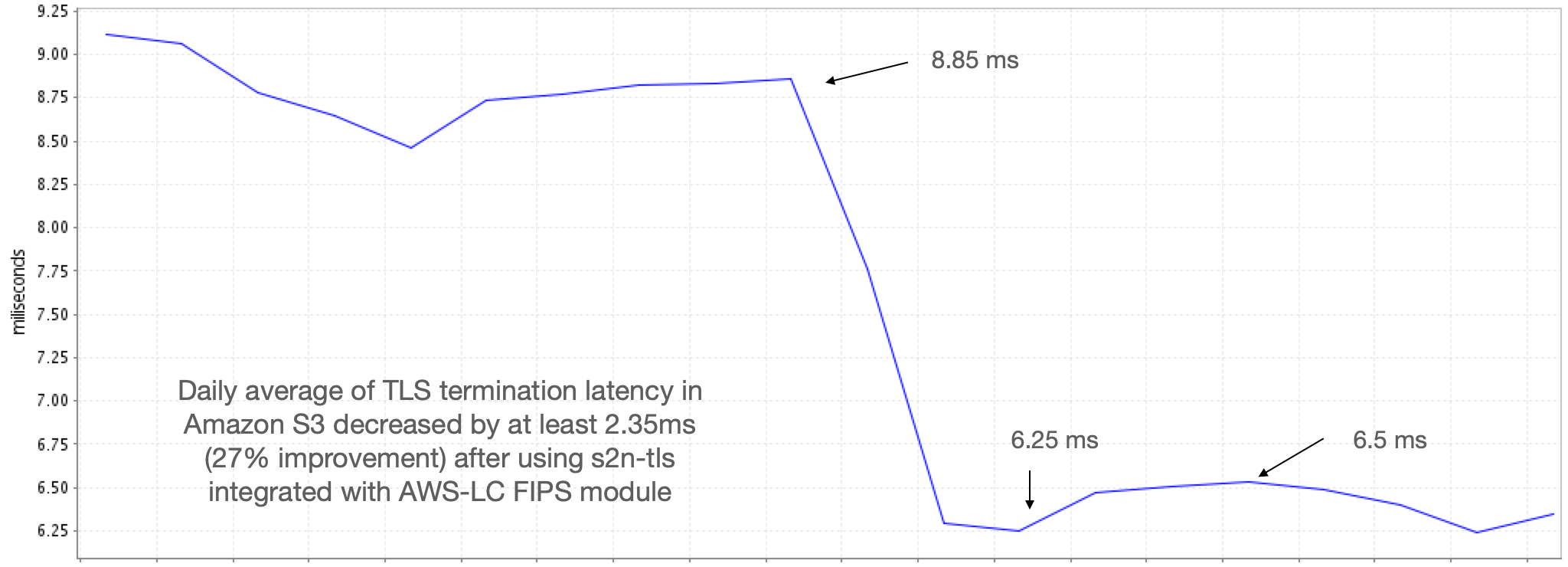
In Figure 1 that follows, we highlight the percentage of performance improvements compared to AWS-LC FIPS 1.0 in versions 2.0 and 3.0. The improvements achieved in 2.0 are maintained in 3.0 and are not repeated in the graph. The graph also includes symmetric-key improvements. In AES-256-GCM, which is widely used in TLS to encrypt the communication after the session has been established, the increase is on average 115 percent across Intel Ice Lake and Graviton4 to encrypt a 16 KB message. In AES-256-XTS, which is used in disk storage, encrypting a 256 B input is 360 percent faster on Intel Ice Lake and 90 percent faster on Graviton4.
Figure 1: Graph of performance improvements in versions 2.0 and 3.0 of AWS-LC FIPS
How to use ML-KEM today
You can configure both s2n-tls and AWS-LC TLS libraries to enable hybrid post-quantum security with ML-KEM today by enabling X25519MLKEM768 and SecP256r1MLKEM768 for key exchange. We’ve integrated support for both of these hybrid algorithms in AWS-LC libssl and s2n-tls using each library’s exisiting TLS configuration APIs. To negotiate a TLS connection, use one of the following commands:
# S2N-tls Client CLI Example
./s2n/build/bin/s2nc -c default_pq -i <hostname><port>
Conclusion
In this post, we described the ongoing development, optimization, and validation of the cryptography that we provide to our customers and products through our open source cryptographic library, AWS-LC. We introduced the addition of FIPS-validated post-quantum algorithms and provided configuration options to begin using these algorithms today to protect against future threats.
AWS-LC-FIPS 3.0 is part of our commitment to continually validate new versions of AWS-LC as we add new algorithms within the FIPS boundary as they become specified, and as we raise the performance and formal verification bar on existing algorithms. Through this commitment, we continue to support the wider developer community of Rust, Java and Python developers by providing integrations into the AWS Libcrypto for Rust (aws-lc-rs) and ACCP 2.0 libraries. We facilitate integration into CPython so that you can build against AWS-LC and use it for all cryptography in the Python standard library. We enabled rustls to provide FIPS support.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
NIST’s second draft of its “SP 800-63-4“—its digital identify guidelines—finally contains some really good rules about passwords:
The following requirements apply to passwords:
lVerifiers and CSPs SHALL require passwords to be a minimum of eight characters in length and SHOULD require passwords to be a minimum of 15 characters in length.
Verifiers and CSPs SHOULD permit a maximum password length of at least 64 characters.
Verifiers and CSPs SHOULD accept all printing ASCII [RFC20] characters and the space character in passwords.
Verifiers and CSPs SHOULD accept Unicode [ISO/ISC 10646] characters in passwords. Each Unicode code point SHALL be counted as a signgle character when evaluating password length.
Verifiers and CSPs SHALL NOT impose other composition rules (e.g., requiring mixtures of different character types) for passwords.
Verifiers and CSPs SHALL NOT require users to change passwords periodically. However, verifiers SHALL force a change if there is evidence of compromise of the authenticator.
Verifiers and CSPs SHALL NOT permit the subscriber to store a hint that is accessible to an unauthenticated claimant.
Verifiers and CSPs SHALL NOT prompt subscribers to use knowledge-based authentication (KBA) (e.g., “What was the name of your first pet?”) or security questions when choosing passwords.
Verifiers SHALL verify the entire submitted password (i.e., not truncate it).
On August 13th, 2024, the US National Institute of Standards and Technology (NIST) published the first three cryptographic standards designed to resist an attack from quantum computers: ML-KEM, ML-DSA, and SLH-DSA. This announcement marks a significant milestone for ensuring that today’s communications remain secure in a future world where large-scale quantum computers are a reality.
In this blog post, we briefly discuss the significance of NIST’s recent announcement, how we expect the ecosystem to evolve given these new standards, and the next steps we are taking. For a deeper dive, see our March 2024 blog post.
Why are quantum computers a threat?
Cryptography is a fundamental aspect of modern technology, securing everything from online communications to financial transactions. For instance, when visiting this blog, your web browser used cryptography to establish a secure communication channel to Cloudflare’s server to ensure that you’re really talking to Cloudflare (and not an impersonator), and that the conversation remains private from eavesdroppers.
Much of the cryptography in widespread use today is based on mathematical puzzles (like factoring very large numbers) which are computationally out of reach for classical (non-quantum) computers. We could likely continue to use traditional cryptography for decades to come if not for the advent of quantum computers, devices that use properties of quantum mechanics to perform certain specialized calculations much more efficiently than traditional computers. Unfortunately, those specialized calculations include solving the mathematical puzzles upon which most widely deployed cryptography depends.
As of today, no quantum computers exist that are large and stable enough to break today’s cryptography, but experts predict that it’s only a matter of time until such a cryptographically-relevant quantum computer (CRQC) exists. For instance, more than a quarter of interviewed experts in a 2023 survey expect that a CRQC is more likely than not to appear in the next decade.
What is being done about the quantum threat?
In recognition of the quantum threat, the US National Institute of Standards and Technology (NIST) launched a public competition in 2016 to solicit, evaluate, and standardize new “post-quantum” cryptographic schemes that are designed to be resistant to attacks from quantum computers. On August 13, 2024, NIST published the final standards for the first three post-quantum algorithms to come out of the competition: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. A fourth standard based on FALCON is planned for release in late 2024 and will be dubbed FN-DSA, short for FFT (fast-Fourier transform) over NTRU-Lattice-Based Digital Signature Algorithm.
The publication of the final standards marks a significant milestone in an eight-year global community effort managed by NIST to prepare for the arrival of quantum computers. Teams of cryptographers from around the world jointly submitted 82 algorithms to the first round of the competition in 2017. After years of evaluation and cryptanalysis from the global cryptography community, NIST winnowed the algorithms under consideration down through several rounds until they decided upon the first four algorithms to standardize, which they announced in 2022.
This has been a monumental effort, and we would like to extend our gratitude to NIST and all the cryptographers and engineers across academia and industry that participated.
Security was a primary concern in the selection process, but algorithms also need to be performant enough to be deployed in real-world systems. Cloudflare’s involvement in the NIST competition began in 2019 when we performed experiments with industry partners to evaluate how algorithms under consideration performed when deployed on the open Internet. Gaining practical experience with the new algorithms was a crucial part of the evaluation process, and helped to identify and remove obstacles for deploying the final standards.
Having standardized algorithms is a significant step, but migrating systems to use these new algorithms is going to require a multi-year effort. To understand the effort involved, let’s look at two classes of traditional cryptography that are susceptible to quantum attacks: key agreement and digital signatures.
Key agreement allows two parties that have never communicated before to establish a shared secret over an insecure communication channel (like the Internet). The parties can then use this shared secret to encrypt future communications between them. An adversary may be able to observe the encrypted communication going over the network, but without access to the shared secret they cannot decrypt and “see inside” the encrypted packets.
However, in what is known as the “harvest now, decrypt later” threat model, an adversary can store encrypted data until some point in the future when they gain access to a sufficiently large quantum computer, and then can decrypt at their leisure. Thus, today’s communication is already at risk from a future quantum adversary, and it is urgent that we upgrade systems to use post-quantum key agreement as soon as possible.
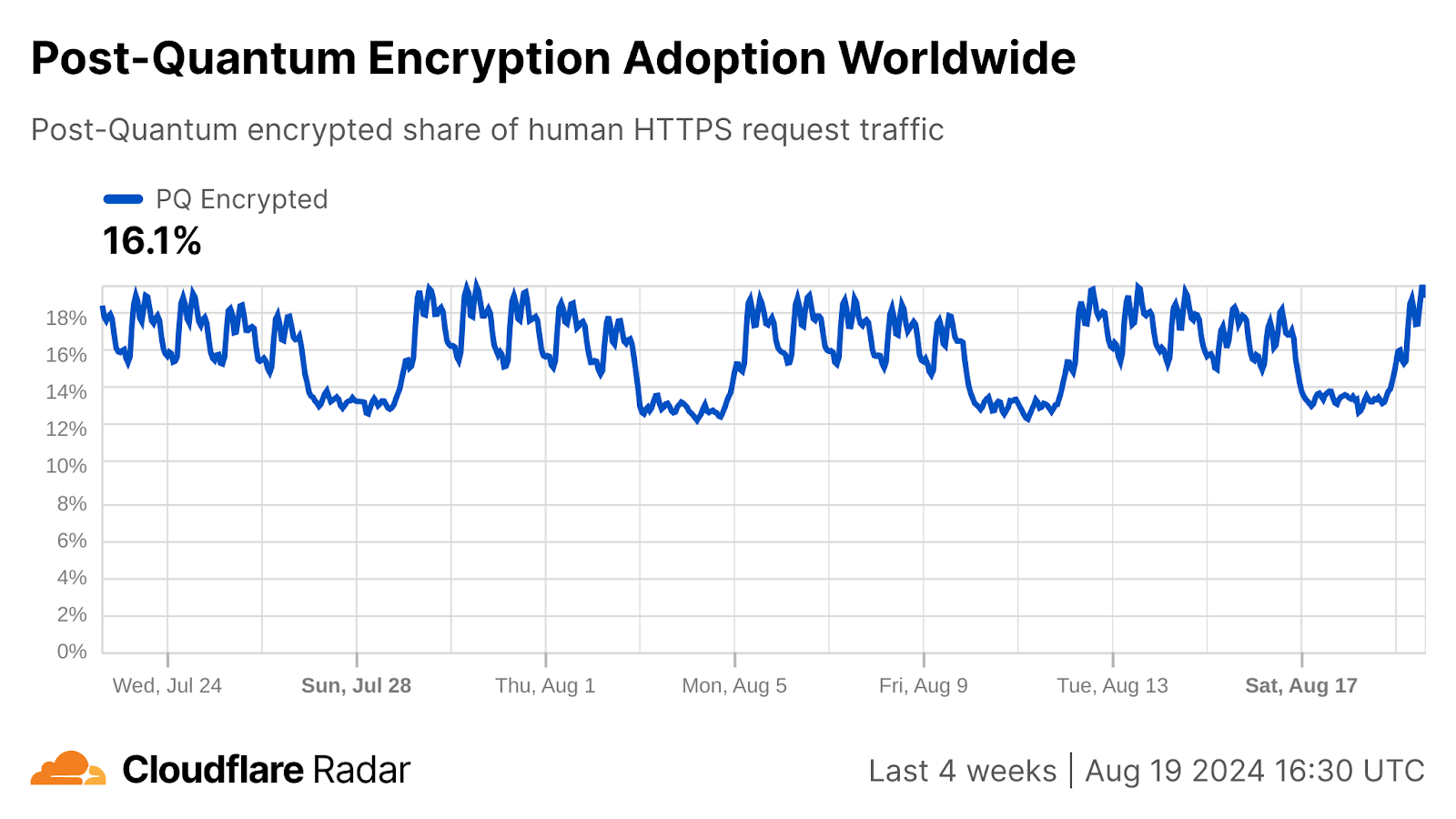
In 2022, soon after NIST announced the first set of algorithms to be standardized, Cloudflare worked with industry partners to deploy a preliminary version of ML-KEM to protect traffic arriving at Cloudflare’s servers (and our internal systems), both to pave the way for adoption of the final standard and to start protecting traffic as soon as possible. As of mid-August 2024, over 16% of human-generated requests to Cloudflare’s servers are already protected with post-quantum key agreement.
Percentage of human traffic to Cloudflare protected by X25519Kyber, a preliminary version of ML-KEM as shown on Cloudflare Radar.
Other players in the tech industry have deployed post-quantum key agreement as well, including Google, Apple, Meta, and Signal.
Signatures are crucial to ensure that you’re communicating with who you think you are communicating. In the web public key infrastructure (WebPKI), signatures are used in certificates to prove that a website operator is the rightful owner of a domain. The threat model for signatures is different than for key agreement. An adversary capable of forging a digital signature could carry out an active attack to impersonate a web server to a client, but today’s communication is not yet at risk.
While the migration to post-quantum signatures is less urgent than the migration for key agreement (since traffic is only at risk once CRQCs exist), it is much more challenging. Consider, for instance, the number of parties involved. In key agreement, only two parties need to support a new key agreement protocol: the client and the server. In the WebPKI, there are many more parties involved, from library developers, to browsers, to server operators, to certificate authorities, to hardware manufacturers. Furthermore, post-quantum signatures are much larger than we’re used to from traditional signatures. For more details on the tradeoffs between the different signature algorithms, deployment challenges, and out-of-the-box solutions see our previous blog post.
Reaching consensus on the right approach for migrating to post-quantum signatures is going to require extensive effort and coordination among stakeholders. However, that work is already well underway. For instance, in 2021 we ran large scale experiments to understand the feasibility of post-quantum signatures in the WebPKI, and we have more studies planned.
What’s next?
Now that NIST has published the first set of standards for post-quantum cryptography, what comes next?
In 2022, Cloudflare deployed a preliminary version of the ML-KEM key agreement algorithm, Kyber, which is now used to protect double-digit percentages of requests to Cloudflare’s network. We use a hybrid with X25519, to hedge against future advances in cryptanalysis and implementation vulnerabilities. In coordination with industry partners at the NIST NCCoE and IETF, we will upgrade our systems to support the final ML-KEM standard, again using a hybrid. We will slowly phase out support for the pre-standard version X25519Kyber768 after clients have moved to the ML-KEM-768 hybrid, and will quickly phase out X25519Kyber512, which hasn’t seen real-world usage.
Now that the final standards are available, we expect to see widespread adoption of ML-KEM industry-wide as support is added in software and hardware, and post-quantum becomes the new default for key agreement. Organizations should look into upgrading their systems to use post-quantum key agreement as soon as possible to protect their data from future quantum-capable adversaries. Check if your browser already supports post-quantum key agreement by visiting pq.cloudflareresearch.com, and if you’re a Cloudflare customer, see how you can enable post-quantum key agreement support to your origin today.
Adoption of the newly-standardized post-quantum signatures ML-DSA and SLH-DSA will take longer as stakeholders work to reach consensus on the migration path. We expect the first post-quantum certificates to be available in 2026, but not to be enabled by default. Organizations should prepare for a future flip-the-switch migration to post-quantum signatures, but there is no need to flip the switch just yet.
After three rounds of evaluation and analysis, NIST selected four algorithms it will standardize as a result of the PQC Standardization Process. The public-key encapsulation mechanism selected was CRYSTALS-KYBER, along with three digital signature schemes: CRYSTALS-Dilithium, FALCON, and SPHINCS+.
These algorithms are part of three NIST standards that have been finalized:
One – ML-KEM [PDF] (based on CRYSTALS-Kyber) – is intended for general encryption, which protects data as it moves across public networks. The other two –- ML-DSA [PDF] (originally known as CRYSTALS-Dilithium) and SLH-DSA [PDF] (initially submitted as Sphincs+)—secure digital signatures, which are used to authenticate online identity.
A fourth algorithm – FN-DSA [PDF] (originally called FALCON) – is slated for finalization later this year and is also designed for digital signatures.
NIST continued to evaluate two other sets of algorithms that could potentially serve as backup standards in the future.
One of the sets includes three algorithms designed for general encryption – but the technology is based on a different type of math problem than the ML-KEM general-purpose algorithm in today’s finalized standards.
NIST plans to select one or two of these algorithms by the end of 2024.
Amazon Web Services (AWS) is pleased to announce the successful attestation of our conformance with the National Institute of Standards and Technology (NIST) Secure Software Development Framework (SSDF), Special Publication 800-218. This achievement underscores our ongoing commitment to the security and integrity of our software supply chain.
Executive Order (EO) 14028, Improving the Nation’s Cybersecurity (May 12, 2021) directs U.S. government agencies to take a variety of actions that “enhance the security of the software supply chain.” In accordance with the EO, NIST released the SSDF, and the Office and Management and Budget (OMB) issued Memorandum M-22-18, Enhancing the Security of the Software Supply Chain through Secure Software Development Practices, requiring U.S. government agencies to only use software provided by software producers who can attest to conformance with NIST guidance.
A FedRAMP certified Third Party Assessment Organization (3PAO) assessed AWS against the 42 security tasks in the SSDF. Our attestation form is available in the Cybersecurity and Infrastructure Security Agency (CISA) Repository for Software Attestations and Artifacts for our U.S. government agency customers to access and download. Per CISA guidance, agencies are encouraged to collect the AWS attestation directly from CISA’s repository.
As always, we value your feedback and questions. Reach out to the AWS Compliance team through the Contact Us page. To learn more about our other compliance and security programs, see AWS Compliance Programs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) provides tools that simplify automation and monitoring for compliance with security standards, such as the NIST SP 800-53 Rev. 5 Operational Best Practices. Organizations can set preventative and proactive controls to help ensure that noncompliant resources aren’t deployed. Detective and responsive controls notify stakeholders of misconfigurations immediately and automate fixes, thus minimizing the time to resolution (TTR).
By layering the solutions outlined in this blog post, you can increase the probability that your deployments stay continuously compliant with the National Institute of Standards and Technology (NIST) SP 800-53 security standard, and you can simplify reporting on that compliance. In this post, we walk you through the following tools to get started on your continuous compliance journey:
This post covers quite a few solutions, and these solutions operate in different parts of the security pillar of the AWS Well-Architected Framework. It might take some iterations to get your desired results, but we encourage you to start small, find your focus areas, and implement layered iterative changes to address them.
For example, if your organization has experienced events involving public Amazon Simple Storage Service (Amazon S3) buckets that can lead to data exposure, focus your efforts across the different control types to address that issue first. Then move on to other areas. Those steps might look similar to the following:
Use Security Hub and Prowler to find your public buckets and monitor patterns over a predetermined time period to discover trends and perhaps an organizational root cause.
Apply IAM policies and SCPs to specific organizational units (OUs) and principals to help prevent the creation of public buckets and the changing of AWS account-level controls.
Set up Automated Security Response (ASR) on AWS and then test and implement the automatic remediation feature for only S3 findings.
Remove direct human access to production accounts and OUs. Require infrastructure as code (IaC) to pass through a pipeline where CloudFormation Guard scans IaC for misconfigurations before deployment into production environments.
Detective controls
Implement your detective controls first. Use them to identify misconfigurations and your priority areas to address. Detective controls are security controls that are designed to detect, log, and alert after an event has occurred. Detective controls are a foundational part of governance frameworks. These guardrails are a second line of defense, notifying you of security issues that bypassed the preventative controls.
Security Hub NIST SP 800-53 security standard
Security Hub consumes, aggregates, and analyzes security findings from various supported AWS and third-party products. It functions as a dashboard for security and compliance in your AWS environment. Security Hub also generates its own findings by running automated and continuous security checks against rules. The rules are represented by security controls. The controls might, in turn, be enabled in one or more security standards. The controls help you determine whether the requirements in a standard are being met. Security Hub provides controls that support specific NIST SP 800-53 requirements. Unlike other frameworks, NIST SP 800-53 isn’t prescriptive about how its requirements should be evaluated. Instead, the framework provides guidelines, and the Security Hub NIST SP 800-53 controls represent the service’s understanding of them.
Using this step-by-step guide, enable Security Hub for your organization in AWS Organizations. Configure the NIST SP 800-53 security standard for all accounts, in all AWS Regions that are required to be monitored for compliance, in your organization by using the new centralized configuration feature; or if your organization uses AWS GovCloud (US), by using this multi-account script. Use the findings from the NIST SP 800-53 security standard in your delegated administrator account to monitor NIST SP 800-53 compliance across your entire organization, or a list of specific accounts.
Figure 1 shows the Security Standard console page, where users of the Security Hub Security Standard feature can see an overview of their security score against a selected security standard.
Figure 1: Security Hub security standard console
On this console page, you can select each control that is checked by a Security Hub Security Standard, such as the NIST 800-53 Rev. 5 standard, to find detailed information about the check and which NIST controls it maps to, as shown in Figure 2.
Figure 2: Security standard check detail
After you enable Security Hub with the NIST SP 800-53 security standard, you can link responsive controls such as the Automated Security Response (ASR), which is covered later in this blog post, to Amazon EventBridge rules to listen for Security Hub findings as they come in.
Prowler
Prowler is an open source security tool that you can use to perform assessments against AWS Cloud security recommendations, along with audits, incident response, continuous monitoring, hardening, and forensics readiness. The tool is a Python script that you can run anywhere that an up-to-date Python installation is located—this could be a workstation, an Amazon Elastic Compute Cloud (Amazon EC2) instance, AWS Fargate or another container, AWS CodeBuild, AWS CloudShell, AWS Cloud9, or another compute option.
Figure 3 shows Prowler being used to perform a scan.
Figure 3: Prowler CLI in action
Prowler works well as a complement to the Security Hub NIST SP 800-53 Rev. 5 security standard. The tool has a native Security Hub integration and can send its findings to your Security Hub findings dashboard. You can also use Prowler as a standalone compliance scanning tool in partitions where Security Hub or the security standards aren’t yet available.
At the time of writing, Prowler has over 300 checks across 64 AWS services.
In addition to integrations with Security Hub and computer-based outputs, Prowler can produce fully interactive HTML reports that you can use to sort, filter, and dive deeper into findings. You can then share these compliance status reports with compliance personnel. Some organizations run automatically recurring Prowler reports and use Amazon Simple Notification Service (Amazon SNS) to email the results directly to their compliance personnel.
Get started with Prowler by reviewing the Prowler Open Source documentation that contains tutorials for specific providers and commands that you can copy and paste.
Preventative controls
Preventative controls are security controls that are designed to prevent an event from occurring in the first place. These guardrails are a first line of defense to help prevent unauthorized access or unwanted changes to your network. Service control policies (SCPs) and IAM controls are the best way to help prevent principals in your AWS environment (whether they are human or nonhuman) from creating noncompliant or misconfigured resources.
IAM
In the ideal environment, principals (both human and nonhuman) have the least amount of privilege that they need to reach operational objectives. Ideally, humans would at the most only have read-only access to production environments. AWS resources would be created through IaC that runs through a DevSecOps pipeline where policy-as-code checks review resources for compliance against your policies before deployment. DevSecOps pipeline roles should have IAM policies that prevent the deployment of resources that don’t conform to your organization’s compliance strategy. Use IAM conditions wherever possible to help ensure that only requests that match specific, predefined parameters are allowed.
The following policy is a simple example of a Deny policy that uses Amazon Relational Database Service (Amazon RDS) condition keys to help prevent the creation of unencrypted RDS instances and clusters. Most AWS services support condition keys that allow for evaluating the presence of specific service settings. Use these condition keys to help ensure that key security features, such as encryption, are set during a resource creation call.
You can use an SCP to specify the maximum permissions for member accounts in your organization. You can restrict which AWS services, resources, and individual API actions the users and roles in each member account can access. You can also define conditions for when to restrict access to AWS services, resources, and API actions. If you haven’t used SCPs before and want to learn more, see How to use service control policies to set permission guardrails across accounts in your AWS Organization.
Use SCPs to help prevent common misconfigurations mapped to NIST SP 800-53 controls, such as the following:
Prevent governed accounts from leaving the organization or turning off security monitoring services.
Build protections and contextual access controls around privileged principals.
Mitigate the risk of data mishandling by enforcing data perimeters and requiring encryption on data at rest.
Although SCPs aren’t the optimal choice for preventing every misconfiguration, they can help prevent many of them. As a feature of AWS Organizations, SCPs provide inheritable controls to member accounts of the OUs that they are applied to. For deployments in Regions where AWS Organizations isn’t available, you can use IAM policies and permissions boundaries to achieve preventative functionality that is similar to what SCPs provide.
The following is an example of policy mapping statements to NIST controls or control families. Note the placeholder values, which you will need to replace with your own information before use. Note that the SIDs map to Security Hub NIST 800-53 Security Standard control numbers or NIST control families.
For a collection of SCP examples that are ready for your testing, modification, and adoption, see the service-control-policy-examples GitHub repository, which includes examples of Region and service restrictions.
You should thoroughly test SCPs against development OUs and accounts before you deploy them against production OUs and accounts.
Proactive controls
Proactive controls are security controls that are designed to prevent the creation of noncompliant resources. These controls can reduce the number of security events that responsive and detective controls handle. These controls help ensure that deployed resources are compliant before they are deployed; therefore, there is no detection event that requires response or remediation.
CloudFormation Guard
CloudFormation Guard (cfn-guard) is an open source, general-purpose, policy-as-code evaluation tool. Use cfn-guard to scan Information as Code (IaC) against a collection of policies, defined as JSON, before deployment of resources into an environment.
Cfn-guard can scan CloudFormation templates, Terraform plans, Kubernetes configurations, and AWS Cloud Development Kit (AWS CDK) output. Cfn-guard is fully extensible, so your teams can choose the rules that they want to enforce, and even write their own declarative rules in a YAML-based format. Ideally, the resources deployed into a production environment on AWS flow through a DevSecOps pipeline. Use cfn_guard in your pipeline to define what is and is not acceptable for deployment, and help prevent misconfigured resources from deploying. Developers can also use cfn_guard on their local command line, or as a pre-commit hook to move the feedback timeline even further “left” in the development cycle.
Use policy as code to help prevent the deployment of noncompliant resources. When you implement policy as code in the DevOps cycle, you can help shorten the development and feedback cycle and reduce the burden on security teams. The CloudFormation team maintains a GitHub repo of cfn-guard rules and mappings, ready for rapid testing and adoption by your teams.
Figure 4 shows how you can use Guard with the NIST 800-53 cfn_guard Rule Mapping to scan infrastructure as code against NIST 800-53 mapped rules.
Figure 4: CloudFormation Guard scan results
You should implement policy as code as pre-commit checks so that developers get prompt feedback, and in DevSecOps pipelines to help prevent deployment of noncompliant resources. These checks typically run as Bash scripts in a continuous integration and continuous delivery (CI/CD) pipeline such as AWS CodeBuild or GitLab CI. To learn more, see Integrating AWS CloudFormation Guard into CI/CD pipelines.
Many other third-party policy-as-code tools are available and include NIST SP 800-53 compliance policies. If cfn-guard doesn’t meet your needs, or if you are looking for a more native integration with the AWS CDK, for example, see the NIST-800-53 rev 5 rules pack in cdk-nag.
Responsive controls
Responsive controls are designed to drive remediation of adverse events or deviations from your security baseline. Examples of technical responsive controls include setting more stringent security group rules after a security group is created, setting a public access block on a bucket automatically if it’s removed, patching a system, quarantining a resource exhibiting anomalous behavior, shutting down a process, or rebooting a system.
Automated Security Response on AWS
The Automated Security Response on AWS (ASR) is an add-on that works with Security Hub and provides predefined response and remediation actions based on industry compliance standards and current recommendations for security threats. This AWS solution creates playbooks so you can choose what you want to deploy in your Security Hub administrator account (which is typically your Security Tooling account, in our recommended multi-account architecture). Each playbook contains the necessary actions to start the remediation workflow within the account holding the affected resource. Using ASR, you can resolve common security findings and improve your security posture on AWS. Rather than having to review findings and search for noncompliant resources across many accounts, security teams can view and mitigate findings from the Security Hub console of the delegated administrator.
The architecture diagram in Figure 5 shows the different portions of the solution, deployed into both the Administrator account and member accounts.
Figure 5: ASR architecture diagram
The high-level process flow for the solution components deployed with the AWS CloudFormation template is as follows:
Detect – AWS Security Hub provides customers with a comprehensive view of their AWS security state. This service helps them to measure their environment against security industry standards and best practices. It works by collecting events and data from other AWS services, such as AWS Config, Amazon GuardDuty, and AWS Firewall Manager. These events and data are analyzed against security standards, such as the CIS AWS Foundations Benchmark. Exceptions are asserted as findings in the Security Hub console. New findings are sent as Amazon EventBridge events.
Initiate – You can initiate events against findings by using custom actions, which result in Amazon EventBridge events. Security Hub Custom Actions and EventBridge rules initiate Automated Security Response on AWS playbooks to address findings. One EventBridge rule is deployed to match the custom action event, and one EventBridge event rule is deployed for each supported control (deactivated by default) to match the real-time finding event. Automated remediation can be initiated through the Security Hub Custom Action menu, or, after careful testing in a non-production environment, automated remediations can be activated. This can be activated per remediation—it isn’t necessary to activate automatic initiations on all remediations.
Orchestrate – Using cross-account IAM roles, Step Functions in the admin account invokes the remediation in the member account that contains the resource that produced the security finding.
Log – The playbook logs the results to an Amazon CloudWatch Logs group, sends a notification to an Amazon SNS topic, and updates the Security Hub finding. An audit trail of actions taken is maintained in the finding notes. On the Security Hub dashboard, the finding workflow status is changed from NEW to either NOTIFIED or RESOLVED. The security finding notes are updated to reflect the remediation that was performed.
The NIST SP 800-53 Playbook contains 52 remediations to help security and compliance teams respond to misconfigured resources. Security teams have a choice between launching these remediations manually, or enabling the associated EventBridge rules to allow the automations to bring resources back into a compliant state until further action can be taken on them. When a resource doesn’t align with the Security Hub NIST SP 800-53 security standard automated checks and the finding appears in Security Hub, you can use ASR to move the resource back into a compliant state. Remediations are available for 17 of the common core services for most AWS workloads.
Figure 6 shows how you can remediate a finding with ASR by selecting the finding in Security Hub and sending it to the created custom action.
Figure 6: ASR Security Hub custom action
Findings generated from the Security Hub NIST SP 800-53 security standard are displayed in the Security Hub findings or security standard dashboards. Security teams can review the findings and choose which ones to send to ASR for remediation. The general architecture of ASR consists of EventBridge rules to listen for the Security Hub custom action, an AWS Step Functions workflow to control the process and implementation, and several AWS Systems Manager documents (SSM documents) and AWS Lambda functions to perform the remediation. This serverless, step-based approach is a non-brittle, low-maintenance way to keep persistent remediation resources in an account, and to pay for their use only as needed. Although you can choose to fork and customize ASR, it’s a fully developed AWS solution that receives regular bug fixes and feature updates.
To get started, see the ASR Implementation Guide, which will walk you through configuration and deployment.
Several options are available to concisely gather results into digestible reports that compliance professionals can use as artifacts during the Risk Management Framework (RMF) process when seeking an Authorization to Operate (ATO). By automating reporting and delegating least-privilege access to compliance personnel, security teams may be able to reduce time spent reporting compliance status to auditors or oversight personnel.
Let your compliance folks in
Remove some of the burden of reporting from your security engineers, and give compliance teams read-only access to your Security Hub dashboard in your Security Tooling account. Enabling compliance teams with read-only access through AWS IAM Identity Center (or another sign-on solution) simplifies governance while still maintaining the principle of least privilege. By adding compliance personnel to the AWSSecurityAudit managed permission set in IAM Identity Center, or granting this policy to IAM principals, these users gain visibility into operational accounts without the ability to make configuration changes. Compliance teams can self-serve the security posture details and audit trails that they need for reporting purposes.
Meanwhile, administrative teams are freed from regularly gathering and preparing security reports, so they can focus on operating compliant workloads across their organization. The AWSSecurityAudit permission set grants read-only access to security services such as Security Hub, AWS Config, Amazon GuardDuty, and AWS IAM Access Analyzer. This provides compliance teams with wide observability into policies, configuration history, threat detection, and access patterns—without the privilege to impact resources or alter configurations. This ultimately helps to strengthen your overall security posture.
For more information about AWS managed policies, such as the AWSSecurityAudit managed policy, see the AWS managed policies.
To learn more about permission sets in IAM Identity Center, see Permission sets.
AWS Audit Manager
AWS Audit Manager helps you continually audit your AWS usage to simplify how you manage risk and compliance with regulations and industry standards. Audit Manager automates evidence collection so you can more easily assess whether your policies, procedures, and activities—also known as controls—are operating effectively. When it’s time for an audit, Audit Manager helps you manage stakeholder reviews of your controls. This means that you can build audit-ready reports with much less manual effort.
Audit Manager provides prebuilt frameworks that structure and automate assessments for a given compliance standard or regulation, including NIST 800-53 Rev. 5. Frameworks include a prebuilt collection of controls with descriptions and testing procedures. These controls are grouped according to the requirements of the specified compliance standard or regulation. You can also customize frameworks and controls to support internal audits according to your specific requirements.
For more information about using Audit Manager to generate automated compliance reports, see the AWS Audit Manager User Guide.
Security Hub Compliance Analyzer (SHCA)
Security Hub is the premier security information aggregating tool on AWS, offering automated security checks that align with NIST SP 800-53 Rev. 5. This alignment is particularly critical for organizations that use the Security Hub NIST SP 800-53 Rev. 5 framework. Each control within this framework is pivotal for documenting the compliance status of cloud environments, focusing on key aspects such as:
Related requirements – For example, NIST.800-53.r5 CM-2 and NIST.800-53.r5 CM-2(2)
Severity – Assessment of potential impact
Description – Detailed control explanation
Remediation – Strategies for addressing and mitigating issues
Such comprehensive information is crucial in the accreditation and continuous monitoring of cloud environments.
To further augment the utility of this data for customers seeking to compile artifacts and articulate compliance status, the AWS ProServe team has introduced the Security Hub Compliance Analyzer (SHCA).
SHCA is engineered to streamline the RMF process. It reduces manual effort, delivers extensive reports for informed decision making, and helps assure continuous adherence to NIST SP 800-53 standards. This is achieved through a four-step methodology:
Active findings collection – Compiles ACTIVE findings from Security Hub that are assessed using NIST SP 800-53 Rev. 5 standards.
Results transformation – Transforms these findings into formats that are both user-friendly and compatible with RMF tools, facilitating understanding and utilization by customers.
Data analysis and compliance documentation – Performs an in-depth analysis of these findings to pinpoint compliance and security shortfalls. Produces comprehensive compliance reports, summaries, and narratives that accurately represent the status of compliance for each NIST SP 800-53 Rev. 5 control.
Findings archival – Assembles and archives the current findings for downloading and review by customers.
The diagram in Figure 7 shows the SHCA steps in action.
Figure 7: SHCA steps
By integrating these steps, SHCA simplifies compliance management and helps enhance the overall security posture of AWS environments, aligning with the rigorous standards set by NIST SP 800-53 Rev. 5.
The following is a list of the artifacts that SHCA provides:
RMF-ready controls – Controls in full compliance (as per AWS Config) with AWS Operational Recommendations for NIST SP 800-53 Rev. 5, ready for direct import into RMF tools.
Controls needing attention – Controls not fully compliant with AWS Operational Recommendations for NIST SP 800-53 Rev. 5, indicating areas that require improvement.
Control compliance summary (CSV) – A detailed summary, in CSV format, of NIST SP 800-53 controls, including their compliance percentages and comprehensive narratives for each control.
Security Hub NIST 800-53 Analysis Summary – This automated report provides an executive summary of the current compliance posture, tailored for leadership reviews. It emphasizes urgent compliance concerns that require immediate action and guides the creation of a targeted remediation strategy for operational teams.
Original Security Hub findings – The raw JSON file from Security Hub, captured at the last time that the SHCA state machine ran.
User-friendly findings summary –A simplified, flattened version of the original findings, formatted for accessibility in common productivity tools.
As shown in Figure 8, the Security Hub NIST 800-53 Analysis Summary adopts an OpenSCAP-style format akin to Security Technical Implementation Guides (STIGs), which are grounded in the Department of Defense’s (DoD) policy and security protocols.
Organizations can use AWS security and compliance services to help maintain compliance with the NIST SP 800-53 standard. By implementing preventative IAM and SCP policies, organizations can restrict users from creating noncompliant resources. Detective controls such as Security Hub and Prowler can help identify misconfigurations, while proactive tools such as CloudFormation Guard can scan IaC to help prevent deployment of noncompliant resources. Finally, the Automated Security Response on AWS can automatically remediate findings to help resolve issues quickly. With this layered security approach across the organization, companies can verify that AWS deployments align to the NIST framework, simplify compliance reporting, and enable security teams to focus on critical issues. Get started on your continuous compliance journey today. Using AWS solutions, you can align deployments with the NIST 800-53 standard. Implement the tips in this post to help maintain continuous compliance.
NIST has released version 2.0 of the Cybersecurity Framework:
The CSF 2.0, which supports implementation of the National Cybersecurity Strategy, has an expanded scope that goes beyond protecting critical infrastructure, such as hospitals and power plants, to all organizations in any sector. It also has a new focus on governance, which encompasses how organizations make and carry out informed decisions on cybersecurity strategy. The CSF’s governance component emphasizes that cybersecurity is a major source of enterprise risk that senior leaders should consider alongside others such as finance and reputation.
[…]
The framework’s core is now organized around six key functions: Identify, Protect, Detect, Respond and Recover, along with CSF 2.0’s newly added Govern function. When considered together, these functions provide a comprehensive view of the life cycle for managing cybersecurity risk.
The updated framework anticipates that organizations will come to the CSF with varying needs and degrees of experience implementing cybersecurity tools. New adopters can learn from other users’ successes and select their topic of interest from a new set of implementation examples and quick-start guides designed for specific types of users, such as small businesses, enterprise risk managers, and organizations seeking to secure their supply chains.
This is a big deal. The CSF is widely used, and has been in need of an update. And NIST is exactly the sort of respected organization to do this correctly.
Apple announced PQ3, its post-quantum encryption standard based on the Kyber secure key-encapsulation protocol, one of the post-quantum algorithms selected by NIST in 2022.
I am of two minds about this. On the one hand, it’s probably premature to switch to any particular post-quantum algorithms. The mathematics of cryptanalysis for these lattice and other systems is still rapidly evolving, and we’re likely to break more of them—and learn a lot in the process—over the coming few years. But if you’re going to make the switch, this is an excellent choice. And Apple’s ability to do this so efficiently speaks well about its algorithmic agility, which is probably more important than its particular cryptographic design. And it is probably about the right time to worry about, and defend against, attackers who are storing encrypted messages in hopes of breaking them later on future quantum computers.
CCGs offer security guidance mapped to 16 different compliance frameworks for more than 130 AWS services and integrations. Customers can select from the frameworks and services available to see how security “in the cloud” applies to AWS services through the lens of compliance.
CCGs focus on security topics and technical controls that relate to AWS service configuration options. The guides don’t cover security topics or controls that are consistent across AWS services or those specific to customer organizations, such as policies or governance. As a result, the guides are shorter and are focused on the unique security and compliance considerations for each AWS service.
We value your feedback on the guides. Take our CCG survey to tell us about your experience, request new services or frameworks, or suggest improvements.
CCGs provide summaries of the user guides for AWS services and map configuration guidance to security control requirements from the following frameworks:
National Institute of Standards and Technology (NIST) 800-53
NIST Cybersecurity Framework (CSF)
NIST 800-171
System and Organization Controls (SOC) II
Center for Internet Security (CIS) Critical Controls v8.0
ISO 27001
NERC Critical Infrastructure Protection (CIP)
Payment Card Industry Data Security Standard (PCI-DSS) v4.0
Department of Defense Cybersecurity Maturity Model Certification (CMMC)
HIPAA
Canadian Centre for Cyber Security (CCCS)
New York’s Department of Financial Services (NYDFS)
Federal Financial Institutions Examination Council (FFIEC)
Cloud Controls Matrix (CCM) v4
Information Security Manual (ISM-IRAP) (Australia)
Information System Security Management and Assessment Program (ISMAP) (Japan)
CCGs can help customers in the following ways:
Shorten the process of manually searching the AWS user guides to understand security “in the cloud” details and align configuration guidance to compliance requirements
Determine the scope of controls applicable in risk assessments or audits based on which AWS services are running in customer workloads
Assist customers who perform due diligence assessments on new AWS services under consideration for use in their organization
Provide assessors or risk teams with resources to identify which security areas are handled by AWS services and which are the customer’s responsibility to implement, which might influence the scope of evidence required for assessments or internal security checks
Provide a basis for developing security documentation such as control responses or procedures that might be required to meet various compliance documentation requirements or fulfill assessment evidence requests
The AWS Global Security & Compliance Acceleration (GSCA) Program connects customers with AWS partners that can help them navigate, automate, and accelerate building compliant workloads on AWS by helping to reduce time and cost. GSCA supports businesses globally that need to meet security, privacy, and compliance requirements for healthcare, privacy, national security, and financial sectors. To connect with a GSCA compliance specialist, complete the GSCA Program questionnaire.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The winner of the Best Paper Award at Crypto this year was a significant improvement to lattice-based cryptanalysis.
This is important, because a bunch of NIST’s post-quantumoptions base their security on lattice problems.
I worry about standardizing on post-quantum algorithms too quickly. We are still learning a lot about the security of these systems, and this paper is an example of that learning.
On May 20, 2023, the Federal Risk and Authorization Management Program (FedRAMP) released the FedRAMP Rev.5 baselines. The FedRAMP baselines were updated to correspond with the National Institute of Standards and Technology’s (NIST) Special Publication (SP) 800-53 Rev. 5 Catalog of Security and Privacy Controls for Information Systems and Organizations and SP 800-53B Control Baselines for Information Systems and Organizations. AWS is transitioning to the updated security requirements and assisting customers by making new resources available (additional information on these resources below). AWS security and compliance teams are analyzing both the FedRAMP baselines and templates, along with the NIST 800-53 Rev. 5 requirements, to help ensure a seamless transition. This post details the high-level milestones for the transition of AWS GovCloud (US) and AWS US East/West FedRAMP-authorized Regions and lists new resources available to customers.
Background
The NIST 800-53 framework is an information security standard that sets forth minimum requirements for federal information systems. In 2020, NIST released Rev. 5 of the framework with new control requirements related to privacy and supply chain risk management, among other enhancements, to improve security standards for industry partners and government agencies. The Federal Information Security Modernization Act (FISMA) of 2014 is a law requiring the implementation of information security policies for federal Executive Branch civilian agencies and contractors. FedRAMP is a government-wide program that promotes the adoption of secure cloud service offerings across the federal government by providing a standardized approach to security and risk assessment for cloud technologies and federal agencies. Both FISMA and FedRAMP adhere to the NIST SP 800-53 framework to define security control baselines that are applicable to AWS and its agency customers.
Key milestones and deliverables
The timeline for AWS to transition to FedRAMP Rev. 5 baselines will be predicated on transition guidance and requirements issued by the FedRAMP Program Management Office (PMO), our third-party assessment (3PAO) schedule, and the FedRAMP Provisional Authorization to Operate (P-ATO) authorization date. Below you will find a list of key documents to help customers get started with Rev. 5 on AWS, as well as timelines for the AWS preliminary authorization schedule.
Key Rev. 5 AWS documents for customers:
AWS FedRAMP Rev5 Customer Responsibility Matrix (CRM) – Made available on AWS Artifact September 1, 2023 (attachment within the AWS FedRAMP Customer Package).
AWS Customer Compliance Guides (CCG) V2 – AWS Customer Compliance Guides are now available on AWS Artifact. CCGs are mapped to NIST 800-53 Rev. 5 and nine additional compliance frameworks.
AWS GovCloud (US) authorization timeline:
3PAO Rev. 5 annual assessment: January 2024–April 2024
Estimated 2024 Rev. 5 P-ATO letter delivery: Q4 2024
AWS US East/West commercial authorization timeline:
3PAO Rev 5. annual assessment: March 2024–June 2024
Estimated 2024 Rev. 5 P-ATO letter delivery: Q4 2024
The AWS transition to FedRAMP Rev. 5 baselines will be completed in accordance with regulatory requirements as defined in our existing FedRAMP P-ATO letter, according to the FedRAMP Transition Guidance. Note that FedRAMP P-ATO letters and Defense Information Systems Agency (DISA) Provisional Authorization (PA) letters for AWS are considered active through the transition to NIST SP 800-53 Rev. 5. This includes through the 2024 annual assessments of AWS GovCloud (US) and AWS US East/West Regions. The P-ATO letters for each Region are expected to be delivered between Q3 and Q4 of 2024. Supporting documentation required for FedRAMP authorization will be made available to U.S. Government agencies and stakeholders in 2024 on a rolling basis and based on the timeline and conclusion of 3PAO assessments.
How to contact us
For questions about the AWS transition to the FedRAMP Rev. 5 baselines, AWS and its services, or for compliance questions, contact [email protected].
To learn more about AWS compliance programs, see the AWS Compliance Programs page. For more information about the FedRAMP project, see the FedRAMP website.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
The NIST elliptic curves that power much of modern cryptography were generated in the late ’90s by hashing seeds provided by the NSA. How were the seeds generated? Rumor has it that they are in turn hashes of English sentences, but the person who picked them, Dr. Jerry Solinas, passed away in early 2023 leaving behind a cryptographic mystery, some conspiracy theories, and an historical password cracking challenge.
So there’s a $12K prize to recover the hash seeds.
Some of the backstory here (it’s the funniest fucking backstory ever): it’s lately been circulating—though I think this may have been somewhat common knowledge among practitioners, though definitely not to me—that the “random” seeds for the NIST P-curves, generated in the 1990s by Jerry Solinas at NSA, were simply SHA1 hashes of some variation of the string “Give Jerry a raise”.
At the time, the “pass a string through SHA1” thing was meant to increase confidence in the curve seeds; the idea was that SHA1 would destroy any possible structure in the seed, so NSA couldn’t have selected a deliberately weak seed. Of course, NIST/NSA then set about destroying its reputation in the 2000’s, and this explanation wasn’t nearly enough to quell conspiracy theories.
But when Jerry Solinas went back to reconstruct the seeds, so NIST could demonstrate that the seeds really were benign, he found that he’d forgotten the string he used!
If you’re a true conspiracist, you’re certain nobody is going to find a string that generates any of these seeds. On the flip side, if anyone does find them, that’ll be a pretty devastating blow to the theory that the NIST P-curves were maliciously generated—even for people totally unfamiliar with basic curve math.
Note that this is not the constants used in the Dual_EC_PRNG random-number generator that the NSA backdoored. This is something different.
AWS Cryptography is pleased to announce that today, the National Institute for Standards and Technology (NIST) awarded AWS-LC its validation certificate as a Federal Information Processing Standards (FIPS) 140-3, level 1, cryptographic module. This important milestone enables AWS customers that require FIPS-validated cryptography to leverage AWS-LC as a fully owned AWS implementation.
AWS-LC is an open source cryptographic library that is a fork from Google’s BoringSSL. It is tailored by the AWS Cryptography team to meet the needs of AWS services, which can require a combination of FIPS-validated cryptography, speed of certain algorithms on the target environments, and formal verification of the correctness of implementation of multiple algorithms. FIPS 140 is the technical standard for cryptographic modules for the U.S. and Canadian Federal governments. FIPS 140-3 is the most recent version of the standard, which introduced new and more stringent requirements over its predecessor, FIPS 140-2. The AWS-LC FIPS module underwent extensive code review and testing by a NIST-accredited lab before we submitted the results to NIST, where the module was further reviewed by the Cryptographic Module Validation Program (CMVP).
Our goal in designing the AWS-LC FIPS module was to create a validated library without compromising on our standards for both security and performance. AWS-LC is validated on AWS Graviton2 (c6g, 64-bit AWS custom Arm processor based on Neoverse N1) and Intel Xeon Platinum 8275CL (c5, x86_64) running Amazon Linux 2 or Ubuntu 20.04. Specifically, it includes low-level implementations that target 64-bit Arm and x86 processors, which are essential to meeting—and even exceeding—the performance that customers expect of AWS services. For example, in the integration of the AWS-LC FIPS module with AWS s2n-tls for TLS termination, we observed a 27% decrease in handshake latency in Amazon Simple Storage Service (Amazon S3), as shown in Figure 1.
Figure 1: Amazon S3 TLS termination time after using AWS-LC
AWS-LC integrates CPU-Jitter as the source of entropy, which works on widely available modern processors with high-resolution timers by measuring the tiny time variations of CPU instructions. Users of AWS-LC FIPS can have confidence that the keys it generates adhere to the required security strength. As a result, the library can be run with no uncertainty about the impact of a different processor on the entropy claims.
AWS-LC is a high-performance cryptographic library that provides an API for direct integration with C and C++ applications. To support a wider developer community, we’re providing integrations of a future version of the AWS-LC FIPS module, v2.0, into the AWS Libcrypto for Rust (aws-lc-rs) and ACCP 2.0 libraries . aws-lc-rs is API-compatible with the popular Rust library named ring, with additional performance enhancements and support for FIPS. Amazon Corretto Crypto Provider 2.0 (ACCP) is an open source OpenJDK implementation interfacing with low-level cryptographic algorithms that equips Java developers with fast cryptographic services. AWS-LC FIPS module v2.0 is currently submitted to an accredited lab for FIPS validation testing, and upon completion will be submitted to NIST for certification.
Today’s AWS-LC FIPS 140-3 certificate is an important milestone for AWS-LC, as a performant and verified library. It’s just the beginning; AWS is committed to adding more features, supporting more operating environments, and continually validating and maintaining new versions of the AWS-LC FIPS module as it grows.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
I just read an article complaining that NIST is taking too long in finalizing its post-quantum-computing cryptography standards.
This process has been going on since 2016, and since that time there has been a huge increase in quantum technology and an equally large increase in quantum understanding and interest. Yet seven years later, we have only four algorithms, although last week NIST announced that a number of other candidates are under consideration, a process that is expected to take “several years.
The delay in developing quantum-resistant algorithms is especially troubling given the time it will take to get those products to market. It generally takes four to six years with a new standard for a vendor to develop an ASIC to implement the standard, and it then takes time for the vendor to get the product validated, which seems to be taking a troubling amount of time.
Yes, the process will take several years, and you really don’t want to rush it. I wrote this last year:
Ian Cassels, British mathematician and World War II cryptanalyst, once said that “cryptography is a mixture of mathematics and muddle, and without the muddle the mathematics can be used against you.” This mixture is particularly difficult to achieve with public-key algorithms, which rely on the mathematics for their security in a way that symmetric algorithms do not. We got lucky with RSA and related algorithms: their mathematics hinge on the problem of factoring, which turned out to be robustly difficult. Post-quantum algorithms rely on other mathematical disciplines and problems—code-based cryptography, hash-based cryptography, lattice-based cryptography, multivariate cryptography, and so on—whose mathematics are both more complicated and less well-understood. We’re seeing these breaks because those core mathematical problems aren’t nearly as well-studied as factoring is.
[…]
As the new cryptanalytic results demonstrate, we’re still learning a lot about how to turn hard mathematical problems into public-key cryptosystems. We have too much math and an inability to add more muddle, and that results in algorithms that are vulnerable to advances in mathematics. More cryptanalytic results are coming, and more algorithms are going to be broken.
As to the long time it takes to get new encryption products to market, work on shortening it:
The moral is the need for cryptographic agility. It’s not enough to implement a single standard; it’s vital that our systems be able to easily swap in new algorithms when required.
Whatever NIST comes up with, expect that it will get broken sooner than we all want. It’s the nature of these trap-door functions we’re using for public-key cryptography.
Amazon Web Services (AWS) has released Customer Compliance Guides (CCGs) to support customers, partners, and auditors in their understanding of how compliance requirements from leading frameworks map to AWS service security recommendations. CCGs cover 100+ services and features offering security guidance mapped to 10 different compliance frameworks. Customers can select any of the available frameworks and services to see a consolidated summary of recommendations that are mapped to security control requirements.
CCGs summarize key details from public AWS user guides and map them to related security topics and control requirements. CCGs don’t cover compliance topics such as physical and maintenance controls, or organization-specific requirements such as policies and human resources controls. This makes the guides lightweight and focused only on the unique security considerations for AWS services.
Customer Compliance Guides work backwards from security configuration recommendations for each service and map the guidance and compliance considerations to the following frameworks:
National Institute of Standards and Technology (NIST) 800-53
NIST Cybersecurity Framework (CSF)
NIST 800-171
System and Organization Controls (SOC) II
Center for Internet Security (CIS) Critical Controls v8.0
ISO 27001
NERC Critical Infrastructure Protection (CIP)
Payment Card Industry Data Security Standard (PCI-DSS) v4.0
Department of Defense Cybersecurity Maturity Model Certification (CMMC)
HIPAA
Customer Compliance Guides help customers address three primary challenges:
Explaining how configuration responsibility might vary depending on the service and summarizing security best practice guidance through the lens of compliance
Assisting customers in determining the scope of their security or compliance assessments based on the services they use to run their workloads
Providing customers with guidance to craft security compliance documentation that might be required to meet various compliance frameworks
CCGs are available for download in AWS Artifact. Artifact is your go-to, central resource for AWS compliance-related information. It provides on-demand access to security and compliance reports from AWS and independent software vendors (ISVs) who sell their products on AWS Marketplace. To access the new CCG resources, navigate to AWS Artifact from the console and search for Customer Compliance Guides. To learn more about the background of Customer Compliance Guides, see the YouTube video Simplify the Shared Responsibility Model.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
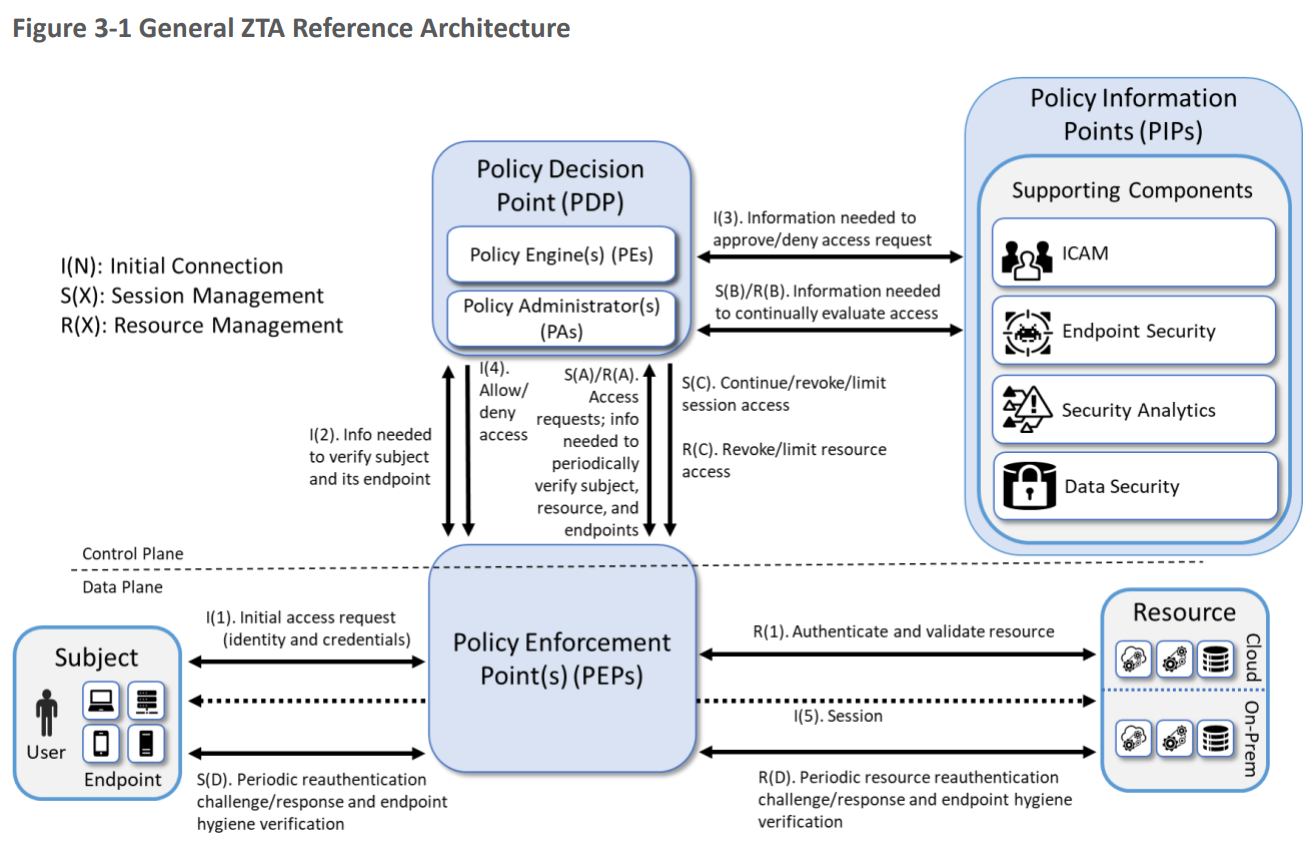
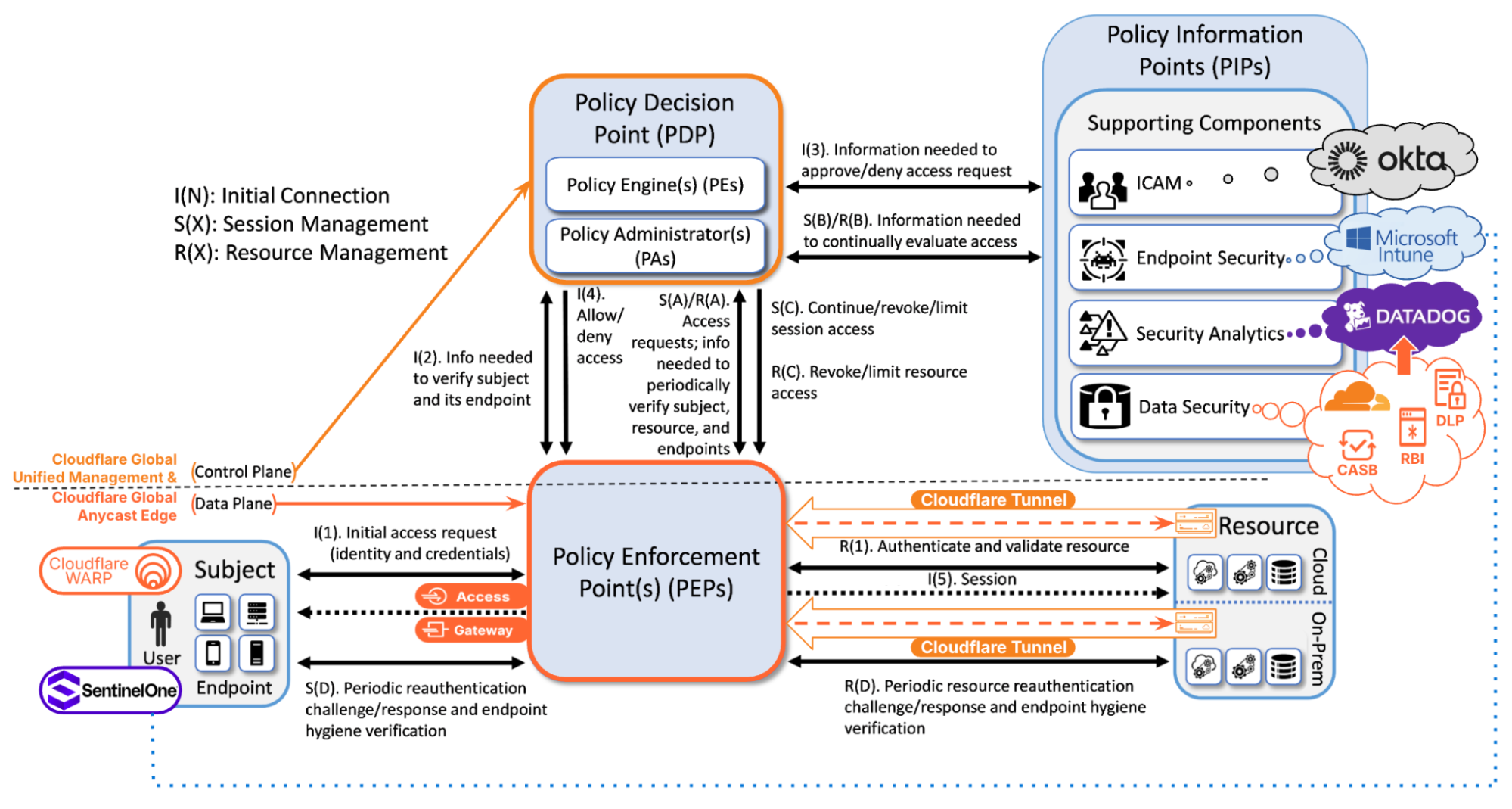
 We’re excited to announce that
We’re excited to announce that