Greg Kroah-Hartman has announced the release of the 5.17.6, 5.15.38, 5.10.114, and 5.4.192 stable kernels. As usual, these
contain important fixes throughout the tree; users of those series should upgrade.
Today, Cloudflare – in partnership with Vercel, Shopify, and individual core contributors to both Node.js and Deno – is announcing the establishment of a new Community Group focused on the interoperable implementation of standardized web APIs in non-web browser, JavaScript-based development environments.
The W3C and the Web Hypertext Application Technology Working Group (or WHATWG) have long pioneered the efforts to develop standardized APIs and features for the web as a development environment. APIs such as fetch(), ReadableStream and WritableStream, URL, URLPattern, TextEncoder, and more have become ubiquitous and valuable components of modern web development. However, the charters of these existing groups have always been explicitly limited to considering only the specific needs of web browsers, resulting in the development of standards that are not readily optimized for any environment that does not look exactly like a web browser. A good example of this effect is that some non-browser implementations of the Streams standard are an order of magnitude slower than the equivalent Node.js streams and Deno reader implementations due largely to how the API is specified in the standard.
Serverless environments such as Cloudflare Workers, or runtimes like Node.js and Deno, have a broad wide range of requirements, issues, and concerns that are simply not relevant to web browsers, and vice versa. This disconnect and the lack of clear consideration of these differences while the various specifications have been developed, has led to a situation where the non-browser runtimes have implemented their own bespoke, ad-hoc solutions for functionality that is actually common across the environments.
This new effort is changing that by providing a venue to discuss and advocate for the common requirements of all web environments, deployed anywhere throughout the stack.
What’s in it for developers?
Developers want their code to be portable. Once they write it, if they choose to move to a different environment (from Node.js to Deno, for instance) they don’t want to have to completely rewrite it just to make it keep doing the exact same thing it already was.
One of the more common questions we get from Cloudflare users is how they can make use of some arbitrary module published to npm that makes use of some set of Node.js-specific or Deno-specific APIs. The answer usually involves pulling in some arbitrary combination of polyfill implementations. The situation is similar with the Deno project, which has opted to integrate a polyfill of the full Node.js core API directly into their standard library. The more these environments implement the same common standards, the more the developer ecosystem can depend on the code they write just working, regardless of where it is being run.
Cloudflare Workers, Node.js, Deno, and web browsers are all very different from each other, but they share a good number of common functions. For instance, they all provide APIs for generating cryptographic hashes; they all deal in some way with streaming data; they all provide the ability to send an HTTP request somewhere. Where this overlap exists, and where the requirements and functionality are the same, the environments should all implement the same standardized mechanisms.
The naming of this group is something that took us a while to settle on because it is critical to understanding the goals the group is trying to achieve (and what it is not). The key element is the phrase “web-interoperable”.
We use “web” in exactly the same sense that the W3C and WHATWG communities use the term – precisely: web browsers. The term “web-interoperable”, then, means implementing features in a manner that is either identical or at least as consistent as possible with the way those features are implemented in web browsers. For instance, the way that the new URL() constructor works in browsers is exactly how the new URL() constructor should work in Node.js, in Deno, and in Cloudflare Workers.
It is important, however, to acknowledge the fact that Node.js, Deno, and Cloudflare Workers are explicitly not web browsers. While this point should be obvious, it is important to call out because the differences between the various JavaScript environments can greatly impact the design decisions of standardized APIs. Node.js and Deno, for instance, each provide full access to the local file system. Cloudflare Workers, in contrast, has no local file system; and web browsers necessarily restrict applications from manipulating the local file system. Likewise, while web browsers inherently include a concept of a website’s “origin” and implement mechanisms such as CORS to protect users against a variety of security threats, there is no equivalent concept of “origins” on the server-side where Node.js, Deno, and Cloudflare Workers operate.
Up to now, the W3C and WHATWG have concerned themselves strictly with the needs of web browsers. The new Web-interoperable Runtimes Community Group is explicitly addressing and advocating for the needs of everyone else.
It is not intended that WinterCG will go off and publish its own set of independent standard APIs. Ideas for new specifications that emerge from WinterCG will first be submitted for consideration by existing work streams in the W3C and WHATWG with the goal of gaining the broadest possible consensus. However, should it become clear that web browsers have no particular need for, or interest in, a feature that the other environments (such as Cloudflare Workers) have need for, WinterCG will be empowered to move forward with a specification of its own – with the constraint that nothing will be introduced that intentionally conflicts with or is incompatible with the established web standards.
WinterCG will be open for anyone to participate; it will operate under the established W3C processes and policies; all work will be openly accessible via the “wintercg” GitHub organization; and everything it does will be centered on the goal of maximizing interoperability.
Work in Progress
WinterCG has already started work on a number of important work items.
“The Minimum Common Web Platform API is a curated subset of standardized web platform APIs intended to define a minimum set of capabilities common to Browser and Non-Browser JavaScript-based runtime environments.”
Or put another way: It is a minimal set of existing web APIs that will be implemented consistently and correctly in Node.js, Deno, and Cloudflare Workers. Most of the APIs, with some exceptions and nuances, already exist in these environments, so the bulk of the work remaining is to ensure that those implementations are conformant to their relative specifications and portable across environments.
The table below lists all the APIs currently included in this subset (along with an indication of whether the API is currently or likely soon to be supported by Node.js, Deno, and Cloudflare Workers):
Whenever one of the environments diverges from the standardized definition of the API (such as Node.js implementation of setTimeout() and setInterval()), clear documentation describing the differences will be made available. Such differences should only exist for backwards compatibility with existing code.
Web Cryptography Streams
The Web Cryptography API provides a minimal (and very limited) APIs for common cryptography operations. One of its key limitations is the fact that – unlike Node.js’ built-in crypto module – it does not have any support for streaming inputs and outputs to symmetric cryptographic algorithms. All Web Cryptography features operate on chunks of data held in memory, all at once. This strictly limits the performance and scalability of cryptographic operations. Using these APIs in any environment that is not a web browser, and trying to make them perform well, quickly becomes painful.
To address that issue, WinterCG has started drafting a new specification for Web Crypto Streams that will be submitted to the W3C for consideration as part of a larger effort currently being bootstrapped by the W3C to update the Web Cryptography specification. The goal is to bring streaming crypto operations to the whole of the web, including web browsers, in a way that conforms with existing standards.
A subset of fetch() for servers
With the recent release of version 18.0.0, Node.js has joined the collection of JavaScript environments that provide an implementation of the WHATWG standardized fetch() API. There are, however, a number of important differences between the way Node.js, Deno, and Cloudflare Workers implement fetch() versus the way it is implemented in web browsers.
For one, server environments do not have a concept of “origin” like a web browser does. Features such as CORS intended to protect against cross-site scripting vulnerabilities are simply irrelevant on the server. Likewise, where web browsers are generally used by one individual user at a time and have a concept of a globally-scoped cookie store, server and serverless applications can be used by millions of users simultaneously and a globally-scoped cookie store that potentially contains session and authentication details would be both impractical and dangerous.
Because of the acute differences in the environments, it is often difficult to reason about, and gain consensus on, proposed changes in the fetch standard. Some proposed new API, for instance, might be fantastically relevant to fetch users on a server but completely useless to fetch users in a web browser. Some set of security concerns that are relevant to the Browser might have no impact whatsoever on the server.
To address this issue, and to make it easier for non-web browser environments to implement fetch in a consistent way, WinterCG is working on documenting a subset of the fetch standard that deals specifically with those different requirements and constraints.
Critically, this subset will be fully compatible with the fetch standard; and is being cooperatively developed by the same folks who have worked on fetch in Node.js, Deno, and Cloudflare Workers. It is not intended that this will become a competing definition of the fetch standard, but rather a set of documented guidelines on how to implement fetch correctly in these other environments.
We’re just getting started
The Web-interoperable Runtimes Community Group is just getting started, and we have a number of ambitious goals. Participation is open to everyone, and all work will be done in the open via GitHub at https://github.com/wintercg. We are actively seeking collaboration with the W3C, the WHATWG, and the JavaScript community at large to ensure that web features are available, work consistently, and meet the requirements of all web developers working anywhere across the stack.
We are starting our Platform Week focused on the most important aspect of a developer platform — developers. At the core of every announcement this week is developer experience. In other words, it doesn’t matter how groundbreaking the technology is if at the end of the day we’re not making your job as a developer easier.
Earlier today, we announced the general availability of a new Wrangler version, making it easier than ever to get started and develop with Workers. We’re also excited to announce that we’re partnering with StackBlitz. Together, we will bring the Wrangler experience closer to you – directly to your browser, with no dependencies required!
StackBlitz is a web-based code editor provided with a fresh and fast development environment on each page load. StackBlitz’s development environments are powered by WebContainers, the first WebAssembly-based operating system, which boots secure development environments entirely within your browser tab.
Introducing new Wrangler, running in your browser
One of the Wrangler improvements we announced today is the option to easily run Wrangler in any Node.js environment, including your browser which is now powered by WebContainers!
StackBlitz’s WebContainers are optimized for starting any project within seconds, including the installation of all dependencies. Whenever you’re ready to start a fresh development environment, you can refresh the browser tab running StackBlitz’s editor and have everything instantly ready to go.
Don’t just take our word for it, you can test this out yourself by opening up a sample project on https://workers.new/typescript. Note: currently, only Chromium based browsers are supported.
You can think of WebContainers as an in-browser operating system: they include features like a file system, multi-process and multi-threading application support, and a virtualized TCP network stack with the use of ServiceWorkers.
Powering a better developer experience and documentation
We’re excited about all the possibilities that instant development environments running in the browser open us up to. For example, they enable us to embed or link full code projects directly from our documentation examples and tutorials without waiting for a remote server to spin up a container with your environment.
Try out the following templates and have a little sneak peek of the developer experience we are working together to enable, as running a new Workers application locally was never easier!
StackBlitz supports running Wrangler in a local mode today, and we are working together to enable features that require authentication to bring the full developer lifecycle inside your browser – including development on the edge, publishing, and debugging or tailing logs of your published Workers.
Share what you have built with us and stay tuned for more updates! Make sure to follow us on Twitter or join our Discord Developers Community server.
Last November, we announced the beta release of a full rewrite of Wrangler, our CLI for building Cloudflare Workers. Since then, we’ve been working round the clock to make sure it’s feature complete, bug-free, and easy to use. We are proud to announce that Wrangler goes public today for general usage, and can’t wait to see what people build with it!
Rewrites can be scary. Our goal for this version of Wrangler was backward compatibility with the original version, while significantly improving the developer experience. I’d like to take this opportunity to present 10 reasons why you should upgrade to the new Wrangler!
1. It’s simpler to install:
A simpler way to get started.
Previously, folks would have to install @cloudflare/wrangler globally on a system. This made it hard to use different versions of Wrangler across projects. Further, it was hard to install on some CI systems because of lack of access to a user’s root folder. Sometimes, folks would forget to add the @cloudflare scope when installing, confusing them when a completely unrelated package was installed and didn’t work as expected.
Let’s fix that. We’ve simplified this by now publishing to the wrangler package, so you can run npm install wrangler and it works as expected. You can also install it locally to a project’s package.json, like any other regular npm package. It also works across a much broader range of CPU architectures and operating systems, so you can use it on more machines.
This makes it a lot more convenient when starting. But why stop there?
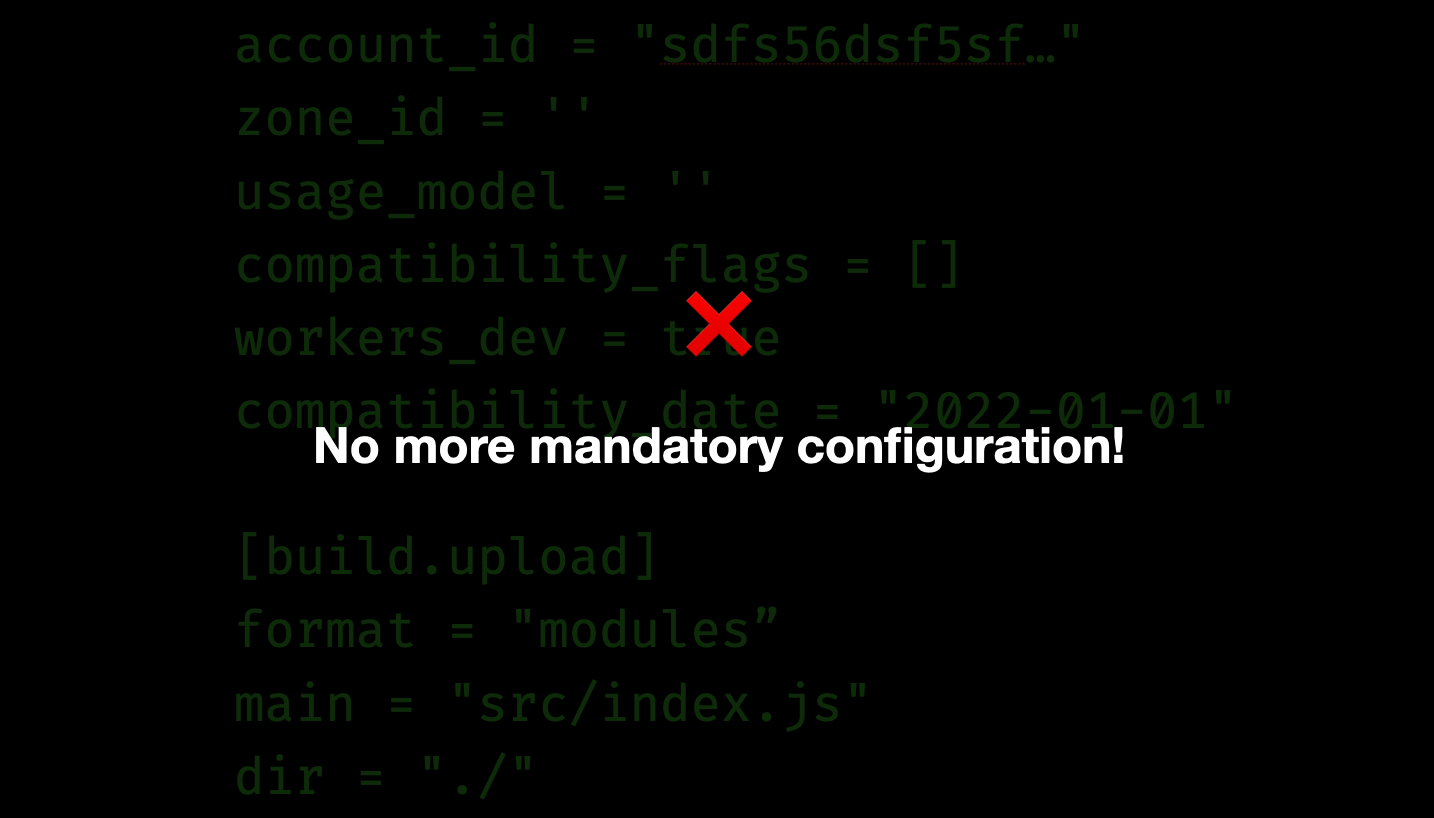
2. Zero config startup:
Get started with zero configuration
It’s now much simpler to get started with a new project. Previously, you would have to create a wrangler.toml configuration file, and fill it in with details about your cloudflare account, how the project was structured, setting up a custom build process and so on. We heard feedback from many of you who would get frustrated during this step, and how it would take many minutes before you could get to developing a simple Worker.
Let’s fix that. You no longer need to create a configuration file when starting, and none of the fields are mandatory. Wrangler infers details about your account and project as you start developing, and you can add configuration incrementally when you need to.
In fact, you don’t even need to install Wrangler to start! You can create a Worker (say, as index.js) and use npx (a utility that comes installed with node.js) to fetch Wrangler from the npm registry and start developing immediately!
This is great for extremely simple Workers, but why stop there?
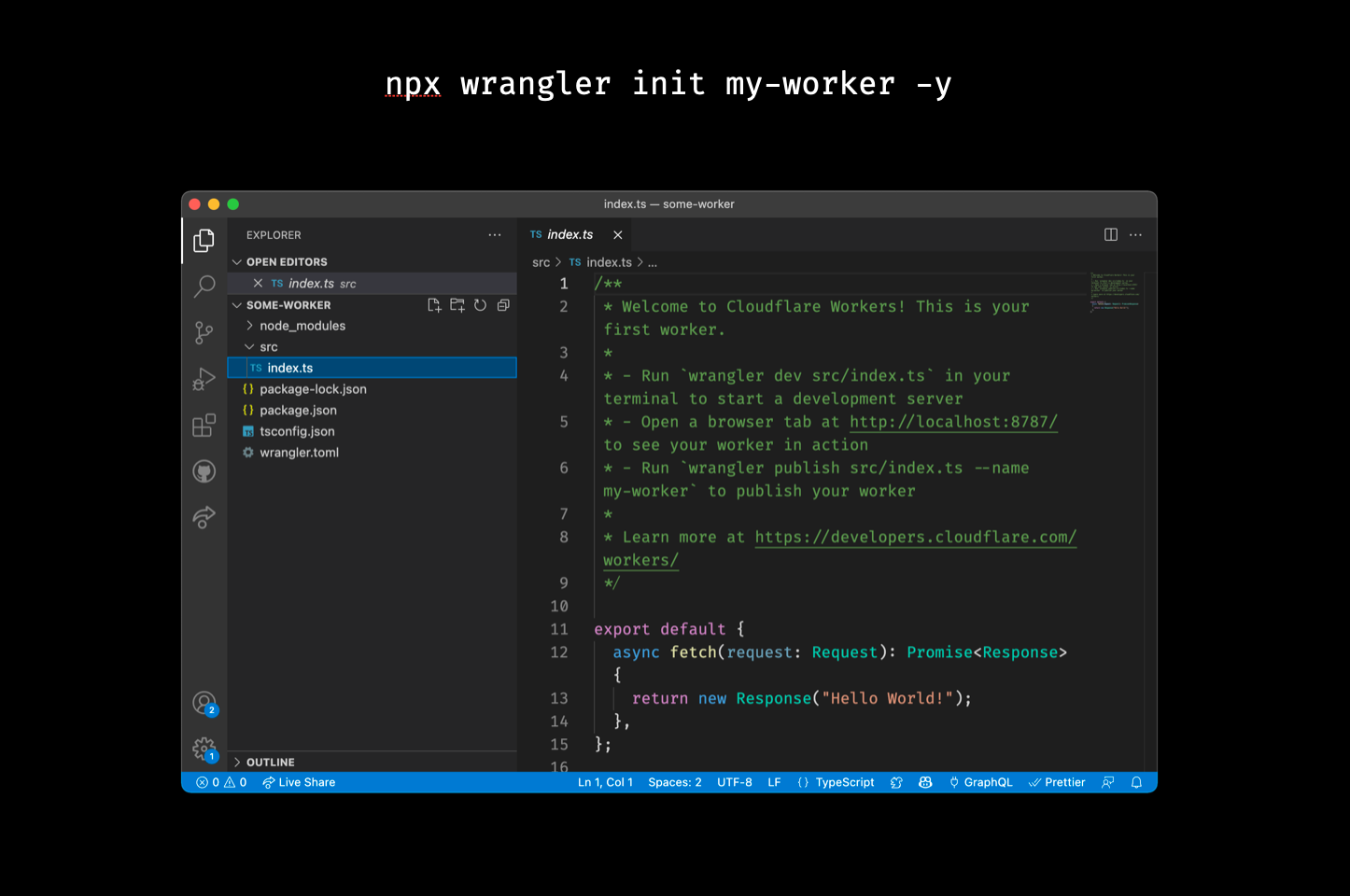
3. wrangler init my-worker -y, one liner to set up a full project:
We noticed users would struggle to set up a project with Wrangler, even after they’d installed Wrangler and configured wrangler.toml. Most users want to set up a package.json, commonly use typescript to write code, and set up git to track changes in this project. So, we expanded the wrangler init <project name> command to set up a production grade project. You can optionally choose to use typescript, install the official type definitions for Workers, and use git to track changes.
My favorite trick here is to pass -y to accept all questions without asking. Try running npx wrangler init my-worker -y in your terminal today!
One line to set up a full Workers project
4. --local mode:
Wrangler typically runs a development server on our global network, setting up a local proxy when developing, so you can develop against a “real” environment in the cloud. This is great for making sure the code you develop will behave the same in development, and after you deploy it to production. The trade-off here is it’s harder to develop code when you have a bad Internet connection, or if you’re running tests on a CI machine. It’s also marginally slower to iterate while coding. Users have asked us for a long time to be able to ‘run’ their code locally on their machines, so that they can iterate quickly and run tests in environments like CI.
Wrangler now lets you develop on your machine by simply calling wrangler dev --local, and no additional configuration. This is powered by Miniflare, a fully featured simulator of the Cloudflare Workers runtime. You can even toggle across ‘edge’ and ‘local’ modes by tapping the ‘L’ hotkey when developing; however you prefer!
Local mode, powered by Miniflare.
5. Tail any Worker, any time:
Tail your logs anywhere, anytime.
It’s useful to be able to “tail” a Worker’s output to a terminal, and see what’s going on in real time. While you can already view these logs in the Workers dashboard, some people are more comfortable seeing the logs in their terminal, and then slicing and dicing to debug any issues that may be occuring. Previously, you would have to checkout a Worker’s repository locally, install dependencies, and then call wrangler tail in the project folder. This was clearly cumbersome, and relied on developer expertise to see something as simple as a Worker’s logs.
Now you can simply call npx wrangler tail <worker name> in your terminal, without any configuration or setup, and immediately see the logs that you expect. We use this ourselves to quickly inspect our production Workers and see what’s going on inside them!
6. Better warnings and errors, everywhere:
One of the worst feelings a developer can face is being presented with an error when writing code, and not knowing how to fix it and proceed. We heard feedback from many of you who were frustrated with the lack of error messages, and how you would spend hours trying to figure out what went wrong. We’ve now added new error and warning messages, so you can easily spot the problems in your code. When possible, we also include steps you can follow to fix your Worker, including things that you can simply copy and paste! This makes Wrangler much more friendly to use, and we promise the experience will only get better.
7. On-demand developer tools for debugging:
We introduced initial support for debugging Workers in Wrangler in September which enables debugging a Worker directly on our global network. However, getting started with debugging was still a bit cumbersome, because you would have to start Wrangler with an --inspect flag, then open a special page in your browser (chrome://inspect), configuring it to detect Wrangler running on a special port, and then launching the debugger. This would also mean you might have lost any debugging messages that were logged before you opened the Chrome developer tools.
We fixed this. Now you don’t need to pass any special flags when starting up. You can simply hit the D hotkey when developing and a developer tools instance pops up in your browser. And by buffering the messages before you even start up the devtools, you don’t lose any logs or errors! You can also use VS Code developer tools to directly hook into your Worker’s debugging session!
8. A modern module system:
Modern JavaScript isn’t simply about the syntax that the language supports, but also writing code as modules, and leveraging the extremely broad ecosystem of community libraries and frameworks. Previously, Wrangler required that you set up webpack or a custom build with bundlers (like rollup, vite, or esbuild, to name a few) to consume libraries and modules. This introduces a lot of friction, especially when starting a new project and trying out new ideas.
Now, support for npm modules comes out of the box, with no extra configuration required! You can install any package from the npm registry, organize your own code with modules, and it all works as expected. We’re also introducing an experimental node.js compatibility mode for using node.js modules that wouldn’t previously work without setting up your own polyfills! This means you can use popular frameworks and libraries that you’re already familiar with while focusing on delivering value to your users.
9. Closes many outstanding issues:
A rewrite should be judged not just by the new features that are implemented, but by how many existing issues are resolved. We went through hundreds of outstanding issues and bugs with Wrangler, and are happy to say that we solved almost all of them! Across the board, every command and feature got a facelift, bug fixes, and test coverage to make sure it doesn’t break in the future. Developers on using Cloudflare Workers will be glad to hear that simply upgrading Wrangler will immediately fix previous concerns and problems. Which leads us to my absolute favorite feature…
10. A commitment to improve:
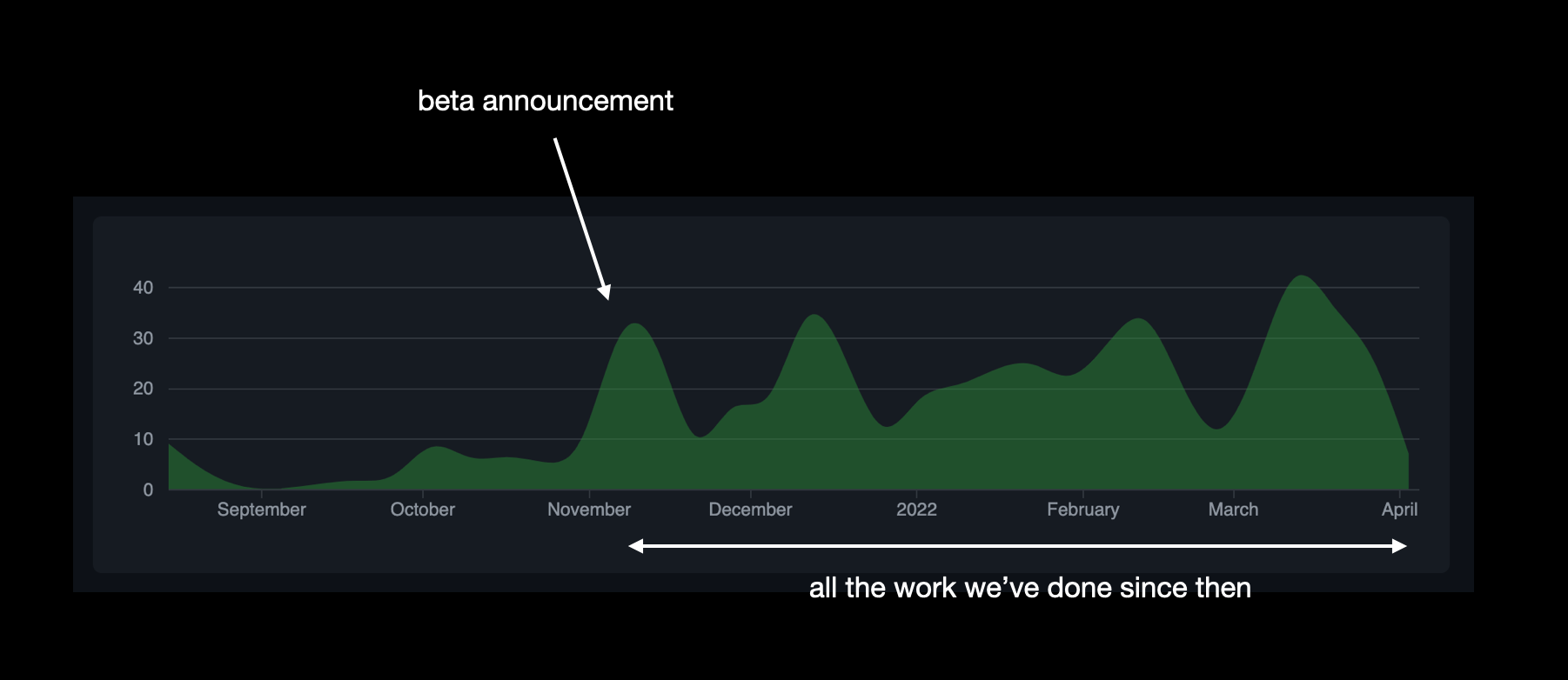
The effort into building wrangler v2.0, visualised.
Wrangler has always been special software for us. It represents the primary interface that developers use to interact and use Cloudflare Workers, and we have major plans for the future. We have invested time, effort and resources to make sure Wrangler is the best tool for developers to use, and we’re excited to see what the future holds. This is a commitment to our users and community that we will only keep improving on this foundation, and folks can expect their feedback and concerns to be heard loud and clear.
In early 2020, we sat down and tried thinking if there’s a way to load third-party tools on the Internet without slowing down websites, without making them less secure, and without sacrificing users’ privacy. In the evening, after scanning through thousands of websites, our answer was “well, sort of”. It seemed possible: many types of third-party tools are merely collecting information in the browser and then sending it to a remote server. We could theoretically figure out what it is that they’re collecting, and then instead just collect it once efficiently, and send it server-side to their servers, mimicking their data schema. If we do this, we can get rid of loading their JavaScript code inside websites completely. This means no more risk of malicious scripts, no more performance losses, and fewer privacy concerns.
But the answer wasn’t a definite “YES!” because we realized this is going to be very complicated. We looked into the network requests of major third-party scripts, and often it seemed cryptic. We set ourselves up for a lot of work, looking at the network requests made by tools and trying to figure out what they are doing – What is this parameter? When is this network request sent? How is this value hashed? How can we achieve the same result more securely, reliably and efficiently? Our team faced these questions on a daily basis.
When we joined Cloudflare, the scale of everything changed. Suddenly we were on thousands of websites, serving more than 10,000 requests per second. Users are writing to us every single day over our Discord channel, the community forum, and sometimes even directly on Twitter. More often than not, their messages would be along the lines of “Hi! Can you please add support for X?” Cloudflare Zaraz launched with around 30 tools in its library, but this market is vast and new tools are popping up all the time.
Changing our trust model
In my previous blog post on how Zaraz uses Cloudflare Workers, I included some examples of how tool integrations are written in Zaraz today. Usually, a “tool” in Zaraz would be a function that prepares a payload and sends it. This function could return one thing – clientJS, JavaScript code that the browser would later execute. We’ve done our best so that tools wouldn’t use clientJS, if it wasn’t really necessary, and in reality most Zaraz-built tool integrations are not using clientJS at all.
This worked great, as long as we were the ones coding all tool integrations. Customers trusted us that we’d write code that is performant and safe, and they trusted the results they saw when trying Zaraz. Upon joining Cloudflare, many third-party tool vendors contacted us and asked to write a Zaraz integration. We quickly realized that our system wasn’t enforcing speed and safety – vendors could literally just dump their old browser-side JavaScript into our clientJS variable, and say “We have a Cloudflare Zaraz integration!”, and that wasn’t our vision at all.
We want third-party tool vendors to be able to write their own performant, safe server-side integrations. We want to make it possible for them to reimagine their tools in a better way. We also want website owners to have transparency into what is happening on their website, to be able to manage and control it, and to trust that if a tool is running through Zaraz, it must be a good tool — not because of who wrote it, but because of the technology it is constructed within. We realized that to achieve that we needed a new format for defining third-party tools.
Introducing Managed Components
We started rethinking how third-party code should be written. Today, it’s a black box – you usually add a script to your site, and you have zero clue what it does and when. You can’t properly read or analyze the minified code. You don’t know if the way it behaves for you is the same way it behaves for everyone else. You don’t know when it might change. If you’re a website owner, you’re completely in the dark.
Tools do many different things. The simple ones just collected information and sent it somewhere. Often, they’d set some cookies. Sometimes, they’d install some event listeners on the page. And widget-based tools can literally manipulate the page DOM, providing new functionality like a social media embed or a chatbot. Our new format needed to support all of this.
Managed Components is how we imagine the future of third-party tools online. It provides vendors with an API that allows them to do much more than a normal script can, including keeping code execution outside the browser. We designed this format together with vendors, for vendors, while having in mind that users’ best interest is everyone’s best interest long-term.
From the get-go, we built Managed Components to use a permission-based system. We want to provide even more transparency than Zaraz does today. As the new API allows tools to set cookies, change the DOM or collect IP addresses, all those abilities require being granted a permission. Installing a third-party tool on your site is similar to installing an app on your phone – you get an explanation of what the tool can and can’t do, and you can allow or disallow features to a granular level. We previously wrote about how you can use Zaraz to not send IP addresses to Google Analytics, and now we’re doubling down in this direction. It’s your website, and it’s your decision to make.
Every Managed Component is a JavaScript module at its core. Unlike today, this JavaScript code isn’t sent to the browser. Instead, it is executed by a Components Manager. This manager implements the APIs that are then used by the component. It dispatches server-side events that originate in the browser, providing the components with access to information while keeping them sandboxed and performant. It handles caching, storage and more — all so that the Managed Components can implement their logic without worrying so much about the surrounding.
An example analytics Managed Component can look something like this:
The above component gets notified whenever a page view occurs, and it then creates some payload with the visitor user-agent and page URL and sends that as a POST request to the vendor’s server. This is very similar to how things are done today, except this doesn’t require running any code at all in the browser.
But Managed Components aren’t just doing what was previously possible but better, they also provide dramatic new functionality. See for example how we’re exposing server-side endpoints:
export default function (manager) {
const api = manager.proxy("/api", "https://api.example.com");
const assets = manager.serve("/assets", "assets");
const ping = manager.route("/ping", (request) => new Response(204));
}
These three lines are a complete shift in what’s possible for third-parties. If granted the permissions, they can proxy some content, serve and expose their own endpoints – all under the same domain as the one running the website. If a tool needs to do some processing, it can now off-load that from the browser completely without forcing the browser to communicate with a third-party server.
Exciting new capabilities
Every third-party tool vendor should be able to use the Managed Components API to build a better version of their tool. The API we designed is comprehensive, and the benefits for vendors are huge:
Same domain: Managed Components can serve assets from the same domain as the website itself. This allows a faster and more secure execution, as the browser needs to trust and communicate with only one server instead of many. This can also reduce costs for vendors as their bandwidth will be lowered.
Website-wide events system: Managed Components can hook to a pre-existing events system that is used by the website for tracking events. Not only is there no need to provide a browser-side API to your tool, it’s also easier for your users to send information to your tool because they don’t need to learn your methods.
Server logic: Managed Components can provide server-side logic on the same domain as the website. This includes proxying a different server, or adding endpoints that generate dynamic responses. The options are endless here, and this, too, can reduce the load on the vendor servers.
Server-side rendered widgets and embeds: Did you ever notice how when you’re loading an article page online, the content jumps when some YouTube or Twitter embed suddenly appears between the paragraphs? Managed Components provide an API for registering widgets and embed that render server-side. This means that when the page arrives to the browser, it already includes the widget in its code. The browser doesn’t need to communicate with another server to fetch some tweet information or styling. It’s part of the page now, so expect a better CLS score.
Reliable cross-platform events: Managed Components can subscribe to client-side events such as clicks, scroll and more, without needing to worry about browser or device support. Not only that – those same events will work outside the browser too – but we’ll get to that later.
Pre-Response Actions: Managed Components can execute server-side actions before the network response even arrives in the browser. Those actions can access the response object, reading it or altering it.
Integrated Consent Manager support: Managed Components are predictable and scoped. The Component Manager knows what they’ll need and can predict what kind of consent is needed to run them.
The right choice: open source
As we started working with vendors on creating a Managed Component for their tool, we heard a repeating concern – “What Components Managers are there? Will this only be useful for Cloudflare Zaraz customers?”. While Cloudflare Zaraz is indeed a Components Manager, and it has a generous free tier plan, we realized we need to think much bigger. We want to make Managed Components available for everyone on the Internet, because we want the Internet as a whole to be better.
Today, we’re announcing much more than just a new format.
WebCM is a reference implementation of the Managed Components API. It is a complete Components Manager that we will soon release and maintain. You will be able to use it as an SDK when building your Managed Component, and you will also be able to use it in production to load Managed Components on your website, even if you’re not a Cloudflare customer. WebCM works as a proxy – you place it before your website, and it rewrites your pages when necessary and adds a couple of endpoints. This makes WebCM 100% framework-agnostic – it doesn’t matter if your website uses Node.js, Python or Ruby behind the scenes: as long as you’re sending out HTML, it supports that.
That’s not all though! We’re also going to open source a few Managed Components of our own. We converted some of our classic Zaraz integrations to Managed Components, and they will soon be available for you to use and improve. You will be able to take our Google Analytics Managed Component, for example, and use WebCM to run Google Analytics on your website, 100% server-side, without Cloudflare.
Tech-leading vendors are already joining
Revolutionizing third-party tools on the internet is something we could only do together with third-party vendors. We love third-party tools, and we want them to be even more popular. That’s why we worked very closely with a few leading companies on creating their own Managed Components. These new Managed Components extend Zaraz capabilities far beyond what’s possible now, and will provide a safe and secure onboarding experience for new users of these tools.
Drift – Drift helps businesses connect with customers in moments that matter most. Drift’s integration will let customers use their fully-featured conversation solution while also keeping it completely sandboxed and without making third-party network connections, increasing privacy and security for our users.
CrazyEgg – Crazy Egg helps customers make their websites better through visual heatmaps, A/B testing, detailed recordings, surveys and more. Website owners, Cloudflare, and Crazy Egg all care deeply about performance, security and privacy. Managed Components have enabled Crazy Egg to do things that simply aren’t possible with third-party JavaScript, which means our mutual customers will get one of the most performant and secure website optimization tools created.
We also already have customers that are eager to implement Managed Components:
Hopin Quote:
“I have been really impressed with Cloudflare’s Zaraz ability to move Drift’s JS library to an Edge Worker while loading it off the DOM. My work is much more effective due to the savings in page load time. It’s a pleasure to work with two companies that actively seek better ways to increase both page speed and load times with large MarTech stacks.” – Sean Gowing, Front End Engineer, Hopin
If you’re a third-party vendor, and you want to join these tech-leading companies, do reach out to us, and we’d be happy to support you on writing your own Managed Component.
What’s next for Managed Components
We’re working on Managed Components on many fronts now. While we develop and maintain WebCM, work with vendors and integrate Managed Components into Cloudflare Zaraz, we’re already thinking about what’s possible in the future.
We see a future where many open source runtimes exist for Managed Components. Perhaps your infrastructure doesn’t allow you to use WebCM? We want to see Managed Components runtimes created as service workers, HTTP servers, proxies and framework plugins. We’re also working on making Managed Components available on mobile applications. We’re working on allowing unofficial Managed Components installs on Cloudflare Zaraz. We’re fixing a long-standing issue of the WWW, and there’s so much to do.
We will very soon publish the full specs of Managed Components. We will also open source WebCM, the reference implementation server, as well as many components you can use yourself. If this is interesting to you, reach out to us at [email protected], or join us on Discord.
450,000 developers have used Cloudflare Workers since we launched.
When we announced Cloudflare Workers nearly five years ago, we had no idea if we’d ever be in this position. But a lot of care, hard work — not to mention dogfooding — later, we’ve been absolutely blown away by the use cases and applications built on our developer platform, not to mention the community that’s grown around the product.
My job isn’t just speaking to developers who are already using Cloudflare Workers, however. I spend a lot of time talking to developers who aren’t yet using Workers, too. Despite how cool the tech is — the performance, the ability to just code without worrying about anything else like containers, and the total cost advantages — there are two things that cause developers to hesitate in engaging with us on Workers.
The first: they worry about being locked in. No matter how bullish on the technology you are, if you’re betting the future of a company on a development platform, you don’t want the possibility of being held to ransom. And second: as a developer, you want a local development environment to quickly iterate and test your changes. These concerns might seem unrelated, but they always come up in the form of the same question: can Cloudflare please open source the runtime?
We’re excited to put these concerns to bed. As the first announcement of Platform Week, today Cloudflare is announcing the open sourcing of the Workers runtime under the Apache-2.0 license!
While the code itself will be the best answer to most of the questions you have (we still have some work to do before we’re ready to share it), the questions we did want to answer today were: why are we doing this, and why now?
Development on the web has always been done in the open. If you’re like me, maybe your very first experience writing and looking at code was clicking on “View Source” on a website, and inspecting the HTML to see what pieces you could borrow. So many of the foundational pieces you build on today are open source, from the site, to the browser, to the many frameworks and libraries that are now available to developers. The same is true for us, so much of what we’re able to build is standing on the shoulders of giants like V8.
It was never our intention to introduce opaqueness into the stack, but in reality, when we first announced Workers five years ago, we took a really huge bet.
We wanted to give developers the ability to program on our network, but couldn’t do it at the expense of performance or security. While building on a battle tested technology like V8 seemed promising from a security standpoint, existing runtimes built on V8, couldn’t give us the security guarantees we needed to run a large multi-tenant environment, without the added security layer of a container, which would introduce latency (read: cold starts). Not only were cold starts not acceptable, but in reality, our data centers are much smaller than the centralized monoliths of traditional cloud. Even if we could run existing applications on the edge without cold starts, the code footprint would be far too large to enable every single one of our customers to have access to compute on every node of our global network.
So, we had to get inventive, and the first place we looked was web standards, or the Service Workers API. While Service Workers were designed to run in the browser, the model of Requests and Responses fit our use case really well. And, we liked the idea of the code you write being portable to other environments (and hoped that new players that came up would support the same model).
And that’s exactly what happened.
This all might seem obvious in retrospect, but at the time, it was a huge bet. We didn’t know at the time whether this was going to work. Whether this approach would take off, whether this would all work at scale, whether developers would adopt this model, despite it diverging from what JavaScript looked like on the server-side at the time…
What we did know was that we had a lot to prove, that we didn’t want to lock anyone in, and that open sourcing something properly is not an effort we wanted to take lightly. We wanted to support our community the same way we felt supported by all the open source projects we ourselves were building upon.
Now, it feels like we’re finally there, and we believe the next step in our runtime’s evolution is to give it to the world, and let developers build with it wherever they want, however they want.
Of course, since we’re talking about open source, we already know what you’re going to ask next: what license are we going to use? We plan to use the Apache-2.0 license — we want developers to be able to build on our platform freely.
What’s next?
Open sourcing the runtime alone is not enough to allow developers to write code, free of lock in concerns, which is why we have another announcement coming up today.
And after that, well, if you’ve been following Cloudflare for a while, you know that there’s a certain time in the year, when we like to give back to the Internet. That might be a pretty good bet for the timing of what’s next! 🙂
Security updates have been issued by CentOS (firefox and thunderbird), Debian (ecdsautils and libz-mingw-w64), Fedora (cifs-utils, firefox, galera, git, java-1.8.0-openjdk, java-11-openjdk, java-17-openjdk, java-latest-openjdk, mariadb, maven-shared-utils, mingw-freetype, redis, and seamonkey), Mageia (dcraw, firefox, lighttpd, rsyslog, ruby-nokogiri, and thunderbird), Scientific Linux (thunderbird), SUSE (giflib, kernel, and libwmf), and Ubuntu (dbus and rsyslog).
МОЧА го били напръскали с дрон. Бил оцветен с цветовете на една държава. Няма да казвам коя. Лично аз одобрявам с цялото си сърце тази постъпка. Това е цивилизационна позиция,…
The 5.18-rc6 kernel prepatch is out for
testing. “Please do go test it all out – because things may look
good now, but continued testing is the only thing that will make
sure.”
Principled. It’s one of Cloudflare’s three core values (alongside curiosity and transparency).
It’s a word that we came back to quite a bit in thinking through a question that has been foundational in driving us for this year’s Platform Week: what makes a truly great developer platform?
Of course, when it comes to evaluating developer platforms, the temptation is to focus on the “feeds and speeds” part of the equation. Who is the fastest? Who has the coolest tech? Who lets you do stuff that previously you could not?
Undoubtedly, these are all important questions. But we realized that the fun and shiny things which are often answers to these questions can easily become distractions from the true promise of developing on the Internet — and even traps that the less principled developer platforms can use to lure you into their arms.
The promise being, of course: that you can pull together solutions from a variety of different providers, to build something greater than what you’d be able to do with any one of them alone. That you can build something based on whatever is best when you sit down to create your application. And of course, if something better subsequently comes along, then you can switch to it and take advantage of that, too. When you think about it, it makes sense: all the Internet really is a network based on a common set of standards that allows us all to talk to each other.
And yet, when it comes to the cloud platforms, it feels like we’re further away from that promise than ever before.
How did that happen?
When you start to think about why: well, many of the winners of the cloud have become too big for their (and our) own good. The same players that were underdogs have become incumbents — not just bending the world to their will, but sticking to their assumptions of what the world looked like a decade ago. We went from a highly competitive environment, with an even distribution of power, to something entirely unbalanced. Somewhere along the way, Hotel California became the theme song of the cloud: a friendly face welcomes you in… and then you can’t leave.
This manifests in many ways.
Sometimes it takes the form of egregious egress fees, where you are stuck with using in-ecosystem tooling instead of the best tool for the job. We don’t believe in that. We want an Internet that allows for specialization, where developers can use the best across several offerings, bringing together those services to build something incredible. But that requires giving developers freedom of choice: without hidden pricing considerations pushing you to stay with large, incumbent vendors. In fact, in many respects, freedom of choice is the promise of the Internet for developers.
We want to get back to that.
But it’s not just pricing. Other times, lock-in happens through the code or APIs needed to build with a service. Developers tie their applications to the services that power them, and eventually, without you even realizing it, it becomes incredibly cumbersome to switch off. We’ve watched the Internet become more proprietary, where vendors offer products as a service without the ability to run them anywhere else. Of course, that’s where standards come in, defining the same language and behavior across vendors.
Developers win when we open up the APIs we support and languages we speak, and rally several competing options around a common set. Continuously winning a developer’s business shouldn’t be because you’ve made someone dependent on you, and they can’t get out — it should be because what you’re offering is better than the alternatives.
When that happens, developers win.
This Platform Week, we don’t want to deliver on just new and shiny things (though there will be a few of those, too!). We want to deliver on principles. On letting the best solution win. On breaking developers out of lock in: whether because of code, or because of economics.
To get this right, we must start at the very beginning — the foundation. Everything we do is built on the foundation of the open web and open standards. That’s not something we take lightly, and certainly not something we take for granted. We decided the right way to kick this week off would be by giving back, and helping do what we can to help push the web, and those open standards forward.
So, that’s the foundation. But now you need the right blocks to build on it.
There’s one building block we know you’re excited about, it’s data. And we are too, which is why we’ll be giving you an update on a certain something we’ve had in beta the last little while. And that’s not all, either: there may even be a sequel.
Data is one thing, but applications need to share that data with services to extract value. This week we’ll make it easier and cheaper to connect the pieces of your stack together, enabling the sending of information where you need it, when you need it.
As we all know, the reason we all work so hard as developers is to enable that most critical of functionality: sharing pictures and videos of cats and babies. There are always better ways of doing it though, and we’re going to dedicate a whole day to new ways to upload, stream and share these gems.
And finally, we want to help the Internet become more programmable. Platforms offer real customizability to the developers they serve: enabling them to do things that the platform creator itself never envisioned. When you work with the application services component of Cloudflare, you can customize bot scores, load balancing rules, routing — all by programming our network. And we’re not just talking about relying on APIs to do things that we, the original developer, initially envisioned. We’re talking about true programmability. Whether you want to build a customized bot within an existing chat application, or a bespoke experience on an eCommerce website builder, we’re excited to move development beyond the era of the API into true programmability, beyond our walls, right across the web.
But back to it: principled.
Yes, we’re going to be delivering this week on all the innovation that you’ve come to expect from us. And you know what we can’t wait to see? All the amazing things you’re able to build — but it won’t just be on us. In fact, it might not be on us at all, and that’s completely ok. What we’re excited about is you building things on all the incredible providers out there, the ones that are equally dedicated to helping build a better Internet for all developers.
Late last year, we hosted Full Stack Week, with a focus on new products, features, and partnerships to continue growing Cloudflare’s developer platform. As part of Full Stack Week, we also hosted the Developer Speaker Series, bringing 12 speakers in the web dev community to our 24/7 online TV channel, Cloudflare TV. The talks covered topics across the web development ecosystem, which you can rewatch at any time.
We loved organizing the Developer Speaker Series last year. But as developers know far too well, our ecosystem changes rapidly: what may have been cutting edge back in November 2021 can be old news just a few months later in 2022. That’s what makes conferences and live speaking events so valuable: they serve as an up-to-date reference of best practices and future-facing developments in the industry. With that in mind, we’re excited to announce a new edition of our Developer Speaker Series for 2022!
Check out the eleven expert web dev speakers, developers, and educators that we’ve invited to speak live on Cloudflare TV! Here are the talks you’ll be able to watch, starting tomorrow morning (May 9 at 09:00 PT):
The Bootcampers Companion – Caitlyn Greffly In her recent book, The Bootcamper’s Companion, Caitlyn dives into the specifics of how to build connections in the tech field, understand confusing tech jargon, and make yourself a stand-out candidate when looking for your first job. She’ll talk about some top tips and share a bit about her experience as well as what she has learned from navigating tech as a career changer.
Engaging Ecommerce with the Visual Web – Colby Fayock Experiences on the web have grown increasingly visual, from displaying product images to interactive NFTs, but not paying attention to how media is delivered can impact Core Web Vitals, creating a bad UX with slow-loading pages, hurting your store’s conversion and potentially losing sales.
How can we effectively leverage media to showcase products creating engaging experiences for our store? We’ll talk about the media’s role in ecomm and how we can take advantage of it while optimizing delivery.
Testing Web Applications with Playwright – Debbie O’Brien Testing is hard, testing takes time to learn and to write, and time is money. As developers, we want to test. We know we should, but we don’t have time. So how can we get more developers to do testing? We can create better tools.
Let me introduce you to Playwright, a reliable tool for end-to-end cross browser testing for modern web apps, by Microsoft and fully open source. Playwright’s codegen generates tests for you in JavaScript, TypeScript, Dot Net, Java or Python. Now you really have no excuses. It’s time to play your tests wright.
Building serverless APIs: how Fauna and Workers make it easy – Rob Sutter Building APIs has always been tricky when it comes to setting up architecture. FaunaDB and Workers remove that burden by letting you write code and watch it run everywhere.
Business context is developer productivity – John Feminella A major factor in developer productivity is whether they have the context to make decisions on their own, or if instead they can only execute someone else’s plan. But how do organizations give engineers the appropriate context to make those decisions when they weren’t there from the beginning?
On the edge of my server – Brian Rinaldi Edge functions can be potentially game changing. You get the power of serverless functions but running at the CDN level – meaning the response is incredibly fast. With Cloudflare Workers, every worker is an edge function. In this talk, we’ll explore why edge functions can be powerful and explore examples of how to use them to do things a normal serverless function can’t do.
Ten things I love about Wrangler 2 – Sunil Pai We spent the last six months rewriting wrangler, the CLI for building and deploying Cloudflare Workers. Almost every single feature has been upgraded to be more powerful and user-friendly, while still remaining backward compatible with the original version of wrangler. In this talk, we’ll go through some of the best parts about the rewrite, and how it provides the foundation for all the things we want to build in the future.
L is for Literacy – Henri Helvetica It’s 2022, and web performance is now abundantly important, with an abundance of available metrics, used by — you guessed it — an abundance of developers, new and experienced. All quips aside, the complexities of the web has led to increased complexities in web performance. Understanding, or literacy in web performance is as important as the four basic language skills. ‘L is for Literacy’ is a lively look at performance lexicon, backed by enlightening data all will enjoy.
Cloudflare Pages Updates – Greg Brimble Greg Brimble, a Systems Engineer working on Pages, will showcase some of this week’s announcements live on Cloudflare TV. Tune in to see what is now possible for your Cloudflare Pages projects. We’re excited to show you what the team has been working on!
Migrating to Cloudflare Pages: A look into git control, performance, and scalability – James Ross James Ross, CTO of Nodecraft, will discuss how moving to Pages brought an improved experience for both users and his team building the future of game servers.
If you want to see the full schedule for the Developer Speaker Series, go to our landing page. It shows each talk, including speaker info and timing, as well as time zones for international viewers. When a talk goes live, tuning in is simple – just visit cloudflare.tv to start watching.
New this year, we’ve also prepared a Discord channel to follow the live conversation with other viewers! If you haven’t joined Cloudflare’s Discord server, get your invite.
През седмицата темата с киберсигурността получи фокус покрай детайлите около атаката срещу пощите. В няколко интервюта описах общата картина, но ми се иска да направя малко по-пълно описание на това какво сме имали, какво сме направили за тези месеци и какво предстои.
Започвам със забележката, че ще използвам „киберсигурност“, макар че правилният термин в повечето случаи е „мрежова и информационна сигурност“. Правомощията на министъра на електронното управление са именно за „мрежова и информационна сигурност“ и то само в администрацията и част от доставчиците на съществени услуги (напр. в сектор енергетика). Български пощи не е в този обхват към момента.
Защитата на мрежовата и информационна сигурност е комплекс от технически и организационни мерки, които изискват добро планиране, приоритизиране, изпълнение и контрол в мащаба на държавната администрация (и в по-широк смисъл – на целия обществен сектор). Действаме с бързи стъпки, доколкото ни позволява наличният човешки ресурс.
1. Какво намерихме?
Към началото на мандата състоянието на информационните ресурси (т.е. хардуер, софтуер, мрежово оборудване, лицензи) беше силно незадоволително. Липсва адекватна, централизирана картина къде какво има, на какъв етап е от своя технологичен живот и какви са политиките по неговото подновяване. Има администрации с компютри на по 10 години, напр. Има системи без поддръжка (заради неплащани лицензи или по други причини). Всичко това са проблеми и за киберсигурността – в стари и излезли от поддръжка от производителите системи често има уязвимости. Всичко това го докладвах на Министерския съвет преди месец в рамките на годишния доклад за състоянието на информационните ресурси.
Преди 4 години от Демократична България публикувахме план за действие след срива на Търговския регистър. Половината от мерките са изпълнени, но със спорно качество – напр. регистърът на информационните ресурси е почти безполезен, резервните копия се правят централизирано от твърде малко администрации (с бавна скорост и липса на някои ключови функционалности), а на държавни облак му липсват важни процедури за присъединяване, вградени услуги за киберсигурност и др.
Базови добри практики във връзка с киберсигурността също не се прилагаха. Прости пароли, липса на двуфакторна автентикация, публично видими портове за отдалечен достъп (RDP), за портове за администрация на защитни стени и друг защитен софтуер – всичко това е вектор за атака. На много места липсва оперативно наблюдение на системите във връзка с оглед идентифициране на опити за първоначално проникване. Дори на местата, където има такова, не са свързани достатъчно много източници на информация, така че картината е непълна. Има и фрапиращи случаи, като една администрация, в която всички потребители са били администратори – за по-лесно. В пощите имаше не по-малко фрапиращи лоши практики.
Дирекцията за мрежова и информационна сигурност в Държавна агенция „Електронно управление“ е 16 души. Това е крайно недостатъчно за да покрие правомощията на агенцията (а вече – на министерството) по линия на киберсигурността. Капацитетът по останалите администрации в момента го установяваме в детайли, но общата картина не е розова – ИТ експертите в администрацията не са добре платени и правят всичко – от смяна на принтери, до конфигуриране на инструменти за киберсигурност.
Мога да изреждам още доста проблеми и примери, но от една страна е излишно, от друга страна не следва да разкривам детайли отвътре, от които някой може да се възползва (споделеното в горния параграф са неща, които в голяма степен са публично достъпни).
2. Какво свършихме
За този кратък период от време, в който преструктурираме една държавна агенция в две структури министерство и изпълнителна агенция, по линия на киберсигурността сме направили следното:
Изпратихме писма до всички институции да подобрят настройките на системите си, свързани с изпращане на имейли (т.е. потенциални фишинг атаки от тяхно име)
Сканирахме (вкл. с продължаващ абонамент за сканиране) всички администрации за публично достъпни системи, които не следва да бъдат достъпни. Напр. RDP (отдалечен достъп) – от около 60 отворени в началото, вече има само 10, като за тях предстоят санкции за ръководителите, тъй като това е нарушение на наредбата към Закона за киберсигурност
България стана 30-тата държава в света с абонамент за Have I Been Pwned – безплатна услуга, която ни дава информация за изтекли пароли за имейли на държавната администрация. Изтеклите пароли са от външни сайтове, но тъй като потребителите често използват една и съща парола, при информация за изтекла парола, трябва да бъдат принуждаване да сменят настоящата си
Блокирахме 48 хиляди IP адреса, свързани със злонамерена активност от Русия и Беларус (с първо писмо до интернет доставчиците – 45 хиляди и още 3 хиляди с последващо писмо)
Събрахме списък с доброволци и подготвихме договори за тестове за проникване (penetration tests) – първите такива тестове вече са започнали
Мигрирахме почти всички администрации към Защитения интернет възел на държавната администрация
В началото на войната спешно проверихме някои от най-критичните обекти и отправихме препоръки за повишаване на сигурността
Институтът за публична администрация, координирано с МЕУ, подготви информационен курс за защита от фишинг атаки
Подготвихме изменение на Закона за киберсигурност, за да включим вътре Български пощи и други публични предприятия, които в момента не се контролират от никоя институция по линия на мрежовата и информационна сигурност
Подготвихме изменения на Постановление на Министерския съвет за включване на Български пощи и БНБ в списъка със стратегически обекти, които обследва ДАНС
Увеличихме броя места за специалисти по киберсигурност в структурата на министерството (т.е. дирекцията няма да е вече само 16 души)
3. Какво предстои тази година
Немалка част от конкретните мерките, които предстои да вземем, ще бъдат класифицирана информация, тъй като пряко засягат националната сигурност. Но общите политики за повишаване на нивото на мрежова и информационна сигурност са не по-малко важни:
Приемане на всички подготвени нормативни изменения – в Закона за киберсигурност (за включване на пощите), в постановлението на Министерския съвет за стратегическите обекти
Приемане на Решение на Министерския съвет с правила за отговор на инциденти – най-важното при много от типовете атаки е бързата и адекватна реакция. Затова от най-високо ниво ще „спуснем“ какви да са стъпките, които всяка администрация да следва при инцидент.
Изменение на класификатора на длъжностите в администрацията и свързаните с него нормативни актове с цел повишаване на нивата на заплащане на специалисти по киберсигурност. Въвеждане и на позиция „стажант по киберсигурност“, така че да привличаме незавършили студенти с прилични заплати – тяхната експертиза вече е на достатъчно ниво, за да могат да бъдат полезни.
Подготовка и приемане на нова стратегия за киберсигурност
Структуриране на отношенията с частния сектор. Държавата няма достатъчно капацитет за оперативни наблюдения, триаж и отговор и трябва да бъде подпомагана от частния сектор. Трябва, обаче, да го направим по структуриран и адекватен начин, а не „всяка администрация сама да си преценя“ какво точно ѝ трябва и как да го получи
Транспониране на втората директива за мрежова и информационна сигурност веднага след като бъде приета на ниво Европейски съюз
Използване на максималните възможности на наличните системи за киберзащита (в момента много от тях не са адекватно настроени) и закупуване и инсталиране на нови
Обновяване на регистъра на информационните ресурси и поддържането му актуален, така че да могат да се правят реални политики за информационните ресурси (обновяване, спиране от експлоатация, управление, бюджетиране)
Регламентиране на централизирано закупуване на шаблонизирани решения за киберсигурност (няма смисъл всяка администрация да „открива топлата вода“)
Повишаване на нивото на киберсигурност в частния сектор в рамките на Програмата за научни изследвания, иновации и дигитализация за интелигентна трансформация
Засилване на ефективните проверки по Закона за киберсигурност – администрациите трябва да спазват поне действащата нормативна уредба, в която има немалко добри практики
Развиване на експертния капацитет на служителите в администрацията чрез обучения, съвместно с Института за публична администрация
Изграждане на център за оперативно наблюдение на мрежовата и информационна сигурност (Security operations center – SOC) в структурата на Министерство на електронното управление
Създаване на Националния компетеностен център по киберсигурност с цел стимулиране на екосистемата от експерти и организации – бизнес, университети, държава, неправителствен сектор
Засилен обмен на данни с партньорски държави, в т.ч. т.нар. индикатори на компрометиране (indicators of compromise). Т.е. когато един IP адрес опита да проникне в инфраструктура напр. в Естония, след неговото установяване в България да знаем за него и да го блокираме автоматично, преди изобщо да е опитал да „атакува“ и нас.
4. Заключение
Извън всички тези детайли, наличието на министерство означава, че тази политика е представена на масата на Министерския съвет. Което значително допринася за спазването първия принцип от цитирания по-горе план за действие, който бяхме предложили през 2018 г. – „Неделимост на киберустойчивостта от националната сигурност – политическото ниво трябва да е наясно, че срив, умишлен или не, в критични системи, се отразява директно на националната сигурност.“
Администрацията и службите за сигурност вече знаят, че киберсигурността е важна на политическо ниво. А това е важно за устойчивостта – спорадични мерки не вършат работа, ако у хората, които работят това ежедневно, няма увереност, че темата е важна на най-високо ниво.
Имаме много за наваксване. Рисковете са високи, ресурсите (човешки) са малко, а задачите са много и мащабни. Това прави нещата предизвикателни, но и мотивиращи. Сега е моментът да въведем трайна политика за киберустойчивост. Която включва много конкретика и технически детайли, но и много дългосрочни меки мерки за повишаване на капацитета.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.