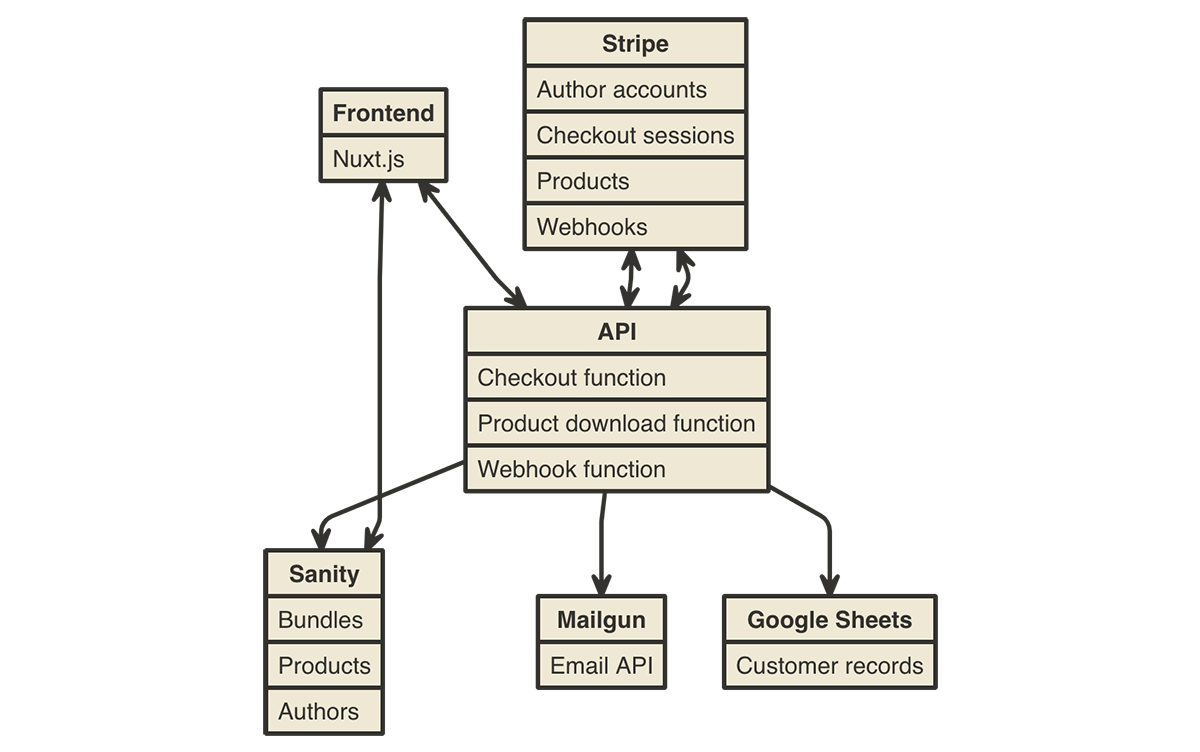
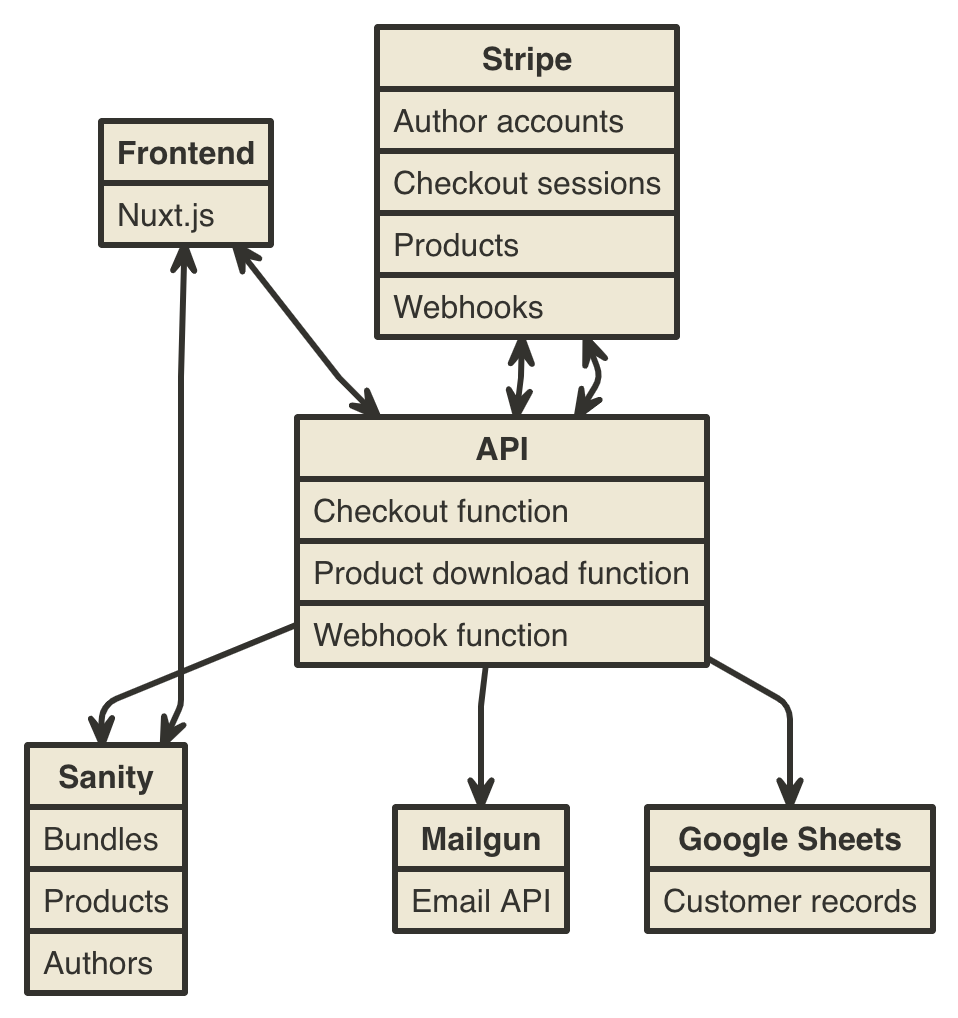
Post Syndicated from Kristian Freeman original http://blog.cloudflare.com/magic-in-minutes-how-to-build-a-chatgpt-plugin-with-cloudflare-workers/


Today, we're open-sourcing our ChatGPT Plugin Quickstart repository for Cloudflare Workers, designed to help you build awesome and versatile plugins for ChatGPT with ease. If you don’t already know, ChatGPT is a conversational AI model from OpenAI which has an uncanny ability to take chat input and generate human-like text responses.
With the recent addition of ChatGPT plugins, developers can create custom extensions and integrations to make ChatGPT even more powerful. Developers can now provide custom flows for ChatGPT to integrate into its conversational workflow – for instance, the ability to look up products when asking questions about shopping, or retrieving information from an API in order to have up-to-date data when working through a problem.
That's why we're super excited to contribute to the growth of ChatGPT plugins with our new Quickstart template. Our goal is to make it possible to build and deploy a new ChatGPT plugin to production in minutes, so developers can focus on creating incredible conversational experiences tailored to their specific needs.
How it works
Our Quickstart is designed to work seamlessly with Cloudflare Workers. Under the hood, it uses our command-line tool wrangler to create a new project and deploy it to Workers.
When building a ChatGPT plugin, there are three things you need to consider:
- The plugin's metadata, which includes the plugin's name, description, and other info
- The plugin's schema, which defines the plugin's input and output
- The plugin's behavior, which defines how the plugin responds to user input
To handle all of these parts in a simple, easy-to-understand API, we've created the @cloudflare/itty-router-openapi package, which makes it easy to manage your plugin's metadata, schema, and behavior. This package is included in the ChatGPT Plugin Quickstart, so you can get started right away.
To show how the package works, we'll look at two key files in the ChatGPT Plugin Quickstart: index.js and search.js. The index.js file contains the plugin's metadata and schema, while the search.js file contains the plugin's behavior. Let's take a look at each of these files in more detail.
In index.js, we define the plugin's metadata and schema. The metadata includes the plugin's name, description, and version, while the schema defines the plugin's input and output.
The configuration matches the definition required by OpenAI's plugin manifest, and helps ChatGPT understand what your plugin is, and what purpose it serves.
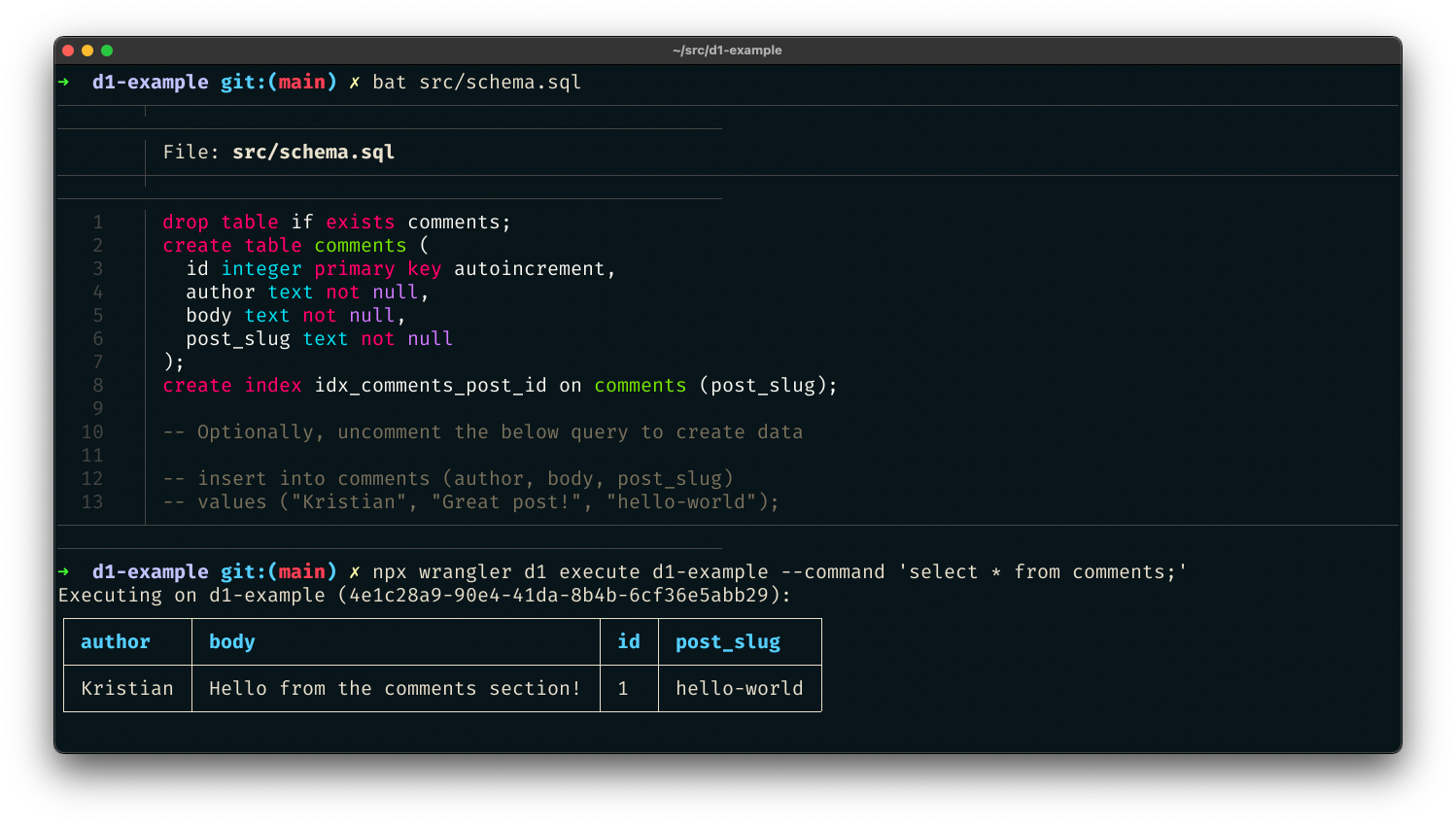
Here's what the index.js file looks like:
import { OpenAPIRouter } from "@cloudflare/itty-router-openapi";
import { GetSearch } from "./search";
export const router = OpenAPIRouter({
schema: {
info: {
title: 'GitHub Repositories Search API',
description: 'A plugin that allows the user to search for GitHub repositories using ChatGPT',
version: 'v0.0.1',
},
},
docs_url: '/',
aiPlugin: {
name_for_human: 'GitHub Repositories Search',
name_for_model: 'github_repositories_search',
description_for_human: "GitHub Repositories Search plugin for ChatGPT.",
description_for_model: "GitHub Repositories Search plugin for ChatGPT. You can search for GitHub repositories using this plugin.",
contact_email: '[email protected]',
legal_info_url: 'http://www.example.com/legal',
logo_url: 'https://workers.cloudflare.com/resources/logo/logo.svg',
},
})
router.get('/search', GetSearch)
// 404 for everything else
router.all('*', () => new Response('Not Found.', { status: 404 }))
export default {
fetch: router.handle
}
In the search.js file, we define the plugin's behavior. This is where we define how the plugin responds to user input. It also defines the plugin's schema, which ChatGPT uses to validate the plugin's input and output.
Importantly, this doesn't just define the implementation of the code. It also automatically generates an OpenAPI schema that helps ChatGPT understand how your code works — for instance, that it takes a parameter "q", that it is of "String" type, and that it can be described as "The query to search for". With the schema defined, the handle function makes any relevant parameters available as function arguments, to implement the logic of the endpoint as you see fit.
Here's what the search.js file looks like:
import { ApiException, OpenAPIRoute, Query, ValidationError } from "@cloudflare/itty-router-openapi";
export class GetSearch extends OpenAPIRoute {
static schema = {
tags: ['Search'],
summary: 'Search repositories by a query parameter',
parameters: {
q: Query(String, {
description: 'The query to search for',
default: 'cloudflare workers'
}),
},
responses: {
'200': {
schema: {
repos: [
{
name: 'itty-router-openapi',
description: 'OpenAPI 3 schema generator and validator for Cloudflare Workers',
stars: '80',
url: 'https://github.com/cloudflare/itty-router-openapi',
}
]
},
},
},
}
async handle(request: Request, env, ctx, data: Record<string, any>) {
const url = `https://api.github.com/search/repositories?q=${data.q}`
const resp = await fetch(url, {
headers: {
'Accept': 'application/vnd.github.v3+json',
'User-Agent': 'RepoAI - Cloudflare Workers ChatGPT Plugin Example'
}
})
if (!resp.ok) {
return new Response(await resp.text(), { status: 400 })
}
const json = await resp.json()
// @ts-ignore
const repos = json.items.map((item: any) => ({
name: item.name,
description: item.description,
stars: item.stargazers_count,
url: item.html_url
}))
return {
repos: repos
}
}
}The quickstart smooths out the entire development process, so you can focus on crafting custom behaviors, endpoints, and features for your ChatGPT plugins without getting caught up in the nitty-gritty. If you aren't familiar with API schemas, this also means that you can rely on our schema and manifest generation tools to handle the complicated bits, and focus on the implementation to build your plugin.
Besides making development a breeze, it's worth noting that you're also deploying to Workers, which takes advantage of Cloudflare's vast global network. This means your ChatGPT plugins enjoy low-latency access and top-notch performance, no matter where your users are located. By combining the strengths of Cloudflare Workers with the versatility of ChatGPT plugins, you can create conversational AI tools that are not only powerful and scalable but also cost-effective and globally accessible.
Example
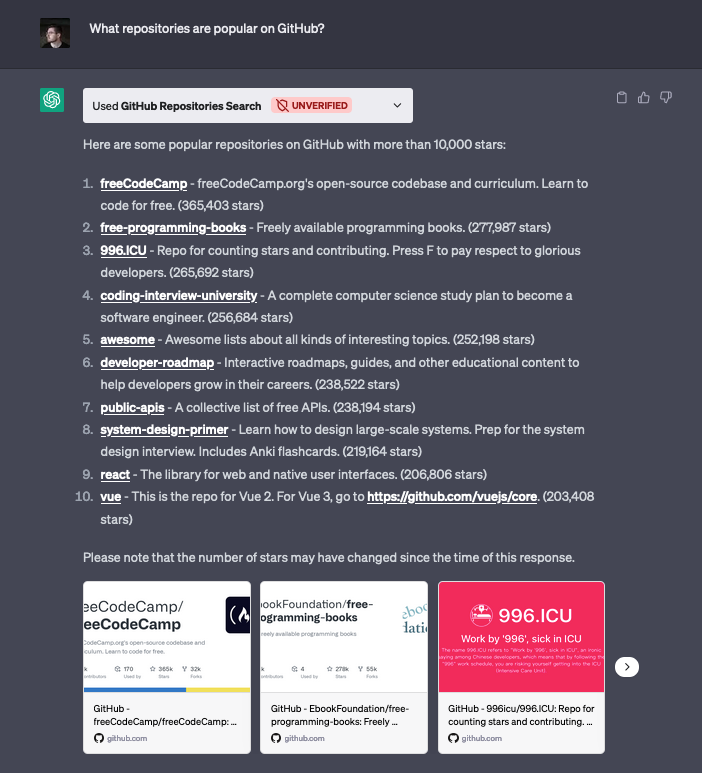
To demonstrate the capabilities of our quickstarts, we've created two example ChatGPT plugins. The first, which we reviewed above, connects ChatGPT with the GitHub Repositories Search API. This plugin enables users to search for repositories by simply entering a search term, returning useful information such as the repository's name, description, star count, and URL.
One intriguing aspect of this example is the property where the plugin could go beyond basic querying. For instance, when asked "What are the most popular JavaScript projects?", ChatGPT was able to intuitively understand the user's intent and craft a new query parameter for querying both by the number of stars (measuring popularity), and the specific programming language (JavaScript) without requiring any explicit prompting. This showcases the power and adaptability of ChatGPT plugins when integrated with external APIs, providing more insightful and context-aware responses.
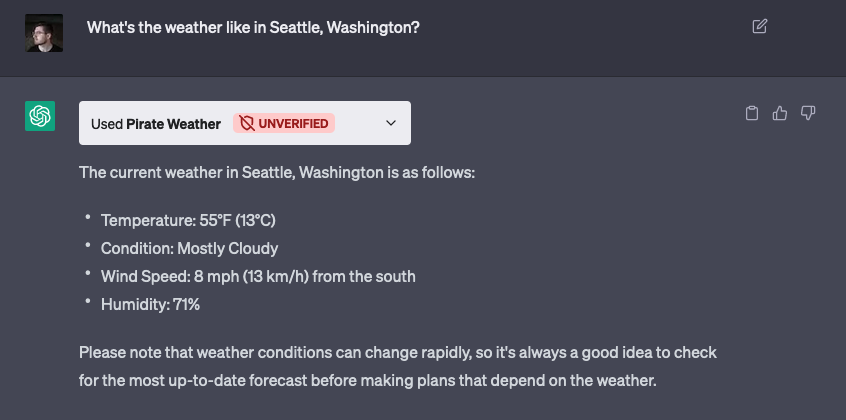
The second plugin uses the Pirate Weather API to retrieve up-to-date weather information. Remarkably, OpenAI is able to translate the request for a specific location (for instance, “Seattle, Washington”) into longitude and latitude values – which the Pirate Weather API uses for lookups – and make the correct API request, without the user needing to do any additional work.
With our ChatGPT Plugin Quickstarts, you can create custom plugins that connect to any API, database, or other data source, giving you the power to create ChatGPT plugins that are as unique and versatile as your imagination. The possibilities are endless, opening up a whole new world of conversational AI experiences tailored to specific domains and use cases.
Get started today
The ChatGPT Plugin Quickstarts don’t just make development a snap—it also offers seamless deployment and scaling thanks to Cloudflare Workers. With the generous free plan provided by Workers, you can deploy your plugin quickly and scale it infinitely as needed.
Our ChatGPT Plugin Quickstarts are all about sparking creativity, speeding up development, and empowering developers to create amazing conversational AI experiences. By leveraging Cloudflare Workers' robust infrastructure and our streamlined tooling, you can easily build, deploy, and scale custom ChatGPT plugins, unlocking a world of endless possibilities for conversational AI applications.
Whether you're crafting a virtual assistant, a customer support bot, a language translator, or any other conversational AI tool, our ChatGPT Plugin Quickstarts are a great place to start. We're excited to provide this Quickstart, and would love to see what you build with it. Join us in our Discord community to share what you're working on!