Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=4-qk00lOi6M
Twelve-Year-Old Linux Vulnerability Discovered and Patched
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/01/twelve-year-old-linux-vulnerability-discovered-and-patched.html
It’s a privilege escalation vulnerability:
Linux users on Tuesday got a major dose of bad news — a 12-year-old vulnerability in a system tool called Polkit gives attackers unfettered root privileges on machines running most major distributions of the open source operating system.
Previously called PolicyKit, Polkit manages system-wide privileges in Unix-like OSes. It provides a mechanism for nonprivileged processes to safely interact with privileged processes. It also allows users to execute commands with high privileges by using a component called pkexec, followed by the command.
It was discovered in October, and disclosed last week — after most Linux distributions issued patches. Of course, there’s lots of Linux out there that never gets patched, so expect this to be exploited in the wild for a long time.
Of course, this vulnerability doesn’t give attackers access to the system. They have to get that some other way. But if they get access, this vulnerability gives them root privileges.
Монтана – я я има, я я нема…
Post Syndicated from Николай Марченко original https://bivol.bg/%D0%BC%D0%BE%D0%BD%D1%82%D0%B0%D0%BD%D0%B0-%D1%8F-%D1%8F-%D0%B8%D0%BC%D0%B0-%D1%8F-%D1%8F-%D0%BD%D0%B5%D0%BC%D0%B0.html
понеделник 31 януари 2022

„Язовиро“. Така си го знаем в Монтана. Така го знаехме и преди, когато живеехме в Михайловград. За грандиозното му комунистическо строителство, заради което са затрити от картата на света селата…
Handy Tips #22: Deploying Zabbix in the AWS cloud platform
Post Syndicated from Arturs Lontons original https://blog.zabbix.com/handy-tips-22-deploying-zabbix-in-the-aws-cloud-platform/19343/
The post Handy Tips #22: Deploying Zabbix in the AWS cloud platform appeared first on Zabbix Blog.
Kernel prepatch 5.17-rc2
Post Syndicated from original https://lwn.net/Articles/883237/rss
The 5.17-rc2 kernel prepatch is out for
testing.
Nothing hugely surprising here – it’s a bit on the bigger side for
being an rc2, but maybe part of that is that there’s a NFS client
merge-window pull request that got merged late due to it having
been marked as spam.
What If? 2
Post Syndicated from original https://xkcd.com/2575/

Mail day #30 Pogo Pins, Roborock Parts, GY modules, scalpels etc
Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=O8QIWArrHfI
The Dirt
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/dirt/


An Explanation…
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=bqGa8Y6CXiY
Grundig MS300 Micro System – Nothing to see here, move along
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=GxHzkizAOVc
Friday Squid Blogging: Cephalopods Thirty Million Years Older Than Previously Thought
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2022/01/friday-squid-blogging-cephalopods-thirty-million-years-older-than-previously-thought.html
New fossils from Newfoundland push the origins of cephalopods to 522 million years ago.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
По буквите: Чапалику, Уайтхед, Петрова
Post Syndicated from Зорница Христова original https://toest.bg/po-bukvite-capaliku-whitehead-petrova/
В емблематичната си колонка, започната още през 2008 г. във в-к „Култура“, Марин Бодаков ни представяше нови литературни заглавия и питаше с какво точно тези книги ни променят. Вярваме, че е важно тази рубрика да продължи. От човек до човек, с нова книга в ръка.
„Всеки полудява по свой начин“ от Стефан Чапалику
превод от албански Русана Бейлери, София: изд. „Ерго“, 2022
 Когато падна Берлинската стена, много хора тръгнаха да пътешестват на Запад – кой както успееше. Най-добрият приятел на баща ми отиде в Северна Корея. Логиката му беше желязна: вие се връщате и ви е криво, а аз се върнах и знаете ли колко ми харесва тук!
Когато падна Берлинската стена, много хора тръгнаха да пътешестват на Запад – кой както успееше. Най-добрият приятел на баща ми отиде в Северна Корея. Логиката му беше желязна: вие се връщате и ви е криво, а аз се върнах и знаете ли колко ми харесва тук!
Ако тръгнете да пътешествате в Албания на Енвер Ходжа – поне такава, каквато е описана в книгата на Стефан Чапалику, – няма да ви се получи така. Градчето Шкодра от началото на 70-те е „Амаркорд“, пълно с чудати персонажи: бродиращия на гергеф поет; учителя, уволнен заради издърпано с хартия ухо (уши може да се дърпат, но хигиеничната хартийка е буржоазен навик); зашеметяващата Миралда с тънката бяла рокля на точки, седнала на велосипеда на съседа; една пълна къща с всевъзможни роднини и съседи, сред които и местният, познат на всички доносник. И с детайли като любовната песен във възхвала на сармичките.
Историите са напоени със сладкия сироп на етнографските детайли, например теспиче – албански десерт, който се пече като огромна курабия, а после се реже и напоява като баклава. И това е единият пласт – сладко-носталгична картина като от „Баща ми бояджията“, в която е възможно уволненият учител (вече читалищен режисьор) да отмъсти на някогашните си съселяни, като спре тока насред представлението и подучи актьорите да замерят зрителите със смокини.
Тази сладко-лепнеща носталгия обаче е удар и по нас. Защото и ние си спомняме развеселени за вещния свят на социализма – какво е да имаш телефон, а после и телевизор, да се съберат всички съседи у вас да гледат „Последно танго в Париж“, пък да падне антената… И у нас споменът за немислимата несвобода е сиропиран от сладостта на детството и тъгата по него.
Но Стефан Чапалику разказва и друга история – в неговия „Амаркорд“ проблясва образът на Енвер Ходжа, който е или не е „в хладилника“, тоест умрял, без това да е оповестено; провиждат се единични актове на съпротива – вуйчото в затвора, католическият свещеник, осмелил се да протестира срещу съборената камбанария, убитите при опит за бягство момчета… на фона на масовото примирение с несвободата. И необходимостта да мислиш за тази несвобода и онова, което е направила тя с теб, с близките ти.
Например: духът на недоволството се затваря в клана, в семейството – хората не смеят да се занимават с истинския проблем и започват да се занимават едни с други. Например: примирението мимикрира като леност, „ленивото нежелание да кажеш не“, едва ли не близко до първосигналния опит да излекуваш всичко с бабешки илачи, за да не се занимаваш с болници. Например: като не може да възтържествува над диктатора, градът се е „избавил с лекота от дързостта да възтържествува над вътрешния страх“. Приел е присърце максимата „Живей незабележимо“.
Градът се капсулира. В него като в някакво подводно царство плуват отломки от външния свят – предмети и привички от миналото, хванати чужди радиостанции или филми. Ти си призрак – не участваш в света. Като съпротивата на мъжа, отказал да излиза от вкъщи, защото нямало полски или английски плат, от който да ушие панталон – всъщност нищо не променя, само остава затворен до края на живота си. Една от малките битови съпротиви. Подобни жестове, казва авторът, само гъделичкаха системата, караха я да се чувства жива. За сметка на всеки, отказал се от смелостта да се изправи сам пред нея.
Е, как се чувства един български читател след подобно пътуване? Най-напред – малко по-разбран. Казвам се еди-как си и съм израснал в малка комунистическа балканска страна. Чувството за вина ми е спестено, защото съм бил дете. Усещането за безтегловност – не.
Впрочем „Всеки полудява по свой начин“ e първата част от трилогия, последната книга от която е написана в София, в Къщата за литература и превод.
„Харлемски рокади“ от Колсън Уайтхед
превод от английски Ангел Игов, София: изд. „Лист“, 2021
 Ако „Всеки полудява по свой начин“ припомня клаустрофобията отсам Берлинската стена, моят подстъп към „Харлемски рокади“ на Колсън Уайтхед беше през сумрачното претрупано помещение на телевизионен и радиосервиз, чийто възрастен собственик не пита откъде идват уредите, които така майсторски поправя. Беше през усещането за безнадеждност на мястото, чиято окаяност прави мечтата за придвижване нагоре не просто его, а „измъкване“ от вечерната несигурност на улиците и абсолютната сигурност на шума и другите несгоди.
Ако „Всеки полудява по свой начин“ припомня клаустрофобията отсам Берлинската стена, моят подстъп към „Харлемски рокади“ на Колсън Уайтхед беше през сумрачното претрупано помещение на телевизионен и радиосервиз, чийто възрастен собственик не пита откъде идват уредите, които така майсторски поправя. Беше през усещането за безнадеждност на мястото, чиято окаяност прави мечтата за придвижване нагоре не просто его, а „измъкване“ от вечерната несигурност на улиците и абсолютната сигурност на шума и другите несгоди.
Героят Рей Карни изглежда разбираем – познатият и тук типаж, който не се интересува от политика, не се интересува от права, иска просто малко да се позамогне и да се усеща спокоен за семейството си. Не се интересува дори от джаз – въпреки че е началото на 60-те в Ню Йорк. Твърде е обикновен за това. И се опитва да спазва закона, за разлика от баща си… но лесно му минава.
„Харлемски рокади“ е гангстерска история – леко водевилна, защото схемите често дават накъсо. Освен това „Харлемски рокади“ е и роман в духа на „новата журналистика“ – неслучайно Колсън Уайтхед споделя в интервю възхищението си от Норман Мейлър и Том Улф. Също като „Кладата на суетата“, и неговият роман показва герои, които са всъщност типажи, само че палитрата от характери е обединена от общ цвят – цвета на кожата. В центъра са гореспоменатият Рей Карни и неговият братовчед Фреди – близки нюанси в сивата зона между закона и престъпността, и цяла редица персонажи нагоре и надолу по социалната стълбица.
И стъпва върху конкретни исторически събития. Историческият фон на книгата са протестите в Харлем от 1964 г., които ужасно приличат на протестите след смъртта на Джордж Флойд през лятото на 2020 г.: бял полицай убива чернокож (през 1964-та това е петнайсетгодишният Джеймс Пауъл) и предизвиква масов гняв срещу полицейското насилие, демонстрации и безредици, които скоро придобиват разрушителен характер – но не успяват да променят много.
Всъщност романът е излязъл месеци преди събитията от 2020-та; запитан за съвпадението, Уайтхед казва, че за съжаление, не е нужно да си пророк, за да видиш, че тези сценарии се повтарят периодично – през 1943-та, 1967-та и т.н. В детството си героят му дори има панталонки, които баща му е задигнал по време на безредици. Той самият е твърде прагматичен, за да се интересува от каквато и да било борба срещу расизма, и приема фактите на сегрегацията без особен вътрешен коментар. Читателят е този, който ги забелязва и осмисля – басейнът, изпразнен, защото си се изкъпал в него; безопасните“ туристически маршрути за чернокожи, организирани от жената на Рей; знаменитият хотел „Тереза“, приел гости като Луис Армстронг, Дюк Елингтън, Джозефин Бейкър и др. не за друго, а защото останалите хотели в града са само за бели.
Впрочем гореспоменатите маршрути са далечна препратка към най-известния роман на Уайтхед, „Подземната железница“, за който авторът получава първия си „Пулицър“ за белетристика (вторият е през 2020-та за „Момчетата от Никел“). „Подземната железница“ някога са се наричали каналите за прехвърляне на избягали чернокожи на север; романът на Уайтхед е алтернативна история, в която значението на израза е буквализирано, като подземна железопътна мрежа с предполагаемо безопасни гари. Препратката към периода на робството в „Харлемски рокади“ е само една, но пък каква: замисленият от героите обир в хотел „Тереза“ се случва на 19 юни, Juneteenth, официалния празник на освобождението на робите в САЩ. Само че, както отбелязва героят, Линкълн всъщност оповестява края на робството на 1 януари; 19 юни е денят, в който робите в Тексас разбират за това.
П.П. Оригиналното заглавие на романа, Harlem Shuffle, препраща към песен на чернокожия дует „Боб енд Ърл“, записана през 1963 г., тоест малко преди описваните безредици. Вероятно я познавате в кавъра на „Ролинг Стоунс“.
„Нещотърсач“ от Екатерина Петрова
София: изд. „Жанет 45“, 2021
 В издадената наскоро от СОНМ „Палечка“ френският мислител Мишел Сер говори за това колко трудно е в днешния затрупан от информация свят да направиш избор, да привилегироваш едно знание пред друго. Какво избираш да научиш? И по-важното – защо?
В издадената наскоро от СОНМ „Палечка“ френският мислител Мишел Сер говори за това колко трудно е в днешния затрупан от информация свят да направиш избор, да привилегироваш едно знание пред друго. Какво избираш да научиш? И по-важното – защо?
Другият сериозен въпрос пред съвременния дигитален човек е усещането за реалност. Да, светът е потенциално достъпен – но както показа пандемията, виртуалното не стига, то просто не дава усещане за живот. Да не говорим за усещането за време в съвременния свят, постоянния „шок от бъдещето“ или „настоящето“, изплъзващия се миг.
„Нещотърсач: 44 (не)обикновени предмета от близо и далеч“ на Екатерина Петрова предлага индивидуално житейско решение, което би допаднало на много хора, макар малцина да го прилагат така изкусно. В нейната книга знанието служи като лупа, с която да видиш по-ясно какво си преживял току-що; като грапавина, която те задържа по наклонената плоскост на времето и ти пречи да достигнеш края му, „преди да си живял“. Знанието е хедонистично, то подслажда, разширява, осмисля това, което ти се е случило – с любезното съдействие на приятели, книги и разбира се, интернет. Освен това ти помага да „опаковаш“ максимален обем настояще в предмет, който да те изстреля обратно в преживения момент, да му помогне да „изплува в ума ти“, да ти „дойде наум“ – което е всъщност етимологичното значение на souvenir. Да, като мадлените на Пруст – неслучайно книгата започва с тях.
„Нещотърсач“ е един вид библиотека от такива предмети, всеки от които с „опашка“ от лична история, пътуване, културен контекст, пресичащи се нишки. От цветните традиционни ботуши в Бутан до рисувания абажур от Кюстендорф, създаденото от Кустурица филмово, но и обитаемо село или репликата на плочка на Гауди от паважа в Барселона, книгата има за цел да достави на читателя максимално удоволствие от съзнанието, че пребиваваш в един безкраен и интересен свят – и го прави, включително на ниво езикова игра и умелост.
Освен всичко друго, „Нещотърсач“ е показно за object-based learning, обучение с помощта на предмети, на внимателното вглеждане в тях и техните смисли – метод, от който българското образование би имало безспорна полза (и за чието въвеждане работи Тодор Петев). Отделно от това, книгата ме кара да се размечтая какво би станало, ако предметите в нашите музеи се радваха на такива щедри майсторски описания.
За читателя обаче оставям удоволствието да се отпусне в креслото и да попътува с тях – не като заместител на истинското пътуване (Екатерина Петрова не крие, че заместители няма), а като вдъхновение за бъдещи пътешествия и бъдещо вглеждане в предметния свят наоколо. За насладата ще му помогне и майсторското оформление на книгата, дело на Люба Халева.
П.П. Не успях да устоя на изкушението да си представя кои два предмета бих взела като сувенири от света на първите две описани книги. За „Харлемски рокади“ – вероятно празната бутилка, пъхната в ръката на Рей Карни по време на безредиците с инструкции да я напълни с бензин, да запали фитила и да я метне по някоя витрина. За „Всеки полудява по свой начин“ – хм, бих подминала предметите от социалистическия бит, включени у нас в „Инвентарна книга на социализма“, дори и будилия толкова страсти телевизор, и бих потърсила вместо това някакъв чарк от заглушителна станция. Стига да не са още тайна, разбира се. А ако са? Значи заглушителната станция още действа.
Активните дарители на „Тоест“ получават постоянна отстъпка в размер на 20% от коричната цена на всички заглавия от каталозите на „Ерго“, „Лист“ и „Жанет 45“, както и на няколко други български издателства в рамките на партньорската програма Читателски клуб „Тоест“. За повече информация прочетете на toest.bg/club.
Заглавна илюстрация: © Александра Димитрова
Седмицата (24–28 януари)
Post Syndicated from Йоанна Елми original https://toest.bg/editorial-24-28-jan-2022/
Януари почти мина и замина, а с него и първият ретрограден Меркурий – феномен, за който не чухме нищо от нито един правителствен астролог. А скептиците казват, че нямало промяна.
Всъщност в някои вселени наистина няма: например в тази на БСП, където времето сякаш тече различно. Миналата събота партията проведе, оказа се, второ заседание на своя 50-ти Конгрес. Интересно е да се обърне внимание на това число, тъй като летоброенето на левицата е малко… неясно.
Както столетницата с гордост твърди, тя е наследница на създадената през 1891 г. на връх Бузлуджа БСДП, обособена през 1903 г. в БРСДП (тесни социалисти), която пък по-късно е преименувана на БКП. Според информацията в „Уикипедия“ през 1919 г. БРСДП (т.с.) провежда своя ХХII конгрес, който става I конгрес на БКП. За цялата си 71-годишна история БКП провежда общо 14 конгреса, последният от които е през 1990 г. Два месеца след него БКП се преименува на БСП. Излиза, че в Българската социалистическа партия броят и конгресите преди БКП, а за 32-годишната си история дотук е провела още 14 конгреса, за да стигне до това число 50… На което, изглежда, „забива“, понеже още през септември 2020 г. левицата отбеляза този юбилей.

Встрани от метафизиката – не съществува промяна, която да застигне председателката на партията Корнелия Нинова. Ако Хераклит ни бе съвременник, вместо да гази в реката и да се чуди дали водата е една и съща, можеше просто да посети някое n по ред партийно мероприятие и да се увери, че в живота някои неща наистина са константа: българското партийно лидерство е вечно непоклатимо дори пред другата константа – политическите провали. По този повод Венелина Попова ни предлага задълбочен анализ относно лидерството и миналото на БСП, както и прогноза защо партията ще продължава да губи електорална подкрепа.

Но не всичко е толкова тъжно и потискащо. Съдбата най-сетне даде почивка на скъпите ни нерви, опънати от задълбочени спорове в социалните мрежи в какво точно се състои световният заговор. За по-малко от денонощие получихме възможността да докажем своята експертност по международно военно дело, стратегия и геополитика и да се впуснем с отдавна познатия нам плам да бистрим отношенията Русия–Украйна–САЩ. И за да се спасим от информационно удавяне, Йовко Ламбрев избра да зададе най-важните въпроси на политолога с докторска степен по международни отношения Димитър Бечев, който не очаква мащабно нахлуване в Украйна, но има други опасения относно сложната ситуация.

Ако това ви успокоява, много тенденции сочат, че не е нужно да стигаме до Украйна, ако искаме да се готвим за война. Такава вече се води за умовете на българите, и то от години, а плодовете ѝ жънем днес, смята Емилия Милчева. В своя анализ тази седмица тя припомня генезиса на антидемократичната пропаганда в България, както и политическото безсилие пред нея и я обвързва с настоящите събития в Украйна и със закъснялата позиция на българските власти.
Емилия задава множество въпроси, които вероятно ще останат без отговор, като например каква е нашата външнополитическа позиция спрямо българското малцинство в Украйна. За да продължи промяната в това направление, трябва най-първо да имаме промяна. В противен случай разполагането на натовски контингент ще бъде употребено, също както и робската енергийна зависимост от Москва, ненарушена от никое правителство досега, пише Емилия.
За вниманието на българската онлайн и офлайн „експертна“ общност се надпреварва и друга тема: отношенията между България и Северна Македония. Ако не сте чели статията на Александър Малинов по темата – препоръчвам я от позицията на човек, който е запознат с политиката в региона единствено по линията на националната си принадлежност.

Светла Енчева също следи темата и миналата седмица разгледа някои от актуалните опорни точки. Тази седмица тя отговаря на една реплика на президента Румен Радев, с която той коментира разни права по такъв начин, че няма как човек да не се запита какво всъщност е искал да каже. Светла идва на помощ и ни превежда през зараждането на концепцията за индивидуалните права, обяснявайки как те се свързват с правата на определени групи, а впоследствие – и с правата на цялото общество. Дано един от най-важните държавни мъже прочете… ама надали.
Да, в „Тоест“ сме големи любители на загубените каузи, като се почне от модела ни на финансиране, през отказа да ви провокираме със сензационни заглавия, та чак до опитите ни да събираме ценно съдържание, което ще остарее добре. Много критици ще кажат, че сме напълно заблудени, но на нас ни се ще да вярваме, че просто сме големи романтици. Защото кой друг, ако не някой романтик би ви подбирал книги с обич и с надеждата, че ще успеем да почетем във време на дигитална какофония?

Зорница Христова идва на помощ с препоръки от Албания, Щатите и с една специална книга, която събира света в себе си. От усещането за безтегловност на Стефан Чапалику в романа му „Всеки полудява по свой начин“ за Албания от 70-те до гангстерската история „Харлемски рокади“ на американеца Колсън Уайтхед, която засяга расовите проблеми през 60-те – сякаш с препоръките си в рубриката „По буквите“ Зорница ни показва надеждата в трудните истории от миналото, предлагайки ни шанс за бавно осъзнаване и внимателно вглеждане поне от сигурността на настоящето. Да, хубаво е да знаем, че и друго страшно е отминало.
Разбира се, такива сюблимни моменти на прозрение траят кратко, прекъснати от поредната нотификация за поредното бедствие. Зън! Но преди това не пропускайте да се разходите из колекцията от предмети на Екатерина Петрова – българска преводачка от английски език, която дебютира като автор с книгата си „Нещотърсач“ и съвместно с художничката Люба Халева ни е подготвила също толкова привлекателно, но пък много по-позитивно изживяване от т.нар. doomscrolling.
Макар и през януари да прекарах в социалните мрежи повече време, отколкото ми се искаше (личи ли си от бюлетина?), успях да посветя по-голямата част на разговори с приятели и четене на интересни източници, като се възмутих силно едва пет пъти, при четири от които дори си замълчах! Препоръчвам ви да направите същото и да внимавате много какво четете, защото съвсем скорошно проучване на катедрата по комуникации в Амстердамския университет показва, че частично невярната информация е много по-трудна за поправяне в ума ни от напълно невярната. Остава препоръката да разчитаме на надеждни източници, а също и да избягваме „необратимата предубеденост“, по думите на д-р Георги Керемидчиев в това чудесно интервю.
За интересуващите се от американска политика и от история изобщо препоръчвам силното есе на Джон Гринспан и Питър Мансоу за това колко е важно как учим, запомняме и интерпретираме историята. Потърпете още малко студа и нека ви сгрява мисълта, че предстои едно много хубаво литературно лято. Ако ли не, скарайте се с някого във Facebook, колкото да не е без хич. Винаги може да се оправдаете с ретроградния Меркурий – не сме се променили чак толкова.
Connecting an Industrial Universal Namespace to AWS IoT SiteWise using HighByte Intelligence Hub
Post Syndicated from Michael Brown original https://aws.amazon.com/blogs/architecture/connecting-an-industrial-universal-namespace-to-aws-iot-sitewise-using-highbyte-intelligence-hub/
This post was co-authored with Michael Brown, Sr. Manufacturing Specialist Architect, AWS; Dr. Rajesh Gomatam, Sr. Partner Solutions Architect, Industrial Software Specialist, AWS; Scott Robertson, Sr. Partner Solutions Architect, Manufacturing, AWS; John Harrington, Chief Business Officer, HighByte; and Aron Semie, Chief Technology Officer, HighByte
Merging industrial and enterprise data across multiple on-premises deployments and industrial verticals can be challenging. This data comes from a complex ecosystem of industrial-focused products, hardware, and networks from various companies and service providers. This drives the creation of data silos and isolated systems that propagate one-to-one integration strategy.
To avoid these issues and scale industrial IoT implementations, you must have a universal namespace. This software solution acts as a centralized repository for data, information, and context, where any application or device can consume and publish data needed for a specific action.
HighByte Intelligence Hub does just that. It is a middleware solution for universal namespace that helps you build scalable, modern industrial data pipelines in AWS. It also allows users to collect data from various sources, add context to the data being collected, and transform it to a format that other systems can understand.
Overview of solution
HighByte Intelligence Hub, illustrated in Figure 1, lets you configure a single dedicated abstraction layer (HighByte refers to this as the DataOps layer). This allows you to connect with various vendor schema standards, protocols, and databases. From there, you can model data and apply context for data sustainability.

Figure 1. HighByte Intelligence Hub
HighByte Intelligence Hub uses a unique modeling engine. This allows you to act on real-time data to transform, normalize, and combine it with other sources into an asset model. This model can be deployed and reused as necessary. It represents the real world, and it is available to multiple connections and configurable flow paths simultaneously.
For example, Figure 2 shows a model of a hydronic heating system that was created with HighByte Intelligence Hub.

Figure 2. Creating a model of a hydronic heating system in HighByte Intelligence Hub
With this model, you can define a connection to AWS IoT SiteWise and publish the model directly. This way, the general model and the instance of the model will immediately be available in AWS.
This model can also:
- Send the temperature and current information from this system to a database for reporting. You can do this without changing anything from the original configuration.
- Add another connection in HighByte Intelligence Hub for AWS IoT Core (MQTT) and publish the existing model information to the fully managed AWS IoT Core service.
- Stream the hydronic data into an industrial data lake on AWS, as shown in Figure 3, by adding an Amazon Kinesis Data Firehose connection in HighByte Intelligence Hub and attaching the existing flows to it.

Figure 3. AWS reference architecture for HighByte Intelligence Hub
The next sections will take a closer look at how to configure HighByte Intelligence Hub to work with AWS.
Prerequisites
For this walkthrough, you must have the following prerequisites:
- An AWS account
- Access to AWS IoT Sitewise
- A copy of HighByte Intelligence Hub
- Access to industrial data source(s)
Note that this post shows the major steps to connect HighByte Intelligence Hub to AWS IoT SiteWise; we will not dive too deeply into all areas of configuration. Please refer to the HighByte Intelligence Hub documentation for specific questions and the AWS service documentation for a full explanation.
Let’s get started!
- After logging into HighByte Intelligence Hub, create connections to AWS by selecting the “Connections” tab on the menu on the top right corner of the screen.
Figure 4 shows the following four connections to AWS resources:
- AWS IoT Core – US East 1 Region
- AWS IoT SiteWise – US East 1 Region
- Kinesis Data Firehose – US East 1 Region
- AWS IoT Greengrass edge device – located on-premises
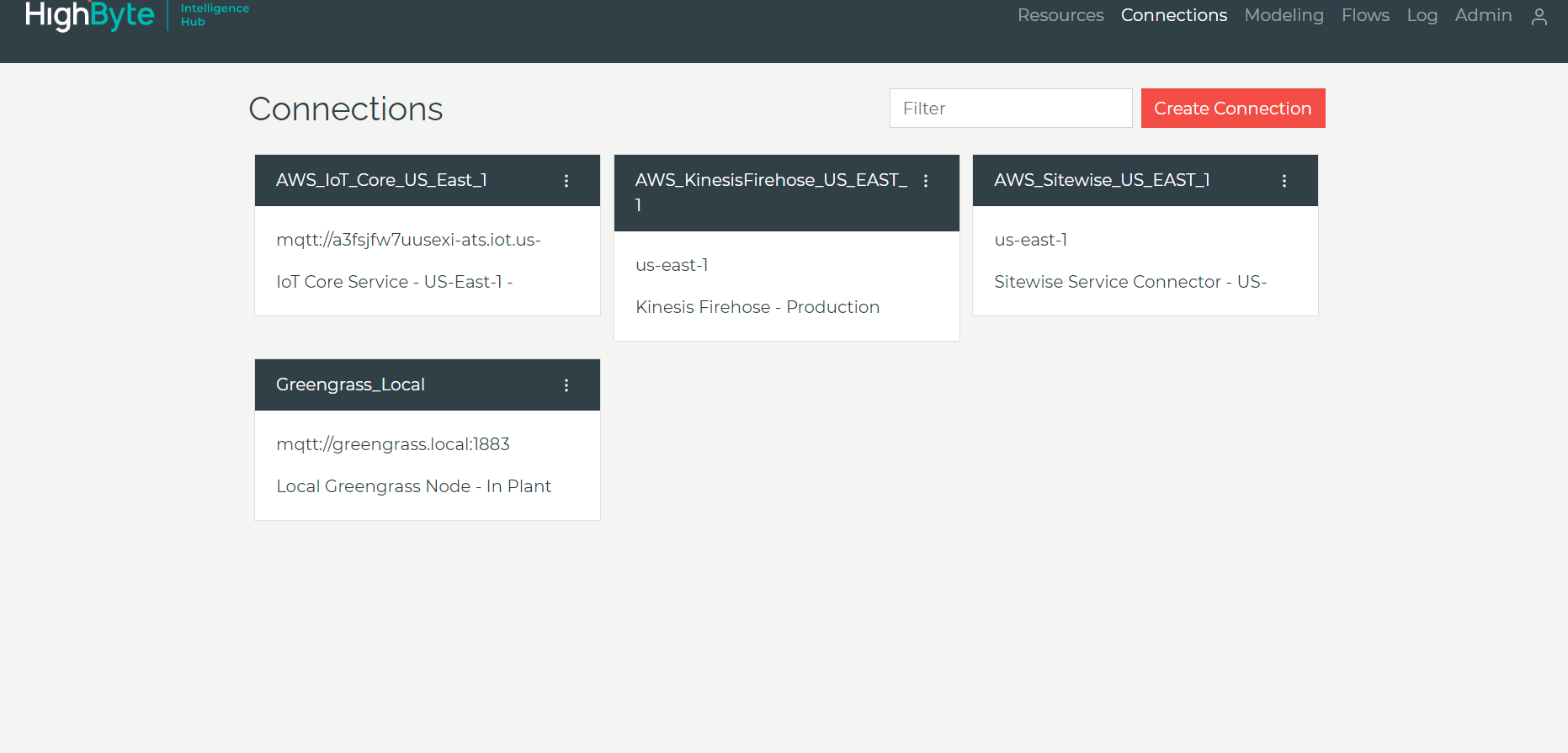
Figure 4. HighByte Intelligence Hub AWS connections
For each connection, HighByte Intelligence Hub uses native AWS security and connectivity patterns. Figure 5 shows the AWS IoT SiteWise connection settings as an example.

Figure 5. AWS IoT SiteWise connection settings
Figure 5 shows where to provide an AWS access key and secret key that’s attached to an appropriate AWS Identity and Access Management (IAM) role. This role must have the required AWS IoT SiteWise permissions.
- Now that you have your connections created, let’s build a model. Select “Modeling” on the menu on the top right corner of the screen. Define all the attribute names and the data types that you want to include in the model. When you are finished, you should have something that looks like Figure 6, which shows the attribute names, attribute types, if it is an array or not, and if it a required attribute for the model.

Figure 6. HighByte Intelligence Hub hydronic heating model
- Next, create an instance of the asset model. To do this, use the “Actions” dropdown menu on the upper right corner and select “create instance,” because it will preserve your model name.

Figure 7. Hydronic model instance
As shown in Figure 7, you can produce a standardized model and attach normalized labels that map multiple protocols such as OPC, MQTT, and SQL data sources. In our example, our data sources are all MQTT.
- Now, take your new model instance and assign a flow (Figure 8) that details the source and destination.
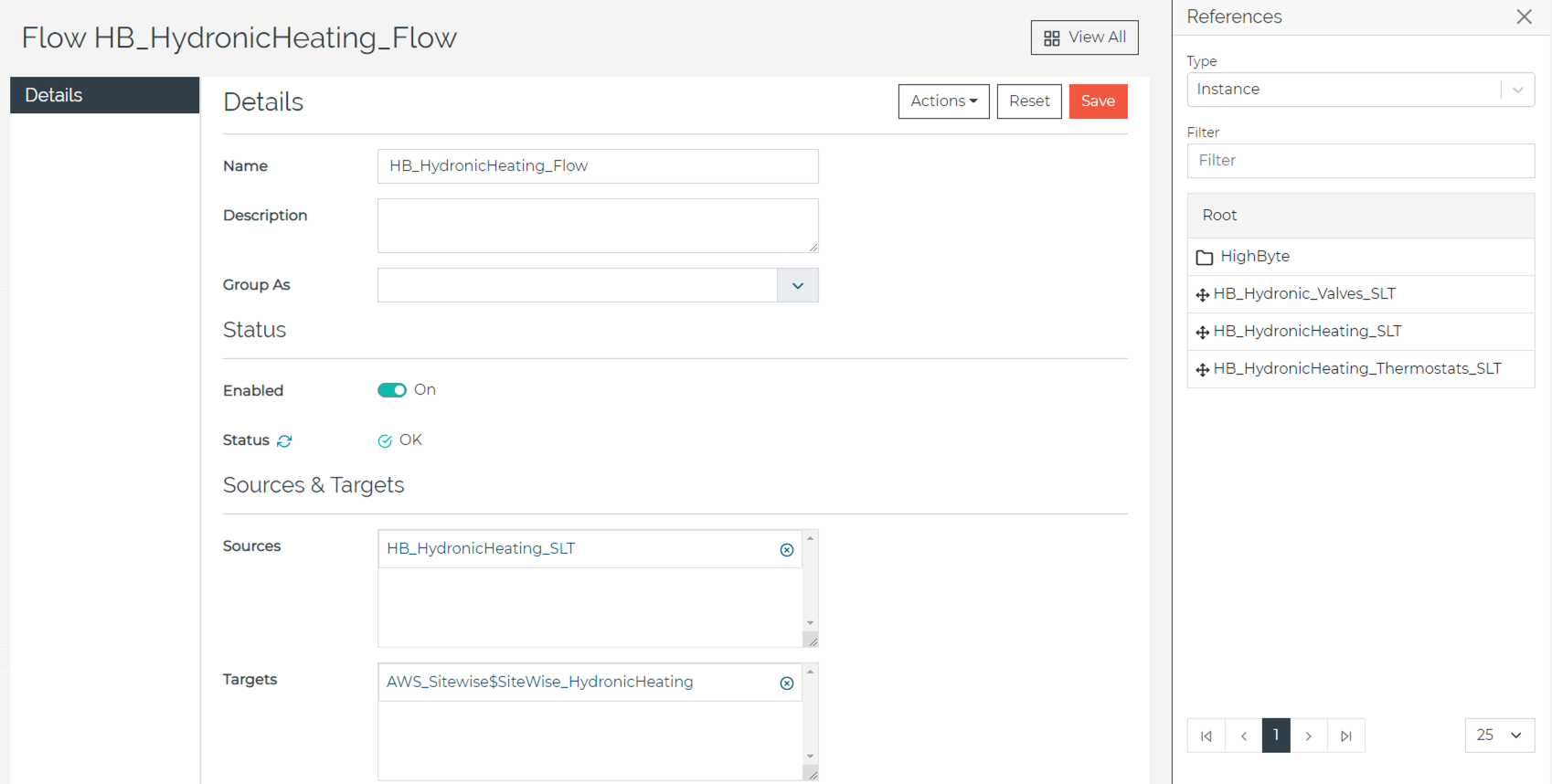
Figure 8. HighByte Intelligence Hub flow
In this step, as shown in Figure 8, drag and drop the instance of the hydronic model from the right side of the screen to the “Sources” box in the middle of the screen. Then, change the reference type to “Output” from the dropdown menu, select AWS IoT SiteWise as the connection, and drag and drop the AWS IoT SiteWise instance to the “Target” box.
From here, you’ll select the following flow settings, as shown on Figure 9:
- Interval – How often you send data
- Mode – Always send, On-Change, On-True, or While True
- Publish Mode – All Data, Only Changes, Only Changes Compressed
- Enabled – On or Off
Once you turn the Enabled switch to On and submit, your data will show up in AWS IoT SiteWise.
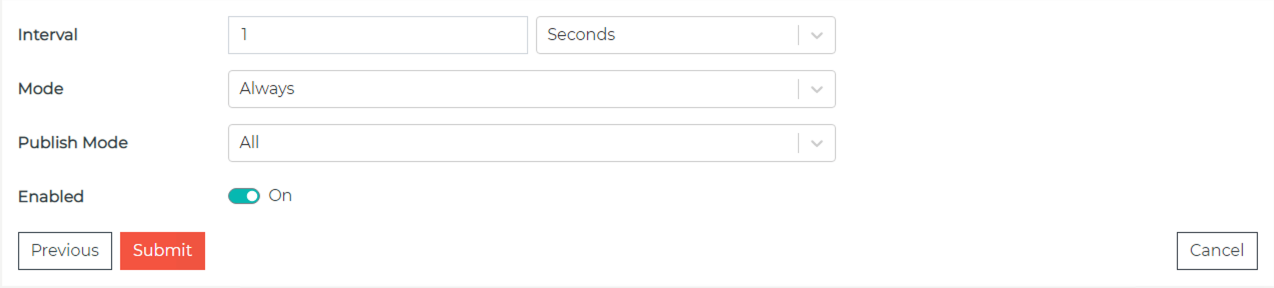
Figure 9. HighByte Intelligence Hub flow settings
Now you’ve configured your MQTT data sources, created a HighByte Intelligence Hub model and instance, and defined a flow to send the data to AWS IoT SiteWise!
Next, let’s see how your model and data are represented.
When HighByte Intelligence Hub first connects to AWS IoT SiteWise, the hub creates an AWS IoT SiteWise model. The model is configured through the AWS IoT SiteWise API. As shown in Figure 10, the name and type from the HighByte Intelligence Hub model are copied to the measurement name and data type in the AWS IoT SiteWise model. Likewise, the AWS IoT SiteWise model name will inherit from the HighByte Intelligence Hub model name.

Figure 10. AWS IoT SiteWise model
After the model has been created, HighByte Intelligence Hub will create an AWS IoT SiteWise asset using the model it just created. The asset name will be inherited from the hub instance name. As Figure 11 shows, data will flow from the HighByte Intelligence Hub input data source and through the flow definition, using the attributes defined in the model.
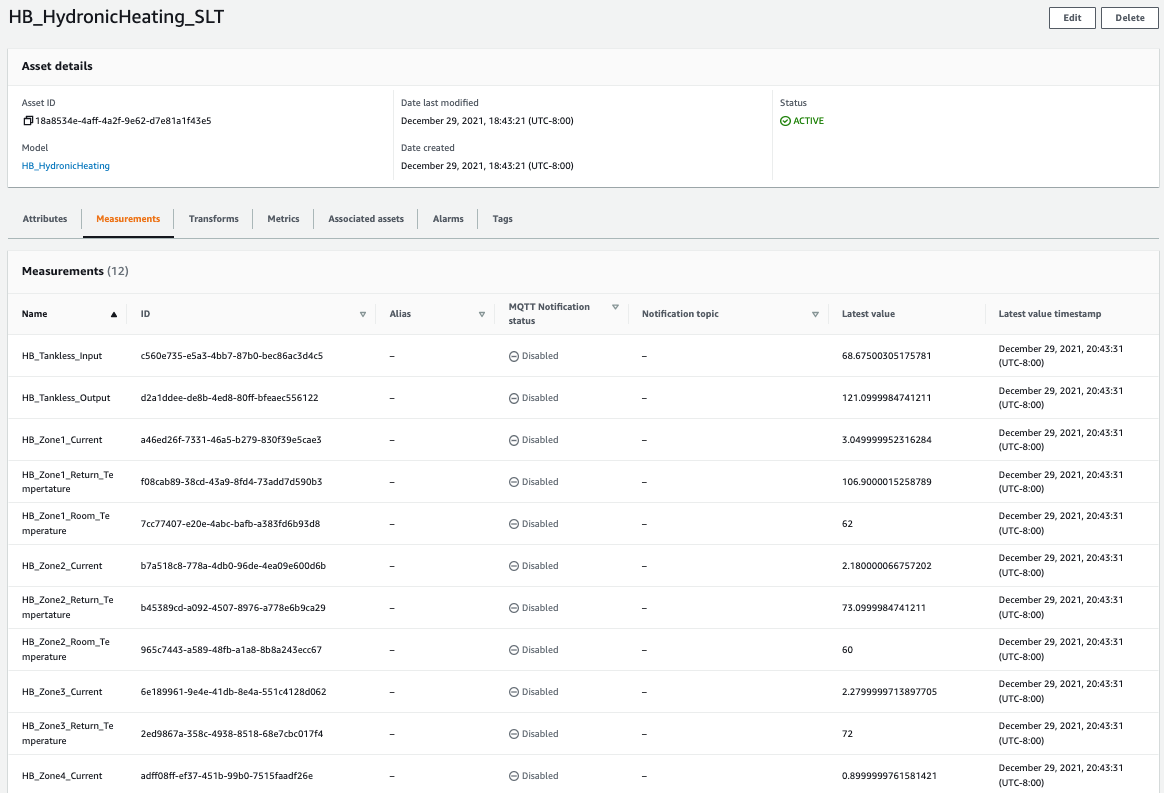
Figure 11. AWS IoT SiteWise asset
The final step in this process is to set up a visualization of the data in the AWS IoT SiteWise portal by creating a dashboard and adding visualization to it. After you do this, the display shown in Figure 12 will update as new data comes into AWS IoT SiteWise.

Figure 12. AWS IoT SiteWise portal dashboard
Conclusion
HighByte Intelligence Hub is the first industrial DataOps solution designed specifically for operational technology and information technology teams. It allows you to securely connect, merge, model, and flow industrial data to enterprise systems in AWS Cloud without writing or maintaining code.
This post showed you how to integrate HighByte Intelligence Hub with AWS to quickly model and extract data so that multiple teams can simultaneously analyze, interpret, and use the data without constraint and generate rich data models in minutes.
Ready to get started? Try out HighByte Intelligence Hub today.
Matthew McConaughey & Garth Jennings | Sing 2 | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=pwNHAXFlGOU
Hybrid Cloud and Modern Workflows for Media Teams
Post Syndicated from Amanda Fesunoff original https://www.backblaze.com/blog/hybrid-cloud-and-modern-workflows-for-media-teams/
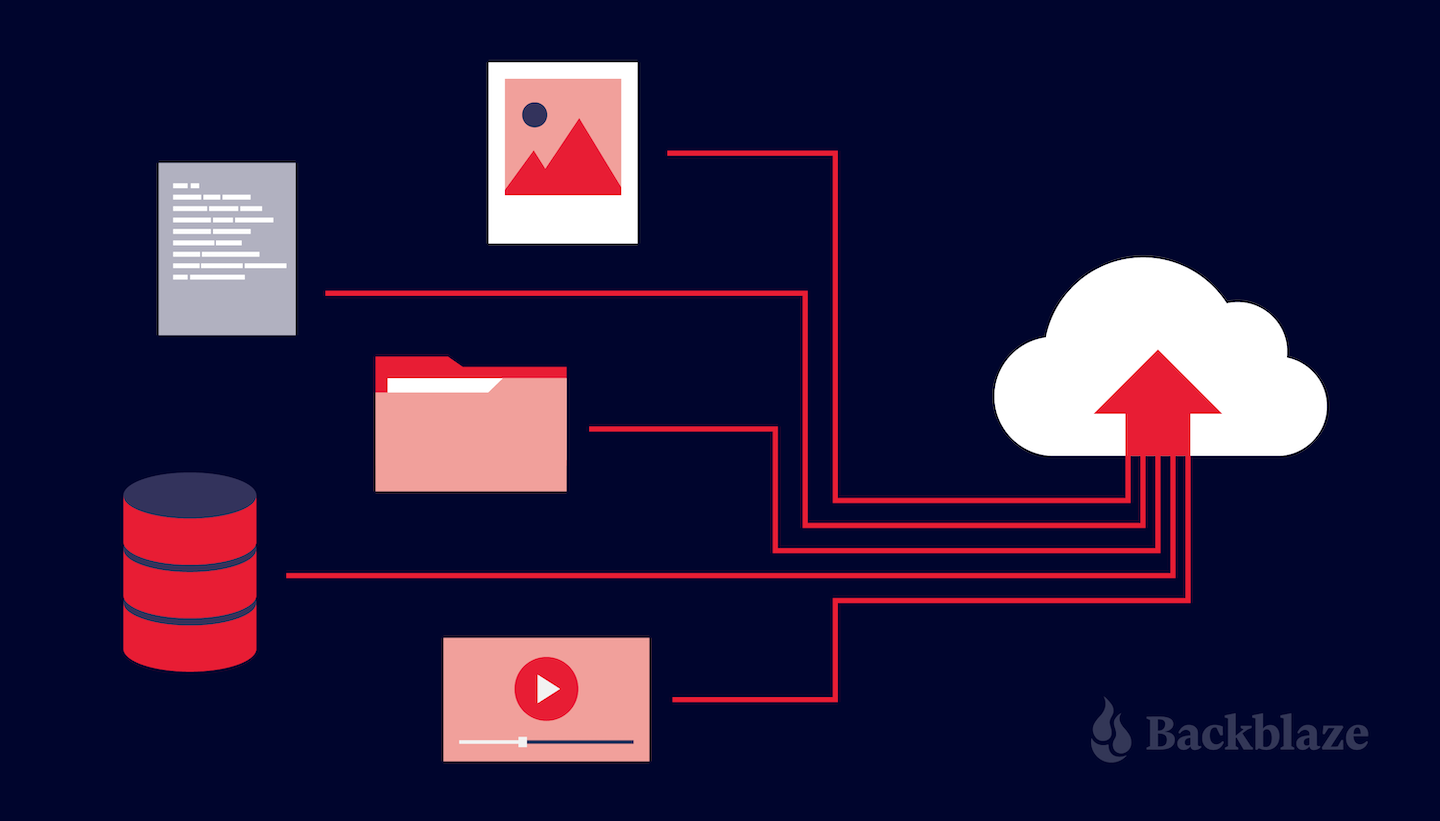
By any metric, the demands on media workflows are growing at an unprecedented rate. A Coughlin Associates Report of media and entertainment professionals predicts that overall cloud storage capacity for media and entertainment is expected to grow over 13.8 times between 2020 and 2026 (101.1EB to 140EB). It also predicts that, by the next decade, total video captured for a high-end digital production could be hundreds of petabytes, approaching one exabyte.
Businesses in the media and entertainment industry—from creative teams to production houses to agencies—must manage larger and larger stores of data and streamline production workflows that interact with those stores of data. Optimizing data-heavy workflows provides you with time and cost savings you can reinvest to prioritize the creative work that drives your business.
In today’s post, we’ll examine the trends shaping the media storage landscape, walk through each step of the media workflow, and provide strategies and tactics for reducing friction at each step along the way. Read on to learn how to modernize your media workflow to meet today’s data-heavy demands.

Media Technology Trends and Impacts on Media Workflows
Technology is driving changes in media workflows. The media landscape of today looks very different than it did even a few short years ago. If you’re responsible for managing data and workflows for a creative team, understanding the broad trends in the media landscape can help you prepare to optimize your workflows and future-proof your data infrastructure. Here are a few key trends we see driving change across the media storage landscape.
Trend 1: Increased Demand for VR and Higher Resolution 4K and 8K Video Is Driving Workflow Modernization
While VR has been somewhat slow to build steam, demand for VR experiences has grown as the technology evolved. The industry as a whole is growing at a fast pace, with the global VR market size projected to increase from less than $5 billion in 2021 to more than $12 billion by 2024. Today, demands for stereoscopic VR, and VR in general, have increased storage requirements as data sets grow exponentially. Similarly, higher resolution demands more from media workflows, including more storage space, greater standards for compression, and higher performance hardware. All of these files also need to be constantly available and secure. As such, media workflows increasingly value scalable storage, as having to wait for additional storage may cause delays in project momentum/delivery.
Trend 2: Archiving and Content Preservation Needs Are Driving Storage Growth
While the need to digitally convert data from traditional film and tape has slowed, the enormous demand for digital storage for archived content continues to grow. According to the Coughlin Report, more than 174 exabytes of new digital storage will be used for archiving and content conversion and preservation by 2024.
Just as your storage needs for active projects continues to grow as file sizes continue to expand, expect to invest in storage for archival purposes as production continues apace. Furthermore, if you have content conversion or preservation needs, plan for storage needs to house digital copies. The plus side of this surge in archival and preservation demand is that the storage market will continue to be competitive, giving you plenty of choices at competitive rates.
Trend 3: Cloud Adoption Is Playing an Important Role in Enabling Collaboration Across Teams and Geographies
A study by Mesa of nearly 700 decision-makers and managers from media and entertainment companies found that they expect that 50% of their workforce will continue to work remotely. Accessing resources remotely used to be a challenge mired by latency issues, restrictions on file size, and subpar collaboration tools, but cloud adoption has eased these issues and will continue to do so as companies increasingly embrace long-term remote collaboration.
As you think about future-proofing your architecture, one factor to consider is cost, but also designing an architecture that enables your existing workflows to function remotely. A cloud storage provider with predictable pricing can address cost considerations and make cloud adoption even more of a no-brainer. And media workflows can adopt cloud-native solutions or integrate existing on-premises infrastructure with the cloud without additional hardware purchasing and maintenance. The result is that time and money that would have been spent on hardware can be reinvested into adopting new technology, meeting customers’ needs, and differentiating from competitors.

Steps in the Modern Media Workflow
With an understanding of these overarching trends, media and entertainment professionals can evaluate and analyze their workflow to meet future demands. To illustrate that, we’ll walk through an example cloud storage setup within a media workflow, including:
- Ingest to Local Storage.
- Video Editing Software.
- Media Asset Managers.
- Archive.
- Backup.
- Transcoding Software.
- Content Delivery.
- Cloud Storage.
Ingest to Local Storage
Creatives doing work in progress need high performance, local access storage such as NAS, SANs, etc. These are often backed up to cloud storage to have an off-site version of the current projects. Some examples include Synology and QNAP NAS devices as well as the OWC Jellyfish system. With Synology, you can use their Cloud Sync application to sync your files directly to your cloud bucket. Synology also offers many built-in integrations to various cloud providers. For QNAP, you can use QNAP Hybrid Backup Sync to archive or back up your content to your cloud account. OWC Jellyfish is optimized for video production workflows, and the Jellyfish lineup is embraced by video production teams for on-prem storage.
Video Editing Software
Video editing software is used to edit, modify, generate, or manipulate a video or movie file. Backblaze has a number of tools we support depending on your workflow. Adobe Premiere Pro and Avid Media Composer are two examples of film and video editing software. They are used to create videos, television shows, films, and commercials.
Media Asset Managers
A media asset manager, or MAM, is software used to add metadata, manage content, store media in a hybrid cloud, and share media. Examples of MAMs include iconik, eMAM, EditShare, and Archiware. You can store your media files directly to the cloud from these and other media asset managers, enabling monetization and quicker content delivery of older content.
Archive
An archive often consists of completed projects and infrequently-used assets that are stored away to keep primary production storage capacities under control. Examples of archive tools include LTO tape, external hard drives, servers, and cloud providers.
Backup
A backup is often used with new projects where raw media files are ingested into their systems and then backed up in case of accidental deletion so that they can be easily restored. Examples include LTO tape, external hard drives, servers, and cloud providers.
Transcoding Software
Transcoding software converts encoded digital files into an alternative digital format so that it can be viewed on the widest possible range of devices.
Content Delivery
Content delivery networks (CDNs) enable easy distribution of your content to customers. Examples include Fastly and Cloudflare. CDNs store content on edge servers closer to end users, speeding performance and reducing latency.
Cloud Storage
Cloud storage is integrated with all of the above tools, making it easy to store high resolution, native files for backup, active archives, primary storage, and origin stores. The media workflow tools have easy access to the stored content in the cloud via their user interface. Storing content in the cloud allows teams to easily collaborate, share, reuse, and distribute content. Cloud storage is also emerging as the storage of choice for workflows that use cloud-based MAMs.

The Benefits of Using a Hybrid Cloud Model for Media Workflows
Because media teams need both fast access and scalable storage, many adopt a hybrid cloud storage strategy. A hybrid cloud strategy combines a private cloud with a public cloud. For most media teams, the private cloud is typically hosted on on-premises infrastructure, but can be hosted by a third party. The key difference between a private and public cloud is that the infrastructure, hardware, and software for a private cloud are maintained on a private network used exclusively by your business or organization.
In a hybrid cloud workflow, media teams have fast, on-premises storage for active projects combined with the scalability of a public cloud to accommodate the large amounts of data media teams generate. Looking specifically at the cloud storage functions above, it is important to keep your local storage lean and mean so that it is fast and operating at peak performance for your creative team. This achieves two things. First, you don’t have to invest more in local storage which can be expensive and time consuming to maintain. And second, you can offload older projects to the cloud while maintaining easy accessibility.
According to a survey of IT decision makers who adopted a hybrid cloud approach: 26% of them said faster innovation was the most important benefit their business gained. 25% said it allowed them to have faster responses to their customers. 22% said it provided their business with better collaboration. Benefits of a hybrid cloud approach for media teams include:
- Affordability: Cloud storage can be lower cost versus expanding your own physical infrastructure.
- Accessibility: A hybrid cloud provides increased collaboration for a remote workforce.
- Scalability: Cloud scalability provides ease and control with scaling up or down.
- Innovation: Media teams have an increased ability to quickly test and launch new products or projects, when not bogged down by physical infrastructure.
- Data Protection & Security: Media teams benefit from reduced downtime and can bounce back quicker from events, failures, or disasters.
- Flexibility: Hybrid solutions allow media teams to maintain control of sensitive or frequently used data on-premises while providing the flexibility to scale in the cloud.
Want to learn more about hybrid clouds? Download our free e-book, “Optimizing Media Workflows in the Cloud,” today.
The post Hybrid Cloud and Modern Workflows for Media Teams appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Metasploit weekly wrap-up
Post Syndicated from Dean Welch original https://blog.rapid7.com/2022/01/28/metasploit-wrap-up-146/
I’m sure you know what’s coming, more Log4Shell

For those wondering when the Log4Shell remediation nightmare will end, I’m afraid I can’t give you that. What I can give you, though, is a new Log4Shell module! With the new module from zeroSteiner you can expect to get unauthenticated RCE on the Ubiquiti UniFi Controller Application via a POST request to the /api/login page. Be sure to leverage the module’s check function since scanners detecting header injection may not work.
A new getsystem technique for Meterpreter
smashery has done an amazing job working on giving us a fifth getsystem technique on the Windows Meterpreter. This newest addition ports Clément Labro’s PrintSpoofer technique to Metasploit. It gains SYSTEM privileges from the LOCAL SERVICE and NETWORK SERVICE accounts by abusing the SeImpersonatePrivilege privilege. Like the other getsystem techniques, this attack takes place entirely in memory without any additional configuration on both 32-bit and 64-bit versions of Windows. It has been tested successfully on Windows 8.1 / Server 2016 and later. Unlike some of the other getsystem technqiues this one also has the advantage of not starting services which is often an action that is identified as malicious. Users can run this elevation technique directory by using the getsystem -t 5 command in Meterpreter. Now exploits that yield sessions LOCAL SERVICE and NETWORK SERVICE permissions can easily be upgraded to full SYSTEM level privileges.
New module content (2)
- Grandstream UCM62xx IP PBX sendPasswordEmail RCE by jbaines-r7, which exploits CVE-2020-5722 – A new exploit module for CVE-2020-5722 has been added which exploits an unauthenticated SQL injection vulnerability and a command injection vulnerability affecting the Grandstream UCM62xx IP PBX series of devices to go from an unauthenticated remote user to
rootlevel code execution. - UniFi Network Application Unauthenticated JNDI Injection RCE (via Log4Shell) by Nicholas Anastasi, RageLtMan, and Spencer McIntyre, which exploits CVE-2021-44228 – A module has been added to exploit CVE-2021-44228, an unauthenticated RCE in the Ubiquiti Unifi controller application versions 5.13.29 through 6.5.53 in the
rememberfield of a POST request to the/api/loginpage. Successful exploitation results in OS command execution in the context of the server application.
Enhancements and features
- #15904 from smashery – This PR adds the logic to support a fifth
getsystemoption using SeImpersonatePrivilege to gain SYSTEM privileges using the Print Spooler primitive on Windows. It is the Framework side of https://github.com/rapid7/metasploit-payloads/pull/509. - #16020 from VanSnitza – The
exploit/scanner/auxiliary/scada/modbusclientmodule has been enhanced to support command 0x2B which gives clear text info about a device. Additionally the module’s code has been updated to comply with RuboCop standards. - #16090 from audibleblink – A new method
user_data_directoryhas been added tolib/msf/base/config.rbto allow users that use private Metasploit modules to keep module resources organized in the same way that MSF does for core modules, all whilst keeping their ~/.msf4 directory portable between installs. - #16096 from zeroSteiner – The implementation of the
ReverseListenerCommandListenerCommdatastore options have now been updated to support specifying-1to refer to the most recently created session without having to either remember what it was or change it when a new session is created. - #16106 from bwatters-r7 – This PR updates the stdapi_fs_delete_dir command to recursively delete the directory. Previously, we discovered some inconsistencies in the handling of directory deletion across Meterpreter payloads, and this implements a fix in the Linux Meterpreter to support recursive deletion of directories, even if they contain files, matching implementations in other Meterpreter types.
Bugs fixed
- #16054 from namaenonaimumei – This PR updates John the Ripper (JTR) compatibility by altering the flag used to prevent logging.
- #16104 from zeroSteiner – Fixes a crash in the portfwd command which occurred when pivoting a reverse_http Python Meterpreter through a reverse_tcp Windows Meterpreter
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
binary installers (which also include the commercial edition).
[$] Handling argc==0 in the kernel
Post Syndicated from original https://lwn.net/Articles/882799/rss
By now, most readers are likely to be familiar with the Polkit vulnerability known as CVE-2021-4034.
The fix for Polkit is relatively straightforward and is being rolled out
across the net. The root of this problem, though, lies in a
misunderstanding about how programs are run on Unix-like systems. This
problem is highly likely to exist in other programs, so it would be nice to
find a more general solution. The best place to address this issue may be
in the kernel, but properly working around this
misunderstanding without causing regressions is not an easy task.
This Weird Mouse Calculator Numpad USB Thing from 2008
Post Syndicated from LGR original https://www.youtube.com/watch?v=IZghNXI1t7s
Security updates for Friday
Post Syndicated from original https://lwn.net/Articles/883047/rss
Security updates have been issued by CentOS (java-1.8.0-openjdk), Debian (graphicsmagick), Fedora (grafana), Mageia (aom and roundcubemail), openSUSE (log4j and qemu), Oracle (parfait:0.5), Red Hat (java-1.7.1-ibm and java-1.8.0-openjdk), Slackware (expat), SUSE (containerd, docker, log4j, and strongswan), and Ubuntu (cpio, shadow, and webkit2gtk).