Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=nNEKtOCR7cE
Simplify setup of Amazon Detective with AWS Organizations
Post Syndicated from Karthik Ram original https://aws.amazon.com/blogs/security/simplify-setup-of-amazon-detective-with-aws-organizations/
Amazon Detective makes it easy to analyze, investigate, and quickly identify the root cause of potential security issues or suspicious activities by collecting log data from your AWS resources. Amazon Detective simplifies the process of a deep dive into a security finding from other AWS security services, such as Amazon GuardDuty and AWS SecurityHub. Detective uses machine learning, statistical analysis, and graph theory to build a linked set of data that enables customers to easily conduct faster and more efficient security investigations.
In this post you will learn about the new AWS Organizations integration with Amazon Detective, where new and existing Detective customers can delegate any account in their organization to be the delegated Detective administrator account, and can centrally manage the Detective behavior graph database for an organization with up to 1,200 accounts.
Customers tell us that they want to manage security findings and investigations across multiple AWS Accounts. Depending on the customer this can be 100s or 1000s of accounts. AWS Organizations integration with security services, including GuardDuty, Security Hub and AWS IAM Access Analyzer comes in handy by helping customers centralize management and governance of their environments as they scale and grow their AWS accounts and resources. Adding to the list, Detective is now integrated with AWS Organizations to simplify security posture management across all existing and future AWS accounts across an organization. Organizations integration is available in all AWS Regions that Detective supports.
Detective is aware of your existing delegated administrator accounts for other AWS Security services such as GuardDuty or Security Hub. Using this awareness, Detective recommends that you choose the same account as the administrator account for Detective, as shown in Figure 1. For a more complete walk though of how to enable your accounts, visit the AWS Detective Documentation.

Figure 1. Setting delegated administrator
You can then use the same account to manage all of your security services. AWS recommends you align your Detective administrator account with your GuardDuty and SecurityHub administrator accounts, to enable seamless integration between Detective and those services.
- In GuardDuty or Security Hub, when viewing details for a GuardDuty finding, you can pivot from the finding details to the Detective finding profile.
- In Detective, when investigating a GuardDuty finding, you can choose the option to archive that finding.
Once designated, the chosen account becomes the administrator account for the organization behavior graph. They can enable any organization account as a member account in the organization behavior graph, and can configure Detective to automatically enable organization accounts when they join the organization.

Figure 2. Auto-enabling Organization accounts
The Detective administrator account can also manually invite other accounts to join the organization behavior graph.

Figure 3. Inviting accounts to join the Organization behavior graph
From Detective, the administrator account can centrally conduct security investigations across the organization
Considerations for AWS Organizations support
Some considerations and recommendations around Organizations support for Detective:
- Detective allows up to 1,200 member accounts in each behavior graph.
- The Detective administrator account becomes the administrator account for the organization’s behavior graph.
- An account can be a member account of multiple behavior graphs in the same Region. An account can accept multiple invitations. An organization account can be enabled as a member account in the organization behavior graph, and can then also accept invitations to other behavior graphs.
- An account can only be the administrator account of one behavior graph per Region, but can be an administrator account in different Regions.
- Changes to an organization are not immediately reflected in Detective. For most changes, such as new and removed organization accounts, it can take up to an hour for Detective to be notified.
Other recent updates from Amazon Detective
Additional support for all GuardDuty findings
With the recent expansion of security investigation support for Amazon Simple Storage Service (S3) and DNS-related findings on Amazon GuardDuty, Amazon Detective now provides full coverage of all detections from GuardDuty. Security analysts can now easily investigate and analyze the root cause of all GuardDuty findings using Detective, using the Investigate in Detective option in GuardDuty and Security Hub for further investigation.
New resource focused view
In addition to these integrations with AWS Organization and GuardDuty, Detective now makes it even easier for a security analyst to investigate entities and behaviors using a revamped user experience as seen in Figure 4. Amazon Detective presents a unified view of user and resource interactions over time, with all the context and details in one place, to help you quickly analyze the root cause of a security finding.

Figure 4. New resource focused view
New finding overview
The new finding overview provides an expanded set of details for each finding, and provides links to the profiles for each involved entity as seen in the right panel in Figure 4. With this unified view, you can visualize all of the details and context in one place, while identifying the underlying reasons for the findings. This resource-focused view helps you understand the connections between resources affected by a security finding, and further helps you drill down into relevant historical activity to quickly determine the root cause.
Integration with Splunk
Amazon Detective, in coordination with the Splunk Trumpet project, has released the ability to pivot from an Amazon GuardDuty finding in Splunk directly to an Amazon Detective entity profile. Customers can now quickly identify the root cause of potential security issues or suspicious activities. This setting can be enabled on the Splunk Trumpet project installation page by selecting Detective GuardDuty URLs from the AWS CloudWatch Events dropdown.
Amazon Detective’s interactive visualizations make it easy to investigate and analyze issues more thoroughly and effectively, with minimal effort. Using these visualizations, customers can easily filter large sets of event data into specific timelines, with all the details, context, and guidance needed to help you to investigate quickly. For example; Amazon Detective enables you to view login attempts on a geolocation map, drill down into relevant historical activity, quickly determine a root cause, and if necessary, take action to resolve the issue.
Amazon Detective makes it easy to analyze, investigate, and quickly identify the root cause of potential security issues. To get started, enable a 30-day free trial of Amazon Detective with just a few clicks in the AWS Management console. See the AWS Regions page for a list of all Regions where Detective is available. To learn more, visit the Amazon Detective product page.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMR
Post Syndicated from Udit Mehrotra original https://aws.amazon.com/blogs/big-data/new-features-from-apache-hudi-0-7-0-and-0-8-0-available-on-amazon-emr/
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development by providing record-level insert, update, and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon Simple Storage Service (Amazon S3) or Hadoop Distributed File System (HDFS). You can use it to comply with data privacy regulations and simplify data ingestion pipelines that deal with late-arriving or updated records from streaming data sources, or to ingest data using change data capture (CDC) from transactional systems. Apache Hudi is integrated with open-source big data analytics frameworks like Apache Spark, Apache Hive, Presto, and Trino. It allows you to maintain data in Amazon S3 or HDFS in open formats like Apache Parquet and Apache Avro.
Starting with release version 5.28.0, Amazon EMR installs the Hudi component by default when you install Spark, Hive, Presto, or Trino. Since the inclusion of Apache Hudi within Amazon EMR, there has been several improvements and bug fixes that have been added to Apache Hudi. Apache Hudi graduated as a top-level Apache project on June 2020.
In this post, we provide a summary of some of the key new features and capabilities included since Apache Hudi release versions 0.7.0 and 0.8.0. These new features and capabilities of Hudi are available since Amazon EMR releases 5.33.0 and 6.3.0:
- Clustering
- Metadata-based file listing
- Amazon CloudWatch integration
- Optimistic Concurrency Control
- Amazon EMR configuration support and improvements
- Apache Flink integration
- Kafka commit callbacks
- Other improvements
Clustering
We see more use cases that need high throughput ingestion to data lakes. However, faster data ingestion often leads to smaller data file sizes that often adversely affects query performance, because a large number of small files increases the costly I/O operations required to return results. Another concern that we see is that the organization of data during ingestion is different from the organization that would be most efficient when querying the data. For example, it’s convenient to ingest ecommerce orders by OrderDate as they come in, but when queried, it’s better if orders for a single customer are stored together.
Apache Hudi version 0.7.0 introduces a new feature that allows you to cluster the Hudi tables. Clustering in Hudi is a framework that provides a pluggable strategy to change and reorganize the data layout while also optimizing the file sizes. With clustering, you can now optimize query performance without having to trade-off data ingest throughput.
You can use clustering to rewrite the data using different methods as per the different use case requirements:
- Improve query performance with data locality – This changes the data layout on disk by sorting the data on one or many user-specified columns. With this approach, we can improve query performance by using the Parquet file format’s ability to perform predicate push-down and skip the unwanted files and Parquet row groups. This strategy can also control the file size to avoid small files.
- Improve data freshness – This requirement assumes that the data locality is not important or taken care of already at the time of ingestion. It’s ideal for use cases where fresh data is important, where data is ingested using several small files and stitched or merged later using the clustering framework.
You can run the clustering table service asynchronously or synchronously. It also introduces the new action type REPLACE, which identifies the clustering action in the Hudi metadata timeline.
In the following example, we create two Copy on Write (CoW) Hudi tables: amazon_reviews and amazon_reviews_clustered using Amazon EMR release version 6.3.0.
We use spark-shell to create the Hudi tables. Start the Spark shell by running the following on the Amazon EMR primary node:
We then create the Hudi table amazon_reviews using the BULK_INSERT operation and without clustering enabled:
We then create the Hudi table amazon_reviews_clustered using BULK_INSERT operation and inline clustering enabled and sorted by columns star_rating and total_votes:
Let’s query these two tables and validate performance difference. To validate the performance, we will use Spark SQL CLI – a convenient tool to run the Hive metastore service in local mode and execute queries input from the command line. To start the Spark SQL CLI, we execute the following command:
We restart the Spark SQL CLI (spark-sql) session between each run in order to avoid caching or warm executors, which may impact query performance.
Let’s run the query against the non-clustered Hudi table by running the following in the spark-sql interface:
Let’s also run the same query on our clustered table from the spark-sql interface:
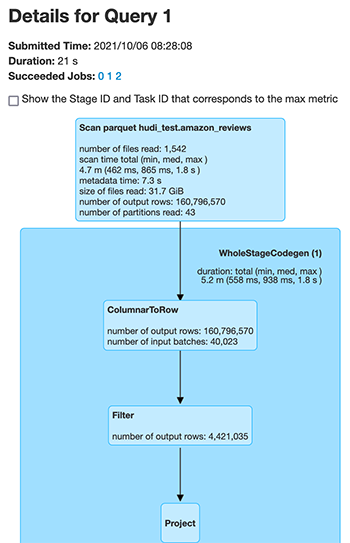
Let’s compare the underlying file scan performance for the two different Hudi tables. The following screenshot is the output from the Spark UI, which shows the changes in the files scanned for the same number of output rows. First we see the files scanned for the unclustered Hudi table.
Next, we see the files scanned for the clustered Hudi table.
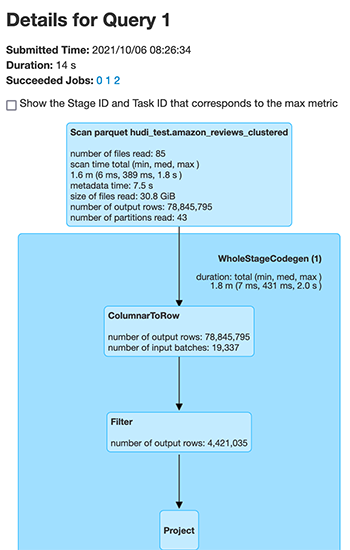
The number of files scanned by Spark dropped from 1,542 files for the unclustered Hudi dataset to 85 files for the clustered Hudi dataset for the exact same data. Also, the number of records scanned reduced from 160,796,570 to 78,845,795.
We compared the performance of the preceding query for the amazon_reviews (non-clustered) and amazon_reviews_clustered (clustered) Hudi dataset, across Spark SQL, Hive, and PrestoDB. The cluster configuration used was 1 leader (m5.4xlarge) and 2 cores (m5.4xlarge).
The following chart provides the query performance comparison using different engines for the Hudi table, which are unclustered, and for the Hudi table, which is clustered.

We found that with clustering enabled for the Hudi table, the query performance increased for all three query engines, ranging from 28% to 63%. The following table provides the details for the query performance for the Hudi table, both with clustering enabled and disabled.
| Query Engine | Non-clustered Table | Clustered Table | Query Runtime Improvement |
| Time (in seconds) | Time (in seconds) | ||
| Spark SQL | 21.6 | 15.4 | 28.7 % |
| Hive | 96.3 | 47 | 51.3 % |
| PrestoDB | 11.7 | 4.3 | 63.25 % |
Metadata-based file listing
Hudi write operations like compaction, cleaning, and global index, as well as queries, perform a file system listing to get the current view of the partitions and files in the dataset. For small datasets, this shouldn’t impact the performance drastically. However, when working with large data, this listing operation can impact the performance negatively when reading the files. For example, with HDFS as the underlying data store, the list operation for a large number of files or partitions can overwhelm HDFS NameNode and affect the stability of job. In cases where Amazon S3 is used as the underlying data store, O(N) calls for N partitions with a large number of files is time-consuming and can also result in throttling errors.
With Apache Hudi version 0.7.0, you can change this behavior by enabling metadata-based listing for Hudi tables. This partitions and files list is stored in an internal metadata table, which is implemented using a Hudi Merge on Read (MoR) table. This metadata table can take all the advantages of the Hudi MoR table, which includes the capability of low-latency updates, and the ability to atomically commit metadata updates and easily roll back if write fails. It also makes it easy to keep metadata in sync with the Hudi table because both use a timeline for traceability. This index of the file list is stored using HFiles for base and log file format for delta updates. The HFile format allows point-lookups of specific records based on record key. The goal is to reduce O(N) list calls for N partitions to O(1) get call to read the metadata.
We compared query performance for a Hudi dataset with metadata listing enabled vs. not enabled. For this example, we used a larger dataset of 3 TB with Amazon EMR release version 6.3.0. We used the following code snippet to create the metadata enabled and not enabled dataset by setting the HoodieMetadataConfig.METADATA_ENABLE_PROP (hoodie.metadata.enable) config:
On the query engine side, we can enable it via the following methods:
- Spark data source:
- Spark SQL CLI:
- Hive:
- PrestoDB:
We used the following query to compare query performance via Hive and PrestoDB:
The following chart provides the query performance comparison.

We found that with metadata listing, query execution runtime decreased by around 25% for the Hive engine, and by around 32% for PrestoDB. The following table provides the details of query execution runtime with and without metadata listing.
| Query Engine | Metadata Disabled | Metadata Enabled | Query Runtime Improvement |
| Time (in seconds) | Time (in seconds) | ||
| Hive | 415.28533 | 310.02367 | 25.35% |
| Presto | 72 | 48.6 | 32.50% |
Metadata listing considerations
With Hudi 0.7.0 and 0.8.0, you may not observe noticeable improvements for queries via Spark SQL (with metadata listing), because Hudi relies on Spark’s InMemoryFileIndex to do the actual file listing and can’t use the metadata. You may observe improvements because HoodieROPathFilter uses the metadata for its filtering. However, with Hudi release 0.9.0, we’re introducing a custom FileIndex implementation for Hudi to use metadata for file listing instead of relying on Spark. Therefore, from 0.9.0, you will observe noticeable performance improvements for Spark SQL queries.
Amazon CloudWatch integration
Apache Hudi provides MetricsReporter implementations like JmxMetricsReporter, MetricsGraphiteReporter, and DatadogMetricsReporter, which you can use to publish metrics to user-specified sinks. Amazon EMR, with its release 6.4.0 having Hudi 0.8.0, has introduced CloudWatchMetricsReporter, which you can use to publish these metrics to Amazon CloudWatch. It helps publish Hudi writer metrics like commit duration, rollback duration, file-level metrics (number of files added or deleted per commit), record-level metrics (records inserted or updated per commit) and partition-level metrics (partitions inserted or updated per commit). This is useful in debugging Hudi jobs, as well as making decisions around cluster scaling.
You can enable the CloudWatch metric via the following configurations:
The following table summarizes additional configurations that you can change if needed.
| Configuration | Description | Value |
| hoodie.metrics.cloudwatch.report.period.seconds | Frequency (in seconds) at which to report metrics to CloudWatch | Default value is 60 seconds, which is fine for the default 1-minute resolution offered by CloudWatch |
| hoodie.metrics.cloudwatch.metric.prefix | Prefix to be added to each metric name | Default value is empty (no prefix) |
| hoodie.metrics.cloudwatch.namespace | CloudWatch namespace under which metrics are published | Default value is Hudi |
| hoodie.metrics.cloudwatch.maxDatumsPerRequest | Maximum number of datums to be included in one request to CloudWatch | Default value is 20, which is same as the CloudWatch default |
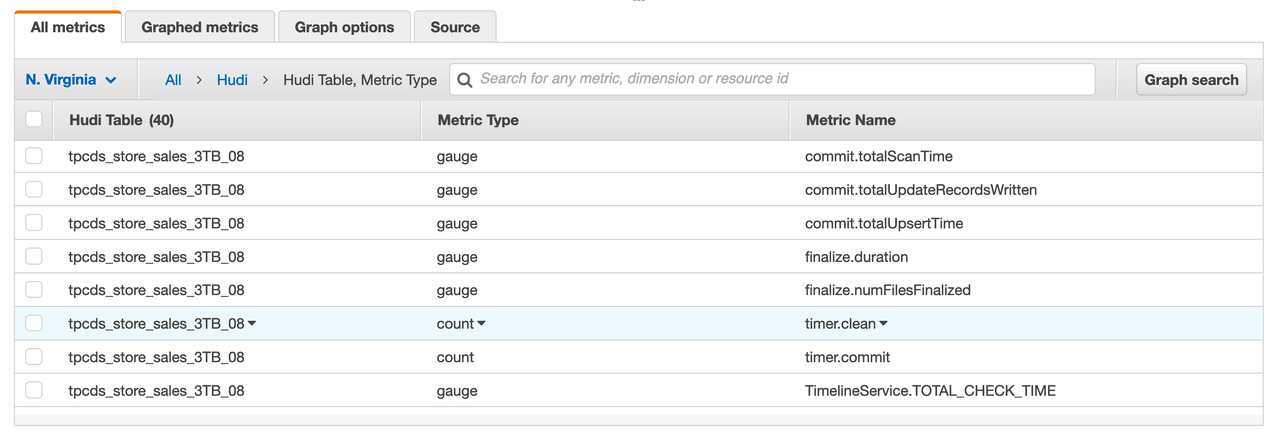
The following screenshot shows some of the metrics published for a particular Hudi table, including the type of metric and its name. These are dropwizard metrics; gauge represents the exact value at a point in time, and counter represents a simple incrementing or decrementing integer.
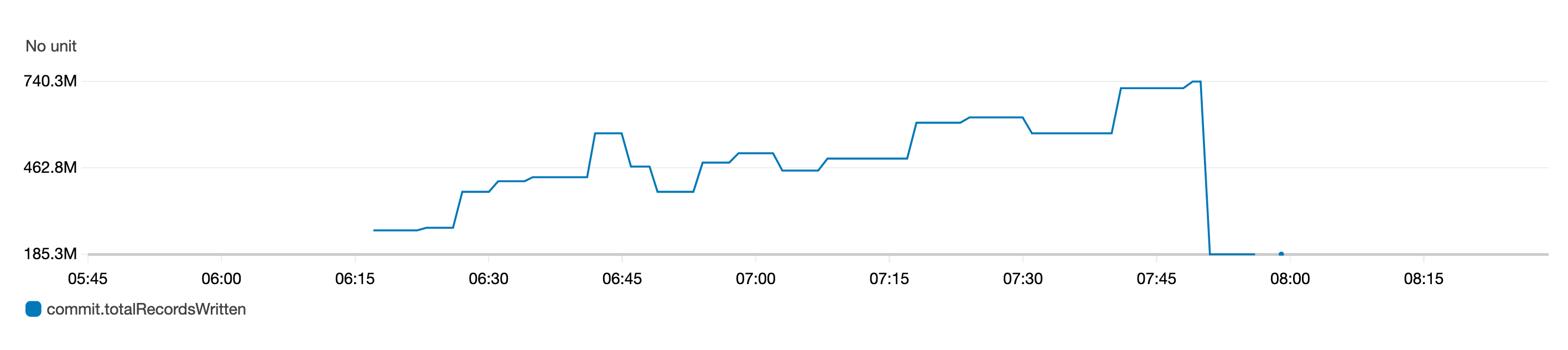
The following graph of the gauge metric represents the total records written to a table over time.
The following graph of the counter metric represents the number of commits increasing over time.
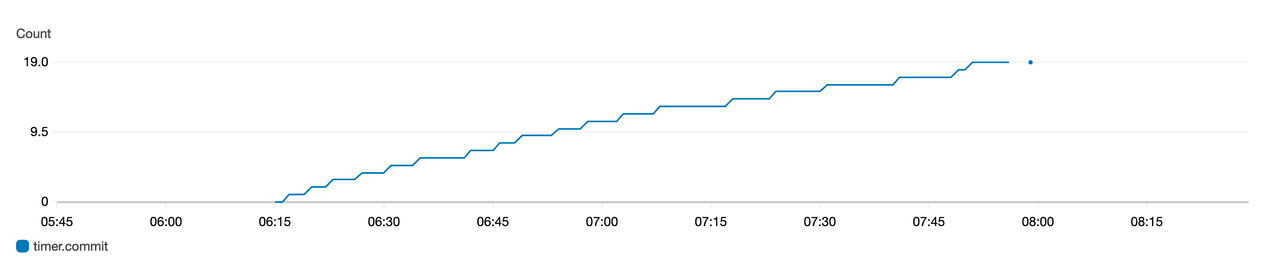
Optimistic Concurrency Control
A major feature that has been introduced with Hudi 0.8.0, and available since Amazon EMR release 6.4.0, is Optimistic Concurrency Control (OCC) to enable multiple writers to concurrently ingest data into the same Hudi table. This is file-level OCC, which means that for any two commits (or writers) happening to the same table at the same time, both are allowed to succeed if they don’t have writes to overlapping files. The feature requires acquiring locks, for which you can use either Zookeeper or HiveMetastore. For more information about the guarantees provided, see Concurrency Control.
Amazon EMR clusters have Zookeeper installed, which you can use as a lock provider to perform concurrent writes from the same cluster. To make it easier to use, Amazon EMR preconfigures the lock provider in the newly introduced /etc/hudi/conf/hudi-defaults.conf file (see the next section) via the following properties:
Although the lock provider is preconfigured, enabling of OCC still needs to be handled by the users either via Hudi job options or at cluster level via the Amazon EMR Configurations API:
Amazon EMR configuration support and improvements
Amazon EMR release 6.4.0 has introduced the ability to configure and reconfigure Hudi via the configurations feature. Hudi configurations that are needed across jobs and tables can now be configured at cluster level via the hudi-defaults classification or /etc/hudi/conf/hudi-defaults.conf file, similar to other applications like Spark and Hive. The following code is an example of the hudi-defaults classification to enable metadata-based listing and CloudWatch metrics:
Amazon EMR automatically configures suitable defaults for a few configs, to improve the user experience by removing the need for customers having to pass them:
- HIVE_URL_OPT_KEY is configured to the cluster’s Hive server URL and no longer needs to be specified. This is particularly useful when running a job in Spark cluster mode, where users previously had to determine and themselves specify the Amazon EMR primary IP.
- HBase specific configurations, which are useful for using HBase index with Hudi.
- Zookeeper lock provider specific configuration, as discussed under concurrency control, which makes it easier to use OCC.
Additional changes have been introduced to reduce the number of configurations that users need to pass, and to infer automatically where possible:
- The partitionBy API can now be used to specify partition column.
- When enabling Hive Sync, it’s no longer mandatory to pass HIVE_TABLE_OPT_KEY, HIVE_PARTITION_FIELDS_OPT_KEY, or HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY. These configs can be inferred from the Hudi table name and partition fields itself.
- KEYGENERATOR_CLASS_OPT_KEY is not mandatory to pass if you’re using
SimpleKeyGeneratororComplexKeyGenerator, and can be inferred depending on whether there are single or multiple record key columns.
Apache Flink integration
Apache Hudi started off with a very tight integration with Apache Spark. With release version 0.7.0, we now have integrations available to ingest data using Apache Flink. It required decoupling Spark from the internal table format, writers, and table services code in a way that can be used by other evolving engines in the industry like Flink.
Hudi 0.7.0 provides initial Flink support via HooodieFlinkStreamer, which you can use to write CoW tables by streaming data from a Kafka topic using Apache Flink. For example, you can use the following Flink command to start reading the topic ExampleTopic from the Kafka brokers broker-1, broker-2, and broker-3 running on port 9092:
With Hudi 0.8.0, there have been major improvements in Flink integration performance and scalability, as well as the introduction of new features like SQL connector for both source and sink, writer for MoR, batch reader for CoW and MoR, streaming reader for MoR, and state-backed indexing with bootstrap support. For more information about Flink integration design, see Apache Hudi meets Apache Flink. To get started with Flink SQL, see Flink Guide.
Kafka commit callbacks
The previous version (0.6.0) of Apache Hudi introduced write commit callback functionality. With this functionality, Hudi can send a callback message every time a successful commit arrives to the Hudi dataset. The write commit callback supported HTTP method in the previous release. With Apache Hudi release version 0.7.0, Hudi now supports write commit callback for Kafka as well. Using Kafka for sending the callback messages for every successful commit can now enable you to build asynchronous data pipelines or business processing logic every time the Hudi dataset sees a new commit. You can now build incremental ETL pipelines for processing new events that arrive in the Hudi data lake.
The implementation of Kafka commit callback uses HoodieWriteCommitKafkaCallback as the hoodie.write.commit.callback.class. Besides setting the commit callback class, you can also set up additional parameters for the Kafka bootstrap servers and the topic configurations.
The following is a code snippet where commit callback messages are published to the Kafka topic ExampleTopic hosted on the Kafka brokers b-1.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com, b-2.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com, and b-3.demo-hudi.xxxxxx.xxx.kafka.us-east-1.amazonaws.com when writing to a Hudi dataset:
The following is how the messages appear in your Kafka topic:
A downstream pipeline can now easily query these events from Kafka and process the incremental data into derived Hudi tables.
Other improvements
Besides the aforementioned improvements, there have been some additional changes worth mentioning. On the writer side, there are the following improvements:
- Support for Spark 3 – Support for writing and querying the data using Apache Spark 3 is now available with Apache Hudi 0.7.0 onwards. This works with Scala 2.12 bundle for
hudi-spark-bundle. - Insert overwrite and insert overwrite table write operations – Apache Hudi 0.7.0 introduces two new operations,
insert_overwriteandinsert_overwrite_table, to support batch ETL jobs where an entire table or partition is overwritten during each execution. You can use these operations instead of theupsertoperation, and it’s must cheaper to run. - Delete partitions – The new API is now available since 0.7.0 to delete an entire partition. This helps avoid the use of record-level deletes.
- Java writer support – Hudi 0.7.0 introduced Java-based writing support via the
HoodieJavaWriteClientclass.
Similarly, on the query integration side, there have been the following improvements:
- Structured streaming reads – Hudi 0.8.0 introduced a Spark structured streaming source implementation via the
HoodieStreamSourceclass. You can use it to support streaming reads from Hudi tables. - Incremental query on MoR – Since Hudi 0.7.0, we now have incremental query support for MoR tables, which you can use to incrementally pull data by downstream applications.
Conclusion
The new features introduced in Apachi Hudi enable you to build decoupled solutions by using features like Kafka commit callback and Flink integration with Apache Hudi with Amazon EMR. You can also improve your overall performance of the Hudi data lake by using the capabilities of clustering and metadata tables.
About the Authors
 Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.
Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.
 Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 16 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Gagan Brahmi is a Specialist Solutions Architect focused on Big Data & Analytics at Amazon Web Services. Gagan has over 16 years of experience in information technology. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Вестник Der Standard (Австрия) „Без Виктория“
Post Syndicated from Николай Марченко original https://bivol.bg/%D0%B1%D0%B5%D0%B7-%D0%B2%D0%B8%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D1%8F-%D1%80%D0%B0%D0%B7%D0%BA%D0%B0%D0%B7%D1%8A%D1%82-%D0%BD%D0%B0-%D0%B4%D0%B8%D0%BC%D0%B8%D1%82%D1%8A%D1%80-%D0%B4.html
понеделник 20 декември 2021

Сайтът за разследваща журналистика “Биволъ” публикува превода на статията* в един от най-авторитетните австрийски и европейски вестници Der Standard, посветена на предстоящото излизане на фотокнига на Димитър Динев и Евгения…
Query cross-account AWS Glue Data Catalogs using Amazon Athena
Post Syndicated from Louis Hourcade original https://aws.amazon.com/blogs/big-data/query-cross-account-aws-glue-data-catalogs-using-amazon-athena/
Many AWS customers rely on a multi-account strategy to scale their organization and better manage their data lake across different projects or lines of business. The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. Using a centralized Data Catalog offers organizations a unified metadata repository and minimizes the administrative overhead related to sharing data across different accounts, thereby expanding access to the data lake.
Amazon Athena is one of the popular choices to run analytical queries in data lakes. This interactive query service makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you’re charged based on the amount of data scanned by your queries.
In May 2021, Athena introduced the ability to query Data Catalogs across multiple AWS accounts, enabling you to access your data lake without the complexity of replicating catalog metadata in individual AWS accounts. This blog post details the procedure for using the feature.
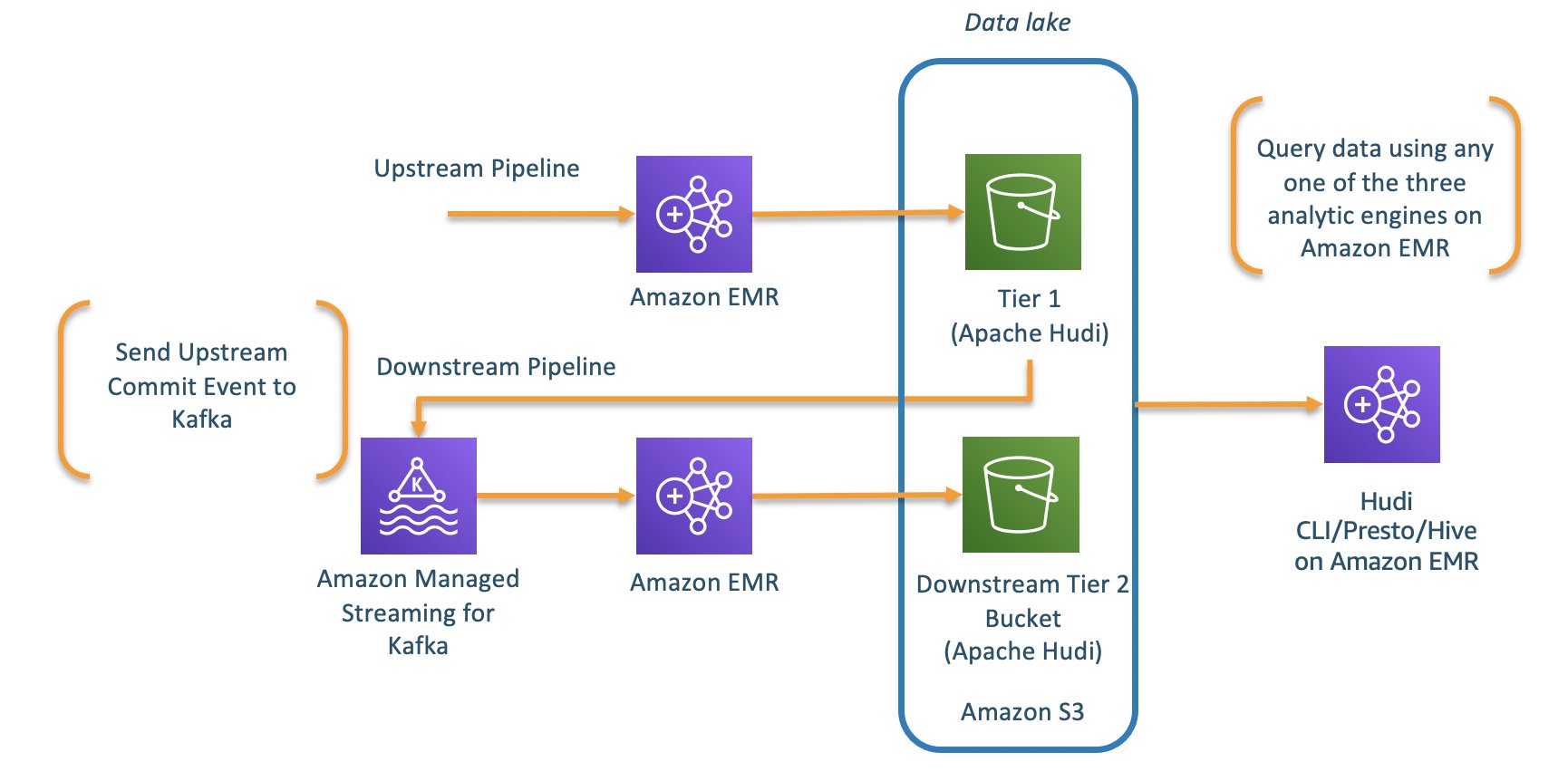
Solution overview
The following diagram shows the necessary components used in two different accounts (consumer account and producer account, hosting a central Data Catalog) and the flow between the two for cross-account Data Catalog access using Athena.

Our use case showcases Data Catalog sharing between two accounts:
- Producer account – The account that administrates the central Data Catalog
- Consumer account – The account querying data from the producer’s Data Catalog (the central Data Catalog)
In this walkthrough, we use the following two tables, extracted from an ecommerce dataset:
- The orders table logs the website’s orders and contains the following key attributes:
- Row ID – Unique entry identifier in the orders table
- Order ID – Unique order identifier
- Order date – Date the order was placed
- Profit – Profit value of the order
- The returns table logs the returned items and contains the following attributes:
- Returned – If the order has been returned (Yes/No)
- Order ID – Unique order identifier
- Market – Region market
We walk you through the following high-level steps to use this solution:
- Set up the producer account.
- Set up the consumer account.
- Set up permissions.
- Register the producer account in the Data Catalog.
- Query your data.
You use Athena in the consumer account to perform different operations using the producer account’s Data Catalog.
First, you use the consumer account to query the orders table in the producer account’s Data Catalog.

Next, you use the consumer account to join the two tables and retrieve information about lost profit from returned items. The returns table is in the consumer’s Data Catalog, and the orders table is in the producer’s.

Prerequisites
The following are the prerequisites for this walkthrough:
- Two AWS accounts.
- An AWS Identity and Access Management (IAM) principal with access to AWS resources used in this solution.
- Querying Data Catalogs across accounts only works with Athena engine V2. To check if your Athena workgroup is running on this engine, select the Workgroup tab on the left of the Athena console.

This lists all your Athena workgroups. Make sure that the one you use runs on Athena engine version 2.

If all your workgroups are using Athena engine version 1, you need to update the engine version of an existing workgroup or create a new workgroup with the appropriate version.
Set up the producer account
In the producer account, complete the following steps:
- Create an S3 bucket for your producer’s data. For information about how to secure your S3 bucket, see Security Best Practices for Amazon S3.
- In this bucket, create a prefix named
orders. - Download the orders table in CSV format and upload it to the
ordersprefix. - Run the following Athena query to create the producer’s database:
- Run the following Athena query to create the orders table in the producer’s database. Make sure to replace <your-producer-s3-bucket-name> with the name of the bucket you created.
Set up the consumer account
In the consumer account, complete the following steps:
- Create an S3 bucket for your consumer’s data.
- In this bucket, create a prefix named
returns. - Download the returns table in CSV format and upload it to the
returnsprefix. - Run the following Athena query to create the consumer’s database:
- Run the following Athena query to create the returns table in the consumer’s database. Make sure to replace <your-consumer-s3-bucket-name> with the name of the bucket you created.
Set up permissions
For the consumer account to query data in the producer account, we need to set up permissions.
First, we give the consumer account permission to access the producer account’s AWS Glue resources.
- In the producer account’s Data Catalog settings, add the following AWS Glue resource policy, which grants the consumer account access to the Data Catalog:


Next, we give the consumer account permission to list and get data from the S3 bucket in the producer account.
- In the producer account, add the following S3 bucket policy to the bucket <Producer-bucket>, which stores the data:
Register the producer account’s Data Catalog
At this stage, you have set up the required permissions to access the central Data Catalog in the producer account from the consumer account. You now need to register the central Data Catalog as a data source in Athena.
- In the consumer account, go the Athena console and choose Connect data source.

- Select S3 – AWS Glue Data Catalog as the data source selection.

- Select AWS Glue Data Catalog in another account.
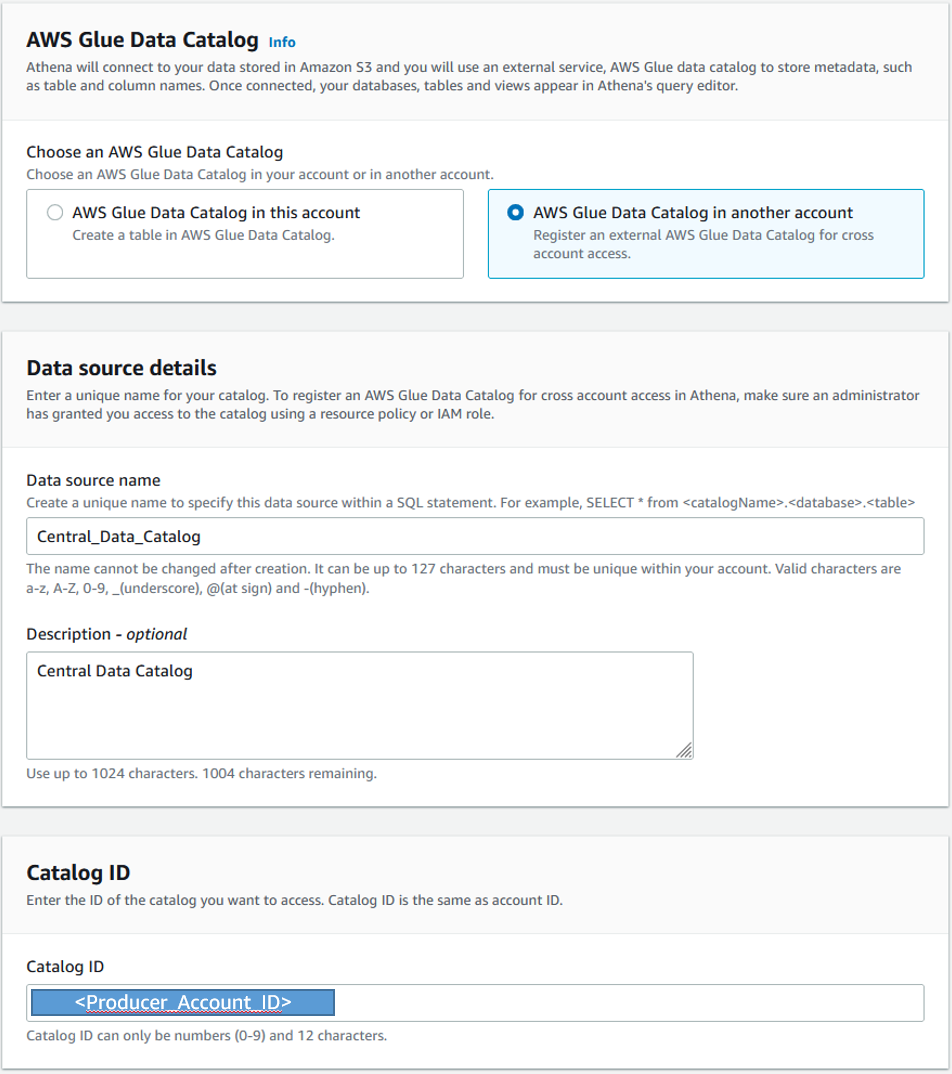
You then need to provide some information regarding the central Data Catalog you want to register.
- For Data source name, enter a name for the catalog (for example,
Central_Data_Catalog). This serves as an alias in the consumer account, pointing to the central Data Catalog in the producer account.
- For Catalog ID, enter the producer account ID.
- Choose Register to complete the process.

Query your data
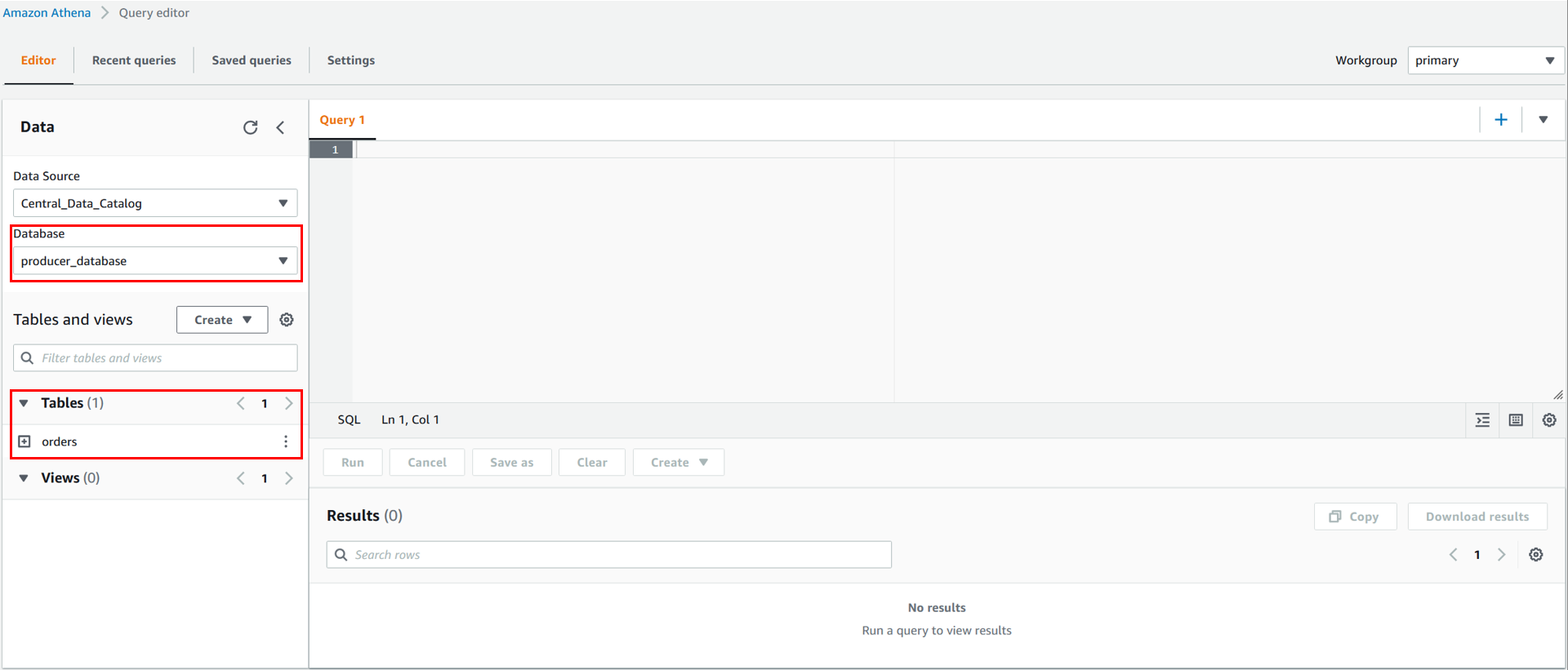
You have now registered the central Data Catalog as a data source in the consumer account. In the Athena query editor, you can then choose Central_Data_Catalog as a data source. Under Database, you can see all the databases for which you were granted access in the producer account’s AWS Glue resource policy. The same applies for the tables. After completing the steps in the earlier sections, you should see the orders table from producer_database located in the producer account.
You can start querying the Data Catalog of the producer account directly from Athena in the consumer account. You can test this by running the following SQL query in Athena:
This SQL query extracts the first 10 rows of the orders table located in the producer account.
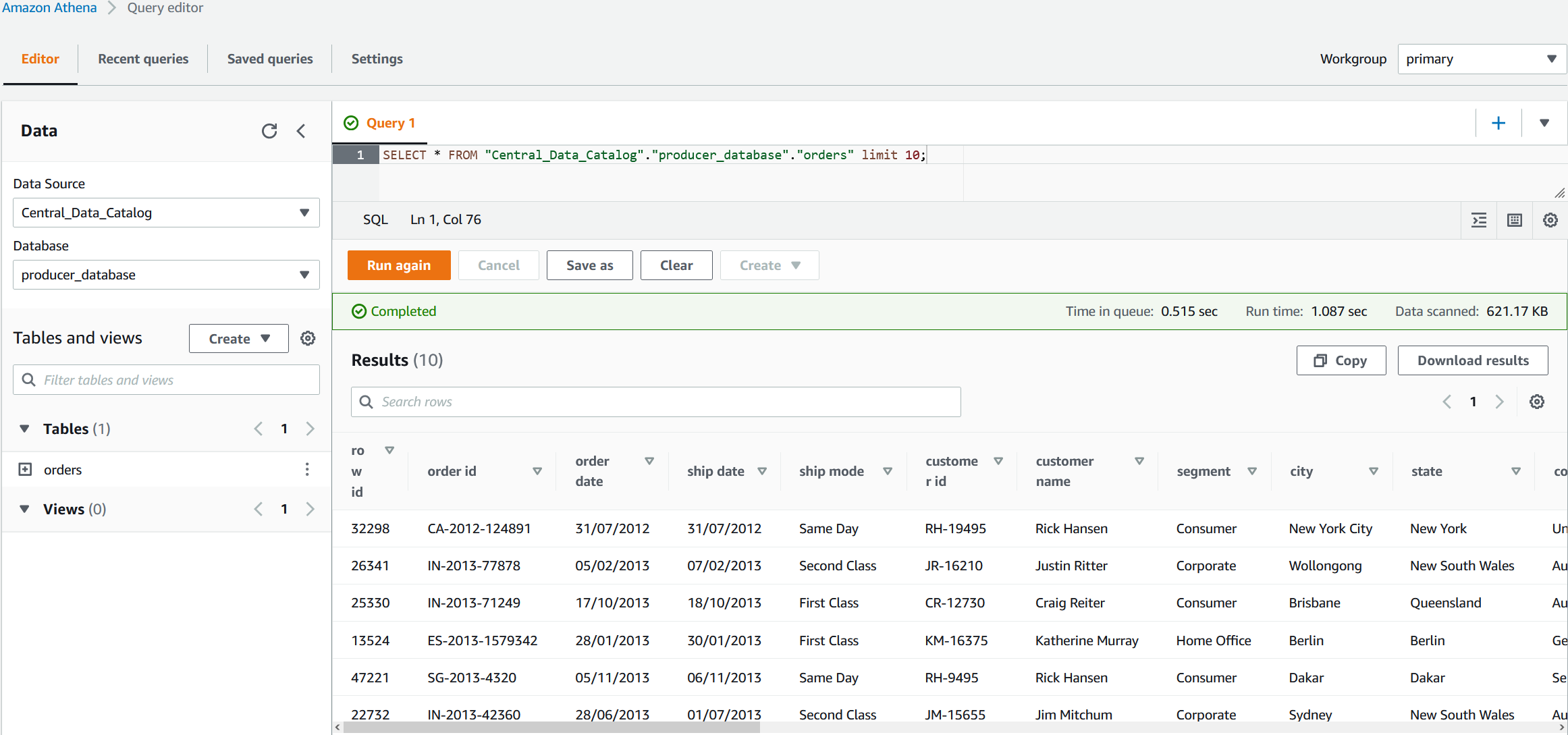
You just queried a Data Catalog located in another AWS account, which enables you to easily access your central Data Catalog and scale your data lake strategy.
Now, let’s see how we can join two tables that are in different AWS accounts. In our scenario, the returns table is in the consumer account and the orders table is in the producer account. Suppose you want to join the two tables and see the total amount of items returned in each market. The Athena built-in support for cross-account Data Catalogs makes this operation easy. In the Athena query editor, run the following SQL query:
In this SQL query, you use both the consumer’s Data Catalog AwsDataCatalog and the producer’s Data Catalog Central_Data_Catalog to join tables and get insights from your data.
Limitations and considerations
The following are some limitations that you should take into consideration before using Athena built-in support for cross-account Data Catalogs:
- This Athena feature is available only in Regions where Athena engine version 2 is supported. For a list of Regions that support Athena engine version 2, see Athena engine version 2. To upgrade a workgroup to engine version 2, see Changing Athena Engine Versions.
- As of this writing, CREATE VIEW statements that include a cross-account Data Catalog are not supported.
- Cross-Region Data Catalog queries are not supported.
Clean up
After you query and analyze the data, you should clean up the resources used in this tutorial to prevent any recurring AWS costs.
To clean up the resources, navigate to the Amazon S3 console in both the provider and consumer accounts, and empty the S3 buckets. Also, navigate to the AWS Glue console and delete the databases.
Conclusion
In this post, you learned how to query data from multiple accounts using Athena, which allows your organization to access to a centralized Data Catalog. We hope that this post helps you build and explore your data lake across multiple accounts.
To learn more about AWS tools to manage access to your data, check out AWS Lake Formation. This service facilitates setting up a centralized data lake and allows you to grant users and ETL jobs cross-account access to Data Catalog metadata and underlying data.
About the Authors
 Louis Hourcade is a Data Scientist in the AWS Professional Services team. He works with AWS customer across various industries to accelerate their business outcomes with innovative technologies. In his spare time he enjoys running, climbing big rocks, and surfing (not so big) waves.
Louis Hourcade is a Data Scientist in the AWS Professional Services team. He works with AWS customer across various industries to accelerate their business outcomes with innovative technologies. In his spare time he enjoys running, climbing big rocks, and surfing (not so big) waves.
 Sara Kazdagli is a Professional Services consultant specialized in data analytics and machine learning. She helps customers across different industries build innovative solutions and make data-driven decisions. Sara holds a MSc in Software engineering and a MSc in data science. In her spare time, she likes to go on hikes and walks with her australian shepherd dog Kiba.
Sara Kazdagli is a Professional Services consultant specialized in data analytics and machine learning. She helps customers across different industries build innovative solutions and make data-driven decisions. Sara holds a MSc in Software engineering and a MSc in data science. In her spare time, she likes to go on hikes and walks with her australian shepherd dog Kiba.
 Jahed Zaïdi is an AI/ML & Big Data specialist at AWS Professional Services. He is a builder and a trusted advisor to companies across industries, helping them innovate faster and on a larger scale. As a lifelong explorer, Jahed enjoys discovering new places, cultures, and outdoor activities.
Jahed Zaïdi is an AI/ML & Big Data specialist at AWS Professional Services. He is a builder and a trusted advisor to companies across industries, helping them innovate faster and on a larger scale. As a lifelong explorer, Jahed enjoys discovering new places, cultures, and outdoor activities.
The Windsor Castle: 40 Sovereigns, 25 Ghosts and 1 Big Fire
Post Syndicated from Geographics original https://www.youtube.com/watch?v=jMQdhIZNja8
More on NSO Group and Cytrox: Two Cyberweapons Arms Manufacturers
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2021/12/more-on-nso-group-and-cytrox-two-cyberweapons-arms-manufacturers.html
Citizen Lab published another report on the spyware used against two Egyptian nationals. One was hacked by NSO Group’s Pegasus spyware. The other was hacked both by Pegasus and by the spyware from another cyberweapons arms manufacturer: Cytrox.
We haven’t heard a lot about Cytrox and its Predator spyware. According to Citzen Lab:
We conducted Internet scanning for Predator spyware servers and found likely Predator customers in Armenia, Egypt, Greece, Indonesia, Madagascar, Oman, Saudi Arabia, and Serbia.
Cytrox was reported to be part of Intellexa, the so-called “Star Alliance of spyware,” which was formed to compete with NSO Group, and which describes itself as “EU-based and regulated, with six sites and R&D labs throughout Europe.”
In related news, Google’s Project Zero has published a detailed analysis of NSO Group’s zero-click iMessage exploit: FORCED ENTRY.
Based on our research and findings, we assess this to be one of the most technically sophisticated exploits we’ve ever seen, further demonstrating that the capabilities NSO provides rival those previously thought to be accessible to only a handful of nation states.
By the way, this vulnerability was patched on 13 Sep 2021 in iOS 14.8.
In 2021, the Internet went for TikTok, space and beyond
Post Syndicated from João Tomé original https://blog.cloudflare.com/popular-domains-year-in-review-2021/

The years come and go, Internet traffic continues to grow (at least so far and with some ‘help’ from the pandemic), and Internet applications, be they websites, IoT devices or mobile apps, continue to evolve throughout the year, depending on if they attract human beings.
We’ll have a more broad Internet traffic-related Year in Review 2021 in the next few days (you can check the 2020 one here), but for now, let’s focus on the most popular domains this year according to our data on Cloudflare Radar and those domains’ changes in our popularity ranking. With Alexa.com going away, if you need a domain ranking, you can get it from Cloudflare.
We’ll focus on space (NASA and SpaceX flew higher), e-commerce (Amazon and Taobao rule), and social media (TikTok ‘danced’ to take the crown from Facebook). We’ll also take a little ‘bite’ on video streaming wars. Netflix is a Squid Game of its own and January 2021 was at the highest in our ranking — probably lockdown and pandemic-related.
Chat domains (WhatsApp, what else) will also be present and, of course, the less established metaverse domains of sorts (Roblox took the lead from Fortnite late in the game). Come with us, let’s travel through 2021.
The following will show the way Cloudflare saw Internet traffic focusing on specific domains (some of which have many websites aggregated into them) and their highs and lows in our global popularity ranking.
Top Sites: Google dethroned by the young ‘padawan’ TikTok
Let’s start with our Top Domains Ranking and 2021 brought us a very interesting duel for the Number 1 spot in our global ranking. Google.com (which includes Maps, Translate, Photos, Flights, Books, and News, among others) ended 2020 as the undefeated leader in our ranking — from September to December of last year it was always on top. Back then TikTok.com was only ranked #7 or #8.
Top 10 — Most popular domains (late) 2021
1 TikTok.com
2 Google.com
3 Facebook.com
4 Microsoft.com
5 Apple.com
6 Amazon.com
7 Netflix.com
8 YouTube.com
9 Twitter.com
10 WhatsApp.com
Top 10 — Most popular domains (late) 2020
1 Google.com
2 Facebook.com
3 Microsoft.com
4 Apple.com
5 Netflix.com*
6 Amazon.com
7 TikTok.com
8 YouTube.com
9 Instagram.com *
10 Twitter.com
Amazon was #5 in November, but Netflix surpassed in December 2020 (on some days it was higher than Apple, in #4); Instagram and Twitter were constantly changing positions throughout November and December.
2021 told a different story. It was on February 17, 2021, that TikTok got the top spot for a day. Back in March, TikTok got a few more days and also in May, but it was after August 10, 2021, that TikTok took the lead on most days. There were some days when Google was #1, but October and November were mostly TikTok’s days, including on Thanksgiving (November 25) and Black Friday (November 26).

There are other trends we can see comparing both years — for 2020 we only show data of the end of the year, after September (Cloudflare Radar was launched that month). For example, Facebook.com was steadily number #2 across 2020, but with TikTok.com going up Facebook is now a solid #3, followed by Microsoft.com (Office365 and Teams numbers are included there) and by Apple.com (App Store and Apple TV+ numbers are included), the same trend as in 2020.
Amazon.com is the juggernaut that follows, but it is interesting to see that since January 2021 the e-commerce website (we will talk more about that category in a few paragraphs) jumped in front of Apple.com. But Apple got back in front, after September, with some exceptions like November 28, 2021, the day before Cyber Monday — and also December 1 and 6.
Christmas time, Netflix time
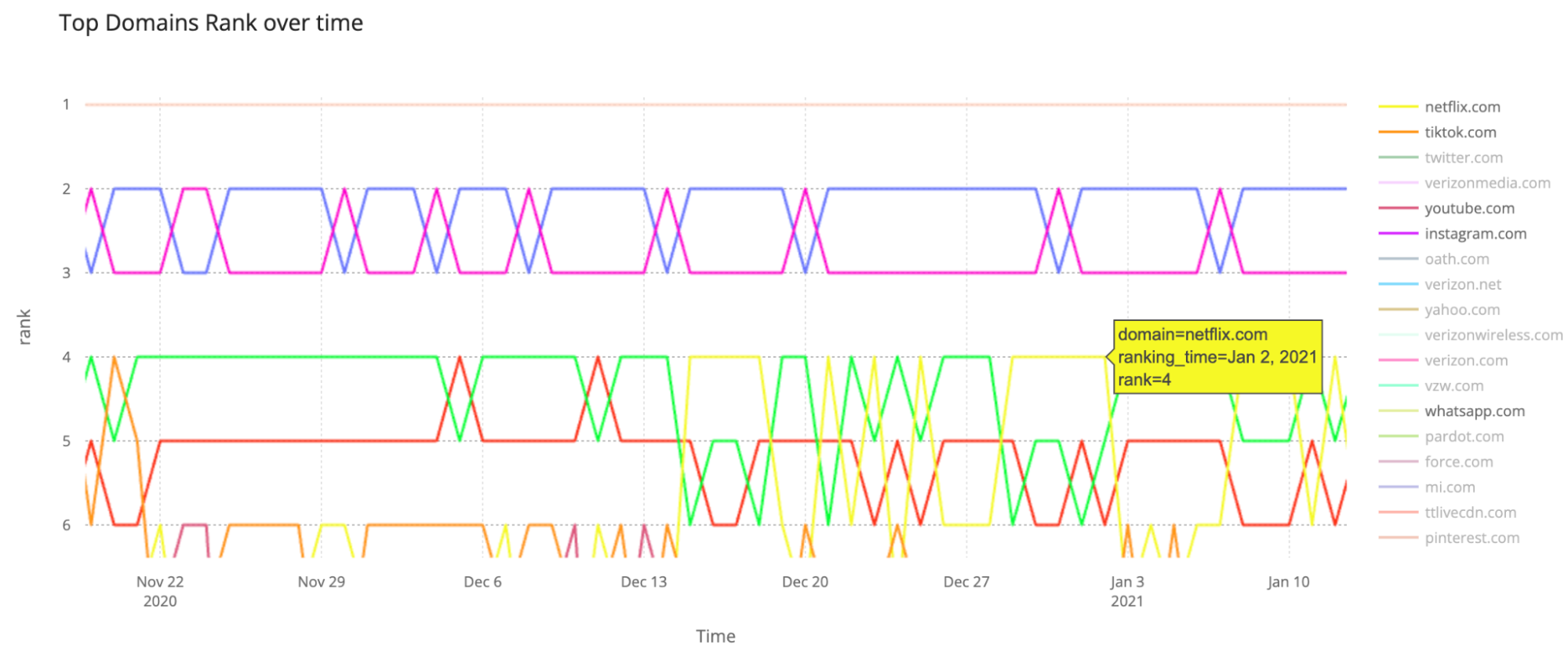
Another trend is that Netflix surpassed Amazon in December 2020, especially around Christmas week. On some days around 2020 Christmas, Netflix was even higher than Apple, in #4, that is the case with December 23, 25, and from December 29 to January 2, 2021.
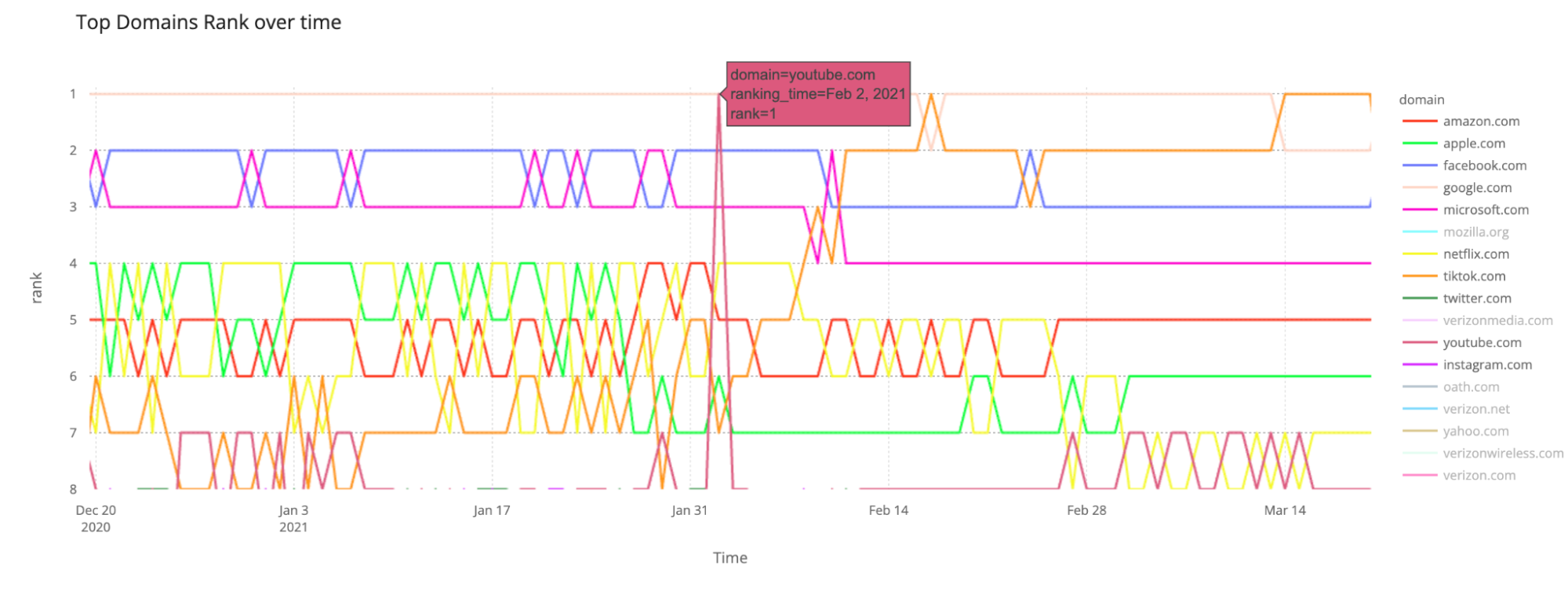
February 2, 2021: The day YouTube (and an aerobics instructor) ruled the world
In our global popularity ranking we also saw another trend: YouTube, usually ranked #6 or #7, got to the top spot of our list on February 2, 2021 — and only on that day.

Why? One can only guess, but back then, although it was the week of the Super Bowl (some commercials, like the one from Doritos with Matthew McConaughey, were out on that day), there was another big newsworthy event: the Myanmar coup d’état on February 1, 2021. How can a coup in a Southeast Asian country have an impact on YouTube? A video of a fitness instructor who unwittingly filmed as the takeover unfolds behind her took the Internet by storm and became viral as the memes started to pour in.
That February day was also the one where Donald Trump announced his new legal team for the impeachment trial after the previous one quit, and Jeff Bezos announced he would step down as Amazon’s CEO. That was also the week prior to a record in YouTube’s history. On February 11, 2021, the video “Baby Shark Dance” from Korean education brand Pinkfong was the new most-viewed YouTube video of all time, surpassing the former record holder “Despacito” by Luis Fonsi.
Google Trends also shows that the week of February 2 was the one in 2021 that “YouTube” was more searched on Google.
Social media: There’s a new kid in town
In what was the second year of the pandemic, social media domains continued high on our ranking. The nine main social media applications were all in our top 100 list of most popular global domains — the only one out is Quora.com (during 2021 it was between #687 and #242).
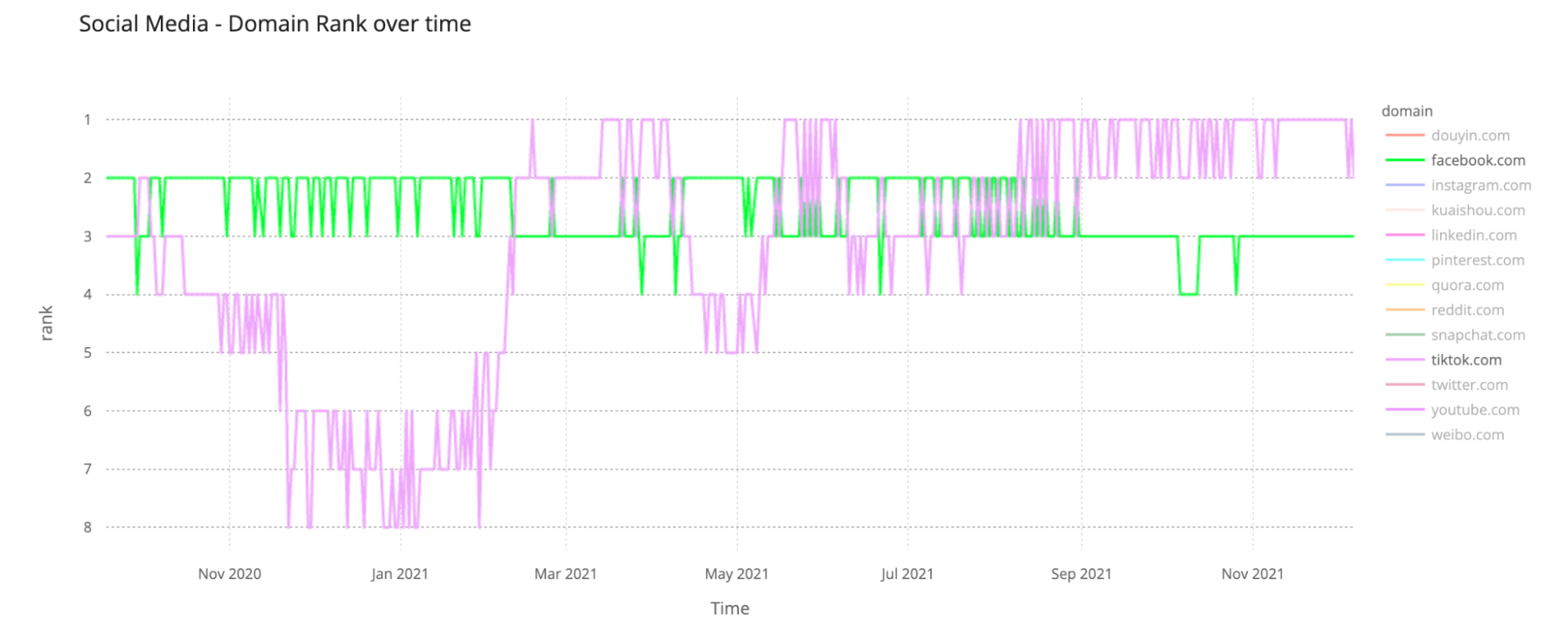
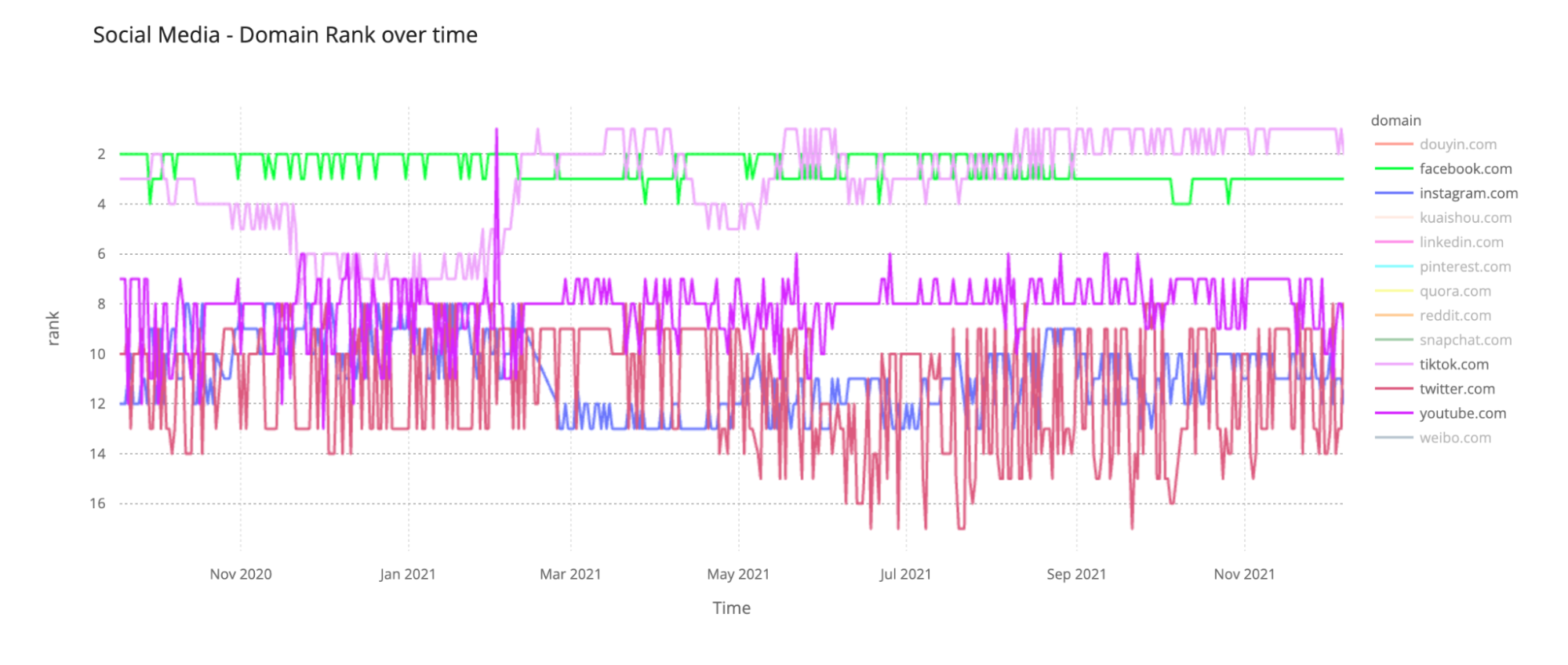
We can see that TikTok (who also surpassed Google, as we explained before in the global #1 spot) took Facebook from its crown of the most popular social media website-domain in our ranking. So, that should mean that TikTok got more Internet traffic from our standpoint (our ranking is derived from our public DNS resolver 1.1.1.1 and so it’s not related to the number of unique users or visitors it gets per month) — Facebook is, by far, the platform with more users worldwide).
Top 10 — Most popular social media domains (late) 2021
1 TikTok.com
2 Facebook.com
3 YouTube.com
4 Twitter.com
5 Instagram.com
6 Snapchat.com
7 Reddit.com
8 Pinterest.com
9 LinkedIn.com
10 Quora.com
Top 10 — Most popular social media domains (late) 2020
1 Facebook.com
2 TikTok.com
3 YouTube.com
4 Instagram.com
5 Twitter.com
6 Snapchat.com
7 Reddit.com
8 Pinterest.com
9 LinkedIn.com
10 Quora.com
The Facebook outage — that we explained from our standpoint extensively — on October 4, 2021, also had an impact on Facebook’s position in our ranking, leading to Facebook.com losing its #3 position (it was #4) for seven days in a row in that week. This number of days in #4 was something that never happened before (since September 2020) to the social media giant.
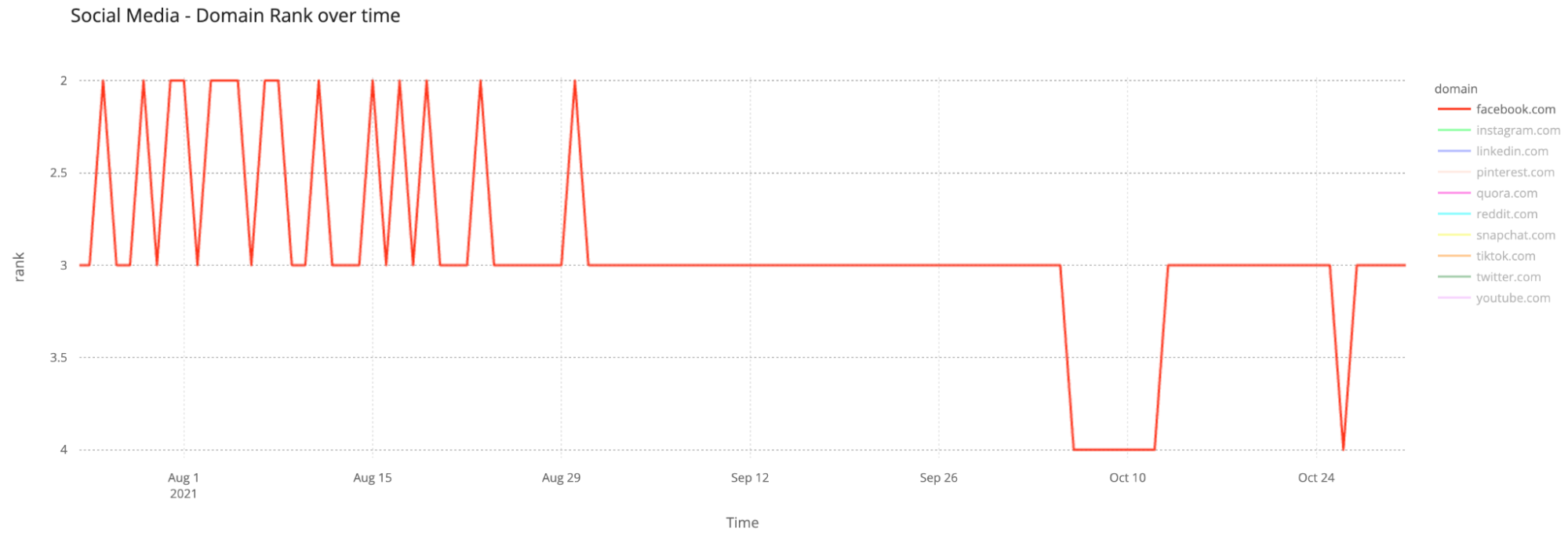
Looking to the top 10 list, it’s also clear that, just looking to social media domains, YouTube comes third and Twitter got a bump up and beat Instagram in 2021, getting the #5 place (barely, in what was a very close race). Back in late 2020 Twitter was behind Instagram in our ranking.
LinkedIn is the ninth most popular social media domain in our ranking and is still in our top 100 and throughout 2021 it got higher in our list, especially in February and March. The social media for professionals then started to drop in June and July (in the Northern Hemisphere’s summer), starting in late August to climb again and by November it reached the #52 place, the highest of the year in our global ranking — in January it was ~#78. In a year when terms like The Great Resignation and the reset of people and organizations’ mindsets were talked about, it makes sense to see this social media platform growing.

Streaming: The (Squid) Netflix Game rules
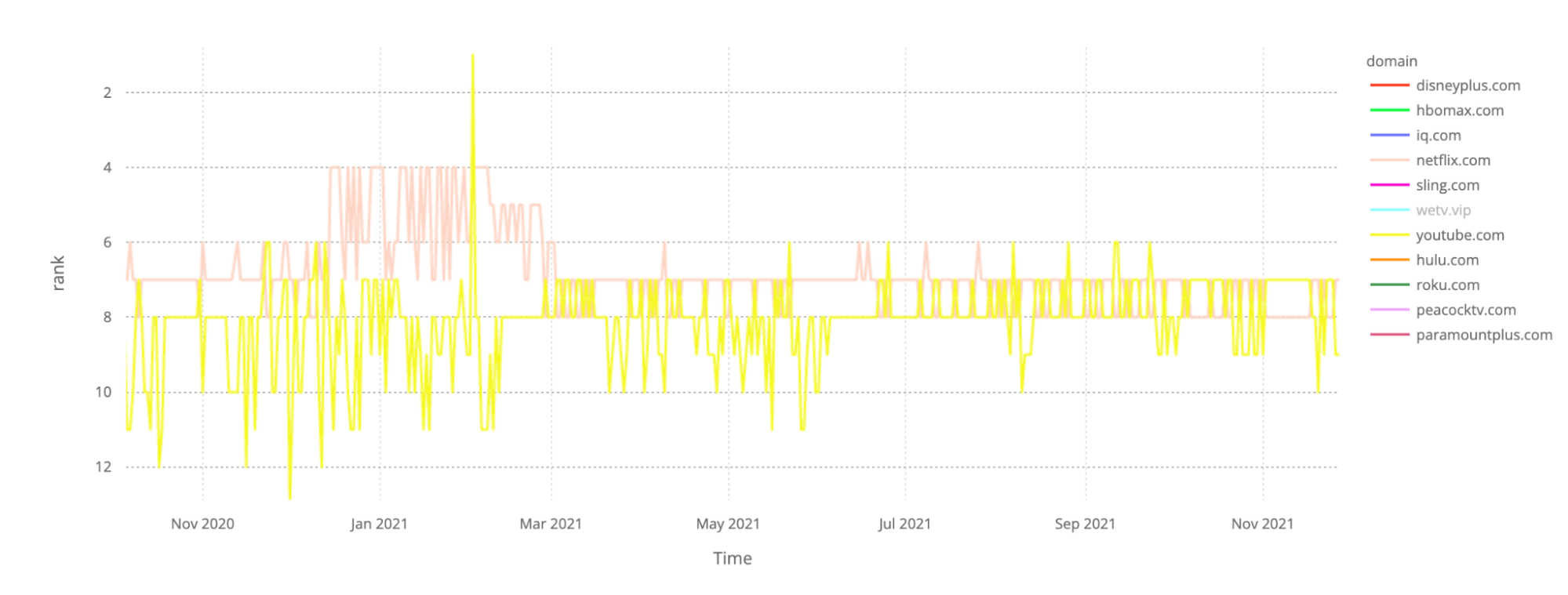
The so-called video streaming wars got another important round in 2021 with new players appearing and old ones having amazing numbers — not only in subscribers, revenue, and content budgets but also in… Internet traffic. In our ranking, Netflix is still the undefeated hero.
We added YouTube.com (its most important service is free) to the list to compare with the big numbers from Netflix, and still, the Squid Game phenomenon platform won our ranking for most of the year. Amazon Prime is not included because the streaming service mainly uses Amazon.com (ranked #5 or #6 most of the year) as a domain.
The days of the year when Netflix was more popular? January was a great month with Netflix reaching the #4 spot in our global ranking in the first two days of the year (and also all the weekends of January, Fridays included), going through February in the #5 place. For the rest of 2021, the platform was mostly #7. Yes, on the weekends Netflix seems to have a better performance in our ranking.
Roku.com seems to be the next video streaming platform after those two traffic giants, getting around the #80 position in our ranking through 2021. In late 2020 Hulu.com was the next one, but HBOMax.com surpassed Hulu in July 2021 and entered our top 100 list. In 2021, Disneyplus.com also rose in our ranking and surpassed the app-based TV service Sling.com later in the year. Our top 10 chart also includes Iq.com (iQiyi), the Chinese online video platform.
Top 10 — Most popular video streaming domains (late) 2021
1 Netflix.com
2 YouTube.com
3 Roku.com
4 HBOMax.com
5 Hulu.com
6 Peacocktv.com
7 Disneyplus.co
8 ParamountPlus.com
9 Sling.com
10 Iq.com
Top 10 — Most popular video streaming domains (late) 2020
1 Netflix.com
2 YouTube.com
3 Roku.com
4 Hulu.com
5 HBOMax.com
6 Peacocktv.com
7 Sling.com
8 Disneyplus.com
9 Iq.com
10 Wetv.vip
Netflix vs YouTube
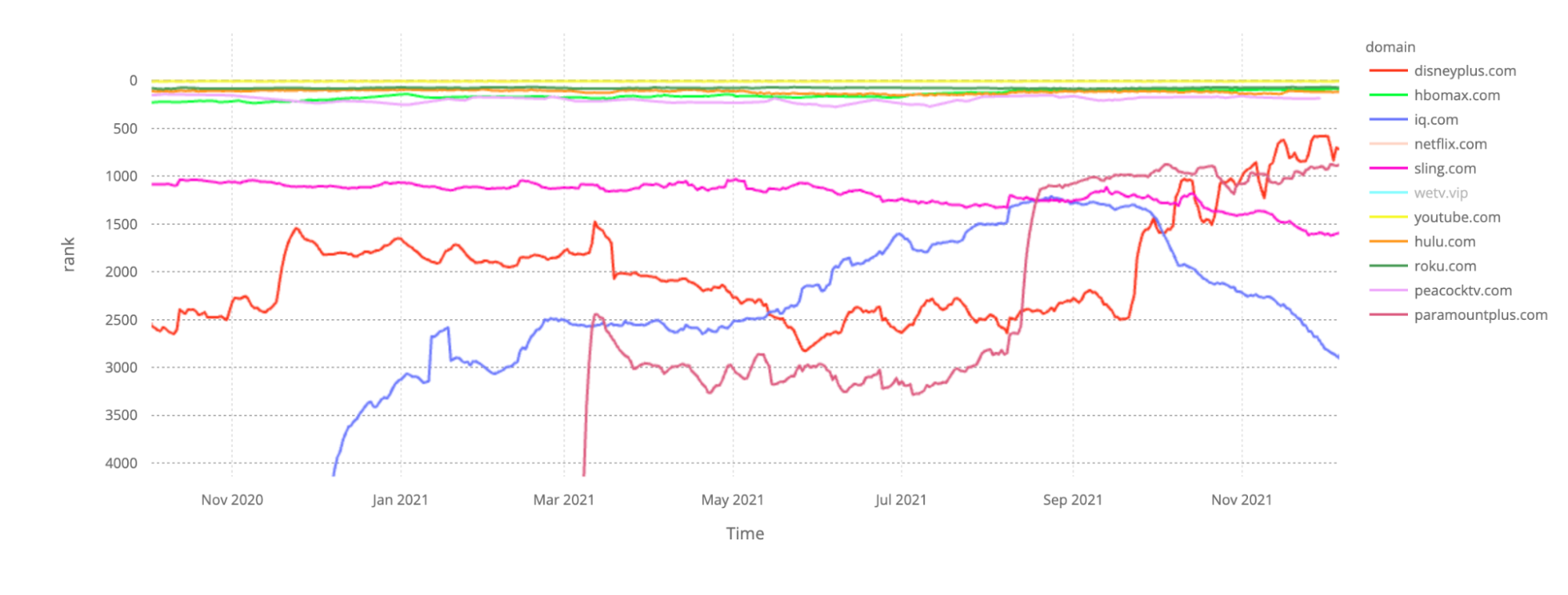
E-commerce: Podium to Amazon, Taobao and eBay
Since the pandemic started e-commerce has continued to strive and grow at an even faster pace than before. The top four e-commerce domains (Amazon, Taobao, eBay and Walmart) in our global ranking are all in the top 100 and that happens steadily throughout the year.
The fifth in the e-commerce list, the Chinese giant Jd.com had a few periods that it also entered the top 100 mainly in May and especially June — on the day of the 618 shopping event, on June 18, 2021, it reached #68 on our list, beating Walmart.com and almost catching Ebay.com.
In the following list it is easy to see that Jd.com surpassed Shopify.com in 2021, occupying the #5 place, and also Bestbuy.com and Target.com rose from one year to another.
Top 10 — Most popular e-commerce domains (late) 2021
1 Amazon.com
2 Taobao.com
3 Ebay.com
4 Walmart.com
5 Jd.com
6 Shopify.com
7 Bestbuy.com
8 Target.com
9 Rakuten.co.jp
10 Homedepot.com
Top 10 — Most popular e-commerce domains (late) 2020
1 Amazon.com
2 Taobao.com
3 Ebay.com
4 Walmart.com
5 Shopify.com
6 Jd.com
7 Olx.com.br
8 Rakuten.co.jp
9 Target.com
10 Bestbuy.com*
Shein.com went ahead of Bestbuy.com and Target.com from December 19 to 24, 2020*
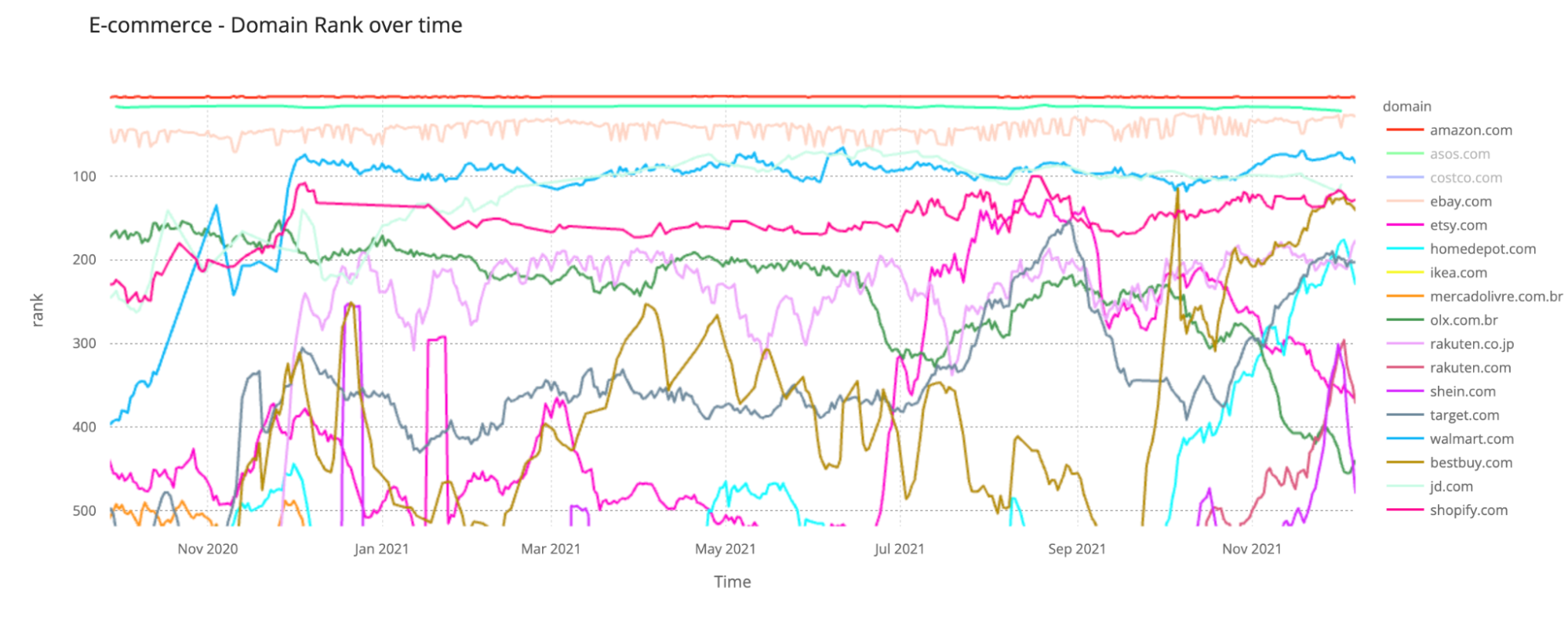
Here are other trends:
- Amazon.com is a domain, as we already explained, with more than e-commerce services (that’s why globally it ranks between #4 and #6). In 2021, it had some good days in January and in late April 2021, reaching #4, but by the end of the year it got its best days in our ranking, especially on the day before Cyber Monday, November 28, and on December 1 and 6 — it reached #5.
- Taobao.com had its best day of the year in our global ranking on August 20 — #15 — and by the popular Chinese shopping day, Singles’ Day, November 11, it was #17.
- Ebay.com had a solid year and a good late August (#29 on August 31) and grew more after Cyber Monday, peaking on December 1, reaching #27.
- Shopify had a great August (reaching #100 on August 18), the same with Etsy.com that peaked at #128 on August 21. Walmart had a great June (#66) and also end of November (it reached #70).
- Ikea.com had a big increase in importance throughout the year and got very near to Homedepot.com’s position in September (peaked in the #695 position in our global ranking), staying up through November.
- Best Buy peaked on October 6 and had a high growth throughout November, also matching Shopify in December.

- Shein.com, the global Chinese online fast-fashion retailer, went high in our ranking for the Christmas of 2020 — it went ahead of Bestbuy.com and Target.com from December 19 to 24, 2020, reaching the #253 position. In March, it had another peak, and it got the best position in 2021 in our ranking after Cyber Monday — it reached #301 on December 1, 2021.

2021: A Space Odyssey (for NASA, SpaceX, Blue Origin and Virgin Galactic)
This year was also a big year for space travel with several achievements. Spacecraft from three Mars exploration programs from the United Arab Emirates, China, and the United States arrived at Mars in February — NASA’s Perseverance rover landed on February 18, 2021, and after that the Ingenuity drone made history, being the first powered aircraft flight on another planet in human history. And there is also another big space event just around the corner — the James Webb Telescope launch.
Virgin Galactic (July 11), Blue Origin (July 20) and SpaceX (September 16 — but with several other events before that regarding satellites and reuse of space capsules) also stormed the Internet with space tourism achievements with different scopes. Only SpaceX offered an orbital ride.
In terms of domains, NASA.gov was way ahead of the others, but Elon Musk’s SpaceX.com was definitely second in our global ranking, followed by Blueorigin.com. Virgingalactic.com only appears once in our top 100k ranking on July 17 and 18 (a few days after Richard Branson’s spaceflight).
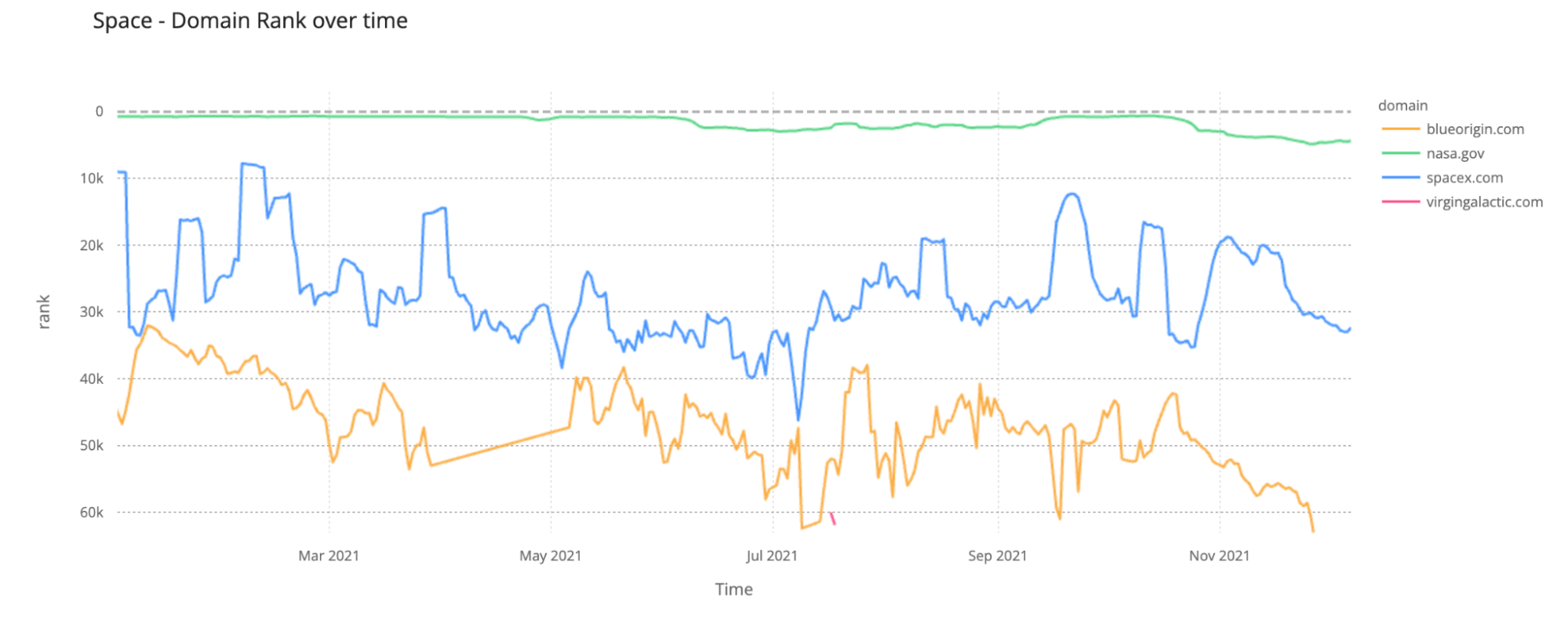
Since last year NASA is high on our global ranking, in the top 1,000 domains of our list, but after the rover Perseverance landed on Mars on February 18 NASA.gov entered our top 700 ranking — the highest day of that month was February 25, when it reached #657. In the summer it went down in our ranking, but it picked up in late September and on October 13, 2021, reached the highest position of the year (#637). That was the day the press conference about NASA’s Lucy mission, the agency’s first to Jupiter’s Trojan asteroids, took place (the launch was on October 16).
SpaceX.com had a great start of February, it entered our top 8,000, a month with a launch of 60 new Starlink internet satellites into orbit amidst a missed rocket landing and a fresh $850 million of new investment. And then it was after September 16, 2021, with the first orbital launch of an all-private crew, Inspiration4, that it flew again in our ranking.
For Blue Origin, after a strong start of the year — it reached our #32,000 on January 10 (a few days before New Shepard 4’s first test flight) — it went up between July 20- 27 after its first crewed flight, with Jeff Bezos onboard. It also went up in our ranking a few days after October 13, 2021 (the day William Shatner flew aboard a Blue Origin suborbital capsule).
Messaging or chat: WhatsApp, what else?
There aren’t as many messaging or chat platforms as there are popular social media sites, video streaming, or e-commerce platforms. So, this ranking is slim, and even slimmer because Messenger (uses Facebook.com) or iMessage (uses Apple.com) aren’t included. Snapchat is both a social media platform and a messaging app — the same with Instagram — and we added them in the social media ranking. If they were here they would be higher than WeChat but behind WhatsApp — Instagram actually started 2021 (it got to #8) in front of WhatsApp until February and went as low as #13 and Snapchat went between #29 to #16.
Top — Most popular chat domains (late) 2021
1 WhatsApp.com
2 WeChat.com
3 Signal.org
4 Telegram.com
Top — Most popular chat domains (late) 2020
1 WhatsApp.com
2 Signal.org
3 WeChat.com
4 Telegram.com
From our standpoint, WhatsApp is the undisputed leader of the messaging apps ranging from as low as #13 in our global ranking to as high as #8. Its best parts of the year were late March, late April, late October and then late November going through December 2021 as #8 in our ranking.

How Signal skyrocketed in January (and WeChat in February)
All the others are far away in our ranking, but 2021 brought three trends we should highlight:
- Signal.org had an incredible month of January — on January 3 it was in #1815 in our ranking and by January 20 it rose to #766, a climb in more than 1,000 positions in just 17 days. Why? WhatsApp’s new privacy policy was in the headlines in the second week of January.

- WeChat.com also had an amazing jump in our ranking, but more in February and by April it surpassed Signal.org — it went from #3142 at the start of February to #979 by April 25 and by October both of the messaging apps were almost tied at ~#370 and had a significantly higher place in our ranking than in late 2020.
- Telegram.com on the other hand had a decrease in ranking throughout the year and ended up in the top 38,000.
“You can’t just materialize anywhere in the Metaverse, like Captain Kirk beaming down from on high. This would be confusing and irritating to the people around you. It would break the metaphor. Materializing out of nowhere (or vanishing back into Reality) is considered to be a private function best done in the confines of your own House.“
― Neal Stephenson, Snow Crash (1992)
Metaverse: Don’t mess with Roblox
Back in November, we heard in the halls of Web Summit — the 42,000 in-person tech global event in Lisbon — that in a way the metaverse is already here (Roblox’s Global Head of Music had some thoughts on virtual concerts). But we’re still far from the promise of almost living in the virtual world that books like Neal Stephenson’s Snow Crash or Ernest Cline’s Ready Player One showed us.
Oculus shipped a lot of headsets and there are immersive experiences out there that are Metaverse-like (a step further than the now-usual-for-most spending all day working, learning, communicating through a screen) and we focused on that ones, like Fortnite, Roblox, Second Life (the oldest, from 2003), Minecraft and Oculus. But Oculus.com doesn’t have enough direct traffic (playing games using Oculus headset could direct the traffic elsewhere) to be in our top 100k domains ranking, and the same happens with Minecraft.
Top — Most popular metaverse domains (late) 2021
1 Roblox.com
2 Epicgames.com (Fortnite)
3 Secondlife.com
Oculus.com and Minecraft.net are not in our 100,000 ranking
Top — Most popular metaverse domains (late) 2020
1 Epicgames.com (Fortnite)
2 Roblox.com
3 Secondlife.com
Oculus.com and Minecraft.net are not in our 100,000 ranking
The (short) list from 2020 and 2021 shows us that Roblox.com surpassed Epicgames.com (the home of the popular Fortnite) for the first time in July reaching back then #27 in our list. But it was after late September that it was consistently in front of the rival game platform, ending the year on a good note reaching #20 in our ranking.

Epicgames.com (Fortnite) started the year a lot better, reaching #14 on January 5, 2021, but it started to lose importance in February and that deepened after May, but mostly in July and August. It never truly recovered and ended the year between #26 and #47, depending on the day.
Conclusion: Human (online) trends
The Internet is not a quiet place, the same way humans on Earth (especially during a pandemic) aren’t quiet or passive but active and reactive. Although on the top of our domain ranking there don’t seem to be drastic ups and downs throughout the year (TikTok, and YouTube, were the exceptions), we saw how an event like the Myanmar coup and the subsequent viral video may have brought YouTube to #1 on our ranking. We also saw how e-commerce was affected throughout the year, how space-related websites had a big (online) year with important events, and how Netflix rose around Christmas time.
And remember: you can keep an eye on Cloudflare Radar to monitor how we see Internet traffic globally and in every country.
Security updates for Monday
Post Syndicated from original https://lwn.net/Articles/879228/rss
Security updates have been issued by Debian (apache-log4j2, firefox-esr, libssh2, modsecurity-apache, and tang), Fedora (lapack, log4j, rust-libsqlite3-sys, rust-rusqlite, xorg-x11-server, and xorg-x11-server-Xwayland), Mageia (bind, botan2, chromium-browser-stable, dovecot, hiredis, keepalived, log4j, matio, mediawiki, olm, openssh, pjproject, privoxy, vim, and watchdog), openSUSE (barrier, nim, and python-pip), Oracle (ipa and samba), Scientific Linux (ipa and samba), SUSE (log4j), and Ubuntu (apache-log4j2, htmldoc, python3.6, python3.7, python3.8, and python3.8, python3.9).
Forgotten Airship: USS Macon
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=U2h1NNpxcFM
Handy Tips #17: Master and dependent items for bulk metric collection
Post Syndicated from Arturs Lontons original https://blog.zabbix.com/handy-tips-17-master-and-dependent-items-for-bulk-metric-collection/18291/
Comic for 2021.12.20
Post Syndicated from Explosm.net original http://explosm.net/comics/6059/
New Cyanide and Happiness Comic
Immunity
Post Syndicated from original https://xkcd.com/2557/

Kernel prepatch 5.16-rc6
Post Syndicated from original https://lwn.net/Articles/879158/rss
The 5.16-rc6 kernel prepatch is out for
testing.
Regardless of what happens, I will be making an rc8 – not because
this release looks particularly problematic, but simply due to the
seasonal holidays. There’s no point in releasing a final 5.16 and
opening the merge window when people are still on holiday or just
coming back. So we’ll have at least one extra week of rc this
release, even if no nasty issues appear.
Comic for 2021.12.19
Post Syndicated from Explosm.net original http://explosm.net/comics/6058/
New Cyanide and Happiness Comic
Canon
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/canon/


Loran Nordgren | Discovering the Human Element | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=y-tKGGkdw4w
I Have Been Appointed As E-Governance Minister of Bulgaria
Post Syndicated from Bozho original https://techblog.bozho.net/i-have-been-appointed-as-e-governance-minister-of-bulgaria/
Last week the Bulgarian National assembly appointed the new government. I am one of the appointed ministers – a minister for electronic governance.
The portfolio includes digitizing registers and processes in all government institutions, reducing bureaucracy, electronic identity, cybersecurity, digital skills and more.
Thanks to all my readers for following this blog throughout the years. I will be sharing some digital policy details here from now on while I’m minister. That may include some technical articles, but they are unlikely to be developer-oriented.
I hope to make some important changes and put forward key ideas for e-governance and digital policy that can be used as an example outside my country (last time I was involved in public policy, I helped pass an “open source law”).
I’ve written a few articles about IT people looking for challenges – not just technical challenges. And I think that’s a great challenge where I’ll have to put all my knowledge and skills to work for the common good.
The post I Have Been Appointed As E-Governance Minister of Bulgaria appeared first on Bozho's tech blog.
What Has NASA Done Ever for Us – The CMOS Image Sensor
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=d9nkhEGYAPk
The Scope Clock – from Cathode Corner
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=50XL37kJ3ME