Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=6ynSA0uZ704
Good night, and good luck, motherf*ckers
Post Syndicated from Дарина Сарелска original https://www.toest.bg/good-night-and-good-luck-motherf-ckers/

С думите „Мълчанието е краят на свободата“ един белокос американски журналист закрива централната емисия новини на CBS на 9 януари 2015 г. Часове по-рано двама въоръжени терористи са нахлули в редакцията на френското сатиричното издание Charlie Hebdo в Париж, за да убият 12 души, включително някои от най-известните френски карикатуристи. Не харесвали карикатурите им.
„Врагът знае къде сме уязвими“, казва Скот Пели във финала на онази емисия.
Силата на един народ зависи от качеството на информацията, която получава. А когато журналистите бъдат принудени да мълчат, свободата започва да изчезва. Мълчанието е краят на свободата.
Пауза, общ план, светлините угасват, преливка към черно, музика, финална шапка.
Единайсет години по-късно същият този американски журналист е уволнен дисциплинарно. На Доналд Тръмп не му харесва предаването, в което той работи. А новинарят ветеран вече трябва да защитава мисията на журналистиката не от терористи в чужда държава, а доста по-близо до дома. „Вие убивате „60 минути“, казва той на собствените си началници, обвинявайки ги публично в некомпетентност, задкулисни сделки и политически натиск.


Скот Пели. Източник: Commons Wikimedia. Фотограф: John Ramspott
Бунтът на кореспондентите
В понеделник сутринта екипът на „60 минути“ се събира на планьорка да се запознае с новия изпълнителен продуцент на предаването, избран лично от наскоро инсталираната шефка на новините Бари Уайс – консервативна коментаторка без телевизионен опит, промотирана официално с идеята да направи новините „по-балансирани“ и съобразени с вкуса на „по-голяма част от Америка“. Неофициално – да ги калибрира по вкуса на Доналд Тръмп, който открито е заявявал своята неприязън конкретно към „60 минути“ и изобщо към журналистите като „враговете на народа“.
Срещата е дни след Черния четвъртък – така журналистите в екипа наричат серията уволнения няколко дни по-рано, когато Уайс е опразнила столчетата на двама от дългогодишните продуценти на шоуто заедно с две от най-опитните кореспондентки – Шарън Алфонси и Сесилия Вега. Малко преди тях по свое желание си е тръгнал Андерсън Купър, а година по-рано и легендарният изпълнителен продуцент на предаването Бил Оуенс, който обяснява решението си с корпоративни промени, пречещи му да си върши работата.
Напуснатите вече говорят открито за цензура, натиск за смекчаване на тона и масажиране на фактите. Най-често в полза на Израел и Белия дом.
„Нямате необходимата квалификация. Доведени сте, за да унищожите „60 минути“ и точно това правите“, казва в прав текст Пели на ръководството под аплодисментите на своите колеги. И настоява да знае защо колегите му са уволнени. Вместо отговор получава упреци от ръководството, че е „груб“.
Но Пели не отстъпва:
Знаете ли кое беше грубо? Черният четвъртък беше груб. Да кажеш на Таня Саймън, че трябва да си тръгне до пет часа̀. Да изпратиш Драган Михайлович в отдел „Човешки ресурси“, за да бъде уволнен, защото никой не е могъл да го погледне в очите. Да не обсъдиш договорите на Шарън Алфонси и Сесилия Вега. Просто да ги извикаш и да им кажеш, че са уволнени. Това е грубост. Това тук е разговор. Онова беше грубост. И вие участвахте в нея.
Черен бланк. Тишина. Няма музика. А финалната шапка идва на следващия ден, когато Пели е поредният уволнен.
Тo speak truth to power („да говориш истината в очите на властта“) – един от фундаменталните принципи на американската журналистика не издържа собствения си вътрешноведомствен стрес тест. След над половин век в професията един журналист си тръгва заради въпроси и заради „лошо поведение“. Защото е казал истината в лицето на властта. Защото мълчанието, както разбрахме, е краят на свободата.
Няма повече въпроси
Ден по-късно в онлайн среща Бари Уайс застава пред екипа и обяснява уволнението с „нарушено доверие“ и липса на „взаимно уважение“. Изказва и благодарности за дългогодишната работа на ветерана Пели. Този път няма допълнителни въпроси от екипа. Смразяващият ефект на поголовната сеч на най-големите имена в редакцията тепърва ще дава своите плодове – и вътре в екипа, и в гилдията, и в обществото. А доволен, разбира се, ще е основно Тръмп. И Дейвид Елисън – медийният магнат, собственик на Skydance, който, след като придоби Paramount и CBS, сега чака държавно ОК за поредната си мегахапка – този път пакетът е CNN, HBO и редица филмови студиа. Залогът е 110 млрд. долара, а на пътя отново стоят само няколко подписа на държавни служители, назначено от Тръмп.
Познато ли ви звучи? Неизбежно е – след като отвъд океана вече се прилагат тактиките на Виктор Орбан и балканските олигарси за превземане на медии, няма как да не ни се стори мила и родна тази картинка.
С уговорката, че да сравняваме Америка с България, CBS с Нова телевизия и „60 минути“ с който и да е нашенски сутрешен блок е като да сравняваме терористите от Charlie Hebdo с орките на ПИК и „Блиц“, но все пак накрая ще стигнем до някои неизбежни паралели. С признателност и благодарност, че и тук, и там – в Америка, все още властта не убива журналисти. Само ги умълчава. И това изглежда съвсем достатъчно.
Историята на една предизвестена смърт
За американската публика „60 минути“ е институция. Повече от половин век предаването задава стандарта за телевизионна журналистика, разследвания и дълбочинни интервюта. Всяка неделя вечер в 19:00 започва познатото тиктакане на часовника, превърнало се в една от най-разпознаваемите емблеми на американските медии.
Последващите 60 минути често опаковат историите, които задават тона както на политическия разговор във Вашингтон, така и на разговорите около масата за вечеря в милиони американски домове. Дори и днес, във време, когато телевизионната аудитория намалява, а онлайн платформите променят начина, по който хората консумират новини, и въпреки дългогодишните пропагандни атаки на Тръмп и на влиятелни консервативни подкастъри срещу „либералния уклон на старите медии“, „60 минути“ си остава най-гледаното новинарско предаване в Съединените щати.
Най-близката аналогия за българската публика вероятно би била комбинация между най-силните години на „Всяка неделя“ и „Панорама“. Минус Държавна сигурност. Плюс много пари. Докато ролята на комунистическите служби дълбоко опорочават българския златен век на телевизията, тук става дума за поколения журналисти, изграждани въпреки комерсиализма в професионалната култура и традициите на политическа автономност и с огромно влияние над културното ДНК на нацията.
Корените на тази култура водят към легендарния журналист Едуард Р. Мъроу. Именно неговото леко дръзко, леко високомерно Good night, and good luck се превръща в запазена марка и символ на гръбнака, характера и дори дозата „лошо възпитание“, необходими на един журналист, за да се изправи срещу властта в най-мрачните години на маккартизма, когато Америка преследва различните по убеждения и идеология. Днес същата институция, която превърна тези думи в свое знаме, изглежда, не е готова да плати цената на това наследство.



Едуард Р. Мъроу в кадри от филма Challenge of Ideas (1961). Източник: Internet Archive
Предизвестената смърт на легендарното американско предаване започва почти веднага след изборите, които връщат Доналд Тръмп в Белия дом за втори мандат.
Поводът е интервю на Камала Харис за „60 минути“ по време на предизборната кампания. Тръмп обвинява CBS, че е манипулирала монтажа на разговора, и завежда дело срещу телевизията за намеса в изборите. По това време почти всички медийни и правни експерти са единодушни, че подобен иск няма никакви шансове за успех в американски съд. Но точно тогава Paramount чака извънредно важно регулаторно одобрение за многомилиардната сделка по придобиването ѝ от Skydance. И избира да сключи извънсъдебно споразумение и да плати 16 млн. долара на кампанията на Тръмп, макар и без да признава вина.
Именно тук започват първите сериозни съмнения. Дали това е просто бизнес, или червен флаг, че една от най-големите медийни компании в Америка е готова да прави редакционни компромиси в името на по-големи корпоративни интереси?
Дългогодишният продуцент на „60 минути“ Бил Оуенс напуска в разгара на тази криза и разсейва съмненията. В продължение на десетилетия Оуенс е един от пазителите на редакционните стандарти на предаването. При напускането си заявява, че вече не може да гарантира независимостта, необходима за работата му, тъй като корпорацията има други приоритети.
Следващият курбан, даден на олтара на това необходимо приятелство между династията Елисън и президента Тръмп, е Стивън Колбер. Само дни след като назовава в ефир споразумението между Paramount и Тръмп „огромен подкуп“, CBS обявява края на неговото The Late Show. Малко по-късно държавното одобрение за придобиването в крайна сметка е получено, а Тръмп дори приема да даде интервю за „60 минути“.
Предаването обаче си остава следваща мишена за отстрел от Тръмп. С десетки постове в своята социална мрежа Truth Social президентът атакува журналистите на програмата, наричайки ги „измамници“ и „политически функционери“, като заплашва открито с отнемане на лицензи. Резултатът не закъснява – точно когато на тезгяха е нова огромна бизнес хапка: фамилията Елисън е на път да придобие и CNN заедно с апетитен пакет развлекателни медийни брандове. И пак се чака един подпис, който няма как да дойде без кимане от Белия дом.
Когато президентът едва ли не казва „Ще използвам силата на държавата, за да си осигуря медии, каквито си харесвам“ и когато се заобиколи с приятели олигарси, които получават лъвския пай от бизнес сделки срещу политически услуги, ние в Източна Европа нямаме никакво съмнение какво се случва. Хронологията е ясна и тенденцията за политическо quid pro quo, макар и юридически недоказуема, е видима с просто око.
Как се стига до Черния четвъртък
Хронология на сделките, натиска и редакционните отстъпки
Skydance обявява сделка за придобиване на Paramount, собственик на CBS, за 8 млрд. долара. Необходимо е одобрение от Федералната комисия по комуникации.
Доналд Тръмп печели президентските избори. Малко преди това завежда дело срещу CBS заради интервюто на Камала Харис в „60 минути“.
Тръмп встъпва в длъжност. Paramount още чака одобрение на сделката със Skydance.
След 22 години начело на „60 минути“ Бил Оуенс подава оставка. Заявява, че вече не може да взема независими редакционни решения.
Paramount плаща 16 млн. долара по извънсъдебно споразумение с Тръмп, без да признава вина.
В ефира на CBS Стивън Колбер нарича споразумението с Тръмп „огромен подкуп“.
CBS обявява, че прекратява шоуто на Стивън Колбер, считано от май 2026 г.
Федералната комисия одобрява сделката между Paramount и Skydance.
Бари Уайс е назначена за главна редакторка на CBS News. Решението е спорно заради липсата на телевизионен новинарски опит.
Шарън Алфонси обвинява ръководството, че е спряло неин репортаж за депортирането на мигранти към затвора CECOT в Ел Салвадор по политически причини.
Paramount Skydance обявява споразумение за придобиване на Warner Bros. Discovery в сделка за около 110 млрд. долара.
Масови уволнения в „60 минути“. Решението за сливането на Paramount Skydance и Warner Bros. Discovery се очаква до два месеца.
Парадоксът е, че като цяло телевизията, която е най-пострадала в борбата с рейтингите (в последните години CBS традиционно изостава зад ABC и NBC), в крайна сметка решава да убие двете си най-рейтингови програми. Шоуто на Стивън Колбер беше лидер сред късните вечерни програми в Америка до спирането му миналия месец. „60 минути“ остава най-гледаното новинарско предаване в страната повече от половин век след създаването му. Това са двете марки, които продължават да носят престиж, влияние и публика на CBS, и то не само по телевизора. И Колбер, и „60 минути“ продължават да събират милиони гледания и споделяния онлайн. На теория това са програмите, които една телевизия би трябвало да пази най-много.
Само че рейтингите вече не са това, което бяха, а телевизионният бизнес – такъв, какъвто го познаваме, е на доизживяване.
Така за семейство Елисън залогът не са няколко рейтинг точки повече, а многомилиардните сливания, придобивания и корпоративни сделки, които зависят от благоволението на регулатори и политици. Както казваше Ахмед Доган, „поне едно кимане от нас трябва“. Доказателства за пряка сделка няма. Но няма и друг възможен отговор на въпроса защо една телевизия би жертвала най-ценното си.
Може би защото, докато телевизията престава да бъде апетитен бизнес сама по себе си, все още има някакво влияние, което ѝ позволява да бъде инструмент за бизнес. Валута за разкешване. Ефирът става фасада, а журналистиката – разменна монета в една много по-голяма игра. Място, на което се изграждат отношения, печели се достъп и се договарят решения, струващи много повече от рекламното време между две новинарски емисии. Този завой в бизнес модела е далеч по-видим на малки пазари като нашия, където парите просто свършват по-бързо.
Големите търговски оператори у нас, като част от мултинационални компании с разнородни бизнес интереси, отдавна практикуват този модел. В него телевизията е само рекламна витрина, през която се отварят (или затварят) врати към далеч по-доходоносни сделки и индустрии.
За семейство Елисън това може да означава филмови студиа, стрийминг платформи и развлекателни империи. За далеч по-скромния български пазар – телекомуникации, обществени поръчки, инфраструктурни проекти, влакове, мотриси – всичко зависи от политическата благосклонност. А тя се договаря на мегдана на телевизора.
Същото, ама различно
С това паралелите между Америка и България като че ли се поизчерпват.
Ние нямаме нито „60 минути“, нито Стивън Колбер. Имаме Слави Трифонов. Нямаме Бил Оуенс, имаме Антон Хекимян. Нямаме Скот Пели, имаме Бареков. Българската Бари Уайс е жена с много имена, но среща като тази с екипа на „60 минути“ не мисля, че някога ѝ се е случвала.
Иначе, и в Нова телевизия чакаха одобрение за придобиване от братята Кирил и Георги Домусчиеви през 2019 г. И го дочакаха. След серия от черни четвъртъци, макар и не само в четвъртък, прочистили десетки знакови лица на медията. Тогава покойният вече чешки бизнесмен Петр Келнер не успя да получи кимване от когото трябва. Компенсираха го малко по-късно с bTV, където също в годините последваха санитарна сеч и уволнения с благодарности – за лошо поведение и неподходящи чаши. По своя път минаха и БНТ, и БНР, макар и не толкова успешно.
И у нас политическите чистки в медиите обикновено се обясняват с купешки клишета за нарушени стандарти за обективност, плурализъм и баланс. Fair and balanced („честно и балансирано“), между другото, е мотото на всички бариуайски по света и у нас.
Схемата може и да е същата. Но съпротивата не е. С изключение на БНР, където гилдията се надигна и предотврати уволнението на Силвия Великова.
Съществена е и друга разлика. Битова е, но не е незначителна и обяснява тишината, с която се убиват медии у нас. Повечето от споменатите американски журналисти излизат извън ефир вече милионери. Пазарът е огромен, а публика дебне отвсякъде.
У нас малкото независими гласове, отстранени и изтъргувани срещу някой подпис или кимане за милиони, живеят от заплата до заплата, не могат да си платят нито сигурността, нито адвокатите, докато се изправят срещу лицата на одържавената българска мафия, борят се за миниатюрна аудитория и често плащат много по-висока лична цена.
Но да, журналистиката, дори опакована в бизнес модел, все пак си остава кауза. И мисия. В услуга на обществото. Иначе от нея няма смисъл.
Неслучайно през последните седмици социалните мрежи зад океана започнаха да преработват емблематичното сбогуване на Мъроу в далеч по-мрачен и гневен вариант:
Good night, and good luck, motherfuckers.
В наши дни фразата заживя собствен живот като бунтарска и саркастична версия на оригинала. След кризата около CBS тя се превърна в нещо средно между хаштаг и среден пръст към институцията, пре/продала собствените си принципи. За мнозина тя е и символично сбогуване с американската илюзия за непробиваемата защита на Първата поправка.
Най-добре го каза един американски студент, получил в пика на скандала стипендия именно от CBS, за да следва журналистика. Застанал до Скот Пели по време на раздаването на наградите „Еми“ за журналистика („60 минути“ печели две статуетки, между другото, ако искате да видите как животът имитира началото на „Дяволът носи Прада“ 2), 18-годишния Сантяго Кампос казва тези думи и изправя на крака целия журналистически елит в залата:
Искам да благодаря на CBS News за тази щедра подкрепа за образованието ми. Но искам също да отбележа, че докато корпоративните елити все по-силно овладяват каналите, по които достига информацията до обществото, журналистиката в служба на хората става все по-трудна за намиране, но и все по-необходима. А това, което хората искат, е истината. Затова, ако някога се поколебаете да произнесете думата „геноцид“ или предпочетете да замълчите пред очевидни лъжи, запитайте се: „За кого го правя?“ Надявам се да изберете нас.
Това е.
А алтернативата:
Good night, and good luck, motherfuckers.
Comic for 2026.06.05 – Accountant
Post Syndicated from Explosm.net original https://explosm.net/comics/accountant
New Cyanide and Happiness Comic
Прогресът на Радев тръгва с остеритет
Post Syndicated from Емилия Милчева original https://www.toest.bg/progresut-na-radev-trugva-s-osteritet/

Съдебната реформа е поставена на стендбай, а правителството на Румен Радев спешно търси пари – от пенсионерските ковид добавки до административните разходи. Налага се да прави и инвентаризация на скелетите в гардероба, за да оправдае обещанията за борба с корупцията. Така приключва първият месец на новото мнозинство, получило твърде много политически капитал и твърде малко финансова свобода за действие.
Каквито и наследени договори, съмнителни (и) неразплатени разходи или неизгодни решения да открива новата власт, ще трябва да намери трудното решение как да финансира собствените си политики, като се побере в лимита за дефицит от 3% от БВП.
Европейската комисия препоръча да започне процедура за прекомерен дефицит спрямо България, очаквайки превишение на разходите над приходите от 4,1% за 2026 г. и 4,3% за 2027 г. Последната дума има Съветът на ЕС. Ако предложението бъде прието, публичните финанси на България ще бъдат под надзора на Европейската комисия през следващите няколко години. Ще се наложи кабинетът да представи план с коригиращи мерки, който да договори с Европейската комисия, и до 6 месеца да започне да го изпълнява.
Амбициите на вицепремиера и финансов министър Гълъб Донев са да бъде свита дупката в бюджета до края на 2026 г. и чрез орязване на разходите да се измъкне от процедурата, за да избегне властта на надзора от Брюксел.
Правителството тепърва ще внася бюджета за 2026-та през юли, което означава, че в последните пет месеца на годината държавата ще работи с ограничен ресурс. Причината е, че Министерството на финансите (МФ) настоява да получи заявки за бюджет, който е 90% от миналогодишния, макар че през изминалите месеци структурите на бюджетна издръжка са харчили без такъв лимит.
Междувременно управляващите разкриват наследените задължения. Към май 2026 г. общият размер на неразплатените разходи от 2024, 2025 и началото на 2026 г. е бил 2,2 млрд. евро. Те включват фактурирани, но неплатени проекти на Агенция „Пътна инфраструктура“ и на общините, като тези разходи са заложени в закона за бюджета, но без да бъдат осигурени необходимите средства.
Допълнителен риск за бюджета идва от проектите по Плана за възстановяване и устойчивост (ПВУ). По тях МФ първо плаща на изпълнителите с бюджетни средства, а едва след това подава искане за възстановяване към Европейската комисия при изпълнение на съответните етапи и цели. Това означава, че всяко забавяне на реформите или на плащанията от Брюксел временно прехвърля тежестта върху българския бюджет. Така МФ се оказва принудено да финансира проекти, за които формално има европейски ресурс, но реално парите може да пристигнат много по-късно. Или да не дойдат, ако някоя от целите в Плана не е изпълнена от българските власти.
Все още не е обявено публично каква е сумата на декларираните по ПВУ за разплащане проекти.
България има и задължения по „президентския“ договор с турската компания „Боташ“, по който до май 2025 г. са платени 600 млн. лева (306,8 млн. евро), макар да е бил използван капацитет за 15 пъти по-малка сума. Ежедневно задължението на българската страна е за 1,05 млн. лв. (536 900 евро).
Темата за „Боташ“ се появява и изчезва от обществения интерес с променлива интензивност, но се зашумя отново, когато бившият енергиен министър, участвал в сключването на договора, беше назначен в Държавната консолидационна компания. Постът му стана причина лидерът на „Продължаваме промяната“ Асен Василев да обяви, че възнаграждението на Росен Христов ще е 11 160 евро, или 18 минимални работни заплати, какъвто е таванът по закон.
По-късно председателят на парламентарната група на „Прогресивна България“ Петър Витанов съобщи по bTV, че заплатата ще е 1878 евро, а Христов заплаши със съд лидера на ПП.
Проблемът за новото правителство е, че сега ще търси средства не за да реализира своите политики, а за да плаща за решения, взети от предишните управления и превърнали се в задължения на държавата.
Неизбежното: съкращения и реформи
Парадоксално, но факт. Натовареното с най-големи очаквания правителство след години на политически кризи ще трябва да ореже публични разходи, да извърши съкращения, да намали дела на сивата икономика и корупцията, ако иска да си осигури някакво финансовото благополучие и обществен престиж. Процедурата за прекомерен дефицит му развързва ръцете да предприеме непопулярни мерки, например дългоочакваната административна реформа. Абсолютното мнозинство, с което разполага, пък му осигурява необходимата подкрепа без напрежение от коалиционни партньори.
Проблемът е, че икономическата и политическата логика рядко съвпадат.
В следващите месеци кабинетът ще трябва едновременно да съкращава разходи и да убеждава избирателите, че управлява успешно. И това в навечерието на президентски избори и година преди местния вот, когато всяко евро за инвестиции в общински проекти има и политическа стойност.
Кметовете, които се канят да се присъединят към „Прогресивна България“, ще очакват финансиране на инвестиционните си проекти.
Гласувалите за Румен Радев близо 1 445 000 български граждани, които очакваха от него „да оправи държавата“, „да сложи ред“, не са очаквали остеритет.
Според Радев „тежкото наследство, което получаваме, е резултат на безхаберие, некомпетентност, волунтаризъм, популизъм и грабеж“.
Всички българи ще плащаме вересиите на олигархията и на предишните управления.
Това обяснение вероятно ще e убедително за някои избиратели. Проблемът е, че част от решенията, които днес натоварват бюджета, бяха вземани и от служебни кабинети, назначавани именно от президента Радев.
От ковид пандемията насам почти всяко управление добавяше нови постоянни разходи, без да осигурява устойчив източник за финансирането им. Временните антикризисни мерки, като интегрираните в пенсиите добавки и енергийните помощи за бизнеса, постепенно се превърнаха в трайни ангажименти. Социалните плащания и заплатите в публичния сектор растяха с темпове, които изпреварваха реалния икономически растеж.
Автоматичният механизъм за МВР и Министерството на отбраната се превърна в голям бюджетен проблем през миналата и тази година, когато започна да генерира двуцифрени годишни увеличения на възнагражденията, независимо от общото състояние на бюджета.
Тези политики на правителствата в последните пет години, които се изпълняваха и от назначените от президента Румен Радев служебни кабинети, дебалансираха бюджета. Върху тях тежат и безпринципните назначения в държавната администрация. Новата власт ще обяви огромните заплати, от порядъка на 20–25 000 евро, раздавани в държавни дружества и предприятия, които при това са на загуба.
Инвентаризацията на наследството включва и твърдения за злоупотреби при големи инфраструктурни проекти. Регионалният министър Иван Шишков вече обяви, че има подадени сигнали до прокуратурата за строителството на автомагистрала „Хемус“ и за обществени поръчки по европейски програми, поставили под риск около 127 млн. евро европейско финансиране.
Като президент обаче Радев не е критикувал обвързаните с минималната и средната работна заплата увеличения в силовия сектор. Нещо повече, във втория си мандат като държавен глава беше критикувал по-високите повишения в МВР, а не в Министерството на отбраната.
Засега е ясно, че ще отпаднат автоматичните увеличения на заплатите в съдебната система и висшето образование. Дали правителството ще посмее да отреже МВР и Министерството на отбраната, които по закон трябва да получат със задна дата увеличените си отново от 1 януари 2026 г. възнаграждения?
Във Вътрешното министерство има и друг проблем – работещите пенсионери. Според отговор на министър Демерджиев на парламентарен въпрос от Мартин Димитров от „Демократична България“ към 30 април техният брой е 1098.
Засега управляващите говорят основно за съкращаване на разходи. Правителството се отказа да купува ракети за F-16 за 957 млн. долара заради липсата на средства.
Първите, които ще усетят остеритета, са пенсионерите – социалната група с най-ниски доходи. В действителност от 1 юли пенсиите им ще се увеличат с по-малко от 7,8%, защото от сегашните суми ще бъде извадена ковид добавката от 30,68 евро, а в отпуснатите нови пенсии изобщо ще липсва. Няма всички пенсионери да умрат заради 2 евро, каза Константин Проданов от „Прогресивна България“ в спор с лидера на „Продължаваме промяната“ Асен Василев.
За хората с най-ниски доходи обаче 2 евро тежат много повече от 1,09 евро по-малка субсидия за партиите, които занапред ще получават по 3 евро за всеки действителен глас.
Депутатите все още не са премахнали автоматичното увеличение на заплатите им на всеки три месеца. Тяхното основно възнаграждение се равнява на три средни в обществения сектор и в момента е 4326 евро, като към него се получават добавки за комисии и безотчетните ⅔ от тази сума за сътрудници, наем на офиси и др.
Изглежда невъзможно България да се върне към правилата от времето на валутния борд, когато държавата не си позволяваше да харчи повече, отколкото получаваше. Как ще бъдат съкратени разходите и кои социални групи ще понесат тази тежест, ще проличи още при съставянето на бюджета за тази година.
Някои икономисти вече предупреждават, че ако бюджетната консолидация не даде резултат, процедурата по свръхдефицит може да доведе не само до ограничения на разходите, но и до натиск за повишаване на данъци.
Първият месец от управлението не даде отговор дали Румен Радев ще успее да изпълни обещанията за по-малко корупция и по-ефективна държава.
Ако мнозинството обаче успее да превърне бюджетната криза в повод за реформи, може да излезе по-силно от нея. Ако се ограничи до счетоводни икономии и търсене на виновни, ще остане поредното управление, което е управлявало дефицита, вместо да се занимава с причините за него. След бюджета следва тестът със съдебната реформа.
Въпросът е дали избирателите могат да бъдат убедени, че остеритетът е промяна.
CAMERA MAN Takes on Cosplay Photography (Comic Con 2026)
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=UMYxQx4omQo
Planetary Science
Post Syndicated from xkcd.com original https://xkcd.com/3255/

Dave Airlie on Linux Kernel Maintenance (SE Radio)
Post Syndicated from corbet original https://lwn.net/Articles/1076478/
The Software Engineering Radio podcast has put up an
interview with graphics maintainer Dave Airlie. Much of what is in
there will not be news to LWN readers, but it is an interesting overview of
the life of a large-subsystem maintainer.
I was talking to a few of the Rust people, and I thought: these are
very young people, these are a group of people in their 20s, maybe
30s, they are a younger cohort of developers than the people I am
normally used to dealing with. I thought there was maybe a good
way we could bring these groups together. I think that having
young people coming into the kernel using Rust is valuable… So I
thought that I should be supportive of bringing Rust into the
kernel.
Query Amazon Redshift using natural language with Kiro
Post Syndicated from Hitesh Dodiya original https://aws.amazon.com/blogs/big-data/query-amazon-redshift-using-natural-language-with-kiro/
It’s Monday morning and your VP pings you: “Revenue dropped 15 percent over the weekend. What happened?” The clock starts. You open the AWS Management Console, find the right Amazon Redshift cluster, open the query editor, and start hunting. Which database has the revenue data, analytics_db or reporting_db? Is the table called orders, transactions, or sales_events? You find it, but now you need the schema. Is the amount column total_amount, revenue, or order_value? 20 minutes in, you haven’t answered the question. You’ve been navigating infrastructure.
This scenario plays out daily across data teams, and it’s why the landscape is shifting. With AI agents entering the analytics workflow, a growing number of business users can now perform complex data analysis. They no longer need to file a ticket with the data engineering team and wait days for a response. The bottleneck is no longer SQL expertise. It’s the friction between having a question and getting an answer.
The Amazon Redshift MCP server paired with Kiro removes that friction. Instead of memorizing cluster endpoints, reverse-engineering schemas, and hand-writing SQL, you describe what you need in plain text and get results. That Monday morning question becomes a single sentence: “Show me daily revenue for the past two weeks, broken down by region.” Kiro finds the cluster, discovers the schema, writes the query, and returns the answer in seconds, not minutes.
In this post, you learn how to:
- Install and configure Kiro with the Amazon Redshift MCP server.
- Discover clusters, databases, and schemas using natural language.
- Run analytical queries and cross-cluster comparisons conversationally.
- Implement security best practices for production Amazon Redshift environments.
You can use Kiro in two forms: Kiro integrated development environment (IDE), a full desktop development environment, and Kiro command line interface (CLI), which brings the same AI capabilities directly to your terminal. The Redshift MCP server works with both. The CLI experience is particularly well suited for the conversational analytics workflow this post describes, because you can start querying your data warehouse from a terminal session without opening an IDE.
Important: Before using this integration with production Amazon Redshift environments, read the Security tips section. This section covers critical considerations around AWS Identity and Access Management (IAM) permissions and Kiro autonomy modes.
What is the Amazon Redshift MCP server?
The Model Context Protocol (MCP) is an open standard that provides AI agents with secure connections to external data sources and tools. The Amazon Redshift MCP server is an open source implementation that bridges the Kiro AI agent with your Amazon Redshift infrastructure.
With the Redshift MCP server, you can:
- Automatically find both provisioned clusters and serverless workgroups with cluster discovery.
- Browse databases, schemas, tables, and columns with metadata exploration.
- Run SQL in READ ONLY mode with built-in safety protections with safe query execution.
- Work with multiple clusters and workgroups simultaneously with multi-cluster support.
The server translates your natural language requests into the appropriate Amazon Redshift Data API calls and SQL queries. No manual endpoint configuration or SQL writing is required.
How the Redshift MCP server relates to the AWS MCP server
You might have noticed that AWS also offers the AWS MCP server (part of the Agent Toolkit for AWS), which provides broad access to AWS services, including the Redshift Data API. A common question is: if the AWS MCP server can already reach Redshift, why add a dedicated Redshift MCP server?
The two are complementary, not competing. The AWS MCP server gives Kiro general AWS capabilities (service decision guides, SDK usage guidance, troubleshooting skills, and access to AWS APIs). The Redshift MCP server adds a purpose-built analytics layer on top. It provides single-call query execution (compared to a minimum of three API calls for submit, poll, and fetch), read-only safety by default, transparent provisioned and serverless cluster handling, and dedicated metadata navigation tools. Upcoming features like query plan explanation, native identity propagation, cluster analysis, and UDF discovery will further extend this specialized layer.
You can use both together, or use the Amazon Redshift MCP server on its own. There’s no either-or requirement.
Setting it up
The following sections walk you through the installation and configuration process.
Prerequisites
Before you begin, make sure that you have:
On your machine:
- Kiro IDE or Kiro CLI installed.
- Python 3.10 or newer.
- The uv package manager from Astral.
On AWS:
- AWS credentials configured through the AWS Command Line Interface (AWS CLI), environment variables, or IAM roles.
- At least one Amazon Redshift provisioned cluster or serverless workgroup.
- IAM permissions for Amazon Redshift access (see the following section).
Step 1: Install the uv package manager
If you don’t have uv installed, run one of the following commands.
For macOS or Linux:
For Windows PowerShell:
Then install Python 3.10 or newer if needed:
Step 2: Configure IAM permissions
Your AWS identity needs the following permissions. Attach this policy to your IAM user or role:
You also need database-level permissions: SELECT on tables you want to query, USAGE on schemas you want to explore, and connection access to the target databases.
Step 3: Configure the MCP server in Kiro
Open (or create) your Kiro MCP configuration file and add the Amazon Redshift server.
For Kiro IDE:
- User-level configuration (applies globally):
~/.kiro/settings/mcp.json. - Workspace-level configuration (applies to a specific project):
.kiro/settings/mcp.json.
For Kiro CLI:
- User-level configuration:
~/.kiro/settings/mcp.json. - Workspace-level configuration:
.kiro/settings/mcp.jsonin your project directory.
The configuration format is the same for both. Add the following:
Tip: Replace AWS_PROFILE and AWS_DEFAULT_REGION with values matching your environment. If you use AWS_REGION instead of AWS_DEFAULT_REGION, AWS_REGION takes higher precedence.
Note: Windows users: use uv instead of uvx with additional args. See the Amazon Redshift MCP server documentation for the Windows-specific configuration.
Step 4: Verify the connection
In Kiro IDE, restart Kiro (or reconnect MCP servers from the MCP Server view in the Kiro feature panel). Then open the Kiro chat and enter the following prompt:
If everything is configured correctly, Kiro discovers your clusters and lists them with details like cluster identifiers, status, node types, and endpoints.
Practical examples
The following scenarios show how Kiro and the Amazon Redshift MCP server work together in real-world workflows.
Tip: If you want Kiro to show the SQL that it executes alongside every result, tell it at the beginning of your session:
For every query you run against Amazon Redshift, show me the exact SQL you executed along with the results.
Kiro follows this instruction for the rest of the conversation. For a permanent setup, add this rule to a steering file (see the Tips section that follows) so you don’t need to repeat it. The following examples reflect this behavior.
Example 1: Discover and explore your infrastructure
Without Kiro: Log in to the AWS Management Console, navigate to Amazon Redshift, choose clusters, open the query editor, sign in to each database, and manually browse schemas.
With Kiro:
Kiro responds with a structured overview:
Found two provisioned clusters and one serverless workgroup:
- analytics-cluster (provisioned, 2x ra3.xlplus nodes, available)
- reporting-cluster (provisioned, 4x ra3.4xlarge nodes, available)
- etl-workgroup (serverless, available)
Then drill deeper:
Kiro uses the MCP metadata tools to explore the cluster. No SQL is needed for discovery:
Database: analytics_db (local)
information_schema— system schemapg_catalog— system schemapublic— default schemasales— user-created schema
Database: dev (local)
information_schema— system schemapg_catalog— system schemapublic— default schema
The only user-created schema is sales in the analytics_db database.
There are five base tables in analytics_db.sales:
customersorder_itemsordersproductsreturns
| Column | Type | Nullable |
order_id |
INTEGER | NO |
customer_id |
INTEGER | NO |
order_date |
TIMESTAMP | NO |
total_amount |
numeric(12,2) | NO |
status |
VARCHAR(20) | YES |
Each request builds on the previous context. Kiro remembers which cluster you’re exploring and navigates the hierarchy for you.
Example 2: On-demand data analysis in plain English
Without Kiro: Write SQL from scratch, guess at column names, run the query, fix syntax errors, iterate.
With Kiro:
Kiro does the following:
- Identifies the relevant cluster and database.
- Explores the schema to find customer and order tables.
- Understands the table relationships.
- Generates and runs the appropriate SQL, showing you the query first.
- Presents the results in a readable format.
The response includes the query and results:
Query executed:
| customer_id | customer_name | total_orders | total_spent |
| 4821 | Acme Corp | 347 | $1,284,500.00 |
| 1190 | Globex Inc | 289 | $1,102,340.00 |
| 7734 | Initech LLC | 256 | $987,210.00 |
| … | … | … | … |
You didn’t need to remember table names, column names, or join conditions. Kiro figured it out by exploring the metadata first. You can see exactly what it ran, copy the SQL, and reuse it.
Example 3: Cross-cluster data comparison
Without Kiro: Open two SQL clients, sign in to different clusters, run similar queries, manually compare results in a spreadsheet.
With Kiro:
Kiro queries both environments, aligns the results, and provides a comparison, showing every query it runs along the way.
Query executed on analytics-cluster:
Query executed on etl-workgroup:
Sales data comparison: Analytics vs ETL.
| Metric | Analytics Cluster | ETL Workgroup | Status |
| Total Records | 172,456 | 172,456 | Match |
| Total Revenue | $110,765,431 | $110,765,431 | Match |
| Q4 Transactions | 38,061 | 38,061 | Match |
Because both queries are visible, you can verify that Kiro compared the same metrics on both sides, with no hidden assumptions.
Example 4: Schema documentation on demand
Without Kiro: Manually document table structures in a wiki or spreadsheet. Documentation frequently falls out of date.
With Kiro:
Kiro explores every table using the discovery tools and produces structured documentation.
Table: sales.customers
| Column | Type | Nullable | Description |
customer_id |
INTEGER | NO | Primary key |
customer_name |
VARCHAR(255) | NO | |
email |
VARCHAR(255) | YES | |
created_at |
TIMESTAMP | NO |
Table: sales.orders
| Column | Type | Nullable | Description |
order_id |
INTEGER | NO | Primary key |
customer_id |
INTEGER | NO | FK to customers |
order_date |
TIMESTAMP | NO | |
total_amount |
numeric(12,2) | NO | |
status |
VARCHAR(20) | YES |
(continues for all tables in the schema…)
You can paste this directly into your team wiki or README, and anyone can rerun the same discovery flow to refresh the docs later.
Example 5: Troubleshooting data quality
Query executed:
Out of 172,456 rows: 0 NULL customer_ids, 3 NULL total_amounts.
Query executed:
Found two duplicate order_ids: order 88412 (two occurrences), order 91003 (two occurrences).
Query executed:
Date range: 2024-01-01 to 2025-04-20. Found three missing dates: 2024-03-15, 2024-07-04, 2024-12-25 (likely holidays).
Every query is right there in the response. You can copy them into your own SQL client, modify them, or save them as reusable scripts.
Tips for getting the most out of Kiro and Redshift
- Start with discovery. Begin each session by asking Kiro to list your clusters and explore the database structure. This gives the agent context for subsequent queries.
- Be specific about which cluster. If you have multiple clusters, mention the cluster name in your request to avoid ambiguity.
- Iterate gradually. Start with simple questions and build complexity. Ask for a count before asking for a full breakdown.
- Use steering files for team conventions. Create a
.kiro/steering/redshift.mdfile in your project with details about your cluster naming conventions, important schemas, and common query patterns. This gives Kiro persistent context about your environment.
Example steering file:
That last Query Transparency rule is a small addition with a big impact. By default, Kiro might summarize results without showing the underlying SQL. Adding this steering instruction makes every query visible, which helps maintain consistent behavior across your data team and supports auditing, learning, and trust.
- Use hooks for automation. Set up agent hooks to run common validation queries automatically. For example, trigger a data quality check whenever you edit a specific SQL file.
- Verify important results. Always cross-check critical business findings with stakeholders before acting on them.
Security tips
When configured with least privilege IAM policies and Supervised mode, the Redshift MCP server provides multiple layers of protection. Under the AWS shared responsibility model, you are responsible for configuring access controls appropriately.
Safety layers at a glance
- Data stays in your account. The MCP server runs locally, queries run inside your Amazon Redshift cluster, and no data is sent to third-party services.
- Content not used for training. Enterprise users are excluded from service improvement usage. Free or individual tier users can opt out in Kiro settings.
- Read-only by default. Every query is wrapped in a read-only transaction, preventing accidental writes.
- Standard IAM controls. Kiro only gets permissions you’ve explicitly granted.
- Supervised mode. Review each agent action before it’s applied in production environments.
Important caveat: The read-only enforcement only applies to queries routed through the MCP server’s execute_query tool. Kiro also has shell access. If your IAM credentials have write permissions, direct CLI calls (aws redshift-data execute-statement) bypass this guardrail entirely.
Takeaway: Use least privilege IAM policies (scoped to read and describe operations only) as your primary defense. Avoid broad policies like AdministratorAccess or AmazonRedshiftFullAccess. When IAM is properly scoped, even a direct CLI call cannot perform writes.
Verify Kiro’s output
Kiro is a powerful assistant, but it’s not infallible. Like any AI tool, it can misinterpret your intent, generate incorrect SQL, or present results that look plausible but are wrong. Examples include a misplaced join, a wrong filter, or an aggregation that silently excludes rows. This is especially important when working with production data where decisions have real business impact.
Treat Kiro’s output as a strong starting point, not a final answer. Review the SQL it generates before acting on the results. Use the Query Transparency steering rule (described in the Tips section) so you can see the exact query behind every result. When findings inform business decisions, validate them independently by running the query yourself, cross-checking with a colleague, or comparing against a known baseline.
Summary
| Layer | What it protects against |
| MCP server read-only mode | Accidental writes through the MCP execute_query tool |
| Least privilege IAM policy | Write operations via any path, including direct CLI calls |
| Kiro Supervised mode | Unreviewed autonomous actions by the agent |
Defense in depth: use these layers together for production environments.
What you can achieve with Kiro and Amazon Redshift
| Before | Now you can |
| Switch between the console, SQL clients, and documentation | Use one interface for discovery, querying, and analysis |
| Memorize cluster endpoints, database names, and schemas | Ask in plain text and let Kiro discover the structure |
| Write SQL from scratch for every query | Describe what you want and get results |
| Manually compare data across clusters | Run single-sentence cross-cluster analysis |
| Schema documentation is frequently stale | Generate fresh docs on demand |
| Onboarding new analysts takes days | New team members can explore immediately |
Every minute you spend hunting for a table name or debugging a SQL syntax error is a minute that you’re not spending on actual analysis. You can reduce that overhead by letting Kiro handle the mechanical parts (discovery, navigation, and query construction) so you can focus on the questions that matter to your business.
Cleaning up
If you created Amazon Redshift resources specifically for this walkthrough, or if you no longer need the MCP server integration, follow these steps. They help you avoid ongoing charges and remove the configuration.
- Remove the MCP server configuration.
- Detach the IAM policy.
- Delete test Amazon Redshift resources (if applicable).
- Uninstall uv (optional).
Conclusion
In this post, you learned how to set up Kiro with the Amazon Redshift MCP server to query your data warehouse using natural language. You explored cluster discovery, schema browsing, analytical queries, cross-cluster comparisons, and data quality checks, all without writing SQL from scratch or switching between tools.
To go further:
- New to Amazon Redshift? Get started with Amazon Redshift to create your first cluster or serverless workgroup.
- Read the MCP protocol specification to understand how AI agents work with external tools.
- Visit kiro.dev for Kiro’s full capabilities, including specs, hooks, and steering files.
As you get comfortable with the basics, try combining steering files with agent hooks to automate recurring workflows like daily data quality checks or weekly schema documentation refreshes.
About the author
Amazon Cognito unlocks advanced capabilities with next-generation infrastructure
Post Syndicated from Howie Li original https://aws.amazon.com/blogs/security/amazon-cognito-unlocks-advanced-capabilities-with-next-generation-infrastructure/
Amazon Cognito recently introduced high-throughput performance for demanding workloads, customer-managed keys for full control over data encryption at rest, and multi- Region replication for business continuity improvement. These capabilities were made possible through a next-generation storage infrastructure designed for extensibility and scale. To deliver this, we migrated hundreds of millions of user profiles, and you probably didn’t even notice. In this post, we walk through what’s new, the architecture behind it, and how we got here with a zero-downtime migration that kept your applications running.
New capabilities now available on Cognito
The migration to the new infrastructure wasn’t just about maintaining existing functionality—it created the foundation for delivering capabilities that solve customer challenges while positioning Amazon Cognito for continuous improvements.
High-throughput performance: The new architecture supports the higher request volumes and scale requirements of modern applications while maintaining the low latency performance that your applications depend on—able to support tens of millions of users per user pool and thousands of transactions per second (TPS).
Customer-managed keys: Customers can now use their own encryption keys stored in AWS Key Management Service (AWS KMS) for encrypting data at rest. This provides enhanced security control and capabilities, giving customers full ownership over their encryption key lifecycle.
Multi-Region replication: Customers can now synchronize their entire user pool data, including user passwords, attributes, and configurations to another user pool in another Region of their choice. This means that customers can implement business continuity strategies and maintain authentication availability in case of a Regional failover, helping their applications remain accessible to users even during unexpected disruptions.
An architecture for innovation
The new architecture uses a purpose-built storage layer designed for extensibility and scale of identity operations. We anchored the new architecture around a set of design tenets:
- Identity-first design: The storage layer understands user identities. There’s no client-specific business logic and no generalizations beyond identity management; keeping the system focused, portable, and optimized.
- Avoid one-way doors: Deliver value incrementally while keeping architectural choices reversible, so we can evolve as new needs arise.
- Backward compatible: Changes to the underlying infrastructure should never break customers’ applications.
These tenets shaped every architectural decision. The architecture separates into independently deployable domains. Previously, while using Amazon Cloud Directory, the service architecture relied on a single data store to persist all customer information. This provided straightforward data traversal mechanisms but required multi-service coordination to adjust database schema when new features were required. The new architecture uses different datasets, allowing them to evolve independently for faster feature iterations.
Migration with zero-downtime
Migrating users requires extreme precautions and a strategy designed to maintain zero downtime and ensure data integrity at every step. Our approach prioritizes both immediate stability and long-term flexibility through the following measures:
- Shadow mode validation: We ran customer API requests through both old and new infrastructures simultaneously, comparing response structures, status codes, and behavioral characteristics. The validation was designed so that sensitive information was never exposed in plaintext during comparison. We accounted for known variances—for example, timestamps could differ slightly between systems—so that only meaningful discrepancies surfaced as actionable alerts.
- Data backfill: Before switching a user pool to the new infrastructure, we performed a bulk backfill of all existing user records from the legacy system into the new storage. The backfill ran alongside live traffic with dual-write capturing any changes made during the backfill window, ensuring no data loss or stale data. Shadow mode served as the validation layer for the backfill; as we addressed more edge cases in data syncing, shadow mode match rates increased, confirming data completeness before we proceeded to the switchover.
- Dual-write architecture: We implemented a system where all identity operations were simultaneously written to both legacy and new services, with comprehensive validation to ensure consistency. Even when a dual-write to the new infrastructure failed, the operation still succeeded in the legacy system, preserving all customer-initiated requests. This means any dual-write failure was contained as an internal consistency issue and not customer-impacting.
- Anti–entropy validation: We implemented a data validation and correction system that continuously compared records across old and new infrastructures, detecting and resolving any data divergence. Anti-entropy scans compared user attributes, credential hashes, group memberships, and configurations, among other records. When true discrepancies were found, the system automatically reconciled them using the legacy system as the source of truth. This layer was able to catch edge cases that shadow mode and dual writes alone could not cover.
- Incremental rollout with rollback capability: We established controlled deployment phases with immediate rollback capabilities. After switching a user pool to the new infrastructure, we continued replicating all writes back to the legacy system, ensuring we can revert any user pool to the legacy infrastructure at any point without data loss. If a rollback was needed during migration, an orchestrator replayed entries in timestamp order, syncing user profiles back to the legacy system.
Lessons learned for infrastructure modernization
This modernization taught us valuable principles that apply to any large-scale infrastructure project, therefore we choose to share these learnings to help you perform similar migrations.
- Customer access patterns drive architecture decisions: Analyzing actual customer access patterns revealed that identity workloads follow predictable patterns, which meant we could adopt a synchronous dual-write approach that balanced completeness with operational simplicity. This principle applies to any domain-specific migration: understand your workload’s actual access patterns before reaching for general-purpose solutions.
- Behavioral preservation requires techniques beyond traditional testing: Ensuring equivalent functionality across old and new systems was straightforward. Preserving identical API behavior was not. Functional tests validate intended behaviors, but we identified scenarios where customers had built applications around specific API behaviors such that a change could have silently broken their applications. For example, concurrent writes to the same user could resolve to different final states between old and new systems where writes all succeed but outcome diverges slightly. Similarly, customers who write an attribute and immediately read it are affected by the consistency window. Subtle timing differences in when updates become visible could cause stale reads. These aren’t functional failures, but behavior under real traffic patterns can vary. Shadow mode verification surfaced edge cases that automated tests alone would have missed. Invest in these techniques early.
- Gradual validation builds confidence that testing alone cannot: Layer multiple independent validation techniques, such as shadow mode, dual writes, and anti-entropy scans—each covering a different access pattern. No single approach will catch everything, and the gaps between them are where production issues hide. Incremental rollout with immediate rollback capability lets you validate each step while maintaining the ability to revert quickly.
- Key principles for your own modernization projects: Invest in purpose-built solutions, design for extensibility, and implement gradual validation. Or use managed services so your infrastructure improves without effort on your part while your applications keep running; helping you focus on your business needs.
Conclusion
In this post, we shared the high-level approach and learnings from the Amazon Cognito infrastructure modernization that create a foundation for modern identity management capabilities. The new Cognito infrastructure is live, delivering capabilities such as customer-managed keys and multi-Region replication. As the migration continues, all Cognito customers will gain access to these capabilities on the same service they rely on today, with no action required.
Ready to modernize your authentication infrastructure? Visit Amazon Cognito to learn more.
If you have feedback about this post, submit comments in the Comments section below.
How the Supreme Court May Have Undermined Its Own Stability
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/hwb4g7KGYp4
Gain visibility into DDoS attacks with flow logs in AWS Shield Advanced
Post Syndicated from Ken Kitts original https://aws.amazon.com/blogs/security/gain-visibility-into-ddos-attacks-with-flow-logs-in-aws-shield-advanced/
Reconstructing distributed denial of service (DDoS) attack traffic used to mean combining data from multiple sources after the fact. AWS Shield Advanced attack flow logs change that—they capture traffic metadata during attacks so you can pinpoint sources, verify mitigations, and feed your existing analysis pipelines.
Shield publishes logs to Amazon Simple Storage Service (Amazon S3), Amazon CloudWatch Logs, or Amazon Data Firehose using the same CloudWatch Logs delivery infrastructure as other AWS flow logs, so they fit directly into the monitoring and analysis tools you already use.
In this post, you will learn how Shield Advanced attack flow logs capture metadata during DDoS events, what each field in a flow log entry means, and how to enable and configure flow logging for your protected resources.
How DDoS attacks affect your applications
A DDoS attack floods an application with traffic, making it unavailable to users. Infrastructure-layer attacks saturate bandwidth and exhaust connection tables—you see packet loss and timeouts.
Shield Advanced is a managed DDoS protection service that detects and mitigates attacks for Amazon CloudFront distributions, Elastic Load Balancing load balancers, Amazon Route 53 hosted zones, AWS Global Accelerator standard accelerators, and Elastic IP (EIP) addresses. See the AWS Shield Advanced documentation for full coverage details. Initially, Shield Advanced will provide infrastructure-layer attack flow logs for EIP protections, with support for additional resource types to follow.
Key benefits
Flow logs help you understand attacks in several ways:
- Reconstruct traffic patterns – Query logs after an attack to analyze volume, source distribution, and protocol mix without relying only on aggregate CloudWatch metrics.
- Identify attack origins – The
srccountryandlocationfields show where traffic originated and which AWS edge location it entered. - Verify mitigation behavior – The action field records what Shield did with each flow.
Logs go to Amazon S3, CloudWatch Logs, or Data Firehose. You can then query them with Amazon Athena (a serverless query service for analyzing data in Amazon S3), route them to third-party Security Information and Event Management (SIEM) platforms or build CloudWatch Logs Insights queries (an interactive log analysis feature) without deploying new infrastructure.
What attack flow logs capture
Log records capture source and destination IP addresses and ports, protocol, packet and byte counts, the action Shield Advanced took, and TCP flags. They also include the AWS ingress location where traffic entered and a two-letter country code for the traffic source when available. Logs are written at 5-minute intervals and are available during an active attack and after it concludes.
The maximum file size is 75 MB. If a file reaches that limit within the 5-minute window, the file will be closed, published, and a new file will start. Flow logs support JSON, plain text, W3C, and Parquet output formats and contain the following fields:
| Field | Description |
| protection_arn | Amazon Resource Name (ARN) of the Shield protection |
| event_timestamp | Timestamp of log generation |
| version | Flow log version number |
| srcaddr | Source IP address |
| dstaddr | Destination IP address |
| srcport | Source port |
| dstport | Destination port |
| protocol | IP protocol number |
| packets | Packet count within the aggregation window |
| bytes | Byte count within the aggregation window |
| starttime | Aggregation window start time |
| endtime | Aggregation window end time |
| action | Action taken by Shield |
| location | AWS ingress location |
| sampling_rate | Sampling rate used during packet processing |
| tcp_flags | TCP flags from the packet |
| srccountry | Two-letter country code for the traffic source |
How to configure flow logs for Shield Advanced protected resources
The following steps walk you through creating the CloudWatch Logs delivery resources that connect a Shield Advanced protection to your preferred log destination.
Prerequisites
Before configuring flow logs, make sure you have:
- An active Shield Advanced subscription
- At least one existing Shield Advanced protection
- AWS Identity and Access Management (IAM) permissions to create CloudWatch Logs delivery resources (
logs:PutDeliverySource,logs:PutDeliveryDestination,logs:CreateDelivery)
Flow logs incur standard CloudWatch Logs vended log charges, and the destination resources (S3 bucket storage, CloudWatch Logs log group storage, or Firehose data processing) incur separate charges. Review the Vended Logs entry on the CloudWatch pricing page and the pricing for your chosen destination service before enabling flow logs on high-traffic resources.
How it works
Log delivery requires three objects:
- DeliverySource – Represents the Shield Advanced protection that produces the logs
- DeliveryDestination – Represents where logs should be sent (Amazon S3, CloudWatch Logs, or Amazon Data Firehose)
- Delivery – Connects the source to the destination
This three-object model lets you reuse destinations across multiple sources and manage delivery pipelines independently. For example, you can send logs from multiple Shield protections to the same S3 bucket by creating multiple DeliverySource objects that reference the same DeliveryDestination.
Because Shield Advanced attack flow logs use the CloudWatch Logs delivery infrastructure, you can aggregate them across accounts and Regions just like other vended logs. Deliver directly to a centralized S3 bucket with a cross-account policy, replicate CloudWatch Logs log groups using cross-account cross-Region centralization rules, or stream to a shared Firehose stream using cross-account subscriptions. Explore these options to build a unified view of DDoS attack traffic across your multi-account, multi-Region footprint.
Step 1: Create your destination resource
Choose a destination:
- Option A – S3 bucket: Best for long-term storage and Athena queries. See Creating an S3 bucket.
- Option B – CloudWatch Logs log group: Best for real-time monitoring and CloudWatch Logs Insights. See Create a log group in CloudWatch Logs.
- Option C – Data Firehose delivery stream: Best for streaming to third-party tools and SIEMs. See Create a Firehose stream.
Step 2: Configure the destination resource policy (if needed)
The destination resource needs a policy that grants the CloudWatch Logs delivery service write permissions. The policy varies by destination type. For more information, see Logs sent to Amazon S3, Logs sent to CloudWatch Logs, or Logs sent to Firehose.
For Amazon S3 destinations, you have two options:
- Automatic policy creation: If your bucket has no existing resource policy and you have the
s3:GetBucketPolicyands3:PutBucketPolicypermissions, AWS automatically creates the required policy when you create the delivery in step 6. You can skip to step 3. - Manual policy update: If you need to customize the policy or your organization requires pre-approved policies, create the policy manually by following the instructions for Logs sent to Amazon S3.
Step 3: Get your protection ARN
Shield Advanced is a global service and uses the us-east-1 AWS Region for management. Run the following command to list your Shield Advanced protections.
In the output, copy the ProtectionArn value for the protection you want to log.
Step 4: Create a delivery source
Run the following command to create the delivery source, replace <protection-arn> with the ProtectionArn value from step 3.
The --resource-arn is the ARN of your Shield Advanced protection—not the protected resource itself. Shield Advanced creates a separate protection object that wraps your resource, and flow logs are generated by that protection layer rather than the underlying resource.
Step 5: Create a delivery destination
Run the following command to create the delivery destination, replace <resource-arn> with the ARN of the destination resource you created in step 1.
The --delivery-destination-configuration parameter takes a JSON object with a destinationResourceArn key whose value is the ARN of your S3 bucket, log group, or Firehose stream.
In the output, copy the value of the top-level ARN field—this is the delivery destination ARN (different from the bucket ARN). You will use this in step 6.
Step 6: Create the delivery
Run the following command to connect the delivery source to the delivery destination, replace <delivery-destination-arn> with the delivery destination ARN from step 5.
Step 7: Verify the delivery
Run the following command to confirm the delivery is active.
After delivery is active, Shield Advanced publishes flow log records to your destination during DDoS events.
Clean up
To avoid ongoing charges, delete the resources you created.
- Delete the delivery:
- Delete the delivery source:
- Delete the delivery destination:
- (Optional) Back up flow log data if you need to retain logs for compliance or analysis.
- Delete the destination resource. Warning: Deleting the destination resource will permanently delete all flow log data.
For an S3 bucket:
For a CloudWatch Logs log group:
For a Firehose stream:
Conclusion
Shield Advanced attack flow logs provide the visibility you need to understand and respond to DDoS attacks effectively. By integrating with your existing observability infrastructure, they deliver actionable insights without requiring new tooling or complex setup. Enable flow logs on your Shield Advanced protections today to gain immediate visibility into attack patterns and strengthen your DDoS defense posture.
Next steps:
- Build an Athena table to query logs in Amazon S3
- Interactively search and analyze your log data in Amazon CloudWatch Logs
- Create CloudWatch alarms on attack patterns
For the full reference about flow log configuration, see the AWS Shield Advanced documentation.
If you have feedback about this post, submit comments in the Comments section below.
Getting started with Amazon SES Agent Skills for AI-assisted email development
Post Syndicated from Bruno Giorgini original https://aws.amazon.com/blogs/messaging-and-targeting/getting-started-with-amazon-ses-agent-skills-for-ai-assisted-email-development/
Building email infrastructure with Amazon Simple Email Service (SES) involves navigating identity verification, authentication protocols, configuration sets, bounce handling, and deliverability monitoring. Developers often spend time reading documentation and iterating on API calls before getting their first email sent correctly. AI coding agents can accelerate this process, but without domain-specific context, they frequently generate code using the legacy V1 API, skip authentication setup, or miss production requirements like tenant isolation.
Today, we are releasing Amazon SES Agent Skills, an open source set of agent skills that give AI coding agents the context they need to build email integrations correctly from the start. The skills work with Kiro, Claude Code, and any agent that supports the open Agent Skills format.
What are agent skills?
Agent skills are structured context packages that teach AI agents how to use a specific service correctly. Rather than relying on general training data (which may be outdated or incomplete), a skill provides the agent with validated patterns, common mistake avoidance, and step-by-step workflows for a specific domain.
When you install the Amazon SES agent skills, your AI agent gains access to:
- The correct API version and SDK client to use (SES V2, not V1)
- The required order of operations (verify identity before sending, create configuration set before going to production)
- Production-ready patterns including tenant isolation, bounce handling, and email validation
- Common mistakes and how to avoid them
- Executable example scripts in Python, Node.js, and Java
Two skills, two use cases
Amazon SES has two distinct capabilities that use different API clients:
| Skill | Use case | SDK client |
|---|---|---|
aws-ses |
Sending email (transactional, marketing, notifications) |
sesv2 |
aws-mail-manager |
Receiving and processing inbound email (routing, filtering, archiving, SMTP relay) |
mailmanager |
These are different APIs with different clients. A common mistake agents make without this context is mixing them up or using the legacy ses client for sending.
Installing the skills
Install both skills:
npx skills add amazon-ses/skills
Or install a specific skill:
npx skills add amazon-ses/skills --skill aws-ses
npx skills add amazon-ses/skills --skill aws-mail-manager
Once installed, the skill activates automatically when you ask your agent about email-related tasks.
What the agent experience looks like
After installing the aws-ses skill, ask your agent: “Help me send my first email with Amazon SES.”
Without the skill, an agent might generate code using the deprecated V1 API, skip identity verification, or omit a configuration set. With the skill, the agent follows the correct workflow:
- Verifies your identity is set up (domain or email address)
- Checks sandbox status and recommends simulator addresses for testing
- Creates a configuration set for event tracking
- Sets up a tenant for workload isolation
- Generates code using the V2 API with proper error handling
Here is an example of what the agent produces for a Python quickstart:
import boto3
from botocore.exceptions import ClientError
client = boto3.client('sesv2', region_name='us-east-1')
try:
response = client.send_email(
FromEmailAddress='[email protected]',
Destination={'ToAddresses': ['[email protected]']},
Content={
'Simple': {
'Subject': {'Data': 'Hello from Amazon SES'},
'Body': {'Text': {'Data': 'This email was sent using Amazon SES V2 API.'}}
}
},
ConfigurationSetName='my-config-set',
TenantName='my-tenant'
)
print(f"Message sent: {response['MessageId']}")
except ClientError as e:
print(f"Send failed: {e.response['Error']['Code']} - {e.response['Error']['Message']}")
The agent knows to use sesv2 (not ses), includes a configuration set for observability, uses a tenant for isolation, and sends to a simulator address for safe testing.
What the Mail Manager skill provides
For inbound email processing, the aws-mail-manager skill teaches the agent the core pipeline architecture:
Internet → Ingress Point → Traffic Policy → Rule Set → Action
The skill ensures the agent creates resources in the correct dependency order (traffic policy and rule set before ingress point), uses the correct condition syntax (union types with exactly one key per object), and waits for the ingress point to reach ACTIVE status before recommending DNS changes.
How the skills are structured
Each skill contains:
- SKILL.md — The entry point that describes capabilities, common mistakes, and when to use the skill
- references/ — Task-oriented guides for specific workflows (identity verification, configuration sets, tenant setup, troubleshooting)
- scripts/ or examples/ — Executable code the agent can reference or adapt
The agent loads only the context relevant to your current task. Ask about sending email and it loads the sending guides. Ask about archiving inbound email and it loads the archive reference.
Prerequisites
To use the skills, you need:
- An AI coding agent that supports the Agent Skills format (Kiro, Claude Code, or compatible tools)
- An AWS account with Amazon SES access
- AWS credentials configured (environment variables, shared credentials file, or IAM role)
- The SDK for your language: Python (
boto3), Node.js (@aws-sdk/client-sesv2), or Java (software.amazon.awssdk:sesv2)
Try it today
The Amazon SES Agent Skills are available now on GitHub:
- Repository: amazon-ses/skills
- License: Apache-2.0
Install the skills, ask your agent to help you send your first email, and see how structured context changes the development experience. If you find issues or want to contribute, open an issue or pull request on the repository.
Additional resources
[$] Splicing out vmsplice()
Post Syndicated from corbet original https://lwn.net/Articles/1075838/
The splice()
and vmsplice()
system calls are meant to improve performance for certain data-movement
tasks by minimizing (or avoiding altogether) system calls and the copying
of data. They also have a long history of security problems. The recent
flood of LLM-discovered vulnerabilities has drawn attention, once again, to
splice() and vmsplice(); as a result, they may end up
being removed altogether.
Japan’s District Mascots: Last Week Tonight with John Oliver (Bonus Segments)
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=UMG5_6ybpV0
Trump’s Pardons & Jan. 6th #lastweektonight
Post Syndicated from LastWeekTonight original https://www.youtube.com/shorts/quoewSXtGq4
Customize federated sign-in with new Amazon Cognito Lambda trigger
Post Syndicated from Abrom Douglas original https://aws.amazon.com/blogs/security/customize-federated-sign-in-with-new-amazon-cognito-lambda-trigger/
You can use Amazon Cognito user pools to add sign-up and sign-in functionality to your web and mobile applications. You can authenticate users directly with Amazon Cognito managed accounts using passwords, passwordless flows, or custom authentication flows, or let users federate in through external identity providers (IdP) using SAML, OpenID Connect, or social providers such as Google, Facebook, Sign in with Apple, or Login with Amazon. For consumers, identity federation means fewer passwords to remember and a smoother sign-in experience. For business-to-business (B2B) software as a service (SaaS) providers, it means your tenants’ organizations keep control of their own identities rather than managing credentials on their behalf. But federation can also introduce challenges for enterprises and application developers. What happens when your enterprise customer’s SAML provider sends hundreds of group memberships that exceed attribute size limits? Or when your ecommerce customer forgets they already have an account and tries to sign in with a different social provider, creating duplicate records?
In this blog post, I introduce the inbound federation Lambda trigger for Amazon Cognito, a new feature that gives you programmatic control over federated authentication flows. This AWS Lambda trigger intercepts the federated authentication response immediately after your external identity provider responds to Cognito, so you can transform, filter, and enrich user attributes before the user profile is created and user attributes are mapped in your user pool.
Understanding the inbound federation Lambda trigger
The inbound federation Lambda trigger is invoked after your Amazon Cognito user pool has received and verified the response from the external IdP. The request payload for the federated IdP response is then sent from Cognito to your Lambda function and you will receive the following information:
- The common parameters of Amazon Cognito Lambda triggers (including
userPoolIdandclientId) - Which external IdP was used (for example,
providerName) - The
providerType(SAML, OIDC, Login with Amazon, and so on) - Attribute data from the external IdP specific to the user signing in
The specific format of this attribute data depends on the provider type, view the Inbound federation Lambda trigger parameters section in the docs to learn more. If the external IdP is a SAML provider, you will receive a JSON key-pair listing of the user’s attributes from the IdP assertion. If the external IdP is an OIDC provider (or social provider), you will receive the access token and attribute data from the /userinfo endpoint, along with an ID token if one was provided. See Figure 1 for a detailed flow of a federated sign-in with an Amazon Cognito user pool configured to use the inbound federation Lambda trigger.
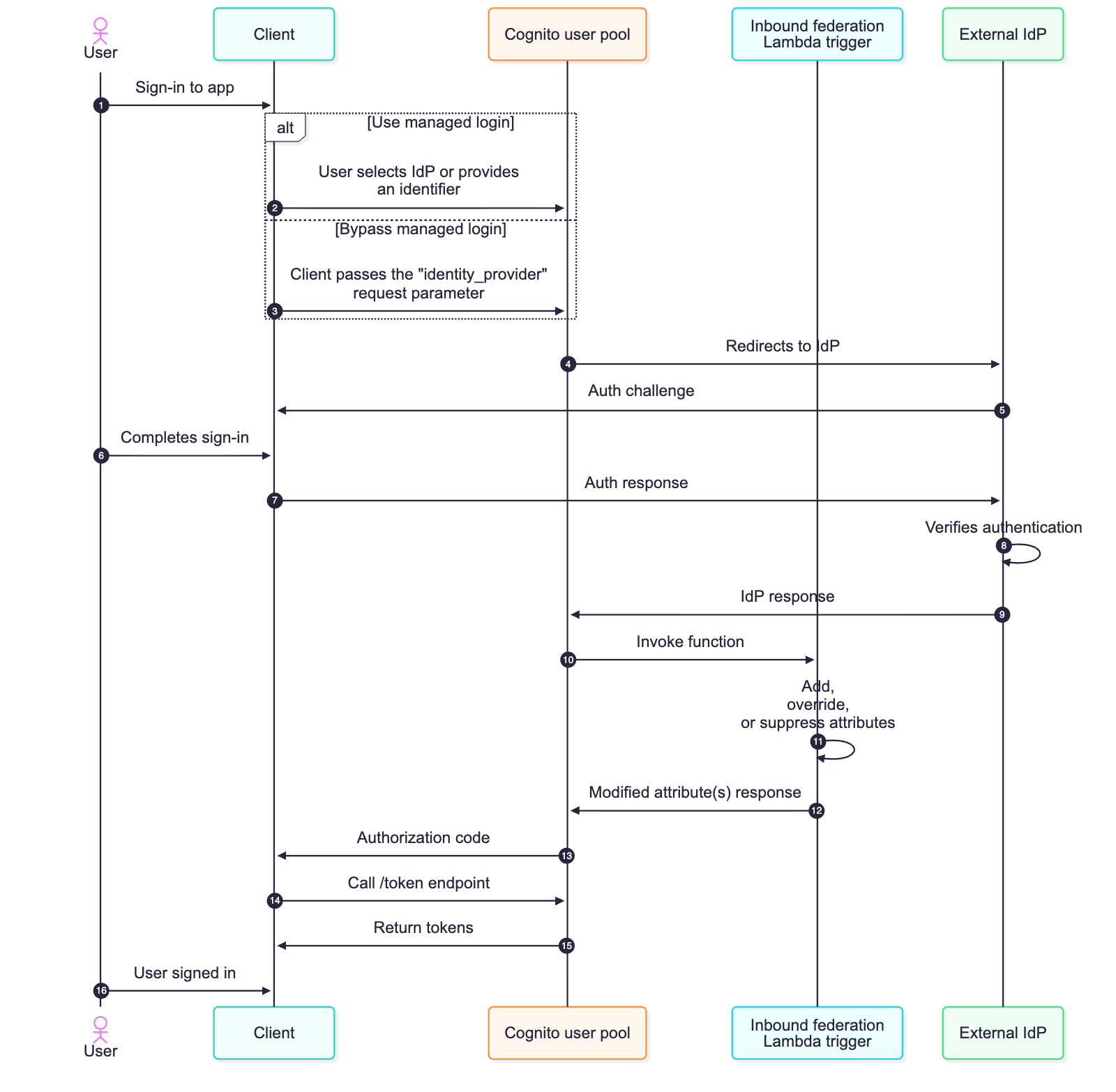
Figure 1: Sequence flow of a federated login configured with the inbound federation Lambda trigger
- The user begins using the application but is required to sign in first.
- The managed login is rendered, and the user can select which IdP they want to sign in with. If identifiers are used with SAML or OIDC providers, the user enters their email address and Amazon Cognito looks up the domain of their provided email and routes them to the appropriate IdP.
- Alternatively, the managed login can be bypassed by the client providing the identity_provider request parameter.
- Amazon Cognito sends the authentication request to the appropriate IdP.
- The external IdP challenges the user to sign in.
- The user completes the sign-in process required by the external identity provider.
- The challenge response is sent to the external IdP.
- The IdP verifies that the sign-in is successful. If there are any subsequent challenges, such as multi-factor authentication (MFA), additional rounds of authentication challenges and responses take place. This is determined by the configuration and settings of the external IdP.
- The external IdP sends a response to the Amazon Cognito user pool, and Cognito validates the cryptographic signature and that it hasn’t been tampered with.
- Amazon Cognito sends attribute data from the IdP to the inbound federation Lambda function
- Attribute data for the authenticated user and the common parameters for Amazon Cognito are available for the Lambda function to add, modify, or suppress according to your requirements.
- Your added, modified, or suppressed attributes are returned to Amazon Cognito. These are attribute values that map to the user’s profile in Cognito—whether the user profile was just created or is being updated for a returning user.
- Continuing the OAuth 2.0 authorization code grant, Amazon Cognito sends an authorization code to the client.
- The client then calls the
/tokenendpoint with the authorization code.
Note: It’s a security best practice to use confidential clients and to use OAuth 2.0 Proof Key for Code Exchange (PKCE) extension whenever possible. - An access, ID, and refresh token is returned to the client.
- The user has signed into the application. ID tokens can be used to identify who the user is (authentication), and access tokens can be used to determine what the user can do (authorization).
Common federation challenges and use cases
Federation introduces complexity that varies depending on your use case. For B2B and SaaS applications, you’re often not in control of your customers’ IdPs, including what attributes they send or how they format them. As an example, an enterprise customer will configure their SAML response to include every group a user belongs to. This could be hundreds of groups or long group identifiers, and if the group membership of the user is mapped to an Amazon Cognito attribute, this can lead to a scenario where the Cognito attribute size limit is exceeded, causing federated sign-ins to fail.
Challenges for business-to-customer (B2C) applications can differ from B2B use cases. For B2C applications, organizations shouldn’t be required to think about identity providers. The ability to sign-up and sign-in should be seamless for consumer-facing applications. Customers visiting a consumer-facing application might create an account with email and password, forget they created created it, and then later try signing in with Facebook (or other social provider). Without proper account linking in Amazon Cognito, you then have multiple user records for the same user, which could lead to fragmented purchase history and a frustrating customer experience.
Both B2B and B2C use cases might need to look up external data just prior to completing the sign-in process, such as additional roles and access for B2B users or looking up active orders for B2C users. Another example could be the need to normalize data just prior to storing it in the user profile within the Amazon Cognito user pool or even discarding personally identifiable information (PII) prior to storing it in your Cognito user pool.
With the inbound federation Lambda trigger, you can handle these B2B and B2C use cases programmatically, and do so without requiring modification of your applications or coordinating IdP-specific changes with external IdPs. In this section, I dive deeper into two common use cases: oversized group attributes, common with B2B customers, and automated account linking, common with B2C customers.
Use case 1: Filtering oversized group attributes
If you have B2B and SaaS use cases, it’s a common practice to use group membership from the IdP to determine the level of access you have within the SaaS service. This is a great way to still provide some access control back to the enterprise customers themselves. The groups can be used to represent the roles a user will have or for some form of coarse-grained authorization. However, your customers might inadvertently send a large number of groups a user is a member of, thus leading to an oversized attribute payload.
Another common scenario is where the syntax and format of group name a user belongs to can arrive in various formats across different IdPs; such as a canonical name (for example, example.com/groups/myApp-readOnly), a distinguished name (common with LDAP based systems and such as cn=myApp-readOnly,OU=groups,DC=example,DC=com), or a plain text string (such as myApp-readOnly). Instead of having downstream authorization logic to accommodate different variations of a group name, you can now normalize how groups are represented prior to storing the user’s attribute data using the inbound federation Lambda trigger.
To expand this, imagine your enterprise customer uses a SAML IdP, such as Active Directory Federation Services (AD FS), in front of Active Directory (AD). When their users authenticate, AD FS sends a groups attribute containing every AD group the user belongs to. For users in large organizations, this can be hundreds of groups, and the attribute is mapped to an Amazon Cognito attribute, this could result in a string that exceeds 2,048-character limit per attribute of Cognito. Authentication would fail in this scenario, ultimately leading to support tickets because enterprise customers would be unable to sign in. Even if certain users didn’t exceed this limit, because of a smaller number of group memberships, this would result in the collection and storing of unnecessary data in your Cognito user pool.
Previously, you would need to work with your customer’s IT department to modify their SAML configuration to filter groups at the source—a process that could take weeks and require multiple approval cycles because it involves a change to the federation configuration. Especially for SaaS customers, this isn’t a scalable approach because you could integrate with hundreds of external IdPs. With the inbound federation Lambda trigger, you can solve this by filtering the groups to only those relevant to your application and normalizing the nomenclature of these groups. The following Lambda function filters the groups attribute to include only groups relevant to your application and normalizes the names of groups.
This approach reduces a large group list to only what is applicable to your application. Authentication succeeds, and you maintain control over your user pool’s data without depending on external configuration changes.
Use case 2: Automatic account linking
The second use case addresses a challenge that’s particularly common in B2C facing ecommerce or any consumer-facing applications; although it can also be applicable to B2B scenarios. Imagine you’re running an online retail store. A customer creates an account with their email and password to make a purchase. A few months later, they return to your site but forgot they already created an account and they see the Login with Amazon button and decide to sign in this way. Without account linking, Amazon Cognito creates a new federated user because these are technically distinct accounts, and now this customer has two separate accounts with different purchase histories and saved preferences.
This fragmentation creates a poor customer experience and complicates your business operations. You can’t see the customer’s complete purchase history, loyalty points are split across accounts, and your analytics show two distinct customers instead of one.
The inbound federation Lambda trigger can be used to solve this by automatically linking federated identities to existing local accounts based on email address. While account linking can also be implemented in a pre-sign-up Lambda trigger, the inbound federation trigger runs on every federated sign-in, not just the first, giving you access to the latest IdP attributes and the ability to apply linking logic continuously rather than only at initial account creation. If no local Amazon Cognito account exists, you can create one and then link the social provider account to it. The local account can serve as the primary identity, ensuring consistent JSON Web Tokens (JWTs) regardless of how the user signs in. The following is an example of an inbound federation Lambda trigger that can help address this use case.
Every federated sign-in will invoke the inbound federation Lambda trigger, and the logic is straightforward. When a user authenticates with an external identity provider, the trigger extracts their email from the federated response and searches the user pool for a local Cognito account with that same email. If one exists—such as if the user originally signed up with email and password—the Lambda function links the federated identity to that existing local account. If no local account exists, the trigger creates one on the fly as a passwordless account (confirmed, suppressing any emails, and ready for passwordless email one-time passcode (OTP) sign-in), then links the federated identity to it. In both cases, the local account is set as the primary profile. This means the user’s JWTs always carry the same sub-claim regardless of how they sign in—directly, or through Google, Facebook, or SAML—your application sees one consistent identity. The preceding Lambda trigger is also smart enough to check whether a linked account already exists before making the call, so returning users who’ve already been linked don’t generate unnecessary API calls. And because the local account supports passwordless authentication, a user who first arrived through federation can later sign in directly with an emailed OTP—or even add a password later through your applications account settings. The local account is always the anchor.
Best practices
As you implement these patterns, keep a few best practices in mind. Your Lambda function must be completed within 5 seconds, so optimize for speed to help ensure the federated sign-in process is able to successfully complete. If you’re making external calls within the inbound federation Lambda function, like Amazon DynamoDB queries or API requests, implement caching where possible. Handle errors gracefully—if your Lambda function throws an exception or an error, authentication could fail for the user. Consider logging the error and returning the original event back to Amazon Cognito rather than failing authentication for a legitimate user attempting to sign in. Here are some additional best practices for working with Lambda functions.
For the account linking use case, automatic linking relies on matching the email from the federated identity to a local account. However, there are scenarios where this match won’t exist. For example, Apple’s Hide My Email feature generates a unique alias for each app, so the federated email won’t match any existing local account. This is an effective privacy feature but it also blocks the ability to automatically link accounts. In cases like these, your application will need to implement a user-initiated account linking flow, such as prompting the user to verify ownership of both email addresses before calling the AdminLinkProviderForUser API to complete the link.
Monitor your Lambda function performance using Amazon CloudWatch metrics. Set up alarms for errors, timeouts, and throttling so you can respond quickly if issues arise. I also recommend capturing sample event payloads from a CloudWatch log group during your initial development and deployment—these will be valuable for local testing and debugging which can lead to quicker resolution if issues arise in your production environment. This is especially important as different IdPs (namely SAML and OIDC providers) may respond with varying attribute and value syntaxes. Consider implementing CloudWatch alarms to alert your security and operational teams if authentication failures spike, which could indicate an attempted attack, misconfiguration, or provide insight into further optimization of your inbound federation Lambda trigger.
Conclusion
In this post, you learned about the new inbound federation Lambda trigger for Amazon Cognito and how it can solve various use cases. You walked through two common federation challenges and reviewed some sample code to help resolve those challenges. For B2B and SaaS applications, the inbound federation Lambda trigger gives you control when dealing with oversized attributes from external identity providers (such as group membership) without requiring coordination with enterprise IT teams. For B2C and consumer-facing applications, it enables seamless account linking across multiple authentication methods, creating a unified customer experience.
The new Lambda trigger works with SAML, OIDC, and supported social providers, and is available now in AWS Regions where Amazon Cognito is available. To learn more about the new Lambda trigger and others, see the Amazon Cognito Developer Guide.
What federation challenges are you facing in your applications? I’d love to hear about your use cases in the comments below and over at AWS re:Post.
Build governance dashboards for Amazon SageMaker Catalog with Amazon Quick
Post Syndicated from Steve Phillips original https://aws.amazon.com/blogs/big-data/build-governance-dashboards-for-amazon-sagemaker-catalog-with-amazon-quick/
Maintaining visibility into your data catalog’s health requires more than ad-hoc queries. Data stewards and compliance teams need automated dashboards that surface governance metrics and alert them when issues arise. These issues include undocumented assets, missing ownership, and stale metadata.
In a previous post, we showed you how to query Amazon SageMaker Catalog metadata using SQL by using the metadata export feature. This post builds on that foundation by demonstrating how to create governance dashboards with Amazon Quick.
Amazon Quick is an agentic AI-powered digital workspace that provides integrated analytics, automation, and research capabilities. With Amazon Quick Sight, a component of Amazon Quick, you can create interactive dashboards and visualizations with automatic chart suggestions and machine learning (ML) insights.
We walk through how to connect Amazon Quick Sight to your Amazon SageMaker Catalog metadata and build governance dashboards using natural language prompts.
Solution overview
This solution extends the metadata export architecture by adding a visualization layer:
- Amazon SageMaker Catalog exports asset metadata daily to Amazon Simple Storage Service (Amazon S3) Tables
- Amazon Athena queries the metadata using standard SQL
- Amazon Quick Sight connects to Athena for interactive dashboards
- Amazon Quick uses natural language to build visualizations
Figure 1 – Amazon SageMaker Catalog governance dashboard architecture
Prerequisites
Before you begin, complete the following steps from Analyzing your data catalog: Query SageMaker Catalog metadata with SQL. You must also have the following:
- Amazon SageMaker Catalog metadata export enabled
- Amazon Athena configured with query results S3 bucket
- AWS Lake Formation permissions configured for AWS Identity and Access Management (IAM)-based access
- Verified that the
asset_metadata.assettable contains data
Additionally, you need:
- Amazon Quick Sight subscription (Standard or Enterprise edition)
- AWS Identity and Access Management permissions to create Amazon Quick Sight datasets and dashboards
Building a governance dashboard with Amazon Quick Sight
To visualize catalog health metrics, connect Amazon Quick Sight to your Athena metadata tables.
Configure Amazon Quick Sight permissions
- Grant permissions to the Amazon Quick Sight service role.
The Amazon Quick Sight service role (default name: aws-quicksight-service-role-v0) needs permissions to access Amazon S3 Tables and AWS Glue catalog:
Add this as an inline policy to the Amazon Quick Sight service role in the IAM console.
- Grant AWS Lake Formation permissions:
Both the Amazon Quick Sight service role and your Amazon Quick Sight admin user need AWS Lake Formation permissions on the S3 Tables catalog. First, find your Amazon Quick Sight admin user ARN by running this AWS Command Line Interface (AWS CLI) command:
Amazon Quick Sight users are managed in the Amazon Quick Sight home AWS Region (us-east-1).To grant permissions, use the Lake Formation console.
- Navigate to AWS Lake Formation in the AWS Management Console.
- Select Data permissions and Grant.
- For Principals, choose SAML users and groups.
- Enter your Amazon Quick Sight admin user ARN (from the preceding command).
- Under LF-Tags or catalog resources, choose Named Data Catalog resources.
- For Catalogs, choose the S3 Tables catalog: ACCOUNT_ID:s3tablescatalog/aws-sagemaker-catalog.
- For Databases, choose asset_metadata.
- Under Tables, choose asset.
- For Table permissions, choose Select and Describe.
- Select Grant.
Figure 2 – Grant access to Amazon SageMaker Catalog resources
- Repeat steps 1–9 for the Amazon Quick Sight service role, but in step 2 choose IAM users and roles instead.
When choosing the catalog in the Lake Formation console, you must choose the full S3 Tables catalog identifier (ACCOUNT_ID:s3tablescatalog/aws-sagemaker-catalog) to see the asset_metadata database.
Create an Amazon Quick Sight dataset.
Access S3 Tables data by creating a Quick Sight dataset using an Amazon Athena data source and the custom SQL option. An S3 Tables data source is also available but requires additional permissions. See Introducing new data source with S3 Tables in Amazon Quick for using S3 Tables as an Amazon Quick data source.
- Open Amazon Quick Sight in the AWS Management Console.
- Select Analyses and Create analysis.
Figure 3 – Create Amazon Quick Sight analysis
- Choose Create dataset and Create data source.

Figure 4 – Create dataset
- Select Amazon Athena as the data source and select Next.
- Enter a Data source name (for example, “SageMaker Catalog Metadata”) and choose Create data source.
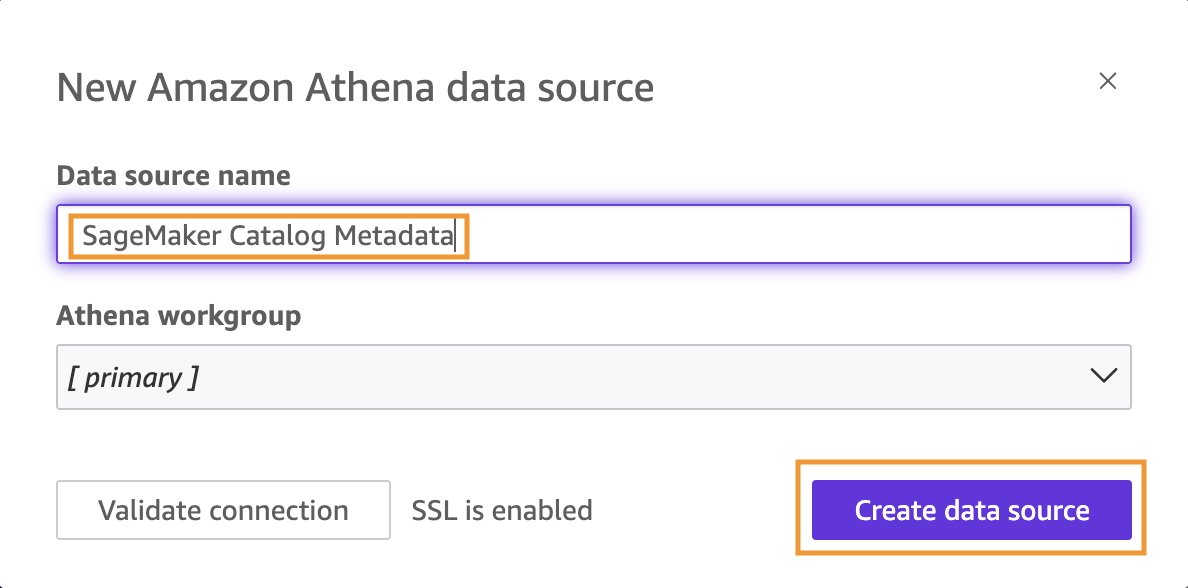
Figure 5 – Create data source
- Select Use custom SQL and enter a custom SQL query that references the S3 Tables catalog using the full three-part name.
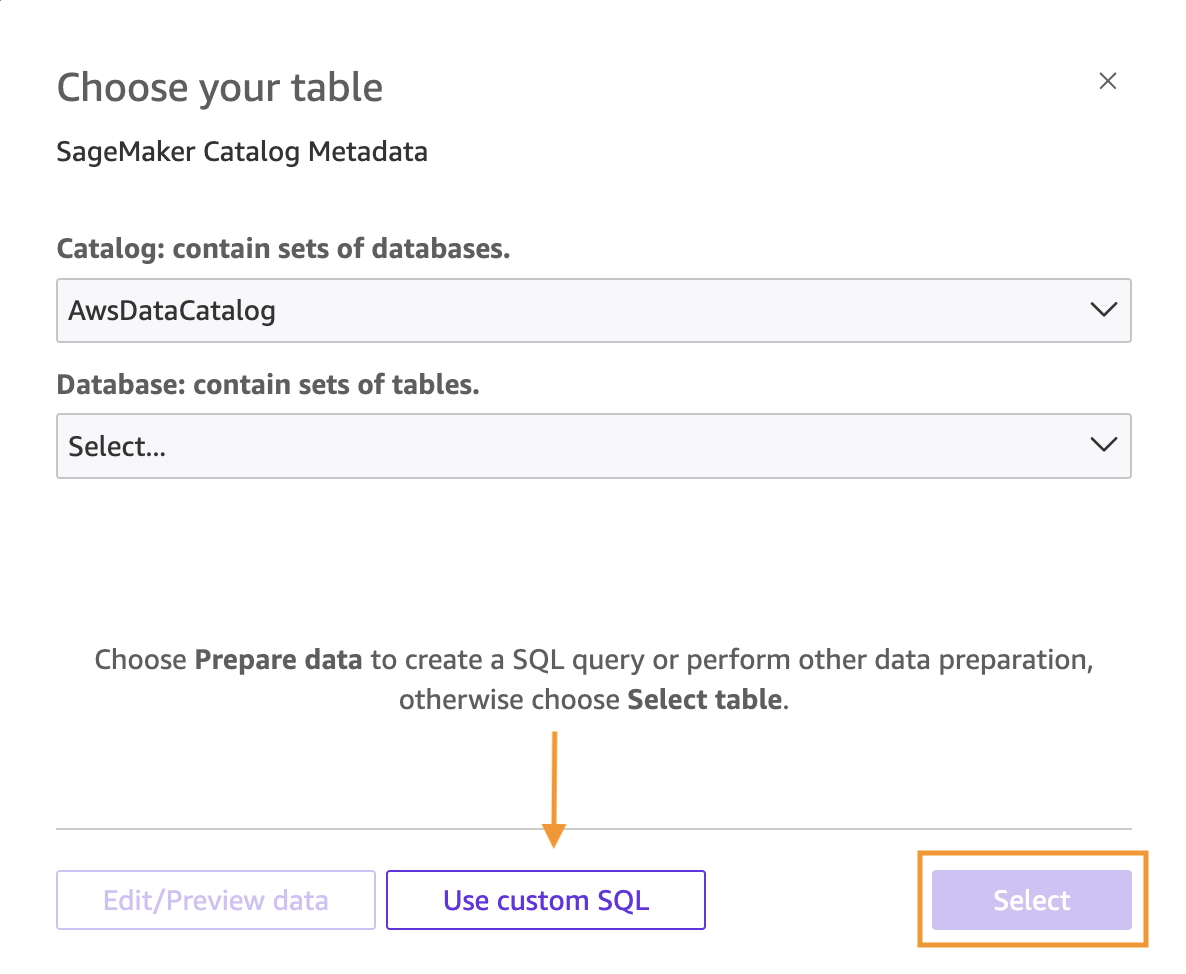
Figure 6 – Use custom SQL
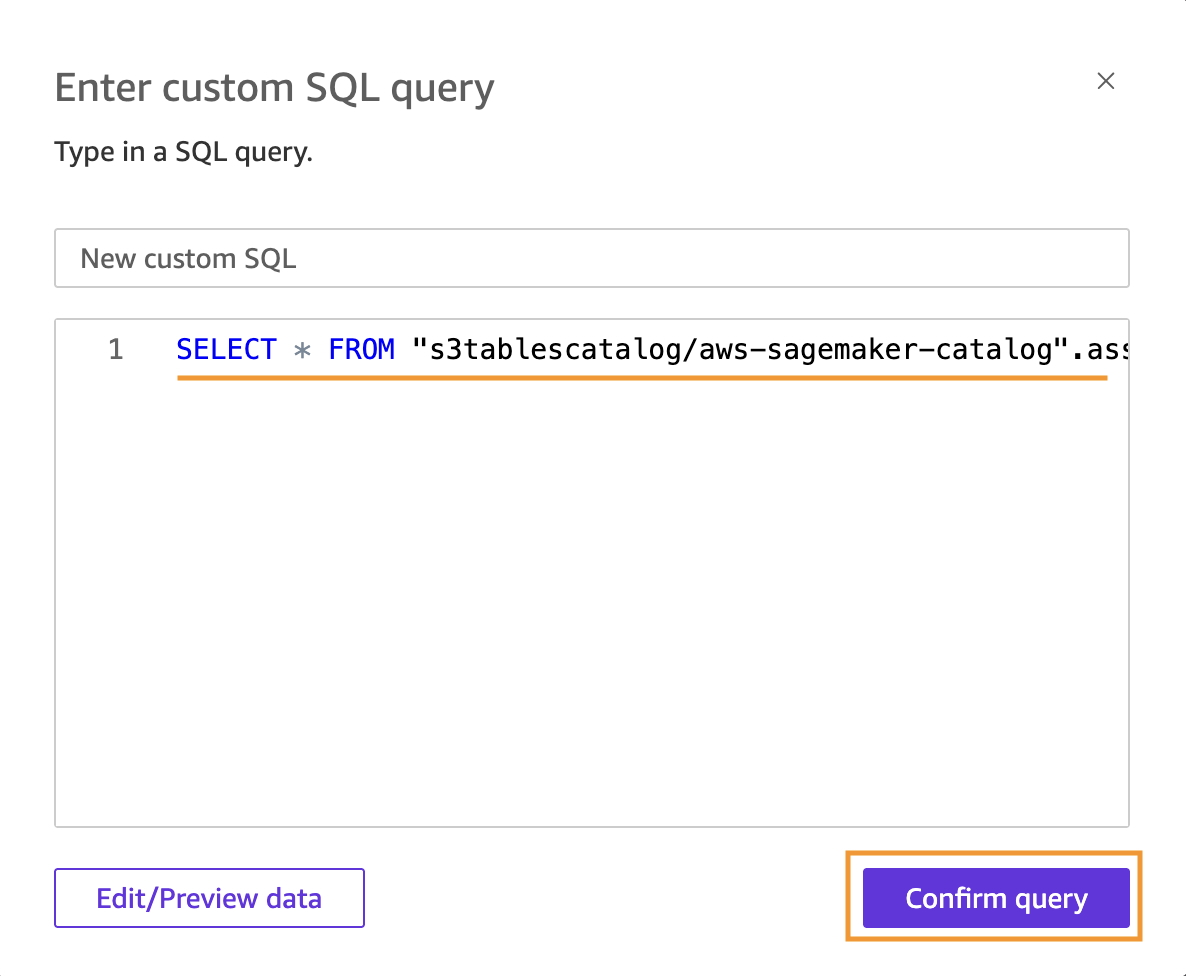
Figure 7 – Enter custom SQL
SELECT * FROM "s3tablescatalog/aws-sagemaker-catalog".asset_metadata.asset
- Select Confirm query.
- Choose Directly query your data (SPICE import may fail with S3 Tables catalogs)

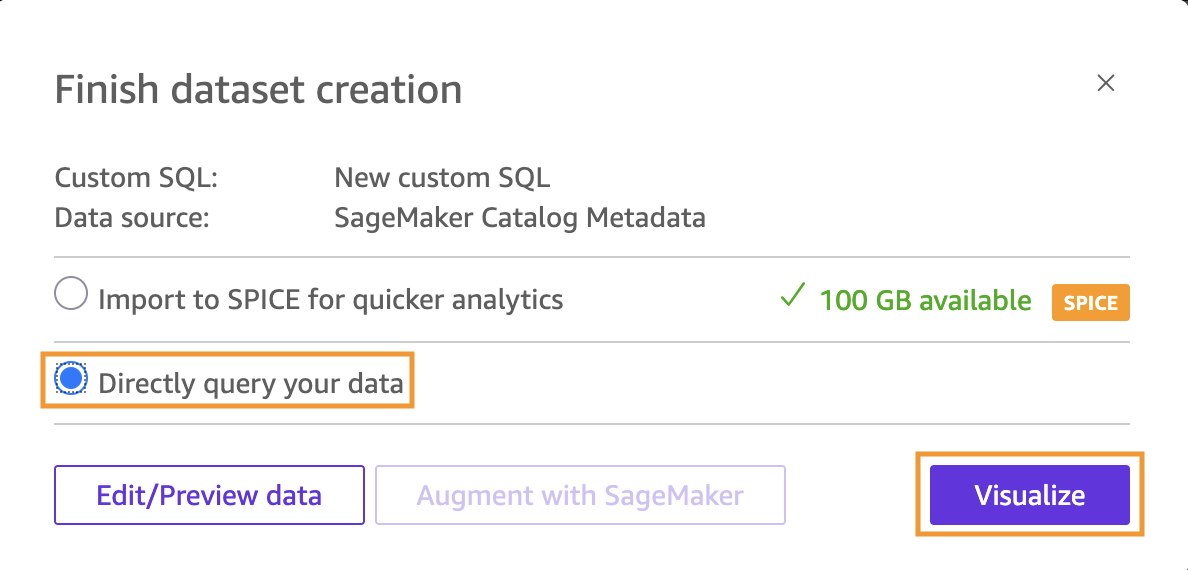
Figure 8 – Directly query your data
- Choose Visualize and Create to start building your dashboard.
Create visualizations with Amazon Quick.
With Amazon Quick, you can build governance dashboards using natural language prompts. This removes the need for manual field configuration. This approach is faster and more intuitive than traditional dashboard building.The Amazon Quick Sight user must have AdminPro or AuthorPro subscription (the Build feature isn’t available for Reader users).Start building your dashboard with the following steps:
- Select Build in the top toolbar to open the natural language builder.
Figure 9 – Amazon Quick build dashboard
- You will see a text box where you can describe the visualization that you want to create.
Create each visualization using natural language. For each of the six recommended visualizations, enter the corresponding natural language prompt, select Build, then choose ADD TO ANALYSIS.
Figure 11 – Add to analysis
Visualization 1: Asset inventory by type
Show count of asset_id by resource_type_enum as a pie chart
After the pie chart is created, choose ADD TO ANALYSIS.
Visualization 2: Documentation completeness
Show count of asset_id where business_description is not null asa KPI
After the KPI is created, choose ADD TO ANALYSIS.
Visualization 3: Monthly registration trends
Show count of asset_id by asset_created_time month as a line chart
After the line chart is created, choose ADD TO ANALYSIS.
Visualization 4: Asset count by account
Show count of asset_id by account_id as a bar chart
After the bar chart is created, choose ADD TO ANALYSIS.
Visualization 5: Namespace distribution
Show count of asset_id by namespace as a treemap
After the treemap is created, choose ADD TO ANALYSIS.
Visualization 6: Resource type by namespace
Show count of asset_id by resource_type_enum and namespace as a heat map
Choose ADD TO ANALYSIS
- Arrange and publish your governance dashboard with the following steps:
- Delete any empty or unwanted visualizations by choosing the three dots menu and choosing Delete.
- Arrange visualizations by dragging them into your preferred layout.
- Resize visualizations to emphasize key metrics.
- Add titles to each visualization for clarity.
- Choose PUBLISH in the top right corner.
- Enter a dashboard name: “SageMaker Catalog Governance Dashboard”.
- Verify these options are selected:
- Allow executive summary.
- Allow sharing stories.
- Allow sharing scenarios.
- Choose Publish dashboard.
Figure 12 – Amazon SageMaker Catalog governance dashboard
-
- Analyze your dashboard with natural language.
After you publish, you can ask questions about your governance data:
-
- On the dashboard, choose Analyze this dashboard in a Scenario in the top center.
- In the Data to Insights panel, enter natural language questions such as:
- “Which resource types have the lowest documentation rates?”
- “How many assets were registered last month compared to this month?”
- “What percentage of assets lack ownership information?”
- Choose Submit to generate AI-powered insights.
Amazon Quick analyzes your data and provides insights with supporting visualizations.
-
- Generate executive summaries
Create automated governance reports for data stewards and compliance teams:
-
- Choose the Amazon Quick logo in the top left to return to the home page
- Select Dashboards from the left panel
- Choose your “SageMaker Catalog Governance Dashboard”
- Choose the Create dropdown menu in the top right
- Select Executive Summary
Amazon Quick will automatically generate a summary with key governance insights, including Total asset counts and growth trends, Documentation completeness metrics, Ownership coverage statistics, and Classification distribution analysis.
-
- Create governance stories.
Build governance reports that combine multiple dashboards:
-
- From the Create dropdown, select Story.
- Enter a prompt: “Write a summary of catalog governance metrics and data quality trends”.
- Choose Add to select dashboards to include in the report.
- Choose Build (this might take a few minutes to complete).
Amazon Quick will generate a narrative report combining your visualizations with AI-generated insights. Share the reports with leadership or compliance teams.
Governance dashboards contain metadata such as ownership and classification details. Restrict access to users who need it. In the Amazon Quick Sight console, open the dashboard, choose Share, and grant access to named users or a dedicated Quick Sight group (for example, data-stewards) instead of selecting Everyone in this account. Review the dashboard’s permissions periodically and remove entries that are no longer needed.
Cleaning up
To avoid ongoing charges, clean up the resources created in this walkthrough. Delete Amazon Quick Sight resources including the dashboard, analyses, and dataset.
Conclusion
In this post, you connected Amazon Quick Sight to your Amazon SageMaker Catalog metadata export, built governance dashboards using the Amazon Quick natural language prompts. This approach gives data stewards and compliance teams visibility into catalog health through six key visualizations covering asset inventory, documentation completeness, registration trends, account distribution, classification coverage, and stale asset detection.
Together with the metadata export and SQL query capabilities covered in the Analyzing your data catalog: Query SageMaker Catalog metadata with SQL post, this solution provides a complete, low-overhead governance monitoring pipeline from raw catalog metadata to executive-ready.
To learn more about Amazon SageMaker Catalogs, see Amazon SageMaker Catalog documentation. To expand the work done with Amazon Quick, review Amazon Quick Sight documentation.
About the authors
Accelerate SQL development with SageMaker Data Agent in Query Editor
Post Syndicated from Jason Ramos original https://aws.amazon.com/blogs/big-data/accelerate-sql-development-with-sagemaker-data-agent-in-query-editor/
When you develop SQL against Amazon Redshift and Amazon Athena, you spend time finding the right tables across hundreds of databases, writing complex joins and aggregations, debugging failed queries without context from previous attempts, and re-specifying filters for every new question. Amazon SageMaker Data Agent in Query Editor takes a different approach. You describe what you need in natural language, and the Data Agent generates the SQL. It references your actual tables through AWS Glue Data Catalog, proposes step-by-step plans for complex questions, retains context across your session, and offers one-click error recovery with Fix with AI. In this post, you learn how to use Data Agent in Query Editor to explore data, build multi-step analyses, recover from errors, and summarize results using a public education dataset.
Solution overview
You can go from a natural language question to executable SQL in seconds. Data Agent in Query Editor provides a conversational interface with direct access to your AWS data environment, so you spend less time on query mechanics and more time on analysis. Data Agent in Query Editor focuses specifically on SQL development against Amazon Redshift and Amazon Athena. (For Python, SQL, and PySpark across broader analytical and machine learning (ML) workloads, use Data Agent in notebooks.)
Data Agent provides four key capabilities:
- Catalog-aware SQL generation. You don’t need to browse catalog structures or memorize schema details. Data Agent reads your table metadata directly.
- Querybook and session context. You build on previous work. Data Agent uses context from your earlier queries and results.
- Step-by-step planning. You review and approve a structured plan before Data Agent generates SQL.
- Fix with AI. You recover from failed queries with one click.
Data Agent integrates with AWS Glue Data Catalog and reads your actual table names, column types, descriptions, and relationships, so generated SQL references your real tables. Each follow-up question builds on your current Query Editor session—the SQL cells in your querybook, the active connection, your selected cell, and execution results from previously run cells. For complex requests, Data Agent produces a structured plan that specifies which data to retrieve, how to aggregate it, and what filters to apply. You review and approve each step before Data Agent proceeds. When a query fails, choose Fix with AI to get a corrected query based on the error and the failed cell’s context.
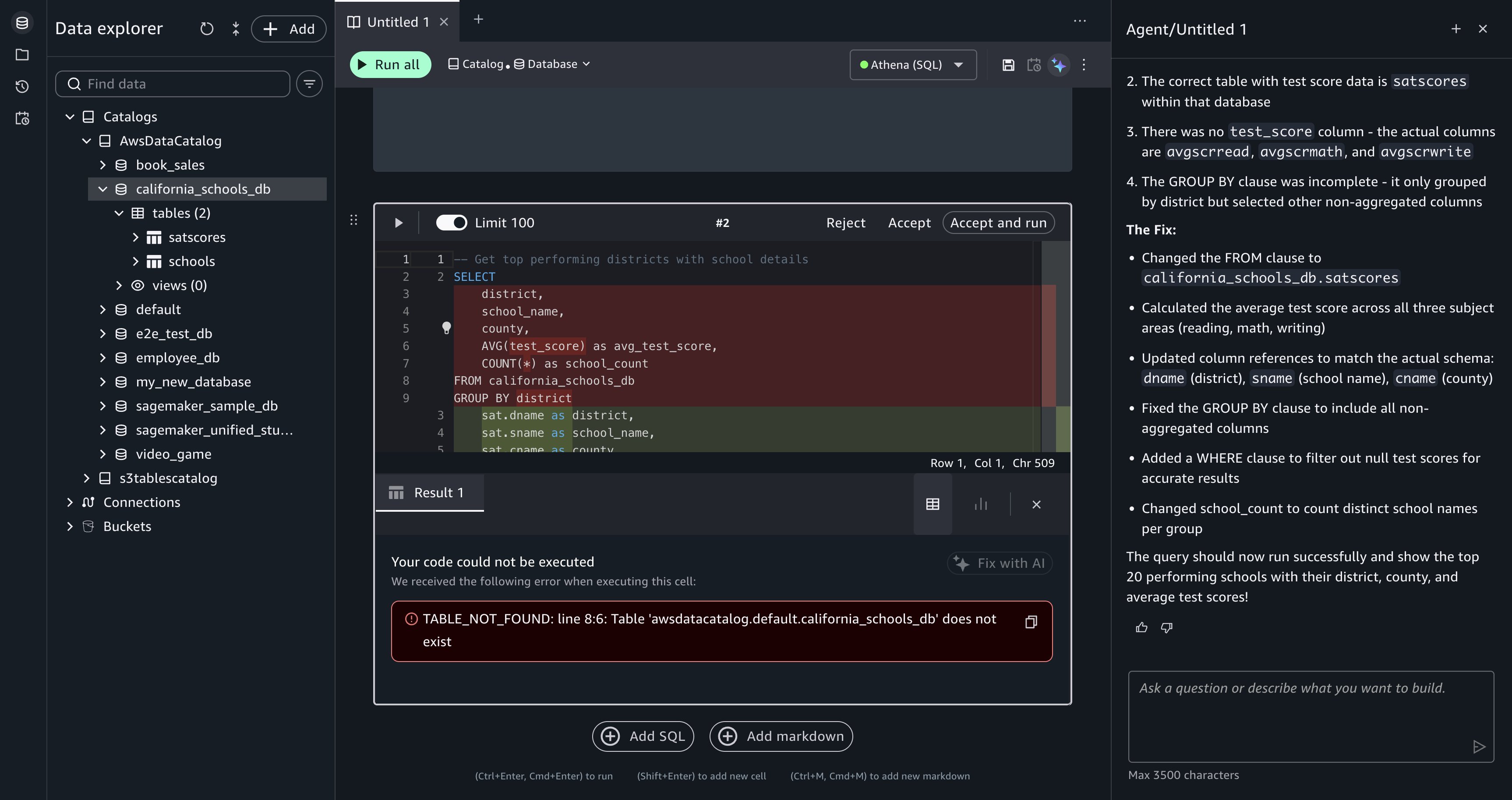
[Figure 1: The Query Editor Fix with AI panel, showing a corrected SQL query ready for your review.]
Walkthrough: Education data analysis
In this section, you use Data Agent in Query Editor to analyze California schools data and identify where SAT improvement investment has the most impact. The walkthrough covers four tasks:
- Explore available data.
- Build a multi-step analysis plan.
- Summarize insights from your queries.
- Recover from a failed query.
The same workflow applies to your own data, whether you are analyzing sales figures, operational metrics, or financial records.
The California schools dataset contains SAT score results, school demographic information, and county-level data for public schools across California. The dataset includes tables that organize SAT scores by subject (reading, writing, math), school details (name, address, county, district), and enrollment figures. After you upload the data into your project database, you directly access the tables from Query Editor through your Amazon Athena or Amazon Redshift Lakehouse connection.
Prerequisites
To complete this walkthrough, you need intermediate SQL knowledge and basic familiarity with the AWS Management Console. You don’t need prior AWS Glue experience, but familiarity with data catalogs (centralized metadata repositories) helps.
You can choose one of two setup paths:
- Quick start (5 minutes). SageMaker Unified Studio provides a sample database (
sagemaker_sample_db) with pre-loaded data. To explore it, choose Data in the navigation pane, expand AwsDataCatalog, and selectsagemaker_sample_db. - Full setup (30–45 minutes). Upload the California schools dataset into your project’s Lakehouse database. This dataset is publicly available from the California Department of Education. Download the SAT scores, school information, and county-level data files, then upload them through the SageMaker Unified Studio UI. In your project, go to Build, choose Query editor, right-click your project database in the Data explorer, and choose Create table. Drag and drop each CSV file to create the tables. SageMaker Unified Studio stores the data in the project-managed Amazon Simple Storage Service (Amazon S3) location, registers it in AWS Glue Data Catalog, and applies AWS Lake Formation governance automatically.
Running queries against Amazon Athena or Amazon Redshift might incur costs. For pricing details, refer to Amazon Athena pricing and Amazon Redshift pricing. For detailed setup instructions, refer to AWS Identity and Access Management (IAM)-based domains and projects. Before starting the walkthrough, you must have a SageMaker Unified Studio IAM-based domain with a project using the SQL analytics or All Capabilities project profile. The project automatically provisions an AWS Glue database, the required IAM role, and Athena or Redshift Lakehouse connections.
[Figure 2: The Data Explorer panel in Query Editor, showing the california_schools_db and sagemaker_sample_db tables.]
Explore available data. To start, enter the following prompt in the Data Agent panel:
Data Agent searches AWS Glue Data Catalog, locates the relevant tables, and generates an initial exploratory query that retrieves SAT score records. It adds a SQL cell directly to your querybook.
- Review the generated SQL in the comparison view, which highlights the proposed code.
- Choose Accept, Reject, or Accept and run.
- After you run the cell, the results appear inline, giving you a view of the data (column names, score ranges, and the number of records) before you write SQL.
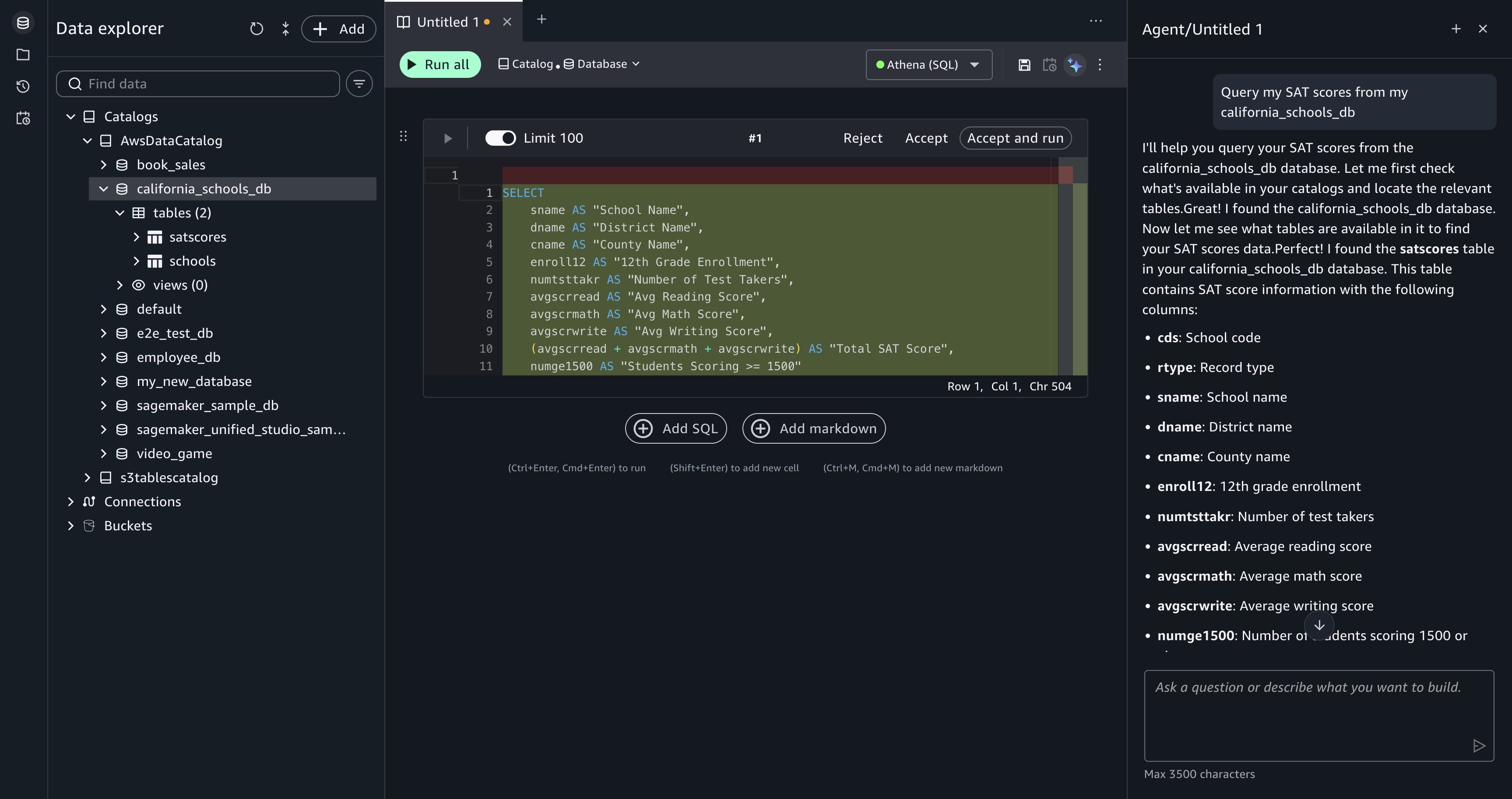
[Figure 3: Data Agent returns an exploratory query for the california_schools_db tables, ready for your review.]
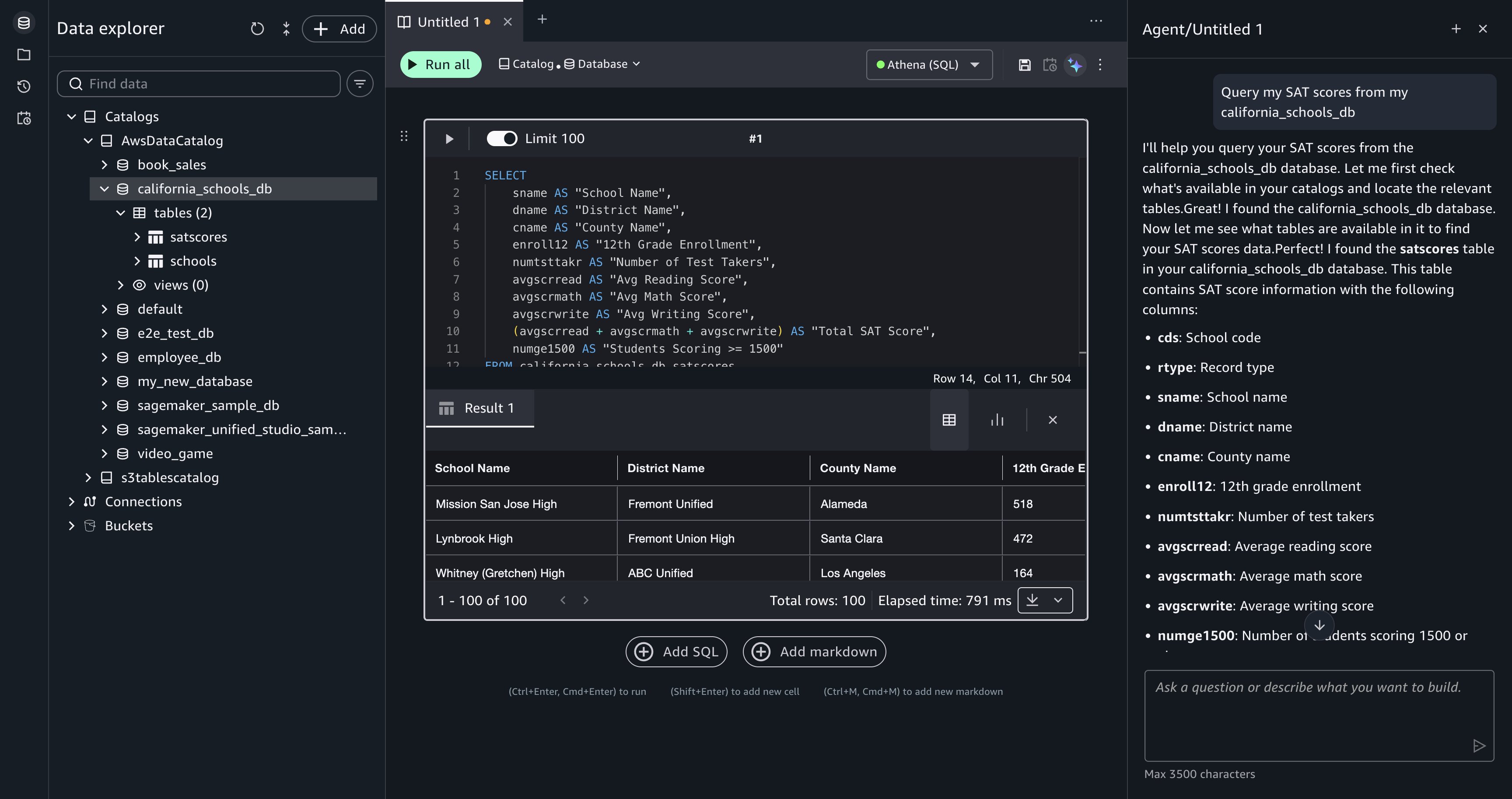
[Figure 4: The SQL query results appear beneath the cell after you choose Accept and run.]
Build a multi-step analysis plan. With the data explored, enter a more complex analytical question:
Data Agent proposes a step-by-step plan before generating SQL. For this request, Data Agent breaks the question into three steps:
- Aggregate SAT scores by county and subject to find performance patterns.
- Filter to counties with a sufficient number of schools and rank the lowest performers.
- Join school address data to produce a final detailed list.
Review the plan in the Data Agent panel and choose Run step-by-step to proceed.
[Figure 5: Data Agent proposes a multi-step plan with options to Cancel plan or Run step-by-step.]
Data Agent generates SQL for each step and adds it as a separate querybook cell. Review each cell’s SQL in the comparison view, then choose Accept and run to execute it. The results from each step are visible inline, so you can verify the intermediate output (county-level aggregations, the filtered ranking, and the final school list) before moving to the next step. When the steps are complete, your querybook contains the full analytical progression from raw scores to a detailed investment list.
[Figure 6: Each plan step produces a querybook cell that you can review and run independently.]
Summarize insights from your queries. After running the analysis, enter the following prompt:
Data Agent has context on your querybook, including the SQL and the query results from each cell. It generates a natural language summary: which counties are underperforming, which subjects (reading, writing, or math) need the most attention in each county, and how many schools appear on the investment list. This summary provides a starting point for a report or presentation.
[Figure 7: Data Agent summarizes insights from the accumulated query results in the querybook.]
Recover from a failed query. During the analysis, a generated query might produce an error, for example, referencing a column name that doesn’t match the schema or a join condition that returns unexpected results. When a cell fails, Query Editor displays the error message and a Fix with AI option.
Choose Fix with AI, and Data Agent reads the error in the context of the failed cell, then generates corrected SQL and updates the querybook cell. Run the corrected cell to verify the fix.
[Figure 8: After you choose Fix with AI, Data Agent is prompted to generate a corrected query for the failed cell.]
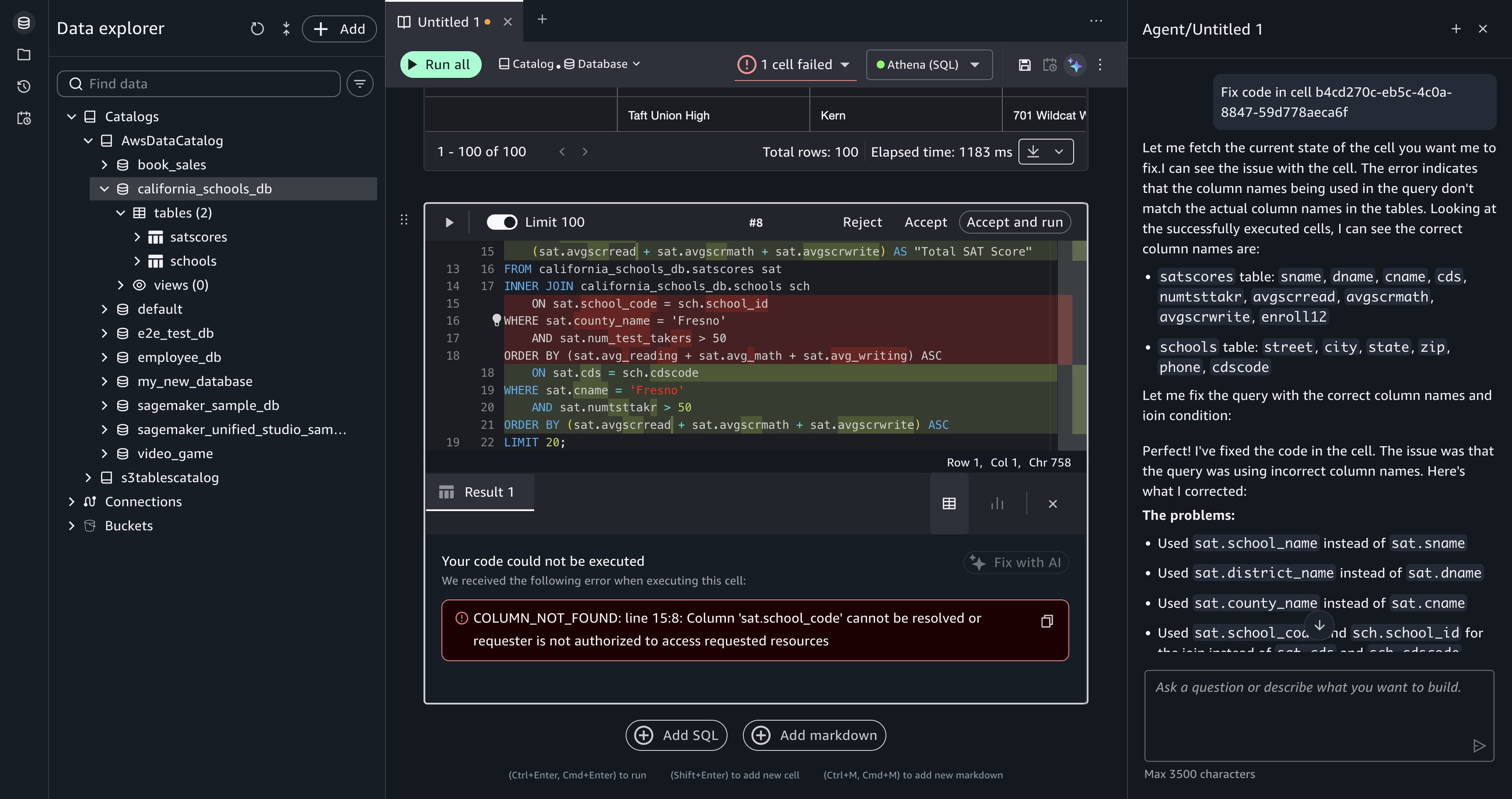
[Figure 9: Data Agent returns corrected SQL for you to review.]
Security and governance
Data Agent operates within your AWS environment and only accesses data that your IAM policies explicitly permit. Your existing IAM access controls and AWS Lake Formation permissions determine what data Data Agent can reach. To use Data Agent, your project role must have permissions to invoke specific Amazon DataZone APIs. For more information, refer to Actions, resources, and condition keys for Amazon DataZone.
Data Agent includes content filtering that prevents it from responding to off-topic requests, requests to reveal its system prompt, and requests for internal technical implementation details. Data Agent is restricted to AWS-related topics and English-language output.
Amazon SageMaker stores your natural language prompts and generated SQL in the AWS Region where you created your SageMaker Unified Studio domain. Data Agent doesn’t store your data, querybook context, or catalog metadata.
To opt out of data usage for service improvement, configure an AI services opt-out policy for Amazon DataZone in AWS Organizations. For more information, refer to Data storage in the SageMaker Data Agent, Service improvement, and AI services opt-out policies.
Clean up
The walkthrough creates querybook cells in your Query Editor session but doesn’t provision standalone infrastructure. To remove the generated SQL cells, delete them from your querybook or delete the querybook itself.
If you uploaded the California schools dataset specifically for this walkthrough, remove the following resources to avoid ongoing charges:
- SageMaker Unified Studio domain. If you created a domain solely for this walkthrough, delete it to stop incurring charges. Refer to the SageMaker Unified Studio administration guide for deletion steps.
- Uploaded tables. In the Data explorer, right-click each table you created and choose Delete table to remove the data from your project database and the underlying S3 storage.
- Amazon Athena query results. Amazon Athena stores query results in an S3 output location. Delete the query result files from that bucket, or delete the bucket if you created it solely for this walkthrough.
- Amazon CloudWatch logs. If Amazon Athena queries generated CloudWatch log groups, delete those log groups to avoid storage charges.
Conclusion
Data Agent in Query Editor brings conversational, catalog-aware SQL development to your Amazon Redshift and Amazon Athena workloads. In this post, you explored unfamiliar data, built a multi-step investment analysis, recovered from query errors, and summarized findings through natural language prompts.
Data Agent works within your existing IAM and AWS Lake Formation security controls, keeps your data within your AWS environment, and retains context across your analytical workflow so each question builds on the last.
Get started with these next steps:
- Run your first prompt. Open Query Editor in your SageMaker Unified Studio domain and enter
Show me the top 10 tables in my catalog with the most columns. For setup, refer to the SageMaker Unified Studio getting started guide. - Add descriptions to your AWS Glue Data Catalog. Table descriptions and column-level business metadata improve the quality of generated SQL. For best practices, refer to Populating the AWS Glue Data Catalog.
- Try a multi-step analysis. Enter
Which product categories had declining revenue quarter-over-quarter, and which regions drove the decline?and review Data Agent’s plan step by step.
For more information, refer to the Amazon SageMaker Data Agent documentation, the What’s New blog post, Amazon Redshift documentation, and Amazon Athena documentation. To learn how Data Agent works in notebooks, refer to Accelerate context-aware data analysis and ML workflows with Amazon SageMaker Data Agent.
About the authors
Microsoft to Join the AI Dev Mini-PC Market With Upcoming Surface RTX Spark Dev Box
Post Syndicated from Ryan Smith original https://www.servethehome.com/microsoft-to-join-the-ai-dev-mini-pc-market-with-upcoming-surface-rtx-spark-dev-box/
Microsoft is joining the AI dev box mini-PC market with the announcement of the Surface RTX Spark Dev Box. Due later this year, it will offer a pre-loaded dev environment, powered by NVIDIA’s new RTX Spark SoC
The post Microsoft to Join the AI Dev Mini-PC Market With Upcoming Surface RTX Spark Dev Box appeared first on ServeTheHome.
How Long Will a $199 Power Station Run a Home Server?
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/shorts/excZRXQEZMg