Post Syndicated from Technology Connextras original https://www.youtube.com/watch?v=Y2qSaD1v4cQ
STH Q1 2025 Letter from the Editor Re-calibration and Expansion
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/sth-q1-2025-letter-from-the-editor-re-calibration-and-expansion/
In the STH Q1 2025 Letter from the Editor, we go behind-the-scenes at STH and talk about what we have been working on
The post STH Q1 2025 Letter from the Editor Re-calibration and Expansion appeared first on ServeTheHome.
Comic for 2025.03.30 – The Flash
Post Syndicated from Explosm.net original https://explosm.net/comics/the-flash
New Cyanide and Happiness Comic
Stepmother
Post Syndicated from Oglaf! -- Comics. Often dirty. original https://www.oglaf.com/stepmother/


The Mark 17 Thermonuclear Bomb
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=KVVc1uMvYos
The Crucial 128GB DDR5-5600 SODIMM Kit We Are Using in Mini PCs
Post Syndicated from John Lee original https://www.servethehome.com/the-crucial-128gb-ddr5-5600-sodimm-kit-we-are-using-in-mini-pcs/
These Crucial 64GB DDR5-5600 SODIMMs come in pairs for 128GB in the kit allowing for more memory in mini PCs (and notebooks)
The post The Crucial 128GB DDR5-5600 SODIMM Kit We Are Using in Mini PCs appeared first on ServeTheHome.
Four stable kernel updates
Седмицата (24–29 март)
Post Syndicated from Надежда Радулова original https://www.toest.bg/sedmitsata-24-29-mart/

41 по-голямо ли е, или е по-малко от 35? Това е задачка за първокласник и отговорът е еднозначен. Освен ако, разбира се, не докопаш грешните топки. Е, тогава се оказва, че си в друг номер и само си мислиш, че джуркаш тото топки, а всъщност вадиш зайче от шапка. Но вместо зайче – куку! – излиза Пеевски. Така да се каже, кой друг да излезе от шапката, пардон, от сферата с тотото?! Та то му е родно… И е редно да размаха пръст, защото в тази сфера по-добра от мама няма!
Изобщо, темата с „грешните топки“ се оказва водеща тази седмица. Високопоставени служители на президентската администрация в САЩ разнообразили седянката си, като открехнали вратата и – без сами да разберат как – поканили и главния редактор на The Atlantic Джефри Голдбърг. И това, докато обсъждали строго секретни военни атаки срещу хутите в Йемен. Грешка! За капак Тръмп коментира, че не харесвал особено The Atlantic. Ех, значи… Единственото, което мога да посъветвам тези мъдри държавни мъже, е следващия път да поканят на седянката и Пеевски.
Ехо, къде без него?! Та у нас вече открито се говори за „правителството на Пеевски“. Пийте един деган, преди да прочетете седмичния вътрешнополитически обзор на Емилия Милчева – не вземете ли таблетката, свят ще ви се завие и ще ви се доповръща. В „Марш на скок за още власт за ГЕРБ“ новите назначения в регулаторите само досипват в угодните на ГЕРБ и Пеевски порции власт, опозицията е шизо, а на всичкото отгоре може да се окаже, че европрокурорката Теодора Георгиева е играла Снежанка в „Осемте джуджета“, и то в компанията на джуджето Худини, известно като Пепи Еврото.
Пак по темата за „топките“ – поредни две български шпионки, част от руска шпионска мрежа, са разследвани и разкрити от Би Би Си. Цветелина Генчева и Цветанка Дончева са провеждали операции за наблюдение, подпомагащи дейността на наскоро заловените и осъдени за шпионаж в Лондон шестима българи. От снимките на Цветелина и Цветанка, от публикациите на техни познати и от самото разследване оставаме с впечатлението, че „момичетата на Марсалек“ нямат много общо с „момичетата на Бонд“ и всъщност са доста „ниски топки“. Тюх, да му се не види! Не били компютри, а компоти, не били шпионки, а пионки.
И така, тупайки топката все по-ниско, преминаваме към игра в центъра на терена. „В центъра на терена“ у нас означава даден въпрос – като например мизогинното и направо човеконенавистно питане „Допустимо ли е жена да кърми на работното си място?“, пък било то и в пленарната зала – периодично да се превръща в социална дъвка. Ад. Имам чувството, че живеем в оня филм с Бил Мъри и всеки ден се събуждаме с все същия отново неразрешен проблем, в трепетно очакване мармотът да изпълзи от дупката си, белким и у нас се запролети…
Междувременно на терена на голямата игра, поне привидно, такива въпроси отдавна са разрешени. Или съществуват в доста по-богата палитра от нюанси. (Което всъщност невинаги е за добро, но нейсе…) Да вземем например Алис Вайдел. „Как е възможно хомосексуална жена да е начело на „Алтернатива за Германия“?“ – пита Светла Енчева и дава няколко по-прости и няколко по-сложни отговора на въпроса. Да започнем с това, че нито АзГ е „Възраждане“, нито привържениците на партията, включително самата Алис Вайдел, са толкова отявлено анти-ЛГБТИ, колкото нашите крайнодесни патриоти и популисти. Именно това позволява сексуалната идентичност на Вайдел да бъде ловко инструментализирана, така че да легитимира АзГ като толерантна партия и заедно с това да подсили контура на заплахата, която мюсюлманските имигранти представляват за жените и хомосексуалните според наратива на крайнодесните. Ха сега де…
Връщаме се на родния черно-бял терен, където, както се разбрахме, нюансите са кът и ако искаш да разрешиш един проблем, най-лесно е просто да го забраниш. Така действаме и с наркотиците. Един ден забраняваме едно вещество, появява се друго, забраняваме и него, появява се трето – бам! – отстрелваме го. И така… до безкрайност като в тъпа аркадна игра. А работещата стратегия не се заключава в забрани и санкции, а в превенция, и то на много нива. Повече за борбата с наркотиците по принцип и в момента, по света и у нас четете в статията на Юлия Георгиева „Слонът в стаята, или защо употребата на наркотици се увеличава“.
И докато се сипят забрани отляво и отдясно, и докато МОН се занимава с религиозното обучение и централизираното дисциплиниране на децата в училище, седмицата удря дъното с новината за (само!) 8-годишното лишаване от свобода, присъдено на нечовешкия изрод Петър Чернев. Въпросният малтретирал 5-годишния си доведен син, вследствие на което детето – според данни от ТЕЛК – е загубило 60% от здравето си (вероятно се има предвид физическото; за психическото не става дума, не и в България!). Майката на детето – безучастна свидетелка на издевателствата – се разминава с парична глоба от 4000 лв. Държава, в която бебетата се хранят скришно, сакън да не нарушат общественото благоприличие, в която се въвежда оценка за дисциплина на децата, а малтретиращите ги възрастни едва ли не биват помилвани, заслужава всичко, което ѝ се случва и предстои да ѝ се случи.
Дърпаме завесата, за да влезе малко слънце, преди да сме се угнетили до смърт. За това ни помага Ина Иванова, която ни среща с „Димитър Панайотов и Александър Николов от „Ден“: С лице към фактите“. Документалистиката им е пример за отговорност и грижа към отделния човек и уж незначителните житейски подробности, за вчувстване в съдбите на другите, за неотстъпно вървене на страната на справедливостта – не абстрактната, а тази, която ни се разкрива във всекидневните избори и жестове.
Удължаваме удоволствието от срещите с „Тези хора“ чрез редовната ни рубрика за книжни срещи, които също няма да ни разочароват. Тази седмица в „По буквите“ Зорница Христова ни препоръчва новата дългоочаквана и „безспорна“ стихосбирка на Никола Петров и три пиеси на Тенеси Уилямс в превод на Евгения Панчева. И двете книги рязко ни издигат над „ниските топки“ на деня и ни напомнят, че четенето все още е един от малкото познати начини за оцеляване.
За нови начини на оцеляване и разумно съществуване става дума и в научните новини от Михаил Ангелов, където „Титанови сърца, генни редакции, биополимери и една космическа одисея с щастлив край“ обрисуват реалност, която точно в този исторически момент изглежда почти паралелна на обитаваната от нас. В нея обречените оцеляват, болните получават по-добра грижа, а Космосът е точка, в която духът (а не амбицията) укрепва и се извисява.
Стихотворението на месец март е от Рада Александрова. В него има и дъжд, и болка, и тържество, и една особена тъмна и природна радост, която изригва само напролет.
Ще възкръсне ли
тази земя.
Ще растат ли
треви и дървета.
Пита стихотворението. И ние питаме същото, борим се със страховете си и се опитваме да не губим надежда.
Оставяме ви да изпратите седмицата и месеца в компанията на любимата ни E.T., която – поради извънземното си естество – следи сигналите и прозира строго секретните връзки в реалността, включително телефонните между Веска, Стефка, Янка, Ванга и така до Нострадамус по права линия.
Ако и вие смятате, че е важно да не изгубим сигнала, може да ни подкрепите, лесно е – клик-клик, пиу-пиу. Айде готово.
Приятно четене!
Foundation Model for Personalized Recommendation
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/foundation-model-for-personalized-recommendation-1a0bd8e02d39
By Ko-Jen Hsiao, Yesu Feng and Sudarshan Lamkhede
Motivation
Netflix’s personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including “Continue Watching” and “Today’s Top Picks for You.” (Refer to our recent overview for more details). However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models.
Particularly, these models predominantly extract features from members’ recent interaction histories on the platform. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. This limitation has inspired us to develop a foundation model for recommendation. This model aims to assimilate information both from members’ comprehensive interaction histories and our content at a very large scale. It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). In NLP, the trend is moving away from numerous small, specialized models towards a single, large language model that can perform a variety of tasks either directly or with minimal fine-tuning. Key insights from this shift include:
- A Data-Centric Approach: Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one. This approach prioritizes the accumulation of large-scale, high-quality data and, where feasible, aims for end-to-end learning.
- Leveraging Semi-Supervised Learning: The next-token prediction objective in LLMs has proven remarkably effective. It enables large-scale semi-supervised learning using unlabeled data while also equipping the model with a surprisingly deep understanding of world knowledge.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. By scaling up semi-supervised training data and model parameters, we aim to develop a model that not only meets current needs but also adapts dynamically to evolving demands, ensuring sustainable innovation and resource efficiency.
Data
At Netflix, user engagement spans a wide spectrum, from casual browsing to committed movie watching. With over 300 million users at the end of 2024, this translates into hundreds of billions of interactions — an immense dataset comparable in scale to the token volume of large language models (LLMs). However, as in LLMs, the quality of data often outweighs its sheer volume. To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
Tokenizing User Interactions: Not all raw user actions contribute equally to understanding preferences. Tokenization helps define what constitutes a meaningful “token” in a sequence. Drawing an analogy to Byte Pair Encoding (BPE) in NLP, we can think of tokenization as merging adjacent actions to form new, higher-level tokens. However, unlike language tokenization, creating these new tokens requires careful consideration of what information to retain. For instance, the total watch duration might need to be summed or engagement types aggregated to preserve critical details.

This tradeoff between granular data and sequence compression is akin to the balance in LLMs between vocabulary size and context window. In our case, the goal is to balance the length of interaction history against the level of detail retained in individual tokens. Overly lossy tokenization risks losing valuable signals, while too granular a sequence can exceed practical limits on processing time and memory.
Even with such strategies, interaction histories from active users can span thousands of events, exceeding the capacity of transformer models with standard self attention layers. In recommendation systems, context windows during inference are often limited to hundreds of events — not due to model capability but because these services typically require millisecond-level latency. This constraint is more stringent than what is typical in LLM applications, where longer inference times (seconds) are more tolerable.
To address this during training, we implement two key solutions:
- Sparse Attention Mechanisms: By leveraging sparse attention techniques such as low-rank compression, the model can extend its context window to several hundred events while maintaining computational efficiency. This enables it to process more extensive interaction histories and derive richer insights into long-term preferences.
- Sliding Window Sampling: During training, we sample overlapping windows of interactions from the full sequence. This ensures the model is exposed to different segments of the user’s history over multiple epochs, allowing it to learn from the entire sequence without requiring an impractically large context window.
At inference time, when multi-step decoding is needed, we can deploy KV caching to efficiently reuse past computations and maintain low latency.
These approaches collectively allow us to balance the need for detailed, long-term interaction modeling with the practical constraints of model training and inference, enhancing both the precision and scalability of our recommendation system.
Information in Each ‘Token’: While the first part of our tokenization process focuses on structuring sequences of interactions, the next critical step is defining the rich information contained within each token. Unlike LLMs, which typically rely on a single embedding space to represent input tokens, our interaction events are packed with heterogeneous details. These include attributes of the action itself (such as locale, time, duration, and device type) as well as information about the content (such as item ID and metadata like genre and release country). Most of these features, especially categorical ones, are directly embedded within the model, embracing an end-to-end learning approach. However, certain features require special attention. For example, timestamps need additional processing to capture both absolute and relative notions of time, with absolute time being particularly important for understanding time-sensitive behaviors.
To enhance prediction accuracy in sequential recommendation systems, we organize token features into two categories:
- Request-Time Features: These are features available at the moment of prediction, such as log-in time, device, or location.
- Post-Action Features: These are details available after an interaction has occurred, such as the specific show interacted with or the duration of the interaction.
To predict the next interaction, we combine request-time features from the current step with post-action features from the previous step. This blending of contextual and historical information ensures each token in the sequence carries a comprehensive representation, capturing both the immediate context and user behavior patterns over time.
Considerations for Model Objective and Architecture
As previously mentioned, our default approach employs the autoregressive next-token prediction objective, similar to GPT. This strategy effectively leverages the vast scale of unlabeled user interaction data. The adoption of this objective in recommendation systems has shown multiple successes [1–3]. However, given the distinct differences between language tasks and recommendation tasks, we have made several critical modifications to the objective.
Firstly, during the pretraining phase of typical LLMs, such as GPT, every target token is generally treated with equal weight. In contrast, in our model, not all user interactions are of equal importance. For instance, a 5-minute trailer play should not carry the same weight as a 2-hour full movie watch. A greater challenge arises when trying to align long-term user satisfaction with specific interactions and recommendations. To address this, we can adopt a multi-token prediction objective during training, where the model predicts the next n tokens at each step instead of a single token[4]. This approach encourages the model to capture longer-term dependencies and avoid myopic predictions focused solely on immediate next events.
Secondly, we can use multiple fields in our input data as auxiliary prediction objectives in addition to predicting the next item ID, which remains the primary target. For example, we can derive genres from the items in the original sequence and use this genre sequence as an auxiliary target. This approach serves several purposes: it acts as a regularizer to reduce overfitting on noisy item ID predictions, provides additional insights into user intentions or long-term genre preferences, and, when structured hierarchically, can improve the accuracy of predicting the target item ID. By first predicting auxiliary targets, such as genre or original language, the model effectively narrows down the candidate list, simplifying subsequent item ID prediction.
Unique Challenges for Recommendation FM
In addition to the infrastructure challenges posed by training bigger models with substantial amounts of user interaction data that are common when trying to build foundation models, there are several unique hurdles specific to recommendations to make them viable. One of unique challenges is entity cold-starting.
At Netflix, our mission is to entertain the world. New titles are added to the catalog frequently. Therefore the recommendation foundation models require a cold start capability, which means the models need to estimate members’ preferences for newly launched titles before anyone has engaged with them. To enable this, our foundation model training framework is built with the following two capabilities: Incremental training and being able to do inference with unseen entities.
- Incremental training : Foundation models are trained on extensive datasets, including every member’s history of plays and actions, making frequent retraining impractical. However, our catalog and member preferences continually evolve. Unlike large language models, which can be incrementally trained with stable token vocabularies, our recommendation models require new embeddings for new titles, necessitating expanded embedding layers and output components. To address this, we warm-start new models by reusing parameters from previous models and initializing new parameters for new titles. For example, new title embeddings can be initialized by adding slight random noise to existing average embeddings or by using a weighted combination of similar titles’ embeddings based on metadata. This approach allows new titles to start with relevant embeddings, facilitating faster fine-tuning. In practice, the initialization method becomes less critical when more member interaction data is used for fine-tuning.
- Dealing with unseen entities : Even with incremental training, it’s not always guaranteed to learn efficiently on new entities (ex: newly launched titles). It’s also possible that there will be some new entities that are not included/seen in the training data even if we fine-tune foundation models on a frequent basis. Therefore, it’s also important to let foundation models use metadata information of entities and inputs, not just member interaction data. Thus, our foundation model combines both learnable item id embeddings and learnable embeddings from metadata. The following diagram demonstrates this idea.

To create the final title embedding, we combine this metadata-based embedding with a fully-learnable ID-based embedding using a mixing layer. Instead of simply summing these embeddings, we use an attention mechanism based on the “age” of the entity. This approach allows new titles with limited interaction data to rely more on metadata, while established titles can depend more on ID-based embeddings. Since titles with similar metadata can have different user engagement, their embeddings should reflect these differences. Introducing some randomness during training encourages the model to learn from metadata rather than relying solely on ID embeddings. This method ensures that newly-launched or pre-launch titles have reasonable embeddings even with no user interaction data.
Downstream Applications and Challenges
Our recommendation foundation model is designed to understand long-term member preferences and can be utilized in various ways by downstream applications:
- Direct Use as a Predictive Model The model is primarily trained to predict the next entity a user will interact with. It includes multiple predictor heads for different tasks, such as forecasting member preferences for various genres. These can be directly applied to meet diverse business needs..
- Utilizing embeddings The model generates valuable embeddings for members and entities like videos, games, and genres. These embeddings are calculated in batch jobs and stored for use in both offline and online applications. They can serve as features in other models or be used for candidate generation, such as retrieving appealing titles for a user. High-quality title embeddings also support title-to-title recommendations. However, one important consideration is that the embedding space has arbitrary, uninterpretable dimensions and is incompatible across different model training runs. This poses challenges for downstream consumers, who must adapt to each retraining and redeployment, risking bugs due to invalidated assumptions about the embedding structure. To address this, we apply an orthogonal low-rank transformation to stabilize the user/item embedding space, ensuring consistent meaning of embedding dimensions, even as the base foundation model is retrained and redeployed.
- Fine-Tuning with Specific Data The model’s adaptability allows for fine-tuning with application-specific data. Users can integrate the full model or subgraphs into their own models, fine-tuning them with less data and computational power. This approach achieves performance comparable to previous models, despite the initial foundation model requiring significant resources.
Scaling Foundation Models for Netflix Recommendations
In scaling up our foundation model for Netflix recommendations, we draw inspiration from the success of large language models (LLMs). Just as LLMs have demonstrated the power of scaling in improving performance, we find that scaling is crucial for enhancing generative recommendation tasks. Successful scaling demands robust evaluation, efficient training algorithms, and substantial computing resources. Evaluation must effectively differentiate model performance and identify areas for improvement. Scaling involves data, model, and context scaling, incorporating user engagement, external reviews, multimedia assets, and high-quality embeddings. Our experiments confirm that the scaling law also applies to our foundation model, with consistent improvements observed as we increase data and model size.

Conclusion
In conclusion, our Foundation Model for Personalized Recommendation represents a significant step towards creating a unified, data-centric system that leverages large-scale data to increase the quality of recommendations for our members. This approach borrows insights from Large Language Models (LLMs), particularly the principles of semi-supervised learning and end-to-end training, aiming to harness the vast scale of unlabeled user interaction data. Addressing unique challenges, like cold start and presentation bias, the model also acknowledges the distinct differences between language tasks and recommendation. The Foundation Model allows various downstream applications, from direct use as a predictive model to generate user and entity embeddings for other applications, and can be fine-tuned for specific canvases. We see promising results from downstream integrations. This move from multiple specialized models to a more comprehensive system marks an exciting development in the field of personalized recommendation systems.
Acknowledgements
Contributors to this work (name in alphabetical order): Ai-Lei Sun Aish Fenton Anne Cocos Anuj Shah Arash Aghevli Baolin Li Bowei Yan Dan Zheng Dawen Liang Ding Tong Divya Gadde Emma Kong Gary Yeh Inbar Naor Jin Wang Justin Basilico Kabir Nagrecha Kevin Zielnicki Linas Baltrunas Lingyi Liu Luke Wang Matan Appelbaum Michael Tu Moumita Bhattacharya Pablo Delgado Qiuling Xu Rakesh Komuravelli Raveesh Bhalla Rob Story Roger Menezes Sejoon Oh Shahrzad Naseri Swanand Joshi Trung Nguyen Vito Ostuni Wei Wang Zhe Zhang
Reference
- C. K. Kang and J. McAuley, “Self-Attentive Sequential Recommendation,” 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 2018, pp. 197–206, doi: 10.1109/ICDM.2018.00035.
- F. Sun et al., “BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer,” Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ‘19), Beijing, China, 2019, pp. 1441–1450, doi: 10.1145/3357384.3357895.
- J. Zhai et al., “Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations,” arXiv preprint arXiv:2402.17152, 2024.
- F. Gloeckle, B. Youbi Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve, “Better & Faster Large Language Models via Multi-token Prediction,” arXiv preprint arXiv:2404.19737, Apr. 2024.
![]()
Foundation Model for Personalized Recommendation was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Comic for 2025.03.29 – Future Granny again
Post Syndicated from Explosm.net original https://explosm.net/comics/future-granny-again
New Cyanide and Happiness Comic
Obscure Weapon of the American Civil War
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=xfJE3y65RaA
Will SpaceX Starlink Have Too Many Satellites in Orbit?
Post Syndicated from Curious Droid original https://www.youtube.com/watch?v=S4MblZpDums
The Key Feature for Server CPUs is Still Two Threads Per Core
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/the-key-feature-for-server-cpus-amd-still-two-threads-per-core/
We take a look at SMT in 2025 and why the two threads per core regime is still dominant in the enterprise, perhaps becoming moreso
The post The Key Feature for Server CPUs is Still Two Threads Per Core appeared first on ServeTheHome.
Enhance governance with metadata enforcement rules in Amazon SageMaker
Post Syndicated from Pradeep Misra original https://aws.amazon.com/blogs/big-data/enhance-governance-with-metadata-enforcement-rules-in-amazon-sagemaker/
The next generation of SageMaker brings together widely adopted AWS machine learning and analytics capabilities, delivering an integrated experience with unified access to all data. Amazon SageMaker Lakehouse supports unified data access, and Amazon SageMaker Catalog, built on Amazon DataZone, offers catalog and governance features to meet enterprise security needs. Amazon SageMaker Catalog now supports metadata rules allowing organizations to enforce metadata standards across data publishing and subscription workflows.
A rule is a formal agreement that enforces specific metadata requirements across user workflows (e.g., publishing assets to the catalog, requesting data access) within the Amazon SageMaker Unified Studio portal. For instance, a metadata enforcement rule can specify the required information for creating a subscription request or publishing a data asset or a data product to the catalog, ensuring alignment with organizational standards. Metadata rules also enable the creation of custom approval workflows for subscriptions to assets, using collected metadata to facilitate access decisions or auto-fulfillment—outside of SageMaker.
By standardizing metadata practices, Amazon SageMaker Catalog enables customers to meet compliance requirements, enhance audit readiness, and streamline access workflows for greater efficiency and control. One such customer is Amazon Shipping Tech, which uses SageMaker Catalog for cataloging, discovery, sharing, and governance across their data ecosystem:
“We’re building an Analytics Ecosystem to drive discovery across the organization—but without consistent metadata, even our most valuable data can go unused. This feature empowers more teams to actively contribute to metadata curation with the right governance in place. It allows us to set clear standards for data producers while streamlining the collection of required subscription details—no extra templates needed. By enforcing standard metadata attributes, we improve discoverability, add context to each request, and strengthen support for analytics and GenAI solutions.”
— Saurabh Pandey, Principal Data Engineer at Amazon Shipping Tech
Sample use-cases
Metadata rules could help in the following use cases:
- A producer at an automobile company is preparing to publish a new dataset into the organization’s data catalog. The domain owner for the automotive domain requires that the producer include metadata fields such as Model Year, Region, and Compliance Status. Before the dataset can be published, automated checks make sure that these fields are correctly filled out according to the predefined standards.
- A consumer is requesting access to data assets in SageMaker. To meet organization standards and support audit and reporting needs, they must complete the subscription request, fill out a detailed form that includes the project purpose, and attach an email link with pre-approval and compliance training evidence to request subscription for financial data product. The data owner reviews the request, checking that all required metadata are provided before granting access.
Key benefits
Key benefits of new metadata enforcement rules include:
- Enhanced control for domain (unit) owners – Admins can enforce additional metadata fields on subscription and publishing workflows, which must be adhered to by data users. This process supports thorough reviews and enforces organizational compliance.
- Custom workflow support – You can create custom workflows for fulfilling subscriptions on non-managed assets by capturing essential metadata from data consumers. This metadata is used to configure access or support specific business requirements.
In this post, we guide you through two workflows: setting up metadata enforcement rules for a specific domain and publishing an asset or data product in a catalog, and setting up metadata enforcement rules for a specific domain and subscribing to an asset or data product that is owned by a project within that domain.
Solution Overview: Metadata Enforcement for Publishing
In this solution, we’ll walk through two workflows: setting up metadata enforcement for publishing, and setting up metadata enforcement for subscription.
Prerequisites
To follow this post, you should have a SageMaker Unified Studio domain set up with a domain owner or domain unit owner privileges. For instructions, refer to the following Getting started guide.
Set up metadata enforcement for publishing
In this section, we show you how to set up metadata rules for a specific domain as a domain admin. We also explain what happens when you publish an asset or data product in a catalog with these rules applied.
Create a domain unit for the marketing team
As a domain admin, complete the following steps:
- On the SageMaker Unified Studio console, choose the Govern dropdown menu and choose Domain units.

- Choose CREATE DOMAIN UNIT.

- Provide details shown in the following screenshot and choose CREATE DOMAIN UNIT.




You can see the domain unit as shown in the following screenshot.

Enable a metadata form creation policy in the Marketing domain unit
Complete the following steps:
- Navigate to the AUTHORIZATION POLICIES tab in the Marketing domain unit and choose Metadata form creation policy.

- Choose ADD POLICY GRANT.

- Select All projects in a domain unit and add a policy grant.
- You can also select specific projects that can create metadata forms.
- Choose ADD POLICY GRANT.



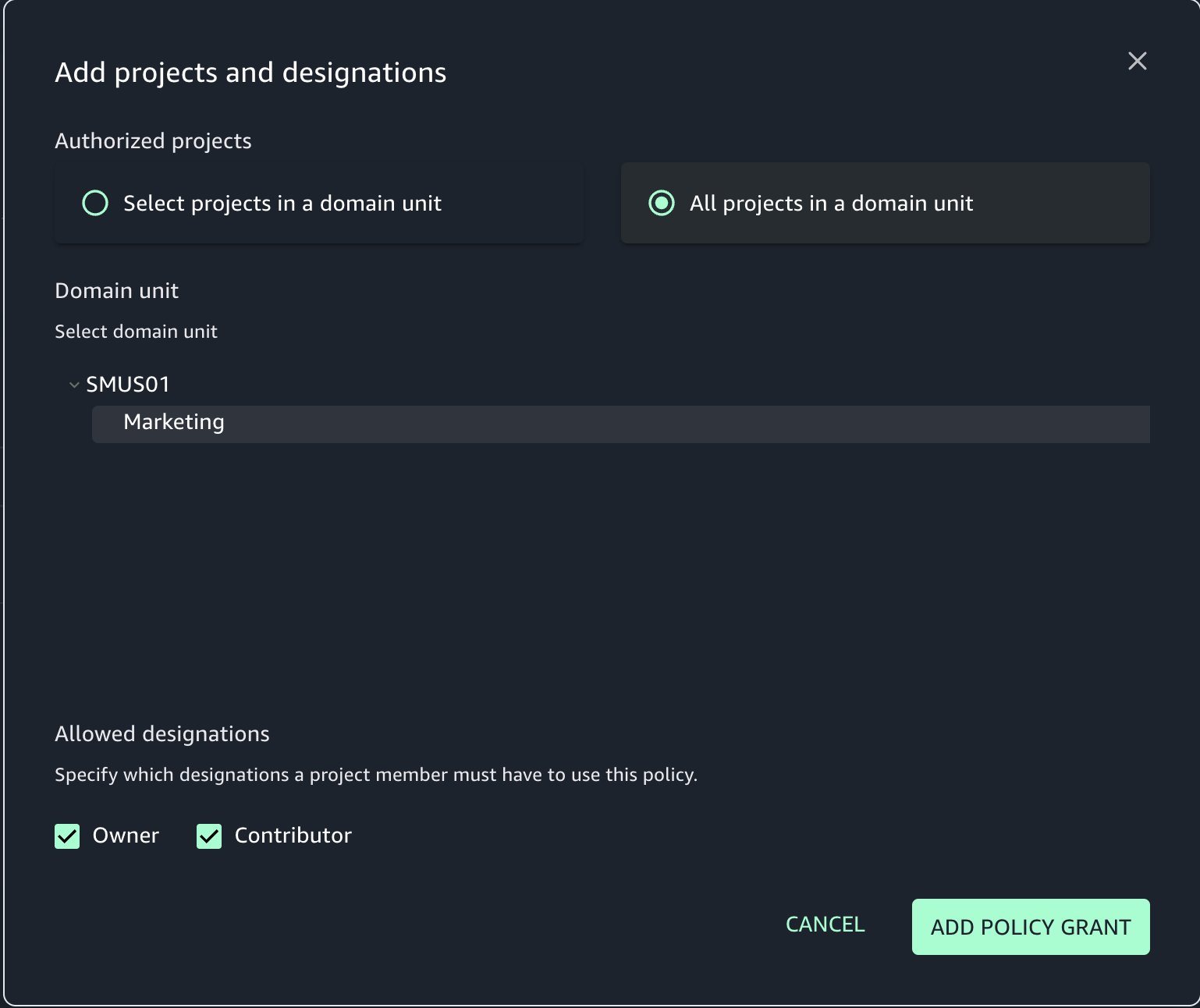
You can see the policy now created for the Marketing domain unit.

Create a metadata form to be enforced for assets before publishing
To create a metadata form, complete the following steps:
- In the
publish-1project, choose Metadata entities under Project catalog in the navigation pane. - On the Metadata forms tab, choose CREATE METADATA FORM.

- Provide a display name, technical name, and description.
- Choose CREATE METADATA FORM.

- After you create the form, you can choose CREATE FIELD to enforce fields that should be there in all published assets.

- Provide details as shown in the following screenshot.
- Select Searchable, Required, and Publishing because these fields are required before publishing.
- Choose CREATE FIELD.

- Add another field as shown in the following screenshot.






Both fields created with the Publishing action will require values before publishing to the catalog.

Create rules for asset publishing
Complete the following steps:
- In the
publish-1 - Choose the Marketing domain unit.

- On the Rules tab, choose ADD.

- Create the rule configuration with details in the following screenshot and add the metadata form created in the previous step.
- You can select the scope of enforcement by asset type and projects.
- Choose ADD RULE to create the rule.




The publishing enforcement rule publish_rules is now created.

Create a project in the Marketing domain unit
Create a project named publish-1 in the Marketing domain unit. To learn how to create a project, refer to Create a project.
Create an asset in the project
Rules work on assets managed by the SageMaker Catalog or on custom assets. To create an asset, complete the following steps:
- In the
publish-1project, choose Assets under Project catalog in the navigation pane. - On the Create dropdown menu, choose Create asset.

- Provide an asset name and description, then choose Next.

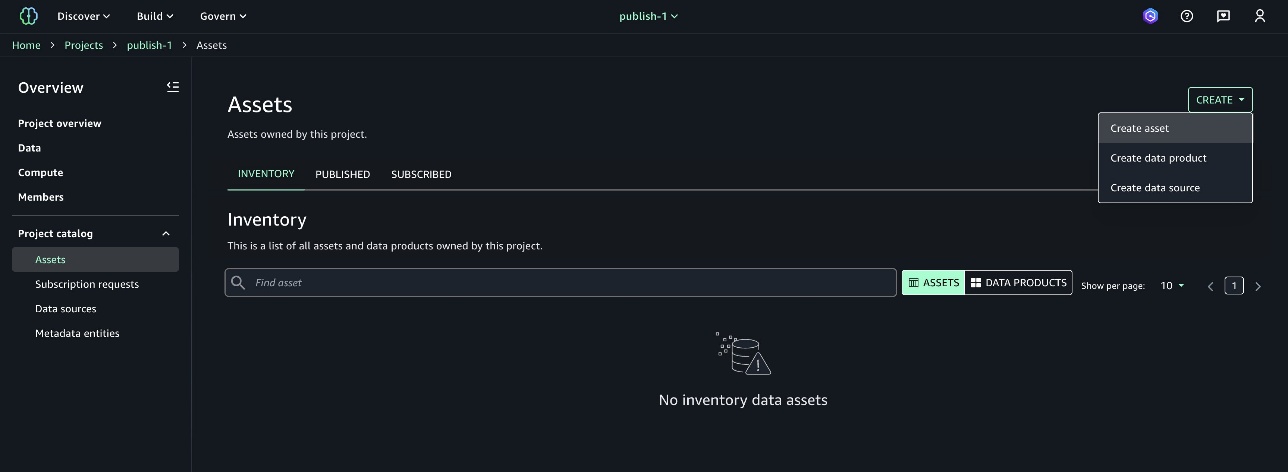

For this solution, you will create an Amazon Simple Storage Service (Amazon S3) object collection.
- For Asset type, choose S3 object collection.
- For S3 location ARN¸ enter the Amazon Resource Name (ARN) of the S3 object.
- Choose Next.

- Choose CREATE.



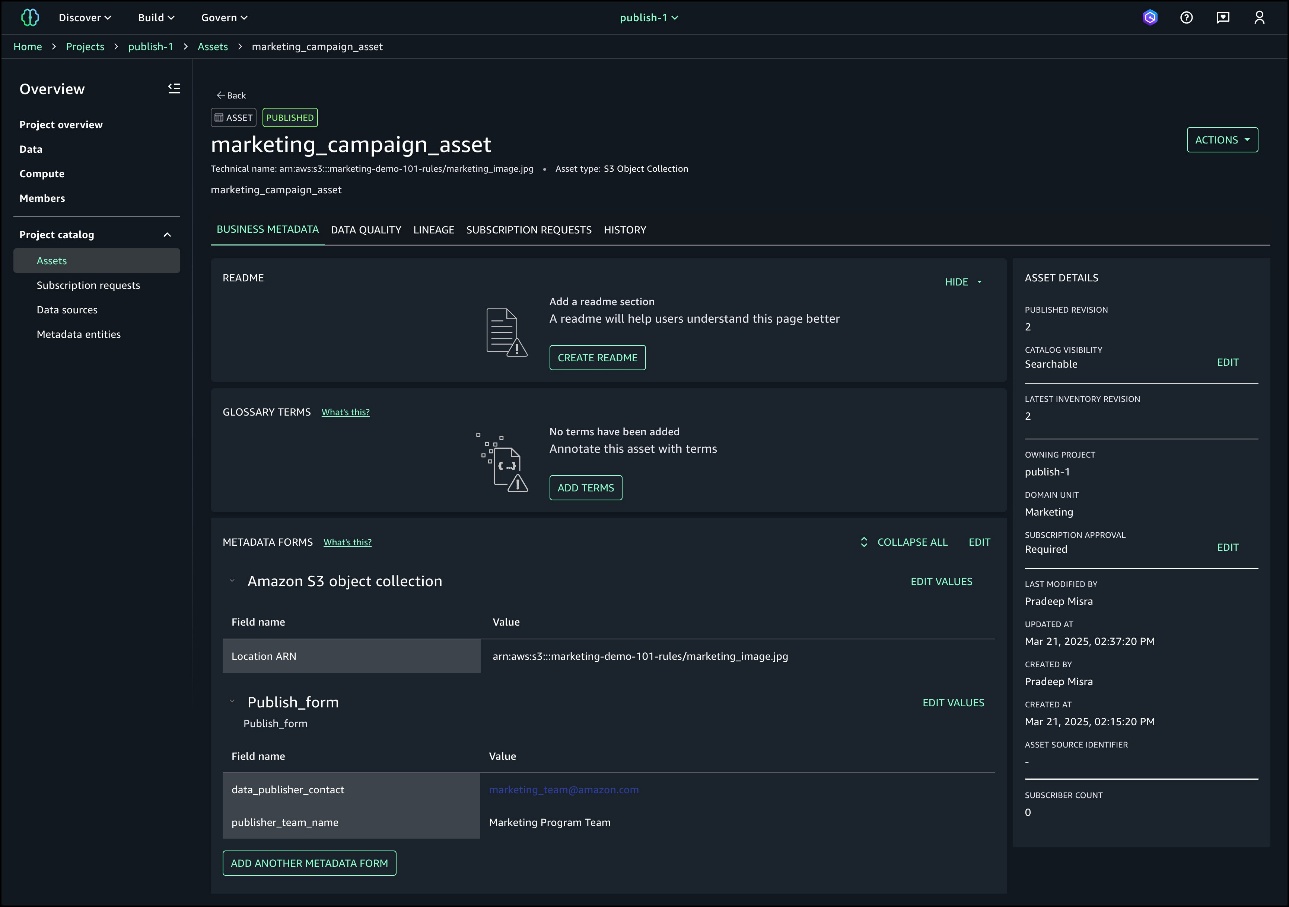
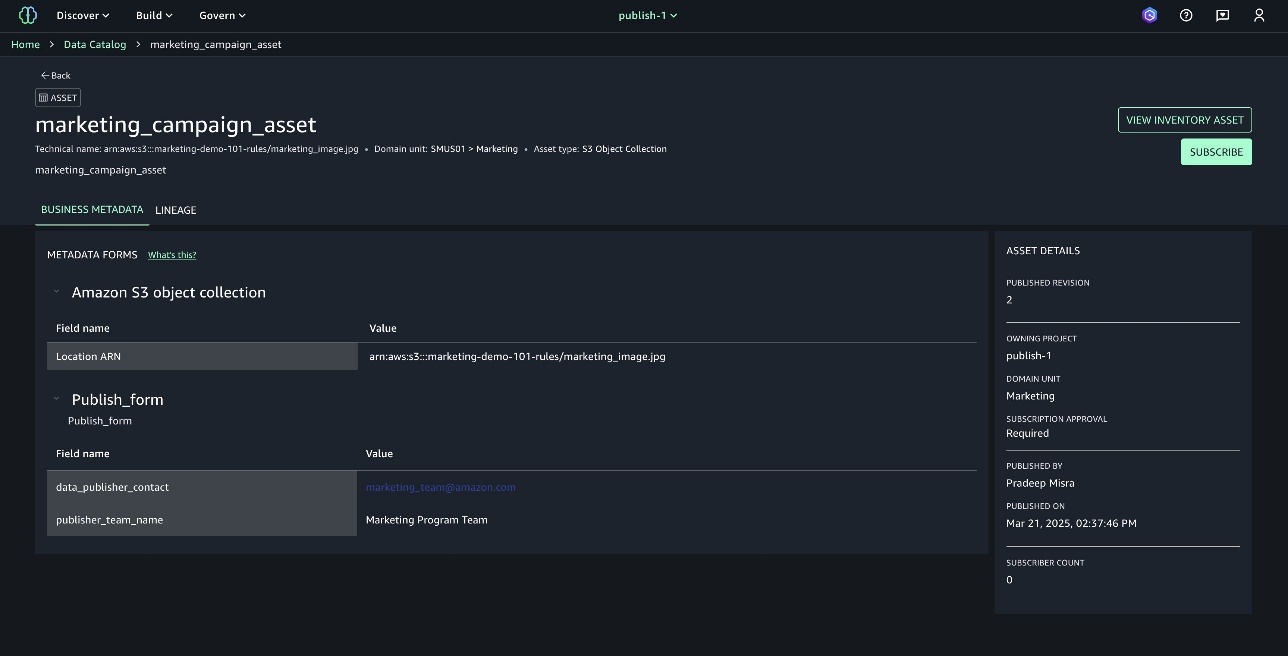
The asset marketing_campaign_asset is now created. This is still an inventory asset and not published to the catalog.

Publish rules enforcement
Asset details now show that the required values are missing for the mandatory form Publish_form.

You can try to publish without the required fields and the system will throw an error to enforce publishing metadata rules, as shown in the following screenshot.

To fix the issue, edit the value for the metadata form to provide the required info.

Provide details for the fields and choose SAVE.

Choose PUBLISH ASSET now and the asset will be published to the catalog.

You can see the asset is published with the required fields enforced with rules.
Set up metadata enforcement for subscription requests
In this section, we show you how to set up metadata rules for a specific domain as a domain admin. We also explain what happens when you subscribe to an asset or data product with these rules applied.
Create rules for asset subscription
Complete the following steps:
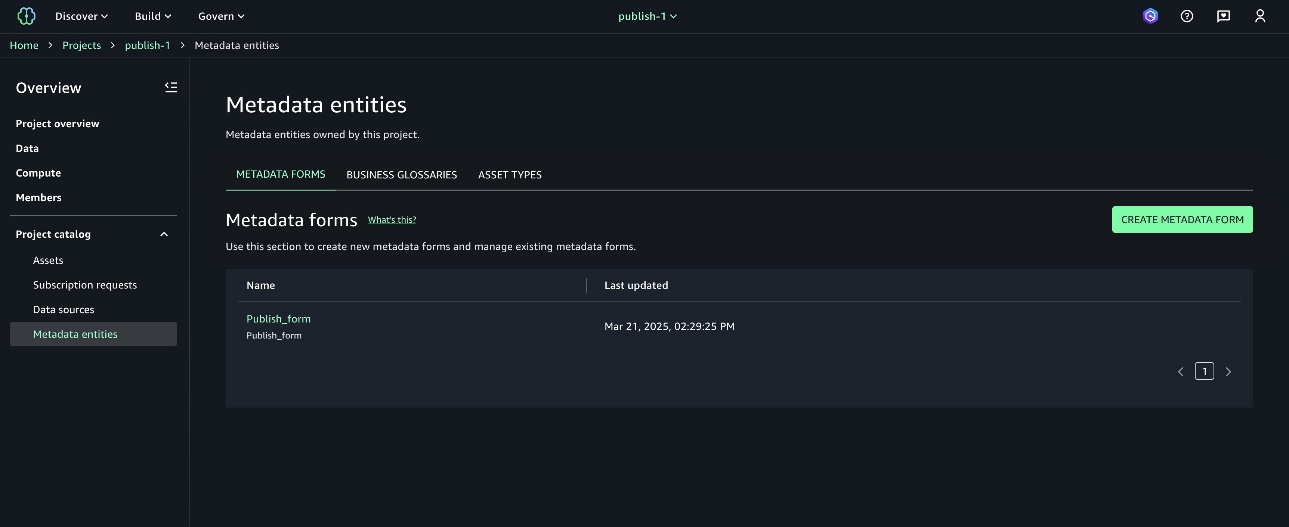
- Navigate to the project used in the previous section and choose Metadata entities under Project catalog in the navigation pane.
- On the Metadata forms tab, choose CREATE METADATA FORM to create a new form.

- Provide a form name and description, then choose CREATE METADATA FORM.

- Add fields to the form by choosing CREATE FIELD and turning on Enabled.

- Add a field for subscribers to explain the use case when requesting access.




Create rules for asset subscription
Complete the following steps:
- On the project page, choose Domain units under Domain Management in the navigation pane.
- Choose the Marketing domain unit.


We already have a publishing rule.
- On the Rules tab, choose ADD to add a new rule.

- Provide details for the new rule.
- Specify the action as Subscription request.
- Add the metadata form created in the previous steps (
Subscribe_form). - Choose the scope and projects for enforcement as shown in the following screenshot.
- Choose ADD RULE.



You will see the subscription enforcement rule is now created.
Subscribe the asset
Complete the following steps to subscribe the asset:
- On the project page, navigate to the marketing asset.
- Choose SUBSCRIBE.

The subscribe form is now attached in the request for the user to provide information.

After a data consumer submits a subscription request, the data producer receives it along with the provided metadata—such as Use Case. This allows producers to review the request before granting access.
Clean up
To avoid incurring additional charges, delete the Amazon SageMaker domain. Refer to Delete domains for the process.
Conclusion
In this post, we discussed metadata rules and how to implement them for both publishing and subscribing to assets across different domains, demonstrating effective metadata governance practices.
The new metadata enforcement rule in Amazon SageMaker strengthens data governance by enabling domain unit owners to establish clear metadata requirements for data users, streamlining catalog health and enhancing data governance process for access request. This feature enables organizations to align with organization’s metadata standards, implement custom workflows, and provide a consistent, governed data workflow experience.
The feature is supported in AWS Commercial Regions where Amazon SageMaker is currently available. To get started with metadata rules—
- Read the user guide for creating rules in the publishing workflow
- Read the user guide for creating rules in subscription requests
About the Authors
 Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments, building LEGOs and watching anime with his daughters.
 Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on LinkedIn.
Ramesh H Singh is a Senior Product Manager Technical (External Services) at AWS in Seattle, Washington, currently with the Amazon SageMaker team. He is passionate about building high-performance ML/AI and analytics products that enable enterprise customers to achieve their critical goals using cutting-edge technology. Connect with him on LinkedIn.
 Sandhya Edupuganti is a Senior Engineering Leader spearheading Amazon DataZone (aka) SageMaker Catalog. She is based in Seattle Metro area and has been with Amazon for over 17 years leading strategic initiatives in Amazon Advertising, Amazon-Retail, Latam-Expansion and AWS Analytics.
Sandhya Edupuganti is a Senior Engineering Leader spearheading Amazon DataZone (aka) SageMaker Catalog. She is based in Seattle Metro area and has been with Amazon for over 17 years leading strategic initiatives in Amazon Advertising, Amazon-Retail, Latam-Expansion and AWS Analytics.
Friday Squid Blogging: Squid Werewolf Hacking Group
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/03/friday-squid-blogging-squid-werewolf-hacking-group.html
In another rare squid/cybersecurity intersection, APT37 is also known as “Squid Werewolf.”
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
AWS continues to support government cloud security and shape FedRAMP’s evolution toward automated compliance
Post Syndicated from Hazem Eldakdoky original https://aws.amazon.com/blogs/security/aws-continues-to-support-government-cloud-security-and-shape-fedramps-evolution-toward-automated-compliance/
AWS has been a proud participant in FedRAMP since 2013. As FedRAMP continues to modernize federal cloud security assessments, we are excited to support this transformation toward a more automated and efficient compliance framework. Today, we’re emphasizing our support for both APN partners and government customers through this evolution and sharing our perspective on these important changes.
On Monday, March 24, the General Services Administration announced a major overhaul of how it supports cloud service provider IT security authorizations as part of FedRAMP. AWS remains dedicated to maintaining support for existing FedRAMP authorizations while preparing for the new program framework, titled FedRAMP 20x (FR 20x). This means continuing to comply with all current processes, including continuous monitoring, as part of existing authorizations of our own services until government processes formally change.
Going forward, we intend to participate in industry working groups to help shape implementation standards. We are also investing in tools and services that will help both partner and agency customers adapt to the new compliance model in order to securely accelerate their cloud journeys. We look forward to supporting FedRAMP to “do once, and reuse many.”
Key updates for our partners and customers:
- Adopting an automation-first approach. Automation accelerates the availability and use of the latest cloud services by federal customers. AWS continues to enhance our automated compliance verification capabilities to align with FR 20x’s vision.
- Streamlining the authorization process. FedRAMP is moving toward a more efficient authorization process that leverages automation and continuous monitoring. AWS is well positioned to support this transition through our extensive suite of Cloud Governance services.
- Enhancing security validation. The new framework will emphasize real-time compliance verification and automated control validation. AWS continues to invest in capabilities that will help customers meet these evolving requirements while maintaining the highest security standards.
Looking ahead: The modernization of FedRAMP represents an important step forward in federal cloud security. AWS remains committed to providing our government customers with the tools, resources, and support they need to succeed in this evolving landscape.
We encourage our customers to:
- Continue operating under current FedRAMP guidelines
- Stay informed about upcoming changes through AWS channels
- Engage with their account manager for further guidance
- Begin exploring automation capabilities for security compliance
As these changes roll out, AWS will continue to provide updates and guidance to help our customers navigate the transition successfully. For the latest information about AWS compliance offerings and FedRAMP authorizations, please visit our FedRAMP Compliance page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Edmundson: a modern Plasma Login Manager
Post Syndicated from jzb original https://lwn.net/Articles/1015763/
KDE contributor David Edmundson has published
a blog post about improving KDE Plasma’s login experience by
replacing SDDM
with a new Plasma Login Manager.
It’s worth stressing nothing is official or set in stone yet,
whilst it has come up in previous Plasma online meetings and in the
2023 Akademy. I’m posting this whilst starting a more official
discussion on the plasma-devel mailing list.Oliver Beard and I have made a new mutli-process greeter, that uses
the same startup mechanism as the desktop session. It doesn’t have all
the features that we propose at the start of the blog, but an
architecture where features and services can be slowly and safely
added.
That discussion is here
for those who would like to follow along. The prototype is currently
in two repositories: plasma-login
for the frontend work, and plasma-login-manager,
which is a fork of SDDM.
Comic for 2025.03.28 – The Great Flood
Post Syndicated from Explosm.net original https://explosm.net/comics/the-great-flood
New Cyanide and Happiness Comic
Metasploit Wrap-Up 03/28/2025
Post Syndicated from Jack Heysel original https://blog.rapid7.com/2025/03/28/metasploit-wrap-up-03-28-2025/
Windows LPE – Cloud File Mini Filer Driver Heap Overflow

This Metasploit release includes an exploit module for CVE-2024-30085, an LPE in cldflt.sys which is known as the Windows Cloud Files Mini Filer Driver. This driver allows users to manage and sync files between a remote server and a local client. The exploit module allows users with an existing session on an affected Windows device to seamlessly escalate their privileges to NT AUTHORITY\SYSTEM. This module has been tested on Windows workstation versions 10_1809 through 11_23H2 and Windows server versions 2022 to 22_23H2.
New module content (3)
GLPI Inventory Plugin Unauthenticated Blind Boolean SQLi
Authors: jheysel-r7 and rz
Type: Auxiliary
Pull request: #19974 contributed by jheysel-r7
Path: gather/glpi_inventory_plugin_unauth_sqli
AttackerKB reference: CVE-2025-24799
Description: This adds an auxiliary module for an Unauth Blind Boolean SQLi (CVE-2025-24799) vulnerability in GLPI <= 1.0.18 when the Inventory Plugin is installed and enabled.
Eramba (up to 3.19.1) Authenticated Remote Code Execution Module
Authors: Niklas Rubel, Sergey Makarov, Stefan Pietsch, Trovent Security GmbH, and msutovsky-r7
Type: Exploit
Pull request: #19957 contributed by msutovsky-r7
Path: linux/http/eramba_rce
AttackerKB reference: CVE-2023-36255
Description: This adds an exploit for CVE-2023-36255 which is an authenticated command injection vulnerability in Eramba.
Windows Cloud File Mini Filer Driver Heap Overflow
Authors: Alex Birnberg, bwatters-r7, and ssd-disclosure
Type: Exploit
Pull request: #19802 contributed by bwatters-r7
Path: windows/local/cve_2024_30085_cloud_files
AttackerKB reference: CVE-2024-30085
Description: Local Privilege Escalation for Windows, exploiting CVE-2024-30085. It allows escalating an existing session to higher privileges.
Bugs fixed (3)
- #19932 from adfoster-r7 – Fixes a crash when running the
exploits/windows/mssql/mssql_payloadmodule against previously opened Microsoft SQL Server sessions. - #19962 from e2002e – This preemptively updates the API host for the ZoomEye search module to reflect changes made by the upstream organization.
- #19987 from zeroSteiner – This updates the Ivanti and Sonicwall Bruteforce modules to use #initialize methods that accept a single argument as the LoginScanner classes should. It also renames the modules to follow the standard convention and adds a small fix to catch an unhandled connection error that was being thrown by the Sonicwall module.
Documentation
You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
Get it
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
NEVER MISS AN EMERGING THREAT
Be the first to learn about the latest vulnerabilities and cybersecurity news.
Bastogne: World War II’s Most Famous Town? #sponsored
Post Syndicated from Geographics original https://www.youtube.com/watch?v=hdVjO1WLMv0