Post Syndicated from xkcd.com original https://xkcd.com/3072/

Post Syndicated from xkcd.com original https://xkcd.com/3072/
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/running-the-deepseek-r1-671b-model-at-fp16-fidelity-alongside-amd-virtualized-workloads/
We show you how you can run the 1.27TB Deepseek-R1 671B model at FP16, and even look at running it alongside VMs in your clusters
The post Running the Deepseek-R1 671B Model at FP16 Fidelity Alongside Virtualized Workloads appeared first on ServeTheHome.
Post Syndicated from Enrico Liguori original https://aws.amazon.com/blogs/architecture/announcing-the-well-architected-data-residency-with-hybrid-cloud-services-lens/
As organizations increasingly take advantage of the benefits of hybrid cloud architectures, they are often faced with the challenge of balancing data residency requirements with the flexibility of the cloud. To help you navigate this complex landscape, we are excited to introduce the AWS Well-Architected Data Residency with Hybrid Cloud Services (DRHC) Lens paper.
The AWS Well-Architected Framework provides a consistent approach for evaluating architectures and applying best practices to build reliable, secure, efficient, and cost-effective systems in the cloud. The framework is based on six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
The DRHC Lens identifies a set of key design principles to help you in the development and deployment of Well-Architected hybrid cloud workloads:
In addition to these design principles, the lens provides detailed guidance across the six pillars of the Well-Architected Framework:
All AWS customers with data residency requirements, including government agencies, healthcare providers, financial institutions, and public sector industries who are looking for guidance on these architectural patterns, can use the DRHC Lens. When designing and maintaining your architecture with data residency in mind, the following roles can benefit from this lens:
The new Well-Architected Data Residency with Hybrid Cloud Services Lens is available now. Use the lens whitepaper to adopt your hybrid cloud workloads according to the tenants of the Well-Architected Framework while maintaining data sovereignty requirements.
Applying the Data Residency with Hybrid Cloud Services Lens to your architecture helps validate your data handling practices and provides actionable recommendations to address gaps. AWS will continue to update the whitepaper as new services and features are released. Using the lens can help you consistently apply the latest patterns to meet your requirements. This allows you to deploy applications to meet your business objectives and requirements.
Post Syndicated from Ryan Emmons original https://blog.rapid7.com/2025/04/03/etr-ivanti-connect-secure-cve-2025-22457-exploited-in-the-wild/

On Thursday, April 3, 2025, Ivanti disclosed a critical severity vulnerability affecting Ivanti Connect Secure, Pulse Connect Secure, Policy Secure, and ZTA Gateways. CVE-2025-22457 is a stack-based buffer overflow vulnerability that allows remote, unauthenticated attackers to execute code on the target device. Ivanti’s advisory indicates that CVE-2025-22457 is known to be exploited in the wild; Google’s Mandiant division attributes this activity to suspected China-nexus actors.
Ivanti’s advisory indicates that the vulnerability was “initially identified as a product bug” and patched in Ivanti Connect Secure version 22.7R2.6 (released February 11, 2025). Per Mandiant, CVE-2025-22457 is “a buffer overflow with a limited character space, and therefore it was initially believed to be a low-risk denial-of-service vulnerability.” However, on April 3, Ivanti publicly acknowledged known exploitation in the wild of supported Ivanti Connect Secure and End-of-Support Pulse Connect Secure appliances for remote code execution in some customer environments.
The following products and versions are vulnerable to CVE-2025-22457:
Ivanti has a full table of affected versions and corresponding solution estimates in their advisory.
A patch is available (initially released on February 11, 2025) for CVE-2025-22457 in Ivanti Connect Secure. However, the advisory states that patches for Ivanti Policy Secure and ZTA Gateways will not be available until April 21, 2025 and April 19, 2025, respectively. Pulse Connect Secure 9.1x reached End-of-Support on December 31, 2024 and won’t be patched. For the latest information, please refer to the Ivanti advisory.
Customers should apply the available Ivanti Connect Secure patch immediately, without waiting for a typical patch cycle to occur. Ivanti’s advisory notes that “Customers should monitor their external ICT and look for web server crashes. If your ICT result shows signs of compromise, you should perform a factory reset on the appliance and then put the appliance back into production using version 22.7R2.6.” Notably, ICT results may vary; a factory reset should be performed if exploitation is suspected, regardless of ICT results.
For the latest information, please refer to the vendor advisory.
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2025-22457 in Ivanti Connect Secure with a vulnerability check expected to be available in today’s (April 3, 2025) content release.
Post Syndicated from Explosm.net original https://explosm.net/comics/flamethrower
New Cyanide and Happiness Comic
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=KhLjy0eym1w
Post Syndicated from Balaji Mohan original https://aws.amazon.com/blogs/big-data/correlate-telemetry-data-with-amazon-opensearch-service-and-amazon-managed-grafana/
Troubleshooting a large, complex, distributed enterprise application involves challenges like tracing requests across multiple services, identifying performance bottlenecks across the stack, and understanding cascading failures between dependent services. Customers often need to work with isolated data to identify the underlying cause of the problem. By correlating different signals like logs, traces, metrics, and other performance indicators, you can get valuable insight into what caused the problem, where, and why.
Amazon OpenSearch Service is a managed service to deploy, operate, and search data at scale within AWS. Amazon Managed Grafana is a secure data visualization service to query operational data from multiple sources, including OpenSearch Service.
In this post, we show you how to use these services to correlate the various observability signals that improve root cause analysis, thereby resulting in reduced Mean Time to Resolution (MTTR). We also provide a reference solution that can be used at scale for proactive monitoring of enterprise applications to avoid a problem before they occur.
The following diagram shows the solution architecture for collecting and correlating various enterprise telemetry signals at scale.

At the core of this architecture are applications composed of microservices (represented by orange boxes) running on Amazon Elastic Kubernetes Service (Amazon EKS). These microservices contain instrumentation that emit telemetry data in the form of metrics, logs, and traces. This data is exported into the OpenTelemetry Collector, which serves as a central vendor agnostic gateway to collect this data uniformly.
In this post, we use an OpenTelemetry demo application as a sample enterprise application. Large enterprise customers typically separate their observability signal data into various stores for scalability, fault isolation, access control, and ease of operation. To aid in these functions, we recommend and use Amazon OpenSearch Ingestion for a serverless, scalable, and fully managed data pipeline. We separate log and trace data and send them to distinct OpenSearch Service domains. The solution also sends the metrics data to Amazon Managed Service for Prometheus.
We use Amazon Managed Grafana as a data visualization and analytics platform to query and visualize this data. We also show how to employ correlations as a valuable tool to gain insights from these signals spread across various data stores.
The following sections outline building this architecture at scale.
Complete the following prerequisite steps:
Before setting up the ingestion pipelines, you need to create the necessary AWS Identity and Access Management (IAM) policies and roles. This process involves creating two policies for domain and OSIS access, followed by creating a pipeline role that uses these policies.
Complete the following steps to create an IAM policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "es:DescribeDomain",
"Resource": "arn:aws:es:*:{accountId}:domain/*"
},
{
"Effect": "Allow",
"Action": [ "es:ESHttpGet", "es:HttpHead", "es:HttpDelete", "es:HttpPatch", "es:HttpPost", "es:HttpPut" ],
"Resource": "arn:aws:es:us-east-1:{accountId}:domain/otel-traces"
},
{
"Effect": "Allow",
"Action": [ "es:ESHttpGet", "es:HttpHead", "es:HttpDelete", "es:HttpPatch", "es:HttpPost", "es:HttpPut" ],
"Resource": "arn:aws:es:us-east-1:{accountId}:domain/otel-logs"
}
}
]
}
// Replace {accountId} with your own values{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "osis:Ingest",
"Resource": "arn:aws:osis:us-east-1:{accountId}:pipeline/osi-pipeline-otellogs"
},
{
"Effect": "Allow",
"Action": "osis:Ingest",
"Resource": "arn:aws:osis:us-east-1:{accountId}:pipeline/osi-pipeline-oteltraces"
}
]
}
// Replace {accountId} with your own valuesComplete the following steps to create a pipeline role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"eks.amazonaws.com",
"osis-pipelines.amazonaws.com"
],
"AWS": "{nodegroup_arn}"
},
"Action": "sts:AssumeRole"
}
]
}
// Replace {nodegroup_arn} with your own valuesosis-policy and domain-policy you just created.PipelineRole.To enable access for the pipeline role in OpenSearch Service domains, complete the following steps:
Then, complete the following steps for each OpenSearch Service domain (logs and traces domains).
This procedure uses the all_access role for demonstration purposes only. This grants full administrative privileges to the pipeline role, which violates the principle of least privilege and could pose security risks. For production environments, you should create a custom role with minimal permissions required for data ingestion, limit permissions to specific indexes and operations, consider implementing index patterns and time-based access controls, and regularly audit role mappings and permissions. For detailed guidance on creating custom roles with appropriate permissions, refer to Security in Amazon OpenSearch Service.
PiplelineRole.
Complete the following steps to create a pipeline for logs:
version: "2"
otel-logs-pipeline:
source:
otel_logs_source:
path: "/v1/logs"
sink:
- opensearch:
hosts: ["{OpenSearch_domain_endpoint}"]
aws:
sts_role_arn: "arn:aws:iam::{accountId}:role/osi-pipeline-role"
region: "us-east-1"
serverless: false
index: "observability-otel-logs%{yyyy-MM-dd}"
# To get the values for the placeholders:
# 1. {OpenSearch_domain_endpoint}: You can find the domain endpoint by navigating to the Amazon Managed Opensearch managed clusters in the AWS Management Console, and then clicking on the domain.
# After obtaining the necessary values, replace the placeholders in the configuration with the actual values. Complete the following steps to create a pipeline for traces:
version: "2"
entry-pipeline:
source:
otel_trace_source:
path: "/v1/traces"
processor:
- trace_peer_forwarder:
sink:
- pipeline:
name: "span-pipeline"
- pipeline:
name: "service-map-pipeline"
span-pipeline:
source:
pipeline:
name: "entry-pipeline"
processor:
- otel_traces:
sink:
- opensearch:
index_type: "trace-analytics-raw"
hosts: ["{OpenSearch_domain_endpoint}"]
aws:
sts_role_arn: "arn:aws:iam::{accountId}:role/osi-pipeline-role"
region: "us-east-1"
service-map-pipeline:
source:
pipeline:
name: "entry-pipeline"
processor:
- service_map:
sink:
- opensearch:
index_type: "trace-analytics-service-map"
hosts: ["{OpenSearch_domain_endpoint}"]
aws:
sts_role_arn: "arn:aws:iam::{accountId}:role/osi-pipeline-role"
region: "us-east-1"
# To get the values for the placeholders:
# 1. {OpenSearch_domain_endpoint}: You can find the domain endpoint by navigating to the Amazon Managed Opensearch managed clusters in the AWS Management Console, and then clicking on the domain. # 2. {accountId}: This is your AWS account ID. You can find your account ID by clicking on your username in the top-right corner of the AWS Management Console and selecting "My Account" from the dropdown menu.
# After obtaining the necessary values, replace the placeholders in the configuration with the actual values. Use the EKS cluster you set up earlier along with AWS CloudShell or another tool to complete these steps:
Now you can complete the following steps to install the application.
git clone https://github.com/aws-samples/sample-correlation-opensearch-repositorycd deployment_fileskubectl apply -f .kubectl expose deployment opentelemetry-demo-frontendproxy --type=LoadBalancer --name=frontendproxy
By following these steps, you can successfully install and access demo applications on your EKS cluster.
The OpenTelemetry Collector is a tool that manages the receiving, processing, and exporting of telemetry data from your application to a target repository.
In this step, we send logs and traces to OpenSearch Service and metrics to Amazon Managed Prometheus. The OpenTelemetry Collector also works with popular data repositories like Jaeger and a variety of other open source and commercial platforms. In this section, we include steps to configure the OpenTelemetry Collector in an EKS environment. Then we deploy the demo application and explore the OpenTelemetry exporters using AWS Managed Solutions instead of the open source versions.
Complete the following steps:
kubectl edit configmap opentelemetry-demo-otelcol -n otel-demoexporters:
logging: {}
otlphttp/logs:
logs_endpoint: "<AWS_OPENSEARCH_LOG_INGESTION_URL>/v1/logs"
auth:
authenticator: sigv4auth
compression: none
otlphttp/traces:
traces_endpoint: "<AWS_OPENSEARCH_TRACE_INGESTION_URL>/v1/traces"
auth:
authenticator: sigv4auth
compression: none
prometheusremotewrite:
endpoint: "<AWS_MANAGED_PROMETHEUS_ENDPOINT>"
auth:
authenticator: sigv4auth sigv4auth:
assume_role:
arn: "arn:aws:iam::{accountId}:role/osi-pipeline-role"
sts_region: "us-east-1"
region: "us-east-1"
service: "osis"
# {accountId}: replace accountID with your account idkubectl rollout restart deployment opentelemetry-demo-otelcol -n otel-demoWith these changes, the OpenTelemetry Collector will send trace data to the OpenSearch Service domain, metrics data to the AWS Managed Service for Prometheus endpoint, and log data to the OpenSearch Service domain.
Before you can visualize your logs and traces, you need to configure OpenSearch Service as a data source in your Amazon Managed Grafana workspace. This configuration is done through the Amazon Managed Grafana console.
Complete the following steps to configure the OpenSearch Service data source:
logstash-*).If the test is successful, you should see a green notification with the message “Data source is working.”
Complete the following steps to configure the Prometheus data source:
If the test is successful, you should see a green notification with the message “Data source is working.”
To establish connections between your logs and traces data, you need to set up data correlations in Amazon Managed Grafana. This allows you to navigate seamlessly between related logs and traces. Follow these steps in your Amazon Managed Grafana workspace:

otel-traces) from the dropdown list and define the query that will execute when the link is followed. You can use variables to query specific field values. For example, traceId: ${__value.raw}.
traceID.


In Amazon Managed Grafana, using the Prometheus data source, locate the desired instance for correlation. The instance ID will be displayed as a link. Follow the link to open the corresponding log details in a panel on the right side of the page.

With the logs to traces correlation configured, you can access trace information directly from the logs page. Choose traces on the log details panel to view the corresponding trace data.

The following screenshot demonstrates the node graph visualization showing the correlation flow: instance metrics to logs to traces.
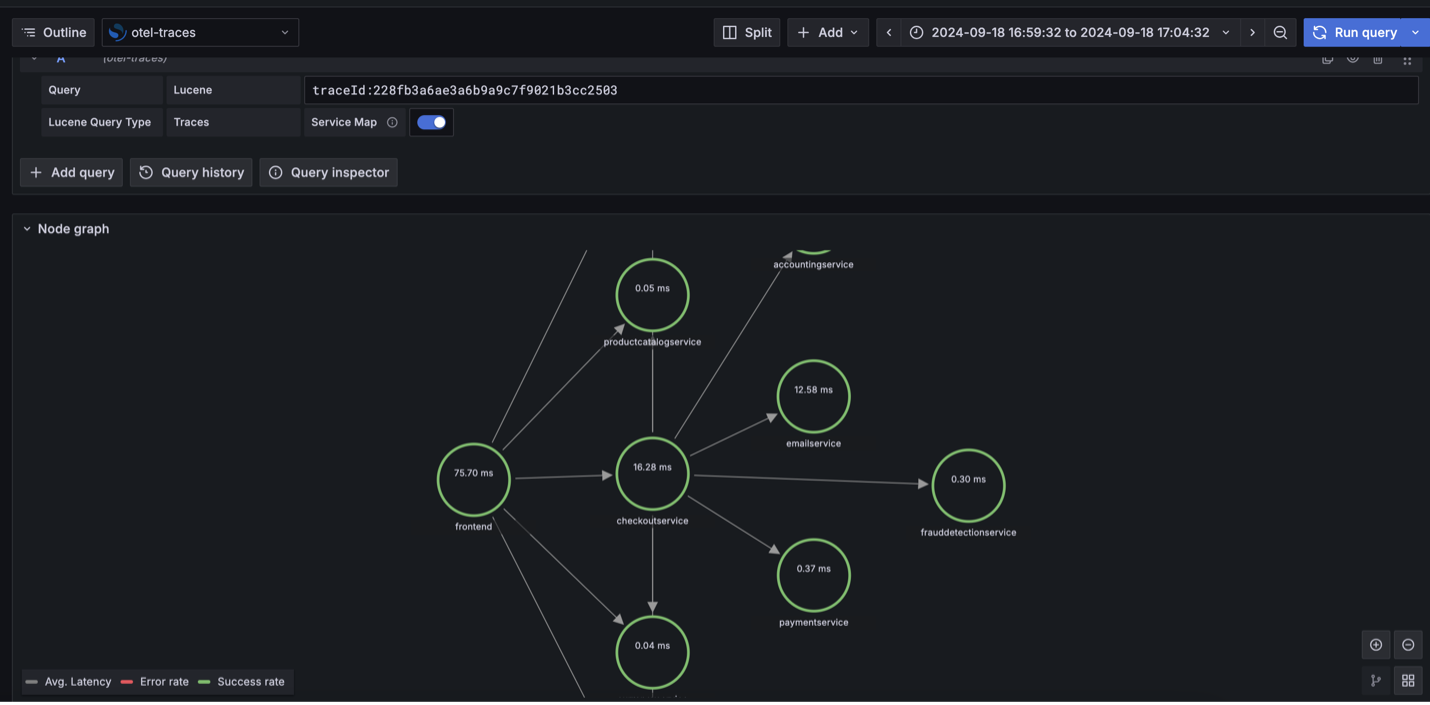
Remove the infrastructure for this solution when not in use to avoid incurring unnecessary costs.
In this post, we showed how to use correlation as a helpful tool to gain insight into observability data stored in various stores.
Separating logs and traces into dedicated domains provides the following benefits:
You can use this solution as a reference to build a scalable observability solution for your enterprise to detect, investigate, and remediate problems faster. This ability, when used along next-generation artificial intelligence and machine learning (AI/ML), helps to not only proactively react but predict and prevent problems before they occur. You can learn more about AI/ML with AWS.
 Balaji Mohan is a Senior Delivery Consultant specializing in application and data modernization to the cloud. His business-first approach provides seamless transitions, aligning technology with organizational goals. Using cloud-centered architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth.
Balaji Mohan is a Senior Delivery Consultant specializing in application and data modernization to the cloud. His business-first approach provides seamless transitions, aligning technology with organizational goals. Using cloud-centered architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth.
 Senthil Ramasamy is a Senior Database Consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database services, helping them with database migrations to the AWS Cloud and improving the value of their solutions when using AWS.
Senthil Ramasamy is a Senior Database Consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database services, helping them with database migrations to the AWS Cloud and improving the value of their solutions when using AWS.
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=09zTXD0IMSY
Post Syndicated from corbet original https://lwn.net/Articles/1016013/
Address-space isolation may well be, as Brendan Jackman said at the
beginning of his memory-management-track session at the 2025 Linux Storage,
Filesystem, Memory-Management, and BPF Summit, “some security
“. But it also holds the potential to protect the kernel from
bullshit
a wide range of vulnerabilities, both known and unknown, while reducing the
impact of existing mitigations. Implementing address-space isolation with
reasonable performance, though, is going to require some significant
changes. Jackman was there to get feedback from the memory-management
community on how those changes should be implemented.
Post Syndicated from corbet original https://lwn.net/Articles/1016011/
The kernel must often step through the page tables of one or more processes
to carry out various operations. This “page-table walking” tends to be
performed by ad-hoc (duplicated) code all over the kernel. Oscar Salvador
used a memory-management-track session at the 2025 Linux Storage,
Filesystem, Memory-Management, and BPF Summit to talk about strategies to
unify the kernel’s page-table walking code just a little bit by making
hugetlb pages look more like ordinary pages.
Post Syndicated from corbet original https://lwn.net/Articles/1016365/
Version
1.86.0 of the Rust language has been released. Changes include support
for trait upcasting, the ability to index multiple elements of HashMaps and
slices mutably, and a number of stabilized APIs.
Post Syndicated from jake original https://lwn.net/Articles/1016361/
Security updates have been issued by AlmaLinux (expat), Debian (chromium, commons-vfs, firefox-esr, php-horde-editor, php-horde-imp, and thunderbird), Fedora (corosync, firefox, nextcloud, and suricata), Mageia (curl and upx), Oracle (emacs, fence-agents, freetype, kernel, libreoffice, libxml2, nginx:1.24, podman, python-jinja2, and tigervnc), Red Hat (firefox and python-jinja2), SUSE (assimp, ffmpeg-4, firefox, ghostscript, GraphicsMagick, libxslt, and tomcat), and Ubuntu (linux, linux-aws, linux-aws-5.15, linux-gcp, linux-gke, linux-gkeop,
linux-ibm, linux-intel-iotg, linux-kvm, linux-lowlatency,
linux-lowlatency-hwe-5.15, linux-meta-raspi, linux-nvidia-tegra,
linux-oracle, linux-oracle-5.15, linux-raspi, linux, linux-azure, linux-azure-5.4, linux-bluefield, linux-gcp,
linux-ibm, linux-kvm, linux-oracle, linux-oracle-5.4, linux-xilinx-zynqmp, linux-fips, linux-fips, linux-aws-fips, linux-gcp-fips, linux-hwe-5.15, and linux-realtime, linux-intel-iot-realtime).
Post Syndicated from Deanna Lam original https://blog.cloudflare.com/improve-your-media-pipelines-with-the-images-binding-for-cloudflare-workers/
When building a full-stack application, many developers spend a surprising amount of time trying to make sure that the various services they use can communicate and interact with each other. Media-rich applications require image and video pipelines that can integrate seamlessly with the rest of your technology stack.
With this in mind, we’re excited to introduce the Images binding, a way to connect the Images API directly to your Worker and enable new, programmatic workflows. The binding removes unnecessary friction from application development by allowing you to transform, overlay, and encode images within the Cloudflare Developer Platform ecosystem.
In this post, we’ll explain how the Images binding works, as well as the decisions behind local development support. We’ll also walk through an example app that watermarks and encodes a user-uploaded image, then uploads the output directly to an R2 bucket.
Cloudflare Images was designed to help developers build scalable, cost-effective, and reliable image pipelines. You can deliver multiple copies of an image — each resized, manipulated, and encoded based on your needs. Only the original image needs to be stored; different versions are generated dynamically, or as requested by a user’s browser, then subsequently served from cache.
With Images, you have the flexibility to transform images that are stored outside the Images product. Previously, the Images API was based on the fetch() method, which posed three challenges for developers:
First, when transforming a remote image, the original image must be retrieved from a URL. This isn’t applicable for every scenario, like resizing and compressing images as users upload them from their local machine to your app. We wanted to extend the Images API to broader use cases where images might not be accessible from a URL.
Second, the optimization operation — the changes you want to make to an image, like resizing it — is coupled with the delivery operation. If you wanted to crop an image, watermark it, then resize the watermarked image, then you’d need to serve one transformation to the browser, retrieve the output URL, and transform it again. This adds overhead to your code, and can be tedious and inefficient to maintain. Decoupling these operations means that you no longer need to manage multiple requests for consecutive transformations.
Third, optimization parameters — the way that you specify how an image should be manipulated — follow a fixed order. For example, cropping is performed before resizing. It’s difficult to build a flow that doesn’t align with the established hierarchy — like resizing first, then cropping — without a lot of time, trial, and effort.
But complex workflows shouldn’t require complex logic. In February, we released the Images binding in Workers to make the development experience more accessible, intuitive, and user-friendly. The binding helps you work more productively by simplifying how you connect the Images API to your Worker and providing more fine-grained control over how images are optimized.
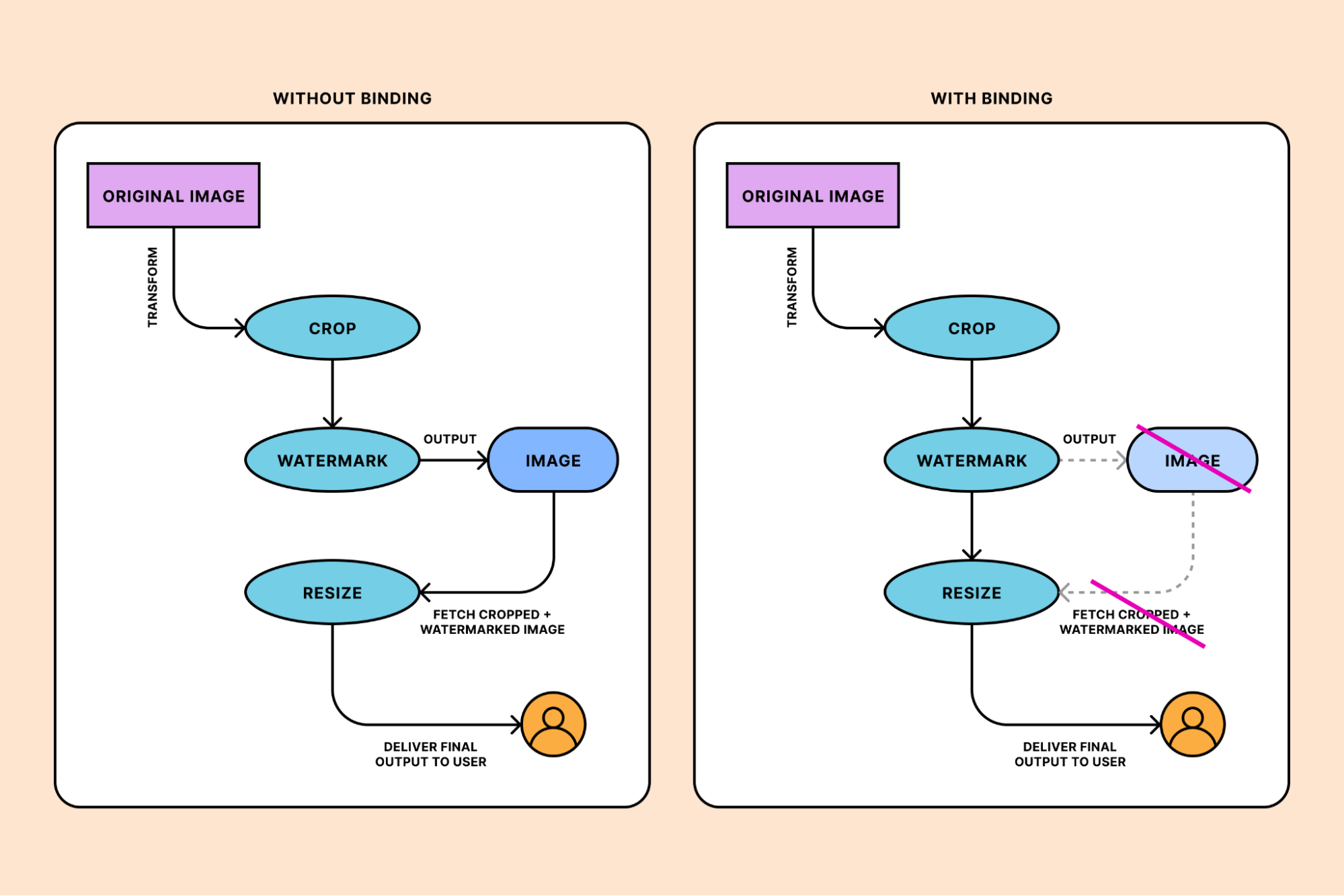
Since optimization parameters follow a fixed order, we’d need to output the image to resize it after watermarking. The binding eliminates this step.
Bindings connect your Workers to external resources on the Developer Platform, allowing you to manage interactions between services in a few lines of code. When you bind the Images API to your Worker, you can create more flexible, programmatic workflows to transform, resize, and encode your images — without requiring them to be accessible from a URL.
Within a Worker, the Images binding supports the following functions:
.transform(): Accepts optimization parameters that specify how an image should be manipulated
.draw(): Overlays an image over the original image. The overlaid image can be optimized through a child transform() function.
.output(): Defines the output format for the transformed image.
.info(): Outputs information about the original image, like its format, file size, and dimensions.
At a high level, a binding works by establishing a communication channel between a Worker and the binding’s backend services.
To do this, the Workers runtime needs to know exactly which objects to construct when the Worker is instantiated. Our control plane layer translates between a given Worker’s code and each binding’s backend services. When a developer runs wrangler deploy, any invoked bindings are converted into a dependency graph. This describes the objects and their dependencies that will be injected into the env of the Worker when it runs. Then, the runtime loads the graph, builds the objects, and runs the Worker.
In most cases, the binding makes a remote procedure call to the backend services of the binding. The mechanism that makes this call must be constructed and injected into the binding object; for Images, this is implemented as a JavaScript wrapper object that makes HTTP calls to the Images API.
These calls contain the sequence of operations that are required to build the final image, represented as a tree structure. Each .transform() function adds a new node to the tree, describing the operations that should be performed on the image. The .draw() function adds a subtree, where child .transform() functions create additional nodes that represent the operations required to build the overlay image. When .output() is called, the tree is flattened into a list of operations; this list, along with the input image itself, is sent to the backend of the Images binding.
For example, let’s say we had the following commands:
env.IMAGES.input(image)
.transform(rotate:90})
.draw(
env.IMAGES.input(watermark)
.transform({width:32})
)
.transform({blur:5})
.output({format:"image/png"})Put together, the request would look something like this:
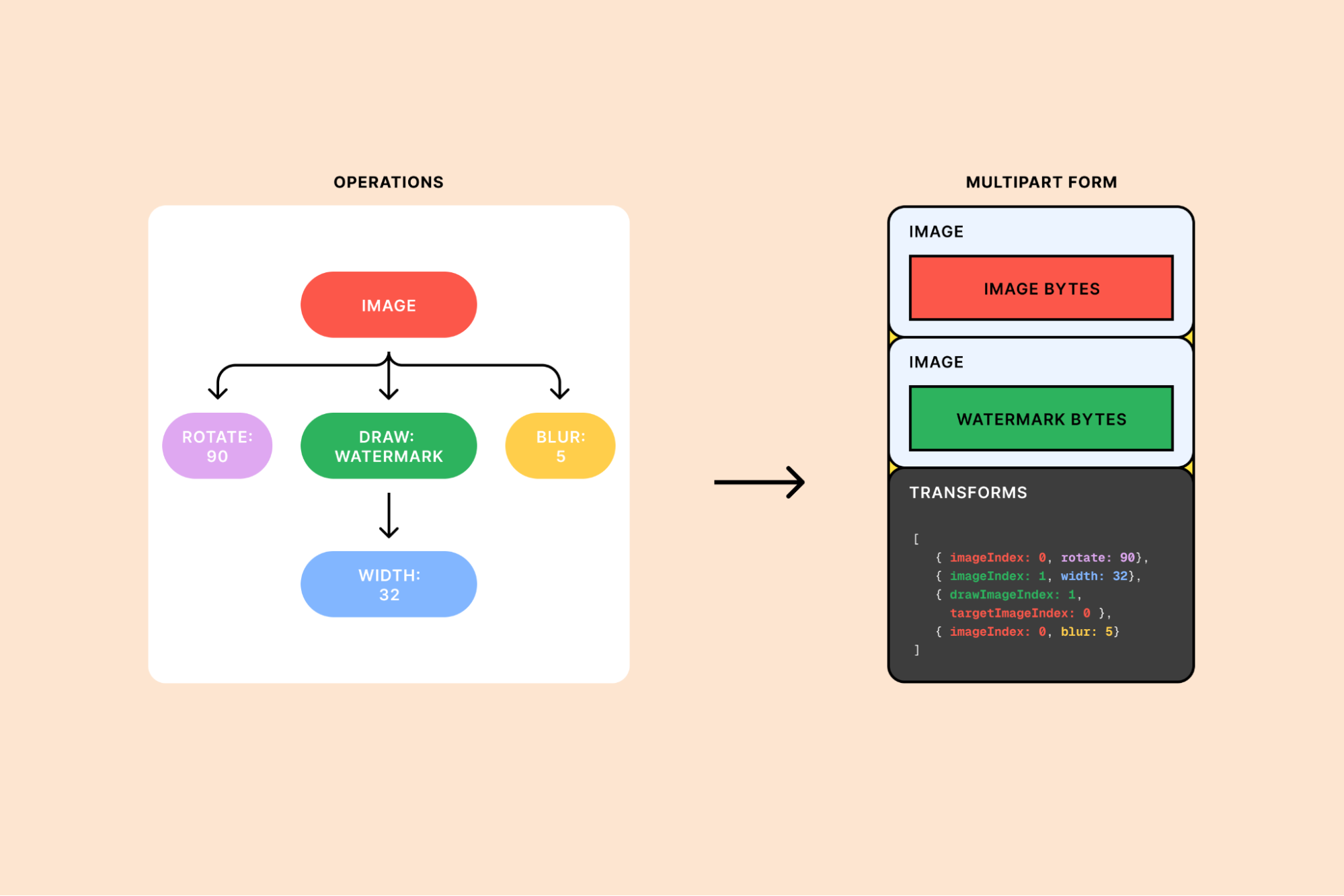
To communicate with the backend, we chose to send multipart forms. Each binding request is inherently expensive, as it can involve decoding, transforming, and encoding. Binary formats may offer slightly lower overhead per request, but given the bulk of the work in each request is the image processing itself, any gains would be nominal. Instead, we stuck with a well-supported, safe approach that our team had successfully implemented in the past.
Beyond the core capabilities of the binding, we knew that we needed to consider the entire developer lifecycle. The ability to test, debug, and iterate is a crucial part of the development process.
Developers won’t use what they can’t test; they need to be able to validate exactly how image optimization will affect the user experience and performance of their application. That’s why we made the Images binding available in local development without incurring any usage charges.
As we scoped out this feature, we reached a crossroad with how we wanted the binding to work when developing locally. At first, we considered making requests to our production backend services for both unit and end-to-end testing. This would require open-sourcing the components of the binding and building them for all Wrangler-supported platforms and Node versions.
Instead, we focused our efforts on targeting individual use cases by providing two different methods. In Wrangler, Cloudflare’s command-line tool, developers can choose between an online and offline mode of the Images binding. The online mode makes requests to the real Images API; this requires Internet access and authentication to the Cloudflare API. Meanwhile, the offline mode requests a lower fidelity fake, which is a mock API implementation that supports a limited subset of features. This is primarily used for unit tests, as it doesn’t require Internet access or authentication. By default, wrangler dev uses the online mode, mirroring the same version that Cloudflare runs in production.
Let’s look at an example app that transforms a user-uploaded image, then uploads it directly to an R2 bucket.
To start, we created a Worker application and configured our wrangler.toml file to add the Images, R2, and assets bindings:
[images]
binding = "IMAGES"
[[r2_buckets]]
binding = "R2"
bucket_name = "<BUCKET>"
[assets]
directory = "./<DIRECTORY>"
binding = "ASSETS"In our Worker project, the assets directory contains the image that we want to use as our watermark.
Our frontend has a <form> element that accepts image uploads:
const html = `
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Upload Image</title>
</head>
<body>
<h1>Upload an image</h1>
<form method="POST" enctype="multipart/form-data">
<input type="file" name="image" accept="image/*" required />
<button type="submit">Upload</button>
</form>
</body>
</html>
`;
export default {
async fetch(request, env) {
if (request.method === "GET") {
return new Response(html, {headers:{'Content-Type':'text/html'},})
}
if (request.method ==="POST") {
// This is called when the user submits the form
}
}
};Next, we set up our Worker to handle the optimization.
The user will upload images directly through the browser; since there isn’t an existing image URL, we won’t be able to use fetch() to get the uploaded image. Instead, we can transform the uploaded image directly, operating on its body as a stream of bytes.
Once we read the image, we can manipulate the image. Here, we apply our watermark and encode the image to AVIF before uploading the transformed image to our R2 bucket:
var __defProp = Object.defineProperty;
var __name = (target, value) => __defProp(target, "name", { value, configurable: true });
function assetUrl(request, path) {
const url = new URL(request.url);
url.pathname = path;
return url;
}
__name(assetUrl, "assetUrl");
export default {
async fetch(request, env) {
if (request.method === "GET") {
return new Response(html, {headers:{'Content-Type':'text/html'},})
}
if (request.method === "POST") {
try {
// Parse form data
const formData = await request.formData();
const file = formData.get("image");
if (!file || typeof file.arrayBuffer !== "function") {
return new Response("No image file provided", { status: 400 });
}
// Read uploaded image as array buffer
const fileBuffer = await file.arrayBuffer();
// Fetch image as watermark
let watermarkStream = (await env.ASSETS.fetch(assetUrl(request, "watermark.png"))).body;
// Apply watermark and convert to AVIF
const imageResponse = (
await env.IMAGES.input(fileBuffer)
// Draw the watermark on top of the image
.draw(
env.IMAGES.input(watermarkStream)
.transform({ width: 100, height: 100 }),
{ bottom: 10, right: 10, opacity: 0.75 }
)
// Output the final image as AVIF
.output({ format: "image/avif" })
).response();
// Add timestamp to file name
const fileName = `image-${Date.now()}.avif`;
// Upload to R2
await env.R2.put(fileName, imageResponse.body)
return new Response(`Image uploaded successfully as ${fileName}`, { status: 200 });
} catch (err) {
console.log(err.message)
}
}
}
};We’ve also created a gallery in our documentation to demonstrate ways that you can use the Images binding. For example, you can transcode images from Workers AI or draw a watermark from KV on an image that is stored in R2.
Looking ahead, the Images binding unlocks many exciting possibilities to seamlessly transform and manipulate images directly in Workers. We aim to create an even deeper connection between all the primitives that developers use to build AI and full-stack applications.
Have some feedback for this release? Let us know in the Community forum.
Post Syndicated from LGR original https://www.youtube.com/watch?v=AEKWyAGCIu0
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/04/web-3-0-requires-data-integrity.html
If you’ve ever taken a computer security class, you’ve probably learned about the three legs of computer security—confidentiality, integrity, and availability—known as the CIA triad. When we talk about a system being secure, that’s what we’re referring to. All are important, but to different degrees in different contexts. In a world populated by artificial intelligence (AI) systems and artificial intelligent agents, integrity will be paramount.
What is data integrity? It’s ensuring that no one can modify data—that’s the security angle—but it’s much more than that. It encompasses accuracy, completeness, and quality of data—all over both time and space. It’s preventing accidental data loss; the “undo” button is a primitive integrity measure. It’s also making sure that data is accurate when it’s collected—that it comes from a trustworthy source, that nothing important is missing, and that it doesn’t change as it moves from format to format. The ability to restart your computer is another integrity measure.
The CIA triad has evolved with the Internet. The first iteration of the Web—Web 1.0 of the 1990s and early 2000s—prioritized availability. This era saw organizations and individuals rush to digitize their content, creating what has become an unprecedented repository of human knowledge. Organizations worldwide established their digital presence, leading to massive digitization projects where quantity took precedence over quality. The emphasis on making information available overshadowed other concerns.
As Web technologies matured, the focus shifted to protecting the vast amounts of data flowing through online systems. This is Web 2.0: the Internet of today. Interactive features and user-generated content transformed the Web from a read-only medium to a participatory platform. The increase in personal data, and the emergence of interactive platforms for e-commerce, social media, and online everything demanded both data protection and user privacy. Confidentiality became paramount.
We stand at the threshold of a new Web paradigm: Web 3.0. This is a distributed, decentralized, intelligent Web. Peer-to-peer social-networking systems promise to break the tech monopolies’ control on how we interact with each other. Tim Berners-Lee’s open W3C protocol, Solid, represents a fundamental shift in how we think about data ownership and control. A future filled with AI agents requires verifiable, trustworthy personal data and computation. In this world, data integrity takes center stage.
For example, the 5G communications revolution isn’t just about faster access to videos; it’s about Internet-connected things talking to other Internet-connected things without our intervention. Without data integrity, for example, there’s no real-time car-to-car communications about road movements and conditions. There’s no drone swarm coordination, smart power grid, or reliable mesh networking. And there’s no way to securely empower AI agents.
In particular, AI systems require robust integrity controls because of how they process data. This means technical controls to ensure data is accurate, that its meaning is preserved as it is processed, that it produces reliable results, and that humans can reliably alter it when it’s wrong. Just as a scientific instrument must be calibrated to measure reality accurately, AI systems need integrity controls that preserve the connection between their data and ground truth.
This goes beyond preventing data tampering. It means building systems that maintain verifiable chains of trust between their inputs, processing, and outputs, so humans can understand and validate what the AI is doing. AI systems need clean, consistent, and verifiable control processes to learn and make decisions effectively. Without this foundation of verifiable truth, AI systems risk becoming a series of opaque boxes.
Recent history provides many sobering examples of integrity failures that naturally undermine public trust in AI systems. Machine-learning (ML) models trained without thought on expansive datasets have produced predictably biased results in hiring systems. Autonomous vehicles with incorrect data have made incorrect—and fatal—decisions. Medical diagnosis systems have given flawed recommendations without being able to explain themselves. A lack of integrity controls undermines AI systems and harms people who depend on them.
They also highlight how AI integrity failures can manifest at multiple levels of system operation. At the training level, data may be subtly corrupted or biased even before model development begins. At the model level, mathematical foundations and training processes can introduce new integrity issues even with clean data. During execution, environmental changes and runtime modifications can corrupt previously valid models. And at the output level, the challenge of verifying AI-generated content and tracking it through system chains creates new integrity concerns. Each level compounds the challenges of the ones before it, ultimately manifesting in human costs, such as reinforced biases and diminished agency.
Think of it like protecting a house. You don’t just lock a door; you also use safe concrete foundations, sturdy framing, a durable roof, secure double-pane windows, and maybe motion-sensor cameras. Similarly, we need digital security at every layer to ensure the whole system can be trusted.
This layered approach to understanding security becomes increasingly critical as AI systems grow in complexity and autonomy, particularly with large language models (LLMs) and deep-learning systems making high-stakes decisions. We need to verify the integrity of each layer when building and deploying digital systems that impact human lives and societal outcomes.
At the foundation level, bits are stored in computer hardware. This represents the most basic encoding of our data, model weights, and computational instructions. The next layer up is the file system architecture: the way those binary sequences are organized into structured files and directories that a computer can efficiently access and process. In AI systems, this includes how we store and organize training data, model checkpoints, and hyperparameter configurations.
On top of that are the application layers—the programs and frameworks, such as PyTorch and TensorFlow, that allow us to train models, process data, and generate outputs. This layer handles the complex mathematics of neural networks, gradient descent, and other ML operations.
Finally, at the user-interface level, we have visualization and interaction systems—what humans actually see and engage with. For AI systems, this could be everything from confidence scores and prediction probabilities to generated text and images or autonomous robot movements.
Why does this layered perspective matter? Vulnerabilities and integrity issues can manifest at any level, so understanding these layers helps security experts and AI researchers perform comprehensive threat modeling. This enables the implementation of defense-in-depth strategies—from cryptographic verification of training data to robust model architectures to interpretable outputs. This multi-layered security approach becomes especially crucial as AI systems take on more autonomous decision-making roles in critical domains such as healthcare, finance, and public safety. We must ensure integrity and reliability at every level of the stack.
The risks of deploying AI without proper integrity control measures are severe and often underappreciated. When AI systems operate without sufficient security measures to handle corrupted or manipulated data, they can produce subtly flawed outputs that appear valid on the surface. The failures can cascade through interconnected systems, amplifying errors and biases. Without proper integrity controls, an AI system might train on polluted data, make decisions based on misleading assumptions, or have outputs altered without detection. The results of this can range from degraded performance to catastrophic failures.
We see four areas where integrity is paramount in this Web 3.0 world. The first is granular access, which allows users and organizations to maintain precise control over who can access and modify what information and for what purposes. The second is authentication—much more nuanced than the simple “Who are you?” authentication mechanisms of today—which ensures that data access is properly verified and authorized at every step. The third is transparent data ownership, which allows data owners to know when and how their data is used and creates an auditable trail of data providence. Finally, the fourth is access standardization: common interfaces and protocols that enable consistent data access while maintaining security.
Luckily, we’re not starting from scratch. There are open W3C protocols that address some of this: decentralized identifiers for verifiable digital identity, the verifiable credentials data model for expressing digital credentials, ActivityPub for decentralized social networking (that’s what Mastodon uses), Solid for distributed data storage and retrieval, and WebAuthn for strong authentication standards. By providing standardized ways to verify data provenance and maintain data integrity throughout its lifecycle, Web 3.0 creates the trusted environment that AI systems require to operate reliably. This architectural leap for integrity control in the hands of users helps ensure that data remains trustworthy from generation and collection through processing and storage.
Integrity is essential to trust, on both technical and human levels. Looking forward, integrity controls will fundamentally shape AI development by moving from optional features to core architectural requirements, much as SSL certificates evolved from a banking luxury to a baseline expectation for any Web service.
Web 3.0 protocols can build integrity controls into their foundation, creating a more reliable infrastructure for AI systems. Today, we take availability for granted; anything less than 100% uptime for critical websites is intolerable. In the future, we will need the same assurances for integrity. Success will require following practical guidelines for maintaining data integrity throughout the AI lifecycle—from data collection through model training and finally to deployment, use, and evolution. These guidelines will address not just technical controls but also governance structures and human oversight, similar to how privacy policies evolved from legal boilerplate into comprehensive frameworks for data stewardship. Common standards and protocols, developed through industry collaboration and regulatory frameworks, will ensure consistent integrity controls across different AI systems and applications.
Just as the HTTPS protocol created a foundation for trusted e-commerce, it’s time for new integrity-focused standards to enable the trusted AI services of tomorrow.
This essay was written with Davi Ottenheimer, and originally appeared in Communications of the ACM.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=u3ZWYetlUlo
Post Syndicated from Bobby Whyte original https://www.raspberrypi.org/blog/supporting-teachers-to-integrate-ai-in-k-12-cs-education/
Teaching about artificial intelligence (AI) is a growing challenge for educators around the world. In our current seminar series, we are gaining insights from international computing education researchers on how to teach about AI and data science in the classroom. In our second seminar, Franz Jetzinger from the Technical University of Munich, Germany, presented his work on supporting teachers to integrate AI into their classrooms. Franz brings a wealth of relevant experience to his research as an accomplished textbook author and K–12 computer science teacher.

Franz started by demonstrating how widespread AI systems and technologies are becoming. He argued that embedding lessons about AI in the classroom presents three challenges:
As various models and frameworks for teaching about AI already exist, Franz’s research aims to address the second and third challenges — there is a notable lack of empirical evidence integrating AI in K–12 settings or teacher professional development (PD) to support teachers.
In Bavaria, computer science (CS) has been a compulsory high school subject for over 20 years. However, a recent update has brought compulsory CS lessons (including AI) to Year 11 students (15–16 years old). Competencies targeted in the new curriculum include defining AI, explaining the functionality of different machine learning algorithms, and understanding how artificial neurons work.

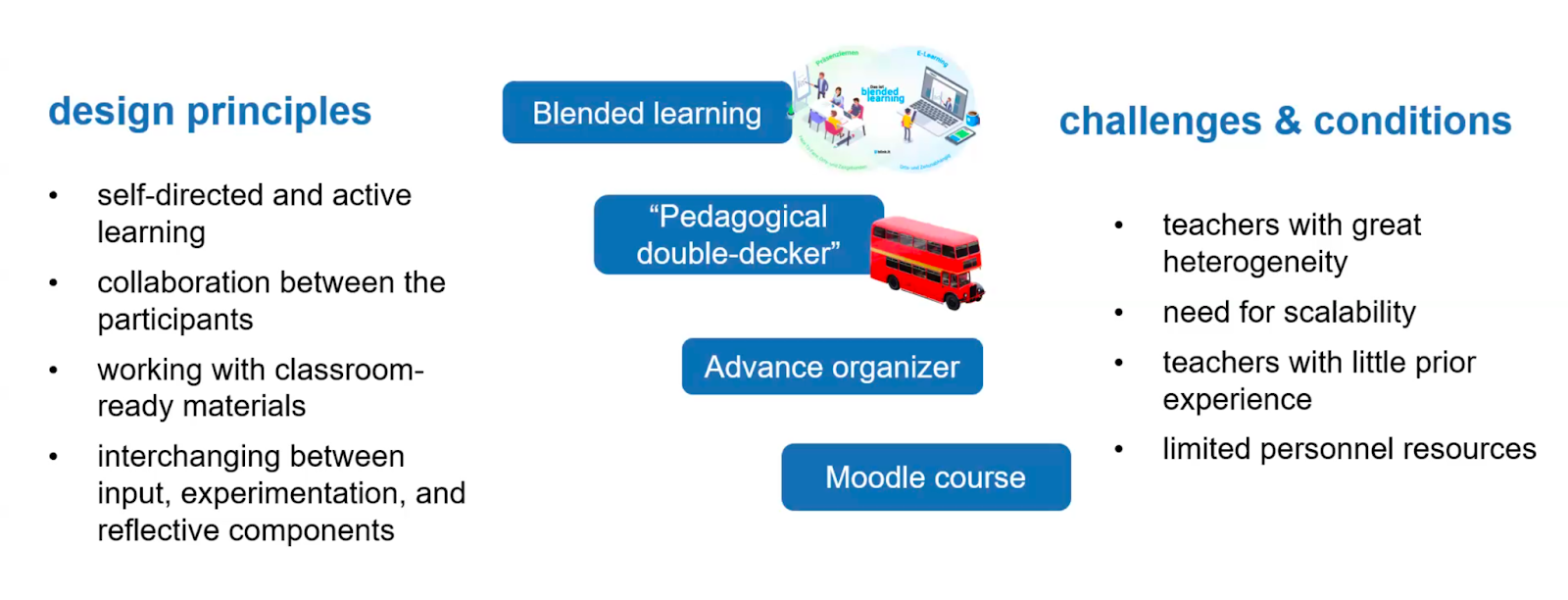
To help prepare teachers to effectively teach this new curriculum and about AI, Franz and colleagues derived a set of core competencies to be used along with existing frameworks (e.g. the Five Big Ideas of AI) and the Bavarian curriculum. The PD programme Franz and colleagues developed was shaped by a set of key design principles:
Over 300 teachers attended the MOOC, which had an introductory session beforehand and a follow-up workshop. The programme’s effectiveness was evaluated with a pre/post assessment where teachers completed a survey of 15 closed, multiple-choice questions on their AI competencies and knowledge. Pre/post comparisons showed teachers’ scores improved significantly having taken part in the PD. This is surprising as a large proportion of participants achieved high pre-scores, indicating a highly motivated cohort with notable prior experience teaching about AI.
Additionally, a group of teachers (n=9) were invited to give feedback on which aspects of the PD programme they felt contributed to the success of implementing the curriculum in the classroom. They reported that the PD programme supported content knowledge and pedagogical content knowledge well, but they required additional support to design suitable learning assessments.
A separate strand of Franz’s research focuses on the other key challenge of how to effectively teach about AI. Franz engaged teachers (n=14) in action research, a method whereby teachers engage in classroom-based research projects. The project explored what topic-specific difficulties students faced during the lessons and how teachers adapted their teaching to overcome these challenges.

Findings revealed that students struggled with determining whether AI would benefit certain tasks (e.g. object recognition, text-to-speech) or not (e.g. GPS positioning, sorting data). Franz and colleagues reasoned that students were largely not aware of how AI systems deal with uncertainty and overestimated their capabilities. Therefore, an important step in teaching students about AI is defining ‘what an AI problem is’.

Similarly, students struggled with distinguishing between rule-based and data-driven approaches, believing in some cases that a trained model becomes ‘rule-based’ or that all data models are data-driven. Students also struggled with certain data science concepts, such as hyperparameter, overfitting and underfitting, and information gain. Franz’s team argue that the chosen tool, Orange Data Mining, did not provide an appropriate scaffold for encountering these concepts.
Finally, teachers found challenges in bringing real-world examples into the classroom, including the use of reinforcement learning and neural networks. Franz and colleagues reasoned that focusing on the function of neural networks, as opposed to their structure, would aid student understanding. The use of high-quality (i.e. well-prepared) real-world data sets was also suggested as a strategy for bridging theoretical ideas with practical examples.
Franz’s research provides important insights into the discipline-specific challenges educators face when introducing AI into the classroom. It also underscores the importance of appropriate professional development and age-appropriate and research-informed materials and tools to support students engaging with ideas about AI, data science, and machine learning.

If you are interested in reading more about Franz’s work on teacher professional development, you can read his paper on a scalable professional development offer for computer science teachers or you can learn more about his research group here.
In our current seminar series, we are exploring teaching about AI and data science. Join us at our next seminar on Tuesday 8 April at 17:00–18:30 BST to hear David Weintrop, Rotem Israel-Fishelson, and Peter F. Moon from the University of Maryland introduce ‘API Can Code’, an interest-driven data science curriculum for high-school students.
To sign up and take part in the seminar, click the button below; we will then send you information about joining. We hope to see you there.
The schedule of our upcoming seminars is online. You can catch up on past seminars on our previous seminars and recordings page.
The post Supporting teachers to integrate AI in K–12 CS education appeared first on Raspberry Pi Foundation.
Post Syndicated from Светла Енчева original https://www.toest.bg/pedofiliata-sreshtu-koyato-se-protestira-i-pedofiliata-za-koyato-se-mulchi/

Когато жестокост към дете стане централна тема в новините, обществото не остава безразлично. Такъв е случаят с 5-годишния Адриан, малтретиран от доведения си баща с такава жестокост, че детето се е молело да бъде убито. На всичко отгоре насилникът е записвал клипчета с издевателствата си. Майката на момченцето е знаела какво се случва, но не е направила нищо.
Присъдата на пастрока Петър Чернев от 8 години затвор предизвиква масово възмущение. В Пловдив се организира протест „Справедливост за Адриан – малтретираното дете от Пловдив! Бездействието е съучастие!“. Протести се организират и в други градове – например София, Варна и Стара Загора. Те обаче са под различен наслов: „Не на насилието над деца и педофилията!“
В случая с Адриан има физическо и психическо насилие, но не и сексуално. Как педофилията стана тема на протестите (с изключение на пловдивския)? Формалният повод за това е новината за петима мъже, арестувани за притежание на материали, съдържащи сексуална експлоатация на деца на възраст от 2 месеца до 14 години. Но така формулираната тема има и друга функция – да измести обществения гняв от основния проблем.
„Тази тема няма политически пристрастия“, обосновава във Facebook решението си да се включи в софийския протест Кристина Петкова, заместник-председателка на ДСБ, част от коалицията ПП–ДБ. Тя обещава да инициира „разговор с експерти за вдигане размера на наказанията за педофилия“.
„Тоест“ се обърна към Петкова с два въпроса: откъде и по чия инициатива темата за педофилията е присъединена към тази за насилието над Адриан и има ли според нея политически сили или групи, свързани с организацията на протеста. Тя отговори, че не е от организаторите, но мисли, че връзката между двете теми „е по линия на насилието като цяло“. И уточни, че за нея темата няма партийни пристрастия, но се опасява, че „Възраждане“ злоупотребяват и използват дори такива случаи, за да насаждат омраза“. Беше обаче категорична: „Ще отида в сряда (2 април – б.р.), защото въпросът е принципен и касае защита на децата ни.“
Макар от „Война и мир“ да огласиха, че и Националната мрежа за децата (НМД) ще се включи в протеста, това не стана. Вместо това НМД разпространи отворено писмо, в което се подчертава сериозността на домашното насилие (наред с други форми на насилие над деца) и се апелира за реформа на законодателството в тази област.
Софийският протест срещу насилието над деца и педофилията се организира от „Война и мир“, „Поход за Семейството“ и Георги Драганов – основен двигател на сайта „Война и мир“, с който е свързана и едноименната страница във Facebook. Драганов е също сред организаторите на протестите във Варна и Стара Загора.
„Война и мир“ изповядва крайнодясна, националистическа, антикомунистическа и евроскептична идеология. Сайтът подкрепя „Луковмарш“ и е против еврото. В интернет страницата са публикувани доста статии против Конвенцията на Съвета на Европа за превенция и борба с насилието над жени и домашното насилие, по-известна като Истанбулската конвенция. Педофилията също е тема във „Война и мир“, като тя често се асоциира от авторите в сайта с ЛГБТИ хората, които пък се представят в негативна светлина.
„Поход за Семейството“ е асоциация, която ежегодно организира шествия против „София прайд“. Тя е свързана с ултраконсервативни християнски групи, например Асоциация „Общество и ценности“ и Сдружение „РОД Интернешънъл“, които са против нормативни документи като Истанбулската конвенция, Закона за социалните услуги, Стратегията за детето и като цяло се противопоставят на опитите да се ограничи домашното насилие. Те защитават „традиционните семейни ценности“, тоест разбирането, че бракът е само между мъж и жена, и „правата на родителите“, което ще рече, че според асоциацията публичните институции не трябва да се месят в семейните отношения.
Яхването от „Война и мир“ и „Поход за семейството“ на обществения гняв от насилието над Адриан и от 8-годишната присъда на пастрока му успява да размие повода за този гняв. А той е, че детето е било най-уязвимо там, където едно дете трябва да е най-сигурно – в семейството си, при майка си и мъжа ѝ. В случая става дума именно за домашно насилие, макар бащата на Адриан – Венислав Алексиев, да не е съгласен, тъй като интерпретира словосъчетанието „домашно насилие“ буквално. Пред БНТ той казва:
Домашно насилие? Ами кое му е домашното? Той не му е нито баща, нито Адриан се е водил на този адрес. Той е бил като гостенин там.
Алексиев не е длъжен да познава закона, но в него не пише, че е задължително насилието над едно дете да се извършва на постоянния адрес на жертвата или от кръвен родител, за да се квалифицира като домашно. Напротив – достатъчно е насилникът да е „лице, което е съпруг или бивш съпруг на родителя“ или дори „лице, с което родителят се намира или е бил във фактическо съпружеско съжителство или в интимна връзка“. Освен това бездействието на майката също влиза в определението за домашно насилие.
Когато обаче към темата на протеста се включва и педофилията, това измества фокуса от домашното насилие. Вече става дума просто за едни лоши хора, които злоупотребяват с деца.
и са тъжна констатация за неспособността на публичните институции да оценяват риска и да предотвратяват подобни престъпления.
На 31 март например се разбра, че жената, причинила смъртта на двете си деца във Вакарел, няма да бъде съдена, а изпратена в психиатрия, защото ги е убила в състояние на невменяемост. Нямало е кой да ѝ окаже адекватна професионална помощ, нито да прецени, че децата ѝ са в риск.
Друга майка, убила двете си деца в Сандански, получи на първа инстанция доживотна присъда. Междувременно самата тя спечели дело за домашно насилие срещу бащата на децата. И тук е нямало институция, която да спре ескалиращата спирала на насилието.
Повече са обаче случаите на мъже, убили децата си – със или без майките им. Посочваме няколко от тях без претенции за изчерпателност. Двайсет и шест годишен мъж прострелва смъртоносно момиченце на една годинка, убива 23-годишната му майка и прави неуспешен опит да се самоубие. Друг намушква фатално с нож двегодишното си дете и също прави опит за самоубийство, който не сполучва. Трети хвърля 4-годишното си дете от мост и след като то умира, заплашва да се самоубие. Четвърти убива двумесечното си бебе в старозагорско село.
Що се отнася до физическото и психическото насилие над деца, и тук примерите са преизобилни. Ето само два от един и същи град – Стара Загора:
През февруари 2025 г. баща пребива двете си дъщери, на 14 и на 9 години, като по-голямото момиче е настанено в болница поради травмите си.
Майка държи сина си и дъщеря си заключени около шест години, а институциите знаят за това, но си правят оглушки. Децата са изведени от семейството чак през февруари 2024 г., когато дъщерята е вече пълнолетна – на 21 години.
Но нека поговорим за педофилията. Винаги ли държавата реагира адекватно, когато научи за сексуално насилие над деца? Зависи какви са децата и кой е насилникът.
Печално известен е случаят с осъдения и издирван за педофилия във Великобритания Даниел Хъл (споменат и в отвореното писмо на НМД). В Сливен той безпроблемно става протестантски пастор. Четиринайсет деца свидетелстват, че им е посягал сексуално. Част от тях са разпитвани от полицията по крайно неподходящ за възрастта им начин – посред нощ, докато майките им чакат в студа отвън. Въпреки показанията им няма кой да осъди Хъл, защото съдия след съдия си правят отвод. Няма и кой да организира масови протести в защита на децата – те са български граждани, но са ромчета. На тях се гледа като на втора категория хора.
Няма и масово възмущение и протести срещу случаите на сексуална злоупотреба в домове с деца, лишени от родителска грижа. Нито срещу това, че малолетни са принуждавани да проституират, понякога от родителите си (и често със знанието им). Понеже в повечето случаи пак става дума за ромски деца.
Доминиращата представа за педофилията в България е, че тя е някаква външна на семейството заплаха. Има лоши чичковци в интернет, които се опитват да съблазнят децата. Или непознати, причакващи невръстните си жертви, за да ги отвлекат и да издевателстват сексуално над тях. Но ако децата споделят откровено с родителите си, възрастните ще им помогнат да избегнат огромната част от заплахите. Когато се протестира срещу педофилията, правят се законови промени и се предлагат по-строги наказания, обикновено се имат предвид именно такива хора.
Вярно е, че има педофили, които се оглеждат за деца онлайн или пък по паркове и градинки. Но сред посягащите сексуално на малолетни не са изключение и хора, които са познати на семействата на жертвите си, може и да са близки приятели, може и да са роднини, а някои са дори роднини или членове на семейството.
Как реагират в тези случаи родителите на пострадалите деца? Дали винаги ще повярват на детето, ако то каже, че някой техен близък злоупотребява сексуално с него? И дали, ако знаят, че такава злоупотреба действително съществува, винаги ще направят нужното, за да я преустановят, да защитят и да подкрепят детето? Отговорът на тези въпроси, за съжаление, е невинаги.
Известната канадска писателка Алис Мънро например е знаела за сексуалните посегателства на мъжа си към дъщеря ѝ от предишен брак и не е направила нищо. Извършителят пък обвинявал жертвата, че е „развала на дома“. Когато вече порасналата дъщеря носи в полицията писмата на пастрока си, в които той говори за сексуалните си отношения с нея, Мънро я нарича лъжкиня.
Лесно щеше да бъде, ако историята с Мънро е някакво чудовищно изключение. Професионалният опит на моя позната психотерапевтка обаче попарва тази надежда. Тя ми е разказвала, че при всички случаи от практиката ѝ, когато единият родител, в общия случай родният или доведеният баща, е насилвал сексуално детето си, другият родител, в общия случай майката, е знаела, но си е затваряла очите. Тези майки са търсели психологическа помощ заради някакъв друг проблем – свой или на детето си, – но в течение на терапията тайната е излизала наяве.
Първият случай е на деветгодишно момиче, чийто съсед се опитал да му посегне. Детето успяло да избяга, но мъжът го заплашил, че ако каже на родителите си, ще го убие. След време го срещнал на стълбите във входа на жилищния блок и повторил заплахата. Момичето десет години не посмяло да каже на никого и всеки път, щом излизало или влизало във входа, изпитвало ужас. Разказало на майка си чак когато било на 19 години – вече пълнолетно. Майката обвинила дъщеря си. Семейството не ѝ повярвало и даже пускало малката ѝ племенница да си играе с дъщерята на съседа педофил. В неговия апартамент.
Вторият случай е на момиче, излязло да разхожда кучето си в двора на своето училище. Видял го портиерът и го заговорил. По едно време почнал да го притиска до стената и да го опипва, докато рецитира „Зайченцето бяло“. Детето избягало, след което споделило с майка си. Тя обещала да каже на класната, за да се вземат мерки. Момичето не чуло повече нищо по въпроса – нито от майка си, нито от класната. Все едно нищо не се е случило. А портиерът продължил да работи в училището още много години.
Третият случай е на 13-годишно момиче, прекарващо лятото при дядо си на морето. Понеже той бил работил от малък, смятал, че е крайно време и внучката му да се научи на труд. Пратил я на работа на туристическо корабче, макар да е незаконно. Момичето било доволно, че е „юнга“ и получава дребни пари, и изпитало гордост, че капитанът го поканил на личен разговор. Когато капитанът се опитал да посегне на тийнейджърката, тя избягала. И разказала всичко. Пред мен дядото защити извършителя и обвини внучката: „Той е мъж, това е нормално, но тя защо е отишла при него в извънработно време?“ А майката на момичето го помоли да му потърси работа и следващото лято.
Популистките протести срещу педофилията и по-строгите наказания срещу извършителите на сексуални престъпления над деца едва ли ще постигнат друг ефект, освен да отвличат общественото внимание от проблеми като домашното насилие.
В контекста на организираните протести МВР най-сетне пусна т.нар. регистър на педофилите – година и седем месеца след приемането му в парламента по предложение на „Възраждане“. Той обаче едва ли ще доведе до смислени резултати, защото законодателството в тази област е изначално сбъркано. И въвеждането на по-строги наказания няма да го оправи.
Ще се опитам накратко да обясня само един аспект на сбърканото законодателството (а кусурите му са доста повече). В Наказателния кодекс (НК) е забранен сексът с деца под 14-годишна възраст, тоест малолетни. В него не се посочва възрастова граница, отвъд която интимните отношения с лица под определена възраст са недопустими. Националният регистър на педофилите, описан в Закона за закрила на детето, обаче включва хората, осъдени за сексуални посегателства срещу малолетни и непълнолетни, тоест под 18 години.
Нека дам пример, за да илюстрирам проблема. Ако лице на 50 години има интимна връзка с 14-годишно дете по взаимно съгласие, това според НК е законно. Съответно лицето няма да влезе в регистъра и ще има право да работи с деца. В него ще влезе обаче 18-годишен тийнейджър, осъден за сексуално посегателство над своя 17-годишна съученичка. Момчето може да е упражнило насилие, но дали е педофил? Ако това ви изглежда абсурдно, проблемът не е „във вашия телевизор“.
но без популизъм и пропагандни кампании и не под политически, религиозен или друг натиск, а спокойно, трезво и с помощта на експерти в областта.
Няма как да се постигнат резултати в борбата срещу педофилията, ако децата не се възприемат като личности с човешко достойнство, вместо да се смятат за собственост на родителите си или ценността им да се преценява спрямо етноса, социалното им положение или други техни характеристики.
Такъв подход обаче изисква промяна в нагласите и практиките на институциите – от полицията, съда и прокуратурата до социалните служби, училището и детската градина – както и сериозна работа с родителите. Не можем да очакваме, че децата ще бъдат защитени, ако в средата около тях доминират сексистки стереотипи, срам от търсенето на справедливост („Какво ще кажат хората?“), обвиняване на жертвите, толериране на насилниците и зариване на главите в пясъка.
Post Syndicated from Cliff Robinson original https://www.servethehome.com/mlperf-inference-v5-0-released-amd-intel-nvidia/
The new MLPerf Inference v5.0 results are out with new submissions for configurations from NVIDIA, Intel Xeon, and AMD Instinct MI325X
The post MLPerf Inference v5.0 Results Released appeared first on ServeTheHome.
Post Syndicated from jake original https://lwn.net/Articles/1015512/
Inside this week’s LWN.net Weekly Edition: