На последното заседание на комисията по електронно управление беше повдигнат въпроса за кадровото осигуряване в администрацията във връзка с информационните технологии и електронното управление.
Това е сериозен дългосрочен проблем, който има нужда от стратегическо решение. Да, държавата аутсорсва ИТ дейности, но дори управлението на аутсорсинга изисква вътрешен капацитет. Още повече, че има стратегически функции, които държавата трябва да може да обезпечи сама.
В тази посока направихме две първи стъпки преди година и нещо: да дадем възможност за заплати с над 80% спрямо нормата за администрацията за определени категории ИТ специалисти и да започнем централизирането на т.нар. service desk услуги в изпълнителната агенция към МЕУ.
Но трябва много по-широк обхват на реформата. Имам разписана базова концепция, която стъпва на принципа на „споделените услуги“ и разделя тези услуги на пет групи:
Разработка на софтуер, инфраструктура (мрежи и хардуер), системна администрация и интеграция, мрежова и информационна сигурност, service desk.
Разпокъсаността на експертите по различните структури в държавата не е ефективна и трябва да се премине към консолидация и споделени услуги. Това обаче трябва да се претегли спрямо секторната експертиза, която се изисква в някои администрации.
Такъв подход ще позволи не просто по-високи заплати, а създаване на екипи и структури, които могат да привличат повече хора, да гарантират кариерно развитие. Иначе казано – да не са типична администрация, а ИТ организации, с мислене и начин на работа на ИТ организация.
В следващите месеци ще обсъждам и развивам тази концепция, докато тя стигне до своето законодателно изражение. Защото без да създадем подходяща институционална среда, ще продължаваме да си говорим, че „няма хора“.
Many processor vendors provide a mechanism to allow some bits of a pointer
value to be used to store unrelated data; these include Intel’s linear address masking (LAM), AMD’s upper address ignore, and Arm’s top-byte
ignore. A set of researchers has now come up with a way (that
they call “SLAM”) to use those features to bypass many checks on pointer
validity, opening up a new set of Spectre attacks.
In response to SLAM, Intel made plans to provide software guidance
prior to the future release of Intel processors which support LAM
(e.g., deploying LAM jointly with LASS). Linux engineers developed
patches to disable LAM by default until further guidance is
available. ARM published an advisory to provide guidance on future
TBI-enabled CPUs. AMD did not implement guidance updates and
pointed to existing Spectre v2 mitigations to address the SLAM
exploit described in the paper.
Earlier this year, it seemed like every headline or dinner conversation was earmarked by the buzzwords “generative AI.” And while 2023 has been a benchmark year for the adoption of generative AI, it’s not entirely a new technology. Arguably, AI has been around since the ‘60s, but the AI as we know it today came to be with the invention of machine learning frameworks known as neural networks (you can read more about that here).
For the past few years at GitHub, we’ve been experimenting with generative AI models to create new, meaningful tools for developers—which is how GitHub Copilot was born. And since GitHub Copilot’s initial preview release in 2021, we’ve been thinking a lot about how generative AI can (and should) empower developers to be more productive at every stage of the software development lifecycle. That led us to our vision for the future of AI-powered software development with GitHub Copilot, which we covered in detail this year at GitHub Universe 2023.
In this blog post, we’ll explore some of the experiments we’ve conducted with generative AI models over the past few years, as well as take a behind-the-scenes look at some of our key learnings. We’ll also explore what going from a concept to a product looks like with a radically new technology.
Predictable. We want to create tools that guide developers towards their end goals but don’t suprise or overwhelm them.
Tolerable. As we’ve seen, AI models can be wrong. Users should be able to spot incorrect suggestions easily, and address them at a low cost to focus and productivity.
Steerable. When a response isn’t right or isn’t what a user is looking for, they should be able to steer the AI towards a solution. Otherwise, we’re optimistically banking on the models producing perfect answers.
Verifiable. Solutions must be easy to evaluate. The models are not perfect, but they can be very helpful tools if users verify their outputs.
Last year, researchers from GitHub Next, our R&D department focused on the future of software development, were given advanced access to OpenAI’s large language model (LLM) that would soon be released as GPT-4.
“At the time, no one had seen anything like this,” Idan Gazit, senior director of research for GitHub Next recalls. “It became a race to discover what the new models are capable of doing and what kinds of applications are possible tomorrow that were impossible yesterday.”
So, the GitHub Next team did what they do best: experiment. Over the course of several months, researchers from GitHub Next used the GPT-4 model to develop potential new tools and features that could be used across the GitHub platform. Once the team identified the projects that showed true value, the sprint to build began.
“In classic GitHub Next fashion, we sat down and spiked a bunch of ideas and saw what looked promising or exciting to us,” Gazit explains. “And then we doubled down on the things that we believed would bear fruit.”
In the time between receiving the model and the slated announcement of the model’s release in March 2023, the team had come up with several concepts and technical previews.
At the time, no one had seen anything like this. It became a race to discover what the new models are capable of doing and what kinds of applications are possible tomorrow that were impossible yesterday.
– Idan Gazit, Senior Director of Research // GitHub Next
As these projects came together, senior leadership at GitHub began to think about what these meant for the future of GitHub Copilot. Mario Rodriguez, VP of product management, says, “We knew we wanted to make an announcement of our own around the joint Microsoft and OpenAI announcement of GPT-4. At that time, GitHub Next had a set of investments that they were making that they thought were worthwhile for the announcement. Those investments were not production-ready—they were more future-focused.” He explains, “But that got us thinking, so we put pen to paper and came up with the ambition behind the latest evolution of GitHub Copilot.”
Thinking ahead
As teams at GitHub thought about evolving GitHub Copilot beyond a pair programmer in the IDE, they imagined a future where GitHub Copilot was:
Ubiquitous across every tool that developers use and integrated into every task that developers perform.
Conversational by default, so that natural language can be used to achieve anything.
Personalized to the context and knowledge of the individual, project, team, and community.
This thought exercise, in conjunction with GitHub Next’s work to conceptualize and create new tools that could revolutionize the developer workflow, crystallized what would make up the latest evolution of GitHub Copilot. And on March 22, 2023, the technical preview for what GitHub Copilot would evolve into was released to the world with GitHub Copilot Chat and the following technical previews created by GitHub Next:
So, what happened behind the scenes to come up with these previews? Let’s find out.
Experimenting with AI’s place in the developer experience
If you asked just about any developer what’s something that is specifically unique to GitHub, it would be pretty shocking if they didn’t say “pull requests.” Pull requests play a central role in the GitHub developer experience—they’re not only a point of collaboration, but a gateway for teams to view and approve any changes to code.
“GitHub invented pull requests, so we started thinking, how could we add AI smarts around pull requests?” Rice says. “We tried a bunch of stuff—we prototyped automatic code suggestions for reviews, we had a sort of summarize mode, and a bunch of other things around test generation.” But as the deadline of March 22 approached, a few of these prototyped features weren’t working as desired, so Rice and team began focusing their attention and efforts solely on the summary feature.
With the early version of Copilot for Pull Requests, a developer could submit their pull request and the AI model would generate a description and walkthrough of the code in the first comment to provide important context for the reviewer.
“We did an internal study of the feature with Hubbers and it didn’t go well,” Rice laughs. It wasn’t that the developers didn’t like what the feature was trying to achieve, it was the user experience, Rice believes, they were having challenges with. “The developers were concerned that the AI would be wrong. But there’s two things: you have the content the AI generates and then you have the way that it’s presented to the user and how it interacts with the workflow. At first, we focused a lot on the first bit, the AI-generated content, but it turned out that the second bit was far more crucial in getting this thing to fly,” he explains.
To work around this, Rice and team decided to pivot and use the same AI-generated content but frame it differently. “Instead of a comment, we put it as a suggestion to the developer that let them get a preview of what the description of their pull request could look like that they could then edit,” Rice says. “So, we moved it to a suggestion system, and all of a sudden the feedback changed to ‘wow, these are helpful suggestions.’ The content was exactly the same as before, it was just presented differently.”
Nobody’s perfect—not even AI
For Rice, the key takeaway during this process was the importance of how the AI output is presented to the developer, rather than the total accuracy of the suggestion. That doesn’t mean that it’s acceptable for the AI to be completely wrong, but it does mean that a developer’s demand for the quality of the suggestion sits on a spectrum—developers will view something as it fits within their workflow regardless of what is served to them. When the content was served as a suggestion that the developer had the authority to accept and edit, the typical attitude toward the feature changed.
Eddie Aftandilian, a principal researcher that headed up the development of another GitHub Copilot feature, shared some similar sentiments and takeaways throughout the process of building Copilot for Docs. In late 2022, Aftandilian and Johan Rosenkilde were examining embeddings and retrievals, and they prototyped a vector database for a different GitHub Copilot experiment. “This got us thinking, what if we could use this for retrievals of things other than just code,” Aftandilian remembers. “Once we got access to GPT-4, we realized we could use the retrieval engine to search a large corpus of documentation, and then compose those search results into a prompt that elicits better, more topical answers based on the documentation,” he explains.
“Since GitHub is all about developer tools, we thought, how can we make this into a useful developer tool?” Aftandilian says. Developers spend an enormous amount of time poring over docs to find solutions—and as Aftandilian plainly puts it, “No one really likes reading documentation!” He continues, “It also can be hard to get the right answer out of docs, too. So, it seemed like there was an opportunity here for something that could answer a developer’s question more directly and unblock them. It’s also an area of the development process that we felt was underexplored. We spend a lot of time searching around for answers, which can be a real pain point, and we thought we could do better with these new LLMs.”
Aftandilian, along with Devon Rifkin, Jake Donham, and Amelia Wattenberger, also deployed their early version of Copilot for Docs to Hubbers, extending GitHub Copilot’s reach to GitHub’s internal docs in addition to public documentation. But once the preview reached public testing, he got some interesting feedback about the quality of the AI outputs.
“One challenge we came across during the development process was that the models don’t always give the right answer or the right document,” Aftandilian says. “To address this, we built in the capability for our answers to provide references or links to other documentation. We found that when we deployed it, the feedback we received was that developers didn’t mind if the output wasn’t always perfectly correct if the linked references made it easier to evaluate what the AI produced. They were using Copilot for Docs as a search engine,” he says.
The UX needs to be tolerant of AI’s mistakes—you can’t assume that the AI will always be right.
– Eddie Aftandilian, Principal Researcher // GitHub Next
Another key learning for Aftandilian was that human feedback is the true gold standard for developing AI-based tools. “One of our conclusions was that you should ship something sooner rather than later to get real, human feedback to drive improvements,” he says.
And similar to Rice’s earlier point, user experience is also critical to the success of these AI-powered tools. “The UX needs to be tolerant of AI’s mistakes—you can’t assume that the AI will always be right,” Aftandilian says. “Initially we were focused on getting everything right, but we soon learned that the chat-like modality of Copilot for Docs makes the answers feel less authoritative and folks are more tolerant of the responses when they point the user in the right direction. The AI isn’t always perfect, but it’s a great start.”
Small but mighty
In October 2022, the entire GitHub Next team met up in Oxford, England to get together and discuss all of the projects that they were currently working on, as well as some exciting—and maybe even far-fetched—ideas.
“One of the things that I pitched at this crazy ideas session was a project that would use LLMs to help you figure out CLI commands,” Johan Rosenkilde, a principal researcher for GitHub Next, recalls. “I was thinking about something that could use natural language prompts to describe what you wanted to do in the command line, then some sort of GUI or interface pops up that helps you narrow down what you want to do.”
As Rosenkilde talked through his pitch, one of his colleagues, Matt Rothenberg, began writing an application that did almost exactly that. “By the time my talk ended, he asked if he could show me something, and my mind was just blown,” Rosenkilde laughs. That thirty-minute prototype was the genesis for what would become Copilot for CLI.
“What he had created clearly showed that there was something of value here, but it lacked maturity of course,” Rosenkilde says. “And so what we did was carve out time to refine this rough demo into something that we could deliver to developers,” he says. By the time March 2023 rolled around, they had a preview that brought the power of GitHub Copilot right to the CLI for developers to quickly ask for and receive their desired shell commands, including a breakdown that explains each part of the command—without ever needing to search the web for answers.
When reflecting on the process of taking this app from that original, scrappy version to a technical preview, Rosenkilde echoes Rice and Aftandilian in his appreciation for the subtlety of UX decisions.
“I’m a backend person: I’m heavy on theory and I like really difficult problems that cause me to think for weeks about a solution,” Rosenkilde says. “Matt was the UX guy, and he iterated extremely quickly through a lot of options. So much of the success of this application hinged on the UX, and that’s a lesson that I’ve taken with me. All that we do in GitHub Next, in the end, is think up tools that will add value to the user experience, so it’s crucial that we get the design right and that it fits in with what the AI model can do. As we know, the AI models aren’t perfect, but when they are imperfect, the cost to the user should be as low as possible,” Rosenkilde says.
That simple fact is what informs the explanation field that can be found in Copilot for CLI. “This actually wasn’t part of the original UI. As the product matured, we came up with the explanation field, but we had some difficulty with the LLM producing the structured type of explanations we sought. It’s very unnatural for a language model to produce something that looks like this, I had to hit it with a very large hammer,” he jokes. “We wanted it to be clearly structured, but if you just ask the AI to explain a shell command, it would feed you a long paragraph that is not readily scannable and might not include the details you want.”
Rosenkilde also felt that it was important to add the explanation field to help developers learn about shell scripts and double check that they have received the correct command. “It’s also a security feature because you can read in natural language whether the command will change files you didn’t expect to change,” he explains. This multifaceted explanation field is not only useful, it’s a testament to the UX of the application. “When you have such a small application, you want every feature to have multiple different uses so that you can package up a lot of complexity in something that visually is very simple.”
Where we’re headed
We’re focused on something great here: creating delightful AI experiences for everyone who interacts with the GitHub platform. And while we’re working on it, we invite you to be part of the process. You can get involved by joining the waitlists for our current previews and giving us your honest feedback on what you think and what you want to see going forward.
Cloudflare recently announced Workers AI, giving developers the ability to run serverless GPU-powered AI inference on Cloudflare’s global network. One key area of focus in enabling this across our network was updating our Baseboard Management Controllers (BMCs). The BMC is an embedded microprocessor that sits on most servers and is responsible for remote power management, sensors, serial console, and other features such as virtual media.
To efficiently manage our BMCs, Cloudflare leverages OpenBMC, an open-source firmware stack from the Open Compute Project (OCP). For Cloudflare, OpenBMC provides transparent, auditable firmware. Below describes some of what Cloudflare has been able to do so far with OpenBMC with respect to our GPU-equipped servers.
Ouch! That’s HOT!
For this project, we needed a way to adjust our BMC firmware to accommodate new GPUs, while maintaining the operational efficiency with respect to thermals and power consumption. OpenBMC was a powerful tool in meeting this objective.
OpenBMC allows us to change the hardware of our existing servers without the dependency of our Original Design Manufacturers (ODMs), consequently allowing our product teams to get started on products quickly. To physically support this effort, our servers need to be able to supply enough power and keep the GPU and the rest of the chassis within operating temperatures. Our servers had power supplies that had sufficient power to support new GPUs as well as the rest of the server’s chassis, so we were primarily concerned with ensuring they had sufficient cooling.
With OpenBMC, our first approach to enabling our product teams to start working with the GPUs was to simply blast fans directly in line with the GPU, assuming the GPU was running at Thermal Design Power (TDP, the maximum heat from a given source). Unfortunately, because of the heat given off by these new GPUs, we could not keep them below 95˚C when they were fully stressed. This prompted us to install another fan to help keep the GPU cool and helped us bring a fully stressed GPU down to 65˚C. This served as our baseline before we began the process of fine-tuning the fan Peripheral Integral Derivative (PID) controller to handle variation in temperature in a more nuanced manner. Below shows a graph of the baseline described above:
With this baseline in place, tuning becomes a tedious iteration of PID constants. For those unfamiliar with PID controllers, we use the following equation to describe the control output given the error as input.
To break this down, u(t) represents our control output, e(t) is the error signal, and Kp, Ki, and Kd are the proportional gain, integral gain, and derivative gain constants, respectively. To briefly describe how each of these components work, I will isolate each of the components. Our error, or e(t), is simply the difference between the target temperature and the current temperature, so if our target temperature is 50 ˚C and my current is 60 ˚C, the e(t) for the proportional component is 10 ˚C. If u(t) = Kp⋅e(t), we can see that u(t) is = Kp⋅10. Any given Kp could drastically affect the control output u(t) and is responsible for how quickly the controller adjusts to approaching the target. The Ki⋅∫e(t)dt accumulates the error over time. The scenario where the controller reaches steady state but does not hit the target setpoint is called steady-state error. The integral component accumulating that error is intended for resolving this scenario but can also cause oscillations if the integral gain is too large. Lastly, the derivative portion, Kd⋅∂e(t)/∂t, can be seen as Kd⋅(the slope at the given point in time). You can imagine that the more quickly the controller approaches the target, the greater the slope, and the slower the approach, the less slope. Another way to look at it is that with faster oscillations, the greater the derivative portion, and slower oscillations, the lesser the derivative portion.
With this in mind, the following points are taken into consideration when we manually tune the controller:
Avoid oscillations at the target setpoint, i.e. avoid letting the temperature fluctuate above or below the specified temperature. Oscillations — specifically variations of fan speed and pulse width modulation (generally the power supplied to the fan), increase mechanical wear on components. We want these servers to last the entire five-year lifecycle while also not costing us capital expenses for replacing components or operating expenses in terms of the electricity we expend.
Approach the target setpoint as quickly as possible — with the above graph, we see the temperature settle somewhere between 63 ˚C and 65 ˚C quickly, but that’s because the fans are currently at 100% load. Settling at the target setpoint quickly means our fans are able to quickly adjust to the heat expended by the GPU or any component.
The proportional gain affects how quickly the controller approaches the setpoints
The integral gain is used to remove steady-state errors.
The derivative gain is based of the rate of change and is used to remove oscillations
With a better understanding of the PID controller theory, we can see how we can iterate toward our final product. Our initial trial from a full load fan had some difficulties finding the setpoints, as shown by the oscillations on the left side of the graph. As we learned above, by adjusting our integral and derivative gains we were able to help reduce the oscillations. We can see the controller trying to lock in around the 70C, but our intended target was 65 ˚C (if it were to lock in at 70 ˚C, this would be a clear example of steady-state error). The last point we worked to resolve was to improve the speed at which it approaches the setpoint, which we were able to tune with by adjusting proportional gain.
OpenBMC fan configurations are easily configurable JSON files to manually tune PID settings. The graphs presented come from comma-separated-value (CSV) files generated from OpenBMC’s PID controller application and allow us to easily iterate and improve our configuration. Several iterations later, we got our final product. We had a tad bit of overshoot in the beginning, but this is a strong enough result for us to leave the PID controller for now.
Talk to me GPU
In order to source the temperature data for the PID tuning above, we had to establish communication with the GPU. The first thing we did was identify the route from the BMC to the GPU and Peripheral Component Interconnect Express (PCIe) slot. Looking at our ODM’s schematics for the BMC and motherboard, we found a System Management Bus (SMBus) line to a mux or switch connecting to the PCIe slot. For embedded developers out there, the SMBus protocol is similar to Inter-Integrated Circuit (I2C) bus protocol, with minor differences in electrical and clock speed requirements. With a physical path to communication established, we next needed to communicate with the GPU in software.
OpenBMC applications, Linux kernel drivers, and the software tools we can add for development make the configuration and operation of devices such as fans, analog-to-digital converters (ADC), and power supplies as simple as possible. The first thing we try as a test is to get some temperature sensor data from the GPU’s onboard temperature sensor and inventory information from the Electrically-Erasable Programmable Read-Only Memory (EEPROM). We can verify the temperature sensor data with tooling provided by our GPU vendor, and the inventory information can be verified against the asset sheet provided to us when the device was delivered. Building the eerpog tool, we can try communicating with the eeprom:
~$ eeprog -f -16 /dev/i2c-23 0x50 -r 0x00:200
eeprog 0.7.5, a 24Cxx EEPROM reader/writer
Copyright (c) 2003 by Stefano Barbato - All rights reserved.
Bus: /dev/i2c-23, Address: 0x50, Mode: 16bit
Reading 200 bytes from 0x0
<redacted> Ver 0.02
This tool will produce block read requests over SMBus and dump the returned information. For temperature, the TMP75 temperature sensor is commonly used for many temperature sensors in server commodity components. We can manually bind the temperature sensor in sysfs like this:
With our temperature sensor and inventory information, we can now leverage OpenBMC’s applications for simple configuration to make this information available via the Intelligent Platform Management Interface (IPMI) or Redfish, a REST based protocol for communicating with the BMC. For adding these components, we will focus on Entity-Manager.
Entity-Manager is OpenBMC’s means of making physical components available to the BMC’s software via JSON configuration files. OpenBMC applications refer to information made available with these configurations to make sensor data and inventory data available over BMC interfaces and raise alerts when going out of bounds of critically configured settings. The following is the configuration we use as a result of our discoveries above:
Entity-Manager probes the I2C buses for all the EEPROMs for inventory information, possibly detailing what’s available on the buses. It will then try to match the information with a given JSON configuration’s “Probe” member, and if there is a match, it will take the configuration and configure the configurations as part of what is exposed. The end result is the FRU and GPU_TEMP available on IPMI.
$~ ipmi 517m206 sdr |grep GPU_TEMP
GPU_TEMP | 39 degrees C | ok
$~ ipmi 517m206 fru print 151
FRU Device Description : <redacted> (ID 151)
Board Mfg Date : Mon Mar 27 18:13:00 2023 UTC
Board Mfg : <redacted>
Board Product : <redacted>
Board Serial : <redacted>
Board Part Number : <redacted>
Open-Source firmware moving forward
Cloudflare has been able to leverage OpenBMC to gain more control and flexibility with our server configurations, without sacrificing the efficiency at the core of our network. While we continue to work closely with our ODM partners, our ongoing GPU deployment has underscored the importance of being able to modify server firmware without being locked to traditional device update cycles. For those who are interested in considering making the jump to open-source firmware, check out OpenBMC here!
Today’s blog is written by Dr Alex Hadwen-Bennett, who we worked with to find out primary school learners’ experiences of engaging with culturally relevant Computing lessons. Alex is a Lecturer in Computing Education at King’s College London, where he undertakes research focusing on inclusive computing education and the pedagogy of making.
For this reason, a particular focus of the Raspberry Pi Foundation’s academic research programme is to support Computing teachers in the use of culturally relevant pedagogy. This pedagogy involves developing learning experiences that deliberately aim to enable all learners to engage with and succeed in Computing, including by bringing their culture and interests into the classroom.
At the beginning of this study, teachers adapted two units of work that cover digital literacy skills
Conducting the focus groups
For the focus groups, the Foundation team asked teachers from three schools to each choose four learners to take part. All children in the three focus groups had taken part in all the lessons involving the culturally adapted resources. The children were both boys and girls, and came from diverse cultural backgrounds where possible.
The questions for the focus groups were prepared in advance and covered:
Perceptions of Computing as a subject
Reflections of their experiences of the engaging with culturally adapted resources
Perceptions of who does Computing
Outcomes from the focus groups
“I feel happy that I see myself represented in some way.”
“It was nice to do something that actually represented you in many different ways, like your culture and your background.”
– Statements of learners who participated in the focus groups
When the learners were asked about what they did in their Computing lessons, most of them made references to working with and manipulating graphics; fewer made references to programming and algorithms. This emphasis on graphics is likely related to this being the most recent topic the learners engaged with. The learners were also asked about their reflections on the culturally adapted graphics unit that they had recently completed. Many of them felt that the unit gave them the freedom to incorporate things that related to their interests or culture. The learners’ responses also suggested that they felt represented in the work they completed during the unit. Most of them indicated that their interests were acknowledged, whereas fewer mentioned that they felt their cultural backgrounds were highlighted.
“Anyone can be good at computing if they have the passion to do it.”
– Statement by a learner who participated in a focus group
When considering who does computing, the learners made multiple references to people who keep trying or do not give up. Whereas only a couple of learners said that computer scientists need to be clever or intelligent to do computing. A couple of learners suggested that they believed that anyone can do computing. It is encouraging that the learners seemed to associate being good at computing with effort rather than with ability. However, it is unclear whether this is associated with the learners engaging with the culturally adapted resources.
Reflections and next steps
While this was a small-scale study, the focus groups findings do suggest that engaging with culturally adapted resources can make primary learners feel more represented in their Computing lessons. In particular, engaging with an adapted unit led learners to feel that their interests were recognised as well as, to a lesser extent, their cultural backgrounds. This suggests that primary-aged learners may identify their practical interests as the most important part of their background, and want to share this in class.
Finally, the responses of the learners suggest that they feel that perseverance is a more important quality than intelligence for success in computing and that anyone can do it. While it is not possible to say whether this is directly related to their engagement with a culturally adapted unit, it would be an interesting area for further research.
The Foundation would like to extend thanks to Cognizant for funding this research, and to the primary computing teachers and learners who participated in the project.
С Оксана Глазунова и Елена Санина се срещаме онлайн. Те имаха готовност да говорят на български език, но по предложение на „Тоест“ използваха предимно родния си език. Преводът от руски е на Светла Енчева.
Първо бих ви помолила да се представите накратко.
О: Аз съм Оксана Глазунова, театрална режисьорка от Русия.
Е: Аз съм Елена Санина, актриса и преподавателка от Русия.
В Русия сте имали проблеми заради политическите ви позиции. Може ли да разкажете повече за това?
О: И с политическите ни позиции, и със сексуалната ни ориентация. Напуснахме Русия през 2021 г. Сега много ни е страх за приятелите ни, които са в Русия, защото законодателството става по-репресивно. Във Върховния съд на Русия ще се гледа иск на Правосъдното министерство за признаване на ЛГБТ движението за екстремистка организация [няколко дни след интервюто Върховният съд на Русия действително обяви ЛГБТ за екстремистка организация – б.а.]. Вече не се изненадваме от ожесточението…
Занимаваме се професионално не само с театър и спектакли, работим също като педагози – и с деца, и с възрастни. Когато заминахме, по закон не можехме да работим с деца. Защото в Русия вече съществуваше законът за ЛГБТ пропагандата, който забранява на хората, отнасящи се към нашата социална група, да работят с деца. А когато вече бяхме тук, беше приет закон, по силата на който вече е забранено да работим и с възрастни – заради „ЛГБТ пропаганда“.
Открити ли бяхте за сексуалната си ориентация?
О: Криехме се, разбира се. Но имахме снимки в социалните мрежи… Когато подадохме молби за убежище за първи път и отидохме в съда в Бургас, събрахме всички наши снимки в социалните мрежи за последните десет години и ги предоставихме като доказателство, че сме двойка. Но в Русия, естествено, ни се налагаше да се крием. Много често работим заедно. И дори да казваме, че сме просто колеги или роднини, хората виждат, че идваме и си тръгваме заедно. Трудно е да го скрием, защото в Русия нещата с личните граници са много зле. Много е трудно в женски колектив, защото всички питат защо не си омъжена, защо нямаш деца…
И тук питат…
О: Не (смеят се). В България за първи път мога открито да говоря за сексуалната си ориентация.
Да, в България ЛГБТ хората могат да са открити, аз например съм. Имах предвид обаче, че и тук хората питат защо нямаш семейство и деца. Но да се върна към темата – може ли да дадете примери, когато сте били репресирани в Русия?
Е: Работехме в културния дом и – ако може да го кажа меко – не се вписвахме в колектива. Наши колеги ни агитираха, доколкото културният дом също е държавна институция, да ходим на митинги за Путин, за „Единна Русия“, за [Сергей] Собянин. Собянин е кметът на Москва. Защото работещите в културни учреждения просто са длъжни да го правят. Съответно ние всячески се опитвахме да изклинчим, защото е в противоречие с нашите политически позиции.
Разбраха и че сме двойка и живеем заедно. Невъзможно е да скриеш принципите си. За нас не е важно каква е ориентацията ти, важен е животът ти и зад какво стоиш. Когато все пак разбраха за нас, ни извикаха в кабинета и казаха: „Не сте подходящи за нашето учреждение, вие сте ЛГБТ, опозиционери. Напишете, че напускате по собствено желание.“ Сега не можем да докажем, че са ни принудили да напуснем, защото в трудовата книжка пише „Напуснала по собствено желание“.
О: Нашия театър го закриха от пожарната инспекция заради несъответствие с правилата за пожарна безопасност. Наложиха ни огромна глоба, защото сме имали много тесни врати. Но вратите нямаше как да се сменят, защото бяхме наели помещение в сграда – паметник на културата.
Заради всички тези неща ли решихте да напуснете Русия?
О: Да, защото ситуацията ставаше все по-лоша и по-лоша. През цялото време се сблъсквахме с цензура – и в театралните постановки, и в работата с учениците… Последните години се стигна дотам, че искаха да одобряват текстовете на спектаклите ни. Затова решението назря. А след избухването на войната не успяхме да тръгнем по друг път, освен да станем бежанци.
Е: Пристигнахме в България преди войната, купихме си жилище. Но за да получиш виза за България – за обучение или работа, – трябва разрешение от Русия. Когато дойдохме, се опитахме да останем на законно основание с помощта на брат ми, но избухна войната. Брат ми загуби целия си бизнес и нищо не стана с документите. Разбрахме, че не можем да се върнем в Русия, защото за един месец от 24 февруари 2022 г., докато подадохме молби за убежище на 25 март, Русия прие огромно количество репресивни закони, в т.ч. и за ЛГБТ.
О: И се въведе военна цензура.
Е: Просто разбрахме, че ни грози опасност. Защото открито се изказвахме против войната в социалните мрежи. Работехме с украински бежанци, с деца. Разбрахме, че ако се върнем, ще бъдем преследвани.
О: А тук можем да бъдем свободни. Беше много приятно откритие да отидем на митинг и полицията да е там, за да ни пази. Защото в Русия, ако отидеш на митинг, полицията идва да те бие и да те арестува.
Елена (вляво) и Оксана. Личен архив
Имам един може би странен въпрос: защо решихте да кандидатствате за убежище точно в България? България не е много добра страна за бежанци. И за ЛГБТ хора не е добра страна, но за бежанци – особено.
О: Когато подавахме молбите си за убежище, не знаехме това. (Смеят се.)
Е: Когато преди войната се подготвяхме да дойдем в България – защото в Русия стана просто невъзможно да творим, а творчеството е огромна част от живота и от нас самите, – се влюбихме в страната. Защото останахме с впечатлението, че тук има хора, които много се интересуват и разбират от култура. Приветливи, добри, хубави хора. За първи път дойдохме през 2019 г. и се влюбихме в Бургас. Бяхме на прайд в София същата година…
О: Първият ни прайд!
Е: И независимо че там [във връзка с прайда – б.а.] също имаше някакви вълнения, все пак вярваме, че страната ви върви по демократичен път, макар и бавно. Вярваме, че България няма да тръгне след Русия, защото Русия върви към пропаст.
На прайда в София видях огромен радостен флаг, висящ на сграда, мисля, че беше сграда на институт [знамето на прайда беше закачено на сградата на Френския културен институт – б.а.]. Емоциите ме изпълниха, защото в Русия това е невъзможно.
Може ли да разкажете за делата си в Държавната агенция за бежанците (ДАБ)?
Е: За първи път подадохме молба за убежище през 2022 г. Много дълго чакахме за интервю. Нямахме адвокат, защото просто не намерихме. Всички адвокати в Бургас се занимавали с недвижими имоти, а с бежанци – никой. Тръгнахме сами. Много дълго чакахме за интервю, защото ДАБ в Баня [регистрационно-приемателния център на ДАБ в село Баня край Нова Загора – б.а.] не можеше да намери преводач.
Интервюто се състоя в най-горещия ден от лятото. Преди нас имаше момиче, което интервюираха четири часа, а ние чакахме. За интервюто с нас вече нямаше достатъчно време и само казваха: „Хайде по-бързо, хайде по същество.“ Преводачката беше страшно уморена. Стаята беше малка и много задушна.
О: Сега вече знаем някои неща. Разбираме, че имаше нарушения от интервюиращите, но и ние много неща казвахме с неправилни термини, защото нямахме адвокат.
Е: И защото ни подвеждаха.
О: След това все пак намерихме адвокат в Бургас, който се занимава с бежанци, и обжалвахме. Той направи всичко, което можа, но нито моят съдия, нито съдията на Елена застана на наша страна. В съда се държаха странно – на моето дело практически нямах възможност да кажа нищо, а Елена я разпитваха половин час. На нея ѝ стана лошо.
Е: Съдийката на Оксана не знаеше какво се случва в Русия. Тя не разбираше какви документи ѝ даваме, изобщо не беше в час. Затова Оксана не можа да каже и дума в своя защита. А мен ме разпитваха дълго. Въпросите, които съдийката задаваше, просто се губеха. Тя задава въпрос, започвам да отговарям, но не разбира нищо и задава още един въпрос.
О: Елена толкова се уплаши на моето дело, че щеше да загуби съзнание.
Е: Малко като паническа атака. Защото изпитвах чувство за отговорност – аз говорех и заради нея на нейното дело. И това, което щях да кажа, беше много важно. Адвокатът каза, че просто ще ме разпитат като свидетел, ще отговоря на два въпроса. А толкова дълго ме разпитваха! Аз изобщо бях за първи път в съд в живота си.
На моето дело всичко изглеждаше добре. Съдийката много ми съчувстваше, по човешки. Попита ме: „Искате ли да отменя решението на ДАБ?“ Аз отговорих: „Да“. Тя разбираше всичко, което казвам, и беше в течение какво се случва в Русия. Говорих много добре и по същество. Но за съжаление, получихме отказ, макар да бяхме убедени, че ще спечелим.
После беше Върховният съд [Върховният административен съд, ВАС – б.а.]. На делото дойде и нашата адвокатка, която се занимава конкретно с ЛГБТ – Деница Любенова, забележителна адвокатка. Тя ни каза, че в началото не сме направили нещата правилно. Делото беше само по документи – дадохме ги на съдията и толкова, буквално за 5 минути.
Но най-интересното беше, че делото във ВАС на Оксана протече без нито тя, нито адвокатът да бъдат уведомени. Тоест те сами са проверили нещо и са отказали. Когато имахме дело в Административния съд в Бургас, бяхме получили на адреса си уведомление от съда кога ще се гледа то. От София не получихме никакво официално уведомление. Не бяхме и информирани, че вече има решение на ВАС.
Отидохме в ДАБ след съда за удължаване на документите ни [временни документи за хора, търсещи убежище – б.а.]. Оказа се, че от половин година има решение на ВАС за отказ. И когато отидохме за втори път след три месеца, ни съобщиха, че делото е загубено, производството е прекратено. Тогава Деница [Любенова] каза, че ще подадем [молба за убежище] за втори път, тъй като обстоятелствата са се променили. За тази година [в Русия] бяха приети нови репресивни закони, в това число политически и за ЛГБТ.
Подготвихме второто заявление. Но този път от ДАБ в София много дълго не искаха да приемат документите ни. Изпращаха ни ту в „Овча купел“, ту във „Враждебна“. И все пак в „Овча купел“ приеха документите ни от втория път, когато вече позвънихме в централния офис. Приеха ги, издадоха ни входящи номера и след това… ни отказаха.
Помня деня, когато отидохме да вземем решението. Към нас дойдоха веднага три жени. Застанаха като стена: „Разбирате ли български?“ Отговорих [на български]: „Аз мога да разбера думичката „не“.
Връчиха ни отказите. Беше напълно ясно, че разбират, че не са прави. Ние сме актриси, наблюдателни хора сме. Една от жените попита Оксана: „Искате ли да знаете причините за отказа?“ „Но защо? Аз знам, че съм права.“ „Ами тогава пак ще се срещнем“, казаха те, а ние отговорихме: „Да, да, да.“
О: Приложихме нотариалния акт за апартамента, защото той е на името на двете. Тоест парите бяха мои – от продажбата на апартамента ми в Москва. Но го купихме на името и на двете като доказателство, че сме двойка. В моя случай ДАБ изобщо не спомена това в отказа. А в решението на Елена написа, че наличието на собственост върху апартамент не е повод за искане на убежище (смее се).
Бяхме приложили и документ, че сме се занимавали с благотворителна дейност. Помагахме да се събират пари за украинските бежанци и провеждахме събития с деца бежанци от Украйна. Проектът на фондацията, която организира това, е екологичен – хората да слязат от автомобилите и да се качат на велосипеди. И това стои в заглавието. Въпреки че документите ни с Елена бяха еднакви, в нейния отказ бяха реагирали, сякаш нищо подобно не е правила, а в моя пишеше, че пропагандата на здравословен живот чрез каране на велосипед също не е основание за убежище и не се преследва в Русия.
Всъщност това, което правят [от ДАБ – б.а.] не само по отношение на нас, а и на други наши приятели, търсещи политическо убежище, е, ако нещо могат да оспорят, да го оспорят, а това, което не могат да оспорят, просто го игнорират.
Е: Или го преиначават по някакъв начин.
Ако ви депортират в Русия, какво ще ви се случи?
О: Надявам се, че няма.
Аз също. Но ако все пак ви върнат в Русия, какво ви очаква там?
О: Мисля, че затвор. Несъмнено. Много показателен и ужасен е случаят с художничката Александра Скочиленко. Тя прекара половин година в ареста и сега я осъдиха на седем години и половина затвор. Александра също е против войната и е ЛГБТ, има приятелка и двете открито са заявявали сексуалната си ориентация. Мисля, че това също е повлияло на присъдата.
Изобщо, оставам с впечатлението, че понастоящем руските власти нарочно провеждат такива дела, за да се изплашат останалите и да си мълчат.
С какво се занимавате в България?
Е: Продължаваме артистичната си дейност в читалище, правим малки представления за рускоговорещи. Привличаме и пълнолетни българоговорещи, които се интересуват от театър.
О: Имаме огромен професионален и педагогически опит. Успях да заснема клип онлайн за артрок група в Русия. Антивоенен клип. Те [членовете на групата – б.а.] също се страхуват, но се опитват да направят нещо. Казах им да не обявяват, че аз съм режисьорът, защото тук давам интервюта, ходя по митинги. Ако не ги свързват с мен, ще бъдат в по-голяма безопасност. За първи път през живота си снимах клип онлайн (смее се). Но много ни харесва да работим и в България.
Е: Скоро ще има дебют на нашата група. Ще четем сонети на Шекспир на български.
О: Миналата година работихме с деца. Имахме група рускоговорещи деца, сред които и украинчета. Мисля, че това е много важно, защото, когато периодично между тях възникват спорове или някакви обяснения кой от каква националност е, кой откъде е, ние се опитваме да балансираме всичко и да покажем, че има творчество, има мирен живот, всички хора са индивидуалности, не трябва никой да бъде съден по етнически признак и т.н.
Имате ли вече приятели в България?
И двете: Да, да.
О: Запознахме се с много хора. Участвахме в мастърклас по имерсивен театър. Запознахме се с хора на изкуството в България. Беше наистина страхотно, много приятно. И сега си общуваме и може би ще създадем нещо интересно и творческо.
Искате ли да добавите нещо, за което не съм ви попитала?
О: Вярвам, че всичко ще бъде наред с правата и свободите в България, защото България е много хубава държава. Сега тук има много бежанци от Русия и Украйна, които могат да бъдат полезни, защото истински са обикнали тази страна и искат да имат принос. Да не бъдат в тежест, да не използват ресурсите ѝ, а да дадат нещо на хората.
Е: Усещаме ценността си, понеже призванието ни е да говорим с хората, да им помагаме. Преподавателската дейност чрез театър, чрез актьорски тренинги много помага да бъдеш вътрешно свободен и по-разкрепостен. Иска ни се да продължаваме да правим това.
О: Вече не можем да впишем тези ценности в Русия, но можем да го направим тук, без да бъдем преследвани. Мисля, че от това трябва да последва нещо хубаво. Защото Русия няма да успее да убие всичко добро, което е съществувало в нея. То може да се съхрани и преумножи – ако не в Русия, то извън границите ѝ.
The Common Vulnerabilities and Exploits
(CVE) system is the main mechanism for tracking various security
flaws,
using the omnipresent CVE number—even vulnerabilities with fancy names and
web sites
have CVE numbers. But the CVE system is not without its critics and, in
truth, the incentives between the reporting side and those responsible for
handling the bugs have always been misaligned, which leads to abuse of
various kinds. There have been efforts to
combat some of those abuses along the way; a newly announced
“!CVE” project is meant to track vulnerabilities “that are not
acknowledged by vendors but
still are serious security issues“.
In our increasingly digital world, affordable access to high-speed broadband is a necessity to fully participate in our society, yet there are still millions of American households without internet access. HR&A Advisors—a multi-disciplinary consultancy with extensive work in the broadband and digital equity space is helping its state, county, and municipal clients deliver affordable internet access by analyzing locally specific digital inclusion needs and building tailored digital equity plans.
The first step in this process is mapping the digital divide. Which households don’t have access to the internet at home? Where do they live? What are their specific needs?
Public data sources aren’t sufficient for building a true understanding of digital inclusion needs. To fill in the gaps in existing data, HR&A creates digital equity surveys to build a more complete picture before developing digital equity plans. HR&A has used Amazon Redshift Serverless and CARTO to process survey findings more efficiently and create custom interactive dashboards to facilitate understanding of the results. HR&A’s collaboration with Amazon Redshift and CARTO has resulted in a 75% reduction in overall deployment and dashboard management time and helped the team achieve the following technical goals:
Load survey results (CSV files) and geometry data (shape files) in a data warehouse
Perform geo-spatial transformations using extract, transform, and load (ELT) jobs to join geometry data with survey results within the data warehouse to allow for visualization of survey results on a map
Integrate with a business intelligence (BI) tool for advanced geo-spatial functions, visualizations, and mapping dashboards
Scale data warehouse capacity up or down to address workloads of varying complexity in a cost-efficient manner
In this post, we unpack how HR&A uses Amazon Redshift spatial analytics and CARTO for cost-effective geo-spatial measurement of digital inclusion and internet access across multiple US states.
Before we get to the architecture details, here is what HR&A and its client, Colorado’s Office of the Future of Work, has to say about the solution.
“Working with the team at HR&A Advisors, Colorado’s Digital Equity Team created a custom dashboard that allowed us to very effectively evaluate our reach while surveying historically marginalized populations across Colorado. This dynamic tool, powered by AWS and CARTO, provided robust visualizations of which regions and populations were interacting with our survey, enabling us to zoom in quickly and address gaps in coverage. Ensuring we were able to seek out data from those who are most impacted by the digital divide in Colorado has been vital to addressing digital inequities in our state.”
— Melanie Colletti, Digital Equity Manager at Colorado’s Office of the Future of Work
“AWS allows us to securely house all of our survey data in one place, quickly scrub and analyze it on Amazon Redshift, and mirror the results through integration with data visualization tools such as CARTO without the data ever leaving AWS. This frees up our local computer space, greatly automates the survey cleaning and analysis step, and allows our clients to easily access the data results. Following the proof of concept and development of first prototype, almost all of our state clients showed interest in using the same solution for their states.”
— Harman Singh Dhodi, Analyst at HR&A Advisors, Inc.
Storing and analyzing large survey datasets
HR&A used Redshift Serverless to store large amounts of digital inclusion data in one place and quickly transform and analyze it using CARTO’s analytical toolkit to extend the spatial capabilities of Amazon Redshift and integrate with CARTO’s data visualization tools—all without the data ever leaving the AWS environment. This cut down significantly on analytical turnaround times.
The CARTO Analytics Toolbox for Redshift is composed of a set of user-defined functions and procedures organized in a set of modules based on the functionality they offer.
The following figure shows the solution and workflow steps developed during the proof of concept with a virtual private cloud (VPC) on Amazon Redshift.
Figure 1: Workflow illustrating data ingesting, transformation, and visualization using Redshift and CARTO.
In the following sections, we discuss each phase in the workflow in more detail.
Data ingestion
HR&A receives survey data as wide CSV files with hundreds of columns in each file and related spatial data in hexadecimal Extended Well-Known Binary (EWKB) in the form of shape files. These files are stored in Amazon Simple Storage Service (Amazon S3).
The Redshift COPY command is used to ingest the spatial data from shape files into the native GEOMETRY data type supported in Amazon Redshift. A combination of Amazon Redshift Spectrum and COPY commands are used to ingest the survey data stored as CSV files. For the files with unknown structures, AWS Gluecrawlers are used to extract metadata and create table definitions in the Data Catalog. These table definitions are used as the metadata repository for external tables in Amazon Redshift.
For files with known structures, a Redshift stored procedure is used, which takes the file location and table name as parameters and runs a COPY command to load the raw data into corresponding Redshift tables.
Data transformation
Multiple stored procedures are used to split the raw table data and load it into corresponding target tables while applying the user-defined transformations.
These transformation rules include transformation of GEOMETRY data using native Redshift geo-spatial functions, like ST_Area and ST_length, and CARTO’s advanced spatial functions, which are readily available in Amazon Redshift as part of the CARTO Analytics Toolbox for Redshift installation. Furthermore, all the data ingestion and transformation steps are automated using an AWS Lambda function to run the Redshift query when any dataset in Amazon S3 gets updated.
Data visualization
The HR&A team used CARTO’s Redshift connector to connect to the Redshift Serverless endpoint and built dashboards using CARTO’s SQL interface and widgets to assist mapping while performing dynamic calculations of the map data as per client needs.
The following are sample screenshots of the dashboards that show survey responses by zip code. The counties that are in lighter shades represent limited survey responses and need to be included in the targeted data collection strategy.
The first image shows the dashboard without any active filters. The second image shows filtered map and chats by respondents who took the survey in Spanish. The user can select and toggle between features by clicking on the respective category in any of the bar charts.
The result: A new standard for automatically updating digital inclusion dashboards
After developing the first interactive dashboard prototype with this methodology, five of HR&A’s state clients (CA, TX, NV, CO, and MA) showed interest in the solution. HR&A was able to implement it for each of them within 2 months—an incredibly quick turnaround for a custom, interactive digital inclusion dashboard.
HR&A also realized about a 75% reduction in overall deployment and dashboard management time, which meant the consulting team could redirect their focus from manually analyzing data to helping clients interpret and strategically plan around the results. Finally, the dashboard’s user-friendly interface made survey data more accessible to a wider range of stakeholders. This helped build a shared understanding when assessing gaps in each state’s digital inclusion landscape and allowed for a targeted data collection strategy from areas with limited survey responses, thereby supporting more productive collaboration overall.
Conclusion
In this post, we showed how HR&A was able to analyze geo-spatial data in large volumes using Amazon Redshift Serverless and CARTO.
With HR&A’s successful implementation, it’s evident that Redshift Serverless, with its flexibility and scalability, can be used as a catalyst for positive social change. As HR&A continues to pave the way for digital equity, their story stands as a testament to how AWS services and its partners can be used in addressing real-world challenges.
We encourage you to explore Redshift Serverless with CARTO for analyzing spatial data and let us know your experience in the comments.
About the authors
Harman Singh Dhodi is an Analyst at HR&A Advisors, Harman combines his passion for data analytics with sustainable infrastructure practices, social inclusion, economic viability, climate resiliency, and building stakeholder capacity. Harman’s work often focuses on translating complex datasets into visual stories and accessible tools that help empower communities to understand the challenges they’re facing and create solutions for a brighter future.
Kiran Kumar Tati is an Analytics Specialist Solutions Architect based out of Omaha, NE. He specializes in building end-to-end analytic solutions. He has more than 13 years of experience with designing and implementing large scale Big Data and Analytics solutions. In his spare time, he enjoys playing cricket and watching sports.
Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She helps customers architect data analytics solutions at scale on AWS. Outside of work she enjoys traveling and trying new cuisines.
Washim Nawaz is an Analytics Specialist Solutions Architect at AWS. He has worked on building and tuning data warehouse and data lake solutions for over 15 years. He is passionate about helping customers modernize their data platforms with efficient, performant, and scalable analytic solutions. Outside of work, he enjoys watching games and traveling.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.





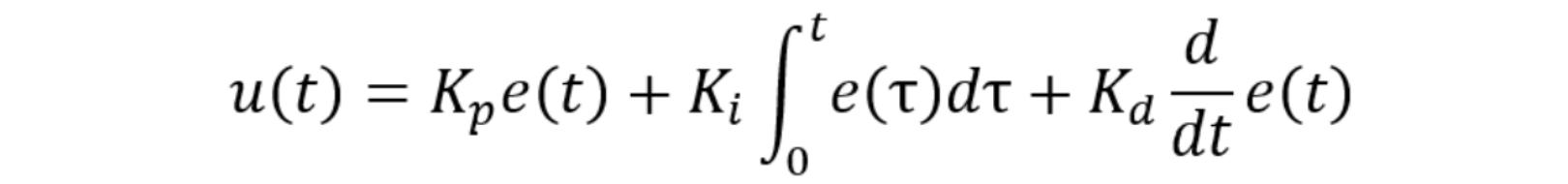











 Harman Singh Dhodi is an Analyst at HR&A Advisors, Harman combines his passion for data analytics with sustainable infrastructure practices, social inclusion, economic viability, climate resiliency, and building stakeholder capacity. Harman’s work often focuses on translating complex datasets into visual stories and accessible tools that help empower communities to understand the challenges they’re facing and create solutions for a brighter future.
Harman Singh Dhodi is an Analyst at HR&A Advisors, Harman combines his passion for data analytics with sustainable infrastructure practices, social inclusion, economic viability, climate resiliency, and building stakeholder capacity. Harman’s work often focuses on translating complex datasets into visual stories and accessible tools that help empower communities to understand the challenges they’re facing and create solutions for a brighter future. Kiran Kumar Tati is an Analytics Specialist Solutions Architect based out of Omaha, NE. He specializes in building end-to-end analytic solutions. He has more than 13 years of experience with designing and implementing large scale Big Data and Analytics solutions. In his spare time, he enjoys playing cricket and watching sports.
Kiran Kumar Tati is an Analytics Specialist Solutions Architect based out of Omaha, NE. He specializes in building end-to-end analytic solutions. He has more than 13 years of experience with designing and implementing large scale Big Data and Analytics solutions. In his spare time, he enjoys playing cricket and watching sports. Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She helps customers architect data analytics solutions at scale on AWS. Outside of work she enjoys traveling and trying new cuisines.
Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She helps customers architect data analytics solutions at scale on AWS. Outside of work she enjoys traveling and trying new cuisines.